深度学习推理引擎---ONNX Runtime
一、基础概念
1. 什么是ONNX Runtime?
- 定位:由微软开发的跨平台推理引擎,专为优化ONNX(Open Neural Network Exchange)模型的推理性能设计。
- 目标:提供高效、可扩展的推理能力,支持从云到边缘的多硬件部署。
- 核心优势:
- 支持多框架模型转换为ONNX后统一推理(如PyTorch、TensorFlow、MXNet等)。
- 深度优化硬件加速(CPU/GPU/TPU/NPU等),内置自动优化技术。
- 跨平台(Windows/Linux/macOS/嵌入式系统)和编程语言(Python/C++/C#/Java等)。
2. 与其他推理引擎的对比
| 特性 | ONNX Runtime | TensorRT | OpenVINO |
|---|---|---|---|
| 框架兼容性 | 多框架(ONNX统一) | NVIDIA生态优先 | Intel硬件优先 |
| 硬件支持 | 通用(CPU/GPU/TPU等) | NVIDIA GPU | Intel CPU/GPU |
| 量化支持 | 动态/静态量化 | 静态量化为主 | 支持多种量化 |
| 部署场景 | 云、边缘、嵌入式 | 数据中心、边缘 | 边缘推理 |
二、架构与核心组件
1. 整体架构

