python 自动化教程
文章目录
- 前言
- 整数变量
- 字符串变量
- 列表变量
- 算术操作
- 比较操作
- 逻辑操作
- if语句
- for循环遍历列表
- while循环
- 定义函数
- 调用函数
- 导入模块
- 使用模块中的函数
- 启动Chrome浏览器
- 打开网页
- 定位元素并输入内容
- 提交表单
- 关闭浏览器
- 发送GET请求获取网页内容
- 使用BeautifulSoup解析HTML
- 提取网页标题
- 读取CSV文件
- 数据预览
- 数据清洗 - 删除包含缺失值的行
- 数据分析 - 统计描述
- 创建新目录
- 复制文件
- 移动文件
- 读取销售数据Excel文件
- 数据清洗 - 假设去除重复行
- 数据分析 - 计算每个产品的总销售额
- 生成新报表
- 邮件配置
- 添加邮件正文
- 添加附件
- 发送邮件
- 等待页面特定元素加载完成
- 配置日志记录
- 下载必要数据
- 模拟鼠标点击
- 模拟键盘输入
前言
在当今快节奏的工作环境中,重复性任务耗时费力,而 Python 自动化技术宛如神奇助手,能极大提升效率。这份教程将带你开启 Python 自动化学习之旅,从基础语法、常用自动化库,到办公、爬虫等实战场景,助力你快速掌握这一高效技能,轻松应对工作挑战。
一、Python 自动化基础
(一)Python 基础语法回顾
变量与数据类型
Python 拥有多种数据类型,如整数(int)、浮点数(float)、字符串(str)、列表(list)、元组(tuple)、字典(dict)等。变量声明无需指定类型,直接赋值即可。例如:
整数变量
age = 25
字符串变量
name = "John"
列表变量
fruits = [“apple”, “banana”, “cherry”]
操作符
包括算术操作符(如+、-、*、/、%)、比较操作符(如==、!=、>、<、>=、<=)、逻辑操作符(and、or、not)等。
算术操作
result = 5 + 3
比较操作
is_greater = 10 > 5
逻辑操作
is_valid = (age > 18) and (name!= “”)
条件语句与循环语句
条件语句(if、elif、else)用于根据条件执行不同代码块;循环语句(for、while)可实现代码重复执行。
if语句
if age >= 18:
print(“成年人”)
else:
print(“未成年人”)
for循环遍历列表
for fruit in fruits:
print(fruit)
while循环
count = 0
while count < 5:
print(count)
count += 1
函数与模块
函数通过def关键字定义,提升代码复用性;模块是包含 Python 代码的文件,使用import导入。
定义函数
def add_numbers(a, b):
return a + b
调用函数
sum_result = add_numbers(3, 4)
导入模块
import math
使用模块中的函数
sqrt_result = math.sqrt(16)
(二)Python 自动化常用库
Selenium - Web 浏览器自动化
Selenium 可模拟用户在浏览器中的操作,如点击、输入、滚动等,常用于 Web 测试和爬虫开发。
安装:通过pip install selenium安装。需下载对应浏览器的 WebDriver,如 ChromeDriver。
基本操作示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
启动Chrome浏览器
driver = webdriver.Chrome()
打开网页
driver.get(“https://www.example.com”)
定位元素并输入内容
element = driver.find_element(By.NAME, “q”)
element.send_keys(“Python自动化”)
提交表单
element.submit()
关闭浏览器
driver.quit()
Requests 与 BeautifulSoup - 网络爬虫
Requests库用于发送 HTTP 请求获取网页内容,BeautifulSoup库用于解析和提取网页数据。
安装:pip install requests beautifulsoup4。
示例代码:
import requests
from bs4 import BeautifulSoup
发送GET请求获取网页内容
response = requests.get(“https://www.example.com”)
使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, ‘html.parser’)
提取网页标题
title = soup.find(‘title’).text
print(title)
Pandas - 数据处理与分析
Pandas 在数据处理和分析方面功能强大,可读写文件、清洗数据、分析数据等。
安装:pip install pandas。
示例:
import pandas as pd
读取CSV文件
data = pd.read_csv(‘data.csv’)
数据预览
print(data.head())
数据清洗 - 删除包含缺失值的行
cleaned_data = data.dropna()
数据分析 - 统计描述
summary = cleaned_data.describe()
print(summary)
OS 与 Shutil - 文件和目录操作
os模块用于操作系统交互,shutil模块用于文件和目录操作。
安装:这两个模块是 Python 标准库,无需额外安装。
