基于策略的强化学习方法之策略梯度(Policy Gradient)详解
在前文中,我们已经深入探讨了Q-Learning、SARSA、DQN这三种基于值函数的强化学习方法。这些方法通过学习状态值函数或动作值函数来做出决策,从而实现智能体与环境的交互。
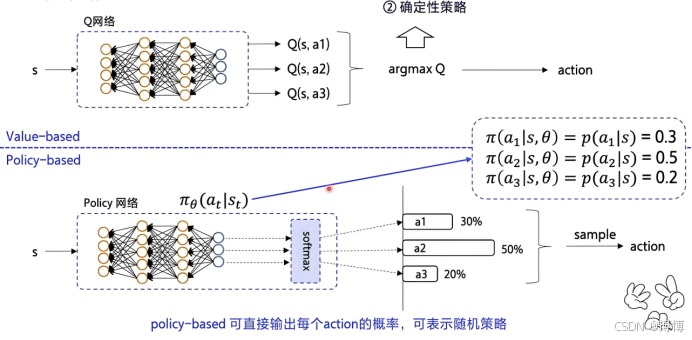
策略梯度是一种强化学习算法,它直接对策略进行建模和优化,通过调整策略参数以最大化长期回报的期望值。与基于值函数的方法不同,策略梯度特别适用于连续动作空间和随机策略场景。本文将从核心原理、数学推导、算法流程到代码实现等多个方面,全面解析策略梯度。
基于值函数的强化学习算法之Q-Learning详解:基于值函数的强化学习算法之Q-Learning详解_网格世界q值-CSDN博客
基于值函数的强化学习算法之SARSA详解:基于值函数的强化学习算法之SARSA详解_基于函数近似的sarsa算法-CSDN博客
基于值函数的强化学习算法之深度Q网络(DQN)详解:基于值函数的强化学习算法之深度Q网络(DQN)详解_如何用深度神经网络近似q函数-CSDN博客
一、核心思想
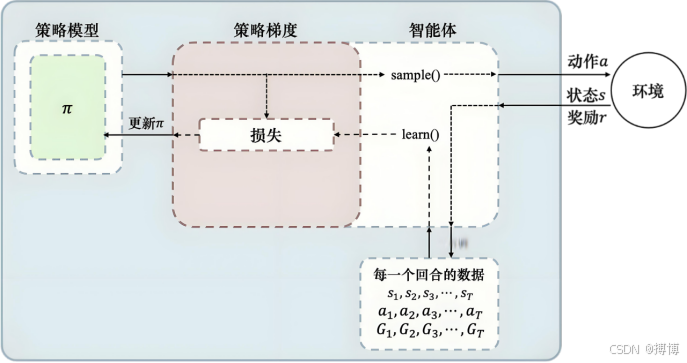
策略梯度方法的核心理念在于通过梯度上升的方式调整策略参数θ,目的是为了直接对目标函数J(θ)进行优化,也就是期望回报进行优化。这一方法的基本流程可以详细描述如下:
(1)策略建模:首先,我们采用一个参数化的函数πθ(a|s)来代表策略,这个函数能够根据当前状态s输出一个概率分布,该分布指示了在给定状态下采取各个可能动作a的概率。
(2)轨迹采样:接下来,策略模型与环境进行交互,通过这种方式,我们可以收集到一系列的状态-动作-奖励序列,这些序列被统称为轨迹。这些轨迹记录了智能体在环境中探索和学习的过程。
(3)梯度估计:然后,我们需要计算目标函数J(θ)关于策略参数θ的梯度。这个梯度反映了在当前策略下,参数θ的微小变化将如何影响期望回报。通过这个梯度信息,我们可以对参数进行更新,目的是为了增加高回报轨迹出现的概率。
(4)迭代优化:最后,通过不断地重复采样轨迹和更新参数的过程,我们能够逐步地改进策略,从而逼近最优策略。这个过程是一个迭代的过程,每一次迭代都旨在使策略更加接近于能够获得最大期望回报的状态。
梯度上升法是一种基于一阶导数信息的迭代优化算法,它通过迭代地调整参数来实现目标函数值的增加。在每一次迭代中,算法会根据当前位置的梯度方向来更新参数或变量的值,目的是为了逐步地接近目标函数的最大值点。这种方法在许多优化问题中都得到了广泛的应用,特别是在策略梯度方法中,梯度上升法扮演了至关重要的角色。
有关梯度上升法的详细内容,可以参考我在CSDN上的文章:函数优化算法之:梯度上升法(Gradient Ascent)_梯度上升算法-CSDN博客
二、数学推导
策略梯度方法通过直接优化策略参数θ来最大化期望累积回报。其核心在于计算目标函数J(θ)的梯度,并利用梯度上升法更新策略。
策略梯度的推导过程大致如下:
(1)定义目标函数为期望累积回报。
(2)将梯度转化为对轨迹概率的期望。
(3)应用对数导数技巧,将对轨迹概率的梯度转化为各时间步策略对数概率的梯度之和。
(4)利用因果关系,将总回报分解为各时间步的未来回报,从而得到每个时间步的梯度项。
(5)引入基线以减少估计的方差。
1. 目标函数定义
根据上面的分析,目标函数J(θ)是期望累积回报。假设一个轨迹τ是由状态、动作、奖励组成的序列,即![]() ,策略的目标是最大化期望累积回报,那么期望回报可以表示为:
,策略的目标是最大化期望累积回报,那么期望回报可以表示为:
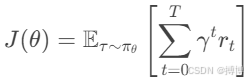
其中τ表示一条轨迹,γ∈[0,1]是折扣因子,平衡当前与未来奖励的重要性。πθ是参数θ下的策略。E是期望(平均值)。我们需要找到∇θ J(θ),即目标函数J(θ)对θ的梯度,然后用梯度上升法更新θ。
接下来的问题就是如何计算这个梯度。由于期望是在策略πθ下计算的,而策略本身依赖于θ,所以需要使用似然比技巧或者REINFORCE算法中的方法。
这里会用到对数导数技巧。比如,对于某个函数f(x)的期望,其梯度可以写成期望的导数,通过log函数的导数来表达。具体来说,对于期望E_{x~p(x)} [f(x)],其梯度∇θ可以写成E_{x~p(x)} [f(x) ∇θ log p(x)],这里假设p(x)依赖于θ。
2. 轨迹概率分解
轨迹τ的概率由策略和环境动态共同决定:
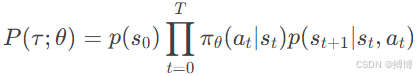
其中:p(s0)是初始状态分布,πθ(at|st)是策略选择的动作概率,p(st+1|st,at)是环境的状态转移概率。
3. 梯度表达式
