PyTorch LSTM练习案例:股票成交量趋势预测
文章目录
- 案例介绍
- 源码地址
- 代码实现
- 导入相关库
- 数据获取和处理
- 搭建LSTM模型
- 训练模型
- 测试模型
- 绘制折线图
- 主函数
- 绘制结果
案例介绍
- 本例使用长短期记忆网络模型对上海证券交易所工商银行的股票成交量做一个趋势预测,这样可以更好地掌握股票买卖点,从而提高自己的收益率。
源码地址
- stock_prediction
代码实现
导入相关库
import os
import pandas as pd
import torch # 导入PyTorch库
import torch.nn as nn # 导入神经网络模块
import torch.optim as optim # 导入优化器模块
from tqdm import tqdm # 导入tqdm库,用于显示进度条
import matplotlib.pyplot as plt # 导入matplotlib库,用于绘制图表
from copy import deepcopy as copy # 导入deepcopy函数,用于深拷贝对象
from torch.utils.data import DataLoader, TensorDataset # 导入DataLoader和TensorDataset类,用于加载数据
数据获取和处理
data.csv文件中包括开盘价,收盘价,最高价,最低价,成交量5个数据特征,使用每天的收盘价作为学习目标,每个样本都包含连续几天的数据作为一个序列样本,然后,将数据划分为训练集和测试集供后续使用。- GetData类用于获取和处理数据,它具有以下方法:
init(self, stock_id,save_path):初始化方法,接受股票ID和数据保存路径作为参数,并将它们存储在实例变量中。getData(self):获取数据的方法,获取股票历史数据并进行处理,然后保存到文件中。返回处理后的数据。process_data(self,n):处理数据的方法,将数据分为特征和标签,并划分为训练集和测试集。接受滑动窗口大小n作为参数。如果数据为空,则调用getData方法获取数据。返回训练集的特征、测试集的特征、训练集的标签和测试集的标签。
# 获取数据
class GetData:def __init__(self, stock_id, save_path):"""初始化方法:param stock_id: 股票id:param save_path: 数据保存路径"""self.min_value = Noneself.max_value = Noneself.stock_id = stock_idself.save_path = save_pathself.data = Nonedef getData(self):"""获取数据数据处理并保存:return: None""""""# 获取股票数据self.data = ts.get_hist_data(self.stock_id).iloc[::-1]# 选取特定列作为数据self.data = self.data[["open", "close", "high", "low", "volume"]]# 计算数据列的最大值和最小值self.max_value = self.data['volume'].max()self.min_value = self.data['volume'].min()# 归一化处理self.data = self.data.apply(lambda x: (x - min(x)) / (max(x) - min(x)))# 保存数据self.data.to_csv(self.save_path)return self.data"""# 本地数据data.csv由于是归一化后的数据,所以最大值和最小值并不准确,所以运行结果会有误差,重在体验整个项目的逻辑即可columns = ['open', 'close', 'high', 'low', 'volume']self.data = pd.read_csv(self.save_path, names=columns, header=0)# 计算数据列的最大值和最小值self.max_value = self.data['volume'].max()self.min_value = self.data['volume'].min()return self.datadef process_data(self, n):"""处理数据:param n: 滑动窗口大小:return: 训练集的特征、测试集的特征、训练集的标签、测试集的标签"""if self.data is None:self.getData()# 提取特征和标签数据"""iloc 是 Pandas 库中用于按位置索引选取数据的方法"""feature = [self.data.iloc[i: i + n].values.tolist()for i in range(len(self.data) - n + 2)if i + n < len(self.data)]label = [self.data.close.values[i + n]for i in range(len(self.data) - n + 2)if i + n < len(self.data)]# 划分训练集和数据集train_x = feature[:500]test_x = feature[500:]train_y = label[:500]test_y = label[500:]return train_x, test_x, train_y, test_y
搭建LSTM模型
- 定义一个Model的神经网络模块,包含一个LSTM层和线性层,在初始化方法中接受一个参数
n,并创建一个LSTM层和一个线性层。 - 在前向传播方法中,通过LSTM层处理输入x得到输出
lstm_output和隐藏状态hidden_state, cell_state,然后通过线性处理num_layers得到最终输出final_output ,最终返回final_output `作为模型的输出。
# 搭建LSTM模型: 单层单向LSTM网络+全连接层输出
class Model(nn.Module):def __init__(self, n):# 初始化方法super(Model, self).__init__() # 调用父类的初始化方法# 定义LSTM层 输入大小为n, 隐藏层大小为256,批次优先为Trueself.lstm_layer = nn.LSTM(input_size=n, hidden_size=256, batch_first=True)# 定义全连接层 输入特征数为256, 输出特征数为1 有偏差self.linear_layer = nn.Linear(in_features=256, out_features=1, bias=True)# 向前传播方法def forward(self, x):"""x: 输入数据(通常是时间序列的特征)lstm_output: LSTM 层的输出序列hidden_state: LSTM 的隐藏状态(用于传递长期记忆)cell_state: LSTM 的细胞状态(仅在 LSTM 中存在)final_output: 经过全连接层后的最终输出"""# LSTM 层的前向传播,得到输出和隐藏状态lstm_output, (hidden_state, cell_state) = self.lstm_layer(x)# 获取隐藏状态的维度:batch_size, num_layers, hidden_sizebatch_size, num_layers, hidden_size = hidden_state.shape# 将隐藏状态输入全连接层,需要先展平为二维final_output = self.linear_layer(hidden_state.view(batch_size * num_layers, hidden_size))return final_output
训练模型
- 模型训练包括训练,测试,损失计算和模型保存等功能。
# 训练模型
def train_model(epoch, train_dataloader, test_dataloader, optimizer, early_stop, model):"""训练模型的函数:param model: 模型:param early_stop: 提前停止的轮数:param optimizer: 优化器:param epoch: 训练轮次:param train_dataloader: 训练数据加载器:param test_dataloader: 测试数据加载器:return:"""best_model = None # 用于保存最佳模型train_loss = 0 # 训练损失test_loss = 0 # 测试损失best_loss = 100 # 最佳损失epoch_cnt = 0 # 训练轮次计数器for i in range(epoch):total_train_loss = 0 # 训练总损失total_train_num = 0 # 训练总样本数total_test_loss = 0 # 测试总损失total_test_num = 0 # 测试总样本数for x, y in tqdm(train_dataloader, desc=f"Epoch:{i} | Train Loss:{train_loss} | Test Loss:{test_loss}"):x_num = len(x) # 当前批次样本数p = model(x) # 模型预测 ✅ 使用 model(x),而不是 Model(x)loss = loss_func(p, y) # 计算损失optimizer.zero_grad() # 清空梯度loss.backward() # 反向传播optimizer.step() # 更新参数total_train_loss += loss.item() # 训练损失累加total_train_num += x_num # 训练样本数累加# 计算训练损失train_loss = total_train_loss / total_train_numfor x, y in test_dataloader:x_num = len(x) # 当前批次样本数p = model(x) # 模型预测 ✅ 使用 model(x),而不是 Model(x)loss = loss_func(p, y) # 计算损失optimizer.zero_grad() # 清空梯度loss.backward() # 反向传播optimizer.step() # 更新参数total_test_loss += loss.item() # 测试损失累加total_test_num += x_num # 测试样本数累加test_loss = total_test_loss / total_test_num# 如果当前测试损失小于最佳损失,则更新最佳模型和轮次计数器 否则 轮次计数器加1if test_loss < best_loss:best_loss = test_lossbest_model = copy(model) # ✅ 使用 copy(model),而不是 copy(Modeltorch.save(best_model.state_dict(), './best_model.pth')epoch_cnt = 0else:epoch_cnt += 1if epoch_cnt > early_stop:break测试模型
