FlashInfer - 测试的GPU H100 SXM、A100 PCIe、RTX 6000 Ada、RTX 4090
FlashInfer - 测试的GPU H100 SXM、A100 PCIe、RTX 6000 Ada、RTX 4090
flyfish

GPU 技术参数术语
1. Memory bandwidth (GB/s)
中文:显存带宽(单位:GB/秒)
定义:显存(GPU 内存)与 GPU 核心之间每秒的数据传输速率,反映显存与计算单元之间的“数据高速公路”宽度。
作用:带宽越高,GPU 每秒能处理的数据量越大,尤其影响需要频繁读写显存的场景(如大规模矩阵运算、高分辨率图形渲染)。
例:H100 SXM 的 3352 GB/s 远高于 RTX 4090 的 1008 GB/s,适合需要海量数据吞吐的 AI 训练。
2. Number of SM
中文:流多处理器数量(SM,Streaming Multiprocessors)
定义:NVIDIA GPU 的核心计算单元,每个 SM 包含多个 CUDA 核心、Tensor Core、共享内存等组件,是并行计算的基本单元。
作用:SM 数量越多,GPU 的并行计算能力越强(尤其是矩阵运算、图形渲染等并行任务)。
例:RTX Ada 6000 的 142 个 SM 多于 RTX 4090 的 128 个,适合更复杂的专业图形计算。
3. Peak Tensor Cores Performance (TFLops/s)
中文:峰值张量核心性能(单位:万亿次运算/秒)
定义:Tensor Core 是 NVIDIA GPU 中专门优化矩阵运算的硬件单元,用于加速 AI 训练和推理中的矩阵乘法与累加(如 FP16/BF16 混合精度计算)。
作用:性能越高,AI 模型训练/推理速度越快,是衡量 GPU 机器学习能力的核心指标。
例:H100 的 989 TFLops 远高于 A100 的 312 TFLops,使其成为大模型训练的首选。
4. Peak (Non-Tensor Cores) FP32 Performance (TFLops/s)
中文:峰值(非张量核心)FP32 浮点性能(单位:万亿次运算/秒)
定义:不依赖 Tensor Core 时,GPU 传统浮点单元(CUDA 核心)处理 32 位单精度浮点运算(FP32)的峰值性能,用于衡量传统科学计算、图形渲染等场景的能力。
作用:FP32 是图形渲染(如 3D 建模、光线追踪)和部分科学计算的基础,性能越高,传统浮点任务速度越快。
例:RTX Ada 6000 的 90 TFLops 高于 A100 的 20 TFLops,更适合专业图形处理。
5. Max Shared Memory (KB/SM)
中文:每 SM 最大共享内存(单位:KB/流多处理器)
定义:每个 SM 内部的高速缓存,用于存储线程块内共享的数据,速度远快于显存,减少对外部显存的访问。
作用:共享内存容量越大,线程间数据交互效率越高,适合需要高频数据共享的并行计算(如 AI 训练中的小批量数据处理)。
例:H100 每 SM 228 KB 共享内存,支持更高效的本地化数据处理。
6. L2 Cache (KB)
中文:二级缓存(单位:KB)
定义:GPU 芯片上的全局高速缓存,介于显存和 SM 共享内存之间,存储常用数据以减少显存访问延迟。
作用:容量越大,数据命中率越高,延迟越低,尤其对需要频繁访问非连续数据的场景(如深度学习中的参数读取、科学计算中的数组操作)有显著优化。
例:RTX Ada 6000 的 98304 KB(96MB)L2 缓存是四款中最大的,适合专业软件的复杂数据处理。
| 参数 | 核心影响场景 | 数值意义 |
|---|---|---|
| 显存带宽 | 数据密集型任务(AI 训练、高分辨率渲染) | 越高,数据吞吐量越快 |
| SM 数量 | 并行计算能力(矩阵运算、图形渲染) | 越多,并行任务处理能力越强 |
| Tensor Core 性能 | AI 训练/推理(矩阵乘法为主) | 越高,AI 计算速度越快 |
| FP32 性能 | 传统浮点任务(图形渲染、科学计算) | 越高,传统浮点运算越快 |
| 共享内存(每 SM) | 线程内数据共享效率 | 越大,本地化数据处理效率越高 |
| L2 缓存 | 全局数据访问延迟 | 越大,数据缓存命中率越高 |
在 NVIDIA GPU 的技术规格中,sm_xx(如 sm_90、sm_80、sm_89)代表 计算能力版本(Compute Capability),用于标识 GPU 架构支持的硬件特性和指令集,是 NVIDIA 定义的一套技术标准。以下是具体含义和解析:
sm_xx
sm_xx 是 NVIDIA 用于标识 GPU 架构能力的“技术身份证”,直接决定了 GPU 支持的计算精度、指令集和硬件特性。选择 GPU 或开发 CUDA 程序时,需根据 sm_xx 判断其是否满足任务需求(如 AI 训练需要 sm_80 以上的 Tensor Core 支持,而老旧架构可能无法运行新框架的优化功能)。
1. 计算能力版本的定义
