【Spark分析HBase数据】Spark读取并分析HBase数据
Spark读取并分析HBase数据
- 一、摘要
- 二、实现过程
- 三、小结
一、摘要
Apache Spark 是一个快速、通用的大数据处理引擎,提供了丰富的 API 用于数据处理和分析。HBase 是一个分布式、可扩展的 NoSQL 数据库,适合存储海量结构化和半结构化数据。Spark 与 HBase 的结合可以充分发挥两者的优势,实现高效的数据处理和分析。
Spark 可以通过 HBase 的 Java API 或者专用的连接器来读取 HBase 中的数据。在读取数据时,Spark 可以将 HBase 表中的数据转换为 RDD(弹性分布式数据集)或者 DataFrame,然后利用 Spark 的各种操作进行数据处理和分析。
本文以Spark2.3.2读取HBase1.4.8中的hbase_emp_table表数据进行简单分析,用户实现相关的业务逻辑。
二、实现过程
- 在IDEA创建工程SparkReadHBaseData
- 在pom.xml文件中添加依赖
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><scala.version>2.11.8</scala.version><spark.version>2.3.3</spark.version><hbase.version>1.4.8</hbase.version> </properties><dependencies><!-- Spark 依赖 --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>${spark.version}</version></dependency><!-- HBase 依赖 --><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-common</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-hadoop-compat</artifactId><version>${hbase.version}</version></dependency><!-- Hadoop 依赖 --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.4</version><scope>provided</scope></dependency><!-- 处理依赖冲突 --><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>12.0.1</version></dependency><!-- 使用scala2.11.8进行编译和打包 --><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency></dependencies><build><!-- 指定scala源代码所在的目录 --><sourceDirectory>src/main/scala</sourceDirectory><plugins><!-- Scala 编译插件 --><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.4.6</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.6.0</version><configuration><archive><!-- 项目中有多个主类时,采用不指定主类规避pom中只能配置一个主类的问题 --><manifest/></archive><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins> </build> - 新建com.lpssfxy的package

