风控域——风控决策引擎系统设计
摘要
本文详细介绍了风控决策引擎系统的设计与应用。决策引擎系统是一种智能化工具,可自动化、数据驱动地辅助或替代人工决策,广泛应用于金融、医疗、营销、风控等领域。文章阐述了决策引擎的核心功能,包括自动化决策、动态规则管理、实时处理和模型集成,以及系统组成,涵盖数据输入层、规则引擎和模型服务层。此外,还探讨了决策引擎的典型应用场景、技术架构、组件设计,以及风控决策引擎系统的技术方案、设计难点和重点。
1. 决策引擎系统介绍
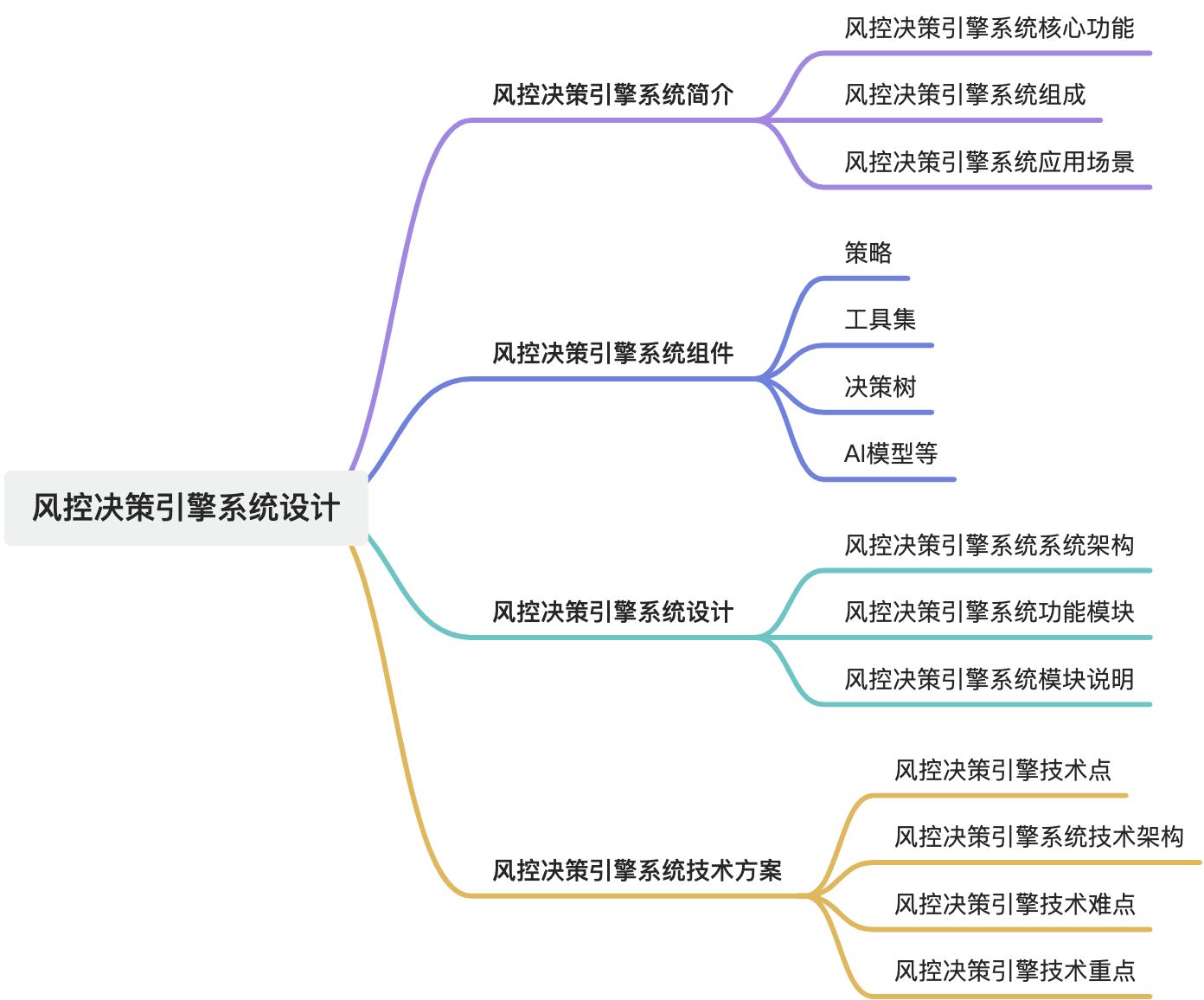
决策引擎系统是一种通过自动化、数据驱动的方式辅助或替代人工决策的智能化工具。它结合规则、数据分析、机器学习模型和业务流程逻辑,快速生成决策结果,广泛应用于金融、医疗、营销、风控等领域。
决策引擎,常用于金融反欺诈、金融信审等互金领域,由于黑产、羊毛党行业的盛行,风控决策引擎在电商、支付、游戏、社交等领域也有了长足的发展,刷单、套现、作弊,凡是和钱相关的业务都离不开风控决策引擎系统的支持保障。决策引擎和规则引擎比较接近(严格说决策引擎包含规则引擎,之前也有叫专家系统,推理引擎),它实现了业务决策与程序代码的分离。风控决策引擎系统是在大数据支撑下,根据行业专家经验制定规则策略、以及机器学习/深度学习/AI领域建立的模型运算,对当前的业务风险进行全面的评估,并给出决策结果的一套系统。
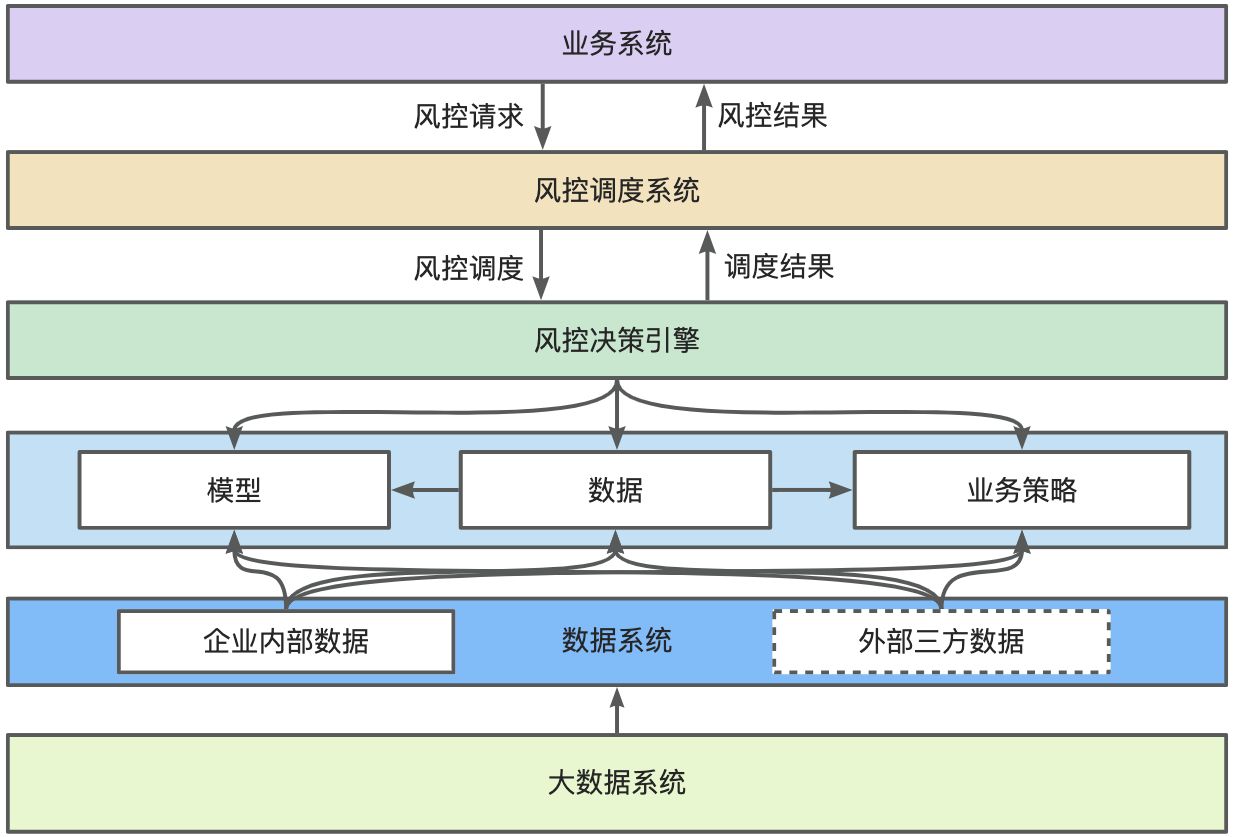
1.1. 决策引擎核心功能
- 自动化决策:基于预设规则或模型,自动处理大量数据并生成决策(如贷款审批、风险预警)。
- 动态规则管理:支持灵活配置规则(如“如果用户消费金额>1000元,则提升信用评分”),无需修改代码即可更新逻辑。
- 实时处理:对高并发场景(如电商秒杀、反欺诈)实现毫秒级响应。
- 模型集成:融合机器学习模型(如随机森林、XGBoost)和传统规则,提升复杂场景的决策准确性。
1.2. 决策引擎系统组成
数据输入层
- 结构化数据(数据库、API)
- 非结构化数据(文本、图像)
- 实时流数据(Kafka、Flink)
规则引擎
- 解析规则库(如Drools、Aviator),支持逻辑表达式(IF-THEN-ELSE)。
- 示例:信用卡反欺诈规则——“单日境外交易次数>3次则拦截”。
模型服务层
- 集成训练好的AI模型(如评分卡、神经网络),用于预测(如用户流失概率)。
- 常用框架:TensorFlow、PyTorch、Scikit-learn。
决策执行层
- 输出结果至下游系统(如短信通知、订单系统)。
- 支持人工审核旁路机制(如高风险交易需人工复核)。
监控与优化
- 实时跟踪决策效果(如模型准确率、规则命中率)。
- A/B测试功能,对比不同策略的效果。
1.3. 决策引擎典型应用场景
金融风控
- 贷款审批:结合征信数据、收入水平自动通过/拒绝申请。
- 反洗钱:检测异常交易模式(如频繁小额转账后大额转出)。
营销推荐
- 电商场景:根据用户历史行为推荐商品(协同过滤+实时点击数据)。
- 优惠券发放:识别高价值客户定向推送。
医疗诊断
- 辅助诊断:基于症状、检验结果匹配疾病概率(如IBM Watson Health)。
- 治疗方案推荐:结合临床指南和患者个体差异。
运营优化
- 动态定价:根据供需关系、竞争价格实时调整(如网约车、航空公司)。
- 资源调度:智能分配服务器资源应对流量高峰。
2. 决策引擎组件设计
| 组件 | 作用 | 典型使用场景 |
| 策略 | 顶层组合策略 | 贷款审批整体流程 |
| 子策略 | 单项业务逻辑判断 | 黑名单检测、信用评分 |
| 工具集 | 通用计算和数据处理方法 | 时间差计算、正则校验 |
| 决策表 | 多条件匹配 | 收入、年龄、金额等结构化判断 |
| 决策树 | 流程判断路径 | 黑名单 → 次数判断 → 决策 |
| 函数库 | 业务函数封装 | 是否在名单中,风险得分计算 |
| 索引表 | 外部数据缓存 | 地区风险等级、名单数据 |
| 决策结果 | 输出处理结果 | 审批通过/拒绝,理由输出 |
2.1. 策略
定义:一组规则或子策略的集合,用于解决特定业务场景的决策问题。
功能:
- 封装业务逻辑,如风控策略、营销策略。
- 支持优先级管理(如先执行反欺诈策略,再执行优惠券发放策略)。
作用:策略是决策引擎的顶层组合单元,通常代表一个完整的风控决策流程,如“是否放款”、“是否交易拦截”等。它负责组织和协调子策略执行,综合各部分的结果,输出最终决策。
示例:贷款审批策略,包含:身份核验策略、信用策略、反欺诈策略
public interface Strategy {DecisionResult execute(Map<String, Object> context);
