语音识别——语音转文字
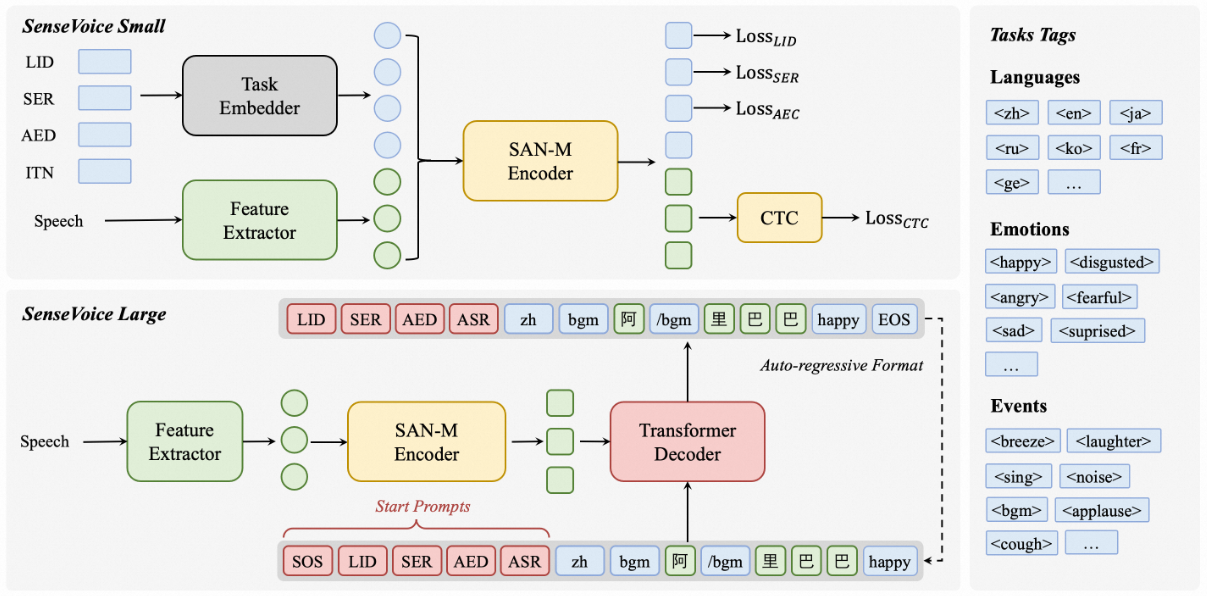
SenseVoiceSmall阿里开源大模型,SenseVoice 是具有音频理解能力的音频基础模型,包括语音识别(ASR)、语种识别(LID)、语音情感识别(SER)和声学事件分类(AEC)或声学事件检测(AED)。经过超过40万小时的数据训练,支持50多种语言
SenseVoice 专注于高精度多语言语音识别、情感辨识和音频事件检测
- 多语言识别: 采用超过 40 万小时数据训练,支持超过 50 种语言,识别效果上优于 Whisper 模型。
- 富文本识别:
- 具备优秀的情感识别,能够在测试数据上达到和超过目前最佳情感识别模型的效果。
- 支持声音事件检测能力,支持音乐、掌声、笑声、哭声、咳嗽、喷嚏等多种常见人机交互事件进行检测。
- 高效推理: SenseVoice-Small 模型采用非自回归端到端框架,推理延迟极低,10s 音频推理仅耗时 70ms,15 倍优于 Whisper-Large。
- 微调定制: 具备便捷的微调脚本与策略,方便用户根据业务场景修复长尾样本问题。
- 服务部署: 具有完整的服务部署链路,支持多并发请求,支持客户端语言有,python、c++、html、java 与 c# 等。
项目地址:https://github.com/FunAudioLLM/SenseVoice
以下为模型调用方法,输出的文字可能会包括一些表情,可以通过正则化的方式移除这些表情:
import pyaudio
import numpy as np
import wave
import osfrom funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocessmodel = AutoModel(model=r"D:\Downloads\SenseVoiceSmall",trust_remote_code=True,remote_code="./model.py", vad_model="fsmn-vad",vad_kwargs={"max_single_segment_time": 30000},device="cpu",use_itn=True,disable_update=True,disable_pbar = True,disable_log = True
)# 利用语音识别模型将音频数据转换为文本
def sound2text(audio_file):"""利用语音识别模型将音频数据转换为文本"""# enres = model.generate(input=audio_file,cache={},language="zh", # "zh", "en", "yue", "ja", "ko", "nospeech"use_itn=True,batch_size_s=60,merge_vad=True, #merge_length_s=15,)text = rich_transcription_postprocess(res[0]["text"])return textif __name__ == "__main__":# 读取音频文件audio_file = r"C:\Users\lvkong\Desktop\temp_wave\waving_20250513_135512_嗯鹅.wav"# 如果音频文件存在,直接读取if os.path.exists(audio_file):with wave.open(audio_file, 'rb') as wf:audio_data = wf.readframes(wf.getnframes())else:# 否则录制一段音频print("请开始说话(录音5秒钟)...")CHUNK = 1024FORMAT = pyaudio.paInt16CHANNELS = 1RATE = 16000RECORD_SECONDS = 5p = pyaudio.PyAudio()stream = p.open(format=FORMAT,channels=CHANNELS,rate=RATE,input=True,frames_per_buffer=CHUNK)frames = []for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):data = stream.read(CHUNK)frames.append(data)stream.stop_stream()stream.close()p.terminate()# 保存录音with wave.open(audio_file, 'wb') as wf:wf.setnchannels(CHANNELS)wf.setsampwidth(p.get_sample_size(FORMAT))wf.setframerate(RATE)wf.writeframes(b''.join(frames))audio_data = b''.join(frames)print(f"录音已保存为 {audio_file}")# 利用语音识别模型将音频数据转换为文本text = sound2text(audio_file)# 输出文本print("识别结果:")print(text)正则化移除除中文外的其他内容:
# 提取字符串中的汉字
def extract_chinese(input_string):"""提取字符串中的汉字:param input_string: 原始字符串:return: 转换后的中文字符串"""# 使用正则表达式提取所有汉字chinese_characters = re.findall(r'[\u4e00-\u9fa5]', input_string)# 将汉字列表合并为字符串chinese_text = ''.join(chinese_characters)# 返回中文字符串return chinese_text此外,SenseVoiceSmall模型还支持pipeline的方式加载调用
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasksinference_pipeline = pipeline(task=Tasks.auto_speech_recognition,model=r'D:\Downloads\SenseVoiceSmall',model_revision="master",device="cuda:0",use_itn=True,disable_update=True)rec_result = inference_pipeline(r"D:\Project\Chat_Project\output_5.wav")
print(rec_result)之前的代码有bug,存在录制的音频速度过快的问题,及音频每帧会丢失部分的问题,这代码修复了以上的bug,具体修改如下:
1. 增加了循环缓冲区:
- 添加了collections.deque作为音频缓冲区,存储最近约15秒的音频
- 确保每个音频块都被保存,而不只是被检测为语音的部分
2. 优化了语音检测算法:
- 降低了VAD判断条件的严格性,使用"或"操作而不是"与"操作
- 这样即使VAD或频谱分析其中一个未检测到语音,也能保留有效帧
3. 改进了process_chunk函数:
- 每个音频块无条件添加到循环缓冲区
- 当检测到语音开始时,添加前300ms的音频(避免丢失起始部分)
- 即使在非语音状态下也保存音频数据,确保连续性
4. 完善了音频处理流程:
- 添加了语音开始和结束的提示信息
- 使用AUDIO_RATE常量替代硬编码的采样率
- 统一了音频数据的处理方式
import pyaudio
import webrtcvad
import numpy as np
from pypinyin import pinyin, Style # 如果后续需要用,可按需使用
import re
import pyttsx3
import datetime
import os
import wave
import collectionsfrom funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
from modelscope.pipelines import pipeline
# from deepseek_api_reply_once import get_deepseek_response # 非流式输出
from deepseek_api_connect_internet import get_deepseek_response# 确保临时音频目录存在
os.makedirs("temp_wave", exist_ok=True)# 参数配置
AUDIO_RATE = 48000 # 采样率(支持8000, 16000, 32000或48000)
CHUNK_SIZE = 1440 # 每块大小(30ms,保证为10/20/30ms的倍数)
VAD_MODE = 1 # VAD 模式(0-3,数值越小越保守)# 初始化 VAD
vad = webrtcvad.Vad(VAD_MODE)# 初始化 ASR 模型
sound_recongnition_model = AutoModel(model=r"D:\Downloads\SenseVoiceSmall",trust_remote_code=False ,remote_code="./model.py",vad_model="fsmn-vad",vad_kwargs={"max_single_segment_time": 30000},# device="cuda:0",device="cuda:0",use_itn=True,disable_update = True,disable_pbar = True,disable_log = True)# 初始化说话人验证模型
sound_verifier_model = pipeline(task='speaker-verification',model=r'D:\Downloads\speech_campplus_sv_zh-cn_3dspeaker_16k'
)# 把deepseek大模型输出的文字通过语音合成输出
def talkContent(content):"""使用系统文字转语音朗读内容,提高运行效率"""# 初始化引擎一次,后续复用engine = pyttsx3.init()# 设置朗读速度engine.setProperty('rate', 160)# 朗读内容engine.say(content)# 只调用一次 runAndWait() 处理完所有加入队列的内容engine.runAndWait()# 用于匹配关键词的拼音
def extract_chinese_and_convert_to_pinyin(input_string):"""提取字符串中的汉字,并将其转换为拼音。:param input_string: 原始字符串:return: 转换后的拼音字符串"""# 使用正则表达式提取所有汉字chinese_characters = re.findall(r'[\u4e00-\u9fa5]', input_string)# 将汉字列表合并为字符串chinese_text = ''.join(chinese_characters)# 转换为拼音pinyin_result = pinyin(chinese_text, style=Style.NORMAL)# 将拼音列表拼接为字符串pinyin_text = ' '.join([item[0] for item in pinyin_result])return pinyin_textdef calibrate(stream, calibration_seconds=2, chunk_duration_ms=30):"""校准背景噪音:录制指定时长的音频,计算平均幅值与标准差,从而设置自适应阈值参数:calibration_seconds: 校准时间(秒)chunk_duration_ms: 每块时长(毫秒)返回:amplitude_threshold: 设定的音频幅值阈值"""print("开始校准背景噪音,请保持安静...")amplitudes = []num_frames = int(calibration_seconds * (1000 / chunk_duration_ms))for _ in range(num_frames):audio_chunk = stream.read(CHUNK_SIZE, exception_on_overflow=False)audio_data = np.frombuffer(audio_chunk, dtype=np.int16)amplitudes.append(np.abs(audio_data).mean())mean_noise = np.mean(amplitudes)std_noise = np.std(amplitudes)amplitude_threshold = mean_noise + 2 * std_noiseprint(f"校准完成:噪音均值={mean_noise:.2f},标准差={std_noise:.2f},设置阈值={amplitude_threshold:.2f}")return amplitude_threshold# 保存音频数据为WAV文件