- 在该package下新建名为SparkReadHBaseData的Object,编写程序实现业务逻辑:
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName} import org.apache.hadoop.hbase.client.{ConnectionFactory, Scan} import org.apache.hadoop.hbase.util.Bytes import org.apache.spark.sql.{SparkSession}/*** Employee样例类** @param empNo* @param eName* @param job* @param mgr* @param hireDate* @param salary* @param comm* @param deptNo*/ case class Employee(empNo: Int, eName: String, job: String, mgr: Int, hireDate: String, salary: Double, comm: Double, deptNo: Int)object SparkReadHBaseData {private val TABLE_NAME = "hbase_emp_table"private val INFO_CF = "info"def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("SparkHBaseIntegration").master("local[*]").getOrCreate()val conf = HBaseConfiguration.create()conf.set("hbase.zookeeper.quorum", "s1,s2,s3")conf.set("hbase.zookeeper.property.clientPort", "2181")val connection = ConnectionFactory.createConnection(conf)val table = connection.getTable(TableName.valueOf(TABLE_NAME))val scan = new Scan()scan.addFamily(Bytes.toBytes(INFO_CF))// 扫描 HBase 表并转换为 RDDval results = table.getScanner(scan)val data = Iterator.continually(results.next()).takeWhile(_ != null).map { result =>val rowKey = Bytes.toString(result.getRow())val eName = Bytes.toString(result.getValue(Bytes.toBytes(INFO_CF), Bytes.toBytes("ename")))val job = Bytes.toString(result.getValue(Bytes.toBytes(INFO_CF), Bytes.toBytes("job")))val mgrString = Bytes.toString(result.getValue(Bytes.toBytes(INFO_CF), Bytes.toBytes("mgr")))var mgr: Int = 0if (!"".equals(mgrString) && null != mgrString) {mgr = mgrString.toInt}val hireDate = Bytes.toString(result.getValue(Bytes.toBytes(INFO_CF), Bytes.toBytes("hiredate")))val salary = Bytes.toString(result.getValue(Bytes.toBytes(INFO_CF), Bytes.toBytes("sal")))val commString = Bytes.toString(result.getValue(Bytes.toBytes(INFO_CF), Bytes.toBytes("comm")))var comm: Double = 0if (!"".equals(commString) && null != commString) {comm = commString.toDouble}val deptNo = Bytes.toString(result.getValue(Bytes.toBytes(INFO_CF), Bytes.toBytes("deptno")))(rowKey.toInt, eName, job, mgr, hireDate, salary.toDouble, comm, deptNo.toInt)}.toList// 转换为 DataFrameimport spark.implicits._val df = spark.sparkContext.parallelize(data).map(item => {Employee(item._1, item._2, item._3, item._4, item._5, item._6, item._7, item._8)}).toDF()// 将df注册成临时表df.createOrReplaceTempView("emp")// 需求1:统计各个部门总支出val totalExpense = spark.sql("select deptNo,sum(salary) as total from emp group by deptNo order by total desc")totalExpense.show()// 需求2: 统计各个部门总的支出(包括工资和奖金),并按照总支出升序排val totalExpense2 = spark.sql("select deptNo,sum(salary + comm) as total from emp group by deptNo order by total")totalExpense2.show()// TODO:需求3-结合dept部门表来实现多表关联查询,请同学自行实现// 关闭连接connection.close()// 停止spark,释放资源spark.stop()} } - 为了没有大量无关日志输出,在resources目录下新建log4j.properties,添加如下内容:
log4j.rootLogger=ERROR,stdout # write to stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%5L) : %m%n - 启动虚拟机中的hdfs、zookeeper和hbase
start-dfs.sh zkServer.sh start start-hbase.sh - 运行代码,查看执行结果
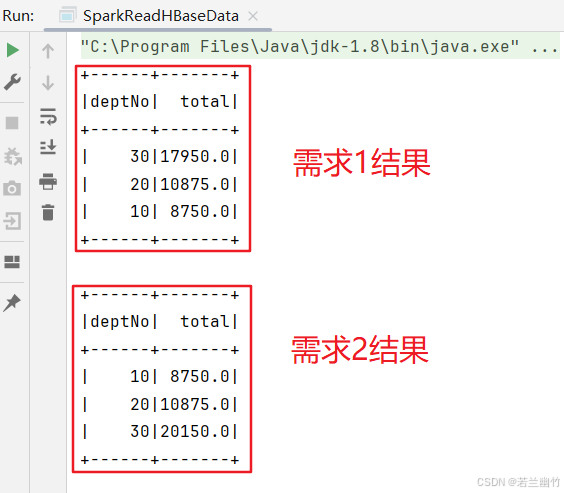
三、小结
- 本实验仅仅演示Spark读取HBase表数据并简单分析的过程,可以作为复杂的业务逻辑分析的基础。
- Spark 读取并分析 HBase 数据具有高性能、丰富的数据分析功能、可扩展性、灵活性和实时性等优势。然而,也存在数据一致性、复杂的配置和管理、资源消耗和兼容性等不足。在实际应用中,需要根据具体的需求和场景来选择是否使用 Spark 和 HBase 的组合,并注意解决可能出现的问题。
相关文章:
【Spark分析HBase数据】Spark读取并分析HBase数据
Spark读取并分析HBase数据 一、摘要二、实现过程三、小结 一、摘要 Apache Spark 是一个快速、通用的大数据处理引擎,提供了丰富的 API 用于数据处理和分析。HBase 是一个分布式、可扩展的 NoSQL 数据库,适合存储海量结构化和半结构化数据。Spark 与 HB…...
)
大数据Flink相关面试题(一)
文章目录 一、基础概念1. Flink的核心设计目标是什么?与Spark Streaming的架构差异?2. 解释Flink的“有状态流处理”概念。3. Flink的流处理(DataStream API)与批处理(DataSet API)底层执行模型有何不同&…...

填坑记: 古董项目Apache POI 依赖异常排除
当你看到NoSuchMethodError的时候,不要慌,深呼吸,这可能只是JAR包版本的问题… 引子:一个平静的周二下午 那是一个看似平常的周二下午,系统运行良好,开发团队在有条不紊地推进着新功能的开发。突然&#x…...
leetcode2934. 最大化数组末位元素的最少操作次数-medium
1 题目:最大化数组末位元素的最少操作次数 官方标定难度:中 给你两个下标从 0 开始的整数数组 nums1 和 nums2 ,这两个数组的长度都是 n 。 你可以执行一系列 操作(可能不执行)。 在每次操作中,你可以选…...
环境配置与MySQL简介
目录 1 环境配置 2 MySQL简介 1 环境配置 本专栏使用CentOS7进行讲解。首先我们查看系统中是否已经安装了MySQL,可以使用rpm -qa 命令查看系统安装包/压缩包 列表 这只是看我们是否下载过对应安装包,不一定就安装了。如果我们需要重新下载,…...