}public class LoanStrategy implements Strategy {private List<SubStrategy> subStrategies = List.of(new FraudSubStrategy(),new ScoreSubStrategy());@Overridepublic DecisionResult execute(Map<String, Object> context) {for (SubStrategy sub : subStrategies) {DecisionResult result = sub.evaluate(context);if ("REJECT".equals(result.getDecision())) {return result;}}return new DecisionResult("APPROVE", 90, List.of("信用良好"));}
}2.2. 子策略
定义:策略的细分单元,用于模块化复杂业务逻辑。
功能:
- 独立管理某类规则(如“IP频率检测”作为独立子策略)。
- 支持动态加载和替换(如A/B测试不同子策略)。
作用:子策略是策略的组成部分,处理更细化的逻辑,比如“是否命中黑名单”、“近7日申请次数”等,是策略下的具体业务判断逻辑。
示例:反欺诈策略下的 “手机号异常策略”、“设备指纹检测策略”
public interface SubStrategy {DecisionResult evaluate(Map<String, Object> context);
}public class FraudSubStrategy implements SubStrategy {@Overridepublic DecisionResult evaluate(Map<String, Object> context) {boolean isBlacklisted = (boolean) context.getOrDefault("blacklist", false);if (isBlacklisted) {return new DecisionResult("REJECT", 0, List.of("命中黑名单"));}return new DecisionResult("PASS", 20, List.of());}
}2.3. 工具集
定义:提供辅助函数、数据校验、特征计算等通用能力的工具库。
功能:
- 时间窗口统计(如近1小时交易次数)。
- 数据标准化(如将IP地址转换为地理区域)。
作用:提供通用函数,如数据格式转换、时间比较、正则验证、外部接口封装等,是子策略执行逻辑的重要技术支撑工具。
示例:判断注册时间距今是否小于30天、手机号归属地解析
public class ToolSet {public static int daysBetween(Date start, Date end) {return (int) ChronoUnit.DAYS.between(start.toInstant().atZone(ZoneId.systemDefault()).toLocalDate(),end.toInstant().atZone(ZoneId.systemDefault()).toLocalDate());}public static boolean isValidMobile(String mobile) {return mobile != null && mobile.matches("^1[3-9]\\d{9}$");}
}2.4. 决策表
定义:以表格形式定义条件与动作的映射,适合规则逻辑简单的场景。
功能:
- 直观管理多条件组合(如优惠券发放规则)。
- 支持Excel/CSV等格式维护,便于业务人员参与。
作用:决策表是多条件组合判断工具,业务可以通过配置表格而非编码实现逻辑控制,适用于组合规则较多、结构固定的场景。
示例:
| 年龄 | 收入 | 贷款金额 | 结果 |
| <25 | <5000 | >10000 | 拒绝 |
| 25-40 | >8000 | <50000 | 通过 |
public class DecisionTable {public static String evaluate(int age, int income, int amount) {if (age < 25 && income < 5000 && amount > 10000) return "REJECT";if (age >= 25 && income > 8000 && amount < 50000) return "APPROVE";return "REVIEW";}
}2.5. 决策树
定义:树形结构模型,通过分支逻辑实现决策流程。
功能:
- 处理层级化决策(如订单状态流转)。
- 支持可视化编辑(如树形界面配置)。
作用:通过树状结构表示决策路径,适合嵌套判断、流程型判断逻辑,业务可视化好理解。
示例:
是否命中黑名单?
