MapReduce 模型
引言
MapReduce 是分布式计算领域的里程碑式模型,由 Google 在 2004 年论文中首次提出,旨在简化海量数据处理的复杂性。其核心思想是通过函数式编程的 Map (映射)和 Reduce (归约)阶段,将任务拆解为并行化子任务,隐藏分布式调度、容错、负载均衡等底层细节。Hadoop 的 MapReduce 实现将其普及至工业界,成为大数据生态系统的基石。尽管后续框架(如 Spark、Flink)在性能和易用性上有所改进,但理解 MapReduce 的设计哲学仍是掌握分布式计算的关键。
一、MapReduce 编程模型核心机制
1. 定义
MapReduce是面向大数据并行处理的计算模型、框架和平台,它隐含了以下三层含义:
1)MapReduce是一个基于集群的高性能并行计算平台(Cluster Infrastructure)。它允许用市场上普通的商用服务器构成一个包含数十、数百至数千个节点的分布和并行计算集群。
2)MapReduce是一个并行计算与运行软件框架(Software Framework)。它提供了一个庞大但设计精良的并行计算软件框架,能自动完成计算任务的并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行任务以及收集计算结果,将数据分布存储、数据通信、容错处理等并行计算涉及到的很多系统底层的复杂细节交由系统负责处理,大大减少了软件开发人员的负担。
3)MapReduce是一个并行程序设计模型与方法(Programming Model & Methodology)。它借助于函数式程序设计语言Lisp的设计思想,提供了一种简便的并行程序设计方法,用Map和Reduce两个函数编程实现基本的并行计算任务,提供了抽象的操作和并行编程接口,以简单方便地完成大规模数据的编程和计算处理 。
2. 详细工作流程
-
Input Splitting(输入分片)
- 输入数据(如 HDFS 文件)被划分为固定大小的 Split(默认与 HDFS Block 对齐,如 128MB)。
- 每个 Split 由一个 Map Task 处理,Split 的划分需确保数据局部性(Data Locality),即尽可能在存储数据的节点上执行 Map 任务,减少网络传输。
-
Map 阶段
- Map 函数 处理键值对
<k1, v1>,生成中间结果<k2, v2>列表。例如,在 WordCount 中,输入为(行偏移量, 文本行),输出为(单词, 1)。 - 内存缓冲区:Map 输出先写入环形内存缓冲区(默认 100MB),达到阈值(如 80%)时触发 Spill(溢写) 到磁盘,生成临时文件。
- Map 函数 处理键值对
-
Combiner(可选优化)
- 本地 Reduce:在 Map 端对相同 Key 的中间结果进行预聚合(如
(word, [1,1,1])→(word, 3)),减少网络传输量。 - Combiner 的逻辑通常与 Reduce 函数相同,但需满足结合律(如求和、最大值)。
- 本地 Reduce:在 Map 端对相同 Key 的中间结果进行预聚合(如
-
Shuffle & Sort(核心阶段)
- Partition(分区):按 Key 的哈希值将数据分配到不同 Reduce 任务(默认
HashPartitioner)。例如,numReduceTasks=3时,每个 Key 会被映射到分区 0、1 或 2。 - Sort(排序):每个分区内按键排序,确保 Reduce 任务接收有序输入。
- Fetch(拉取数据):Reduce 任务从所有 Map 节点拉取对应分区的数据,进行归并排序(Merge Sort)。
- Partition(分区):按 Key 的哈希值将数据分配到不同 Reduce 任务(默认
-
Reduce 阶段
- Reduce 函数 处理
<k2, [v2]>列表,生成最终结果<k3, v3>。例如,对(word, [3,2,5])求和得到(word, 10)。 - 输出写入 HDFS 或其他存储系统,每个 Reduce 任务生成一个结果文件。
- Reduce 函数 处理
-
任务调度与容错
- JobTracker(Hadoop 1.x) / ResourceManager(YARN):负责资源分配和任务调度。
- TaskTracker / NodeManager:执行具体的 Map 或 Reduce 任务。
- 容错机制:
- Worker 故障:重新调度其未完成的任务。
- Master 故障:单点故障需手动恢复(Hadoop 1.x 的缺陷,YARN 改进)。