示例:
import os
import shutil
创建新目录
os.mkdir(‘new_directory’)
复制文件
shutil.copy(‘example.txt’, ‘new_directory/example.txt’)
移动文件
shutil.move(‘new_directory/example.txt’, ‘another_directory/’)
二、Python 自动化实战应用
(一)自动化办公
文件处理
批量重命名文件:假设要将某文件夹下所有图片文件(.jpg格式)重命名,在文件名前加上 “image_” 前缀。
import os
folder_path = ‘your_folder_path’
for filename in os.listdir(folder_path):
if filename.endswith(’.jpg’):
new_name = ‘image_’ + filename
os.rename(os.path.join(folder_path, filename), os.path.join(folder_path, new_name))
文件分类整理:将不同类型文件分类存放到对应文件夹。
import os
import shutil
folder_path = ‘your_folder_path’
file_types = {
‘images’: [’.jpg’, ‘.png’, ‘.jpeg’],
‘documents’: [‘.doc’, ‘.docx’, ‘.pdf’],
‘videos’: [‘.mp4’, ‘.avi’, ‘.mkv’]
}
for filename in os.listdir(folder_path):
file_extension = os.path.splitext(filename)[1]
for category, extensions in file_types.items():
if file_extension in extensions:
category_folder = os.path.join(folder_path, category)
if not os.path.exists(category_folder):
os.makedirs(category_folder)
shutil.move(os.path.join(folder_path, filename), os.path.join(category_folder, filename))
数据分析与报表生成
以处理销售数据为例,从 Excel 文件读取数据,分析后生成新报表。
import pandas as pd
读取销售数据Excel文件
sales_data = pd.read_excel(‘sales_data.xlsx’)
数据清洗 - 假设去除重复行
unique_sales_data = sales_data.drop_duplicates()
数据分析 - 计算每个产品的总销售额
product_sales = unique_sales_data.groupby(‘Product’)[‘Sales’].sum()
生成新报表
product_sales.to_excel(‘product_sales_report.xlsx’, index=True)
邮件发送
使用smtplib和email库发送自动化邮件,如发送包含销售报表的邮件。
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.mime.application import MIMEApplication
邮件配置
sender_email = "your_email@example.com"
receiver_email = "recipient_email@example.com"
password = "your_email_password"
message = MIMEMultipart()
message[‘Subject’] = "销售报表"
message[‘From’] = sender_email
message[‘To’] = receiver_email
添加邮件正文
body = "这是本月的销售报表,请查收。"
message.attach(MIMEText(body, ‘plain’))
添加附件
with open(‘product_sales_report.xlsx’, ‘rb’) as file:
part = MIMEApplication(file.read(), Name=‘product_sales_report.xlsx’)
part[‘Content-Disposition’] = f’attachment; filename=“product_sales_report.xlsx”'
message.attach(part)
发送邮件
with smtplib.SMTP(‘smtp.example.com’, 587) as server:
server.starttls()
server.login(sender_email, password)
server.sendmail(sender_email, receiver_email, message.as_string())
(二)Web 爬虫自动化
简单网页数据抓取
抓取某新闻网站最新新闻标题和链接。
import requests
from bs4 import BeautifulSoup
url = “https://news.example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, ‘html.parser’)
