【Python爬虫 !!!!!!政府招投标数据爬虫项目--医疗实例项目文档(提供源码!!!)!!!学会Python爬虫轻松赚外快】
政府招投标数据爬虫项目--医疗实例项目文档
- 1. 项目概述
- 1.1 项目目标
- 1.2 技术栈
- 2. 系统架构
- 2.1 模块划分
- 2.2 流程示意图
- 3. 核心模块设计
- 3.1 反爬处理模块(`utils/anti_crawler.py`)
- 3.1.1 功能特性
- 3.1.2 关键代码
- 3.2 爬虫模块(`crawler/spiders/`)
- 3.2.1 基类设计(`base_spider.py`)
- 3.2.2 医疗爬虫示例(`medical_spider.py`)
- 3.3 数据库设计(`database/models.py`)
- 3.3.1 数据表结构
- 3.3.2 枚举类型
- 3.4 数据分析模块(`analyzer/data_processor.py`)
- 3.4.1 分析维度
- 3.4.2 关键算法
- 4. 系统配置与部署
- 4.1 环境搭建
- 4.2 配置文件(`config.py`)
- 5. 使用说明
- 5.1 启动爬虫
- 5.2 日志查看
- 5.3 数据分析报告
- 附录:核心代码片段
- 免责声明
1. 项目概述
1.1 项目目标
爬取医疗领域的政府招投标项目数据,实现反爬机制处理、数据存储、数据分析及可视化,为招投标市场分析提供数据支持。
1.2 技术栈
- 编程语言:
Python 3.8+ - 异步框架:
Asyncio(网络请求并发处理) - 数据存储:
MySQL + SQLAlchemy ORM - 反爬技术:
Selenium(JS渲染)、代理IP池、User-Agent轮换、验证码识别 - 数据分析:
Scikit-learn(聚类分析)、Pandas(数据处理)、Matplotlib/WordCloud(可视化) - 通知模块:
SMTP邮件通知
2. 系统架构
2.1 模块划分
项目根目录
├── config.py # 配置文件
├── main.py # 主程序入口
├── crawler # 爬虫模块
│ ├── spiders # 具体爬虫实现
│ │ ├── base_spider.py # 爬虫基类
│ │ ├── construction_spider.py # 建筑项目爬虫
│ │ └── medical_spider.py # 医疗项目爬虫(优化新增)
│ └── SpiderManager.py # 爬虫管理器
├── analyzer # 数据分析模块
│ └── data_processor.py # 数据处理与分析
├── database # 数据库模块
│ └── models.py # 数据库模型定义
├── utils # 工具模块
│ ├── anti_crawler.py # 反爬处理
│ ├── proxy_pool.py # 代理IP池(优化新增)
│ └── notifier.py # 通知模块(优化新增)
└── requirements.txt # 依赖清单
2.2 流程示意图
目标网站 → 反爬处理(代理/UA/JS渲染/验证码) → 数据解析 → 数据库存储 → 数据分析(关键词/预算/趋势/聚类) → 可视化报告 → 邮件通知
3. 核心模块设计
3.1 反爬处理模块(utils/anti_crawler.py)
3.1.1 功能特性
- User-Agent轮换:随机切换浏览器指纹,支持Chrome、Firefox等多种UA
- 代理IP池:多来源获取代理,定期刷新,验证有效性(
utils/proxy_pool.py) - JS渲染:使用Selenium无头浏览器处理动态内容,模拟人类浏览行为(滚动、悬停)
- 验证码识别:支持图片验证码和reCAPTCHA,对接第三方打码平台
3.1.2 关键代码
# 模拟人类浏览行为(滚动和鼠标移动)
def _simulate_human_behavior(self):scroll_heights = [300, 500, 800, 1200]for height in scroll_heights:self.js_driver.execute_script(f"window.scrollTo(0, {height});")time.sleep(random.uniform(0.5, 1.5))# 随机悬停可点击元素elements = self.js_driver.find_elements(By.CSS_SELECTOR, 'a, button')for elem in random.sample(elements, min(3, len(elements))):ActionChains(self.js_driver).move_to_element(elem).perform()time.sleep(0.3)
3.2 爬虫模块(crawler/spiders/)
3.2.1 基类设计(base_spider.py)
- 异步请求:使用
aiohttp实现高并发爬取,控制并发量(默认5个任务) - 日志记录:记录爬取进度、成功/失败次数,写入数据库日志表(
CrawlerLog) - 异常处理:重试机制(默认3次),失败通知管理员
3.2.2 医疗爬虫示例(medical_spider.py)
# 分页爬取处理
async def _crawl_next_pages(self, url, selector, max_pages=5):for page in range(max_pages):html = await self.fetch(url)if not html: breaksoup = self.get_soup(html)# 解析当前页项目for item in soup.select(selector):item_url = self._parse_item_url(item)items.append(item_url)# 提取下一页链接next_url = soup.select_one('.next-page')['href']url = self._build_absolute_url(next_url)await asyncio.sleep(3) # 控制请求间隔return items
