pytorch小记(十九):深入理解 PyTorch 的 `torch.randint()` 与 `.long()` 转换
pytorch小记(十九):深入理解 PyTorch 的 `torch.randint` 与 `.long` 转换
- 一、`torch.randint()` 基本概念
- 示例:生成一个二维随机整型张量
- 二、为什么需要调用 `.long()`
- 三、典型场景示例
- 1. 随机索引采样
- 2. 伪标签生成
- 3. 直接在 GPU 上生成 LongTensor
- 四、`.long()` 的几种等价写法
- 五、小结
在使用 PyTorch 进行深度学习建模或数据处理时,常常需要生成随机整数张量作为索引、伪标签或其它用途。本文将深入讲解 PyTorch 中的 torch.randint() 函数,以及为什么/如何结合 .long() 方法将张量转换为 64 位整型(LongTensor)。文末还会给出多种典型场景的实战示例,帮助你在项目中快速上手。
一、torch.randint() 基本概念
torch.randint() 用来在指定范围内均匀随机生成整数张量。它的函数签名如下:
torch.randint(low: int = 0,high: int,size: Tuple[int, ...],*,dtype: torch.dtype = torch.int64,layout: torch.layout = torch.strided,device: Optional[torch.device] = None,requires_grad: bool = False
) → Tensor
low:随机整数的下界(包含),默认为 0。high:随机整数的上界(不包含),必须指定。size:输出张量的形状,例如(batch_size,)、(2, 3)、(B, C, H, W)。dtype:输出张量的数据类型,默认是torch.int64(LongTensor)。device:生成张量所在设备,如'cpu'或者'cuda'。
示例:生成一个二维随机整型张量
import torch# 在 [0, 10) 范围内,生成 2×3 的随机整数张量
x = torch.randint(0, 10, (2, 3))
print(x)
# 可能输出:
# tensor([[2, 7, 1],
# [5, 0, 9]])
print(x.dtype) # torch.int64 (默认 LongTensor)
二、为什么需要调用 .long()
虽然 torch.randint 默认即可生成 torch.int64 的张量,但在以下场景中,我们仍常见到 .long() 的调用:
-
确保索引类型
PyTorch 中,张量索引用的必须是 LongTensor(torch.int64)。如果手动指定了其它整型(如torch.int32或torch.uint8),则需要.long()转换:idx32 = torch.randint(0, 100, (16,), dtype=torch.int32) print(idx32.dtype) # torch.int32idx64 = idx32.long() print(idx64.dtype) # torch.int64 # 这样才能用 idx64 在其它张量上进行索引 -
满足损失函数要求
例如torch.nn.CrossEntropyLoss要求标签(targets)是 LongTensor:num_classes = 10 batch_size = 32labels = torch.randint(0, num_classes, (batch_size,)) # 默认就是 int64 # labels = labels.long() # 如果你不确定 dtype,可以显式调用logits = torch.randn(batch_size, num_classes) loss_fn = torch.nn.CrossEntropyLoss() loss = loss_fn(logits, labels) -
统一数据类型
在复杂模型或数据管道中,手动控制 dtype 能避免莫名的类型不一致错误。显式地在生成后调用.long(),可以给下游代码带来更好的可读性和健壮性。
三、典型场景示例
1. 随机索引采样
在自定义采样、数据重排或分批时,需要一组随机索引:
import torchnum_samples = 1000
batch_size = 64# 生成 [0, num_samples) 范围内,大小为 batch_size 的随机索引
indices = torch.randint(0, num_samples, (batch_size,)).long()# 假设 data 是一个形状为 [num_samples, ...] 的张量
data = torch.randn(num_samples, 3, 224, 224)
batch = data[indices] # 用 long 类型索引
2. 伪标签生成
在无监督或对抗训练中,有时需要生成伪标签(fake labels):
import torch
import torch.nn as nnnum_classes = 5
batch_size = 16# 随机生成伪标签
fake_labels = torch.randint(0, num_classes, (batch_size,)).long()# 用 CrossEntropyLoss 计算损失
logits = torch.randn(batch_size, num_classes, requires_grad=True)
criterion = nn.CrossEntropyLoss()
loss = criterion(logits, fake_labels)
loss.backward()
3. 直接在 GPU 上生成 LongTensor
如果希望生成的随机张量直接存放在 GPU 上,同样可以指定 device,并明确 dtype:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
batch_size, num_classes = 32, 10# 一步到位生成 GPU 上的 LongTensor
labels = torch.randint(0, num_classes, (batch_size,),device=device, dtype=torch.int64)
print(labels.device, labels.dtype) # cuda:0 torch.int64
四、.long() 的几种等价写法
tensor.long()tensor.to(torch.int64)tensor.type(torch.int64)
它们的效果相同,大家可根据个人或团队习惯任选其一。通常推荐使用 .long(),因为更简洁。
五、小结
-
torch.randint(low, high, size):生成位于[low, high)的均匀随机整数张量,默认 dtype 是torch.int64。 -
.long():将任意整型或浮点型张量转换为torch.int64(LongTensor),常用于索引、标签或保证数据类型一致。 -
典型用途:
- 随机采样索引
- 生成分类伪标签
- 在 GPU 上直接生成 long 型张量
-
最佳实践:在不确定 dtype 时显式调用
.long(),或通过dtype=torch.int64与device='cuda'一次性完成生成。
相关文章:
:深入理解 PyTorch 的 `torch.randint()` 与 `.long()` 转换)
pytorch小记(十九):深入理解 PyTorch 的 `torch.randint()` 与 `.long()` 转换
pytorch小记(十九):深入理解 PyTorch 的 torch.randint 与 .long 转换 一、torch.randint() 基本概念示例:生成一个二维随机整型张量 二、为什么需要调用 .long()三、典型场景示例1. 随机索引采样2. 伪标签生成3. 直接在 GPU 上生…...

