DS新论文解读(2)

上一章忘了说论文名字了,是上图这个名字
我们继续,上一章阅读地址:
dsv3新论文解读(1)
这论文剩下部分值得说的我觉得主要就是他们Infra通信的设计
先看一个图
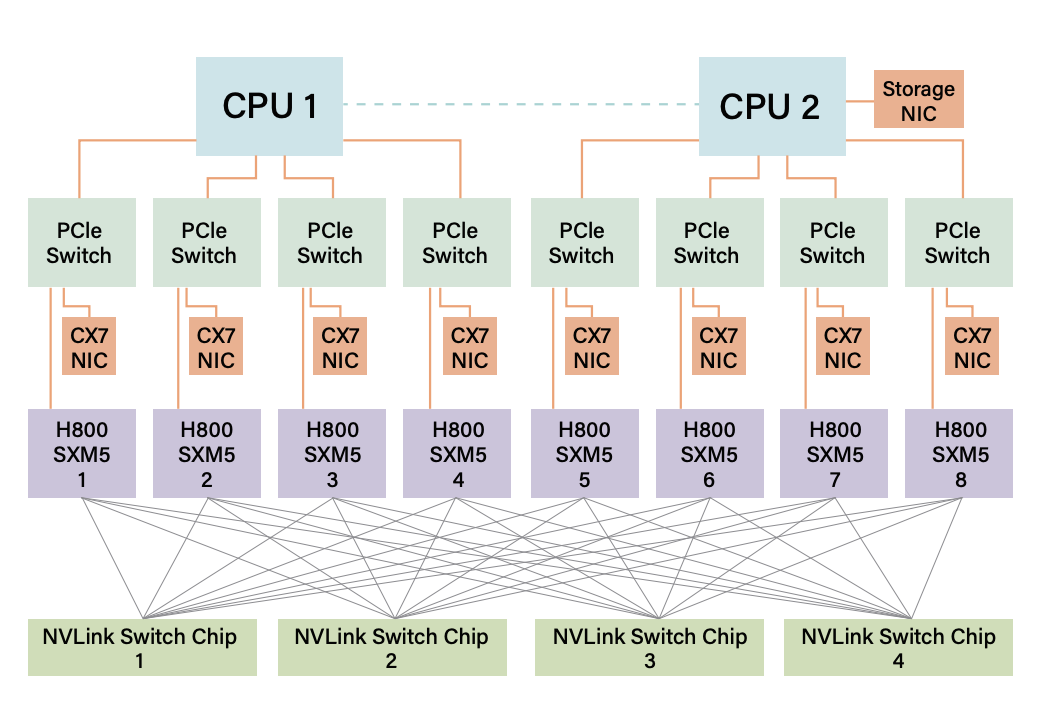
这个是一个标准的h800 8卡with 8cx7 nic的图,2个cpu,每个cpu管着4个pcie,每个pcie连接 网卡(cx7 400g)和 gpu卡(这里是h800),负责gpu的流量要找本机以外的gpu通信
也就是node0的gpu0要是node1的gpu0,或者gpu1 通信,它就需要把数据先发给pcie在发给cx7 然后再发到ib或者roce交换机上,再发到对端的node1,再进行一次反操作,这个东西,看起来就很费延迟对吧?
那就尽量走nvlink
这里面有几个可以考虑的点
-
cpu-gpu的nvlink,它应该是没买gracecpu,它用的是800,所以这个没法做到
-
(Model Co-Design: Node-Limited Routing)提到,在他们的节点限制路由策略中,会利用节点内 NVLink 的更高带宽进行数据转发:“通过利用更高的 NVLink 带宽,路由到同一节点的令牌可以通过 IB 发送一次,然后通过 NVLink 转发到其他节点内的 GPU。” 这体现了在实际设计中,当有选择时,会优先利用 NVLink 的高带宽特性进行节点内 GPU 间通信。
这两个好理解一点
还有一个和上一篇文章一样,能看出来DS他们对硬件设计的野心很大
论文中第 4.5.2 节提出了一个建议:“I/O Die Chiplet 集成”
那么什么是“I/O Die Chiplet 集成”?
这个概念是基于现代处理器和加速器设计中越来越流行的 Chiplet(小芯片)架构。
传统单片设计 (Monolithic Die):过去,一个复杂的芯片(如CPU或GPU)通常是在一整块硅片上制造出来的。
Chiplet 设计:现在,为了提高良率、灵活性和成本效益,设计师倾向于将一个大芯片的功能拆分成多个较小的、专门化的“小芯片”(Chiplets)。这些 Chiplets 可以在同一封装基板上被紧密地互连起来,共同构成一个完整的系统。
I/O Die (输入/输出小芯片):在 Chiplet 设计中,常常会有一个专门的 I/O Die。这个小芯片负责处理整个封装体的大部分或全部对外输入输出接口,比如连接内存的控制器、连接其他设备的 PCIe 控制器、以及其他各种 I/O 接口。
将 NIC 集成到 I/O Die 中:论文的建议是,不再将网络接口卡 (NIC) 做成一个独立的、插在主板 PCIe 插槽上的卡,而是将 NIC 的核心功能直接集成到处理器的 I/O Die 这个小芯片上,或者做成一个与 I/O Die 通过极高带宽、极低延迟接口紧密相连的专用网络 Chiplet。
同一封装内连接到计算 Die:集成了 NIC 功能的 I/O Die 会通过封装内部的、非常短的高速互连通道直接连接到计算 Die。
那么回到我们的考虑,为什么这种集成方式能“显著减少通信延迟并缓解 PCIe 带宽争用”呢?
与传统的 PCIe 连接方式(即计算核心通过主板上的 PCIe 插槽连接外部独立的 NIC 卡)相比,这种集成方式有以下优势:
显著减少通信延迟:
物理距离大大缩短:信号在芯片封装内部传输的距离远小于跨越主板到 PCIe 插槽的距离。更短的距离意味着更低的信号传播延迟。
更高效的内部互连协议:封装内部的 Chiplet间互连可以使用比通用 PCIe 协议更专用、更低开销的通信协议。PCIe 协议为了兼容性和长距离传输,本身带有一定的协议开销(如包头、状态管理、错误校验等)。内部互连可以更精简。
可能避免额外的 PCIe 组件:传统的 PCIe 路径可能需要经过主板上的 PCIe Retimer(信号中继器)或 PCIe Switch(交换芯片),这些都会引入额外的延迟。封装内集成可以实现更直接的连接。
缓解 PCIe 带宽争用:
专用高带宽路径:计算 Die 与包含 NIC 功能的 I/O Die 之间的封装内互连通道,可以设计得比标准的 PCIe x16 (有人抬杠说我要乘160呢?你出去,这里不合适和你)链路更宽、更快,为网络数据提供一条专用的、高吞吐量的“高速公路”。
减轻外部 PCIe 总线压力:当 NIC 功能集成在处理器封装内并直接服务于计算 Die 时,计算 Die 与网络之间的数据交换主要通过这个内部高速通道进行。这样,处理器对外的 PCIe 通道(用于连接其他外设、存储等)的带宽就不会被网络 I/O 大量占用,从而减少了争用。
更直接的访问:计算 Die 可以更直接、更高效地访问网络功能,数据不需要在多个芯片和总线之间进行多次周转。
但是为什么现在硬件厂商不这么做?
个大硬件厂商:我又能卖算力卡,又能卖网卡,我赚两份钱,我听你BB?你TM算老几?
当然也客观存在这需求和市场的roi平衡的问题。
我们继续
另外一个值得说的就剩下网络了
除了能用NVlink尽量用NVlink以外,虽然H800的NVlink确实比H100/200差多了,严格版本跟A100差不多,但是也比PCIE要强好几倍,所以他们训练的时候尽量不用TP,但是NVlink还是起了很大作用的,能不走pcie,尽量不走,但是如果跨机器通信比如任何的集合通信,还是绕不过PCIE---IB----PCIE--CPU---GPU这条路径的
这条路径其实有一个大问题,就是多对1,比如all-gather的时候,会有很大瓶颈。所以DS它们改了传统的胖树FAT tree网络(一般企业其实现在如果为了clos也就是2层网络,我们姑且就当无阻塞的spine-leaf来看)。改成了分平面的spine-left的 MPFT
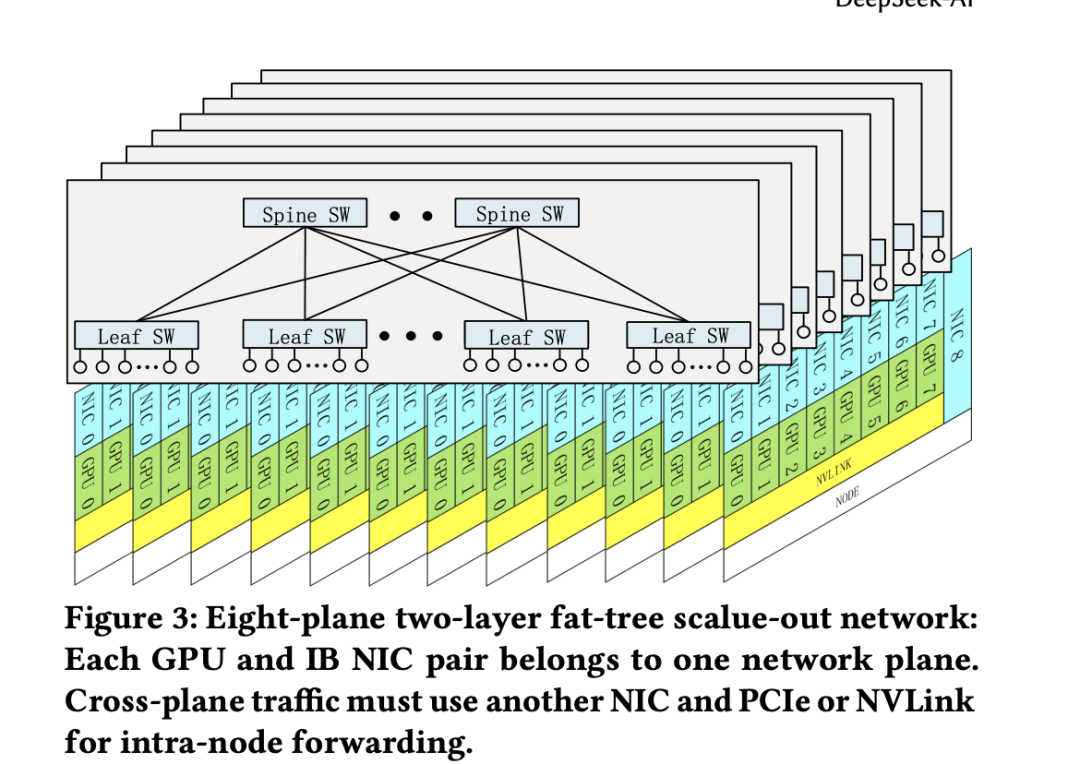
如上图画的,正常我们部署DC内不AI网络的时候
leaf就不说了。spine一般都是复用的,而且必须要有连接,比如你从一个leaf要去的另一个leaf switch 它俩挂在不通的spine下,你的包是过不去的(这个和tcp或者ib就无关了,就是无力上过不去)
那它这么设计的目的其实刚才也讲了,就是为了缓解并发多对1,或者多对对的压力,把流量固定在一个平面内,比如上图
每个node有8块gpu,每个gpu对应一块nic(IB或者roce)
那node0的gpu0发给自己内部机器的gpu1-7就nvlink就完事了
但是node0的gpu0要发node1的gpu0的话,你就必须走gpu---pcie--cpu---pcie--nic--ib--对面 这条路
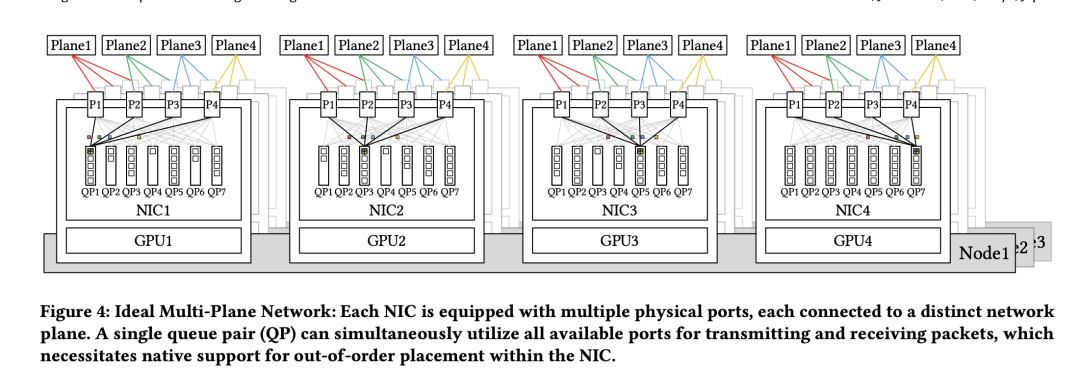
但是由于平面的隔离,如上图,每个QP就自己玩自己的(QP是ib
的概念,你要是不懂就当乘tcp的socket来看就好理解了)。相当于至少给你减少了7/8的流量,对pcie和 ib交换机的压力那都是显著的减轻的
那么问题来了,如果node0的gpu0要发流量给gou1的gpu1怎么办???
平面是完全隔离的,按说就过不去了
这个时候nvlink又上场了,借用它的快速,低延迟的能力
这个路径变成了:
1-数据在 Node0 的 GPU0 上准备好。
2-由于目标 Node1 的 GPU1 是通过平面1接入网络的,如果 Node0 希望通过平面1将数据发送给 Node1 的 GPU1,那么数据不能直接从 Node0 的 NIC0 (平面0) 发出。
3-根据论文的“跨平面流量”规则,Node0 的 GPU0 需要将数据在节点内部通过高速互联(NVLink )传递给 Node0 的 GPU1(因为 Node0 的 GPU1 配对的是 NIC1,NIC1 连接到平面1)。
4-然后,Node0 的 GPU1 将数据交给其配对的 NIC1。
5-Node0 的 NIC1 通过**外部IB网络(平面1)**将数据发送到 Node1 的 NIC1。
6-Node1 的 NIC1 接收数据后,传递给 Node1 的 GPU1
多平面胖树MPFT网络的优势:
多轨胖树 (MRFT) 的子集:MRFT(Multi-Rail Fat-Tree, MRFT) 是Nvidia做DGCX pod的推荐,MPFT 拓扑是更广泛的多轨胖树 架构的一个特定子集(我之前说过DS大多数时候,不做什么新东西,主要是按着老的feature进行优化是它们的核心能力)。因此,NVIDIA 和 NCCL 为多轨网络开发的现有优化(如 NCCL 的 PXN 技术,用于处理平面间隔离问题)可以无缝地应用于 MPFT,这也就不用DS它们为了这个事情来现改集合通信了。
成本效益 (Cost Efficiency):MPFT 使得使用两层胖树 (FT2) 拓扑就能支持超过1万个端点,与三层胖树 比如MRFT标准的(FT3) 相比显著降低了网络成本。其每端点成本甚至略优于成本效益较高的 Slim Fly (SF) 拓扑。
流量隔离 (Traffic Isolation):每个平面独立运行,一个平面的拥塞不会影响其他平面,提高了整体网络稳定性。
延迟降低 (Latency Reduction):两层拓扑通常比三层胖树具有更低的延迟,特别适合延迟敏感的应用,如 MoE 模型的训练和推理。
鲁棒性 :理想情况下,多端口 NIC 提供多个上行链路,单个端口故障不会中断连接,可以实现快速透明的故障恢复。但论文也指出,由于当前 400G NDR InfiniBand 的限制,他以后上CX8的时候,也许就不这么考虑了,页说不定。跨平面通信需要节点内转发,这会在推理时引入额外延迟。如果未来硬件能实现之前讨论的纵向与横向网络融合,这种延迟可以显著降低。
性能分析 :
为了验证 MPFT 设计的有效性,团队在集群上进行了实际实验,比较了 MPFT 和单平面多轨胖树 (Single-Plane Multi-Rail Fat Tree, MRFT) 的性能。
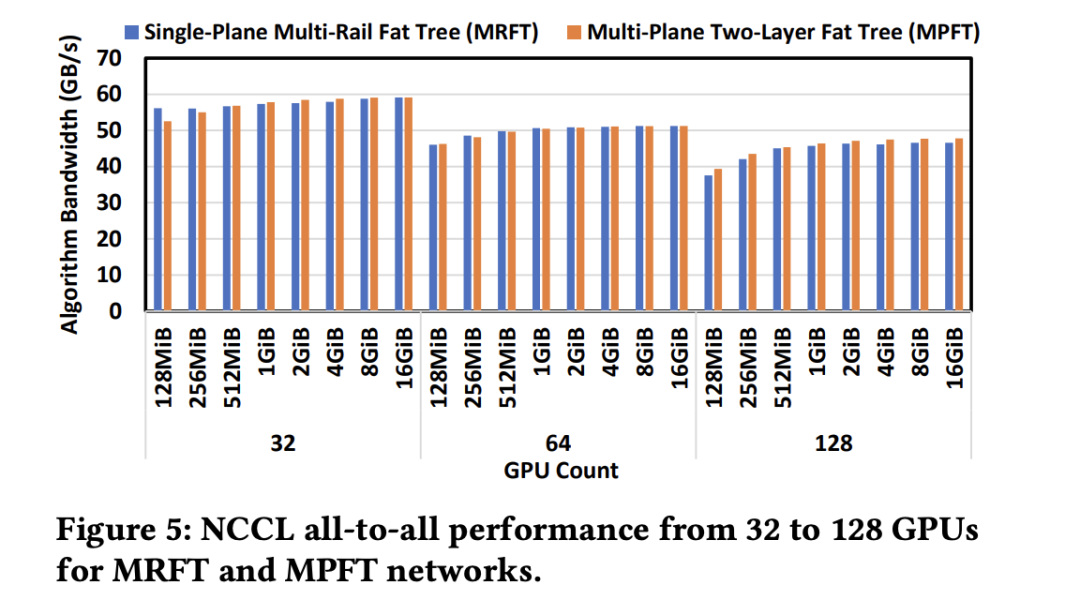
All-to-All 通信和 EP 场景:实验结果如上图显示,MPFT 网络的 all-to-all 性能与 MRFT 非常相似。这归功于 NCCL 的 PXN 机制,该机制通过 NVLink 优化了多轨拓扑中的流量转发,MPFT 也从中受益。
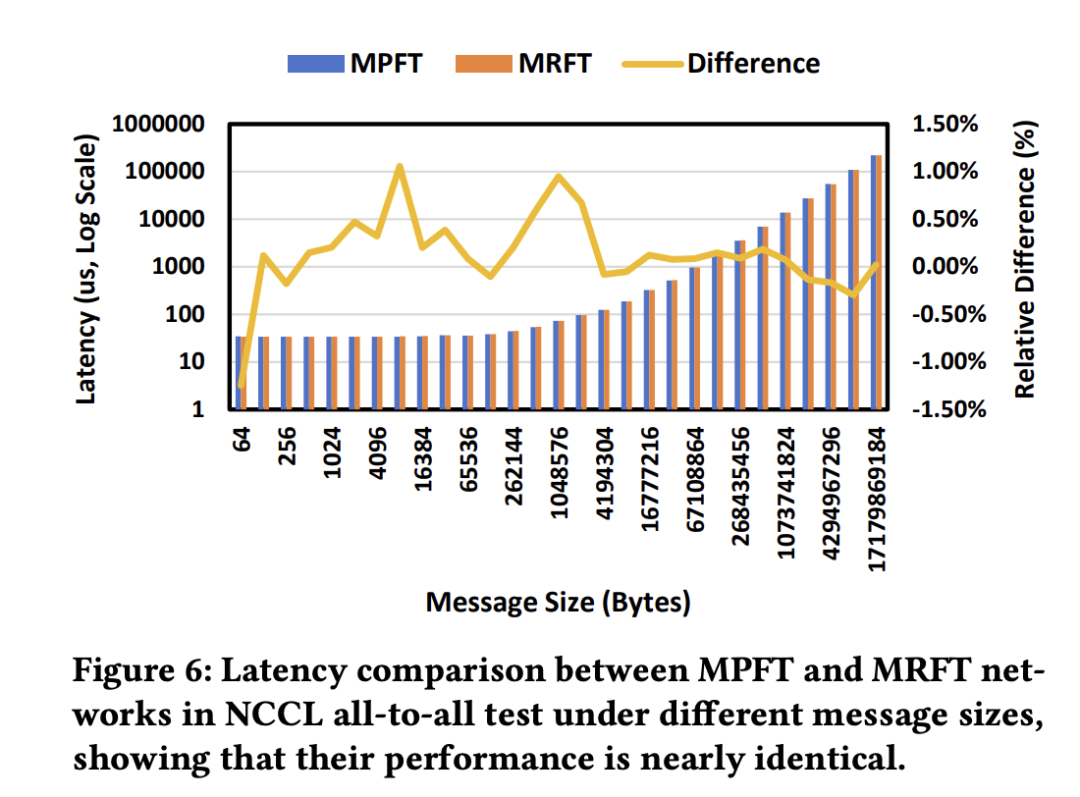
如上图在16个GPU上进行的 all-to-all 通信测试显示,不同消息大小下,MPFT 和 MRFT 之间的延迟差异可以忽略不计。
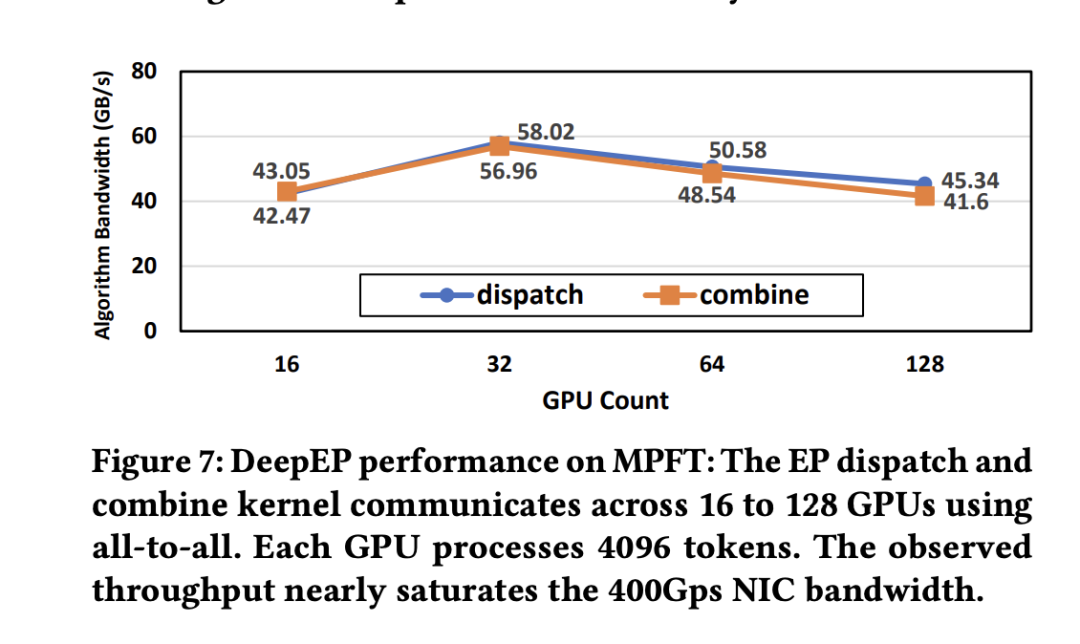
DeepEP 性能:在 MPFT 上测试 EP 通信模式,如上图,每个 GPU 实现了超过 40GB/s 的高带宽,满足了训练需求。
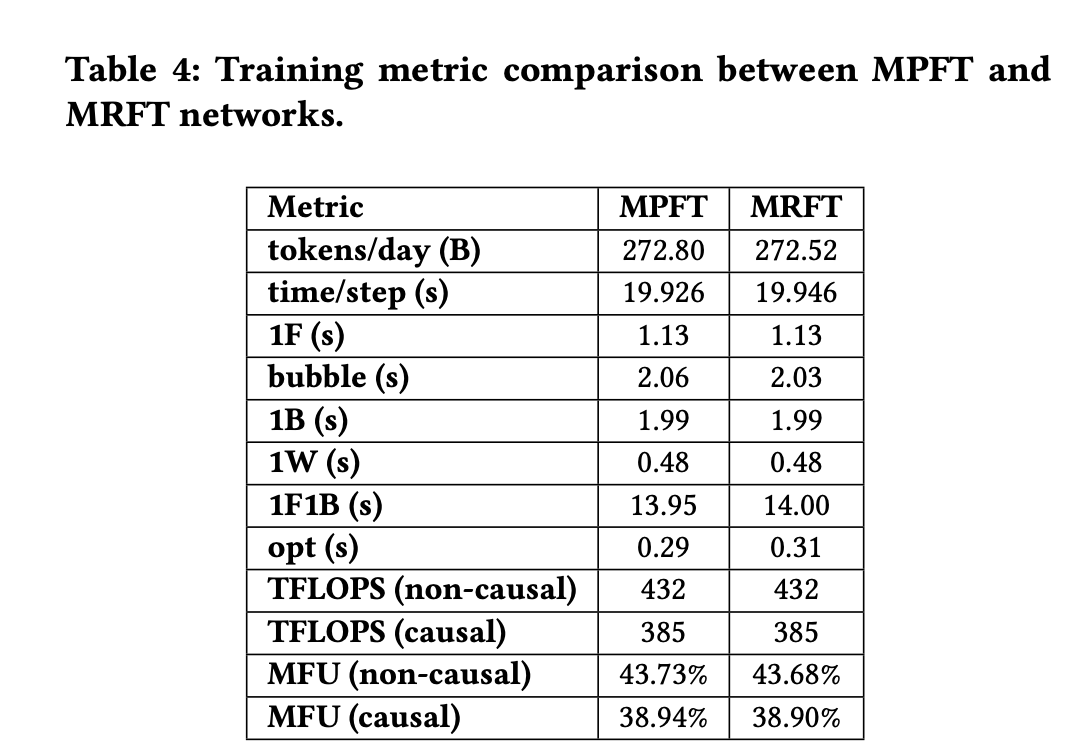
DeepSeek-V3 模型训练吞吐量:在2048个GPU上训练V3模型时,MPFT 和 MRFT 的性能指标(如每日处理 token 数、每步时间、各阶段耗时、TFLOPS、MFU等,见上表)几乎相同,观察到的差异在正常波动和测量误差范围内。
所以就是便宜的方案也能干MRFT的事(DS主打便宜高效率,这个是一直贯穿始终的研究)
剩下其他的什么MLA,MTP,MOE啥的我以前都讲过了,大家感兴趣可以翻我以前的文章,这个论文就解读完了。
下次见。
相关文章:
DS新论文解读(2)
上一章忘了说论文名字了,是上图这个名字 我们继续,上一章阅读地址: dsv3新论文解读(1) 这论文剩下部分值得说的我觉得主要就是他们Infra通信的设计 先看一个图 这个是一个标准的h800 8卡with 8cx7 nic的图…...
html文件cdn一键下载并替换
业务场景: AI生成的html文件,通常会使用多个cdn资源、手动替换or下载太过麻烦、如下py程序为此而生,指定html目录自动下载并替换~ import os import requests from bs4 import BeautifulSoup from urllib.parse import urlparse import has…...

