Text2SQL:自助式数据报表开发---0517
Text2SQL技术
早期阶段:依赖于人工编写的规则模板来匹配自然语言和SQL语句之间的对应关系
机器学习阶段:采用序列到序列模型等机器学习方法来学习自然语言与SQL之间的关系
LLM阶段:借助LLM强大的语言理解和代码生成能力,利用提示工程,微调等方法将Text2SQL性能提升到新的高度
我们目前已处于LLM阶段,基于LLM 的 Text-to-saL系统会包含以下几个步骤
自然语言理解:分析用户输入的自然语言问题,理解其意图和语义。
模式链接: 将问题中的实体与数据库模式中的表和列进行链接。
SQL生成:根据理解的语义和模式链接结果,生成相应的 SQL查询语句。
SQL执行:在数据库上执行SQL查询,将结果返回给用户,(function call)
LLM模型选择
闭源模型,收费且数据上传服务器

开源模型:

Qwen72B开源天花板,但贵,会用7B比较多
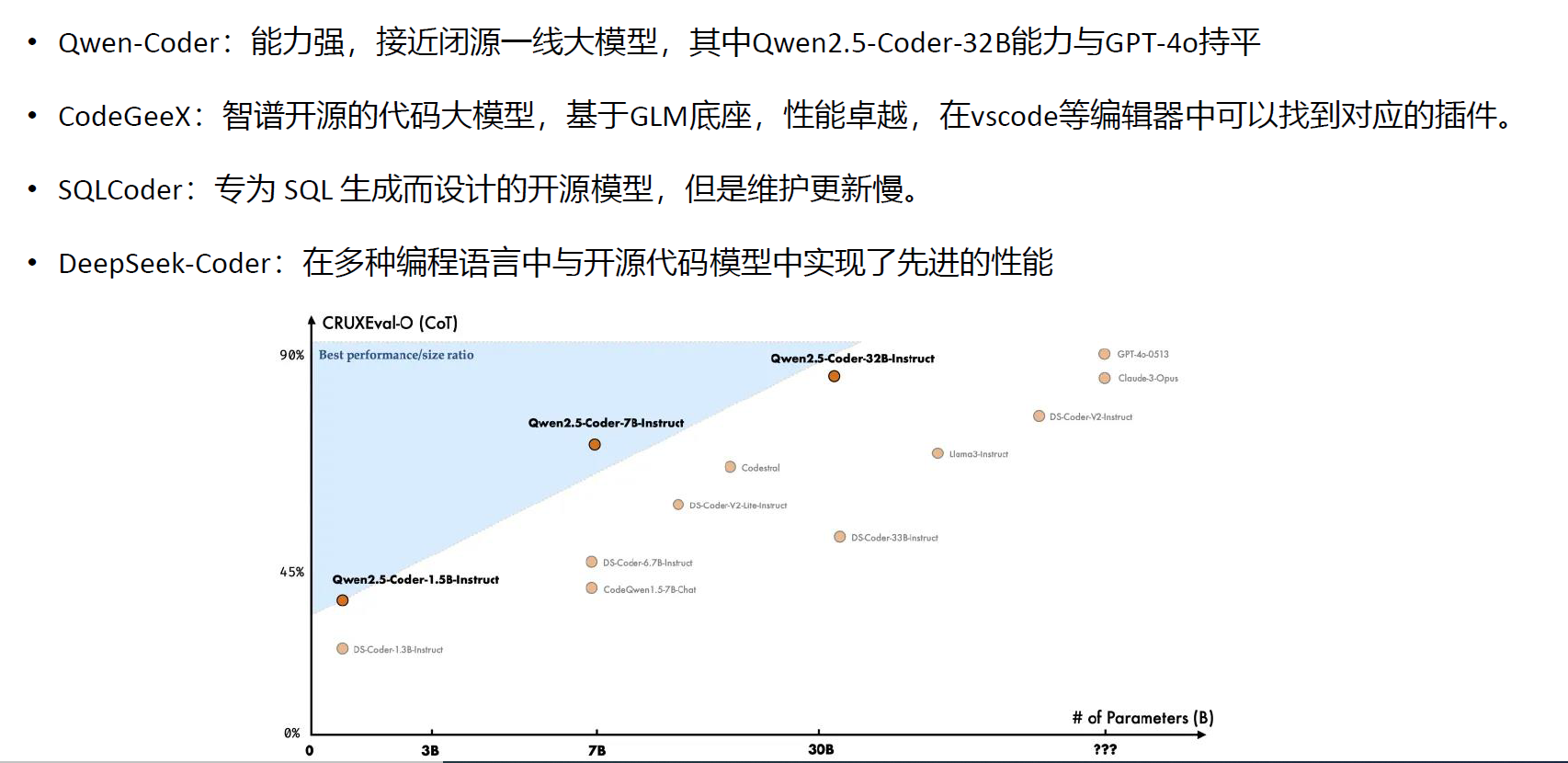
横向是参数,纵向是性能,性价比看斜率
写代码Qwen-coder,CodeGeex
Function Call-->SQL执行
搭建SQL Copilot

LangChain中的SQL Agent
SQL Agent如何通过自然语言,撰写SQL
1)通过 sql_db_list_tables,看到数据库中的表都有哪些
2)思考,我需要查哪张表(基于用户的Query)
3)Action: sql_db_schema
找到对应数据表的 表结构(CREATE TABLE)
4)基于表结构,和用户的Query =>撰写SQL语句
5)执行SQL =>得到SQL执行后的结果
6)再思考是否能回答用户的问题
Thinking:如果表特别多的情况下,不可能把所有表结构传入大模型吧
是的,如果有10万张表,光是10万张表名,大模型都看不过来;
助手是分业务场景的,每个业务场景的表的数量就不会太多,分而治之。
Thinking:可不可以用知识库来限定使用的表结构?