sm_xx 中的 sm 是 Streaming Multiprocessor(流多处理器)的缩写,xx 是版本号,格式为 主版本.次版本(如 9.0、8.0、8.9),用于区分不同代次的 GPU 架构及其技术特性。
- 主版本(第一个数字):代表 GPU 架构的代次(如 Hopper 是 9.0,Ampere 是 8.0)。
- 次版本(第二个数字):代表同代架构中的小版本迭代(如 Ada Lovelace 架构下的
8.9可能针对特定型号优化)。
2. 各 sm_xx 的具体含义
| 架构名称 | 计算能力(sm_xx) | 对应 GPU 型号 | 核心特性 |
|---|---|---|---|
| Hopper | sm_90(9.0) | H100 SXM、H100 PCIe 等 | 支持第四代 Tensor Core(FP8/FP16/BF16 混合精度计算)、双精度浮点性能大幅提升,专为 AI 训练和科学计算设计。 |
| Ampere | sm_80(8.0) | A100 PCIe、RTX 3090 等 | 引入第三代 Tensor Core(支持 FP16/BF16)、稀疏矩阵加速,兼顾 AI 训练和高性能计算(HPC)。 |
| Ada Lovelace | sm_89(8.9) | RTX Ada 6000、RTX 4090 等 | 第四代 Tensor Core(支持 FP8 混合精度)、Ada 架构优化图形渲染(如光线追踪加速),同时兼容 CUDA 12.x 及新指令集,平衡 AI 与图形性能。 |
3. 计算能力的作用
(1)区分硬件特性
- 不同
sm_xx对应不同的硬件功能,例如:sm_90(Hopper)支持 FP8 精度计算,适合大模型训练的低精度加速;sm_80(Ampere)首次支持 TF32 格式,简化 FP32 计算流程;sm_89(Ada)支持 双并发矩阵运算,提升 Tensor Core 利用率。
(2)指导 CUDA 开发
开发者需根据 GPU 的计算能力编译 CUDA 代码,确保兼容性:
- 例如,使用 PyTorch/TensorFlow 时,框架会检查
sm_xx以启用对应优化(如sm_90支持更高效的混合精度训练)。 - 低计算能力的 GPU(如
sm_80)无法运行依赖sm_90特性的代码。
(3)性能定位
- 主版本号越高,架构越新(如
9.0 > 8.0),通常代表更强的计算能力和更先进的技术(但次版本号可能因型号定位调整,如sm_89是 Ada 架构的高端版本,高于同代低端型号的sm_86)。
4. 常见误区与说明
- 非 SM 数量:这里的
sm_xx不是流多处理器(SM)的数量,而是计算能力版本(前文提到的Number of SM才是 SM 数量,如 H100 有 132 个 SM)。 - 同架构不同型号的次版本:
- Ada Lovelace 架构下,RTX 4090(
sm_89)和 RTX 4060(可能为sm_86)主版本均为 8,但次版本不同,反映硬件规格差异(如 SM 数量、显存带宽)。
- Ada Lovelace 架构下,RTX 4090(
- 历史版本示例:
- Volta 架构(V100):
sm_70(7.0) - Pascal 架构(GTX 1080):
sm_61(6.1)
- Volta 架构(V100):
165 (f32 accum)`和 330 (f16 accum)
165 (f32 accum) 和 330 (f16 accum) 分别表示 Tensor Core 在 FP32 累加和 FP16 累加时的峰值计算能力,反映了 GPU 在不同精度需求下的性能上限。前者适合高精度任务,后者适合追求速度的场景,是 NVIDIA 混合精度计算技术的核心体现。
在 GPU 规格中,165 (f32 accum) 和 330 (f16 accum) 描述的是 Tensor Core(张量核心)的峰值计算性能,具体含义如下:
1. 核心术语解析
(1)Tensor Core
NVIDIA GPU 中专门加速矩阵运算(如矩阵乘法 + 累加,GEMM)的硬件单元,主要用于深度学习中的卷积神经网络(CNN)和Transformer模型计算,可大幅提升训练/推理速度。
(2)f32 accum / f16 accum
f32:32位浮点数(FP32,单精度浮点数)。f16:16位浮点数(FP16,半精度浮点数)。accum:累加器(Accumulator)的精度,即矩阵运算结果累加时使用的数据精度(不是输入数据的精度)。- Tensor Core 通常支持混合精度计算,例如输入可能是更低精度(如 FP16/BF16),但累加结果用更高精度(如 FP32)以减少误差。
2. 数值含义
以 RTX 4090 为例:
-
165 (f32 accum):
Tensor Core 在 累加结果为 FP32 精度时的峰值性能,即每秒钟可完成 165 万亿次矩阵乘法 + 累加运算(TFLops/s)。- 场景:当需要高精度计算(如科学计算、部分需要稳定性的训练任务)时使用。
-
330 (f16 accum):