- 在代码中定义一个名为test_model的函数,用于测试模型并返回预测值、真实标签以及测试损失,函数接收一个名为test_dataLoader_的DataLoader参数,其中包含测试数据。
- 在函数内部,首先创建了空的预测值列表pred和真实标签列表label。然后创建了一个模型对象model_f,加载了预先保存的模型状态字典
./best_model.pth,并将模型设置为评估模式。 - 接着,通过遍历
test_dataLoader中的数据进行预测。对每个数据样本x,模型预测p,计算损失
值并累加到total_test_loss中。同时,将预测值和真实标签分别添加到pred和label列表中。 - 最后,计算平均测试损失test_loss,并将预测值列表pred、真实标签列表label和测试损失test_loss作为结果返回。
def test_model(test_dataloader):"""测试模型,并返回预测值、真实标签和测试损失:param test_dataloader: 测试数据加载器:return: pred,label,test_loss"""pred = [] # 预测值列表label = [] # 真实标签列表model_f = Model(5) # 创建模型对象model_f.load_state_dict(torch.load('./best_model.pth')) # 加载最佳模型model_f.eval() # 设置模型为评估模式total_test_loss = 0total_test_num = 0for x, y in test_dataloader:x_num = len(x)p = model_f(x) # ✅ 使用 model_f(x)loss = loss_func(p, y)total_test_loss += loss.item()total_test_num += x_num# 将预测值和真实标签添加到列表中pred.extend(p.data.squeeze(1).tolist())label.extend(y.data.tolist())# 获取预测值和真实标签test_loss = total_test_loss / total_test_numreturn pred, label, test_loss
绘制折线图
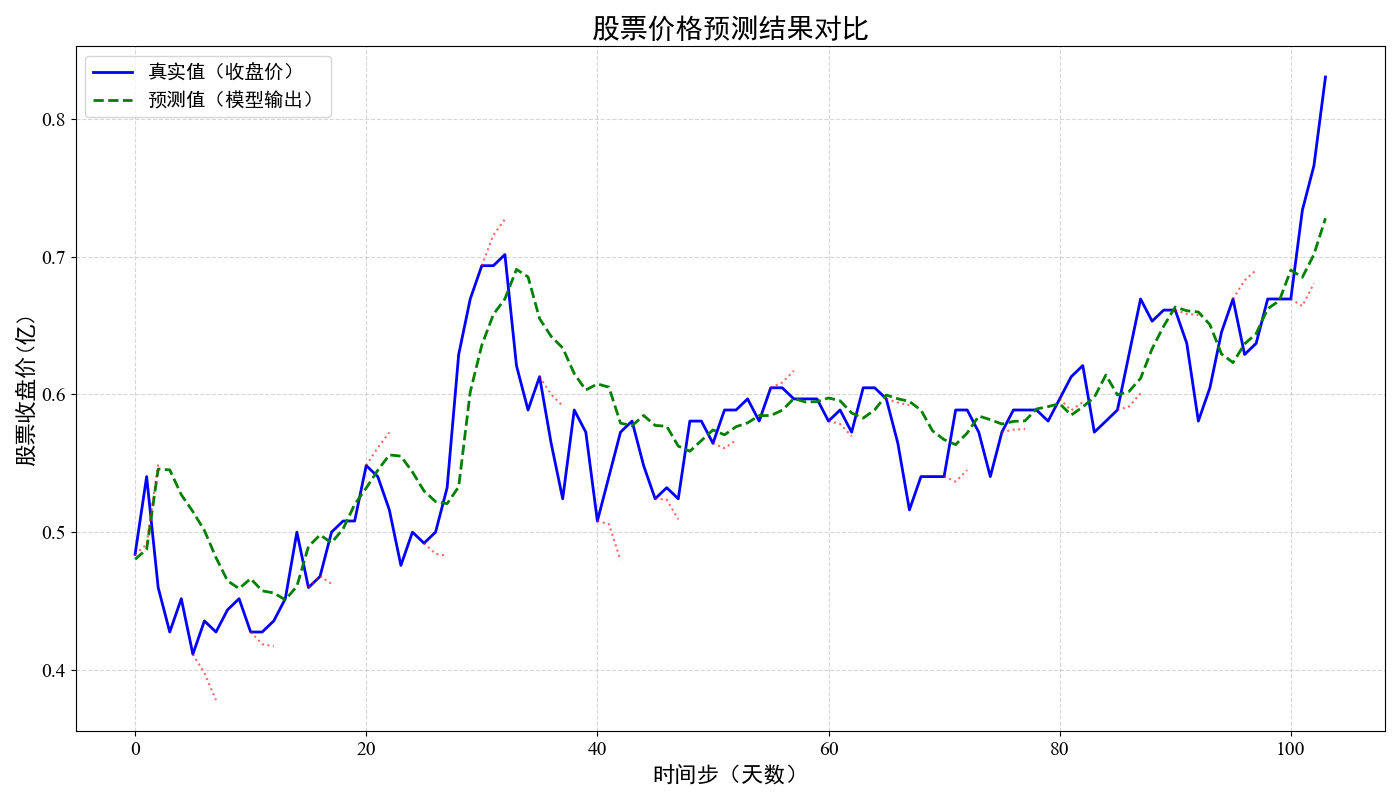
- 绘制股票日成交量的折线图,并输出模型测试集的损失。
def plot_img(data, pred):"""绘制真实值与预测值对比图:param data: 真实标签列表:param pred: 模型预测值列表:return:"""# 设置支持中文的字体plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题plt.figure(figsize=(14, 8))# 绘制真实值曲线plt.plot(range(len(data)), data, color='blue', label='真实值(收盘价)', linewidth=2)# 绘制预测值曲线plt.plot(range(len(pred)), pred, color='green', label='预测值(模型输出)', linestyle='--', linewidth=2)# 添加预测区间(每5个点绘制一个3天的预测区间)for i in range(0, len(pred) - 3, 5):price = [data[i] + pred[j] - pred[i] for j in range(i, i + 3)]plt.plot(range(i, i + 3), price, color='red', alpha=0.6, linestyle=':', linewidth=1.5)# 设置标题和标签plt.title('股票价格预测结果对比', fontsize=20)plt.xlabel('时间步(天数)', fontsize=16)plt.ylabel('股票收盘价(亿)', fontsize=16)# 设置刻度字体plt.xticks(fontproperties='Times New Roman', size=14)plt.yticks(fontproperties='Times New Roman', size=14)# 显示图例plt.legend(loc='upper left', fontsize=14)# 显示网格plt.grid(True, linestyle='--', alpha=0.5)# 展示图形plt.tight_layout()plt.show()
主函数
-
初始化设置
- 定义超参数(训练轮次、批次大小等)。
- 创建模型和数据加载对象,指定股票ID和数据保存路径。
-
数据处理
- 获取股票数据,按时间窗口(5天)生成输入序列和标签。
- 将数据转换为PyTorch张量,并分批次加载(
batch_size=20)。
-
模型训练
- 使用均方误差损失和Adam优化器训练模型。
- 监控验证损失,若连续5轮无改进则提前停止,保存最佳模型。
-
模型测试
- 加载保存的最佳模型,在测试集上预测并计算损失。
- 将预测值和真实值反归一化,还原为原始价格。
-
结果输出
- 绘制预测值与真实值的对比图。
- 打印测试集上的最终损失值。
- 设置参数 → 加载并预处理数据 → 训练模型(含早停) → 测试并还原预测结果 → 可视化输出。
if __name__ == '__main__':# 超参数days_num = 5 # 天数epoch = 20 # 训练轮次fea = 5 # 特征数量batch_size = 20 # 批次大小early_stop = 5 # 提前停止轮次# 创建模型对象model = Model(fea)# 创建数据加载器gd = GetData(stock_id='601398', save_path='./data.csv')train_x, test_x, train_y, test_y = gd.process_data(days_num)# 将数据转换为张量train_x = torch.tensor(train_x).float()test_x = torch.tensor(test_x).float()train_y = torch.tensor(train_y).float()test_y = torch.tensor(test_y).float()# 构建训练数据集和测试数据集train_data = TensorDataset(train_x, train_y)train_dataloader = DataLoader(train_data, batch_size=batch_size)test_data = TensorDataset(test_x, test_y)test_dataloader = DataLoader(test_data, batch_size=batch_size)# 创建损失函数和优化器loss_func = nn.MSELoss()optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型train_model(epoch, train_dataloader, test_dataloader, optimizer, early_stop, model)# 只有模型存在时才进行测试if os.path.exists('./best_model.pth'):pred, label, test_loss = test_model(test_dataloader)else:print("模型文件不存在,请先完成训练并确保模型已保存。")# 将预测值和真实标签转换为真实价格pred = [ele * (gd.max_value - gd.min_value) + gd.min_value for ele in pred]data = [ele * (gd.max_value - gd.min_value) + gd.min_value for ele in label]# 绘制图像plot_img(data, pred)print(f"模型损失:{test_loss}")
绘制结果
相关文章:
PyTorch LSTM练习案例:股票成交量趋势预测
文章目录 案例介绍源码地址代码实现导入相关库数据获取和处理搭建LSTM模型训练模型测试模型绘制折线图主函数 绘制结果 案例介绍 本例使用长短期记忆网络模型对上海证券交易所工商银行的股票成交量做一个趋势预测,这样可以更好地掌握股票买卖点,从而提高…...