期望回报的梯度∇θ J(θ)应该等于轨迹τ的回报乘以该轨迹概率的对数梯度,再取期望。因此目标函数的梯度为:
![]()
其中![]() 是轨迹的总折扣回报。
是轨迹的总折扣回报。
通过交换积分和梯度运算(假设合理),可写为:
![]()
这里P(τ;θ)是轨迹τ在策略πθ下的概率。而轨迹的概率可以分解为各时间步的策略选择概率和状态转移概率的乘积,参考上面的公式P(τ;θ)。
4. 对数概率梯度展开
展开轨迹概率的对数梯度:
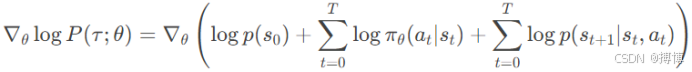
由于p(s0)和状态转移概率 p(st+1|st,at)与θ无关,因此在计算∇θ log P(τ;θ)时,这部分的导数会消失,其梯度为零,只剩下策略概率的对数梯度之和,因此:
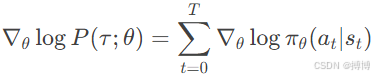
5. 策略梯度定理
将上述结果代入梯度表达式:
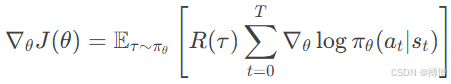
不过这里可能有个问题,因为轨迹的回报是整个累积奖励,而每个动作的对数概率梯度是各个时间步的。这时候可能需要交换求和顺序,或者更准确地说,每个时间步t的动作对之后的所有奖励都有影响。
利用因果关系(当前动作不影响过去奖励),将总回报R(τ)分解为各时间步的未来回报 Gt:
![]()
不过,实际上在REINFORCE算法中,通常用整个轨迹的回报Gt来作为每个时间步t的回报,然后对每个时间步的梯度进行加权。因此,梯度可以(通过似然比技巧(Likelihood Ratio Trick)推导梯度)可重写为:
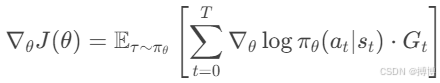
这里,Gt就是从时刻 t开始的累计折扣回报。这样,每个动作的对数概率梯度乘以从该时刻开始的回报总和,然后加起来求期望。
这样推导出来的梯度公式就是策略梯度定理的结果。也就是说,策略梯度等于期望中的每个时间步的对数概率梯度乘以后续的回报,然后求和。
6. 引入基线(Baseline)减少方差
添加基线 b(st)(通常为状态值函数 V(st)),以降低方差,不改变期望:
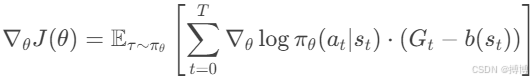
最优基线为![]() ,通常用值函数近似
,通常用值函数近似![]() ,即Actor-Critic方法。
,即Actor-Critic方法。
7. 蒙特卡洛估计
通过采样N条轨迹,计算梯度估计:
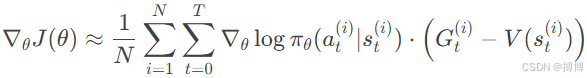
策略梯度通过直接优化策略参数,绕过了值函数估计的复杂性,尤其适用于连续动作空间。其核心在于利用蒙特卡洛采样和梯度上升,通过调整策略使高回报轨迹的概率增加。后续改进算法(如Actor-Critic、PPO)通过引入值函数和约束优化,进一步提升了性能与稳定性。
三、算法流程(以REINFORCE为例)
REINFORCE 是最基础的策略梯度算法,使用蒙特卡洛采样估计梯度。
1. 算法步骤
(1)初始化策略参数 θ。
(2)循环训练(每回合):
采样轨迹:使用当前策略 πθ 与环境交互,生成轨迹 τ。
计算回报:为每个时间步计算 ![]() 。
。
梯度估计:计算梯度![]() 。
。
参数更新:![]() ,其中 α为学习率。
,其中 α为学习率。
(3)重复直到策略收敛。
2. 伪代码
while not converged:collect trajectory τ using π_θcompute G_t for each step t in τcompute gradients: grad = Σ [∇log π(a_t|s_t) * G_t]θ = θ + α * grad四、策略梯度变体
| 算法 | 核心改进 | 优点 |
| REINFORCE | 蒙特卡洛采样,无基线 | 实现简单 |
| Actor-Critic | 引入Critic网络估计基线V(s),使用TD误差替代Gt | 降低方差,加速收敛 |
| PPO | 通过剪切概率比限制策略更新幅度,提升稳定性 | 训练稳定,适用于复杂任务 |
| TRPO | 在信任域内优化策略,保证单调改进 | 理论保证强,适合高维动作空间 |
五、优缺点分析
1.优点
(1)直接优化策略:适用于连续动作空间(如机器人控制)。
(2)自然探索性:通过随机策略自动平衡探索与利用。
(3)策略表达灵活:可建模任意复杂策略(如概率分布)。
2.缺点
(1)高方差:梯度估计方差大,需大量样本或方差缩减技术。
(2)局部最优:易收敛到局部最优策略。
(3)样本效率低:通常需要更多环境交互。
六、代码实现(PyTorch)
以下为使用策略梯度(REINFORCE)解决CartPole问题的完整代码。
CMD中安装依赖:
pip install torch gym matplotlib pandaspython代码:
import torchimport gymimport numpy as npimport matplotlib.pyplot as pltfrom torch.distributions import Categoricalfrom IPython import displayfrom matplotlib import animationenv = gym.make('CartPole-v0').unwrappednum_inputs = env.observation_space.shape[0]num_actions = env.action_space.npolicy = torch.nn.Sequential(torch.nn.Linear(num_inputs, 128),torch.nn.ReLU(),torch.nn.Linear(128, num_actions),torch.nn.Softmax(dim=1),)optimizer = torch.optim.Adam(policy.parameters(), lr=1e-2)def select_action(state):state = torch.from_numpy(state).float().unsqueeze(0)probs = policy(state)m = Categorical(probs)action = m.sample()policy.save动作选择概率和对数概率return action.item(), m.log_prob(action)def train(num_episodes):rewards = []for i_episode in range(1, num_episodes + 1):state = env.reset()total_reward = 0for t in range(10000):action, log_prob = select_action(state)state, reward, done, _ = env.step(action)total_reward += rewardoptimizer.zero_grad()loss = -log_prob * rewardloss.backward()optimizer.step()if done:breakrewards.append(total_reward)if i_episode % 10 == 0:print(f'Episode {i_episode}, Avg Reward: {np.mean(rewards[-10:])}')return rewardsrewards = train(500)plt.plot(rewards)plt.show()代码解析与运行结果
(1)策略网络:输出动作概率分布,使用softmax确保概率和为1。
(2)动作选择:根据概率分布采样动作,并记录对数概率。
(3)回报计算:反向计算折扣回报,并进行归一化处理以减少方差。
(4)训练曲线:随着训练进行,累计奖励应逐步上升并稳定在最大值(CartPole为200)。
典型输出:
Observation space: Box([-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38], [4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38], (4,), float32)Action space: Discrete(2)Using device: cudaStart training...Episode 50, Avg Reward: 42.3Episode 100, Avg Reward: 86.5...Episode 500, Avg Reward: 200.0Average test reward: 200.0 ± 0.0可视化输出:
(1)生成training_progress.png文件,包含原始奖励曲线和50轮移动平均曲线。
(2)自动保存训练过程中间模型(每50轮)。
(3)在./video目录生成测试视频。
七、总结
策略梯度通过直接优化策略参数,为处理连续控制和高维状态空间提供了灵活框架。其变体(如Actor-Critic、PPO)通过引入值函数和约束优化,进一步提升了性能与稳定性。理解策略梯度是掌握深度强化学习的重要基础,后续可结合具体场景选择进阶算法。
相关文章:
基于策略的强化学习方法之策略梯度(Policy Gradient)详解
在前文中,我们已经深入探讨了Q-Learning、SARSA、DQN这三种基于值函数的强化学习方法。这些方法通过学习状态值函数或动作值函数来做出决策,从而实现智能体与环境的交互。 策略梯度是一种强化学习算法,它直接对策略进行建模和优化,…...

