MindSpore框架学习项目-ResNet药物分类-数据增强
目录
1.数据增强
1.1设置运行环境
1.1.1数据预处理
数据预处理代码解析
1.1.2数据集划分
数据集划分代码说明
1.2数据增强
1.2.1创建带标签的可迭代对象
1.2.2数据预处理与格式化(ms的data格式)
从原始图像数据到 MindSpore 可训练 / 评估的数据集的完整构建流程
1.2.3加载数据
加载数据代码说明
1.2.4类别标签说明
1.3数据可视化
数据可视化代码说明
本项目可以在华为云modelart上租一个实例进行,也可以在配置至少为单卡3060的设备上进行
https://console.huaweicloud.com/modelarts/
Ascend环境也适用,但是注意修改device_target参数
需要本地编译器的一些代码传输、修改等可以勾上ssh远程开发
说明:项目使用的数据集来自华为云的数据资源。项目以深度学习任务构建的一般流程展开(数据导入、处理 > 模型选择、构建 > 模型训练 > 模型评估 > 模型优化)。
主线为‘一般流程’,同时代码中会标注出一些要点(# 要点1-1-1:设置使用的设备
)作为支线,帮助学习mindspore框架在进行深度学习任务时一些与pytorch的差异。
可以只看目录中带数字标签的部分来快速查阅代码。
本系列
MindSpore框架学习项目-ResNet药物分类-数据增强-CSDN博客
MindSpore框架学习项目-ResNet药物分类-构建模型-CSDN博客
MindSpore框架学习项目-ResNet药物分类-模型训练-CSDN博客
MindSpore框架学习项目-ResNet药物分类-模型评估-CSDN博客
MindSpore框架学习项目-ResNet药物分类-模型优化-CSDN博客
1.数据增强
1.1设置运行环境
要求:设置执行设备为GPU mindspore还支持CPU/Ascend
import mindspore# 要点1-1-1:设置使用的设备
mindspore.set_context(device_target='GPU') # CPU/Ascend
print(mindspore.get_context(attr_key='device_target'))这里返回GPU
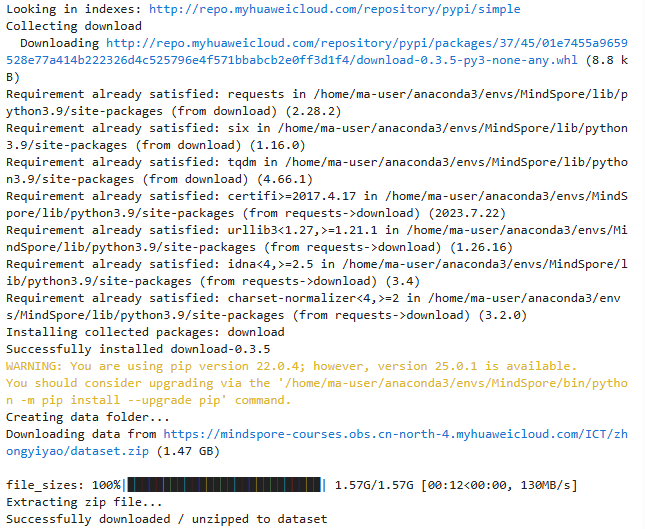
# 下载数据
!pip install download
from download import download
import os
url = "https://mindspore-courses.obs.cn-north-4.myhuaweicloud.com/ICT/zhongyiyao/dataset.zip"
if not os.path.exists("dataset"):
download(url, "dataset", kind="zip")
1.1.1数据预处理
原图片尺寸为4k比较大,预处理将图片resize到1000*1000
from PIL import Image
import numpy as np
data_dir = "dataset/zhongyiyao/zhongyiyao"
new_data_path = "dataset1/zhongyiyao"
if not os.path.exists(new_data_path):for path in ['train','test']:
data_path = data_dir + "/" + path
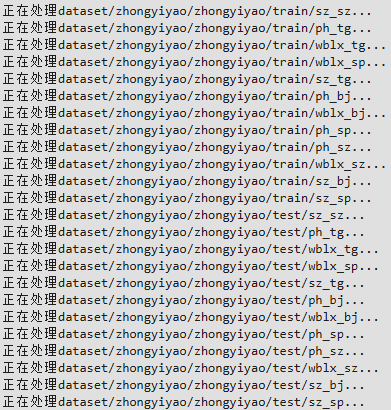
classes = os.listdir(data_path)for (i,class_name) in enumerate(classes):
floder_path = data_path+"/"+class_nameprint(f"正在处理{floder_path}...")for image_name in os.listdir(floder_path):try:
image = Image.open(floder_path + "/" + image_name)
image = image.resize((1000,1000))
target_dir = new_data_path+"/"+path+"/"+class_nameif not os.path.exists(target_dir):
os.makedirs(target_dir)if not os.path.exists(target_dir+"/"+image_name):
image.save(target_dir+"/"+image_name)except:pass
数据预处理代码解析
1. 核心功能
将原始数据集(dataset/zhongyiyao/zhongyiyao)中的图像按类别整理到新路径(dataset1/zhongyiyao),统一图像尺寸为1000×1000,并跳过损坏文件,为后续模型训练准备标准格式数据。
2. 关键代码说明
(1) 数据目录初始化
data_dir = "dataset/zhongyiyao/zhongyiyao" # 原始数据集根目录(含train/test子目录)
new_data_path = "dataset1/zhongyiyao" # 目标数据集根目录(整理后的数据存放路径)
作用:定义原始数据路径和目标路径,确保后续处理围绕固定目录展开。
项目意义:统一数据入口 / 出口路径,避免硬编码,方便后续数据集加载(如 MindSpore 的ds.ImageFolderDataset要求类别子目录结构)。
(2) 遍历原始数据目录
for path in ['train','test']: # 处理训练集和测试集
data_path = data_dir + "/" + path # 拼接原始数据路径(如dataset/zhongyiyao/zhongyiyao/train)
classes = os.listdir(data_path) # 获取类别目录(如"ph_sp"、"sz_bj"等中药材类别)
逻辑:按 “数据集类型(train/test)→ 类别→ 图像” 三级结构遍历,符合图像分类任务的标准数据组织格式(类别作为子目录)。
MindSpore 关联:MindSpore 的ds.ImageFolderDataset要求数据按[root]/[split]/[class]/[image]结构存储,此处代码直接生成该格式,便于后续数据集加载。
(3) 图像尺寸统一与保存
image = Image.open(floder_path + "/" + image_name) # 读取图像
image = image.resize((1000, 1000)) # 统一尺寸(模型输入预处理第一步)
target_dir = new_data_path+"/"+path+"/"+class_name # 目标路径(如dataset1/zhongyiyao/train/ph_sp)
os.makedirs(target_dir, exist_ok=True) # 创建目标类别目录(自动处理多级目录)
image.save(target_dir+"/"+image_name) # 保存处理后的图像
核心操作:尺寸统一:深度学习模型要求输入图像尺寸一致,先调整为 1000×1000(后续可在数据管道中进一步缩放到模型所需尺寸,如 224×224)。
目录创建:exist_ok=True避免重复创建目录报错,确保鲁棒性。
(4) 损坏文件处理
try:# 图像读取、处理、保存逻辑
except:pass # 跳过无法读取的损坏文件(数据清洗关键步骤)
作用:避免因个别损坏图像导致整个数据处理流程中断,确保数据集的可用性(训练时若遇到损坏文件会直接报错,预处理阶段清洗可提前规避)。
3. 在项目中的定位(深度学习流程)
阶段:数据导入与预处理(项目的基础环节,直接影响模型训练效果)。
目标:整理数据目录结构,适配 MindSpore 的ds.ImageFolderDataset加载格式。
统一图像尺寸,完成基础数据清洗(过滤损坏文件),为后续数据增强(如随机裁剪、翻转)和模型输入做准备。
4. 与 MindSpore 的关联(框架差异支线)
数据加载适配:
MindSpore 的数据集加载接口(如ds.ImageFolderDataset)依赖 “类别子目录” 结构,此处代码生成的dataset1/zhongyiyao/train/[class]格式可直接被识别,无需额外转换。预处理灵活性:
图像尺寸可在 MindSpore 数据管道中动态调整(如ds.vision.Resize((224, 224))),此处预处理阶段统一为 1000×1000 是为了标准化原始数据,后续可通过管道灵活处理。
1.1.2数据集划分
导入sklearn(机器学习库)的model_selection模块的数据集划分方法train_test_split;
shutil是 Python 的标准库,主要用于文件和目录的高级操作,如文件复制、移动、删除,以及目录的递归操作等。
from sklearn.model_selection import train_test_split
