零基础入门Hadoop:IntelliJ IDEA远程连接服务器中Hadoop运行WordCount
今天我们来聊一聊大数据,作为一个Hadoop的新手,我也并不敢深入探讨复杂的底层原理。因此,这篇文章的重点更多是从实际操作和入门实践的角度出发,带领大家一起了解大数据应用的基本过程。我们将通过一个经典的案例——WordCounter,来帮助大家入门。简单来说,这个案例的目标是从一个文本文件中读取每一行,统计其中单词出现的频率,最后生成一个统计结果。表面上看,这个任务似乎不难,毕竟我们在本地用Java程序就可以很轻松地实现。
然而,实际情况并非如此简单。虽然我们能够在一台计算机上通过简单的Java程序完成类似的任务,但在大数据的场景下,数据量远远超过一台机器能够处理的能力。此时,单纯依赖一台机器的计算资源就无法应对庞大的数据量,这正是分布式计算和存储技术的重要性所在。分布式计算将任务拆分为多个子任务,并利用多台机器协同工作,从而实现高效处理海量数据,而分布式存储则可以将数据切分并存储在多个节点上,解决数据存储和访问的瓶颈。

因此,通过今天的介绍,我希望能够带大家从一个简单的例子出发,逐步理解大数据处理中如何借助Hadoop这样的分布式框架,来高效地进行数据计算和存储。
环境准备
Hadoop安装
这里我不太喜欢在本地 Windows 系统上进行安装,因为本地环境中通常会积累很多不必要的文件和配置,可能会影响系统的干净与流畅度。因此,演示的重点将放在以 Linux 服务器为主的环境上,通过 Docker 实现快速部署。
我们将利用宝塔面板进行一键式安装,只需通过简单的操作即可完成整个部署过程,免去手动敲命令的麻烦,让安装变得更加便捷和快速。
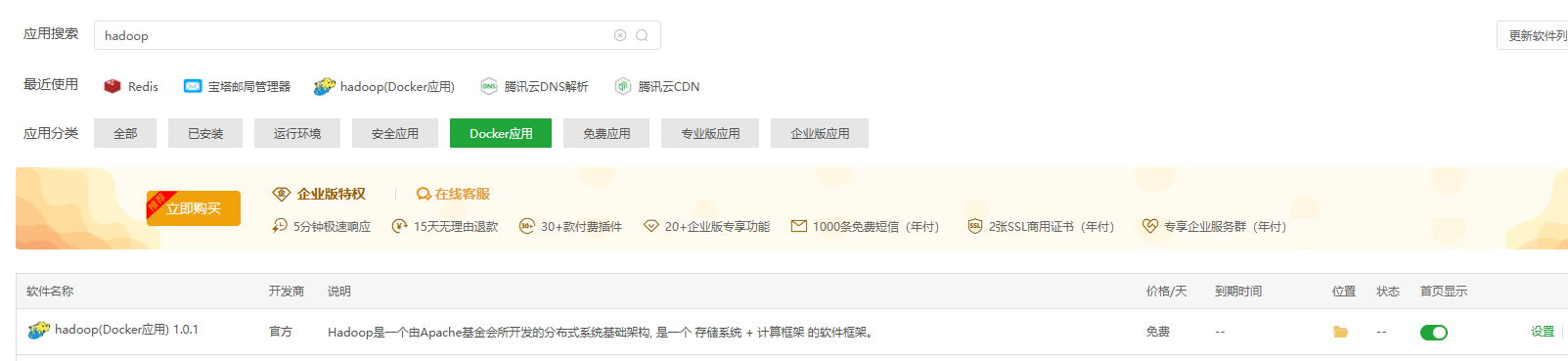
开放端口
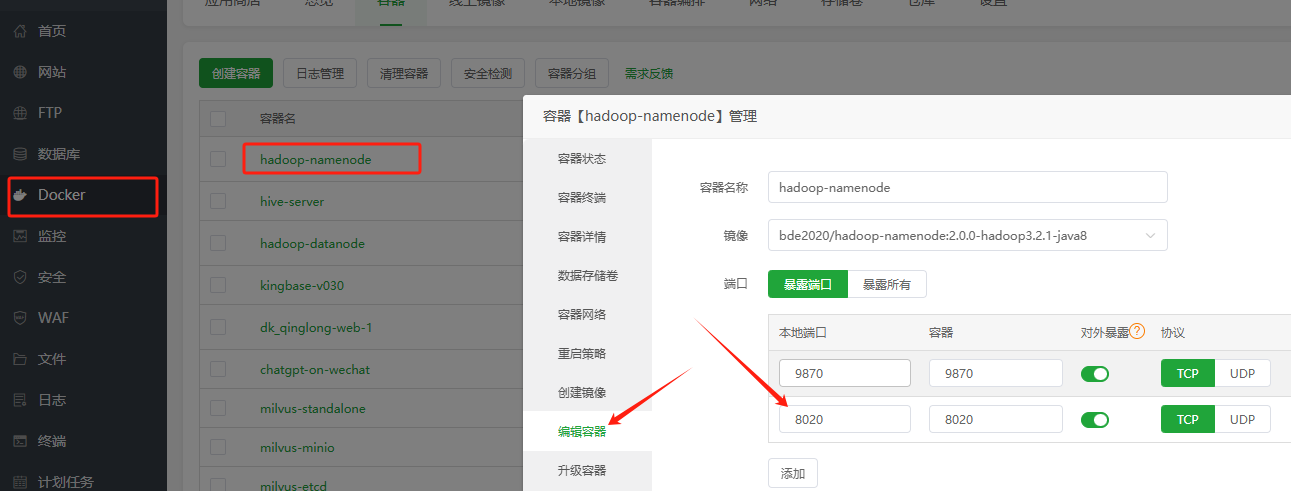
这里,系统本身已经对外开放了部分端口,例如 9870 用于访问 Web UI 界面,但有一个重要的端口 8020 并没有开放。这个端口是我们需要通过本地的 IntelliJ IDEA 进行连接和使用的,因此必须手动进行额外的配置,确保该端口能够正常访问。具体操作可以参考以下示意图进行设置,以便顺利完成连接。
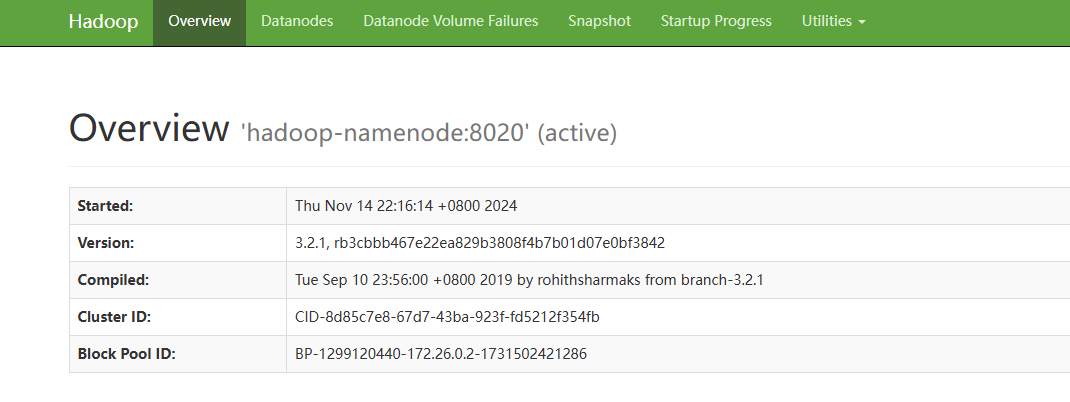
如果你已经成功启动并完成配置,那么此时你应该能够顺利访问并查看 Web 页面。如图所示:
项目开发
创建项目
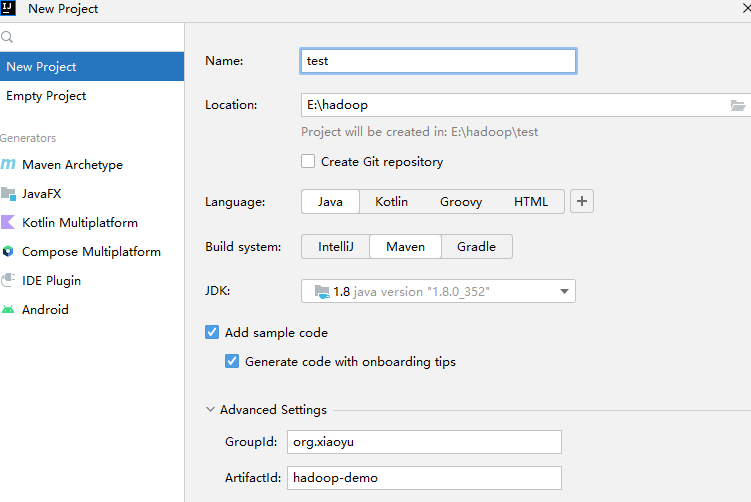
我们可以直接创建一个新的项目,并根据项目需求手动配置相关的项目信息,例如 groupId、artifactId、version 等基本配置。为了确保兼容性和稳定性,我们选择使用 JDK 8 作为开发环境版本。
首先,让我们先来查看一下项目的文件目录结构,以便对整个项目的组织形式和文件分布有一个清晰的了解。
tree /f 可以直接生成
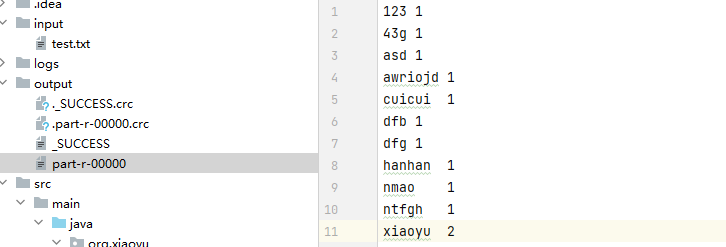
├─input
│ test.txt
├─output
├─src
│ ├─main
│ │ ├─java
│ │ │ └─org
│ │ │ └─xiaoyu
│ │ │ InputCountMapper.java
│ │ │ Main.java
│ │ │ WordsCounterReducer.java
│ │ │
│ │ └─resources
│ │ core-site.xml
│ │ log4j.xml
接下来,我们将实现大数据中的经典示例——“Hello, World!” 程序,也就是我们通常所说的 WordCounter。为了实现这个功能,首先,我们需要编写 MapReduce 程序。在 Map 阶段,主要的任务是将输入的文件进行解析,将数据分解并转化成有规律的格式(例如,单词和其出现次数的键值对)。接着,在 Reduce 阶段,我们会对 Map 阶段输出的数据进行汇总和统计,最终得到我们想要的统计结果,比如每个单词的出现次数。
此外,我们还需要编写一个启动类——Job 类,用来配置和启动 MapReduce 任务,确保 Map 和 Reduce 阶段的流程能够顺利进行。通过这整套流程的实现,我们就完成了一个基本的 WordCounter 程序,从而理解了 MapReduce 的核心思想与应用。
