利用 Amazon Bedrock Data Automation(BDA)对视频数据进行自动化处理与检索

当前点播视频平台搜索功能主要是基于视频标题的关键字检索。对于点播平台而言,我们希望可以通过优化视频搜索体验满足用户通过模糊描述查找视频的需求,从而提高用户的搜索体验。借助 Amazon Bedrock Data Automation(BDA)技术,运用 AI 自动剖析视频内容,提取关键信息,通过向量搜索达成语义智能匹配,实现多角度(视频关键字、台词、场景描述)视频检索,有利于提升用户搜索效率,增加平台活跃度,也为视频创作者创造更多曝光机遇。 在下文中,我们会基于 Amazon Bedrock Data Automation(BDA)实现视频处理与双路召回的解决方案进行描述。
Amazon Bedrock Data Automation 功能概述
Bedrock Data Automation(BDA)是基于云的服务,借助生成式 AI,能将文档、图像、视频和音频等非结构化内容,高效转化为结构化格式,自动提取、生成关键信息,助力开发人员快速构建应用程序,执行复杂工作流程。目前支持 us-east-1 和 us-west-2 两个地区。
从输出结果角度,BDA 支持标准结果和自定义结果的输出,当用户选择自定义结果的输出时,可以用 prompt 的方式去生成想要的结果。自定义的结构可以保存为蓝图为 BDA 项目所使用。目前自定义结果的输出支持文档和图片。
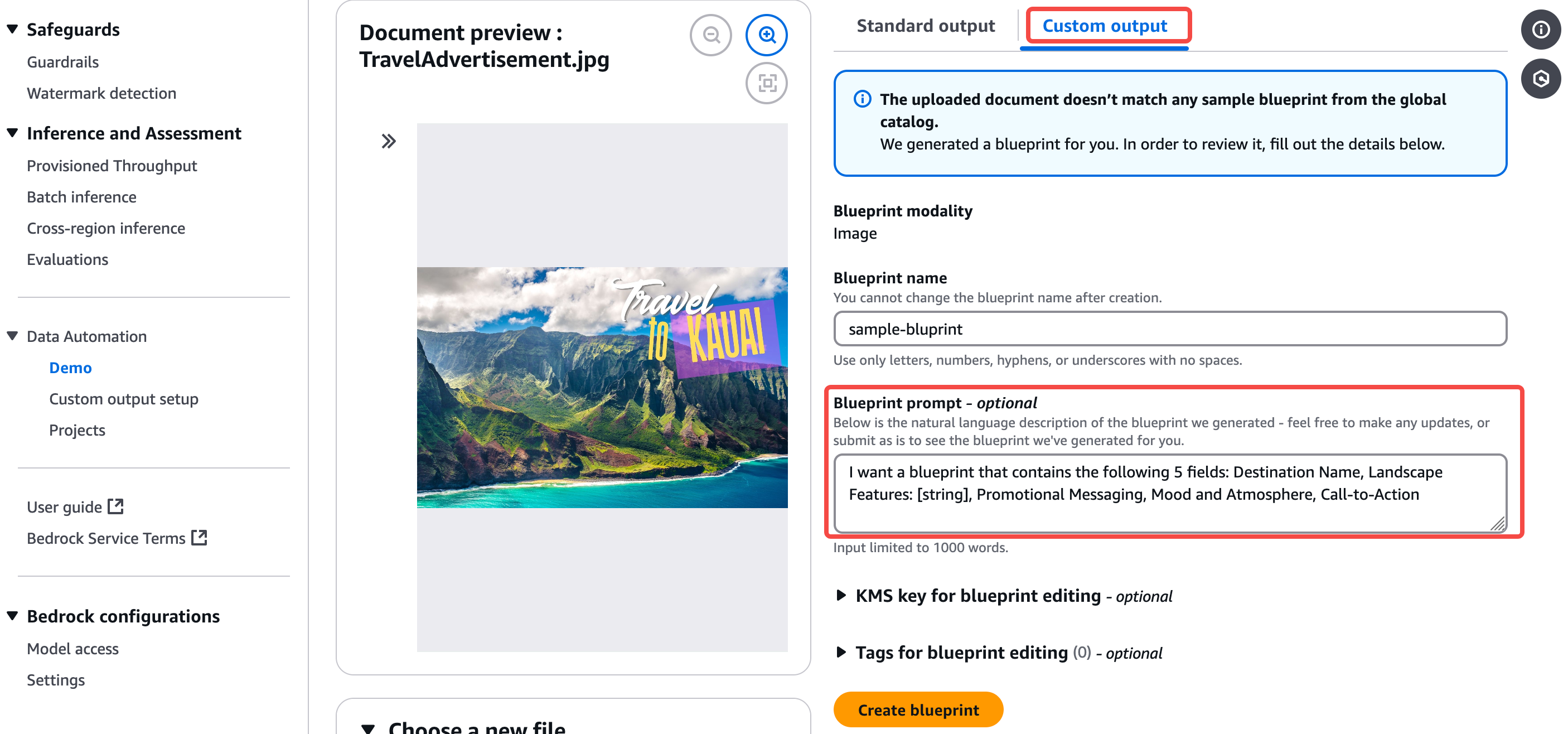
标准结果的输出则对四种不同类型的数据源做了预定义的输出结构,例如对于文档数据,标准输出结果如下图所示,从而可以为不同下游应用所用:
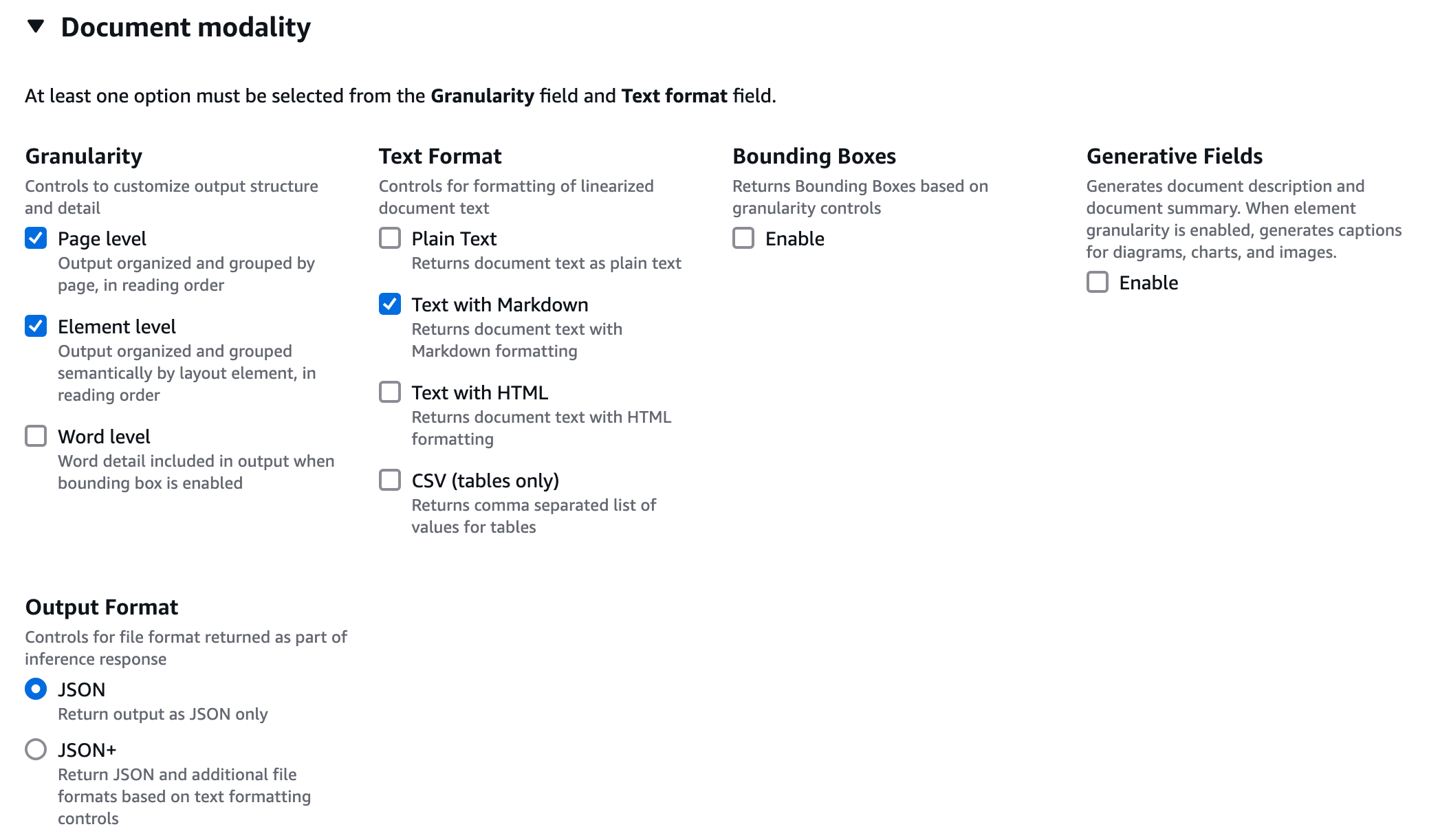
您可以手动在操作台上测试 DBA 的各种功能包括文档,图片,视频和音频等,以下我们以视频 Demo 为例。
首先找到 Amazon Bedrock 在控制台的位置,然后点击左侧工具栏中 Data Automation 下的 Demo:
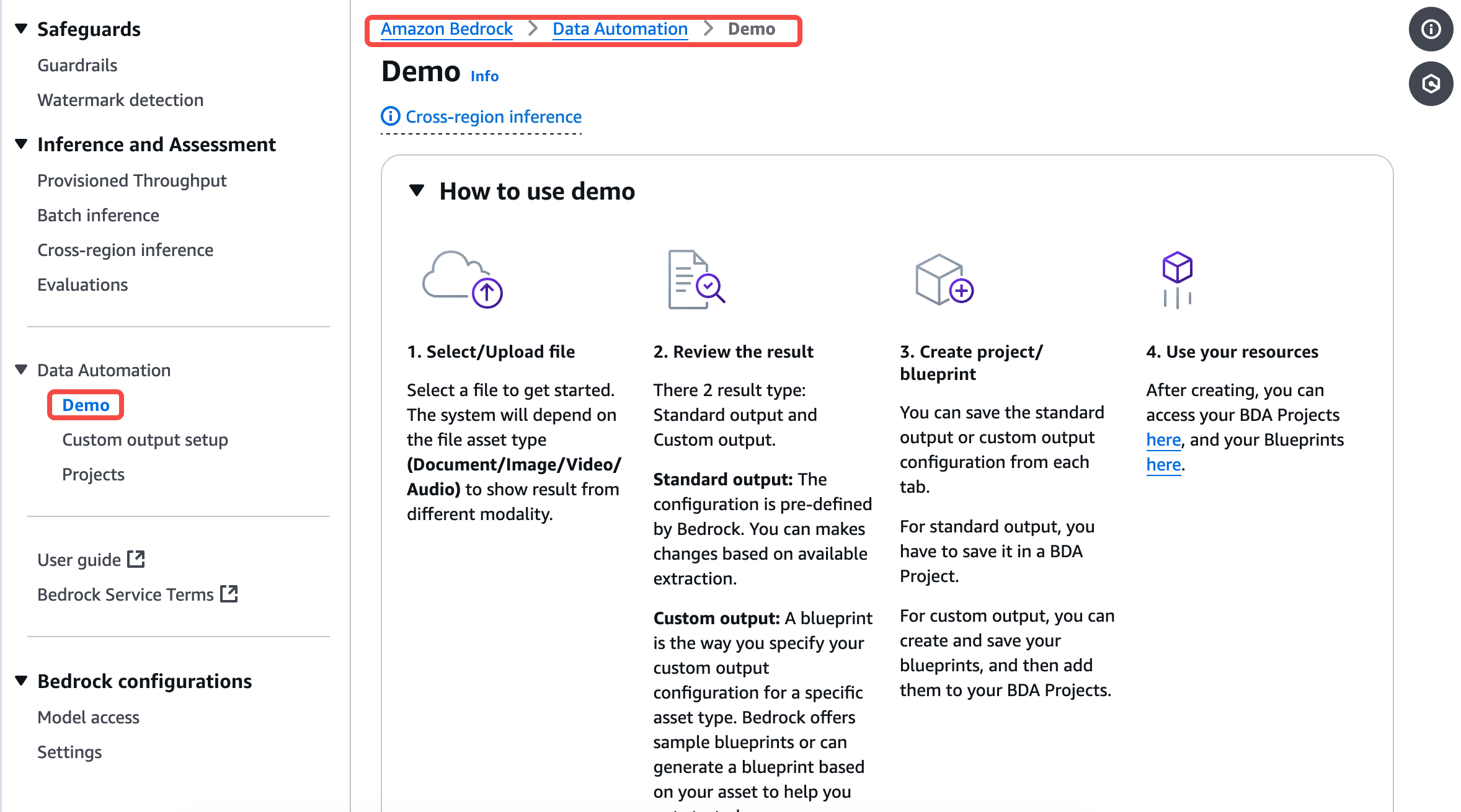
在工具栏中的 Demo中,您可以选择用已存在 Demo 上的数据,或从本地/Amazon S3 中上传的数据做为源数据进行测试:
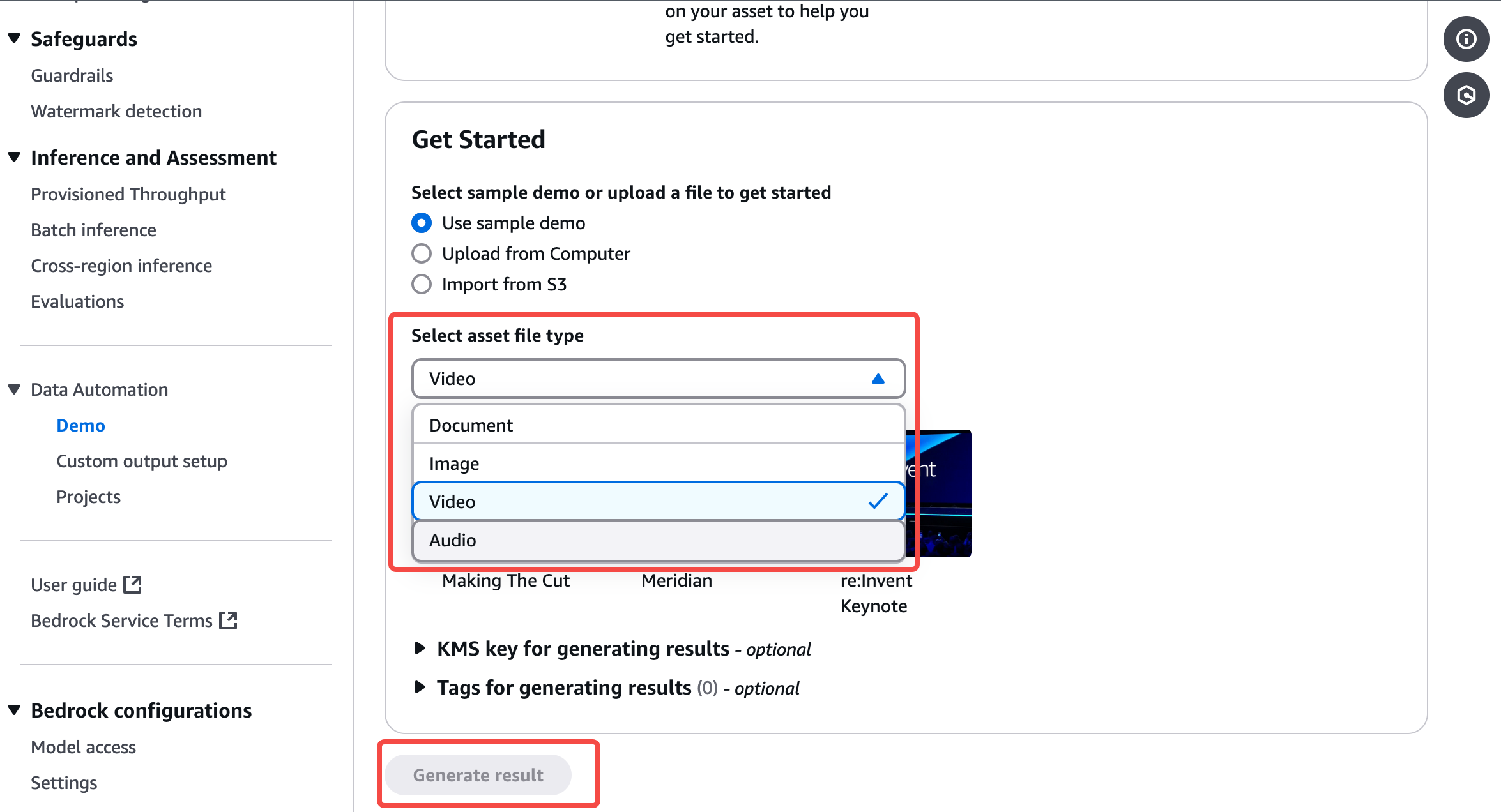
最后点击 Generate result,便可以在左侧输出相关结果,并可以选择标准数据结果或前面蓝图制定好的自定义输出结果。
在视频处理中,BDA 可以生成完整视频摘要、章节摘要、提取 IAB 分类法、完整音频脚本、视频文字、进行徽标检测和内容审核等。在推出 BDA 之前,传统对视频的 RAG 还是基于手工对切片处理,并手工通过 SaaS 或大模型对视频声音摘录,文字提取。BDA 简化了这一流程,输出的内容以 Json 文档的形式呈现。
Json 文档结构目前版本主要包含以下几个部分:Metadata、shots、chapters、video、statistics
-
Metadata 包含视频的基本信息,如资产 ID、格式、帧率、编码、时长、分辨率等。
-
Shots 是 DBA 自动将视频分割成多个镜头,每个镜头包括开始和结束的时间码,开始和结束的时间戳(毫秒),开始和结束的帧索引,持续时间,置信度,所属章节索引。
-
Chapters 是 DBA 自动将视频分割成多个章节,每个章节包含开始和结束的时间码,开始和结束的时间戳(毫秒),开始和结束的帧索引,持续时间,包含的镜头索引,章节摘要,转录文本,IAB 分类,内容审核等。其中,IAB 分类可以帮助广告找到视频中可以切入的点,让广告的引入可以更加流畅。
-
Video 里面包含了视频总结和视频整体的转录文本。视频整体的转录文本包含了每个章节的转录文本。
-
Statistics 主要是对视频数据的统计,包含了镜头数量统计,章节统计和视频中发言人的数量。
在本文中,我们主要用到了 DBA 视频处理的处理手段,来将视频数据转化成 json 结构数据为用户提供文字搜索功能。以下是相关架构的介绍。
相关架构说明
架构总览
整个视频处理与检索系统主要由 Amazon S3、Amazon EventBridge、Amazon Lambda、Amazon Bedrock、Amazon DocumentDB、Amazon API Gateway 和 Amazon CloudFront 等组件构成,各组件协同工作,实现视频数据的自动化处理与高效检索。
相关技术组件
-
Amazon S3:作为对象存储服务,负责存储视频文件和处理后的 json 文件。它具有高可靠性、高扩展性和低成本等优势,为视频数据的存储提供了稳定的基础。
-
Amazon EventBridge:作为系统中关键的事件触发中枢,负责监测特定事件的发生。一旦检测到视频文件上传至 S3 或 S3 路径中文件生成,它便迅速响应,精准触发相应的 Lambda 函数调用。
-
Amazon Lambda:基于无服务器计算架构,允许用户直接通过代码实现各种功能。在本系统中,Lambda 承担了多项重要任务,如调用 Bedrock API 处理视频,将非结构化的视频数据转化为结构化的 json 文件;调用 Bedrock 上的模型(如 titan-embed-text-v2:0)为 json 文件内容生成 embedding,以便后续进行向量检索。