├─ 是 → 拒绝
└─ 否 → 申请次数是否 >3?├─ 是 → 审核└─ 否 → 通过public class DecisionTree {public String evaluate(Map<String, Object> context) {if ((boolean) context.getOrDefault("blacklist", false)) {return "REJECT";}int applyCount = (int) context.getOrDefault("applyCountLast7Days", 0);return applyCount > 3 ? "REVIEW" : "APPROVE";}
}2.6. AI大模型
定义:是基于历史数据训练出的预测模型,能够自动判断当前业务实体(如用户、订单、设备等)是否存在风险、是否值得授信、是否可能欺诈等。在风控决策中,它通常用于评分、风险预测、欺诈识别、拒贷预警等环节。
作用:对用户、交易等打分,例如信用评分、欺诈风险评分。识别刷单、套现、虚假注册等黑灰产行为。根据模型分值提供推荐结果,如“拒绝、人工复核、通过”。自动从行为数据中提取风险模式,挖掘隐含的欺诈信号。在交易发生的毫秒级内快速给出结果,用于高性能实时决策场景。
示例:
- 模型服务化:模型以 API 形式暴露,例如
/predict?userId=xxx&deviceId=yyy - 模型嵌入式计算:模型以 jar/pmml/onxx 格式嵌入系统中运行
- 模型与规则联合:模型输出作为决策引擎中的一个条件或子策略输入
数据来源
- 用户行为数据(如登录次数、下单频率)
- 设备指纹、IP 画像
- 历史交易数据
- 外部数据源(芝麻分、多头借贷、黑名单)
2.7. 函数库
定义:可复用的计算逻辑集合,支持自定义函数扩展。
功能:
- 封装复杂计算(如风险评分公式)。
- 集成机器学习模型推理。
作用:提供业务相关函数封装,便于规则中调用,如是否在名单中、风险分计算、规则表达式计算等。
示例:isInBlacklist(userId)、getUserScore(userId)
public class FunctionLibrary {public static boolean isInBlacklist(String userId) {return List.of("u001", "u002").contains(userId);}public static double getRiskScore(Map<String, Object> features) {double score = 50;if ((int) features.getOrDefault("applyCount", 0) > 5) score -= 10;if ((boolean) features.getOrDefault("hasOverdue", false)) score -= 20;return score;}
}2.8. 索引表
定义:优化查询性能的数据结构,用于快速匹配规则条件。
功能:
- 加速规则条件过滤(如IP黑名单查询)。
- 支持内存索引(如布隆过滤器)或数据库索引。
作用:提供结构化静态数据存储,如风险等级表、黑名单表、规则字典等,适合缓存类或高频数据访问。
示例:地域风险等级表、命中规则标签表
public class IndexTable {private static final Map<String, String> REGION_RISK = Map.of("北京", "高风险","广州", "中风险");public static String getRegionRisk(String city) {return REGION_RISK.getOrDefault(city, "未知");}
}2.9. 决策结果
定义:最终输出的决策结论及附加信息。
功能:
- 标准化输出格式(如JSON Schema)。
- 包含决策依据(如触发规则ID、模型置信度)。
作用:承载决策引擎的最终输出,供调用者(如放款系统、支付系统)使用。
示例:
{"decision": "REJECT","score": 60,"reason": ["命中黑名单", "风险得分低"]
}
public class DecisionResult {private String decision;private double score;private List<String> reasons;public DecisionResult(String decision, double score, List<String> reasons) {this.decision = decision;this.score = score;this.reasons = reasons;}// Getter/Setter 略
}
3. 决策引擎系统设计
3.1. 决策引擎系统架构
- 业务规则配置灵活:支持多种规则表达方式(决策表、表达式、脚本、决策树等)
- 决策逻辑可组合:支持策略、子策略嵌套组合与重用
- 执行链路可追踪:提供每次决策的完整执行路径、结果和原因
- 低代码/可视化支持:提供规则配置平台供业务人员使用
- 实时/批量执行兼容:支持 API 实时决策与批量离线评分
- 与大数据模型平台集成:支持模型远程加载与调用(如 TensorFlow、PMML、Python模型)
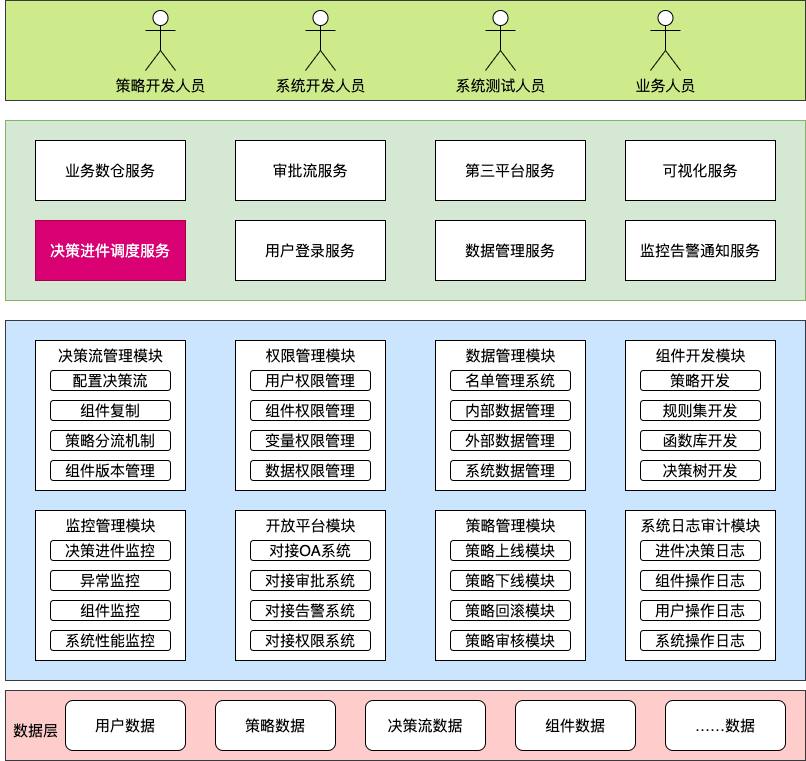
3.2. 决策引擎功能模块划分
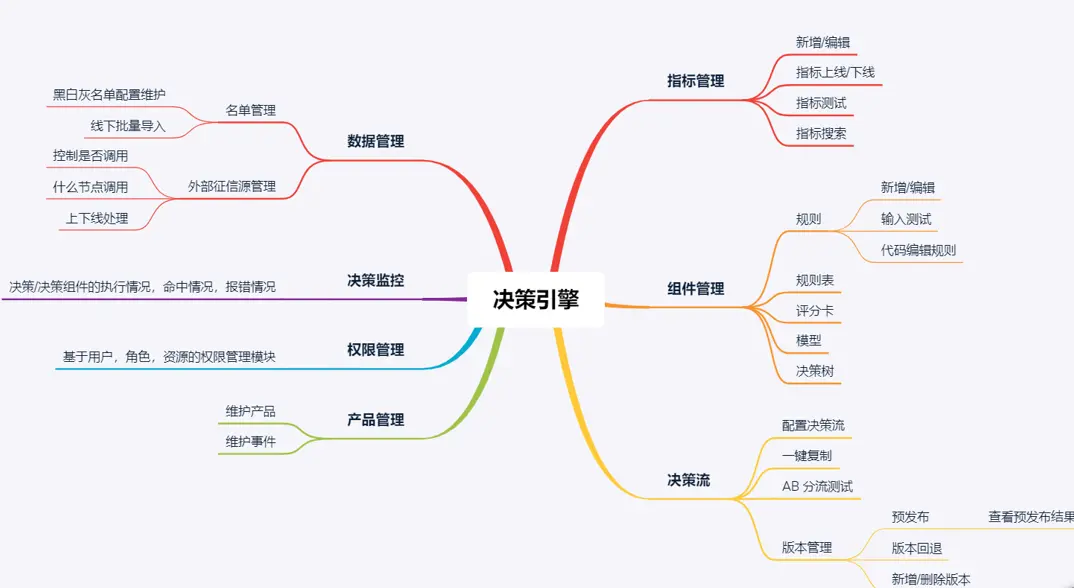
| 模块 | 功能说明 |
| 策略管理 | 策略流程设计、组合子策略、版本控制 |
| 子策略管理 | 单个规则或模型封装,支持复用 |
| 决策表管理 | 结构化规则配置,支持 Excel 导入导出 |
| 决策树管理 | 树状规则路径设计与执行 |
| 规则引擎 | 执行具体规则(表达式、脚本、模型等) |
| 模型服务 | 支持加载外部模型并参与决策 |