3.3 数据库设计(database/models.py)
3.3.1 数据表结构
| 表名 | 功能描述 | 核心字段 |
|---|---|---|
bidding_projects | 招投标项目表 | id, title, url, type(枚举), publish_date, budget, content |
crawler_logs | 爬虫日志表 | spider_name, start_time, end_time, status, items_crawled |
keyword_stats | 关键词统计表 | keyword, count, type(枚举), date |
3.3.2 枚举类型
class ProjectType(enum.Enum):CONSTRUCTION = "construction" # 建筑MEDICAL = "medical" # 医疗TOURISM = "tourism" # 旅游HOTEL = "hotel" # 酒店
3.4 数据分析模块(analyzer/data_processor.py)
3.4.1 分析维度
- 关键词统计:使用jieba分词,提取高频关键词并生成词云
- 预算分析:计算均值、标准差,绘制箱线图对比不同类型项目预算
- 时间趋势:按日/周统计项目数量,生成趋势曲线
- 地域分析:通过关键词匹配提取项目地域信息,绘制地域分布饼图
- 聚类分析:K-means算法自动分类项目,PCA可视化聚类结果
3.4.2 关键算法
# 肘部法则确定最佳聚类数
def _find_optimal_clusters(self, X, max_k=10):wss = [KMeans(k).fit(X).inertia_ for k in range(1, max_k+1)]deltas = [wss[i]-wss[i+1] for i in range(len(wss)-1)]return deltas.index(max(deltas)) + 1 # 选择拐点处的k值
4. 系统配置与部署
4.1 环境搭建
# 安装依赖
pip install sqlalchemy aiohttp beautifulsoup4 selenium webdriver-manager pandas numpy scikit-learn pyvirtualdisplay# 初始化数据库
mysql -u root -p
CREATE DATABASE bidding_data CHARACTER SET utf8mb4;
4.2 配置文件(config.py)
DB_CONFIG = { # 数据库配置'host': 'localhost','port': 3306,'user': 'root','password': 'your_password','database': 'bidding_data'
}EMAIL_CONFIG = { # 邮件通知配置(可选)'smtp_server': 'smtp.example.com','smtp_port': 587,'username': 'sender@example.com','password': 'email_password','sender': 'sender@example.com','recipients': ['recipient1@example.com', 'recipient2@example.com']
}
5. 使用说明
5.1 启动爬虫
python main.py
5.2 日志查看
- 控制台日志:记录爬取进度、反爬处理状态、数据分析结果
- 数据库日志:
crawler_logs表存储爬虫任务的开始/结束时间、成功数、错误信息
5.3 数据分析报告
- 自动生成图片报告(预算分析图、趋势图、词云等),存储在项目根目录
- 邮件通知:包含文字报告和图表附件(需配置
EMAIL_CONFIG)
附录:核心代码片段
main.py:项目启动入口,协调各模块初始化anti_crawler.py:反爬处理核心逻辑,包含JS渲染和验证码解决方案data_processor.py:数据分析算法实现,包含K-means聚类和可视化代码
免责声明
- 本项目涉及网络爬虫、数据解析等技术操作,可能因目标网站反爬策略调整、网络波动、代码漏洞等原因导致爬取失败、数据错误或账号封禁。我们不对上述风险导致的任何直接或间接损失(包括但不限于数据丢失、设备损坏、业务中断等)承担责任。
- 本项目可能依赖第三方库(如 Scrapy、Redis、MySQL 等)或服务(如代理 IP、验证码识别平台),因第三方原因导致的任何问题,我们不承担连带责任。
- 本项目的源代码、文档、架构设计等知识产权归开发团队所有,受《中华人民共和国著作权法》保护。未经书面授权,禁止任何形式的复制、修改、传播或商业化使用。
- 爬取的政府招投标数据版权归原发布方所有,本项目仅作为技术实现示例,不主张对数据的版权或所有权。
源码下载:《Python爬虫-实战医疗项目》
相关文章:
!!!学会Python爬虫轻松赚外快】)
【Python爬虫 !!!!!!政府招投标数据爬虫项目--医疗实例项目文档(提供源码!!!)!!!学会Python爬虫轻松赚外快】
政府招投标数据爬虫项目--医疗实例项目文档 1. 项目概述1.1 项目目标1.2 技术栈 2. 系统架构2.1 模块划分2.2 流程示意图 3. 核心模块设计3.1 反爬处理模块(utils/anti_crawler.py)3.1.1 功能特性3.1.2 关键代码 3.2 爬虫模块(crawler/spider…...