Tensor Core 在 累加结果为 FP16 精度时的峰值性能,即每秒钟可完成 330 万亿次矩阵乘法 + 累加运算(TFLops/s)。- 场景:当允许较低精度以换取更高速度时使用(如深度学习中的混合精度训练,可加速计算并减少显存占用)。
3. 为什么会有两种累加精度?
(1)精度与速度的平衡
- FP32 累加:结果更精确(减少数值误差),但计算吞吐量较低(因为每次累加需要处理更多位)。
- FP16 累加:结果精度较低,但吞吐量更高(适合对精度不敏感的任务,如大部分深度学习训练/推理)。
(2)硬件设计特性
Tensor Core 支持 混合精度计算(如输入为 FP16,累加结果为 FP32),但部分 GPU(如消费级显卡)为了平衡性能与成本,会针对不同累加精度提供不同的峰值性能指标。
- 例如:RTX 4090 的 Tensor Core 输入可能支持 FP16,但累加器可配置为 FP16 或 FP32,前者吞吐量翻倍(330 vs 165)。
Tensor Cores和 Non-Tensor Cores
在NVIDIA GPU架构中,Tensor Cores 和 Non-Tensor Cores(即传统CUDA核心) 是两类不同的计算单元
- Tensor Cores:为矩阵运算而生,是深度学习和高性能计算的“加速器”,牺牲通用性换取极致特定场景性能;
- Non-Tensor Cores:通用计算主力,覆盖图形渲染、标量运算等广泛任务,但在矩阵运算上效率远低于Tensor Cores。
1. 架构设计与定位
-
Tensor Cores
- 专用加速核心:从Volta架构(如V100)开始引入,专为矩阵运算(尤其是深度学习中的矩阵乘法和累加操作,即GEMM:General Matrix Multiplication)设计的专用硬件单元。
- 优化目标:聚焦于加速神经网络中的关键运算(如卷积层、全连接层),大幅提升训练和推理效率。
-
Non-Tensor Cores(传统CUDA核心)
- 通用计算单元:即GPU中传统的浮点运算单元(FP32/FP64核心),负责处理通用计算任务(如标量运算、图形渲染、科学计算等),不针对特定矩阵运算优化。
- 定位:处理非矩阵相关的通用计算,或作为Tensor Cores的补充(如处理无法向量化的复杂逻辑)。
2. 核心功能与运算类型
-
Tensor Cores
- 核心操作:支持 矩阵乘累加(MMA),即一次运算完成 M × N + N × K = M × K M \times N + N \times K = M \times K M×N+N×K=M×K 的矩阵运算,并累加结果(Accumulate)。
- 数据类型支持:
- 主要支持 混合精度计算,例如:
- FP16矩阵乘法 + FP32累加(FP16 Accum);
- BF16矩阵乘法 + FP32累加(BF16 Accum,如Hopper架构);
- 部分架构也支持FP32矩阵运算(如H100的FP32 Tensor Core)。
- 主要支持 混合精度计算,例如:
- 性能优势:相同时间内,Tensor Cores的矩阵运算吞吐量远高于传统CUDA核心(例如H100的Tensor Core性能是其Non-Tensor Cores FP32性能的14倍以上)。
-
Non-Tensor Cores(传统CUDA核心)
- 核心操作:处理单个标量的浮点运算(FP32/FP64)或整数运算(INT32),例如加减乘除、三角函数等。
- 数据类型支持:主要支持FP32、FP64、INT32等通用数据类型,不支持专用的矩阵运算优化。
3. 应用场景
-
Tensor Cores
- 深度学习:加速训练(如PyTorch/TensorFlow的自动混合精度训练)和推理(如大模型推理加速);
- 科学计算:加速矩阵分解、线性代数运算(如cuBLAS库中的GEMM优化)。
-
Non-Tensor Cores
- 图形渲染:处理图形管线中的顶点着色、像素着色等通用计算;
- 通用计算:如加密、数据处理、非矩阵相关的科学计算(如FFT、微分方程求解);
- 控制逻辑:处理条件判断、分支逻辑等难以向量化的任务。
4. 性能对比(以H100为例)
| 指标 | Tensor Cores | Non-Tensor Cores (FP32) |
|---|---|---|
| 峰值性能 | 989 TFLops (FP16 Accum) | 67 TFLops |
| 每运算能耗 | 极低(专用硬件优化) | 较高(通用计算) |
| 矩阵运算吞吐量 | 极高(单次处理64x64矩阵) | 低(需调用大量标量运算) |
相关文章:
FlashInfer - 测试的GPU H100 SXM、A100 PCIe、RTX 6000 Ada、RTX 4090
FlashInfer - 测试的GPU H100 SXM、A100 PCIe、RTX 6000 Ada、RTX 4090 flyfish GPU 技术参数术语 1. Memory bandwidth (GB/s) 中文:显存带宽(单位:GB/秒) 定义:显存(GPU 内存)与 GPU 核心…...