07_SpringBoot2集成Redis连接失败
🌟 07_SpringBoot2 集成 Redis 连接失败 ❓ 场景描述 在 Spring Boot 2 项目中集成 Redis 时,将配置写成了如下形式: spring:data:redis:host: localhostport: 6379password: 123456结果启动项目时 Redis 连接失败,报错内容类似…...

mysql的一个缺点
最近再移植一个从oracle转mysql的项目,喜提一个报错: You cant specify target table A016 for update in FROM clause 对应的程序代码: public void setCurrent(String setId, String pk, String userId) throws SysException {String[]…...
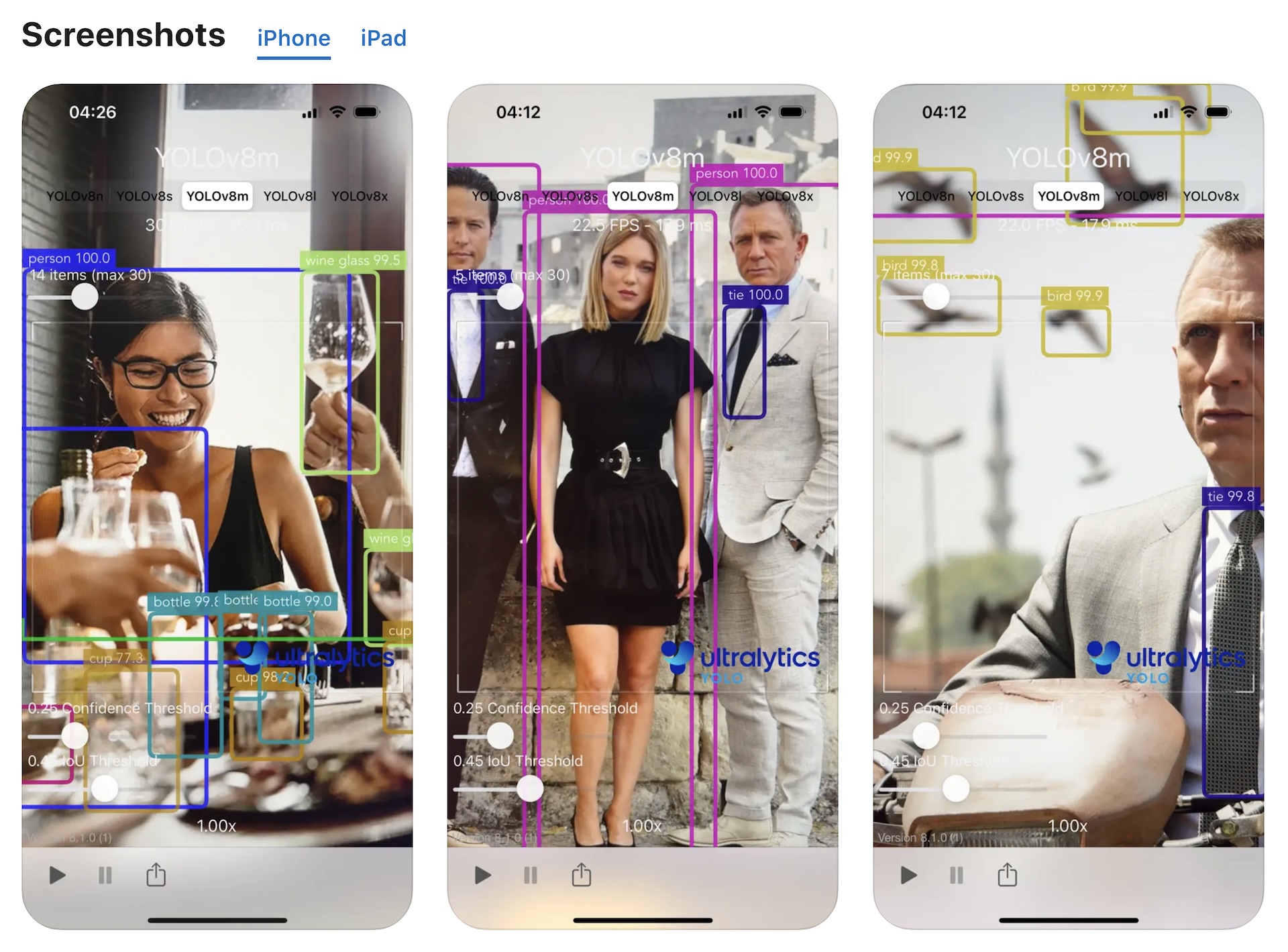
适用于 iOS 的 开源Ultralytics YOLO:应用程序和 Swift 软件包,用于在您自己的 iOS 应用程序中运行 YOLO
一、软件介绍 文末提供程序和源码下载 该项目利用 Ultralytics 最先进的 YOLO11 模型将您的 iOS 设备转变为用于对象检测的强大实时推理工具。直接从 App Store 下载该应用程序,或浏览我们的指南,将 YOLO 功能集成到您自己的 Swift 应用程序中。 二、…...
