代码随想录训练营第二十三天| 572.另一颗树的子树 104.二叉树的最大深度 559.N叉树的最大深度 111.二叉树的最小深度
572.另一颗树的子树:
状态:已做出
思路:
这道题目当时第一时间不是想到利用100.相同的树思路来解决,而是先想到了使用kmp,不过这个题目官方题解确实是有kmp解法的,我使用的暴力解法,kmp的大致思路是使用前序遍历整个树的节点,并且要把所有的空子树都考虑进去,不然会出现前序相同树的结构不同的情况,这些节点都放入一个char型数组中,空节点可以任意使用一个字符来表示,做到这一步后就完全是把题目转变为了kmp问题,使用kmp来解决既可,暴力解法的思路:使用和100.相同的树相似的做法,遍历root的每个节点,把每个节点都看成一颗子树,然后这个子树和subRoot使用和100题相同的做法,查看两个树是否相同就能判断出最后的结果了。总体来说暴力解法的时间复杂度是O(n*m),而kmp的时间复杂度优化到O(n+m),n和m分别是root和subRoot的节点树。
代码如下:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public://两颗树进行比较是否相同bool dfs(TreeNode* root,TreeNode* sub) {if(!root && !sub) return true;if(!root || !sub ||(root->val!=sub->val)) return false;//这里的if语句把三种不相等的情况都包含进去了bool a1=dfs(root->left,sub->left);bool a2=dfs(root->right,sub->right);return a1 && a2;//需要左右子树都为真才说明这两个树相同}//这个函数是用来遍历树的每个节点的,让每个子树都和subRoot判断bool Subreturn(TreeNode* left, TreeNode* right) {bool rusult=dfs(left,right);if(rusult) return true;if(left==nullptr) return false;bool a1=Subreturn(left->left,right);bool a2=Subreturn(left->right,right);return a1 || a2;//使用递归来遍历所有root的节点,最后只要有一处子树和sunRoot相同就符合题意}bool isSubtree(TreeNode* root, TreeNode* subRoot) {if(!root) return false;return Subreturn(root,subRoot);}
};遇到的困难:
当时做这道题目一开始以为使用100题的思路是优解,所以没想过暴解,就一直在想使用这个思路怎能去优化解决题目,但是发现一直出现问题,因为这道题要优化时间的话必须要考虑判断出错后怎么去回溯,这就让我想到了kmp,随后看完官方的解法后才知道这到题目使用判断相同数的思路就是暴力解法,必须要每个节点都判断才能得到正确答案,官方题解还给出了一种使用哈希树的解法,听着就你难,所以完全看思路。
收获:
这道题目使用判断是否是相同的数的方法就是暴力,通过练习熟悉一下这种解法,做法和之前的100题几乎一样,这道题目跟字符串求是否有相同子串的思想很像。
104.二叉树的最大深度:
文档讲解:代码随想录|104.二叉树的最大深度
视频讲解:二叉树的高度和深度有啥区别?究竟用什么遍历顺序?很多录友搞不懂 | LeetCode:104.二叉树的最大深度_哔哩哔哩_bilibili
状态:已做出
思路:
这下题目之前我使用层序遍历解决过,这次主要是使用前序和后续来解决这代题目。后序的思路:使用后续就是求根结点的最大高度,我的递归结束条件是节点为空时返回0,每次递归设置两个变量,分别保存这个节点的左右子树的层数有多少,最后去这两者的最大值,最后返回最大值加一,按照这个递归思路打到根结点就能返回最大深度。前序思路:前序是求最深的叶子结点深度。和后序递归不同,递归代码的参数我多设计了一个变量n,用来记录此时的层级,在递归到节点为空后返回n结束递归,每层设置两个变量来保存次节点的左右子树的最大深度,然后去这两个变量的最大值,直接返回最大值就可以了。
后序遍历:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:int dfs(TreeNode* root) {if(root==nullptr) {return 0;//这里返回零是为了从最深的地方开始不断向上回溯来记录高度}int sum1=dfs(root->left);int sum2=dfs(root->right);int n=max(sum1,sum2);//去最大值return ++n;//这里需要把此时的节点考虑进去,所以要加一}int maxDepth(TreeNode* root) {if(!root) return 0;return dfs(root);}
};前序遍历:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:int dfs(TreeNode* root,int n) {if(root==nullptr) {return n;//返回n,因为这里空节点不考虑}int sum1=dfs(root->left,n+1);//每次都要让参数加一,记录层级int sum2=dfs(root->right,n+1);int num=max(sum1,sum2);return num;//这里之所以不加一是因为在遍历后序节点的时候num就已经把加一操作包含进去了,比如如果只有根节点的话,最后不加一也返回深度为1}int maxDepth(TreeNode* root) {if(!root) return 0;return dfs(root,0);}
};遇到的困难:
这道题目使用前后序来做比层序遍历难一点,其中的难点就是难以控制递归的代码,不好记录层级,首先后序我使用递归返回0的方式是为了考虑最后节点为空的那一层,随后使用两个变量分别保存左右子树的最大深度,就是没一层每一层的递归来找到最后根结点的最大深度的,这个点就是是递归抽象的地方,需要由深到浅来思考,不然就会想错,最后返回的最大值我多加了1是为了把这一层考虑进去,因为左右子节点的最大高度都求出了,最后要加上这一次的层级返回。前序递归结束返回n是因为我在每层都讲n累加了,所以直接返回n就行了,下面的两个变量的递归传入n+1就是累加层级,最后和后序一样返回最大值,这里不和后序一样返回最大值加一是因为在左右子树递归后判断的最大值就已经把这一层级考虑进去了,所以直接返回。
收获:
这道题目使用层序遍历比递归方法要简单,主要是层序好理解,递归还是有点抽象,这道题对加深递归理想有一定的帮助,相比前中后序的简单递归,这道题目需要更加了解递归的规则才能合理分配出层级或者高度的改变。
559.N叉树的最大深度 :
文档讲解:代码随想录|104.二叉树的最大深度
状态:已做出
思路:
这道题目和上一道求二叉树最大深度一样,我使用了前序后序和层序三种遍历方式去实现了这道题目。这里后序实现最后结束递归是返回的1,因为这里二叉树后序不一样,二叉树可以递归到空节点,但是N叉树不能,所以这里返回后必须要把这一层考虑进去,所以返回放是1,随后的操作二叉树的就差不多了,就是要使用循环来一直遍历一个节点的所有节点,每次循环记比较大小,保存这些节点的最大值,最后好和二叉树思想一样,返回最大值加一。前序则和二叉树放最大深度求法没太大的区别,直接改成循环遍历所有直接点既可。层序遍历相比于递归就简单多了,层序遍历所有节点,记录每层层级最后返回就可以了。
后序遍历:
/*
// Definition for a Node.
class Node {
public:int val;vector<Node*> children;Node() {}Node(int _val) {val = _val;}Node(int _val, vector<Node*> _children) {val = _val;children = _children;}
};
*/class Solution {
public:int dfs(Node* root) {if(!root->children.size()) return 1;//这里是返回1,因为最后是遇到叶子节点才结束递归,要算上叶子节点int ans=0;//这里和而二叉树不同,需要循环遍历所有子节点。其他和二叉树的思路差不多for(int i=0;i<root->children.size();++i) {int sum=dfs(root->children[i]);ans=max(sum,ans);}return ans+1;//算上此节点层级}int maxDepth(Node* root) {if(!root) return 0;return dfs(root);}
};前序遍历:
/*
// Definition for a Node.
class Node {
public:int val;vector<Node*> children;Node() {}Node(int _val) {val = _val;}Node(int _val, vector<Node*> _children) {val = _val;children = _children;}
};
*/class Solution {
public:int dfs(Node* root,int n) {if(!root->children.size()) return n;//这里在递归参数就考虑到了加一的情况,所以直接返回nint ans=0;for(int i=0;i<root->children.size();++i) {int sum=dfs(root->children[i],n+1);ans=max(sum,ans);}return ans;}int maxDepth(Node* root) {if(!root) return 0;return dfs(root,1);}
};层序遍历:
/*
// Definition for a Node.
class Node {
public:int val;vector<Node*> children;Node() {}Node(int _val) {val = _val;}Node(int _val, vector<Node*> _children) {val = _val;children = _children;}
};
*/class Solution {
public:int maxDepth(Node* root) {if(!root) return 0;queue<Node*>qu;qu.push(root);int n=0;while(!qu.empty()) {int size=qu.size();++n;//每一层都要加上层级for(int i=0;i<size;++i) {Node* temp=qu.front();qu.pop();for(int j=0;j<temp->children.size();++j) {qu.push(temp->children[j]);}}}return n;}
};遇到的困难:
这道题目难点就是N叉树有多个节点,需要在递归和层序遍历里面设置一个循环来遍历所有结点,还有一点就是N叉树因为不会递归到空节点,所以后序需要对代码进行一点细节的改善。
收获:
这道题目就是二叉树的进阶,和二叉树的求法没太大区别,练习能进一步理解二叉树的代码思路。
111.二叉树的最小深度:
文档讲解:代码随想录|111.二叉树的最小深度
视频讲解:看起来好像做过,一写就错! | LeetCode:111.二叉树的最小深度_哔哩哔哩_bilibili
状态:已做出
思路:
这道题目使用层序我之前做过,这次主要是使用前序和后序的递归来实现,这道题目我觉得使用递归实现起来比求最大深度还要麻烦一点,这里容易出错的问题文档中有明确说明,就是不明确处理叶子结点就会出现误判,比如根结点的左子树为空时,不管右子树是否为空最后出现的最小深度都是1。这道题的具体要求是要我们求根结点到最浅层级的深度有多大,所以递归的结束条件我这里设置的是到叶子节点后结束递归,后序为了考虑这一层所以返回1,前序我这里在递归里设置了一个参数n来记录层级,和二叉树的思路有点点相似,每到一层就n+1。不管是后序还是前序都先设置两个变量,并让变量指向int最大值,因为每次都需要比较取最小值,而且每次递归都要判断此节点做右子树必须是非空才能进行递归,这样是为了不出现考虑空节点层级的情况。
代码如下:
后序遍历:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:int dfs(TreeNode* root) {if(!root->left && !root->right) return 1;int sum1=INT_MAX,sum2=INT_MAX;//这里先设置两个变量为最大值,因为下面的递归困难会因为子节点为空而不会改变变量的值//这里是为了避免文档所说的错误,所以设置了if语句if(root->left)sum1=dfs(root->left);if(root->right)sum2=dfs(root->right);return min(sum1,sum2)+1;}int minDepth(TreeNode* root) {if(!root) return 0;return dfs(root);}
};前序遍历:
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:int dfs(TreeNode* root,int n) {if(!root->left && !root->right) return n;//叶子节点就直接返回结束递归int sum1=INT_MAX,sum2=INT_MAX;if(root->left)sum1=dfs(root->left,n+1);if(root->right)sum2=dfs(root->right,n+1);return min(sum1,sum2);}int minDepth(TreeNode* root) {if(!root) return 0;return dfs(root,1);//这里设置为1是直接先把根节点考虑进去了}
};遇到的困难:
使用层序遍历求最小比求最大要简单,没想到使用递归却相反,求最小反而细节处更多。
收获:
以上这些题目主要都是使用递归去实现的,主要是提升对递归的掌握成程度。
相关文章:

代码随想录训练营第二十三天| 572.另一颗树的子树 104.二叉树的最大深度 559.N叉树的最大深度 111.二叉树的最小深度
572.另一颗树的子树: 状态:已做出 思路: 这道题目当时第一时间不是想到利用100.相同的树思路来解决,而是先想到了使用kmp,不过这个题目官方题解确实是有kmp解法的,我使用的暴力解法,kmp的大致思…...

单向循环链表C语言实现实现(全)
#include<stdio.h> #include<stdlib.h> #define TRUE 1 #define FASLE 0//定义宏标识判断是否成功 typedef struct Node {int data;struct Node* next; }Node;Node* InitList() {Node* list (Node*)malloc(sizeof(Node));list->data 0;//创建节点保存datalist…...
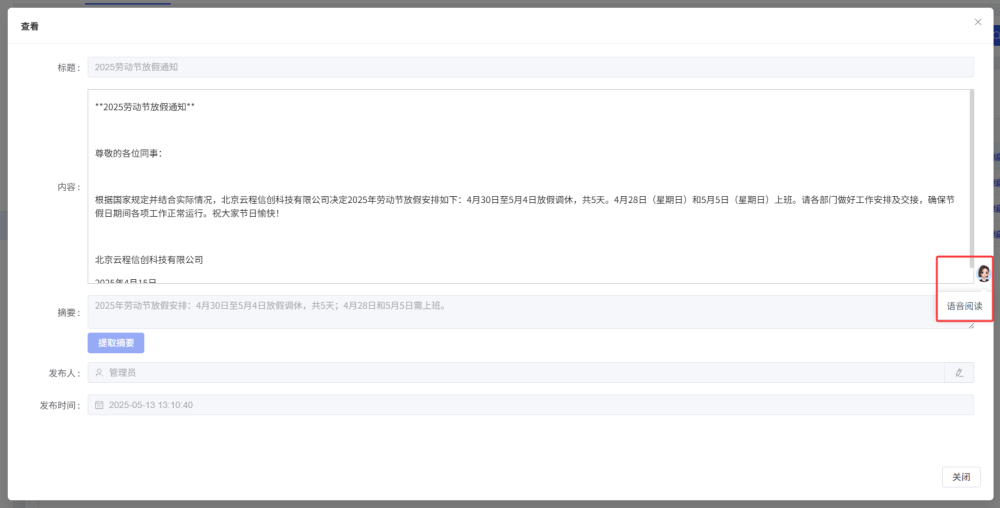
【AI大模型】赋能【传统业务】
在数字化转型的浪潮下,传统业务流程(如通知公告管理、文档处理等)仍依赖人工操作,面临效率低、成本高、易出错等问题。以企业通知公告为例,从内容撰写、摘要提炼到信息分发,需耗费大量人力与时间࿰…...

