[MySQL数据库] SQL优化
🌸个人主页:https://blog.csdn.net/2301_80050796?spm=1000.2115.3001.5343
🏵️热门专栏:
🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm=1001.2014.3001.5482
🍕 Collection与数据结构 (93平均质量分)https://blog.csdn.net/2301_80050796/category_12621348.html?spm=1001.2014.3001.5482
🧀线程与网络(97平均质量分) https://blog.csdn.net/2301_80050796/category_12643370.html?spm=1001.2014.3001.5482
🍭MySql数据库(95平均质量分)https://blog.csdn.net/2301_80050796/category_12629890.html?spm=1001.2014.3001.5482
🍬算法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12676091.html?spm=1001.2014.3001.5482
🍃 Spring(97平均质量分)https://blog.csdn.net/2301_80050796/category_12724152.html?spm=1001.2014.3001.5482
🎃Redis(97平均质量分)https://blog.csdn.net/2301_80050796/category_12777129.html?spm=1001.2014.3001.5482
🐰RabbitMQ(97平均质量分) https://blog.csdn.net/2301_80050796/category_12792900.html?spm=1001.2014.3001.5482
感谢点赞与关注~~~

目录
- 1. 插入数据
- 1.1 Insert
- 1.2 大批量插入数据
- 2. 主键优化
- 3. order by优化
- 4. group by优化
- 5. limit优化
- 6. count优化
- 6.1 概述
- 6.2 count用法
- 7. update优化
1. 插入数据
1.1 Insert
如果我们需要一次性往数据库表中插入多条数据,可以从下面三个方面进行优化.
insert into tb_test values(1,'tom');
insert into tb_test values(2,'cat');
insert into tb_test values(3,'jerry');
.....
- 优化方案一:
批量插入数据
Insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
- 减少网络开销,单批次插入比多批次插入减少了客户端和服务器之间的往返通信.
- 降低SQL解析成本,MySQL只需要在服务层解析一次SQL语句,而不是多次.
- 减少日志写入,InnoDB的事务日志(redo log)可以批量写入
- 优化方案二:
手动控制事务
start transaction;
