排序算法之高效排序:快速排序,归并排序,堆排序详解
排序算法之高效排序:快速排序、归并排序、堆排序详解
- 前言
- 一、快速排序(Quick Sort)
- 1.1 算法原理
- 1.2 代码实现(Python)
- 1.3 性能分析
- 二、归并排序(Merge Sort)
- 2.1 算法原理
- 2.2 代码实现(Java)
- 2.3 性能分析
- 三、堆排序(Heap Sort)
- 3.1 算法原理
- 3.2 代码实现(C++)
- 3.3 性能分析
- 四、三种高效排序算法的对比与适用场景
- 总结
前言
相较于上一期我讲的冒泡、选择、插入等基础排序,快速排序、归并排序和堆排序凭借更优的时间复杂度,成为处理大规模数据排序任务的首选方案。本文我将深入剖析这三种高效排序算法的原理、实现细节、性能特点及适用场景,助力你掌握它们在实际开发中的应用技巧。
一、快速排序(Quick Sort)
1.1 算法原理
快速排序由托尼・霍尔(Tony Hoare)于 1959 年提出,是一种基于分治思想的排序算法。其核心步骤如下:
选择基准值:从数组中选取一个元素作为基准值(通常选择第一个、最后一个或中间元素)。
分区操作:将数组分为两个子数组,使得左边子数组的所有元素都小于等于基准值,右边子数组的所有元素都大于基准值。
递归排序:对左右两个子数组分别递归地进行快速排序。
通过不断重复上述步骤,最终使整个数组达到有序状态。例如,对于数组[5, 3, 8, 6, 2],若选择5作为基准值,经过分区操作后,数组变为[3, 2, 5, 6, 8],然后分别对[3, 2]和[6, 8]进行递归排序,最终得到有序数组[2, 3, 5, 6, 8]。

1.2 代码实现(Python)
def quick_sort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr) // 2]left = [x for x in arr if x < pivot]middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quick_sort(left) + middle + quick_sort(right)
上述代码中,首先判断数组长度,若小于等于 1 则直接返回。接着选取基准值,通过列表推导式将数组分为小于、等于、大于基准值的三个部分,最后递归地对左右子数组进行排序并合并。
1.3 性能分析
时间复杂度:
平均情况下,快速排序的时间复杂度为 O ( n log n ) O(n \log n) O(nlogn) ,其中n为数组元素个数。
最坏情况下(如数组已有序且每次选择的基准值为最大或最小元素),时间复杂度退化为 O ( n 2 ) O(n^2) O(n2) 。
空间复杂度:快速排序的空间复杂度主要取决于递归调用栈的深度。平均情况下,空间复杂度为 O ( log n ) O(\log n) O(logn) ;在最坏情况下,递归深度达到n,空间复杂度为 O ( n ) O(n) O(n) 。
稳定性:快速排序是不稳定的排序算法,因为在分区过程中,相同元素的相对顺序可能会发生改变。
二、归并排序(Merge Sort)
2.1 算法原理
归并排序同样基于分治思想,它将一个数组分成两个大致相等的子数组,分别对两个子数组进行排序,然后将排好序的子数组合并成一个最终的有序数组。具体步骤如下:
分解:将待排序数组不断平均分成两个子数组,直到子数组长度为 1(单个元素可视为有序)。
排序:对每个子数组进行排序(可使用其他排序方法,通常也是递归地使用归并排序)。
合并:从最底层开始,将两个有序的子数组合并成一个更大的有序数组,不断向上合并,直至得到整个有序数组。
例如,对于数组[8, 4, 2, 1, 7, 6, 3, 5],先分解为多个子数组,再依次排序并合并,最终得到有序数组[1, 2, 3, 4, 5, 6, 7, 8]。

