计算机组成与体系结构:替换策略(MRU LRU PLRU LFU)
目录
🎲 MRU(最近最常使用)
🪜 操作流程:
🎲 LRU(最近最少使用)
🪜 操作流程:
示例
🔍 Age Bits(年龄位)
核心思想:
模拟过程:
存储代价
🎲 PLRU(Pseudo-Least Recently Used)
为什么需要 Pseudo-LRU?
🪜 操作流程:
情况一:Cache 未满 (初始填充阶段)
情况二:Cache 已满 但命中(访问命中的块)
情况三:Cache 已满 且未命中(发生替换)
查找 PLRU 块(≈ 最久未使用)
查找 MRU 块(≈ 最近访问过)
优点:
🎲 LFU(Least Frequently Used)策略
Frequency-Based Policy(频率驱动的策略)
🪜 操作流程:
前面我们探讨了几种不同类型的缓存替换策略,包括简单随机选择的 Random 策略,基于块进入缓存先来后到顺序的 FIFO 和 LIFO 策略,以及理想但不可实现的基于未来访问预测的 Optimal 策略。
然而,许多高效的替换策略并非依赖于随机性或简单的年龄,而是利用块的访问历史信息来推测哪些块未来最可能被再次访问。接下来,我们将介绍一类广泛应用的策略,它们正是基于这种访问历史,特别是块的最近使用情况来做出决策,这其中包括 Most Recently Used (MRU)、Least Recently Used (LRU) 以及其近似实现 Pseudo Least Recently Used (PLRU)。
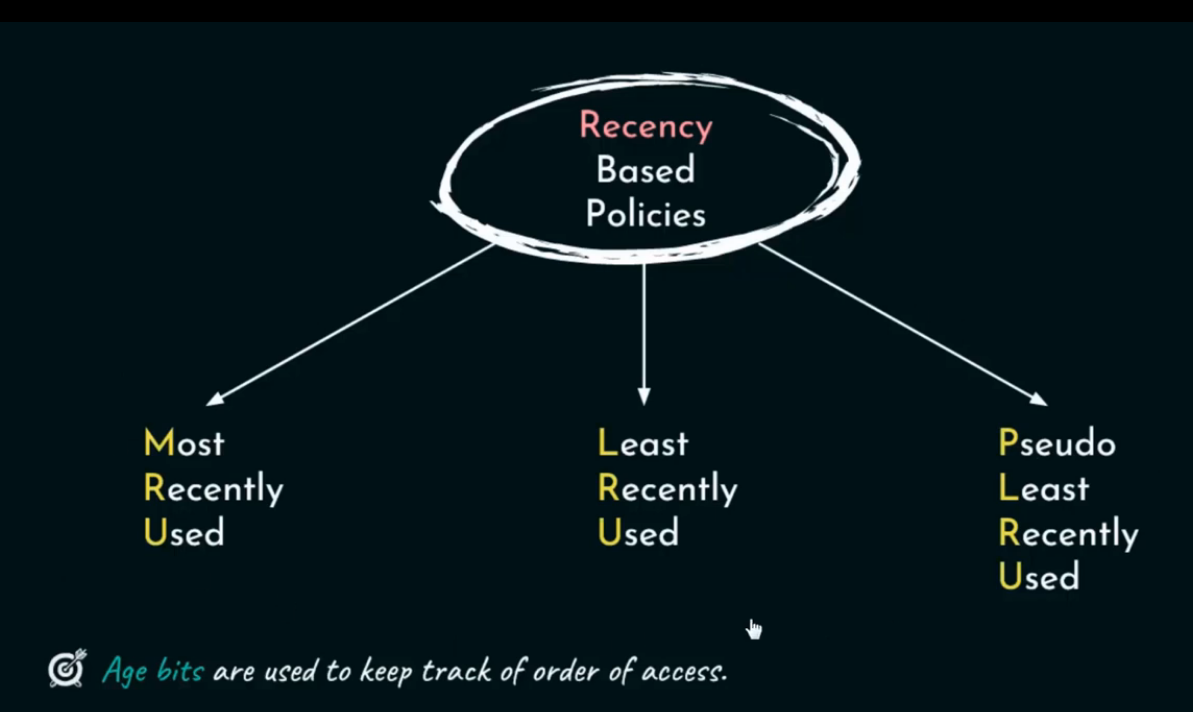
🎲 MRU(最近最常使用)
每当需要替换缓存中的一个块时,总是淘汰最近刚刚被访问过的缓存块。
也就是说,谁最近被访问,就谁先被淘汰。

🪜 操作流程:
-
CPU 访问某个数据地址;
-
若发生 Cache Miss 且缓存已满;
-
查找“最近刚被访问的缓存块”;
-
替换掉它,把新数据加载进来。
假设当前缓存为 [A, B, C],刚访问过 C,现在访问 D:
-
Cache 满了 → 采用 MRU → 替换 C(最近刚访问过);
-
结果变成
[A, B, D]