def save_audio_to_wav(audio_data, sample_rate, channels, filename):"""将音频数据保存为WAV文件参数:audio_data: 字节数组格式的音频数据sample_rate: 采样率channels: 通道数filename: 要保存的文件名"""if not audio_data:return# 确保目录存在os.makedirs(os.path.dirname(filename), exist_ok=True)# 直接保存with wave.open(filename, 'wb') as wf:wf.setnchannels(channels)wf.setsampwidth(2) # 16位采样宽度 2*8=16wf.setframerate(sample_rate)wf.writeframes(audio_data)print(f"已保存音频文件: {filename}")class SpeechDetector:"""SpeechDetector 负责处理音频块,结合能量预处理、VAD 和频谱分析进行语音检测,并在检测到语音结束后调用 ASR 模型进行转写,返回识别结果文本。"""def __init__(self, amplitude_threshold):self.amplitude_threshold = amplitude_threshold# 音频缓冲区,用于存储所有音频数据,包括非语音部分self.speech_buffer = bytearray()# 使用循环缓冲区存储最近的所有音频数据self.audio_buffer = collections.deque(maxlen=500) # 存储约15秒的音频# 连续帧状态,用于平滑判断语音是否开始/结束self.speech_state = False # True:正在录入语音;False:非语音状态self.consecutive_speech = 0 # 连续语音帧计数self.consecutive_silence = 0 # 连续静音帧计数self.required_speech_frames = 2 # 连续语音帧达到此值后确认进入语音状态(例如 2 帧大约 60ms)self.required_silence_frames = 34*1 # 连续静音帧达到此值后确认语音结束(例如 15 帧大约 450ms)self.long_silence_frames = 34*5 # 连续静音帧达到此值后确认语音结束(例如 34 帧大约 1s)def analyze_spectrum(self, audio_chunk):"""通过频谱分析检测语音特性:1. 对音频块应用汉宁窗后计算 FFT2. 统计局部峰值数量(峰值必须超过均值的1.5倍)3. 当峰值数量大于等于3时,认为该块具有语音特征"""audio_data = np.frombuffer(audio_chunk, dtype=np.int16)if len(audio_data) == 0:return False# 应用汉宁窗减少 FFT 泄露window = np.hanning(len(audio_data))windowed_data = audio_data * window# 计算 FFT 并取正频率部分spectrum = np.abs(np.fft.rfft(windowed_data))spectral_mean = np.mean(spectrum)peak_count = 0for i in range(1, len(spectrum) - 1):if (spectrum[i] > spectrum[i - 1] and spectrum[i] > spectrum[i + 1] and spectrum[i] > spectral_mean * 1.5):peak_count += 1return peak_count >= 3def is_speech(self, audio_chunk):"""判断当前音频块是否包含语音:1. 先通过能量阈值预过滤低幅值数据2. 再结合 VAD 检测与频谱分析判断"""threshold = self.amplitude_threshold if self.amplitude_threshold is not None else 11540.82audio_data = np.frombuffer(audio_chunk, dtype=np.int16)amplitude = np.abs(audio_data).mean()if amplitude < threshold:return False# 降低VAD判断条件的严格性,只检查VAD结果或频谱结果之一vad_result = vad.is_speech(audio_chunk, AUDIO_RATE)spectral_result = self.analyze_spectrum(audio_chunk)return vad_result and spectral_result # 使用或操作而不是与操作,降低检测条件def process_chunk(self, audio_chunk):"""处理每个音频块,并在识别到语音结束后返回文本结果。修改后的工作流程:- 每个音频块都会被添加到循环缓冲区中- 对当前块进行语音检测- 根据语音状态管理并处理录音数据- 返回识别结果和完整的音频数据"""recognized_text = Nonetemp_speech_buffer = None# 始终将音频块添加到循环缓冲区,确保所有音频数据都被保存self.audio_buffer.append(audio_chunk)is_speech_chunk = self.is_speech(audio_chunk)if is_speech_chunk:self.consecutive_speech += 1self.consecutive_silence = 0if not self.speech_state and self.consecutive_speech >= self.required_speech_frames:# 检测到语音开始,初始化speech_bufferself.speech_state = Trueself.speech_buffer = bytearray()# 将最近缓冲区中的数据(包括语音前部分)加入到speech_bufferfor chunk in list(self.audio_buffer)[-10:]: # 添加前300ms的音频self.speech_buffer.extend(chunk)print("检测到语音开始")# 在语音状态下,继续添加音频块if self.speech_state:self.speech_buffer.extend(audio_chunk)else: # 当前块不是语音self.consecutive_silence += 1self.consecutive_speech = 0# 在语音状态下,继续添加非语音块(保证完整性)if self.speech_state:self.speech_buffer.extend(audio_chunk)# 长时间无语音处理if self.consecutive_silence >= self.long_silence_frames and not self.speech_state:recognized_text = "长时间无语音"self.consecutive_silence = 0return recognized_text, None# 语音结束判断if self.speech_state and self.consecutive_silence >= self.required_silence_frames:if len(self.speech_buffer) > CHUNK_SIZE * 5:print(f"\n======采集到的语音数据长度:{len(self.speech_buffer)}")# 临时保存当前语音段temp_speech_buffer = bytes(self.speech_buffer)# 保存音频数据到WAV文件timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")wav_filename = f"temp_wave/waving_{timestamp}.wav"try:save_audio_to_wav(temp_speech_buffer, AUDIO_RATE, 1, wav_filename)recognized_text = self.sound2text(wav_filename)os.remove(wav_filename) # 使用os.remove删除单个文件except Exception as e:print(f"保存音频文件时出错或者删除临时文件时出错: {e}")# 重置状态,准备下一段语音录入self.speech_state = Falseself.speech_buffer = bytearray()return recognized_text, temp_speech_bufferdef sound2text(self, audio_data):"""利用语音识别模型将音频数据转换为文本"""res = sound_recongnition_model.generate(input=audio_data,cache={},language="zh", # 支持 "zh", "en", 等use_itn=True,batch_size_s=60,merge_vad=True,merge_length_s=15,)text_string = rich_transcription_postprocess(res[0]["text"])return text_string def ASR_API(stream, detector):"""ASR_API 函数:打开音频流,校准背景噪音,并持续监听语音。每次处理音频块后,如果识别到结果,则实时输出文本识别结果。"""while True:# 从流中准确读取一个音频块audio_chunk = stream.read(CHUNK_SIZE, exception_on_overflow=False)# 处理音频块chinese_string, wave_data = detector.process_chunk(audio_chunk)# 若识别到结果,则输出(无结果时不输出)if chinese_string:yield chinese_string, wave_dataif __name__ == "__main__":import timep = pyaudio.PyAudio()stream = p.open(format=pyaudio.paInt16,channels=1,rate=AUDIO_RATE,input=True,frames_per_buffer=CHUNK_SIZE,input_device_index=1)# 校准背景噪音,获取幅值阈值amplitude_threshold = calibrate(stream)detector = SpeechDetector(amplitude_threshold=amplitude_threshold)key_word_pinyin = "ni hao xiao pang"print("开始监听,请开始说话...(按 Ctrl+C 停止)")while True:#============================================================================================================#for recognized_text, _ in ASR_API(stream, detector):print("识别结果:", recognized_text)#============================================================================================================## 回收资源,当需要把音频流资源分配给其他的程序时,需要调用"stream.stop_stream()和stream.close()"stream.stop_stream()stream.close()p.terminate()
相关文章:
语音识别——语音转文字
SenseVoiceSmall阿里开源大模型,SenseVoice 是具有音频理解能力的音频基础模型,包括语音识别(ASR)、语种识别(LID)、语音情感识别(SER)和声学事件分类(AEC)或…...
兰亭妙微:用系统化思维重构智能座舱 UI 体验
兰亭妙微设计专注于以产品逻辑驱动的界面体验优化,服务领域覆盖AI交互、智能穿戴、IoT设备、智慧出行等多个技术密集型产业。我们倡导以“系统性设计”为方法论,在用户需求与技术边界之间找到最优解。 此次智能驾驶项目,我们为某车载平台提供…...