pom依赖
这里没有什么好说的,直接添加相关依赖即可:
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.2.0</version>
</dependency>
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.2.0</version>
</dependency>
<dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version>
</dependency>
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.2.0</version>
</dependency><!--mapreduce-->
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>3.2.0</version>
</dependency>
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-common</artifactId><version>3.2.0</version>
</dependency>
core-site.xml
这里配置的我们远程Hadoop连接配置信息:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>fs.defaultFS</name><value>hdfs://你自己的ip:8020</value></property>
</configuration>
test.txt
我们此次主要以演示为主,因此并不需要处理非常大的文件。为了简化演示过程,我在此仅提供了一部分数据。
xiaoyu xiaoyu
cuicui ntfgh
hanhan dfb
yy yy
asd dfg
123 43g
nmao awriojd
InputCountMapper
先来构建一下InputCountMapper类。代码如下:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class InputCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString().trim();for (int i = 0; i < line.split(" ").length; i++) {word.set(line.split(" ")[i]);context.write(word, one);}}
}
在Hadoop的MapReduce编程中,写法其实是相对简单的,关键在于正确理解和定义泛型。你需要集成一个Mapper类,并根据任务的需求为其定义四个泛型类型。在这个过程中,每两个泛型组成一对,形成K-V(键值对)结构。以上面的例子来说,输入数据的K-V类型是LongWritable-Text,输出数据的K-V类型定义为Text-IntWritable。这里的LongWritable、Text、IntWritable等都是Hadoop自定义的数据类型,它们代表了不同的数据格式和类型。除了String在Hadoop中被替换成Text,其他的数据类型通常是在后面加上Writable后缀。
接下来,对于Mapper类的输出格式,我们已经在代码中定义了格式类型。然而,需要注意的是,我们重写的map方法并没有直接返回值。相反,Mapper类会通过Context上下文对象来传递最终结果。
因此,我们只需要确保在map方法中将格式化后的数据存入Context,然后交给Reducer处理即可。
WordsCounterReducer
这一步的代码如下:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WordsCounterReducer extends Reducer<Text, IntWritable, Text, IntWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}context.write(key, new IntWritable(sum));}
}
