【深度学习之四】知识蒸馏综述提炼
知识蒸馏综述提炼
目录
知识蒸馏综述提炼
前言
参考文献
一、什么是知识蒸馏?
二、为什么要知识蒸馏?
三、一点点理论
四、知识蒸馏代码
总结
前言
知识蒸馏作为一种新兴的、通用的模型压缩和迁移学习架构,在最近几年展现出蓬勃的活力。综合看的一些知识蒸馏综述总结如下。
参考文献
[1]邵仁荣,刘宇昂,张伟,等.深度学习中知识蒸馏研究综述[J].计算机学报,2022,45(08):1638-1673.
一、什么是知识蒸馏?
知识蒸馏本质上属于迁移学习的范畴,其主要思路是将已训练完善的模型作为教师模型,通过控制“温度”从模型的输出结果中“蒸馏”出“知识”用于学生模型的训练,并希望轻量级的学生模型能够学到教师模型的“知识”,达到和教师模型相同的表现。这里的“知识”狭义上的解释是教师模型的输出中包含了某种相似性,这种相似性能够被用迁移并辅助其它模型的训练,Hinton称之为“暗知识”;广义上的解释是教师模型能够被利用的一切知识形式,如特征、参数、模块等等。而“蒸馏”是指通过某些方法(如控制参数),能够放大这种知识的相似性,并使其显现的过程;由于这一操作类似于化学实验中“蒸馏”的操作,因而被形象地称为“知识蒸馏”。知识蒸馏的发展历程如图1所示,根据不同的划分形式,知识蒸馏框架又可细分如图2所示,图3-4对比了不同方法的优缺点。
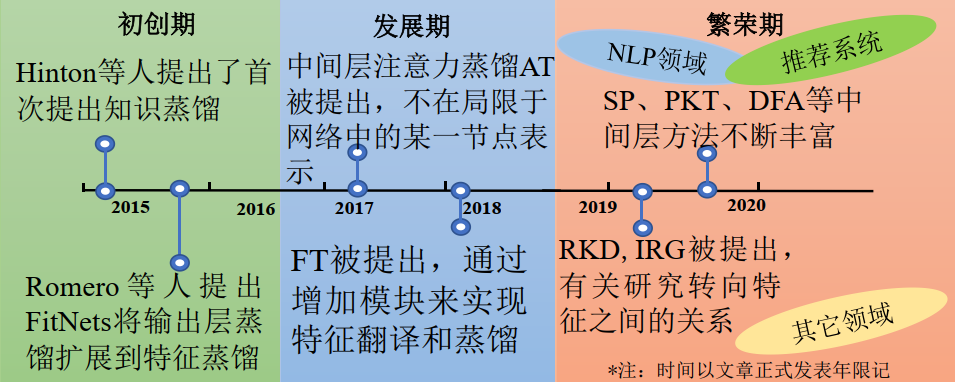
图1 知识蒸馏的发展历程
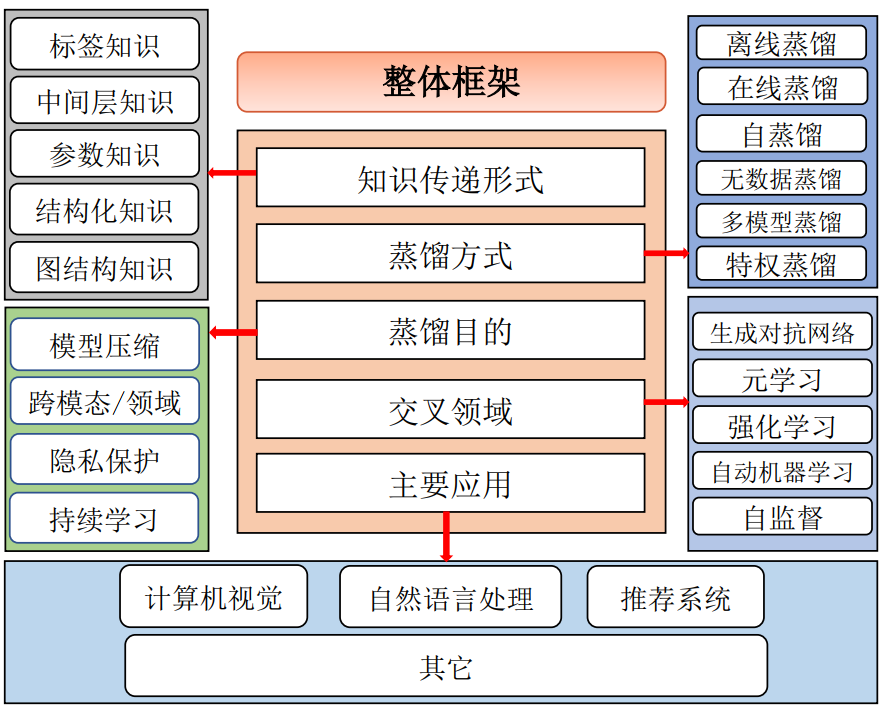
图2 知识蒸馏整体分类框架