- 前端(Frontend):解析ONNX模型,验证模型结构合法性。
- 优化器(Optimizer):
- 图形优化:算子融合(如Conv+BN+ReLU合并)、常量折叠、死代码消除等。
- 硬件感知优化:根据目标设备生成最优计算图(如CPU上使用MKL-DNN,GPU上使用CUDA/CUDNN)。
- 执行提供器(Execution Providers, EP):
- 负责底层硬件的计算调度,支持多EP(如CPU EP、CUDA EP、TensorRT EP等),可配置优先级。
- 支持异构执行(如CPU+GPU协同计算)。
- 运行时(Runtime):管理内存分配、线程调度、输入输出绑定等。
2. 关键技术模块
- 模型序列化与反序列化:支持模型加载时的动态形状推理。
- 内存管理:基于Arena的内存池技术,减少动态分配开销。
- 并行执行:利用OpenMP/线程池实现算子级并行,支持多会话并发。
三、安装与环境配置
1. 安装方式
- pip安装(推荐):
# CPU版本 pip install onnxruntime # GPU版本(需提前安装CUDA/CUDNN) pip install onnxruntime-gpu - 源码编译:支持自定义硬件后端(如ROCM、DirectML),需配置CMake和依赖库。
- Docker镜像:微软官方提供
mcr.microsoft.com/onnxruntime镜像,含预编译环境。
2. 环境验证
import onnxruntime as ort
print(ort.get_device()) # 输出"CPU"或"GPU"
print(ort.get_available_providers()) # 查看支持的执行提供器
四、模型加载与推理流程
1. 基本流程
import numpy as np
import onnxruntime as ort# 1. 加载模型
model_path = "model.onnx"
ort_session = ort.InferenceSession(model_path, providers=["CPUExecutionProvider"]) # 可指定EP优先级# 2. 准备输入数据(需匹配模型输入形状和类型)
input_name = ort_session.get_inputs()[0].name
input_data = np.random.randn(1, 3, 224, 224).astype(np.float32) # 示例输入(如ImageNet格式)# 3. 执行推理
outputs = ort_session.run(None, {input_name: input_data}) # None表示获取所有输出# 4. 处理输出
print(outputs[0].shape) # 输出形状
2. 动态形状处理
- 模型导出时需指定动态轴(如
dynamic_axes={"input": {0: "batch_size"}})。 - 推理时支持动态batch_size,但需确保输入维度与模型定义一致。
3. 输入输出绑定
- 预绑定内存以提升性能:
ort_session.bind_input(0, input_data) # 直接绑定numpy数组内存 ort_session.run_with_iobinding() # 高效执行
五、模型优化技术
1. 内置优化选项
- 图形优化级别:
ort_session = ort.InferenceSession(model_path,providers=["CPUExecutionProvider"],sess_options=ort.SessionOptions(graph_optimization_level=ort.GraphOptimizationLevel.ORT_ENABLE_ALL # 开启全优化) )ORT_DISABLE_ALL:关闭优化。ORT_ENABLE_BASIC:基础优化(算子融合、常量折叠)。ORT_ENABLE_EXTENDED:扩展优化(如层融合、形状推理)。ORT_ENABLE_ALL:全优化(含硬件特定优化)。
2. 量化(Quantization)
- 动态量化:无需校准数据,直接对模型权重进行量化(适用于快速部署)。
from onnxruntime.quantization import quantize_dynamic quantized_model = quantize_dynamic(model_path, "quantized_model.onnx") - 静态量化:使用校准数据集优化量化精度(推荐用于生产环境):
from onnxruntime.quantization import quantize_static, CalibrationDataReaderclass MyDataReader(CalibrationDataReader):def get_next(self):# 生成校准数据(如numpy数组)return {"input": np.random.randn(1, 3, 224, 224).astype(np.float32)}quantize_static(model_path, "quantized_model.onnx", data_reader=MyDataReader()) - 量化优势:模型体积减小75%+,CPU推理速度提升2-5倍(需硬件支持INT8计算)。
3. 算子融合(Operator Fusion)
- 合并连续算子(如Conv+BN+ReLU→FusedConv),减少内存访问开销。
- 支持自定义融合规则(通过
onnxruntime.transformers库扩展)。
4. 模型转换与简化
- 使用
onnxoptimizer工具简化模型:from onnxoptimizer import optimize optimized_model = optimize(onnx.load(model_path), ["fuse_bn_into_conv"])
六、硬件支持与性能调优
1. 执行提供器(EP)列表
| 硬件类型 | 执行提供器名称 | 依赖库/驱动 | 优化场景 |
|---|---|---|---|
| CPU | CPUExecutionProvider | MKL-DNN/OpenBLAS | 通用CPU推理 |
| NVIDIA GPU | CUDAExecutionProvider | CUDA/CUDNN | 高性能GPU推理 |
| AMD GPU | ROCMExecutionProvider | ROCm/HIP | AMD显卡推理 |
| Intel GPU | OpenVINOExecutionProvider | OpenVINO Runtime | Intel集成显卡推理 |
| TensorRT | TensorRTExecutionProvider | TensorRT | NVIDIA GPU深度优化 |
| DirectML | DirectMLExecutionProvider | DirectML(Windows) | Windows机器学习加速 |
| 边缘设备(ARM) | CoreMLExecutionProvider | CoreML(macOS/iOS) | Apple设备推理 |
2. GPU性能调优关键参数
sess_options = ort.SessionOptions()
sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
sess_options.execution_mode = ort.ExecutionMode.ORT_SEQUENTIAL # 顺序执行或并行