在Hadoop的MapReduce编程中,Reduce阶段的写法也遵循固定模式。首先,我们需要集成Reducer类,并定义好四个泛型参数,类似于Mapper阶段。这四个泛型包括输入键值对类型、输入值类型、输出键值对类型、以及输出值类型。
在Reduce阶段,输入数据的格式会有所变化,尤其是在值的部分,通常会变成Iterable类型的集合。这个变化的原因是,Mapper阶段处理时,我们通常将每个单词的出现次数(或其他统计信息)作为1存入Context。比如,假设在Mapper阶段遇到单词“xiaoyu”时,我们每次都会输出一个(xiaoyu, 1)的键值对。结果,如果单词“xiaoyu”在输入数据中出现多次,Context会把这些键值对合并成一个Iterable集合,像是(xiaoyu, [1, 1]),表示该单词出现了两次。
在这个例子中,Reduce阶段的操作非常简单,只需要对每个Iterable集合中的值进行累加即可。比如,对于xiaoyu的输入集合(xiaoyu, [1, 1]),我们只需要将其所有的1值累加起来,得出最终的结果2。
Main
最后我们需要生成一个Job,代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class Main {static {try {System.load("E:\\hadoop.dll");//建议采用绝对地址,bin目录下的hadoop.dll文件路径} catch (UnsatisfiedLinkError e) {System.err.println("Native code library failed to load.\n" + e);System.exit(1);}}public static void main(String[] args) throws Exception{Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "wordCounter"); job.setJarByClass(Main.class);job.setMapperClass(InputCountMapper.class);job.setReducerClass(WordsCounterReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path("file:///E:/hadoop/test/input"));FileOutputFormat.setOutputPath(job, new Path("file:///E:/hadoop/test/output"));System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
好的,这里所展示的是一种完全固定的写法,但在实际操作过程中,需要特别注意的是,我们必须通过 Windows 环境来连接远程的 Hadoop 集群进行相关操作。这个过程中会遇到很多潜在的问题和坑,尤其是在配置、连接、权限等方面。
接下来,我将逐一解析并解决这些常见的难题,希望能为大家提供一些实际的参考和指导,帮助大家更顺利地完成操作。
疑难解答
目录不存在
如果你并不是以本地 Windows 目录为主,而是以远程服务器上的目录为主进行操作,那么你可能会采用类似以下的写法:
FileInputFormat.addInputPath(job, new Path("/input"));
FileOutputFormat.setOutputPath(job, new Path("/output"));
那么,在这种情况下,我们必须先创建与操作相关的输入目录(input),但需要特别注意的是,切勿提前创建输出目录(output),因为 Hadoop 在运行作业时会自动创建该目录,如果该目录已存在,会导致作业执行失败。因此,只需要进入 Docker 环境并直接执行以下命令即可顺利开始操作。
hdfs dfs -mkdir /input
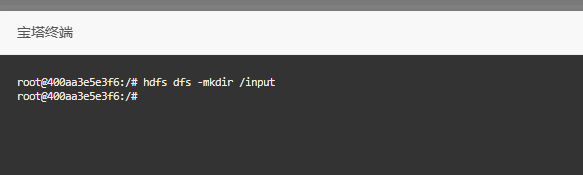
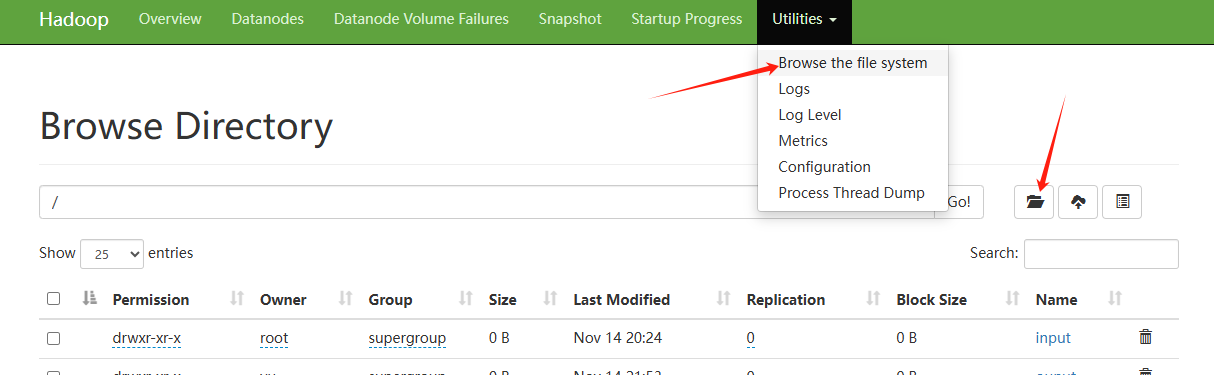
当然,还有一种更简单的方式,就是直接通过图形界面在页面上创建相关目录或资源。具体操作可以参考以下步骤,如图所示:
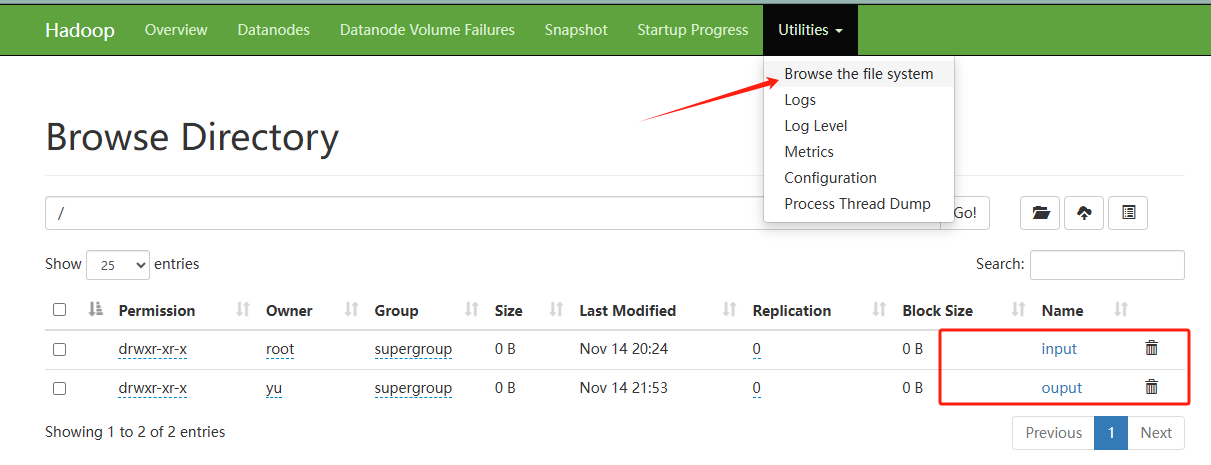