| 工具函数库 | 内置通用函数,如时间计算、名单查询 |
| 数据索引表 | 规则依赖的静态/动态数据(名单、字典等) |
| 决策执行引擎 | 执行策略,输出最终决策结果 |
| 决策日志审计 | 保存执行过程、链路、输入输出等 |
| 可视化控制台 | 提供界面配置与运行监控 |
| 权限和角色管理 | 控制规则和策略的使用权限 |
3.3. 决策引擎功能说明
3.3.1. 策略管理
- 创建策略(包含多个子策略)
- 配置执行顺序/条件
- 版本控制与灰度发布
3.3.2. 子策略配置
- 类型:表达式、脚本、模型、决策表、树
- 输入参数配置
- 命中规则 → 决策码 → 权重/分数/标签输出
3.3.3. 决策表支持
- 多字段组合判断
- 可视化配置与 Excel 导入
- 命中条件配置优先级
3.3.4. 决策树配置
- 条件分支可视化配置
- 节点支持表达式/调用子策略
- 末端输出决策码
3.3.5. 规则执行引擎
- DSL 表达式解析执行(SpEL、MVEL)
- 脚本执行支持(Groovy、JavaScript)
- 模型调用支持(Python 接口、PMML 模型)
3.3.6. 模型调用模块
- 模型类型:LR/XGBoost/NN
- 远程 HTTP 调用或嵌入式推理
- 支持输入特征映射及版本控制
3.3.7. 决策结果管理
- 决策码(如 REJECT, REVIEW, APPROVE)
- 风控评分
- 命中规则列表
- 决策原因(支持多语言)
3.3.8. 决策日志审计
- 输入参数快照
- 命中子策略与规则链路
- 输出结果与时间耗时
- 可用于追责、回溯、调试
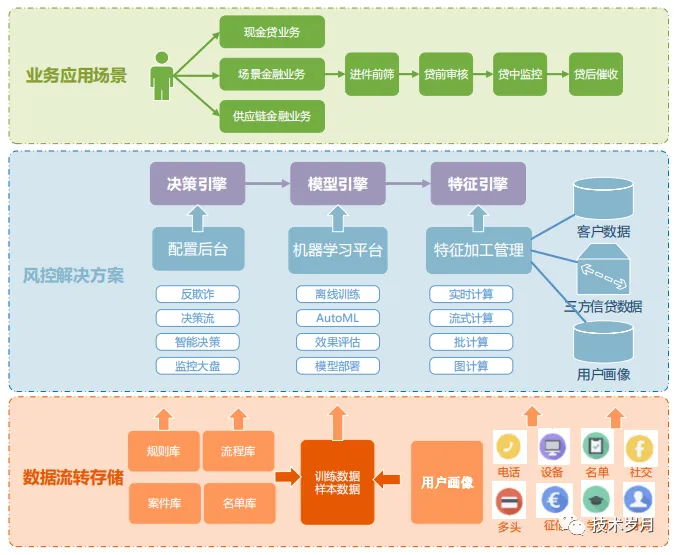
4. 风控决策引擎系统技术方案
风控决策引擎是金融、支付、电商等领域的核心系统,用于实时识别和拦截高风险行为(如欺诈、信用违约、异常操作等)。其设计需要兼顾实时性、准确性、灵活性、可扩展性和可解释性。风控决策引擎典型技术栈。风控决策引擎的核心是在毫秒级内平衡风险识别准确性与业务效率。设计时需重点关注:
- 规则与模型的协同:静态规则兜底,动态模型增强灵活性。
- 性能与可解释性的权衡:复杂模型需配套解释能力。
- 对抗黑产的演化能力:持续迭代规则和模型,适应新型攻击模式。
| 模块 | 技术选型示例 |
| 规则引擎 | Drools、Easy Rules、自研DSL |
| 流处理 | Flink、Kafka Streams |
| 模型服务 | TensorFlow Serving、TorchServe |
| 数据存储 | Redis(缓存)、HBase(持久化) |
| 监控 | Prometheus + Grafana、ELK |
| 部署 | Kubernetes、Docker |
4.1. 决策引擎技术实现
数据源 → 数据清洗 → 特征工程 → 规则引擎/模型推理 → 决策输出 → 监控反馈关键技术
- 规则引擎:Drools、OpenL Tablets
- 实时计算:Apache Flink、Kafka Streams
- 模型部署:TensorFlow Serving、MLflow
- 可视化:Kibana、Superset(监控看板)
4.2. 风控决策引擎技术点
4.2.1. 系统架构设计
- 分层架构:分为接入层(API网关)、规则引擎层、模型计算层、数据存储层、监控层。
- 微服务化:模块解耦(如规则管理、模型推理、日志分析),支持独立扩缩容。
- 高可用设计:多机房容灾、负载均衡、熔断降级(如Sentinel/Hystrix)。
4.2.2. 规则引擎
- 规则管理:支持动态配置规则(如Drools、Aviator脚本引擎),提供DSL(领域专用语言)简化规则编写。
- 规则执行:基于决策树、图计算或有限状态机(FSM)优化执行路径,减少计算延迟。
- 规则优先级:处理规则冲突(如冲突检测、权重评分)。
4.2.3. 实时计算与流处理
- 流式计算框架:使用Flink、Storm或Kafka Streams处理实时事件流。
- 特征工程:实时计算用户行为特征(如滑动窗口统计、统计类特征)。
- 异步处理:非关键路径异步化(如日志存储、模型更新)。
4.2.4. 机器学习模型
- 模型部署:TensorFlow Serving、PyTorch TorchServe等模型服务框架。
- 在线学习:支持模型动态更新(如PS-Worker架构、在线增量训练)。
- 模型融合:规则与模型结果加权(如加权投票、Stacking集成)。
4.2.5. 数据存储与缓存
- 实时查询:Redis(特征缓存)、HBase(历史数据存储)。
- OLAP分析:ClickHouse、Doris用于事后风险分析。
- 时序数据库:InfluxDB存储用户行为时序数据。
4.2.6. 服务治理
- 全链路追踪:SkyWalking、Zipkin监控请求链路。
- 灰度发布:AB测试、金丝雀发布降低规则变更风险。
4.3. 风控决策引擎设计难点
4.3.1. 高性能与低延迟
挑战:每秒处理数十万并发请求(如支付风控),需优化规则执行效率。
解决方案:
- 规则预编译(如将Drools规则转换为字节码)。
- 异步非阻塞IO(Netty框架)。
- 内存计算(避免频繁IO,如Redis Pipeline批量读取)。
4.3.2. 动态规则与模型更新
- 挑战:业务方需实时调整策略,但模型重载可能导致服务中断。
- 解决方案:
-
- 规则热加载(Lua脚本热更新)。
- 模型版本管理(AB测试灰度发布)。
4.3.3. 数据一致性
- 挑战:分布式环境下,特征数据与规则执行结果的一致性。
- 解决方案:
-
- 分布式事务(Seata框架)。
- 最终一致性(通过消息队列异步补偿)。
4.3.4. 可解释性
- 挑战:监管要求风控决策透明化(如欧盟GDPR的“可解释AI”)。
- 解决方案:
-
- 规则引擎天然可解释。
- 模型输出SHAP值或LIME解释(如集成到日志中)。
4.3.5. 对抗攻击与黑产绕过
