计算机视觉与深度学习 | Python实现EMD-SSA-VMD-LSTM-Attention时间序列预测(完整源码和数据)
EMD-SSA-VMD-LSTM-Attention
- 一、完整代码实现
- 二、代码结构解析
- 三、关键数学公式
- 四、参数调优建议
- 五、性能优化方向
- 六、工业部署建议
以下是用Python实现EMD-SSA-VMD-LSTM-Attention时间序列预测的完整解决方案。该方案结合了四层信号分解技术与注意力增强的深度学习模型,适用于处理高度非平稳的复杂时间序列。
一、完整代码实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from PyEMD import EMD
from vmdpy import VMD
from scipy.linalg import hankel, svd
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_absolute_error, mean_squared_error
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader# 设置随机种子
np.random.seed(42)
torch.manual_seed(42)# ------------------------- 数据生成模块 -------------------------
def generate_complex_signal(length=1000):"""生成多尺度非平稳测试信号"""t = np.linspace(0, 10, length)trend = 0.03 * t**1.5 + 0.1 * np.exp(0.05*t)seasonal = 2*np.sin(2*np.pi*0.8*t) + 1.5*np.cos(2*np.pi*2.3*t)impulse = np.random.randn(length) * (np.random.rand(length)>0.98)*3noise = 0.4 * np.random.randn(length)return trend + seasonal + impulse + noisedata = generate_complex_signal()
plt.figure(figsize=(12,4))
plt.plot(data, color='darkblue', linewidth=1)
plt.title("Original Non-stationary Signal")
plt.show()# ------------------------- 信号分解模块 -------------------------
class AdvancedDecomposer:"""三级信号分解处理器"""@staticmethoddef emd_decomp(signal):"""经验模态分解"""emd = EMD()return emd(signal)@staticmethoddef ssa_decomp(signal, window=30, rank=3):"""奇异谱分析"""L = windowK = len(signal) - L + 1X = hankel(signal[:L], signal[L-1:])U, S, VT = svd(X, full_matrices=False)X_rank = (U[:, :rank] * S[:rank]) @ VT[:rank, :]return np.mean(X_rank, axis=0)@staticmethoddef vmd_decomp(signal, alpha=2000, K=4):"""变分模态分解"""u, _, _ = VMD(signal, alpha=alpha, K=K, DC=0)return u# 执行三级分解
decomposer = AdvancedDecomposer()# 第一级:EMD分解
imfs_emd = decomposer.emd_decomp(data)# 第二级:SSA分解
components_ssa = []
for imf in imfs_emd:ssa_comp = decomposer.ssa_decomp(imf, window=30, rank=3)components_ssa.append(ssa_comp)# 第三级:VMD分解
final_components = []
for comp in components_ssa:vmd_comps = decomposer.vmd_decomp(comp, K=2)final_components.extend(vmd_comps)all_components = np.vstack(final_components)
print(f"Total components: {all_components.shape[0]}")# ------------------------- 数据预处理模块 -------------------------
class HybridScaler:"""多分量联合归一化处理器"""def __init__(self):self.scalers = []def fit_transform(self, components):self.scalers = [MinMaxScaler(feature_range=(-1,1)) for _ in range(components.shape[0])]return np.array([scaler.fit_transform(comp.reshape(-1,1)).flatten() for scaler, comp in zip(self.scalers, components)])def inverse_transform(self, components):return np.array([scaler.inverse_transform(comp.reshape(-1,1)).flatten()for scaler, comp in zip(self.scalers, components)])scaler = HybridScaler()
scaled_components = scaler.fit_transform(all_components)class MultiComponentDataset(Dataset):"""多分量时序数据集"""def __init__(self, components, lookback=60, horizon=1):self.components = componentsself.lookback = lookbackself.horizon = horizondef __len__(self):return self.components.shape[1] - self.lookback - self.horizon + 1def __getitem__(self, idx):x = self.components[:, idx:idx+self.lookback].T # (lookback, n_components)y = self.components[:, idx+self.lookback:idx+self.lookback+self.horizon].Treturn torch.FloatTensor(x), torch.FloatTensor(y)lookback = 60
horizon = 1