图3 不同“知识”表达形式的优缺点
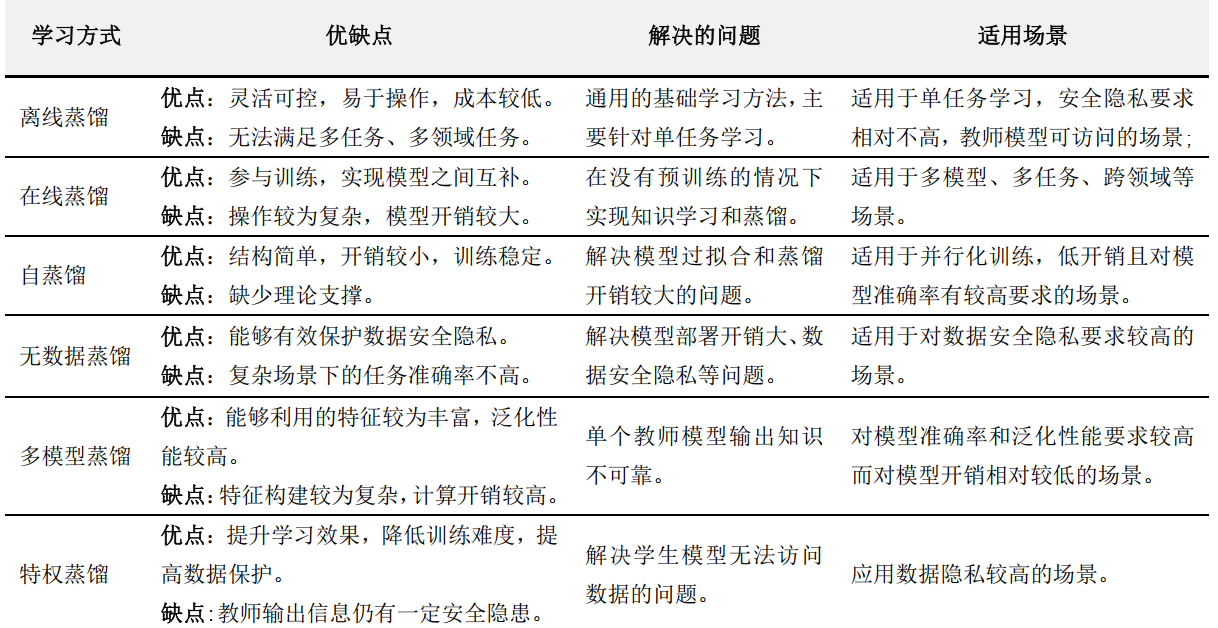
图4 不同蒸馏方法的优缺点
二、为什么要知识蒸馏?
深度学习在计算机视觉、语音识别、自然语言处理等内的众多领域中均取得了令人难以置信的性能。但是,当前的一些SOTA模型也存在一定的局限,比如过于依赖计算设备的性能
模型压缩
随着任务的复杂性增加、性能要求愈高,导致神经网络模型的结构愈加复杂,这直接导致了计算成本的急剧上升,严重限制了其在移动嵌入式设备上的部署和应用。
跨模态/跨领域
知识蒸馏结合跨领域能够很好地解决交叉任务和不同任务上知识的融合。通过重用跨任务模型的知识有助于提升目标域的泛化效果和鲁棒性。其存在的主要问题在于源域中的数据分布和目标域数据分布不一致,可能会带来一定的偏差,因此在迁移过程中需要考虑域适应(Domain Adaptation)的问题。
隐私保护
传统的深度学习模型很容易受到隐私攻击。因此,出于隐私或机密性的考虑,大多数数据集都是私有的,不会公开共享。特别是在处理生物特征数据、患者的医疗数据等方面。因此,模型获取用于模型训练优质数据,并不现实。对于模型来说,既希望能访问这些隐私数据的原始训练集,而又不能将其直接暴露给应用。因而,可以通过教师-学生结构的知识蒸馏来隔离的数据集的访问。让教师模型学习隐私数据,并将知识传递给外界的模型。
持续学习
持续学习(Continual Learning) 是指一个学习系统能够不断地从新样本中学习新的知识,并且保存大部分已经学习到的知识,其学习过程也十分类似于人类自身的学习模式。但是持续学习需要面对一个非常重要的挑战是灾难性遗忘,即需要平衡新知识与旧知识之间的关系。知识蒸馏能够将已学习的知识传递给学习模型实现“知识”的增量学习(Incremental Learning)
三、一点点理论
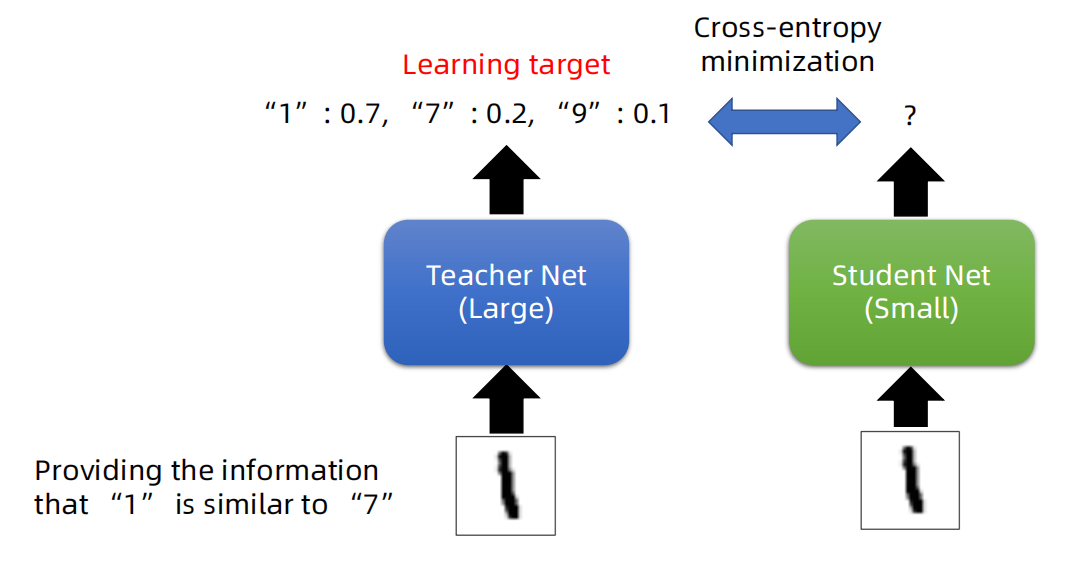
图1 “暗知识”
以手写数字为例,教师网络对数字1 11的预测标签为" 1 " : 0.7 , " 7 " : 0.2 , " 9 " : 0.1,这里1的预测概率最大为 0.7 是正确的分类,但是标签" 7 " " 9 " 的预测概率也能提供一些信息,就是说 " 7 " , " 9 " 和预测标签1 还是有某种预测的相似度的。如果把这个信息也教会学生网络,学生网络就可以了解到这种类别之间的相似度,可以看作为学习到了教师网络中隐藏的知识,对于学生网络的分类是有帮助的。
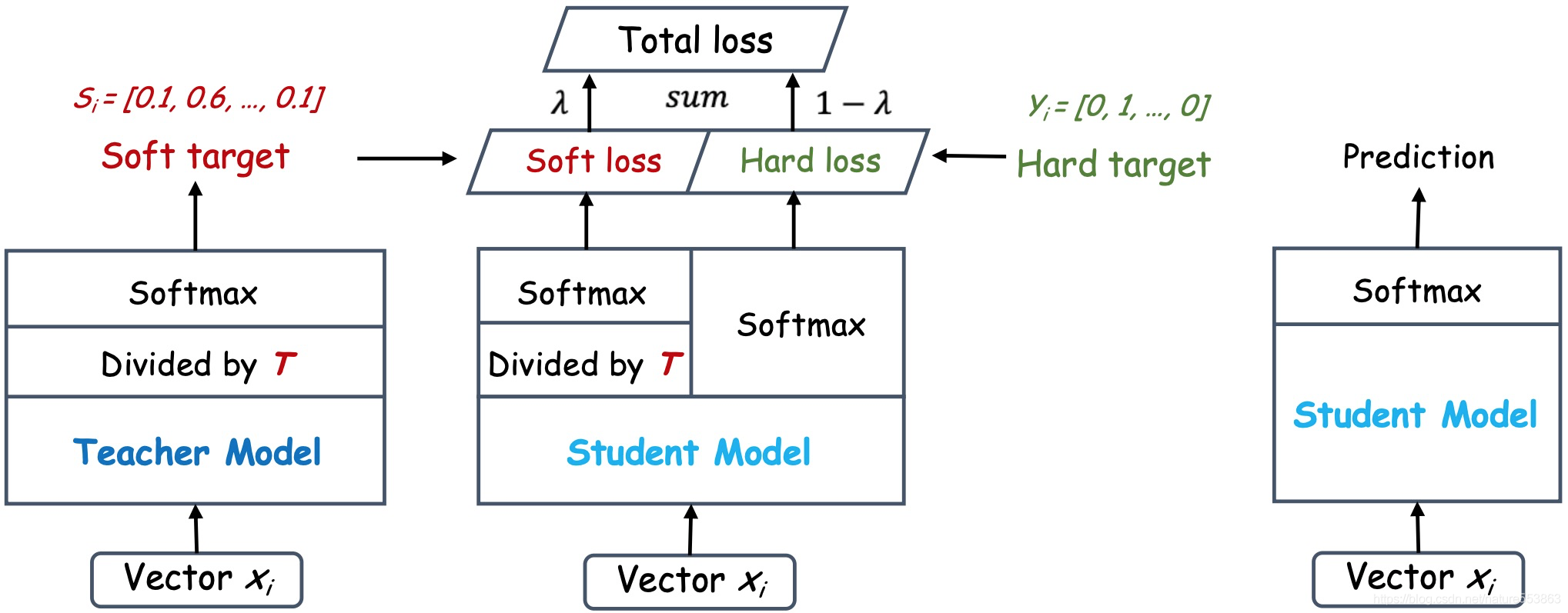
图2 知识蒸馏的过程
如上图所示,教师网络(左侧)的预测输出除以温度参数(Temperature)之后、再做Softmax计算,可以获得软化的概率分布(软目标或软标签),数值介于0 − 1之间,取值分布较为缓和。Temperature数值越大,分布越缓和;而Temperature数值减小,容易放大错误分类的概率,引入不必要的噪声。针对较困难的分类或检测任务,Temperature通常取1 ,确保教师网络中正确预测的贡献。硬目标则是样本的真实标注,可以用One-hot矢量表示。Total loss设计为软目标与硬目标所对应的交叉熵的加权平均(表示为KD loss与CE loss),其中软目标交叉熵的加权系数越大,表明迁移诱导越依赖教师网络的贡献,这对训练初期阶段是很有必要的,有助于让学生网络更轻松的鉴别简单样本,但训练后期需要适当减小软目标的比重,让真实标注帮助鉴别困难样本。另外,教师网络的预测精度通常要优于学生网络,而模型容量则无具体限制,且教师网络推理精度越高,越有利于学生网络的学习。
教师网络与学生网络也可以联合训练,此时教师网络的暗知识及学习方式都会影响学生网络的学习,具体如下(式中三项分别为教师网络Softmax输出的交叉熵loss、学生网络Softmax输出的交叉熵loss、以及教师网络数值输出与学生网络Softmax输出的交叉熵loss)
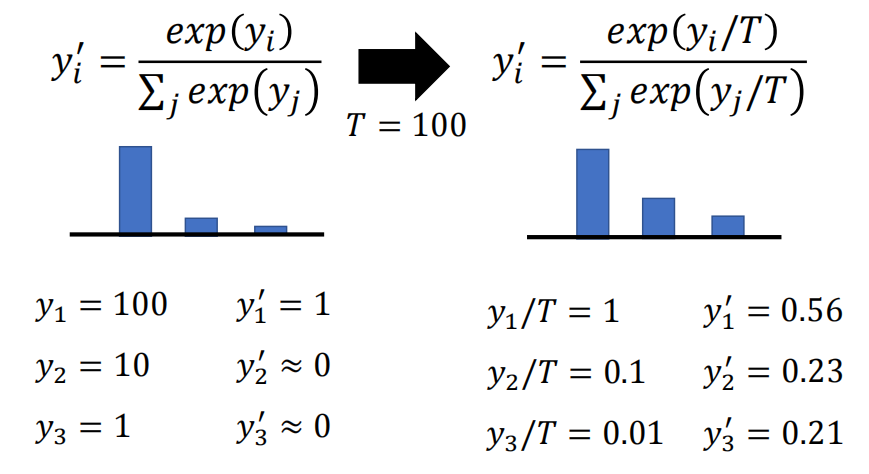
图3 温度函数的作用
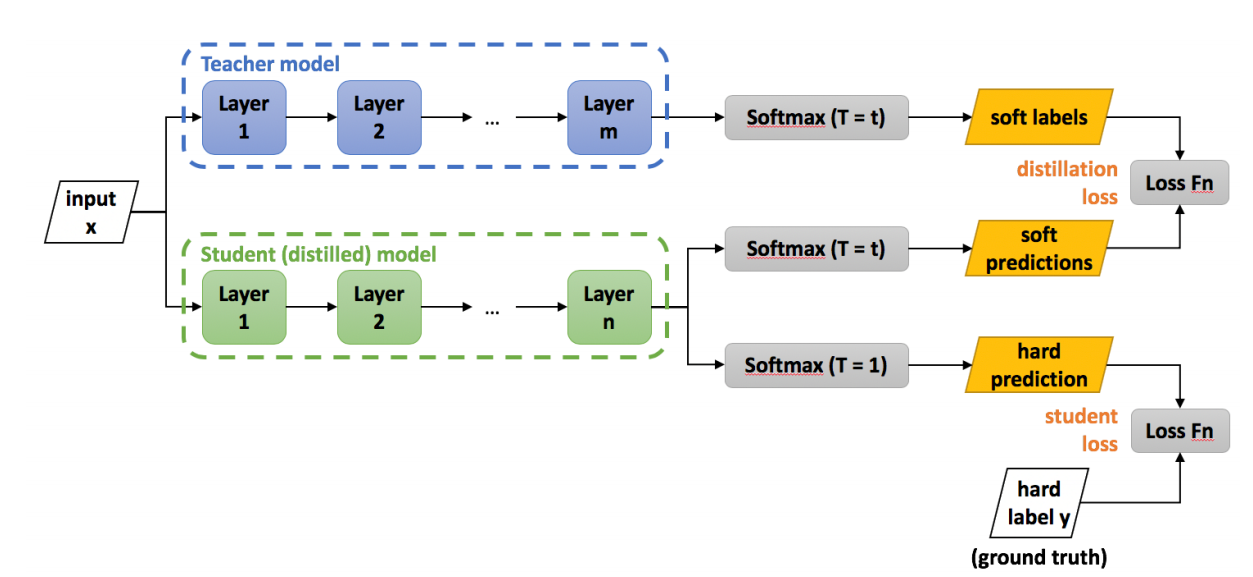
图4 损失函数的计算步骤
在分类网络中知识蒸馏的 Loss 计算
上部分教师网络,它进行预测的时候, softmax要进行升温,升温后的预测结果我们称为软标签(soft label)
学生网络一个分支softmax的时候也进行升温,在预测的时候得到软预测(soft predictions),然后对soft label和soft predictions 计算损失函数,称为distillation loss ,让学生网络的预测结果接近教师网络;
学生网络的另一个分支,在softmax的时候不进行升温T =1,此时预测的结果叫做hard prediction 。然后和hard label也就是 ground truth直接计算损失,称为student loss 。