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
insert into tb_test values(4,'Tom'),(5,'Cat'),(6,'Jerry');
insert into tb_test values(7,'Tom'),(8,'Cat'),(9,'Jerry');
commit;
- 减少事务开销,如果不是手动提交的话,默认每条语句都是一条事务,这样就会导致不停的刷盘写日志的操作.批量操作可以减少磁盘IO的压力.
- 减少锁的持有时间,表锁和行锁在整个事务中只需要获取一次.
- 总的来说: 自动提交,每条语句都会占用一个完整的事务开销,多条Insert会共享一个事务的开销.
- 优化方案三:
主键顺序插入,性能要高于乱序插入:
主键乱序插入 : 8 1 9 21 88 2 4 15 89 5 7 3
主键顺序插入 : 1 2 3 4 5 7 8 9 15 21 88 89
优化方案三的具体原因我们下面会介绍.
1.2 大批量插入数据
如果一次性需要插入大批量数据.使用insert语句插入新能比较低,==此时可以使用MySQL数据库提供load指令进行插入.操作如下:
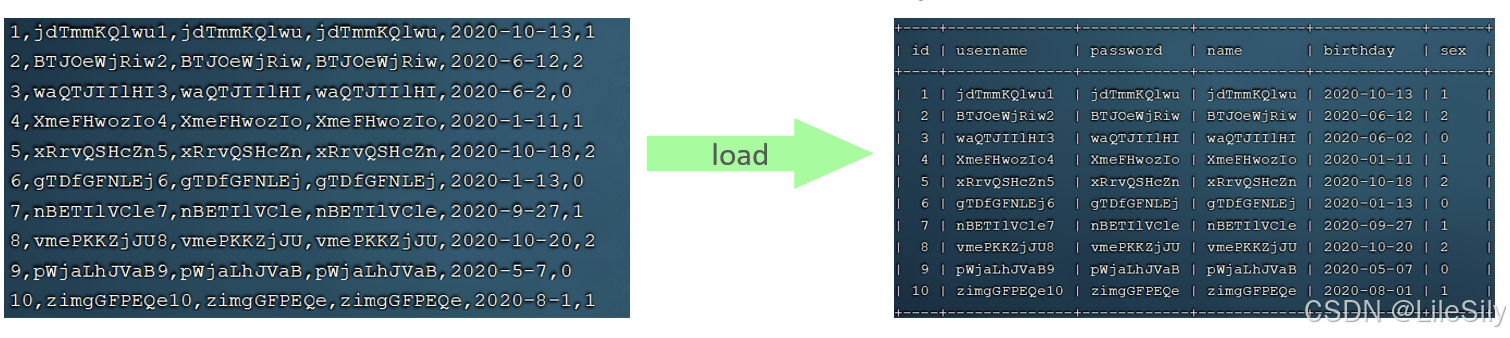
可以执行如下的指令,将数据脚本文件中的加载到表结构中:
-- 客户端连接服务端时,加上参数 -–local-infile
mysql –-local-infile -u root -p
-- 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile = 1;
-- 执行load指令将准备好的数据,加载到表结构中
load data local infile '/root/sql1.log' into table tb_user fields
terminated by ',' lines terminated by '\n' ;
2. 主键优化
在上面,我们提到,主键顺序插入的性能要高于乱序插入,下面,我们就来具体介绍一下原因,然后分析一下主键应该如何设计.
- 数据组织方式
在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表
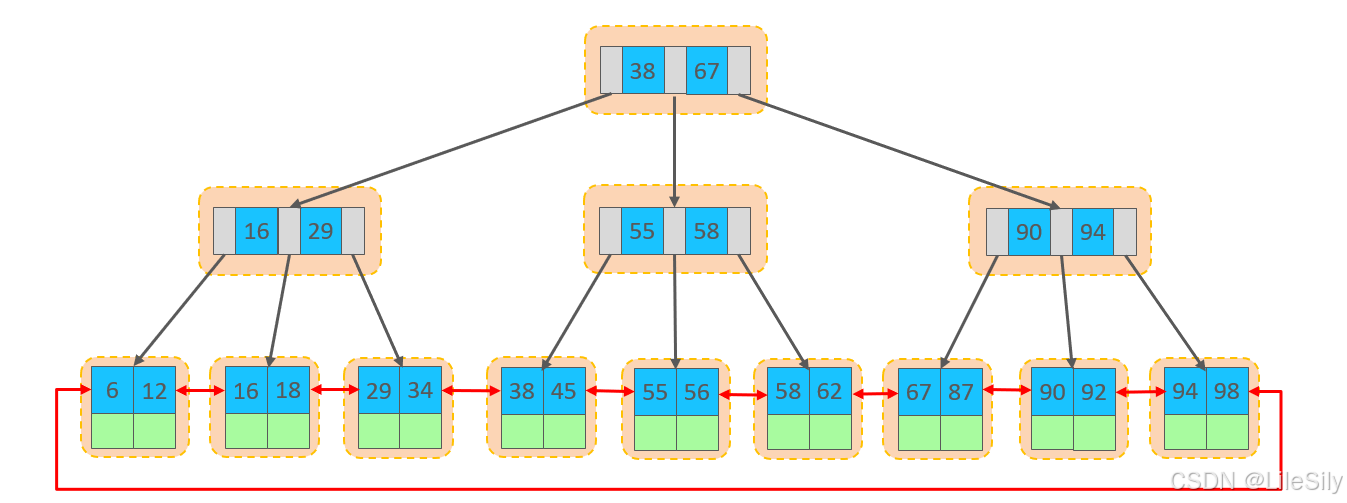
行数据,都是存储在聚集索引的叶子结点上的,而我们之前也讲过InnoDB的逻辑结构图:
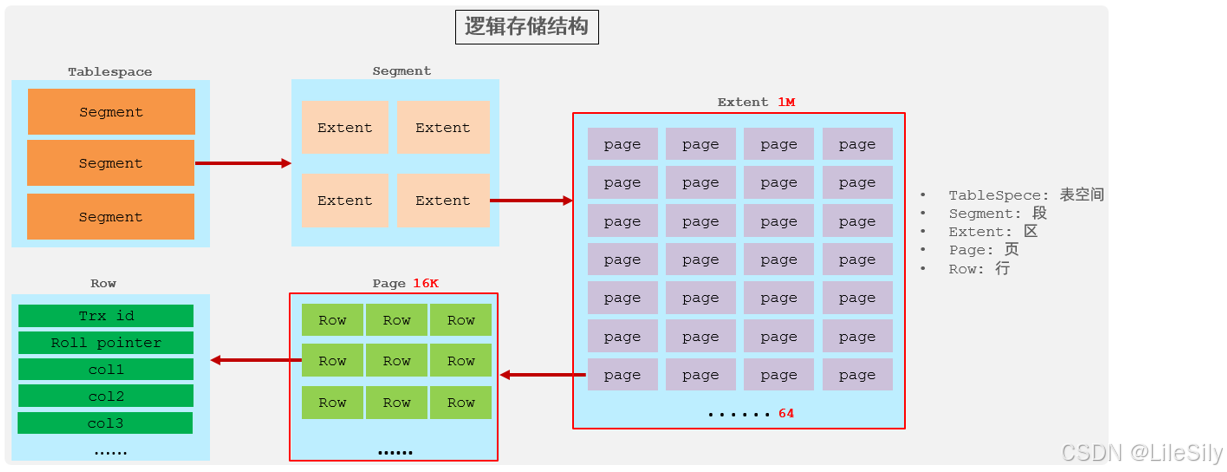
在InnoDB引擎中,数据行时记录在逻辑结构page页中的,而每个页的大小是固定的,默认16KB.那也就意味着,一个页中所存储的行也是有限的,如果插入的行数据row在该页中存储不小,将会存储到下一个页中,页与页之间会通过指针连接. - 页分裂
页可以为空,也可以填充一半,也可以填充100%,每个页包含了2-N行数据,根据主键排列.
- 主键顺序插入效果
从磁盘中申请页,主键顺序插入
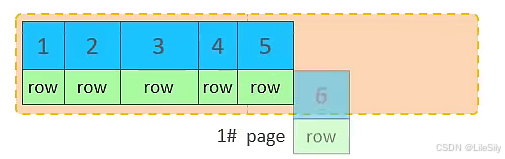
第一个页没有满,继续往第一页插入
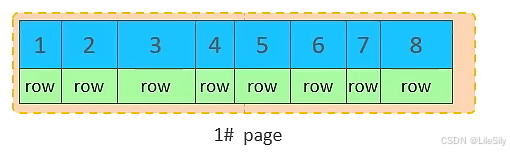
当第一个页写满之后,再写入第二个页,页与页之间会通过指针连接

