Multimodal models —— CLIP,LLava,QWen
目录
CLIP
CLIP训练
CLIP图像分类
CLIP框架
Text Enocder
Image Encoder
LLava系列
LLava
LLava贡献
LLava模型结构
总结
LLava两阶段训练
LLava 1.5
LLava 1.6
QWen
CLIP
CLIP是OpenAI 在 2021 年发布的,最初用于匹配图像和文本的预训练神经网络模型,这个任务在多模态领域比较常见,可以用于文本图像检索。CLIP的思想是使用大量图片文本对来进行预训练,以学习图像和文本之间的对齐关系。CLIP有两个模态,一个是文本模态,另一个是视觉模态,包括两个主要部分:Text Encoder 和 Image Encoder。
CLIP训练
CLIP的训练阶段基于对比学习的,如给定64个图片文本对,那么对应的就是64条文本和64张图片,在对比学习中,图片文本对本身就是正样本,而该文本与其他的63张图片构成了负样本,相对应的这张图片与另外63条文本构成了负样本。基于余弦相似度,在对比学习的这个过程中,我们可以知道配对的图片文本其余弦相似度最高(如图1(1)矩阵的主对角线),而当前样本的文本与另外的63张图片余弦相似度应较小。通过这种对比学习方式,来让相似的图片文本尽可能拉近,不相似的图片文本尽可能拉远。
CLIP图像分类
CLIP在下游任务图像分类中的应用中也表现出色。
- 首先对于给定的图像分类任务(例如,将图像分为“猫”、“狗”、“鸟”等),首先将所有可能的类别名称转换为文本描述。例如,对于类别“猫”,可以构造提示(prompt)如“a photo of a cat”、“a picture of a cat”等。通常会使用一个模板,如“a photo of a {object}”。
- 将这些文本描述通过文本编码器来获得每个类别的文本嵌入。
- 对于一张待分类的图像,则通过图像编码器来获得图像的嵌入表示。
- 计算图像嵌入与所有类别文本嵌入之间的余弦相似度。
- 选择相似度最高的类别来作为图像的预测类别。
收益于在大量图片文本对上的对比学习,CLIP在零样本的情况下,也能很好的实现图像的分类。将所有类别以一个相同prompt进行表示,并通过编码所有类别文本的表示,通过计算待测图片与所有类别文本之间的余弦相似度,来选择相似度最高的类别文本,所预测的类别就是该类别文字中的类别。
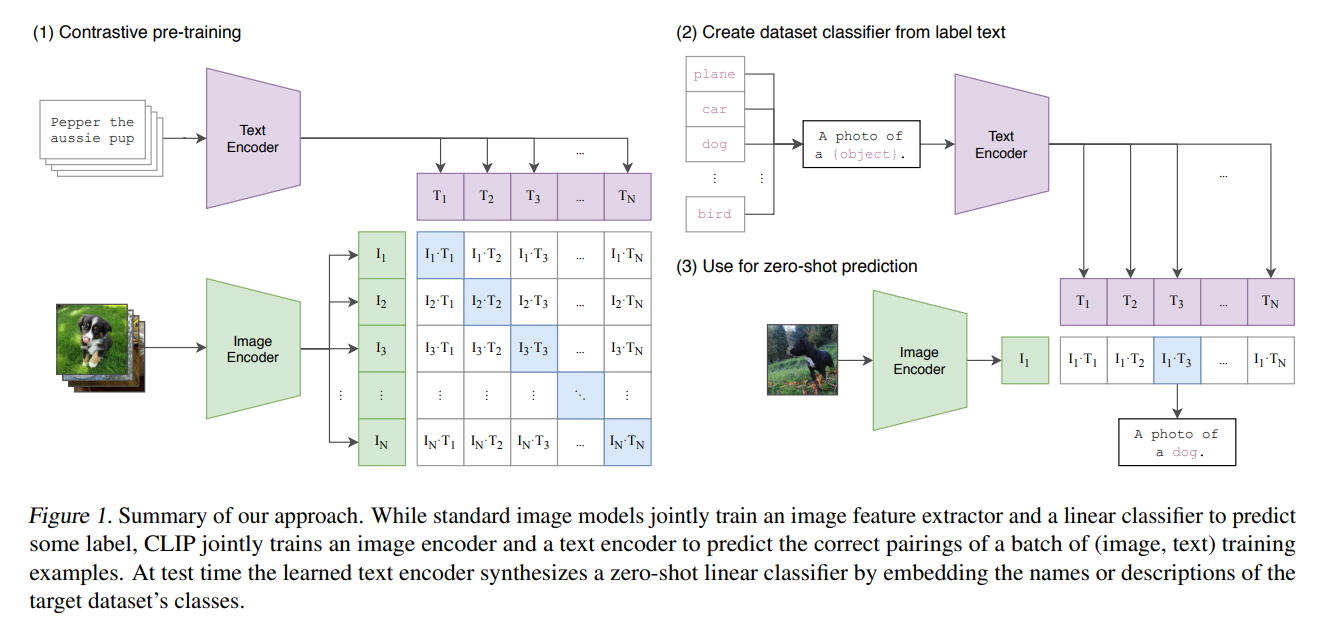
图1 CLIP方法
CLIP框架
CLIP的框架主要是两大部分,分别是Text Encder 和 Image Encoder。
Text Enocder
Text Encoder本质上与BERT差不多。
Image Encoder
Processor
首先是图像处理,借鉴了Transformer在NLP领域的成功,ViT将图像进行分割来作为一系列的tokens进行处理。CLIP中ViT模块Embedding包含以下几个关键部分:
- 图像分块。由于Transformer处理的是序列数据,为了让Transformer能够处理图像,ViT首先需要将输入的二维图像分割成一系列固定大小的、不重叠的小块(patches)。在这个过程中,首先需要对输入的图片分辨率进行修改,统一分辨率,如CLIP-VIT--base-Patch32中,ViT模块的图片分辨率都被统一压缩为224*224,每一个图像块的分辨率为32*32,因此一张224*224的图片将被切分49块(224/32 * 224/32)。每个图像块都是32*32*3的张量,3表示通道数,表示图片由红绿蓝三种通道所形成。