sess_options.intra_op_num_threads = 8 # 单算子内部线程数
sess_options.inter_op_num_threads = 4 # 算子间并行线程数# CUDA特定配置
cuda_provider_options = {"device_id": "0", # 指定GPU设备ID"arena_extend_strategy": "kSameAsRequested", # 内存分配策略"cudnn_conv_algo_search": "EXHAUSTIVE", # 搜索最优卷积算法
}
ort_session = ort.InferenceSession(model_path, providers=["CUDAExecutionProvider"], provider_options=[cuda_provider_options])
3. 混合精度推理(FP16)
- GPU支持FP16计算,需模型中包含FP16权重或动态转换输入为FP16:
input_data = input_data.astype(np.float16) # 转换为半精度
4. 性能分析工具
- ORT Profiler:生成JSON格式的性能分析报告,定位瓶颈算子:
sess_options.enable_profiling = True ort_session.run(None, {input_name: input_data}) with open("profile.json", "w") as f:f.write(ort_session.end_profiling()) - TensorBoard集成:通过
onnxruntime.transformers库可视化计算图和性能数据。
七、高级主题
1. 自定义算子(Custom Operators)
- 场景:模型包含ONNX不支持的算子(如特定框架的私有算子)。
- 实现步骤:
- 继承
onnxruntime.CustomOp类,实现Compute方法。 - 使用
onnxruntime.InferenceSession注册自定义算子:class MyCustomOp(ort.CustomOp):def __init__(self, op_type, op_version, domain):super().__init__(op_type, op_version, domain)def Compute(self, inputs, outputs):# 自定义算子逻辑(如Python/C++实现)outputs[0].copy_from(inputs[0] * 2) # 示例:双倍输入# 注册算子并创建会话 custom_ops = [MyCustomOp("MyOp", 1, "my_domain")] ort_session = ort.InferenceSession(model_path, providers=["CPUExecutionProvider"], custom_ops=custom_ops)
- 继承
2. 扩展ONNX Runtime
- 自定义执行提供器:为新硬件(如ASIC/NPU)开发EP,需实现
IExecutionProvider接口(C++)。 - Python扩展:通过
c_extension模块加载C++自定义算子,提升性能。
3. 与其他框架集成
- PyTorch:直接使用
torch.onnx.export导出模型为ONNX,无需中间转换。 - TensorFlow:通过
tf2onnx工具转换TensorFlow模型:pip install tf2onnx python -m tf2onnx.convert --saved-model saved_model_dir --output model.onnx - Keras/TensorFlow Lite:先转换为TF模型,再通过
tf2onnx转ONNX。
4. 模型加密与安全
- 使用加密工具(如AES)对ONNX模型文件加密,推理时动态解密加载。
- 限制执行提供器权限(如仅允许CPU执行,禁止GPU)。
八、部署场景与最佳实践
1. 服务器端推理
- 场景:高吞吐量API服务(如图像分类、自然语言处理)。
- 优化策略:
- 使用GPU EP+FP16混合精度,提升吞吐量。
- 启用模型量化(静态量化优先),减少内存占用。
- 多会话并行(
inter_op_num_threads设为CPU核心数)。
2. 边缘设备推理
- 场景:智能摄像头、移动设备、嵌入式系统(如Raspberry Pi)。
- 优化策略:
- 使用轻量级模型(如MobileNet、BERT-Lite)+动态量化。
- 选择对应硬件EP(如CoreML for iOS,NCNN for ARM)。
- 启用内存优化(
arena_extend_strategy=kMinimal)。
3. 分布式推理
- 通过ONNX Runtime Server(ORT Server)实现分布式部署:
# 安装ORT Server docker pull mcr.microsoft.com/onnxruntime/server:latest docker run -p 8080:8080 -v /models:/models onnxruntime/server --model_path /models/resnet50.onnx - 支持gRPC/REST API,负载均衡和动态批处理。
九、故障排除与常见问题
1. 算子不支持
- 原因:模型包含ONNX或ORT不支持的算子(如PyTorch的
torch.nn.InstanceNorm2d)。 - 解决方案:
- 使用
onnxsim简化模型,或手动替换算子。 - 开发自定义算子(见上文)。
- 检查ONNX版本兼容性(ORT支持ONNX 1.2+,建议使用最新版)。
- 使用
2. 性能未达标
- 排查步骤:
- 确认是否启用对应EP(如GPU未被识别)。
- 使用Profiler定位瓶颈算子,检查是否未优化(如未融合的Conv+BN)。
- 调整线程数和内存分配策略(如
intra_op_num_threads设为CPU物理核心数)。
3. 内存泄漏
- 原因:多会话共享内存时未正确释放,或自定义算子未管理内存。
- 解决方案:
- 使用
ORT_SESSIONS_CACHE管理会话缓存,避免重复创建。 - 确保自定义算子正确释放输出内存(如Python中使用
torch.no_grad())。
- 使用
十、生态与未来发展
1. 社区生态
- 工具链:ONNX Model Zoo(预训练模型库)、Netron(模型可视化)。
- 扩展库:
onnxruntime-transformers:优化NLP模型(如BERT、GPT)推理。onnxruntime-training:实验性训练支持(与PyTorch集成)。
2. 未来趋势
- 新硬件支持:持续优化对ARM架构、TPU、边缘NPU的支持。
- 自动化优化:基于AI的自动模型压缩与硬件适配(如AutoQuantization)。
- 云原生集成:与Kubernetes、AWS Lambda等云服务深度整合。
总结
ONNX Runtime是当前最通用的推理引擎之一,其核心竞争力在于跨框架兼容性、硬件无关优化和工程化部署能力。掌握其原理与调优技巧,可显著提升模型在不同场景下的推理效率。建议开发者结合官方文档(ONNX Runtime Documentation)和实际项目需求,深入实践模型优化与部署。
相关文章:
深度学习推理引擎---ONNX Runtime
一、基础概念 1. 什么是ONNX Runtime? 定位:由微软开发的跨平台推理引擎,专为优化ONNX(Open Neural Network Exchange)模型的推理性能设计。目标:提供高效、可扩展的推理能力,支持从云到边缘的…...