- 重复执行:因网络延迟导致的任务重复执行通过幂等性设计处理。
3. MapReduce 工作流程图
+----------------+| 输入数据 ||(如HDFS文件) |+----------------+↓+----------------+| 【输入分片】 | → 文件被切分为多个Split(如128MB)| Input Splitting|+----------------+↓
+---------------+---------------+ +---------------+ +---------------+
| Map Task 1 | Map Task 2 | ... | Map Task N | | Combiner |
| (处理Split 1) | (处理Split 2) | | (处理Split N) | → (可选预聚合)
+---------------+---------------+ +---------------+ +---------------+↓ ↓ ↓+-------------------------------------------------+| 【内存缓冲区】 || - Map输出暂存到环形缓冲区(默认100MB) || - 达到阈值后溢写(Spill)到磁盘 |+-------------------------------------------------+↓+-------------------------------------------------+| 【Shuffle & Sort 阶段】 || 1. 分区(Partitioning):按Key哈希分配到Reducer|| 2. 排序(Sorting):每个分区内按键排序 || 3. 合并(Merge):同分区文件归并排序 |+-------------------------------------------------+↓+-------------------------------------------------+| 【Reduce阶段】 || - Reduce任务拉取对应分区的数据 || - 执行Reduce函数(如求和、聚合) |+-------------------------------------------------+↓+----------------+| 输出结果 ||(写入HDFS等) |+----------------+
4. 详细子流程示意图(含磁盘与网络交互)
Map端:
+----------------+ +----------------+ +----------------+
| Map Task | → | 内存缓冲区 | → | 磁盘溢写文件 |
| (处理输入分片) | |(环形缓冲区) | |(分区、排序) |
+----------------+ +----------------+ +----------------+(Combiner可选)Shuffle阶段:
+----------------+ +----------------+
| Map节点磁盘 | → 网络传输 → | Reduce节点 |
|(中间数据文件) | |(拉取对应分区) |
+----------------+ +----------------+Reduce端:
+----------------+ +----------------+ +----------------+
| 数据归并排序 | → | Reduce函数 | → | 结果写入HDFS |
|(多文件合并) | |(最终聚合计算) | |(part-r-00000)|
+----------------+ +----------------+ +----------------+
5. 数据流示意图
Input Data
→ [Split1, Split2, ...] # 分片
→ [Map Task1 → (k2, v2)]
→ [Combiner] # 本地聚合
→ [Partition & Sort] # 分区排序后写入磁盘
→ [Shuffle] # Reduce 拉取数据
→ [Merge & Sort] # 归并排序
→ [Reduce Task → (k3, v3)]
→ Output Data
流程特点
- 数据本地性优先:Map 任务尽量在存储数据的节点上执行。
- 磁盘密集型:Map 和 Shuffle 阶段频繁读写磁盘(Hadoop MapReduce 的瓶颈之一)。
- 全排序:Shuffle 后数据按键全局排序,适合需要有序输入的场景。