Embedding
- 展平与线性投影。每个带有通道信息的图像块被转换成一个1D的向量,并将其投影到一个统一的嵌入空间中,来使其维度与Transformer的隐藏维度相匹配。对于每个带有通道数32*32*3的图像块,其被展平后维度是32*32*3=3072。随后,这个3072维的展品向量被一个可学习的线性投影层映射到D维的嵌入空间,Clip-ViT-base-patch32中D维是768维。
- 位置编码。在经过上述操作后,图像的表示为[49,768],但这49个图像块没有进行位置编码,如果没有位置编码的话,不能很好地还原整张图像的关系。位置编码的优先级为从左都右,从上到下。因此进行位置编码后,我们可以确定对应位置的图像块在原图像的具体位置。与文本类似,ViT在这部分也添加了一个可学习的[CLS] token,用于最终图像表示。因此一张图片可以最终表示为[50,768], 随后这个embedding后的向量再被归一化后,就被输入到Transformer中进行Encoding了。
后续Encoding的部分与文本的Transformer基本类似,就不再过多介绍了。
LLava系列
LLava
LLava贡献
- 提出一个数据重组方式,使用 ChatGPT/GPT-4 将图像 - 文本对转换为适当的指令格式。
- 大型多模态模型,基于CLIP的ViT模块和文本解码器LLaMa,开发了一个大型多模态大模型——LLava,并在生成的视觉 - 语言指令数据上进行端到端微调。实证研究验证了将生成的数据用于 LMM 进行 instruction-tuning 的有效性,并为构建遵循视觉 agent 的通用指令提供了较为实用的技巧。
LLava模型结构
视觉编码器CLIP-ViT-large-patch14 + LLM Vicuna。
两个模型通过一个简单的映射矩阵进行连接,这个矩阵负责将视觉和语言特征对齐或转换,以便在一个统一的空间内对它们进行操作。
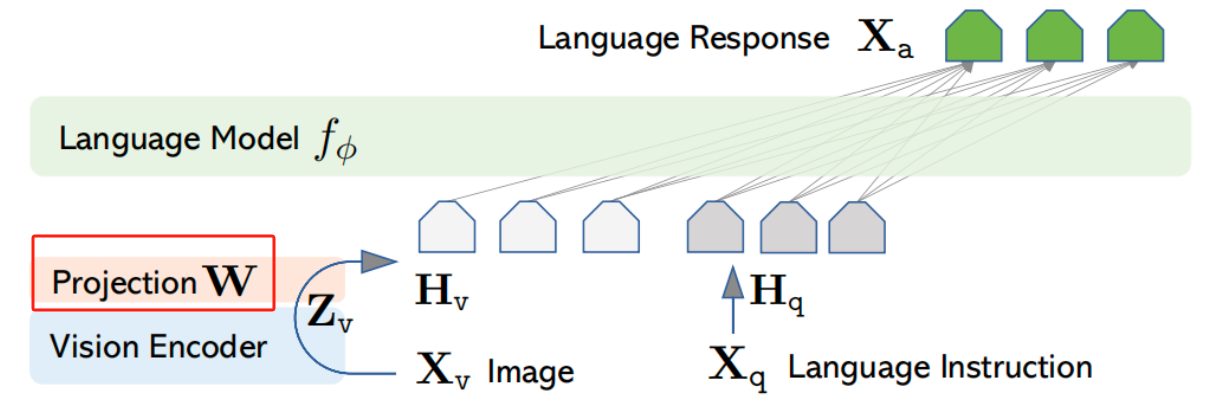
对于输入图像Xv,经过视觉编码器后得到Zv,需要注意的是Zv不是CLIP-ViT最终的输出,论文是将ViT模块Transformer最后一层之前和之后的视觉特征都考虑上了,这可能因为不同层的网格特征可能包含不同层次的信息,前一层特征可能更聚焦于局部细节,而后一层特征可能侧重于更全局、抽象的图像属性 ,综合考虑这些特征,有助于模型更好地理解图像内容。随后再通过可训练的投影矩阵进行映射,将Zv映射为Hv,来保持视觉模态维度与文本模态维度保持一致,从而实现多模态维度的对齐。
总结
LLaVa的模型结构非常简单,就是一个CLIP - ViT + LLaMA,为了与文本维度进行对齐,设计一个可学习的投影矩阵来对齐视觉模态和文本模态的维度。
LLava两阶段训练
阶段一:特征对齐预训练。由于从CLIP提取的特征与word embedding不在同一个语义表达空间,因此,需要通过预训练,将image token embedding对齐到text word embedding的语义表达空间。这个阶段冻结Vision Encoder和LLM模型的权重参数,只训练插值层Projection W的权重。即提升视觉模态维度投影到文本模态维度上的表现。
阶段二:端到端训练。这个阶段,依然冻结Vision Encoder的权重,训练过程中同时更新插值层Projection W和LLM语言模型的权重,训练考虑Multimodal Chatbot和Science QA两种典型的任务。