JAVA Spring MVC+Mybatis Spring MVC的工作流程*,多表连查
目录 注解总结 将传送到客户端的数据转成json数据 **描述一下Spring MVC的工作流程** 1。属性赋值 BeanUtils.copyProperties(addUserDTO,user); 添加依赖: spring web、mybatis framework、mysql driver Controller和ResponseBody优化 直接改成RestControl…...

ctr查看镜像
# 拉取镜像到 k8s.io 命名空间 sudo nerdctl --namespace k8s.io pull nginx:1.23.4 # 验证镜像是否已下载 sudo nerdctl --namespace k8s.io images 下载镜像到k8s.io名称空间下 nerdctl --namespace k8s.io pull zookeeper:3.6.2 sudo ctr image pull --namespace k8s.io …...
VueUse/Core:提升Vue开发效率的实用工具库
文章目录 引言什么是VueUse/Core?为什么选择VueUse/Core?核心功能详解1. 状态管理2. 元素操作3. 实用工具函数4. 浏览器API封装5. 传感器相关 实战示例:构建一个拖拽上传组件性能优化技巧与原生实现对比常见问题解答总结 引言 在现代前端开发…...

数字格式化库 accounting.js的使用说明
accounting.js 是一个用于格式化数字、货币和金额的轻量级库,特别适合财务和会计应用。以下是其详细使用说明: 安装与引入 通过 npm 安装: bash 复制 下载 npm install accounting 引入: javascript 复制 下载 const accounting …...

Docker 网络
目录 前言 1. Docker 网络模式 2. 默认 bridge 网络详解 (1)特点 (2)操作示例 3. host 网络模式 (1)特点 (2)操作示例 4. overlay…...
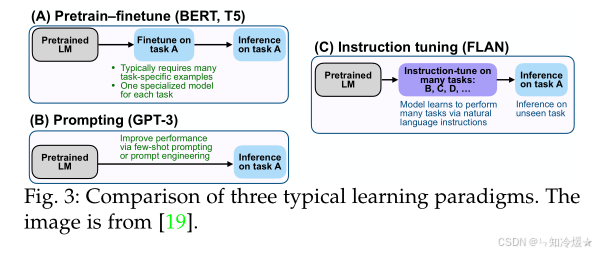
【论文阅读】A Survey on Multimodal Large Language Models
目录 前言一、 背景与核心概念1-1、多模态大语言模型(MLLMs)的定义 二、MLLMs的架构设计2-1、三大核心模块2-2、架构优化趋势 三、训练策略与数据3-1、 三阶段训练流程 四、 评估方法4-1、 闭集评估(Closed-set)4-2、开集评估&…...
增强的YOLOv11主干网络—面向高精度目标检测的结构创新与性能优化)
基于多头自注意力机制(MHSA)增强的YOLOv11主干网络—面向高精度目标检测的结构创新与性能优化
深度学习在计算机视觉领域的快速发展推动了目标检测算法的持续进步。作为实时检测框架的典型代表,YOLO系列凭借其高效性与准确性备受关注。本文提出一种基于多头自注意力机制(Multi-Head Self-Attention, MHSA)增强的YOLOv11主干网络结构,旨在提升模型在复杂场景下的目标特征…...
vue3 elementplus tabs切换实现
Tabs 标签页 | Element Plus <template><!-- editableTabsValue 是当前tab 的 name --><el-tabsv-model"editableTabsValue"type"border-card"editableedit"handleTabsEdit"><!-- 这个是标签面板 面板数据 遍历 editableT…...