news_items = soup.find_all(‘div’, class_=‘news-item’)
for item in news_items:
title = item.find(‘h2’).text
link = item.find(‘a’)[‘href’]
print(f"标题: {title}, 链接: {link}”)
动态网页数据抓取(处理 JavaScript 渲染)
对于使用 JavaScript 动态加载数据的网页,借助 Selenium 配合webdriverwait等待页面加载完成后再抓取。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get(“https://dynamic_news.example.com”)
等待页面特定元素加载完成
wait = WebDriverWait(driver, 10)
news_items = wait.until(EC.presence_of_all_elements_located((By.CLASS_NAME, ‘news-item’)))
for item in news_items:
title = item.find_element(By.TAG_NAME, ‘h2’).text
link = item.find_element(By.TAG_NAME, ‘a’).get_attribute(‘href’)
print(f"标题: {title}, 链接: {link}“)
driver.quit()
三、Python 自动化项目优化与拓展
(一)异常处理与日志记录
异常处理
在自动化脚本中,合理处理异常可避免脚本因错误中断。使用try - except语句捕获异常。
import requests
try:
response = requests.get(“https://nonexistent.example.com”)
response.raise_for_status() # 检查请求是否成功,失败则抛出异常
except requests.RequestException as e:
print(f"请求出错: {e}”)
日志记录
通过logging模块记录脚本运行信息,方便排查问题。
import logging
配置日志记录
logging.basicConfig(filename=‘automation.log’, level=logging.INFO,
format=‘%(asctime)s - %(levelname)s - %(message)s’)
try:
# 自动化脚本代码
result = 10 / 0 # 模拟错误
except ZeroDivisionError as e:
logging.error(f"发生错误: {e}", exc_info=True)
else:
logging.info(“脚本执行成功”)
(二)数据驱动测试与持续集成
数据驱动测试
数据驱动测试将测试用例参数化,从外部文件读取数据运行测试。以 Pandas 读取 Excel 数据进行测试为例:
import pandas as pd
import unittest
def add_numbers(a, b):
return a + b
class DataDrivenTest(unittest.TestCase):
def test_addition(self):
data = pd.read_excel(‘test_data.xlsx’)
for index, row in data.iterrows():
num1 = row[‘Number1’]
num2 = row[‘Number2’]
expected_result = row[‘ExpectedResult’]
result = add_numbers(num1, num2)
self.assertEqual(result, expected_result)
if name == ‘main’:
unittest.main()
持续集成(CI)
利用工具(如 Jenkins、Travis CI 等)自动构建、测试和部署 Python 自动化项目。以 Travis CI 为例,在项目根目录创建.travis.yml文件配置构建和测试流程。
language: python
python:
- "3.11"
install: - pip install -r requirements.txt
script: - python -m unittest discover
此配置指定使用 Python 3.11,安装项目依赖(requirements.txt中列出),并运行单元测试。
(三)与其他技术结合拓展自动化能力
与人工智能(AI)结合
如使用 Python 调用自然语言处理(NLP)库(如 NLTK、SpaCy)对文本数据进行自动化处理和分析。
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
下载必要数据
nltk.download(‘vader_lexicon’)
sia = SentimentIntensityAnalyzer()
text = "这部电影太棒了!"
sentiment = sia.polarity_scores(text)
print(sentiment)
与机器人流程自动化(RPA)结合
通过pyautogui库实现跨系统操作自动化,模拟鼠标和键盘动作。
import pyautogui
模拟鼠标点击
pyautogui.click(100, 100)
模拟键盘输入
pyautogui.typewrite(“Hello, World!”)
相关文章:

python 自动化教程
文章目录 前言整数变量字符串变量列表变量算术操作比较操作逻辑操作if语句for循环遍历列表while循环定义函数调用函数导入模块使用模块中的函数启动Chrome浏览器打开网页定位元素并输入内容提交表单关闭浏览器发送GET请求获取网页内容使…...
简单使用Slidev和PPTist
简单使用Slidev和PPTist 1 简介 前端PPT制作有很多优秀的工具包,例如:Slidev、revealjs、PPTist等,Slidev对Markdown格式支持较好,适合与大模型结合使用,选哟二次封装;revealjs适合做数据切换,…...

RISC-V 开发板 MUSE Pi Pro V2D图像加速器测试,踩坑介绍
视频讲解: RISC-V 开发板 MUSE Pi Pro V2D图像加速器测试,踩坑介绍 今天测试下V2D,这是K1特有的硬件级别的2D图像加速器,参考如下文档,但文档中描述的部分有不少问题,后面会讲下 https://bianbu-linux.spa…...

人工智能100问☞第26问:什么是贝叶斯网络?
贝叶斯网络是基于有向无环图和条件概率表构建的概率图模型,用于表达变量间的条件依赖关系并进行不确定性推理。 一、通俗解释 想象你玩侦探游戏,要通过零散线索推理真相。贝叶斯网络就像一张"因果关系地图"——用箭头把事件连起来,并标注每个事件发生的概率。比…...
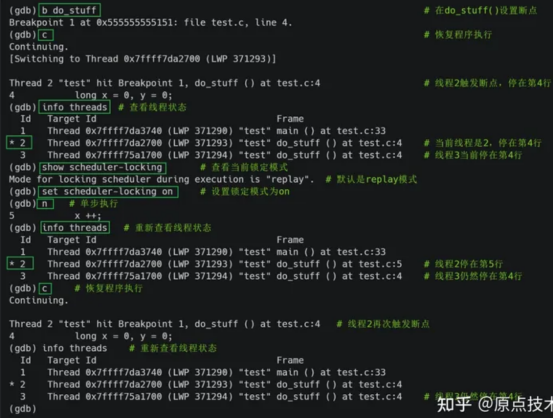
c++多线程debug
debug demo 命令行查看 ps -eLf|grep cam_det //查看当前运行的轻量级进程 ps -aux | grep 执行文件 //查看当前运行的进程 ps -aL | grep 执行文件 //查看当前运行的轻量级进程 pstree -p 主线程ID //查看主线程和新线程的关系 查看线程栈结构 pstack 线程ID 步骤&…...
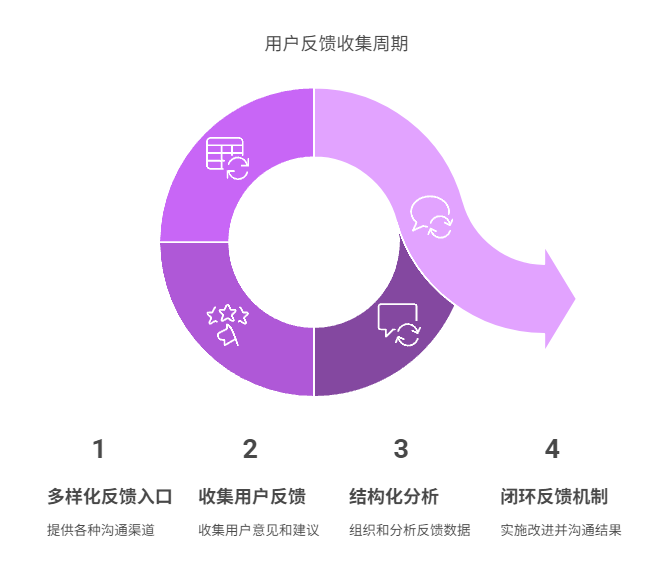
如何畅通需求收集渠道,获取用户反馈?
要畅通需求收集渠道、有效获取用户反馈,核心在于多样化反馈入口、闭环反馈机制、用户分层管理、反馈数据结构化分析等四个方面。其中,多样化反馈入口至关重要,不同用户有不同的沟通偏好,只有覆盖多个反馈路径,才能捕捉…...
)
标准库、HAl库和LL库(PC13初始化)
标准库 (Standard Peripheral Library) c #include "stm32f10x.h"void GPIO_Init_PC13(void) {GPIO_InitTypeDef GPIO_InitStruct;RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOC, ENABLE);GPIO_InitStruct.GPIO_Pin GPIO_Pin_13;GPIO_InitStruct.GPIO_Mode GPIO_…...

LangGraph深度解析:构建持久化、可观测的智能体工作流
一、项目概述与技术定位 1.1 LangGraph核心价值 LangGraph是由LangChain团队推出的开源框架(GitHub仓库:https://github.com/langchain-ai/langgraph),专为构建持久化、状态化的智能体工作流设计。作为LangChain生态系统的战略补充,它解决了传统LLM应用在以下方面的关键…...

设备预测性维护的停机时间革命:中讯烛龙如何用AI重构工业设备管理范式
在工业4.0的智能化浪潮中,非计划停机每年吞噬企业3%-8%的产值。中讯烛龙预测性维护系统通过多模态感知矩阵分布式智能体的创新架构,实现设备健康管理的范式跃迁,帮助制造企业将停机时间压缩70%以上。本文将深度解析技术实现路径与行业级实践方…...

day29 python深入探索类装饰器
目录 一、类装饰器的初步理解 二、类装饰器与函数装饰器的对比 三、类装饰器的实现与应用 (一)为类添加日志功能 (二)动态方法绑定的两种方式 四、手动调用装饰器:类的“后天改造” 五、总结与展望 一、类装饰器…...

