深度学习模型基本框架
简介:
归纳了一套基本框架,以帮助使用者快速创建新的模型,同时有paddlepaddle版本和pytorch版本的,它们虽有差别,但是对于初级使用者,只是两种不同但是很相近的语法而已。都采用paddle平台作为载体来存项目。
模型框架paddle
这里用paddlepaddle的图像分类项目为例,这是项目链接:
花卉分类:https://aistudio.baidu.com/projectdetail/9165955?sUid=15411139&shared=1&ts=1747486226503
1.导入库与参数配置
import os
import zipfile
import random
import json
import paddle
import sys
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from paddle.io import Datasettrain_parameters = {"input_size": [3, 224, 224], # 输入图片的shape"class_dim": -1, # 分类数"src_path": "/home/aistudio/data/data6504/flower7595.zip", # 原始数据集路径"target_path": "/home/aistudio/data/", # 要解压的路径"train_list_path": "/home/aistudio/data/train.txt", # train.txt路径"eval_list_path": "/home/aistudio/data/eval.txt", # eval.txt路径"readme_path": "/home/aistudio/data/readme.json", # readme.json路径"label_dict": {}, # 标签字典"num_epochs": 20, # 训练轮数"train_bath_size": 8, # 训练时每个批次的大小"skip_steps": 10,"save_steps": 300,"learning_strategy": { # 优化函数相关的配置"lr": 0.0001 # 超参数学习率},"checkpoints": "/home/aistudio/work/checkpoints" # 保存的路径}2.数据准备
解压等预处理
生成数据列表(路径-标签)get_data_list得到eval.txt和train.txt
建立数据读取器Reader:
__init__使用txt得到列表(path--labels)
__getitem用序号依次读取列表,使用path时直接加载图片
# # 一、数据准备
# (1)解压原始数据集
#
# (2)按照比例划分训练集与验证集
#
# (3)乱序,生成数据列表
#
# (4)定义数据读取器# In[35]:def unzip_data(src_path, target_path):# 解压原始数据集,将src_path路径下的zip压缩包解压至target_path目录下if (not os.path.isdir(target_path + "Chinese Medicine")):z = zipfile.ZipFile(src_path, "r")z.extractall(path=target_path)z.close()# In[36]:#就是建立2个txt,按照样本--标签的形式
# 函数 生成数据列表
def get_data_list(target_path, train_list_path, eval_list_path):# 存放所有类别的信息class_detail = []# 获取所有类别保存的文件夹名称data_list_path = target_path + "flowers/"class_dirs = os.listdir(data_list_path)# 总的图像数量all_class_images = 0# 存放类别标签class_label = 0# 存放类别数目class_dim = 0# 存储要写进eval.txt和train.txt中的内容trainer_list = []eval_list = []# 读取每个类别for class_dir in class_dirs:if class_dir != ".DS_Store":class_dim += 1# 每个类别的信息class_detail_list = {}eval_sum = 0trainer_sum = 0# 统计每个类别有多少张图片class_sum = 0# 获取类别路径path = data_list_path + class_dir# 获取所有图片img_paths = os.listdir(path)for img_path in img_paths: # 遍历文件夹下的每个图片if img_path.split(".")[-1] == "jpg":name_path = path + '/' + img_path # 每张图片的路径if class_sum % 8 == 0: # 每8张图片取一个做验证数据eval_sum += 1 # test_sum为测试数据的数目eval_list.append(name_path + "\t%d" % class_label + "\n")else:trainer_sum += 1trainer_list.append(name_path + "\t%d" % class_label + "\n")class_sum += 1 # 每类图片的数目all_class_images += 1 # 所有类图片的数目else:continue# 说明的json文件的class_detail数据class_detail_list['class_name'] = class_dir # 类别名称class_detail_list['class_label'] = class_label # 类别标签class_detail_list['class_eval_images'] = eval_sum # 该类数据的测试集数目class_detail_list['class_trainer_images'] = trainer_sum # 该类数据的训练集数目class_detail.append(class_detail_list)# 初始化标签列表train_parameters['label_dict'][str(class_label)] = class_dirclass_label += 1# 初始化分类树train_parameters['class_dim'] = class_dim# 乱序random.shuffle(eval_list)with open(eval_list_path, 'a') as f:for eval_image in eval_list:f.write(eval_image)random.shuffle(trainer_list)with open(train_list_path, 'a') as f2:for train_image in trainer_list:f2.write(train_image)# 说明的json文件信息readjson = {}readjson['all_class_name'] = data_list_path # 文件父目录readjson['all_class_images'] = all_class_imagesreadjson['class_detail'] = class_detailjsons = json.dumps(readjson, sort_keys=True, indent=4, separators=(',', ': '))with open(train_parameters['readme_path'], 'w') as f:f.write(jsons)print('生成数据列表完成!')# In[37]:# 参数初始化src_path = train_parameters['src_path']
target_path = train_parameters['target_path']
train_list_path = train_parameters['train_list_path']
eval_list_path = train_parameters['eval_list_path']# 解压原始数据到指定路径unzip_data(src_path, target_path)# 划分训练集与验证集,乱序,生成数据列表
# 每次生成数据列表前,首先清空 train.txt 和 eval.txt
with open(train_list_path, 'w') as f:f.seek(0)f.truncate()
with open(eval_list_path, 'w') as f:f.seek(0)f.truncate()# 生成数据列表
get_data_list(target_path, train_list_path, eval_list_path)# In[38]:sclass Reader(Dataset):def __init__(self, data_path, mode='train'):'''数据读取器:param data_path:数据集所在路径:param mode: train or eval'''super().__init__()self.data_path = data_pathself.img_paths = []self.labels = []if mode == 'train':with open(os.path.join(self.data_path, "train.txt"), "r", encoding="utf-8") as f:self.info = f.readlines()for img_info in self.info:img_path, label = img_info.strip().split('\t')self.img_paths.append(img_path)self.labels.append(int(label))else:with open(os.path.join(self.data_path, "eval.txt"), "r", encoding="utf-8") as f:self.info = f.readlines()for img_info in self.info:img_path, label = img_info.strip().split('\t')self.img_paths.append(img_path)self.labels.append(int(label))def __getitem__(self, index):# 获取一组数据 :param index: 文件索引号# 第一步打开图像文件并获取label值img_path = self.img_paths[index]img = Image.open(img_path)if img.mode != 'RGB':img = img.convert('RGB')img = img.resize((224, 224), Image.BILINEAR)img = np.array(img).astype('float32')img = img.transpose((2, 0, 1)) / 255label = self.labels[index]label = np.array([label], dtype="int64")return img, labeldef print_sample(self, index: int = 0):print("文件名", self.img_paths[index], "\t标签值", self.labels[index])def __len__(self):return len(self.img_paths)# In[39]:# 训练数据加载
train_dataset = Reader('/home/aistudio/data', mode='train')
train_loader = paddle.io.DataLoader(train_dataset, batch_size=16, shuffle=True)
# 测试数据加载
eval_dataset = Reader('/home/aistudio/data', mode='eval')
eval_loader = paddle.io.DataLoader(eval_dataset, batch_size=8, shuffle=False)# In[40]:train_dataset.print_sample(200)