Android架构之自定义native进程
在Android五层架构中,native层基本上全是c的世界,这些c进程基本上靠android世界的第一个进程init进程创建,init通过rc配置文件,创建了众多的c子进程,也是这众多的c进程,构建了整个android世界的native层。 …...

talk-centos6之间实现
在 CentOS 6.4 上配置和使用 talk 工具,需要注意系统版本较老,很多配置可能不同于现代系统。我会提供 详细步骤 自动化脚本,帮你在两台 CentOS 6.4 机器上实现局域网聊天。 ⸻ 🧱 一、系统准备 假设你有两台主机: …...

《100天精通Python——基础篇 2025 第18天:正则表达式入门实战,解锁字符串处理的魔法力量》
目录 一、认识正则表达式二、正则表达式基本语法2.1 行界定符2.2 单词定界符2.3 字符类2.4 选择符2.5 范围符2.6 排除符2.7 限定符2.8 任意字符2.9 转义字符2.10 反斜杠2.11 小括号2.11.1 定义独立单元2.11.2 分组 2.12 反向引用2.13 特殊构造2.14 匹配模式 三、re模块3.1 comp…...

数组中元素如何交换与打乱
1 问题 在本周学习了java基础语法中的数组,在学习数组后,我们会遇到关于数组中元素的倒序,交换,和无序打乱等问题,在Python中我们可以用list的方法进行元素倒序,那么我们在java中应该如何实现数组用元素的倒序和元素的打乱呢? 2 方法 使用循环,Random类,下标索引实现 关于元素…...
Nuitka 已不再安全? Nuitka/Cython 打包应用逆向工具 -- pymodhook
pymodhook是一个记录任意对Python模块的调用的库,用于Python逆向分析。 pymodhook库类似于Android的xposed框架,但不仅能记录函数的调用参数和返回值,还能记录模块的类的任意方法调用,以及任意派生对象的访问,基于pyob…...
【C】初阶数据结构14 -- 归并排序
本篇文章主要是讲解经典的排序算法 -- 归并排序 目录 1 递归版本的归并排序 1) 算法思想 2) 代码 3) 时间复杂度与空间复杂度分析 (1) 时间复杂度 (2) 空间复杂度 2 迭代版本的归并…...
华为网路设备学习-21 IGP路由专题-路由过滤(filter-policy)
一、路由过滤(filter-policy) 1、用于控制路由更新、接收的一个工具 2、只能过滤路由信息,无法过滤LSA 二、路由过滤(filter-policy)与动态路由协议 1、距离矢量路由协议 RIP动态路由协议 交换的是路由表࿰…...

NestJS 框架深度解析
框架功能分析 NestJS 是一个基于 Node.js 的渐进式框架,专为构建高效、可扩展的服务器端应用程序而设计。其核心理念结合了 面向对象编程(OOP)、函数式编程(FP) 和 函数式响应式编程(FRP)&…...

人脸识别门禁系统技术文档
人脸识别门禁系统技术文档 序言 本文档详细描述了人脸识别门禁系统的技术实现原理与方法。该系统旨在提供高安全性的门禁管理解决方案,通过先进的人脸识别技术,实现无接触式身份验证,提高安全管理效率。 系统整合了人工智能与计算机视觉技…...
SAP 交货单行项目含税金额计算报cx_sy_zerodivide处理
业务背景:SAP交货单只有数量,没有金额,所以开发报表从订单的价格按数量计算交货单的金额。 用户反馈近期报表出现异常: ****2012/12/12 清风雅雨 规格变更 Chg 修改开始 ** 修改原因:由于余数为0时,可能会报错溢出。…...
【Qt】之音视频编程1:QtAV的背景和安装篇
QtAV 背景与核心概念 1. 什么是 QtAV? QtAV 是一个基于 Qt 框架 和 FFmpeg 的多媒体播放库,旨在为 Qt 应用程序提供高性能、跨平台的音视频播放、处理及渲染功能。它封装了 FFmpeg 的底层编解码能力,并通过 Qt 的图形系统(如 QM…...