Clion内置宏$PROJECT_DIR$等
CLion 内置宏 文章目录 CLion 内置宏通用路径相关宏路径相对化宏 官方文档地址: https://www.jetbrains.com/help/clion/built-in-macros.html 通用路径相关宏 宏名称含义说明示例$WORKSPACE_DIR$当前项目所属的工作区根目录路径。/home/user/workspace$PROJECT_D…...

团结引擎开源车模 Sample 发布:光照渲染优化 动态交互全面体验升级
光照、材质与交互效果的精细控制,通常意味着复杂的技术挑战,但借助 Shader Graph 14.1.0(已内置在团结引擎官方 1.5.0 版本中),这一切都变得简单易用。通过最新团结引擎官方车模 Sample,开发者能切身感受到全新光照优化与编辑功能…...

hghac8008漏洞扫描处理
文章目录 环境文档用途详细信息相关文档 环境 系统平台:Linux x86-64 Red Hat Enterprise Linux 7 版本:4.5.10 文档用途 本文只要用于在客户提出hghac8008端口漏洞时,如何进行漏洞处理,本文章的方法已经应用于浪潮云ÿ…...

PyQt5教程:QComboBox下拉列表框的全面解析与实战应用
QComboBox概述 QComboBox是PyQt5中一个集按钮和下拉选项于一体的控件,通常被称为下拉列表框或组合框。它允许用户从预定义的选项列表中选择一个值,是GUI开发中最常用的输入控件之一。 主要特点: 紧凑的界面设计,节省屏幕空间提…...

GAN简读
Abstract 我们提出了一个通过同时训练两个模型的对抗过程来评估生成模型的新框架:一个生成模型 G G G用来捕捉数据特征,还有一个用于估计这个样本是来自训练样本还是 G G G的概率的判别模型 D D D, G G G的训练过程是最大化 D D D犯错的概率。这个框架就相当于一个minimax tw…...

精准测量“双雄会”:品致与麦科信光隔离探头谁更胜一筹
在电子技术飞速发展的当下,每一次精准测量都如同为科技大厦添砖加瓦。光隔离探头作为测量领域的关键角色,能有效隔绝电气干扰,保障测量安全与精准。在众多品牌中,PINTECH品致与麦科信的光隔离探头脱颖而出,成为工程师们…...
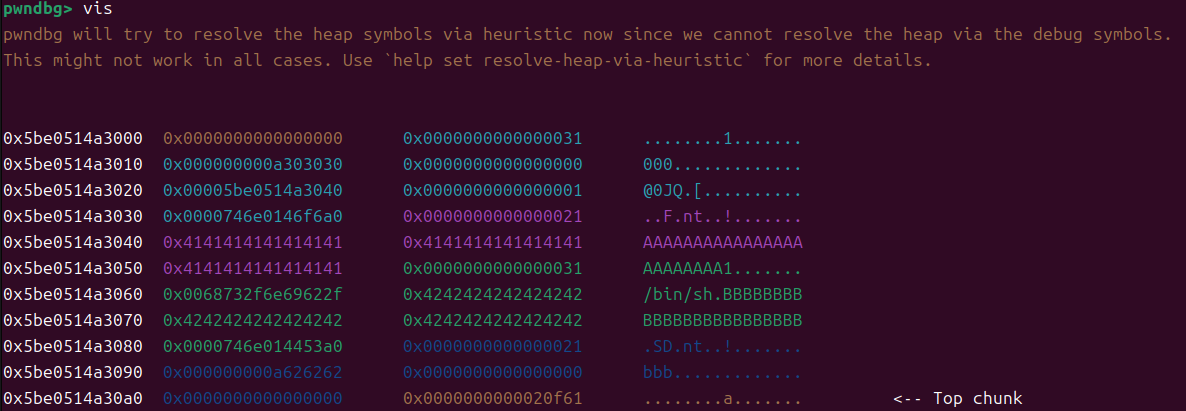
NSSCTF [HNCTF 2022 WEEK4]
题解前的吐槽:紧拖慢拖还是在前段时间开始学了堆的UAF(虽然栈还没学明白,都好难[擦汗]),一直觉得学的懵懵懂懂,不太敢发题解,这题算是入堆题后一段时间的学习成果,有什么问题各位师傅可以提出来,…...