- 挑战:黑产通过模拟正常行为规避规则。
- 解决方案:
-
- 实时特征增强(如设备指纹、IP风险分)。
- 异常模式检测(孤立森林、AutoEncoder无监督模型)。
4.4. 风控决策引擎设计重点
4.4.1. 实时性保障
- 端到端延迟控制在毫秒级(如支付风控需<50ms)。
- 关键路径优化:减少序列化开销(Protobuf替代JSON)、内存池化技术。
4.4.2. 策略灵活性
- 支持多维度策略组合(如用户维度+设备维度+行为维度)。
- 策略版本管理(回滚机制、灰度发布)。
4.4.3. 可扩展性
- 水平扩展能力:无状态服务设计,支持Kubernetes自动扩缩容。
- 插件化架构:允许自定义规则解析器或模型推理模块。
4.4.4. 安全与合规
- 敏感数据脱敏(如手机号部分隐藏)。
- 审计日志:记录所有风控决策过程,满足监管要求。
4.4.5. 监控与运维
- 核心指标监控:QPS、延迟、误杀率、规则命中率。
- 自动化运维:异常规则告警(如规则冲突、模型性能下降)。
博文参考
GitHub - skyhackvip/risk_engine: 天网决策引擎系统
相关文章:
风控域——风控决策引擎系统设计
摘要 本文详细介绍了风控决策引擎系统的设计与应用。决策引擎系统是一种智能化工具,可自动化、数据驱动地辅助或替代人工决策,广泛应用于金融、医疗、营销、风控等领域。文章阐述了决策引擎的核心功能,包括自动化决策、动态规则管理、实时处…...
CAPL Class: TcpSocket (此类用于实现 TCP 网络通信 )
目录 Class: TcpSocketacceptopenclosebindconnectgetLastSocketErrorgetLastSocketErrorAsStringlistenreceivesendsetSocketOptionshutdown函数调用的基本流程服务器端的基本流程客户端的基本流程Class: TcpSocket学习笔记。来自CANoe帮助文档。 Class: TcpSocket accept /…...
数据分析 —— 数据预处理
一、什么是数据预处理 数据预处理(Data Preprocessing)是数据分析和机器学习中至关重要的步骤,旨在将原始数据转换为更高质量、更适合分析或建模的形式。由于真实世界的数据通常存在不完整、不一致、噪声或冗余等问题,预处理可以…...

软件架构风格系列(4):事件驱动架构
文章目录 前言一、从“用户下单”场景看懂事件驱动核心概念(一)什么是事件驱动架构?(二)核心优势:解耦与异步的双重魔法 二、架构设计图:三要素构建事件流转闭环三、Java实战:从简单…...

windows系统各版本下载
以下各版本Windows系统链接来自网友整理,请通过迅雷或者其他支持ED2K或BT的下载工具进行下载。 注:以下为原版系统,未激活、非破解版,仅供下载体验学习,请勿从事商业活动。 Windows 11 Windows 11 (consumer editions…...

arduino平台读取鼠标光电传感器
鼠标坏掉了,大抵是修不好了。(全剧终—) 但是爱动手的小明不会浪费这个鼠标,确认外观没有明显烧毁痕迹后,尝试从电路板上利用光电传感器进行位移的测量,光电传感器(型号:FCT3065&am…...
【Linux网络】网络层
网络层 在复杂的网络环境中确定一个合适的路径 IP 协议 IPV4 点分十进制[0,255].[0,255].[0,255].[0,255]IPV6 IP地址目标网格目标主机 基本概念 主机:配有IP地址,但是不进行路由控制的设备;路由器:即配有IP地址,又能进行路由控制;节点:主机和路由器的统称。 两个问题 路…...

力扣-98.验证二叉搜索树
题目描述 给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。 有效 二叉搜索树定义如下: 节点的左子树只包含 小于 当前节点的数。节点的右子树只包含 大于 当前节点的数。所有左子树和右子树自身必须也是二叉搜索树。 class Solutio…...

5.17本日总结
一、英语 复习list2list29 二、数学 学习14讲部分内容 三、408 学习计组1.2内容 四、总结 高数和计网明天结束当前章节,计网内容学完之后主要学习计组和操作系统 五、明日计划 英语:复习lsit3list28,完成07年第二篇阅读 数学&#…...
大模型学习:Deepseek+dify零成本部署本地运行实用教程(超级详细!建议收藏)
文章目录 大模型学习:Deepseekdify零成本部署本地运行实用教程(超级详细!建议收藏)一、Dify是什么二、Dify的安装部署1. 官网体验2. 本地部署2.1 linux环境下的Docker安装2.2 Windows环境下安装部署DockerDeskTop2.3启用虚拟机平台…...

VSCode launch.json 配置参数详解
使用 launch.json 配置调试环境时,会涉及到多个参数,用于定义调试器的行为和目标执行环境。以下是一些常用的配置参数: 1、"type" :指定调试器的类型,例如 "node" 表示 Node.js 调试器࿰…...

pytest多种断言类型封装为自动化断言规则库
以下是将多种断言类型封装为自动化断言规则库的完整实现方案,包含基础验证规则和扩展机制: import re import time from jsonschema import validate, ValidationError from typing import Dict, Any, Optional, Callableclass ResponseValidator:"""自动...

Oracle数据库如何进行冷备份和恢复
数据库的冷备份指的是数据库处于关闭或者MOUNT状态下的备份,备份文件包括数据文件、日志文件和控制文件。数据库冷备份所用的时间主要受数据库大小和磁盘I/O性能的影响。由于数据库需要关闭才能进行冷备份,所以这种备份技术并不适用724小时的系统。尽管冷…...