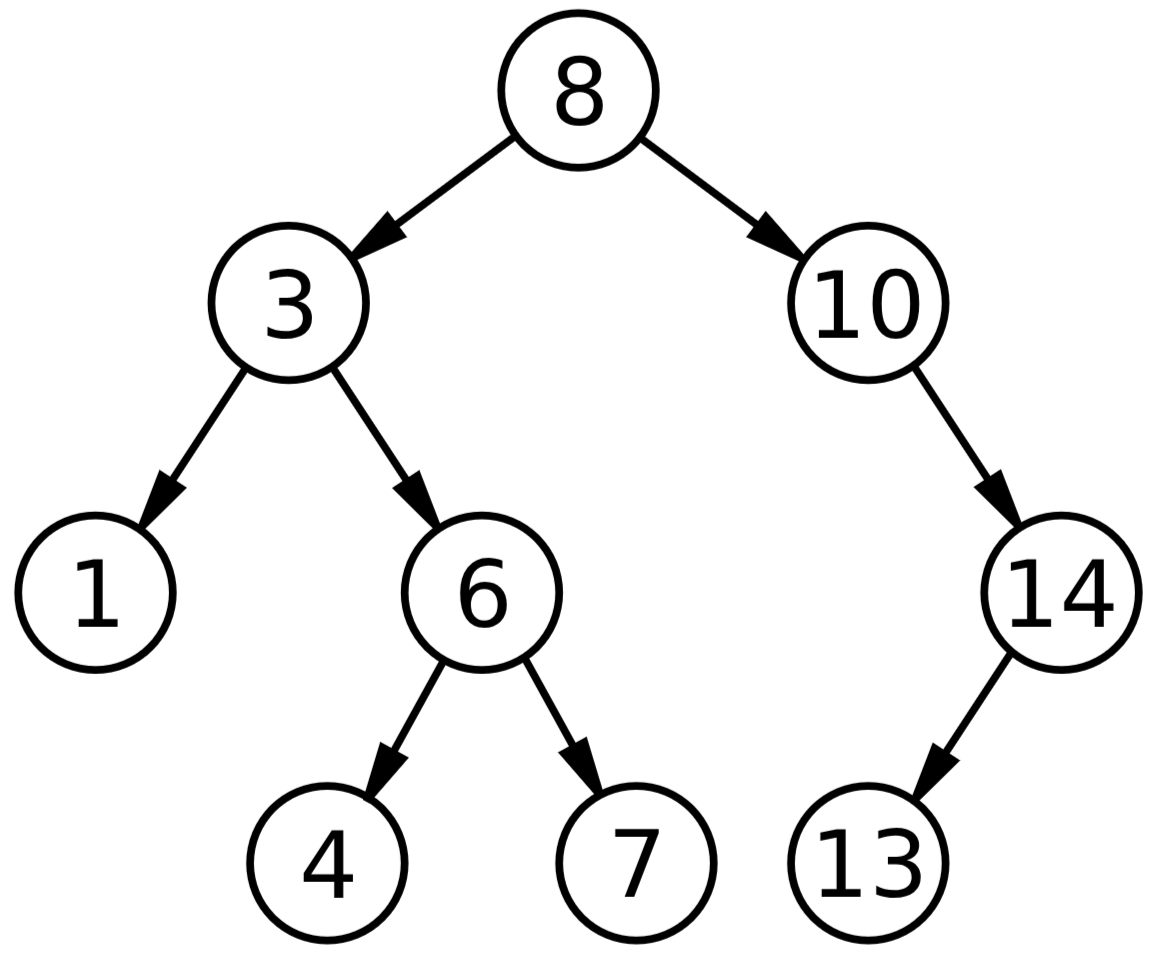
算法与数据结构 - 二叉树结构入门
目录 1. 普通二叉树结构 1.1. 常见术语 1.2. 完全二叉树 (Complete Binary Tree) 1.3. 满二叉树 (Full Binary Tree) 2. 特殊二叉树结构 2.1. 二叉搜索树 (BST) 2.1.1. BST 基本操作 - 查找 2.1.2. BST 基本操作 - 插入 2.1.3. BST 基本操作 - 删除 2.2. 平衡二叉树…...
