多模态大语言模型arxiv论文略读(七十五)

PosterLLaVa: Constructing a Unified Multi-modal Layout Generator with LLM
➡️ 论文标题:PosterLLaVa: Constructing a Unified Multi-modal Layout Generator with LLM
➡️ 论文作者:Tao Yang, Yingmin Luo, Zhongang Qi, Yang Wu, Ying Shan, Chang Wen Chen
➡️ 研究机构: Hong Kong Polytechnic University, Tencent PCG ARC Lab, Tencent AI Lab
➡️ 问题背景:在图形设计中,布局生成是实现自动化设计的关键,它要求以视觉上令人愉悦且遵循约束的方式安排各种多模态设计元素的位置和大小。现有的方法要么在大规模应用中效率低下,要么缺乏处理不同设计需求的灵活性。研究团队提出了一种统一的框架,利用多模态大语言模型(MLLM)来应对多样化的设计任务。
➡️ 研究动机:现有的布局生成方法要么依赖于高度定制的网络架构,缺乏通用性,要么在处理复杂多模态条件时表现不佳。为了解决这些问题,研究团队开发了一个名为PosterLLaVa的统一框架,该框架能够通过简单的输入指令修改来适应各种设计场景,而无需更改模型架构。此外,该框架能够无缝集成用户通过自然语言表达的设计需求,增强模型对特定设计需求的响应能力。
➡️ 方法简介:研究团队提出了一种系统的方法,通过将布局信息表示为结构化的自然语言(JSON格式),并利用预训练的视觉头部将输入图像转换为适应文本标记空间的表示,然后对大语言模型(LLM)进行微调,以解释和生成布局数据。该方法能够处理广泛的布局生成任务,包括用户定义的自然语言规范。
➡️ 实验设计:研究团队在多个公开数据集上进行了实验,包括内容感知布局生成任务。实验设计了不同的因素(如元素数量、分辨率和设计领域),以及不同类型的用户约束(如商业海报和广告横幅),以全面评估模型在不同条件下的表现。此外,研究团队还提出了两个新的数据集(QB-Poster和UC-Poster),用于处理更复杂的实际应用任务,进一步验证了模型的有效性和适应性。
Enhancing Multimodal Large Language Models with Multi-instance Visual Prompt Generator for Visual Representation Enrichment
➡️ 论文标题:Enhancing Multimodal Large Language Models with Multi-instance Visual Prompt Generator for Visual Representation Enrichment
➡️ 论文作者:Wenliang Zhong, Wenyi Wu, Qi Li, Rob Barton, Boxin Du, Shioulin Sam, Karim Bouyarmane, Ismail Tutar, Junzhou Huang
➡️ 研究机构: The University of Texas at Arlington, Amazon
➡️ 问题背景:多模态大语言模型(Multimodal Large Language Models, MLLMs)通过融合视觉表示与大语言模型(LLMs),在各种视觉语言任务中取得了最先进的性能。然而,现有的开源MLLMs主要是在(图像,文本)对上进行预训练,这与现实场景中样本通常由丰富的视觉表示所代表的情况不符。例如,电子商务产品通常会展示多个角度的图片和详细的文字描述,而医学图像分析中的全切片图像(WSI)则需要分割成多个图像块进行处理。因此,将MLLMs应用于具有更丰富视觉输入的多模态任务具有重要的实际意义。
➡️ 研究动机:尽管MLLMs在多种多模态任务中取得了显著成果,但大多数现有的开源MLLMs主要是在(图像,文本)对上进行预训练,这与现实场景中的数据形式不完全匹配。为了更好地处理现实场景中的多模态数据,研究团队提出了一种新的组件——多实例视觉提示生成器(Multi-instance Visual Prompt Generator, MIVPG),以增强视觉表示的丰富性和相关性。
➡️ 方法简介:研究团队提出了一种新的方法——MIVPG,该方法通过考虑图像或图像块之间的相关性,将丰富的视觉表示融入到大语言模型中。MIVPG借鉴了多实例学习(MIL)的思想,将图像或图像块视为一个“包”中的多个“实例”,并通过相关自注意力(CSA)模块来捕捉实例之间的关系。此外,研究团队还证明了常用的QFormer是一种简化的MIL模块,并通过实验展示了MIVPG在多个数据集上的优越性能。
➡️ 实验设计:研究团队在三个公开数据集上进行了实验,包括常见的自然图像、千兆像素大小的病理图像和包含多个图像的电子商务产品。实验设计了不同的场景,以评估MIVPG在不同条件下的表现。实验结果表明,MIVPG在所有数据集上都显著优于QFormer,特别是在数据集较小的情况下,MIVPG的性能提升更为明显。
Evaluation of data inconsistency for multi-modal sentiment analysis
➡️ 论文标题:Evaluation of data inconsistency for multi-modal sentiment analysis
➡️ 论文作者:Yufei Wang, Mengyue Wu
➡️ 研究机构: 上海交通大学 (Shanghai Jiao Tong University)
➡️ 问题背景:多模态情感分析(Multi-Modal Sentiment Analysis, MSA)在人工智能领域,特别是在人机交互中,已成为研究热点。MSA旨在解析个体在不同模态(如文本、音频和视频)中表达的情感。然而,由于人类情感表达的微妙性和复杂性,不同模态之间的情感表达可能存在不一致,这给情感预测带来了挑战。
