【深度学习】残差网络(ResNet)
如果按照李沐老师书上来,学完 VGG 后还有 NiN 和 GoogLeNet 要学,但是这两个我之前听都没听过,而且我看到我导师有发过 ResNet 相关的论文,就想跳过它们直接看后面的内容。
现在看来这不算是不踏实,因为李沐老师说如果卷积神经网络只学一个架构的话,那就学这个 ResNet(Residual Network)。
随着我们设计越来越深的网络,深刻理解“新添加的层如何提升神经网络的性能”变得至关重要。
加了更多层一定更有用吗?如果不是的话,怎么样加入新层可以有效提高精度呢?
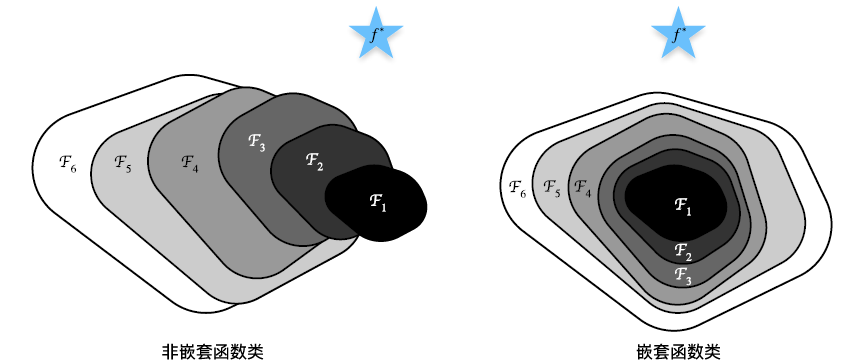
我们通过下图来进行理解。以前我们在网络加入新的卷积层或者全连接层有点像左图中的非嵌套函数类。
尽管随着层数变多(函数 f 1 − f 6 f_1-f_6 f1−f6),能覆盖的最优值范围变大,但不一定能很有效的接近全局最优(蓝色五角星)。
例如左图中实际上加到 f 3 f_3 f3 时的最优值距离五角星更近。
针对这一问题,何恺明等人(2016)提出了残差网络,其核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。
就像右图中的嵌套函数类,每次新加入函数都能保证不会离五角星更远,进而一步一步逼近全局最优。
下面我们看看如何实现“嵌套”。
一、残差块
块的思想我们在 VGG 中就了解过,可以帮助我们设计深层网络。
以前我们是通过串联起各层来扩大函数类(下左图),而残差块(下右图)通过加入一侧的快速通道,来得到 f ( x ) = x + g ( x ) f(x)=x+g(x) f(x)=x+g(x) 的结构。
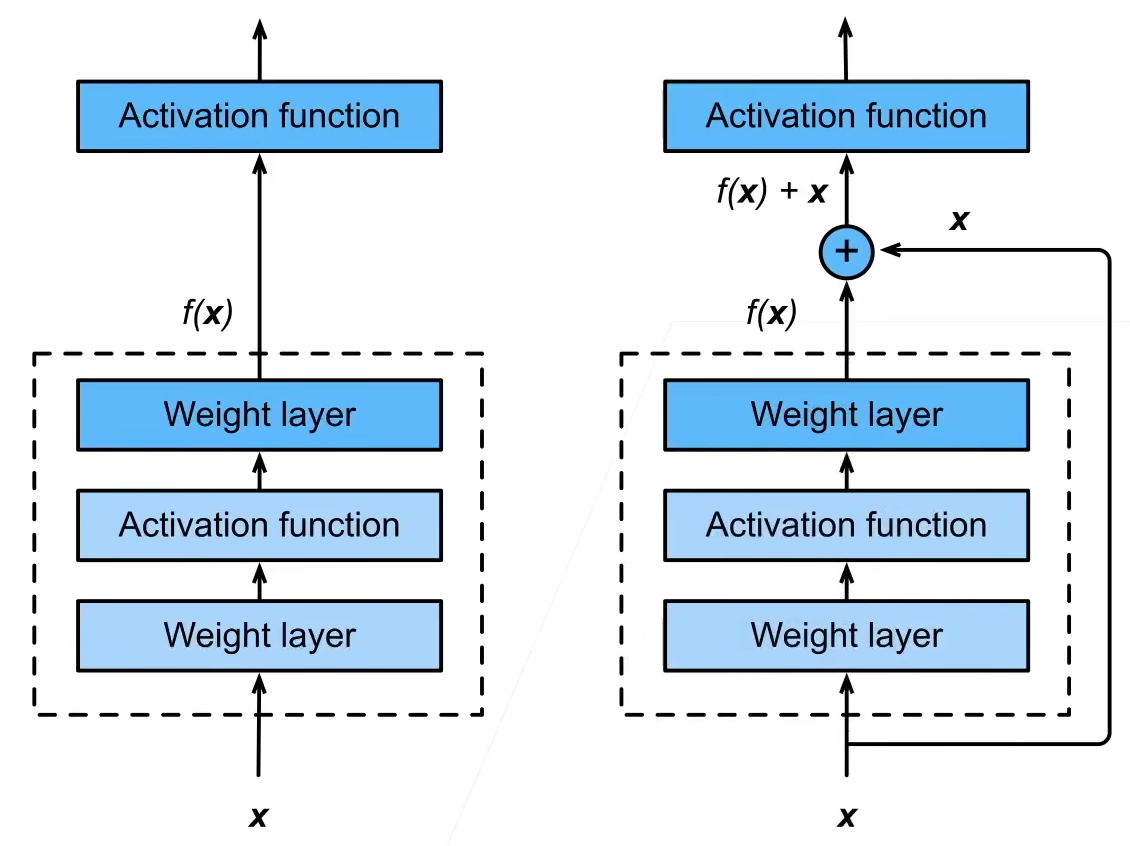
如此的话,就算虚线框中的 g ( x ) g(x) g(x) 没有起到效果,我们也不会退步。
如果虚线框中的各层使得通道数改变,我们就需要加入 1$\times$1 卷积层来进行调整,以保证能加法顺利进行。
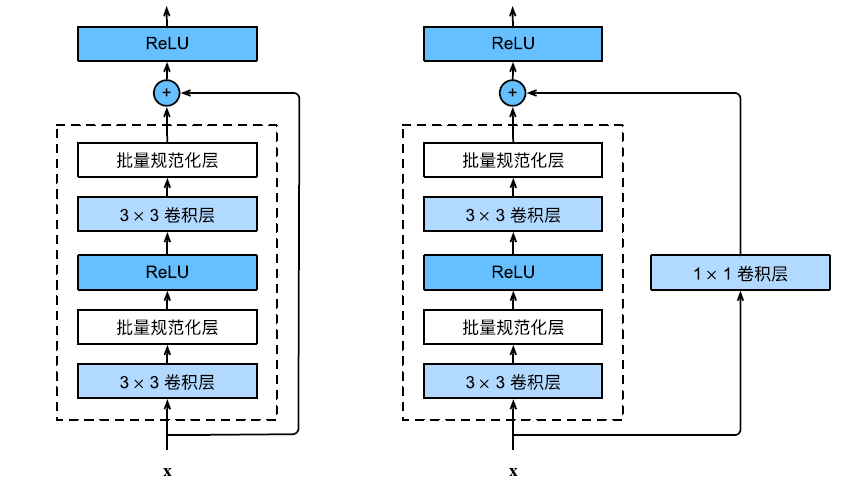
对于上图这类特殊的架构,我们需要采用自定义层的方式来实现。
class Residual(nn.Module): # 定义残差块def __init__(self, input_channels, num_channels,use_1x1conv=False, strides=1):super().