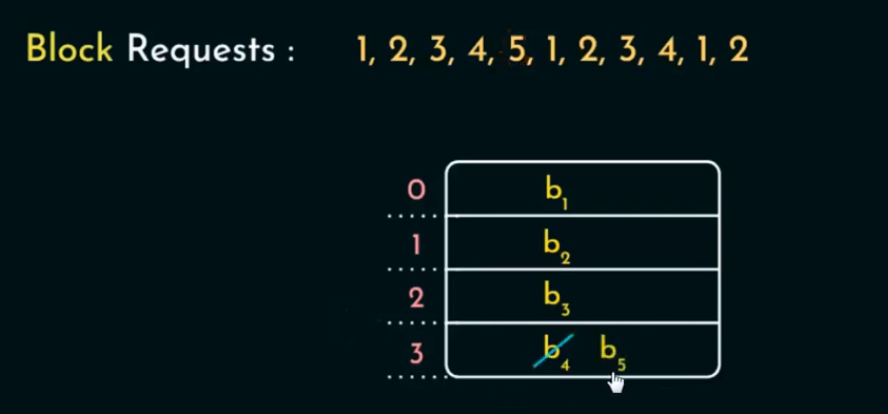

适用场景:
MRU 适用于某些特定访问模式,如:
-
数据被访问后,短期内很少再次被访问;
-
循环访问模式 (Cyclic Patterns)。(例如图片中的1,2,3,4……1,2,3,4……)
🎲 LRU(最近最少使用)
LRU(最近最少使用) 替换策略总是淘汰 最久没有被访问的缓存块。
它利用了程序访问的时间局部性原则:最近访问过的数据更可能在短期内再次使用,因此我们优先保留“最近用过的”,淘汰“最久未使用的”。
🪜 操作流程:
-
每次访问缓存数据时,更新该数据的“最近使用时间”;
-
当发生缓存替换时,淘汰那个最久没有被访问的块。
实现方式常见有:
-
链表记录访问顺序;
-
为每个块打“时间戳”;
-
或用栈模拟。
示例
假设 Cache 容量为 4。访问序列:0, 1, 2, 3, 4, 2, 3, 1, 5, 6
我们按照 LRU 策略模拟整个访问过程,并说明关键点。
LRU 过程
| 步骤 | 访问 | Cache 状态 (LRU, 旧→新) | 替换 | 说明 |
|---|---|---|---|---|
| 1 | 0 | [0] | - | 加入 0 |
| 2 | 1 | [0, 1] | - | 加入 1 |
| 3 | 2 | [0, 1, 2] | - | 加入 2 |
| 4 | 3 | [0, 1, 2, 3] | - | 加入 3 |
| 5 | 4 | [1, 2, 3, 4] | 0 被替换 | 0 最久没用了 |
| 6 | 2 | [1, 3, 4, 2] | - | 2 已在,更新为最近使用 |
| 7 | 3 | [1, 4, 2, 3] | - | 同上 |
| 8 | 1 | [4, 2, 3, 1] | - | 同上 |
| 9 | 5 | [2, 3, 1, 5] | 4 被替换 | 4 最久未访问 |
| 10 | 6 | [3, 1, 5, 6] | 2 被替换 | 2 最久未使用 |
🔍 Age Bits(年龄位)
-
Age Bits 是用于记录每个 cache line “上次使用时间” 的一种方式。
-
在全相联映射中,cache 的任意位置都可以放任意数据,故替换策略必须决定淘汰哪个。
-
Age bits 为每个 cache line 分配一个 计数器或编码值(如 2 位、3 位、4 位...),来表示“谁最老”。
核心思想:
在一个 n 路全相联缓存中,每个缓存块维护一个 age 编码值(0~n-1),表示这个块的“使用新旧程度”。
-
最大 age(n-1) 表示“刚刚访问”(最新);
-
age = 0 表示“最久未访问”(最老);
-
每次访问:
-
被访问块设置为 n-1(最新)
-
所有 age 比它大的块不变
-
所有 age 比它小的块 统一减一
-
-
当替换发生时,选择 age == 0 的块 进行淘汰。

模拟过程:
| 步 | 访问 | Cache 状态 | Age Bits | 替换 | 说明 |
|---|---|---|---|---|---|
| 1 | 0 | [0] | [3, 0, 1, 2] | 无 | 第一次加入,设为3 |
| 2 | 1 | [0, 1] | [2, 3, 0, 1] | 无 | 0老化为2,1为新 |
| 3 | 2 | [0, 1, 2] | [1, 2, 3, 0] | 无 | 所有老化,2最新 |
| 4 | 3 | [0, 1, 2, 3] | [0, 1, 2, 3] | 无 | 所有顺延 |
| 5 | 4 | [1, 2, 3, 4] | [3, 0, 1, 2] | ✅ 替换0 | 0 的 age = 0,淘汰它 |
| 6 | 2 | [1, 2, 3, 4] | [2, 0, 3, 1] | 无 | 2 命中 → age=3,其它老化 |
| 7 | 3 | [1, 2, 3, 4] | [1, 0, 2, 3] | 无 | 3 命中 → age=3,其他减一 |
| 8 | 1 | [1, 2, 3, 4] | [0, 3, 1, 2] | 无 | 1 被访问,更新 age=3,其他老化 |
| 9 | 5 | [2, 3, 1, 5] | [3, 2, 0, 1] | ✅ 替换4 | 4 的 age = 0,被淘汰 |
| 10 | 6 | [3, 1, 5, 6] | [2, 1, 3, 0] | ✅ 替换2 | age=0 的 2 被淘汰 |
存储代价