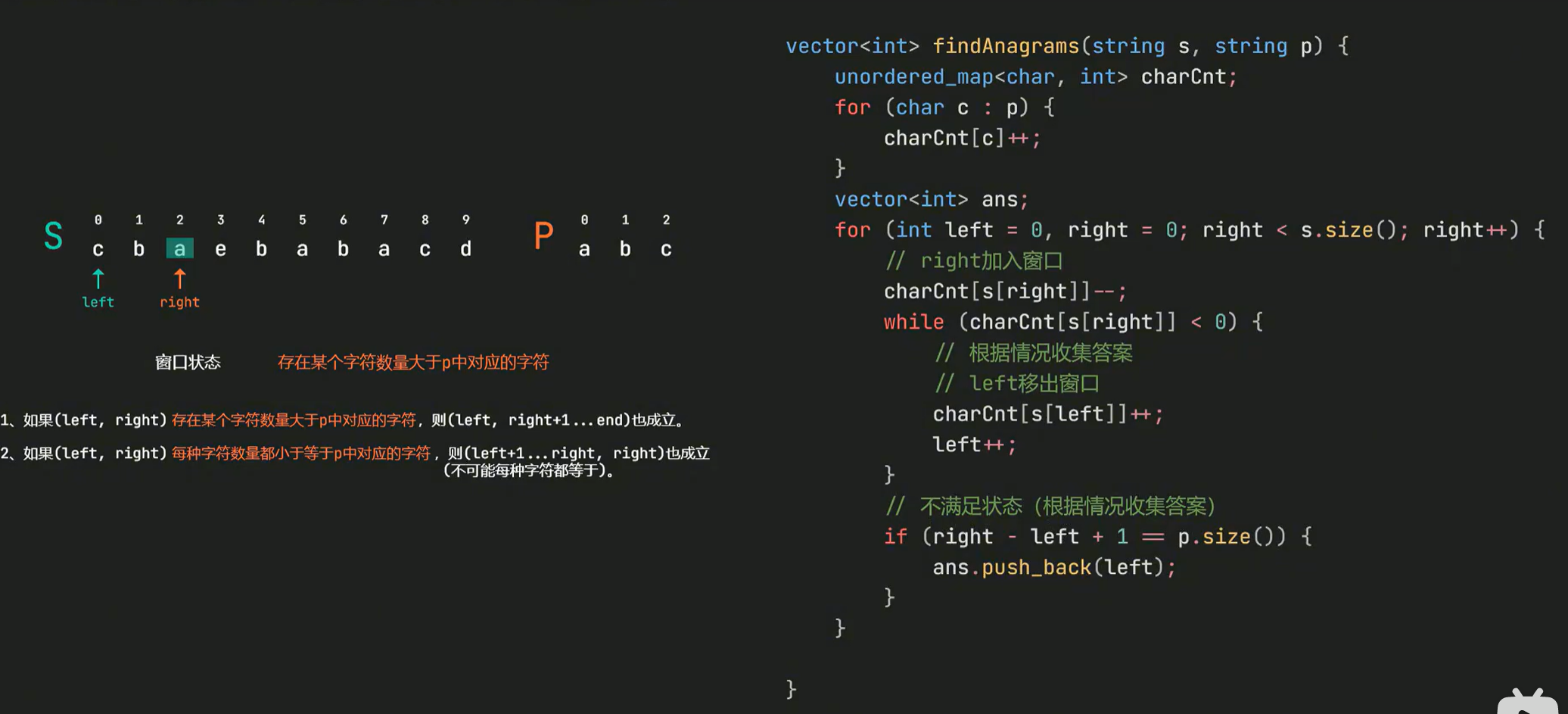
LeetCode Hot100 (2、3、4、5、6、8、9、12)
题2--字母异或位分词 class Solution { public:vector<vector<string>> groupAnagrams(vector<string>& strs) {// 一开始的思路是,对于其中的一个单词,遍历所有排序组合,然后判断这些组合是否在哈希表里//࿰…...

FastMCP:为大语言模型构建强大的上下文和工具服务
FastMCP:为大语言模型构建强大的上下文和工具服务 在人工智能快速发展的今天,大语言模型(LLM)已经成为许多应用的核心。然而,如何让这些模型更好地与外部世界交互,获取实时信息,执行特定任务&am…...

数据结构(3)线性表-链表-单链表
我们学习过顺序表时,一旦对头部或中间的数据进行处理,由于物理结构的连续性,为了不覆盖,都得移,就导致时间复杂度为O(n),还有一个潜在的问题就是扩容,假如我们扩容前是10…...
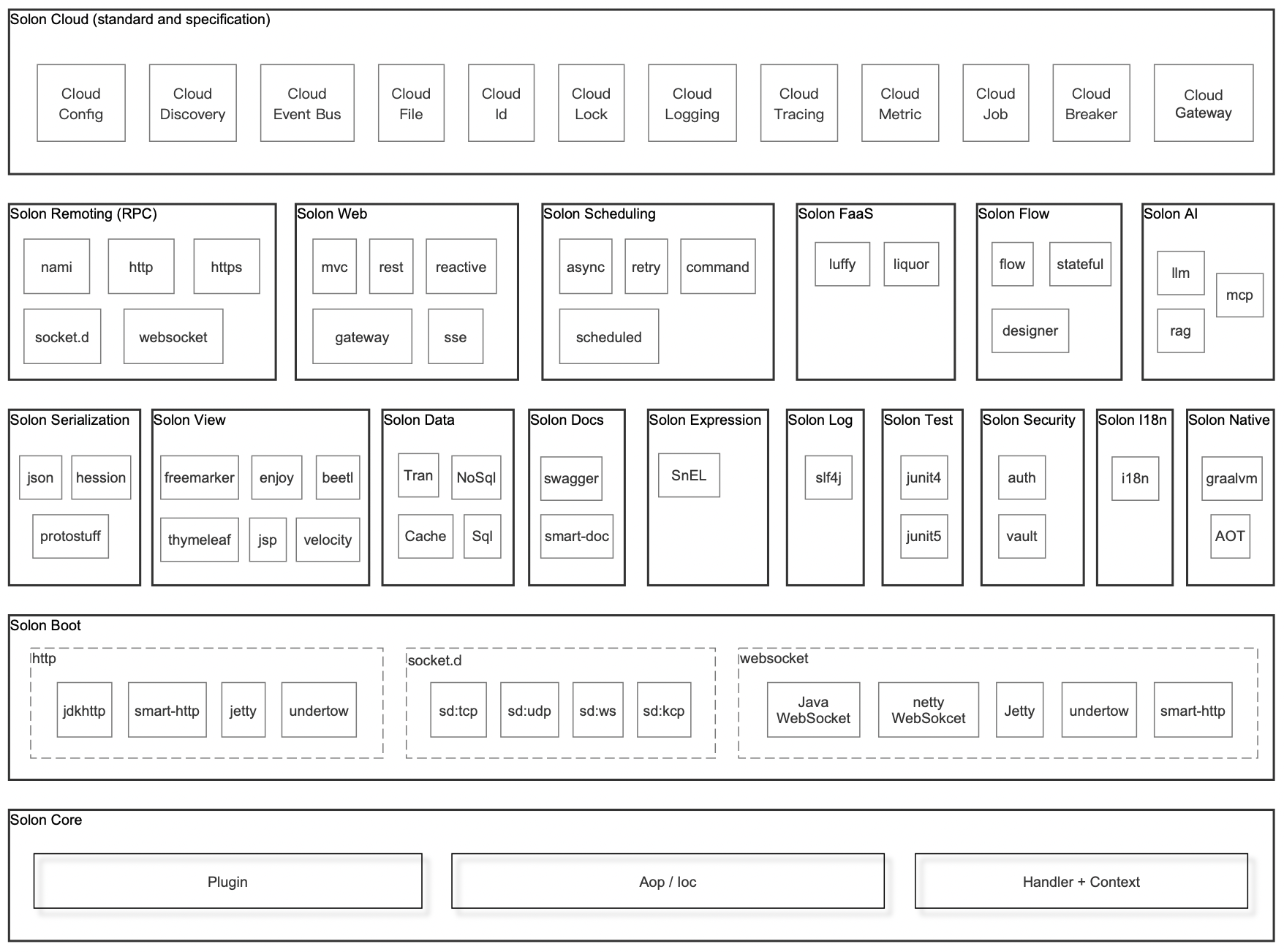
Java Solon v3.3.0 发布(国产优秀应用开发基座)
Solon 框架! Solon 是新一代,Java 企业级应用开发框架。从零开始构建(No Java-EE),有灵活的接口规范与开放生态。采用商用友好的 Apache 2.0 开源协议,是“杭州无耳科技有限公司”开源的根级项目ÿ…...
