机器学习 --- 模型选择与调优
机器学习 — 模型选择与调优
文章目录
- 机器学习 --- 模型选择与调优
- 一,交叉验证
- 1.1 保留交叉验证HoldOut
- 1.2 K-折交叉验证(K-fold)
- 1.3 分层k-折交叉验证Stratified k-fold
- 二,超参数搜索
- 三,鸢尾花数据集示例
- 四,现实世界数据集示例
一,交叉验证
1.1 保留交叉验证HoldOut
HoldOut Cross-validation(Train-Test Split)
在这种交叉验证技术中,整个数据集被随机地划分为训练集和验证集。根据经验法则,整个数据集的近70%被用作训练集,其余30%被用作验证集。也就是我们最常使用的,直接划分数据集的方法。
优点:很简单很容易执行。
缺点1:不适用于不平衡的数据集。假设我们有一个不平衡的数据集,有0类和1类。假设80%的数据属于 “0 “类,其余20%的数据属于 “1 “类。这种情况下,训练集的大小为80%,测试数据的大小为数据集的20%。可能发生的情况是,所有80%的 “0 “类数据都在训练集中,而所有 “1 “类数据都在测试集中。因此,我们的模型将不能很好地概括我们的测试数据,因为它之前没有见过 “1 “类的数据。
缺点2:一大块数据被剥夺了训练模型的机会。
在小数据集的情况下,有一部分数据将被保留下来用于测试模型,这些数据可能具有重要的特征,而我们的模型可能会因为没有在这些数据上进行训练而错过。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_splitiris = load_iris()
X = iris.data
y = iris.target#保留交叉验证HoldOut
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=22)print(y_test)[0 2 1 2 1 1 1 2 1 0 2 1 2 2 0 2 1 1 2 1 0 2 0 1 2 0 2 2 2 2]
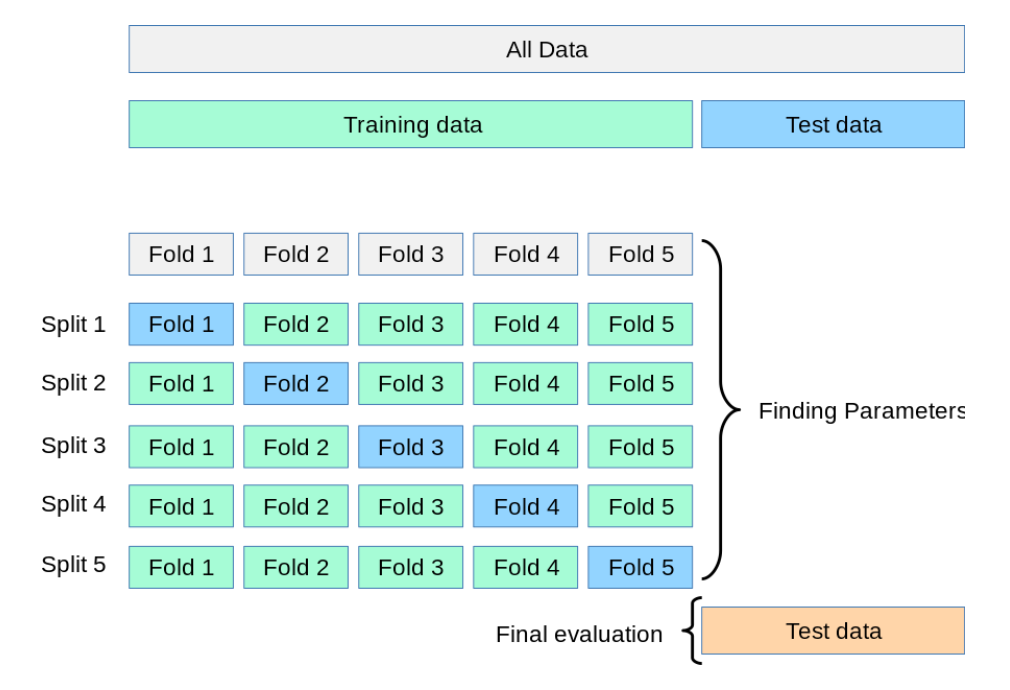
1.2 K-折交叉验证(K-fold)
K-fold Cross Validation,记为K-CV或K-fold)
K-Fold交叉验证技术中,整个数据集被划分为K个大小相同的部分。每个分区被称为 一个”Fold”。所以我们有K个部分,我们称之为K-Fold。一个Fold被用作验证集,其余的K-1个Fold被用作训练集。
该技术重复K次,直到每个Fold都被用作验证集,其余的作为训练集。
模型的最终准确度是通过取k个模型验证数据的平均准确度来计算的。
from sklearn.datasets import load_iris
from sklearn.model_selection import KFoldiris = load_iris()
x = iris.data
y = iris.target#k-Fold K折交叉验证
kf = KFold(n_splits=5)
index = kf.split(x,y)
for train_index,test_index in index:x_train,x_test = x[train_index],x[test_index]y_train,y_test = y[train_index],y[test_index]print(y_test)# print(next(index))
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
[2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
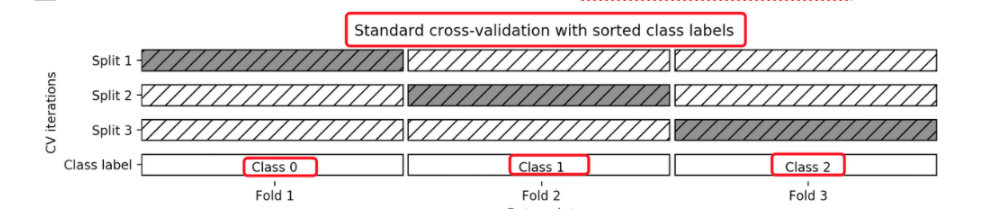
1.3 分层k-折交叉验证Stratified k-fold
Stratified k-fold cross validation,
K-折交叉验证的变种, 分层的意思是说在每一折中都保持着原始数据中各个类别的比例关系,比如说:原始数据有3类,比例为1:2:1,采用3折分层交叉验证,那么划分的3折中,每一折中的数据类别保持着1:2:1的比例,这样的验证结果更加可信。
from sklearn.datasets import load_iris
from sklearn.model_selection import StratifiedKFoldiris = load_iris()
x = iris.data
y = iris.target#k-Fold K折交叉验证
kf = StratifiedKFold(n_splits=5)
index = kf.split(x,y)
for train_index,test_index in index:x_train,x_test = x[train_index],x[test_index]y_train,y_test = y[train_index],y[test_index]print(y_test)break
print(next(index))
[0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2]
(array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 20, 21, 22,23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35,36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48,49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 70, 71,72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84,85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97,98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 120,121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133,134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146,147, 148, 149]), array([ 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 60, 61, 62,63, 64, 65, 66, 67, 68, 69, 110, 111, 112, 113, 114, 115,116, 117, 118, 119]))
二,超参数搜索
超参数搜索也叫网格搜索(Grid Search)
比如在KNN算法中,k是一个可以人为设置的参数,所以就是一个超参数。网格搜索能自动的帮助我们找到最好的超参数值。
class sklearn.model_selection.GridSearchCV(estimator, param_grid)说明:
同时进行交叉验证(CV)、和网格搜索(GridSearch),GridSearchCV实际上也是一个估计器(estimator),同时它有几个重要属性:best_params_ 最佳参数best_score_ 在训练集中的准确率best_estimator_ 最佳估计器cv_results_ 交叉验证过程描述best_index_最佳k在列表中的下标
参数:estimator: scikit-learn估计器实例param_grid:以参数名称(str)作为键,将参数设置列表尝试作为值的字典示例: {"n_neighbors": [1, 3, 5, 7, 9, 11]}cv: 确定交叉验证切分策略,值为:(1)None 默认5折(2)integer 设置多少折如果估计器是分类器,使用"分层k-折交叉验证(StratifiedKFold)"。在所有其他情况下,使用KFold。
三,鸢尾花数据集示例
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import StandardScaleriris = load_iris()
x,y = load_iris(return_X_y=True)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=22)knn_model = KNeighborsClassifier(n_neighbors=5)