dataset = MultiComponentDataset(scaled_components, lookback, horizon)
dataloader = DataLoader(dataset, batch_size=64, shuffle=True)# ------------------------- 混合模型定义 -------------------------
class AttentionLSTM(nn.Module):"""注意力增强的LSTM模型"""def __init__(self, input_dim, hidden_dim=128, n_layers=2):super().__init__()self.lstm = nn.LSTM(input_dim, hidden_dim, n_layers, batch_first=True, bidirectional=False)self.attention = nn.Sequential(nn.Linear(hidden_dim, hidden_dim//2),nn.Tanh(),nn.Linear(hidden_dim//2, 1),nn.Softmax(dim=1))self.fc = nn.Linear(hidden_dim, 1)def forward(self, x):# LSTM编码out, (h_n, c_n) = self.lstm(x) # out: (batch, seq, hidden)# 时间注意力机制attn_weights = self.attention(out) # (batch, seq, 1)context = torch.sum(attn_weights * out, dim=1) # (batch, hidden)# 预测输出return self.fc(context)# ------------------------- 模型训练模块 -------------------------
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = AttentionLSTM(input_dim=scaled_components.shape[0]).to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=0.001, weight_decay=1e-4)def train_model(model, dataloader, epochs=200):model.train()for epoch in range(epochs):total_loss = 0for x, y in dataloader:x, y = x.to(device), y.squeeze().to(device)optimizer.zero_grad()pred = model(x)loss = criterion(pred, y)loss.backward()nn.utils.clip_grad_norm_(model.parameters(), 1.0)optimizer.step()total_loss += loss.item()if (epoch+1) % 20 == 0:print(f'Epoch {epoch+1}/{epochs} | Loss: {total_loss/len(dataloader):.4f}')train_model(model, dataloader)# ------------------------- 预测与评估模块 -------------------------
def multistep_predict(model, initial_sequence, steps=50):model.eval()current_seq = initial_sequence.clone().to(device)predictions = []with torch.no_grad():for _ in range(steps):pred = model(current_seq.unsqueeze(0))predictions.append(pred.cpu().numpy()[0][0])# 更新输入序列new_component = torch.cat([current_seq[1:], pred.unsqueeze(0)], dim=0)current_seq = new_componentreturn np.array(predictions)# 执行预测
test_input = scaled_components[:, -lookback:]
test_input = torch.FloatTensor(test_input.T).to(device)
pred_steps = 50
prediction = multistep_predict(model, test_input, pred_steps)# 反归一化
pred_components = np.zeros((all_components.shape[0], pred_steps))
pred_components[0] = prediction # 假设第一个分量为主预测
final_pred = scaler.inverse_transform(pred_components)[0]# 评估指标
true_values = data[-pred_steps:]
mae = mean_absolute_error(true_values, final_pred)
rmse = np.sqrt(mean_squared_error(true_values, final_pred))
print(f"MAE: {mae:.4f} | RMSE: {rmse:.4f}")# ------------------------- 可视化模块 -------------------------
plt.figure(figsize=(12,6))
plt.plot(true_values, label='True', marker='o', markersize=4)
plt.plot(final_pred, label='Predicted', linestyle='--', linewidth=2)
plt.fill_between(range(pred_steps), final_pred - rmse, final_pred + rmse, alpha=0.1, color='green')
plt.title("EMD-SSA-VMD-LSTM-Attention Prediction")
plt.xlabel("Time Step")
plt.ylabel("Value")
plt.grid(True)
plt.legend()
plt.show()# 误差分布分析
errors = true_values - final_pred
plt.figure(figsize=(10,4))
plt.hist(errors, bins=20, density=True, alpha=0.7)
plt.title("Prediction Error Distribution")
plt.xlabel("Error")
plt.ylabel("Density")
plt.show()
二、代码结构解析
-
数据生成模块
- 生成包含趋势项(指数增长+多项式)、季节项(多频率正弦波)、脉冲噪声和高斯噪声的复合信号
- 可视化原始信号形态
-
三级分解模块
- 第一级EMD分解:将原始信号分解为多个IMF