import shutil
定义数据集切分函数,符合python函数式编程的范式,也方便代码复用
def split_data(X, y, test_size=0.2, val_size=0.2, random_state=42):
"""将数据集划分为训练集、验证集和测试集
"""# 先以8:2的比例划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=random_state)# 再从训练集中抽取 25% 作为验证集
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=val_size/(1-test_size), random_state=random_state) return X_train, X_val, X_test, y_train, y_val, y_test
定义数据的目标路径和数据存储的结构
data_dir = "dataset1/zhongyiyao"
floders = os.listdir(data_dir)
target = ['train','test','valid']
判断不同情况下需要进行的文件系统操作
if set(floders) == set(target):pass
elif 'train' in floders:
floders = os.listdir(data_dir)
new_data_dir = os.path.join(data_dir,'train')
classes = os.listdir(new_data_dir)# 不要让ipython的缓存文件在数据集里,会影响到训练环节if '.ipynb_checkpoints' in classes:
classes.remove('.ipynb_checkpoints')# 图像识别项目 数据为图片imgs和标签labels
imgs = []
labels = []for (i,class_name) in enumerate(classes):
new_path = new_data_dir+"/"+class_name# 逐张添加图片、标签(保持两者的对应关系)for image_name in os.listdir(new_path):
imgs.append(image_name)
labels.append(class_name) imgs_train,imgs_val,labels_train,labels_val = X_train, X_test, y_train, y_test = train_test_split(imgs, labels, test_size=0.2, random_state=42)print("划分训练集图片数:",len(imgs_train))print("划分验证集图片数:",len(imgs_val)) target_data_dir = os.path.join(data_dir,'valid')if not os.path.exists(target_data_dir):
os.mkdir(target_data_dir)for (img,label) in zip(imgs_val,labels_val):
source_path = os.path.join(data_dir,'train',label)
target_path = os.path.join(data_dir,'valid',label)if not os.path.exists(target_path):
os.mkdir(target_path)
source_img = os.path.join(source_path,img)
target_img = os.path.join(target_path,img)
shutil.move(source_img,target_img)else:
phones = os.listdir(data_dir)
imgs = []
labels = []for phone in phones:
phone_data_dir = os.path.join(data_dir,phone)
yaowu_list = os.listdir(phone_data_dir)for yaowu in yaowu_list:
yaowu_data_dir = os.path.join(phone_data_dir,yaowu)
chengdu_list = os.listdir(yaowu_data_dir)for chengdu in chengdu_list:
chengdu_data_dir = os.path.join(yaowu_data_dir,chengdu)for img in os.listdir(chengdu_data_dir):
imgs.append(img)
label = ' '.join([phone,yaowu,chengdu])
labels.append(label)
imgs_train, imgs_val, imgs_test, labels_train, labels_val, labels_test = split_data(imgs, labels, test_size=0.2, val_size=0.2, random_state=42)
img_label_tuple_list = [(imgs_train,labels_train),(imgs_val,labels_val),(imgs_test,labels_test)]for (i,split) in enumerate(spilits):
target_data_dir = os.path.join(data_dir,split)if not os.path.exists(target_data_dir):
os.mkdir(target_data_dir)
imgs_list,labels_list = img_label_tuple_list[i]for (img,label) in zip(imgs_list,labels_list):
label_split = label.split(' ')
source_img = os.path.join(data_dir,label_split[0],label_split[1],label_split[2],img)
target_img_dir = os.path.join(target_data_dir,label_split[1]+"_"+label_split[2])if not os.path.exists(target_img_dir):
os.mkdir(target_img_dir)
target_img = os.path.join(target_img_dir,img)
shutil.move(source_img,target_img)
数据集划分代码说明
这段代码主要功能是将原始图片数据按比例划分为训练集(train)、验证集(valid)、测试集(test),并自动整理文件目录结构。
核心目标
将原始图片数据按比例(默认测试集20%、验证集20%)划分到`train`、`valid`、`test`三个子目录中,解决不同原始目录结构下的数据整理问题,方便后续机器学习模型的训练与评估
代码结构与关键逻辑
代码分为数据划分函数和目录结构处理逻辑两部分:
数据划分函数 `split_data`
def split_data(X, y, test_size=0.2, val_size=0.2, random_state=42):
"""将数据划分为训练集、验证集、测试集"""
# 第一步:划分训练集和测试集(test_size=0.2)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=random_state)
# 第二步:从训练集中划分验证集(val_size/(1-test_size) 是因为验证集占原数据的20%,但此时训练集剩余80%)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=val_size/(1-test_size), random_state=random_state)
return X_train, X_val, X_test, y_train, y_val, y_test
输入:特征数据`X`(图片路径列表)、标签数据`y`(标签列表)、测试集比例`test_size`(默认20%)、验证集比例`val_size`(默认20%)。
输出:训练集、验证集、测试集的特征与标签(共6个集合)。
逻辑:先划分出测试集(占整体20%),再从剩余训练集中划分验证集(占整体20%,因此实际从训练集的80%中取20%/80%=25%)。
实际比例计算:初始训练集占原数据的 80%(即1-test_size=0.8)。
第二次划分时,test_size=val_size/(1-test_size)=0.2/0.8=0.25,即从 80% 的训练集中再抽取 25% 作为验证集。
最终验证集占原数据的比例为:0.8×0.25=0.2(即 20%)。