Python数据分析三剑客:NumPy、Pandas与Matplotlib安装指南与实战入门
Python数据分析三剑客:NumPy、Pandas与Matplotlib安装指南与实战入门 1. 引言 Python数据分析生态:NumPy、Pandas、Matplotlib是数据科学领域的核心工具链。适用场景:数值计算、数据处理、可视化分析(如金融分析、机器学习、科研…...
)
二:操作系统之进程控制块(PCB)
进程的身份证与状态记录:深入理解进程控制块 (PCB) 在我们之前的博客中,我们探讨了进程是什么——程序的一次执行实例,以及进程在其生命周期中会经历的各种状态(新建、就绪、运行、等待、终止)。我们知道,…...
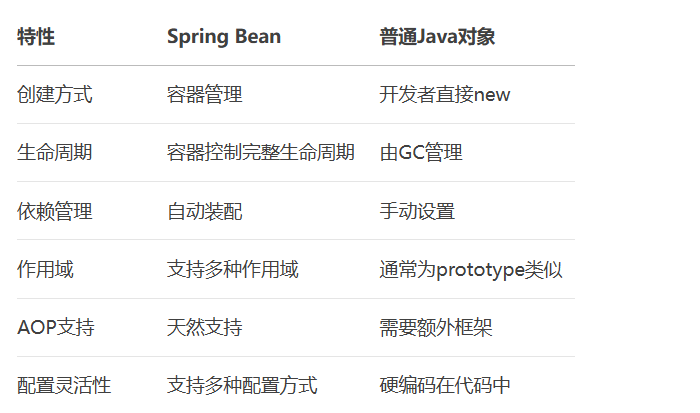
Spring-Beans的生命周期的介绍
目录 1、Spring核心组件 2、Bean组件 2.1、Bean的定义 2.2、Bean的生命周期 1、实例化 2、属性填充 3、初始化 4、销毁 2.3、Bean的执行时间 2.4、Bean的作用域 3、常见问题解决方案 4、与Java对象区别 前言 关于bean的生命周期,如下所示: …...
Android 自定义悬浮拖动吸附按钮
一个悬浮的拨打电话按钮,使用CardViewImageView可能会出现适配问题,也就是图片显示不全,出现这种问题,就直接替换控件了,因为上述的组合控件没有FloatingActionButton使用方便,还可以有拖动和吸附效果不是更…...
)
通过串口设备的VID PID动态获取串口号(C# C++)
摘要 本篇文章主要介绍分别通过C#和C++使用设备VID PID如何动态获取COM口 目录 1 简述 2 VID PID查看方式 3 C#实现通过串口设备的VID PID动态获取串口号 3.1 辅助类实现 3.2 调用实例 4 C++实现通过串口设备的VID PID动态获取串口号 4.1 辅助类实现 4.2 调用实例 1 简…...

[创业之路-361]:企业战略管理案例分析-2-战略制定-使命、愿景、价值观的失败案例
一、失败案例 1、使命方面的失败案例 真功夫创业者内乱:真功夫在创业过程中,由于股权结构不合理,共同创始人及公司大股东潘宇海与实际控制人、董事长蔡达标产生管理权矛盾。双方在公司发展方向、管理改革等方面无法达成一致,导致…...

Window远程连接Linux桌面版
Window远程连接Linux桌面版 卸载RealVNC Server 一、确认是否安装了 VNC Server 先检查是否已安装: which vncserver # 或 dpkg -l | grep vnc # 或 rpm -qa | grep vnc二、在 Debian / Ubuntu 上卸载(.deb 安装) 1. 卸载 RealVNC Serve…...

一种开源的高斯泼溅实现库——gsplat: An Open-Source Library for Gaussian Splatting
一种开源的高斯泼溅实现库——gsplat: An Open-Source Library for Gaussian Splatting 文章目录 一种开源的高斯泼溅实现库——gsplat: An Open-Source Library for Gaussian Splatting摘要Abstract1. 基本思想1.1 设计1.2 特点 2. Nerfstudio&Splatfacto2.1 Nerfstudio2.…...

ARM A64 STR指令
ARM A64 STR指令 1 STR (immediate)1.1 Post-index1.1.1 32-bit variant1.1.2 64-bit variant 1.2 Pre-index1.2.1 32-bit variant1.2.2 64-bit variant 1.3 Unsigned offset1.3.1 32-bit variant1.3.2 64-bit variant 1.4 Assembler symbols 2 STR (register)2.1 32-bit varia…...

C#中的成员常量:编译时的静态魔法
在C#编程中,常量(const)是一个强大而特殊的语言特性,特别是当它们作为类的成员时。本文将深入探讨成员常量的特性、使用场景以及与静态量的区别。 成员常量的基本特性 成员常量是声明在类内部的常量,具有以下核心特点: 声明位置…...