Permission denied
接下来,当你在运行 Job 任务时,系统会在最后一步尝试创建输出目录(output)。然而,由于当前用户并没有足够的权限来进行此操作,因此会出现类似于以下的权限错误提示:Permission denied: user=yu, access=WRITE, inode="/":root:supergroup:drwxr-xr-x。该错误意味着当前用户(yu)试图在根目录下创建目录或文件,但由于该目录的权限设置为只有管理员(root)才能写入,普通用户无法进行写操作,从而导致作业执行失败。
所以你仍需要进入docker容器,执行以下命令:
hadoop fs -chmod 777 /
这样基本上就可以顺利完成任务了。接下来,你可以直接点击进入查看 output 目录下的文件内容。不过需要注意的是,由于我们没有配置具体的 IP 地址,因此在进行文件下载时,你需要手动将文件中的 IP 地址替换为你自己真实的 IP 地址,才能确保下载过程能够顺利进行并成功获取所需的文件。
报错:org.apache.hadoop.io.nativeio.NativeIO$Windows
这种问题通常是由于缺少 hadoop.dll 文件导致的。在 Windows 系统上运行 Hadoop 时,hadoop.dll 或者 winutils.exe 是必需的依赖文件,因为它们提供了 Hadoop 在 Windows 上所需的本地代码支持和执行环境。
为了确保顺利运行,你需要下载对应版本的 hadoop.dll 或者 winutils.exe 文件。已经为你准备好了多个 Hadoop 版本对应的这些文件,所有的文件都可以从以下链接下载:https://github.com/cdarlint/winutils
我们这里只下载一个hadoop.dll,为了不重启电脑,直接在代码里面写死:
static {try {System.load("E:\\hadoop.dll");//建议采用绝对地址,bin目录下的hadoop.dll文件路径} catch (UnsatisfiedLinkError e) {System.err.println("Native code library failed to load.\n" + e);System.exit(1);}
}
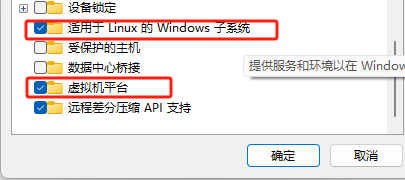
如果仍然有问题,那就配置下windows下的wsl子系统:
使用Windows + R快捷键打开「运行」对话框,执行OptionalFeatures打开「Windows 功能」。
勾选「适用于 Linux 的 Windows 子系统」和「虚拟机平台」,然后点击「确定」。
最终效果
终于成功跑出结果了!在这个过程中,输出的结果是按照默认的顺序进行排序的,当然这个排序方式是可以根据需要进行自定义的。如果你对如何控制排序有兴趣,实际上可以深入了解并调整排序机制。
总结
通过今天的分享,我们简单地了解了大数据处理中一个经典的应用——WordCounter,并通过Hadoop框架的实践,展示了如何使用MapReduce进行分布式计算。虽然表面上看,WordCounter是一个相对简单的程序,但它却揭示了大数据处理中的核心思想。
从安装配置到编写代码,我们一步步走过了Hadoop集群的搭建过程,希望通过这篇文章,你能对大数据应用开发,特别是Hadoop框架下的MapReduce编程,获得一些启发和帮助。大数据的世界庞大而复杂,但每一次小小的实践,都会带你离真正掌握这门技术更近一步。
我是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。同时也是一位腾讯云创作之星、阿里云专家博主、华为云云享专家、掘金优秀作者。
💡 我将不吝分享我在技术道路上的个人探索与经验,希望能为你的学习与成长带来一些启发与帮助。
🌟 欢迎关注努力的小雨!🌟
相关文章:
零基础入门Hadoop:IntelliJ IDEA远程连接服务器中Hadoop运行WordCount
今天我们来聊一聊大数据,作为一个Hadoop的新手,我也并不敢深入探讨复杂的底层原理。因此,这篇文章的重点更多是从实际操作和入门实践的角度出发,带领大家一起了解大数据应用的基本过程。我们将通过一个经典的案例——WordCounter&…...