1️⃣ 为什么是 4!(4 的阶乘)?
-
在一个 4 路 set 中,有 4 个块;
-
为了记录 LRU 的顺序,我们实际上是记录这 4 个块的相对“访问先后顺序”;
-
所有访问顺序的排列组合就是 4 的阶乘:
4!=4×3×2×1=24
-
所以,你要记录某一时刻的完整 LRU 状态,就要能区分这 24 种顺序
2️⃣ 为什么需要 log₂(24) ≈ 4.58 ≈ 5 bit?
-
用二进制编码这 24 个可能的访问顺序,需要的最少位数就是:
log2(24)≈4.58
-
实际上只能使用整数位存储,所以你需要 至少 5 个 bit 才能编码所有顺序。
-
每个 set 都要存这一份顺序信息,因此是 “5 bit per set”。
3️⃣ 如果关联度更高怎么办?
-
关联度越高(如 8-way),排列组合就越多:
8!=40320⇒log2(8!)≈15.38! = 40320 \Rightarrow \log_2(8!) \approx 15.38!=40320⇒log2(8!)≈15.3
-
所以要记录 8-way LRU 顺序,需要 至少 16 bit per set。
-
每个缓存 set 可能数以万计(比如 1024 sets),那么总共光记录顺序就占用了很多 bits。
严格实现 LRU = 记录使用顺序 = 记录块的排列组合状态
-
对于高关联度(如 8-way、16-way)的缓存:
-
排列数量指数级上升
-
对应的编码位数也线性上升(log₂(n!))
-
-
所以:精确 LRU 的实现成本与缓存的关联度呈对数甚至阶乘级增长,最终带来巨大的硬件开销(huge overhead)
🎲 PLRU(Pseudo-Least Recently Used)
为什么需要 Pseudo-LRU?
在 n 路组相联缓存中,想要严格实现 LRU,就得记录每个 cache block 的访问顺序,需要 log₂(n!) bits per set。
例如:
-
4 路组 → 24 种顺序 → 至少 5 bits
-
8 路组 → 40320 种顺序 → 至少 16 bits
随着 n 增加,存储开销和更新逻辑急剧增加,对硬件极不友好。
定义:
Pseudo-LRU 是一种近似实现 LRU 的方法,不精确记录块的使用顺序,而是使用较少的状态信息
来大致估计哪个块最久未被使用,从而做出替换决策。
它并不真正知道“谁最久没被用了”,但能用更少资源推测出“比较可能是最久未用的块”。
 这是一个 8-way set associative cache(每个 set 有 8 个块)使用的 Tree-based PLRU 替换策略。
这是一个 8-way set associative cache(每个 set 有 8 个块)使用的 Tree-based PLRU 替换策略。
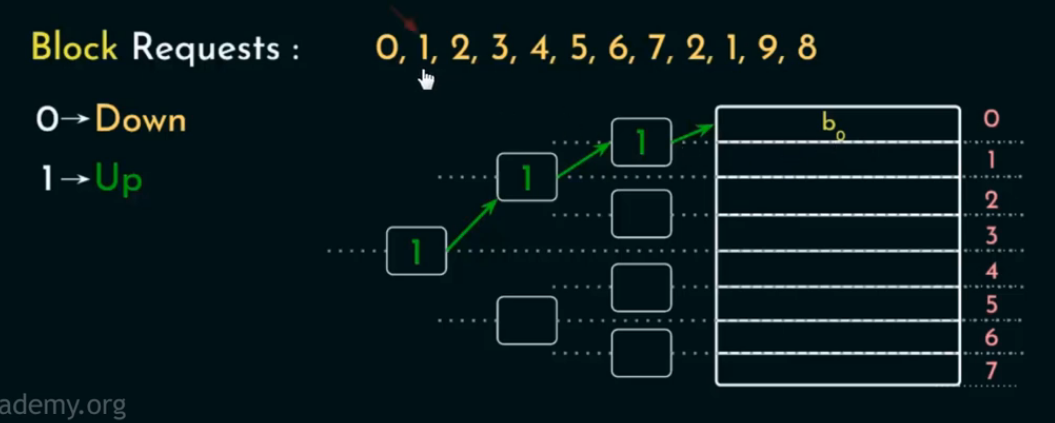
🪜 操作流程:
-
有 7 个方向指示位,分别是:
-
层级 1:1 个 bit(根)
-
层级 2:2 个 bit
-
层级 3:4 个 bit
-
-
每个 bit 表示“下一次替换要往哪边走”
-
0 → Down(左) -
1 → Up(右)
-
-
叶子节点
b₀~b₇是 cache block,表示实际存放数据的 8 个位置。
情况一:Cache 未满 (初始填充阶段)
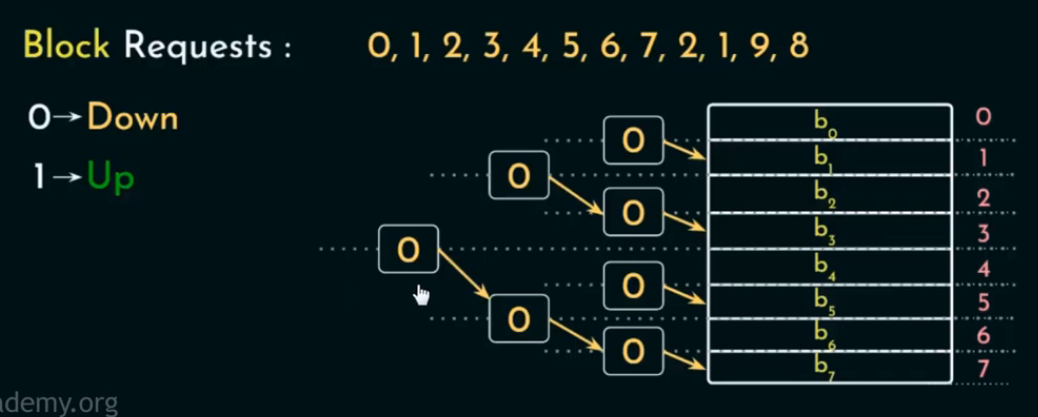
操作流程:
-
将当前 block 加入 cache;
-
通过树结构“访问路径”更新方向位(bits);
在沿路径的每一个判断节点上,都将其方向设为“指向这次访问的方向”; -
不执行任何替换,只更新路径。
🔹 关键点:
Cache 未满时不会有替换,树结构的方向位起到“标记路径已使用”的作用,为未来做准备 。