2.2 代码实现(Java)
import java.util.Arrays;public class MergeSort {public static void mergeSort(int[] arr) {if (arr == null) {return;}int[] temp = new int[arr.length];mergeSort(arr, temp, 0, arr.length - 1);}private static void mergeSort(int[] arr, int[] temp, int left, int right) {if (left < right) {int mid = left + (right - left) / 2;mergeSort(arr, temp, left, mid);mergeSort(arr, temp, mid + 1, right);merge(arr, temp, left, mid, right);}}private static void merge(int[] arr, int[] temp, int left, int mid, int right) {System.arraycopy(arr, left, temp, left, right - left + 1);int i = left;int j = mid + 1;int k = left;while (i <= mid && j <= right) {if (temp[i] <= temp[j]) {arr[k++] = temp[i++];} else {arr[k++] = temp[j++];}}while (i <= mid) {arr[k++] = temp[i++];}while (j <= right) {arr[k++] = temp[j++];}}public static void main(String[] args) {int[] arr = {8, 4, 2, 1, 7, 6, 3, 5};mergeSort(arr);System.out.println(Arrays.toString(arr));}
}
在上述 Java 代码中,mergeSort方法作为入口,调用递归的mergeSort方法进行分解和排序,merge方法用于合并两个有序子数组。通过临时数组temp辅助完成合并操作,保证合并过程中数据的正确处理。
2.3 性能分析
时间复杂度:归并排序无论在最好、最坏还是平均情况下,时间复杂度均为 O ( n log n ) O(n \log n) O(nlogn) ,因为每次分解和合并操作的时间开销相对固定,总操作次数与 n log n n \log n nlogn相关。
空间复杂度:归并排序在合并过程中需要使用额外的空间存储临时数据,空间复杂度为 O ( n ) O(n) O(n) 。
稳定性:归并排序是稳定的排序算法,在合并子数组时,相同元素的相对顺序不会发生改变。
三、堆排序(Heap Sort)
3.1 算法原理
堆排序利用了堆这种数据结构(大顶堆或小顶堆)的特性来实现排序。大顶堆的特点是每个父节点的值都大于或等于其子节点的值,小顶堆则相反。堆排序的主要步骤如下:
建堆:将待排序数组构建成一个大顶堆(升序排序时)或小顶堆(降序排序时)。
交换与调整:将堆顶元素(最大值或最小值)与堆的最后一个元素交换,然后对剩余元素重新调整堆结构,使其再次满足堆的性质。
重复操作:不断重复步骤 2,直到堆中只剩下一个元素,此时数组即为有序状态。
例如,对于数组[4, 6, 8, 5, 9],先构建大顶堆[9, 6, 8, 5, 4],然后将 9 与 4 交换,调整堆为[8, 6, 4, 5, 9],依次类推,最终得到有序数组[4, 5, 6, 8, 9]。

