【C++】哈希的概念与实现
1.哈希概念
通过某种函数使元素的存储位置与它的关键码之间能够建立一一映射的关系,可以不经过任何比较,一次直接从表中得到要搜索的元素。
当向该结构中:
- 插入元素:
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放 - 搜索元素:
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)(或者称散列表)
与其它搜索方法比较:
顺序查找时间复杂度为O(N);二分查找为O( l o g 2 N log_2 N log2N)但须先排成一个有序序列会有一定性能损耗,同时在中间插入删除时间复杂度为O(N);平衡树中时间复杂度即为树的高度为O( l o g 2 N log_2 N log2N)
2.哈希冲突
不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
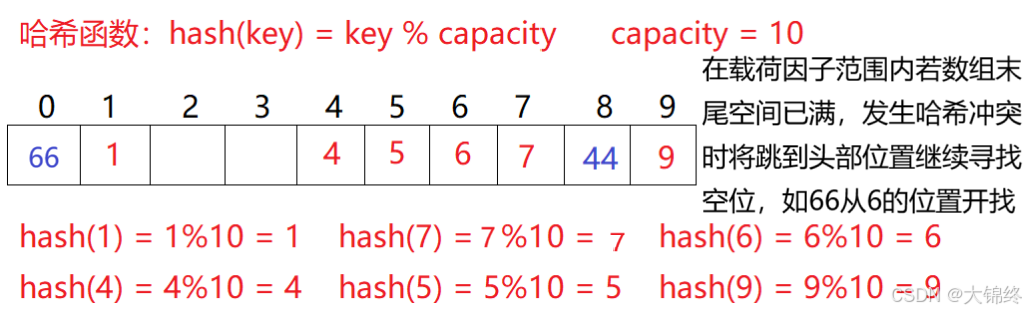
例如6和66,%10都等于6,映射到的地址相同造成冲突。
3.哈希函数
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。
哈希函数设计原则:
1.哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间,不能越界访问
2.哈希函数计算出来的地址能均匀分布在整个空间中
3.哈希函数应该比较简
常见哈希函数:
- 直接定址法–(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
优点:简单、均匀
缺点:需要事先知道关键字的分布情况
使用场景:适合查找比较小且连续的情况- 除留余数法–(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址
认识了解一下非常见哈希函数:
- 平方取中法–(了解)
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址;再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址平方取中法比较适合:不知道关键字的分布,而位数又不是很大的情况- 折叠法–(了解)
折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。折叠法适合事先不需要知道关键字的分布,适合关键字位数比较多的情况- 随机数法–(了解)
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key) = random(key),其中random为随机数函数。通常应用于关键字长度不等时采用此法- 数学分析法–(了解)
设有n个d位数,每一位可能有r种不同的符号,这r种不同的符号在各位上出现的频率不一定相同,可能在某些位上分布比较均匀,每种符号出现的机会均等,在某些位上分布不均匀只有某几种符号经常出现。可根据散列表的大小,选择其中各种符号分布均匀的若干位作为散列地址。通常适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的若干位分布较均匀的情况
注意:哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突
4.哈希表的实现
基本结构
enum STATE
{EXIST,EMPTY,DELETE
};template<class K, class V>
struct HashData
{pair<K, V> _kv;//状态给一个缺省值空STATE _state = EMPTY;
};template<class K,class V,class HashFunc= DefaultHashFunc<K>>
class HashTable
{
private:vector<HashData<K, V>> _table;size_t _n = 0;//存储有效数据的个数
};
1.STATE枚举类型表示哈希表每个槽位中状态
2.节点定义:键值对和槽位状态
3.HashTable哈希表模板类:
使用 vector 动态数组来存储 HashData 对象,表示哈希表的底层存储。_n记录哈希表中有效数据的个数,因为哈希表物理上是一段连续的数组空间,逻辑上是空间不连续的哈希表,存在空位,所以vector自带的capacity容量函数无法表示有效元素个数。
vector::size():返回 _table 中的总槽位数,包括 EMPTY 和 DELETE 的槽位。
有效元素个数:实际存储的有效数据个数(即状态为 EXIST 的槽位数)。
所以通过维护 _n,可以高效地获取哈希表中有效元素的数量
4.1哈希冲突解决
4.2闭散列
也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置“中去。