二、高级应用场景与案例
1. 复杂数据处理案例
-
倒排索引(搜索引擎)
- Map:解析文档,生成
(word, doc_id)。 - Reduce:聚合相同单词的文档列表,输出
(word, [doc1, doc2, ...])。
- Map:解析文档,生成
-
Join 操作(数据关联)
- Map:为来自不同表的记录打标签(如
(user_id, ("Orders", order_data))和(user_id, ("Users", user_data)))。 - Reduce:按
user_id合并订单和用户信息,实现类似 SQL 的 Join。
- Map:为来自不同表的记录打标签(如
-
PageRank 迭代计算
- 多次 MapReduce 迭代:
- Map:计算页面贡献值。
- Reduce:更新页面权重。
- 需通过 ChainMapper/ChainReducer 或外部循环控制迭代。
- 多次 MapReduce 迭代:
2. 与 Spark 的对比
| 特性 | MapReduce | Spark |
|---|---|---|
| 计算模型 | 批处理 | 批处理 + 流处理 + 迭代 |
| 数据存储 | 磁盘中间结果 | 内存 RDD/Dataset |
| Shuffle 性能 | 高延迟(磁盘密集型) | 优化后的内存+磁盘混合 |
| API 易用性 | 需手动编写 Map/Reduce | 高阶 API(SQL、DataFrame) |
| 适用场景 | 离线批处理 | 实时流处理、迭代算法(MLlib) |
三、性能优化深度策略
1. Shuffle 阶段优化
- 压缩中间数据:使用 Snappy 或 LZO 压缩 Map 输出,减少磁盘 I/O 和网络传输。
- 调整缓冲区大小:增大
mapreduce.task.io.sort.mb以减少溢写次数。 - 并行复制(Parallel Fetch):通过
mapreduce.reduce.shuffle.parallelcopies提高 Reduce 拉取数据的并发度。
2. 资源调优
- 任务并行度:
- Map 任务数由输入分片数决定,可通过
mapreduce.input.fileinputformat.split.minsize调整 Split 大小。 - Reduce 任务数需避免过多(增加调度开销)或过少(负载不均),通常设为集群 Slot 数的 0.95~1.75 倍。
- Map 任务数由输入分片数决定,可通过
- JVM 重用:启用 JVM 复用(
mapreduce.job.jvm.numtasks)减少启动开销。
3. 算法级优化
- 避免多次 MR 迭代:通过 ChainMapper 将多个 Map 操作串联,减少任务启动开销。
- 数据倾斜处理:
- 预处理:对倾斜 Key 加盐(如
key_1,key_2),分散到不同 Reduce 任务。 - Combiner 增强:在 Map 端尽可能聚合数据。
- 自定义 Partition:将高频 Key 分配到多个分区。
- 预处理:对倾斜 Key 加盐(如
四、MapReduce 的演进与替代方案
1. Hadoop 生态的改进
- YARN 资源管理:解耦资源调度与任务执行,支持非 MapReduce 任务(如 Spark、Tez)。
- Tez 框架:通过 DAG 执行计划优化任务依赖,减少中间数据落盘次数。
2. Spark 的优势
- 内存计算:RDD 的弹性分布式数据集避免重复读写磁盘。
- DAG 调度:将任务拆分为 Stage,优化 Shuffle 过程。
- 丰富 API:支持 SQL、流处理(Structured Streaming)、机器学习(MLlib)。
3. Flink 的流批一体
- 低延迟:以流处理为核心,支持毫秒级响应。
- 状态管理:提供精确一次(Exactly-Once)语义保障。
五、总结与未来展望
MapReduce 的核心价值在于其 简化分布式编程 的思想,但其磁盘密集型的 Shuffle 机制在高性能场景中逐渐被替代。未来趋势包括:
- 混合计算引擎:如 Spark 和 Flink 的统一批流处理。
- Serverless 化:基于云原生的无服务器架构(如 AWS Glue)进一步隐藏集群管理细节。
- AI 集成:MapReduce 与深度学习框架(如 TensorFlow)结合,支持分布式模型训练。
理解 MapReduce 的局限性(如迭代计算效率低)和设计取舍,是选择更高级框架(如 Spark、Flink)的基础,也是构建高效大数据架构的关键。
相关文章:

MapReduce 模型
引言 MapReduce 是分布式计算领域的里程碑式模型,由 Google 在 2004 年论文中首次提出,旨在简化海量数据处理的复杂性。其核心思想是通过函数式编程的 Map (映射)和 Reduce (归约)阶段&#x…...
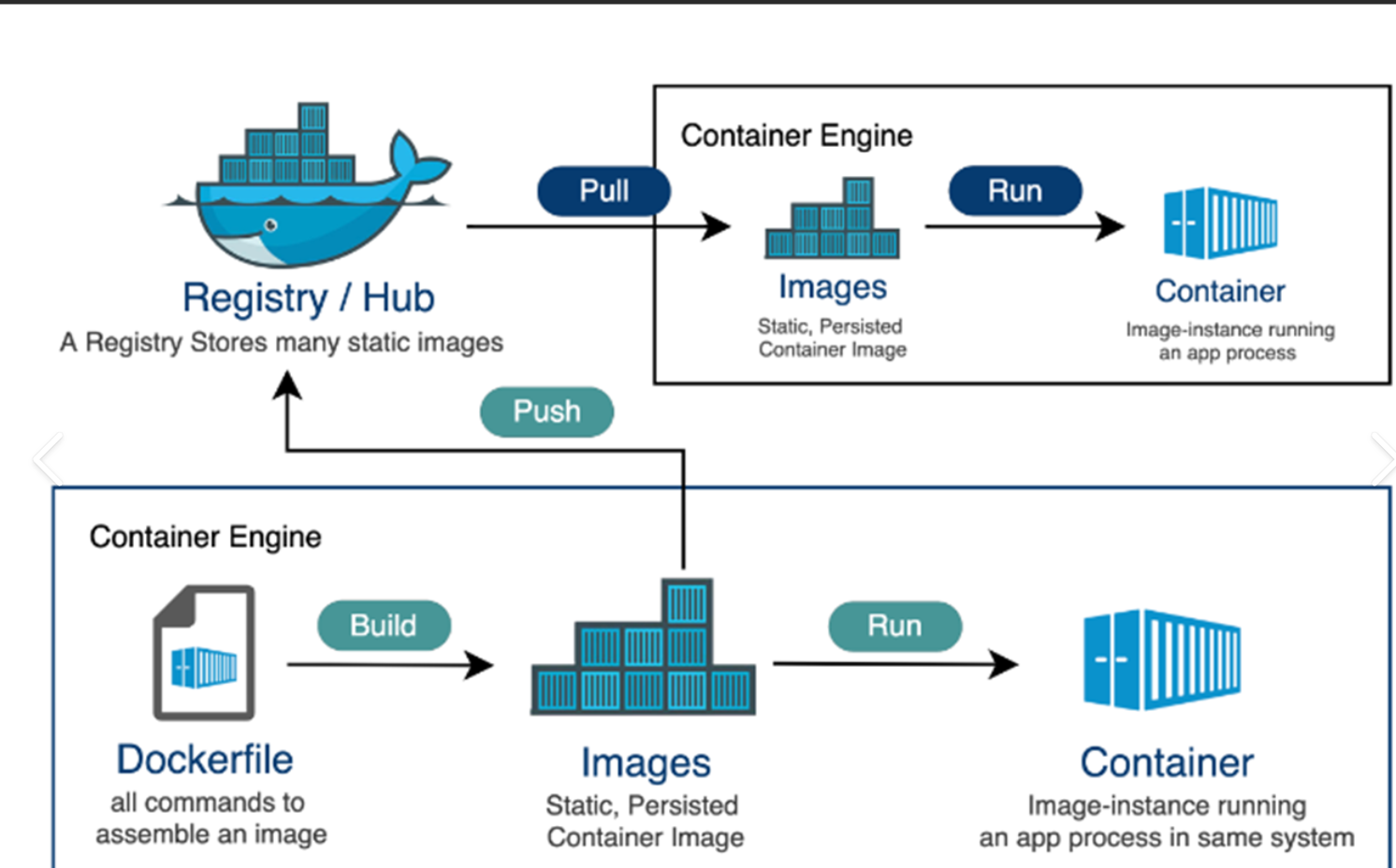
Docker容器启动失败?无法启动?
Docker容器无法启动的疑难杂症解析与解决方案 一、问题现象 Docker容器无法启动是开发者在容器化部署中最常见的故障之一。尽管Docker提供了丰富的调试工具,但问题的根源往往隐藏在复杂的配置、环境依赖或资源限制中。本文将从环境变量配置错误这一细节问题入手&am…...