__init__()self.conv1 = nn.Conv2d(input_channels, num_channels,kernel_size=3, padding=1, stride=strides)self.conv2 = nn.Conv2d(num_channels, num_channels,kernel_size=3, padding=1)if use_1x1conv:self.conv3 = nn.Conv2d(input_channels, num_channels,kernel_size=1, stride=strides)else:self.conv3 = Noneself.bn1 = nn.BatchNorm2d(num_channels)self.bn2 = nn.BatchNorm2d(num_channels)def forward(self, X):Y = F.relu(self.bn1(self.conv1(X)))Y = self.bn2(self.conv2(Y))if self.conv3:X = self.conv3(X)Y += Xreturn F.relu(Y)
ResNet 沿用了 VGG 完整的 3$\times$3 卷积层设计。残差块里首先有两个相同输出通道数的卷积层,每个卷积层后面接一个批量规范化层和激活函数。
上述代码通过调整参数use_1x1conv参数的取值,来决定是否添加 1$\times$1 卷积层。
一般我们在增加通道数时,我们会通过调整strides来使得高宽减半。
实际上,我们还可以改变块中组件的位置,可得到各种残差块的变体。
二、ResNet 模型
ResNet 的第一层为输出通道数 64、步幅 2 的 7$\times 7 卷积层,随后接 B N 层和步幅为 2 的 3 7 卷积层,随后接 BN 层和步幅为 2 的 3 7卷积层,随后接BN层和步幅为2的3\times$3 的最大汇聚层。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.BatchNorm2d(64), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
之后使用 4 个由残差块组成的模块,每个模块由若干个同样输出通道数的残差块组成。
第一个模块的通道数同输入通道数一致。由于之前已经使用了步幅为 2 的最大汇聚层,因此无需减小高和宽。
之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
def resnet_block(input_channels, num_channels, num_residuals,first_block=False): # 生成由残差块组成的模块blk = []for i in range(num_residuals):# 除了第一个模块,其他模块的第一个残差块需要宽高减半if i == 0 and not first_block:blk.append(Residual(input_channels, num_channels,use_1x1conv=True, strides=2))else:blk.append(Residual(num_channels, num_channels))return blk