MCP:开启AI的“万物互联”时代
MCP:开启AI的“万物互联”时代 ——从协议标准到生态革命的技术跃迁 引言:AI的“最后一公里”困境 在2025年的AI技术浪潮中,大模型已从参数竞赛转向应用落地之争。尽管模型能生成流畅的对话、创作诗歌甚至编写代码,但用户逐渐发现…...

企业级IP代理解决方案:负载均衡与API接口集成实践
在全球化业务扩张与数据驱动决策的背景下,企业级IP代理解决方案通过负载均衡技术与API接口集成,可有效应对高频请求、反爬机制及合规风险。以下是基于企业级场景的核心实践要点: 一、负载均衡与IP代理的深度协同 动态IP池的负载均衡策略 轮询…...

Vector和list
一、Vector和list的区别——从“它们是什么”到“区别在哪儿” 1. 它们是什么? Vector:类似于一排排整齐的书架(数组),存放元素时,元素排成一条线,连续存储。可以很快通过编号(索引…...
MongoDB从入门到实战之Windows快速安装MongoDB
前言 本章节的主要内容是在 Windows 系统下快速安装 MongoDB 并使用 Navicat 工具快速连接。 MongoDB从入门到实战之MongoDB简介 MongoDB从入门到实战之MongoDB快速入门 MongoDB从入门到实战之Docker快速安装MongoDB 下载 MongoDB 安装包 打开 MongoDB 官网下载页面&…...