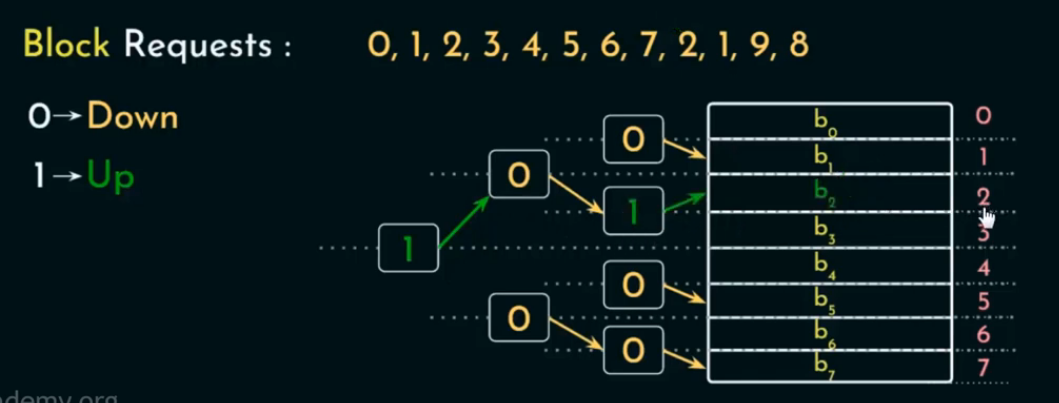
情况二:Cache 已满 但命中(访问命中的块)
操作流程:
-
查找该块是否在 cache;
-
如果 命中,则无需替换;
-
仍然要更新“路径方向 bits”:
-
访问路径上的每个 bit 更新为“指向这次使用的方向”。
-
🔹 关键点:
命中时仍然更新路径,使该块不会很快被淘汰,模仿 LRU“刚访问过”的行为。
情况三:Cache 已满 且未命中(发生替换)
操作流程:
-
Cache 已满,新 block 不在 cache;
-
从根节点开始,把其原本的方向位反转(0→1,1→0)。
-
按照反转后的值,依次读取每个指示位,按照指示的方向走向下一个子节点。
-
一直走到底,直到指向某个叶节点(即某个缓存块),将其视为“最久未使用块”,并进行替换。
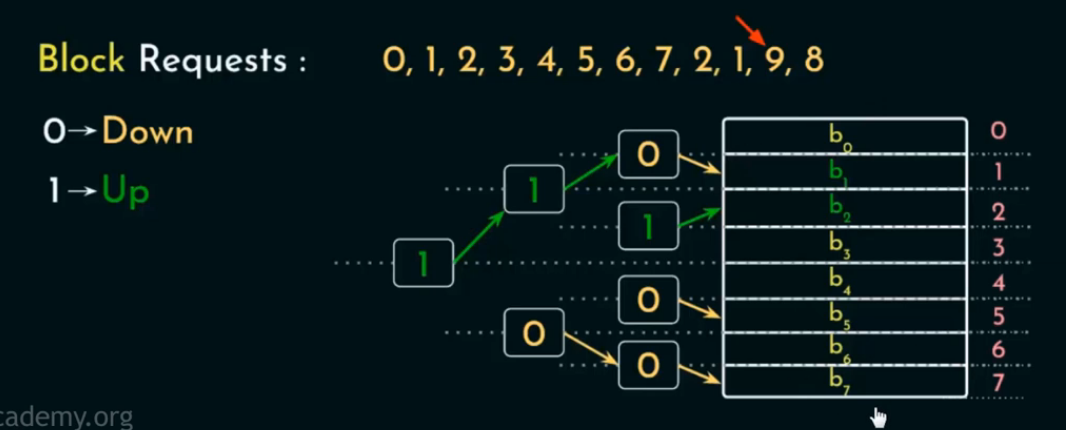
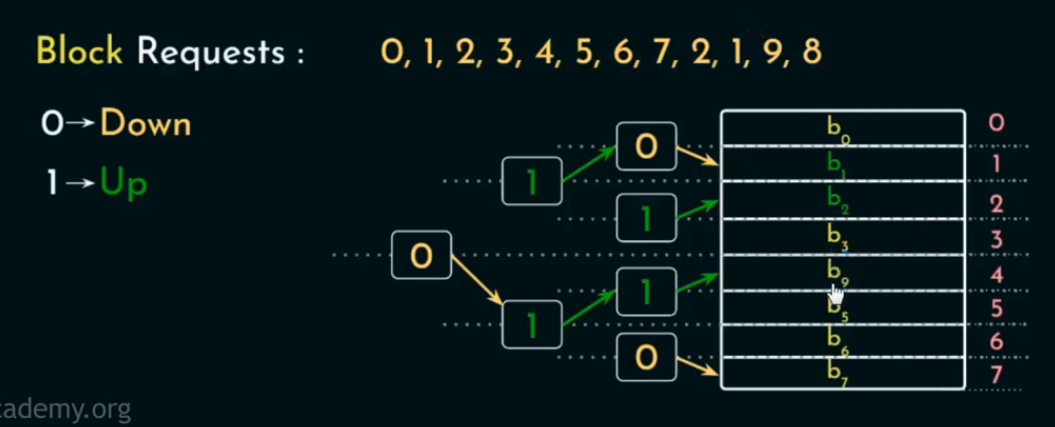
在 替换操作执行完之后(或任意时刻),我们其实可以从树结构中推断出:
-
当前哪个 block 是 PLRU 替换候选者(= 最久未使用(approximate LRU))
-
当前哪个 block 是 MRU(Most Recently Used)(= 最刚刚被访问的)
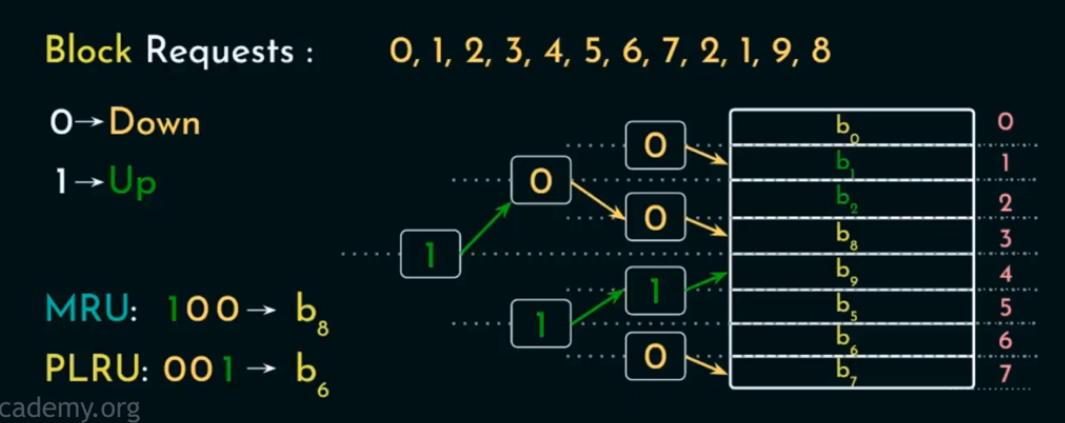
查找 PLRU 块(≈ 最久未使用)
从根开始,严格按照节点当前存储的 bit 指示方向(0=左,1=右)一路向下,直到某个叶子块 → 即为 PLRU 替换候选块。
原因:
-
方向位每次访问时都会沿访问路径反转;
-
所以当前 bit 指示的路径,是上次没有访问的方向;
-
这一路路径就是“最久没有被访问的方向链”;
-
所以走到底的叶节点,就是 Pseudo-LRU 块(最久未用的)。
查找 MRU 块(≈ 最近访问过)
从根开始,按照每个节点 bit 的“反方向”走(即:如果 bit 是 0,就走右;如果 bit 是 1,就走左),直到叶节点 → 即为 MRU 块(最“新”访问过的)
原因:
-
被访问的路径上的 bit 在访问后都会被反转;
-
所以当前的“非选中方向”其实代表的是“最近走过的路径”;
-
沿这个“非选中路径”走下去,就会抵达最近一次访问的块。
优点:
| 优点 | 说明 |
|---|---|
| 硬件开销低 | n 路组仅需 n–1 个 bits(比如 8 路组只用 7 bits) |
| 访问/替换开销低 | 每次访问只更新 log₂(n) 条路径 |
| 接近 LRU 效果 | 在多数程序中命中率与 LRU 接近 |
🎲 LFU(Least Frequently Used)策略
Frequency-Based Policy(频率驱动的策略)
在缓存替换中,频率驱动的策略关注的是:每个缓存块被访问的“频率”而不是“时间顺序”。
即:“谁被访问得少,谁就先走。”
这种策略适用于访问热点长期稳定的场景,比如 Web 缓存、数据库缓存。其中最常用的是LFU策略。
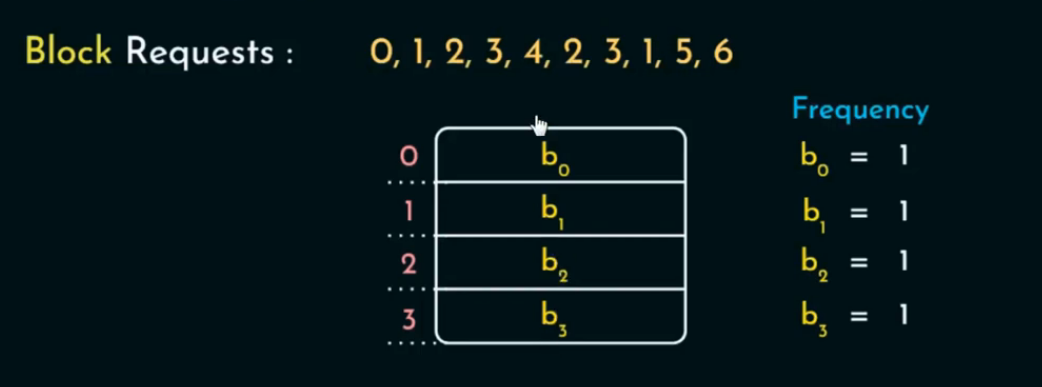
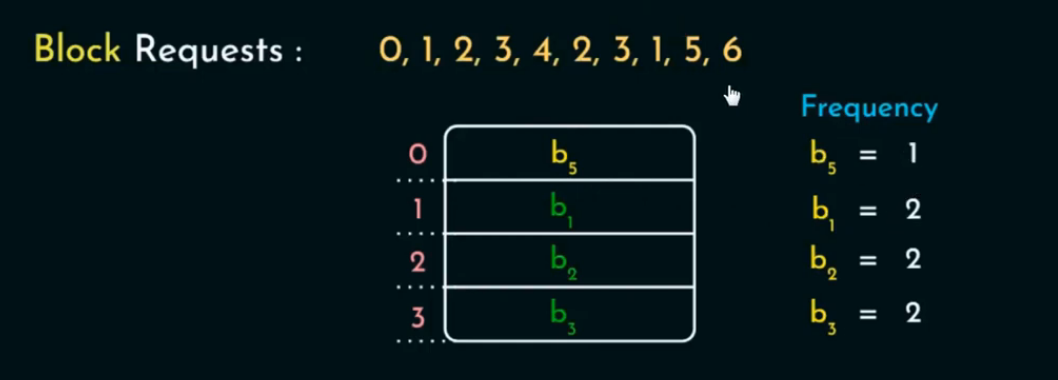
LFU 替换策略始终淘汰访问频率最少的缓存块。每个缓存块都维护一个计数器,记录它被访问的次数。替换时,选择计数最小的块。
🪜 操作流程:
-
每个缓存块都有一个访问频率计数器
freq; -
每次访问:
-
如果 block 在缓存(hit) →
freq++ -
如果不在缓存(miss):
-
若 cache 未满 → 插入该 block,
freq = 1 -
若已满 → 选择
freq最小的块进行替换;
-
-
-
插入新块时,初始化其
freq = 1。
这里采用了FIFO策略:


相关文章:
计算机组成与体系结构:替换策略(MRU LRU PLRU LFU)
目录 🎲 MRU(最近最常使用) 🪜 操作流程: 🎲 LRU(最近最少使用) 🪜 操作流程: 示例 🔍 Age Bits(年龄位) 核心思想…...
websocket入门详解
入门websocket的基础应该掌握一下问题: 1、什么是握手? 2、什么是websocket? 3、websocket和http的区别,应用场景 4、html前端简单代码演示 5、springboot整合websocket使用 6、使用vueelementui打造简单聊天室 7、使用web…...

《数字藏品社交化破局:React Native与Flutter的创新实践指南》
NFT,这种非同质化代币,赋予了数字资产独一无二的身份标识,从数字艺术作品到限量版虚拟物品,每一件NFT数字藏品都承载着独特的价值与意义。当React Native和Flutter这两大跨平台开发框架遇上NFT数字藏品,一场技术与创意…...

(6)python开发经验
文章目录 1 QListWidget样式显示异常2 模块编码错误3 qtcreator开发pyqt编码错误 更多精彩内容👉内容导航 👈👉Qt开发 👈👉python开发 👈 1 QListWidget样式显示异常 main.py import sys from PySide6.QtWi…...

HPC软件使用之ANSYS Fluent
目录 一、软件介绍 二、脚本编写 2.1 jou文件 2.2 slurm脚本文件 三、作业提交及查看 四、案例演示 4.1 网格模型 4.2 jou脚本 4.3 slurm脚本 4.4 计算 4.5 结果查看 从本文开始,我们将介绍如何在超级计算机上使用科学计算、工程仿真计算软件开展计算&am…...

YOLO11解决方案之距离计算探索
概述 Ultralytics提供了一系列的解决方案,利用YOLO11解决现实世界的问题,包括物体计数、模糊处理、热力图、安防系统、速度估计、物体追踪等多个方面的应用。 测量两个物体之间的间距被称为特定空间内的距离计算,YOLO11使用两个边界框的中心…...
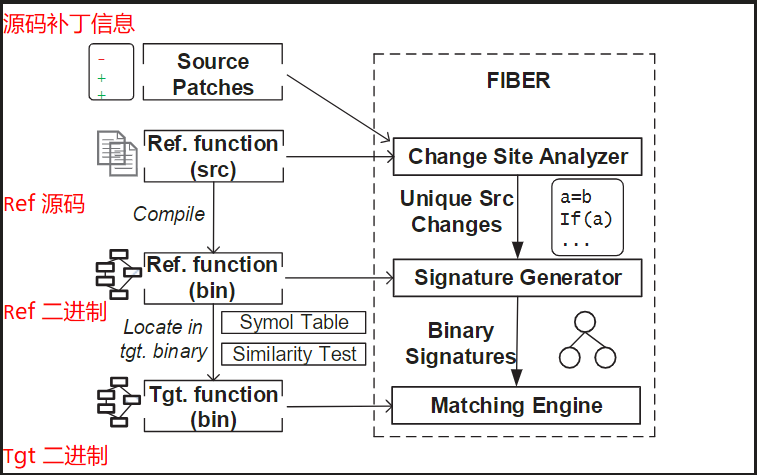
论文学习_Precise and Accurate Patch Presence Test for Binaries
摘要:打补丁是应对软件漏洞的主要手段,及时将补丁应用到所有受影响的软件上至关重要,然而这一点在实际中常常难以做到,研究背景。因此,准确检测安全补丁是否已被集成进软件发行版本的能力,对于防御者和攻击…...
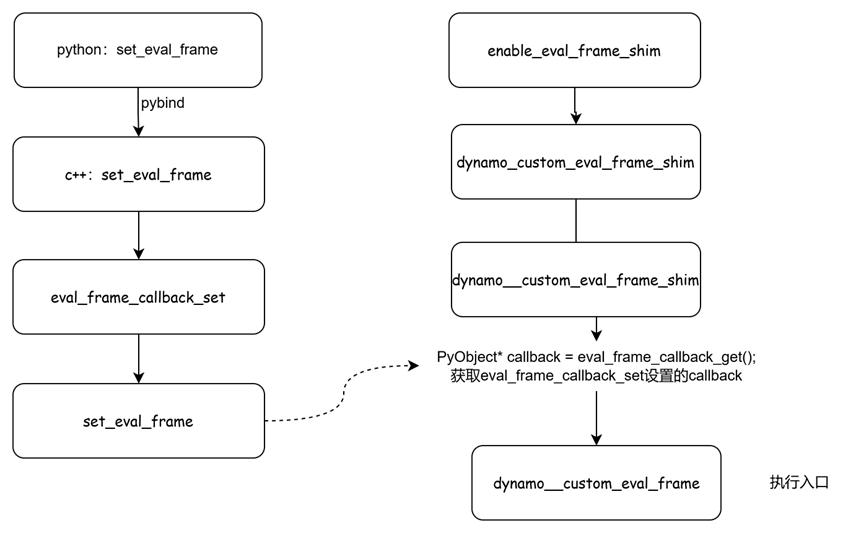
Ascend的aclgraph(九)AclConcreteGraph:e2e执行aclgraph
1回顾 前面的几章内容探讨了aclgraph运行过程中的涉及到的关键模块和技术。本章节将前面涉及到的模块串联起来,对aclgraph形成一个端到端的了解。 先给出端到端运行的代码,如下: import torch import torch_npu import torchair import log…...