LLava 1.5
LLava1.5和LLava在模型架构上基本一样,在文本模型和维度对齐方面做了修改,图像编码器也相应地进行了略微的调整。具体地
- LLM模型,LLM从Vicuna升级为Vicuna v1.5 13B, 模型的参数量更大,效果得到了提升。
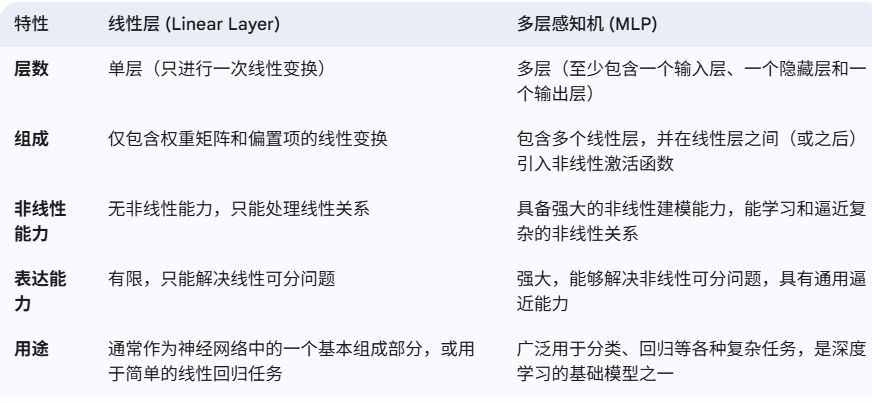
- Connector:原来是通过投影矩阵即线性层来将视觉模态维度映射到文本模态维度,但在LLava中采用MLP去进行映射。MLP和线性层的区别在于MLP是多层线性层的叠加,且在线性层之间/之后引入非线性激活函数。
- Vision Encoder:使用CLIP - VIT - Large336px,输入图像分辨率从224 * 224 增大为 336 *336,对图像的细节理解能力更强。(减少了分辨率降低所带来的细节程度忽略)
- 数据的质量也得到了提高
LLava 1.6
LLava1.6参数量达到34B,参数量为1.5版本相比得到了巨大的提升,在各项指标上提升也十分明显。在推理,OCR和世界知识的能力得到了增强。具体的改变有:
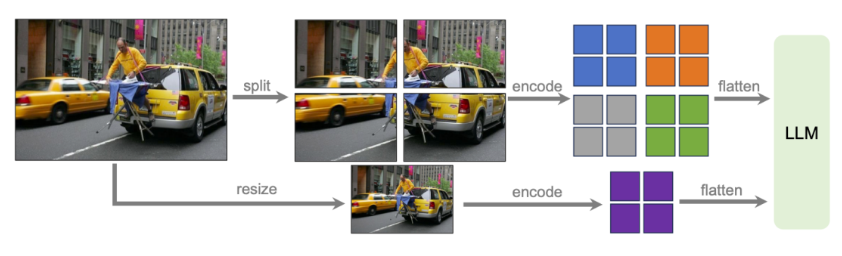
- Vision Encoder:支持更大的分辨率,包括672x672, 336x1344, 1344x336 几种分辨率的输入,并且支持通过图片裁切,编码,合并来实现。图片的细节可以得到充分展示,降低了压缩图片分辨率所带来的影响。
- 参数量大升级,由LLaVA 1.5的13B参数,增加到最多34B参数。
- OCR能力提升:更好的推理和OCR能力:通过修改指令数据集实现
- 更好的视觉对话:在一些场景下,拥有更好的世界知识
QWen
相关文章:
Multimodal models —— CLIP,LLava,QWen
目录 CLIP CLIP训练 CLIP图像分类 CLIP框架 Text Enocder Image Encoder LLava系列 LLava LLava贡献 LLava模型结构 总结 LLava两阶段训练 LLava 1.5 LLava 1.6 QWen CLIP CLIP是OpenAI 在 2021 年发布的,最初用于匹配图像和文本的预训练神经网络模型…...

Python模块化编程进阶指南:从基础到工程化实践
一、模块化编程核心原理与最佳实践 1.1 模块化设计原则 根据企业级项目实践,模块化开发应遵循以下核心原则: 单一职责原则:每个模块只承担一个功能域的任务(如用户认证模块独立于日志模块)接口隔离原则…...

json-server的用法-基于 RESTful API 的本地 mock 服务
json-server 是一个非常方便的工具,用于快速搭建基于 RESTful API 的本地 mock 服务,特别适合前端开发阶段模拟后端数据接口。 🧩 一、安装 npm install -g json-server🚀 二、快速启动 创建一个 db.json 文件(模拟数…...
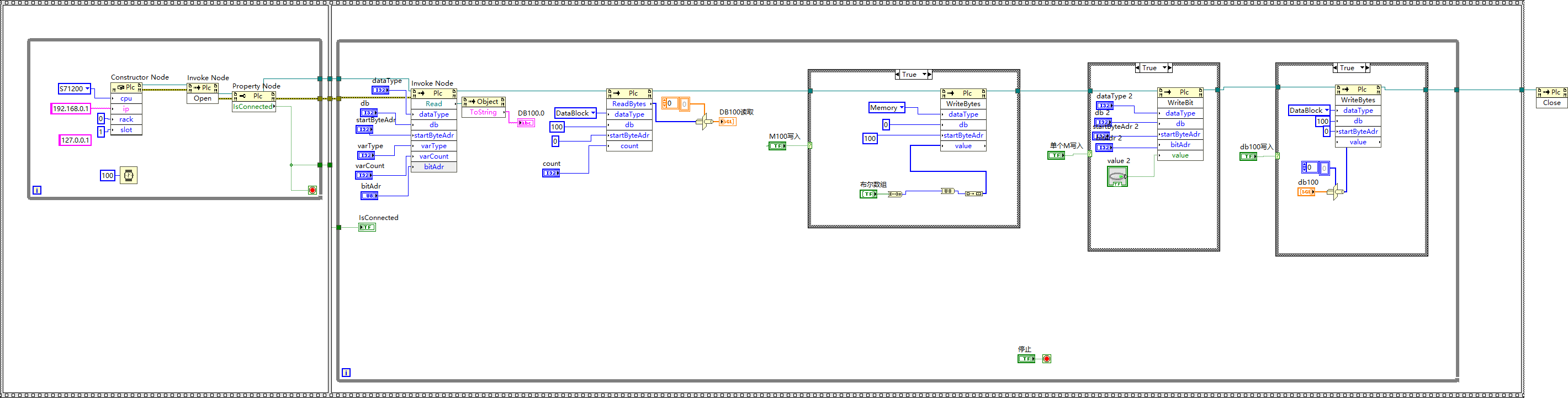
LabVIEW与PLC通讯程序S7.Net.dll
下图中展示的是 LabVIEW 环境下通过调用S7.Net.dll 组件与西门子 PLC 进行通讯的程序。LabVIEW 作为一种图形化编程语言,结合S7.Net.dll 的.NET 组件优势,在工业自动化领域中可高效实现与 PLC 的数据交互,快速构建工业监控与控制应用。相较于…...

