【数据处理】xarray 数据处理教程:从入门到精通
目录
- xarray 数据处理教程:从入门到精通
- 一、简介
- **核心优势**
- 二、安装与导入
- 1. 安装
- 2. 导入库
- 三、数据结构
- (一)DataArray
- (二) Dataset
- (三)关键说明
- 四、数据操作
- (一)索引与切片
- 1. 基于标签选择(`.sel()`)
- 2. 基于位置选择(`.isel()`)
- **3. `.sel()` 和 `.isel()` 联合使用**
- **4. 多维选择与切片**
- 5. 关键说明
- (二) 数据计算
- 1. 聚合运算
- (1) 计算单个维度的平均值
- (2) 计算多个维度的平均值
- (3) 计算单个维度的标准差
- (4) 计算多个维度的标准差
- (5) 忽略缺失值计算统计量
- (6) 关键说明
- 2. 算术运算
- **3. 数据重塑**
- (1) `.stack()`:将多个维度堆叠成一个新维度
- (2) `.transpose()`:调整维度顺序
- (3) `.stack()` + `.transpose()` 联合使用
- (4) 关键说明
- 4. 数据聚合
- 5. 合并两个数据集
- 6. 应用自定义函数
- **五、数据可视化**
- (一)二维分布图
- (二)时间序列图
- 六、高级功能
- (一) 缺失值处理
- 1. 填充缺失值
- 2. 插值
- (二) 时间重采样
- (三)地理信息处理
- 1. 设置坐标系
- 2. 绘制地理投影图
- 七、数据输入与输出
- (一)读取 NetCDF 文件
- (二)保存数据
- 八、性能优化
- (一)分块处理(Dask)
- (二) 内存优化
- 九、总结
- (一)核心流程
- (二)关键优势
- (三)注意事项
xarray 数据处理教程:从入门到精通
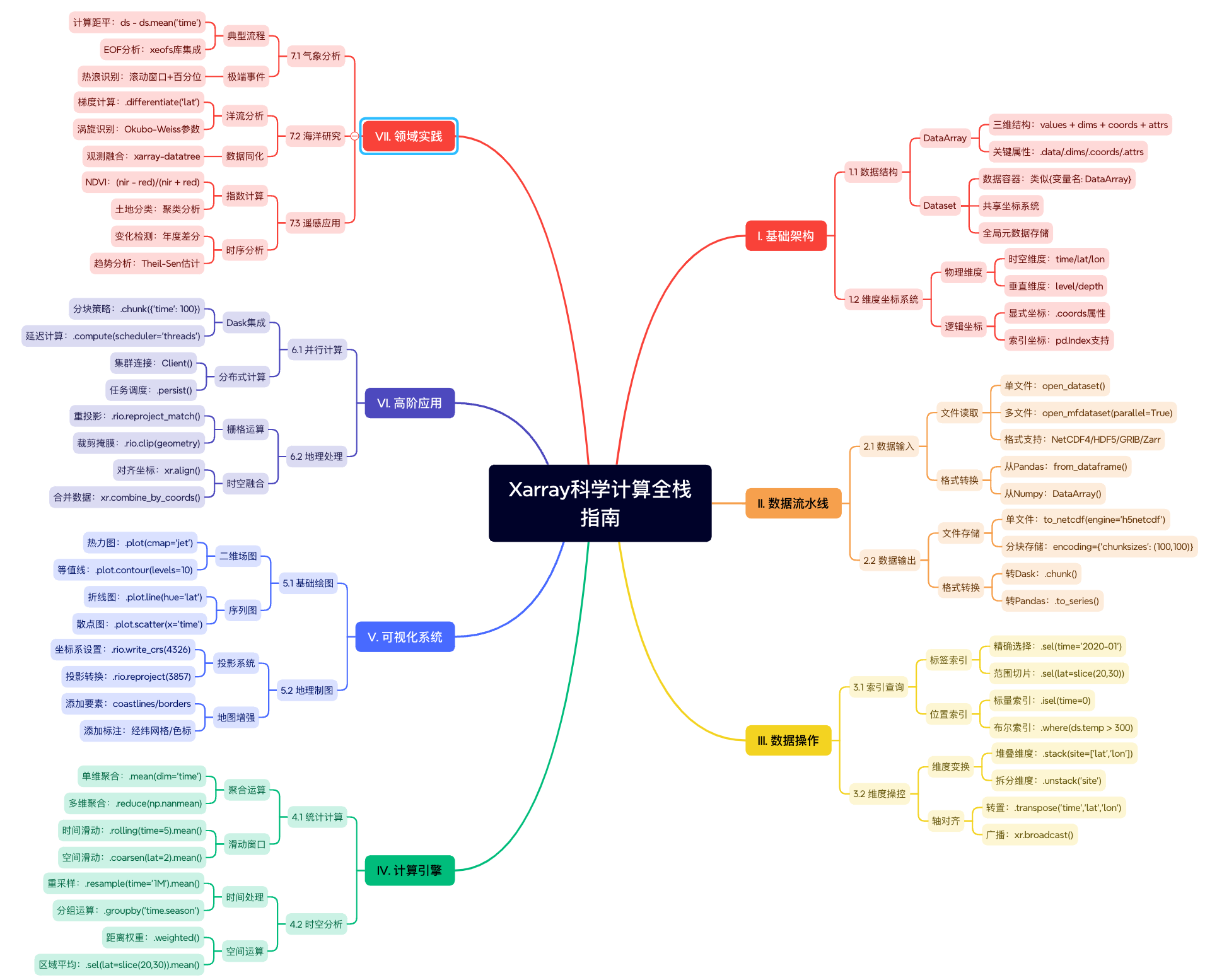
一、简介
xarray 是 Python 中用于处理多维数组数据的库,特别适用于带有标签(坐标)的科学数据(如气象、海洋、遥感等)。它基于 NumPy 和 Pandas,支持高效的数据操作、分析和可视化。
核心优势
- 标签化操作:通过维度名和坐标直接访问数据,无需记忆索引位置。
- 多维支持:天然支持多维数组(如时间、纬度、经度)。
- 集成工具:内置 NetCDF、HDF5 等格式读写,支持 Dask 处理大文件。
- 可视化:与 Matplotlib 深度集成,简化数据绘图流程。
二、安装与导入
1. 安装
pip install xarray netCDF4 dask rioxarray
或使用 Conda:
conda install -c conda-forge xarray netCDF4 dask rioxarray
2. 导入库
import xarray as xr
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
三、数据结构
(一)DataArray
- 定义:带坐标的 N 维数组,类似带标签的 NumPy 数组。
- 示例代码
import xarray as xr
import numpy as npdata = np.random.rand(12, 5, 100, 200)
coords = {'time': np.arange(12),'sample': np.arange(5),'lat': np.linspace(-90, 90, 100),'lon': np.linspace(-180, 180, 200)
}
da = xr.DataArray(data, dims=['time', 'sample', 'lat', 'lon'], coords=coords)
- 输出结果
<xarray.DataArray (time: 12, sample: 5, lat: 100, lon: 200)>
array([[[[...]], # 12个时间步 × 5个样本 × 100纬度 × 200经度的随机值...,[[...]]],...,[[...]]])
Coordinates:* time (time) int64 0 1 2 ... 11* sample (sample) int64 0 1 2 3 4* lat (lat) float64 -90.0 -89.1 -88.2 ... 88.2 89.1 90.0* lon (lon) float64 -180.0 -179.1 -178.2 ... 178.2 179.1 180.0
- 表1:数据结构DataArray
| 操作/方法 | 功能 | 输入参数 | 输出参数 |
|---|---|---|---|
xarray.DataArray | 创建带有维度和坐标的多维数组(如海温数据) | data: 数组数据;dims: 维度名列表;coords: 坐标字典 | 生成的 xarray.DataArray 对象 |
(二) Dataset
-
定义:类似字典的容器,包含多个
DataArray(变量),共享坐标。 -
表:xarray.Dataset 操作总结
| 操作/方法 | 功能 | 输入参数 | 输出参数 |
|---|---|---|---|
xr.Dataset | 创建多变量数据集 | 变量字典、坐标字典 | xarray.Dataset 对象 |
.sel() / .isel() | 按标签或索引选择数据 | 维度名和值 | 子数据集或子数组 |
.mean() / .std() | 计算维度统计量 | 需求平均的维度名 | 统计后的数据集或数据数组 |
.to_netcdf() | 保存为 NetCDF 文件 | 文件路径和写入模式 | 无返回值(保存文件) |
xr.open_dataset() | 读取 NetCDF 文件 | 文件路径和读取引擎 | xarray.Dataset 对象 |
.merge() | 合并两个数据集 | 另一个 Dataset 对象 | 合并后的 xarray.Dataset |
.apply() | 应用自定义函数 | 自定义函数和输入维度 | 应用后的数据集 |
.chunk() | 设置数据分块 | 分块大小字典 | 分块后的 xarray.Dataset |
- 创建示例:
import xarray as xr
import numpy as np
import pandas as pdds = xr.Dataset({"temperature": (["time", "lat", "lon"], np.random.rand(3, 10, 20)),"humidity": (["time", "lat", "lon"], np.random.rand(3, 10, 20)),},coords={"time": pd.date_range("2025-01-01", periods=3),"lat": np.linspace(-90, 90, 10),"lon": np.linspace(-180, 180, 20),}
)
- 输出结果:
<xarray.Dataset>
Dimensions: (time: 3, lat: 10, lon: 20)
Coordinates:* time (time) datetime64[ns] 2025-01-01 2025-01-02 ...* lat (lat) float64 -90.0 -81.0 ... 81.0 90.0* lon (lon) float64 -180.0 -171.0 ... 171.0 180.0
Data variables:temperature (time, lat, lon) float64 0.1234 0.5678 ...humidity (time, lat, lon) float64 0.9876 0.4321 ...
(三)关键说明
- Dataset vs DataArray:
xarray.Dataset适合处理多变量数据(如温度、湿度、降水)。xarray.DataArray适合单一变量的多维数组操作。
- 工作流示例:
# 读取数据并选择子集 ds = xr.open_dataset("data.nc") subset = ds.sel(lat=slice(-90, -60), lon=slice(-180, -120))# 计算统计量并保存 mean_ds = subset.mean(dim="time") mean_ds.to_netcdf("mean_data.nc")
四、数据操作
(一)索引与切片
表:索引与切片
| 操作/方法 | 功能 | 输入参数 | 输出参数 |
|---|---|---|---|