➡️ 研究动机:尽管多模态模型在情感分析方面取得了显著进展,但多模态情感分析仍面临来自单模态情感预测的矛盾。这些矛盾源于每个模态中可能存在语义冲突的信息。人类情感在不同模态中的表达方式多样,有时这些模态可能传达不一致的含义,这使得不同模态的整合和交互变得复杂。目前缺乏处理这种不一致性的基准数据集和对多模态情感识别模型处理不一致情况的适当研究。本研究填补了这一空白,主要贡献在于提出了“多模态冲突数据情感分析”的明确设置,并引入了标准化的基准测试集DiffEmo,用于评估不同模型在处理模态冲突方面的性能。
➡️ 方法简介:研究团队构建了DiffEmo数据集,该数据集从CH-SIMS v2.0数据集中提取了661个冲突数据样本。DiffEmo数据集包括三个不同的测试设置:混合集(Mixed Set)、冲突集(Conflicting Set)和对齐集(Aligned Set),旨在验证处理冲突数据确实是一个更具挑战性的设置。研究团队还对多种模型进行了全面评估,包括多模态大型语言模型(MLLMs),以探讨不同融合方法的有效性。
➡️ 实验设计:实验在DiffEmo数据集的三个不同设置上进行,评估了多种模型的性能,包括传统的多模态情感分析模型和多模态大型语言模型。实验设计了不同的融合方法(如早期融合、晚期融合、混合融合等),以及多任务学习的影响,以全面评估模型在处理冲突数据时的性能。此外,研究团队还进行了消融研究,旨在区分模态冲突数据和模态一致数据。
AD-H: Autonomous Driving with Hierarchical Agents
➡️ 论文标题:AD-H: Autonomous Driving with Hierarchical Agents
➡️ 论文作者:Zaibin Zhang, Shiyu Tang, Yuanhang Zhang, Talas Fu, Yifan Wang, Yang Liu, Dong Wang, Jing Shao, Lijun Wang, Huchuan Lu
➡️ 研究机构: Dalian University of Technology, Shanghai Artificial Intelligence Laboratory
➡️ 问题背景:当前的自动驾驶系统在大规模和动态环境中运行时,通常将高层次指令直接转换为低层次的车辆控制信号。这种做法偏离了多模态大语言模型(MLLMs)的自然语言生成范式,限制了模型的泛化能力,尤其是在未见过的场景和指令中。
➡️ 研究动机:为了充分利用预训练的MLLMs在高层次感知、推理和规划中的潜在能力,研究团队提出了一种分层多代理驾驶系统(AD-H),通过引入中间层次的命令来桥接高层次指令和低层次控制信号之间的差距。这种方法不仅提高了模型的控制精度,还增强了其泛化能力。
➡️ 方法简介:AD-H系统由两个代理组成:一个基于MLLM的规划器和一个轻量级的控制器。规划器负责高层次的决策和规划,生成中间层次的驾驶命令;控制器则将这些命令转换为具体的控制信号。研究团队还构建了一个新的自动驾驶数据集,包含1,753,000帧的多层次指令和驾驶命令注释,以支持分层策略的学习。
➡️ 实验设计:研究团队在CARLA模拟器上进行了广泛的闭环评估,包括标准的LangAuto基准测试以及两个额外的基准测试:LangAuto-Long-Horizon和LangAuto-Novel-Environment。实验评估了AD-H在不同环境和指令下的表现,特别是在长时规划和新环境中的泛化能力。结果表明,AD-H在驾驶性能和泛化能力方面显著优于现有方法。
Wings: Learning Multimodal LLMs without Text-only Forgetting
➡️ 论文标题:Wings: Learning Multimodal LLMs without Text-only Forgetting
➡️ 论文作者:Yi-Kai Zhang, Shiyin Lu, Yang Li, Yanqing Ma, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, De-Chuan Zhan, Han-Jia Ye
➡️ 研究机构: 南京大学、阿里巴巴集团
➡️ 问题背景:多模态大型语言模型(Multimodal Large Language Models, MLLMs)在视觉相关任务中表现出色,但它们在训练过程中会遭遇“文本遗忘”现象,即模型在处理纯文本指令时的表现显著下降。这种现象限制了MLLMs在实际应用中的灵活性和效率。
➡️ 研究动机:为了克服MLLMs的“文本遗忘”问题,研究团队提出了WINGS模型。WINGS通过引入额外的视觉和文本学习模块,旨在平衡模型对视觉和文本信息的注意力分配,从而在保持多模态理解能力的同时,提升纯文本任务的性能。
➡️ 方法简介:WINGS模型通过构建视觉和文本学习模块,并引入基于注意力权重的路由器来动态调整这些模块的输出,以补偿主分支注意力的偏移。这些模块像“翅膀”一样平行于主注意力模块,通过低秩残差注意力(Low-Rank Residual Attention, LoRRA)机制高效地处理视觉和文本信息。
➡️ 实验设计:研究团队在多个基准数据集上进行了实验,包括纯文本问答、视觉问答以及新构建的交错图像-文本(Interleaved Image-Text, IIT)基准。实验结果表明,WINGS在纯文本和多模态任务中均表现出色,特别是在IIT基准上,WINGS在不同视觉相关度的分区中均取得了领先性能。
相关文章:
多模态大语言模型arxiv论文略读(七十五)
PosterLLaVa: Constructing a Unified Multi-modal Layout Generator with LLM ➡️ 论文标题:PosterLLaVa: Constructing a Unified Multi-modal Layout Generator with LLM ➡️ 论文作者:Tao Yang, Yingmin Luo, Zhongang Qi, Yang Wu, Ying Shan, C…...