print(train_dataset.__len__())
eval_dataset.print_sample(0)
print(eval_dataset.__len__())
print(eval_dataset.__getitem__(10)[0].shape)
print(eval_dataset.__getitem__(10)[1].shape)
3.模型构建
根据数据集类型和格式建立模型(我这个初学者喜欢用ai生成然后分析一下就结束)
class ConvPool(paddle.nn.Layer):# 卷积+池化def __init__(self, num_channels, num_filters, filter_size, pool_size, pool_stride, groups, conv_stride=1,conv_padding=1, ):super(ConvPool, self).__init__()for i in range(groups):self.add_sublayer( # 添加子层实例'bb_%d' % i,paddle.nn.Conv2D( # layerin_channels=num_channels, # 通道数out_channels=num_filters, # 卷积核个数kernel_size=filter_size, # 卷积核大小stride=conv_stride, # 步长padding=conv_padding # padding))self.add_sublayer('relu%d' % i,paddle.nn.ReLU())num_channels = num_filtersself.add_sublayer('Maxpool',paddle.nn.MaxPool2D(kernel_size=pool_size, # 池化核大小stride=pool_stride # 池化步长))def forward(self, inputs):x = inputsfor prefix, sub_layer in self.named_children():# print(prefix,sub_layer)x = sub_layer(x)return x# In[42]:class VGGNet(paddle.nn.Layer):# 卷积+池化def __init__(self, num_classes=1000):super(VGGNet, self).__init__()# 第一组:64个卷积核,2个卷积层self.convpool01 = ConvPool(num_channels=3, # 输入通道数(RGB图像)num_filters=64,filter_size=3,pool_size=2,pool_stride=2,groups=2 # 两个连续卷积层)# 第二组:128个卷积核,2个卷积层self.convpool02 = ConvPool(num_channels=64,num_filters=128,filter_size=3,pool_size=2,pool_stride=2,groups=2)# 第三组:256个卷积核,3个卷积层self.convpool03 = ConvPool(num_channels=128,num_filters=256,filter_size=3,pool_size=2,pool_stride=2,groups=3)# 第四组:512个卷积核,3个卷积层self.convpool04 = ConvPool(num_channels=256,num_filters=512,filter_size=3,pool_size=2,pool_stride=2,groups=3)# 第五组:512个卷积核,3个卷积层self.convpool05 = ConvPool(num_channels=512,num_filters=512,filter_size=3,pool_size=2,pool_stride=2,groups=3)# 全连接层self.fc1 = paddle.nn.Linear(512 * 7 * 7, 4096) # 根据输入尺寸计算self.fc2 = paddle.nn.Linear(4096, 4096)self.fc3 = paddle.nn.Linear(4096, num_classes)def forward(self, x, label=None):"""前向计算"""# 卷积层部分out = self.convpool01(x)out = self.convpool02(out)out = self.convpool03(out)out = self.convpool04(out)out = self.convpool05(out)# 展平操作out = paddle.flatten(out, start_axis=1, stop_axis=-1)# 全连接层out = paddle.nn.functional.relu(self.fc1(out))out = paddle.nn.functional.relu(self.fc2(out))out = self.fc3(out)# 计算准确率(如果提供了label)if label is not None:acc = paddle.metric.accuracy(input=out, label=label)return out, accelse:return out4.模型训练与预估
# In[43]:def draw_process(title, color, iters, data, label):plt.title(title, fontsize=24)plt.xlabel("iter", fontsize=20)plt.ylabel(label, fontsize=20)plt.plot(iters, data, color=color, label=label)plt.legend()plt.grid()plt.show()# In[44]:print(train_parameters['class_dim'])
print(train_parameters['label_dict'])# In[45]:from paddle.optimizer.lr import CosineAnnealingDecaymodel = VGGNet()
model.train()
cross_entropy = paddle.nn.CrossEntropyLoss()
optimizer = paddle.optimizer.Adam(learning_rate=train_parameters['learning_strategy']['lr'],parameters=model.parameters())steps = 0
Iters, total_loss, total_acc = [], [], []for epo in range(train_parameters['num_epochs']):for _, data in enumerate(train_loader()):steps += 1x_data = data[0]y_data = data[1]predicts, acc = model(x_data, y_data)loss = cross_entropy(predicts, y_data)loss.backward()optimizer.step()optimizer.clear_grad()if steps % train_parameters["skip_steps"] == 0:Iters.append(steps)total_loss.append(loss.numpy()[0])total_acc.append(acc.numpy()[0])# 打印中间过程print('epo: {}, step: {}, loss is: {}, acc is: {}'.format(epo, steps, loss.numpy(), acc.numpy()))# 保存模型参数if steps % train_parameters["save_steps"] == 0:save_path = train_parameters["checkpoints"] + "/" + "save_dir_" + str(steps) + '.pdparams'print('save model to: ' + save_path)paddle.save(model.state_dict(), save_path)
paddle.save(model.state_dict(), train_parameters["checkpoints"] + "/" + "save_dir_final.pdparams")
draw_process("trainning loss", "red", Iters, total_loss, "trainning loss")
draw_process("trainning acc", "green", Iters, total_acc, "trainning acc")# # 四、模型评估# In[46]:'''
模型评估
'''
from paddle.optimizer.lr import CosineAnnealingDecaymodel__state_dict = paddle.load('work/checkpoints/save_dir_final.pdparams')
model_eval = VGGNet()
model_eval.set_state_dict(model__state_dict)
model_eval.eval()
accs = []for _, data in enumerate(eval_loader()):x_data = data[0]y_data = data[1]predicts = model_eval(x_data)acc = paddle.metric.accuracy(predicts, y_data)accs.append(acc.numpy()[0])
print('模型在验证集上的准确率为:', np.mean(accs))# # 五、模型预测# In[47]:def load_image(img_path):'''预测图片预处理'''img = Image.open(img_path)if img.mode != 'RGB':img = img.convert('RGB')img = img.resize((224, 224), Image.BILINEAR)img = np.array(img).astype('float32')img = img.transpose((2, 0, 1)) / 255 # HWC to CHW 及归一化return imginfer_dst_path = 'data/flowers/rose/'label_dic = train_parameters['label_dict']# In[48]:model__state_dict = paddle.load('work/checkpoints/save_dir_final.pdparams')
model_predict = VGGNet()
model_predict.set_state_dict(model__state_dict)
model_predict.eval()
infer_imgs_path = os.listdir(infer_dst_path)
# print(infer_imgs_path)
for infer_img_path in infer_imgs_path[:10]:infer_img = load_image(infer_dst_path + infer_img_path)infer_img = infer_img[np.newaxis, :, :, :] # reshape(-1,3,224,224)infer_img = paddle.to_tensor(infer_img)result = model_predict(infer_img)lab = np.argmax(result.numpy())print("rose样本: {},被预测为:{}".format(infer_img_path, label_dic[str(lab)]))模型框架pytorch
这里以pytorch的声音情绪识别分类为例,以下是项目链接:
语音情绪识别:https://aistudio.baidu.com/projectdetail/9166158?sUid=15411139&shared=1&ts=1747488195503
这个pytorch仅作为框架示例,改改模型就可以直接用
相关文章:

深度学习模型基本框架
简介: 归纳了一套基本框架,以帮助使用者快速创建新的模型,同时有paddlepaddle版本和pytorch版本的,它们虽有差别,但是对于初级使用者,只是两种不同但是很相近的语法而已。都采用paddle平台作为载体来存项目…...

[Java][Leetcode middle] 134. 加油站
方法一,自己想的,超时 双重循环 从第一个点开始循环尝试, 如果最终能走到终点,说明可行。 public int canCompleteCircuit(int[] gas, int[] cost) {int res -1;int n gas.length;int remainGas;int j;for (int i 0; i < …...
DeepSeek 大模型部署全指南:常见问题、优化策略与实战解决方案
DeepSeek 作为当前最热门的开源大模型之一,其强大的语义理解和生成能力吸引了大量开发者和企业关注。然而在实际部署过程中,无论是本地运行还是云端服务,用户往往会遇到各种技术挑战。本文将全面剖析 DeepSeek 部署中的常见问题,提…...

嵌入式培训之数据结构学习(五)栈与队列
一、栈 (一)栈的基本概念 1、栈的定义: 注:线性表中的栈在堆区(因为是malloc来的);系统中的栈区存储局部变量、函数形参、函数返回值地址。 2、栈顶和栈底: 允许插入和删除的一端…...