.isel() / .sel() | 快速提取特定维度数据 | isel: 按索引提取;sel: 按坐标标签提取 | 提取后的子数组(xarray.DataArray) |
1. 基于标签选择(.sel())
场景:从数据集中提取特定时间步和纬度范围的数据。
subset = ds.sel(time="2025-01-01", lat=-90)
输出结果:
<xarray.Dataset>
Dimensions: (lat: 1, lon: 20)
Coordinates:time datetime64[ns] 2025-01-01lat float64 -90.0lon (lon) float64 -180.0 -171.0 ... 171.0 180.0
Data variables:temperature (lon) float64 0.1234 0.5678 ...humidity (lon) float64 0.9876 0.4321 ...
2. 基于位置选择(.isel())
场景:从数据集中提取第一个时间步和前三个纬度的数据。
# 按索引位置选择数据
subset_isel = ds.isel(time=0, lat=slice(0, 3))
输出结果:
<xarray.Dataset>
Dimensions: (time: 1, lat: 3, lon: 20)
Coordinates:time datetime64[ns] 2025-01-01* lat (lat) float64 -90.0 -76.36 -62.73* lon (lon) float64 -180.0 -171.0 ... 171.0 180.0
Data variables:temperature (time, lat, lon) float64 0.1234 0.5678 ...
3. .sel() 和 .isel() 联合使用
场景:结合标签和索引选择数据(例如,选择特定时间步和固定经度索引)。
# 按时间标签和经度索引选择数据
subset_mixed = ds.sel(time="2025-01-01").isel(lon=0)
输出结果:
<xarray.Dataset>
Dimensions: (time: 1, lat: 10, lon: 1)
Coordinates:time datetime64[ns] 2025-01-01* lat (lat) float64 -90.0 -81.0 ... 81.0 90.0lon float64 -180.0
Data variables:temperature (time, lat, lon) float64 0.1234 0.5678 ...
4. 多维选择与切片
场景:同时选择多个维度(时间、纬度、经度)并使用切片操作。
# 按时间标签、纬度范围和经度切片选择数据
subset_slice = ds.sel(time="2025-01-01",lat=slice(-90, -60),lon=slice(-180, -120)
)
输出结果:
<xarray.Dataset>
Dimensions: (time: 1, lat: 3, lon: 7)
Coordinates:time datetime64[ns] 2025-01-01* lat (lat) float64 -90.0 -76.36 -62.73* lon (lon) float64 -180.0 -163.6 ... -126.3 -120.0
Data variables:temperature (time, lat, lon) float64 0.1234 0.5678 ...
5. 关键说明
-
.sel()vs.isel():.sel():使用坐标标签(如time="2025-01-01"、lat=-90)进行选择,适合已知具体坐标的场景。.isel():使用索引位置(如time=0、lat=slice(0, 3))进行选择,适合已知数组索引的场景。
-
切片操作:
- 可以通过
slice(start, end)实现对维度的范围选择(例如lat=slice(-90, -60))。 - 切片是左闭右开的,即包含
start,不包含end。
- 可以通过
-
多维联合选择:
- 可以联合使用
.sel()和.isel(),例如先按标签选择时间,再按索引选择经度。 - 也可以通过链式调用实现多步选择(如
ds.sel(...).isel(...))。
- 可以联合使用
(二) 数据计算
1. 聚合运算
(1) 计算单个维度的平均值
场景:从数据集中计算时间维度(time)的平均值。
import xarray as xr
import numpy as np
import pandas as pd# 创建示例数据集
ds = xr.Dataset({"temperature": (["time", "lat", "lon"], np.random.rand(3, 10, 20)),"humidity": (["time", "lat", "lon"], np.random.rand(3, 10, 20)),},coords={"time": pd.date_range("2025-01-01", periods=3),"lat": np.linspace(-90, 90, 10),"lon": np.linspace(-180, 180, 20),}
)# 计算时间维度的平均值
mean_time = ds.mean(dim="time")
输出结果:
<xarray.Dataset>
Dimensions: (lat: 10, lon: 20)
Coordinates:* lat (lat) float64 -90.0 -81.0 -72.0 ... 72.0 81.0 90.0* lon (lon) float64 -180.0 -171.0 -162.0 ... 162.0 171.0 180.0
Data variables:temperature (lat, lon) float64 0.4567 0.8901 ...humidity (lat, lon) float64 0.7654 0.3210 ...
(2) 计算多个维度的平均值
场景:从数据集中计算时间和纬度维度的平均值。
# 计算时间和纬度维度的平均值
mean_time_lat = ds.mean(dim=["time", "lat"])
输出结果:
<xarray.Dataset>
Dimensions: (lon: 20)
Coordinates:* lon (lon) float64 -180.0 -171.0 -162.0 ... 162.0 171.0 180.0
Data variables:temperature (lon) float64 0.6789 ...humidity (lon) float64 0.5432 ...
(3) 计算单个维度的标准差
场景:从数据集中计算纬度维度(lat)的标准差。
# 计算纬度维度的标准差
std_lat = ds.std(dim="lat")
输出结果:
<xarray.Dataset>
Dimensions: (time: 3, lon: 20)
Coordinates:* time (time) datetime64[ns] 2025-01-01 ... 2025-01-03* lon (lon) float64 -180.0 -171.0 -162.0 ... 162.0 171.0 180.0
Data variables:temperature (time, lon) float64 0.2345 0.6789 ...humidity (time, lon) float64 0.3456 0.7890 ...
(4) 计算多个维度的标准差
场景:从数据集中计算时间和经度维度的标准差。
# 计算时间和经度维度的标准差
std_time_lon = ds.std(dim=["time", "lon"])
输出结果:
<xarray.Dataset>
Dimensions: (lat: 10)
Coordinates:* lat (lat) float64 -90.0 -81.0 -72.0 ... 72.0 81.0 90.0
Data variables:temperature (lat) float64 0.1234 ...humidity (lat) float64 0.4567 ...
(5) 忽略缺失值计算统计量
场景:数据集中包含缺失值(NaN),需要在计算时跳过缺失值。
# 创建包含缺失值的数据集
ds_nan = xr.Dataset({"temperature": (["time", "lat", "lon"], np.random.rand(3, 10, 20)),},coords={"time": pd.date_range("2025-01-01", periods=3),"lat": np.linspace(-90, 90, 10),"lon": np.linspace(-180, 180, 20),}