HTML-3.3 表格布局(学校官网简易布局实例)
本系列可作为前端学习系列的笔记,代码的运行环境是在HBuilder中,小编会将代码复制下来,大家复制下来就可以练习了,方便大家学习。 系列文章目录 HTML-1.1 文本字体样式-字体设置、分割线、段落标签、段内回车以及特殊符号 HTML…...

Maven构建流程详解:如何正确管理微服务间的依赖关系-当依赖的模块更新后,我应该如何重新构建主项目
文章目录 一、前言二、Maven 常用命令一览三、典型场景说明四、正确的构建顺序正确做法是: 五、为什么不能只在 A 里执行 clean install?六、进阶推荐:使用多模块项目(Multi-module Project)七、总结 一、前言 在现代…...
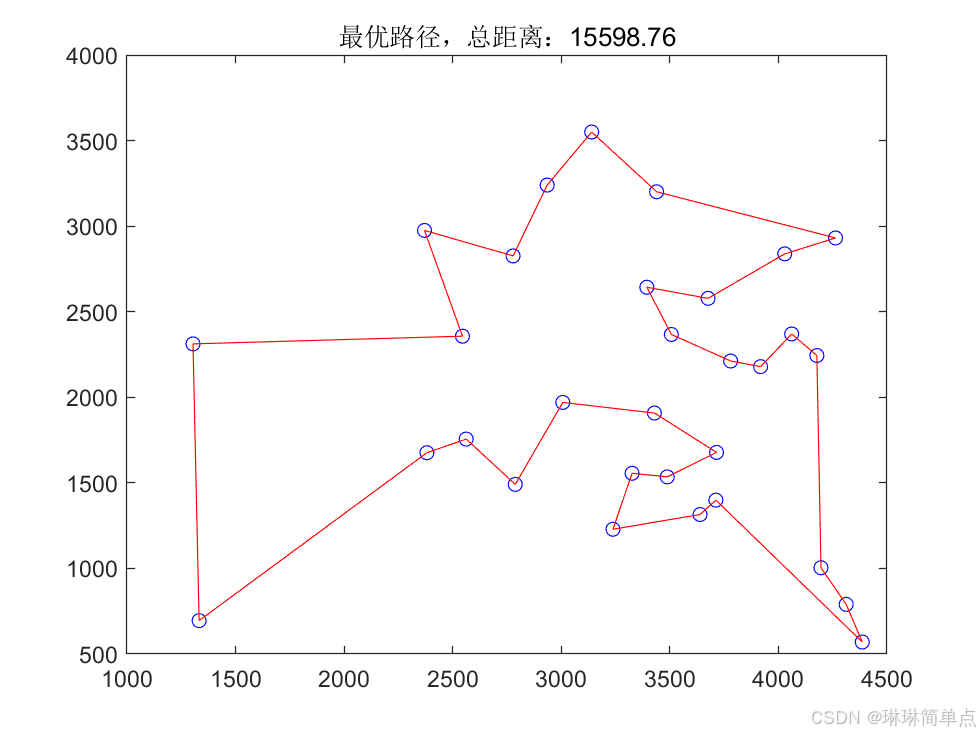
遗传算法求解旅行商问题分析
目录 一、问题分析 二、实现步骤 1)初始化种群 2)计算适应度 3)选择操作 4)交叉操作 5)变异操作 三、求解结果 四、总结 本文通过一个经典的旅行商问题,详细阐述在实际问题中如何运用遗传算法来进…...