总的损失结合了distilation loss和student loss ,并通过系数a加权,来平衡这两种Loss ,比如与教师网络通过MSE损失,学生网络与ground truth通过cross entropy损失, Loss的公式可表示如下:
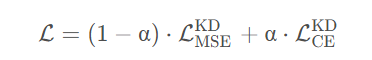
四、知识蒸馏代码
一个简单的基于pytorch实现的知识蒸馏代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt# 超参数设置
batch_size = 64
epochs_teacher = 5 # 教师模型训练轮数
epochs_student = 5 # 学生模型训练轮数
temperature = 5 # 温度参数(关键超参数)
alpha = 0.7 # 蒸馏损失权重
lr = 0.001 # 学习率# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 数据加载
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])train_dataset = datasets.MNIST('data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST('data', train=False, transform=transform)train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 教师模型定义
class TeacherModel(nn.Module):def __init__(self):super().__init__()self.fc1 = nn.Linear(784, 512)self.fc2 = nn.Linear(512, 256)self.fc3 = nn.Linear(256, 10)self.dropout = nn.Dropout(0.5)def forward(self, x):x = x.view(-1, 784)x = torch.relu(self.fc1(x))x = self.dropout(x)x = torch.relu(self.fc2(x))x = self.dropout(x)return self.fc3(x)# 学生模型定义(更简单结构)
class StudentModel(nn.Module):def __init__(self):super().__init__()self.fc1 = nn.Linear(784, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = x.view(-1, 784)x = torch.relu(self.fc1(x))return self.fc2(x)# 训练教师模型
def train_teacher():teacher = TeacherModel().to(device)criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(teacher.parameters(), lr=lr)for epoch in range(epochs_teacher):teacher.train()for data, target in train_loader:data, target = data.to(device), target.to(device)optimizer.zero_grad()output = teacher(data)loss = criterion(output, target)loss.backward()optimizer.step()# 验证teacher.eval()correct = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = teacher(data)pred = output.argmax(dim=1, keepdim=True)correct += pred.eq(target.view_as(pred)).sum().item()print(f"Teacher Epoch {epoch + 1}, Accuracy: {correct / len(test_loader.dataset):.4f}")return teacher# 知识蒸馏训练