)# 随机插入缺失值
ds_nan.temperature.values[0, 0, 0] = np.nan# 计算时间维度的平均值(跳过缺失值)
mean_time_skipna = ds_nan.mean(dim="time", skipna=True)
输出结果:
<xarray.Dataset>
Dimensions: (lat: 10, lon: 20)
Coordinates:* lat (lat) float64 -90.0 -81.0 -72.0 ... 72.0 81.0 90.0* lon (lon) float64 -180.0 -171.0 -162.0 ... 162.0 171.0 180.0
Data variables:temperature (lat, lon) float64 0.4567 0.8901 ...
(6) 关键说明
-
.mean()和.std()的区别:.mean():计算指定维度的平均值。.std():计算指定维度的标准差,默认为样本标准差(ddof=1)。
-
维度选择:
- 可以指定单个维度(如
dim="time")或多个维度(如dim=["time", "lat"])。 - 维度减少后,输出数据集的维度会相应调整(如从
(time, lat, lon)变为(lat, lon))。
- 可以指定单个维度(如
-
缺失值处理:
- 通过
skipna=True可以跳过缺失值(NaN)进行计算,避免因缺失值导致整个统计结果为NaN。
- 通过
2. 算术运算
# 温度乘以 2,降水加 10
new_ds = ds * 2 + 10
3. 数据重塑
总结表格
| 操作/方法 | 功能 | 输入参数 | 输出参数 |
|---|---|---|---|
.stack() | 将多个维度堆叠成一个新维度 | new_dim_name: 新维度名;dim: 原始维度列表 | 维度被堆叠后的 xarray.Dataset |
.transpose() | 调整维度顺序(不改变维度数量) | *dims: 新维度顺序 | 维度顺序调整后的 xarray.Dataset |
(1) .stack():将多个维度堆叠成一个新维度
场景:将 lat 和 lon 维度堆叠成一个名为 space 的新维度。
示例代码
import xarray as xr
import numpy as np
import pandas as pd# 创建示例数据集
ds = xr.Dataset({"temperature": (["time", "lat", "lon"], np.random.rand(3, 10, 20)),},coords={"time": pd.date_range("2025-01-01", periods=3),"lat": np.linspace(-90, 90, 10),"lon": np.linspace(-180, 180, 20),}
)# 将 lat 和 lon 堆叠成 space 维度
stacked_ds = ds.stack(space=["lat", "lon"])
输出结果:
<xarray.Dataset>
Dimensions: (time: 3, space: 200)
Coordinates:* time (time) datetime64[ns] 2025-01-01 2025-01-02 ...space (space) MultiIndex- lat (space) float64 -90.0 -90.0 ... 90.0 90.0- lon (space) float64 -180.0 -171.0 ... 171.0 180.0
Data variables:temperature (time, space) float64 0.1234 0.5678 ...
(2) .transpose():调整维度顺序
场景:将 time, lat, lon 的维度顺序调整为 lon, lat, time。
示例代码:
# 调整维度顺序
transposed_ds = ds.transpose("lon", "lat", "time")
输出结果:
<xarray.Dataset>
Dimensions: (lon: 20, lat: 10, time: 3)
Coordinates:* lon (lon) float64 -180.0 -171.0 ... 171.0 180.0* lat (lat) float64 -90.0 -81.0 ... 81.0 90.0* time (time) datetime64[ns] 2025-01-01 2025-01-02 ...
Data variables:temperature (lon, lat, time) float64 0.1234 0.5678 ...
(3) .stack() + .transpose() 联合使用
场景:先将 lat 和 lon 堆叠成 space,再调整维度顺序为 space, time。
示例代码:
# 堆叠后调整维度顺序
stacked_transposed_ds = ds.stack(space=["lat", "lon"]).transpose("space", "time")
输出结果:
<xarray.Dataset>
Dimensions: (space: 200, time: 3)
Coordinates:space (space) MultiIndex- lat (space) float64 -90.0 -90.0 ... 90.0 90.0- lon (space) float64 -180.0 -171.0 ... 171.0 180.0* time (time) datetime64[ns] 2025-01-01 2025-01-02 ...
Data variables:temperature (space, time) float64 0.1234 0.5678 ...
(4) 关键说明
-
.stack()vs.transpose():.stack():减少维度数量,将多个维度合并为一个新维度(如lat和lon→space)。.transpose():不改变维度数量,仅调整维度的排列顺序(如time, lat, lon→lon, lat, time)。
-
应用场景:
.stack():- 将多维数据转换为二维,便于进行某些计算(如机器学习模型输入)。
- 简化高维数据的可视化(如将
lat和lon合并为space后绘图)。
.transpose():- 调整数据维度顺序以匹配其他数据集或模型的输入格式。
- 提高代码可读性,使维度顺序更符合逻辑(如先经度后纬度)。
-
注意事项:
.stack()会生成MultiIndex,可通过.unstack()恢复原始维度。.transpose()不会修改原始数据,而是返回一个新对象(惰性操作)。
4. 数据聚合
| 操作/方法 | 功能 | 输入参数 | 输出参数 |
|---|---|---|---|
.groupby() / .mean() | 按维度分组计算均值 | group: 分组维度(如 time.month);dim: 聚合维度 | 聚合后的 xarray.DataArray |
.resample() | 时间序列重采样(如日→月) | freq: 重采样频率(如 MS 表示月初);dim: 时间维度名 | 重采样后的 xarray.DataArray |
示例代码
# 按月份分组计算均值
monthly_mean = da.groupby("time.month").mean(dim="time")# 时间序列重采样(日→月)
monthly_resample = da.resample(time="MS").mean()
5. 合并两个数据集
ds2 = xr.Dataset({"precipitation": (["time", "lat", "lon"], np.random.rand(3, 10, 20))})
ds_merged = ds.merge(ds2)
输出结果:
<xarray.Dataset>
Dimensions: (time: 3, lat: 10, lon: 20)
Coordinates:* time (time) datetime64[ns] 2025-01-01 2025-01-02 ...* lat (lat) float64 -90.0 -81.0 ... 81.0 90.0* lon (lon) float64 -180.0 -171.0 ... 171.0 180.0