因此,实际划分比例为 原数据的 60%(训练集):20%(验证集),而非注释中的 “6:2”(60%:20% 是整体比例,而非 “训练集中的 6:2”)。
最终划分比例
正确比例:训练集:60%(原数据的 60%)
验证集:20%(原数据的 20%,来自第一次划分后的训练集)
测试集:20%(原数据的 20%)
目录结构处理逻辑
代码根据原始数据集的目录结构不同,分3种情况处理:
情况1:目录已包含标准划分(train/test/valid)
if set(floders) == set(target):
pass # 无需处理,直接跳过
如果原始目录`dataset1/zhongyiyao`下已经有`train`(训练集)、`test`(测试集)、`valid`(验证集)三个子目录,直接跳过处理
情况2:目录包含train但缺少valid/test
elif 'train' in floders:
# 步骤1:收集训练集中的所有图片和标签
new_data_dir = os.path.join(data_dir,'train') # 原始训练集路径
classes = os.listdir(new_data_dir) # 类别(如不同中药材)
classes.remove('.ipynb_checkpoints') # 移除Jupyter临时文件
imgs = [] # 存储所有图片名
labels = [] # 存储对应标签(类别名)
for class_name in classes:
class_path = os.path.join(new_data_dir, class_name)
for image_name in os.listdir(class_path):
imgs.append(image_name)
labels.append(class_name) # 步骤2:划分训练集和验证集(测试集可能已存在或需额外处理)
imgs_train, imgs_val, labels_train, labels_val = train_test_split(imgs, labels, test_size=0.2, random_state=42) # 步骤3:将验证集图片从原训练集目录移动到valid目录
target_data_dir = os.path.join(data_dir,'valid') # 验证集目标路径
if not os.path.exists(target_data_dir):
os.mkdir(target_data_dir)
for img, label in zip(imgs_val, labels_val):
# 原始路径:dataset1/zhongyiyao/train/[类别]/[图片]
source_path = os.path.join(data_dir, 'train', label, img)
# 目标路径:dataset1/zhongyiyao/valid/[类别]/[图片]
target_path = os.path.join(data_dir, 'valid', label)
if not os.path.exists(target_path):
os.mkdir(target_path)
shutil.move(source_path, os.path.join(target_path, img)) # 移动文件
场景:原始目录只有`train`子目录(可能测试集已单独存在,或需后续处理)。
操作:从`train`目录中提取所有图片和标签,按2:8划分出验证集(占原训练集的20%),并将验证集图片移动到新创建的`valid`目录下对应的类别子目录中。
情况3:原始目录是多层嵌套结构(未划分)
else:
# 步骤1:遍历多层嵌套目录,收集所有图片和标签
phones = os.listdir(data_dir) # 一级目录(如不同设备/场景,phone可能指拍摄设备)
imgs = [] # 存储所有图片名
labels = [] # 标签由多级目录组合:phone_yaowu_chengdu(设备_药材_程度)
for phone in phones:
phone_dir = os.path.join(data_dir, phone)
yaowu_list = os.listdir(phone_dir) # 二级目录(药材类型)
for yaowu in yaowu_list:
yaowu_dir = os.path.join(phone_dir, yaowu)
chengdu_list = os.listdir(yaowu_dir) # 三级目录(药材状态/程度,如“完整”“破损”)
for chengdu in chengdu_list:
chengdu_dir = os.path.join(yaowu_dir, chengdu)
for img in os.listdir(chengdu_dir):
imgs.append(img)
# 标签由三级目录组合(如 "phone1 当归 完整")
labels.append(' '.join([phone, yaowu, chengdu])) # 步骤2:使用split_data函数划分训练集、验证集、测试集(各占60%、20%、20%)
imgs_train, imgs_val, imgs_test, labels_train, labels_val, labels_test = split_data(imgs, labels, test_size=0.2, val_size=0.2) # 步骤3:将划分后的图片移动到对应的train/valid/test目录
# 目标划分目录:train、valid、test(对应split)
splits = ['train','valid','test'] # 注意:原代码中变量名可能拼写错误(spilits应为splits)
img_label_tuple_list = [(imgs_train,labels_train), (imgs_val,labels_val), (imgs_test,labels_test)]
for i, split in enumerate(splits):
target_dir = os.path.join(data_dir, split) # 如 dataset1/zhongyiyao/train
if not os.path.exists(target_dir):
os.mkdir(target_dir)
imgs_list, labels_list = img_label_tuple_list[i]
for img, label in zip(imgs_list, labels_list):
# 解析标签:原标签是 "phone yaowu chengdu",拆分后获取多级目录
label_parts = label.split(' ') # 如 ["phone1", "当归", "完整"]
# 原始图片路径:dataset1/zhongyiyao/phone1/当归/完整/[图片]
source_img = os.path.join(data_dir, label_parts, img) # label_parts解包为多级路径
# 目标类别目录:train/当归_完整(合并药材和程度作为新类别)
target_subdir = os.path.join(target_dir, f"{label_parts[1]}_{label_parts[2]}") # 如 "当归_完整"
if not os.path.exists(target_subdir):
os.mkdir(target_subdir)
# 移动图片到目标路径
shutil.move(source_img, os.path.join(target_subdir, img))
场景:原始目录是多层嵌套结构(如`phone(设备)→ yaowu(药材)→ chengdu(状态)`三级目录),未做任何划分。
操作:
1. 收集数据:遍历所有嵌套目录,提取所有图片路径,并生成复合标签(如`"phone1 当归 完整"`)。
2. 数据划分:使用`split_data`函数按6:2:2划分训练集、验证集、测试集。
3. 整理目录:为每个划分集(train/valid/test)创建目录,并将图片移动到对应目录下的新类别子目录(合并`yaowu`和`chengdu`作为类别名,如`当归_完整`),简化后续模型输入结构。
1.2数据增强
要求:
补充如下代码中的空白处
主要完成:
1. 使用GeneratorDataset接口将数据转换为Dataset
2. 定义相应的裁剪策略,对数据集进行裁剪操作
3. 定义通道变换操作,将输入图像的shape从 <H, W, C> 转换为 <C, H, W>
4. 输出数据集的size大小
1.2.1创建带标签的可迭代对象
导入GeneratorDataset接口将数据转换为Dataset
from mindspore.dataset import GeneratorDataset
import mindspore.dataset.vision as vision
import mindspore.dataset.transforms as transforms
from mindspore import dtype as mstype