Excelize 开源基础库发布 2.9.1 版本更新
Excelize 是 Go 语言编写的用于操作 Office Excel 文档基础库,基于 ECMA-376,ISO/IEC 29500 国际标准。可以使用它来读取、写入由 Excel、WPS、OpenOffice 等办公软件创建的电子表格文档。支持 XLAM / XLSM / XLSX / XLTM / XLTX 等多种文档格式…...

package-lock.json能否直接删除?
package-lock.json能否直接删除? package-lock.json 生成工具:由 npm 自动生成。 触发条件:当运行 npm install 时,如果不存在 package-lock.json,npm 会创建它;如果已存在,npm 会根据它精确安…...
Profibus DP主站转Modbus RTU/TCP网关接艾默生流量计与上位机通讯
Profibus DP主站转Modbus RTU/TCP网关接艾默生流量计与上位机通讯 艾默生流量计与Profibus DP主站转Modbus RTU/TCP网关的通讯,是现代工业自动化中的一个关键环节。为了实现这一过程,我们需要了解一些基础概念和具体操作方法。 在工业自动化系统中&…...

promise的说明
目录 1.说明 2.创建promise 3.处理promise结果 4.promise的链式调用 5.静态方法 6.错误处理及误区 7.then() 内部进行异步操作时,需返回新的 Promise 8.promise链式调用控制异步方法的执行顺序 9.总结 1.说明 Promise 是 JavaScript 中处理异步操作的核心对…...

Pass-the-Hash攻击原理与防御实战指南
当黑客说出"我知道你的密码"时,可能连他们自己都不知道你的真实密码。在Windows系统的攻防战场上,Pass-the-Hash(哈希传递攻击)就像一把可以复制的万能钥匙——攻击者不需要知道密码明文,仅凭密码的…...
Linux proc文件系统 内存影射
文章目录 常见的内存分配函数/proc/pid/ 目录解析 用户进程的内存空间分配算法mmap 分配大内存可能不在堆中换为 malloc 现象相同 常见的内存分配函数 malloc / calloc / realloc(来自 C 标准库) void *malloc(size_t size):分配 size 字节…...
五、Hadoop集群部署:从零搭建三节点Hadoop环境(保姆级教程)
作者:IvanCodes 日期:2025年5月7日 专栏:Hadoop教程 前言: 想玩转大数据,Hadoop集群是绕不开的一道坎。很多小伙伴一看到集群部署就头大,各种配置、各种坑。别慌!这篇教程就是你的“救生圈”。 …...
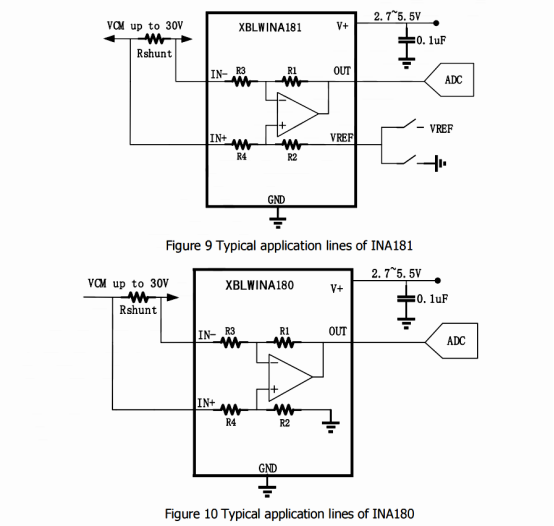
电流检测放大器的优质选择XBLW-INA180/INA181
前言: 在当前复杂的国际贸易环境下,关税的增加使得电子元器件的采购成本不断攀升,电子制造企业面临着巨大的成本压力。为了有效应对这一挑战,实现国产化替代已成为众多企业降低生产成本、保障供应链稳定的关键战略。对此芯伯乐推出…...