一般知识库适用于保存之前查询问题的SQL语句的
Query =>SQL之间的问答对;
RAG的作用是给LLM提供开卷考试;
LLM的考试:用户给你Query,你写SQL
Thinking:如何处理自然语言中隐含的多层逻辑(如嵌套子查询,多条件连接),以此生成复杂的SQL,有什么技巧?
LLM写复杂的SQL,一般处理3张表联查是没有问题;
我们可能会有一些规则,或者存在多个使用字段表达同一个意思***
1)COMMENTS,注释
2)向量数据库,存储着过去的Query => SQL(对的答案)
Thinking:拿到数据库数据后如何保证后续的生成不影响数字的准确?
SQL执行后,得到dataframe,LLM会基于dataframe进行后续的推理
Thinking:如果SQL一直不正确,可否人工写个准确的SQL给大模型,并与问题关联,这里就可以用向量数据库
自己编写(LLM+Prompt)
Thinking:直接使用SQL+LLM会有什么问题?
1)多个相似的数据表 =>导致Langchain会尝试多次生成SQL
2)用户Prompt太宽泛 =>生成的结果,不是用户想要的
所以得给Agent配备专有的知识库,在prompt中动态完善和query相关的context
SQL+向量数据库+LLM:
向量数据库可以提供领域知识,当用户检索某个问题的时候=>从向量数据库中找到相关的内容,放到prompt中=>提升SQL查询的相关性,保留以前的答案
RAG技术(Retrieval Augmented Generational)
在prompt中增加few-shot examples
专门定制搜索工具,从向量数据库中检索到与用户query相近的知识
SQL + 向量数据库+ LLM 使用:
如果想让LLM使用tool(可以按照某个顺序,执行完这个再执行下一个),比较有效的方式是写在prompt中,而不是在tool description中进行定义
向量数据库的作用:
给Prompt提供更多的context,用于LLM进行决策
CASE:保险场景SQL Copilot实战

Qwen2.5 7B或者72B CodeGeex

在这三种写法中,写法3可能是最好的,原因如下:
1. 结构清晰
写法3采用了一种正式的模板格式,将问题、输入和响应明确分开,使整个提示的逻辑非常清晰:
-
Question:明确指出了用户的问题。 -
Input:提供了数据表的建表语句(create_sql),这对于理解表结构和字段非常重要。 -
Response:清晰地指出了生成的 SQL 语句的位置。
这种结构化的方式可以帮助模型更好地理解任务需求,减少歧义。
2. 信息完整
写法3包含了以下关键信息:
-
问题描述:明确指出了用户需要解决的问题。
-
输入数据:提供了数据表的建表语句,帮助模型理解数据结构。
-
输出格式:指定了生成的 SQL 语句的位置和格式。
这种完整性使得模型能够更全面地理解任务,从而生成更准确的 SQL 查询。
3. 易于扩展
写法3的模板化设计使得它非常易于扩展。如果需要增加更多的信息或步骤,可以在模板中轻松添加新的部分。例如,如果需要增加对数据表的中文描述或其他约束条件,可以很方便地整合到模板中。
4. 可读性高
写法3的格式非常清晰,易于阅读和维护。无论对于开发人员还是模型来说,都能快速理解提示的内容和结构。
5. 减少歧义
由于写法3明确了每个部分的内容和格式,减少了模型对提示的误解。相比之下,写法1和写法2虽然也能传递必要的信息,但结构上不如写法3清晰,容易导致模型在理解上出现偏差。
对比其他写法
-
写法1:
-
优点:简洁,直接在提示中包含表描述。
-
缺点:缺乏结构化,模型可能难以快速定位关键信息。
-
-
写法2:
-
优点:使用了注释,提供了一定的结构。
-
缺点:信息组织不够清晰,模型可能需要更多时间来解析提示。
-
总结
写法3通过其清晰的结构、完整的信和高可读性,能够更有效地引导模型生成准确的 SQL 查询。这种模板化的方法不仅提高了生成结果的质量,还便于维护和扩展,因此在实际应用中可能表现最佳。

补全代码能力
Thinking:text2SQL,数据保护问题是不是解决不了,生产环境有落地吗?