当第二个页写满之后,再往第三页写入

- 逐渐乱序插入效果
第一页和第二页都已经写满了,存放如图所示的数据

此时再插入id为50的记录,我们来看看会发生什么现象,会再次开启一个页,写入新的页中吗?
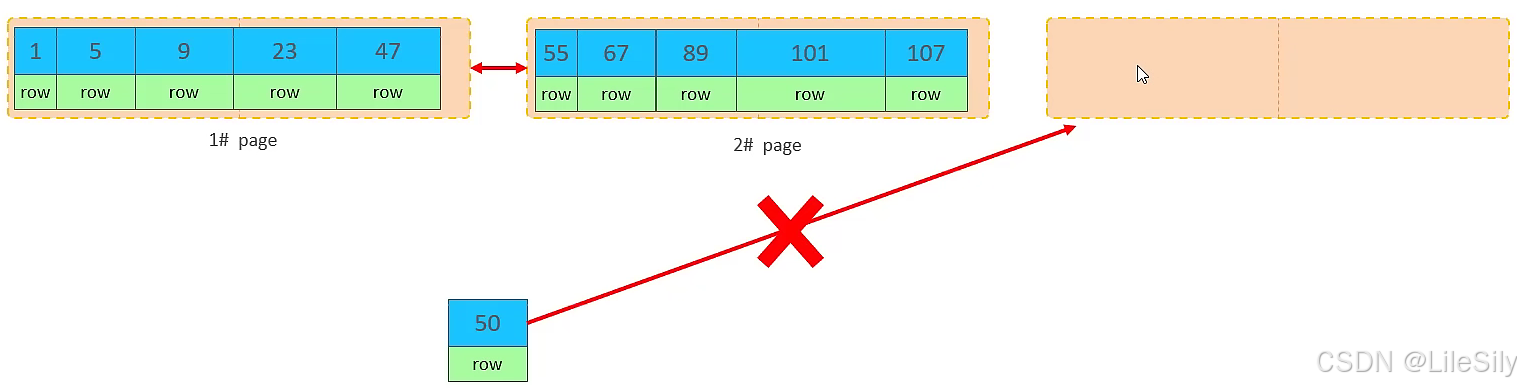 不会,因为,索引结构的叶子结点是有顺序的,按照顺序,应该存储在47之后.
不会,因为,索引结构的叶子结点是有顺序的,按照顺序,应该存储在47之后.
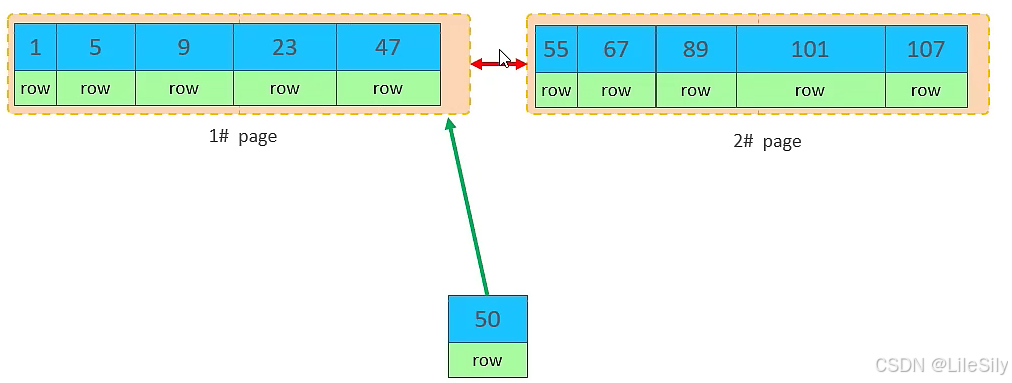
但是47所在的第一页已经满了,存储不了50对应的数据了,那么此时会开辟一个新的页.

但是并不会直接将50存入第三页,而是会将第一页的一半数据移动到第三页,然后在第三页插入50.


移动数据,并插入id为50的数据之后,那么此时,这三个页之间的数据顺序是有问题的.第一页的下一个页应该是第三页,第三页的下一页应该是第二页,所以此时需要重新设置链表指针.

上述的这种现象,称之为"页分裂",是比较耗费性能的操作.
3. 页合并
目前表中已有数据的索引结构(叶子结点)如下:

当我们对已有的数据进行删除的时候,具体的效果如下:
当删除一行记录时,实际上并没有被物理删除,只是被标记为删除并且它的空间变得允许被其他的记录声明使用.

当我们继续删除第二页的数据记录
 当页中删除的记录达到
当页中删除的记录达到MERGE_THRESHOLD(默认为页的50%),InnoDB会开始寻找最靠近的页(前或后)看看是否可以将两个页合并以优化空间使用.


删除数据,并将页合并之后,再次插入新的数据21,则直接插入第三页.

这里面所发生的合并也的这个现象,就称之为"页合并".
4. 索引设计原则
- 满足业务需求的情况下,尽量降低主键的长度.迫不得已的时候可以用其他的,比如分布式系统,可以选择使用雪花算法.
- 插入数据时,尽量选择顺序插入,选择使用
AUTO_INCREMENT自增主键. - 尽量不要使用UUID做主键或者是其他的自然主键,避免出现页分裂的现象,比如身份证号.
- 业务操作时,避免对主键的修改.
3. order by优化
MySQL的排序,有两种方式:
Using filesort: 通过表的索引或者全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,所有不是通过索引直接返回的排序结果都叫FileSort排序.
Using index: 通过有序索引扫描直接返回有序数据,这种情况即为using index,不需要额外排序,操作效率高.
对于以上的两种排序方式,using index的性能高,而using filesort的性能很低,我们在优化排序操作的时候,尽量要优化为using index.
接下来,我们来做一个测试:
- 准备数据
把之前为tb_user表所建立的部分索引直接删除掉
drop index idx_user_phone on tb_user;
drop index idx_user_phone_name on tb_user;
drop index idx_user_name on tb_user;
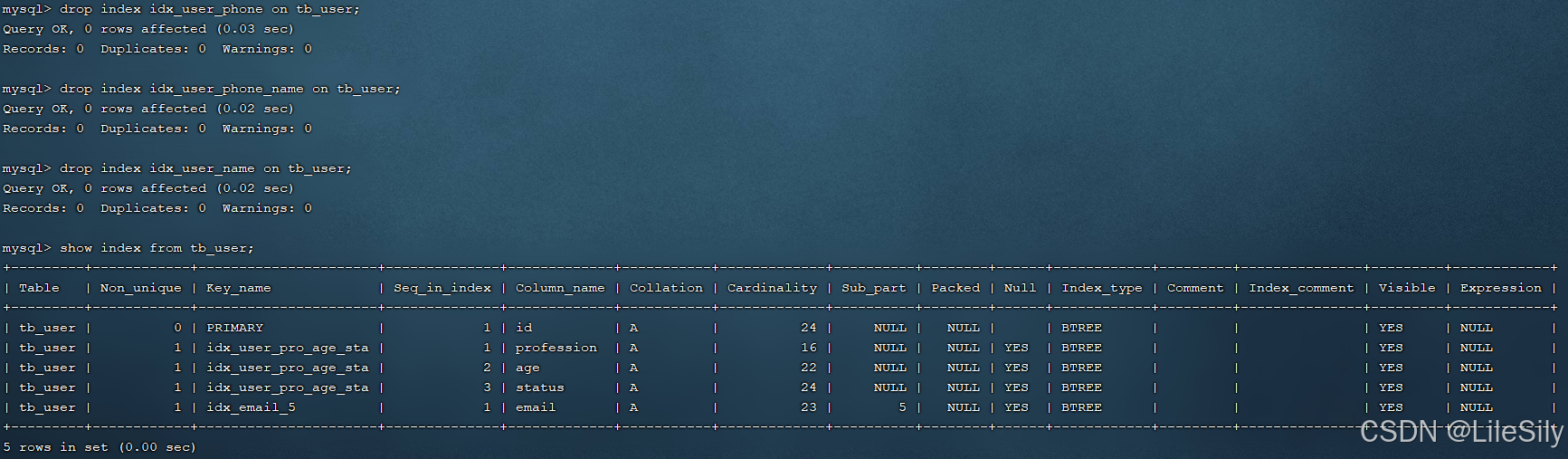
2. 执行排序SQL
explain select id,age,phone from tb_user order by age ;