Angular 知识框架
一、Angular 基础 1. Angular 简介 Angular 是什么? 基于 TypeScript 的前端框架(Google 维护)。 适用于构建单页应用(SPA)。 核心特性 组件化架构 双向数据绑定 依赖注入(DI) 模块化设计…...

企业数字化转型背景下的企业知识管理挑战与经验杂谈
一、引言 在数字化转型的浪潮下,企业知识管理正面临前所未有的挑战。随着数据量的急剧增长,企业内部积累的信息呈现出碎片化、分散化的趋势,传统的知识管理体系已难以有效应对这一变革。首先,信息碎片化问题日益严重,…...
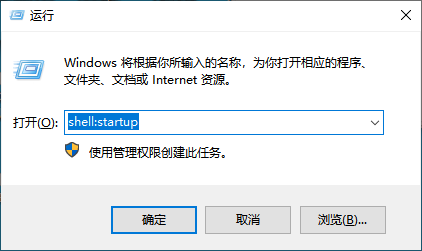
使用frp实现客户端开机自启(含静默运行脚本)
本文整理了如何使用 frp 客户端并实现 Windows 系统下的开机静默自启,适合远程桌面、内网穿透等场景。 📁 目录结构 我将 frp 客户端文件放置在以下路径: F:\git\frp>tree /f 卷 其它 的文件夹 PATH 列表 卷序列号为 A123-0F4E F:. │ …...
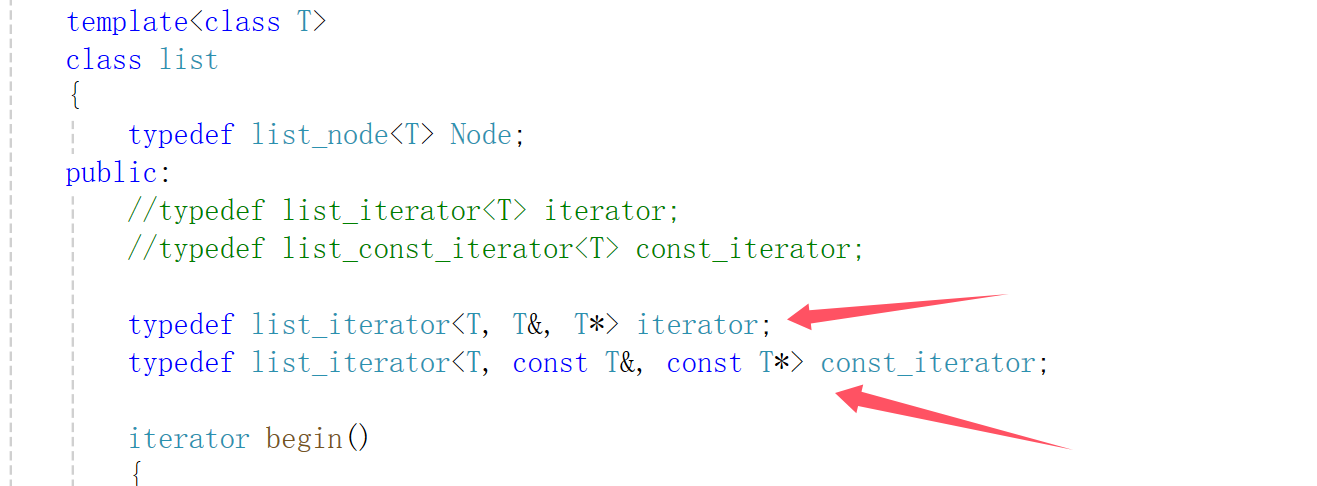
list 容器常见用法及实现
文章目录 1. list 的介绍与使用1.1 list 的介绍1.2 list 的使用1.2.1 list 的构造1.2.2 list iterator 的使用1.2.3 list capacity1.2.4 list element access1.2.5 list modifiers1.2.6 迭代器失效问题 2. list 的模拟实现2.1 值得注意的点:2.2 std::initializer_li…...

iOS视频编码详细步骤(视频编码器,基于 VideoToolbox,支持硬件编码 H264/H265)
iOS视频编码详细步骤流程 1. 视频采集阶段 视频采集所使用的代码和之前的相同,所以不再过多进行赘述 初始化配置: 通过VideoCaptureConfig设置分辨率1920x1080、帧率30fps、像素格式kCVPixelFormatType_420YpCbCr8BiPlanarFullRange设置摄像头位置&am…...

