分布式链路跟踪
目录
链路追踪简介
基本概念
基于代理(Agent)的链路跟踪
基于 SDK 的链路跟踪
基于日志的链路跟踪
SkyWalking
Sleuth + ZipKin
链路追踪简介
分布式链路追踪是一种监控和分析分布式系统中请求流动的方法。它能够记录和分析一个请求在系统中经历的每一步操作,帮助开发者和运维人员了解系统的性能和行为。在微服务架构中,一个请求可能会跨越多个服务节点,而每个服务节点又可能依赖其他多个服务。分布式链路追踪通过生成一个唯一的跟踪ID(Trace ID),并在每个服务节点生成一个跨度(Span),记录每个操作的详细信息,从而形成完整的请求链路。
基本概念
Span 和 Trace
Trace:表示一个完整的请求链路,从请求发起到请求完成,包含了所有相关的 Spans。
Span:表示 Trace 中的一个单独的操作单元,包含操作的开始时间、结束时间、操作名称、相关的元数据(如标签、日志)等信息。一个 Trace 由多个 Spans 组成,形成一个有向无环图(DAG)。
实现方式: 【application名称+Traceid+spanid 】
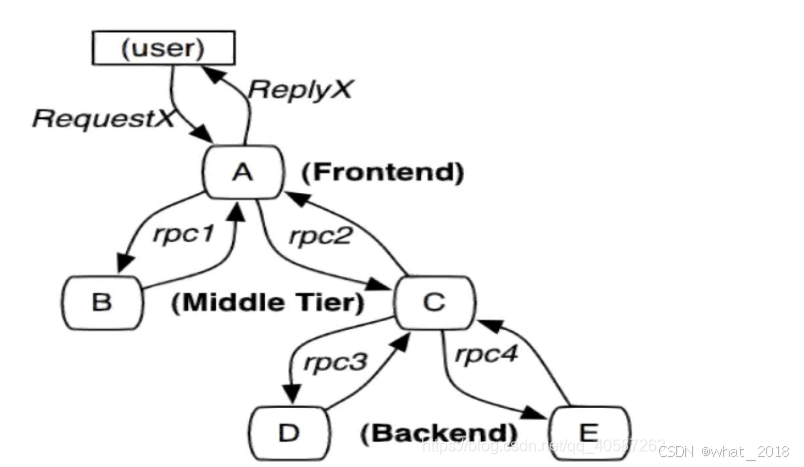
分布式链路追踪(Distributed Tracing),就是将一次分布式请求还原成调用链路,进行日志记录,性能监控并将一次分布式请求的调用情况集中展示。比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
链路跟踪在分布式系统中至关重要,它主要有以下几类,各自具有不同作用和使用方式:
基于代理(Agent)的链路跟踪
- 作用:
- 透明性高:对应用代码侵入性小,通过在应用启动时加载代理,自动收集链路数据。应用开发者无需在业务代码中大量添加跟踪相关代码,就能实现链路跟踪功能。
- 全面收集数据:能自动捕获应用与外部服务(如数据库、消息队列)的交互,全面记录请求从进入应用到离开应用的完整路径,包括网络调用、数据库查询等细节,有助于分析整个分布式系统的调用关系和性能瓶颈。
- 使用方式:
- 选择代理工具:如 SkyWalking Agent、Pinpoint Agent 等。以 SkyWalking Agent 为例,下载对应版本的 Agent 包后,在应用启动命令中添加代理参数,如
java -javaagent:/path/to/skywalking-agent.jar -Dskywalking.agent.service_name=your_service_name -jar your_application.jar。 - 配置代理参数:可在配置文件中设置代理的各种参数,如指定后端收集器地址、采样率等。例如在 SkyWalking 中,可在
agent.config文件里配置collector.backend_service指定后端服务地址。
- 选择代理工具:如 SkyWalking Agent、Pinpoint Agent 等。以 SkyWalking Agent 为例,下载对应版本的 Agent 包后,在应用启动命令中添加代理参数,如
基于 SDK 的链路跟踪
- 作用:
- 定制性强:开发者可以根据业务需求灵活定制链路跟踪逻辑。比如在特定业务场景下,对某些关键操作添加自定义的跟踪标签或注释,更精准地记录和分析业务相关的性能指标。
- 深度集成:与应用代码深度结合,能获取更详细的业务上下文信息。例如,在电商下单场景中,可将订单 ID、用户信息等业务关键数据作为跟踪信息的一部分,方便排查与业务逻辑紧密相关的问题。
- 使用方式:
- 引入 SDK:根据所选择的链路跟踪系统,在项目中引入相应的 SDK。例如,使用 Jaeger 时,对于 Java 项目,在
pom.xml中添加io.jaegertracing:jaeger - client - java依赖。 - 代码埋点:在业务代码中合适的位置添加跟踪代码。例如,在方法入口处创建跨度(Span),在方法结束时结束跨度,并在过程中记录关键信息。以下是使用 Jaeger SDK 在 Java 中简单创建跨度的示例代码:
- 引入 SDK:根据所选择的链路跟踪系统,在项目中引入相应的 SDK。例如,使用 Jaeger 时,对于 Java 项目,在
import io.jaegertracing.Configuration;
import io.jaegertracing.internal.JaegerTracer;
import io.opentracing.Span;
import io.opentracing.Tracer;