STM32 __main汇编分析
在STM32的启动流程中,__main是一个由编译器自动生成的C标准库函数,其汇编级调用逻辑可通过启动文件(如startup_stm32fxxx.s)观察到,但具体实现细节被封装在编译器的运行时库中。以下是其核心逻辑解析: 一、…...

使用GpuGeek高效完成LLaMA大模型微调:实践与心得分享
使用GpuGeek高效完成LLaMA大模型微调:实践与心得分享 🌟嗨,我是LucianaiB! 🌍 总有人间一两风,填我十万八千梦。 🚀 路漫漫其修远兮,吾将上下而求索。 随着大模型的发展࿰…...

华为IP(6)
VLAN聚合 VLAN聚合产生的技术背景 在一般是三层交换机中,通常采用一个VLAN接口的方式实现广播域之间的互通,这在某些情况下导致了IP地址的浪费 因为一个VLAN对应的子网中,子网号、子网广播地址、子网网关地址不能用作VLAN内的主机IP地址&a…...
1:OpenCV—图像基础
OpenCV教程 头文件 您只需要在程序中包含 opencv2/opencv.hpp 头文件。该头文件将包含应用程序的所有其他必需头文件。因此,您不再需要费心考虑程序应包含哪些头文件。 例如 - #include <opencv2/opencv.hpp>命名空间 所有 OpenCV 类和函数都在 cv 命名空…...

第三部分:内容安全(第十六章:网络型攻击防范技术、第十七章:反病毒、第十八章:入侵检测/防御系统(IDS/IPS))
文章目录 第三部分:内容安全第十六章:网络型攻击防范技术网络攻击介绍流量型攻击 --- Flood攻击单包攻击及防御原理扫描窥探攻击畸形报文攻击Smurf攻击Land攻击Fraggle攻击IP欺骗攻击 流量型攻击防御原理DDoS通用攻击防范技术 ---- 首包丢弃TCP类攻击SYN…...
Void: Cursor 的开源平替
GitHub:https://github.com/voideditor/void 更多AI开源软件:发现分享好用的AI工具、AI开源软件、AI模型、AI变现 - 小众AI Void,这款编辑器号称是开源的 Cursor 和 GitHub Copilot 替代品,而且完全免费! 在你的代码库…...

100G QSFP28 BIDI光模块一览:100G单纤高速传输方案|易天光通信
目录 前言 一、易天光通信100G QSFP28 BIDI光模块是什么? 二、易天光通信100G QSFP28 BIDI光模块采用的关键技术 三、100G QSFP28 BIDI光模块的优势 四、以“易天光通信100G BIDI 40km ER1光模块”为例 五、总结:高效组网,从“减”开始 关于…...

基于大模型的脑出血智能诊疗与康复技术方案
目录 一、术前阶段1.1 数据采集与预处理系统伪代码实现流程图1.2 特征提取与选择模块伪代码实现流程图1.3 大模型风险评估系统伪代码实现流程图二、术中阶段2.1 智能手术规划系统伪代码实现流程图2.2 麻醉智能监控系统伪代码实现流程图三、术后阶段3.1 并发症预测系统伪代码片段…...

卓力达电铸镍网:精密制造与跨领域应用的创新典范
目录 引言 一、电铸镍网的技术原理与核心特性 二、电铸镍网的跨领域应用 三、南通卓力达电铸镍网的核心优势 四、未来技术展望 引言 电铸镍网作为一种兼具高精度与高性能的金属网状材料,通过电化学沉积工艺实现复杂结构的精密成型,已成为航空航天、电…...