数据加载与标签生成
class Iterable:
def __init__(self,data_path):
self._data = []
self._label = []
self._error_list = []
if data_path.endswith(('JPG','jpg','png','PNG')):
image = Image.open(data_path)
self._data.append(image)
self._label.append(0)
else:
classes = os.listdir(data_path)
if '.ipynb_checkpoints' in classes:
classes.remove('.ipynb_checkpoints')
for (i,class_name) in enumerate(classes):
new_path = data_path+"/"+class_name
for image_name in os.listdir(new_path):
try:
image = Image.open(new_path + "/" + image_name)
self._data.append(image)
self._label.append(i)
except:
pass def __getitem__(self, index):
return self._data[index], self._label[index] def __len__(self):
return len(self._data) def get_error_list(self,):
return self._error_list
1.2.2数据预处理与格式化(ms的data格式)
def create_dataset_zhongyao(dataset_dir,usage,resize,batch_size,workers):
data = Iterable(dataset_dir)
# 要点1-2-1:使用GeneratorDataset接口将数据转换为Dataset
data_set = GeneratorDataset(source=data, column_names=['image','label'])
trans = []
# 要点1-2-2:定义相应的裁剪策略,对数据集进行裁剪操作
# RandomCrop:
# 1.size (Union[int, Sequence[int]]) - 裁剪图像的输出尺寸大小。设置为700;
# 2.padding (Union[int, Sequence[int]], 可选) - 图像各边填充的像素数。设置为一个包含4个其值为4的元组。
# RandomHorizontalFlip:
# 1.prob (float, 可选) - 图像被翻转的概率设置为0.5
if usage == "train":
trans += [
vision.RandomCrop(size=700, padding=(4,4,4,4)),
vision.RandomHorizontalFlip(prob=0.5)
] trans += [
vision.Resize((resize,resize)),
vision.Rescale(1.0 / 255.0, 0.0),
vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),
# 要点1-2-3:定义通道变换操作,将输入图像的shape从 <H, W, C> 转换为 <C, H, W>
vision.HWC2CHW()
] target_trans = transforms.TypeCast(mstype.int32)
data_set = data_set.map(
operations=trans,
input_columns='image',
num_parallel_workers=workers) data_set = data_set.map(
operations=target_trans,
input_columns='label',
num_parallel_workers=workers) data_set = data_set.batch(batch_size,drop_remainder=True) return data_set
从原始图像数据到 MindSpore 可训练 / 评估的数据集的完整构建流程
1. 数据加载与标签生成(Iterable类)
Iterable类作为数据迭代器,负责:
读取原始数据:支持两种输入格式:单个图像文件(如data_path="a.jpg"):直接加载图像,标签默认设为 0。
类别目录(如data_path="train",内部含class1/, class2/子目录):按子目录遍历图像,标签为子目录的索引(如class1→0, class2→1)。
数据清洗:跳过无法读取的损坏图像(try-except),确保数据可靠性。
2. 数据预处理与格式化(create_dataset_zhongyao函数)
该函数将Iterable加载的原始数据转换为 MindSpore 的Dataset对象,并完成以下关键操作:
数据增强(训练模式):
若usage="train",添加随机裁剪(RandomCrop,尺寸 700,填充 4 像素)和随机水平翻转(RandomHorizontalFlip,概率 0.5),提升模型泛化能力。通用预处理:统一缩放到目标尺寸(resize,如 224×224)
像素归一化(Rescale:0-255→0-1;Normalize:按均值 / 标准差标准化)
通道转换(HWC2CHW):将图像格式从[H, W, C]转为 MindSpore 要求的[C, H, W]
标签处理:将标签类型转换为int32(适配 MindSpore 计算)
分批处理:按batch_size打包数据,丢弃不足一批的剩余样本(drop_remainder=True)
一句话讲:Iterable类把还只是图片的数据先 -> 可迭代的(图片+1个对应标签);数据预处理与格式化(create_dataset_zhongyao函数)把‘可迭代的(图片+1个对应标签)’转换成mindspore输入需要的数据格式(data_set = GeneratorDataset(source=data, column_names=['image','label']))
1.2.3加载数据
对数据集使用定义好的方式进行加载
import mindspore as ms
import random
经过1.2.2的处理,现在每一份数据(图片+1个标签)都是ms的支持数据类型,为此将数据放到我们需要的文件目录下(符合ms在进行训练时对数据的结构化提取范式)
data_dir = "dataset1/zhongyiyao"
train_dir = data_dir+"/"+"train"
valid_dir = data_dir+"/"+"valid"
test_dir = data_dir+"/"+"test"
batch_size = 32
image_size = 224
workers = 4
num_classes = 12
# 要点1-2-4:输出数据集的size大小
dataset_train = create_dataset_zhongyao(dataset_dir=train_dir,
usage="train",
resize=image_size,
batch_size=batch_size,
workers=workers)
step_size_train = dataset_train.get_batch_size() # 返回batch的数量dataset_val = create_dataset_zhongyao(dataset_dir=valid_dir,
usage="valid",
resize=image_size,
batch_size=batch_size,
workers=workers)
step_size_val = dataset_val.get_batch_size() # 返回batch的数量dataset_test = create_dataset_zhongyao(dataset_dir=test_dir,
usage="test",
resize=image_size,
batch_size=batch_size,
workers=workers)
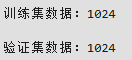
step_size_test = dataset_test.get_batch_size() # 返回batch的数量print(f'训练集数据:{step_size_train*batch_size}\n')
print(f'验证集数据:{step_size_val*batch_size}\n')
print(f'测试集数据:{step_size_test*batch_size}\n')
ps:
代码功能:step_size_train * batch_size计算的是训练集总数据量(同理step_size_val * batch_size是验证集、step_size_test * batch_size是测试集),而非 “每个 epoch 的数据量”。每个 epoch 的数据量本身就是数据集总样本数,与代码计算的结果一致。
训练集、验证集、测试集数据量关系:
三者数据量无需相同,训练也不会因它们不同而 “出现问题”。例如,常见的划分比例(如 6:2:2)会使三者数据量不同,这是正常且合理的,分别用于模型训练、超参数调整和性能评估,功能不同,数据量无需一致。
加载数据代码说明
1. 创建数据集对象
通过create_dataset_zhongyao函数创建训练集、验证集、测试集的数据集对象:
dataset_train = create_dataset_zhongyao(dataset_dir=train_dir, usage="train", ...)
dataset_val = create_dataset_zhongyao(dataset_dir=valid_dir, usage="valid", ...)
dataset_test = create_dataset_zhongyao(dataset_dir=test_dir, usage="test", ...)
函数作用:假设create_dataset_zhongyao是一个自定义的数据加载函数,可能包含以下功能:从指定目录(如train_dir)加载图片和标签;
预处理(resize、归一化、数据增强等,usage="train"时可能包含随机翻转 / 裁剪等增强操作,验证集 / 测试集不增强);
封装为可迭代的数据集对象(如 PyTorch 的DataLoader或 MindSpore 的Dataset),支持按批量输出数据。
2. 获取批量数量1epoch中step--batch,batch的数据容量--batch_size,数据量step*batch_szie
通过get_batch_size()方法获取每个数据集的批量数量(即每个 epoch 需要迭代的次数):
# 训练集的批量数量
step_size_train = dataset_train.get_batch_size()
step_size_val = dataset_val.get_batch_size()
step_size_test = dataset_test.get_batch_size()
mindspore中get_batch_size()是返回batch的数量,和参数设置里‘batch_size = 32’的功能不相同,参数设置里的是每个batch的容量,数据总量=batch的数量*每个batch的容量
1.2.4类别标签说明
- ph-sp:蒲黄-生品
- ph_bj:蒲黄-不及
- ph_sz:蒲黄-适中
- ph_tg:蒲黄-太过
- sz_sp:山楂-生品
- sz_bj:山楂-不及
- sz_sz:山楂-适中
- sz_tg:山楂-太过
- wblx_sp:王不留行-生品
- wblx_bj:王不留行-不及
- wblx_sz:王不留行-适中
- wblx_tg:王不留行-太过
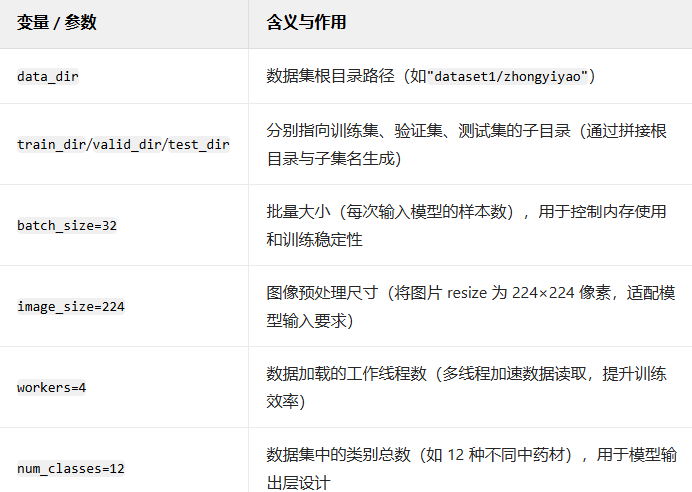
index_label_dict = {}
classes = os.listdir(train_dir)
if '.ipynb_checkpoints' in classes:
classes.remove('.ipynb_checkpoints')
for i,label in enumerate(classes):
index_label_dict[i] = labelindex_label_dict
初始化空字典 index_label_dict
index_label_dict = {}
创建一个空字典,用于存储 “整数索引 → 原始标签名称” 的映射关系(后续用于将模型输出的索引转换为实际标签)
获取训练集的类别目录列表
classes = os.listdir(train_dir)
train_dir是训练集的根目录(如"dataset1/zhongyiyao/train")。
os.listdir(train_dir)会列出该目录下的所有子目录 / 文件,这里假设train_dir的子目录是类别目录(例如ph_sp、sz_bj等,每个目录存储对应类别的图片)。
移除 Jupyter 临时文件
if '.ipynb_checkpoints' in classes:
classes.remove('.ipynb_checkpoints')
.ipynb_checkpoints是 Jupyter Notebook 自动生成的临时文件目录,并非实际的类别目录。
若存在该目录,则从classes列表中移除,避免干扰后续类别标签的统计。
构建 “索引→原始标签” 映射字典
for i, label in enumerate(classes):
index_label_dict[i] = label
使用enumerate(classes)遍历类别列表,i是自动生成的整数索引(从 0 开始),label是类别名称(如ph_sp)。
最终index_label_dict的格式为:{0: 'ph_sp', 1: 'ph_bj', 2: 'ph_sz', ...},即每个类别对应一个唯一的整数索引(模型中常用这种方式表示类别)。
定义 “原始标签→中文标签” 映射字典 label2chin
label2chin = {
'ph_sp':'蒲黄-生品', 'ph_bj':'蒲黄-不及', 'ph_sz':'蒲黄-适中', 'ph_tg':'蒲黄-太过',
'sz_sp':'山楂-生品', 'sz_bj':'山楂-不及', 'sz_sz':'山楂-适中', 'sz_tg':'山楂-太过',
'wblx_sp':'王不留行-生品', 'wblx_bj':'王不留行-不及', 'wblx_sz':'王不留行-适中', 'wblx_tg':'王不留行-太过'
}
键是原始标签(如ph_sp),值是对应的中文标签(如 “蒲黄 - 生品”)。
作用:将模型中使用的原始标签(可能是英文缩写)转换为更易理解的中文描述,方便后续可视化、报告生成或人工检查。
输出 index_label_dict
index_label_dict
直接输出该字典,展示索引与原始标签的对应关系
# 预设中文标签,方便后续可视化和人工检查
label2chin = {'ph_sp':'蒲黄-生品', 'ph_bj':'蒲黄-不及', 'ph_sz':'蒲黄-适中', 'ph_tg':'蒲黄-太过', 'sz_sp':'山楂-生品',
'sz_bj':'山楂-不及', 'sz_sz':'山楂-适中', 'sz_tg':'山楂-太过', 'wblx_sp':'王不留行-生品', 'wblx_bj':'王不留行-不及',
'wblx_sz':'王不留行-适中', 'wblx_tg':'王不留行-太过'}
1.3数据可视化
要求:
补充如下代码的空白处
主要完成:
1. 利用create_dict_iterator API创建数据迭代器,并打印label列表
2. 利用transpose接口将通道维度移动到最后:CHW -> HWC
- 反归一化操作:利用std和mean对image_trans进行反归一化运算
导入可视化库matplotlib.pyplot和科学计算库numpy
import matplotlib.pyplot as plt
import numpy as np
创建数据迭代器,并打印label列表
# 要点1-3-1:利用create_dict_iterator API创建数据迭代器,并打印label列表
data_iter = dataset_train.create_dict_iterator() batch = next(data_iter)
images = batch["image"].asnumpy()
labels = batch["label"].asnumpy()
print(f"Image shape: {images.shape}, Label: {labels}")
![]()
数据可视化,反归一化,matplotlib需要HWC格式呈现正常的图像数据(而AI框架一般为了性能和高效的数据处理需要图像数据为CHW)
plt.figure(figsize=(12, 5))
for i in range(24):
plt.subplot(3, 8, i+1)
# 要点1-3-2:利用transpose接口将通道维度移动到最后:CHW -> HWC
image_trans = np.transpose(images[i], (1,2,0))
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2023, 0.1994, 0.2010])
# 要点1-3-3:反归一化操作:利用std和mean对image_trans进行反归一化运算
image_trans = image_trans*std + mean
image_trans = np.clip(image_trans, 0, 1)
plt.title(index_label_dict[labels[i]])
plt.imshow(image_trans)
plt.axis("off")
plt.show()