-
Amazon Bedrock:Amazon 的 AI 一站式平台,集成了各种先进的 AI 模型,为系统提供强大的 AI 处理能力。在本案例中,其主要提供了 BDA 的视频处理功能和 Titan 模型与 Cohere 模型的调用。其中,对 BDA 的调用需要依赖 BDA 项目对于输出的预定义。在案例中,我们选择以下输出作为数据源进行处理,对于其他项目,具体输出可以按照需要自行勾选:
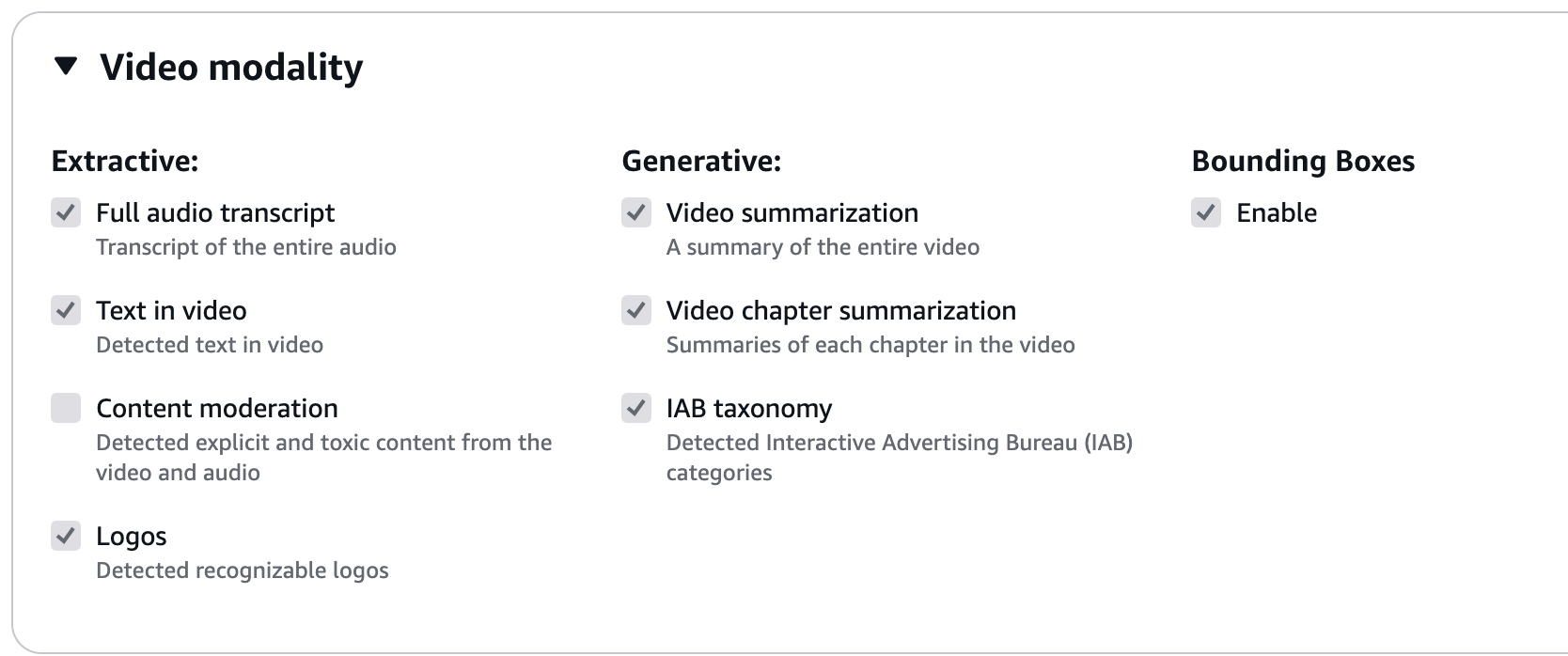
-
Amazon DocumentDB:存储由 BDA 生成的 json 文档。Amazon DocumentDB 兼容 Mongo DB,是原生的完全托管 json 文档数据库,支持向量、文本的存储、索引和聚合。DocumentDB 具备强大的性能和扩展性,能够同时满足操作型和分析型工作负载的需求。
索引是一种数据结构,用于提高数据检索的效率,在文字数据和向量数据的处理中都有着重要作用。我们在Amazon DocumentDB 中创建了文字倒排索引和向量索引为后续检索做准备。由于是文本相似度计算,我们选用余弦相似度(cosine)来用于向量索引。
[{ v: 4, key: { _id: 1 }, name: '_id_', ns: 'VideoData.videodata' },{v: 1,key: { _fts: 'text', _ftsx: 1 },name: 'text_index',ns: 'VideoData.videodata',default_language: 'english',weights: { text: 1 },textIndexVersion: 1},{v: 4,key: { embedding: 'vector' },name: 'vector_index',vectorOptions: {type: 'ivfflat',dimensions: 1024,similarity: 'cosine',lists: 1000},ns: 'VideoData.videodata'}
]-
Amazon API Gateway:作为 API 管理接口,连接前端用户与后端服务。它负责接收前端用户的搜索请求,并将其转发给后端的 Lambda 函数进行处理,同时将后端处理结果返回给前端用户,保障了前后端数据交互的安全和高效。
-
Amazon CloudFront:主要用于加速视频内容的分发和召回。通过在全球范围内部署边缘节点,它能够快速将视频内容传递给用户,减少用户等待时间,提升用户观看视频的流畅度和体验感。
架构图
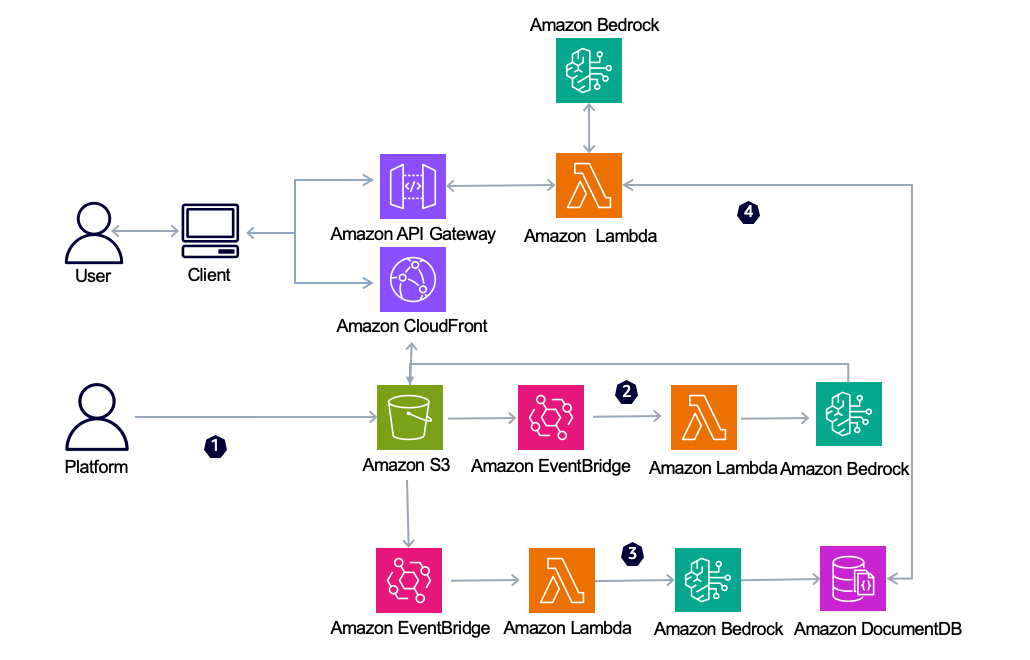
视频检索流程
前置过程
为了更加方便快速地部署和使用本方案,我们创建了基于AWS CDK 的全自动化部署方法: :sample-for-video-search。您可以按照 README 来将整套环境资源快速部署在自己的亚马逊云科技环境中,随后便可以开始以下检索流程:
1. 数据上传
在我们的案例中,平台可以将视频文件(mp4/mov 格式)上传至 Amazon S3 路径中,例如 s3://<bucket-name>/video-input/,作为后续处理的源数据。
2. 视频处理与视频 Json 文件生成
当 Amazon S3 路径中有文件上传完毕时,Amazon EventBridge 会监测到相关事件并触发 Amazon Lambda 调用 Amazon Bedrock API 对视频文件按照实现创建的 DBA 项目进行处理。DBA 项目是利用 Lambda 在视频处理流程前创建。视频处理完成后,生成相应的 json 文件,并将其传回 Amazon S3 存储 s3://<bucket-name>/video-output/。相关示例代码如下:
# invokes bda by async approach with a given input file
def invoke_insight_generation_async(input_s3_uri,output_s3_uri,data_project_arn, blueprints = None):# Extract account ID from project ARNaccount_id = data_project_arn.split(':')[4]# Construct default Profile ARN using fixed us-west-2 region,which currently supports the 2 models required in the following processprofile_arn = f"arn:aws:bedrock:us-west-2:{account_id}:data-automation-profile/us.data-automation-v1"payload = {"inputConfiguration": {"s3Uri": input_s3_uri},"outputConfiguration": {"s3Uri": output_s3_uri},"dataAutomationConfiguration": {"dataAutomationProjectArn": data_project_arn,"stage": "LIVE"},"dataAutomationProfileArn": profile_arn,"notificationConfiguration": {"eventBridgeConfiguration": {"eventBridgeEnabled": True},}}try:response = bda_client_runtime.invoke_data_automation_async(**payload)print(f"Successfully invoked data automation: {response}")return responseexcept Exception as e:print(f"Error invoking data automation: {str(e)}")raise3. 基于视频 Json 文件的 Embedding 处理
之后,Amazon S3 文件生成的规则会再次触发的 Amazon EventBridge,使其启动 Amazon Lambda 调用 Amazon Bedrock 集成的 amazon.titan-embed-text-v2:0 模型,为 Json 文件内容做 向量化用于后续查询。
try:response = bedrock_client.invoke_model(modelId="amazon.titan-embed-text-v2:0",contentType="application/json",accept="application/json",body=json.dumps({"inputText": text}))由于每个 chapter 内的 transcripts 较长,为达到更好的检索效果,会对其进行切片处理,最后将整理好的数据结构存入 DocumentDB。由于是简易环境,我们基于字符长度做了简单的切片处理:
def split_transcript_into_chunks(self, transcript_text, max_chunk_size=500, min_chunk_size=100):if not transcript_text:return []# 如果输入是字典,尝试提取文本if isinstance(transcript_text, dict):if 'text' in transcript_text:transcript_text = transcript_text['text']elif 'representation' in transcript_text and 'text' in transcript_text['representation']:transcript_text = transcript_text['representation']['text']else:transcript_text = json.dumps(transcript_text)# 确保输入是字符串if not isinstance(transcript_text, str):transcript_text = str(transcript_text)# 按句子分割(句号、问号、感叹号后跟空格)# 使用更宽松的模式,允许句子结束后有任何数量的空格sentences = re.split(r'([.!?])\s*', transcript_text)# 处理分割结果,将标点符号重新附加到句子processed_sentences = []i = 0while i < len(sentences):sentence = sentences[i]# 如果是标点符号,附加到前一个句子if i > 0 and sentence in ['.', '!', '?']:processed_sentences[-1] += sentenceelse:processed_sentences.append(sentence)i += 1# 将句子组合成块chunks = []current_chunk = ""for sentence in processed_sentences:# 跳过空句子if not sentence.strip():continue# 如果当前块加上新句子会超过最大大小,保存当前块if current_chunk and len(current_chunk) + len(sentence) + 1 > max_chunk_size:if len(current_chunk) >= min_chunk_size:chunks.append(current_chunk.strip())current_chunk = sentenceelse:if current_chunk:current_chunk += " " + sentenceelse:current_chunk = sentence# 添加最后一个块if current_chunk and len(current_chunk) >= min_chunk_size:chunks.append(current_chunk.strip())return chunks将 Json 文件向量化后,我们将 Json 文件的数据格式进行了处理,使其在 Amazon DocumentDB 中能更好地做检索。