计算机视觉----基础概念、卷积
一、概述 1.计算机视觉的定义 计算机视觉(Computer Vision)是一个跨学科的研究领域,主要涉及如何使计算机能够通过处理和理解数字图像或视频来自动进行有意义的分析和决策。其目标是使计算机能够从视觉数据中获取高层次的理解,类似于人类的视觉处理能力。 具体来说,计算机…...
第三十七节:视频处理-视频读取与处理
引言:解码视觉世界的动态密码 在数字化浪潮席卷全球的今天,视频已成为信息传递的主要载体。从短视频平台的爆火到自动驾驶的视觉感知,视频处理技术正在重塑人类与数字世界的交互方式。本指南将深入探讨视频处理的核心技术,通过Python与OpenCV的实战演示,为您揭开动态影像…...

【自然语言处理与大模型】向量数据库:Chroma使用指南
Chroma是一款功能强大的开源 AI 应用数据库,专为高效数据存储与检索而设计。它不仅支持 Embedding 和 Metadata 的存储,还集成了多项核心功能,包括向量搜索、全文搜索、Document 存储、Metadata 过滤以及多模态检索。此外,Chroma …...
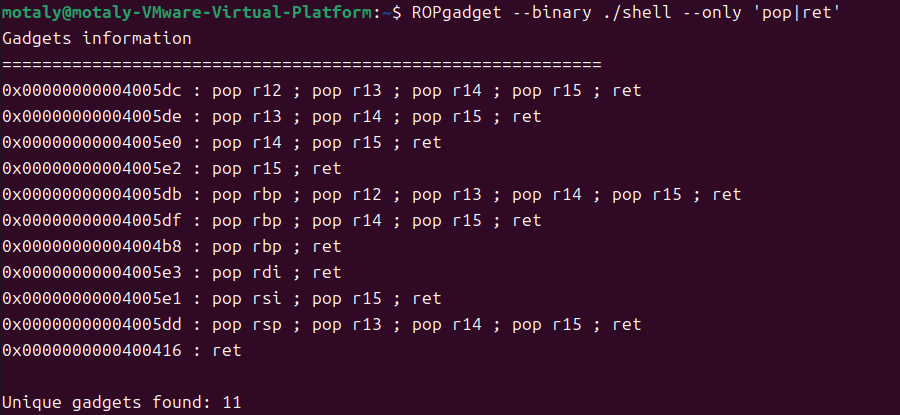
NSSCTF [GFCTF 2021]where_is_shell
889.[GFCTF 2021]where_is_shell(system($0)64位) [GFCTF 2021]where_is_shell (1) 1.准备 motalymotaly-VMware-Virtual-Platform:~$ file shell shell: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.s…...