在生产环境中,可以用开源模型,比如Qwen2.5-Coder
可以用云端数据库,也可以自己电脑本地搭建数据库
Thinking:如何想知道哪个大模型,用哪种格式会效果更好
开源大模型:
Qwen2.5-Coder ***,CodeGeex,SQLCoder =>代码补全大模型
prompt = f"""-- language: SQL
### Question: {query}
### Input: {create sql}
### Response:
Here is the SQL query l have generated to answer the question `{query}:
```sql
''''''
导出建表语句,创建SQL数据表的SQL语句
查询SQL数据,机器学习的建模=>Function Call,让LLM调用Function Call来执行特定的任务。
助手的结构设计:
1)为什么要划分很多助手?
因为用户的需求是多样的,数据表是多样的,Function Call也是多样的;
LLM直接来判断,选择哪个数据表,哪个FunctionCall =>比较困难,容易出错
所以划分不同的助手,每个助手有自己的业务场景(职责),也有自己匹配的数据
表,和Function cal。这样执行起来更清晰
2)能否打造一个 all in one 助手
Step1,先打造多个助手,比如100个
Step2,all in one 助手 =>先判断调用哪个助手
相当于是一个分诊台;
query input =>给到特定的助手;
Vanna使用
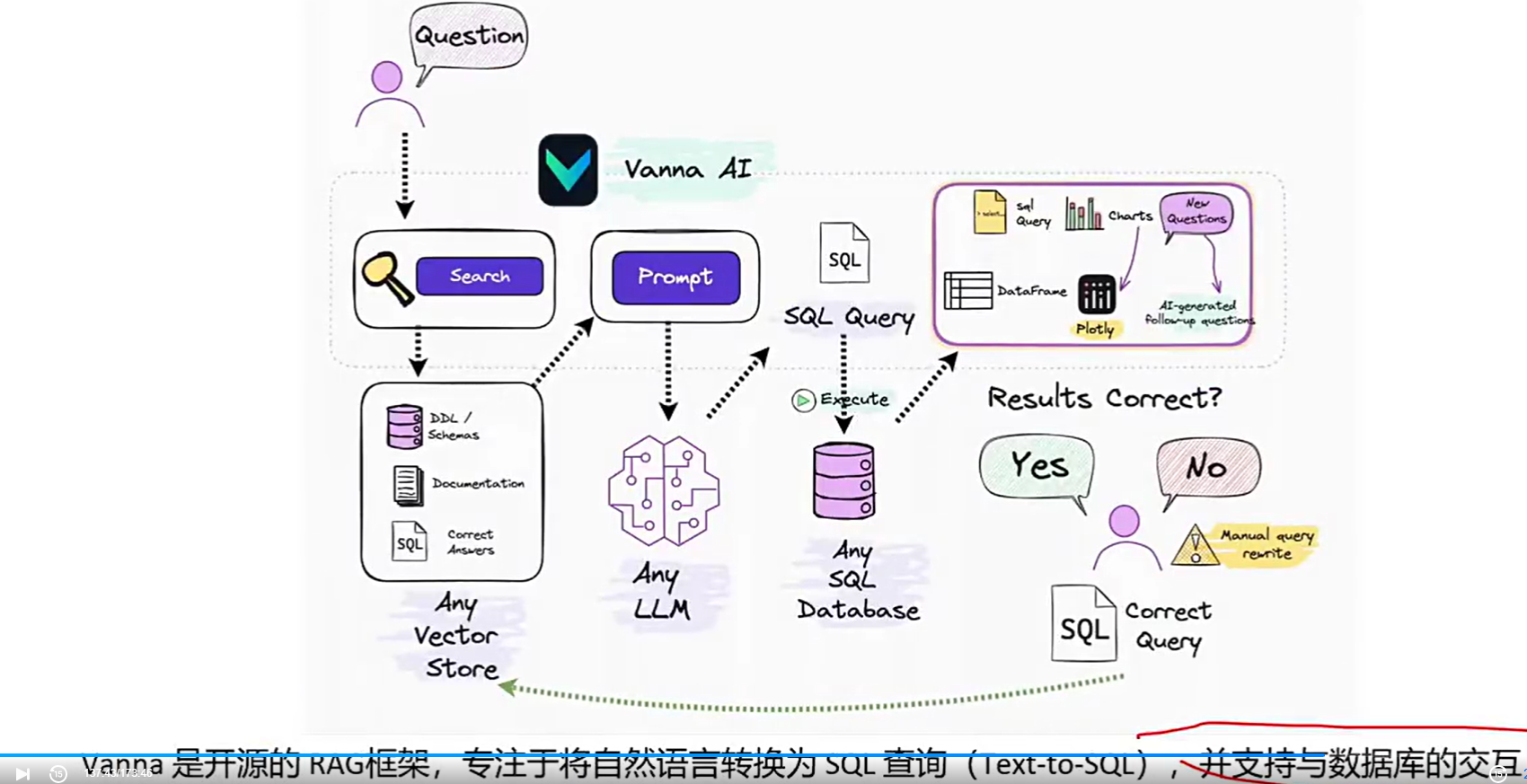

Vanna工作原理:
---训练RAG模型
输入数据库的元数据(如INFORMATION_SCHEMA),DDL语句,文档或示例SQL
模型将这些信息转换为向量并存储到向量库中,用于后续检索
---生成SQL
用户提问时,系统从向量库中检索相关上下文,组装成Prompt发送给LLM
LLM生成SQL后,自动执行并返回结果(表格或图标)
Vanna使用步骤:
vanna安装
pip install vanna,可选扩展如vanna[chromadb,mysql]支持本地化部署
连接数据库
自定义run_sql方法(如MySQL需要通过mysql.connector返回Pandas DataFrame)
训练模型
通过DDL,文档或SQL示例训练,例如:
vn.train(ddl="CREATE TABLE users(id INT PRIMARY KEY,name VARCHAR(100))")
提问与查询
调用vn.ask("查询销售额最高产品"),生成并执行SQL
ask函数