我们这里每个模块使用 2 个残差块,其中其第一个模块使用first_block参数来避免宽高减半。
# b2 不需要通道数翻倍,宽高减半b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))b3 = nn.Sequential(*resnet_block(64, 128, 2))b4 = nn.Sequential(*resnet_block(128, 256, 2))b5 = nn.Sequential(*resnet_block(256, 512, 2))
最后,加入自适应平均汇聚层、展平层和全连接输出层。AdaptiveAvgPool2d的使用可以保证最后的输出为 (1, 1),不用去管池化窗口的大小。
net = nn.Sequential(b1, b2, b3, b4, b5,nn.AdaptiveAvgPool2d((1, 1)),nn.Flatten(), nn.Linear(512, 10))
4 个模块,每个模块两个残差块,一个残差块 2 个卷积层,加上最初的 7$\times$7 卷积层和最后的全连接层,共 18 层,故上述模型通常称为 ResNet-18。
在训练模型之前,我们来观察一下各个模块的输入形状是如何变化的。
# 查看各模块输出形状X = torch.rand(size=(1, 1, 224, 224))for layer in net:X = layer(X)print(layer.__class__.__name__, 'output shape:\t', X.shape)
---------------------------------
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1])
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])
第一个模块出来后是 56$\times$56,我开始算不到,因为光算卷积就已经是小数了,没往下算。后面上网查了下,发现是向下取整的,才明白。
这里放上尺寸的计算公式吧,参考这个:https://www.jianshu.com/p/612edc845ad5
卷积后,池化后尺寸计算公式:
(图像尺寸-卷积核尺寸 + 2*填充值)/步长 +1
(图像尺寸-池化窗尺寸 + 2*填充值)/步长 +1
后面 3 个模块都是通道数加倍,宽高减半,减为 7 × \times × 7 后,最后通过汇聚层变为 1 × \times × 1,聚集所有特征。