深入解析Spring Boot与微服务架构:从入门到实践
深入解析Spring Boot与微服务架构:从入门到实践 引言 Spring Boot作为Java生态中最受欢迎的框架之一,以其简洁的配置和强大的功能赢得了开发者的青睐。本文将带领大家从Spring Boot的基础知识入手,逐步深入到微服务架构的实践,帮…...

【交互 / 差分约束】
题目 代码 #include <bits/stdc.h> using namespace std; using ll long long;const int N 10510; const int M 200 * 500 10; int h[N], ne[M], e[M], w[M], idx; ll d[N]; int n, m; bool st[N]; int cnt[N];void add(int a, int b, int c) {w[idx] c, e[idx] b…...
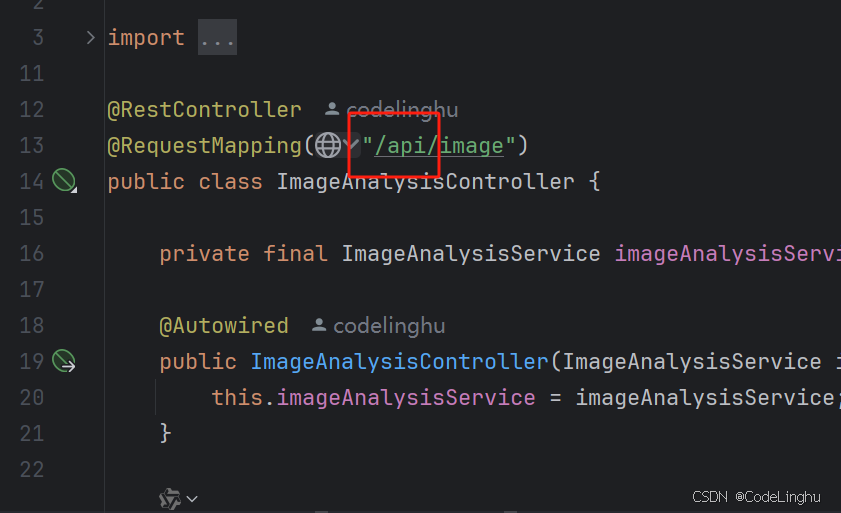
宝塔面板部署前后端项目SpringBoot+Vue2
这篇博客主要用来记录宝塔部署前端后端项目的过程。因为宝塔部署有点麻烦,至少在我看来挺麻烦的。我还是喜欢原始的ssh连接服务器进行操作。但是公司有项目用到了宝塔,没办法啊,只能摸索记录一下。 我们需要提前准备好后端项目的jar包和前端项…...

现代生活健康养生新视角
在科技飞速发展的今天,我们的生活方式发生巨大转变,健康养生也需要新视角。从光线、声音等生活细节入手,能为健康管理开辟新路径。 光线与健康密切相关。早晨接触自然光线,可调节生物钟,提升血清素水平,…...

鸿蒙Next API17新特性学习之如何使用新增鼠标轴事件
今天咱们接着学习鸿蒙开发文档API17版本的新特性——对鼠标轴事件的支持。这对于需要精细交互的应用来说是一个非常有用的特性,例如地图滚动、文档浏览等场景。本文将详细介绍在鸿蒙 Next 中如何使用新增的鼠标轴事件。 开发步骤 环境准备 在开始开发之前&#x…...