RabbitMQ--进阶篇
RabbitMQ 客户端整合Spring Boot 添加相关的依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId> </dependency> 编写配置文件,配置RabbitMQ的服务信息 spri…...
Android Studio报错Cannot parse result path string:
前言 最近在写个小Demo,参考郭霖的《第一行代码》,学习DrawerLayout和NavigationView,不知咋地,突然报错Cannot parse result path string:xxxxxxxxxxxxx 反正百度,问ai都找不到答案,报错信息是完全看不懂…...

matlab求矩阵的逆、行列式、秩、转置
inv - 计算矩阵的逆 用途:计算一个可逆矩阵的逆矩阵。 D [1, 2; 3, 4]; % 定义一个2x2矩阵 D_inv inv(D); % 计算矩阵D的逆 disp(D_inv);det - 计算矩阵的行列式 用途:计算方阵的行列式。 E [1, 2; 3, 4]; determinant det(E); % 计算行列式 disp…...
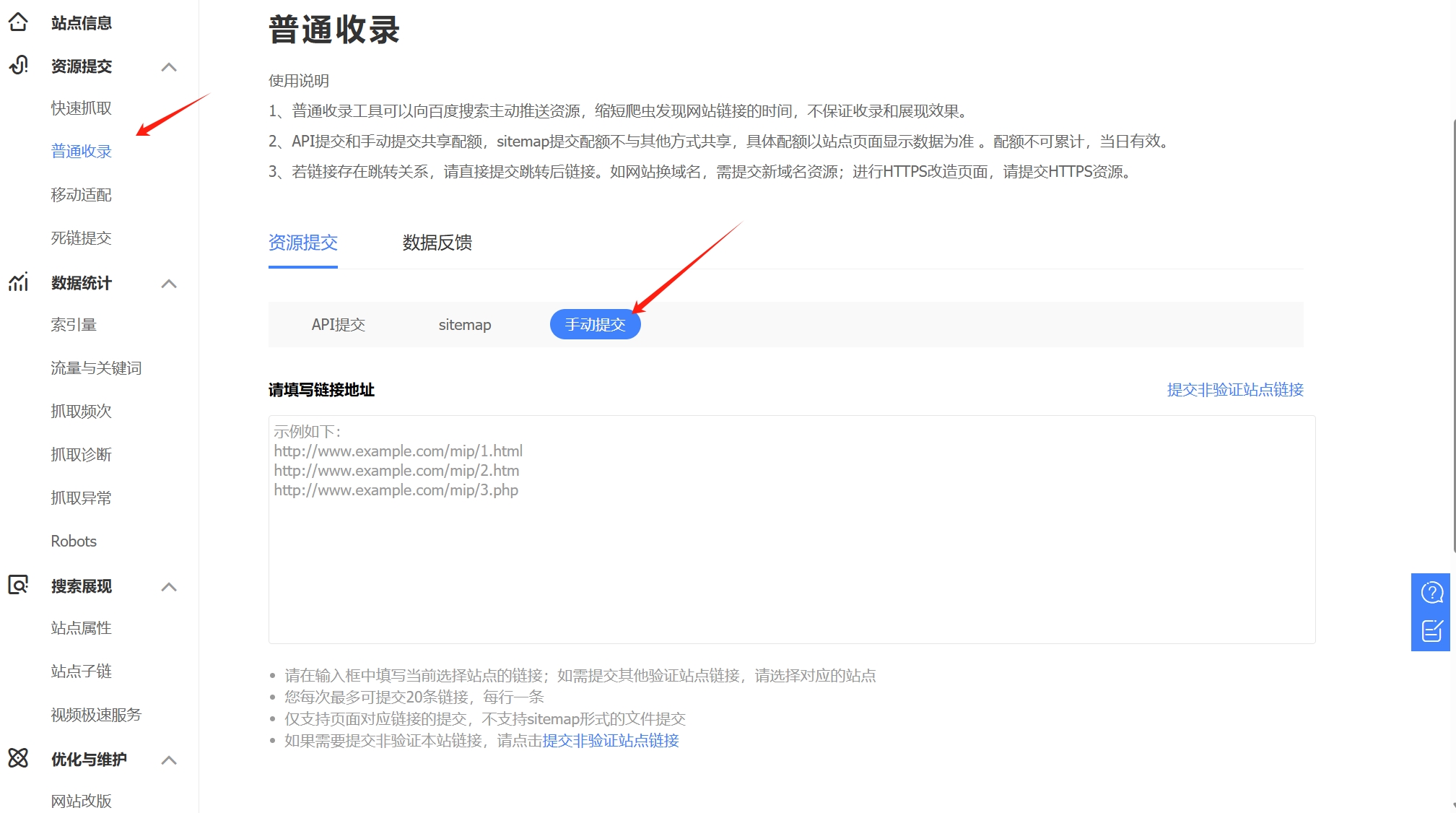
关于网站提交搜索引擎
发布于Eucalyptus-blog 一、前言 将网站提交给搜索引擎是为了让搜索引擎更早地了解、索引和显示您的网站内容。以下是一些提交网站给搜索引擎的理由: 提高可见性:通过将您的网站提交给搜索引擎,可以提高您的网站在搜索结果中出现的机会。当用…...
)
计算机视觉与深度学习 | Python实现EMD-SSA-VMD-LSTM-Attention时间序列预测(完整源码和数据)
EMD-SSA-VMD-LSTM-Attention 一、完整代码实现二、代码结构解析三、关键数学公式四、参数调优建议五、性能优化方向六、工业部署建议 以下是用Python实现EMD-SSA-VMD-LSTM-Attention时间序列预测的完整解决方案。该方案结合了四层信号分解技术与注意力增强的深度学习模型&#…...