explain select id,age,phone from tb_user order by age, phone ;

由于age,phone都没有索引,所以此时再排序时,出现using filesort,排序性能较低.
- 创建索引
-- 创建索引
create index idx_user_age_phone_aa on tb_user(age,phone);
- 创建索引之后,根据age,phone进行升序排序
explain select id,age,phone from tb_user order by age;

explain select id,age,phone from tb_user order by age , phone;

建立索引之后,再次进行排序查询,就由原来的using filesort,变为了using index,性能就比较高了.
- 创建索引之后,根据age,phone进行降序排序.
explain select id,age,phone from tb_user order by age desc , phone desc ;

也出现了using index,但是此时extra出现了backward index scan,这个代表反向扫描索引,因为在MySQL中我们创建的索引,默认索引的叶子结点是从小到大排序的,而此时我们查询排序时,是从大到小,所以在扫描时,就是反向扫描,就会出现backward index scan.在MySQL8版本中,支持降序索引,我们也可以创建降序索引.
- 根据age,phone进行排序,一个降序,一个升序.
explain select id,age,phone from tb_user order by age asc , phone desc ;

因为创建索引时,如果未指定顺序,默认都是按照升序排序的,而查询时,一个升序,一个降序,此时就会出现using filesort.

为了解决上述的问题,我们可以创建一个索引,这个联合索引中age升序排序,phone倒序排序.
- 联合创建索引(age升序排序,phone倒序排序)
create index idx_user_age_phone_ad on tb_user(age asc ,phone desc);

8. 然后再次执行如下sql
explain select id,age,phone from tb_user order by age asc , phone desc ;

升序,降序联合索引结构如图所示:


总结: 由上上述原则,我们可以得出order by优化原则:
- 根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则.
- 尽量使用覆盖索引
- 多字段排序,一个升序,一个降序,此时需要注意联合索引在创建时的规则(asc/desc).
- 如果不可避免出现filesort,大量数据排序时,可以适当增大排序缓冲区的大小.
4. group by优化
分组操作,我们主要来看索引对分组操作的影响.首先我们将tb_user表中的索引全部删除.

接下来,在没有索引的情况下,执行如下sql,查询执行计划:
explain select profession , count(*) from tb_user group by profession ;

然后,我们在针对与profession,age,status创建一个联合索引.
create index idx_user_pro_age_sta on tb_user(profession , age , status);
紧接着,再执行前面相同的sql查看执行计划:
explain select profession , count(*) from tb_user group by profession ;

再执行如下分组查询sql,查看执行计划:


我们发现,如果仅仅根据age分组,就会出现using temporary,而如果是根据profession,age两个字段同时分组,则不会出现using temporary.原因是因为对于分组操作,在联合索引中,也是符合最左前缀法则的.如果分组中跳过了联合索引中的其中一个字段时,后面字段的索引都会失效.
所以在分组操作中,我们需要通过以下两点进行优化,以提升性能:
- 在分组操作时,可以通过索引来提高效率.
- 分组操作时,索引的使用也是满足最左前缀法则的.
5. limit优化
在数据量比较大,如果进行limit分页查询,在查询时,越往后,分页查询效率也越低.
我们一起来看看limit分页查询耗时对比:

通过测试我们会看到,越往后,分页查询效率越低,这就是分页查询的问题所在.
因为,当在进行分页查询时,如果执行limit 2000000,10,此时需要MySQL排序前2000010记录,仅仅返回2000000 - 2000010的记录,将其他记录丢弃,查询的代价非常大.
优化思路: 一般分页查询时,通过创建覆盖索引能够比较好的提高性能,可以通过覆盖索引加子查询的形式进行优化.
6. count优化
6.1 概述
select count(*) from tb_user ;
在之前的测试中,我们发现,如果数据量很大,在执行count操作的时候,非常耗时.
- MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个数,效率很高.
- InnoDB 引擎就麻烦了,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数.
如果要说大幅提升InnoDB表的count效率,主要的优化思路: 自己计数(可以借助Redis这样的数据库进行).
6.2 count用法
count()是一个聚合函数,对于返回的结果集,一行一行的判断,如果count函数参数不是null,累计值就加1,否则不加,最后返回累计值.
用法:count(*)、count(主键)、count(字段)、count(数字)