多模态大语言模型arxiv论文略读(八十一)
What is the Visual Cognition Gap between Humans and Multimodal LLMs? ➡️ 论文标题:What is the Visual Cognition Gap between Humans and Multimodal LLMs? ➡️ 论文作者:Xu Cao, Bolin Lai, Wenqian Ye, Yunsheng Ma, Joerg Heintz, Jintai …...
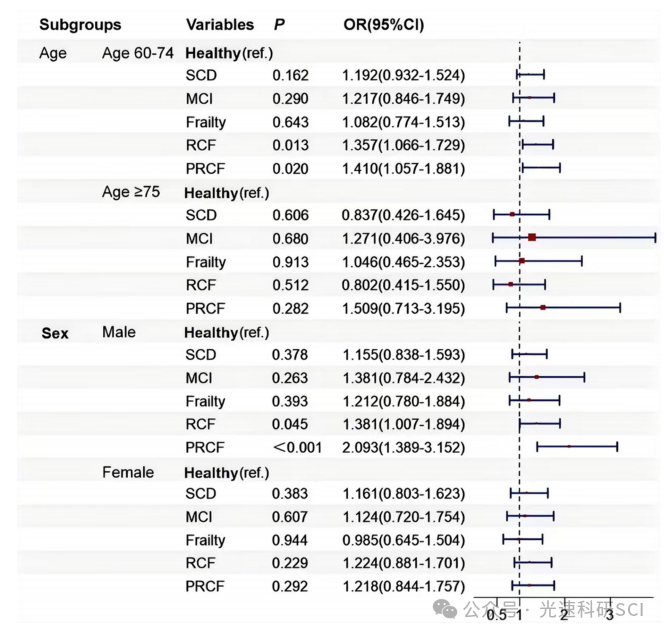
3.4/Q2,Charls最新文章解读
文章题目:Associations between reversible and potentially reversible cognitive frailty and falls in community-dwelling older adults in China: a longitudinal study DOI:10.1186/s12877-025-05872-2 中文标题:中国社区老年人可逆性和…...
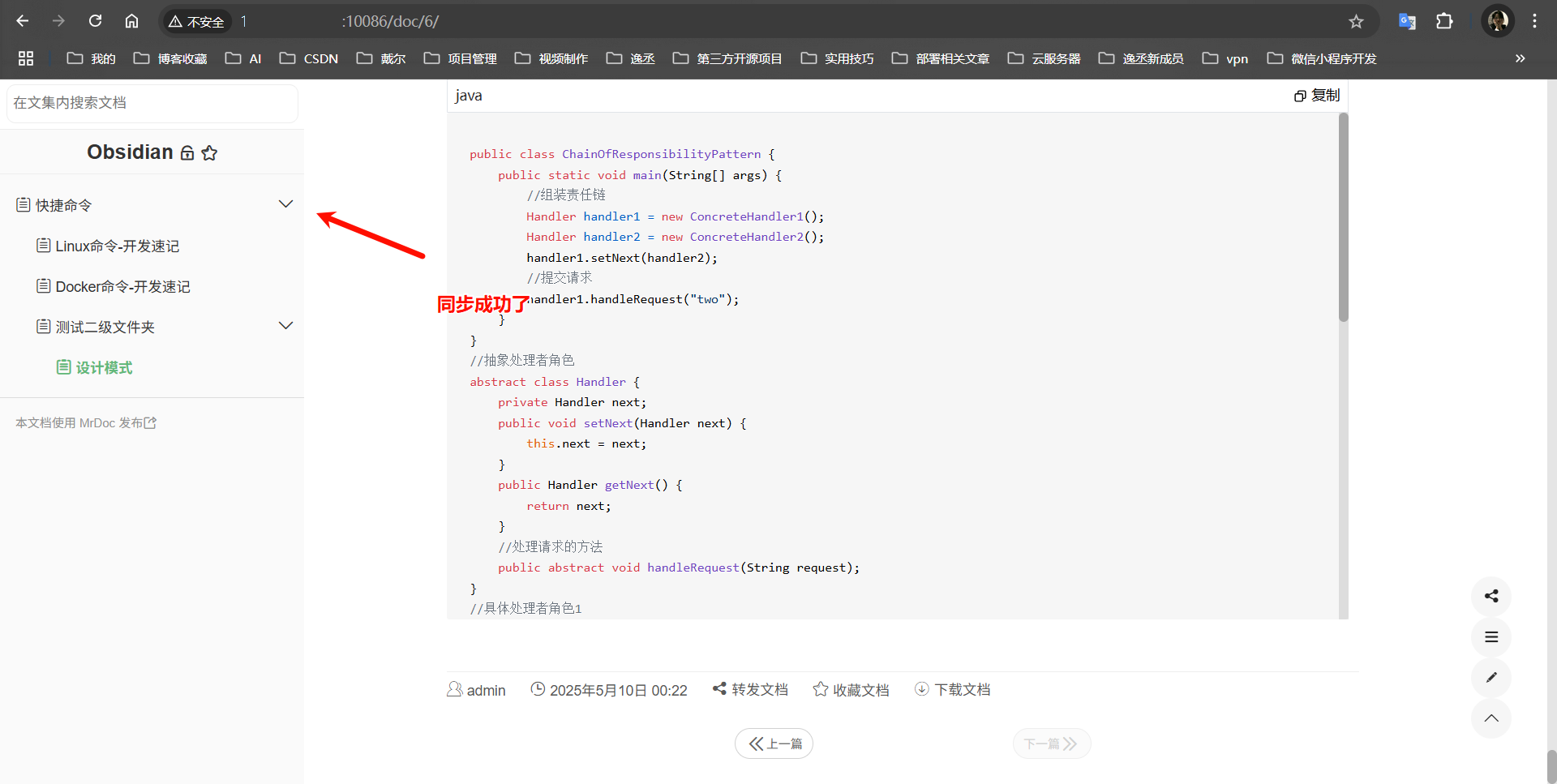
通过觅思文档项目实现Obsidian文章浏览器在线访问
觅思文档项目开源地址 觅思文档项目开源地址:https://gitee.com/zmister/MrDoc 觅思文档部署步骤概览 服务器拉取代码: git clone https://gitee.com/zmister/mrdoc-install.git && cd mrdoc-install && chmod x docker-install.sh &a…...