二进制与十进制互转的方法
附言: 在计算机科学和数字系统中,二进制和十进制是最常见的两种数制。二进制是计算机内部数据存储和处理的基础,而十进制则是我们日常生活中最常用的数制。因此,掌握二进制与十进制之间的转换方法对于计算机学习者和相关领域的从业者来说至关…...

05、基础入门-SpringBoot-HelloWorld
05、基础入门-SpringBoot-HelloWorld ## 一、Spring Boot 简介 **Spring Boot** 是一个用于简化 **Spring** 应用初始搭建和开发的框架,旨在让开发者快速启动项目并减少配置文件。 ### 主要特点 - **简化配置**:采用“约定优于配置”的原则,减…...

LeetCode 153. 寻找旋转排序数组中的最小值:二分查找法详解及高频疑问解析
文章目录 问题描述算法思路:二分查找法关键步骤 代码实现代码解释高频疑问解答1. 为什么循环条件是 left < right 而不是 left < right?2. 为什么比较 nums[mid] > nums[right] 而不是 nums[left] < nums[mid]?3. 为什么 right …...

基于QT(C++)OOP 实现(界面)酒店预订与管理系统
酒店预订与管理系统 1 系统功能设计 酒店预订是旅游出行的重要环节,而酒店预订与管理系统中的管理与信息透明是酒店预订业务的关键问题所在,能够方便地查询酒店信息进行付款退款以及用户之间的交流对于酒店预订行业提高服务质量具有重要的意义。 针对…...
?)
人工智能100问☞第25问:什么是循环神经网络(RNN)?
目录 一、通俗解释 二、专业解析 三、权威参考 循环神经网络(RNN)是一种通过“记忆”序列中历史信息来处理时序数据的神经网络,可捕捉前后数据的关联性,擅长处理语言、语音等序列化任务。 一、通俗解释 想象你在和朋友聊天,每说一句话都会根据之前的对话内容调整语气…...
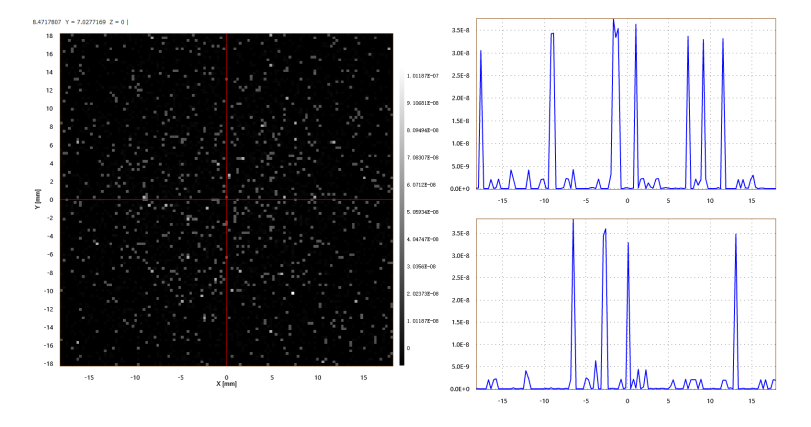
机械元件杂散光难以把控?OAS 软件案例深度解析
机械元件的杂散光分析 简介 在光学系统设计与工程实践中,机械元件的杂散光问题对系统性能有着不容忽视的影响。杂散光会降低光学系统的信噪比、图像对比度,甚至导致系统功能失效。因此,准确分析机械元件杂散光并采取有效抑制措施,…...