3.2 代码实现(C++)
#include <iostream>
#include <vector>
using namespace std;// 调整堆结构
void heapify(vector<int>& arr, int n, int i) {int largest = i;int left = 2 * i + 1;int right = 2 * i + 2;if (left < n && arr[left] > arr[largest]) {largest = left;}if (right < n && arr[right] > arr[largest]) {largest = right;}if (largest != i) {swap(arr[i], arr[largest]);heapify(arr, n, largest);}
}// 堆排序
void heapSort(vector<int>& arr) {int n = arr.size();// 建堆for (int i = n / 2 - 1; i >= 0; --i) {heapify(arr, n, i);}// 交换与调整for (int i = n - 1; i > 0; --i) {swap(arr[0], arr[i]);heapify(arr, i, 0);}
}
上述 C++ 代码中,heapify函数用于调整堆结构,确保以i为根节点的子树满足堆的性质。heapSort函数先进行建堆操作,然后通过不断交换堆顶元素和堆的最后一个元素,并调整堆结构,实现排序功能。
3.3 性能分析
时间复杂度:堆排序的时间复杂度主要由建堆和调整堆两部分组成。建堆的时间复杂度为 O ( n ) O(n) O(n) ,调整堆的时间复杂度为 O ( n log n ) O(n \log n) O(nlogn) ,因此整体时间复杂度为 O ( n log n ) O(n \log n) O(nlogn) ,且在最好、最坏和平均情况下均保持不变。
空间复杂度:堆排序在排序过程中只需要常数级别的额外空间,空间复杂度为 O ( 1 ) O(1) O(1) 。
稳定性:堆排序是不稳定的排序算法,因为在调整堆结构时,相同元素的相对顺序可能会被打乱。
四、三种高效排序算法的对比与适用场景
| 排序算法 | 平均时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 稳定性 | 适用场景 |
|---|---|---|---|---|---|
| 快速排序 | O ( n log n ) O(n \log n) O(nlogn) | O ( n 2 ) O(n^2) O(n2) | O ( log n ) O(\log n) O(logn) | 不稳定 | 数据随机分布、对空间要求不高的场景;适合内部排序,常用于通用排序库 |
| 归并排序 | O ( n log n ) O(n \log n) O(nlogn) | O ( n log n ) O(n \log n) O(nlogn) | O ( n ) O(n) O(n) | 稳定 | 对稳定性有要求、外部排序(如处理大文件)、数据规模较大且内存充足的场景 |
| 堆排序 | O ( n log n ) O(n \log n) O(nlogn) | O ( n log n ) O(n \log n) O(nlogn) | O ( 1 ) O(1) O(1) | 不稳定 | 对空间要求严格、需要在线性时间内找到最大 / 最小元素的场景,如优先队列实现 |
总结
快速排序、归并排序和堆排序作为高效排序算法,在不同的应用场景中发挥着各自的优势。快速排序凭借其简洁高效的特点,在多数常规排序任务中表现出色;归并排序以稳定的性能和适用于外部排序的特性,成为处理大规模数据的可靠选择;堆排序则因其对空间的高效利用和稳定的时间复杂度,在特定场景下展现出独特价值。下期博客中,我将带你探索更多高级排序算法与优化技巧,例如希尔排序、计数排序等,分析它们与快速排序、归并排序、堆排序的差异,以及在不同业务场景中的实际应用案例,帮助大家进一步拓宽排序算法的知识边界。
That’s all, thanks for reading!
创作不易,点赞鼓励;
知识无价,收藏备用;
持续精彩,关注不错过!
相关文章:
排序算法之高效排序:快速排序,归并排序,堆排序详解
排序算法之高效排序:快速排序、归并排序、堆排序详解 前言一、快速排序(Quick Sort)1.1 算法原理1.2 代码实现(Python)1.3 性能分析 二、归并排序(Merge Sort)2.1 算法原理2.2 代码实现…...
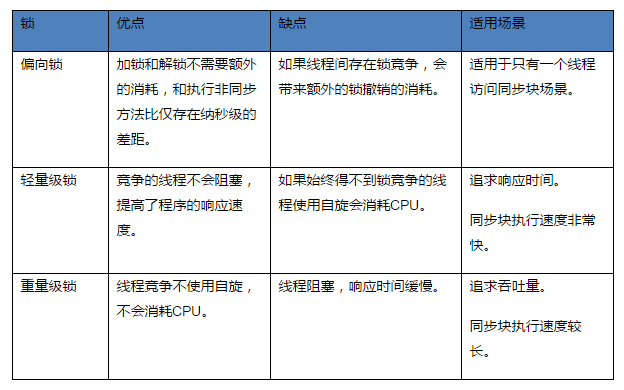
Java 并发编程归纳总结(可重入锁 | JMM | synchronized 实现原理)
1、锁的可重入 一个不可重入的锁,抢占该锁的方法递归调用自己,或者两个持有该锁的方法之间发生调用,都会发生死锁。以之前实现的显式独占锁为例,在递归调用时会发生死锁: public class MyLock implements Lock {/* 仅…...