浅析 Golang 内存管理
文章目录 浅析 Golang 内存管理栈(Stack)堆(Heap)堆 vs. 栈内存逃逸分析内存逃逸产生的原因避免内存逃逸的手段 内存泄露常见的内存泄露场景如何避免内存泄露?总结 浅析 Golang 内存管理 在 Golang 当中,堆…...
)
记录: Windows下远程Liunx 系统xrdp 用到的一些小问题(免费踩坑 记录)
采用liunx Ubuntu22.04版本以下,需要安装 xrdp 或者VNC 具体过程就是下载 在linux命令行里 首先更新软件包:sudo apt update 安装xrdp服务:sudo apt install xrdp 启动XRDP:sudo systemctl start xrdp(如果在启动的…...
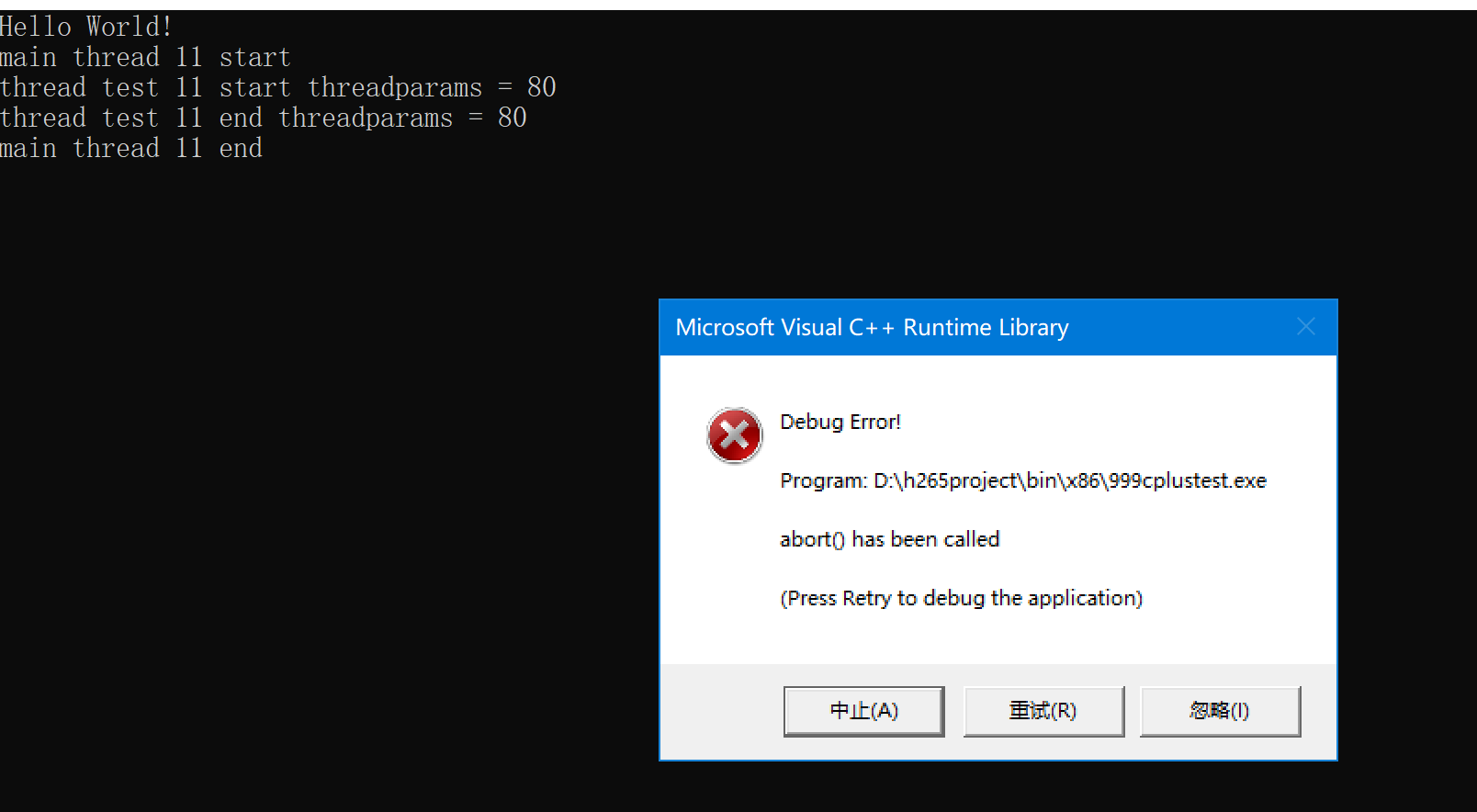