def flatten_video_data(self, video_data, video_name):flattened_data = []# 处理章节chapters = video_data.get('chapters', [])for chapter in chapters:chapter_summary = chapter.get('chapter_summary', {})flattened_chapter_summary = {"video_name": video_name,"source": f"chapter_{chapter.get('chapter_index', 0)}_summary","text": chapter_summary.get('text', ""),"embedding": chapter_summary.get('embedding', []),"start_timestamp_millis": chapter.get('start_timestamp_millis'),"end_timestamp_millis": chapter.get('end_timestamp_millis')}flattened_data.append(flattened_chapter_summary)# 处理章节转录块transcript_chunks = chapter.get('transcript_chunks', [])for chunk in transcript_chunks:flattened_chunk = {"video_name": video_name,"source": f"chapter_{chapter.get('chapter_index', 0)}_transcript_chunk_{chunk.get('chunk_index', 0)}","text": chunk.get('text', ""),"embedding": chunk.get('embedding', []),"start_timestamp_millis": chapter.get('start_timestamp_millis'),"end_timestamp_millis": chapter.get('end_timestamp_millis')}flattened_data.append(flattened_chunk)return flattened_data对视频生成的文字做完向量化和数据格式的整理后,便可以将其存入 Amazon DocumentDB 为用户的检索做准备了。
4. 用户搜索文字的 Embedding 转换
将向量和文字存入 Amazon DocumentDB 后,用户便可以从前端输入搜索文字并选择搜索模式(文本搜索或场景搜索),系统会使用 amazon.titan – embed – text – v2:0 模型对搜索文字进行向量化,以便后续进行向量匹配。
flowchart LRA([接收搜索请求])-->B[解析查询参数]B-->C{执行混合搜索}C-->D[向量搜索]C-->E[文本搜索]D-->F([合并搜索结果])E-->FF-->G([使用Cohere重排序])G-->H([返回最终结果])双路召回与结果重排序:Amazon Lambda 利用转换后的向量,同时进行文字和向量的双路召回。在向量检索中,使用 Amazon Document DB 的聚合 pipeline 对向量相似度进行搜索,根据搜索模式过滤结果,最后通过 project 返回相应字段;
$project:返回相应字段如下:
text: "<sample_text>"
video_name: "<sample_name>.mov"
source: "chapter_6_summary"
start_timestamp_millis: 181666
end_timestamp_millis: 227100similarity:与向量索引一样,我们选择余弦相似度(cosine)来衡量查询向量和文档向量之间的相似性。
top_k:返回的视频数
filter_condition:由于我们的搜索分为场景搜索和台词文本搜索,便以此为筛选,从而用户可以自行选择搜索场景。
pipeline = [{"$search": {"vectorSearch": {"vector": query_embedding,"path": "embedding","similarity": "cosine","k": top_k * 3, # Fetch more results since we'll filter them"efSearch": 64}}},# Add a $match stage to filter results based on search mode (scene/transcripts){"$match": filter_condition},# Limit to top_k results after filtering{"$limit": top_k},{"$project": {"text": 1,"video_name": 1,"source": 1,"start_timestamp_millis": 1,"end_timestamp_millis": 1}}] 文字检索则基于源文件为 json 文本的特点,通过 $text 操作符利用倒排索引进行文本搜索。倒排索引是一种用于快速查找包含特定单词或短语的文档的数据结构。与传统的正向索引(从文档到单词的映射)不同,倒排索引是从单词到文档的映射。
检索完成后,由于同一个 source 可能会同时被向量检索和文字检索出来,从而在合并结果时做了去重处理:
all_results = processed_vector_results + processed_text_results# Remove duplicates based on '_id' and prefer text search resultsunique_results = []seen_ids = set()for result in reversed(all_results): # Reverse the list to process text results firstresult_id = result['_id']if result_id not in seen_ids:seen_ids.add(result_id)unique_results.append(result)unique_results.reverse() # Reverse the list back to original order# Return unique results directlyreturn {"results": unique_results}最后通过 Amazon Bedrock 集成的 cohere.rerank – v3 – 5:0 模型对召回结果进行重排序,并对输出结果进行了整理,而后按照相关度分数返回最符合用户需求的视频。
response = self.bedrock_client.invoke_model(modelId="cohere.rerank-v3-5:0",contentType="application/json",accept="application/json",body=json.dumps({"api_version": 2,"query": query,"documents": documents,"top_n": len(documents)}))总结
将 BDA 作为处理视频的手段之一减少了手工分镜,取帧等的工序。无服务器的架构为整体的设计提供了低成本的计算资源,后续的数据的存储选用 DocumentDB 也是希望可以用灵活地手段做 Json 数据处理。在 AI 模型的加持下,希望本文能够为 AI 与视频搜索提供了一种新思路。
持续改进
作为新功能,目前 BDA 的视频处理功能仅限于标准输出,可以考虑后续加入 Amazon Nova 模型来丰富视频场景描述数据,从而进一步提升视频内容分析的精细度。Amazon Nova 模型能够对视频进行抽帧理解,从每一帧图像中提取更丰富的信息,例如视频场景中的物体细节、变化等。这些额外的信息将被整合到视频检索系统中,使得用户在搜索视频时,能够获得更精准、更丰富的搜索结果。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您了解行业前沿技术和发展海外业务选择推介该服务。
本篇作者
本期最新实验《多模一站通 —— Amazon Bedrock 上的基础模型初体验》
✨ 精心设计,旨在引导您深入探索Amazon Bedrock的模型选择与调用、模型自动化评估以及安全围栏(Guardrail)等重要功能。无需管理基础设施,利用亚马逊技术与生态,快速集成与部署生成式AI模型能力。
⏩️[点击进入实验] 即刻开启 AI 开发之旅
构建无限, 探索启程!
相关文章:
利用 Amazon Bedrock Data Automation(BDA)对视频数据进行自动化处理与检索
当前点播视频平台搜索功能主要是基于视频标题的关键字检索。对于点播平台而言,我们希望可以通过优化视频搜索体验满足用户通过模糊描述查找视频的需求,从而提高用户的搜索体验。借助 Amazon Bedrock Data Automation(BDA)技术&…...