三、训练模型
同之前一样,我们在 Fashion-MNIST 数据集上训练 ResNet。
因为之前定义好了很多训练相关函数,所以训练代码可以非常轻松的写下来。
我都有点想写一个自己的工具包了,这样就不用每次都复制前面的代码,而是像李沐老师的 d2l 一样。
lr, num_epochs, batch_size = 0.05, 10, 128 # ResNet使用的参数train_iter, test_iter = load_data_fashion_mnist(batch_size, resize=224)train(net, train_iter, test_iter, num_epochs, lr, try_gpu())
原本书上的batch_size是 256 的,但是我的 GPU 内存不够,报错,调成了 128。
这次训练是最久的,早知道resize成更小的尺寸了。我看到沐神说他改成 96 只是为了更快运行,就没用 96,想同样用 224,好和前面的模型对比。
训练结果如下:
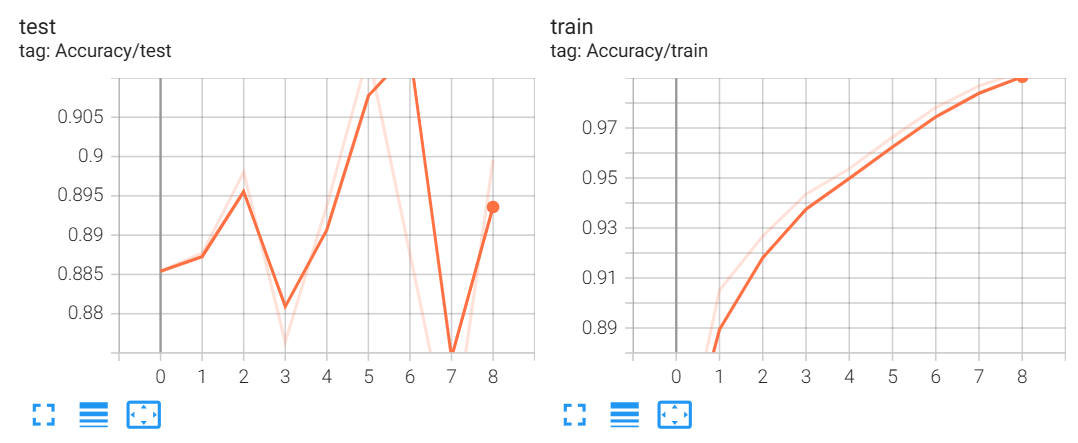
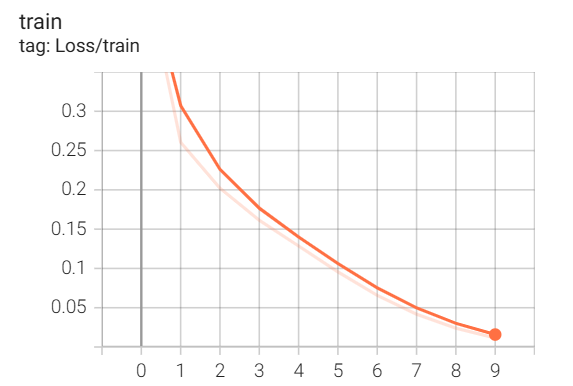
第 10 轮的训练损失为 0.011
第 10 轮的训练精度为 0.998
第 10 轮的测试集精度为 0.926
运行在 cuda:0 上,处理速度为 228.1 样本/秒
这次的处理速度只是 VGG 的一半,但是效果是很不错的,训练损失仅有 0.011,训练精度都接近 100%了都,而且测试集精度也不低。
可以看出 ResNet 确实是非常有效的网络,它对后面的深层网络也产生了非常深远的影响。
相关文章:
【深度学习】残差网络(ResNet)
如果按照李沐老师书上来,学完 VGG 后还有 NiN 和 GoogLeNet 要学,但是这两个我之前听都没听过,而且我看到我导师有发过 ResNet 相关的论文,就想跳过它们直接看后面的内容。 现在看来这不算是不踏实,因为李沐老师说如果…...
《Python星球日记》 第94天:走近自动化训练平台
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、自动化训练平台简介1. Kubeflow Pipelines2. TensorFlow Extended (TFX) 二…...
S7 200 smart连接Profinet转ModbusTCP网关与西门子1200PLC配置案例
控制要求:使用MODBUSTCP通信进行两台PLC之间的数据交换,由于改造现场不能改动程序,只留出了对应的IQ地址。于是客户决定使用网关进行通讯把数据传到plc。 1、读取服务器端40001~40005地址中的数据,放入到VW200~VW208中࿱…...