def distill(teacher, student):student = student.to(device)teacher.eval() # 固定教师模型参数# 定义两个损失函数criterion_ce = nn.CrossEntropyLoss()criterion_kl = nn.KLDivLoss(reduction="batchmean")optimizer = optim.Adam(student.parameters(), lr=lr)for epoch in range(epochs_student):student.train()for data, target in train_loader:data, target = data.to(device), target.to(device)optimizer.zero_grad()# 获取教师和学生的输出with torch.no_grad():teacher_logits = teacher(data)student_logits = student(data)# 计算学生损失(常规交叉熵损失)student_loss = criterion_ce(student_logits, target)# 计算蒸馏损失(KL散度损失)soft_targets = nn.functional.softmax(teacher_logits / temperature, dim=1)soft_output = nn.functional.log_softmax(student_logits / temperature, dim=1)distillation_loss = criterion_kl(soft_output, soft_targets) * (temperature ** 2)# 组合损失total_loss = alpha * student_loss + (1 - alpha) * distillation_losstotal_loss.backward()optimizer.step()# 验证student.eval()correct = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = student(data)pred = output.argmax(dim=1, keepdim=True)correct += pred.eq(target.view_as(pred)).sum().item()print(f"Distillation Epoch {epoch + 1}, Accuracy: {correct / len(test_loader.dataset):.4f}")return student# 普通训练学生模型(作为对比)
def train_student():student = StudentModel().to(device)criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(student.parameters(), lr=lr)for epoch in range(epochs_student):student.train()for data, target in train_loader:data, target = data.to(device), target.to(device)optimizer.zero_grad()output = student(data)loss = criterion(output, target)loss.backward()optimizer.step()# 验证student.eval()correct = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = student(data)pred = output.argmax(dim=1, keepdim=True)correct += pred.eq(target.view_as(pred)).sum().item()print(f"Normal Student Epoch {epoch + 1}, Accuracy: {correct / len(test_loader.dataset):.4f}")return student# 主程序
if __name__ == "__main__":# 训练教师模型print("Training Teacher Model...")teacher = train_teacher()# 普通训练学生模型print("\nTraining Student Model Normally...")normal_student = train_student()# 知识蒸馏训练学生模型print("\nDistilling Knowledge to Student Model...")distilled_student = distill(teacher, StudentModel())总结
本文仅仅简单介绍了知识蒸馏的相关知识,讲解不到的地方请指正!
相关文章:
【深度学习之四】知识蒸馏综述提炼
知识蒸馏综述提炼 目录 知识蒸馏综述提炼 前言 参考文献 一、什么是知识蒸馏? 二、为什么要知识蒸馏? 三、一点点理论 四、知识蒸馏代码 总结 前言 知识蒸馏作为一种新兴的、通用的模型压缩和迁移学习架构,在最近几年展现出蓬勃的活力…...