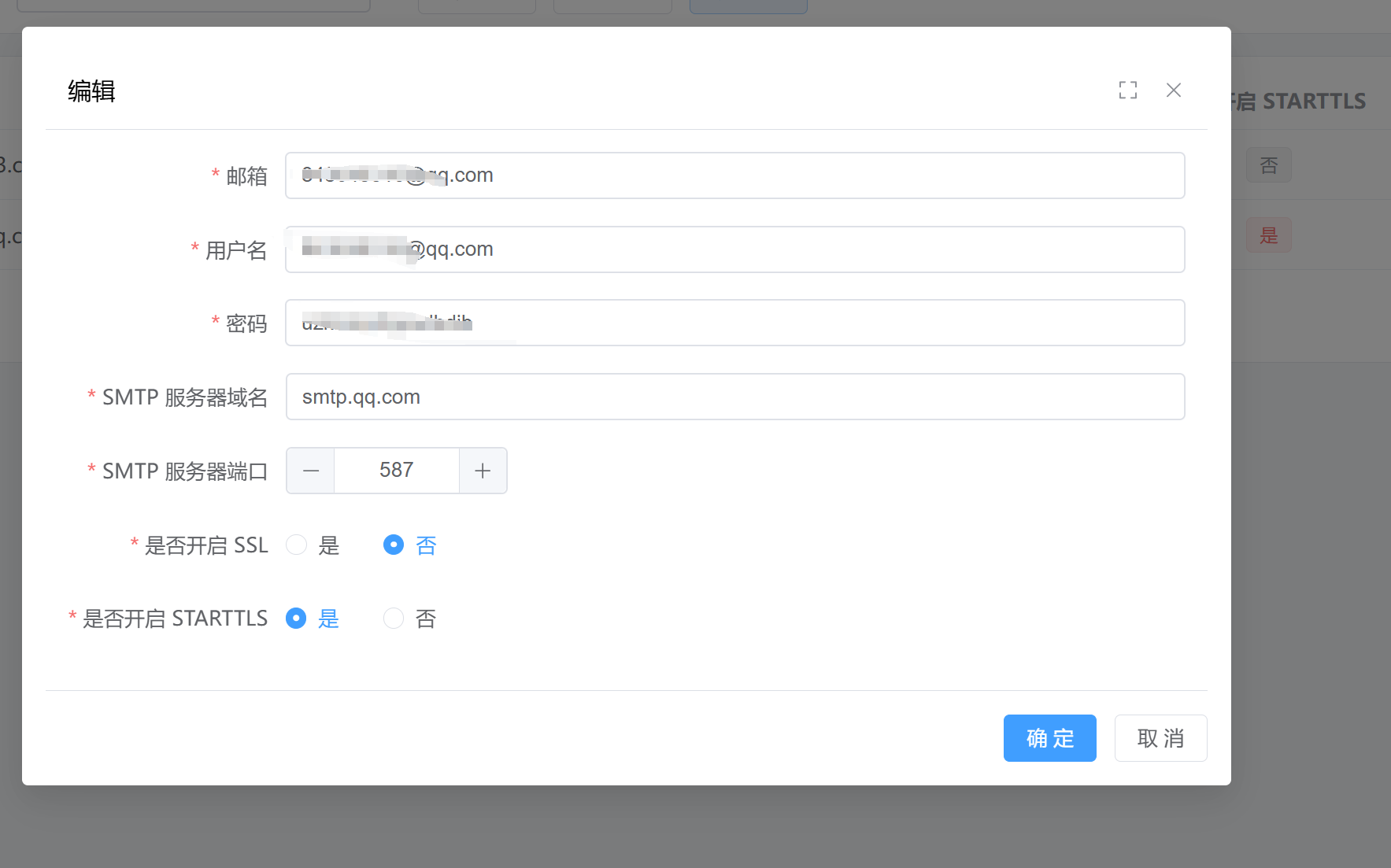
今日积累:若依框架配置QQ邮箱,来发邮件,注册账号使用
QQ邮箱SMTP服务器设置 首先,我们需要了解QQ邮箱的SMTP服务器地址。对于QQ邮箱,SMTP服务器地址通常是smtp.qq.com。这个地址适用于所有使用QQ邮箱发送邮件的客户端。 QQ邮箱SMTP端口设置 QQ邮箱提供了两种加密方式:SSL和STARTTLS。根据您选…...
快速入门机器学习的专有名词
机器学习(Machine Learning) 机器学习是计算机科学的一个领域,目的在于让计算机能够通过学习数据来做出预测或决策,而无需被明确编程来完成任务。 机器学习的工作模式: 数据:机器学习需要数据来“学习”…...
)
C#学习教程(附电子书资料)
概述 C#(读作"C Sharp")是一种由微软开发的现代编程语言,结合了C的高效性和Java的简洁性,专为.NET框架设计。以下是其核心特性和应用领域的详细介绍电子书资料:https://pan.quark.cn/s/6fe772420f95 一、语…...
Python之三大基本库——Matplotlib
好久没来总结了,今天刚好有时间,我们来继续总结一下python中的matplotlib 一、什么是Matplotlib Matplotlib是一个Python的2D绘图库,主要用于将数据绘制成各种图表,如折线图、柱状图、散点图、直方图、饼图等。它以各种硬拷贝…...
Tensorflow 2.X Debug中的Tensor.numpy问题 @tf.function
我在调试YOLOv3模型过程中想查看get_pred函数下面的get_anchors_and_decode函数里grid_shape的数值 #---------------------------------------------------# # 将预测值的每个特征层调成真实值 #---------------------------------------------------# def get_anchors_a…...
element基于表头返回 merge: true 配置列合并
<template><div class"wrap" v-loading"listLoading"><div class"content_wrap mt-10"><div style"text-align: center;"><h3>酿造交酒酒罐统计表({{month}}月{{day}}日)</h3…...