react路由中Suspense的介绍
好的,我们来详细解释一下这个 AppRouter 组件的代码。 这个组件是一个在现代 React 应用中非常常见的模式,特别是在使用 React Router v6 进行路由管理和结合代码分割(Code Splitting)来优化性能时。 JavaScript const AppRout…...
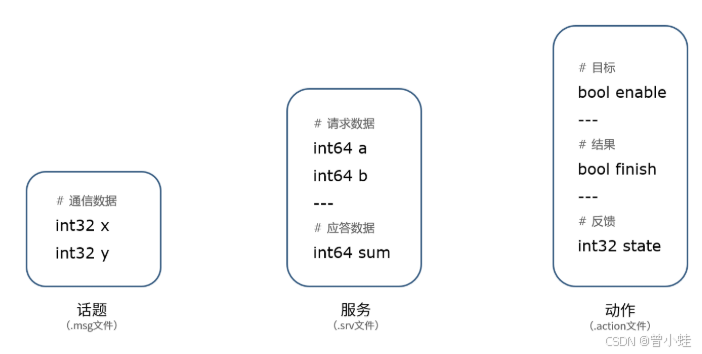
【ROS2】 核心概念6——通信接口语法(Interfaces)
古月21讲/2.6_通信接口 官方文档:Interfaces — ROS 2 Documentation: Humble documentation 官方接口代码实战:https://docs.ros.org/en/humble/Tutorials/Beginner-Client-Libraries/Single-Package-Define-And-Use-Interface.html ROS 2使用简化的描…...