按照效率排序的话: count(字段) < count(主键 id) < count(1) ≈ count(*),所以尽量使用 count(*)
7. update优化
我们主要需要注意一下update语句执行时的注意事项.
update course set name = 'javaEE' where id = 1 ;
当我们在执行更新的sql语句时,会锁定id为1这一行数据,然后事务提交之后,行锁释放.
但是当我们开启多个事务,在执行上述的sql时,我们发现行锁升级为了表锁,导致该update的语句性能大大降低.
InnoDB的行锁是针对索引加的锁,而不是对记录加的锁,并且该索引不能失效,否则就会从行锁自动升级为表锁.
相关文章:
[MySQL数据库] SQL优化
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...
)
AWS VPC 核心笔记(小白向)
AWS VPC 核心笔记(小白向) 一、核心组成:VPC 云上的“私有网络” 组件名类比说明VPC小区你在 AWS 上自定义的私有网络范围子网(Subnet)小区里的楼子网是 VPC 的一个切分区域,决定资源的网络分布ÿ…...

召回11:地理位置召回、作者召回、缓存召回
GeoHash 召回 属于地理位置召回,用户可能对附近发生的事情感兴趣。GeoHash 是一种对经纬度的编码,地图上每个单位矩形的 GeoHash 的前几位是相同的,GeoHash 编码截取前几位后,将相同编码发布的内容按时间顺序(先是时间…...

【AI News | 20250515】每日AI进展
AI Repos 1、helix-db 专用于RAG以及AI应用的一款高性能图向量数据库:HelixDB,比Neo4j快1000倍,比TigerGraph快100倍,向量搜索性能和Qdrant相当。原生支持图形和矢量数据类型,比较适合RAG和AI应用,像知识图…...
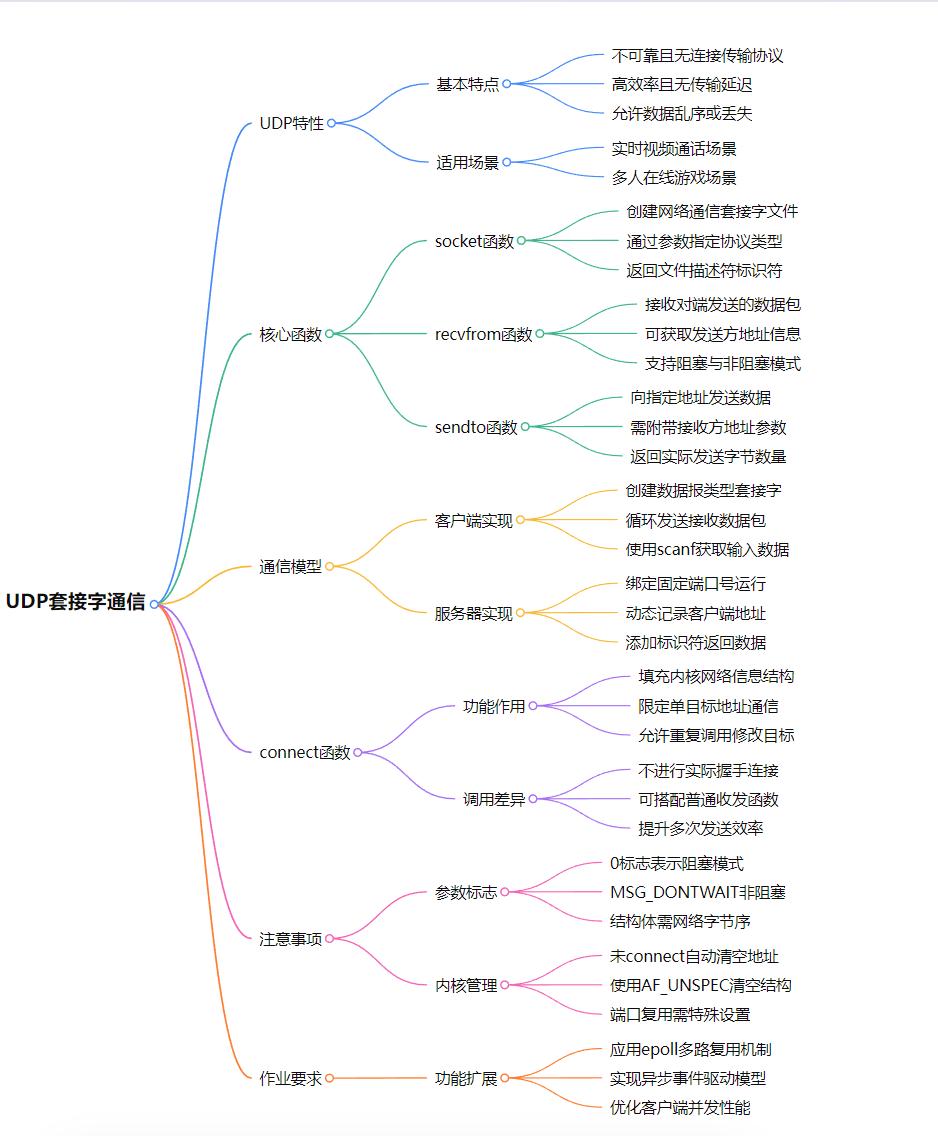
网络编程epoll和udp
# epoll模型核心要点## 1. epoll核心概念### 1.1 高效IO多路复用- 监视列表与激活列表分离- 内核使用红黑树存储描述符- 边缘触发模式(EPOLLET)支持### 1.2 事件触发机制- **水平触发(LT)**:- 默认模式,类似select/poll- 数据未读完持续触发事件- **边缘…...