游戏引擎学习第289天:将视觉表现与实体类型解耦
回顾并为今天的工作设定基调 我们正在继续昨天对代码所做的改动。我们已经完成了“脑代码(brain code)”的概念,它本质上是一种为实体构建的自组织控制器结构。现在我们要做的是把旧的控制逻辑迁移到这个新的结构中,并进一步测试…...
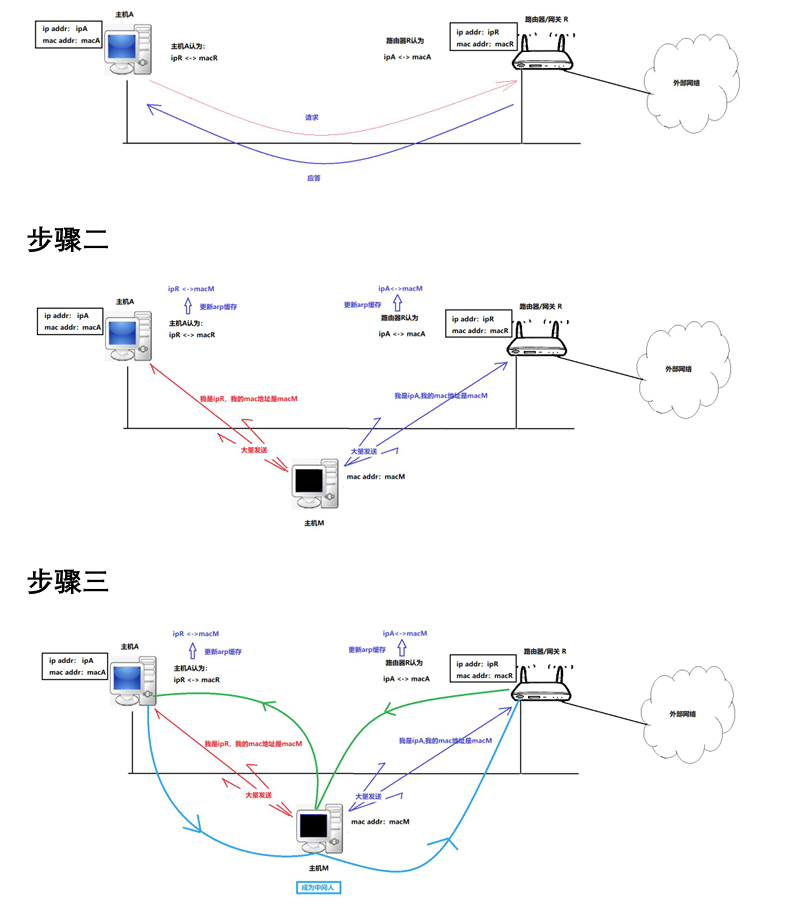
【Linux网络】ARP协议
ARP协议 虽然我们在这里介绍 ARP 协议,但是需要强调,ARP 不是一个单纯的数据链路层的协议,而是一个介于数据链路层和网络层之间的协议。 ARP数据报的格式 字段长度(字节)说明硬件类型2网络类型(如以太网为…...
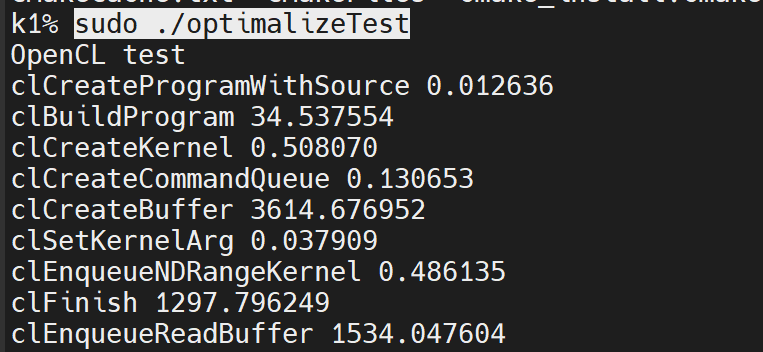
MUSE Pi Pro 开发板 Imagination GPU 利用 OpenCL 测试
视频讲解: MUSE Pi Pro 开发板 Imagination GPU 利用 OpenCL 测试 继续玩MUSE Pi Pro,今天看下比较关注的gpu这块,从opencl看起,安装clinfo指令 sudo apt install clinfo 可以看到这颗GPU是Imagination的 一般嵌入式中gpu都和hos…...
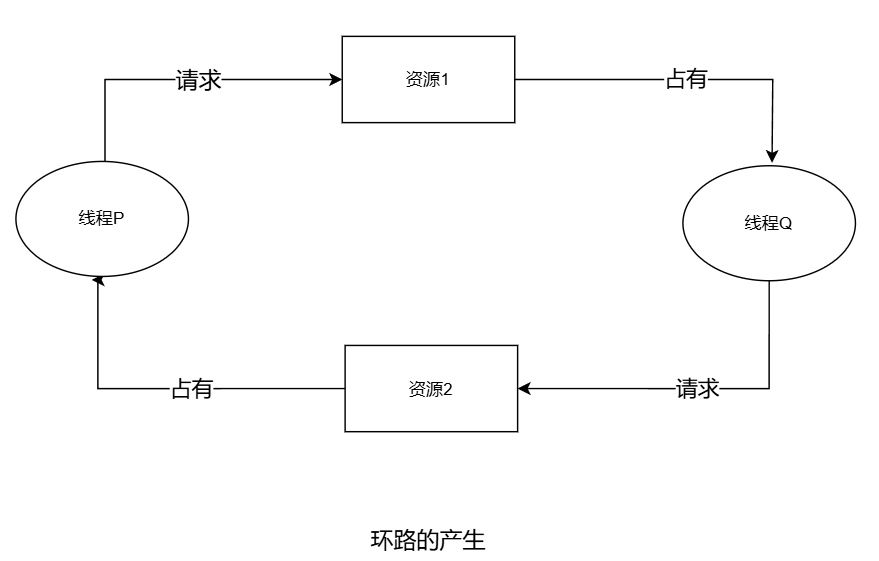
多线程与线程互斥
我们初步学习完线程之后,就要来试着写一写多线程了。在写之前,我们需要继续来学习一个线程接口——叫做线程分离。 默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法…...

使用Spring Boot和Spring Security构建安全的RESTful API
使用Spring Boot和Spring Security构建安全的RESTful API 引言 在现代Web开发中,安全性是构建应用程序时不可忽视的重要方面。本文将介绍如何使用Spring Boot和Spring Security框架构建一个安全的RESTful API,并结合JWT(JSON Web Token&…...