matlab官方免费下载安装超详细教程2025最新matlab安装教程(MATLAB R2024b)
文章目录 准备工作MATLAB R2024b 安装包获取详细安装步骤1. 文件准备2. 启动安装程序3. 配置安装选项4. 选择许可证文件5. 设置安装位置6. 选择组件7. 开始安装8. 完成辅助设置 常见问题解决启动失败问题 结语 准备工作 本教程将帮助你快速掌握MATLAB R2024b的安装技巧&#x…...
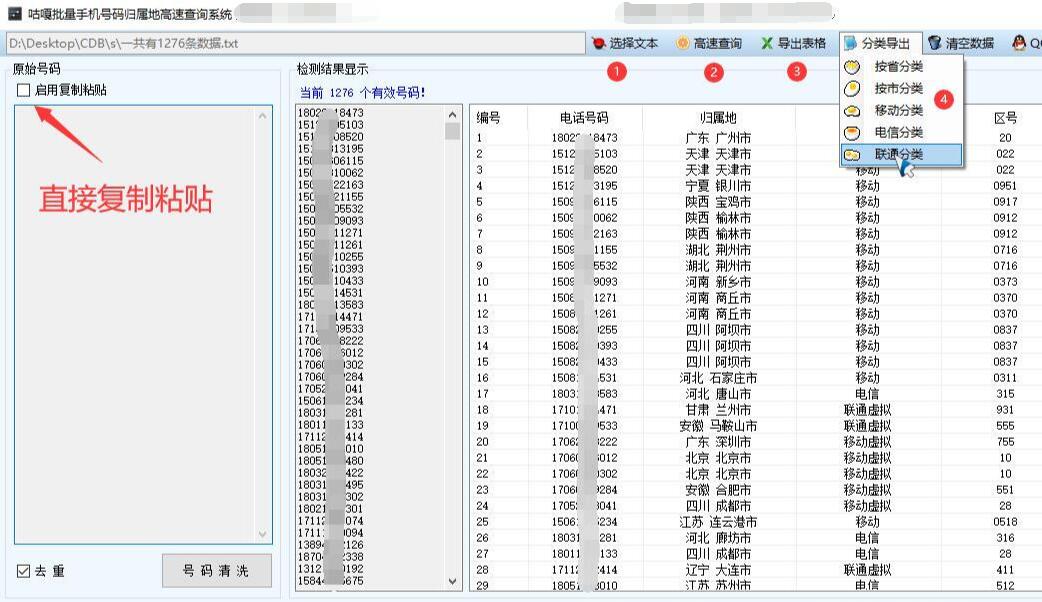
【运营商查询】批量手机号码归属地和手机运营商高速查询分类,按省份城市,按运营商移动联通电信快速分类导出Excel表格,基于WPF的实现方案
WPF手机号码归属地批量查询与分类导出方案 应用场景 市场营销:企业根据手机号码归属地进行精准营销,按城市或省份分类制定针对性推广策略客户管理:快速对客户手机号码进行归属地分类,便于后续客户关系管理数…...
ctf 基础
一、软件安装和基本的网站: 网安招聘网站 xss跨站脚本攻击 逆向:可以理解为游戏里的外挂 pwn最难的题目 密码学: 1、编码:base64 2、加密:凯撒 3、摘要:MD5、SHA1、SHA2 调查取证:杂项&am…...