TypeScript装饰器:从入门到精通
TypeScript装饰器:从入门到精通 什么是装饰器? 装饰器(Decorator)是TypeScript中一个非常酷的特性,它允许我们在不修改原有代码的情况下,给类、方法、属性等添加额外的功能。想象一下装饰器就像给你的代码…...
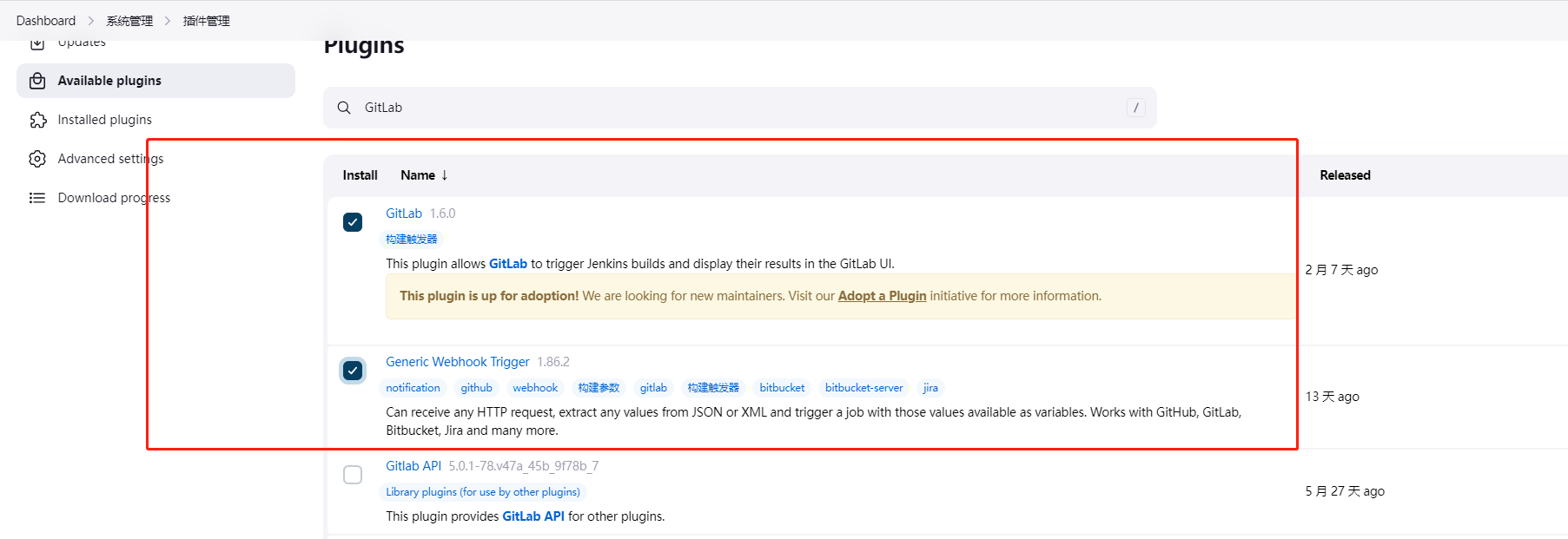
模拟jenkins+k8s自动化部署
参考 Jenkins+k8s实现自动化部署 - 掘金 手把手教你用 Jenkins + K8S 打造流水线环境 - 简书 安装插件 调整插件升级站点 (提高插件下载速度) 默认地址 https://updates.jenkins.io/update-center.json 新地址 http://mirror.xmission.com/jenkins/updates/update-center.json …...
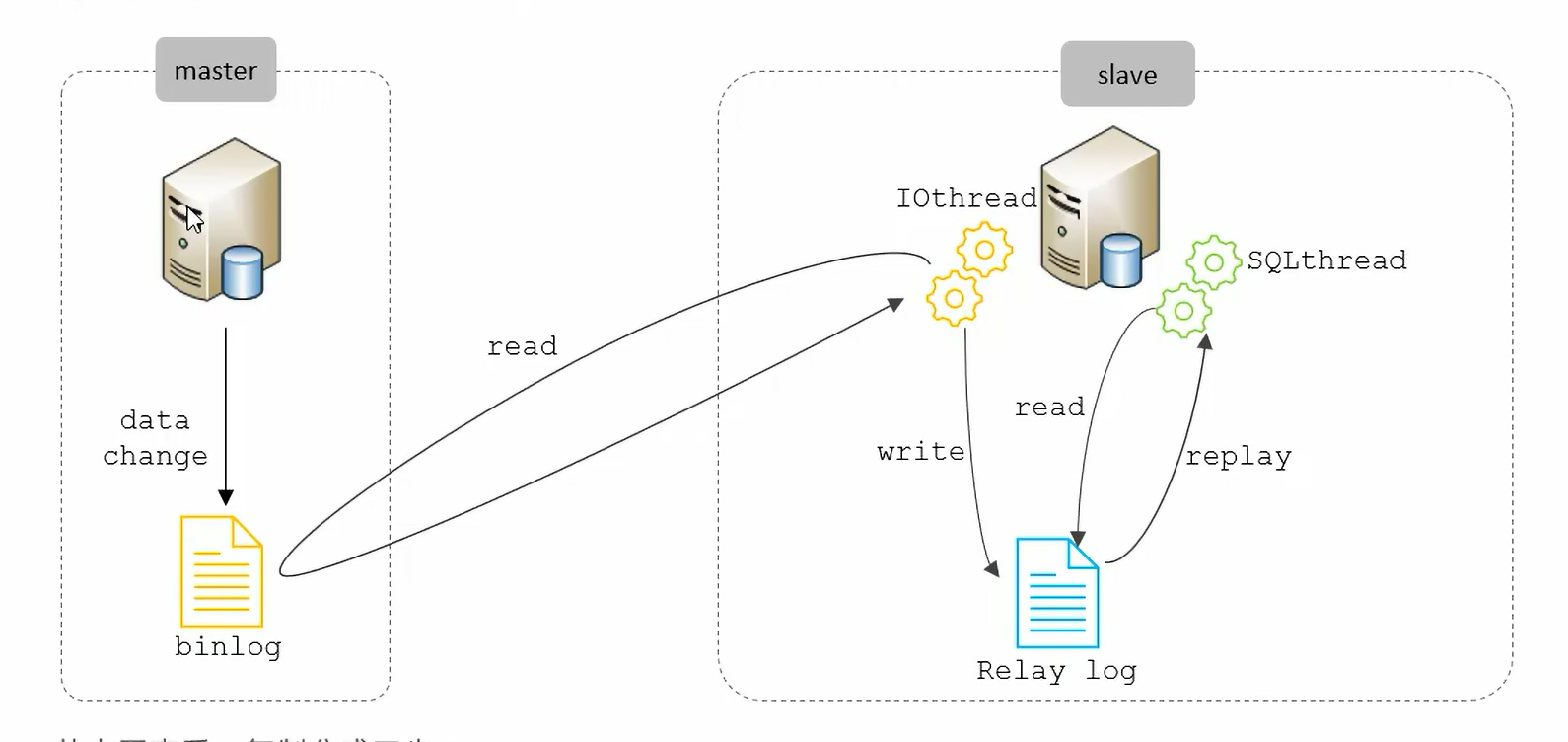
MySQL——十一、主从复制
主从复制是指将主数据库的DDL和DML操作通过二进制日志传入从库服务器中,然后在从库上对这些日志重新执行(重做),从而使得从库和主库的数据保持同步。 优点: 主库出现问题,可以快速切换到从库提供服务实现读…...