Data variables:temperature (time, lat, lon) float64 0.1234 0.5678 ...humidity (time, lat, lon) float64 0.9876 0.4321 ...precipitation (time, lat, lon) float64 0.3456 0.7890 ...
6. 应用自定义函数
def custom_func(arr):return arr.max() - arr.min()ds_custom = ds.apply(custom_func)
输出结果:
<xarray.Dataset>
Dimensions: (time: 3, lat: 10, lon: 20)
Coordinates:* time (time) datetime64[ns] 2025-01-01 2025-01-02 ...* lat (lat) float64 -90.0 -81.0 ... 81.0 90.0* lon (lon) float64 -180.0 -171.0 ... 171.0 180.0
Data variables:temperature (time, lat, lon) float64 0.4321 0.8765 ...humidity (time, lat, lon) float64 0.5432 0.9876 ...
五、数据可视化
表:可视化方法
| 操作/方法 | 功能 | 输入参数 | 输出参数 |
|---|---|---|---|
.plot() | 快速可视化(等值线图、色阶图) | x, y: 维度名;cbar_kwargs: 颜色条参数;transform: 投影转换 | matplotlib.axes.Axes 对象 |
.plot.scatter() | 散点图可视化 | x, y: 维度名;c: 颜色变量;size: 点大小 | matplotlib.axes.Axes 对象 |
- 示例代码
# 绘制等值线图
da.plot.contourf(x="lon", y="lat", cmap="viridis")# 绘制散点图
da.plot.scatter(x="lon", y="lat", c="temperature", size="precipitation")
(一)二维分布图
# 绘制温度的空间分布
ds["temp"].isel(time=0).plot(cmap="viridis")
plt.title("Temperature Distribution")
plt.show()
(二)时间序列图
# 绘制单个网格点的时间序列
ds["temp"].sel(lat=40, lon=100).plot.line(x="time")
plt.title("Temperature Time Series")
plt.show()
六、高级功能
(一) 缺失值处理
1. 填充缺失值
# 用 0 填充缺失值
filled_temp = ds["temp"].fillna(0)
2. 插值
# 使用线性插值填充缺失值
interpolated = ds["temp"].interpolate_na(dim="lat", method="linear")
(二) 时间重采样
# 将日数据重采样为月均值
monthly_mean = ds.resample(time="1M").mean()
(三)地理信息处理
1. 设置坐标系
import rioxarray
ds.rio.write_crs("EPSG:4326", inplace=True) # 设置为 WGS84 坐标系
2. 绘制地理投影图
import cartopy.crs as ccrs
ax = plt.axes(projection=ccrs.PlateCarree())
ds["temp"].isel(time=0).plot(ax=ax, transform=ccrs.PlateCarree())
ax.coastlines()
plt.show()
七、数据输入与输出
表:NetCDF 读取与保存
| 操作/方法 | 功能 | 输入参数 | 输出参数 |
|---|---|---|---|
xr.open_dataset | 读取单个 NetCDF 文件 | filename: 文件路径;engine: 读取引擎(如 netcdf4) | xarray.Dataset 对象 |
xr.to_netcdf | 保存数据为 NetCDF 文件 | filename: 保存路径;mode: 写入模式(如 w 表示覆盖) | 无返回值(直接写入文件) |
xr.open_mfdataset | 批量读取多文件数据集 | paths: 文件路径列表;engine: 读取引擎(如 h5netcdf);parallel: 是否并行读取;preprocess: 预处理函数 | 合并后的 xarray.Dataset |
xr.save_mfdataset | 批量保存数据集到文件 | datasets: 数据集列表;paths: 保存路径列表;encoding: 变量编码参数(如压缩设置) | 无返回值(直接写入文件) |
(一)读取 NetCDF 文件
ds = xr.open_dataset("data.nc") # 读取单个文件
ds = xr.open_mfdataset("data/*.nc", combine="by_coords") # 合并多个文件
示例代码
# 批量读取 NetCDF 文件
import xarray as xr
ds = xr.open_mfdataset("data/*.nc", engine="h5netcdf", parallel=True)# 批量保存数据集
xr.save_mfdataset([ds1, ds2], ["output1.nc", "output2.nc"], encoding={var: {"zlib": True}})
(二)保存数据
# 保存为 NetCDF 文件并启用压缩
ds.to_netcdf("output.nc", encoding={"temp": {"zlib": True}})
八、性能优化
表:数据分块与性能优化
| 操作/方法 | 功能 | 输入参数 | 输出参数 |
|---|---|---|---|
.chunk() | 设置数据分块大小 | chunks: 分块字典(如 {"time": 10, "lat": 100}) | 带分块的 xarray.DataArray |
.compute() | 触发延迟计算 | 无 | 实际计算结果(xarray.DataArray 或 xarray.Dataset) |
(一)分块处理(Dask)
import dask.array as da
ds = ds.chunk({"time": 10}) # 将时间维度分块
(二) 内存优化
- 使用
.persist()或.compute()控制计算时机。 - 避免不必要的中间变量。
示例代码
# 设置分块
da_chunked = da.chunk({"time": 10, "lat": 100})# 触发计算
result = da_chunked.mean().compute()
九、总结
(一)核心流程
- 读取数据 → 2. 访问变量 → 3. 选择/切片 → 4. 计算/分析 → 5. 保存/可视化
(二)关键优势
- 标签化操作:通过维度名和坐标直接访问数据。
- 高效处理:支持多维数据、地理信息和大文件分块。
- 易用性:与 Pandas、Matplotlib 无缝集成。
(三)注意事项
- 使用
.sel()和.isel()时注意维度名称和索引范围。 - 大数据集需结合 Dask 分块处理(
.chunk())。 - 保存时启用压缩(
zlib=True)可减少文件体积。
相关文章:
【数据处理】xarray 数据处理教程:从入门到精通
目录 xarray 数据处理教程:从入门到精通一、简介**核心优势** 二、安装与导入1. 安装2. 导入库 三、数据结构(一)DataArray(二) Dataset(三)关键说明 四、数据操作(一)索…...
qt5.14.2 opencv调用摄像头显示在label
ui界面添加一个Qlabel名字是默认的label 还有一个button名字是pushButton mainwindow.h #ifndef MAINWINDOW_H #define MAINWINDOW_H#include <QMainWindow> #include <opencv2/opencv.hpp> // 添加OpenCV头文件 #include <QTimer> // 添加定…...
)
科技的成就(六十八)
623、杰文斯悖论 杰文斯悖论是1865年经济学家威廉斯坦利杰文斯提出的一悖论:当技术进步提高了效率,资源消耗不仅没有减少,反而激增。例如,瓦特改良的蒸汽机让煤炭燃烧更加高效,但结果却是煤炭需求飙升。 624、代码混…...