1.Redis-key的基本命令
(一)Redis的基本类型 String,List,Set,Hash,Zset 三种特殊类型:geospatial(地理空间数据)、hyperloglog[基数估算(去重计数)]、bitmaps(位图&…...

JavaScript 中级进阶技巧之map函数
作为一名初级 JavaScript 开发者,你可能已经熟悉了基础语法、变量和简单的循环。但要从初级迈向中级,掌握一些高效、优雅的编码技巧是关键。其中,map 函数是中级开发者常用的工具,它不仅能简化代码,还能提升代码的可读…...

PROFIBUS DP转ModbusTCP网关模块于污水处理系统的成功应用案例解读
在当今的工业生产领域,众多企业在生产过程中会产生大量工业废水。若这些废水未经处理直接排放,将会引发严重的工业污染问题。因此,借助科技手段对污水进行有效处理显得尤为重要。在一个污水处理系统中,往往包含来自不同厂家、不同…...

Java实现桶排序算法
1. 桶排序原理图解 桶排序是一种基于分桶思想的非比较排序算法,适用于数据分布较为均匀的场景。其核心思想是将数据分散到有限数量的“桶”中,每个桶再分别进行排序(通常使用插入排序或其他简单的排序算法)。以下是桶排序的步骤&a…...

《Effective Python》第2章 字符串和切片操作——深入理解 Python 中 __repr__ 与 __str__
引言 本文基于学习《Effective Python》第三版 Chapter 2: Strings and Slicing 中的 Item 12: Understand the Difference Between repr and str When Printing Objects 后的总结与延伸。在 Python 中,__repr__ 和 __str__ 是两个与对象打印密切相关的魔术方法&am…...
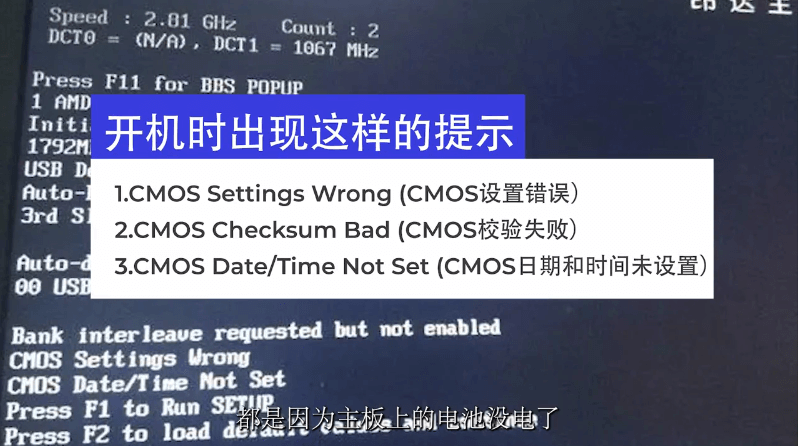
电脑开机提示按f1原因分析及解决方法(6种解决方法)
经常有网友问到一个问题,我电脑开机后提示按f1怎么解决?不管理是台式电脑,还是笔记本,都有可能会遇到开机需要按F1,才能进入系统的问题,引起这个问题的原因比较多,今天小编在这里给大家列举了比较常见的几种电脑开机提示按f1的解决方法。 电脑开机提示按f1原因分析及解决…...
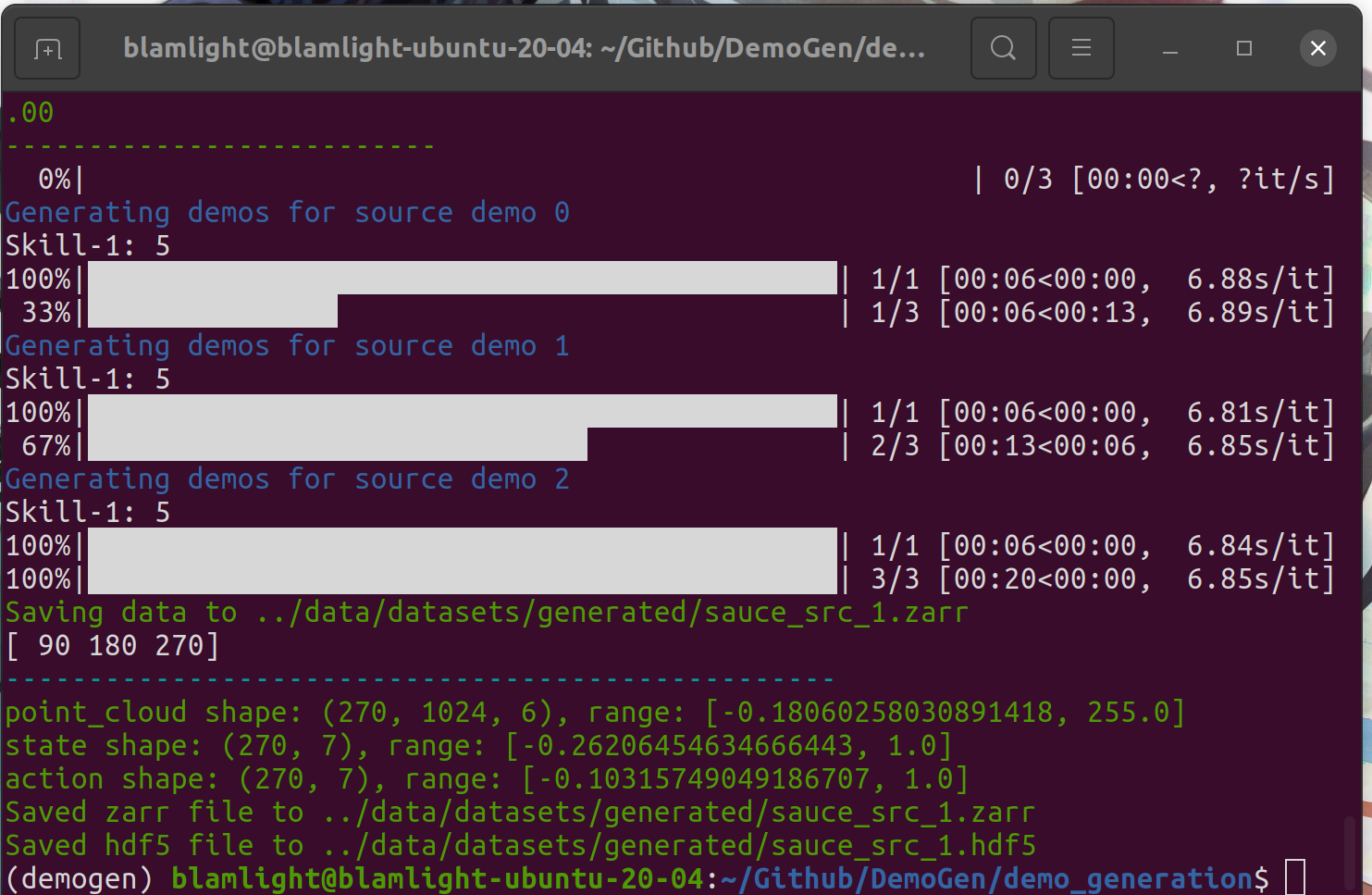
复现:DemoGen 用于数据高效视觉运动策略学习的 合成演示生成 (RSS) 2025
https://github.com/TEA-Lab/DemoGen?tabreadme-ov-file 复现步骤很简单,按照readme配置好conda环境即可运行。 运行: cd demo_generation bash run_gen_demo.sh 等待生成: 查看data文件夹...