WSL 安装 Debian 12 后,Linux 如何安装 vim ?
在 WSL 的 Debian 12 中安装 Vim 非常简单,只需使用 apt 包管理器即可。以下是详细步骤: 1. 更新软件包列表 首先打开终端,确保系统包列表是最新的: sudo apt update2. 安装 Vim 直接通过 apt 安装 Vim: sudo apt …...
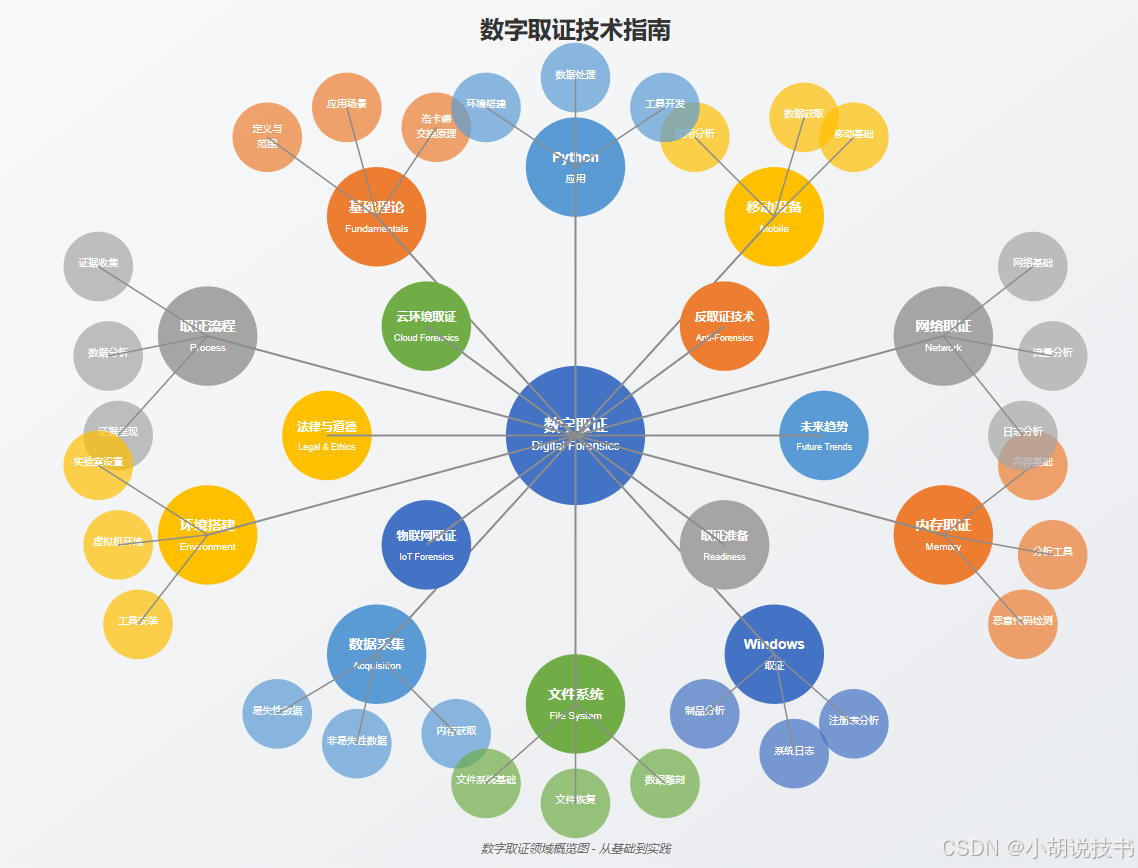
电子数据取证(数字取证)技术全面指南:从基础到实践
为了后续查阅方便,推荐工具先放到前面 推荐工具 数字取证基础工具 综合取证平台 工具名称类型主要功能适用场景EnCase Forensic商业全面的证据获取和分析、强大的搜索能力法律诉讼、企业调查FTK (Forensic Toolkit)商业高性能处理和索引、集成内存分析大规模数据处…...