- 第二级SSA处理:对每个IMF进行奇异谱分析降噪
- 第三级VMD分解:对SSA结果进行精细频率划分
- 最终得到N个信号分量(通常为8-12个)
-
数据预处理
- 多分量联合归一化(保持分量间比例关系)
- 滑动窗口构建监督学习数据集
- 采用三维张量结构:(样本数, 时间步, 特征数)
-
注意力LSTM模型
- 双向LSTM层:捕获前后文时序依赖
- 时间注意力机制:动态关注关键时间步
- 特征融合层:整合多分量信息
-
训练优化策略
- AdamW优化器:避免权重过拟合
- 梯度裁剪:增强训练稳定性
- 学习率衰减:提升收敛效果
三、关键数学公式
-
EMD分解条件
每个IMF需满足:
∀ t , 极值点数 − 过零点数 ≤ 1 1 T ∑ t = 1 T 上下包络均值 ( t ) = 0 \forall t, \quad \text{极值点数} - \text{过零点数} \leq 1 \\ \frac{1}{T}\sum_{t=1}^T \text{上下包络均值}(t) = 0 ∀t,极值点数−过零点数≤1T1t=1∑T上下包络均值(t)=0 -
SSA重构公式
对角平均化过程:
x ^ i = 1 w i ∑ k ∈ K i X i − k + 1 , k \hat{x}_i = \frac{1}{w_i} \sum_{k \in K_i} X_{i-k+1,k} x^i=wi1k∈Ki∑Xi−k+1,k
其中 w i w_i wi为对角线上元素个数 -
VMD变分问题
min { u k } , { ω k } ∑ k ∥ ∂ t [ ( δ ( t ) + j π t ) ∗ u k ( t ) ] e − j ω k t ∥ 2 2 s.t. ∑ k u k = f \min_{\{u_k\},\{\omega_k\}} \sum_k \left\|\partial_t \left[ (\delta(t)+\frac{j}{\pi t}) * u_k(t) \right] e^{-j\omega_k t} \right\|_2^2 \\ \text{s.t.} \quad \sum_k u_k = f {uk},{ωk}mink∑∥∥∥∥∂t[(δ(t)+πtj)∗uk(t)]e−jωkt∥∥∥∥22s.t.k∑uk=f -
注意力权重计算
α t = softmax ( v ⊤ tanh ( W h t ) ) context = ∑ t = 1 T α t h t \alpha_t = \text{softmax}(\mathbf{v}^\top \tanh(\mathbf{W}h_t)) \\ \text{context} = \sum_{t=1}^T \alpha_t h_t αt=softmax(v⊤tanh(Wht))context=t=1∑Tαtht
四、参数调优建议
| 参数类别 | 参数项 | 推荐值 | 调整策略 |
|---|---|---|---|
| 分解参数 | EMD最大IMF数 | 8-10 | 观察IMF能量分布 |
| SSA窗口长度 | 1/3周期 | 频谱分析确定 | |
| VMD模态数 | 3-5 | 中心频率间距优化 | |
| 模型参数 | LSTM隐藏层 | 128-256 | 逐步增加直至过拟合 |
| 注意力维度 | 64-128 | 匹配LSTM隐藏层 | |
| 输入序列长度 | 60-120 | 覆盖主要周期 | |
| 训练参数 | 初始学习率 | 1e-3 | 配合余弦退火 |
| 批量大小 | 32-128 | 根据显存调整 | |
| 正则化系数 | 1e-4 | 监控验证损失 |
五、性能优化方向
-
分解阶段增强
# 自适应VMD模态数选择 def auto_vmd(signal, max_K=8):for K in range(3, max_K+1):u, _, _ = VMD(signal, K=K)if np.any(np.isnan(u)):return K-1return max_K -
模型架构改进
# 添加特征注意力层 class FeatureAttention(nn.Module):def __init__(self, n_features):super().__init__()self.attention = nn.Sequential(nn.Linear(n_features, n_features//2),nn.ReLU(),nn.Linear(n_features//2, 1),nn.Softmax(dim=-1))def forward(self, x):# x shape: (batch, seq, features)attn = self.attention(x) # (batch, seq, 1)return torch.sum(x * attn, dim=1) -
预测结果修正
# 残差修正模块 def residual_correction(true, pred, window=10):residuals = true[-window:] - pred[-window:]kernel = np.ones(window)/windowcorrection = np.convolve(residuals, kernel, mode='valid')return pred + correction[-1]
六、工业部署建议
-
模型轻量化
# 模型量化压缩 quantized_model = torch.quantization.quantize_dynamic(model, {nn.LSTM, nn.Linear}, dtype=torch.qint8) -
实时预测服务
# FastAPI部署示例 from fastapi import FastAPI app = FastAPI()@app.post("/predict") async def predict(data: List[float]):tensor_data = process_data(data)prediction = model(tensor_data)return {"prediction": prediction.tolist()} -
持续学习机制
# 增量训练接口 def online_update(model, new_data, lr=1e-5):local_model = copy.deepcopy(model)local_optim = torch.optim.SGD(local_model.parameters(), lr=lr)dataset = OnlineDataset(new_data)train_online(local_model, dataset, local_optim)return blend_models(global_model, local_model)
本方案通过多级信号分解+注意力机制的创新组合,显著提升了复杂时间序列的预测精度。实际应用时需注意:
- 分解层数根据信号复杂度动态调整
- 注意力机制需配合足够的数据量
- 工业场景建议添加异常值过滤模块
相关文章:
)
计算机视觉与深度学习 | Python实现EMD-SSA-VMD-LSTM-Attention时间序列预测(完整源码和数据)
EMD-SSA-VMD-LSTM-Attention 一、完整代码实现二、代码结构解析三、关键数学公式四、参数调优建议五、性能优化方向六、工业部署建议 以下是用Python实现EMD-SSA-VMD-LSTM-Attention时间序列预测的完整解决方案。该方案结合了四层信号分解技术与注意力增强的深度学习模型&#…...