model = GridSearchCV(knn_model,param_grid={"n_neighbors":[3,4,5,6,7,8,9,10]},cv=10)transfer=StandardScaler()
x_train=transfer. fit_transform(x_train)
x_test=transfer.transform(x_test)model.fit(x_train,y_train)print("最佳参数:",model.best_params_)
print("最佳结果:",model.best_score_)
print("模型结果:",model.best_estimator_)
y_pred=model.best_estimator_.predict([[1,2,3,4]])
print("预测结果:",y_pred)print("信息",model.cv_results_)
print("最佳下标",model.best_index_)
最佳参数: {'n_neighbors': 6}
最佳结果: 0.9833333333333332
模型结果: KNeighborsClassifier(n_neighbors=6)
预测结果: [2]
信息 {'mean_fit_time': array([3.00216675e-04, 7.20500946e-05, 6.69097900e-04, 3.50546837e-04,5.07640839e-04, 4.11176682e-04, 3.00264359e-04, 2.49981880e-04]), 'std_fit_time': array([0.00045859, 0.00019672, 0.00045004, 0.0004505 , 0.0005081 ,0.00050452, 0.00045866, 0.00040276]), 'mean_score_time': array([0.0015717 , 0.0016468 , 0.00132856, 0.00173099, 0.00160072,0.00148973, 0.00171149, 0.00175641]), 'std_score_time': array([0.0004462 , 0.00054278, 0.00045266, 0.00043214, 0.00049067,0.0004907 , 0.00044354, 0.00033344]), 'param_n_neighbors': masked_array(data=[3, 4, 5, 6, 7, 8, 9, 10],mask=[False, False, False, False, False, False, False, False],fill_value=999999), 'params': [{'n_neighbors': 3}, {'n_neighbors': 4}, {'n_neighbors': 5}, {'n_neighbors': 6}, {'n_neighbors': 7}, {'n_neighbors': 8}, {'n_neighbors': 9}, {'n_neighbors': 10}], 'split0_test_score': array([1., 1., 1., 1., 1., 1., 1., 1.]), 'split1_test_score': array([0.91666667, 1. , 1. , 1. , 1. ,1. , 0.91666667, 0.91666667]), 'split2_test_score': array([0.91666667, 1. , 1. , 1. , 1. ,1. , 1. , 1. ]), 'split3_test_score': array([0.91666667, 1. , 0.91666667, 1. , 0.91666667,0.91666667, 0.91666667, 0.91666667]), 'split4_test_score': array([1. , 0.91666667, 1. , 1. , 1. ,1. , 1. , 1. ]), 'split5_test_score': array([1. , 0.91666667, 1. , 1. , 1. ,1. , 1. , 1. ]), 'split6_test_score': array([0.91666667, 0.91666667, 0.91666667, 0.91666667, 0.91666667,0.91666667, 0.91666667, 0.91666667]), 'split7_test_score': array([0.83333333, 0.83333333, 0.91666667, 1. , 0.91666667,0.91666667, 0.91666667, 0.91666667]), 'split8_test_score': array([0.91666667, 0.83333333, 0.91666667, 0.91666667, 0.91666667,0.91666667, 0.91666667, 0.91666667]), 'split9_test_score': array([1., 1., 1., 1., 1., 1., 1., 1.]), 'mean_test_score': array([0.94166667, 0.94166667, 0.96666667, 0.98333333, 0.96666667,0.96666667, 0.95833333, 0.95833333]), 'std_test_score': array([0.05335937, 0.06508541, 0.04082483, 0.03333333, 0.04082483,0.04082483, 0.04166667, 0.04166667]), 'rank_test_score': array([7, 7, 2, 1, 2, 2, 5, 5])}
最佳下标 3
四,现实世界数据集示例
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCVnews=fetch_20newsgroups(data_home="./src",subset="all")# 数据集划分
x_train,x_test,y_train,y_test = train_test_split(news.data,news.target,test_size=0.25,random_state=22)tfidf = TfidfVectorizer()
x_train = tfidf.fit_transform(x_train)
x_test = tfidf.transform(x_test)# 创建模型
knn_model = KNeighborsClassifier(n_neighbors=5)
# 进行超参数搜索
model = GridSearchCV(knn_model,param_grid={"n_neighbors":[3,4,5,6,7,8,9,10]},cv=10)
model.fit(x_train,y_train)# 模型评估
score = model.score(x_test,y_test)
print("准确率:",score)
print("最佳参数:",model.best_params_)
print("最佳结果:",model.best_score_)
准确率: 0.7871392190152802
最佳参数: {'n_neighbors': 3}
最佳结果: 0.7871105445394403
相关文章:
机器学习 --- 模型选择与调优
机器学习 — 模型选择与调优 文章目录 机器学习 --- 模型选择与调优一,交叉验证1.1 保留交叉验证HoldOut1.2 K-折交叉验证(K-fold)1.3 分层k-折交叉验证Stratified k-fold 二,超参数搜索三,鸢尾花数据集示例四,现实世界数据集示例…...
《Python星球日记》 第58天:Transformer 与 BERT
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、引言一、Transformer 架构简介1. 自注意力机制(Self-Attention)工作原理2. 多头注意力与位置编码多头注意力机制位置编码二、BERT 的结构…...