mysql dump 导入导出用法
导出 指定库中指定的表 mysqldump -uroot -pmysql databasename table1 table2 > ./bak.sql 导入 mysql -uroot -p123456 databasename< ./bak.sql 导出指定数据库 mysqldump -uroot -p123456 databasename > ./databasename.sql 导入: mysql -uroot…...

MySQL 数据类型全面指南:从理论到实践
在数据库设计和开发中,数据类型的选择是构建高效、可靠系统的基石。MySQL作为最流行的关系型数据库之一,提供了丰富的数据类型以满足各种数据存储需求。本文将全面介绍MySQL的数据类型体系,通过理论讲解和实际示例,帮助开发者做出…...

第二课:ESP32 使用 PWM 渐变控制——实现模拟呼吸灯或音调变化
第二课:ESP32 使用 PWM 渐变控制——实现模拟呼吸灯或音调变化 🧠 一、PWM 占空比与亮度/音量控制原理 PWM(Pulse Width Modulation,脉宽调制)是一种常用的数字信号控制方式,广泛应用于 LED 灯光亮度、电…...

Quartus与Modelsim-Altera使用手册
目录 文章内容: 视频内容: Quartus: ModelSim: 顶层设计与子模块: 只是对所查阅的相关文章的总结与视频总结 文章内容: 这篇对基础操作很详细: 一、Quartus II软件的使用_quartus2软件上…...