5.18-AI分析师
强化练习1 神经网络训练案例(SG) #划分数据集 #以下5行需要背 folder datasets.ImageFolder(rootC:/水果种类智能训练/水果图片, transformtrans_compose) n len(folder) n1 int(n*0.8) n2 n-n1 train, test random_split(folder, [n1, n2]) #训…...

毕业论文,如何区分研究内容和研究方法?
这个问题问得太好了!😎 “研究内容”和“研究方法”经常被初学者(甚至一些老油条)混淆,尤其写论文开题报告时,一不小心就“内容”和“方法”全混在一块儿,连导师都看懵。 今天就来给大家一文讲…...
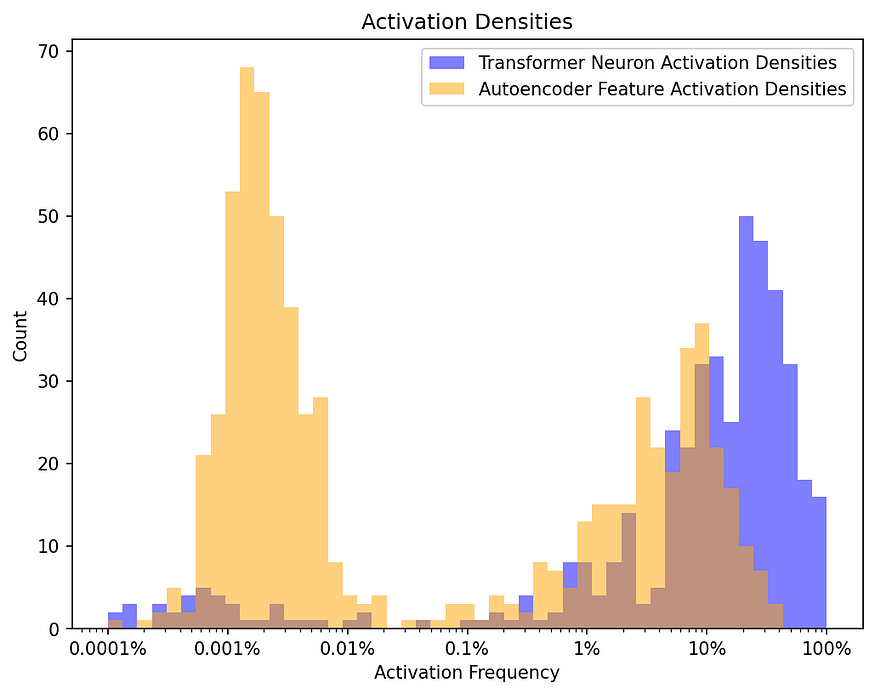
# 深度剖析LLM的“大脑”:单层Transformer的思考模式探索
简单说一下哈 —— 咱们打算训练一个单层 Transformer 加上稀疏自编码器的小型百万参数大型语言模型(LLM),然后去调试它的思考过程,看看这个 LLM 的思考和人类思考到底有多像。 LLMs 是怎么思考的呢? 开源 LLM 出现之后…...
)
三种常见接口测试工具(Apipost、Apifox、Postman)
三种常见接口测试工具(Apipost、Apifox、Postman)的用法及优缺点对比总结: 🔧 一、Apipost ✅ 基本用法 支持 RESTful API、GraphQL、WebSocket 等接口调试自动生成接口文档支持环境变量、接口分组、接口测试用例编写可进行前置…...

EF Core 数据库迁移命令参考
在使用 Entity Framework Core 时,若你希望通过 Package Manager Console (PMC) 执行迁移相关命令,以下是常用的 EF Core 迁移命令: PMC 方式 ✅ 常用 EF Core PMC 命令(适用于迁移) 操作PMC 命令添加迁移Add-Migra…...