基于对抗性后训练的快速文本到音频生成:stable-audio-open-small 模型论文速读
Fast Text-to-Audio Generation with Adversarial Post-Training 论文解析 一、引言与背景 文本到音频系统的局限性:当前文本到音频生成系统性能虽佳,但推理速度慢(需数秒至数分钟),限制了其在创意领域的应用。 研究…...

BUFDS_GTE2,IBUFDS,BUFG缓冲的区别
1、IBUFDS_GTE2 这是 Xilinx FPGA 中专门为 高速收发器(SerDes/GTX/GTH/GTY)参考时钟设计的差分输入缓冲器。 主要功能是将外部的差分时钟信号(如LVDS、LVPECL等)转换为FPGA内部的单端时钟信号,并保证信号的完整性和高…...
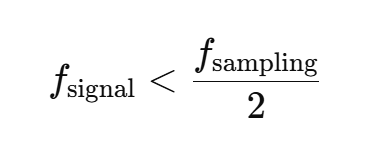
ADC深入——SNR、SFDR、ENOB等概念
目录 SNR(Spurious‑Free Dynamic Range 信噪比) ENOB(Effective Number Of Bits 有效位) SFDR(Spurious‑Free Dynamic Range) 感觉SNR和SFDR差不多?看看下图 输入带宽 混叠 带通采样/欠…...
)
ThinkPad X250电池换电池芯(理论技术储备)
参考:笔记本电池换电芯的经验与心得分享 - 经典ThinkPad专区 - 专门网 换电池芯,需要克服以下问题: 1 拆电池。由于是超声波焊接,拆解比较费力,如果暴力撬,有可能导致电池壳变形... 2 替换电池芯的时候如…...