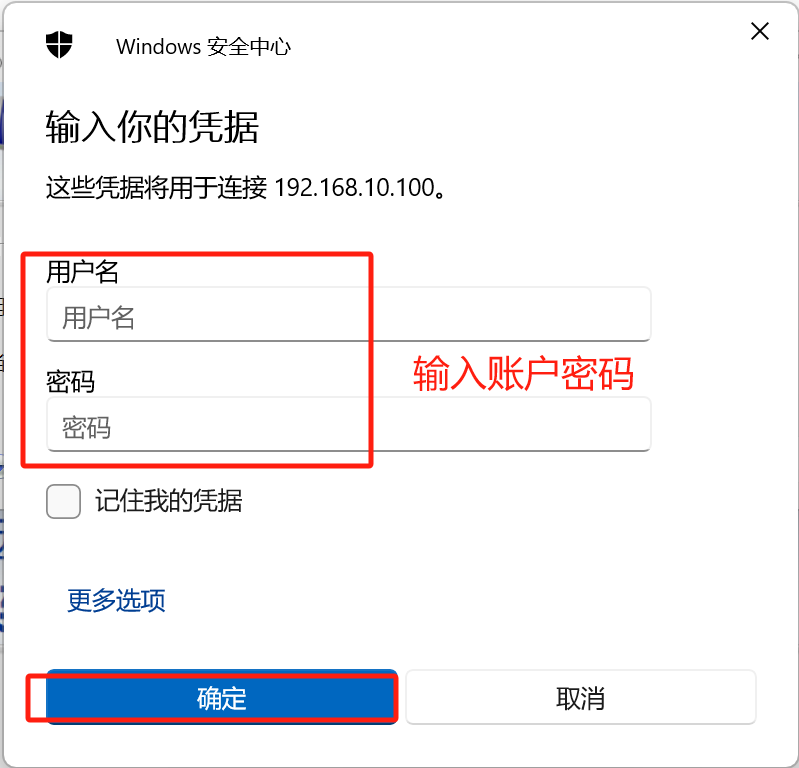
如何使用远程桌面控制电脑
目的: 通过路由器使用pc控制台式机,实现了有线/无线pc与台式机的双向远程桌面控制 最核心就两条:get ip地址与被控制机器的账户与密码。 现象挺神奇:被控制电脑的电脑桌面处于休眠模式,此时强行唤醒被控电脑会导致中断…...
SpringMVC-执行流程
目录 前言 一、SpringMVC执行流程 SpringMVC 主要组件 SpringMVC 的执行流程 简要分析执行流程 总结 前言 理解SpringMVC的执行流程是学习SpringMVC工作原理的重要一步。 项目内容参考:SpringMVC-简介及入门-CSDN博客 一、SpringMVC执行流程 SpringMVC 主要组…...
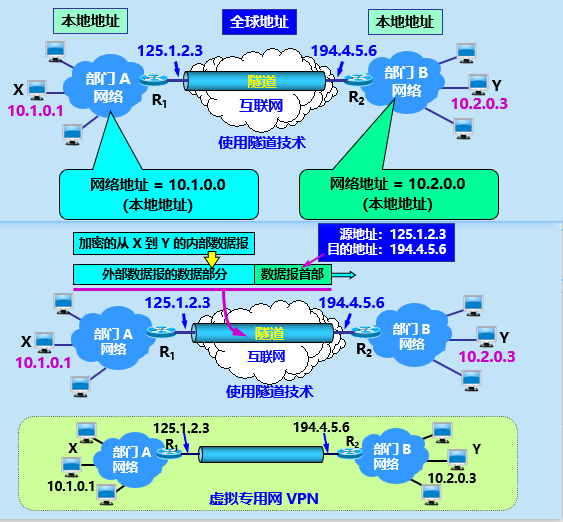
计算机网络网络层(下)
一、互联的路由选择协议(网络层控制层面内容) (一)有关路由选择协议的几个概念 1.理想的路由算法 (1)理想路由算法应具备的特点:算法必须正确和完整的,算法在计算上应简单&#x…...