CK3588下安装linuxdeployqt qt6 arm64
参考资料: Linux —— linuxdeployqt源码编译与打包(含出错解决) linux cp指令报错:cp: -r not specified; cp: omitting directory ‘xxx‘(需要加-r递归拷贝) CMake Error at /usr/lib/x86_64…...
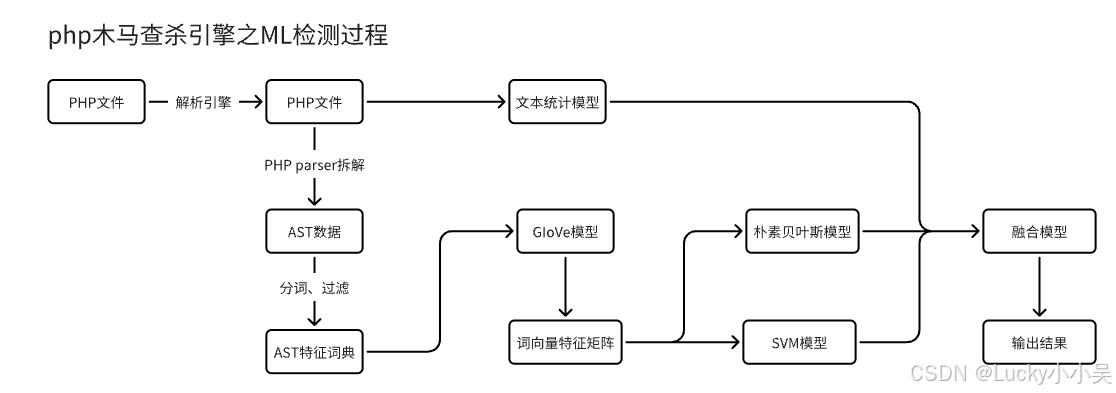
木马查杀引擎—关键流程图
记录下近日研究的木马查杀引擎,将关键的实现流程图画下来 PHP AST通道实现 木马查杀调用逻辑 模型训练流程...