Ubuntu使用Docker搭建SonarQube企业版(含破解方法)
目录 Ubuntu使用Docker搭建SonarQube企业版(含破解方法)SonarQube介绍安装Docker安装PostgreSQL容器Docker安装SonarQube容器SonarQube汉化插件安装 破解生成license配置agent 使用 Ubuntu使用Docker搭建SonarQube企业版(含破解方法ÿ…...

Spark SQL 之 Analyzer
Spark SQL 之 Analyzer // Special case for Project as it supports lateral column alias.case p: Project =>val resolvedNoOuter = p.projectList.map(resolveExpressionByPlanChildren(_, p...

c/c++数据类型转换.
author: hjjdebug date: 2025年 05月 18日 星期日 20:28:52 CST descrip: c/c数据类型转换. 文章目录 1. 为什么需要类型转换?1.1 发生的时机:1.2 常见的发生转换的类型: 2. c语言的类型转换: (Type) value2.1 c语言的类型变换是如何实现的? 规则是什么? 3. c 的static_cast…...
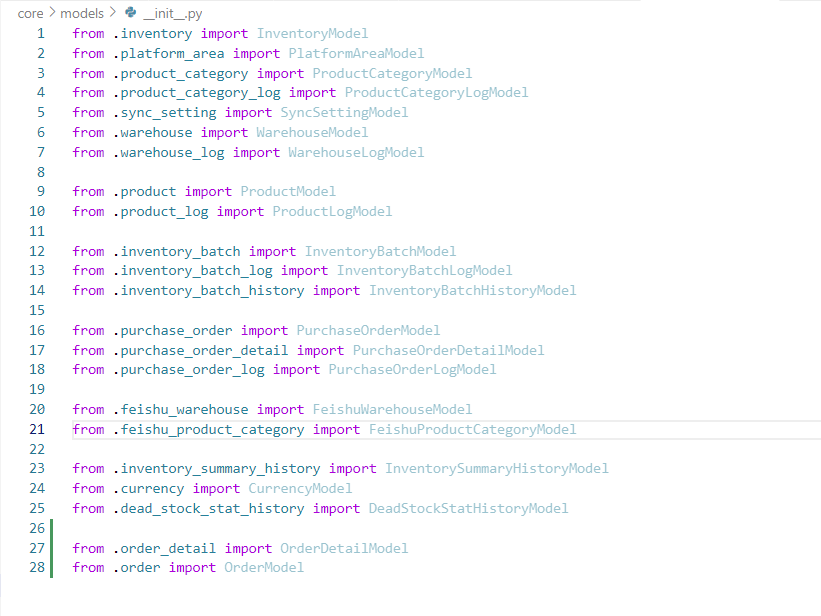
Django 项目的 models 目录中,__init__.py 文件的作用
在 Django 项目的models/init.py文件中,这些导入语句的主要作用是将各个模型类从不同的模块中导入到models包的命名空间中。这样做有以下几个目的: 简化导入路径 当你需要在项目的其他地方使用这些模型时,可以直接从models包导入,…...

实验六:FPGA序列检测器实验
FPGA序列检测器实验(远程实验系统) 文章目录 FPGA序列检测器实验(远程实验系统)一、数字电路基础知识1. 时钟与同步2. 按键消抖原理代码讲解:分频与消抖3. 有限状态机(FSM)设计代码讲解:状态机编码与转移4. 边沿检测与信号同步5. 模块化设计二、实验数字电路整体思想三…...
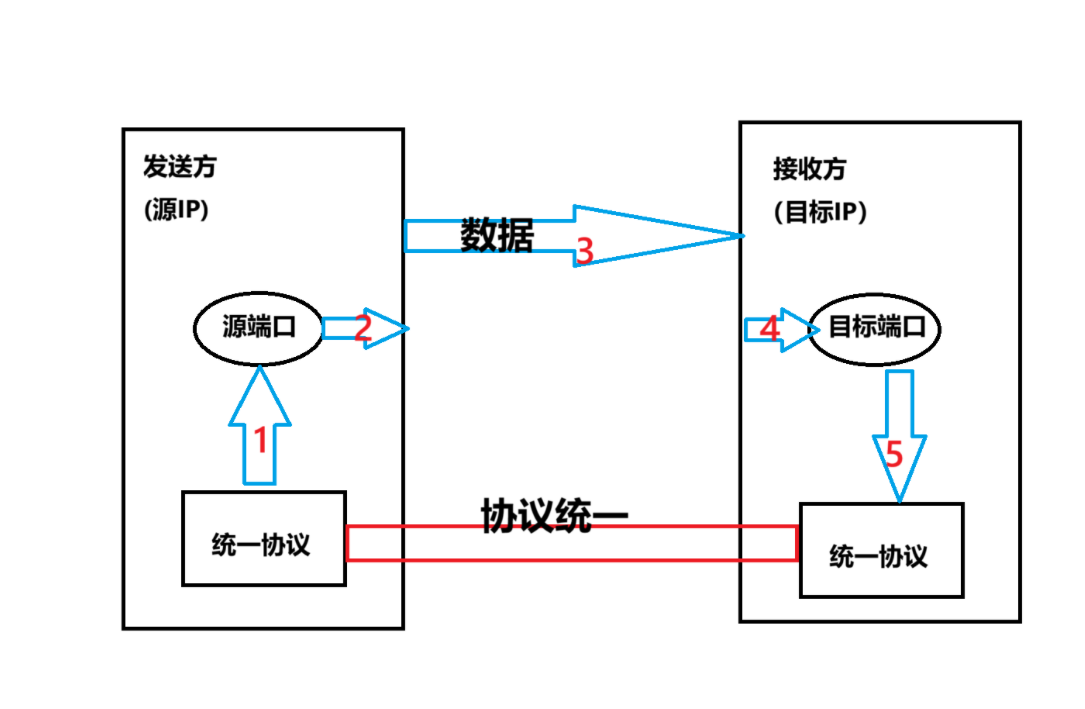
网络的知识的一些概念
1.什么是局域网,什么是广域网 局域网(Local area network)也可以称为本地网,内网,局域网有这几个发展经历: 最开始电脑与电之间是直接用网线连接的 再后来有了集线器() 再后来出…...