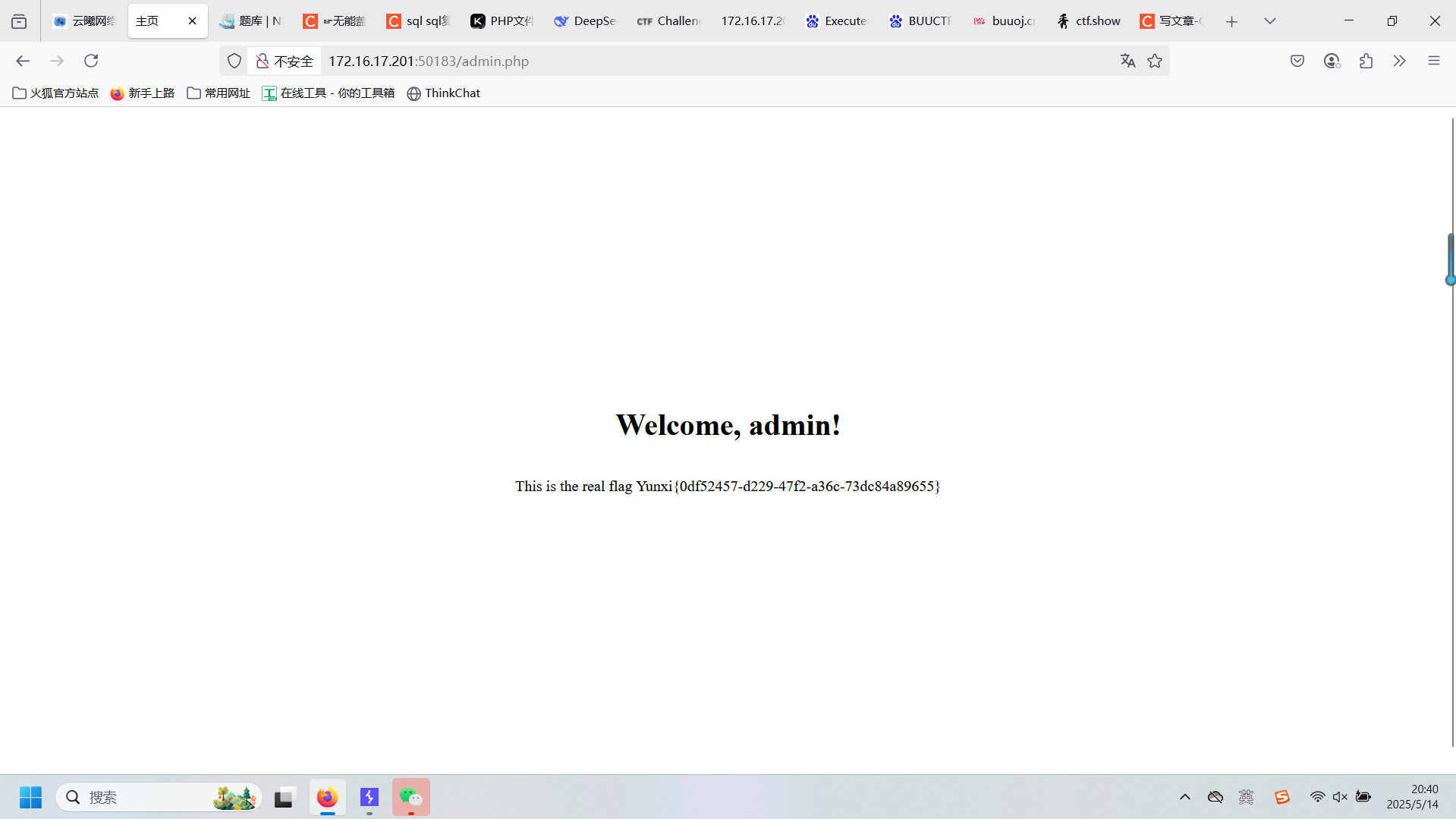
sql sql复习
虽然之前学习过sql,但由于重在赶学习进度,没有学扎实,导致自己刷题的时候有的地方还是模模糊糊,现在主要是复习,补一补知识点。 今日靶场: NSSCTF 云曦历年考核题 在做题之前先回顾一下sql注入的原理&…...
)
MySQL 8.0 OCP 1Z0-908 题目解析(1)
题目001 Choose two. User fwuserlocalhost is registered with the SQL Enterprise Firewall and has been granted privileges for the sakila database. Examine these commands that you executed and the results: mysql> SELECT MODE FROM INFORMATION_SCHEMA.SQL…...
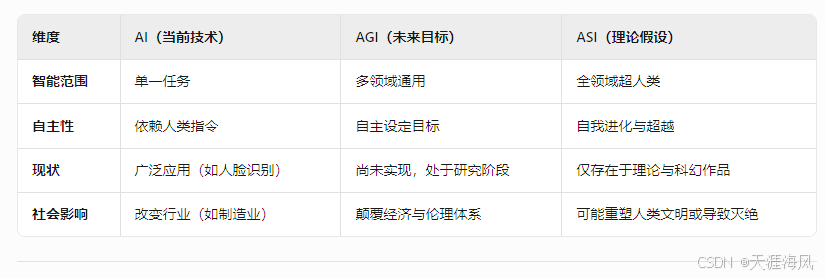
介绍一下什么是 AI、 AGI、 ASI
1. AI(人工智能):工具化的“窄域智能” 定义: AI 是能够执行特定任务的智能系统,依赖大量数据和预设规则,缺乏自主意识和跨领域通用性。 特点: 任务专用:如图像识…...
利用 Amazon Bedrock Data Automation(BDA)对视频数据进行自动化处理与检索
当前点播视频平台搜索功能主要是基于视频标题的关键字检索。对于点播平台而言,我们希望可以通过优化视频搜索体验满足用户通过模糊描述查找视频的需求,从而提高用户的搜索体验。借助 Amazon Bedrock Data Automation(BDA)技术&…...

TypeScript装饰器:从入门到精通
TypeScript装饰器:从入门到精通 什么是装饰器? 装饰器(Decorator)是TypeScript中一个非常酷的特性,它允许我们在不修改原有代码的情况下,给类、方法、属性等添加额外的功能。想象一下装饰器就像给你的代码…...