Nginx核心功能及同类产品对比
Nginx 作为一款高性能的 Web 服务器和反向代理工具,凭借其独特的架构设计和丰富的功能,成为互联网基础设施中不可或缺的组件。以下是其核心功能及与同类产品(如 HAProxy、LVS)的对比优势: 一、Nginx 核心功能 高性能架…...
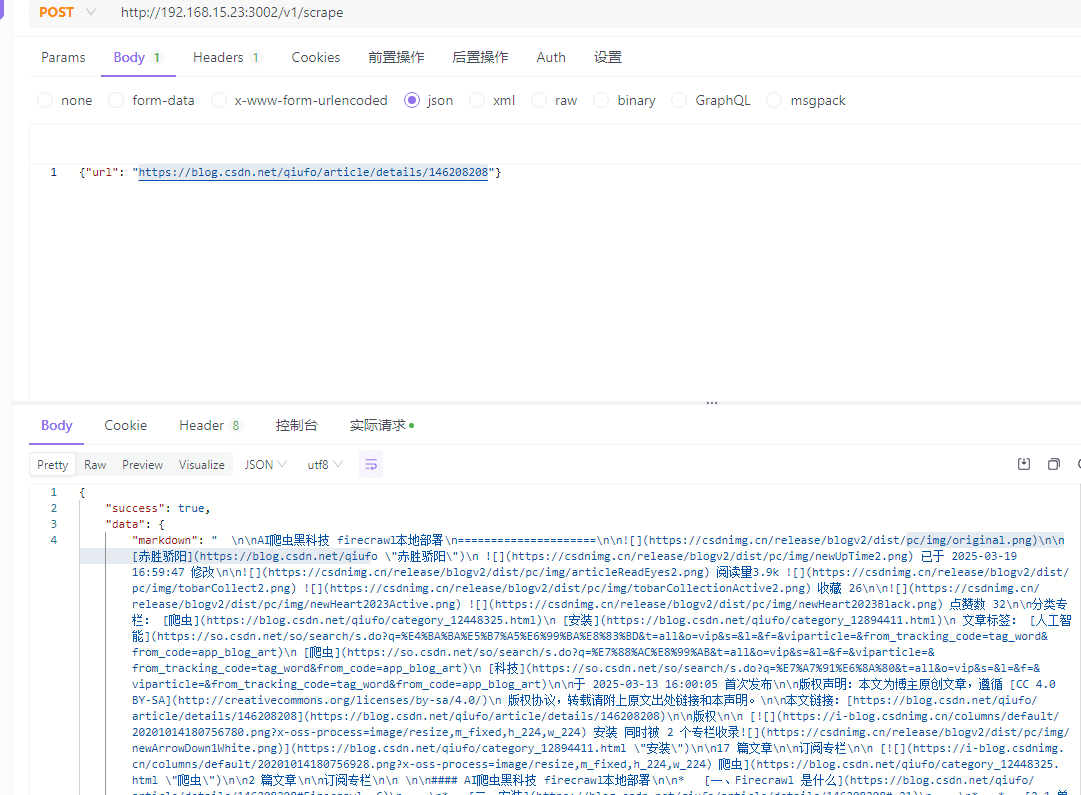
本地部署firecrawl的两种方式,自托管和源码部署
网上资料很多 AI爬虫黑科技 firecrawl本地部署-CSDN博客 源码部署 前提条件本地安装py,node.js环境,嫌弃麻烦直接使用第二种 使用git或下载压缩包 git clone https://github.com/mendableai/firecrawl.git 设置环境参数 cd /firecrawl/apps/api 复制环境参数 …...
2023年12月中国电子学会青少年软件编程(Python)等级考试试卷(六级)答案 + 解析
青少年软件编程(Python)等级考试试卷(六级) 分数:100 题数:38 一、单选题(共25题,共50分) 1. 运行以下程序,输出的结果是?( ) class A(): …...
)
spark:map 和 flatMap 的区别(Scala)
场景设定 假设有一个包含句子的 RDD: scala val rdd sc.parallelize(List("Hello World", "Hi Spark")) 目标是:将每个句子拆分成单词。 1. 用 map 的效果 代码示例 scala val resultMap rdd.map(sentence > sentence…...
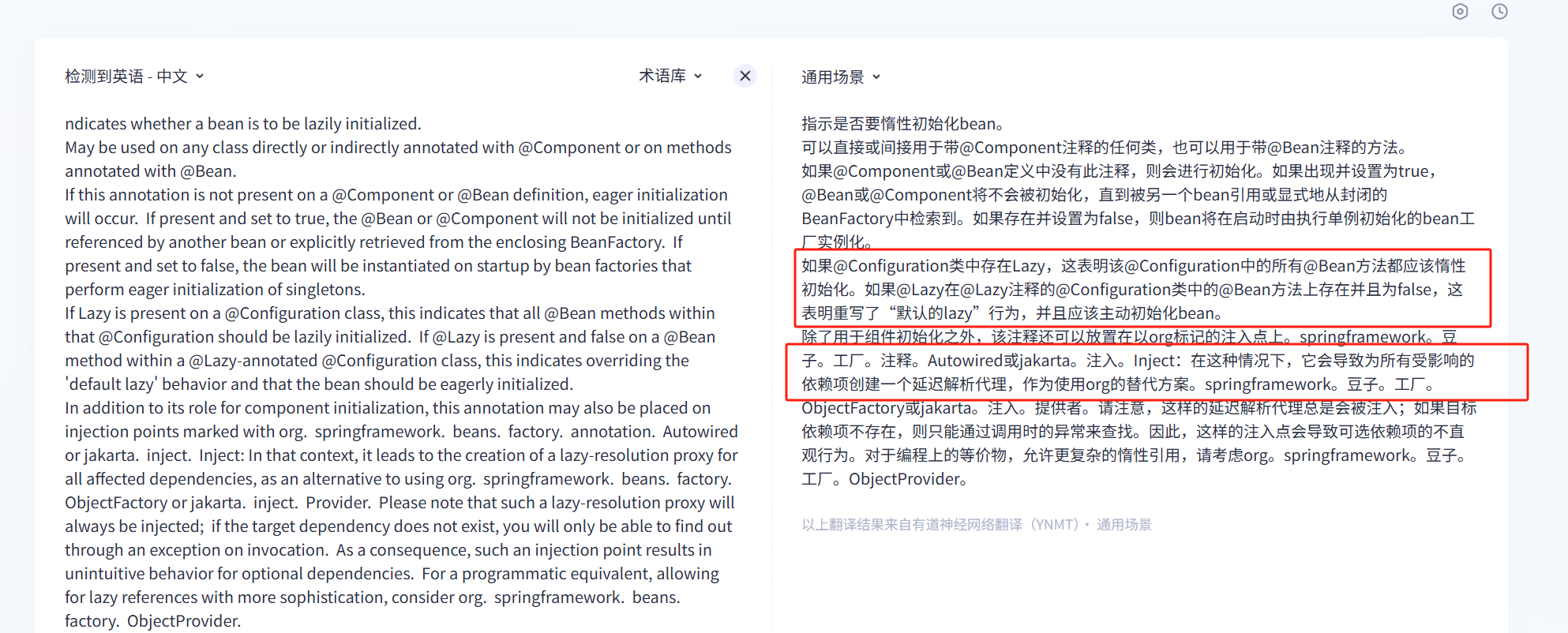
Spring @Lazy注解详解
文章目录 Lazy注解主要作用工作原理使用方法注意事项总结 Lazy注解主要作用 首先,让我们看看Lazy注解的源码,截图如下: 源码注释翻译如下 通过源码,我们可以看到:Lazy注解是一个标记注解,用于标记 bean会…...