作用:用户通过自然语言提问时调用此函数,它是查询的核心入口,会依次调用generate_sql、run_sq1、generate_plotly_code、get_plotly_figure四个函数来完成整个查询及可视化的过程。
工作流程:
-->首先将用户的问题转换成向量表示,然后在向量数据库中检索与问题语义最相似的DDL语句、文档和SQL查询。
-->将检索到的信息和用户的问题一起提供给LLM,生成对应的SaL查询。
-->执行生成的SQL查询,并将查询结果以表格和Plotly图表的形式返回给用户,
比如:vn.ask("查询heros表中 英雄攻击力前5名的英雄")
generate sql函数
作用:根据用户输入的自然语言问题,生成对应的SQL语句。
工作流程:
调用get_similar_question_sql函数,在向量数据库中检索与问题相似的sql/question对。
在向量数据库中检索与问题相似的建表语句ddl。
调用get related ddl函数,
调用get related documentation函数,在向量数据库中检索与问题相似的文档
调用get_sql_prompt函数,结合上述检索到的信息生成prompt,然后将prompt提供给LLM,生成SQL语句。
比如:sql=vn.generate_sql("査询heros表中 英雄攻击力前5名的英雄")
run_sql函数
作用:执行generate_sql函数生成的SQL语句,并返回查询结果
工作流程:将生成的SQL语句发送到连接的数据库中执行,获取并返回查询结果。
比如:
sql=vn.generate_sql("査询heros表中 英雄攻击力前5名的英雄")
vn.run sql(sql)
=========================================================================
结构化数据库 SQL,非结构化数据库 NoSQL
SQL数据库 更有前景;oracle,mysql
AI大模型的项目,要处理数据,哪种数据更有价值,更容易看到结果?
RAG 处理很多非结构化的数据,难点在什么 =>数据清洗
结构化数据的 Text2SQL,更容易看到一些结果
3种搭建Text2SQL的能力:
1)LangChain
2)Vanna
3)开源的大模型 Code大模型的使用+prompt
Thinking:缺乏含义的话,在字段的备注里面加说明
1)字段的注释
2)有时候,还需要提供一些字段值,尤其是针对分类的字段
gender = male
gender ='男’
不光是建表语句需要给到 LLM,针对提问的分类字段,也需要给到大模型
Thinking:能介绍一些非结构化的数据清洗的比较好的方法吗?