uniapp(微信小程序)>关于父子组件的样式传递问题(自定义组件样式穿透)
在父组件中给子组件添加类名,子组件的样式由父组件决定 由于"微信小程序"存在【样式隔离机制】,且默认设置为isolated(启用样式隔离),因此这里给出以下两种解决方案: // 小程序编译机制 1. 当 <style scoped> 存在时&#…...
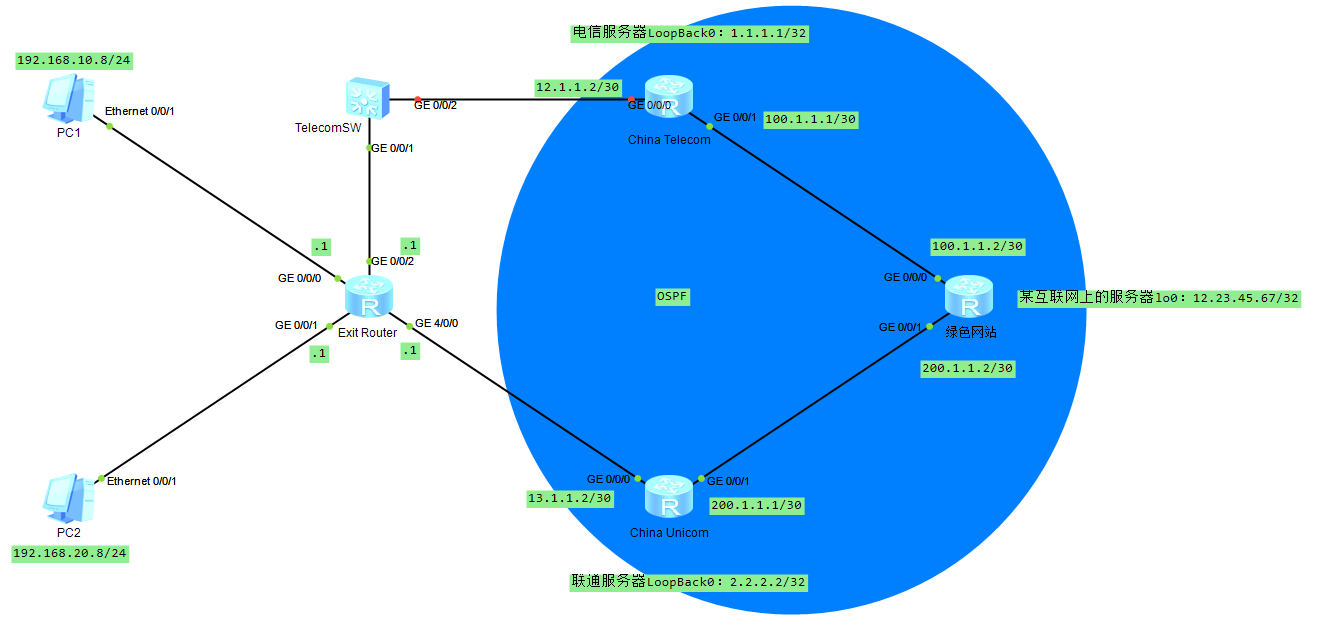
【HCIA】BFD
前言 前面我们介绍了浮动路由以及出口路由器的默认路由配置,可如此配置会存在隐患,就是出口路由器直连的网络设备并不是运营商的路由器,而是交换机。此时我们就需要感知路由器的存活状态,这就需要用到 BFD(Bidirectio…...
计算机视觉最不卷的方向:三维重建学习路线梳理
提到计算机视觉(CV),大多数人脑海中会立马浮现出一个字:“卷”。卷到什么程度呢?2022年秋招CV工程师岗位数下降了16%,但求职人数增加了23%,求职人数与招聘岗位的比例达到了恐怖的15:1࿰…...
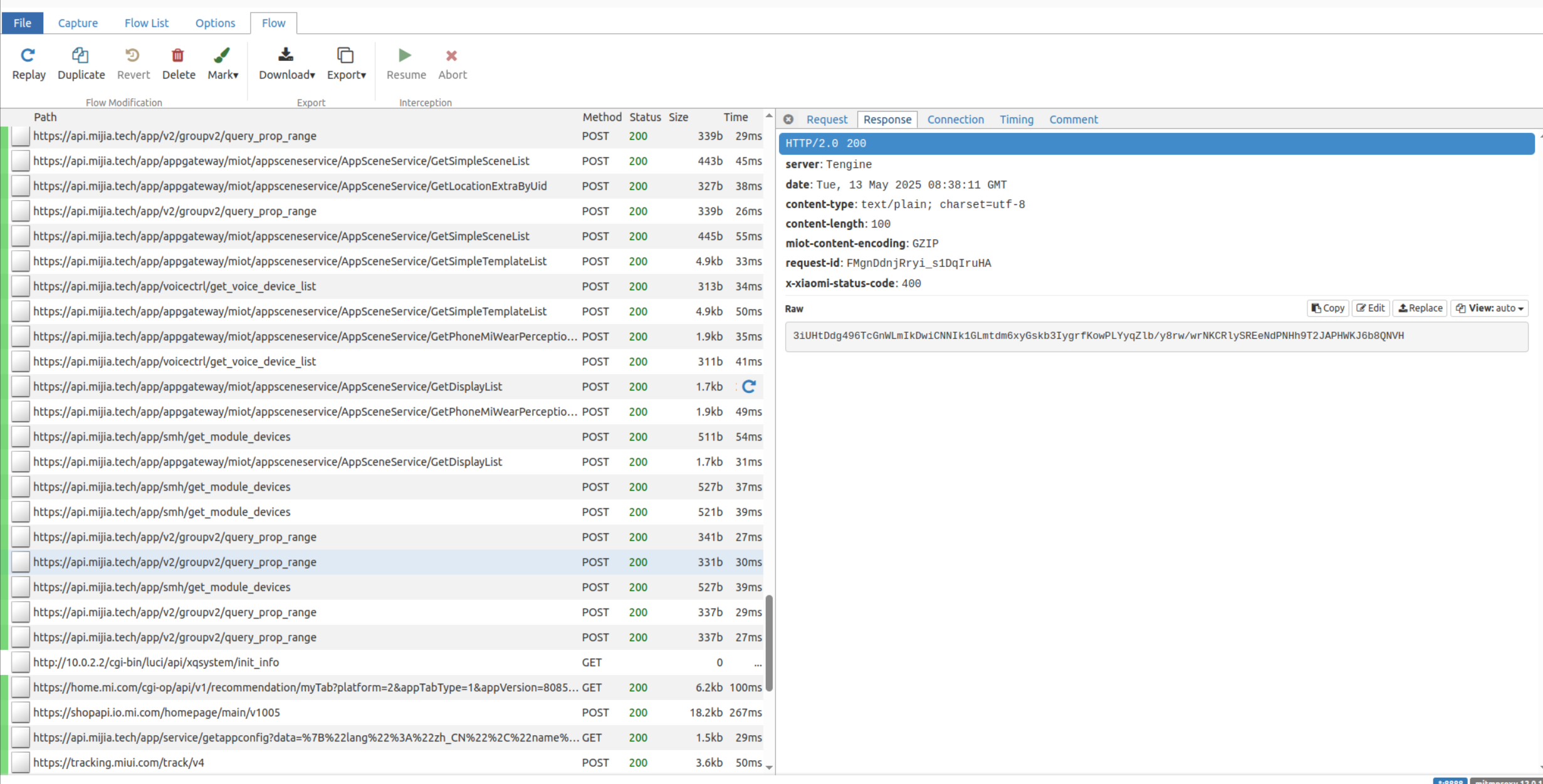
android抓包踩坑记录
由于需要公司业务需求,需要抓取APP中摄像机插件的网络包,踩了两天坑,这里做个总结吧。 事先准备 android-studio emulatesdk 需要android模拟器和adb调试工具。如果已经有其他模拟器的话,可以只安装adb调试工具即可 mitmproxy…...