【hot100-动态规划-300.最长递增子序列】
力扣300.最长递增子序列思路解析 本题要求在一个整数数组 nums 中,找到最长严格递增子序列的长度。子序列是指从原数组中派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。 动态规划思路 定义状态:…...

PostgreSQL malformed array literal异常
现象 在一个存储过程中编写如下代码(省略与本异常无关的代码): declare hbsn_arr varchar(240)[]; #bddm.hbsn 内容类似于{"chain0":["NULL"],"chain1":["FESDF09402342","NULL"],...} …...
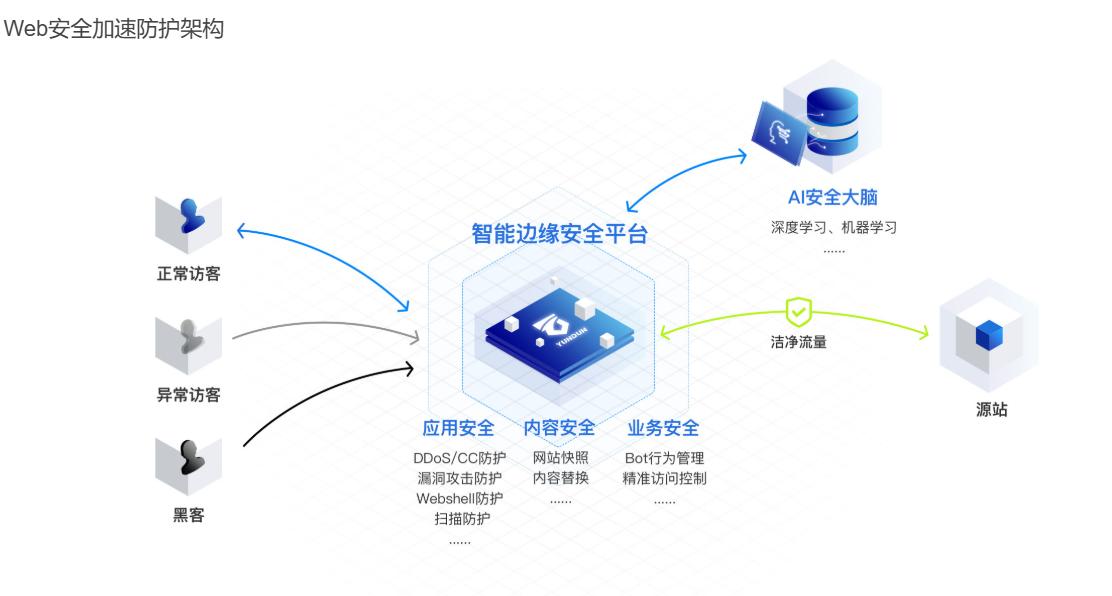
打造网络安全堡垒,企业如何应对DDoS、CC、XSS和ARP攻击
网站已经成为企业展示形象、开展业务和实现线上营销的重要平台。然而,随着网络攻击手段的不断升级,DDoS、CC、XSS、ARP等攻击频频出现,严重威胁到企业的信息安全和业务稳定。本文将详细阐述网站被攻击后应采取的应急措施及预防策略࿰…...

Oracle统计信息收集时的锁持有阶段
Oracle统计信息收集时的锁持有阶段 1 准备阶段(共享模式锁) 锁类型:对象级共享锁(S锁) 持续时间:通常1-5秒 主要操作: 验证对象存在性和权限检查统计信息首选项设置确定采样方法和并行度 监…...

深度解析物理机服务器故障修复时间:影响因素与优化策略
一、物理机故障修复的核心影响因素 物理机作为企业 IT 基础设施的核心载体,其故障修复效率直接关系到业务连续性。故障修复时间(MTTR)受多重因素交叉影响: 1. 故障类型的复杂性 硬件级故障: 简单故障:内存…...

印度全印度游戏联合会(AIGF)介绍与用途
本文为印度AIGF的介绍科普文,自去年开始,印度Rummy类游戏申请印度支付都需要拥有AIGF的会员及产品证书。 如需要rummy可以通过AIGF审核的源。码,或咨询AIGF的相关内容,可以联。系老妙。 全印度游戏联合会(All India G…...

可视化数据图表怎么做?如何实现三维数据可视化?
目录 一、三维数据可视化的要点 1. 明确数据可视化的目标 2. 筛选与整理数据 3. 选择合适的图表类型 4. 运用专业工具制作 5. 优化图表的展示效果 二、数据可视化图表怎么做? 1. 理解三维数据的特性 2. 数据处理与三维建模 3. 设置光照与材质效果 4. 添加…...

什么是模态内异质性,什么是模态间异质性?
首先,理解一下“模态”(Modality)和“异质性”(Heterogeneity)。 模态:你可以简单理解为不同种类或形式的信息。比如: 文字(文本)是一种模态。图片(图像&…...

视频分辨率增强与自动补帧
一、视频分辨率增强 1.传统分辨率增强方法 传统的视频分辨率增强方法主要基于插值技术。这些方法通过对低分辨率视频帧中已知像素点的分布规律和相邻像素之间的相关性进行分析,在两者之间插入新的像素点以达到增加视频分辨率的目的。例如,最近邻插值算…...

【SPIN】用Promela验证顺序程序:从断言到SPIN实战(SPIN学习系列--2)
你写了一段自认为“天衣无缝”的程序,但如何确保它真的没有bug?靠手动测试?可能漏掉边界情况;靠直觉?更不靠谱!这时候,Promela SPIN组合就像程序的“显微镜”——用形式化验证技术,…...