二程运输的干散货船路径优化
在二程运输中,干散货船需要将货物从一个港口运输到多个不同的目的地港口。路径优化的目标是在满足货物运输需求、船舶航行限制等条件下,确定船舶的最佳航行路线,以最小化运输成本、运输时间或其他相关的优化目标。 影响因素 港口布局与距离:各个港口之间的地理位置和距离…...

华为数字政府与数字城市售前高级专家认证介绍
华为数字政府与数字城市售前高级专家认证面向华为合作伙伴售前高级解决方案专家、华为数字政府与数字城市行业解决方案经理(VSE)。 通过认证验证的能力 您将了解数字政府、数字城市行业基础知识,了解该领域内的重点场景;将对华…...

在VSCode中接入DeepSeek的指南
本文将介绍三种主流接入方式,涵盖本地模型调用和云端API接入方案。 一、环境准备 1.1 基础要求 VSCode 1.80+Node.js 16.x+Python 3.8+(本地部署场景)已部署的DeepSeek服务(本地或云端)1.2 安装必备插件 # 打开VSCode插件面板(Ctrl+Shift+X) 搜索并安装: - DeepSeek Of…...
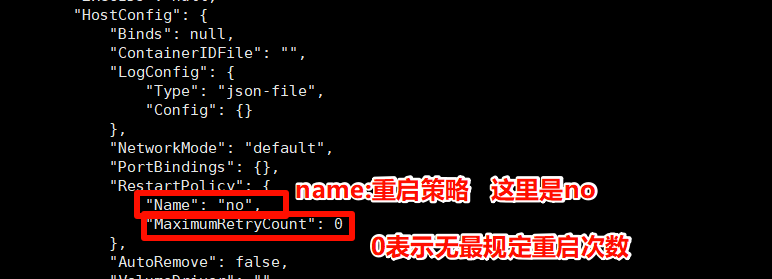
【docker】--容器管理
文章目录 容器重启--restart 参数选项及作用**对比 always 和 unless-stopped****如何查看容器的重启策略?** 容器重启 –restart 参数选项及作用 重启策略 no:不重启(默认)。on-failure:失败时重启(可限…...

基于OpenCV的人脸微笑检测实现
文章目录 引言一、技术原理二、代码实现2.1 关键代码解析2.1.1 模型加载2.1.2 图像翻转2.1.3 人脸检测 微笑检测 2.2 显示效果 三、参数调优建议四、总结 引言 在计算机视觉领域,人脸检测和表情识别一直是热门的研究方向。今天我将分享一个使用Python和OpenCV实现…...