Python列表全面解析:从入门到精通
文章目录 Python列表全面解析:从入门到精通一、列表基础1. 什么是列表?2. 列表特性总结表 二、列表的基本操作(基础)1. 访问元素2. 修改列表 三、列表的常用方法(基础)1. 添加元素的方法2. 删除元素的方法3. 查找和统计方法4. 排序和反转 四、列表的高级…...
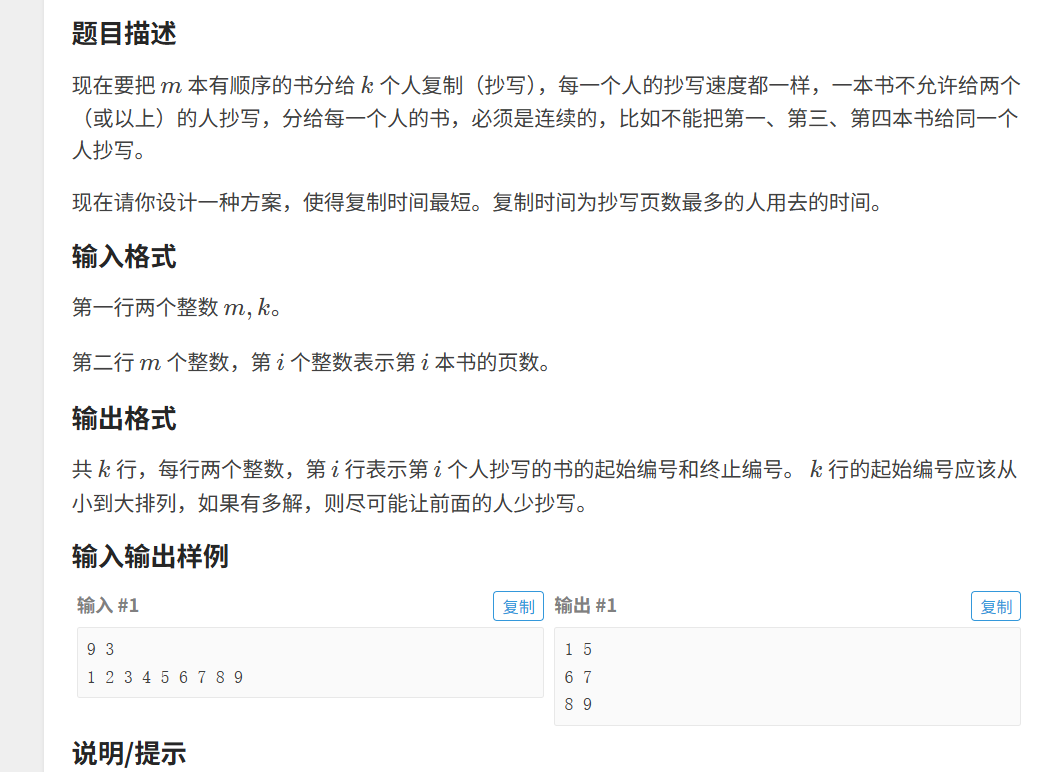
5月18总结
一.算法题总结 1. 解题思路:对于这个题,我最开始想到就是二分,但是头痛的是有三个解,如果我在-100到100之间二分,那么只能得出一个解,然后我就想了一下,这个要求精度,那么0.01这么小…...