Ubuntu操作合集
UFWUncomplicated Firewall 查看状态和规则: 1查看状态sudo ufw status, 2查看详细信息sudo ufw status verbose, 默认策略配置: 1拒绝所有入站sudo ufw default deny incoming 2允许所有出战sudo ufw default allow outgoing …...
)
【TDengine源码阅读】TAOS_DEF_ERROR_CODE(mod, code)
2025年5月13日,周二清晨 #define TAOS_DEF_ERROR_CODE(mod, code) ((int32_t)((0x80000000 | ((mod)<<16) | (code))))这段代码定义了一个宏 TAOS_DEF_ERROR_CODE(mod, code),用于生成一个32位有符号整数(int32_t)形式的错误…...
如何让 Google 收录 Github Pages 个人博客
版权归作者所有,如有转发,请注明文章出处:https://cyrus-studio.github.io/blog/ 如何确认自己的网站有没有被 google 收录 假设网址是:https://cyrus-studio.github.io/blog 搜索:site:https://cyrus-studio.github…...
servlet-api
本次内容总结 1、再次学习Servlet的初始化方法 2、学习Servlet中的ServletContext和<context-param> 3、什么是业务层 4、IOC 5、过滤器 7、TransActionManager、ThreadLocal、OpenSessionInViewFilter 1、再次学习Servlet的初始化方法 1)Servlet生命周期&…...
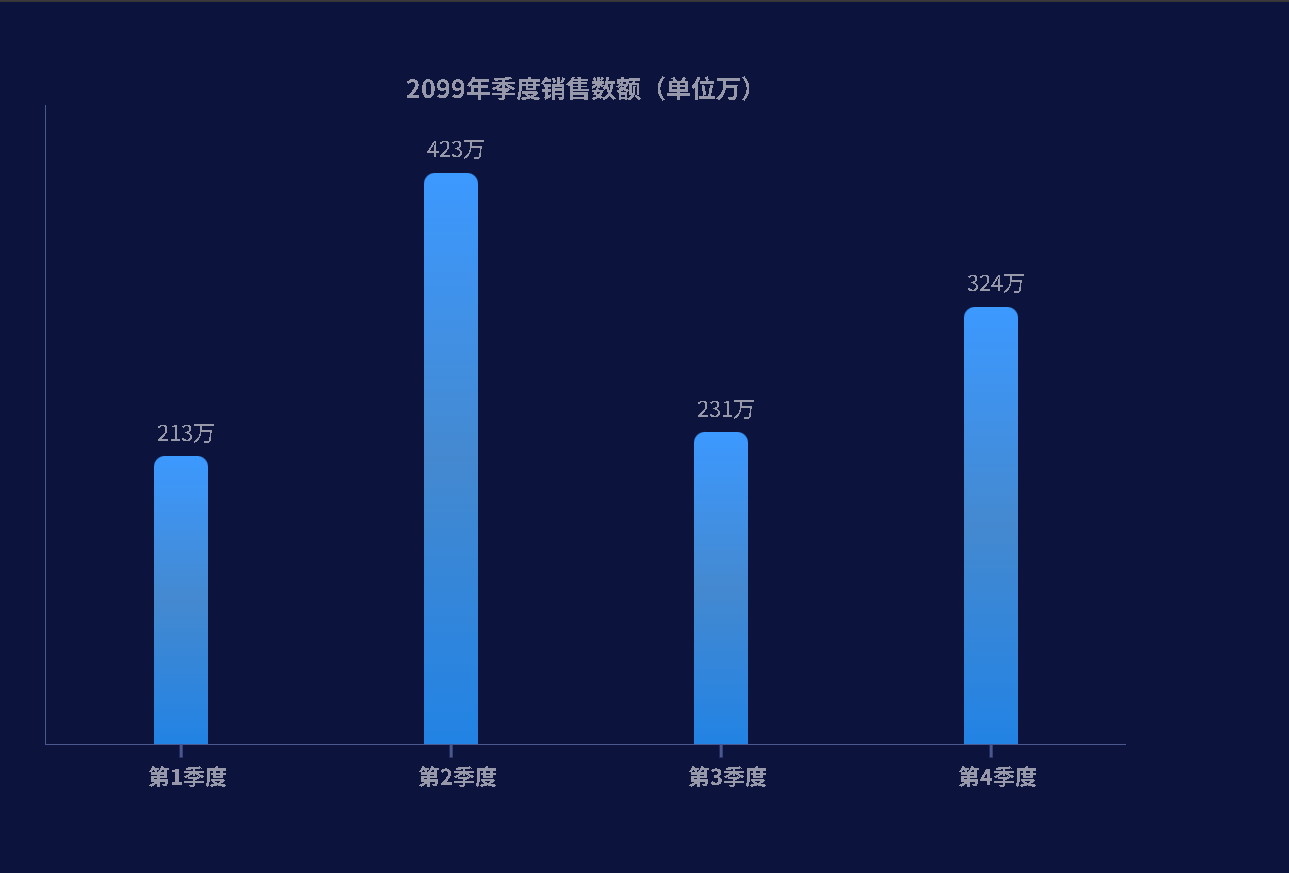
根据输入的数据渲染柱形图
背景:根据不同季度的销售额,生成对应的柱形图,直观的看出差异 效果: 代码 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatibl…...
Java SpringBoot项目JPA查询数据demo
目录 一、前置1、IDEA创建SpringBoot项目2、基础设置、配置 二、JPA查询数据1、配置SQL server连接2、创建实体类QueryEntity.java生成Getter and Setter 3、创建Repository接口QueryRepository.java 4、创建Service服务类QueryService.java 5、创建Controller控制器类QueryCon…...