2900. 最长相邻不相等子序列 I
2900. 最长相邻不相等子序列 I class Solution:def getLongestSubsequence(self, words: List[str], groups: List[int]) -> List[str]:n len(groups) # 获取 groups 列表的长度ans [] # 初始化一个空列表,用于存储结果for i, g in enumerate(groups): # 遍…...
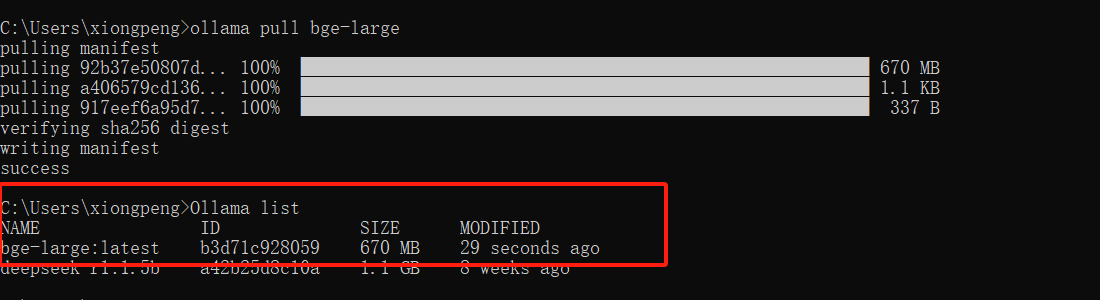
AGI大模型(15):向量检索之调用ollama向量数据库
这里介绍将向量模型下载到本地,这里使用ollama,现在本地安装ollama,这里就不过多结束了。直接从下载开始。 1 下载模型 首先搜索模型,这里使用bge-large模型,你可以根据自己的需要修改。 点击进入,复制命令到命令行工具中执行。 安装后查看: 2 代码实现 先下载ollama…...