React中巧妙使用异步组件Suspense优化页面性能。
文章目录 前言一、为什么需要异步组件?1. 性能瓶颈分析2. 异步组件的价值 二、核心实现方式1. React.lazy Suspense(官方推荐)2. 路由级代码分割(React Router v6) 总结 前言 在 React 应用中,随着功能复…...

学习笔记:黑马程序员JavaWeb开发教程(2025.4.7)
12.9 登录校验-Filter-入门 /*代表所有,WebFilter(urlPatterns “/*”)代表拦截所有请求 Filter是JavaWeb三大组件,不是SpringBoot提供的,要在SpringBoot里面使用JavaWeb,则需要加上ServletComponentScan注…...

11 web 自动化之 DDT 数据驱动详解
文章目录 一、DDT 数据驱动介绍二、实战 一、DDT 数据驱动介绍 数据驱动: 现在主流的设计模式之一(以数据驱动测试) 结合 unittest 框架如何实现数据驱动? ddt 模块实现 数据驱动的意义: 通过不同的数据对同一脚本实现…...

OpenCV-python灰度变化和直方图修正类型
实验1 实验内容 该段代码旨在读取名为"test.png"的图像,并将其转换为灰度图像。使用加权平均值法将原始图像的RGB值转换为灰度值。 代码注释 image cv.imread("test.png")h np.shape(image)[0] w np.shape(image)[1] gray_img np.zeros…...

从 Excel 到 Data.olllo:数据分析师的提效之路
背景:Excel 的能力边界 对许多数据分析师而言,Excel 是入门数据处理的第一工具。然而,随着业务数据量的增长,Excel 的一些固有限制逐渐显现: 操作容易出错,难以审计; 打开或操作百万行数据时&…...

图像定制大一统?字节提出DreamO,支持人物生成、 ID保持、虚拟试穿、风格迁移等多项任务,有效解决多泛化性冲突。
字节提出了一个统一的图像定制框架DreamO,支持人物生成、 ID保持、虚拟试穿、风格迁移等多项任务,不仅在广泛的图像定制场景中取得了高质量的结果,而且在适应多条件场景方面也表现出很强的灵活性。现在已经可以支持消费级 GPU(16G…...
Nginx 动静分离在 ZKmall 开源商城静态资源管理中的深度优化
在 B2C 电商高并发场景下,静态资源(图片、CSS、JavaScript 等)的高效管理直接影响页面加载速度与用户体验。ZKmall开源商城通过对 Nginx 动静分离技术的深度优化,将静态资源响应速度提升 65%,带宽成本降低 40%…...
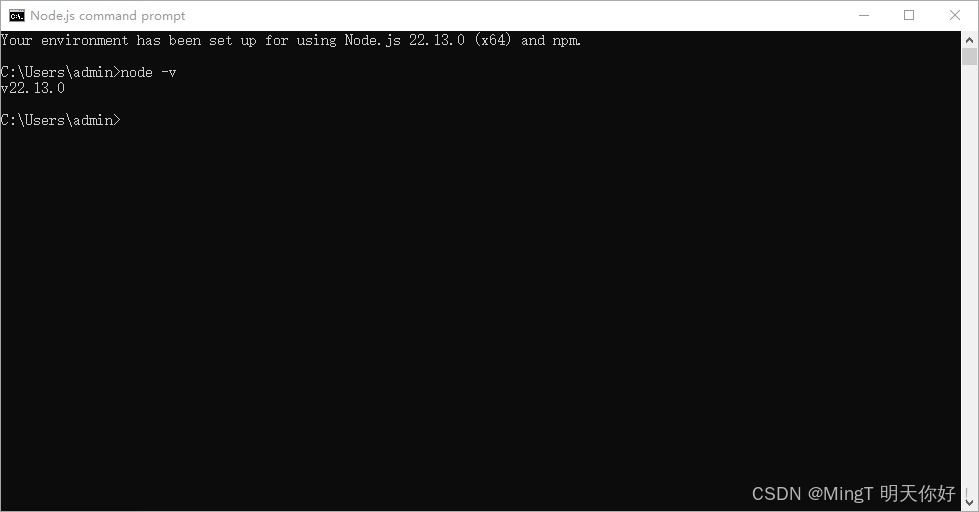
在vs code 中无法运行npm并报无法将“npm”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查
问题: npm : 无法将“npm”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查 原因: 可能是环境变量未正确继承或终端配置不一致 解决方法: 1.找到自己的node.js的版本号 2.重新下载node.js 下载 node.js - https://nodejs.p…...
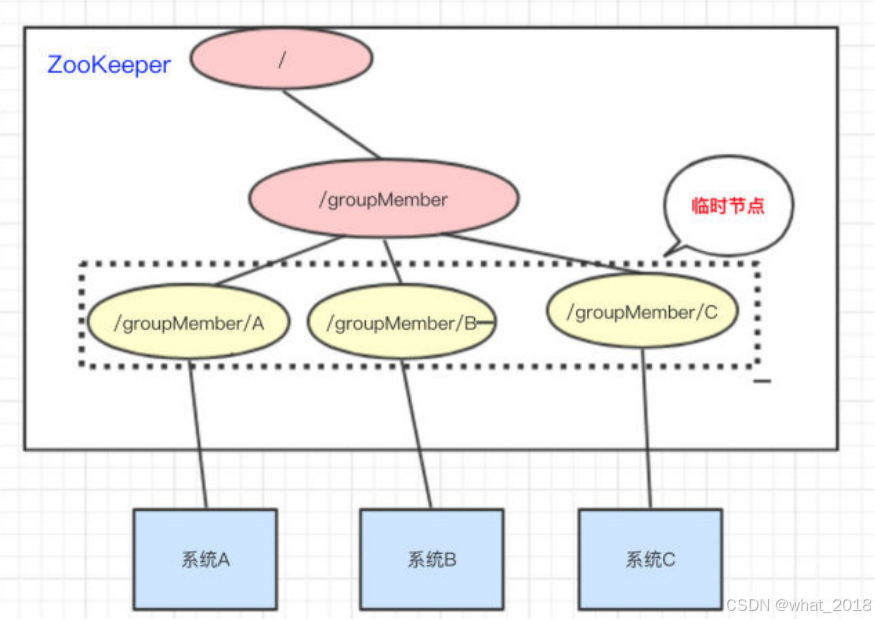
分布式2(限流算法、分布式一致性算法、Zookeeper )
目录 限流算法 固定窗口计数器(Fixed Window Counter) 滑动窗口计数器(Sliding Window Counter) 漏桶算法(Leaky Bucket) 令牌桶算法(Token Bucket) 令牌桶与漏桶的对比 分布式…...
做法!)
2089. 找出数组排序后的目标下标——O(n)做法!
本题要求在一个已排序的数组 nums 中,找出所有等于目标值 target 的元素下标。若不存在这样的元素,则返回 {-1, -1}。解决该问题有两种主要方法:二分查找法和统计计数法。 二分查找法:首先对数组进行排序,然后通过二分…...