掌握HTML文件上传:从基础到高级技巧
HTML中input标签的上传文件功能详解 一、基础概念 1. 文件上传的基本原理 在Web开发中,文件上传是指将本地计算机中的文件(如图片、文档、视频等)传输到服务器的过程。HTML中的<input type"file">标签是实现这一功能的基础…...

UE5无法编译问题解决
1. vs编译 2. 删除三个文件夹 参考...
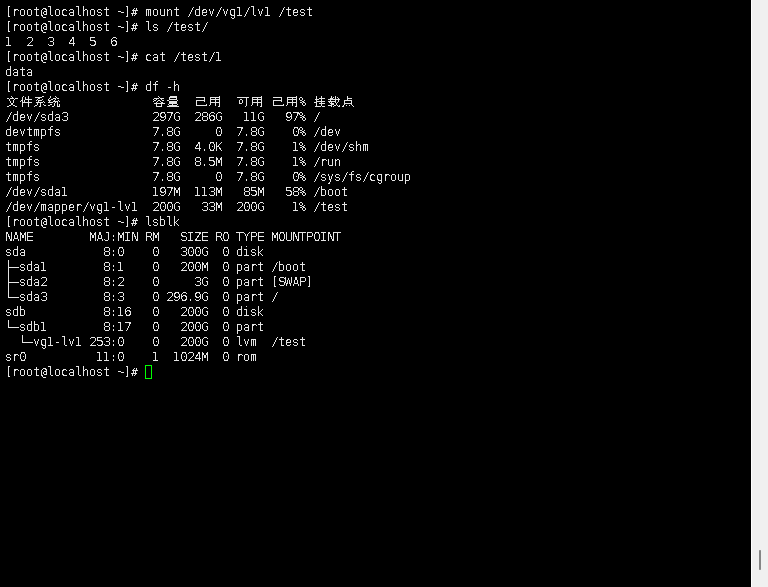
CentOS7原有磁盘扩容实战记录(LVM非LVM)【针对GPT分区】
一、环境 二、命令及含义 fdisk fdisk是一个较老的分区表创建和管理工具,主要支持MBR(Master Boot Record)格式的分区表。MBR分区表支持的硬盘单个分区最大容量为2TB,最多可以有4个主分区。fdisk通过命令行界面进行操…...

机器学习07-归一化与标准化
归一化与标准化 一、基本概念 归一化(Normalization) 定义:将数据缩放到一个固定的区间,通常是[0,1]或[-1,1],以消除不同特征之间的量纲影响和数值范围差异。公式:对于数据 ( x ),归一化后的值…...
AI agent与lang chain的学习笔记 (1)
文章目录 智能体的4大要素一些上手的例子与思考。创建简单的AI agent.从本地读取文件,然后让AI智能体总结。 也可以自己定义一些工具 来完成一些特定的任务。我们可以使用智能体总结一个视频。用户可以随意问关于视频的问题。 智能体的4大要素 AI 智能体有以下几个…...