使用PEFT库将原始模型与LoRA权重合并
使用PEFT库将原始模型与LoRA权重合并 步骤如下: 基础模型加载:需保持与LoRA训练时相同的模型配置merge_and_unload():该方法会执行权重合并并移除LoRA层保存格式:合并后的模型保存为标准HuggingFace格式,可直接用于推…...
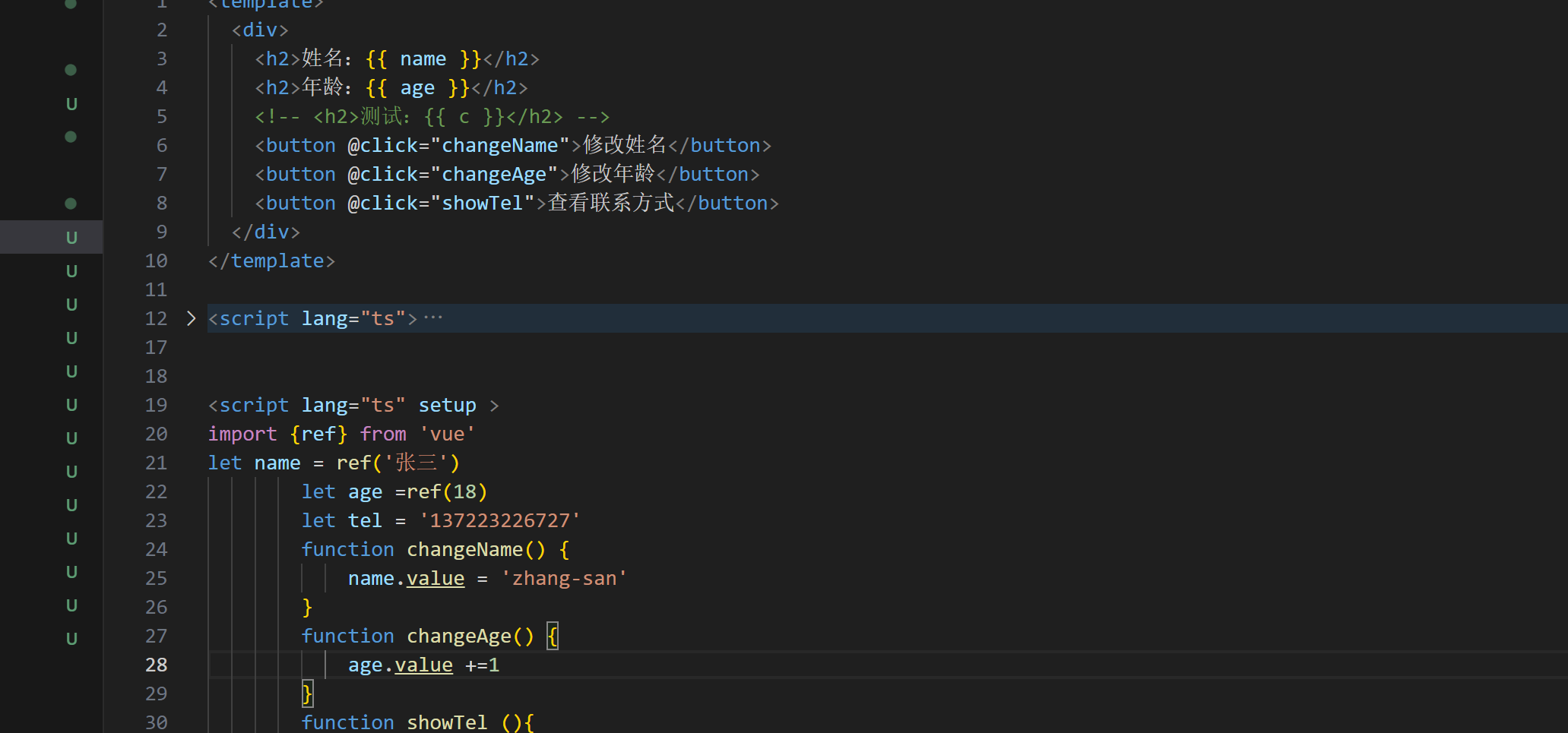
2025-5-15Vue3快速上手
1、setup和选项式API之间的关系 (1)vue2中的data,methods可以与vue3的setup共存 (2)vue2中的data可以用this读取setup中的数据,但是反过来不行,因为setup中的this是undefined (3)不建议vue2和vue3的语法混用…...
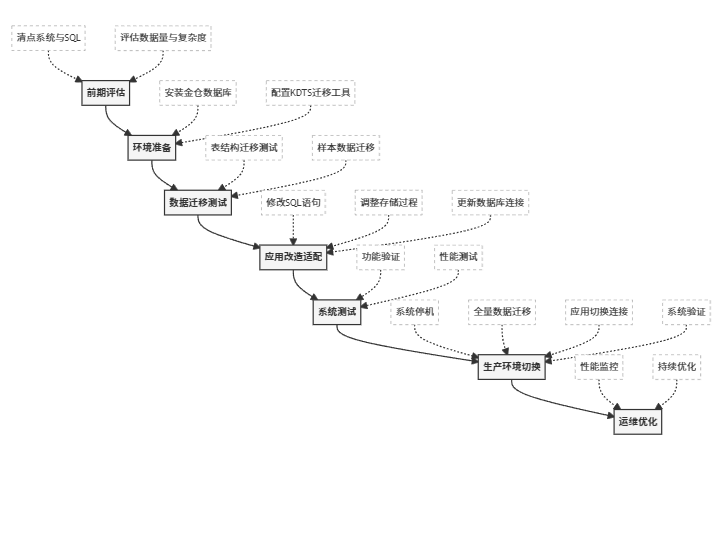
【金仓数据库征文】从生产车间到数据中枢:金仓数据库助力MES系统国产化升级之路
目录 前言一、金仓数据库:国产数据库的中坚力量二、制造业MES系统:数据驱动的生产智能MES系统的核心价值MES系统关键模块与数据库的关系1. BOM管理2. 生产工单与订单管理3. 生产排产与资源调度4. 生产报工与实时数据采集 5. 采购与销售管理 三、从MySQL到…...

HTML17:表单初级验证
表单初级验证 常用方式 placeholder 提示信息 <p>名字:<input type"text" name"username" maxlength"8" size"30" placeholder"请输入用户名"></p>required 非空判断 <p>名字:<input type"…...
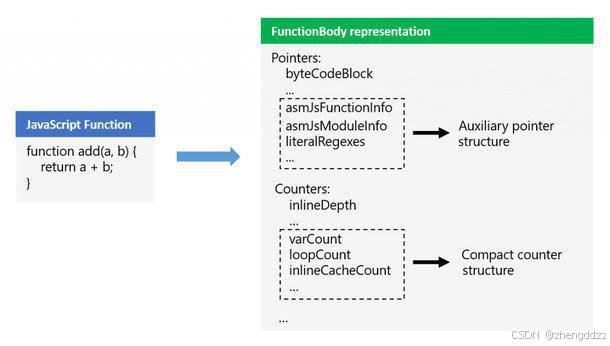
从卡顿到丝滑:JavaScript性能优化实战秘籍
引言 在当今的 Web 开发领域,JavaScript 作为前端开发的核心语言,其性能表现对网页的加载速度、交互响应以及用户体验有着举足轻重的影响。随着 Web 应用的复杂度不断攀升,功能日益丰富,用户对于网页性能的期望也越来越高。从电商…...