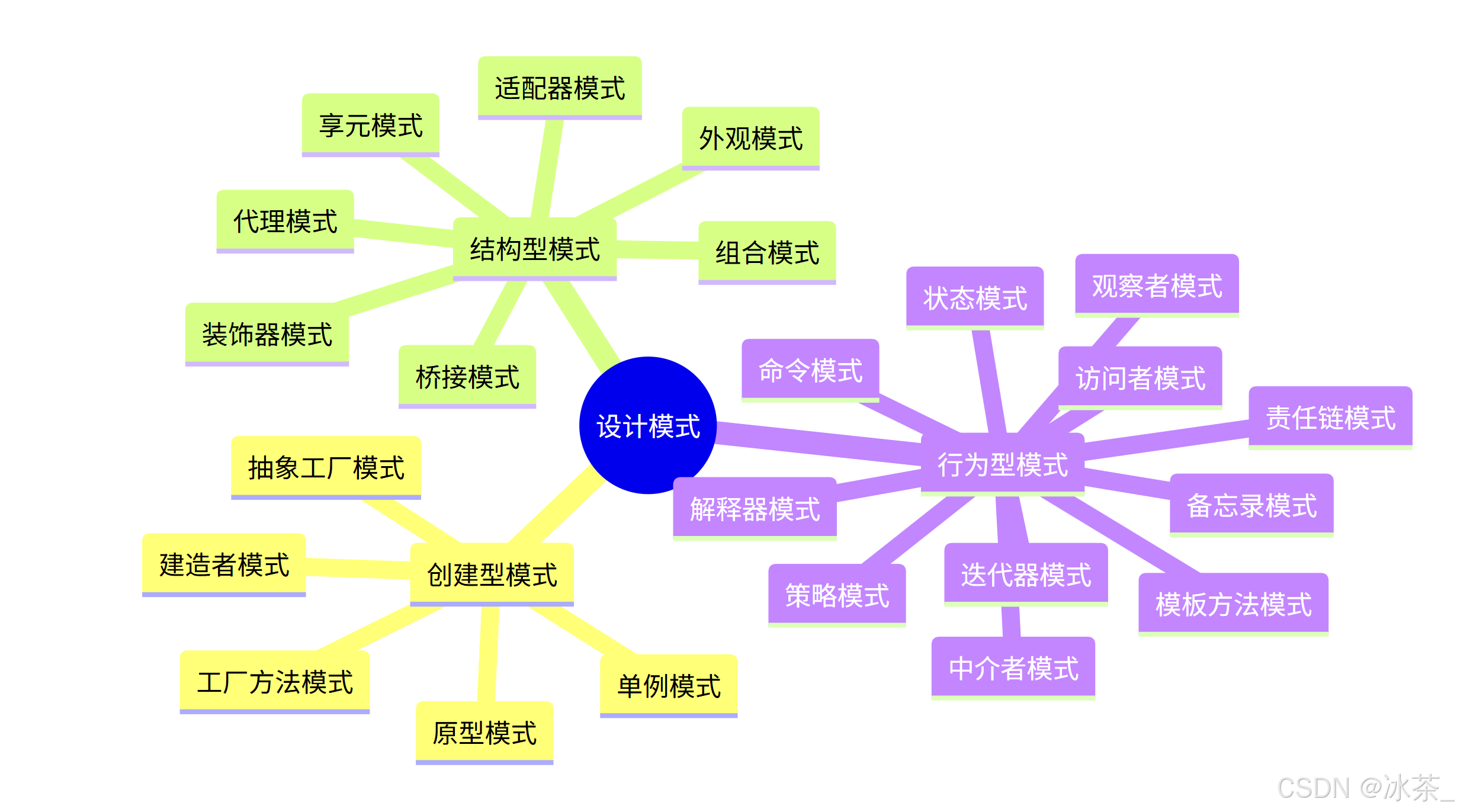
23种设计模式概述详述(C#代码示例)
文章目录 1. 引言1.1 设计模式的价值1.2 设计模式的分类 2. 面向对象设计原则2.1 单一职责原则 (SRP)2.2 开放封闭原则 (OCP)2.3 里氏替换原则 (LSP)2.4 接口隔离原则 (ISP)2.5 依赖倒置原则 (DIP)2.6 合成复用原则 (CRP)2.7 迪米特法则 (LoD) 3. 创建型设计模式3.1 单例模式 (…...

数字化工厂升级引擎:Modbus TCP转Profinet网关助力打造柔性生产系统
在当今的工业自动化领域,通信协议扮演着至关重要的角色。Modbus TCP和Profinet是两种广泛使用的工业通信协议,它们分别在不同的应用场景中发挥着重要作用。然而,有时我们可能需要将这两种协议进行转换,以实现不同设备之间的无缝通…...
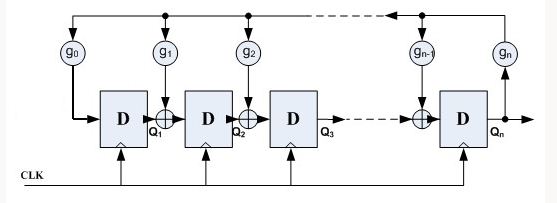
FPGA生成随机数的方法
FPGA生成随机数的方法,目前有以下几种: 1、震荡采样法 实现方式一:通过低频时钟作为D触发器的时钟输入端,高频时钟作为D触发器的数据输入端,使用高频采样低频,利用亚稳态输出随机数。 实现方式二:使用三个…...
【Linux C/C++开发】轻量级关系型数据库SQLite开发(包含性能测试代码)
前言 之前的文件分享过基于内存的STL缓存、环形缓冲区,以及基于文件的队列缓存mqueue、hash存储、向量库annoy存储,这两种属于比较原始且高效的方式。 那么,有没有高级且高效的方式呢。有的,从数据角度上看,࿰…...

2025认证杯第二阶段数学建模B题:谣言在社交网络上的传播思路+模型+代码
2025认证杯数学建模第二阶段思路模型代码,详细内容见文末名片 一、引言 在当今数字化时代,社交网络已然成为人们生活中不可或缺的一部分。信息在社交网络上的传播速度犹如闪电,瞬间就能触及大量用户。然而,这也为谣言的滋生和扩…...
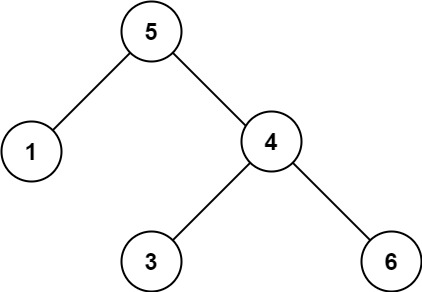
记录算法笔记(2025.5.17)验证二叉搜索树
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。 有效 二叉搜索树定义如下: 节点的左子树只包含 小于 当前节点的数。节点的右子树只包含 大于 当前节点的数。所有左子树和右子树自身必须也是二叉搜索树。 示例 1: 输入&…...