ps:

重点说明:
归一化操作--图像数据预处理:image =(image-mean)/std
反归一化操作--重新回到原来的图像进行数据可视化:image = image*std + mean
数据可视化代码说明
1. 创建画布并设置尺寸
plt.figure(figsize=(12, 5))
功能:创建一个 Matplotlib 画布(figure),用于容纳后续的子图。
figsize=(12,5):设置画布的宽度为 12 英寸,高度为 5 英寸(根据 24 张子图的布局调整尺寸,确保图像清晰)。
2. 循环绘制 24 张子图
for i in range(24):
plt.subplot(3, 8, i+1)
功能:在画布上划分 3 行 8 列的子图网格(共 3×8=24 个位置),循环遍历每个位置绘制一张图片。
plt.subplot(3,8,i+1):指定当前子图的位置(第i+1个位置,索引从 1 开始)。例如,i=0时绘制第 1 个位置(第 1 行第 1 列),i=23时绘制第 24 个位置(第 3 行第 8 列)。
3. 调整图像通道维度顺序(CHW → HWC)
image_trans = np.transpose(images[i], (1,2,0))
背景:在深度学习框架(如 PyTorch)中,图像数据通常以[C, H, W](通道数 × 高度 × 宽度)的格式存储(简称 CHW);但 Matplotlib 的plt.imshow要求图像格式为[H, W, C](高度 × 宽度 × 通道数,简称 HWC)。
操作:使用np.transpose调整维度顺序。(1,2,0)表示将原维度索引(假设images[i]的形状为(3, 224, 224),即 C=3, H=224, W=224)的第 1 维(H)、第 2 维(W)、第 0 维(C)重新排列,得到(224, 224, 3)的 HWC 格式。
4. 反归一化恢复原始图像像素值
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2023, 0.1994, 0.2010])
image_trans = image_trans * std + mean
image_trans = np.clip(image_trans, 0, 1)
背景:在模型训练前,图像通常会进行归一化预处理(公式:(image - mean) / std),将像素值缩放到[0,1]区间并符合模型输入要求。但归一化后的图像无法直接可视化(像素值偏离真实颜色),因此需要反归一化恢复原始像素。
反归一化公式:image = image_normalized * std + mean(逆向操作归一化公式)。
np.clip(image_trans, 0, 1):由于浮点运算误差,反归一化后的像素值可能略微超出[0,1]范围(如 - 0.001 或 1.002),使用clip将其限制在[0,1]内,避免显示异常(如颜色失真)。
5. 设置子图标题并显示图像
plt.title(index_label_dict[labels[i]])
plt.imshow(image_trans)
plt.axis("off")
plt.title(...):设置子图的标题为当前图像的类别标签。labels[i]是图像的类别索引(如 0、1、2...),通过index_label_dict映射为实际类别名称(如ph_sp)。
plt.imshow(image_trans):显示处理后的图像(HWC 格式,像素值已恢复)。
plt.axis("off"):关闭子图的坐标轴显示,使图像更整洁。
6. 显示最终画布
plt.show()
将所有子图绘制到画布上并显示(如在 Jupyter Notebook 中会直接渲染,在脚本中会弹出窗口)。
ps:前面数据处理-数据增强部分使用的图像归一化操作
数据增强部分(训练集专用)
if usage == "train":
trans += [
vision.RandomCrop(size=700, padding=(4,4,4,4)),
vision.RandomHorizontalFlip(prob=0.5)]
功能:这部分代码是专门针对训练集的数据增强操作。
详细解释:vision.RandomCrop(size=700, padding=(4,4,4,4)):对图像进行随机裁剪。首先在图像周围填充 4 个像素,然后随机裁剪出一个大小为 700x700 的区域。这样可以增加数据的多样性,使模型学习到不同位置的特征。
vision.RandomHorizontalFlip(prob=0.5):以 0.5 的概率对图像进行水平翻转。这也是一种常见的数据增强方式,能让模型学习到图像在水平方向上的不同表现。
通用预处理部分
trans += [
vision.Resize((resize,resize)),
vision.Rescale(1.0 / 255.0, 0.0),
vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),# 题目1-2-3:定义通道变换操作,将输入图像的shape从 <H, W, C> 转换为 <C, H, W>
vision.HWC2CHW()
]
功能:这部分代码是对所有数据集(训练集、验证集、测试集)都进行的通用预处理操作。
详细解释:
vision.Resize((resize,resize)):将图像的尺寸调整为 resize x resize 大小,确保所有输入图像的尺寸一致,以适应模型的输入要求。
vision.Rescale(1.0 / 255.0, 0.0):将图像的像素值从 [0, 255] 范围缩放到 [0, 1] 范围。这是因为大多数深度学习模型更适合处理在 [0, 1] 范围内的输入数据。
vision.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]):对图像进行归一化操作。通过减去均值 [0.4914, 0.4822, 0.4465] 并除以标准差 [0.2023, 0.1994, 0.2010],将图像的像素值进一步标准化,有助于模型更快地收敛。
vision.HWC2CHW():将图像的通道维度从 (H, W, C)(高度、宽度、通道数)转换为 (C, H, W)(通道数、高度、宽度)。这是因为很多深度学习框架(如 PyTorch)要求输入图像的格式为 (C, H, W)。
相关文章:
MindSpore框架学习项目-ResNet药物分类-数据增强
目录 1.数据增强 1.1设置运行环境 1.1.1数据预处理 数据预处理代码解析 1.1.2数据集划分 数据集划分代码说明 1.2数据增强 1.2.1创建带标签的可迭代对象 1.2.2数据预处理与格式化(ms的data格式) 从原始图像数据到 MindSpore 可训练 / 评估的数…...