import io.opentracing.util.GlobalTracer;public class ExampleService {private static final Tracer tracer;static {Configuration.SamplerConfiguration samplerConfig = Configuration.SamplerConfiguration.fromEnv().withType("const").withParam(1);Configuration.ReporterConfiguration reporterConfig = Configuration.ReporterConfiguration.fromEnv().withLogSpans(true);Configuration config = new Configuration("example - service").withSampler(samplerConfig).withReporter(reporterConfig);tracer = config.getTracer();GlobalTracer.register(tracer);}public void doBusinessLogic() {Span span = tracer.buildSpan("doBusinessLogic").start();try {// 业务逻辑代码} finally {span.finish();}}
}
基于日志的链路跟踪
- 作用:
- 兼容性好:几乎适用于所有类型的应用,无论应用采用何种技术栈、框架,只要能记录日志,就可实现链路跟踪。这对于一些老旧系统或难以引入其他链路跟踪工具的场景非常适用。
- 辅助排查:通过在日志中添加特定的跟踪标识(如 Trace ID、Span ID),当系统出现问题时,可以根据这些标识从大量日志中快速定位相关联的日志记录,分析问题发生的过程。
- 使用方式:
- 添加跟踪标识到日志:在应用代码中,在记录日志的地方添加 Trace ID 和 Span ID 等跟踪标识。例如,在使用 Logback 作为日志框架的 Java 应用中,可通过 MDC(Mapped Diagnostic Context)来实现。首先在请求入口处生成 Trace ID 并放入 MDC,如下:
import org.slf4j.MDC;
import java.util.UUID;public class RequestInterceptor {public void intercept() {String traceId = UUID.randomUUID().SkyWalking
- 简介:SkyWalking 是一个开源的应用性能监控(APM)系统,专为微服务、云原生架构和基于容器(Docker、Kubernetes)的架构而设计。它提供了分布式链路跟踪、性能指标分析、应用拓扑图展示等功能。
- 特点:
- 低侵入性:通过 Java Agent 方式,对应用代码的侵入性极小,只需要在启动命令中添加相关参数即可启用链路跟踪,无需在业务代码中大量添加跟踪代码。
- 多语言支持:不仅支持 Java,还支持 C++、.NET、Node.js、Python 等多种语言,适用于异构的分布式系统。
- 丰富的可视化界面:其自带的 Web UI 可以直观地展示服务拓扑、链路详情、性能指标等信息,方便运维和开发人员进行问题排查和性能优化。
- 使用步骤:
- 安装 SkyWalking:从 SkyWalking 官方GitHub Releases下载安装包,解压后启动后端和前端。启动后端可在
bin目录下执行startup.sh(Windows 下为startup.bat),前端默认端口为 8080,可通过浏览器访问http://localhost:8080查看监控数据。 - 集成到应用:对于 Java 应用,在
pom.xml中添加依赖:
- 安装 SkyWalking:从 SkyWalking 官方GitHub Releases下载安装包,解压后启动后端和前端。启动后端可在
<dependency><groupId>org.apache.skywalking</groupId><artifactId>apm - agent - core</artifactId><version>[具体版本号]</version>
</dependency>
<dependency><groupId>org.apache.skywalking</groupId><artifactId>apm - spring - boot - starter</artifactId><version>[具体版本号]</version>
</dependency>
然后在application.properties中配置 SkyWalking 相关参数,如:
skywalking.agent.service_name=your - service - name
skywalking.collector.backend_service=localhost:11800
Sleuth + ZipKin
sleuth : 链路追踪器
zipkin:链路分析器(可视化)
- 简介:
- Spring Cloud Sleuth:它是 Spring Cloud 体系中用于分布式链路跟踪的工具包,为 Spring Boot 应用提供了自动配置的分布式跟踪支持。它会自动为应用生成 Trace ID 和 Span ID 等跟踪信息,并将这些信息注入到 HTTP 请求头中,实现跨服务的链路跟踪。