关于机器学习的实际案例
以下是一些机器学习的实际案例: 营销与销售领域 - 推荐引擎:亚马逊、网飞等网站根据用户的品味、浏览历史和购物车历史进行推荐。 - 个性化营销:营销人员使用机器学习联系将产品留在购物车或退出网站的用户,根据客户兴趣定制营销…...
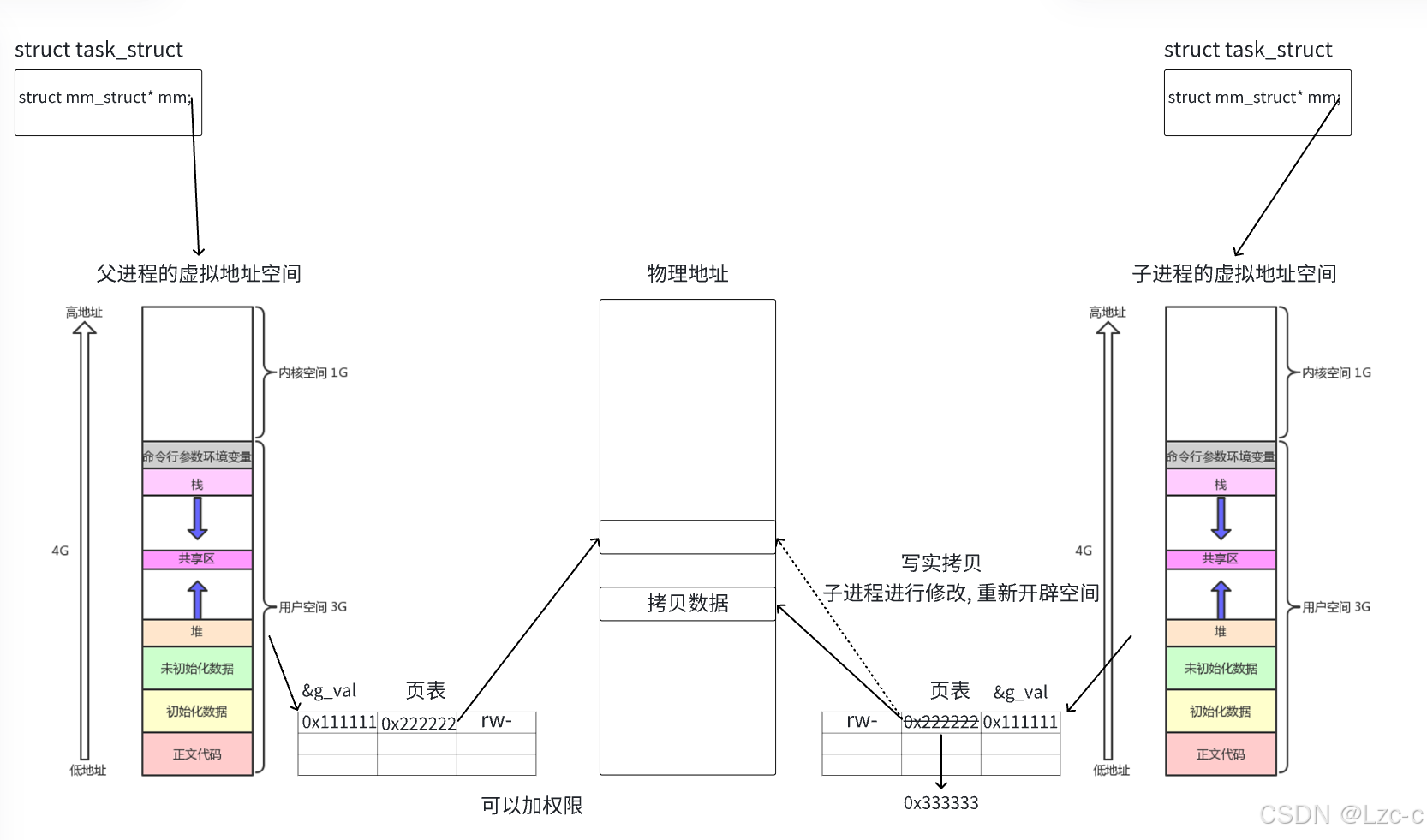
Linux的进程概念
目录 1、冯诺依曼体系结构 2、操作系统(Operating System) 2.1 基本概念 编辑 2.2 目的 3、Linux的进程 3.1 基本概念 3.1.1 PCB 3.1.2 struct task_struct 3.1.3 进程的定义 3.2 基本操作 3.2.1 查看进程 3.2.2 初识fork 3.3 进程状态 3.3.1 操作系统的进程状…...

C++ map容器: 插入操作
1. map插入操作基础 map是C STL中的关联容器,存储键值对(key-value pairs)。插入元素时有四种主要方式,各有特点: 1.1 头文件与声明 #include <map> using namespace std;map<int, string> mapStu; // 键为int,值…...

基于STC89C52的红外遥控的电子密码锁设计与实现
一、引言 电子密码锁作为一种安全便捷的门禁系统,广泛应用于家庭、办公室等场景。结合红外遥控功能,可实现远程控制开锁,提升使用灵活性。本文基于 STC89C52 单片机,设计一种兼具密码输入和红外遥控的电子密码锁系统,详细阐述硬件选型、电路连接及软件实现方案。 二、硬…...

Docker配置容器开机自启或服务重启后自启
要将一个 Docker 容器设置为开机自启,你可以使用 docker update 命令或配置 Docker 服务来实现。以下是两种常见的方法: 方法 1:使用 docker update 设置容器自动重启 使用 docker update 设置容器为开机自启 你可以使用以下命令,…...
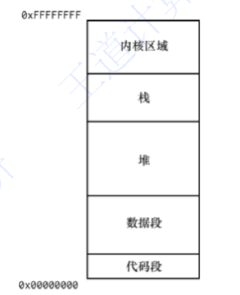
计算机单个进程内存布局的基本结构
这张图片展示了一个计算机内存布局的基本结构,从低地址(0x00000000)到高地址(0xFFFFFFFF)依次分布着不同的内存区域。 代码段 这是程序代码在内存中的存储区域。它包含了一系列的指令,这些指令是计算机执行…...

我的电赛(简易的波形发生器大一暑假回顾)
DDS算法:当时是用了一款AD9833芯片搭配外接电路实现了一个波形发生,配合stm32f103芯片实现一个幅度、频率、显示的功能; 在这个过程中,也学会了一些控制算法;就比如DDS算法,当时做了一些了解,可…...