elementUI如何动态增减表单项
设置prop的字段::prop"configs.${i}.platform" <template><el-dialogtitle"编辑配置":close-on-click-modal"false":before-close"beforeClose":visible.sync"visible"v-if"visible"class&q…...
【iOS】源码阅读(四)——isa与类关联的原理
文章目录 前言OC对象本质探索clang探索对象本质objc_setProperty源码探索 cls与类的关联原理为什么说bits与cls为互斥关系isa的类型isa_t原理探索isa与类的关联 总结 前言 本篇文章主要是笔者在学习和理解类与isa的关联关系时所写的笔记。 OC对象本质探索 在学习和理解类与isa…...

sql server 2019 将单用户状态修改为多用户状态
记录两种将单用户状态修改为多用户状态,我曾经成功过的方法,供参考 第一种方法 USE master; GO -- 终止所有活动连接 DECLARE kill_connections NVARCHAR(MAX) ; SELECT kill_connections KILL CAST(session_id AS NVARCHAR(10)) ; FROM sys.dm_ex…...

uniapp引入七鱼客服微信小程序SDK
小程序引入七鱼sdk 1.微信公众平台引入2.代码引入3.在pagesQiyu.vue初始化企业appKey4.跳转打开七鱼客服 1.微信公众平台引入 账号设置->第三方设置->添加插件->搜索 QIYUSDK ->添加 2.代码引入 在分包中引入插件 "subPackages": [{"root":…...

uniapp 常用 UI 组件库
1. uView UI 特点: 组件丰富:提供覆盖按钮、表单、图标、表格、导航、图表等场景的内置组件。跨平台支持:兼容 App、H5、小程序等多端。高度可定制:支持主题定制,组件样式灵活。实用工具类:提供时间、数组操…...
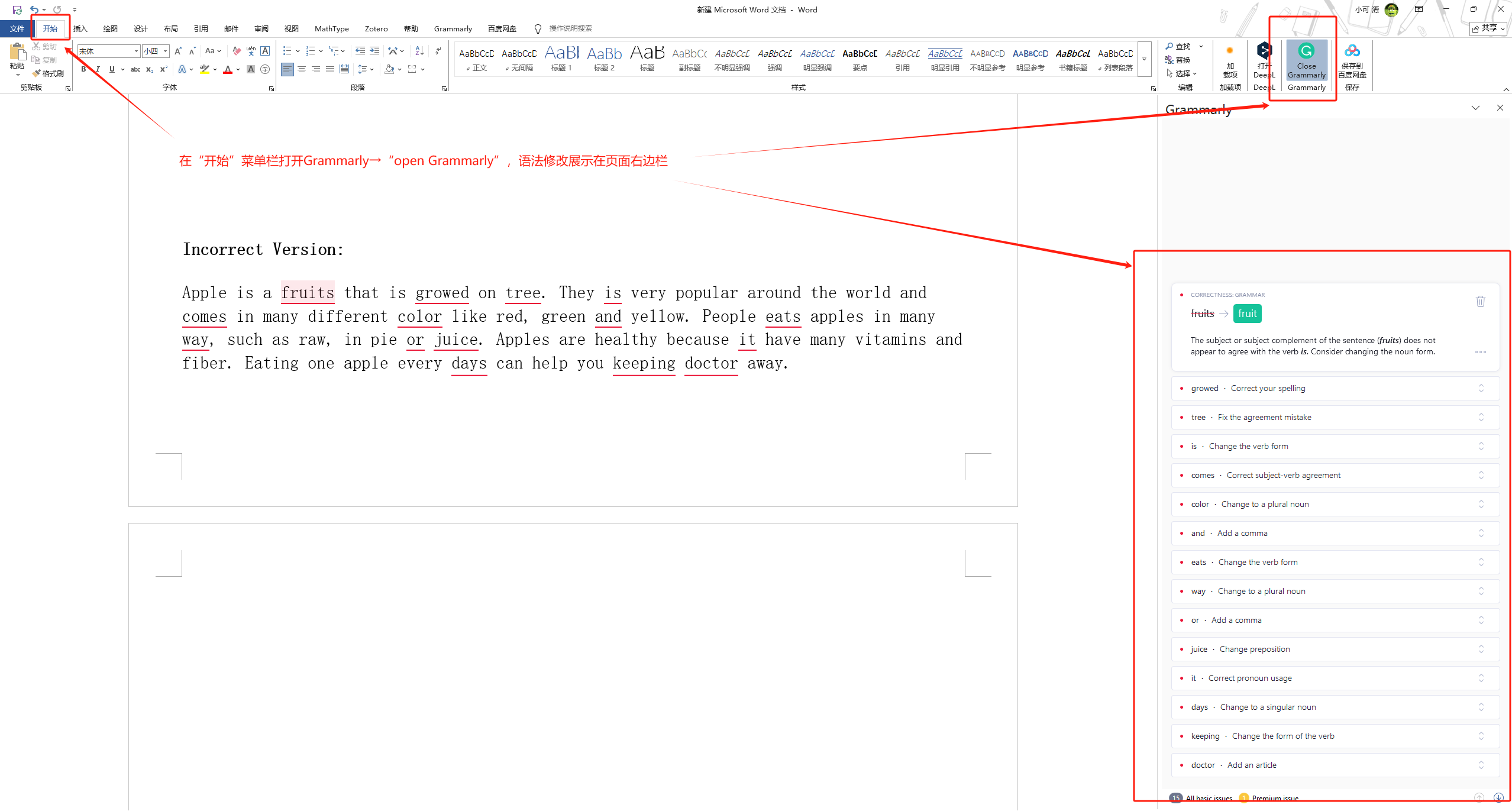
SCI写作开挂!把Grammarly语法修订嵌入word
详细分享如何把Grammarly嵌入Word,实现英文写作时的实时语法校改。 ①进入Grammarly官网 ②点击右上角的“Get Grammarly Its free”会直接跳转到注册或者登录界面,如果还没有账号先注册。 ③注册或登录后进入这个页面,点击“Support”。 ④…...