- ZipKin:是一个分布式跟踪系统,它接收、存储和查询链路数据。它可以与 Sleuth 配合使用,Sleuth 负责收集链路数据并发送给 ZipKin,ZipKin 提供可视化界面来展示链路跟踪信息。
- 特点:
- 与 Spring 生态集成好:Sleuth 与 Spring Boot、Spring Cloud 紧密集成,对于使用 Spring 技术栈构建的微服务系统,使用起来非常方便,几乎可以做到开箱即用。
- 数据收集和存储灵活:ZipKin 支持多种存储后端,如内存、MySQL、Elasticsearch 等,可以根据实际需求选择合适的存储方式来存储链路数据。
- 使用步骤:
- 添加依赖:在 Spring Boot 项目的
pom.xml中添加 Sleuth 和 ZipKin 相关依赖:
- 添加依赖:在 Spring Boot 项目的
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring - cloud - starter - sleuth</artifactId>
</dependency>
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring - cloud - starter - zipkin</artifactId>
</dependency>
- 配置 ZipKin Server:可以通过 Docker 快速启动一个 ZipKin Server 实例:
docker run -d -p 9411:9411 openzipkin/zipkin
- 配置应用:在
application.properties中配置 ZipKin 地址:
spring.zipkin.base - url=http://localhost:9411
spring.sleuth.sampler.probability=1.0
这里spring.sleuth.sampler.probability设置为 1.0 表示对所有请求进行采样跟踪,实际应用中可根据需要调整采样率。
- 对比
- 易用性:
- SkyWalking:对于 Java 应用,通过简单配置 Java Agent 即可启用,对业务代码侵入小,上手相对容易。在异构系统中,多语言支持使其能统一管理不同语言编写的服务的链路跟踪。
- 易用性:
- Sleuth + ZipKin:在 Spring 生态系统内,借助 Spring Boot 的自动配置特性,整合较为便捷,开发人员可以快速上手。然而,对于非 Spring 技术栈的应用,集成难度较大,需要额外的工作来实现跨语言的链路跟踪。
- 性能影响:
- SkyWalking:通过 Java Agent 方式实现链路数据收集,在设计上注重对应用性能的低影响。其采用字节码增强技术,在运行时对类进行增强以收集数据,并且支持灵活的采样策略,可在保证获取足够链路信息的同时,尽量减少对应用性能的损耗。
- Sleuth + ZipKin:Sleuth 在应用内收集链路数据,其对性能的影响取决于采样率设置以及应用内跟踪逻辑的复杂程度。如果采样率过高或跟踪逻辑过于复杂,可能会对应用性能产生一定影响。此外,数据发送到 ZipKin Server 的网络开销也需要考虑。
- 功能特性:
- SkyWalking:除了基本的链路跟踪功能外,还提供了丰富的性能指标分析功能,如服务的响应时间、吞吐量等。其拓扑图展示功能能直观呈现分布式系统中各个服务之间的依赖关系,并且支持告警功能,可根据设定的阈值对性能指标进行实时监控和告警。
- Sleuth + ZipKin:主要聚焦于链路跟踪和可视化展示,通过 ZipKin 的界面可以清晰查看请求的调用链路、每个 Span 的耗时等信息。虽然也能获取一些基本的性能指标,但在指标分析的丰富度和深度上,相较于 SkyWalking 略显不足。同时,ZipKin 本身的告警功能相对较弱,通常需要借助外部工具实现复杂的告警策略。
- 数据存储与扩展性:
- SkyWalking:支持多种存储方式,包括 H2(默认,适合测试环境)、MySQL、Elasticsearch 等。在扩展性方面,通过集群部署方式可以应对大规模分布式系统的链路数据存储和处理需求,能够水平扩展以处理高并发的链路数据收集和查询请求。
- Sleuth + ZipKin:ZipKin 支持内存、MySQL、Elasticsearch 等存储后端。在扩展性方面,虽然也可以通过集群部署来提升性能和存储能力,但在面对超大规模分布式系统时,其架构可能需要更精细的优化和调整,以确保数据的高效存储和查询。例如,在高并发场景下,Elasticsearch 作为存储后端时,需要合理配置索引策略和集群参数。
参考:微服务—链路追踪(Sleuth+Zipkin)_sleuth zipkin-CSDN博客
原来10张图就可以搞懂分布式链路追踪系统原理-阿里云开发者社区
相关文章:
分布式链路跟踪
目录 链路追踪简介 基本概念 基于代理(Agent)的链路跟踪 基于 SDK 的链路跟踪 基于日志的链路跟踪 SkyWalking Sleuth ZipKin 链路追踪简介 分布式链路追踪是一种监控和分析分布式系统中请求流动的方法。它能够记录和分析一个请求在系统中经历的每…...