JSX语法介绍
文章目录 JSX介绍JSX的引入JSX的全称babel转换工具 JSX的基本语法创建组件的第一种方式创建组件父组件传值给子组件 class 关键字的介绍class的基本用法:使用class创建对象使用 class 实现 JS 中的继承 创建组件的第二种方式:使用 class 关键字父组件传值…...

增强 HTNN 服务网格功能:基于 Istio 的BasicAuth 与 ACL 插件开发实战
目录 1.引言 什么是HTNN? 为什么开发 BasicAuth 和 ACL 插件? 2.技术背景 技术栈概览 Istio 与服务网格简述 HTNN 框架与插件机制概览 3.插件开发详解:BasicAuth 与 ACL 3.1 BasicAuth插件 功能点 实现细节 3.2 ACL插件 功能点 …...

c++从入门到精通(四)--动态内存,模板与泛型编程
文章目录 动态内存直接管理内存Shared_ptr类Unique_ptrWeak_ptr动态数组allocator类文本查询程序 模板与泛型编程定义模板函数模板类模板模板参数成员模板控制实例化 模板实参推断重载与模板可变参数模板模板特例化 动态内存 c中动态内存的管理是通过new和delete运算符来实现的…...

C盘清理秘籍:快速提升系统性能
C盘清理的重要性 C盘作为系统盘,存储着操作系统和关键程序文件。随着使用时间的增加,C盘空间会逐渐被占用,导致系统运行缓慢、程序启动延迟等问题。定期清理C盘可以有效提升系统性能,延长硬盘寿命。 清理临时文件 Windows系统在…...

从 Vue3 回望 Vue2:组件设计升级——Options API vs Composition API
文章目录 从 Vue3 回望 Vue2:组件设计升级——Options API vs Composition API1、组件范式:框架设计思想的投影2、Vue2:Options API 的结构与局限结构清晰:新手友好、职责分明核心痛点:逻辑分散,难以聚合复…...

寻找两个正序数组的中位数 - 困难
************* Python topic: 4. 寻找两个正序数组的中位数 - 力扣(LeetCode) ************* Give the topic an inspection. Do the old topic will give you some new sparks. Before that, I do some really good craetive things about my logo. …...
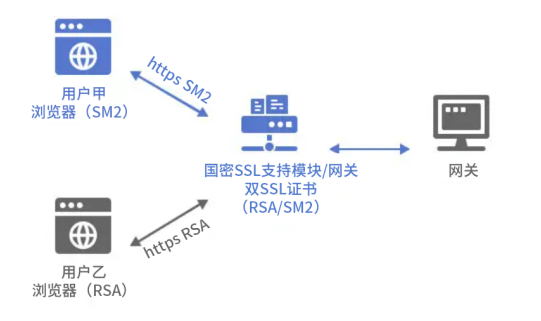
国产密码新时代!华测国密 SSL 证书解锁安全新高度
在数字安全被提升到国家战略高度的今天,国产密码算法成为筑牢网络安全防线的关键力量。华测国密SSL证书凭借其强大性能与贴心服务,为企业网络安全保驾护航,成为符合国家安全要求的不二之选! 智能兼容,告别浏览器适配…...

【金仓数据库征文】从云计算到区块链:金仓数据库的颠覆性创新之路
目录 一、引言 二、金仓数据库概述 2.1 金仓数据库的背景 2.2 核心技术特点 2.3 行业应用案例 三、金仓数据库的产品优化提案 3.1 性能优化 3.1.1 查询优化 3.1.2 索引优化 3.1.3 缓存优化 3.2 可扩展性优化 3.2.1 水平扩展与分区设计 3.2.2 负载均衡与读写分离 …...

互联网大厂Java求职面试:AI与大模型集成的云原生架构设计
互联网大厂Java求职面试:AI与大模型集成的云原生架构设计 引言 在现代互联网企业中,AI与大模型技术的应用已经成为不可或缺的一部分。特别是在短视频平台、电商平台和金融科技等领域,如何高效地将大模型集成到现有的云原生架构中是一个巨大…...