降本增效双突破:Profinet转Modbus TCP助力包布机产能与稳定性双提升
在现代工业自动化领域,ModbusTCP和Profinet是两种常见的通讯协议。它们在数据传输、设备控制等方面有着重要作用。然而,由于这两种协议的工作原理和应用环境存在差异,直接互联往往会出现兼容性问题。此时,就需要一种能够实现Profi…...
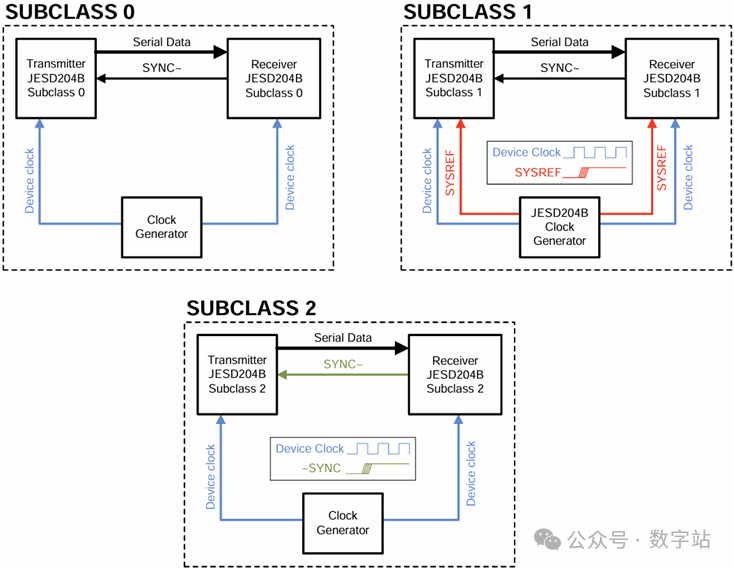
JESD204 ip核使用与例程分析(一)
JESD204 ip核使用与例程分析(一) JESD204理解JESD204 与JESD204 PHY成对使用原因JESD204B IP核JESD204B IP核特点JESD204B IP核配置第一页第二页第三页第四页JESD204 PHY IP核配置第一页第二页JESD204理解 JESD204B是一种针对ADC、DAC设计的传输接口协议。此协议包含四层, …...

V837s-LAN8720A网口phy芯片调试
目录 前言 一、LAN8720A 芯片概述 二、硬件连接 三、设备树配置 四、内核配置 五、网口调试 总结 前言 在嵌入式系统开发中,网络连接是至关重要的一部分。v837s开发板搭载了LAN8720A系列的网口PHY芯片,用于实现以太网连接。在开发过程中,对于网口的稳定性和性能的调试至…...
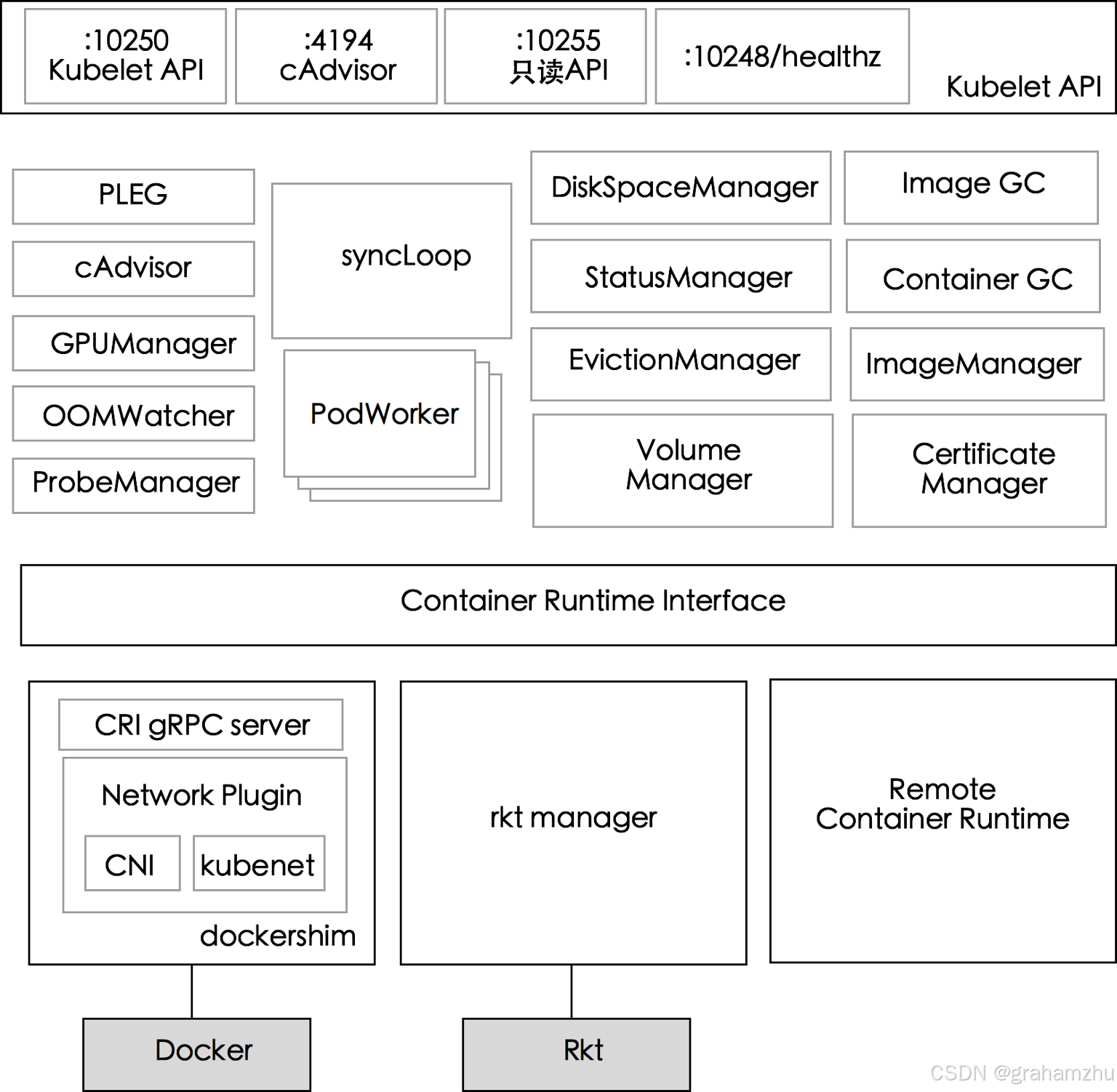
Kubernetes控制平面组件:Kubelet详解(一):API接口层介绍
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