游戏引擎学习第287天:加入brain逻辑
Blackboard:动态控制类似蛇的多节实体 我们目前正在处理一个关于实体系统如何以组合方式进行管理的问题。具体来说,是在游戏中实现多个实体可以共同或独立行动的机制。例如,我们的主角拥有两个实体组成部分,一个是身体࿰…...
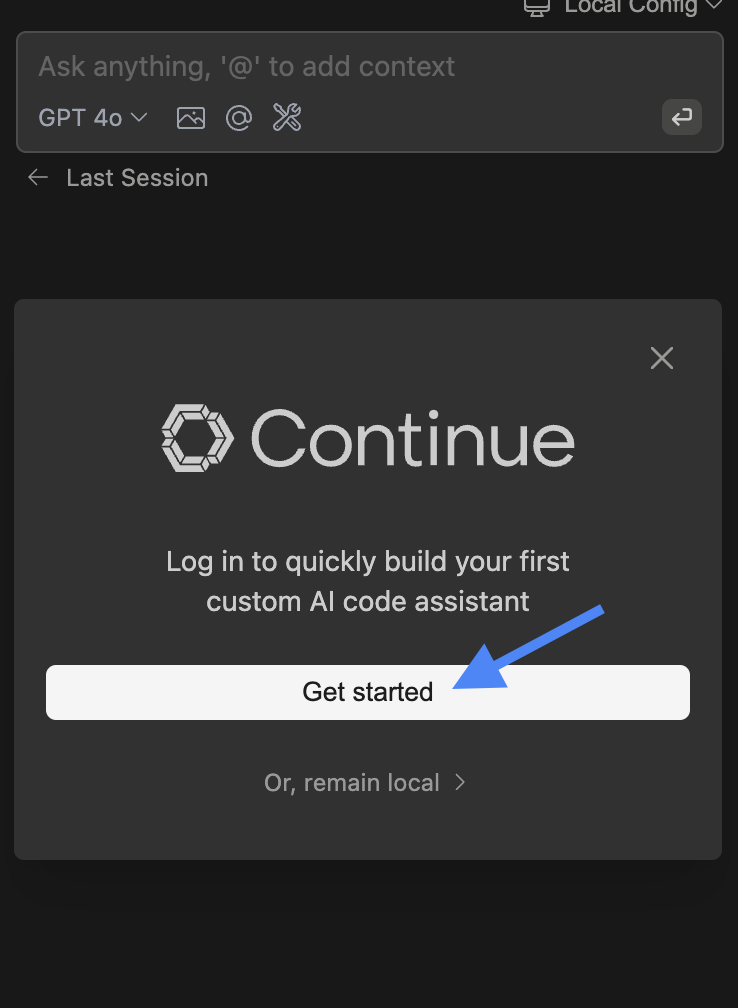
continue通过我们的开源 IDE 扩展和模型、规则、提示、文档和其他构建块中心,创建、共享和使用自定义 AI 代码助手
一、软件介绍 文末提供程序和源码下载 Continue 使开发人员能够通过我们的开源 VS Code 和 JetBrains 扩展以及模型、规则、提示、文档和其他构建块的中心创建、共享和使用自定义 AI 代码助手。 二、功能 Chat 聊天 Chat makes it easy to ask for help from an LLM without…...
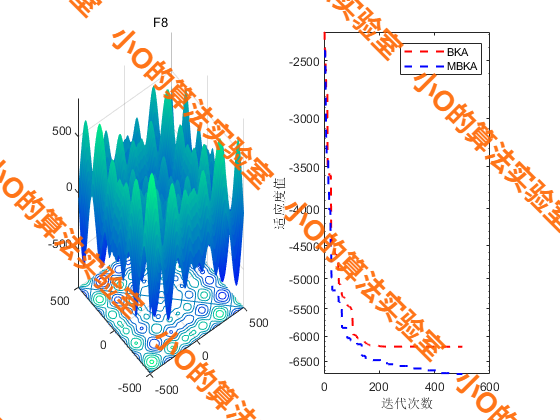
2025年EB SCI2区TOP,多策略改进黑翅鸢算法MBKA+空调系统RC参数辨识与负载聚合分析,深度解析+性能实测
目录 1.摘要2.黑翅鸢优化算法BKA原理3.改进策略4.结果展示5.参考文献6.代码获取7.读者交流 1.摘要 随着空调负载在电力系统中所占比例的不断上升,其作为需求响应资源的潜力日益凸显。然而,由于建筑环境和用户行为的变化,空调负载具有异质性和…...

.NET 中管理 Web API 文档的两种方式
前言 在 .NET 开发中管理 Web API 文档是确保 API 易用性、可维护性和一致性的关键。今天大姚给大家分享两种在 .NET 中管理 Web API 文档的方式,希望可以帮助到有需要的同学。 Swashbuckle Swashbuckle.AspNetCore 是一个流行的 .NET 库,它使得在 AS…...