关于推送后台的webapi demo
文章目录 目录 系列文章目录 文章目录 前言 一、如何实现推送的思考 二、使用步骤 1.引入库 2.连接方法 3. 发送数据 4.结束时发的消息 5.相关的类 总结 前言 手机app一般都有接收消息推送的功能,比如美团app 点的外卖订单推送,那么对于后台如何将消息推…...

中国品牌日 | 以科技创新为引领,激光院“风采”品牌建设结硕果
品牌,作为企业不可或缺的隐形财富,在当今竞争激烈的市场环境中,其构建与强化已成为推动企业持续繁荣的关键基石。为了更好地保护自主研发产品,激光院激光公司于2020年3月7日正式注册“风采”商标,创建拥有自主知识产权…...
GNU Screen 曝多漏洞:本地提权与终端劫持风险浮现
SUSE安全团队全面审计发现,广泛使用的终端复用工具GNU Screen存在一系列严重漏洞,包括可导致本地提权至root权限的缺陷。这些问题同时影响最新的Screen 5.0.0版本和更普遍部署的Screen 4.9.x版本,具体影响范围取决于发行版配置。 尽管GNU Sc…...

05.three官方示例+编辑器+AI快速学习three.js webgl - animation - skinning - ik
本实例主要讲解内容 这个Three.js示例展示了**反向运动学(Inverse Kinematics, IK)**在3D角色动画中的应用。通过加载一个角色模型,演示了如何使用IK技术实现自然的肢体运动控制,如手部抓取物体的动作。 核心技术包括: CCD反向运动学求解器…...

计算机视觉与深度学习 | 激光雷达 vs. RTK+摄像头:谁是智能割草机器人的最优选择?
激光雷达 vs. RTK+摄像头 一、技术原理与核心优势对比二、实际应用中的性能差异三、行业趋势与创新方向四、场景化选择建议五、未来展望激光雷达与RTK+摄像头是智能割草机器人领域两种主流技术路线,各有其适用场景与优劣势。结合行业最新动态与技术演进,以下从多个维度对比分…...
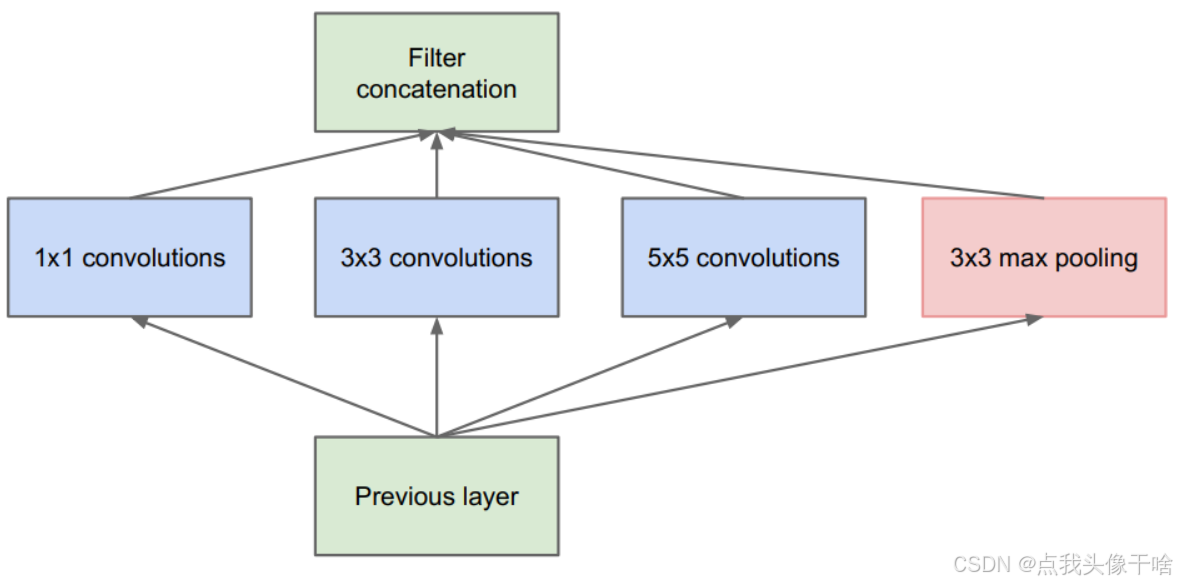
第29节:现代CNN架构-Inception系列模型
引言 Inception系列模型是卷积神经网络(CNN)发展历程中的重要里程碑,由Google研究人员提出并不断演进。这一系列模型通过创新的架构设计,在保持计算效率的同时显著提升了图像识别任务的性能。从最初的Inception v1到最新的Inception-ResNet,每一代Inception模型都引入了突破…...