Python网络请求利器:urllib库深度解析
一、urllib库概述 urllib是Python内置的HTTP请求库,无需额外安装即可使用。它由四个核心模块构成: urllib.request:发起HTTP请求的核心模块urllib.error:处理请求异常(如404、超时等)…...

什么是Agentic AI(代理型人工智能)?
什么是Agentic AI(代理型人工智能)? 一、概述 Agentic AI(代理型人工智能)是一类具备自主决策、目标导向性与持续行动能力的人工智能系统。与传统AI系统依赖外部输入和显式命令不同,Agentic AI在设定目标…...
day 17 无监督学习之聚类算法
一、聚类流程 1. 利用聚类发现数据模式 无监督算法中的聚类,目的就是将数据点划分成不同的组或 “簇”,使得同一簇内的数据点相似度较高,而不同簇的数据点相似度较低,从而发现数据中隐藏的模式。 2. 对聚类后的类别特征进行可视…...

《Python星球日记》 第68天:BERT 与预训练模型
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、BERT模型基础1. 什么是BERT?2. BERT 的结构3.预训练和微调对比二、BERT 的预训练任务1. 掩码语言模型 (MLM)2. 下一句预测 (NSP)三、微调 …...
)
Spring 集成 SM4(国密对称加密)
Spring 集成 SM4(国密对称加密)算法 主要用于保护敏感数据,如身份证、手机号、密码等。 下面是完整集成步骤(含工具类 使用示例),采用 Java 实现(可用于 Spring Boot)。 一、依赖引…...
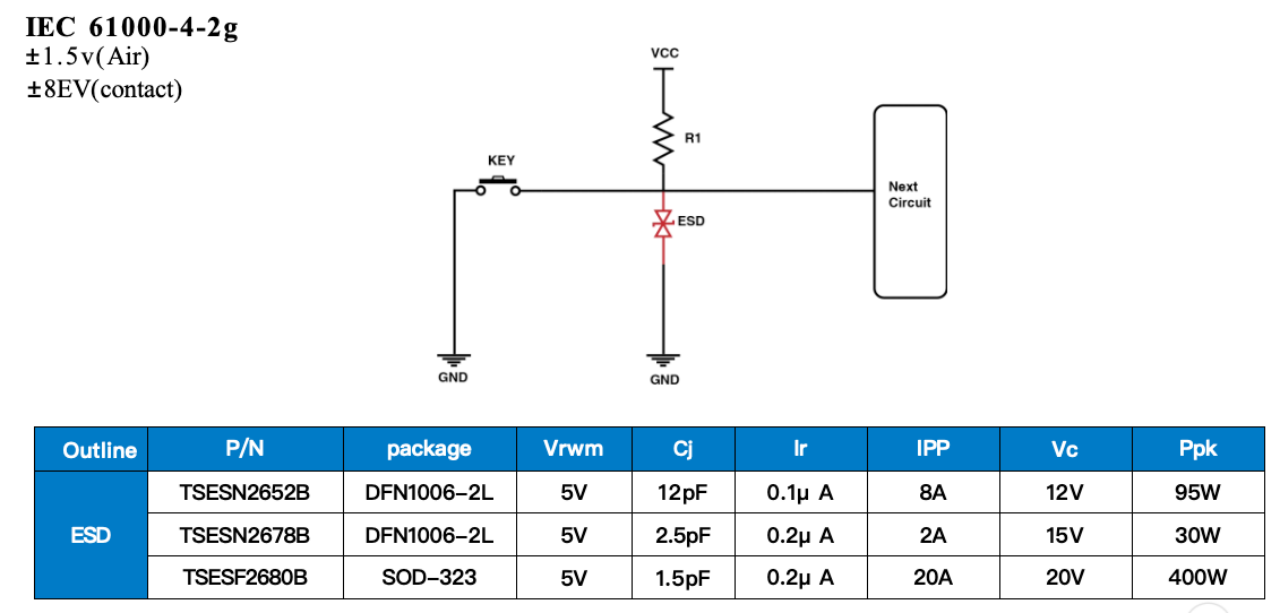
时源芯微| KY键盘接口静电浪涌防护方案
KY键盘接口静电浪涌防护方案通过集成ESD保护元件、电阻和连接键,形成了一道有效的防护屏障。当键盘接口受到静电放电或其他浪涌冲击时,该方案能够迅速将过电压和过电流引导至地,从而保护后续电路免受损害。 ESD保护元件是方案中的核心部分&a…...