刷leetcodehot100返航版--二叉树
二叉树理论基础 二叉树的种类 满二叉树和完全二叉树,二叉树搜索树 满二叉树 如果一棵二叉树只有度为0的结点和度为2的结点,并且度为0的结点在同一层上,则这棵二叉树为满二叉树。 节点个数2^n-1【n为树的深度】 完全二叉树 在完全二叉树…...

chmod 777含义:
1.chmod 777 的含义及其在文件权限中的作用 chmod 777 是一种用于修改 Unix 和 Linux 系统中文件或目录权限的命令。它赋予指定文件或目录的所有用户(文件所有者、所属组成员以及其他用户)完全的访问权限,即 读取 (Read)、写入 (Write) 和 执…...
:混合检索之混合搜索)
AGI大模型(21):混合检索之混合搜索
为了执行混合搜索,我们结合了 BM25 和密集检索的结果。每种方法的分数均经过标准化和加权以获得最佳总体结果 1 代码 先编写 BM25搜索的代码,再编写密集检索的代码,最后进行混合。 from rank_bm25 import BM25Okapi from nltk.tokenize import word_tokenize import jieb…...

双重差分模型学习笔记4(理论)
【DID最全总结】90分钟带你速通双重差分!_哔哩哔哩_bilibili 目录 总结:双重差分法(DID)在社会科学中的应用:理论、发展与前沿分析 一、DID的基本原理与核心思想 二、经典DID:标准模型与应用案例 三、…...

Mysql 8.0.32 union all 创建视图后中文模糊查询失效
记录问题,最近在使用union all聚合了三张表的数据,创建视图作为查询主表,发现字段值为中文的筛选无法生效.......... sql示例: CREATE OR REPLACE VIEW test_view AS SELECTid,name,location_address AS address,type,"1" AS data_type,COALESCE ( update_time, cr…...
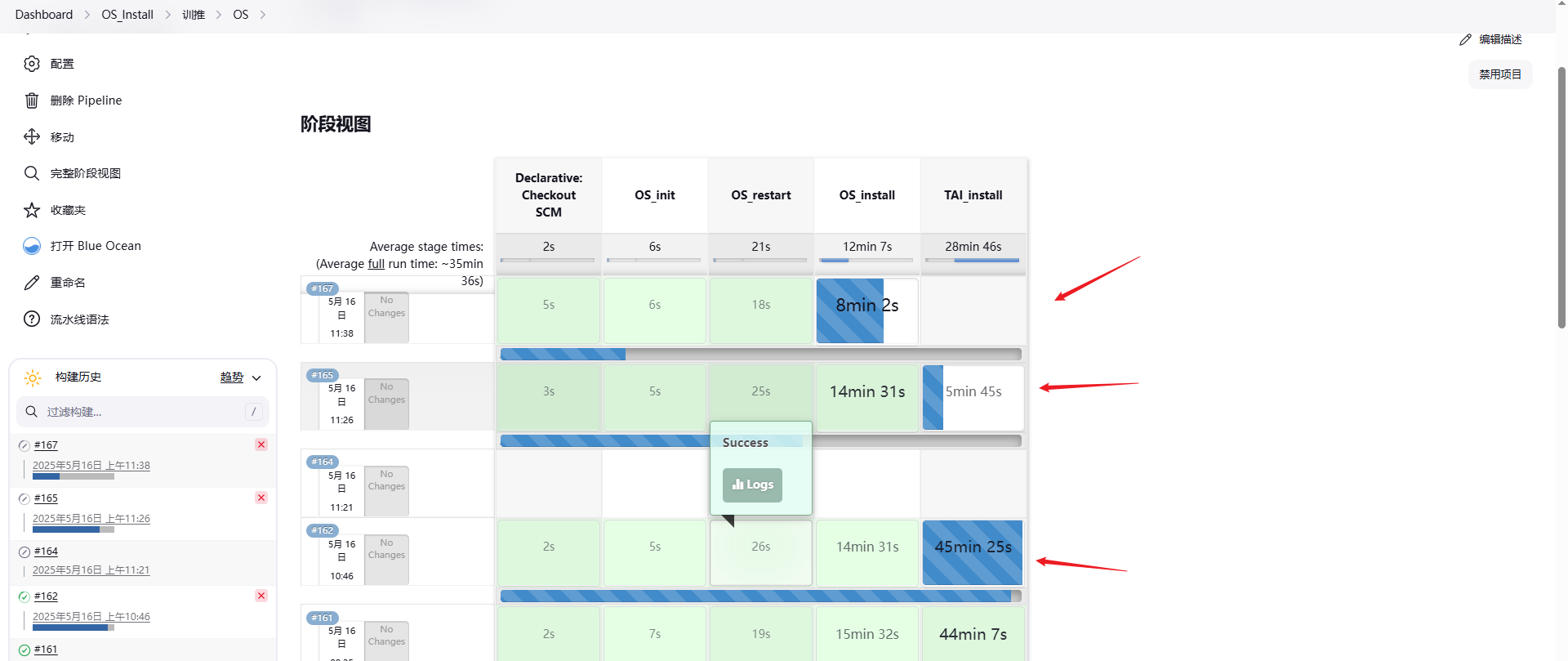
Jenkins 执行器(Executor)如何调整限制?