芯片生态链深度解析(三):芯片设计篇——数字文明的造物主战争
【开篇:设计——数字文明的“造物主战场”】 当英伟达的H100芯片以576TB/s显存带宽重构AI算力边界,当阿里平头哥倚天710以RISC-V架构实现性能对标ARM的突破,这场围绕芯片设计的全球竞赛早已超越技术本身,成为算法、架构与生态标准…...
Rocky Linux 9.5 基于kubeadm部署k8s
一:部署说明 操作系统https://mirrors.aliyun.com/rockylinux/9.5/isos/x86_64/Rocky-9.5-x86_64-minimal.iso 主机名IP地址配置k8s- master192.168.1.1412颗CPU 4G内存 100G硬盘k8s- node-1192.168.1.1422颗CPU 4G内存 100G硬盘k8s- node-2192.168.1.1432…...

--openssl-legacy-provider is not allowed in NODE_OPTIONS 报错的处理方式
解决方案 Node.js 应用: 从 Node.js v17 开始,底层升级到 OpenSSL 3.0,可能导致旧代码报错(如 ERR_OSSL_EVP_UNSUPPORTED)。 通过以下命令启用旧算法支持: node --openssl-legacy-provider your_script.js…...

uart16550详细说明
一、介绍 uart16550 ip core异步串行通信IP连接高性能的微控制器总线AXI,并为异步串行通信提供了 控制接口。软核设计连接了axilite接口。 二、特性 1.axilite接口用于寄存器访问和数据传输 2.16650串口和16450串口的软件和硬件寄存器都是兼容的 3.默认的core配置参数…...