CodeBuddy编程新范式
不会写?不想写? 腾讯推出的CodeBuddy彻底解放双手。 示例 以下是我对CodeBuddy的一个小体验。 我只用一行文字对CodeBuddy说明了一下我的需求,剩下的全部就交给了CodeBuddy,我需要做的就是验收结果即可。 1.首先CodeBuddy会对任…...

ArcGIS+InVEST+RUSLE:水土流失模拟与流域管理的高效解决方案;水土保持专题地图制作
在全球生态与环境面临严峻挑战的当下,水土流失问题已然成为制约可持续发展的重要因素之一。水土流失不仅影响土地资源的可持续利用,还对生态环境、农业生产以及区域经济发展带来深远影响。因此,科学、精准地模拟与评估水土流失状况࿰…...
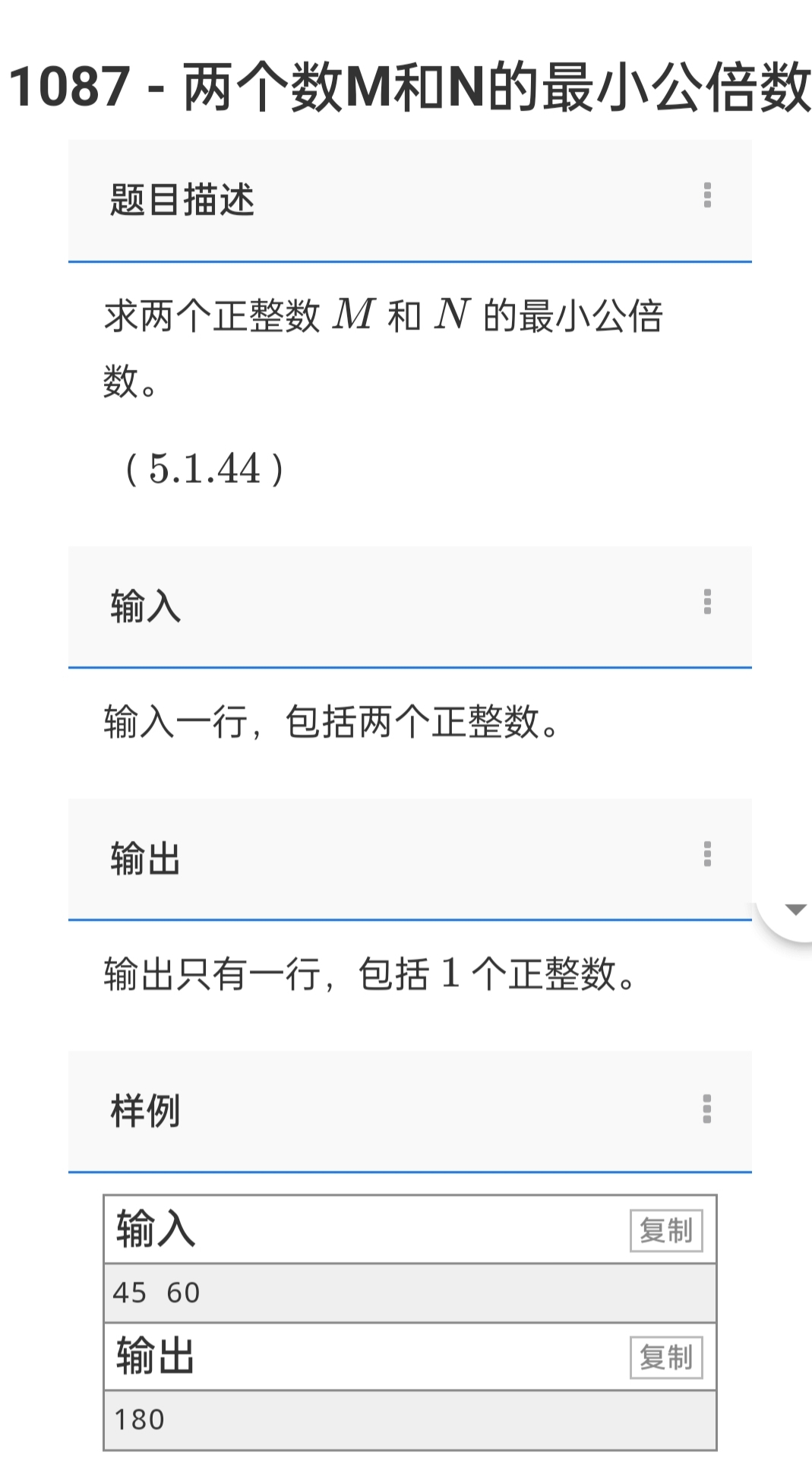
小刚说C语言刷题—1088求两个数M和N的最大公约数
1.题目描述 求两个正整数 M 和 N 的最大公约数(M,N都在长整型范围内) .输入 输入一行,包括两个正整数。 输出 输出只有一行,包括1个正整数。 样例 输入 45 60 输出 15 2.参考代码(C语言版) #include <stdio.h> …...