Step1
项目 SchedulerSim 已搭建完成 ✅ ⸻ ✅ 你现在拥有的: • 🔧 两种调度器(Round Robin SJF) • 📦 模拟进程类 Process • 🧱 清晰结构:OOP 风格 便于扩展 • ✍️ 主函数已演示调度器运行效…...
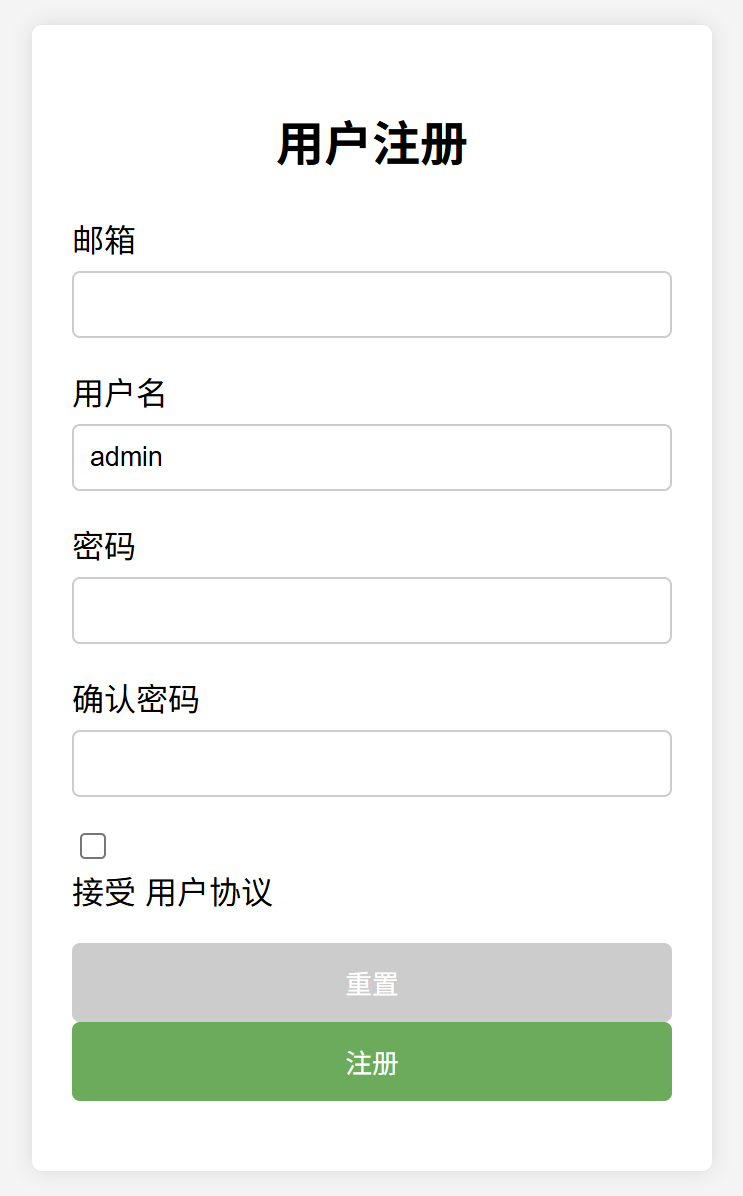
tornado_登录页面(案例)
目录 1.基础知识编辑 2.脚手架(模版) 3.登录流程图(processon) 4.登录表单 4.1后(返回值)任何值:username/password (4.1.1)app.py (4.1.2ÿ…...
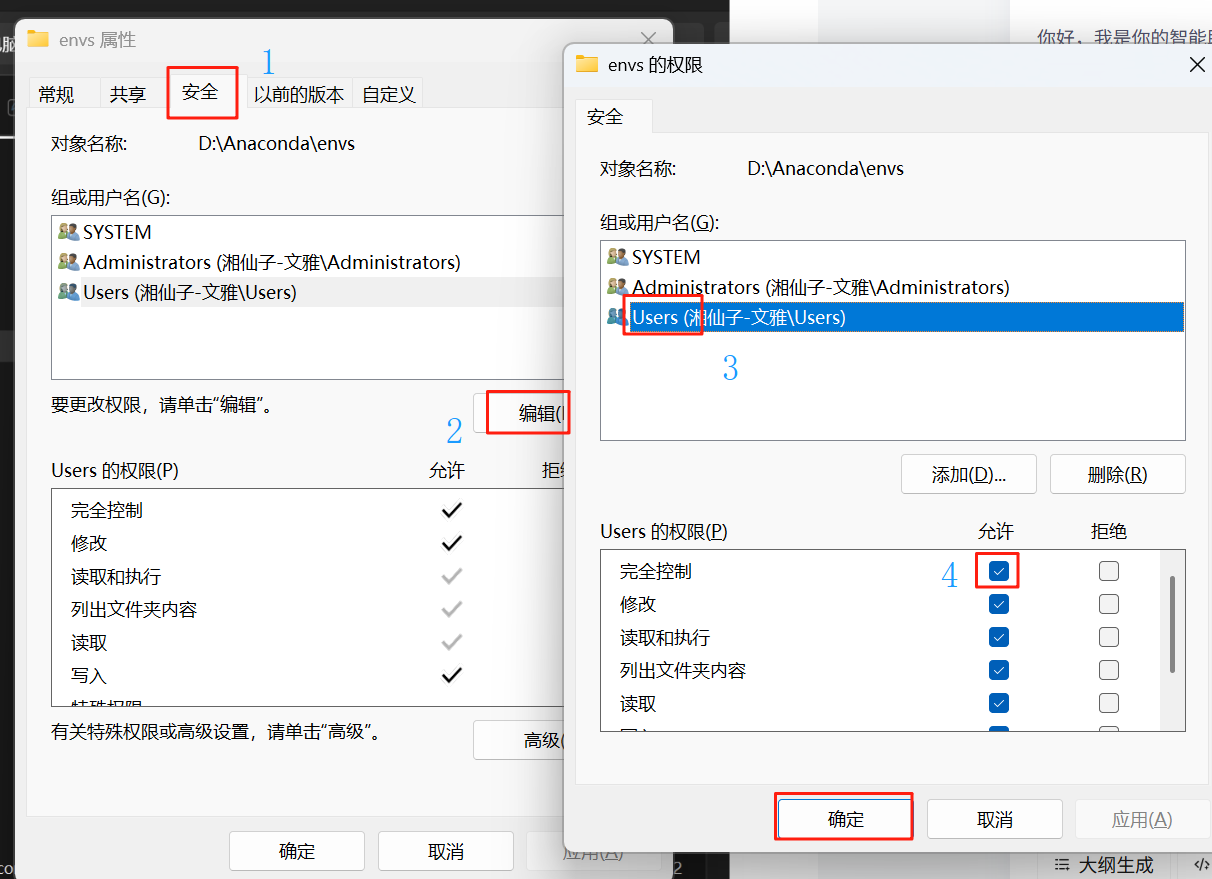
YOLOv12模型部署(保姆级)