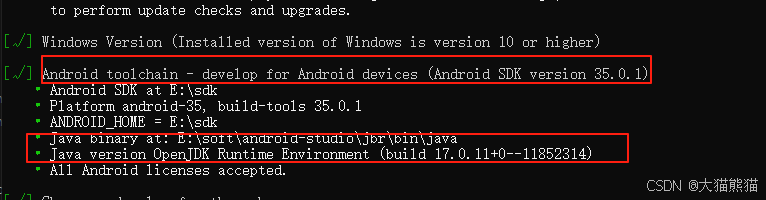
flutter编译时 设置jdk版本
先查看flutter使用的版本 flutter doctor -v设置flutter的jdk目录 flutter config --jdk-dir "E:\soft\android-studio\jbr" 然后再验证下,看是否设置成功...
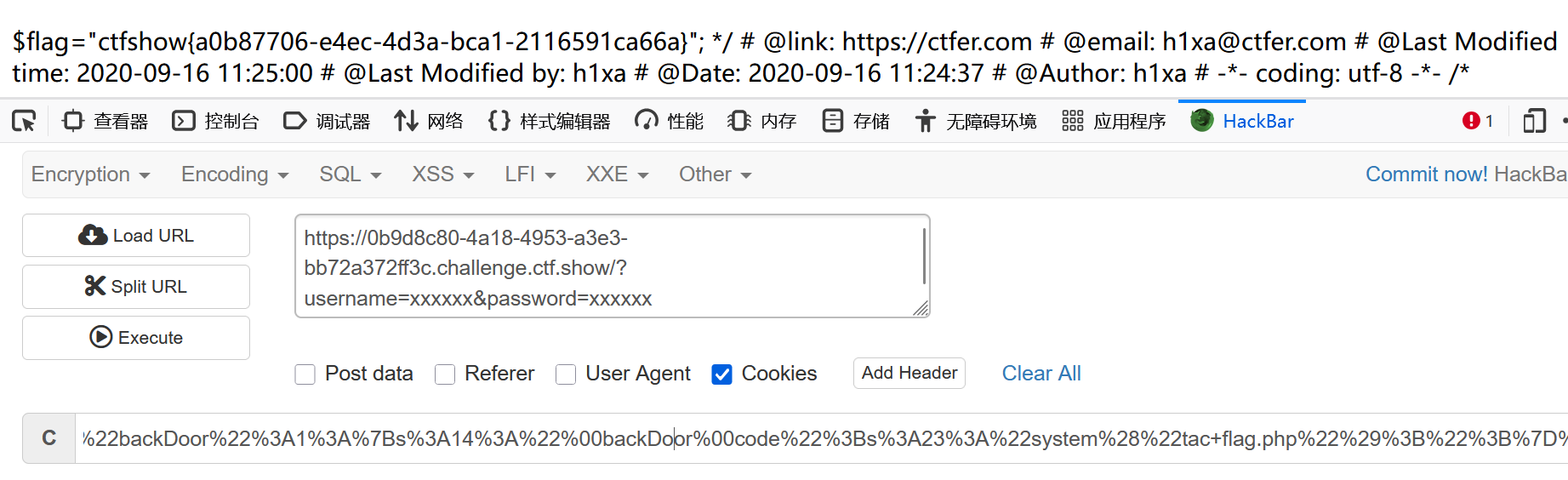
ctfshow——web入门254~258
目录 web入门254 web入门255 web入门256 web入门257 web入门258 反序列化 先来看看其他师傅的讲解 web入门254 源码: <?phperror_reporting(0); highlight_file(__FILE__); include(flag.php);class ctfShowUser{public $usernamexxxxxx;public $passwo…...
【数据处理】xarray 数据处理教程:从入门到精通
目录 xarray 数据处理教程:从入门到精通一、简介**核心优势** 二、安装与导入1. 安装2. 导入库 三、数据结构(一)DataArray(二) Dataset(三)关键说明 四、数据操作(一)索…...
qt5.14.2 opencv调用摄像头显示在label
ui界面添加一个Qlabel名字是默认的label 还有一个button名字是pushButton mainwindow.h #ifndef MAINWINDOW_H #define MAINWINDOW_H#include <QMainWindow> #include <opencv2/opencv.hpp> // 添加OpenCV头文件 #include <QTimer> // 添加定…...
)
科技的成就(六十八)
623、杰文斯悖论 杰文斯悖论是1865年经济学家威廉斯坦利杰文斯提出的一悖论:当技术进步提高了效率,资源消耗不仅没有减少,反而激增。例如,瓦特改良的蒸汽机让煤炭燃烧更加高效,但结果却是煤炭需求飙升。 624、代码混…...

芯片生态链深度解析(三):芯片设计篇——数字文明的造物主战争
【开篇:设计——数字文明的“造物主战场”】 当英伟达的H100芯片以576TB/s显存带宽重构AI算力边界,当阿里平头哥倚天710以RISC-V架构实现性能对标ARM的突破,这场围绕芯片设计的全球竞赛早已超越技术本身,成为算法、架构与生态标准…...
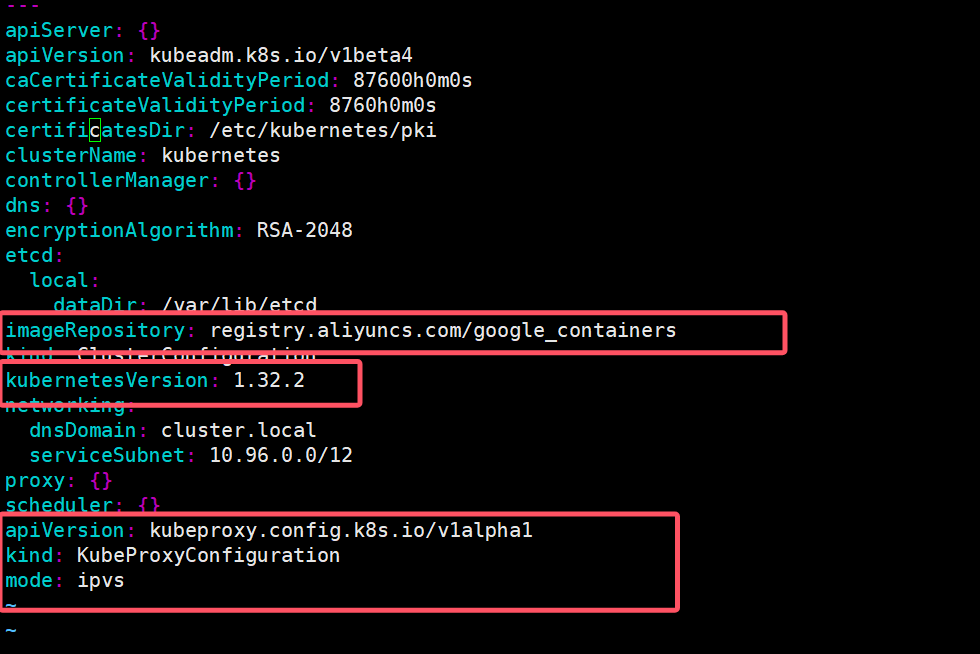
Rocky Linux 9.5 基于kubeadm部署k8s
一:部署说明 操作系统https://mirrors.aliyun.com/rockylinux/9.5/isos/x86_64/Rocky-9.5-x86_64-minimal.iso 主机名IP地址配置k8s- master192.168.1.1412颗CPU 4G内存 100G硬盘k8s- node-1192.168.1.1422颗CPU 4G内存 100G硬盘k8s- node-2192.168.1.1432…...