优化 Spring Boot 应用启动性能的实践指南
1. 引言 Spring Boot 以其“开箱即用”的特性深受开发者喜爱,但随着项目复杂度的增加,应用的启动时间也可能会变得较长。对于云原生、Serverless 等场景而言,快速启动是一个非常关键的指标。 2. 分析启动过程 2.1 启动阶段概述 Spring Boot 的启动流程主要包括以下几个阶…...
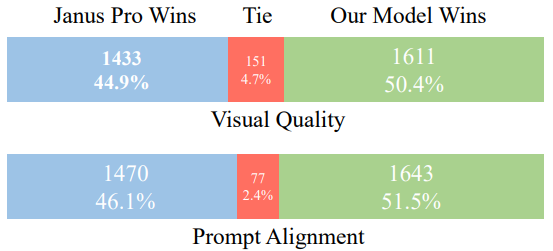
谢赛宁团队提出 BLIP3-o:融合自回归与扩散模型的统一多模态架构,开创CLIP特征驱动的图像理解与生成新范式
BLIP3-o 是一个统一的多模态模型,它将自回归模型的推理和指令遵循优势与扩散模型的生成能力相结合。与之前扩散 VAE 特征或原始像素的研究不同,BLIP3-o 扩散了语义丰富的CLIP 图像特征,从而为图像理解和生成构建了强大而高效的架构。 此外还…...
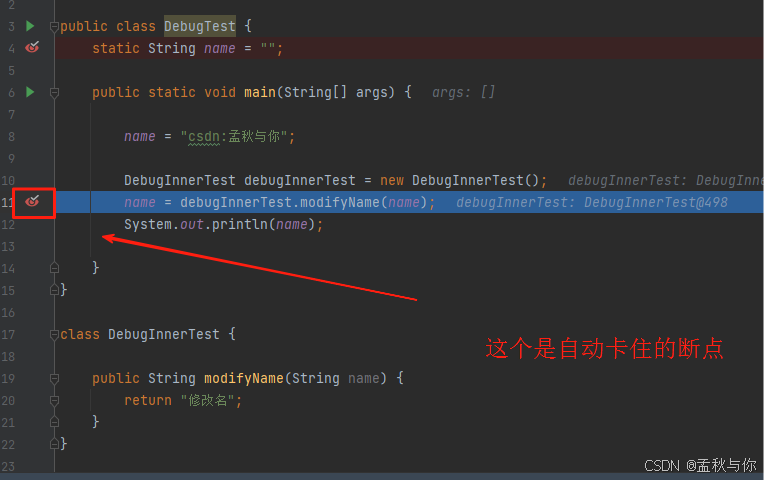
【idea】调试篇 idea调试技巧合集
前言:之前博主写过一篇idea技巧合集的文章,由于技巧过于多了,文章很庞大,所以特地将调试相关的技巧单独成章, 调试和我们日常开发是息息相关的,用好调试可以事半功倍 文章目录 1. idea调试异步线程2. idea调试stream流…...
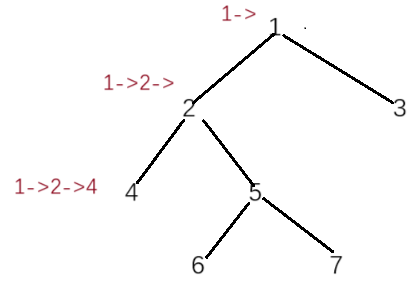
二叉树深搜:在算法森林中寻找路径
专栏:算法的魔法世界 个人主页:手握风云 目录 一、搜索算法 二、回溯算法 三、例题讲解 3.1. 计算布尔二叉树的值 3.2. 求根节点到叶节点数字之和 3.3. 二叉树剪枝 3.4. 验证二叉搜索树 3.5. 二叉搜索树中第 K 小的元素 3.6. 二叉树的所有路径 …...

golang 安装gin包、创建路由基本总结
文章目录 一、安装gin包和热加载包二、路由简单场景总结 一、安装gin包和热加载包 首先终端新建一个main.go然后go mod init ‘项目名称’执行以下命令 安装gin包 go get -u github.com/gin-gonic/gin终端安装热加载包 go get github.com/pilu/fresh终端输入fresh 运行 &…...
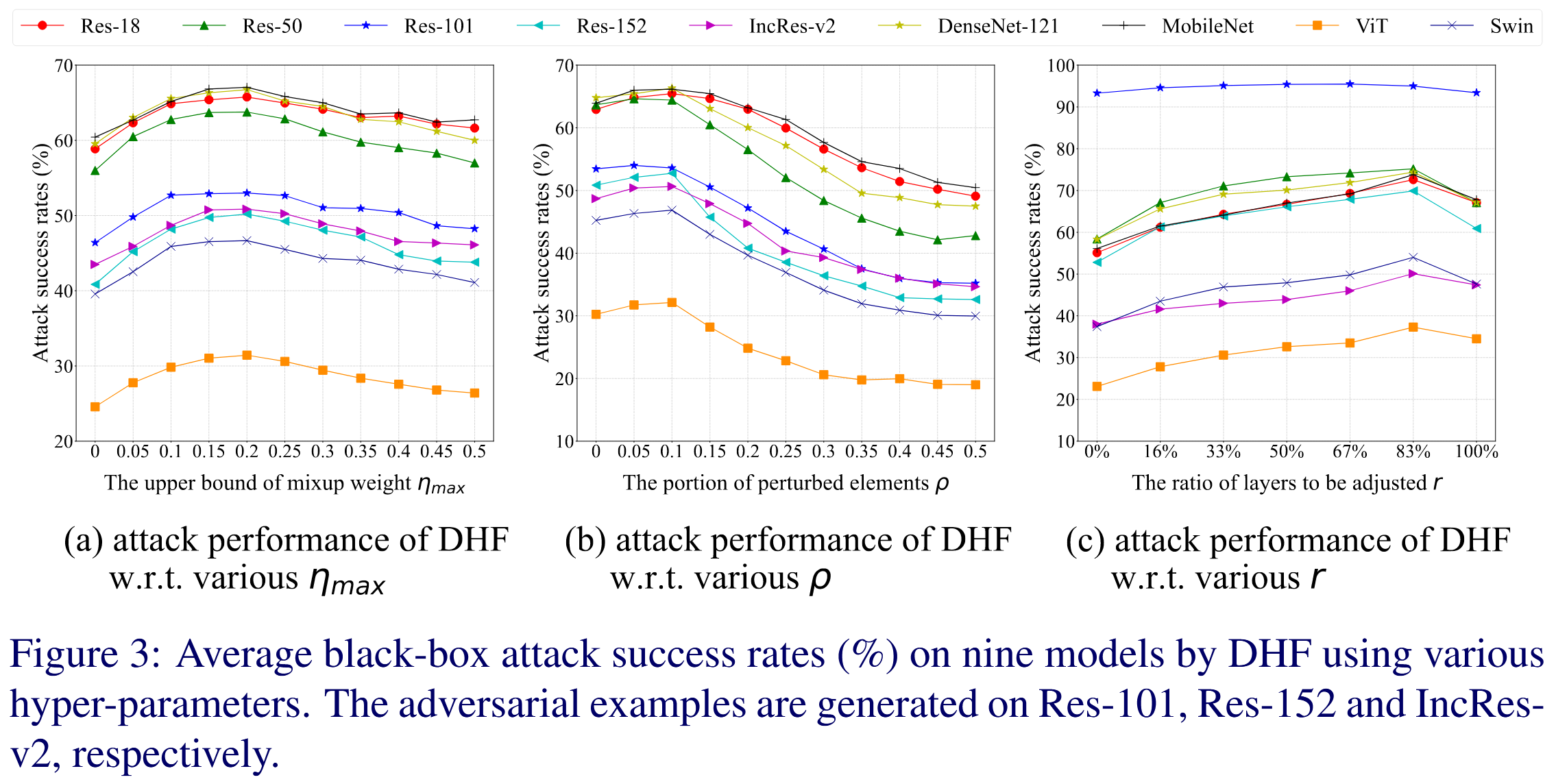
BMVC2023 | 多样化高层特征以提升对抗迁移性
Diversifying the High-level Features for better Adversarial Transferability 摘要-Abstract引言-Introduction相关工作-Related Work方法-Methodology实验-Experiments结论-Conclusion 论文链接 GitHub链接 本文 “Diversifying the High-level Features for better Adve…...
有哪些GIF图片转换的开源工具
以下是关于GIF图片转换的开源工具的详细总结,涵盖功能特点、适用场景及用户评价: 1. FFmpeg 功能特点: 作为开源命令行工具,FFmpeg支持视频转GIF、调整帧率、分辨率、截取片段等操作,可通过脚本批量处理。适用场景: 适合开发者或技术用户进行高效批处理,常用于服务器端自…...
C++—特殊类设计设计模式
目录 C—特殊类设计&设计模式1.设计模式2.特殊类设计2.1设计一个无法被拷贝的类2.2设计一个只能在堆上创建对象的类2.3设计一个只能在栈上创建对象的类2.4设计一个类,无法被继承2.5设计一个类。这个类只能创建一个对象【单例模式】2.5.1懒汉模式实现2.5.2饿汉模…...