芋道项目,商城模块数据表结构
一、需求 最近公司有新的业务需求,调研了一下,决定使用芋道(yudao-cloud)框架,于是从github(https://github.com/YunaiV/yudao-cloud)上克隆项目,选用的是jdk17版本的。根据项目启动手册&#…...

yarn任务筛选spark任务,判断内存/CPU使用超过限制任务
yarn任务筛选spark任务,判断内存/CPU使用超过限制任务 curl -s “http://it-cdh-node01:8088/ws/v1/cluster/apps?statesRUNNING” | jq ‘.apps.app | map(select(.applicationType “SPARK” ) | select(.allocatedMB > 102400 or .allocatedVCores > 50)…...

【氮化镓】HfO2钝化优化GaN 器件性能
2025年,南洋理工大学的Pradip Dalapati等人在《Applied Surface Science》期刊发表了题为《Role of ex-situ HfO2 passivation to improve device performance and suppress X-ray-induced degradation characteristics of in-situ Si3N4/AlN/GaN MIS-HEMTs》的文章。该研究基…...
)
c#的内存指针操作(仅用于记录)
c#也可以直接操作内存指针,如下为示例: unsafe {byte[] a {1,2,3};fixed (byte* p1 a, p2 &a[^1]){Debugger.Log(1, "test", $"max index:{p2-p1}");Debugger.Log(1, "test", $"address:{(long)p1:X}")…...

常见机器学习算法简介:回归、分类与聚类
机器学习说到底,不就三件事: 预测一个数 —— 回归 判断归属哪个类 —— 分类 自动把数据分组 —— 聚类 别背术语,别管定义,先看问题怎么解决。 一、回归(Regression) 干嘛的? 模型输出一…...

SpringBoot项目里面发起http请求的几种方法
在Spring Boot项目中发起HTTP请求的方法 在Spring Boot项目中,有几种常用的方式可以发起HTTP请求,以下是主要的几种方法: 1. 使用RestTemplate (Spring 5之前的主流方式) // 需要先注入RestTemplate Autowired private RestTemplate restT…...

Linux下Nginx源码安装步骤详解
以下是在Linux系统下从源码安装Nginx的详细步骤及解释: 1. 下载Nginx源码 步骤: wget http://nginx.org/download/nginx-1.25.3.tar.gz tar -zxvf nginx-1.25.3.tar.gz cd nginx-1.25.3解释: wget:从官网下载Nginx源码包&#…...
SQLMesh 增量模型从入门到精通:5步实现高效数据处理
本文深入解析 SQLMesh 中的增量时间范围模型,介绍其核心原理、配置方法及高级特性。通过实际案例说明如何利用该模型提升数据加载效率,降低计算资源消耗,并提供配置示例与最佳实践建议,帮助读者在实际项目中有效应用这一强大功能。…...
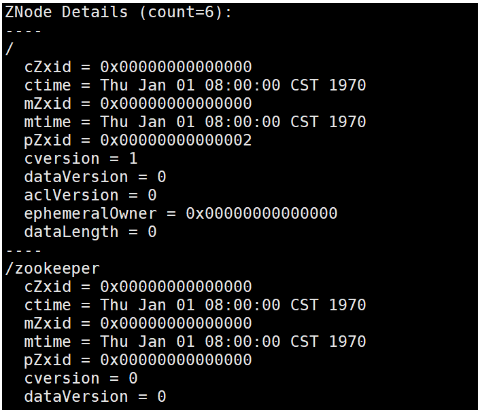
Zookeeper 入门(二)
4. Zookeeper 的 ACL 权限控制( Access Control List ) Zookeeper 的ACL 权限控制,可以控制节点的读写操作,保证数据的安全性,Zookeeper ACL 权 限设置分为 3 部分组成,分别是:权限模式(Scheme)、授权对象(…...
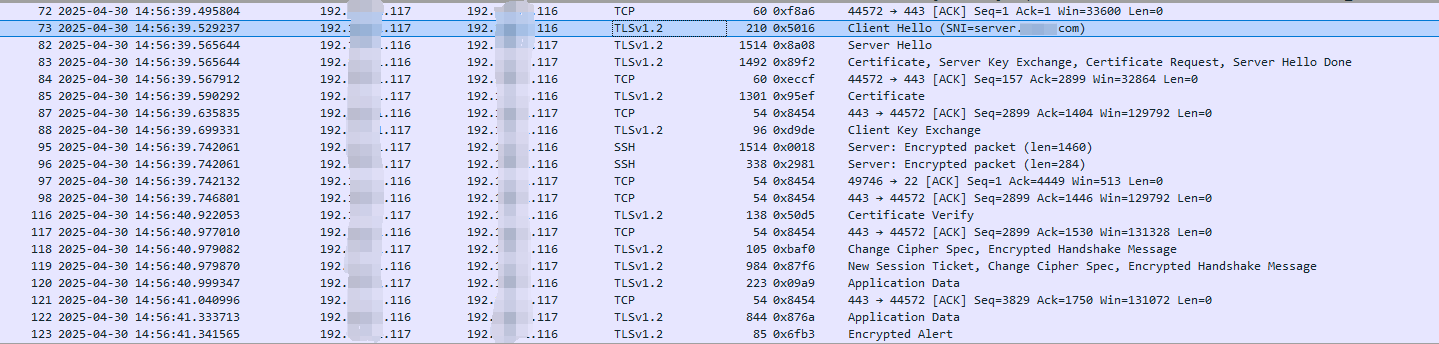
【架构篇】安全架构-双向认证
mTLS(Mutual TLS)详解:双向认证的原理、流程与实践 摘要 mTLS(Mutual TLS)是一种基于数字证书的双向身份验证协议,广泛应用于微服务通信、金融交易等高安全场景。本文深入解析mTLS的工作原理、认证流程、W…...