工具:使用LLM来进行数据清洗
非结构化数据 常见的问题是什么?
1)文件过时
2)标注,文档的注释(摘要、关键词、提一些文档知识的问题)
提升RAG的能力
摘要 =>LLM写摘要
关键词 =>LLM写关键词抽取
给文档知识提一些问题=>LLM写知识问题
机器学习的建模:
1)写代码,可以用Cursor
2)需要了解都有哪些机器学习模型,能做什么
LR线性回归,对特征的重要性进行计算
w1x1+w2x2+w3x3 = y
x1,x2,x3=>年卡人数,促销人数,普通人数
Thinking:机器学习建模这种是不是只有获取不到底层的时候才适用?除此之外在text2SQL中还有什么应用场景?
时间序列=>预测未来一段时间的y
d1,d2,d3,d4...dn,dn+1
相关文章:
Text2SQL:自助式数据报表开发---0517
Text2SQL技术 早期阶段:依赖于人工编写的规则模板来匹配自然语言和SQL语句之间的对应关系 机器学习阶段:采用序列到序列模型等机器学习方法来学习自然语言与SQL之间的关系 LLM阶段:借助LLM强大的语言理解和代码生成能力,利用提示…...
使用Visual Studio将C#程序发布为.exe文件
说明 .exe 是可执行文件(Executable File)的扩展名。这类文件包含计算机可以直接运行的机器代码指令,通常由编程语言(如 C、C、C#、Python 等)编译或打包生成。可以用于执行自动化操作(执行脚本或批处理操…...
连接mysql数据库,写入计算结果)
写spark程序数据计算( 数据库的计算,求和,汇总之类的)连接mysql数据库,写入计算结果
1. 添加依赖 在项目的 pom.xml(Maven)中添加以下依赖: xml <!-- Spark SQL --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.3.0…...
React Flow 边的基础知识与示例:从基本属性到代码实例详解
本文为《React Agent:从零开始构建 AI 智能体》专栏系列文章。 专栏地址:https://blog.csdn.net/suiyingy/category_12933485.html。项目地址:https://gitee.com/fgai/react-agent(含完整代码示例与实战源)。完整介绍…...
oracle 资源管理器的使用
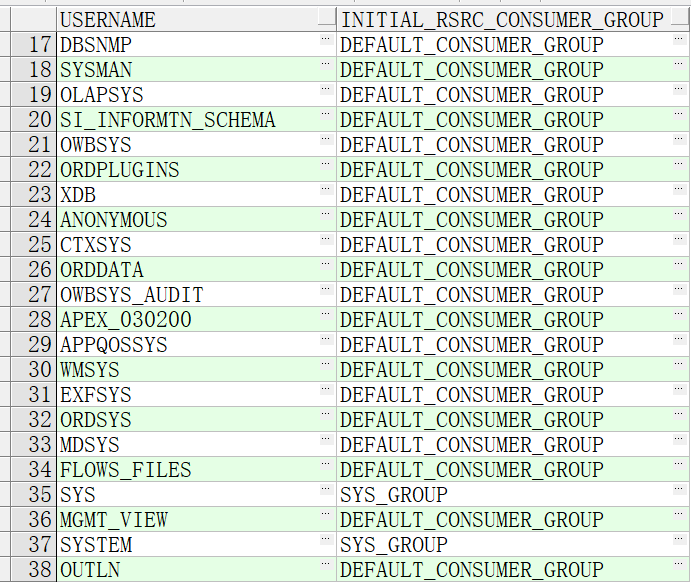
14.8.2资源管理器的使用 资源管理器控制CPU资源使用说明: 第一种分配方法:EMPHASIS CPU 分配方法确定在资源计划中对不同使用者组中的会话的重视程度。CPU占用率的分配级别为从1 到8,级别1 的优先级最高。百分比指定如何将CPU 资源分配给每…...

新手入门系列-linux系统下安装和使用docker
新手入门系列一 virtualbox+vagrant创建linux虚拟机 新手入门系列二 linux系统下安装和使用docker 前言 前面一章节我们安装了unbuntu虚拟机,这一节我们在虚拟机上安装和使用docker。 Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的…...

mysql中4种扫描方式和聚簇索引非聚簇索引【爽文一篇】
目录 一 mysql的聚簇索引&非聚簇索引 1.1 数据表 1.2 聚簇索引 1.3 非聚簇索引 1.4 覆盖索引 二 mysql的4种扫描查询 2.1 全表扫描 2.2 索引扫描 2.3 覆盖索引扫描 2.4 回表扫描 2.5 总结 三 mysql的回表查询详解 3.1 回表查询 一 mysql的聚簇索引&非聚簇…...