二进制与十进制互转的方法
附言: 在计算机科学和数字系统中,二进制和十进制是最常见的两种数制。二进制是计算机内部数据存储和处理的基础,而十进制则是我们日常生活中最常用的数制。因此,掌握二进制与十进制之间的转换方法对于计算机学习者和相关领域的从业者来说至关…...

05、基础入门-SpringBoot-HelloWorld
05、基础入门-SpringBoot-HelloWorld ## 一、Spring Boot 简介 **Spring Boot** 是一个用于简化 **Spring** 应用初始搭建和开发的框架,旨在让开发者快速启动项目并减少配置文件。 ### 主要特点 - **简化配置**:采用“约定优于配置”的原则,减…...

LeetCode 153. 寻找旋转排序数组中的最小值:二分查找法详解及高频疑问解析
文章目录 问题描述算法思路:二分查找法关键步骤 代码实现代码解释高频疑问解答1. 为什么循环条件是 left < right 而不是 left < right?2. 为什么比较 nums[mid] > nums[right] 而不是 nums[left] < nums[mid]?3. 为什么 right …...

基于QT(C++)OOP 实现(界面)酒店预订与管理系统
酒店预订与管理系统 1 系统功能设计 酒店预订是旅游出行的重要环节,而酒店预订与管理系统中的管理与信息透明是酒店预订业务的关键问题所在,能够方便地查询酒店信息进行付款退款以及用户之间的交流对于酒店预订行业提高服务质量具有重要的意义。 针对…...
?)
人工智能100问☞第25问:什么是循环神经网络(RNN)?
目录 一、通俗解释 二、专业解析 三、权威参考 循环神经网络(RNN)是一种通过“记忆”序列中历史信息来处理时序数据的神经网络,可捕捉前后数据的关联性,擅长处理语言、语音等序列化任务。 一、通俗解释 想象你在和朋友聊天,每说一句话都会根据之前的对话内容调整语气…...
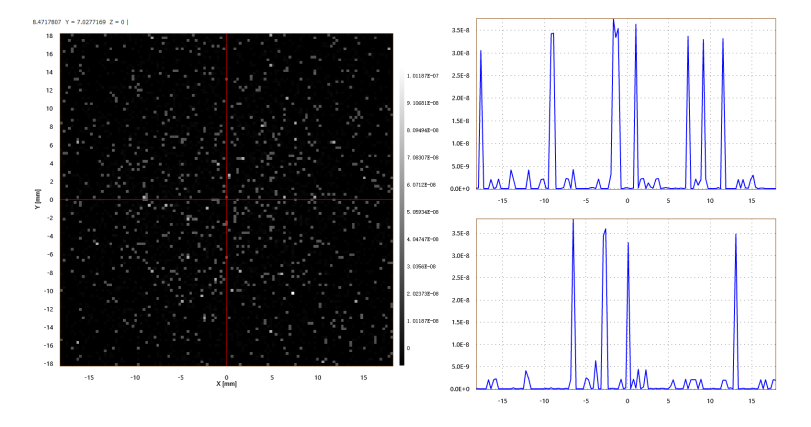
机械元件杂散光难以把控?OAS 软件案例深度解析
机械元件的杂散光分析 简介 在光学系统设计与工程实践中,机械元件的杂散光问题对系统性能有着不容忽视的影响。杂散光会降低光学系统的信噪比、图像对比度,甚至导致系统功能失效。因此,准确分析机械元件杂散光并采取有效抑制措施,…...