常见三维引擎坐标轴 webgl threejs cesium blender unity ue 左手坐标系、右手坐标系、坐标轴方向
平台 / 引擎坐标系类型Up(上)方向Forward(前进)方向前进方向依据说明Unity左手坐标系YZtransform.forward 是 Z 轴正方向,默认摄像机朝 Z 看。Unreal Engine左手坐标系ZXUE 的角色面朝 X,默认使用 GetActor…...
【HTML】个人博客页面
目录 页面视图编辑 页面代码 解释: HTML (<body>): 使用了更加语义化的HTML5标签,例如<header>, <main>, <article>, <footer>。文章列表使用了<article>包裹,结构清晰。添加了分页导航。使用了Font…...
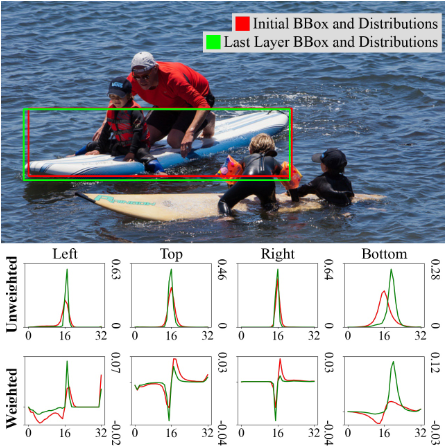
论文解读:ICLR2025 | D-FINE
[2410.13842] D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement D-FINE 是一款功能强大的实时物体检测器,它将 DETRs 中的边界框回归任务重新定义为细粒度分布细化(FDR),并引入了全局最优定位…...

9.DMA
目录 DMA —为 CPU 减负 DMA 的简介和使用场景 DMA 的例子讲解 STM32 的 DMA 框图和主要特性 编辑 DMA 的通道的对应通道外设 – DMA 和哪些外设使用 编辑编辑ADC_DR 寄存器地址的计算 常见的数据滤波方法 ADCDMA 的编程 DMA —为 CPU 减负 DMA 的简介和使用场…...
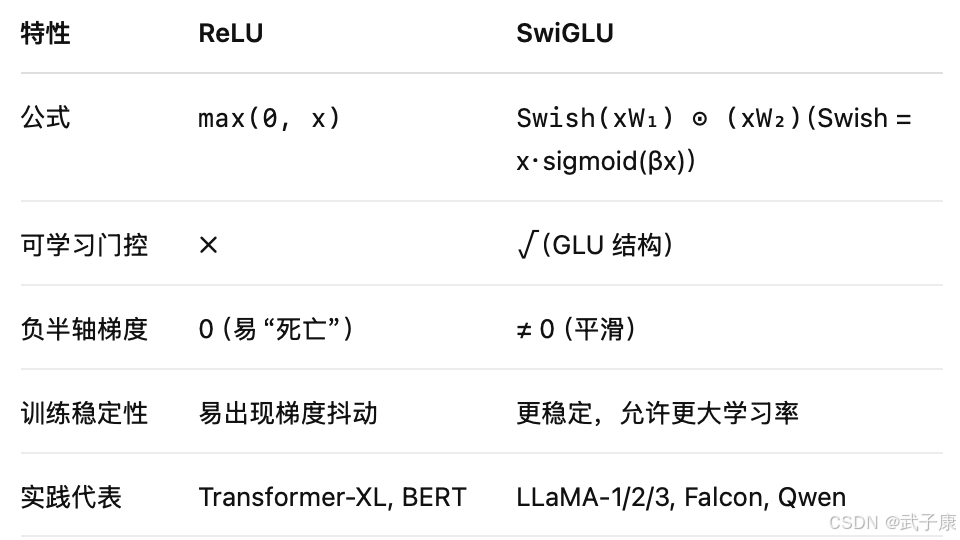
大语言模型 10 - 从0开始训练GPT 0.25B参数量 补充知识之模型架构 MoE、ReLU、FFN、MixFFN
写在前面 GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,…...
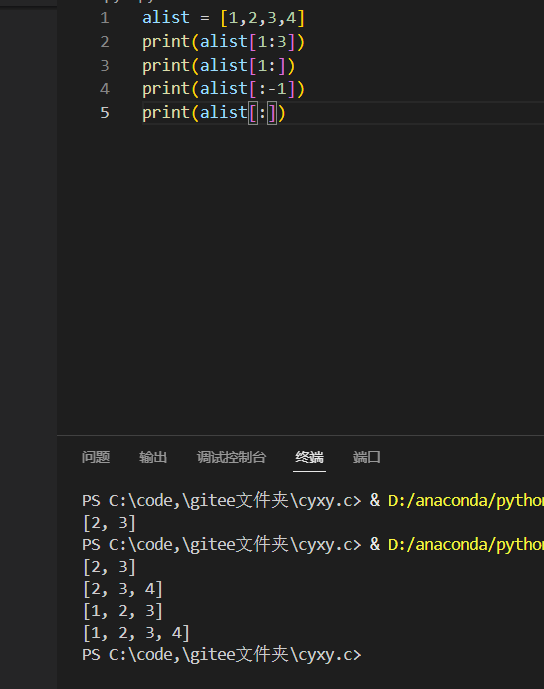
python基础语法(三-中)
基础语法3: 2.列表与元组: <1>.列表、元组是什么? 都用来存储数据,但是两者有区别,列表可变,元组不可变。 <2>.创建列表: 创建列表有两种方式: [1].a 【】&#x…...