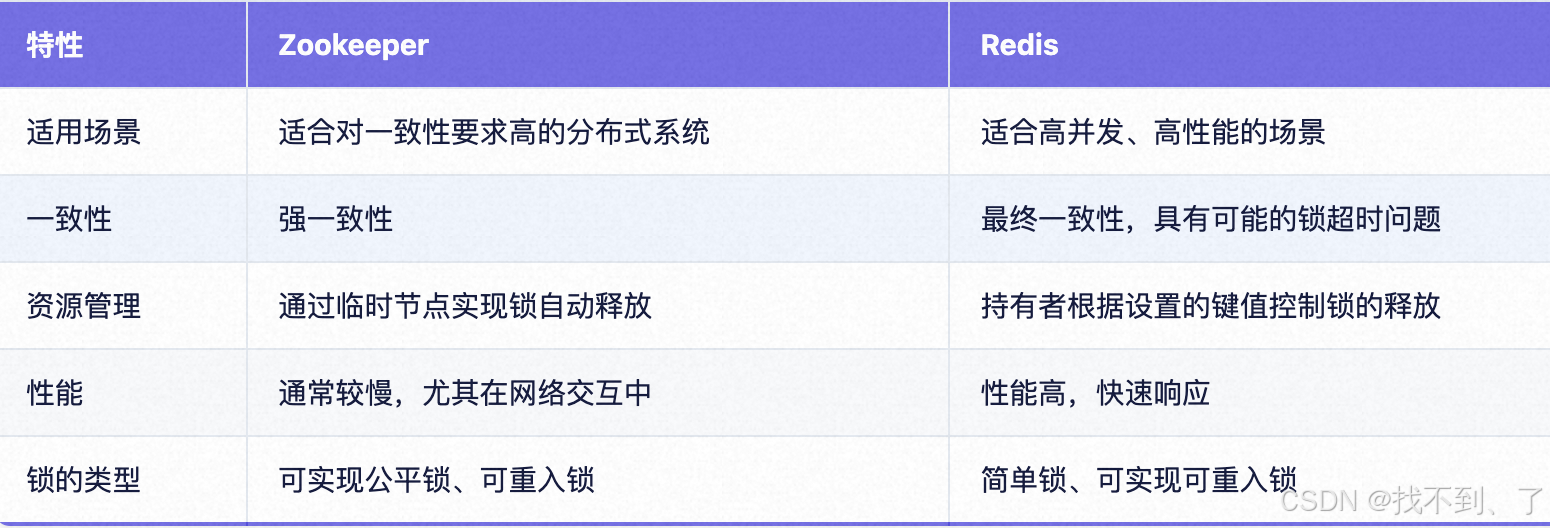
深入学习Zookeeper的知识体系
目录 1、介绍 1.1、CAP 理论 1.2、BASE 理论 1.3、一致性协议ZAB 1、介绍 2、角色 3、ZXID和myid 4、 历史队列 5、协议模式 6、崩溃恢复模式 7、脑裂问题 2、zookeeper 2.1、开源项目 2.2、功能 2.3、选举机制 3、数据模型 3.1、介绍 3.2、znode分类 4、监听…...

主从架构:技术原理与实现
一.简单介绍分布式锁的复习 今天在一个分布式锁的视频讲解中,提到了主从架构,所以有了这篇文章。 当然我们可以先说说分布式锁,可以使用redis的setnxlua脚本实现,或者也可以用redission实现,或者看门狗机制。 由看门…...
大模型核心运行机制
大模型核心运行机制目录 一、核心架构:Transformer的演进与改进1.1 核心组件包括:1.1.1 自注意力机制(Self-Attention)1.1.2 多头注意力(Multi-Head Attention)1.1.3 位置编码(Positional Encod…...

uniapp跨平台开发HarmonyOS NEXT应用初体验
之前写过使用uniapp开发鸿蒙应用的教程,简单介绍了如何配置开发环境和运行项目。那时候的HbuilderX还是4.22版本,小一年过去了HbuilderX的正式版本已经来到4.64,历经了多个版本的更新后,跨平台开发鸿蒙应用的体验大幅提升。今天再…...
2025软考【系统架构设计师】:两周极限冲刺攻略(附知识点解析+答题技巧)
距离2025上半年“系统架构设计师”考试已经只剩最后两周了,还没有准备好的小伙伴赶紧行动起来。为了帮助大家更好的冲刺学习,特此提供一份考前冲刺攻略。本指南包括考情分析、答题技巧、注意事项三个部分,可以参考此指南进行最后的复习要领&a…...

C语言主要标准版本的演进与核心区别的对比分析
以下是C语言主要标准版本的演进与核心区别的对比分析 K&R C(1978年) 定位:非标准化的原始版本,由Brian Kernighan和Dennis Ritchie定义 特性: 基础语法:函数声明无参数列表(如int func…...