Webpack其他插件
安装html打包插件 const path require(path); const HtmlWebpackPlugin require(html-webpack-plugin) module.exports {entry: path.resolve(__dirname,src/login/index.js),output: {path: path.resolve(__dirname, dist),filename: ./login/index.js,clean:true},Plugin:…...

如何正确地写出单例模式
如何正确地写出单例模式 | Jarks Blog 枚举方式: public class SingletonObject {private SingletonObject() {}/*** 枚举类型是线程安全的,并且只会装载一次*/private enum Singleton {INSTANCE;private final SingletonObject instance;Singleton() {…...

常见相机焦段的分类及其应用
相机焦段是指镜头的焦距范围,决定了拍摄时的视角、画面范围和透视效果。不同焦段适合不同的拍摄场景和主题,以下是常见焦段的分类及其应用: 一、焦段的核心概念 焦距:镜头光学中心到成像传感器的距离(单位:…...

Python Matplotlib 库【绘图基础库】全面解析
让AI成为我们的得力助手:《用Cursor玩转AI辅助编程——不写代码也能做软件开发》 一、发展历程 Matplotlib 由 John D. Hunter 于 2003 年创建,灵感来源于 MATLAB 的绘图系统。作为 Python 生态中最早的可视化工具之一,它逐渐成为科学计算领…...
C++ string数据查找、string数据替换、string子串获取
string查找示例见下,代码见下,以及对应运行结果见下: #include<iostream>using namespace std;int main() {// 1string s1 "hellooooworld";cout << s1.find("oooo") << endl;// 2cout << (in…...

入侵检测SNORT系统部署过程记录
原理背景知识: 一、入侵检测系统介绍 1、入侵检测系统 入侵检测(Intrusion Detection) 指通过对计算机网络或计算机系统中的若干关键点收集信息并对其进行分析,从中发现网络或系统中是否有违反安全策略的行为和被攻击的迹象。 入侵检测系统(IDS) 是从网络和系统中收集…...

使用 Java 反射动态加载和操作类
Java 的反射机制(Reflection)是 Java 语言的一大特色,它允许程序在运行时检查、加载和操作类、方法、字段等元信息。通过 java.lang.Class 和 java.lang.reflect 包,开发者可以动态加载类、创建实例、调用方法,甚至在运行时构造新类。反射是 Java 灵活性的核心,广泛应用于…...
关于甲骨文(oracle cloud)丢失MFA的解决方案
前两年,申请了一个招商的多币种信用卡,然后就从网上撸了一个oracle的免费1h1g的服务器。 用了一段时间,人家要启用MFA验证。 啥叫MFA验证,类似与短信验证吧,就是绑定一个手机,然后下载一个app,每…...

vue3项目中使用CodeMirror组件的详细教程,中文帮助文档,使用手册
简介 这是基于 Vue 3 开发的 CodeMirror 组件。该组件基于 CodeMirror 5 开发,仅支持 Vue 3。 除了支持官方提供的各种语法模式外,还额外添加了日志输出展示模式,开箱即用,但不一定适用于所有场景。 如需完整文档和更多使用案例…...

C++ stl中的list的相关函数用法
文章目录 list的介绍list的使用定义方式 插入和删除迭代器的使用获取元素容器中元素个数和容量的控制其它操作函数 list的使用,首先要包含头文件 #include <list>list的介绍 1.list是一种可以在常数范围内在链表中的任意位置进行插入和删除的序列式容器&…...

【网络编程】七、详解HTTP 搭建HTTP服务器
文章目录 Ⅰ. HTTP协议的由来 -- 万维网Ⅱ. 认识URL1、URL的格式协议方案名登录信息 -- 忽略服务器地址服务器端口号文件路径查询字符串片段标识符 2、URL的编码和解码 Ⅲ. HTTP的报文结构1、请求协议格式2、响应协议格式🎏 写代码的时候,怎么保证请求和…...

[Java实战]Spring Boot 快速配置 HTTPS 并实现 HTTP 自动跳转(八)
[Java实战]Spring Boot 快速配置 HTTPS 并实现 HTTP 自动跳转(八) 引言 在当今网络安全威胁日益严峻的背景下,为 Web 应用启用 HTTPS 已成为基本要求。Spring Boot 提供了简单高效的方式集成 HTTPS 支持,无论是开发环境测试还是生产环境部署࿰…...

Spring Boot 中的重试机制
Retryable 注解简介 Retryable 注解是 Spring Retry 模块提供的,用于自动重试可能会失败的方法。在微服务架构和分布式系统中,服务之间的调用可能会因为网络问题、服务繁忙等原因失败。使用 Retryable 可以提高应用的稳定性和容错能力 1。 使用步骤 &…...