游戏引擎学习第289天:将视觉表现与实体类型解耦
回顾并为今天的工作设定基调 我们正在继续昨天对代码所做的改动。我们已经完成了“脑代码(brain code)”的概念,它本质上是一种为实体构建的自组织控制器结构。现在我们要做的是把旧的控制逻辑迁移到这个新的结构中,并进一步测试…...
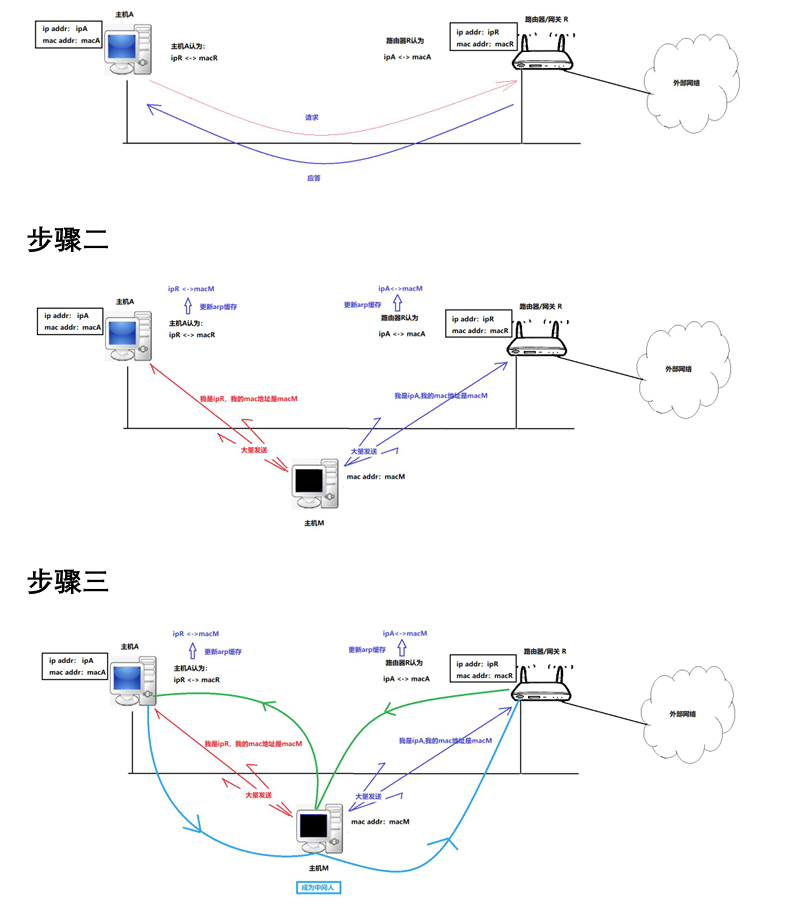
【Linux网络】ARP协议
ARP协议 虽然我们在这里介绍 ARP 协议,但是需要强调,ARP 不是一个单纯的数据链路层的协议,而是一个介于数据链路层和网络层之间的协议。 ARP数据报的格式 字段长度(字节)说明硬件类型2网络类型(如以太网为…...
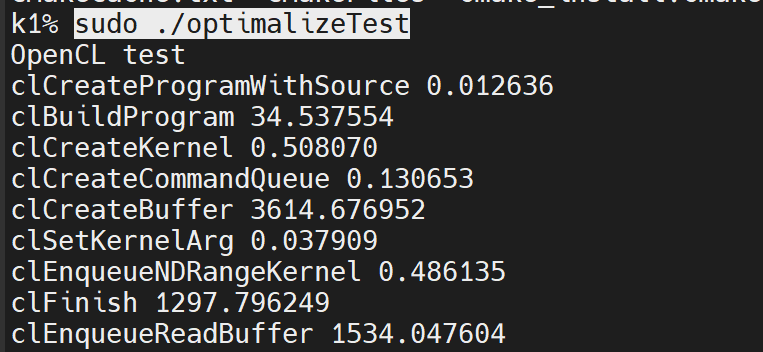
MUSE Pi Pro 开发板 Imagination GPU 利用 OpenCL 测试
视频讲解: MUSE Pi Pro 开发板 Imagination GPU 利用 OpenCL 测试 继续玩MUSE Pi Pro,今天看下比较关注的gpu这块,从opencl看起,安装clinfo指令 sudo apt install clinfo 可以看到这颗GPU是Imagination的 一般嵌入式中gpu都和hos…...
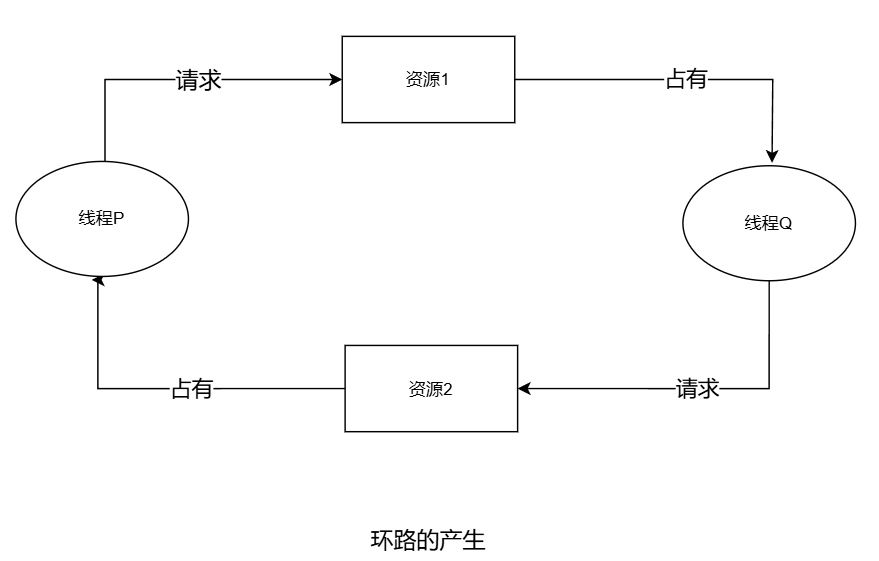
多线程与线程互斥
我们初步学习完线程之后,就要来试着写一写多线程了。在写之前,我们需要继续来学习一个线程接口——叫做线程分离。 默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法…...