【深度学习】将本地工程上传到Colab运行的方法
1、将本地工程(压缩包)上传到一个新的colab窗口:如下图中的 2.zip,如果工程中有数据集,可以删除掉。 2、解压压缩包。 !unzip /content/2.zip -d /content/2 如果解压出了不必要的文件夹可以递归删除: #…...
RabbitMQ 中的六大工作模式介绍与使用
文章目录 简单队列(Simple Queue)模式配置类定义消费者定义发送消息测试消费 工作队列(Work Queues)模式配置类定义消费者定义发送消息测试消费负载均衡调优 发布/订阅(Publish/Subscribe)模式配置类定义消…...
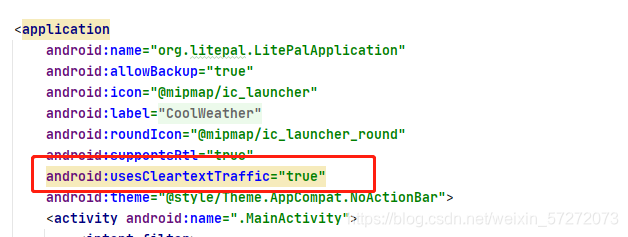
Android HttpAPI通信问题(已解决)
使用ClearTextTraffic是Android中一项重要的网络设置,它控制了应用程序是否允许在不使用HTTPS加密的情况下访问网络。在默认情况下,usescleartexttraffic的值为true,这意味着应用程序可以通过普通的HTTP协议进行网络通信。然而,这样的设置可能会引发一些安全问题,本文将对…...
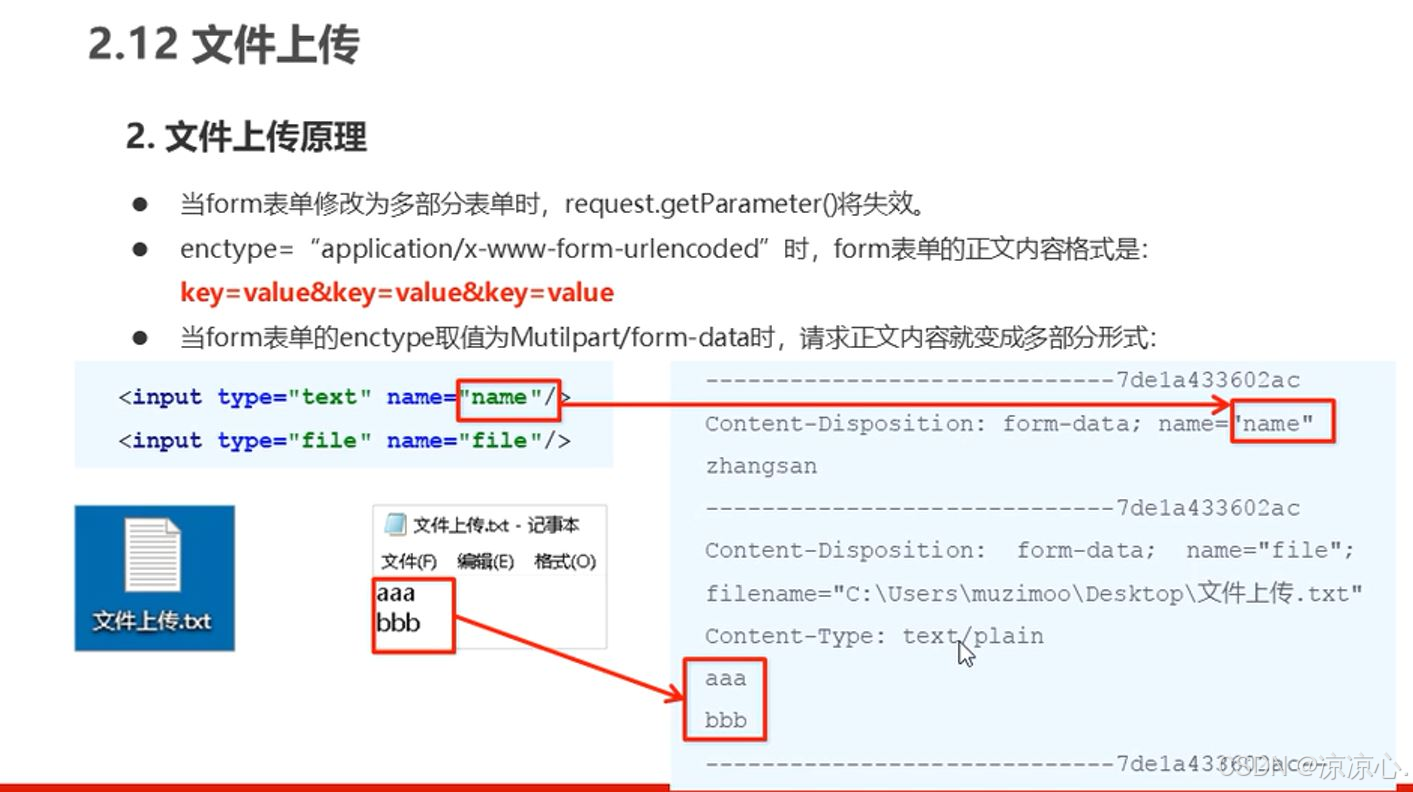
【SSM-SpringMVC(二)】Spring接入Web环境!本篇开始研究SpringMVC的使用!SpringMVC数据响应和获取请求数据
SpringMVC的数据响应方式 页面跳转 直接返回字符串通过ModelAndView对象返回 回写数据 直接返回字符串返回对象或集合 页面跳转: 返回字符串方式 直接返回字符串:此种方式会将返回的字符串与视图解析器的前后缀拼接后跳转 RequestMapping("/con&…...
docker安装mysql8, 字符集,SQL大小写规范,sql_mode
一、Docker安装MySQL 使用Docker安装MySQL,命令如下 docker run -d \-p 3306:3306 \-v mysql_conf:/etc/mysql/conf.d \-v mysql_data:/var/lib/mysql \--name mysql \--restartalways \--privileged \-e MYSQL_ROOT_PASSWORD1234 \mysql:8.0.30参数解释 🐳 dock…...