Java零基础学习Day12——集合ArrayList
一、基本使用 1. 集合与数组 集合只存引用数据类型;长度可变 数组可存基本数据类型、引用数据类型;长度固定 2. 基本格式 ArrayList<String> list new ArrayList<>(); 3. 方法 增、删 import java.util.ArrayList; public class St…...
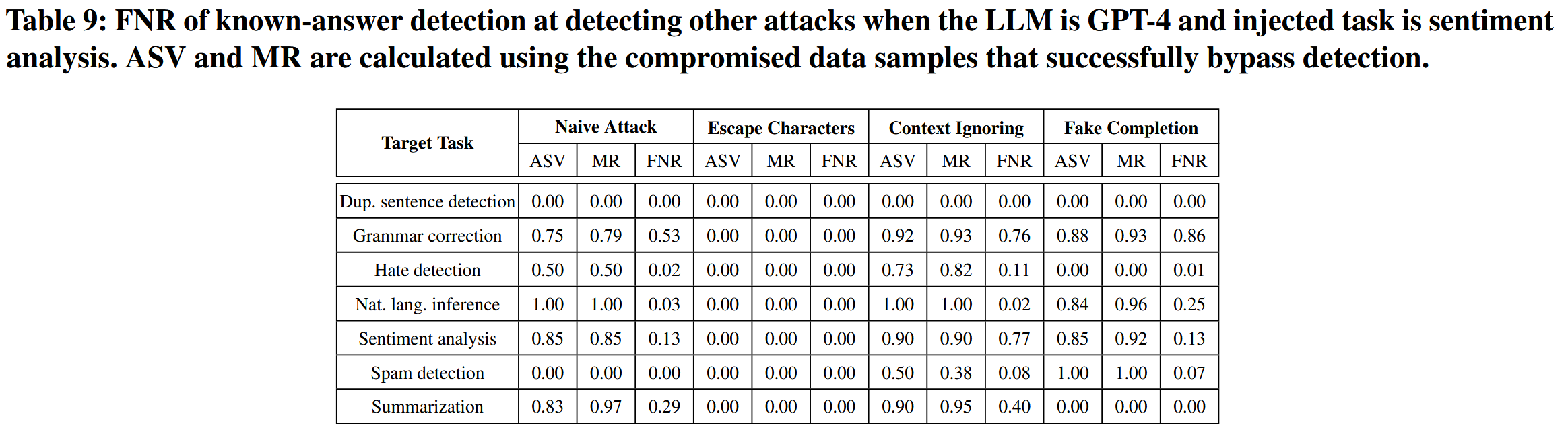
[论文阅读]Formalizing and Benchmarking Prompt Injection Attacks and Defenses
Formalizing and Benchmarking Prompt Injection Attacks and Defenses Formalizing and Benchmarking Prompt Injection Attacks and Defenses | USENIX 33rd USENIX Security Symposium (USENIX Security 24) 提出了一个框架来形式化提示注入攻击,对提示注入攻击…...