ARM A64 LDR指令
ARM A64 LDR指令 1 LDR (immediate)1.1 Post-index1.2 Pre-index1.3 Unsigned offset 2 LDR (literal)3 LDR (register)4 其他LDR指令变体4.1 LDRB (immediate)4.1.1 Post-index4.1.2 Pre-index4.1.3 Unsigned offset 4.2 LDRB (register)4.3 LDRH (immediate)4.3.1 Post-index…...

给大模型“贴膏药”:LoRA微调原理说明书
一、前言:当AI模型开始“叛逆” 某天,我决定教deepseek说方言。 第一次尝试(传统微调): 我:给deepseek灌了100G东北小品数据集,训练三天三夜。结果:AI确实会喊“老铁666”了…但英…...

Spring-messaging-MessageHandler接口实现类ServiceActivatingHandler
ServiceActivatingHandler实现了MessageHandler接口,所以它是一个MessageHandler,在spring-integration中,它也叫做服务激活器(Service Activitor),因为这个类是依赖spring容器BeanFactory的,所…...

asp.net core api RESTful 风格控制器
在 ASP.NET Core API 中,遵循 RESTful 风格的控制器一般具备以下几个关键特征: ✅ RESTful 风格控制器的命名规范 控制器命名 使用 复数名词,表示资源集合,如 ProductsController、UsersController。 路由风格 路由使用 [Rout…...

【甲方安全建设】Python 项目静态扫描工具 Bandit 安装使用详细教程
文章目录 一、工具简介二、工具特点1.聚焦安全漏洞检测2.灵活的扫描配置3.多场景适配4.轻量且社区活跃三、安装步骤四、使用方法场景1:扫描单个Python文件场景2:递归扫描整个项目目录五、结果解读六、总结一、工具简介 Bandit 是由Python官方推荐的静态代码分析工具(SAST)…...