Linux wlan 单频段 dual wifi创建
环境基础 TP LINK WN722N V1网卡linux 主机 查看设备是否支持双ap managed:客户端模式(连接路由器/AP)AP:接入点模式(创建热点)AP/VLAN:支持带VLAN标签的虚拟AP{ AP, mesh point, P2P-GO } &l…...

HOW - React NextJS 的同构机制
文章目录 一、什么是 Next.js 的同构?二、核心目录结构三、关键函数:如何实现不同渲染方式?1. getServerSideProps —— 实现 SSR(每次请求动态获取数据)2. getStaticProps getStaticPaths —— 实现 SSG(…...

c#队列及其操作
可以用数组、链表实现队列,大致与栈相似,简要介绍下队列实现吧。值得注意的是循环队列判空判满操作,在用链表实现时需要额外思考下出入队列条件。 设计头文件 #ifndef ARRAY_QUEUE_H #define ARRAY_QUEUE_H#include <stdbool.h> #incl…...

【CSS】使用 CSS 绘制三角形
一、Border 边框法(最常用) 原理:通过设置元素的宽高为 0,利用透明边框相交形成三角形。 .triangle {width: 0;height: 0;border-left: 50px solid transparent; /* 左侧边框透明 */border-right: 50px solid transparent; /* …...
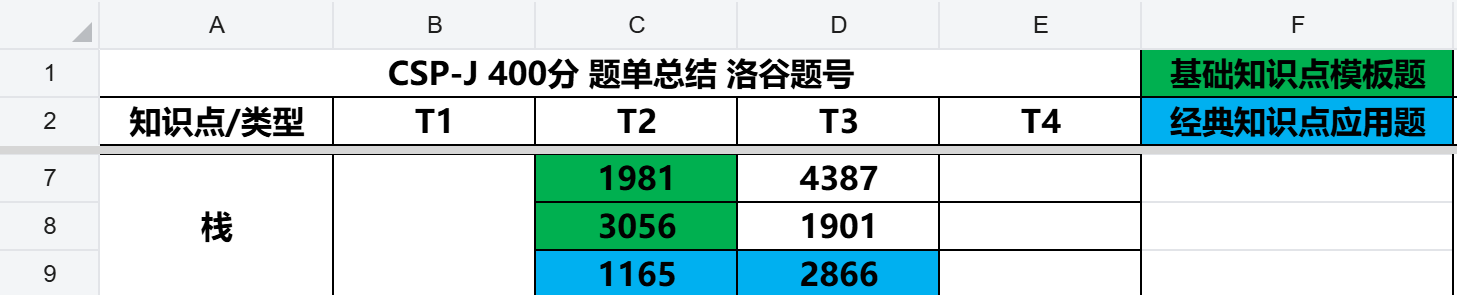
信奥赛-刷题笔记-栈篇-T2-P3056括号调整问题0518
总题单 本部分总题单如下 【腾讯文档】副本-CSP-JSNOI 题单 (未完待续) https://docs.qq.com/sheet/DSmJuVXR4RUNVWWhW?tabBB08J2 栈篇题单 P3056 [USACO12NOV] Clumsy Cows S https://www.luogu.com.cn/problem/P3056 题目描述 Bessie the cow is trying to type …...