赋予AI更强的“思考”能力
刚刚!北大校友、OpenAI前安全副总裁Lilian Weng最新博客来了:Why We Think 原文链接:Why We Think by Lilian Weng 这篇文章关注:如何让AI不仅仅是“知道”答案,更能“理解”问题并推导出答案。通过赋予AI更强的“思…...
Linux Bash | Capture Output / Recall
注:本文为 “Linux Bash | Capture Output / Recall” 相关文章合辑。 英文引文,机翻未校。 中文引文,略作重排。 Automatically Capture Output of the Last Command Into a Variable Using Bash 使用 Bash自动将最后一个命令的输出捕获到…...

2025/5/18
继续研究一下大佬的RAG项目。开始我的碎碎念。 RAG可以分成两部分:一个是问答,一个是数据处理。 问答是人提问,然后查数据库,把查的东西用大模型组织成人话,回答人的提问。 数据处理是把当下知识库里的东西…...

基于Quicker构建从截图到公网图像链接获取的自动化流程
写在前面:本博客仅作记录学习之用,部分图片来自网络,如需引用请注明出处,同时如有侵犯您的权益,请联系删除! 文章目录 前言预备内容转webp程序PicGo设置Quicker设置视频演示总结互动致谢参考 前言 在自建博…...

LeetCode算 法 实 战 - - - 双 指 针 与 移 除 元 素、快 慢 指 针 与 删 除 有 序 数 组 中 的 重 复 项
LeetCode算 法 实 战 - - - 双 指 针 与 移 除 元 素、快 慢 指 针 与 删 除 有 序 数 组 中 的 重 复 项 第 一 题 - - - 移 除 元 素方 法 一 - - - 双 重 循 环方 法 二 - - - 双 指 针方 法 三 - - - 相 向 双 指 针(面 对 面 移 动) 第 二 题 - - -…...
uniapp自定义日历计划写法(vue2)
文章目录 uniapp自定义日历计划写法(vue2)1、效果2、实现源码前言:我们有时候需要实现的日历找不到相应的插件的时候,往往需要手动去写一个日历,以下就是我遇到这样的问题时,手搓出来的一个解决方案,希望可以帮助到更多的人。创作不易,请多多支持uniapp自定义日历计划写…...
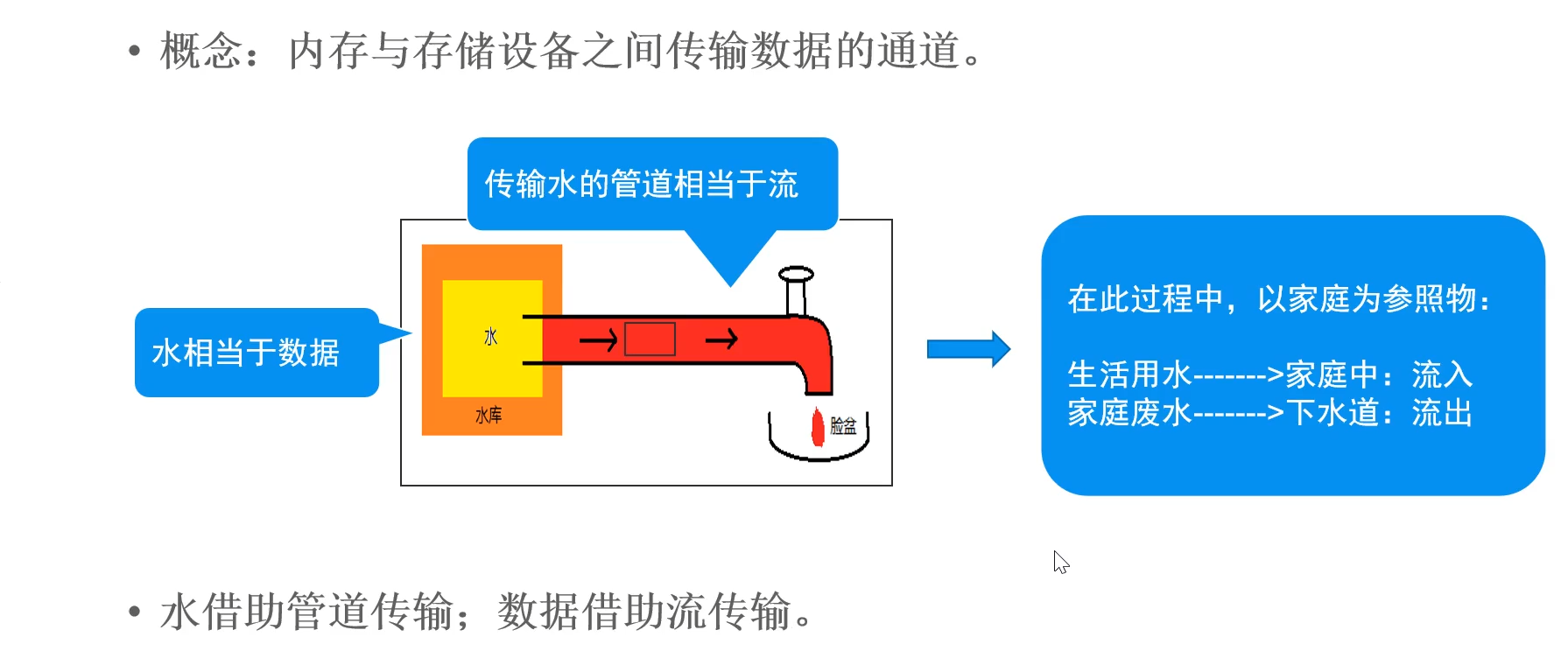
Java IO框架
I/O框架 流 流的分类: 按方向: 输入流:将存储设备的内容读入到内存中 输出流:将内存的内容写入到存储设备中 按单位: 字节流:以字节为单位,可以读取所有数据 字符流:以字符为单…...