目录 现象原因解决 现象 Jenkins 构建时,提示如下: 此刻的心情正如上图中的小老头,火冒三丈,但是不要急,因为每一次错误,都是系统中某个环节在说‘我撑不住了’。 原因 其实是上图的提示表示 Jenkins 当…...

Android 中 权限分类及申请方式
在 Android 中,权限被分为几个不同的类别,每个类别有不同的申请和管理方式。 一、 普通权限(Normal Permissions) 普通权限通常不会对用户隐私或设备安全造成太大风险。这些权限在应用安装时自动授予,无需用户在运行时手动授权。 android.permission.INTERNETandroid.pe…...
编程错题集系列(一)
编程错题集系列(一) 人生海海,山山而川。 谨以此系列作为自己一路的见证。本期重点:明明已经安装相关库,但在PyCharm中无法调用 最大的概率是未配置合适的解释器,也就是你的书放在B房间,你在A…...
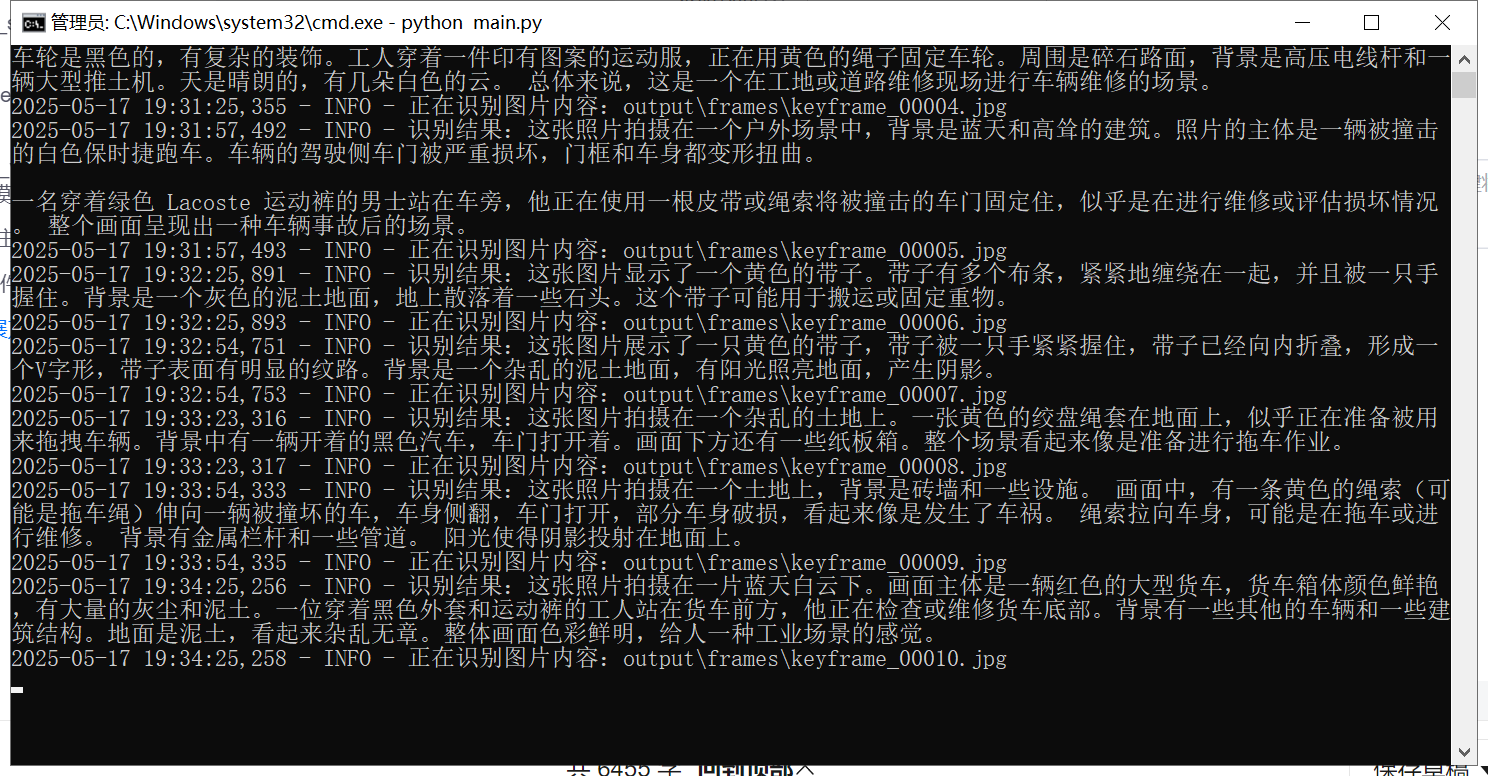
【原创】基于视觉大模型gemma-3-4b实现短视频自动识别内容并生成解说文案
📦 一、整体功能定位 这是一个用于从原始视频自动生成短视频解说内容的自动化工具,包含: 视频抽帧(可基于画面变化提取关键帧) 多模态图像识别(每帧图片理解) 文案生成(大模型生成…...