实习记录小程序|基于SSM+Vue的实习记录小程序设计与实现(源码+数据库+文档)
实习记录小程序 目录 基于SSM的习记录小程序设计与实现 一、前言 二、系统设计 三、系统功能设计 1、小程序端: 2、后台 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂码…...

老旧设备升级利器:Modbus TCP转 Profinet让能效监控更智能
在工业自动化领域,ModbusTCP和Profinet是两种常见的通讯协议。Profinet是西门子公司推出的基于以太网的实时工业以太网标准,而Modbus则是由施耐德电气提出的全球首个真正开放的、应用于电子控制器上的现场总线协议。这两种协议各有各的优点,但…...

【从基础到模型网络】深度学习-语义分割-ROI
在语义分割中,ROI(Region of Interest,感兴趣区域)是图像中需要重点关注的部分。其作用包括:提高效率,减少高分辨率图像的计算量;增强分割精度,聚焦关键语义信息;减少背景…...

Qt控件:交互控件
交互控件 1. QAction核心功能API 1.2 实例应用情况应用场景 1.3 QAction与QPushButton/QToolButton关系QActionQPushButtonQToolButton三者关系 1. QAction ##1. 1简介与API QAction 是一个核心类,用于表示应用程序中的一个操作(如菜单项、工具栏按钮或…...

前端下载ZIP包方法总结
在前端实现下载 ZIP 包到本地,通常有以下几种方法,具体取决于 ZIP 包的来源(静态文件、后端生成、前端动态生成等): 方法 1:直接下载静态文件(最简单) 如果 ZIP 包是服务器上的静态…...

掌握Docker:从运行到挂载的全面指南
目录 1. Docker的运行2. 查看Docker的启动日志3. 停止容器4. 容器的启动5. 删除容器6. 查看容器的详细信息7.一条命令关闭所有容器拓展容器的复制(修改数据不会同步)容器的挂载(修改数据可以同步)挂载到现有容器 1. Docker的运行 …...