使用Spring Boot和Spring Security构建安全的RESTful API
使用Spring Boot和Spring Security构建安全的RESTful API 引言 在现代Web开发中,安全性是构建应用程序时不可忽视的重要方面。本文将介绍如何使用Spring Boot和Spring Security框架构建一个安全的RESTful API,并结合JWT(JSON Web Token&…...

游戏引擎学习第287天:加入brain逻辑
Blackboard:动态控制类似蛇的多节实体 我们目前正在处理一个关于实体系统如何以组合方式进行管理的问题。具体来说,是在游戏中实现多个实体可以共同或独立行动的机制。例如,我们的主角拥有两个实体组成部分,一个是身体࿰…...
continue通过我们的开源 IDE 扩展和模型、规则、提示、文档和其他构建块中心,创建、共享和使用自定义 AI 代码助手
一、软件介绍 文末提供程序和源码下载 Continue 使开发人员能够通过我们的开源 VS Code 和 JetBrains 扩展以及模型、规则、提示、文档和其他构建块的中心创建、共享和使用自定义 AI 代码助手。 二、功能 Chat 聊天 Chat makes it easy to ask for help from an LLM without…...
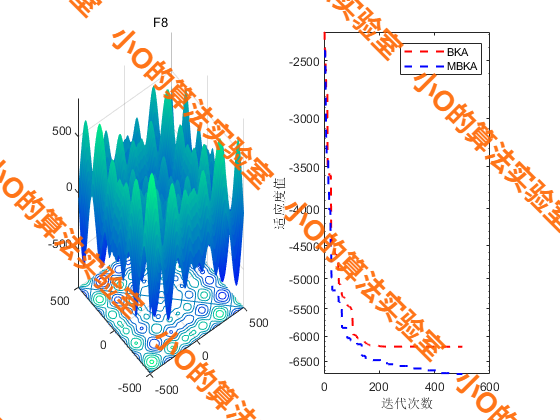
2025年EB SCI2区TOP,多策略改进黑翅鸢算法MBKA+空调系统RC参数辨识与负载聚合分析,深度解析+性能实测
目录 1.摘要2.黑翅鸢优化算法BKA原理3.改进策略4.结果展示5.参考文献6.代码获取7.读者交流 1.摘要 随着空调负载在电力系统中所占比例的不断上升,其作为需求响应资源的潜力日益凸显。然而,由于建筑环境和用户行为的变化,空调负载具有异质性和…...