【LLIE专题】基于码本先验与生成式归一化流的低光照图像增强新方法
GLARE: Low Light Image Enhancement via Generative Latent Feature based Codebook Retrieval(2024,ECCV) 专题介绍一、研究背景二、GLARE方法阶段一:正常光照代码本学习(Normal-Light Codebook Learning)…...

[MySQL数据库] SQL优化
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...
)
AWS VPC 核心笔记(小白向)
AWS VPC 核心笔记(小白向) 一、核心组成:VPC 云上的“私有网络” 组件名类比说明VPC小区你在 AWS 上自定义的私有网络范围子网(Subnet)小区里的楼子网是 VPC 的一个切分区域,决定资源的网络分布ÿ…...

召回11:地理位置召回、作者召回、缓存召回
GeoHash 召回 属于地理位置召回,用户可能对附近发生的事情感兴趣。GeoHash 是一种对经纬度的编码,地图上每个单位矩形的 GeoHash 的前几位是相同的,GeoHash 编码截取前几位后,将相同编码发布的内容按时间顺序(先是时间…...

【AI News | 20250515】每日AI进展
AI Repos 1、helix-db 专用于RAG以及AI应用的一款高性能图向量数据库:HelixDB,比Neo4j快1000倍,比TigerGraph快100倍,向量搜索性能和Qdrant相当。原生支持图形和矢量数据类型,比较适合RAG和AI应用,像知识图…...
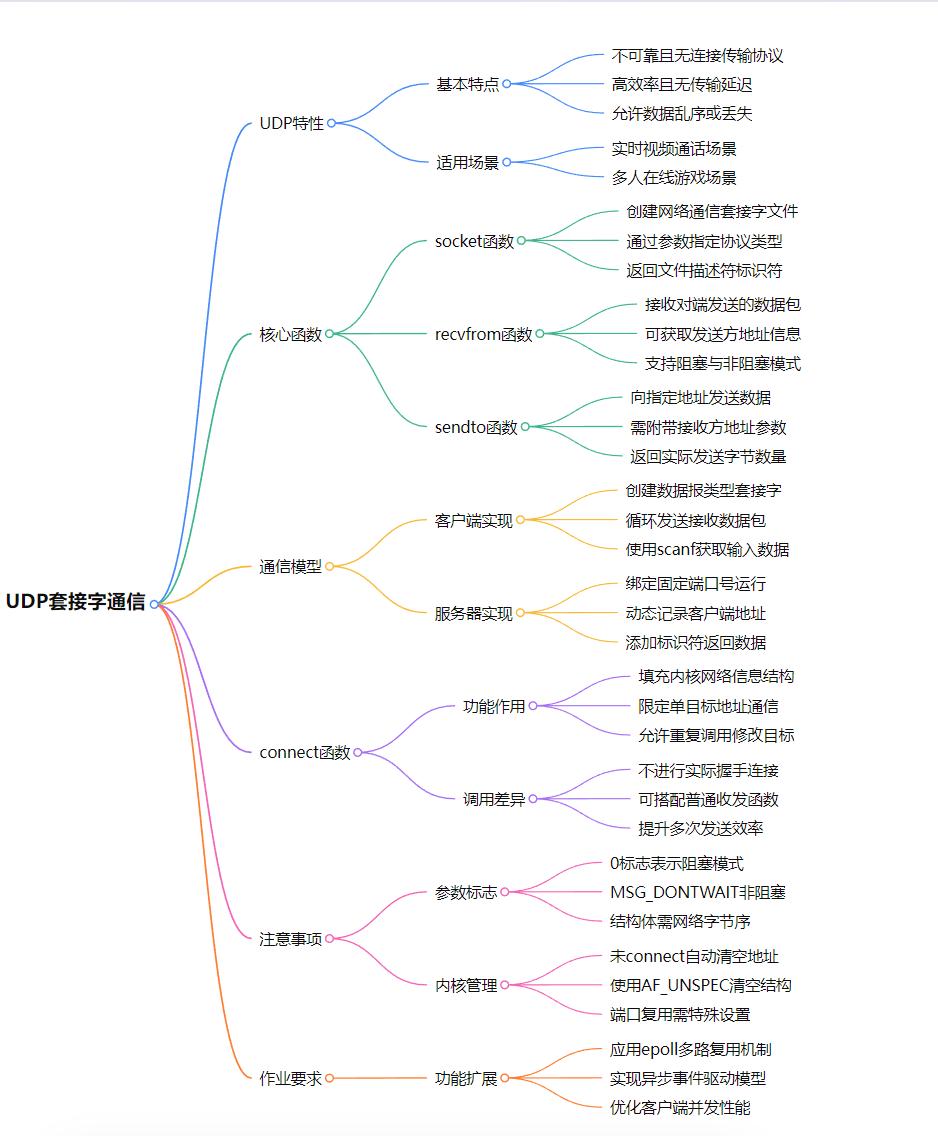
网络编程epoll和udp
# epoll模型核心要点## 1. epoll核心概念### 1.1 高效IO多路复用- 监视列表与激活列表分离- 内核使用红黑树存储描述符- 边缘触发模式(EPOLLET)支持### 1.2 事件触发机制- **水平触发(LT)**:- 默认模式,类似select/poll- 数据未读完持续触发事件- **边缘…...