Pandas pyecharts数据可视化基础③
pyecharts基础绘图案例解析 引言思维导图代码案例分析 提前安装依赖同样操作安装完重新启动Jupyter Notebook三维散点图(代码5 - 40) 代码结果代码解析 漏斗图(代码5 - 41)结果代码解析 词云图(代码5 - 42)…...
)
QMK固件OLED显示屏配置教程:从零开始实现个性化键盘显示(实操部分)
QMK固件OLED显示屏配置教程:从零开始实现个性化键盘显示 📢 前言: 作为一名键盘爱好者,近期研究了QMK固件的OLED显示屏配置,发现网上的教程要么太过复杂,要么过于简单无法实际操作。因此决定写下这篇教程,从零基础出发,带大家一步步实现键盘OLED屏幕的配置与个性化显示…...
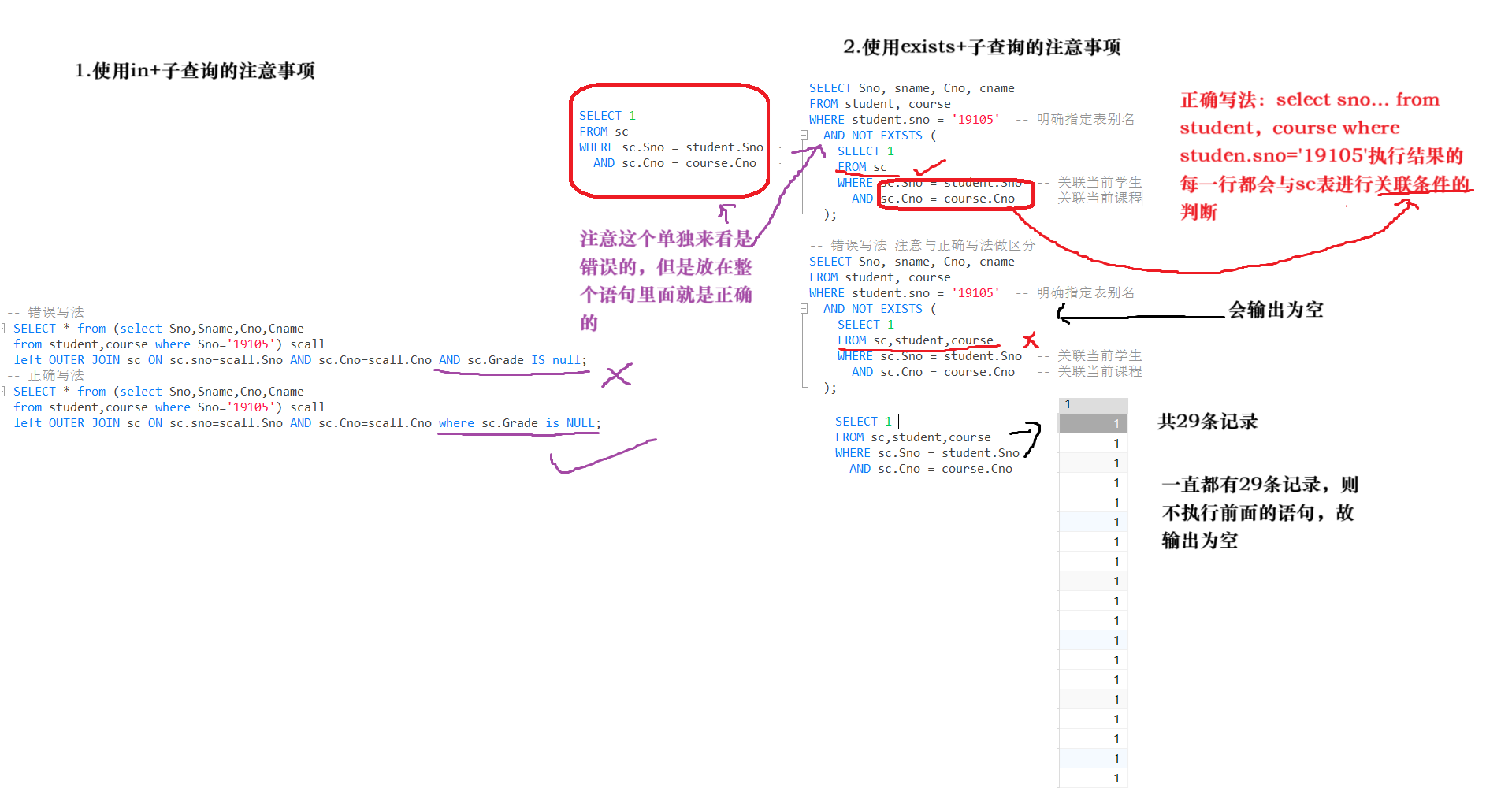
数据库中关于查询选课问题的解法
前言 今天上午起来复习了老师上课讲的选课问题。我总结了三个解法以及一点注意事项。 选课问题介绍 简单来说就是查询某某同学没有选或者选了什么课。然后查询出该同学的姓名,学号,课程号,课程名之类的。 sql文件我上传了。大家可以尝试练…...
基于Bootstrap 的网页html css 登录页制作成品
目录 前言 一、网页制作概述 二、登录页面 2.1 HTML内容 2.2 CSS样式 三、技术说明书 四、页面效果图 前言 Bootstrap是一个用于快速开发Web应用程序和网站的前端框架,由Twitter的设计师Mark Otto和Jacob Thornton合作开发。 它基于HTML、CSS和JavaScri…...

python中http.cookiejar和http.cookie的区别
在Python中,http.cookiejar和http.cookie(通常指http.cookies模块)是两个不同的模块,它们的主要区别如下: 1. 功能定位 http.cookiejar 用于管理HTTP客户端的Cookie,提供自动化的Cookie存储、发送和接收功…...

【NLP 71、常见大模型的模型结构对比】
三到五年的深耕,足够让你成为一个你想成为的人 —— 25.5.8 模型名称位置编码Transformer结构多头机制Feed Forward层设计归一化层设计线性层偏置项激活函数训练数据规模及来源参数量应用场景侧重GPT-5 (OpenAI)RoPE动态相对编码混合专家架构(MoE&#…...