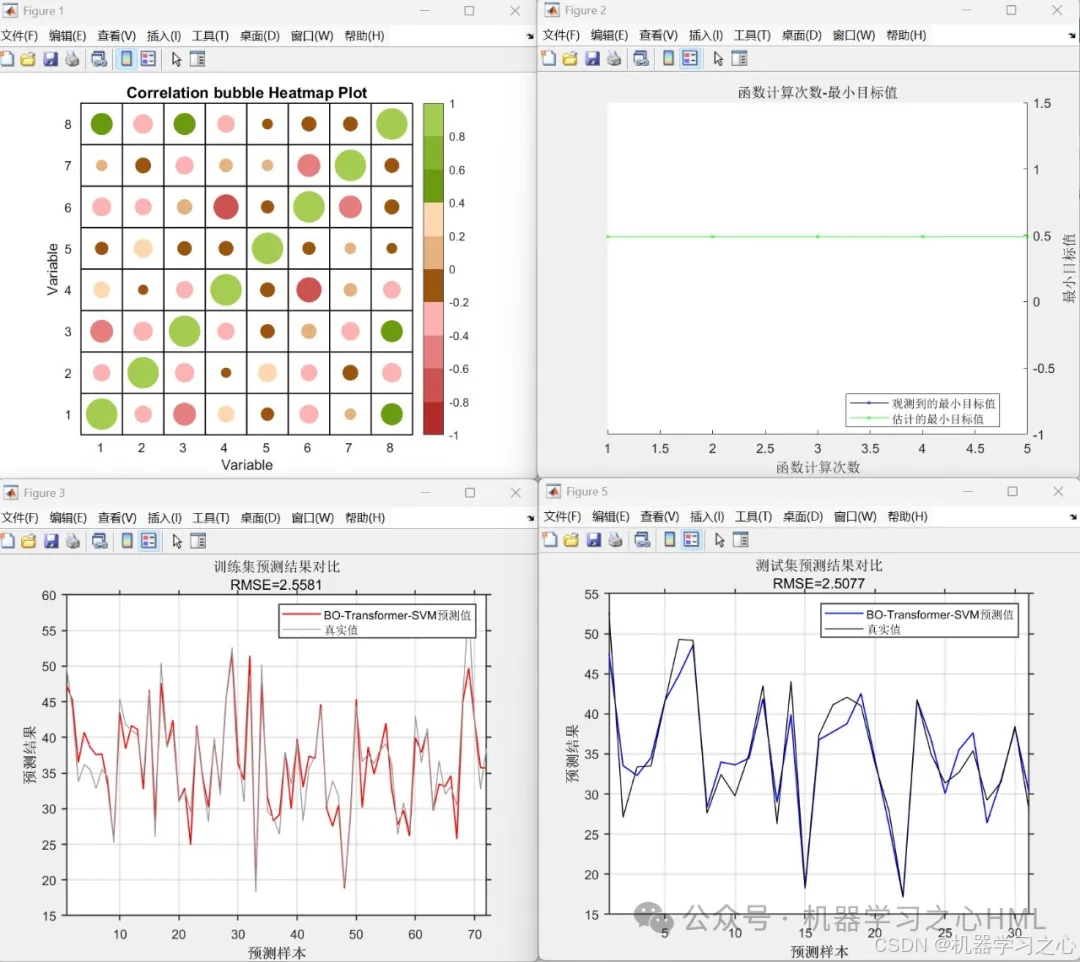
贝叶斯优化Transformer融合支持向量机多变量回归预测,附相关性气泡图、散点密度图,Matlab实现
贝叶斯优化Transformer融合支持向量机多变量回归预测,附相关性气泡图、散点密度图,Matlab实现 目录 贝叶斯优化Transformer融合支持向量机多变量回归预测,附相关性气泡图、散点密度图,Matlab实现效果一览基本介绍程序设计参考资料…...

水平可见直线--上凸包(andrew算法
P3194 [HNOI2008] 水平可见直线 - 洛谷 不过只有90% #include<bits/stdc.h> using namespace std; #define N 100011 typedef long long ll; typedef pair<ll,int> pii; int n; struct no {double k,b;int id; }a[N],an[N]; int k; bool cmp(no a,no b) {if(a.k…...

【mysql】并发 Insert 的死锁问题 第二弹
上次死锁的场景还历历在目(【mysql】并发 Insert 的死锁问题:Deadlock found when trying to get lock; try restarting transaction_1213 - deadlock found when trying to get lock; try-CSDN博客),这次又把代码写死…...