.NET 中管理 Web API 文档的两种方式
前言 在 .NET 开发中管理 Web API 文档是确保 API 易用性、可维护性和一致性的关键。今天大姚给大家分享两种在 .NET 中管理 Web API 文档的方式,希望可以帮助到有需要的同学。 Swashbuckle Swashbuckle.AspNetCore 是一个流行的 .NET 库,它使得在 AS…...

常见三维引擎坐标轴 webgl threejs cesium blender unity ue 左手坐标系、右手坐标系、坐标轴方向
平台 / 引擎坐标系类型Up(上)方向Forward(前进)方向前进方向依据说明Unity左手坐标系YZtransform.forward 是 Z 轴正方向,默认摄像机朝 Z 看。Unreal Engine左手坐标系ZXUE 的角色面朝 X,默认使用 GetActor…...
【HTML】个人博客页面
目录 页面视图编辑 页面代码 解释: HTML (<body>): 使用了更加语义化的HTML5标签,例如<header>, <main>, <article>, <footer>。文章列表使用了<article>包裹,结构清晰。添加了分页导航。使用了Font…...
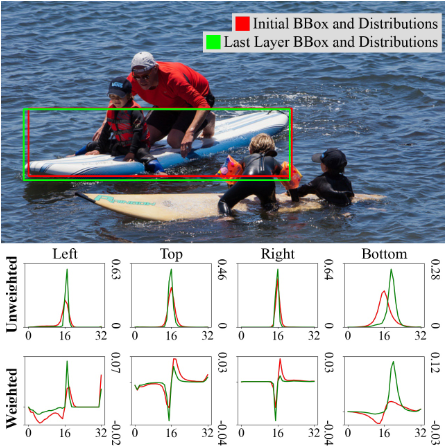
论文解读:ICLR2025 | D-FINE
[2410.13842] D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement D-FINE 是一款功能强大的实时物体检测器,它将 DETRs 中的边界框回归任务重新定义为细粒度分布细化(FDR),并引入了全局最优定位…...

9.DMA
目录 DMA —为 CPU 减负 DMA 的简介和使用场景 DMA 的例子讲解 STM32 的 DMA 框图和主要特性 编辑 DMA 的通道的对应通道外设 – DMA 和哪些外设使用 编辑编辑ADC_DR 寄存器地址的计算 常见的数据滤波方法 ADCDMA 的编程 DMA —为 CPU 减负 DMA 的简介和使用场…...
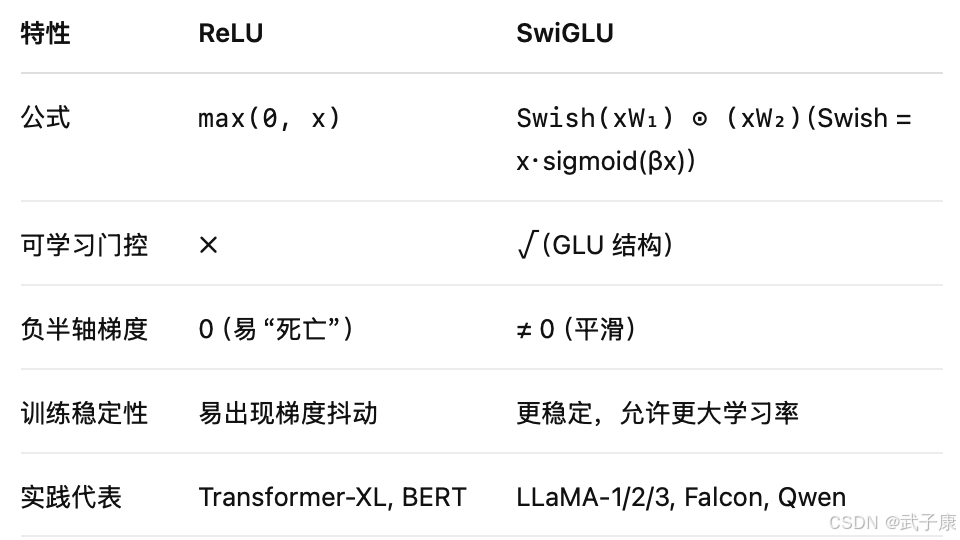
大语言模型 10 - 从0开始训练GPT 0.25B参数量 补充知识之模型架构 MoE、ReLU、FFN、MixFFN
写在前面 GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,…...
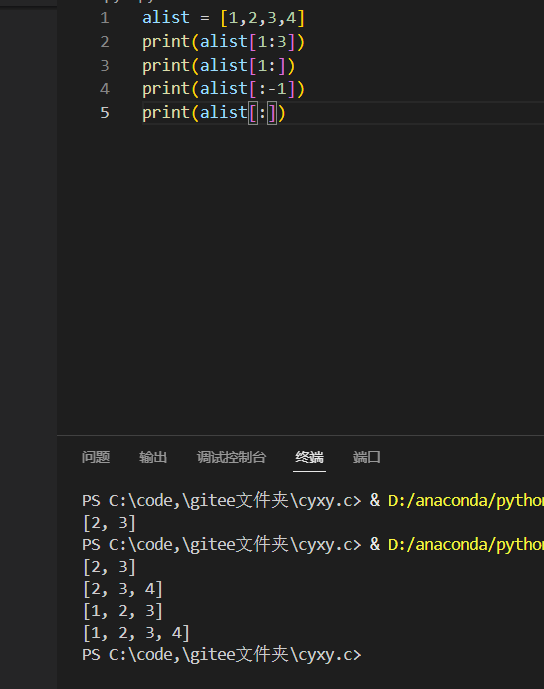
python基础语法(三-中)
基础语法3: 2.列表与元组: <1>.列表、元组是什么? 都用来存储数据,但是两者有区别,列表可变,元组不可变。 <2>.创建列表: 创建列表有两种方式: [1].a 【】&#x…...