How Sam‘s Club nudge customers into buying more
Here’s how Sam’s Club (or similar warehouse memberships) nudge customers into buying more: It’s a classic psychological strategy rooted in sunk cost fallacy and loss aversion. 1. Prepaid Membership Creates a “Sunk Cost” Once you’ve paid the annual …...

ORB特征点检测算法
角点是图像中灰度变化在两个方向上都比较剧烈的点。与边缘(只有一个方向变化剧烈)或平坦区域(灰度变化很小)不同,角点具有方向性和稳定性。 tips:像素梯度计算 ORB算法流程简述 1.关键点检测(使用FAST…...
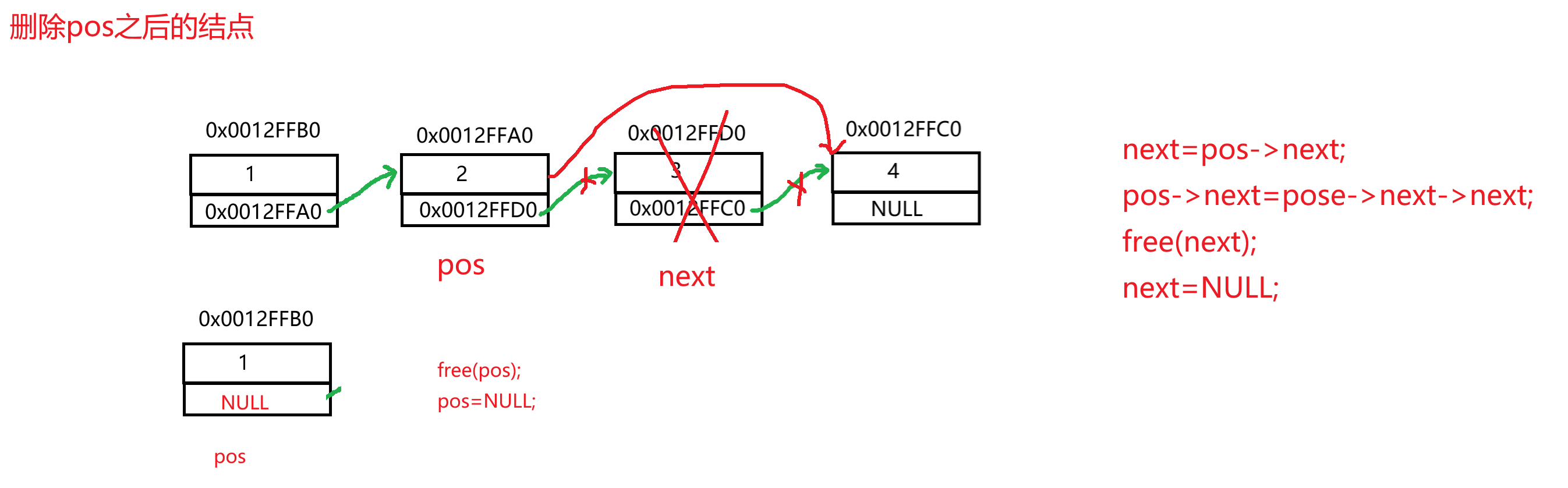
快速通关单链表秘籍
1.单链表概念与结构 1.1 概念 链表是一种逻辑结构连续,物理结构不连续的存储结构,数据结构的逻辑顺序是通过链表中的指针链接次序实现。 光看定义有点不好理解,我们举个简单例子! 我们都看过火车吧,我们看到的火车…...
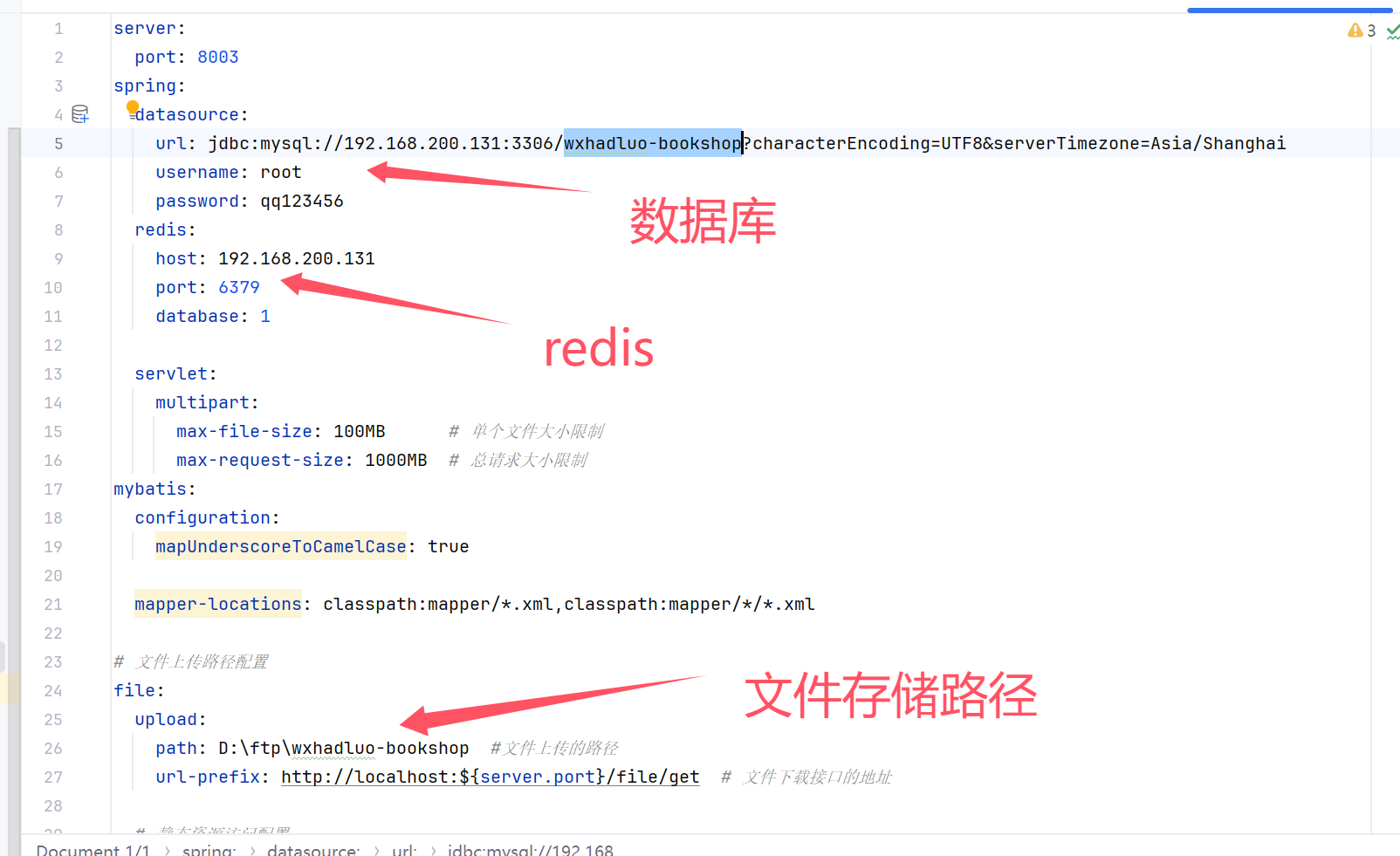
springboot+vue实现在线书店(图书商城)系统
今天教大家如何设计一个图书商城 , 基于目前主流的技术:前端vue,后端springboot。 同时还带来的项目的部署教程。 视频演示 在线书城 图片演示 一. 系统概述 商城是一款比较庞大的系统,需要有商品中心,库存中心,订单…...