redis解决常见的秒杀问题
title: redis解决常见的秒杀问题 date: 2025-03-07 14:24:13 tags: redis categories: redis的应用 秒杀问题 每个店铺都可以发布优惠券,保存到 tb_voucher 表中;当用户抢购时,生成订单并保存到 tb_voucher_order 表中。 订单表如果使用数据…...
TypeScript中文文档
最近一直想学习TypeScript,一直找不到一个全面的完整的TypeScript 中文文档。在网直上找了了久,终于找到一个全面的中文的typescript中文学习站,有学习ts的朋友可以年。 文档地址:https://typescript.uihtm.com 该TypeScript 官…...

Function Calling
在介绍Function Calling之前我们先了解一个概念,接口。 接口 两种常见接口: 人机交互接口,User Interface,简称 UI应用程序编程接口,Application Programming Interface,简称 API接口能「通」的关键,是两边都要遵守约定。 人要按照 UI 的设计来操作。UI 的设计要符合人…...

【搭建Node-RED + MQTT Broker实现AI大模型交互】
搭建Node-RED MQTT Broker实现AI大模型交互 搭建Node-RED MQTT Broker实现AI大模型交互一、系统架构二、环境准备与安装1. 安装Node.js2. 安装Mosquitto MQTT Broker3. 配置Mosquitto4. 安装Node-RED5. 配置Node-RED监听所有网络接口6. 启动Node-RED 三、Node-RED流程配置1. …...