deepin v23.1 音量自动静音问题解决
有的机器上会有音量自动静音问题, 如果你的电脑上也遇到, 这个问题是 Linux 内核的原因, ubuntu上也可能会遇到相同问题(比如你升级了最新内核6.14), 而我测试得6.8.0的内核是不会自动静音的. Index of /mainline 到上面这个链接(linux 内核的官方链接)下载6.8.0的内核, s…...

抢跑「中央计算+区域控制」市场,芯驰科技高端智控MCU“芯”升级
伴随着整车EE架构的加速变革,中国高端车规MCU正在迎来“新格局”。 在4月23日开幕的上海国际车展期间,芯驰科技面向新一代AI座舱推出了X10系列芯片,以及面向区域控制器、电驱和动力域控、高阶辅助驾驶和舱驾融合系统等的高端智控MCU产品E3系…...
》阅读笔记:p82-p82)
《算法导论(第4版)》阅读笔记:p82-p82
《算法导论(第4版)》学习第 17 天,p82-p82 总结,总计 1 页。 一、技术总结 1. Matrix Matrices(矩阵) (1)教材 因为第 4 章涉及到矩阵,矩阵属于线性代数(linear algebra)范畴,如果不熟悉,可以看一下作者推荐的两本…...
day015-进程管理
文章目录 1. 服务开机自启动2. 进程3. 僵尸进程3.1 处理僵尸进程3.2 查看僵尸进程3.2 排查与结束僵尸进程全流程 4. 孤儿进程5. 进程管理5.1 kill三剑客5.2 后台运行 6. 进程监控命令6.1 ps6.1.1 ps -ef6.1.2 ps aux6.1.3 VSZ、RSS6.1.4 进程状态6.1.5 进程、线程 6.2 top6.2.1…...

traceroute命令: -g与-i 参数
[rootwww ~]# traceroute [选项与参数] IP 选项与参数:-i 装置:用在比较复杂的环境,如果你的网络接口很多很复杂时,才会用到这个参数;*举例来说,你有两条 ADSL 可以连接到外部,那你的主机会有两…...
POWER BI添加自定义字体
POWER BI添加自定义字体 POWER BI内置27种字体,今天分享一种很简单的添加自定义字体的方法。以更改如下pbix文件字体为例: 第一步:将该pbix文件重命名为zip文件并解压,找到主题json文件,如下图所示: 第二步…...

SpringAI更新:废弃tools方法、正式支持DeepSeek!
AI 技术发展很快,同样 AI 配套的相关技术发展也很快。这不今天刚打开 Spring AI 的官网就发现它又又又又更新了,而这次更新距离上次更新 M7 版本才不过半个月的时间,那这次 Spring AI 给我们带来了哪些惊喜呢?一起来看。 重点升级…...