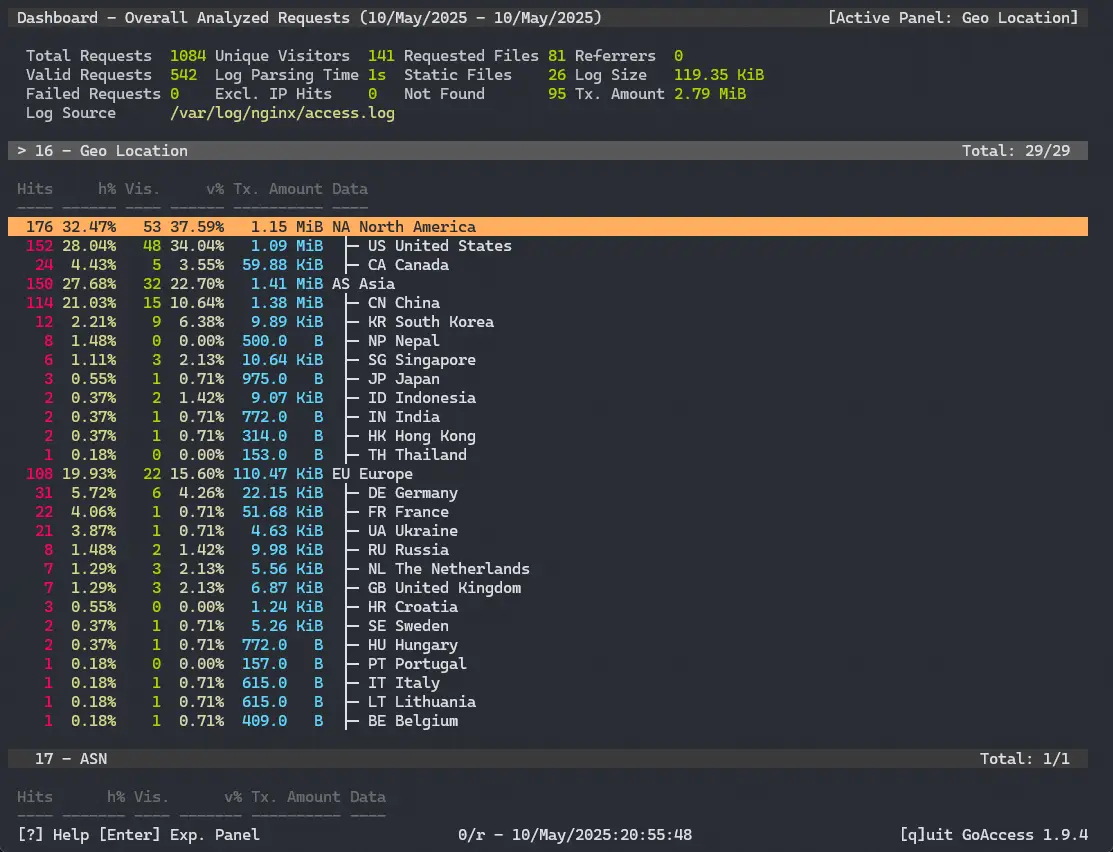
使用 goaccess 分析 nginx 访问日志
介绍 goaccess 是一个在本地解析日志的工具, 可以直接在命令行终端环境中使用 TUI 界面查看分析结果, 也可以导出为更加丰富的 HTML 页面. 官网: https://goaccess.io/ 下载安装 常见的 Linux 包管理器中都包含了 goaccess, 直接安装就行. 以 Ubuntu 为例: sudo apt instal…...

vue3与springboot交互-前后分离【完成登陆验证及页面跳转】
vue3实现与springboot交互【完成登陆及页面跳转】 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是node.js和vue的使用。前后每一小节的内容是存在的有:学习and理解的关联性。【帮帮志系列文章】:…...

【Hot 100】208. 实现 Trie (前缀树)
目录 引言实现 Trie (前缀树)我的解题代码解析代码思路分析优化建议1. 内存泄漏问题2. 使用智能指针优化内存管理3. 输入合法性校验(可选)4. 其他优化 总结 🙋♂️ 作者:海码007📜 专栏:算法专栏…...
【2025最新】Vm虚拟机中直接使用Ubuntu 免安装过程直接使用教程与下载
Ubuntu 是一个基于 Debian 的自由开源 Linux 操作系统,面向桌面、服务器和云计算平台广泛应用。 由英国公司 Canonical Ltd. 维护和发布,Ubuntu 强调易用性、安全性和稳定性,适合个人用户、开发者以及企业部署使用。 Ubuntu 默认使用 GNOME …...

思路解析:第一性原理解 SQL
目录 题目描述 🎯 应用第一性原理来思考这个 SQL 题目 ✅ 第一步:还原每个事件的本质单位 ✅ 第二步:如果一个表只有事件,如何构造事件对? ✅ 第三步:加过滤条件,只保留“同一机器、同一进…...