AI工程 新技术追踪 探讨
文章目录 一、核心差异维度对比二、GitHub对AI工程师的独特价值三、需要警惕的陷阱四、推荐追踪策略五、与传统开发的平衡建议 以下内容整理来自 deepseek 作为AI工程师,追踪GitHub开源项目 对技术成长和职业发展的影响 比传统应用开发工程师 更为显著,…...
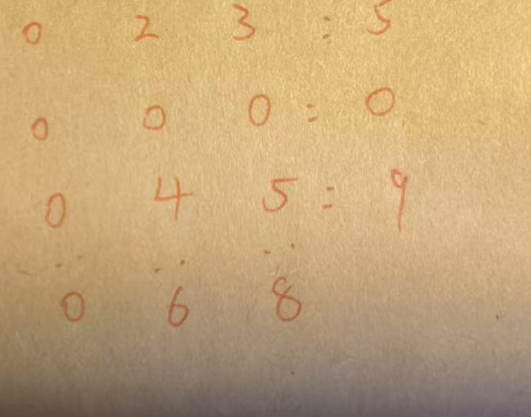
算法题(149):矩阵消除游戏
审题: 本题需要我们找到消除矩阵行与列后可以获得的最大权值 思路: 方法一:贪心二进制枚举 这里的矩阵消除时,行与列的消除会互相影响,所以如果我们先统计所有行和列的总和,然后选择消除最大的那一行/列&am…...

在 Vue 中插入 B 站视频
前言 在 Vue 项目中,有时我们需要嵌入 B 站视频来丰富页面内容,为用户提供更直观的信息展示。本文将详细介绍在 Vue 中插入 B 站视频的多种方法。 使用<iframe>标签直接嵌入,<iframe>标签是一种简单直接的方式,可将 B 站视频嵌…...
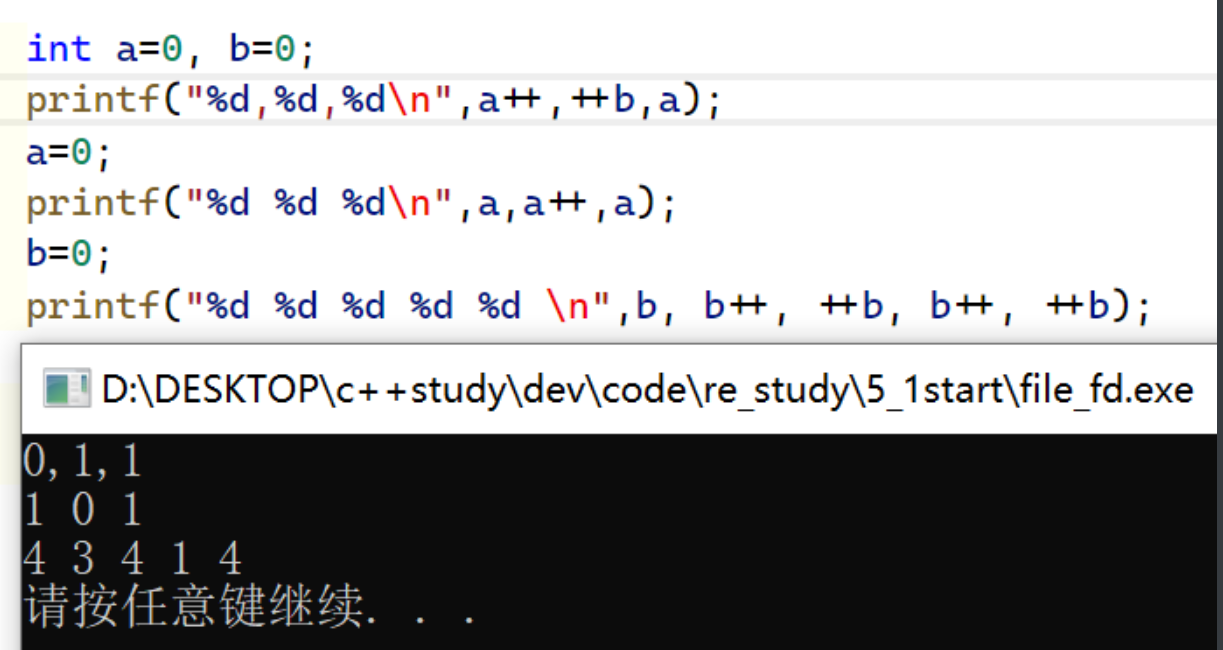
printf函数参数与入栈顺序
01. printf()的核心功能 作用:将 格式化数据 输出到 标准输出(stdout),支持多种数据类型和格式控制。 int printf(const char *format, ...);参数: format:格式字符串,字符串或%开头格式符...:…...

仿生眼机器人(人脸跟踪版)系列之一
文章不介绍具体参数,有需求可去网上搜索。 特别声明:不论年龄,不看学历。既然你对这个领域的东西感兴趣,就应该不断培养自己提出问题、思考问题、探索答案的能力。 提出问题:提出问题时,应说明是哪款产品&a…...