生命之树--树形dp
1.树形dp--在dfs遍历树的同时dp,从上到下递归,到叶子是边界条件 https://www.luogu.com.cn/problem/P8625 #include<bits/stdc.h> using namespace std; #define N 100011 typedef long long ll; typedef pair<ll,int> pii; int n,c; ll …...
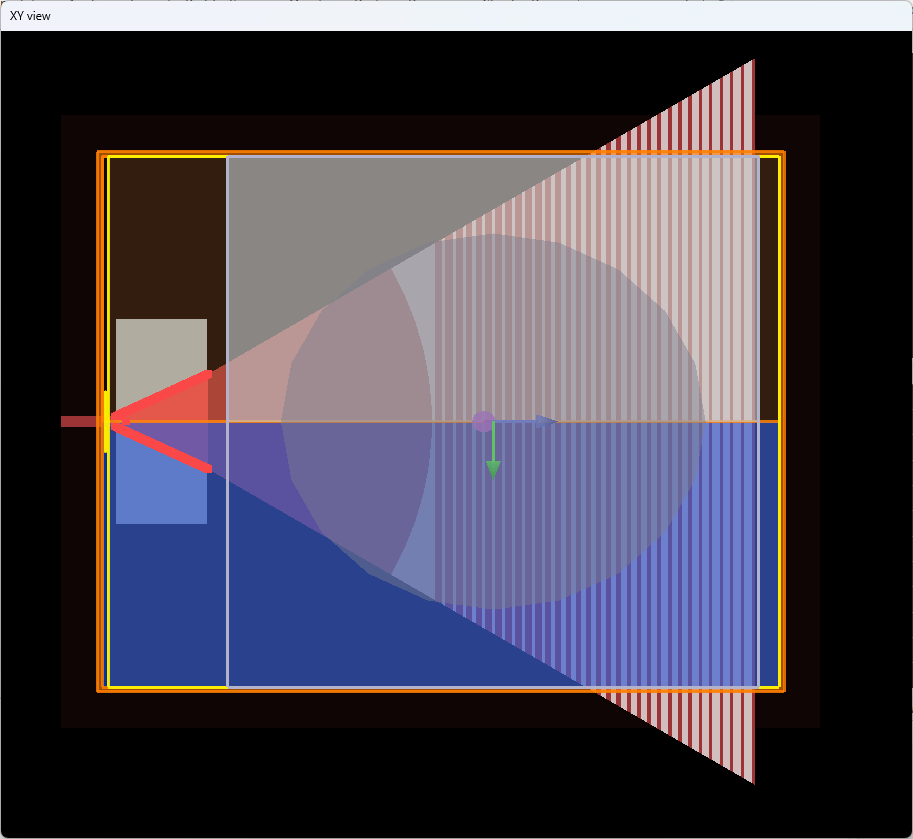
inverse-design-of-grating-coupler-3d
一、设计和优化3D光栅耦合器 1.1 代码讲解 通过预定义的环形间距参数(distances数组),在FDTD中生成椭圆光栅结构,并通过用户交互确认几何正确性后,可进一步执行参数扫描优化。 # os:用于操作系统相关功能(如文件路径操作) import os import sys# lumapi:Lumerical 的…...
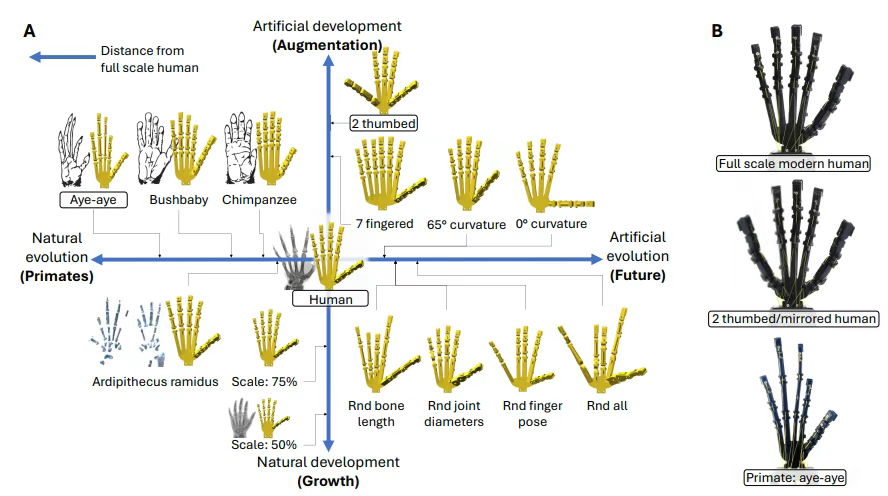
Science Robotics 封面论文:基于形态学开放式参数化的仿人灵巧手设计用于具身操作
人形机械手具有无与伦比的多功能性和精细运动技能,使其能够精确、有力和稳健地执行各种任务。在古生物学记录和动物王国中,我们看到了各种各样的替代手和驱动设计。了解形态学设计空间和由此产生的涌现行为不仅可以帮助我们理解灵巧的作用及其演变&#…...

普通用户的服务器连接与模型部署相关记录
普通用户的服务器连接与模型部署相关记录 一、从登录到使用自己的conda 1.账号登陆: ssh xxx172.31.226.236 2.下载与安装conda: 下载conda: wget -c https://repo.anaconda.com/archive/Anaconda3-2023.03-1-Linux-x86_64.sh 安装con…...

DSU-Net
目录 Abstract 摘要 DSU-Net 模型框架 编码器 轻量级适配器模块 特征融合与协作 解码器 模型优势 实验 代码 总结 Abstract DSU-Net is an improved U-Net model based on DINOv2 and SAM2. It addresses the limitations of existing image segmentation models …...