负载均衡—会话保持技术详解
一、会话保持的定义 会话保持(Session Persistence)是一种负载均衡策略,其核心机制是确保来自同一客户端的连续请求,在特定周期内被定向到同一台后端服务器进行处理。这种机制通过记录和识别客户端的特定标识信息,打破…...
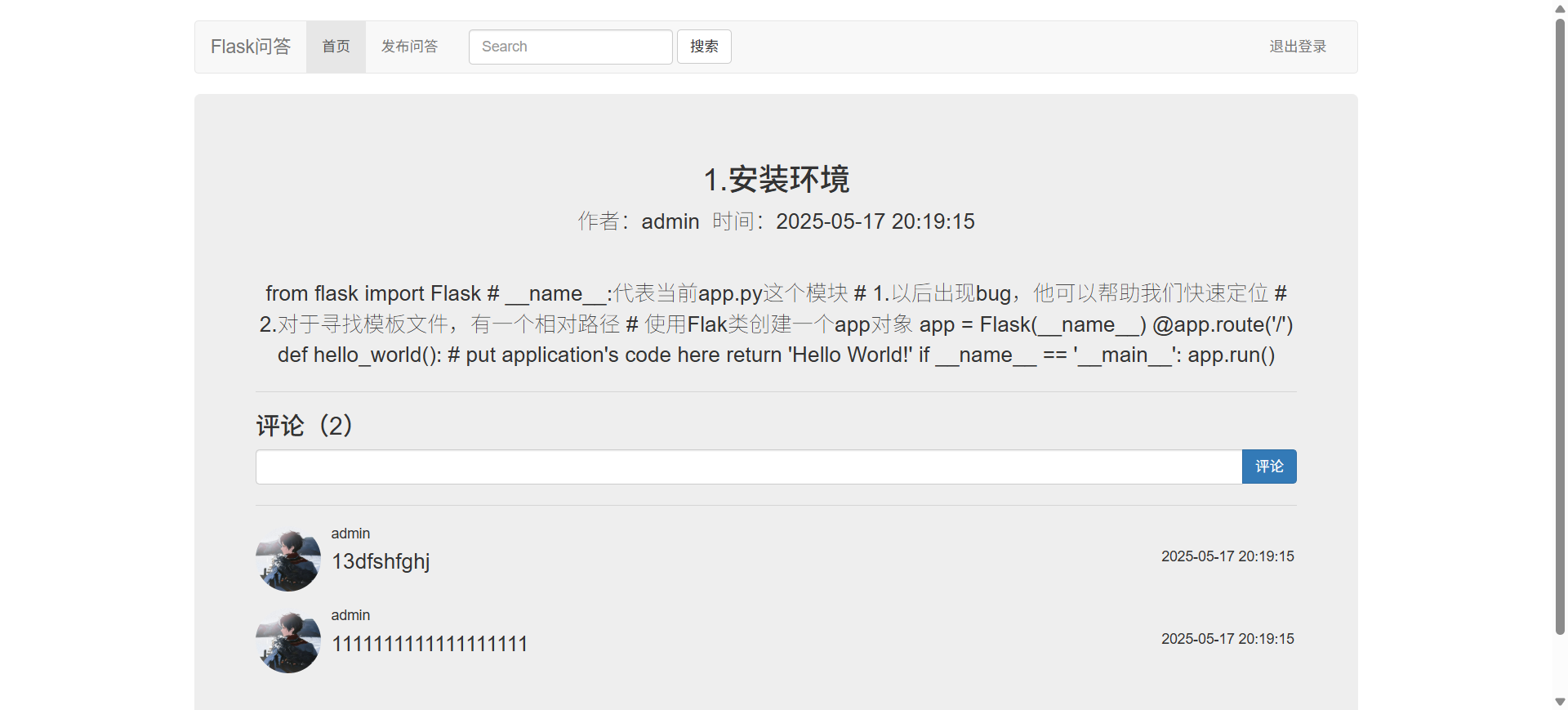
Flask快速入门和问答项目源码
Flask基础入门 源码: gitee:我爱白米饭/Flask问答项目 - 码云 目录 1.安装环境2.【debug、host、port】3.【路由params和query】4.【模板】5.【静态文件】6.【数据库连接】6.1.安装模块6.2.创建数据库并测试连接6.3.创建数据表6.4.ORM增删改查 6.5.ORM模…...
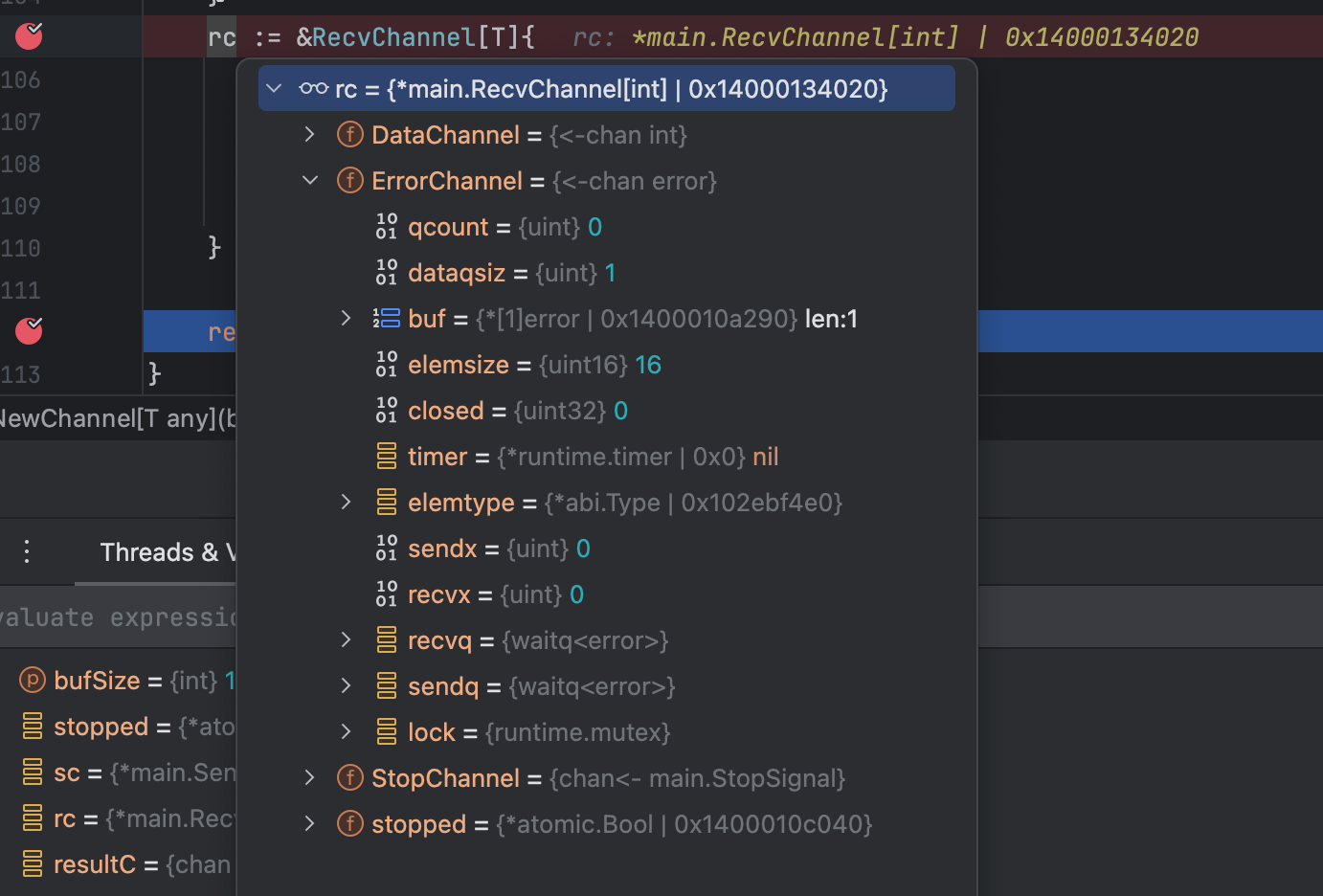
go语法大赏
前些日子单机房稳定性下降,找了好一会才找到真正的原因。这里面涉及到不少go语法细节,正好大家一起看一下。 一、仿真代码 这是仿真之后的代码 package mainimport ("fmt""go.uber.org/atomic""time" )type StopSignal…...
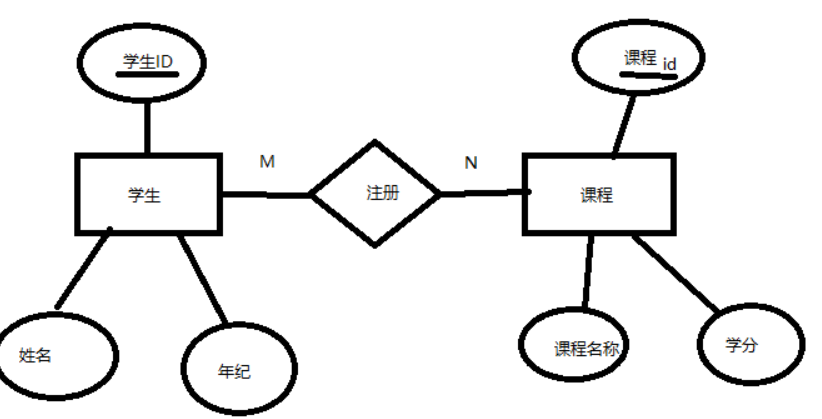
软件工程各种图总结
目录 1.数据流图 2.N-S盒图 3.程序流程图 4.UML图 UML用例图 UML状态图 UML时序图 5.E-R图 首先要先了解整个软件生命周期: 通常包含以下五个阶段:需求分析-》设计-》编码 -》测试-》运行和维护。 软件工程中应用到的图全部有:系统…...