数据库2——查询
查询 学习内容学习感受 学习内容 一、实验目的与要求: 1、掌握SQL单表及多表之间的查询 2、掌握统计及分组函数 二、实验内容: 1.简单查询 ① 从fruits表中检索s_id为100的供货商所供货的水果名和价格 源码: SELECT f_name, f_price FROM…...

Mamba LLM 架构简介:机器学习的新范式
Mamba LLM 架构简介:机器学习的新范式 探索 Mamba LLM 的强大功能,Mamba LLM 是来自一流大学的变革性架构,重新定义了 AI 中的序列处理。语言模型是一种经过训练的机器学习模型,用于在自然语言上执行概率分布。它们的架构主要由多…...
Android 性能优化入门(一)—— 数据结构优化
1、概述 一款 app 除了要有令人惊叹的功能和令人发指交互之外,在性能上也应该追求丝滑的要求,这样才能更好地提高用户体验: 优化目的性能指标优化的方向更快流畅性启动速度页面显示速度(显示和切换)响应速度更稳定稳定性避免出现 应用崩溃&…...
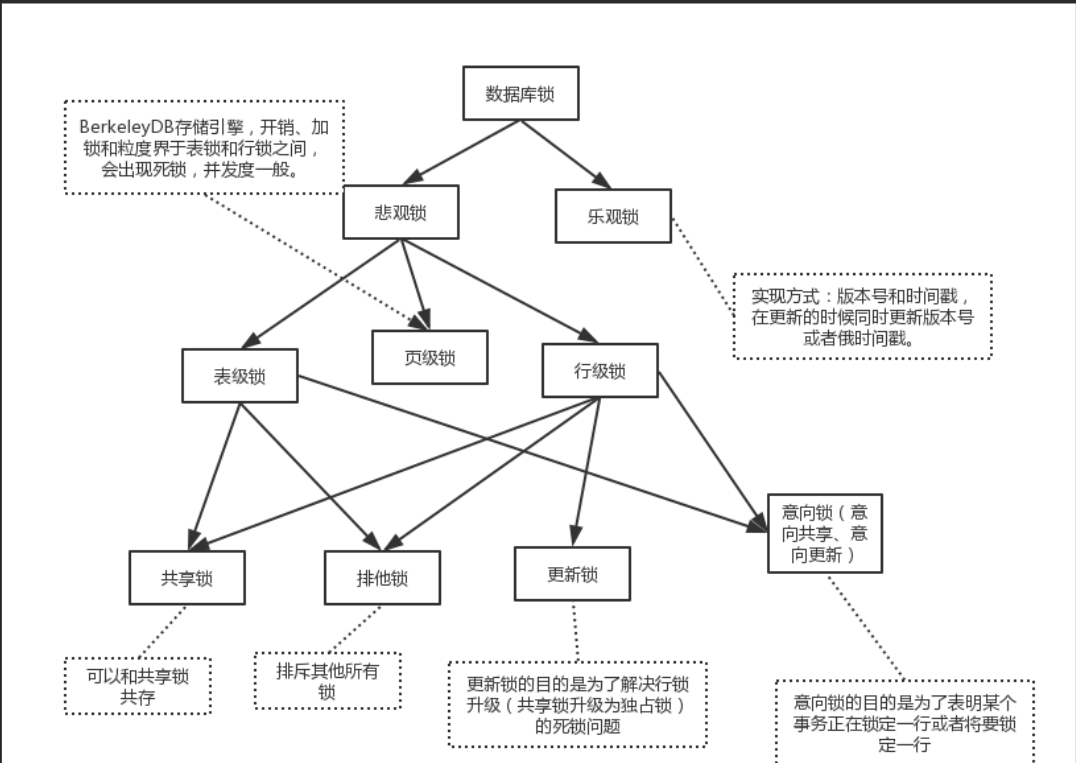
数据库中的锁机制
目录 数据库中的锁机制:原理、分类与实际案例详解 一、数据库锁的核心作用与基本概念 1.1 为什么需要数据库锁? 1.2 锁的分类 二、锁机制的实现与典型场景 2.1 共享锁(Shared Lock) 工作原理 适用场景 代码示例(MySQL) 案例分析 2.2 排他锁(Exclusive Lock) …...