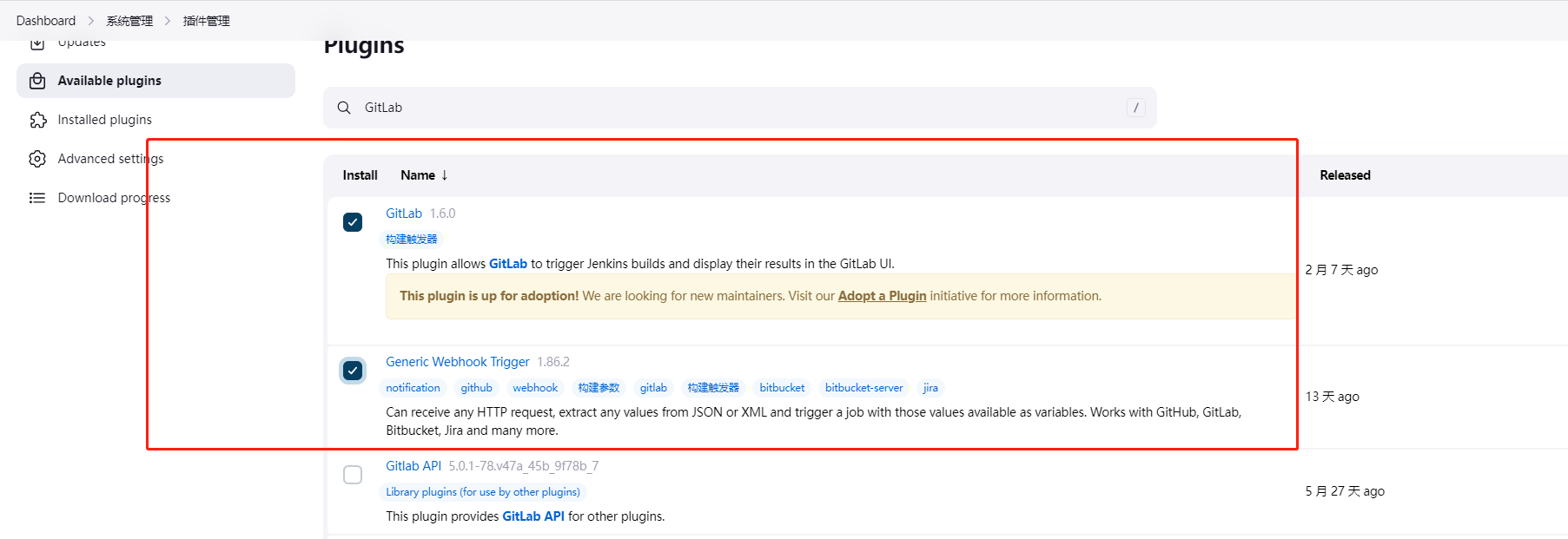
模拟jenkins+k8s自动化部署
参考 Jenkins+k8s实现自动化部署 - 掘金 手把手教你用 Jenkins + K8S 打造流水线环境 - 简书 安装插件 调整插件升级站点 (提高插件下载速度) 默认地址 https://updates.jenkins.io/update-center.json 新地址 http://mirror.xmission.com/jenkins/updates/update-center.json …...
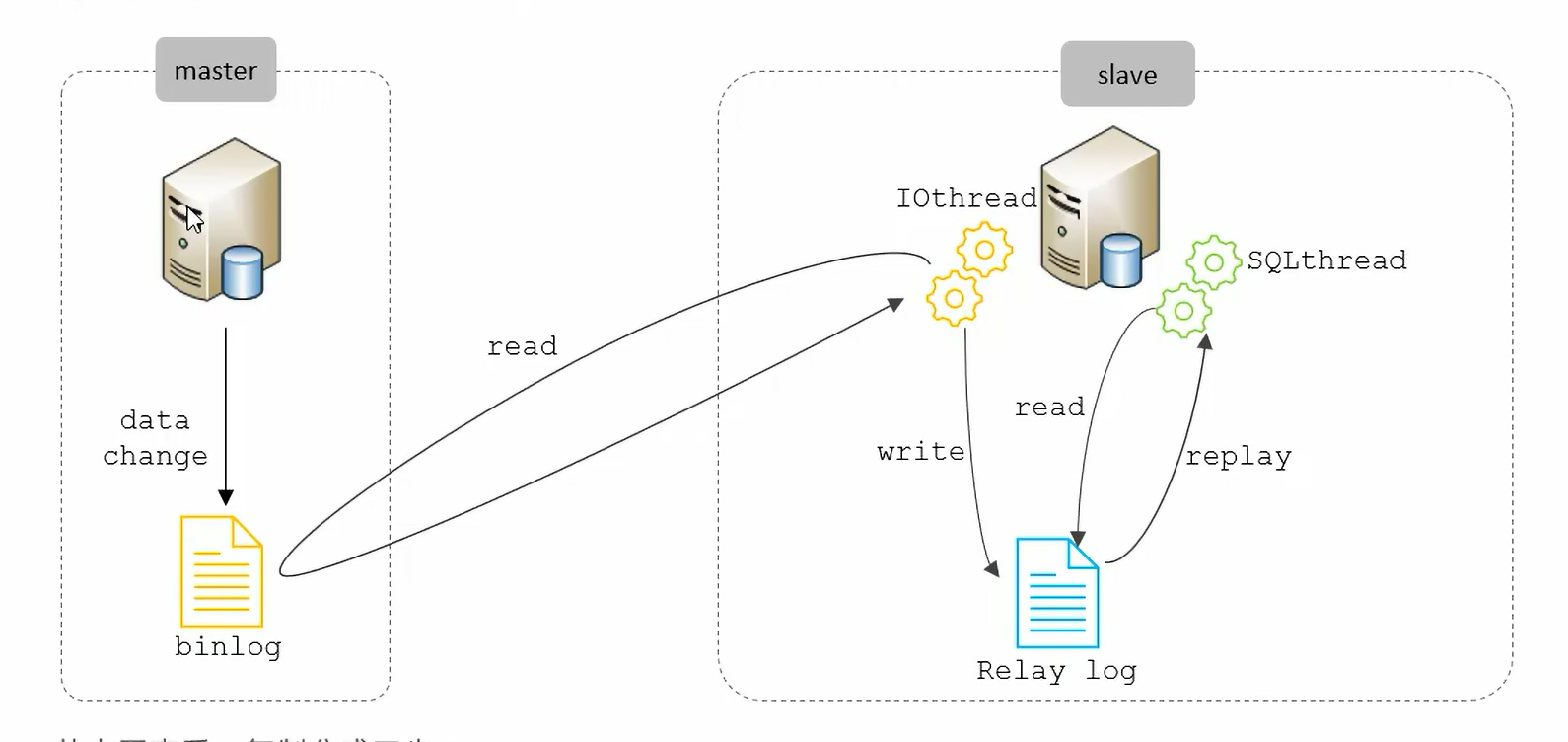
MySQL——十一、主从复制
主从复制是指将主数据库的DDL和DML操作通过二进制日志传入从库服务器中,然后在从库上对这些日志重新执行(重做),从而使得从库和主库的数据保持同步。 优点: 主库出现问题,可以快速切换到从库提供服务实现读…...