elementUI如何动态增减表单项
设置prop的字段::prop"configs.${i}.platform" <template><el-dialogtitle"编辑配置":close-on-click-modal"false":before-close"beforeClose":visible.sync"visible"v-if"visible"class&q…...
【iOS】源码阅读(四)——isa与类关联的原理
文章目录 前言OC对象本质探索clang探索对象本质objc_setProperty源码探索 cls与类的关联原理为什么说bits与cls为互斥关系isa的类型isa_t原理探索isa与类的关联 总结 前言 本篇文章主要是笔者在学习和理解类与isa的关联关系时所写的笔记。 OC对象本质探索 在学习和理解类与isa…...

sql server 2019 将单用户状态修改为多用户状态
记录两种将单用户状态修改为多用户状态,我曾经成功过的方法,供参考 第一种方法 USE master; GO -- 终止所有活动连接 DECLARE kill_connections NVARCHAR(MAX) ; SELECT kill_connections KILL CAST(session_id AS NVARCHAR(10)) ; FROM sys.dm_ex…...

uniapp引入七鱼客服微信小程序SDK
小程序引入七鱼sdk 1.微信公众平台引入2.代码引入3.在pagesQiyu.vue初始化企业appKey4.跳转打开七鱼客服 1.微信公众平台引入 账号设置->第三方设置->添加插件->搜索 QIYUSDK ->添加 2.代码引入 在分包中引入插件 "subPackages": [{"root":…...