08、底层注解-@Configuration详解
# Configuration 注解详解 08、底层注解-Configuration详解 Configuration 是 Spring 框架中用于定义配置类的核心注解,它允许开发者以 Java 代码的形式替代传统的 XML 配置,声明和管理 Bean。 ## 一、基本作用 ### 1. 标识配置类 使用 Configuration…...
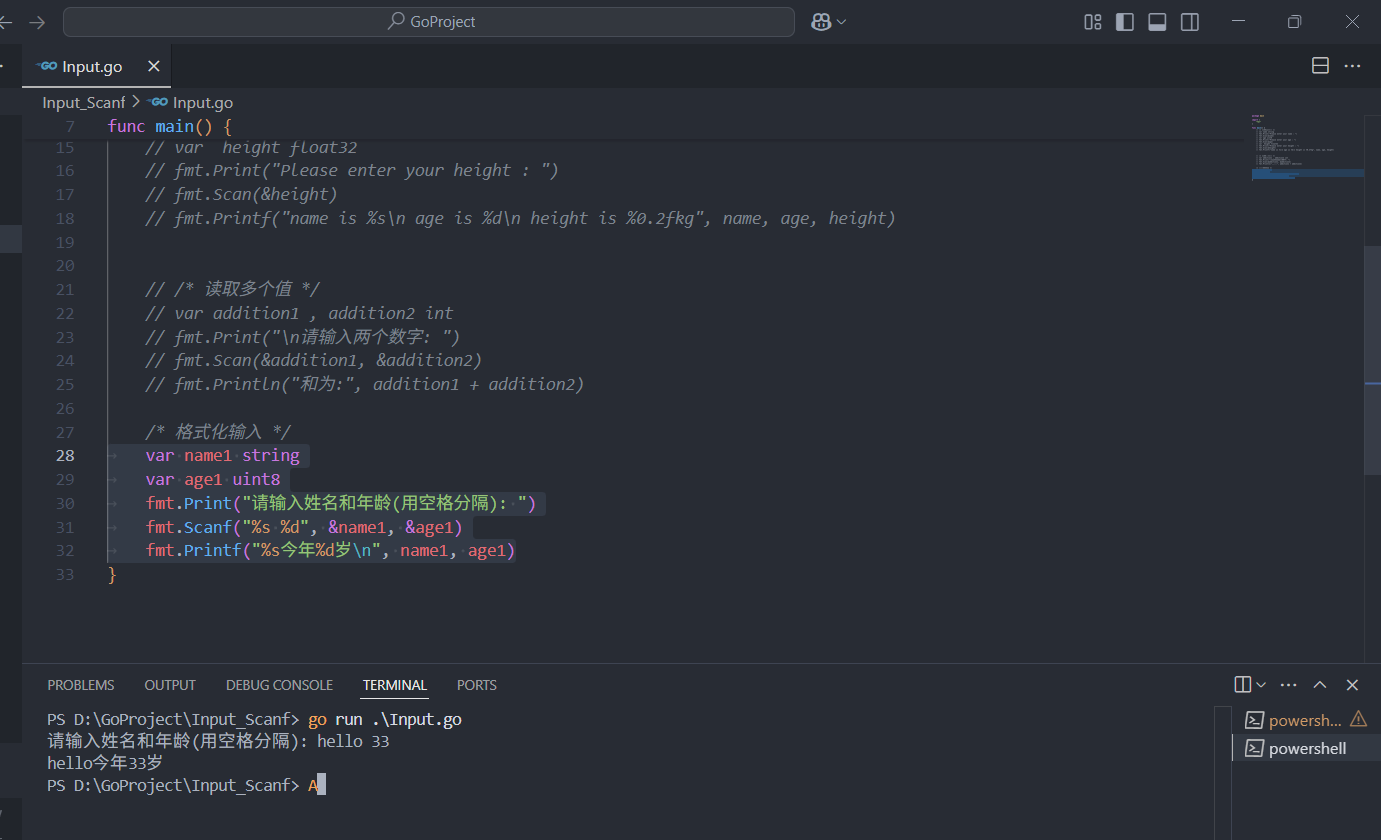
Go语言语法---输入控制
文章目录 1. fmt包读取输入1.1. 读取单个值1.2. 读取多个值 2. 格式化输入控制 在Go语言中,控制输入主要涉及从标准输入(键盘)或文件等来源读取数据。以下是几种常见的输入控制方法: 1. fmt包读取输入 fmt包中的Scan和Scanln函数都可以读取输入…...