硬件厂商的MIB文档详解 | 如何查询OID? | MIB Browser实战指南-优雅草卓伊凡
硬件厂商的MIB文档详解 | 如何查询OID? | MIB Browser实战指南-优雅草卓伊凡 一、硬件厂商的MIB文档是什么? 1. MIB的本质:设备的”数据字典” MIB(Management Information Base) 是SNMP协议的核心数据库,定义了设备…...
阿里开源通义万相 Wan2.1-VACE,开启视频创作新时代
0.前言 阿里巴巴于2025年5月14日正式开源了其最新的AI视频生成与编辑模型——通义万相Wan2.1-VACE。这一模型是业界功能最全面的视频生成与编辑工具,能够同时支持多种视频生成和编辑任务,包括文生视频、图像参考视频生成、视频重绘、局部编辑、背景延展…...
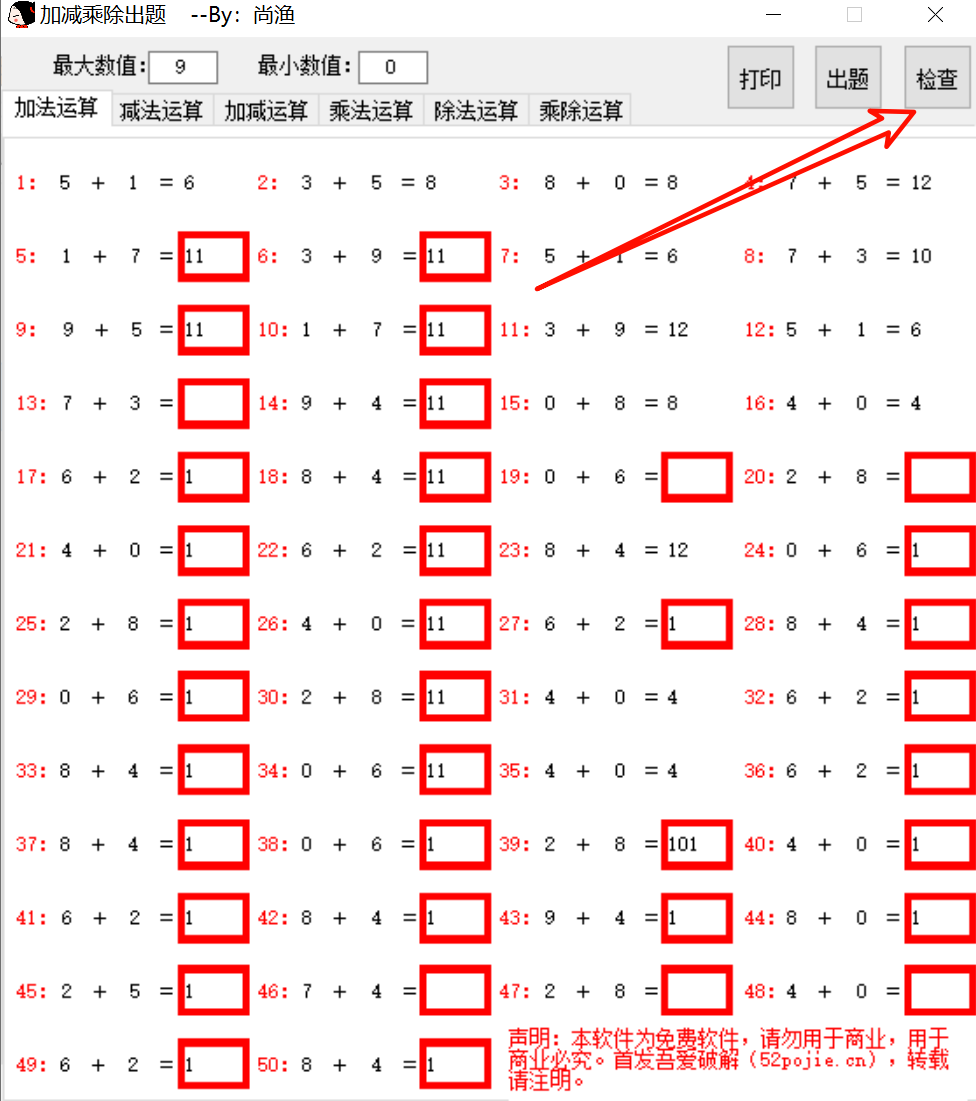
小学数学题批量生成及检查工具
软件介绍 今天给大家介绍一款近期发现的小工具,它非常实用。 软件特点与出题功能 这款软件体积小巧,不足两兆,具备强大的功能,能够轻松实现批量出题。使用时,只需打开软件,输入最大数和最小数,…...
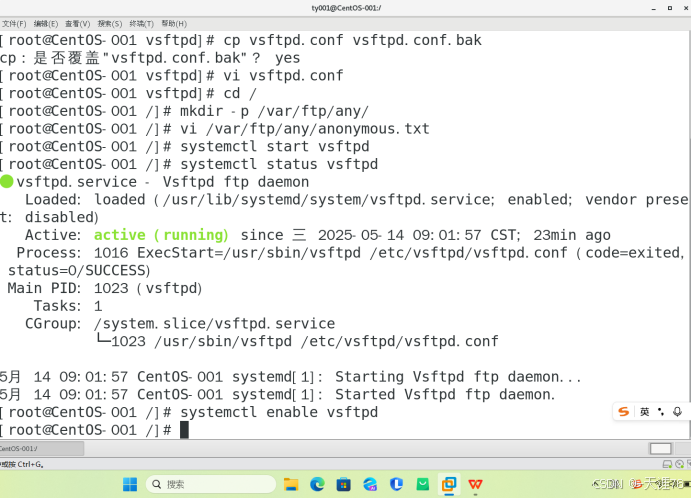
5.13/14 linux安装centos及一些操作命令随记
一、环境准备 VMware Workstation版本选择建议 CentOS 7 ISO镜像下载指引 虚拟机硬件配置建议(内存/处理器/磁盘空间) 二、系统基础命令 一、环境准备 1.VMware Workstation版本选择建议 版本选择依据 选择VMware Workstation的版本时,…...