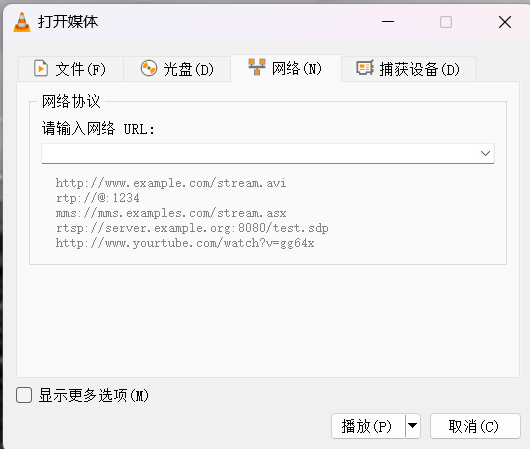
Docker配置SRS服务器 ,ffmpeg使用rtmp协议推流+vlc拉流
目录 演示视频 前期配置 Docker配置 ffmpeg配置 vlc配置 下载并运行 SRS 服务 推拉流流程实现 演示视频 2025-05-18 21-48-01 前期配置 Docker配置 运行 SRS 建议使用 Docker 配置 Docker 请移步: 一篇就够!Windows上Docker Desktop安装 汉化完整指…...
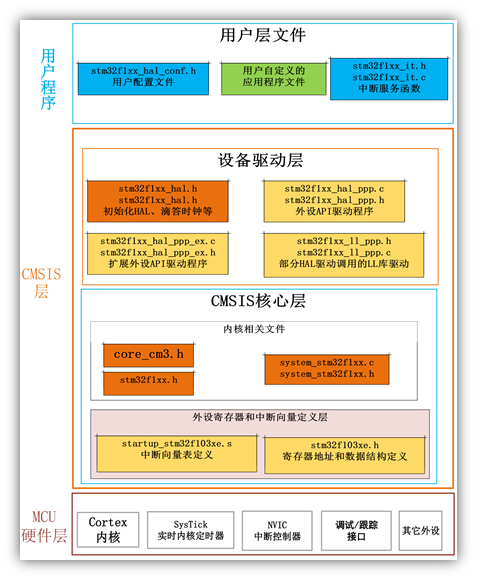
一个stm32工程从底层上都需要由哪些文件构成
原文链接:https://kashima19960.github.io/2025/05/17/stm32/一个stm32工程从底层上都需要由哪些文件构成/ 前言 我最近因为做课设要用到stm32,所以去找了一些开源的stm32工程来看看,然后发现现在新版的keil mdk对于环境的配置跟以前 相比发…...
[Mac] 开发环境部署工具ServBay 1.12.2
[Mac] 开发环境部署工具ServBay 链接:https://pan.xunlei.com/s/VOQS0LDsC_J6XU4p-R6voF6YA1?pwdnbyg# 非常给力的本地 Web 开发/测试环境工具:ServBay。之前我们本地搭个 PHP MySQL Nginx 环境,或者搞个 PHP web 环境啥的,不…...
商城小程序源码介绍
今天要为大家介绍一款基于ThinkPHP、FastAdmin以及UniApp开发的商城小程序源码,这款源码在设计和功能上都有不俗的表现,非常适合想要搭建线上商城的开发者。 该源码采用了ThinkPHP作为后端框架,利用其强大的性能和灵活性,保障了系…...

鸿蒙OSUniApp 实现图片上传与压缩功能#三方框架 #Uniapp
UniApp 实现图片上传与压缩功能 前言 在移动应用开发中,图片上传是一个非常常见的需求。无论是用户头像、朋友圈图片还是商品图片,都需要上传到服务器。但移动设备拍摄的图片往往尺寸较大,直接上传会导致流量消耗过大、上传时间过长&#x…...

科技项目验收测试对软件产品和企业分别有哪些好处?
科技项目验收测试是指在项目的开发周期结束后,针对项目成果进行的一系列验证和确认活动。其目的是确保终交付的产品或系统符合预先设定的需求和标准。验收测试通常包括功能测试、性能测试、安全测试等多个方面,帮助企业评估软件在实际应用中的表现。 科…...

javascript和vue的不同
1. 数据绑定方式 JavaScript(原生) 手动操作 DOM:通过document.querySelector()等方法获取 DOM 元素,然后直接修改其属性或内容。 示例: <div id"counter">0</div> <button onclick"i…...

duxapp 2025-01-06更新 CLI新增帮助支持,优化基础模块结构
CLI 新增帮助命令 yarn duxapp -h yarn duxapp --helpyarn duxapp icon -h yarn duxapp icon create -h基础库 完善所有函数和组件的Types移除 Detail 组件移除 checkLocationPermission 方法移除 duxapp/utils/app.js 有关于模块的方法移除 Queue 队列功能移除 recursionSe…...