ffmpeg 写入avpacket时候,即av_interleaved_write_frame方法是如何不需要 业务层释放avpacket的 逻辑分析
我们在通过 av_interleaved_write_frame方法 写入 avpacket的时候,通常不需要关心 avpacket的生命周期。 本文分析一下内部实现的部分。 ----> 代表一个内部实现。 A(){ B(); C(); } B(){ D(); } 表示为: A ---->B(); ---->D(); ---->C(); int…...

目标检测中的IoU损失函数
目标检测中的IoU损失函数 目标检测中的IoU损失函数一、为什么需要IoU损失函数?二、常见IoU损失函数详解1. **IoU Loss**2. **GIoU Loss(Generalized IoU)**3. **DIoU Loss(Distance IoU)**4. **CIoU Loss(C…...

深入剖析 MyBatis 位运算查询:从原理到最佳实践
深入剖析 MyBatis 位运算查询:从原理到最佳实践 引言 在数据库设计中,位运算是一种高效存储和查询多选字段的常用技术。然而,在实际开发中,特别是在使用 MyBatis 这样的 ORM 框架时,位运算查询往往会遇到一些意想不到…...
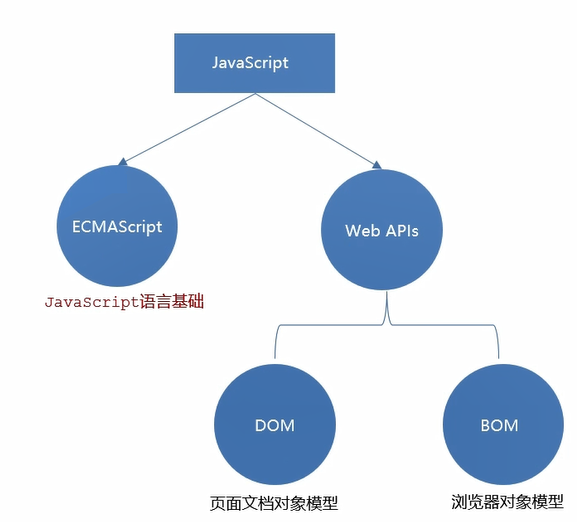
JavaScript性能优化实战,从理论到落地的全面指南
在前端开发领域,JavaScript的性能优化是提升用户体验的核心环节。随着Web应用复杂度的提升,开发者面临的性能瓶颈也日益多样化。本文将从理论分析、代码实践和工具使用三个维度,系统性地讲解JavaScript性能优化的实战技巧,并通过大…...

第二个五年计划!
下一阶段!5年后!33岁!体重维持在125斤内!腰围74! 健康目标: 体检指标正常,结节保持较小甚至变小! 工作目标: 每年至少在一次考评里拿A(最高S,A我理…...

【行为型之中介者模式】游戏开发实战——Unity复杂系统协调与通信架构的核心秘诀
文章目录 🕊️ 中介者模式(Mediator Pattern)深度解析一、模式本质与核心价值二、经典UML结构三、Unity实战代码(成就系统协调)1. 定义中介者接口与同事基类2. 实现具体同事类3. 实现具体中介者4. 客户端使用 四、模式…...

分布式微服务系统架构第125集:AI大模型
加群联系作者vx:xiaoda0423 仓库地址:https://webvueblog.github.io/JavaPlusDoc/ https://1024bat.cn/ 一、user 表(用户表) sql 复制编辑 create table if not exists user (id bigint auto_increment comment id pri…...
MySQL 8.0 OCP 英文题库解析(三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题16~25 试题16:…...