OpenCV 背景建模详解:从原理到实战
在计算机视觉领域,背景建模是一项基础且重要的技术,它能够从视频流中分离出前景目标,广泛应用于运动目标检测、视频监控、人机交互等场景。OpenCV 作为计算机视觉领域最受欢迎的开源库之一,提供了多种高效的背景建模算法。本文将深…...
Transformer 模型与注意力机制
目录 Transformer 模型与注意力机制 一、Transformer 模型的诞生背景 二、Transformer 模型的核心架构 (一)编码器(Encoder) (二)解码器(Decoder) 三、注意力机制的深入剖析 …...

卡顿检测与 Choreographer 原理
一、卡顿检测的原理 卡顿的本质是主线程(UI 线程)未能及时完成某帧的渲染任务(超过 16.6ms,以 60Hz 屏幕为例),导致丢帧(Frame Drop)。检测卡顿的核心思路是监控主线程任务的执行时…...

Baklib加速企业AI数据智理转型
Baklib智理AI数据资产 在AI技术深度渗透业务场景的背景下,Baklib通过构建企业级知识中台架构,重塑了数据资产的治理范式。该平台采用智能分类引擎与语义分析模型,将分散在邮件、文档、数据库中的非结构化数据转化为标准化的知识单元…...
基于协同过滤的文学推荐系统设计【源码+文档+部署】
基于协同过滤的文学推荐系统设计 摘要 随着信息技术的飞速发展和文学阅读需求的日益多样化,构建一个高效、精准的文学推荐系统变得尤为重要。本文采用Spring Boot框架,结合协同过滤算法,设计并实现了一个基于用户借阅行为和社交论坛互动的文学…...