协议不兼容?Profinet转Modbus TCP网关让恒压供水系统通信0障碍
在现代工业自动化领域中,通信协议扮演着至关重要的角色。ModbusTCP和Profinet是两种广泛使用的工业通信协议,它们各自在不同的应用场合中展现出独特的优势。本文将探讨如何通过开疆智能Profinet转Modbus TCP的网关,在恒压供水系统中实现高效的…...

ChatGPT + DeepSeek 联合润色的 Prompt 模板指令合集,用来润色SCI论文太香了!
对于非英语母语的作者来说,写SCI论文的时候经常会碰到语法错误、表达不够专业、结构不清晰以及术语使用不准确等问题。传统的润色方式要么成本高、效率低,修改过程又耗时又费力。虽然AI工具可以帮助我们来润色论文,但单独用ChatGPT或DeepSeek都会存在内容泛泛、专业性不足的…...

全栈项目搭建指南:Nuxt.js + Node.js + MongoDB
全栈项目搭建指南:Nuxt.js Node.js MongoDB 一、项目概述 我们将构建一个完整的全栈应用,包含: 前端:Nuxt.js (SSR渲染)后端:Node.js (Express/Koa框架)数据库:MongoDB后台管理系统:集成在同…...

RAGFlow Arbitrary Account Takeover Vulnerability
文章目录 RAGFlowVulnerability Description[1]Vulnerability Steps[2]Vulnerability Steps[3]Vulnerability Steps RAGFlow RAGFlow is an open-source RAG (Retrieval-Augmented Generation) engine developed by Infiniflow, focused on deep document understanding and d…...
Python 之 Flask 入门学习
安装 Flask 在开始使用 Flask 之前,需要先安装它。可以通过 pip 命令来安装 Flask: pip install Flask创建第一个 Flask 应用 创建一个简单的 Flask 应用,只需要几行代码。以下是一个最基本的 Flask 应用示例: from flask imp…...

微服务,服务粒度多少合适
项目服务化好处 复用性,消除代码拷贝专注性,防止复杂性扩散解耦合,消除公共库耦合高质量,SQL稳定性有保障易扩展,消除数据库解耦合高效率,调用方研发效率提升 微服务拆分实现策略 统一服务层一个子业务一…...

【Ragflow】22.RagflowPlus(v0.3.0):用户会话管理/文件类型拓展/诸多优化更新
概述 在历经三周的阶段性开发后,RagflowPlus顺利完成既定计划,正式发布v0.3.0版本。 开源地址:https://github.com/zstar1003/ragflow-plus 新功能 1. 用户会话管理 在后台管理系统中,新增用户会话管理菜单。在此菜单中&…...
使用PocketFlow构建Web Search Agent
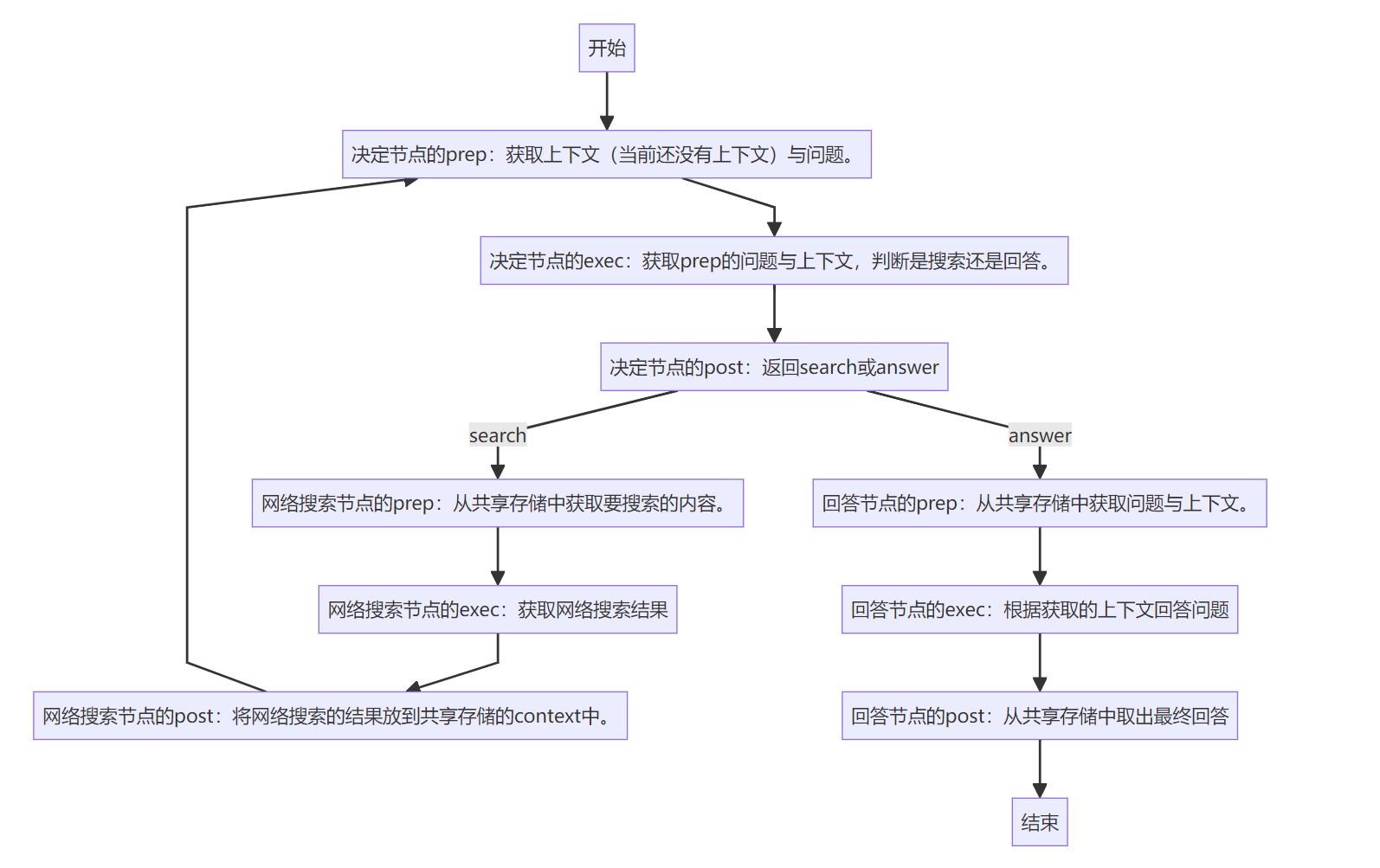
前言 本文介绍的是PocketFlow的cookbook中的pocketflow-agent部分。 回顾一下PocketFlow的核心架构: 每一个节点的架构: 具体介绍可以看上一篇文章: “Pocket Flow,一个仅用 100 行代码实现的 LLM 框架” 实现效果 这个Web S…...
)
安卓基础(Bitmap)
Bitmap 是 Android 开发中一个非常重要的类,用于表示图像数据。它是一个位图对象,存储了图像的像素信息,可以用于显示、处理和保存图像。Bitmap 提供了丰富的 API,用于操作和处理图像数据。 1. Bitmap 的作用 显示图像࿱…...