FastMCP v2:构建MCP服务器和客户端的Python利器
FastMCP v2:构建MCP服务器和客户端的Python利器 引言 在人工智能与大语言模型(LLMs)的应用场景中,如何高效地构建服务器和客户端以实现数据交互与功能调用是关键问题。Model Context Protocol (MCP) 为此提供了一种标准…...

一个WordPress连续登录失败的问题排查
文章目录 1. 问题背景2. 解决方案搜索3. 问题定位4. 排查过程5. 清理空间6. 处理结果7. 后续优化 1. 问题背景 登录请求URL: Request URL: https://www.xxxxxx.com/wp-login.php 返回的响应头信息是: location: https://www.xxxxxx.com/wp-admin/ 证明登录成功。 接下来浏览器…...
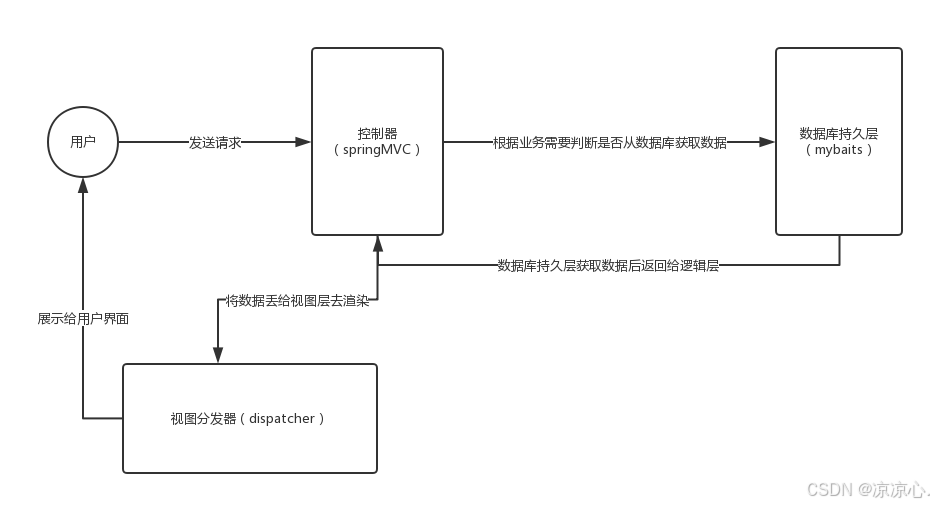
【SSM-SSM整合】将Spring、SpringMVC、Mybatis三者进行整合;本文阐述了几个核心原理知识点,附带对应的源码以及描述解析
SSM整合的基础jar包 需要创建的层级: controller层 该层下需要创建对应的控制器Servlet POJO文件夹 该层下需要创建与数据库对应的POJO类 mapper层 该层下需要创建Mapper的接口实现 service层 该层下需要创建业务层的接口及其接口实现 需要创建的配置文件&#x…...

Go语言超时控制方案全解析:基于goroutine的优雅实现
一、引言 在构建高可靠的后端服务时,超时控制就像是守护系统稳定性的"安全阀",它确保当某些操作无法在预期时间内完成时,系统能够及时止损并释放资源。想象一下,如果没有超时控制,一个简单的数据库查询卡住…...

spark运行架构及核心组件介绍
目录 1. Spark 的运行架构1.1 Driver1.2 Executor1.3 Cluster Manager1.4 工作流程 2. Spark 的核心组件2.1 Spark Core2.2 Spark SQL2.3 Spark Streaming2.4 MLlib2.5 GraphX 3. Spark 架构图4. Spark 的优势4.1 高性能4.2 易用性4.3 扩展性4.4 容错性 5. 总结 1. Spark 的运行…...

idea中编写spark程序
### 在 IntelliJ IDEA 中配置和编写 Spark 程序 要在 IntelliJ IDEA 中高效地开发 Spark 程序,需要完成一系列必要的环境配置以及项目搭建工作。以下是详细的说明。 --- #### 1. 安装与配置 IntelliJ IDEA 为了确保 IDE 可以支持 Scala 开发,首先需要…...