Spark(32)SparkSQL操作Mysql
(一)准备mysql环境 我们计划在hadoop001这台设备上安装mysql服务器,(当然也可以重新使用一台全新的虚拟机)。 以下是具体步骤: 使用finalshell连接hadoop001.查看是否已安装MySQL。命令是: rpm -qa|grep ma…...
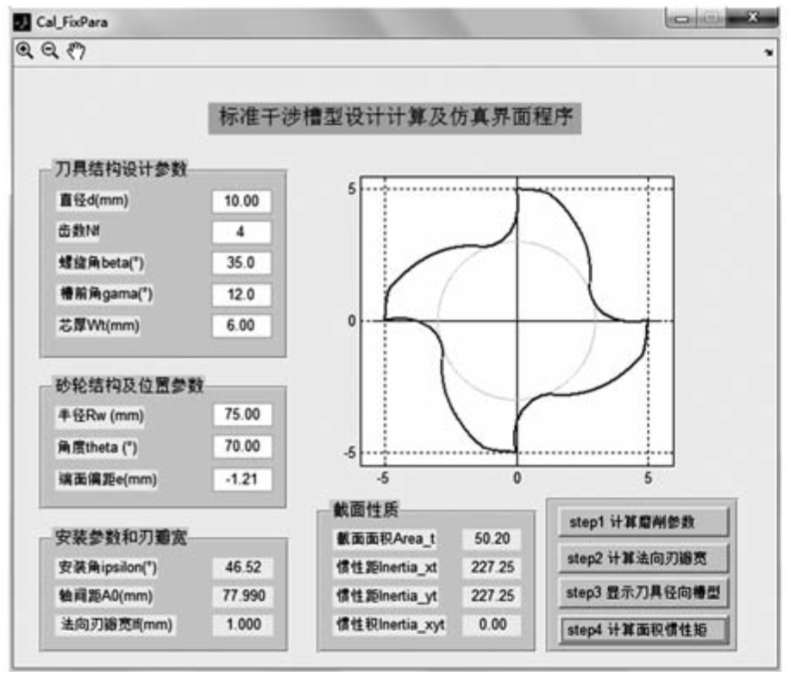
基于 Python 的界面程序复现:标准干涉槽型设计计算及仿真
基于 Python 的界面程序复现:标准干涉槽型设计计算及仿真 在工业设计与制造领域,刀具的设计与优化是提高生产效率和产品质量的关键环节之一。本文将介绍如何使用 Python 复现一个用于标准干涉槽型设计计算及仿真的界面程序,旨在帮助工程师和…...
c++成员函数返回类对象引用和直接返回类对象的区别
c成员函数返回类对象引用和直接返回类对象的区别 成员函数直接返回类对象(返回临时对象,对象拷贝) #include <iostream> class MyInt { public:int value;//构造函数explicit MyInt(int v0) : value(v){}//加法操作,返回对象副本&…...
:混合检索之rank_bm25库来实现词法搜索)
AGI大模型(20):混合检索之rank_bm25库来实现词法搜索
1 混合检索简介 混合搜索结合了两种检索信息的方法 词法搜索 (BM25) :这种传统方法根据精确的关键字匹配来检索文档。例如,如果您搜索“cat on the mat”,它将找到包含这些确切单词的文档。 基于嵌入的搜索(密集检索) :这种较新的方法通过比较文档的语义来检索文档。查…...
数字化转型- 数字化转型路线和推进
数字化转型三个阶段 百度百科给出的企业的数字化转型包括信息化、数字化、数智化三个阶段 信息化是将企业在生产经营过程中产生的业务信息进行记录、储存和管理,通过电子终端呈现,便于信息的传播与沟通。数字化通过打通各个系统的互联互通,…...

字体样式集合
根据您提供的字体样式列表,以下是分类整理后的完整字体样式名称(不含数量统计): 基础样式 • Regular • Normal • Plain • Medium • Bold • Black • Light • Thin • Heavy • Ultra • Extra • Semi • Hai…...