uniapp 常用 UI 组件库
1. uView UI 特点: 组件丰富:提供覆盖按钮、表单、图标、表格、导航、图表等场景的内置组件。跨平台支持:兼容 App、H5、小程序等多端。高度可定制:支持主题定制,组件样式灵活。实用工具类:提供时间、数组操…...
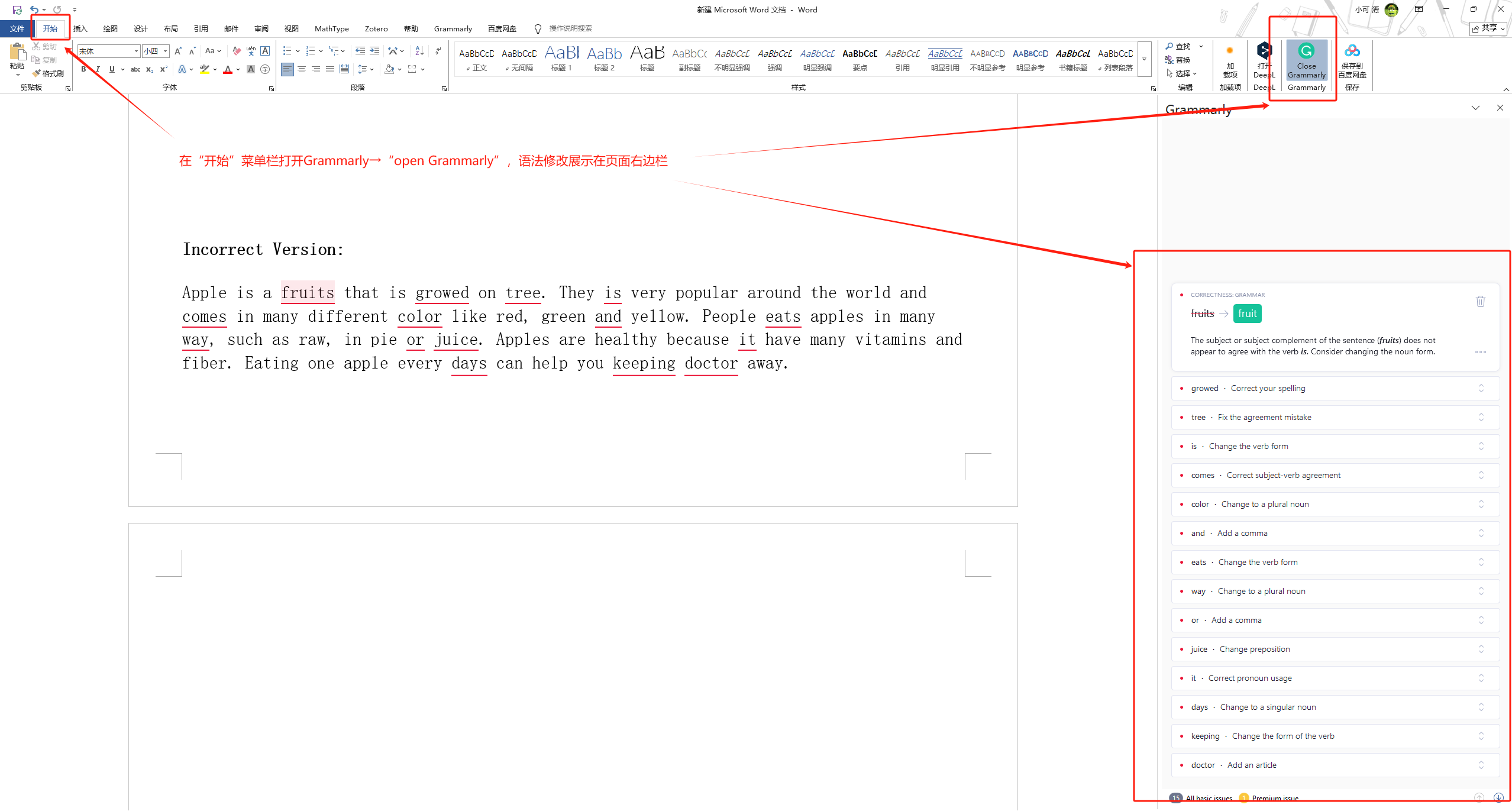
SCI写作开挂!把Grammarly语法修订嵌入word
详细分享如何把Grammarly嵌入Word,实现英文写作时的实时语法校改。 ①进入Grammarly官网 ②点击右上角的“Get Grammarly Its free”会直接跳转到注册或者登录界面,如果还没有账号先注册。 ③注册或登录后进入这个页面,点击“Support”。 ④…...

PostgreSQL 配置设置函数
PostgreSQL 配置设置函数 PostgreSQL 提供了一组配置设置函数(Configuration Settings Functions),用于查询和修改数据库服务器的运行时配置参数。这些函数为数据库管理员提供了动态管理数据库配置的能力,无需重启数据库服务。 …...

2025年5月-信息系统项目管理师高级-软考高项-成本计算题
成本计算题挣值分析、成本计算题如何学?1、PV,EV,AC需要理解,根据题目给出的一些个条件需要求得这些值;2、CV,SV,CPI,SPI公式必须记住,需要根据求得的值判断项目的进度和成本的执行情况&#x…...

力扣-236.二叉树的最近公共祖先
题目描述 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以…...

Go 中闭包的常见使用场景
在 Go 中,闭包(Closure) 是一个函数值,它引用了其定义时所在作用域中的变量。也就是说,闭包可以访问并修改外部作用域中的变量。 Go 中闭包的常见使用场景 ✅ 1. 封装状态(无须结构体) 闭包可…...
SpringBoot中的Lombok库
一)Lombok库简介 Lombok是一个Java库,通过注解的方式简化代码编写,减少样板代码。它能够自动生成getter、setter、构造函数、toString等方法,提升开发效率。Lombok只是一个编译阶段的库,因此不会影响程序的运行。 二…...