C++二项式定理:原理、实现与应用
背景 鉴于复习,问了问清言二项式定理的应用…只好多找些资源…肝要死了… 一、引言 二项式定理是数学中一个基本定理,主要用于展开二项式的幂次。在C编程中,理解并实现二项式定理及其拓展具有重要意义,可以解决组合数学、概率论…...

使用GmSSL v3.1.1实现SM2证书认证
1、首先使用gmssl命令生成根证书、客户端公私钥,然后使用根证书签发客户端证书; 2、然后编写代码完成认证功能,使用根证书验证客户端证书是否由自己签发,然后使用客户端证书验证客户端私钥对随机数的签名是否正确。 第一部分生成根…...

远程实时控制安卓模拟器技术scrcpy
先运行模拟器 ~/Library/Android/sdk/emulator/emulator -avd Medium_Phone_API_25 再检查adb device /Users/xmkjsoft/Downloads/scrcpy-macos-x86_64-v3.2/adb devices 再开始实时获取模拟器画面 /Users/xmkjsoft/Downloads/scrcpy-macos-x86_64-v3.2/scrcpy --video-cod…...
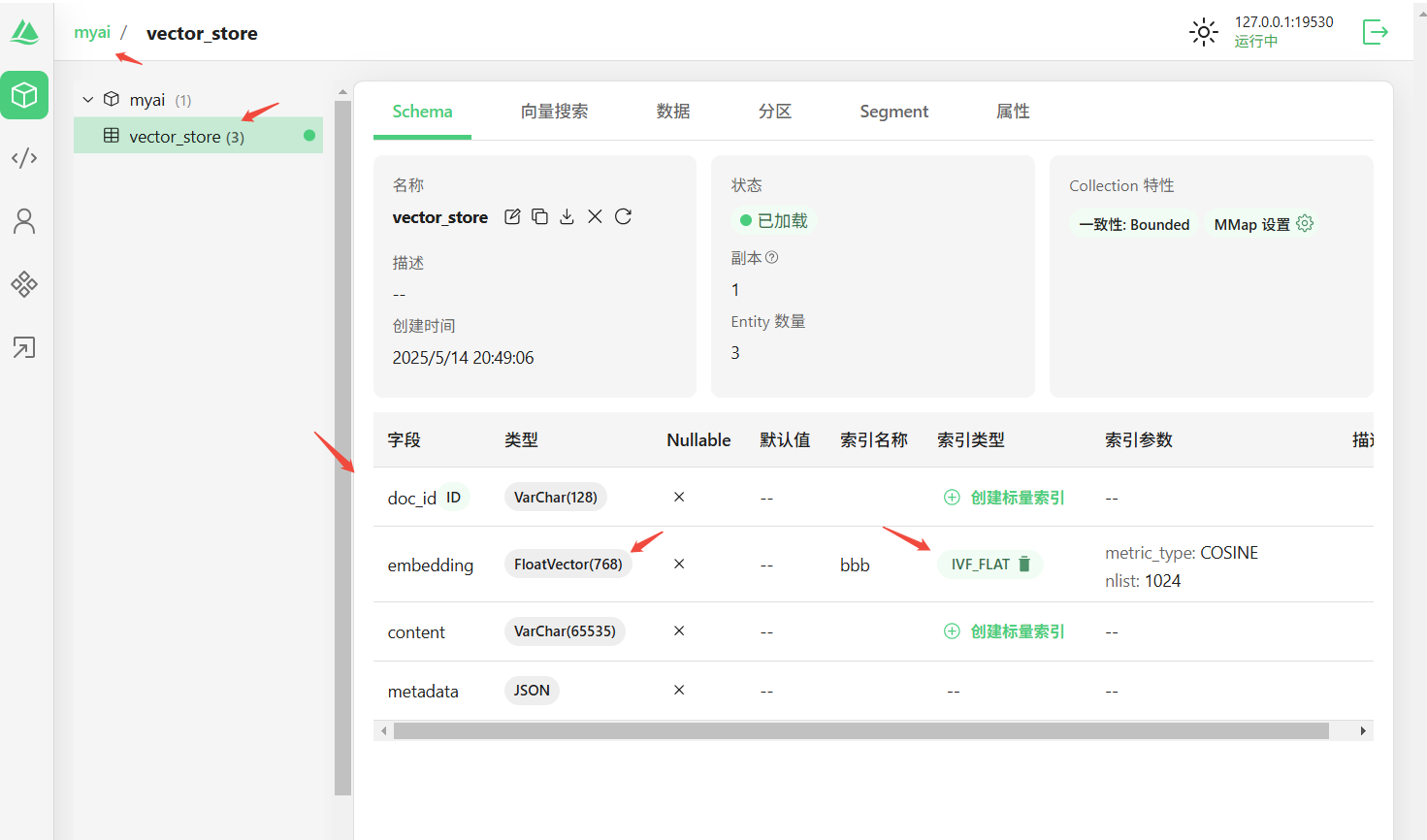
Spring AI(6)——向量存储
向量数据库是一种特殊类型的数据库,在 AI 应用中发挥着至关重要的作用。 在向量数据库中,查询与传统关系型数据库不同。它们执行的是相似性搜索,而非精确匹配。当给定一个向量作为查询时,向量数据库会返回与该查询向量“相似”的…...