R-tree详解
R-tree 是一种高效的多维空间索引数据结构,专为快速检索空间对象(如点、线、区域)而设计。它广泛应用于地理信息系统(GIS)、计算机图形学、数据库等领域,支持范围查询、最近邻搜索等操作。以下是其核心原理…...
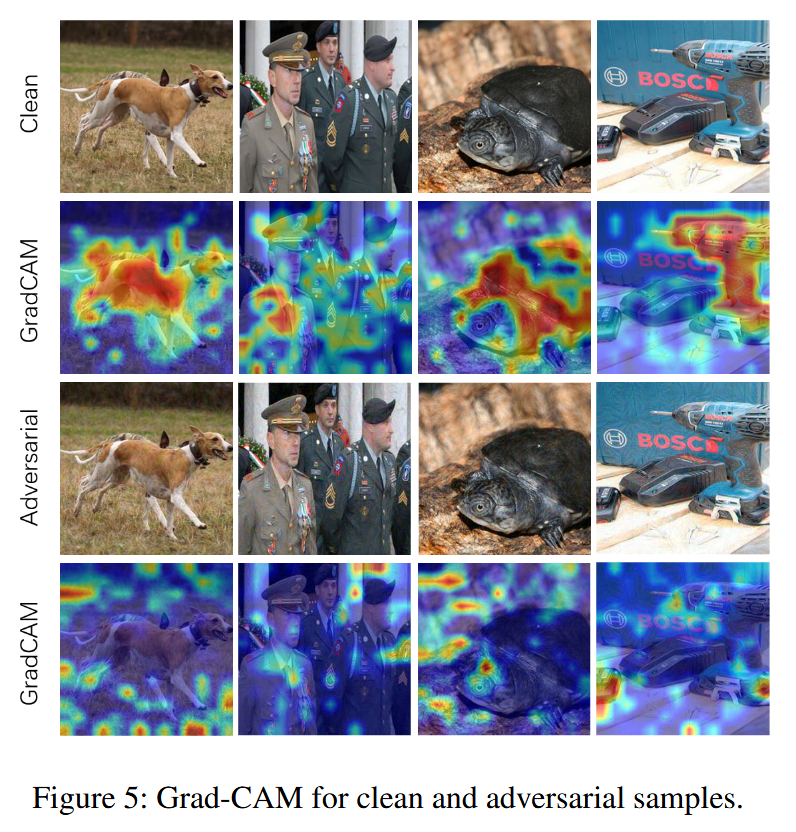
AAAI2024 | 基于特征多样性对抗扰动攻击 Transformer 模型
Attacking Transformers with Feature Diversity Adversarial Perturbation 摘要-Abstract引言-Introduction相关工作-Related Work方法-Methodology实验-Experiments结论-Conclusion 论文链接 本文 “Attacking Transformers with Feature Diversity Adversarial Perturbatio…...