一、下载YOLOv12源码 1.通过网盘分享的文件:YOLOv12 链接: https://pan.baidu.com/s/12-DEbWx1Gu7dC-ehIIaKtQ 提取码: sgqy (网盘下载) 2.进入github克隆YOLOv12源码包 二、安装Anaconda/pycharm 点击获取官网链接(anaconda) 点击获取…...
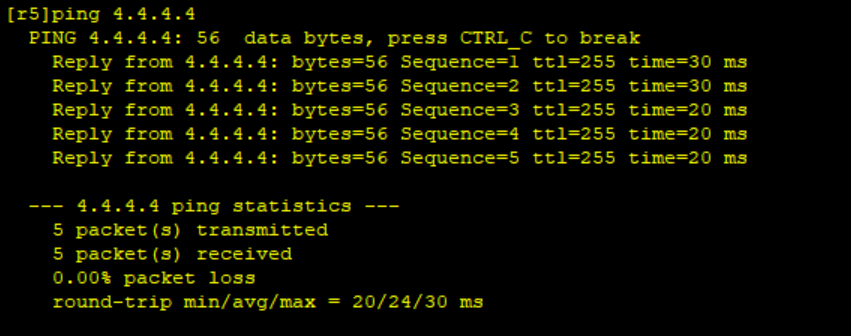
BGP实验练习1
需求: 要求五台路由器的环回地址均可以相互访问 需求分析: 1.图中存在五个路由器 AR1、AR2、AR3、AR4、AR5,分属不同自治系统(AS),AR1 在 AS 100,AR2 - AR4 在 AS 200,AR5 在 AS …...