Spring Data Elasticsearch 中 ElasticsearchOperations 构建查询条件的详解
Spring Data Elasticsearch 中 ElasticsearchOperations 构建查询条件的详解 前言一、引入依赖二、配置 Elasticsearch三、创建模型类(Entity)四、使用 ElasticsearchOperations 进行 CRUD 操作1. 保存数据(Create)2. 获取数据&am…...

react-router基本写法
1. 创建项目并安装所有依赖 npx create-react-app react-router-pro npm i 2. 安装所有的 react router 包 npm i react-router-dom 3. 启动项目 npm run start router/index.js // 创建路由实例 绑定path elementimport Layout from "/pages/Layout"; import…...
【Matlab】最新版2025a发布,深色模式、Copilot编程助手上线!
文章目录 一、软件安装1.1 系统配置要求1.2 安装 二、新版功能探索2.1 界面图标和深色主题2.2 MATLAB Copilot AI助手2.3 绘图区升级2.4 simulink2.5 更多 延迟一个月,终于发布了🤭。 一、软件安装 1.1 系统配置要求 现在的电脑都没问题,老…...

智能语音助手的未来:从交互到融合
摘要 随着人工智能技术的不断进步,智能语音助手已经成为我们生活中不可或缺的一部分。从简单的语音指令到复杂的多模态交互,语音助手正在经历一场深刻的变革。本文将探讨智能语音助手的发展历程、当前的技术瓶颈以及未来的发展方向,特别是其在…...
uniapp,小程序中实现文本“展开/收起“功能的最佳实践
文章目录 示例需求分析实现思路代码实现1. HTML结构2. 数据管理3. 展开/收起逻辑4. CSS样式 优化技巧1. 性能优化2. 防止事件冒泡3. 列表更新处理 实际效果总结 在移动端应用开发中,文本内容的"展开/收起"功能是提升用户体验的常见设计。当列表项中包含大…...

思维链框架:LLMChain,OpenAI,PromptTemplate
什么是思维链,怎么实现 目录 什么是思维链,怎么实现思维链(Chain of Thought)在代码中的实现方式1. 手动构建思维链提示2. 少样本思维链提示3. 自动思维链生成4. 思维链与工具使用结合5. 使用现有思维链框架:LLMChain,OpenAI,PromptTemplate思维链实现的关键要点思维链(C…...
)
HOT100 (哈希双指针)
哈希 1.两数之和(unordered_map) 给定一个整数数组 nums 和一个整数目标值 target,返回满足条件的数组下标 思路:用umap,一边遍历,一边装; class Solution {public:vector<int> twoSum(vector<int>& nums, int target) {unordered_map<int,int> u…...
使用 QGIS 插件 OpenTopography DEM Downloader 下载高程数据(申请key教程)
使用 QGIS 插件 OpenTopography DEM Downloader 下载高程数据 目录 使用 QGIS 插件 OpenTopography DEM Downloader 下载高程数据📌 简介🛠 插件安装方法🌍 下载 DEM 数据步骤🔑 注册 OpenTopography 账号(如使用 Cope…...
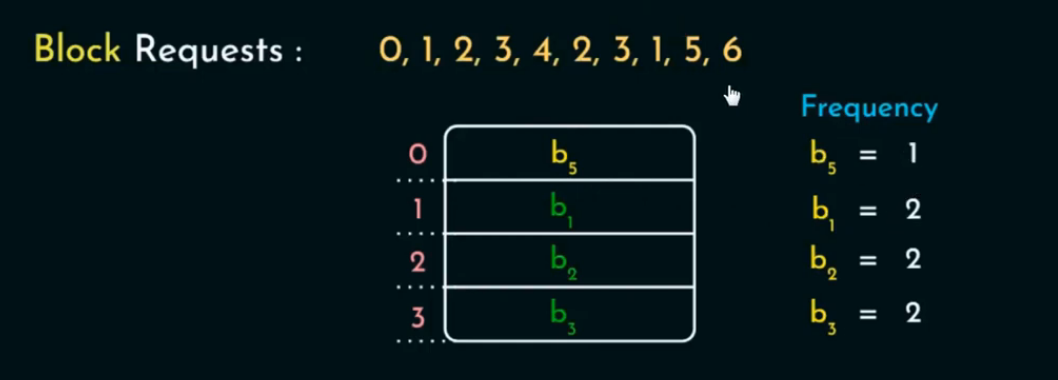
计算机组成与体系结构:替换策略(MRU LRU PLRU LFU)
目录 🎲 MRU(最近最常使用) 🪜 操作流程: 🎲 LRU(最近最少使用) 🪜 操作流程: 示例 🔍 Age Bits(年龄位) 核心思想…...