高可靠低纹波国产4644电源芯片在工业设备的应用
摘要 随着工业自动化和智能化的飞速发展,工业设备对于电源芯片的性能和可靠性提出了前所未有的严格要求。电源芯片作为工业设备的核心供电组件,其性能直接影响到整个设备的运行效率和稳定性。本文以国科安芯的ASP4644四通道降压稳压器为例,通…...

面试--HTML
1.src和href的区别 总结来说: <font style"color:rgb(238, 39, 70);background-color:rgb(249, 241, 219);">src</font>用于替换当前元素,指向的资源会嵌入到文档中,例如脚本、图像、框架等。<font style"co…...
SparkSQL操作Mysql-准备mysql环境
我们计划在hadoop001这台设备上安装mysql服务器,(当然也可以重新使用一台全新的虚拟机)。 以下是具体步骤: 使用finalshell连接hadoop001.查看是否已安装MySQL。命令是: rpm -qa|grep mariadb若已安装,需要先做卸载MyS…...

Linux常用方法
1、查看日志后100行 tail -f -n 100 catalina.out 2、ps命令 ps命令用来列出系统中当前运行的那些进程。ps命令列出的是当前那些进程的快照 ps -ef 显示所有进程信息,连同命令行,ps 与grep 常用组合用法,查找特定进程 ps aux列出目前所有的…...

[c++项目]云备份项目测试
1. 测试概述 测试时间:2024年3月 测试环境:macOS 23.4.0 测试工具:VSCode, CMake, GTest 2. 功能测试 2.1 文件备份功能 测试项预期结果实际结果状态单文件备份成功上传并保存成功✅多文件备份批量上传成功成功✅大文件备份分片上传成功…...
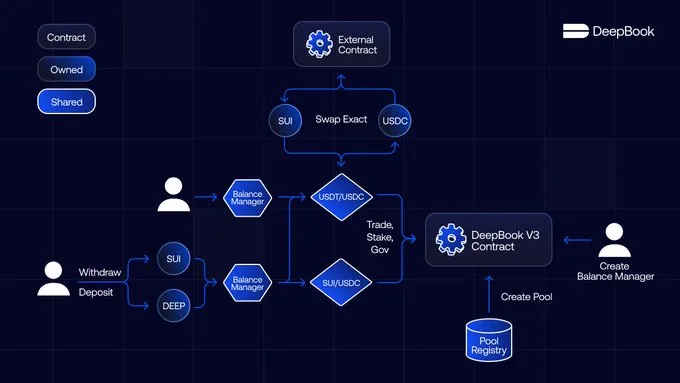
DeepBook 与 CEX 的不同
如果你曾经使用过像币安或 Coinbase 这样的中心化交易所(CEX),你可能已经熟悉了订单簿系统 — — 这是一种撮合买卖双方进行交易的机制。而 DeepBook 是 Sui 上首个完全链上的中央限价订单簿。 那么,是什么让 DeepBook 如此独特&…...

Scrapy框架下地图爬虫的进度监控与优化策略
1. 引言 在互联网数据采集领域,地图数据爬取是一项常见但具有挑战性的任务。由于地图数据通常具有复杂的结构(如POI点、路径信息、动态加载等),使用传统的爬虫技术可能会遇到效率低下、反爬策略限制、任务进度难以监控等问题。 …...

城市扫街人文街头纪实胶片电影感Lr调色预设,DNG/手机适配滤镜!
调色详情 城市扫街人文街头纪实胶片电影感 Lr 调色是通过 Lightroom(Lr)软件,对城市街头抓拍的人文纪实照片进行后期调色处理。旨在赋予照片如同胶片拍摄的质感以及电影般浓厚的叙事氛围,不放过每一个日常又珍贵的瞬间,…...

嵌入式学习笔记 D21:双向链表的基本操作
双向链表的定义与创建双向链表的插入双向链表的查找双向链表的修改双向链表的删除双向链表的逆序MakeFile工具使用 一、双向链表的定义与创建 1.双向链表的定义: 双向链表是在单链表的每个结点中,再设置一个指向其前一个结点的指针域。 struct DOUNode…...
让AI帮我写一个word转pdf的工具
需求分析 前几天,一个美女找我: 阿瑞啊,能不能帮我写个工具,我想把word文件转为pdf格式的 我说:“你直接网上搜啊,网上工具多了去了” 美女说: 网上的要么是需要登录注册会员的,要…...