IP68防水Type-C连接器实测:水下1米浸泡72小时的生存挑战
IP68防水Type-C连接器正成为户外设备、水下仪器和高端消费电子的核心组件。其宣称的“1米水深防护”是否真能抵御长时间浸泡?我们通过极限实测,将三款主流品牌IP68防水Type-C连接器沉入1米盐水(模拟海水浓度)中持续72小时…...
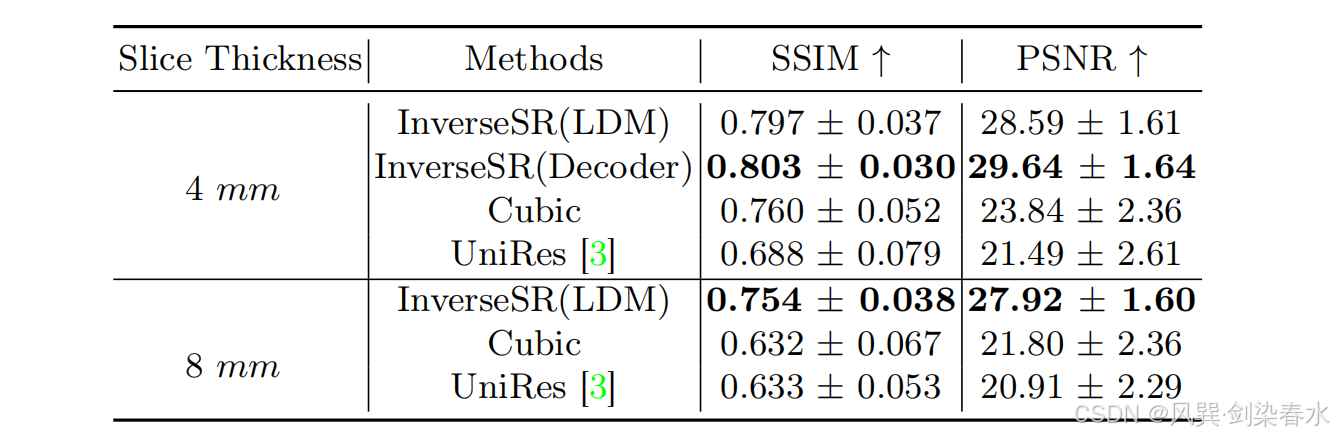
【技术追踪】InverseSR:使用潜在扩散模型进行三维脑部 MRI 超分辨率重建(MICCAI-2023)
LDM 实现三维超分辨率~ 论文:InverseSR: 3D Brain MRI Super-Resolution Using a Latent Diffusion Model 代码:https://github.com/BioMedAI-UCSC/InverseSR 0、摘要 从研究级医疗机构获得的高分辨率(HR)MRI 扫描能够提供关于成像…...
-变量)
React学习(二)-变量
也是很无聊,竟然写这玩意,毕竟不是学术研究,普通工作没那么多概念性东西,会用就行╮(╯▽╰)╭ 在React中,变量是用于存储和管理数据的基本单位。根据其用途和生命周期,React中的变量可以分为以下几类: 1. 状态变量(State) 用途:用于存储组件的内部状态,状态变化会触…...

list重点接口及模拟实现
list功能介绍 c中list是使用双向链表实现的一个容器,这个容器可以实现。插入,删除等的操作。与vector相比,vector适合尾插和尾删(vector的实现是使用了动态数组的方式。在进行头删和头插的时候后面的数据会进行挪动,时…...
基础知识④)
【自然语言处理与大模型】大模型(LLM)基础知识④
(1)微调主要用来干什么? 微调目前最主要用在定制模型的自我认知和改变模型对话风格。模型能力的适配与强化只是辅助。 定制模型的自我认知:通过微调可以调整模型对自我身份、角色功能的重新认知,使其回答更加符合自定义…...
:分布式架构与微服务)
系统架构设计(九):分布式架构与微服务
基础定义 架构类型定义分布式架构指将系统部署在多个服务器节点上,通过网络协作完成整体功能。强调物理上的分布与任务协作。微服务架构一种分布式架构模式,将系统按照业务维度拆分为多个小型自治服务,每个服务可独立开发、部署、伸缩。 核…...
Java 框架配置自动化:告别冗长的 XML 与 YAML 文件
在 Java 开发领域,框架的使用极大地提升了开发效率和系统的稳定性。然而,传统框架配置中冗长的 XML 与 YAML 文件,却成为开发者的一大困扰。这些配置文件不仅书写繁琐,容易出现语法错误,而且在项目规模扩大时ÿ…...