C++ 并发编程(1)再学习,为什么子线程不调用join方法或者detach方法,程序会崩溃? 仿函数的线程启动问题?为什么线程参数默认传参方式是值拷贝?
本文的主要学习点,来自 这哥们的视频内容,感谢大神的无私奉献。你可以根据这哥们的视频内容学习,我这里只是将自己不明白的点,整理记录。 C 并发编程(1) 线程基础,为什么线程参数默认传参方式是值拷贝?_哔…...
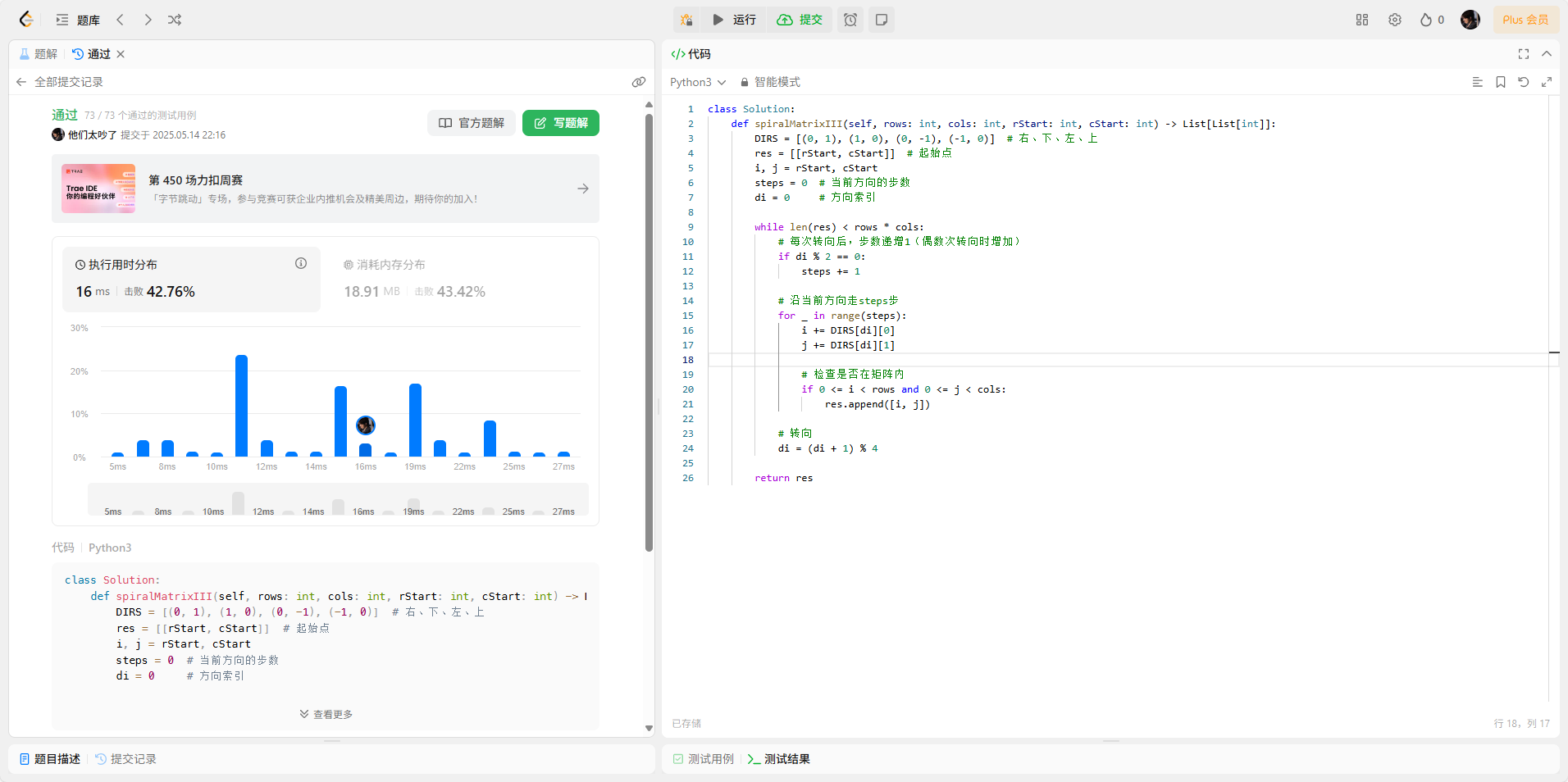
【Python 算法零基础 2.模拟 ④ 基于矩阵】
目录 基于矩阵 Ⅰ、 2120. 执行所有后缀指令 思路与算法 ① 初始化结果列表 ② 方向映射 ③ 遍历每个起始位置 ④ 记录结果 Ⅱ、1252. 奇数值单元格的数目 思路与算法 ① 初始化矩阵 ② 处理每个操作 ③ 统计奇数元素 Ⅲ、 832. 翻转图像 思路与算法 ① 水平翻转图像 ② 像素值…...