e.g. ‘django.db.models.BigAutoField‘.
在Django框架中,django.db.models.BigAutoField 是一个用于数据库模型的字段类型,它用于自动增长的ID字段。这个字段类型特别适用于需要处理大量数据的应用,比如在大型网站或应用中,普通的 AutoField 可能不足以存储增长的ID值&am…...

ACM算法
在ACM模式下使用JavaScript/TypeScript获取输入值 在ACM编程竞赛或在线判题系统(如LeetCode、牛客网等)中,JavaScript/TypeScript需要特定的方式来获取输入值。以下是几种常见的获取输入的方法: 1. 使用Node.js的readline模块 这是最常见的处理ACM模式…...

MySQL入门指南:环境搭建与服务管理全流程
引言 各位开发者朋友们好!今天我们将开启MySQL的学习之旅 🌟 作为世界上最流行的开源关系型数据库,MySQL在Web应用、企业系统等领域占据着举足轻重的地位。无论你是刚入行的新手,还是想系统复习的老鸟,这篇教程都将为…...

【MySQL】别名设置与使用
个人主页:Guiat 归属专栏:MySQL 文章目录 1. 别名基础概念2. 列别名设置2.1 基础语法2.2 特殊字符处理2.3 计算字段示例 3. 表别名应用3.1 基础表别名3.2 自连接场景 4. 高级别名技术4.1 子查询别名4.2 CTE别名 5. 别名执行规则5.1 作用域限制5.2 错误用…...

【内网渗透】——S4u2扩展协议提权以及KDC欺骗提权
【内网渗透】——S4u2扩展协议提权以及KDC欺骗提权 文章目录 【内网渗透】——S4u2扩展协议提权以及KDC欺骗提权[toc]一:Kerberos 委派攻击原理之 S4U2利用1.1原理1.2两种扩展协议**S4U2Self (Service for User to Self)****S4U2Proxy (Service for User to Proxy)*…...

枢轴支压点策略
一种基于枢轴点(Pivot Point)的交易策略,主要用于在趋势行情中进行交易。 策略的核心思路是通过计算前一天的最高价、最低价和收盘价来确定当天的枢轴点,并据此计算出第一和第二阻力位以及第一和第二支撑位。 可以根据这些关键点位…...

Manus逆向工程:AI智能体的“思考”与“行动”
写在前面 本篇博客将基于 Manus 测试的行为日志,尝试反向推演其内部的核心逻辑。我们将探讨它如何巧妙地融合了计划-执行(Plan-Execute) 和 ReAct(Reasoning and Acting,即思考与行动) 两种范式,并灵活运用浏览器和 Python 解释器等工具来攻克复杂任务。 基本逻辑:从…...
Linux——CMake的快速入门上手和保姆级使用介绍、一键执行shell脚本
目录 一、前言 二、CMake简介 三、CMake与其他常见的构建、编译工具的联系 四、CMake入门 1、CMake的使用注意事项 2、基本的概念和术语 3、CMake常用的预定义变量 4、CMakeLists.txt文件的基本结构 五、上手实操 1、示例 编辑 2、一个正式的工程构建 2.1基本构…...

Keil5 MDK 安装教程
## 简介 Keil MDK(Microcontroller Development Kit)是ARM开发的一款集成开发环境(IDE),主要用于ARM Cortex-M系列微控制器的开发。MDK包含了μVision IDE和调试器、ARM C/C编译器、中间件组件等工具。本教程将指导您完…...

深入浅出 IPFS 在 DApps 和 NFT 中的应用:以 Pinata 实战为例
目录 IPFS背景什么是 IPFS?IPFS 在 DApps 与 NFT 中的作用什么是 Pinata?为什么使用它?使用原生IPFS上传下载文件(HTML + JavaScript 示例)使用Pinata上传下载文件(HTML + JavaScript 示例)注册并创建APIKey使用 Pinata 上传文件和JSON(HTML + JavaScript 示例)总结IP…...
如何高效集成MySQL数据到金蝶云星空
MySQL数据集成到金蝶云星空:SC采购入库-深圳天一-OK案例分享 在企业信息化建设中,数据的高效流转和准确对接是实现业务流程自动化的关键。本文将聚焦于一个具体的系统对接集成案例——“SC采购入库-深圳天一-OK”,详细探讨如何通过轻易云数据…...
通过POI实现对word基于书签的内容替换、删除、插入
一、基本概念 POI:即Apache POI, 它是一个开源的 Java 库,主要用于读取 Microsoft Office 文档(Word、Excel、PowerPoint 等),修改 或 生成 Office 文档内容,保存 为对应的二进制或 XML 格式&a…...

FlashInfer - 测试的GPU H100 SXM、A100 PCIe、RTX 6000 Ada、RTX 4090
FlashInfer - 测试的GPU H100 SXM、A100 PCIe、RTX 6000 Ada、RTX 4090 flyfish GPU 技术参数术语 1. Memory bandwidth (GB/s) 中文:显存带宽(单位:GB/秒) 定义:显存(GPU 内存)与 GPU 核心…...

MCP:开启AI的“万物互联”时代
MCP:开启AI的“万物互联”时代 ——从协议标准到生态革命的技术跃迁 引言:AI的“最后一公里”困境 在2025年的AI技术浪潮中,大模型已从参数竞赛转向应用落地之争。尽管模型能生成流畅的对话、创作诗歌甚至编写代码,但用户逐渐发现…...

企业级IP代理解决方案:负载均衡与API接口集成实践
在全球化业务扩张与数据驱动决策的背景下,企业级IP代理解决方案通过负载均衡技术与API接口集成,可有效应对高频请求、反爬机制及合规风险。以下是基于企业级场景的核心实践要点: 一、负载均衡与IP代理的深度协同 动态IP池的负载均衡策略 轮询…...

Vector和list
一、Vector和list的区别——从“它们是什么”到“区别在哪儿” 1. 它们是什么? Vector:类似于一排排整齐的书架(数组),存放元素时,元素排成一条线,连续存储。可以很快通过编号(索引…...
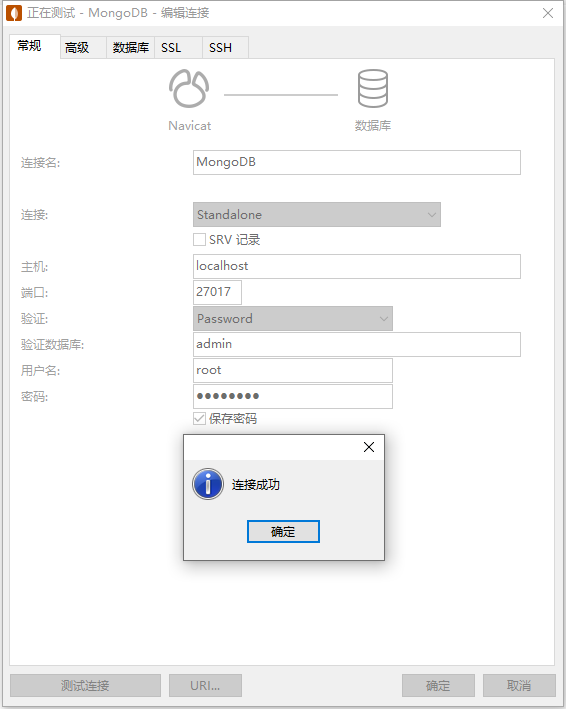
MongoDB从入门到实战之Windows快速安装MongoDB
前言 本章节的主要内容是在 Windows 系统下快速安装 MongoDB 并使用 Navicat 工具快速连接。 MongoDB从入门到实战之MongoDB简介 MongoDB从入门到实战之MongoDB快速入门 MongoDB从入门到实战之Docker快速安装MongoDB 下载 MongoDB 安装包 打开 MongoDB 官网下载页面&…...