vue2集成可在线编辑的思维导图(simple-mind-map)
最近要求做一个可在线编辑的思维导图,经过层层调研和实测,最简单的思维导图导图实现还得是simple-mind-map组件 simple-mind-map中文文档 当前我使用的是vue2项目,目前没试过是否支持vue3,但是看官网描述他们也给了有vue3的demo项…...
[特殊字符])
Java静态变量数据共享深度解析(附多场景案例)[特殊字符]
Java静态变量数据共享深度解析(附多场景案例)🔍 关键词:数据共享 静态变量 线程安全 内存管理 🌐 一、静态变量共享的三大层次 1. 类实例间共享(基础级) class GameServer {// 统计在线玩家数…...
如何在Windows右键新建菜单中添加自定义项,将notepad添加到新建菜单
一、简介 Windows 右键新建菜单的核心管理机制隐藏在注册表的 HKEY_CLASSES_ROOT 根键中。这里存在两种关键注册表项:文件扩展名项和文件类型项,它们共同构成了新建菜单的完整控制体系。 以常见的.txt文件为例,系统通过以下机制实现新建菜单…...

Flink运维要点
一、Flink 运维核心策略 1. 集群部署与监控 资源规划 按业务优先级分配资源:核心作业优先保障内存和 CPU,避免资源竞争。示例:为实时风控作业分配专用 TaskManager,配置 taskmanager.memory.process.size8g。 监控体系 集成 Prom…...
CS016-4-unity ecs
【37】将系统转换为任务 Converting System to Job 【Unity6】使用DOTS制作RTS游戏|17小时完整版|CodeMonkey|【37】将系统转换为任务 Converting System to Job_哔哩哔哩_bilibili a. 将普通的方法,转化成job。第一个是写一个partial struct xxx;第二…...

微信小程序第三方代开发模式技术调研与实践总结
🚀 微信小程序第三方代开发模式技术调研与实践总结 📖 前言 随着企业对私有化品牌运营诉求的增加,许多大型客户希望将原本由 SaaS 平台统一提供的小程序迁移至自有主体(AppID)下运行,同时又希望继续沿用 SaaS 平台的业务服务与数据托管方式。微信开放平台提供的“小程…...
upload-labs通关笔记-第8关 文件上传之点绕过
目录 一、点绕过原理 二、deldot()函数 三、源码分析 四、渗透实战 1、构建脚本test8.php 2、打开靶场 3、bp开启拦截 4、点击上传 5、bp拦截 6、后缀名增加点 7、发包并获取脚本地址 8、访问脚本 本文通过《upload-labs靶场通关笔记系列》来进行upload-labs靶场的渗…...

远程连接电脑的方法?异地远程桌面连接和三方软件实现
远程连接电脑,是指通过网络技术,在一台设备上操控另一台设备的电脑桌面,实现跨地域的操作和管理。在日常工作、技术支持、远程办公等场景中,远程连接电脑都发挥着重要作用。实现远程连接电脑主要有系统自带工具和第三方软件两种方…...

PCL PolygonMesh 与 TextureMesh 源码阅读与简单测试
Title: PCL PolygonMesh 与 TextureMesh 源码阅读与简单测试 文章目录 I . PolygonMesh1. PolygonMesh 结构体2. Vertices 结构体与点云索引3. 测试 PolygonMesh II. TextureMesh1. TextureMesh 结构体2. TexMaterial 结构体3. 纹理坐标与纹理坐标索引4. 测试 TextureMesh 以下…...