在c/c++中,如何使用链表进行插入、删除和遍历功能。
首先,链表由节点组成,每个节点应该包含数据和指向下一个节点的指针。 结构体可以包含数据域和指针域。 比如,假设链表存储整数,那节点的结构体应该有一个int类型的数据和一个指向同样结构体的指针。结构体定义大概是这样的&…...
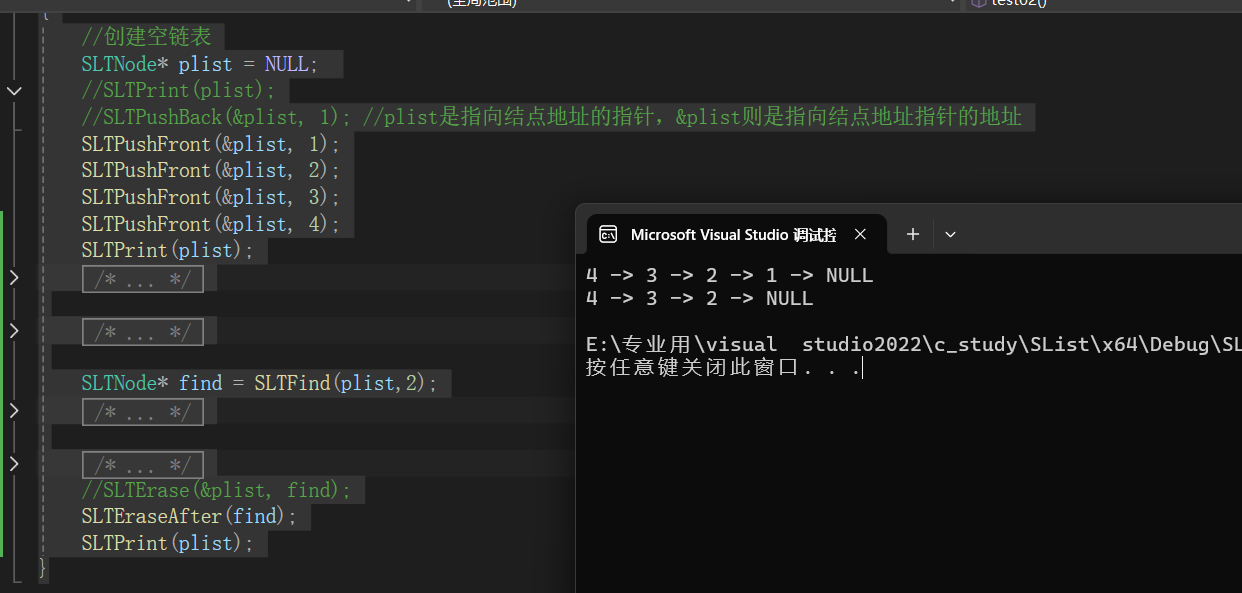
数据结构与算法——单链表(续)
单链表(续) 查找在指定位置之前插入结点在指定位置之后插入结点删除pos位置的结点删除pos位置之后的结点销毁 查找 遍历:pcur指向头结点,循环,当pucr不为空进入循环,pucr里面指向的数据为要查找的值的时候…...
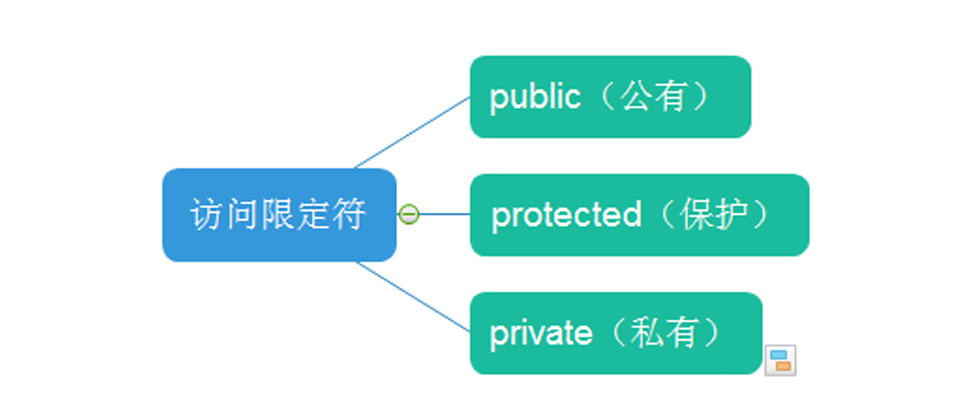
全面且深度学习c++类和对象(上)
文章目录 过程和对象类的引入,类的定义类的访问限定符及封装类的访问限定符封装 类的实例化类大小内存对齐规则: this指针this特性 过程和对象 C语言面向过程设计,c面向对象设计, 举例:洗衣服 C语言:放衣服…...

开源情报如何成为信息攻防的关键资源
相比于传统情报,开源情报具有情报数量大、情报质量好、情报成本低、情报可用性强等优势。这是开源情报能够成为信息攻防关键资源的主要原因。 海量信息让开源情报具有更大潜力。一是开源情报体量巨大。信息化时代是信息爆炸的时代,网络上发布的各种信息…...

【风控】用户特征画像体系
一、体系架构概述 1.1 核心价值定位 风控特征画像体系是通过多维度数据融合分析,构建客户风险全景视图的智能化工具。其核心价值体现在: 全周期覆盖:贯穿客户生命周期的营销、贷前、贷中、贷后四大场景立体化刻画:整合基础数据…...

Android开发-文本输入
在Android应用开发中,文本输入是用户与应用交互的最常见方式之一。无论是登录界面、搜索框还是表单填写,都需要处理用户的文本输入。本文将介绍如何在Android应用中实现和管理文本输入,包括基本控件的使用、事件监听、输入验证以及一些高级功…...
Unity:场景管理系统 —— SceneManagement 模块
目录 🎬 什么是 Scene(场景)? Unity 项目中的 Scene 通常负责什么? 🌍 一个 Scene 包含哪些元素? Scene 的切换与管理 📁 如何创建与管理 Scenes? 什么是Scene Man…...