Ubuntu操作合集
UFWUncomplicated Firewall 查看状态和规则: 1查看状态sudo ufw status, 2查看详细信息sudo ufw status verbose, 默认策略配置: 1拒绝所有入站sudo ufw default deny incoming 2允许所有出战sudo ufw default allow outgoing …...
)
【TDengine源码阅读】TAOS_DEF_ERROR_CODE(mod, code)
2025年5月13日,周二清晨 #define TAOS_DEF_ERROR_CODE(mod, code) ((int32_t)((0x80000000 | ((mod)<<16) | (code))))这段代码定义了一个宏 TAOS_DEF_ERROR_CODE(mod, code),用于生成一个32位有符号整数(int32_t)形式的错误…...
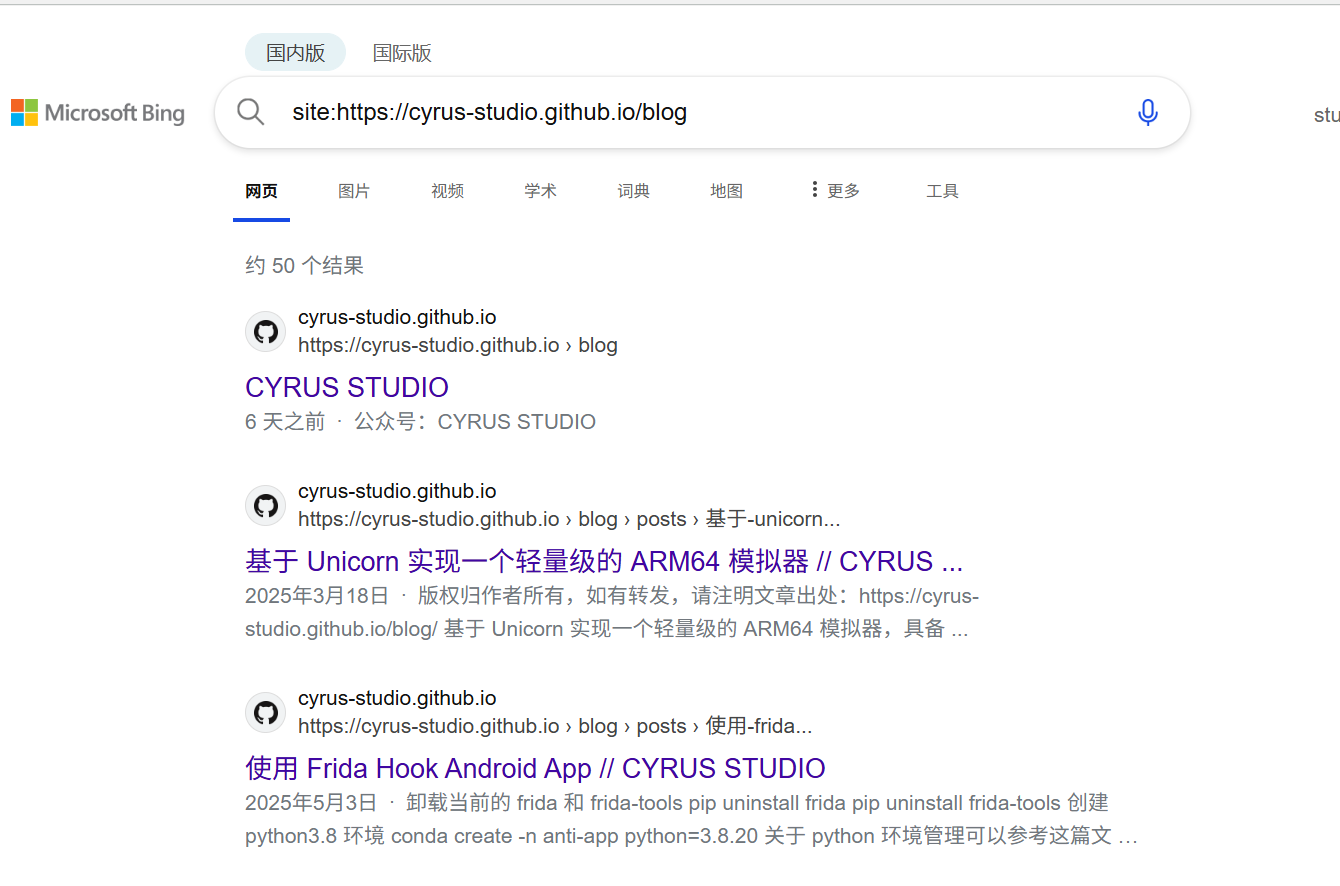
如何让 Google 收录 Github Pages 个人博客
版权归作者所有,如有转发,请注明文章出处:https://cyrus-studio.github.io/blog/ 如何确认自己的网站有没有被 google 收录 假设网址是:https://cyrus-studio.github.io/blog 搜索:site:https://cyrus-studio.github…...
servlet-api
本次内容总结 1、再次学习Servlet的初始化方法 2、学习Servlet中的ServletContext和<context-param> 3、什么是业务层 4、IOC 5、过滤器 7、TransActionManager、ThreadLocal、OpenSessionInViewFilter 1、再次学习Servlet的初始化方法 1)Servlet生命周期&…...