汽车零部件冲压车间MES一体机解决方案
在当前制造业升级的大背景下,提升生产效率、实现精细化管理已成为企业竞争力的关键。特别是在汽车零部件制造领域,冲压车间作为生产流程中的重要一环,其生产数据的实时采集与分析对于确保产品质量、优化生产节拍、降低运营成本至关重要。今天…...

hysAnalyser 从MPEG-TS导出ES功能说明
摘要 hysAnalyser 是一款特色的 MPEG-TS 数据分析工具。本文主要介绍了 hysAnalyser 从MPEG-TS 中导出选定的 ES 或 PES 功能(版本v1.0.003),以便用户知悉和掌握这些功能,帮助分析和解决各种遇到ES或PES相关的实际问题。hysAnalyser 支持主流的MP1/MP2/…...
家里wifi不能上网或莫名跳转到赌博及色情网站就是域名被劫持、DNS被污染了
文章目录 定义上网过程域名被劫持可能阶段案例排查工具 解决方法清除系统DNS缓存查看DNS缓存清除DNS缓存 登录路由器,设置DNS可用的DNS地址: 找网络运营商报警 定义 DNS(Domain Name System,域名系统)劫持,…...

基于SSM实现的健身房系统功能实现十六
一、前言介绍: 1.1 项目摘要 随着社会的快速发展和人们健康意识的不断提升,健身行业也在迅速扩展。越来越多的人加入到健身行列,健身房的数量也在不断增加。这种趋势使得健身房的管理变得越来越复杂,传统的手工或部分自动化的管…...

【Java微服务组件】分布式协调P1-数据共享中心简单设计与实现
欢迎来到啾啾的博客🐱。 记录学习点滴。分享工作思考和实用技巧,偶尔也分享一些杂谈💬。 欢迎评论交流,感谢您的阅读😄。 目录 引言设计一个共享数据中心选择数据模型键值对设计 数据可靠性设计持久化快照 (…...

[Harmony]大文件持久化
1.添加权限 在module.json5文件中添加权限 "requestPermissions": [{"name": "ohos.permission.READ_WRITE_USER_FILE", // 读写用户数据"reason": "$string:read_write_user_file_reason","usedScene": {"…...

pgsql14自动创建表分区
最近有pgsql的分区表功能需求,没想到都2025年了,pgsql和mysql还是没有自身支持自动创建分区表的功能 现在pgsql数据库层面还是只能用老三样的办法来处理这个问题,每个方法各有优劣 1. 触发器 这是最传统的方法,通过创建一个触发…...
cursor/vscode启动项目connect ETIMEDOUT 127.0.0.1:xx
现象: 上午正常使用cursor/vscode,因为需要写前端安装了nodejs16.20和vue2,结果下午启动前端服务无法访问,浏览器一直转圈。接着测试运行最简单的flask服务,vscode报错connect ETIMEDOUT 127.0.0.1:xx,要么…...

Leetcode 3553. Minimum Weighted Subgraph With the Required Paths II
Leetcode 3553. Minimum Weighted Subgraph With the Required Paths II 1. 解题思路2. 代码实现 题目链接:3553. Minimum Weighted Subgraph With the Required Paths II 1. 解题思路 这一题很惭愧,并没有自力搞定,是看了大佬们的解答才有…...

兼顾长、短视频任务的无人机具身理解!AirVista-II:面向动态场景语义理解的无人机具身智能体系统
作者:Fei Lin 1 ^{1} 1, Yonglin Tian 2 ^{2} 2, Tengchao Zhang 1 ^{1} 1, Jun Huang 1 ^{1} 1, Sangtian Guan 1 ^{1} 1, and Fei-Yue Wang 2 , 1 ^{2,1} 2,1单位: 1 ^{1} 1澳门科技大学创新工程学院工程科学系, 2 ^{2} 2中科院自动化研究所…...

springboot踩坑记录
之前运行好端端的项目,今天下午打开只是添加了一个文件之后 再运行都报Failed to configure a DataSource: url attribute is not specified and no embedded datasource could be configured.Reason: Failed to determine a suitable driver class Action: Conside…...

SparkSQL基本操作
以下是 Spark SQL 的基本操作总结,涵盖数据读取、转换、查询、写入等核心功能: 一、初始化 SparkSession scala import org.apache.spark.sql.SparkSession val spark SparkSession.builder() .appName("Spark SQL Demo") .master("…...