Three.js知识框架
一、Three.js 基础概念 1. Three.js 简介 是什么? 基于 WebGL 的 3D JavaScript 库,用于在浏览器中渲染 3D 场景。 核心优势 简化 WebGL 的复杂 API,提供高层封装。 跨平台(支持桌面和移动端)。 适用场景 3D 可视…...

AWS技术助力企业满足GDPR合规要求
GDPR(通用数据保护条例)作为欧盟严格的数据保护法规,给许多企业带来了合规挑战。本文将探讨如何利用AWS(亚马逊云服务)的相关技术来满足GDPR的核心要求,帮助企业实现数据保护合规。 一、GDPR核心要求概览 GDPR的主要目标是保护欧盟公民的个人数据和隐私权。其核心要求包括: 数…...

HTML、CSS 和 JavaScript 基础知识点
HTML、CSS 和 JavaScript 基础知识点 一、HTML 基础 1. HTML 文档结构 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.…...
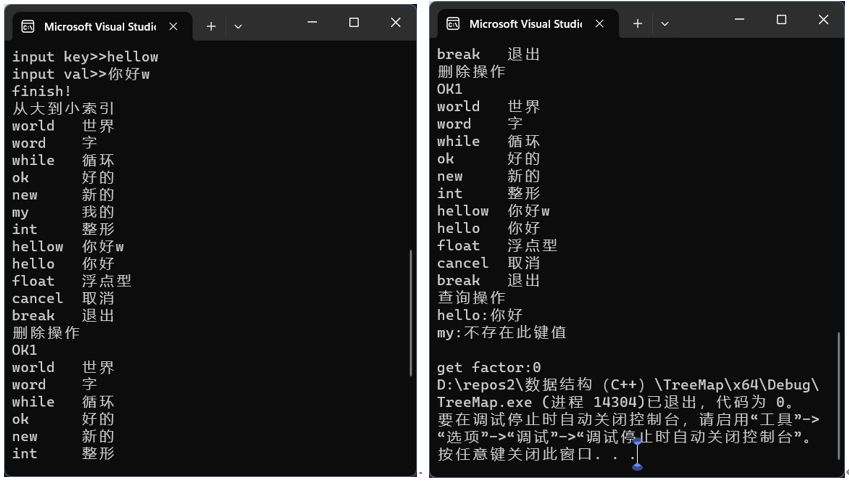
数据结构与算法分析实验12 实现二叉查找树
实现二叉查找树 1、二叉查找树介绍2.上机要求3.上机环境4.程序清单(写明运行结果及结果分析)4.1 程序清单4.1.1 头文件 TreeMap.h 内容如下:4.1.2 实现文件 TreeMap.cpp 文件内容如下:4.1.3 源文件 main.cpp 文件内容如下: 4.2 实现展效果示5…...
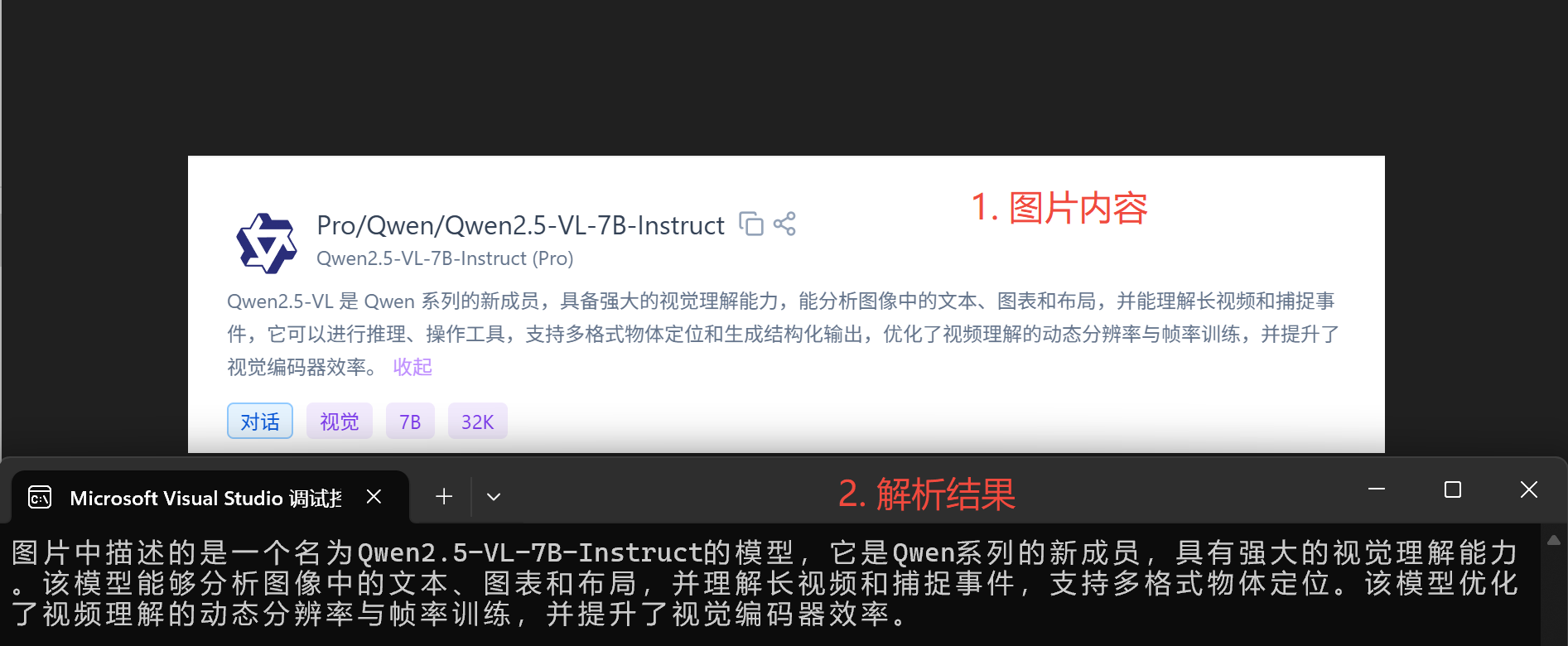
使用 Semantic Kernel 调用 Qwen-VL 多模态模型
使用 Semantic Kernel 调用 Qwen-VL 多模态模型 一、引言 随着人工智能技术的不断发展,多模态模型逐渐成为研究的热点。Qwen-VL 是阿里云推出的大规模视觉语言模型,支持图像、文本等多种输入形式,并能够进行图像描述、视觉问答等多种任务。…...