PostgreSQL 配置设置函数
PostgreSQL 配置设置函数 PostgreSQL 提供了一组配置设置函数(Configuration Settings Functions),用于查询和修改数据库服务器的运行时配置参数。这些函数为数据库管理员提供了动态管理数据库配置的能力,无需重启数据库服务。 …...

2025年5月-信息系统项目管理师高级-软考高项-成本计算题
成本计算题挣值分析、成本计算题如何学?1、PV,EV,AC需要理解,根据题目给出的一些个条件需要求得这些值;2、CV,SV,CPI,SPI公式必须记住,需要根据求得的值判断项目的进度和成本的执行情况&#x…...

力扣-236.二叉树的最近公共祖先
题目描述 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以…...

Go 中闭包的常见使用场景
在 Go 中,闭包(Closure) 是一个函数值,它引用了其定义时所在作用域中的变量。也就是说,闭包可以访问并修改外部作用域中的变量。 Go 中闭包的常见使用场景 ✅ 1. 封装状态(无须结构体) 闭包可…...
SpringBoot中的Lombok库
一)Lombok库简介 Lombok是一个Java库,通过注解的方式简化代码编写,减少样板代码。它能够自动生成getter、setter、构造函数、toString等方法,提升开发效率。Lombok只是一个编译阶段的库,因此不会影响程序的运行。 二…...

《Java 大视界——Java 大数据在智能电网分布式能源协同调度中的应用与挑战》
随着风电、光伏等分布式能源大规模接入电网,传统调度系统面临数据规模激增、响应延迟显著、多源异构数据融合困难等核心问题。本文聚焦Java生态下的大数据技术体系,深入探讨其在智能电网实时监测、负荷预测、资源优化配置等场景中的落地实践。通过分析Sp…...
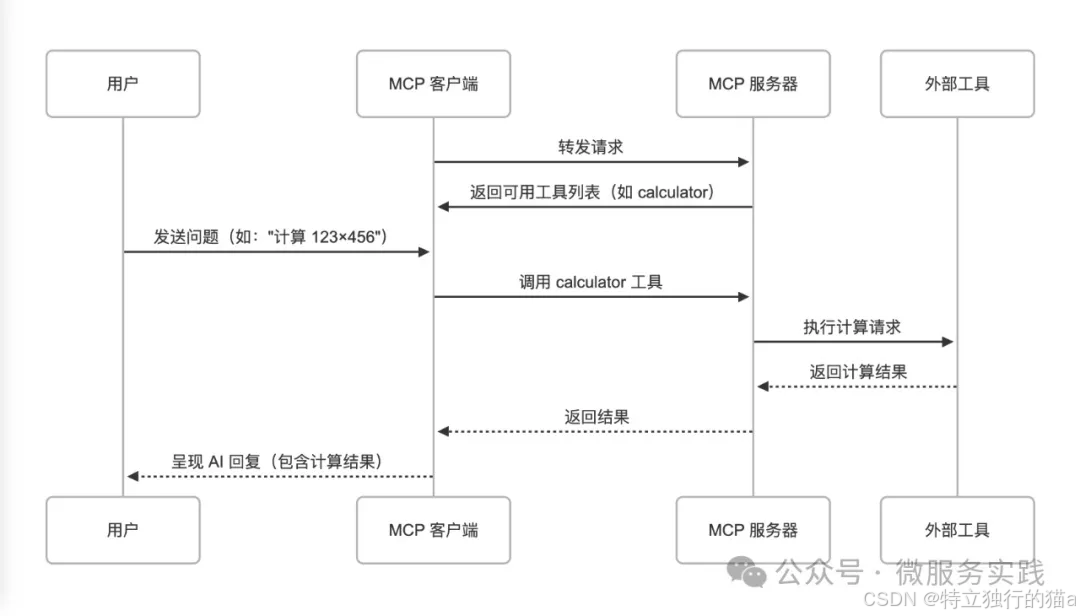
AI中的MCP是什么?MCP的作用及未来方向预测 (使用go-zero 快速搭建MCP服务器)
AI是当下最热的风。在当今AI技术飞速发展的时代,AI的应用已经渗透到我们日常生活的方方面面。然而,随着AI系统的复杂性不断增加,如何让AI具备更强的自主性和灵活性成为了业界关注的焦点。这就引出了Model Context Protocol(MCP&am…...

mac安装cast
背景 pycharm本地运行脚本时提示cast没有安装 问题原因 脚本尝试调用cast命令(以太坊开发工具foundry中的子命令),但您的系统未安装该工具。 从日志可见,错误发生在通过sysutil.py执行shell命令时。 解决方案 方法1…...

conda更换清华源
1、概览 anaconda更换速度更快、更稳定的下载源,在linux环境测试通过。 2、conda源查看 在修改之前可以查看下现有conda源是什么,查看conda配置信息,如下: cat ~/.condarc 可以看到你的conda源,以我的conda源举例&am…...
:[macOS 64bit App开发]: 注意“回车换行“的跨平台使用.)
[原创](现代Delphi 12指南):[macOS 64bit App开发]: 注意“回车换行“的跨平台使用.
[作者] 常用网名: 猪头三 出生日期: 1981.XX.XX 企鹅交流: 643439947 个人网站: 80x86汇编小站 编程生涯: 2001年~至今[共24年] 职业生涯: 22年 开发语言: C/C++、80x86ASM、Object Pascal、Objective-C、C#、R、Python、PHP、Perl、 开发工具: Visual Studio、Delphi、XCode、…...

管理Oracle Data Guard的最佳实践
Oracle Data Guard的中文名字叫数据卫士,顾名思义,它是生产库的一道保障。所以管理Data Guard是DBA的一项重要工作之一,管理Data Guard时主要有以下几个注意点需要引起重视。 备份库的归档日志积压 一般情况下,生产库的归档日志是…...