【网络入侵检测】基于Suricata源码分析运行模式(Runmode)
【作者主页】只道当时是寻常 【专栏介绍】Suricata入侵检测。专注网络、主机安全,欢迎关注与评论。 1. 概要 👋 在 Suricata 中抽象出线程、线程模块和队列三个概念:线程类似进程,可多线程并行执行操作;监听、解码、检…...

AI日报 - 2025年05月19日
🌟 今日概览 (60秒速览) ▎🤖 大模型前沿 | GPT-5传闻再起,将基于全新模型构建,与GPT-4彻底分离;Claude 3.7 Sonnet系统提示泄露,揭示其主动引导对话、多语言支持及安全新特性;研究指出直接复用…...

Spring源码主线全链路拆解:从启动到关闭的完整生命周期
Spring源码主线全链路拆解:从启动到关闭的完整生命周期 一文看懂 Spring 框架从启动到销毁的主线流程,结合原理、源码路径与伪代码三位一体,系统学习 Spring 底层机制。 1. 启动入口与环境准备 原理说明 Spring Boot 应用入口是标准 Java 应…...
Linux常用命令(十四)
目录 vi编辑器命令 1-编辑模式 1)准备一个txt文件并且进入vi 2)按i进入编辑模式 3)按o进入编辑模式 4)按a进入编辑模式 2-底行模式 1)退出vim 2)撤销上次操作 3)设置行号底行模式 4ÿ…...

规则联动引擎GoRules初探
背景说明 嵌入式设备随着物联网在生活和生产中不断渗透而渐渐多起来,数据的采集、处理、分析在设备侧的自定义配置越来越重要。一个可通过图形化配置的数据处理过程,对于加速嵌入式设备的功能开发愈发重要。作为一个嵌入式软件从业者,笔者一…...