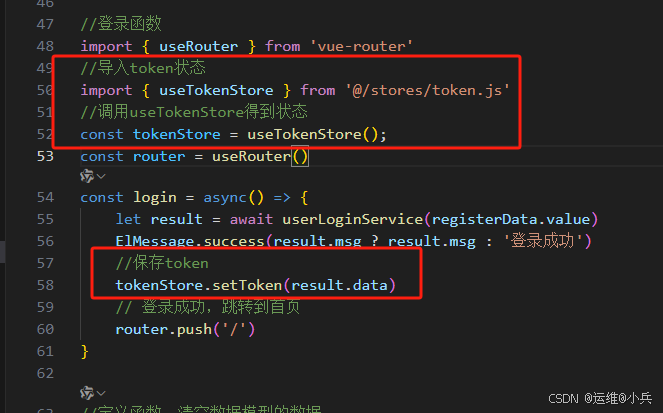
vue使用Pinia实现不同页面共享token
文章目录 一、概述二、使用步骤安装pinia在vue应用实例中使用pinia在src/stores/token.js中定义store在组件中使用store登录成功后,将token保存pinia中向后端API发起请求时,携带从pinia中获取的token 三、参考资料 一、概述 Pinia是Vue的专属状态管理库…...

遨游科普:三防平板是什么?有什么功能?
清晨的露珠还挂在帐篷边缘,背包里的三防平板却已开机导航;工地的尘土飞扬中,工程师正通过它查看施工图纸;暴雨倾盆的救援现场,应急队员用它实时回传灾情数据……这些看似科幻的场景,正因三防平板的普及成为…...

spring MVC 至 springboot的发展流程,配置文件变化
spring mvc Spring MVC 是 Spring 框架中的一个重要模块,用于构建基于 Java 的 Web 应用程序。它基于 MVC(Model-View-Controller)设计模式,提供了灵活、可配置的方式来开发动态网页或 RESTful 服务 ssm SSM 框架…...

深入解析Spring Boot与JUnit 5的集成测试实践
深入解析Spring Boot与JUnit 5的集成测试实践 引言 在现代软件开发中,测试是确保代码质量和功能正确性的关键环节。Spring Boot作为目前最流行的Java Web框架之一,提供了强大的支持来简化测试流程。而JUnit 5作为最新的JUnit版本,引入了许多…...
AI全域智能监控系统重构商业清洁管理范式——从被动响应到主动预防的监控效能革命
一、四维立体监控网络技术架构 1. 人员行为监控 - 融合人脸识别、骨骼追踪与RFID工牌技术,身份识别准确率99.97% - 支持15米超距夜间红外监控(精度0.01lux) 2. 作业过程监控 - UWB厘米级定位技术(误差<0.3米&…...
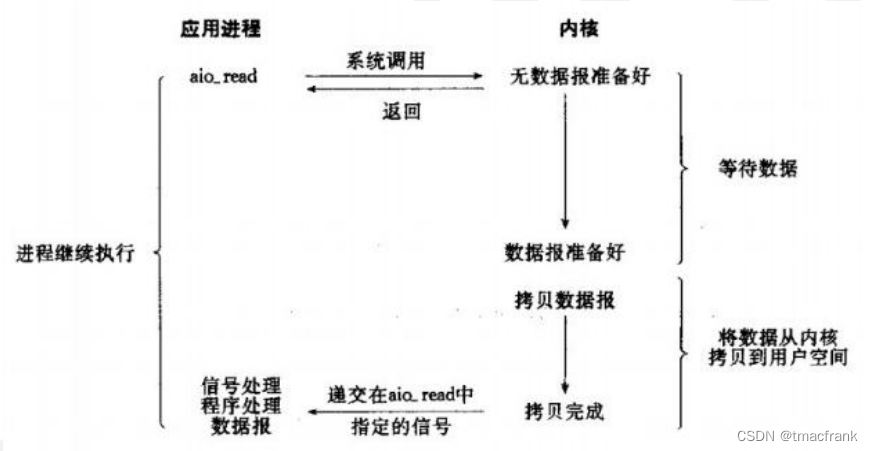
网络编程中的直接内存与零拷贝
本篇文章会介绍 JDK 与 Linux 网络编程中的直接内存与零拷贝的相关知识,最后还会介绍一下 Linux 系统与 JDK 对网络通信的实现。 1、直接内存 所有的网络通信和应用程序中(任何语言),每个 TCP Socket 的内核中都有一个发送缓冲区…...

区块链基本理解
文章目录 前言一、什么是分布式账本(DLT)二、什么是P2P网络?二、共识算法三、密码算法前言 区块链是由一个一个数据块组成的链条,按照时间顺序将数据块逐一链接,通过哈希指针链接,所有的数据块共同维护一份分布式账本(DLT),每个节点(可以理解为一个玩家,一台计算机)都拥…...