Excelize 开源基础库发布 2.9.1 版本更新
Excelize 是 Go 语言编写的用于操作 Office Excel 文档基础库,基于 ECMA-376,ISO/IEC 29500 国际标准。可以使用它来读取、写入由 Excel、WPS、OpenOffice 等办公软件创建的电子表格文档。支持 XLAM / XLSM / XLSX / XLTM / XLTX 等多种文档格式…...

package-lock.json能否直接删除?
package-lock.json能否直接删除? package-lock.json 生成工具:由 npm 自动生成。 触发条件:当运行 npm install 时,如果不存在 package-lock.json,npm 会创建它;如果已存在,npm 会根据它精确安…...
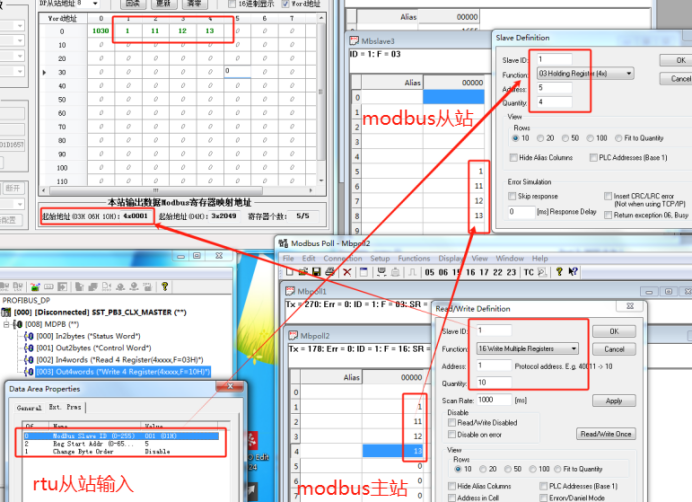
Profibus DP主站转Modbus RTU/TCP网关接艾默生流量计与上位机通讯
Profibus DP主站转Modbus RTU/TCP网关接艾默生流量计与上位机通讯 艾默生流量计与Profibus DP主站转Modbus RTU/TCP网关的通讯,是现代工业自动化中的一个关键环节。为了实现这一过程,我们需要了解一些基础概念和具体操作方法。 在工业自动化系统中&…...

promise的说明
目录 1.说明 2.创建promise 3.处理promise结果 4.promise的链式调用 5.静态方法 6.错误处理及误区 7.then() 内部进行异步操作时,需返回新的 Promise 8.promise链式调用控制异步方法的执行顺序 9.总结 1.说明 Promise 是 JavaScript 中处理异步操作的核心对…...

Pass-the-Hash攻击原理与防御实战指南
当黑客说出"我知道你的密码"时,可能连他们自己都不知道你的真实密码。在Windows系统的攻防战场上,Pass-the-Hash(哈希传递攻击)就像一把可以复制的万能钥匙——攻击者不需要知道密码明文,仅凭密码的…...
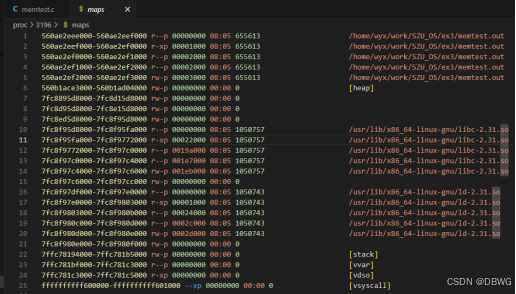
Linux proc文件系统 内存影射
文章目录 常见的内存分配函数/proc/pid/ 目录解析 用户进程的内存空间分配算法mmap 分配大内存可能不在堆中换为 malloc 现象相同 常见的内存分配函数 malloc / calloc / realloc(来自 C 标准库) void *malloc(size_t size):分配 size 字节…...
五、Hadoop集群部署:从零搭建三节点Hadoop环境(保姆级教程)
作者:IvanCodes 日期:2025年5月7日 专栏:Hadoop教程 前言: 想玩转大数据,Hadoop集群是绕不开的一道坎。很多小伙伴一看到集群部署就头大,各种配置、各种坑。别慌!这篇教程就是你的“救生圈”。 …...
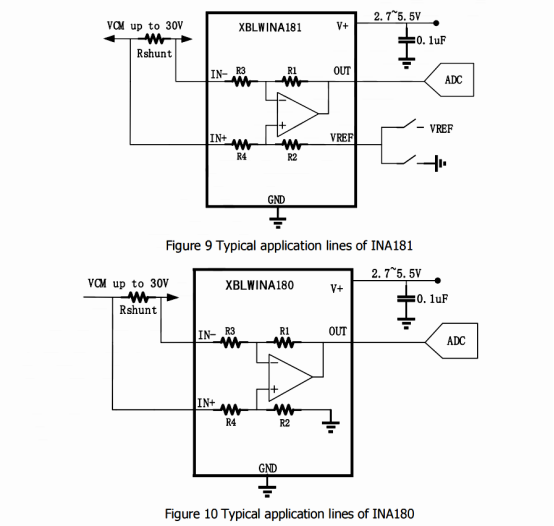
电流检测放大器的优质选择XBLW-INA180/INA181
前言: 在当前复杂的国际贸易环境下,关税的增加使得电子元器件的采购成本不断攀升,电子制造企业面临着巨大的成本压力。为了有效应对这一挑战,实现国产化替代已成为众多企业降低生产成本、保障供应链稳定的关键战略。对此芯伯乐推出…...

5.18-AI分析师
强化练习1 神经网络训练案例(SG) #划分数据集 #以下5行需要背 folder datasets.ImageFolder(rootC:/水果种类智能训练/水果图片, transformtrans_compose) n len(folder) n1 int(n*0.8) n2 n-n1 train, test random_split(folder, [n1, n2]) #训…...

毕业论文,如何区分研究内容和研究方法?
这个问题问得太好了!😎 “研究内容”和“研究方法”经常被初学者(甚至一些老油条)混淆,尤其写论文开题报告时,一不小心就“内容”和“方法”全混在一块儿,连导师都看懵。 今天就来给大家一文讲…...
# 深度剖析LLM的“大脑”:单层Transformer的思考模式探索
简单说一下哈 —— 咱们打算训练一个单层 Transformer 加上稀疏自编码器的小型百万参数大型语言模型(LLM),然后去调试它的思考过程,看看这个 LLM 的思考和人类思考到底有多像。 LLMs 是怎么思考的呢? 开源 LLM 出现之后…...
)
三种常见接口测试工具(Apipost、Apifox、Postman)
三种常见接口测试工具(Apipost、Apifox、Postman)的用法及优缺点对比总结: 🔧 一、Apipost ✅ 基本用法 支持 RESTful API、GraphQL、WebSocket 等接口调试自动生成接口文档支持环境变量、接口分组、接口测试用例编写可进行前置…...