一个简单点的js的h5页面实现地铁快跑的小游戏
以下是一个简化版的"地铁快跑"小游戏H5页面实现。这个游戏包含基本的角色跳跃、障碍物生成和计分系统,使用Canvas绘图技术实现。 完整源码 登录后复制 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-…...
)
作业帮Java后台开发面试题及参考答案(下)
final、finally、finalize 的区别是什么? final、finally和finalize是 Java 中三个功能完全不同的关键字,容易混淆,需从作用域、语法规则和实际用途等方面深入区分。 final的作用 final用于修饰类、方法和变量,体现 “不可变” 特性: 修饰类:表示该类不能被继承,例如 J…...

Hugging Face 中 LeRobot 使用的入门指南
相关源文件 .github/ISSUE_TEMPLATE/bug-report.yml .github/PULL_REQUEST_TEMPLATE.md README.md examples/1_load_lerobot_dataset.py examples/2_evaluate_pretrained_policy.py examples/3_train_policy.py lerobot/scripts/eval.py lerobot/scripts/train.py 本页面提供 …...
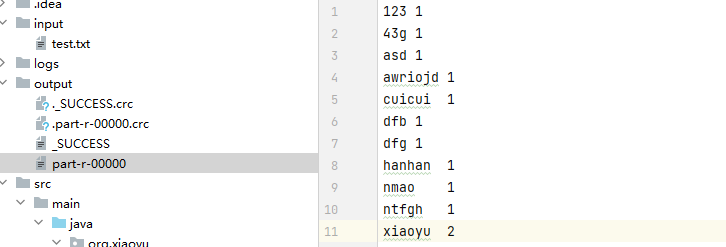
零基础入门Hadoop:IntelliJ IDEA远程连接服务器中Hadoop运行WordCount
今天我们来聊一聊大数据,作为一个Hadoop的新手,我也并不敢深入探讨复杂的底层原理。因此,这篇文章的重点更多是从实际操作和入门实践的角度出发,带领大家一起了解大数据应用的基本过程。我们将通过一个经典的案例——WordCounter&…...

HTML-3.3 表格布局(学校官网简易布局实例)
本系列可作为前端学习系列的笔记,代码的运行环境是在HBuilder中,小编会将代码复制下来,大家复制下来就可以练习了,方便大家学习。 系列文章目录 HTML-1.1 文本字体样式-字体设置、分割线、段落标签、段内回车以及特殊符号 HTML…...

Maven构建流程详解:如何正确管理微服务间的依赖关系-当依赖的模块更新后,我应该如何重新构建主项目
文章目录 一、前言二、Maven 常用命令一览三、典型场景说明四、正确的构建顺序正确做法是: 五、为什么不能只在 A 里执行 clean install?六、进阶推荐:使用多模块项目(Multi-module Project)七、总结 一、前言 在现代…...
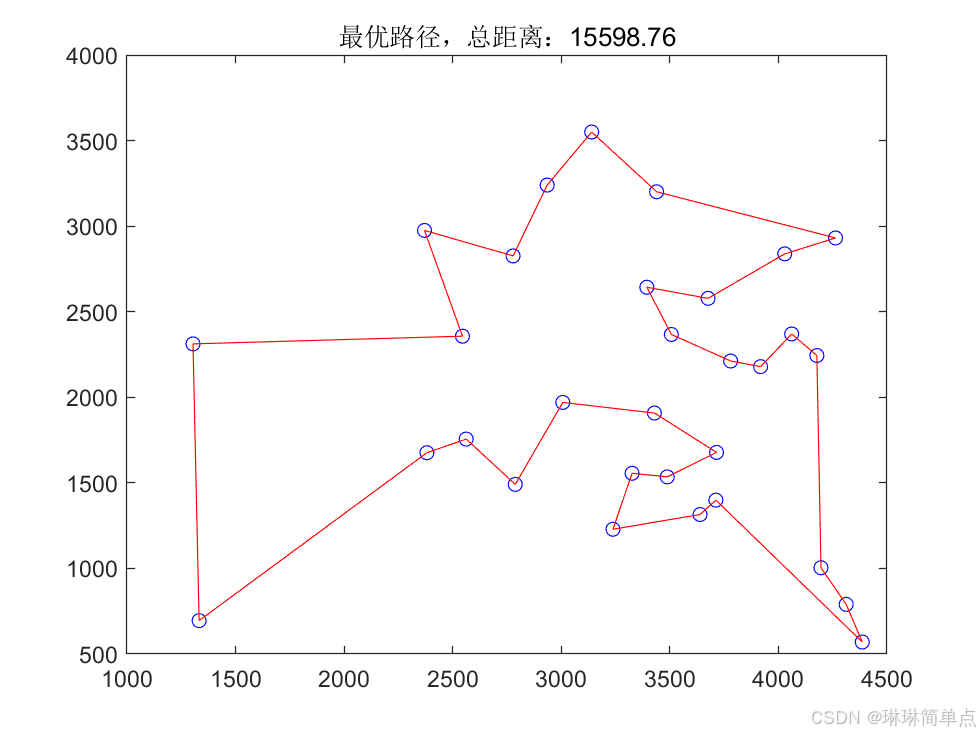
遗传算法求解旅行商问题分析
目录 一、问题分析 二、实现步骤 1)初始化种群 2)计算适应度 3)选择操作 4)交叉操作 5)变异操作 三、求解结果 四、总结 本文通过一个经典的旅行商问题,详细阐述在实际问题中如何运用遗传算法来进…...

【hot100-动态规划-300.最长递增子序列】
力扣300.最长递增子序列思路解析 本题要求在一个整数数组 nums 中,找到最长严格递增子序列的长度。子序列是指从原数组中派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。 动态规划思路 定义状态:…...