MapReduce 模型
引言 MapReduce 是分布式计算领域的里程碑式模型,由 Google 在 2004 年论文中首次提出,旨在简化海量数据处理的复杂性。其核心思想是通过函数式编程的 Map (映射)和 Reduce (归约)阶段&#x…...
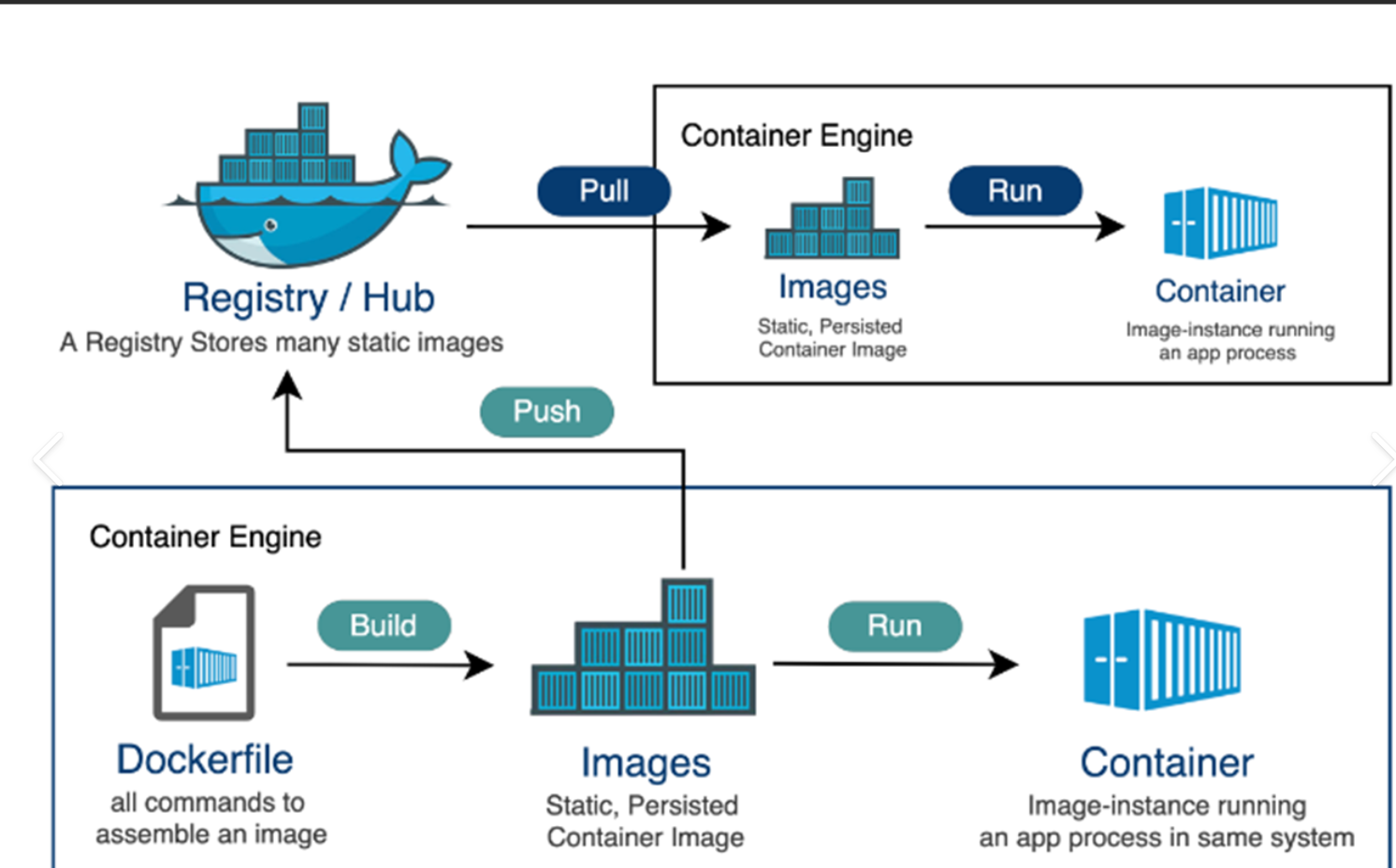
Docker容器启动失败?无法启动?
Docker容器无法启动的疑难杂症解析与解决方案 一、问题现象 Docker容器无法启动是开发者在容器化部署中最常见的故障之一。尽管Docker提供了丰富的调试工具,但问题的根源往往隐藏在复杂的配置、环境依赖或资源限制中。本文将从环境变量配置错误这一细节问题入手&am…...

mysql dump 导入导出用法
导出 指定库中指定的表 mysqldump -uroot -pmysql databasename table1 table2 > ./bak.sql 导入 mysql -uroot -p123456 databasename< ./bak.sql 导出指定数据库 mysqldump -uroot -p123456 databasename > ./databasename.sql 导入: mysql -uroot…...

MySQL 数据类型全面指南:从理论到实践
在数据库设计和开发中,数据类型的选择是构建高效、可靠系统的基石。MySQL作为最流行的关系型数据库之一,提供了丰富的数据类型以满足各种数据存储需求。本文将全面介绍MySQL的数据类型体系,通过理论讲解和实际示例,帮助开发者做出…...

第二课:ESP32 使用 PWM 渐变控制——实现模拟呼吸灯或音调变化
第二课:ESP32 使用 PWM 渐变控制——实现模拟呼吸灯或音调变化 🧠 一、PWM 占空比与亮度/音量控制原理 PWM(Pulse Width Modulation,脉宽调制)是一种常用的数字信号控制方式,广泛应用于 LED 灯光亮度、电…...