【教程】Docker方式本地部署Overleaf
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 目录 背景说明 下载仓库 初始化配置 修改监听IP和端口 自定义网站名称 修改数据存放位置 更换Docker源 更换Docker存储位置 启动Overleaf 创…...
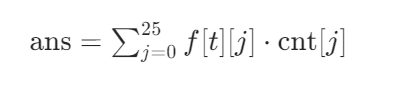
3337|3335. 字符串转换后的长度 I(||)
1.字符串转换后的长度 I 1.1题目 3335. 字符串转换后的长度 I - 力扣(LeetCode) 1.2解析 递推法解析 思路框架 我们可以通过定义状态变量来追踪每次转换后各字符的数量变化。具体地,定义状态函数 f(i,c) 表示经过 i 次转换后࿰…...
PHP黑白胶卷底片图转彩图功能 V2025.05.15
关于底片转彩图 传统照片底片是摄影过程中生成的反色图像,为了欣赏照片,需要通过冲印过程将底片转化为正像。而随着数字技术的发展,我们现在可以使用数字工具不仅将底片转为正像,还可以添加色彩,重现照片原本的色彩效…...
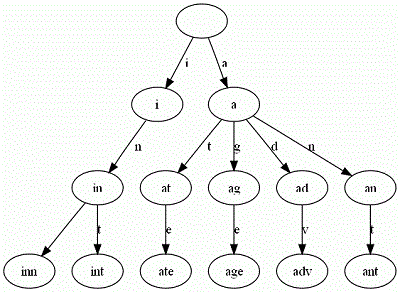
字符串检索算法:KMP和Trie树
目录 1.引言 2.KMP算法 3.Trie树 3.1.简介 3.2.Trie树的应用场景 3.3.复杂度分析 3.4.Trie 树的优缺点 3.5.示例 1.引言 字符串匹配,给定一个主串 S 和一个模式串 P,判断 P 是否是 S 的子串,即找到 P 在 S 中第一次出现的位置。暴力匹…...