股指期货套期保值怎么操作?
股指期货套期保值就是企业或投资者通过持有与其现货市场头寸相反的期货合约,来对冲价格风险的一种方式。换句话说,就是你在股票市场上买了股票(现货),担心股价下跌会亏钱,于是就在期货市场上卖出相应的股指…...
基于IBM BAW的Case Management进行项目管理示例
说明:使用IBM BAW的难点是如何充分利用其现有功能根据实际业务需要进行设计,本文是示例教程,因CASE Manager使用非常简单,这里重点是说明如何基于CASE Manager进行项目管理,重点在方案设计思路上,其中涉及的…...
黑马k8s(七)
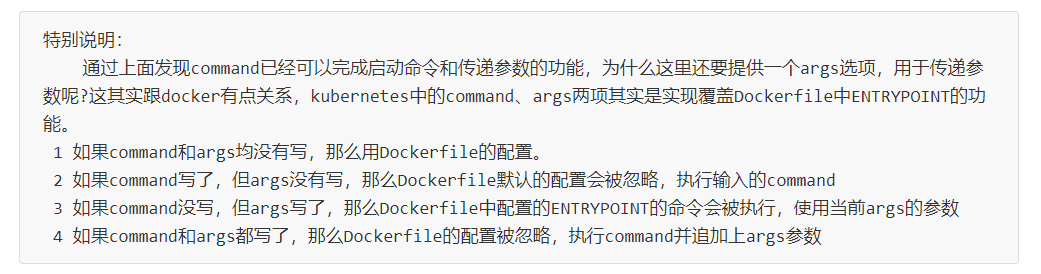
1.Pod介绍 查看版本: 查看类型,这里加s跟不加s没啥区别,可加可不加 2.Pod基本配置 3.镜像拉去策略 本地没有这个镜像,策略是Never,启动失败 查看拉去策略: 更改拉去策略: 4.启动命令 运行的是nginx、busv…...
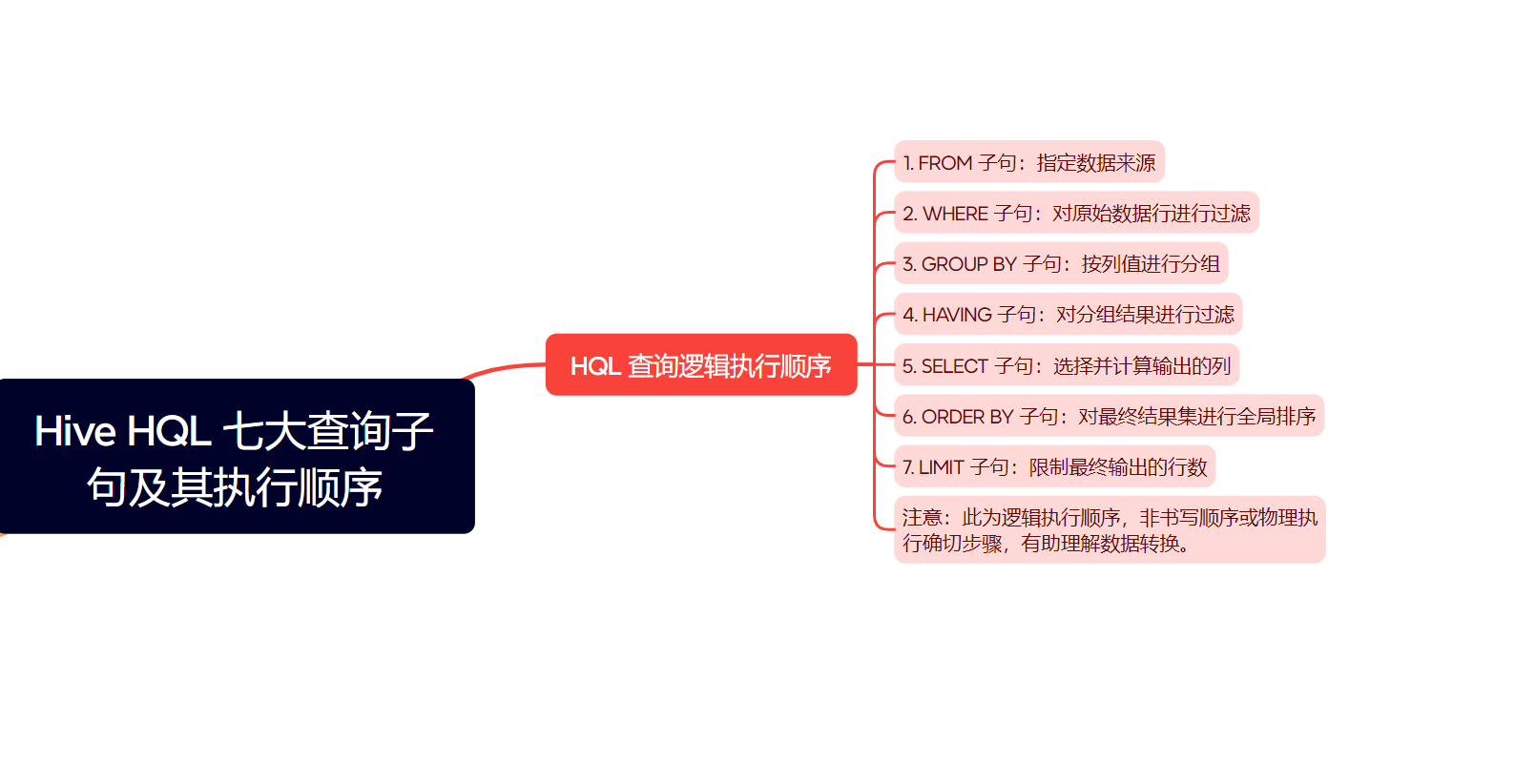
九、HQL DQL七大查询子句
作者:IvanCodes 日期:2025年5月15日 专栏:Hive教程 Apache Hive 的强大之处在于其类 SQL 的查询语言 HQL,它使得熟悉 SQL 的用户能够轻松地对存储在大规模分布式系统(如 HDFS)中的数据进行复杂的查询和分析…...

基于中心点预测的视觉评估与可视化流程
基于中心点预测的视觉评估与可视化流程 基于中心点预测的视觉评估与可视化流程一、脚本功能概览二、可视化与评分机制详解1. 真实框解析2. 调用模型处理帧3. 预测中心点与真实值的对比4. 打分策略5. 图像可视化三、目录结构要求四、运行方式五、应用场景与拓展思路六、总结七,…...
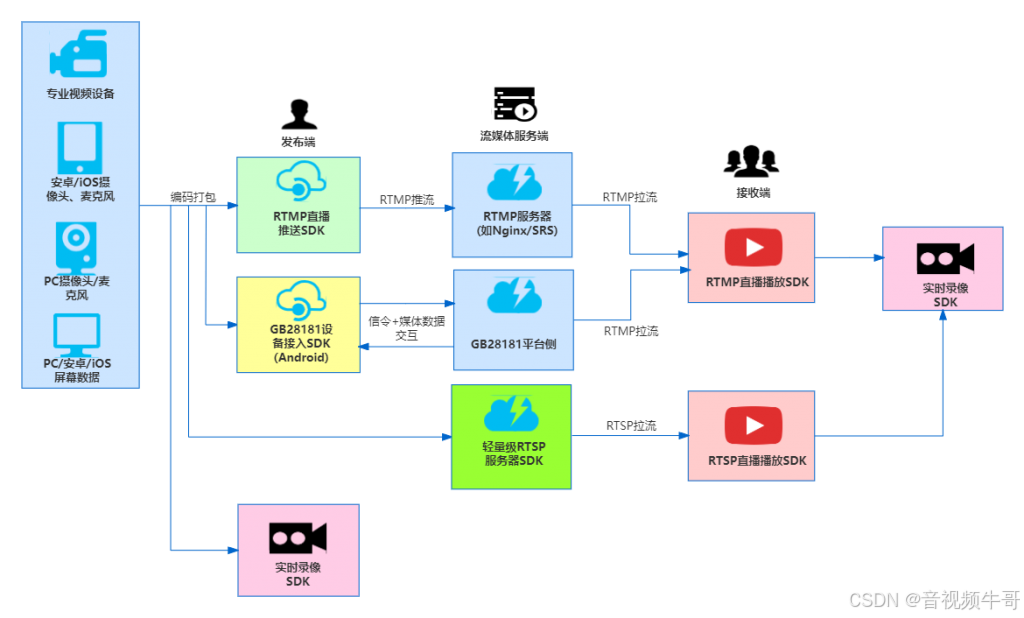
RTSP 播放器技术探究:架构、挑战与落地实践
RTSP 播放器为什么至今无法被淘汰? 在实时视频传输领域,RTSP(Real-Time Streaming Protocol)作为最基础、最常见的协议之一,至今依然被广泛用于监控设备、IP Camera、视频服务器等设备中。然而,要构建一个稳…...

实验5 DNS协议分析与测量
实验5 DNS协议分析与测量 1、实验目的 了解互联网的域名结构、域名系统DNS及其域名服务器的基本概念 熟悉DNS协议及其报文基本组成、DNS域名解析原理 掌握常用DNS测量工具dig使用方法和DNS测量的基本技术 2、实验环境 硬件要求:阿里云云主机ECS 一台。 软件要…...