OrangePi Zero 3学习笔记(Android篇)10 - SPI和从设备
目录 1. 配置内核 2. 修改设备数 3. 修改权限 4. 验证 Zero 3的板子有2个SPI Master接口,其中SPI0接的是板载16MB大小的SPI Nor Flash,SPI1则是导出到26pin的接口上。 spi和i2c有点不同,spi是直接生成spi虚拟设备,所以在dev里…...
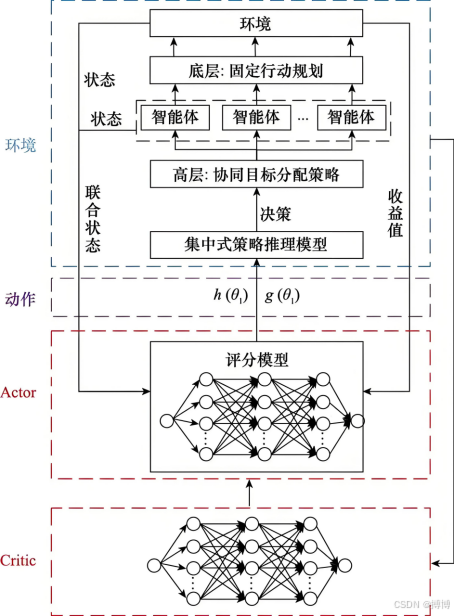
基于策略的强化学习方法之近端策略优化(PPO)深度解析
PPO(Proximal Policy Optimization)是一种基于策略梯度的强化学习算法,旨在通过限制策略更新幅度来提升训练稳定性。传统策略梯度方法(如REINFORCE)直接优化策略参数,但易因更新步长过大导致性能震荡或崩溃…...

跨境电商定价革命:亚马逊“逆向提价“策略背后的价值重构逻辑
导言:打破价格魔咒的销量奇迹 2024年Q3亚马逊平台上演商业悖论:在TOP5000卖家中,12%实施5%-15%温和提价的商户,41%实现单量30.4%的季度增长。这一现象颠覆"低价即流量"的电商铁律,揭开新消费时代"价值定…...
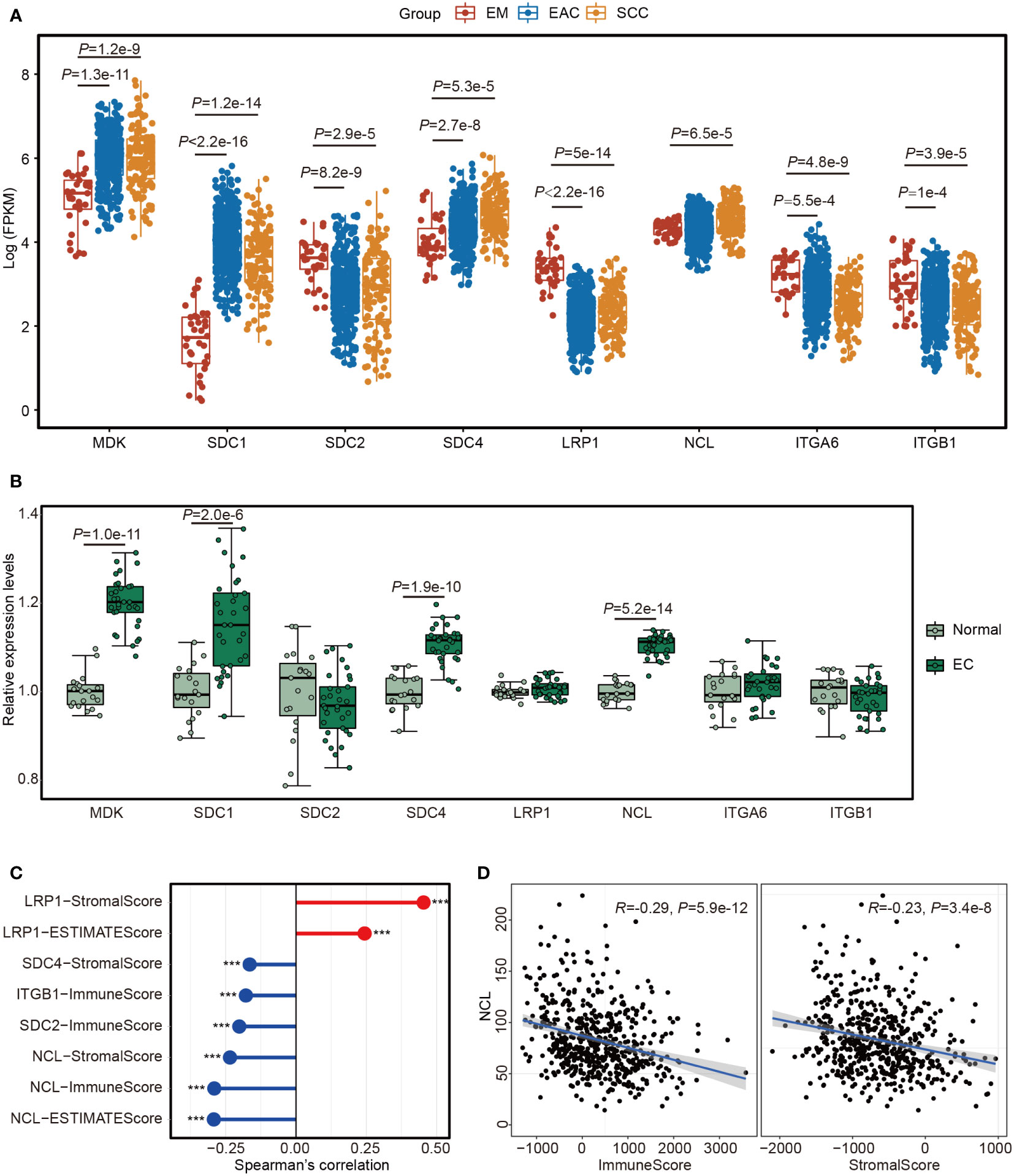
文章复现|(1)整合scRNA-seq 和空间转录组学揭示了子宫内膜癌中 MDK-NCL 依赖性免疫抑制环境
https://www.frontiersin.org/journals/immunology/articles/10.3389/fimmu.2023.1145300/full 目标:肿瘤微环境(TME)在子宫内膜癌(EC)的进展中起着重要作用。我们旨在评估EC的TME中的细胞群体。 方法:我们从GEO下载了EC的单细胞RNA测序(scRNA-seq)和空…...