【React中useRef钩子详解】
一、useRef的核心特性 useRef是React提供的Hook,用于在函数组件中创建可变的持久化引用,具有以下核心特性: 持久化存储 返回的ref对象在组件整个生命周期内保持不变,即使组件重新渲染,current属性的值也不会丢失。无触发渲染 修改ref.current的值不会导致组件重新渲染,适…...

golang-ErrGroup用法以及源码解读笔记
介绍 ErrGroup可以并发执行多个goroutine,并可以很方便的处理错误 与sync.WaitGroup相比 错误处理 sync.WaitGroup只负责等待goroutine执行完成,而不处理返回值或者错误errgroup.Group目前虽然不能直接处理函数的返回值或错误。但是当goroutine返回错…...

17.【.NET 8 实战--孢子记账--从单体到微服务--转向微服务】--微服务基础工具与技术--loki
在微服务中,日志是非常重要的组成部分。它不仅可以帮助我们排查问题,还可以帮助我们分析系统的性能和使用情况。 一、loki简介 loki是一个开源的日志聚合系统,它可以帮助我们高效地收集、存储和分析日志数据。loki的设计理念是“简单、快速…...
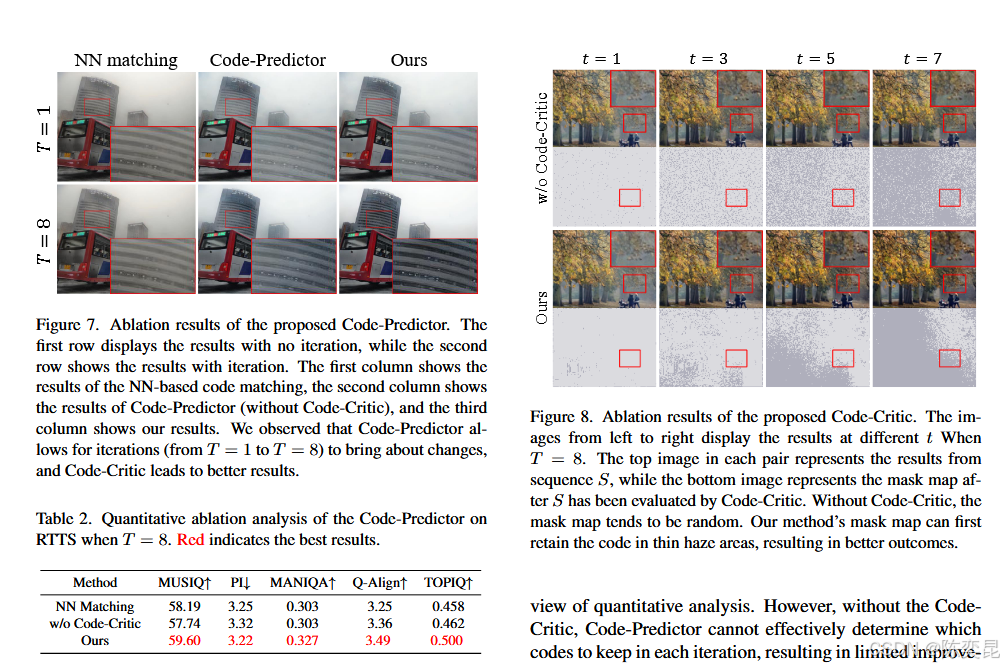
CVPR计算机视觉顶会论文解读:IPC-Dehaze 如何解决真实场景去雾难题
【CVPR 2025】迭代预测-评判编解码网络:突破真实场景去雾的极限 摘要 本文提出了一种名为IPC-Dehaze的创新去雾方法,通过迭代预测-评判框架和码本解码机制,有效解决了现有去雾算法在复杂场景下的性能瓶颈。该方法在多个基准测试中取得了SOT…...
ppy/osu构建 ipad作为osu按键xz笔记2 deepwiki websokect
ipad当x和z键玩osu #无声打osu#没磁轴怎么打osu 下载 .NET (Linux、macOS 和 Windows) | .NET dotnet还行 构建:f5 运行:dotnet run --project osu.Desktop -c Debug deepwiki就是nb uinput是ubuntu的我现在没法调试,放着 import asyn…...

scons user 3.1.2
前言 感谢您抽出时间阅读有关 SCons 的内容。SCons 是一款下一代软件构建工具,或者称为 make 工具,即一种用于构建软件(或其他文件)并在底层输入文件发生更改时使已构建的软件保持最新状态的软件实用程序。 SCons 最显著的特点是…...
大语言模型主流架构解析:从 Transformer 到 GPT、BERT
📌 友情提示: 本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4-turbo模型生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认其准…...