相机Camera日志分析之八:高通Camx HAL架构opencamera三级日志详解及关键字
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:相机Camera日志分析之七:高通Camx HAL架构opencamera二级日志详解及关键字 这一篇我们开始讲: 相机Camera日志分析之八:高通Camx HAL架构opencamera三级日志详解及关键字 目录 【关注我,后续持续…...
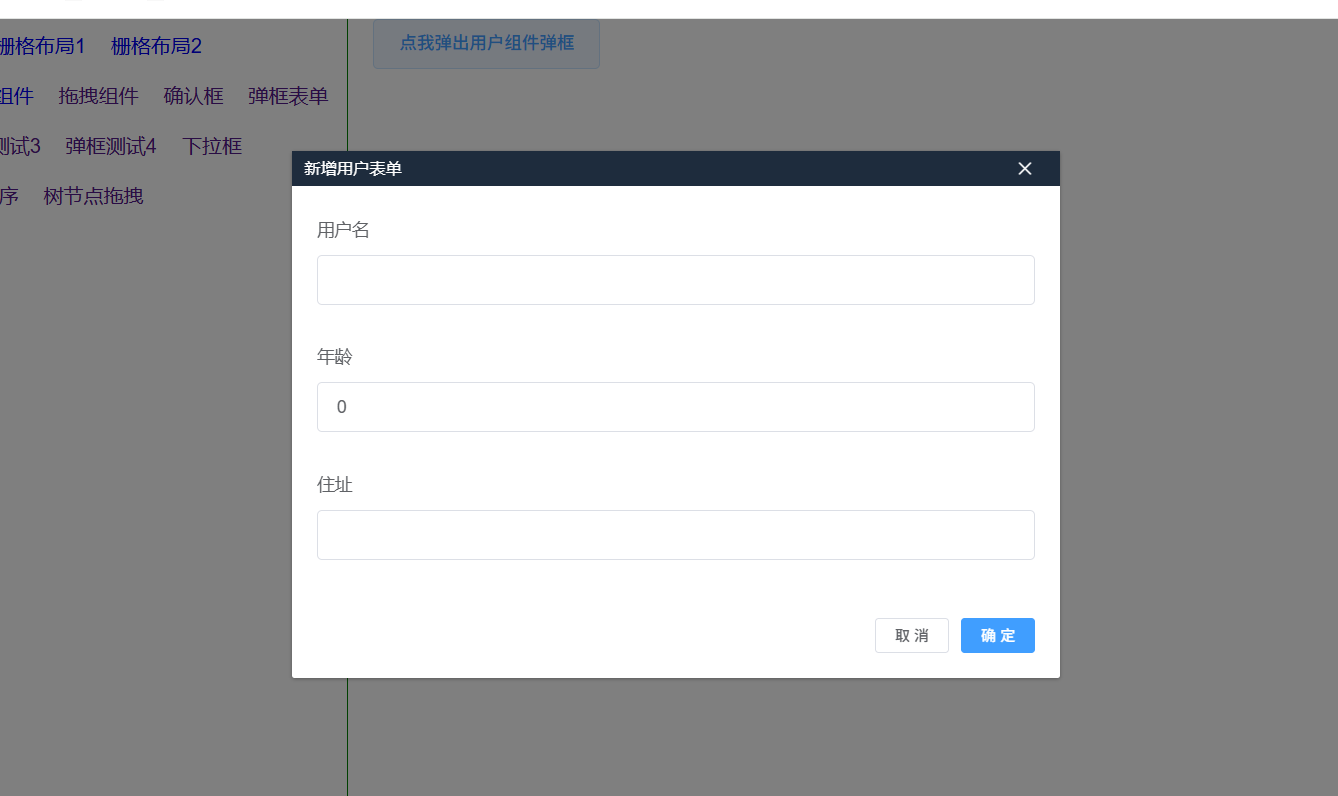
Vue2 elementUI 二次封装命令式表单弹框组件
需求:封装一个表单弹框组件,弹框和表单是两个组件,表单组件以插槽的形式动态传入弹框组件中。 外部组件使用的方式如下: 直接上代码: MyDialog.vue 弹框组件 <template><el-dialog:titletitle:visible.syn…...

Docker入门教程:常用命令与基础概念
目录 简介常用命令Docker 常用命令汇总docker run 命令格式与参数解析 简介 Docker 是一个客户端-服务器(client-server)架构的应用程序,其中包含两个主要组件:Docker 客户端和 Docker 守护进程(也称为 Docker Daemon…...