HTML-3.4 表单form
本系列可作为前端学习系列的笔记,代码的运行环境是在HBuilder中,小编会将代码复制下来,大家复制下来就可以练习了,方便大家学习。 系列文章目录 HTML-1.1 文本字体样式-字体设置、分割线、段落标签、段内回车以及特殊符号 HTML…...
)
阿克曼-幻宇机器人系列教程3- 机器人交互实践(Message)
上一篇文章介绍了如何通过topic操作命令实现与机器人的交互,本篇我们介绍如何通过Message(即topic的下一级)实现与机器人的交互。 和topic一样,首先在一个终端通过ssh命令登录机器人、启动机器人,然后打开另外一个终端…...
【MySQL】服务器配置与管理(相关日志)
🔥个人主页: 中草药 🔥专栏:【MySQL】探秘:数据库世界的瑞士军刀 一、系统变量和选项 当通过mysqld启动数据库服务器时,可以通过选项文件或命令行中提供选项。一般,为了确保服务器在每次运行时…...
【问题】Watt加速github访问速度:好用[特殊字符]
前言 GitHub 是全球知名的代码托管平台,主要用于软件开发,提供 Git 仓库托管、协作工具等功能,经常要用到,但是国内用户常因网络问题难以稳定访问 。 Watt Toolkit(原名 Steam)是由江苏蒸汽凡星科技有限公…...
vue3:十三、分类管理-表格--行内按钮---行删除、批量删除实现功能实现
一、实现效果 增加行内按钮的样式效果,并且可以根绝父组件决定是否显示 增加行内删除功能、批量删除功能 二、增加行内按钮样式 1、增加视图层按钮 由于多个表格都含有按钮功能,所以这里直接在子组件中加入插槽按钮 首先增加表格行<el-table-column></el-table-…...

Web3.0:互联网的去中心化未来
随着互联网技术的不断发展,我们正站在一个新时代的门槛上——Web3.0时代。Web3.0不仅仅是一个技术升级,它更是一种全新的互联网理念,旨在通过去中心化技术重塑网络世界。本文将深入探讨Web3.0的核心概念、技术基础、应用场景以及它对未来的深…...
浏览器设置代理ip后不能上网?浏览器如何改ip地址教程
使用代理IP已成为许多用户保护隐私、绕过地域限制或进行网络测试的常见做法。当浏览器设置代理IP后无法上网时,通常是由于代理配置问题或代理服务器本身不可用。以下是排查和解决问题的详细步骤,以及更改浏览器IP的方法: 一、代理设置后无法上…...

Java应用OOM排查:面试通关“三部曲”心法
开篇点题:OOM——Java应用的“内存爆仓”警报 OOM (OutOfMemoryError) 是啥病?想象一下,你的Java应用程序是一个大仓库,内存就是仓库的存储空间。如果货物(程序运行时创建的对象)越来越多,超出了…...

R语言的专业网站top5推荐
李升伟 以下是学习R语言的五个顶级专业网站推荐,涵盖教程、社区、资源库和最新动态: 1.R项目官网 (r-project.org) R语言的官方网站,提供软件下载、文档、手册和常见问题解答。特别适合初学者和高级用户,是获取R语言核心资源的…...
:设计原则(二):DIP、ISP、LoD)
设计模式系列(03):设计原则(二):DIP、ISP、LoD
本文为设计模式系列第3篇,聚焦依赖倒置、接口隔离、迪米特法则三大设计原则,系统梳理定义、实际业务场景、优缺点、最佳实践与常见误区,适合系统学习与团队协作。 目录 1. 引言2. 依赖倒置原则(DIP)3. 接口隔离原则(ISP)4. 迪米特法则(LoD)5. 常见误区与反例6. 最佳实…...

Java Socket编程完全指南:从基础到实战应用
Socket编程是构建网络应用的基石,Java通过java.net包提供了强大的Socket API。本文将深入解析Java Socket类的核心用法,涵盖TCP/UDP协议实现、多线程通信及性能优化技巧,助您快速掌握网络编程精髓。 一、Socket编程核心概念 1.1 网络通信模型…...