记录:echarts实现tooltip的某个数据常显和恢复
<template><div class"com-wapper"><div class"func-btns"><el-button type"primary" plain click"showPoint(2023)">固定显示2023年数据</el-button><el-button type"success" plain cli…...
八股文--JVM(1)
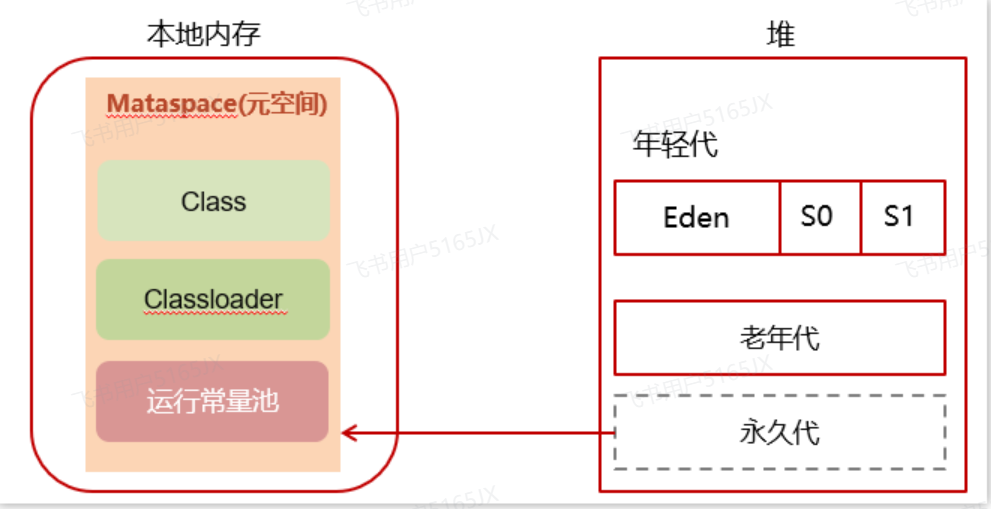
⭐️⭐️JVM内存模型 程序计数器:可以看作是当前线程所执行的字节码的行号指示器,用于存储当前线程正在执行的 Java 方法的 JVM 指令地址。如果线程执行的是 Native 方法,计数器值为 null。是唯一一个在 Java 虚拟机规范中没有规定任何 OutOf…...
从RPA项目说说RPC和MQ的使用。
去年我负责一个 RPA(机器人流程自动化)项目,帮某电商公司搭建订单处理系统。项目里有个场景特别有意思:当用户下单后,系统需要同时触发库存扣减、物流调度、积分发放三个模块。一开始我们想都没想,直接用 R…...
与Self-Consistency在复杂推理任务中的优劣)
【大模型面试每日一题】Day 21:对比Chain-of-Thought(CoT)与Self-Consistency在复杂推理任务中的优劣
【大模型面试每日一题】Day 21:对比Chain-of-Thought(CoT)与Self-Consistency在复杂推理任务中的优劣 📌 题目重现 🌟 面试官:我们在数学推理和逻辑推理任务中发现,Self-Consistency方法比传统…...
UUG杭州站 | 团结引擎1.5.0 OpenHarmony新Feature介绍
PPT下载地址:https://u3d.sharepoint.cn/:b:/s/UnityChinaResources/EaZmiWfAAdFFmuyd6c-7_3ABhvZoaM69g4Uo2RrSzT3tZQ?e2h7RaL 在2025年4月12日的Unity User Group杭州站中,Unity中国OpenHarmony技术负责人刘伟贤带来演讲《团结引擎1.5.0 OpenHarmony新…...

Vue3——父子组件通信
在Vue开发中,组件通信是核心概念之一。良好的组件通信机制能让我们的应用更加清晰、可维护。 父传子defineProps defineProps是一个编译时宏,仅在内部可用,不需要显式导入。声明的 props 会自动暴露给模板。 还返回一个对象,其中…...

游戏引擎学习第276天:调整身体动画
运行游戏,演示我们遇到的拉伸问题,看起来不太好,并考虑切换到更顶视角的视角 我们开始讨论游戏开发中的一些美学决策,特别是在处理动画方面。虽然我们是游戏程序员,通常不负责设计或艺术部分,但因为这是一…...