Java大师成长计划之第22天:Spring Cloud微服务架构
📢 友情提示: 本文由银河易创AI(https://ai.eaigx.com)平台gpt-4o-mini模型辅助创作完成,旨在提供灵感参考与技术分享,文中关键数据、代码与结论建议通过官方渠道验证。 随着企业应用的不断扩展,…...

瀑布模型VS敏捷模型VS喷泉模型
目录 1. 瀑布模型(Waterfall Model) 2. 敏捷模型(Agile Model) 3. 喷泉模型(Fountain Model)...
基于.Net开发的网络管理与监控工具
从零学习构建一个完整的系统 平常项目上线后,不仅意味着开发的完成,更意味着项目正式进入日常运维阶段。在这个阶段,网络的监控与管理也是至关重要的,这时候就需要一款网络管理工具,可以协助运维人员用于日常管理&…...

Python并发编程:开启性能优化的大门(7/10)
1.引言 在当今数字化时代,Python 已成为编程领域中一颗璀璨的明星,占据着编程语言排行榜的榜首。无论是数据科学、人工智能,还是 Web 开发、自动化脚本编写,Python 都以其简洁的语法、丰富的库和强大的功能,赢得了广大…...

Linux 中 open 函数的本质与细节全解析
一、open简介 在 Linux 下,一切皆文件。而对文件的读写,离不开文件的“打开”操作。虽然 C 语言标准库提供了方便的 fopen,但更底层、更强大的是系统调用 open,掌握它能让你对文件系统控制更细致,在系统编程、驱动开发…...

llama.cpp无法使用gpu的问题
使用cuda编译llama.cpp后,仍然无法使用gpu。 ./llama-server -m ../../../../../model/hf_models/qwen/qwen3-4b-q8_0.gguf -ngl 40 报错如下 ggml_cuda_init: failed to initialize CUDA: forward compatibility was attempted on non supported HW warning: n…...

Python Unicode字符串和普通字符串转换
Unicode 是一种字符编码标准,旨在为世界上所有书写系统的每个字符提供一个唯一的数字标识(称为码点)。 码点: 每个 Unicode 字符被分配一个唯一的数字,称为码点表示形式:u 后跟 4-6 位十六进制数…...