剖析提示词工程中的递归提示
递归提示:解码AI交互的本质,构建复杂推理链 递归提示的核心思想,正如示例所示,是将一个复杂任务分解为一系列更小、更易于管理、逻辑上前后关联的子任务。每个子任务由一个独立的提示来驱动,而前一个提示的输出(经过必要的解析和转换)则成为下一个提示的关键输入。这种…...

互联网大厂Java求职面试:AI内容生成平台下的高并发架构设计与性能优化
互联网大厂Java求职面试:AI内容生成平台下的高并发架构设计与性能优化 场景背景: 郑薪苦是一名经验丰富的Java开发者,他正在参加一家匿名互联网大厂的技术总监面试。这家公司专注于基于AI的内容生成平台,支持大规模用户请求和复杂…...

用Redis的List实现消息队列
介绍如何在 Spring Boot 中使用 Redis List 的 BRPOPLPUSH命令来实现一个线程安全且可靠的消息队列。 整合Redis 整合Redis 用Redis的List实现消息队列 Redis的List相关指令 **「LPUSH key element [element ...]」**把元素插入到 List 的首部,如果 List 不存在…...
【C++】类与对象【下】
文章目录 再谈构造函数构造函数的赋值构造函数体赋值:初始化列表explicit关键字 static成员概念特性 C11中成员初始化的新玩法友元友元类 内部类概念 再谈构造函数 构造函数的赋值 构造函数体赋值: 在创建对象时,编译器会通过调用构造函数…...

Python uv包管理器使用指南:从入门到精通
Python uv包管理器使用指南:从入门到精通 作为一名Python开发者,你是否曾经为虚拟环境管理和依赖包安装而头疼?今天我要向大家介绍一个强大的工具——uv包管理器,它将彻底改变你的Python开发体验。 什么是uv包管理器?…...
无人机避障——如何利用MinumSnap进行对速度、加速度进行优化的轨迹生成(附C++python代码)
🔥轨迹规划领域的 “YYDS”——minimum snap!作为基于优化的二次规划经典,它是无人机、自动驾驶轨迹规划论文必引的 “开山之作”。从优化目标函数到变量曲线表达,各路大神疯狂 “魔改”,衍生出无数创新方案。 &#…...

高德地图在Vue3中的使用方法
1.地图初始化 容器创建:通过 <div> 标签定义地图挂载点。 <div id"container" style"height: 300px; width: 100%; margin-top: 10px;"></div> 密钥配置:绑定高德地图安全密钥,确保 API 合法调用。 参…...

Llama:开源的急先锋
Llama:开源的急先锋 Llama1:开放、高效的基础语言模型 Llama1使用了完全开源的数据,性能媲美GPT-3,可以在社区研究开源使用,只是不能商用。 Llama1提出的Scaling Law 业内普遍认为如果要达到同一个性能指标,训练更…...

SDIO EMMC中ADMA和SDMA简介
在SDIO和eMMC技术中,ADMA(Advanced Direct Memory Access)和SDMA(Simple Direct Memory Access)是两种不同的DMA(直接内存访问)模式,用于优化主机控制器与存储器(如eMMC&…...
“redis 目标计算机积极拒绝,无法连接” 解决方法,每次开机启动redis
如果遇到以上问题 先打开“服务” 找到App Readiness 右击-启动 以管理员身份运行cmd,跳转到 安装redis的目录 运行:redis-server.exe redis.windows.conf 以管理员身份打开另一cmd窗口,跳转到安装redis的目录 运行:redis-…...

LeetCode 热题 100 35.搜索插入位置
目录 题目: 题目描述: 题目链接: 思路: 核心思路: 思路详解: 代码: Java代码: 题目: 题目描述: 题目链接: 35. 搜索插入位置 - 力扣&…...

【THRMM】追踪情绪动态变化的多模态时间背景网络
1. 单一模态的局限性 不足:传统方法依赖生理信号(如EEG、ECG)或静态图像特征,数据收集成本高,且无法捕捉动态交互,导致模型泛化性差。 改进:提出THRMM模型,整合多模态数据(面部表情、声学特征、对话语义、场景信息),利用Transformer的全…...