Python60日基础学习打卡D26
算圆形面积 错误代码 import mathdef calculate_circle_area(r):try:S math.pi * r**2except r<0:print("半径不能为负数")return S 正确代码 import mathdef calculate_circle_area(radius):try:if radius < 0:return 0return math.pi * radius…...

牛客网NC22015:最大值和最小值
牛客网NC22015:最大值和最小值 题目描述 题目要求 输入:一行,包含三个整数 a, b, c (1≤a,b,c≤1000000) 输出:两行,第一行输出最大数,第二行输出最小数。 样例输入: …...

浪潮云边协同:赋能云计算变革的强力引擎
在数字化浪潮以排山倒海之势席卷全球的当下,第五届数字中国建设峰会在福州盛大开幕。这场以“创新驱动新变革,数字引领新格局”为主题的行业盛会,宛如一座汇聚智慧与力量的灯塔,吸引了国内外众多行业精英齐聚一堂,共同…...
)
Secs/Gem第七讲(基于secs4net项目的ChatGpt介绍)
好的,那我们现在进入: 第七讲:掉电重连后,为什么设备不再上报事件?——持久化与自动恢复的系统设计 关键词:掉电恢复、状态重建、初始化流程、SecsMessage 缓存机制、自动重连、事件再注册 本讲目标 你将理…...

ruskal 最小生成树算法
https://www.lanqiao.cn/problems/17138/learning/ 并查集ruskal 最小生成树算法 Kruskal 算法是一种用于在加权无向连通图中寻找最小生成树(MST)的经典算法。其核心思想是基于贪心策略,通过按边权从小到大排序并逐步选择边,确保…...
【GESP】C++三级模拟题 luogu-B3848 [GESP样题 三级] 逛商场
GESP三级模拟样题,一维数组相关,难度★★✮☆☆。 题目题解详见:https://www.coderli.com/gesp-3-luogu-b3848/ 【GESP】C三级模拟题 luogu-B3848 [GESP样题 三级] 逛商场 | OneCoderGESP三级模拟样题,一维数组相关,…...
:从客户访谈评分到市场规模估算——移情阶段的实战进阶)
精益数据分析(62/126):从客户访谈评分到市场规模估算——移情阶段的实战进阶
精益数据分析(62/126):从客户访谈评分到市场规模估算——移情阶段的实战进阶 在创业的移情阶段,科学评估用户需求与市场潜力是决定产品方向的关键。今天,我们结合Cloud9 IDE的实战经验与《精益数据分析》的方法论&…...

MAC-OS X 命令行设置IP、掩码、网关、DNS服务器地址
注意:以下命令必须在 $root 特权模式下运行,即:人们需要显著的提权后才能操作。 设置IP sudo networksetup -setmanual "Ethernet" 192.168.0.22 255.255.255.0 192.168.0.8 设置DNS sudo networksetup -setdnsservers "Eth…...

腾讯怎样基于DeepSeek搭建企业应用?怎样私有化部署满血版DS?直播:腾讯云X DeepSeek!
2025新春,DeepSeek横空出世,震撼全球! 通过算法优化,DeepSeek将训练与推理成本降低至国际同类模型的1/10,极大的降低了AI应用开发的门槛。 可以预见,2025年,是AI应用落地爆发之年! ✔…...
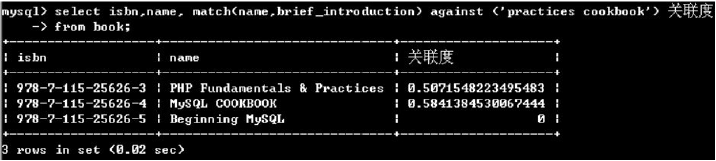
表记录的检索
1.select语句的语法格式 select 字段列表 from 表名 where 条件表达式 group by 分组字段 [having 条件表达式] order by 排序字段 [asc|desc];说明: from 子句用于指定检索的数据源 where子句用于指定记录的过滤条件 group by 子句用于对检索的数据进行分组 ha…...

QT——概述
<1>, Qt概述 Qt 是⼀个 跨平台的 C 图形⽤⼾界⾯应⽤程序框架 Qt ⽀持多种开发⼯具,其中⽐较常⽤的开发⼯具有:Qt Creator、Visual Studio、Eclipse. 一,Qt Creator 集成开发环境(IDE) Qt Creator 是⼀个轻量…...

9.1.领域驱动设计
目录 一、领域驱动设计核心哲学 战略设计与战术设计的分野 • 战略设计:限界上下文(Bounded Context)与上下文映射(Context Mapping) • 战术设计:实体、值对象、聚合根、领域服务的构建原则 统一语言&am…...