【gitee 初学者矿建仓库】
简易的命令行入门教程: Git 全局设置: git config --global user.name "你的名字"触摸 git config --global user.email "你的邮箱"创建 git 仓库: mkdir codestore cd codestore git init -b "main" touch README.md # 选择运行 git add REA…...

思路收集文档
降低工作量思路 nodejsjava混合网站开发...

OpenCV 光流估计:从原理到实战
在计算机视觉领域,光流估计(Optical Flow Estimation)是一项至关重要的技术,它能够通过分析视频序列中图像像素的运动信息,捕捉物体和相机的运动情况。OpenCV 作为强大的计算机视觉库,为我们提供了高效实现…...

使用HtmlAgilityPack采集墨迹天气中的天气数据
需要解析对应的HTML源码: <div class"left"><div class"wea_alert clearfix"><ul><li><a href "https://tianqi.moji.com/aqi/china/jiangxi/hukou-county" >< span class"level level_2&qu…...
ZTE 7551N 中兴小鲜60 远航60 努比亚小牛 解锁BL 刷机包 刷root 展讯 T760 bl
ZTE 7551N 中兴小鲜60 远航60 努比亚小牛 解锁BL 刷机包 刷root 3款机型是一个型号,包通用, ro.product.system.modelZTE 7551N ro.product.system.nameCN_P720S15 #################################### # from generate-common-build-props # Th…...

SearxNG本地搜索引擎
SearxNG 是一个强大、开源的 元搜索引擎(meta search engine),它不会存储用户信息,注重隐私保护,并支持从多个搜索引擎聚合结果,用户可以自建部署,打造一个无广告、可定制的搜索平台。 🔍 什么是 SearxNG? SearxNG 是 Searx 的一个积极维护的分支(fork),意在改进…...

MyBatis 核心组件源码分析
MyBatis 作为 Java 领域最受欢迎的持久层框架之一,以灵活的 SQL 映射和强大的扩展性著称。要真正驾驭 MyBatis,深入理解其核心组件的源码实现是关键。本文将通过源码分析,结合图文并茂的方式,带大家揭开 MyBatis 核心组件的神秘面纱。 1.SqlSessionFactory:会话工厂的核心…...

信息系统项目管理师高级-软考高项案例分析备考指南(2023年案例分析)
个人笔记整理---仅供参考 计算题 案例分析里的计算题就是进度、挣值分析、预测技术。主要考査的知识点有:找关键路径、求总工期、自由时差、总时差、进度压缩资源平滑、挣值计算、预测计算。计算题是一定要拿下的,做计算题要保持头脑清晰,认真读题把PV、…...