Ansible Roles 是一种用于层次化和结构化组织 Ansible Playbook 的机制。
Ansible Roles 是一种用于层次化和结构化组织 Ansible Playbook 的机制。它通过将变量、文件、任务、模板和处理器等放置在单独的目录中,简化了 Playbook 的管理和复用。Roles 自 Ansible 1.2 版本引入,极大地提高了代码的可维护性和可重用性。 目录结构 一个标准的 Ansibl…...
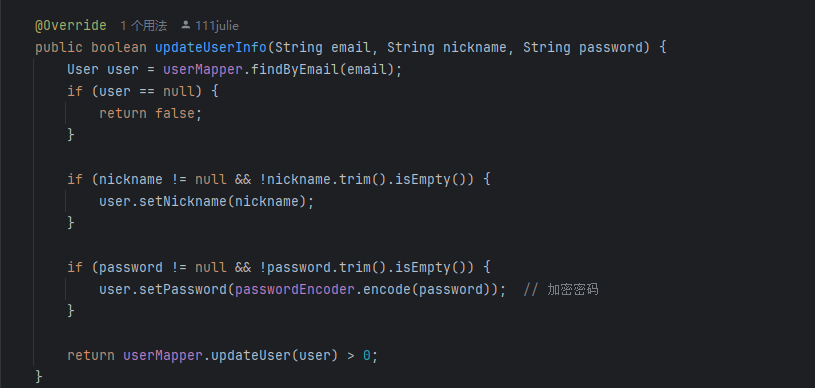
易学探索助手-个人记录(十)
在现代 Web 应用中,用户体验的重要性不断上升。近期我完成了两个功能模块 —— 语音播报功能 与 用户信息修改表单,分别增强了界面交互与用户自管理能力。 一、语音播报功能(SpeechSynthesis) 功能特点 支持播放、暂停、继续、停…...

Linux基础 -- SSH 流式烧录与压缩传输笔记
Linux SSH 流式烧录与压缩传输指南 一、背景介绍 在嵌入式开发和维护中,常常需要通过 SSH 从 PC 向设备端传输大文件(如系统镜像、固件)并将其直接烧录到指定磁盘(如 /dev/mmcblk2)。然而,设备端存储空间…...

学习51单片机01(安装开发环境)
新学期新相貌.......哈哈哈,我终于把贪吃蛇结束了,现在我们来学stc51单片机! 要求:c语言的程度至少要到函数,指针尽量!如果c语言不好的,可以回去看看我的c语言笔记。 1.开发环境的安装&#x…...

事件驱动reactor的原理与实现
fdset 集合:(就是说) fd_set是一个位图(bitmap)结构 每个位代表一个文件描述符 0表示不在集合中,1表示在集合中 fd_set结构(简化): [0][1][2][3][4][5]...[1023] …...

大模型训练简介
在人工智能蓬勃发展的当下,大语言模型(LLM)成为了众多应用的核心驱动力。从智能聊天机器人到复杂的内容生成系统,LLM 的卓越表现令人瞩目。而这背后,大模型的训练过程充满了奥秘。本文将深入探讨 LLM 训练的各个方面&a…...
)
深度解析 MySQL 与 Spring Boot 长耗时进程:从故障现象到根治方案(含 Tomcat 重启必要性分析)
一、典型故障现象与用户痛点 在高并发业务场景中,企业级 Spring Boot 应用常遇到以下连锁故障: 用户侧:网页访问超时、提交表单无响应,报错 “服务不可用”。运维侧:监控平台报警 “数据库连接池耗尽”,To…...
)
More Effective C++:改善编程与设计(上)
More Effective C: 目录 More Effective C: 条款1:仔细区别pointers和 references 条款2:最好使用C转型操作符 条款3:绝对不要以多态方式处理数组 条款4:非必要不要提供default constructor 条款5:对定制的“类型转换函数”保持警觉 …...

TNNLS-2020《Autoencoder Constrained Clustering With Adaptive Neighbors》
核心思想分析 该论文提出了一种名为ACC_AN(Autoencoder Constrained Clustering with Adaptive Neighbors)的深度聚类方法,旨在解决传统子空间聚类方法在处理非线性数据分布和高维数据时的局限性。核心思想是将深度自编码器(Auto…...