量子算法:开启计算新时代的技术密码
摘要 量子算法是利用量子力学特性(如叠加态、纠缠、干涉)设计的计算模型,在特定问题上相比经典算法具有指数级加速优势。本文深入探讨了量子算法的核心原理、代表性算法及其在多个领域的应用,分析了量子算法面临的挑战与未来发展…...
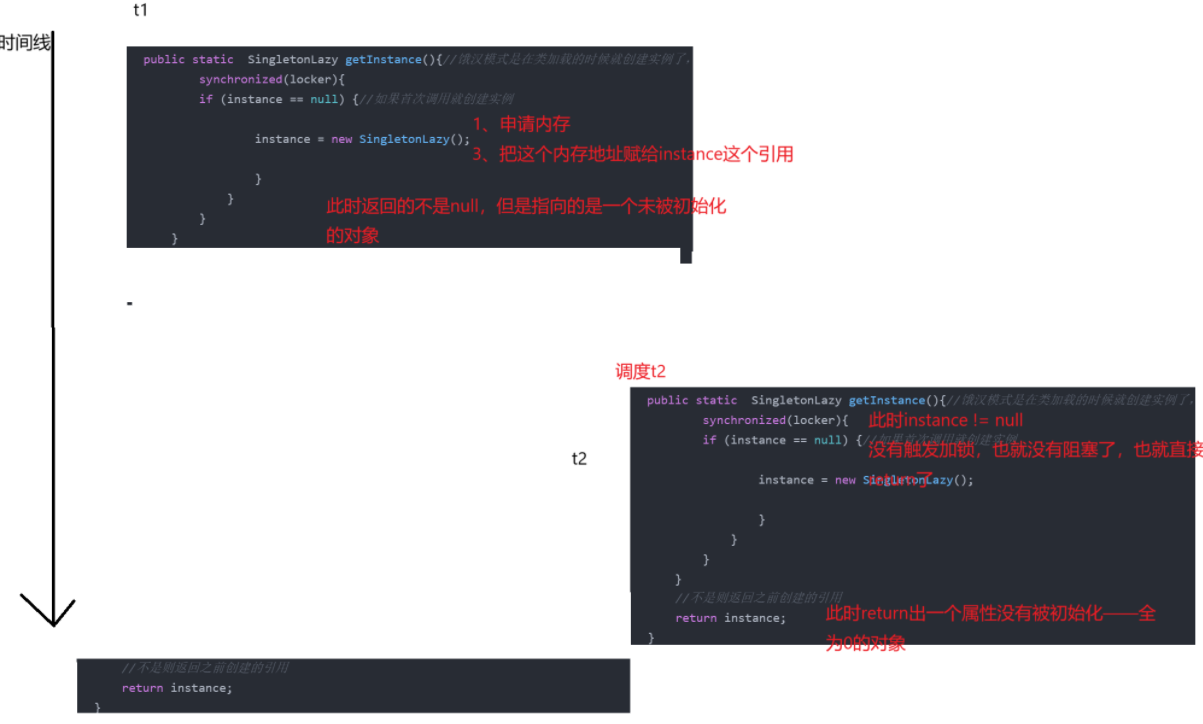
多线程代码案例-1 单例模式
单例模式 单例模式是开发中常见的设计模式。 设计模式,是我们在编写代码时候的一种软性的规定,也就是说,我们遵守了设计模式,代码的下限就有了一定的保证。设计模式有很多种,在不同的语言中,也有不同的设计…...

CSS实现文本自动平衡text-wrap: balance
不再有排版孤行和寡行 我们都知道那些标题,最后一个单词换行并单独站在新行上,破坏了视觉效果,看起来很奇怪。当然,有老式的 手动换行或将内容分成不同部分。但您听说过text-wrap: balance吗? 通过应用text-wrap: bal…...
mac M芯片运行docker-desktop异常问题
虽然mac已经迭代到m4了,但官方的docker-desktop运行仍然有问题,包括但不限于: 命令行docker找不到docker-desk打不开docker-desktop闪退容器起不来 尝试不同版本后,看到了其他可以在mac跑docker的开源方法,更简单、轻…...

主流数据库运维故障排查卡片式速查表与视觉图谱
主流数据库运维故障排查卡片式速查表与视觉图谱 本文件将主文档内容转化为模块化卡片结构,并补充数据库结构图、排查路径图、锁机制对比等视觉图谱,以便在演示、教学或现场排障中快速引用。 📌 故障卡片速查:连接失败 数据库检查…...
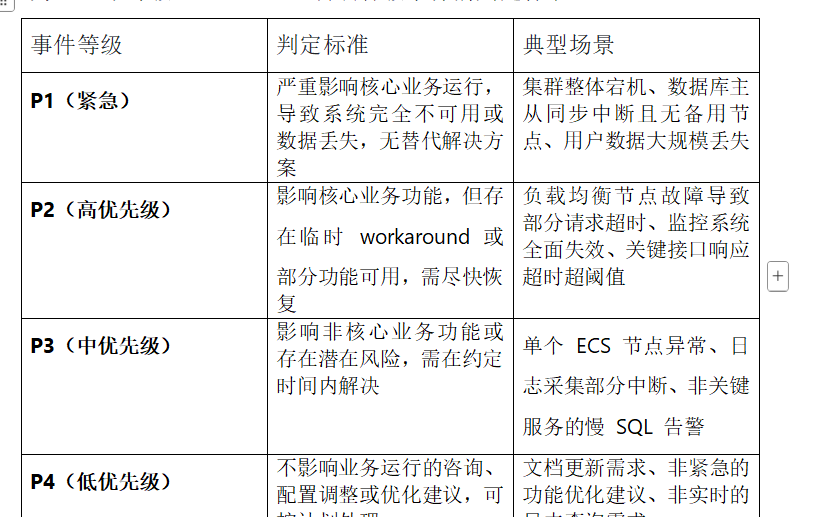
事件响应策略规范模版
事件响应策略 一、事件分级定义 根据事件对业务的影响程度和紧急程度,将事件分为 4个等级(P1-P4),明确各级事件的判定标准:、 二、响应时效承诺 响应时间(从事件确认到首次回复) P1 事件:15 分钟内响应(724 小时电话 / 工单优先接入) P2 事件:30 分钟内响应(工…...

在哪一个终端下运行有影响吗?pip install pillow
在哪一个终端下运行有影响吗?pip install pillow -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn,需要切换到主目录吗? 1. 是否需要切换目录? 不需要切换目录 pip install 安装的包会存放…...

我用 Appuploader绕过 Mac,成功把 iOS 应用上线了 App Store
我以前总觉得,iOS 上架是 macOS Xcode 专属的领域。直到最近项目必须要上架 iOS,团队却没人用 Mac,只能临时组建了一套“跨平台上架流程”。 这篇文章记录我这个“非典型 iOS 开发者”是如何绕开传统 Xcode 流程,借助一系列工具…...

React学习———React Router
React Router React Router 是 React 应用中用于管理路由的流行库,它允许你在单页应用(SPA)中实现导航和页面切换而无需重新加载页面。 安装 npm install react-router-dom核心组件 <BrowserRouter> 使用HTML5的历史记录API&#…...

MGX:多智能体管理开发流程
MGX的多智能体团队如何通过专家混合系统采用全新方法,彻底改变开发流程,与当前的单一智能体工具截然不同。 Lovable和Cursor在自动化我们的特定开发流程方面取得了巨大飞跃,但问题是它们仅解决软件开发的单一领域。 这就是MGX(MetaGPT X)的用武之地,它是一种正在重新定…...

现在环保方面有什么新的技术动态
环保领域的技术发展迅速,尤其在“双碳”目标、数字化转型和可持续发展背景下,涌现出许多创新技术和应用。以下是当前环保领域的新技术动态(截至2024年): 一、碳中和与碳减排技术 CCUS(碳捕集、利用与封存&a…...