Android 手写签名功能详解:从原理到实践
Android 手写签名功能详解 1. 引言2. 手写签名核心实现:SignatureView 类3. 交互层实现:MainActivity 类4. 布局与配置5. 性能优化与扩展方向 1. 引言 在电子政务、金融服务等移动应用场景中,手写签名功能已成为提升用户体验与业务合规性的关…...
Level2.8蛇与海龟(游戏)
#小龟快跑游戏 输入难度(1-5),蛇追到龟,游戏结束 #分析问题:从局部>整体 #游戏画面:创建画笔(海龟蛇)>1.海龟移动(键盘控制)>2.蛇(自动追踪,海龟位置)>3.海龟(限定范围,防止跑出画布之外)>4.游戏&…...

【Android构建系统】如何在Camera Hal的Android.bp中选择性引用某个模块
背景描述 本篇文章是一个Android.bp中选择性引用某个模块的实例。 如果是Android.mk编译时期,在编译阶段通过某个条件判断是不是引用某个模块A, 是比较好实现的。Android15使用Android.bp构建后,要想在Android.bp中通过自定义的一个变量或者条件实现选…...

【Canvas与诗词】醉里挑灯看剑 梦回吹角连营
【成图】 【代码】 <!DOCTYPE html> <html lang"utf-8"> <meta http-equiv"Content-Type" content"text/html; charsetutf-8"/> <head><title>醉里挑灯看剑梦回吹角连营 Draft1</title><style type"…...

Hue面试内容整理-Hue 架构与前后端通信
Cloudera Hue 是一个基于 Web 的 SQL 助手,旨在为数据分析师和工程师提供统一的界面,以便与 Hadoop 生态系统中的各个组件(如 Hive、Impala、HDFS 等)进行交互。其架构设计强调前后端的分离与高效通信,确保系统的可扩展性和可维护性。以下是 Hue 架构及其前后端通信机制的…...

Linux搜索
假如我们要搜索 struct sockaddr_in 我们在命令终端输入 cd/usr/include/ //进入头文件目录地址 /usr/include/ grep " struct sockaddr_in { " *-nir (*是在当前目录,n 是找出来显示行数…...

Git基础原理和使用
Git 初识 一、版本管理痛点 在日常工作和学习中,我们经常遇到以下问题: - 通过不断复制文件来保存历史版本(如报告-v1、报告-最终版等) - 版本数量增多后无法清晰记住每个版本的修改内容 - 项目代码管理存在同样问题 二、版本控…...
实现视频分片上传 OSS
访问 OSS 有两种方式,本文用到的是使用临时访问凭证上传到 OSS,不同语言版本的代码参考: 使用STS临时访问凭证访问OSS_对象存储(OSS)-阿里云帮助中心 1.安装并使用 首先我们要安装 OSS: npm install ali-oss --save 接着我们…...

网络I/O学习(一)
一、什么是网络IO? 就是客户端和服务端之间的进行通信的通道(fd)。 二、网络IO通信步骤 1、建立套接字 int socketfd socket(AF_INET, SOCK_STREAM, 0);struct sockaddr_in servaddr; servaddr.sin_family AF_INET; servaddr.sin_addr.s_addr htonl(INADDR_A…...

4:OpenCV—保存图像
将图像和视频保存到文件 在许多现实世界的计算机视觉应用中,需要保留图像和视频以供将来参考。最常见的持久化方法是将图像或视频保存到文件中。因此,本教程准备解释如何使用 OpenCV C将图像和视频保存到文件中。 将图像保存到文件 可以学习如何保存从…...