请求内存算法题
题意描述 有两个数组输入: mem [32,128,64,192,256]表示有数组长度个设备,每个设备能提供分配的内存大小值(均为4的倍数),数组最大长度200000 reques [64,128,128,128,512]表示请求内存,在mem中找与请求内存大小最相近或相等的…...

(4)python开发经验
文章目录 1 使用ctypes库调用2 使用pybind11 更多精彩内容👉内容导航 👈👉Qt开发 👈👉python开发 👈 1 使用ctypes库调用 说明:ctypes是一个Python内置的库,可以提供C兼容的数据类型…...

深度剖析 GpuGeek 实例:GpuGeek/Qwen3-32B 模型 API 调用实践与性能测试洞察
深度剖析 GpuGeek 实例:GpuGeek/Qwen3-32B 模型 API 调用实践与性能测试洞察 前言 GpuGeek专注于人工智能与高性能计算领域的云计算平台,致力于为开发者、科研机构及企业提供灵活、高效、低成本的GPU算力资源。平台通过整合全球分布式数据中心资源&#…...

MindSpore框架学习项目-ResNet药物分类-数据增强
目录 1.数据增强 1.1设置运行环境 1.1.1数据预处理 数据预处理代码解析 1.1.2数据集划分 数据集划分代码说明 1.2数据增强 1.2.1创建带标签的可迭代对象 1.2.2数据预处理与格式化(ms的data格式) 从原始图像数据到 MindSpore 可训练 / 评估的数…...

e.g. ‘django.db.models.BigAutoField‘.
在Django框架中,django.db.models.BigAutoField 是一个用于数据库模型的字段类型,它用于自动增长的ID字段。这个字段类型特别适用于需要处理大量数据的应用,比如在大型网站或应用中,普通的 AutoField 可能不足以存储增长的ID值&am…...

ACM算法
在ACM模式下使用JavaScript/TypeScript获取输入值 在ACM编程竞赛或在线判题系统(如LeetCode、牛客网等)中,JavaScript/TypeScript需要特定的方式来获取输入值。以下是几种常见的获取输入的方法: 1. 使用Node.js的readline模块 这是最常见的处理ACM模式…...

MySQL入门指南:环境搭建与服务管理全流程
引言 各位开发者朋友们好!今天我们将开启MySQL的学习之旅 🌟 作为世界上最流行的开源关系型数据库,MySQL在Web应用、企业系统等领域占据着举足轻重的地位。无论你是刚入行的新手,还是想系统复习的老鸟,这篇教程都将为…...

【MySQL】别名设置与使用
个人主页:Guiat 归属专栏:MySQL 文章目录 1. 别名基础概念2. 列别名设置2.1 基础语法2.2 特殊字符处理2.3 计算字段示例 3. 表别名应用3.1 基础表别名3.2 自连接场景 4. 高级别名技术4.1 子查询别名4.2 CTE别名 5. 别名执行规则5.1 作用域限制5.2 错误用…...

【内网渗透】——S4u2扩展协议提权以及KDC欺骗提权
【内网渗透】——S4u2扩展协议提权以及KDC欺骗提权 文章目录 【内网渗透】——S4u2扩展协议提权以及KDC欺骗提权[toc]一:Kerberos 委派攻击原理之 S4U2利用1.1原理1.2两种扩展协议**S4U2Self (Service for User to Self)****S4U2Proxy (Service for User to Proxy)*…...

枢轴支压点策略
一种基于枢轴点(Pivot Point)的交易策略,主要用于在趋势行情中进行交易。 策略的核心思路是通过计算前一天的最高价、最低价和收盘价来确定当天的枢轴点,并据此计算出第一和第二阻力位以及第一和第二支撑位。 可以根据这些关键点位…...

Manus逆向工程:AI智能体的“思考”与“行动”
写在前面 本篇博客将基于 Manus 测试的行为日志,尝试反向推演其内部的核心逻辑。我们将探讨它如何巧妙地融合了计划-执行(Plan-Execute) 和 ReAct(Reasoning and Acting,即思考与行动) 两种范式,并灵活运用浏览器和 Python 解释器等工具来攻克复杂任务。 基本逻辑:从…...