基于OpenCV中的图像拼接方法详解
文章目录 引言一、图像拼接的基本流程二、代码实现详解1. 准备工作2. 特征检测与描述detectAndDescribe 函数详解(1)函数功能(2)代码解析(3)为什么需要这个函数?(4)输出数…...
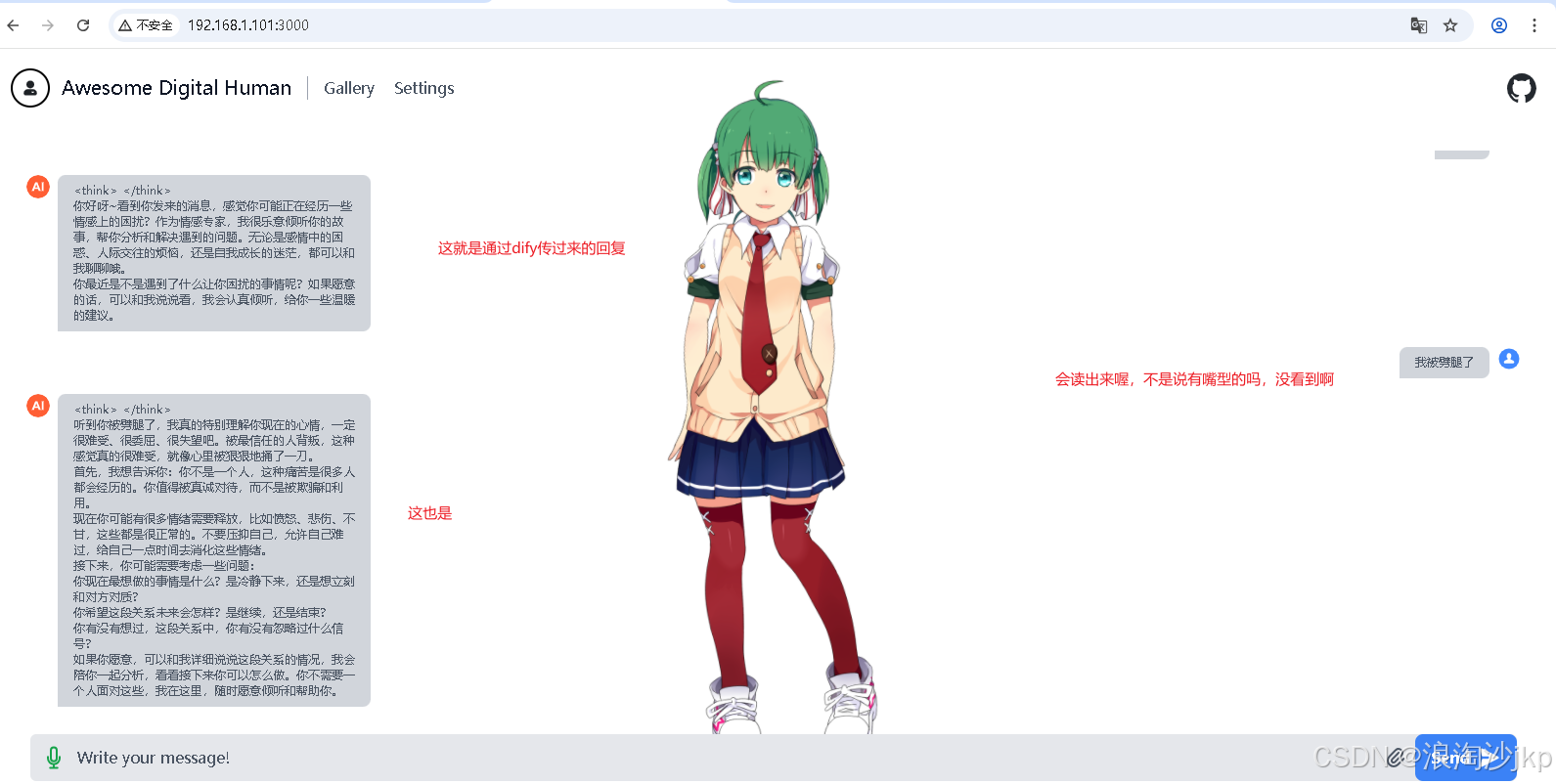
AI大模型学习二十六、使用 Dify + awesome-digital-human-live2d + ollama + ChatTTS打造数字人
一、说明 数字人(Digital Human) 是指通过人工智能(AI)、计算机图形学、语音合成、动作捕捉等技术创建的虚拟人物。它们具备高度拟人化的外观、语言、表情和动作,能够与人类进行交互,甚至承担特定社会角色。…...
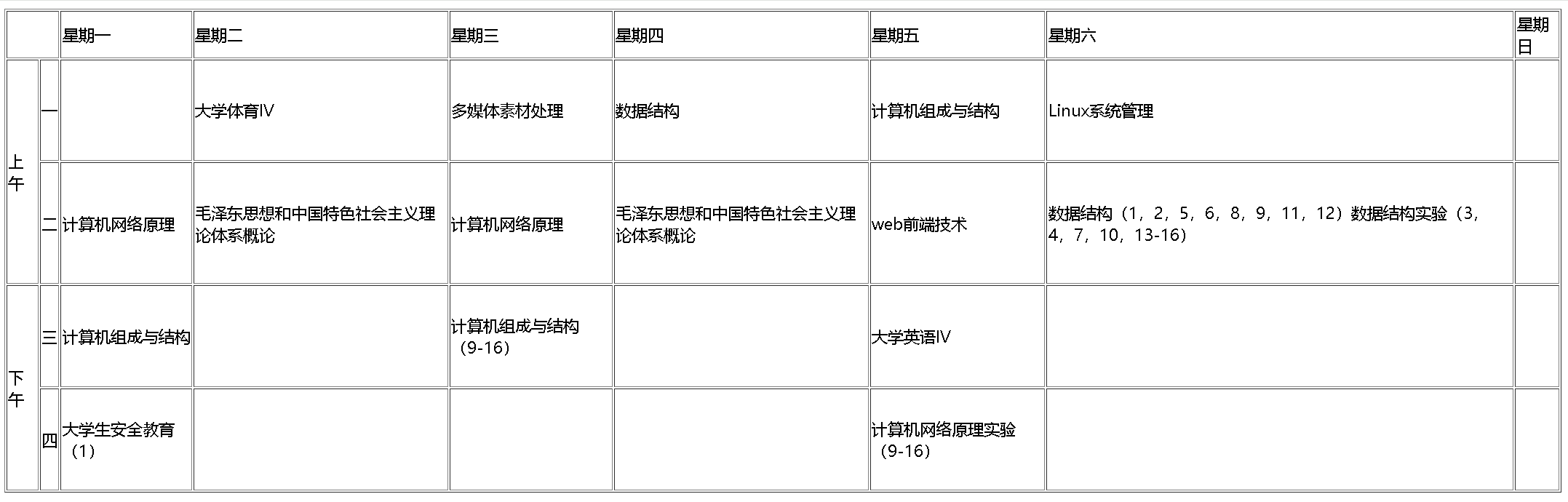
HTML-3.2 表格的跨行跨列(课表制作实例)
本系列可作为前端学习系列的笔记,代码的运行环境是在HBuilder中,小编会将代码复制下来,大家复制下来就可以练习了,方便大家学习。 系列文章目录 HTML-1.1 文本字体样式-字体设置、分割线、段落标签、段内回车以及特殊符号 HTML…...