elementUI源码学习
学习笔记。 最近在看element的table表格优化,又去看了一下element源码框架。element 的架构是很优秀,通过大量的脚本实现工程化,让组件库的开发者专注于事情本身,比如新加组件,一键生成组件所有文件,并完成…...
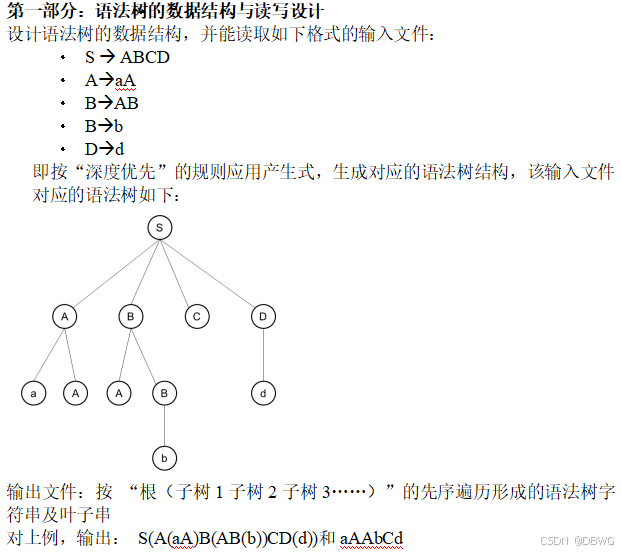
SZU 编译原理
总结自 深圳大学《编译原理》课程所学相关知识。 文章目录 文法语法分析自顶向下的语法分析递归下降分析LL(1) 预测分析法FIRST 集合FOLLOW 集合 文法 乔姆斯基形式语言理论: 表达能力:0型文法 > 1型文法 > 2型文法 > 3型文法。 0 型文法&am…...

实时技术方案对比:SSE vs WebSocket vs Long Polling
早期网站仅展示静态内容,而如今我们更期望:实时更新、即时聊天、通知推送和动态仪表盘。 那么要如何实现实时的用户体验呢?三大经典技术各显神通: SSE(Server-Sent Events):轻量级单向数据流WebSocket:双向全双工通信Long Polling(长轮询):传统过渡方案假设目前有三…...

【程序员AI入门:模型】19.开源模型工程化全攻略:从选型部署到高效集成,LangChain与One-API双剑合璧
一、模型选型与验证:精准匹配业务需求 (一)多维度评估体系 通过量化指标权重实现科学选型,示例代码计算模型综合得分: # 评估指标权重与模型得分 requirements {"accuracy": 0.4, "latency": …...

北斗导航 | 基于深度学习的卫星导航数据训练——检测识别故障卫星
深度学习+故障卫星识别 **1. 数据准备与预处理****2. 模型选择与设计****3. 训练策略****4. 模型优化与验证****5. 实时部署与集成****6. 持续学习与更新****示例模型架构(LSTM + Attention)****挑战与解决方案**🥦🥦🥦🥦🥦🥦🥦🥕🥦🥦🥦🥦🥦🥦�…...

ARM Cortex-M3内核详解
目录 一、ARM Cortex-M3内核基本介绍 (一)基本介绍 (二)主要组成部分 (三)调试系统 二、ARM Cortex-M3内核的内核架构 三、ARM Cortex-M3内核的寄存器 四、ARM Cortex-M3内核的存储结构 五、ARM Co…...

基于Unity的简单2D游戏开发
基于Unity的简单2D游戏开发 摘要 本文围绕基于Unity的简单2D游戏开发进行深入探讨,旨在分析其开发过程中的技术架构与实现策略。通过文献综述与市场分析,研究发现,近年来Unity引擎因其优秀的跨平台特性及可视化编程理念,成为2D游戏开发的主要工具。文章首先梳理了游戏开发的…...

Linux系统编程——exec族函数
我们来完整、系统、通俗地讲解 Linux 系统编程中非常重要的一类函数:exec 族函数(也叫 exec family)。 一、什么是 exec? exec 系列函数的作用是: 用一个新的程序,替换当前进程的内容。 也就是说…...