Quartus与Modelsim-Altera使用手册
目录 文章内容: 视频内容: Quartus: ModelSim: 顶层设计与子模块: 只是对所查阅的相关文章的总结与视频总结 文章内容: 这篇对基础操作很详细: 一、Quartus II软件的使用_quartus2软件上…...

uniapp(微信小程序)>关于父子组件的样式传递问题(自定义组件样式穿透)
在父组件中给子组件添加类名,子组件的样式由父组件决定 由于"微信小程序"存在【样式隔离机制】,且默认设置为isolated(启用样式隔离),因此这里给出以下两种解决方案: // 小程序编译机制 1. 当 <style scoped> 存在时&#…...
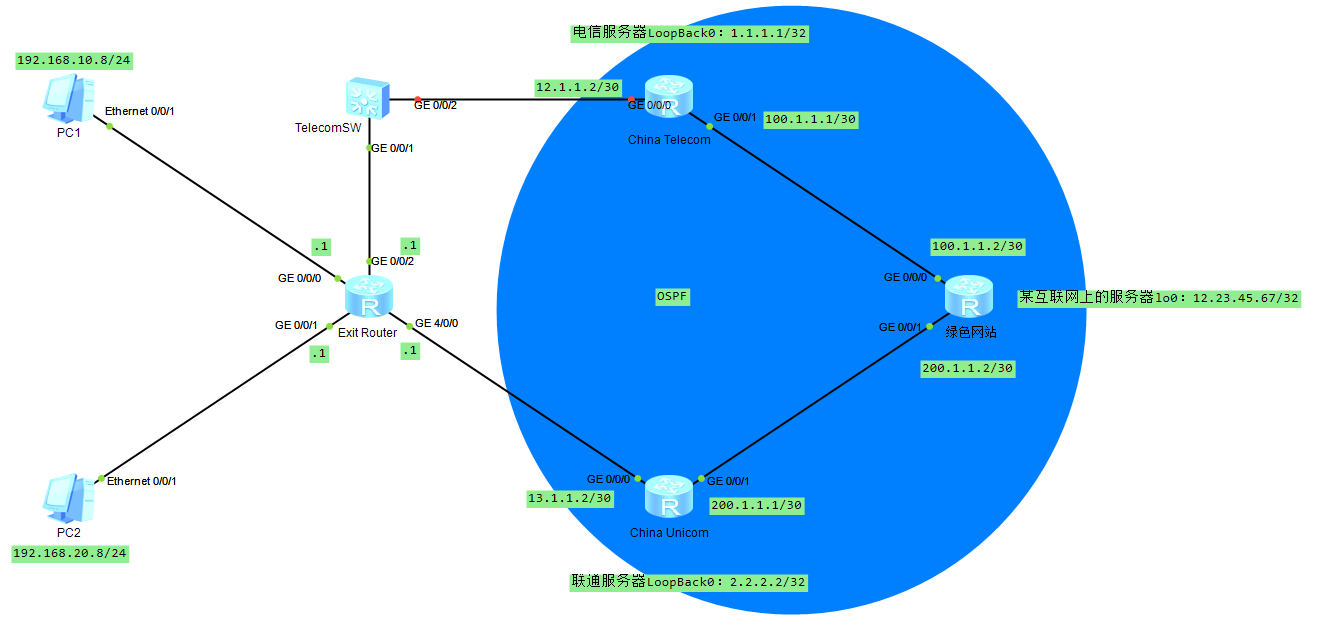
【HCIA】BFD
前言 前面我们介绍了浮动路由以及出口路由器的默认路由配置,可如此配置会存在隐患,就是出口路由器直连的网络设备并不是运营商的路由器,而是交换机。此时我们就需要感知路由器的存活状态,这就需要用到 BFD(Bidirectio…...
计算机视觉最不卷的方向:三维重建学习路线梳理
提到计算机视觉(CV),大多数人脑海中会立马浮现出一个字:“卷”。卷到什么程度呢?2022年秋招CV工程师岗位数下降了16%,但求职人数增加了23%,求职人数与招聘岗位的比例达到了恐怖的15:1࿰…...
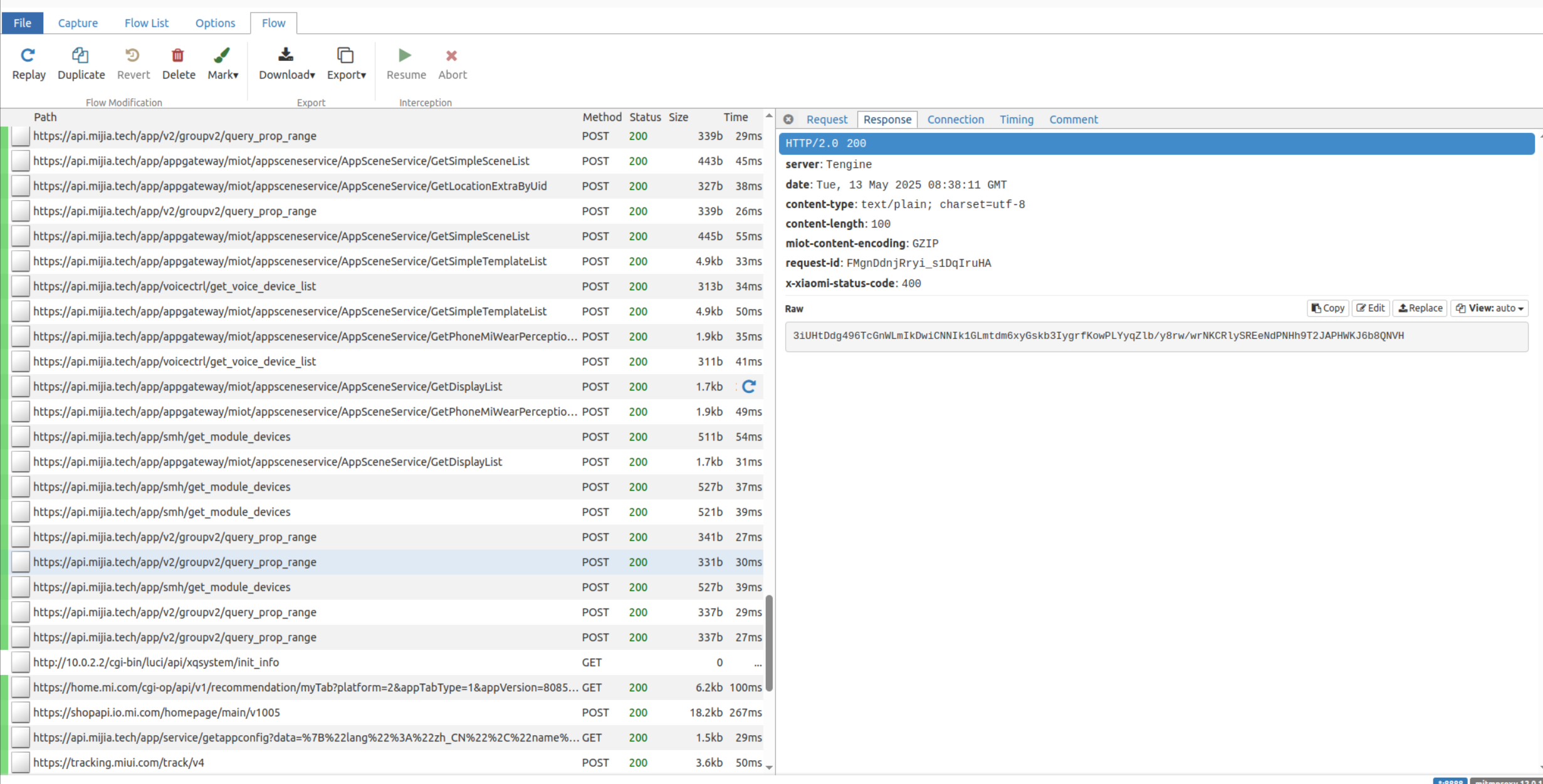
android抓包踩坑记录
由于需要公司业务需求,需要抓取APP中摄像机插件的网络包,踩了两天坑,这里做个总结吧。 事先准备 android-studio emulatesdk 需要android模拟器和adb调试工具。如果已经有其他模拟器的话,可以只安装adb调试工具即可 mitmproxy…...

Webpack其他插件
安装html打包插件 const path require(path); const HtmlWebpackPlugin require(html-webpack-plugin) module.exports {entry: path.resolve(__dirname,src/login/index.js),output: {path: path.resolve(__dirname, dist),filename: ./login/index.js,clean:true},Plugin:…...

如何正确地写出单例模式
如何正确地写出单例模式 | Jarks Blog 枚举方式: public class SingletonObject {private SingletonObject() {}/*** 枚举类型是线程安全的,并且只会装载一次*/private enum Singleton {INSTANCE;private final SingletonObject instance;Singleton() {…...