编程日志5.8
二叉树练习题 1.965. 单值二叉树 - 力扣(LeetCode) /** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode() : val(0), left(nullptr), right(nullptr) {} * TreeNode(int x) :…...

【鸿蒙开发】性能优化
语言层面的优化 使用明确的数据类型,避免使用模糊的数据类型,例如ESObject。 使用AOT模式 AOT就是提前编译,将字节码提前编译成机器码,这样可以充分优化,从而加快执行速度。 未启用AOT时,一边运行一边进…...

2025-05-13 学习记录--Python-循环:while循环 + while-else循环 + for循环 + 循环控制
合抱之木,生于毫末;九层之台,起于累土;千里之行,始于足下。💪🏻 一、循环 ⭐️ (一)、while循环 🍭 初始条件设置 -- 通常是重复执行的 计数器while 条件(判…...
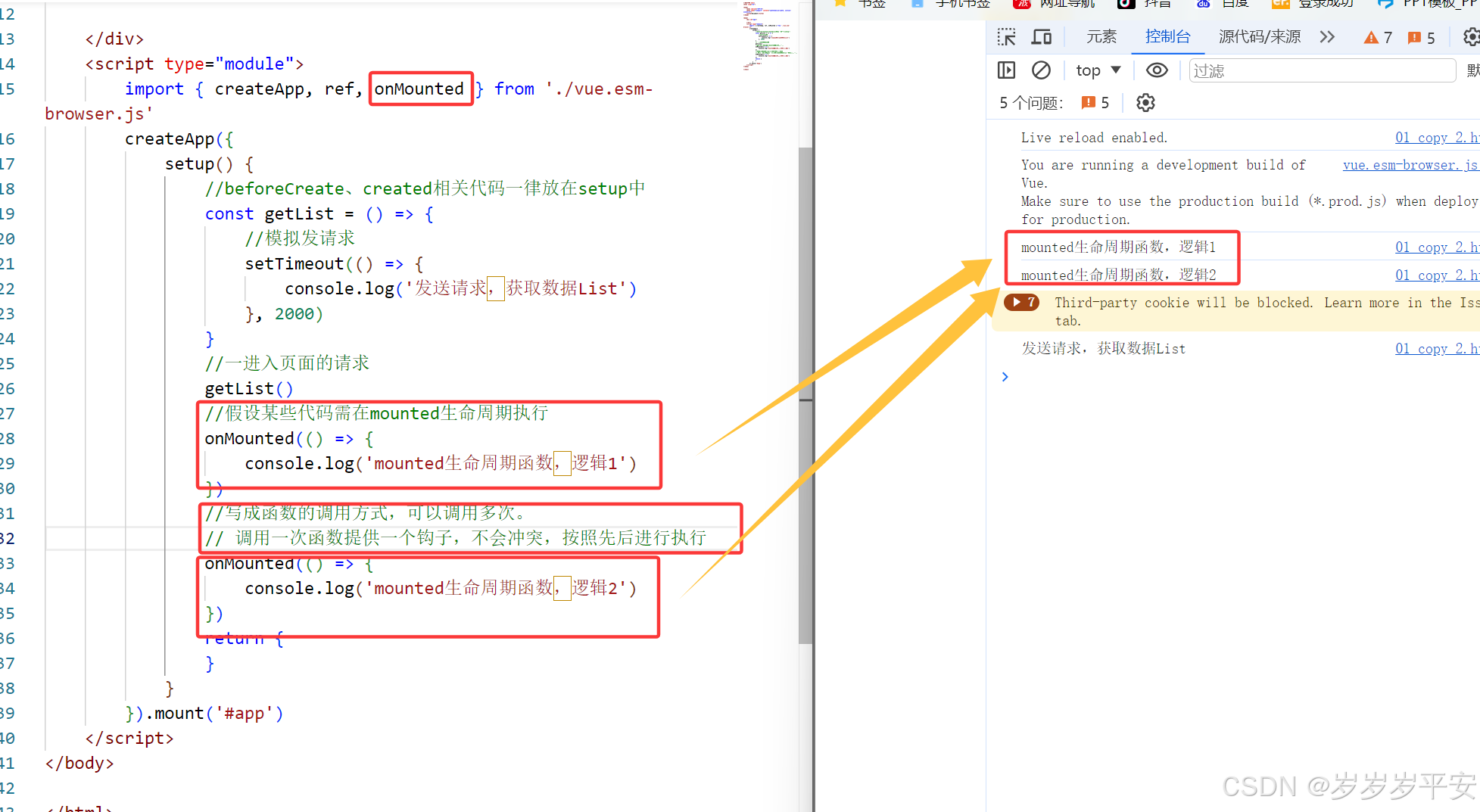
Vue3学习(组合式API——生命周期函数基础)
目录 一、Vue3组合式API中的生命周期函数。 (1)各阶段生命周期涉及函数简单介绍。 <1>创建挂载阶段的生命周期函数。 <2>更新阶段的生命周期函数。 <3>卸载阶段的生命周期函数。 <4>错误处理的生命周期函数。 (2&…...

全面指南:Xinference大模型推理框架的部署与使用
全面指南:Xinference大模型推理框架的部署与使用 Xinference(Xorbits Inference)是一个功能强大的分布式推理框架,专为简化各种AI模型的部署和管理而设计。本文将详细介绍Xinference的核心特性、版本演进,并提供多种部署方式的详细指南,包括本地部署、Docker-Compose部署…...
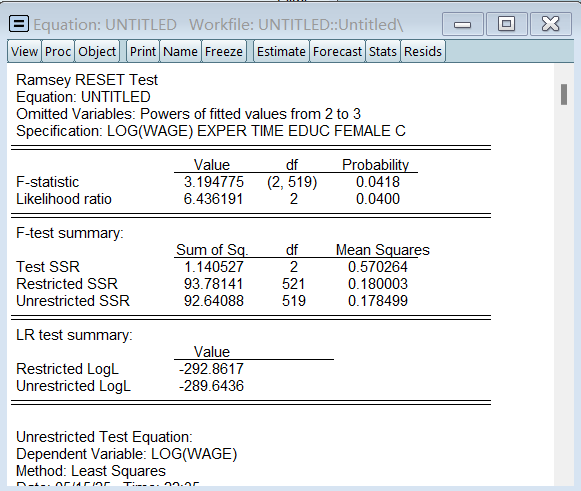
计量——检验与代理变量
1.非嵌套模型的检验 1Davidson-Mackinnon test 判断哪个模型好 log(y)β0β1x1β2x2β3x3u log(y)β0β1log(x1)β2log(x2)β3log(x3)u 1.对logÿ…...