蓝桥杯单片机按键进阶
蓝桥杯单片机按键进阶 ——基于柳离风老师模板及按键进阶教程 文章目录 蓝桥杯单片机按键进阶1、按键测试-按下生效2、按键进阶-松手生效3、按键进阶-按键禁用(未完待续) 1、按键测试-按下生效 key.c #include "key.h"/*** brief 独立按键…...

CSS- 4.3 绝对定位(position: absolute)学校官网导航栏实例
本系列可作为前端学习系列的笔记,代码的运行环境是在HBuilder中,小编会将代码复制下来,大家复制下来就可以练习了,方便大家学习。 HTML系列文章 已经收录在前端专栏,有需要的宝宝们可以点击前端专栏查看! 点…...

Flink 作业提交流程
Apache Flink 的 作业提交流程(Job Submission Process) 是指从用户编写完 Flink 应用程序,到最终在 Flink 集群上运行并执行任务的整个过程。它涉及多个组件之间的交互,包括客户端、JobManager、TaskManager 和 ResourceManager。…...

拓展运算符
拓展运算符(Spread Operator)是ES6中引入的新特性,以下是关于它的一些知识点总结: 语法 拓展运算符的语法是三个点(...),它可以将数组或对象展开成多个元素或属性。 数组中的应用 • 数组展…...
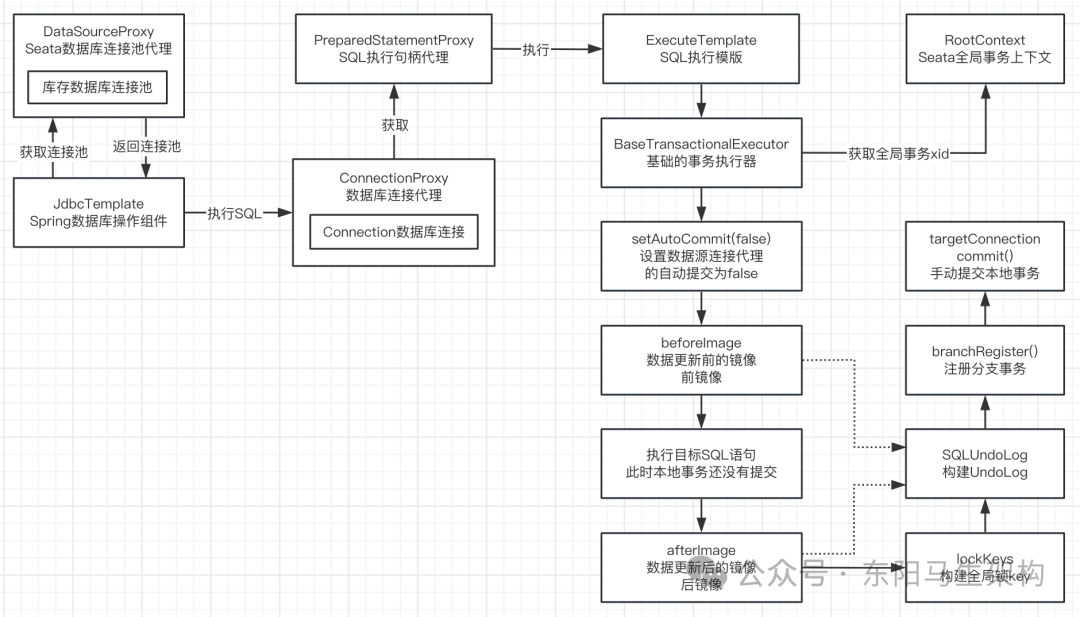
Seata源码—6.Seata AT模式的数据源代理一
大纲 1.Seata的Resource资源接口源码 2.Seata数据源连接池代理的实现源码 3.Client向Server发起注册RM的源码 4.Client向Server注册RM时的交互源码 5.数据源连接代理与SQL句柄代理的初始化源码 6.Seata基于SQL句柄代理执行SQL的源码 7.执行SQL语句前取消自动提交事务的源…...

计算机科技笔记: 容错计算机设计05 n模冗余系统 TMR 三模冗余系统
NMR(N-Modular Redundancy,N 模冗余)是一种通用的容错设计架构,通过引入 N 个冗余模块(N ≥ 3 且为奇数),并采用多数投票机制,来提升系统的容错能力与可靠性。单个模块如果可靠性小于…...

Spring Boot 与 RabbitMQ 的深度集成实践(一)
引言 ** 在当今的分布式系统架构中,随着业务复杂度的不断提升以及系统规模的持续扩张,如何实现系统组件之间高效、可靠的通信成为了关键问题。消息队列作为一种重要的中间件技术,应运而生并发挥着举足轻重的作用。 消息队列的核心价值在于其…...