可采用以下方法
线性探测
- 插入:
从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置止。
- 代码解析
bool Insert(const pair<K, V>& kv)
{//检查扩容,判断是否超出载荷因子//if((double)_n/_table.size()>=0.7)//强制类型转换情况if (10 * _n / _table.size() >= 7)//都转化为int操作{//遍历旧表,重新映射到新表size_t newsize = _table.size() * 2;HashTable<K,V,HashFunc> newht;newht._table.resize(newsize);//遍历旧表数据插入到新表for (size_t i = 0; i < _table.size(); i++){if (_table[i]._state == EXIST){newht.Insert(_table[i]._kv);}}_table.swap(newht._table);}//线性探测,查找空槽位HashFunc hf;size_t hashi = hf(kv.first) % _table.size();while (_table[hashi]._state == EXIST){hashi++;hashi %= _table.size();}_table[hashi]._kv = kv;_table[hashi]._state = EXIST;_n++;return true;
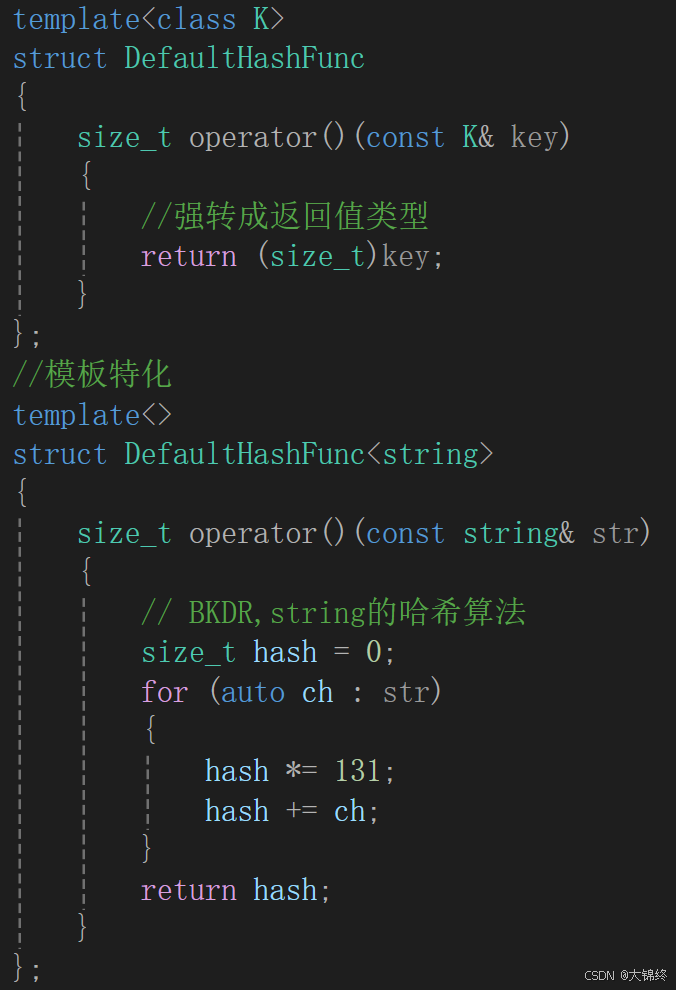
}仿函数部分:
因为Insert的参数是const的_kv,无法进行修改,这时候就需要仿函数(哈希函数)的帮忙,自己控制比较修改方式,将const的键值转化为无符号整型进行取模运算。
运用模板特化进行对string类型键值到整型的转换,采取了BKRD字符串哈希算法来进行转化减少哈希冲突,还有很多种方法可以查文献
检查扩容部分:
扩容后原来冲突的现在不一定冲突了,原来不冲突的现在可能冲突,因为槽位更多了向末尾查找比往前查找的概念更大了,所以冲突关系大概率发生变化。
>采取创建新的哈希表对象来接受原对象的映射,在调用vector的swap函数交换回旧表,新表作为局部对象在扩容操作完后将自动销毁。为什么不是直接创建一个新的动态数组 vector<HashData<K, V>> _newtable来帮助完成扩容操作呢?
因为哈希表对象能保证封装信和内部状态的一致性,因为哈希表内不止有动态数组,还有哈希函数,_n等,可以自动管理载荷因子维护性能。若直接创建动态数组需要重新手动实现哈希逻辑
线性探测部分:
通过HashFunc hf;定义仿函数对象,重载了operator(),可以像普通函数一样调用。
进行取模运算,找空位的循环条件是状态为存在就更新hashi下标索引,循环内再进行取模运算,递增 hashi 时,可能会超出哈希表的大小。取模操作可以将索引“环绕”到哈希表的起始位置,继续从头查找。确保索引在有效范围内。
找到空位后更新状态
载荷因子:
- 查找:
HashData<const K, V>* Find(const K& key)
{HashFunc hf;size_t hashi = hf(key) % _table.size();while (_table[hashi]._state !=EMPTY){//找到了if (_table[hashi]._state == EXIST &&_table[hashi]._kv.first == key){return (HashData<const K, V>*)&_table[hashi];}hashi++;hashi %= _table.size();}return nullptr;
}
返回值key值不可修改,利用线性探测实现查找,当前槽位不是空的,就继续查找,然后检查当前槽位的状态是否为 EXIST,并且槽位中的键值 _kv.first 是否与目标键值 key 相等,匹配返回该槽位指针,否则返回空。
注意返回值要强转指针类型
- 删除:
采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他元素的搜索。比如删除元素4,如果直接删除掉,44查找起来可能会受影响。因此线性探测采用标记的伪删除法来删除一个元素。
bool Erase(const K& key)
{HashData<const K, V>* ret = Find(key);if (ret){ret->_state = EMPTY;_n--;return true;}return false;
}
- 缺点
一旦发生哈希冲突,所有的冲突连在一起,容易产生数据“堆积”,即:不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要许多次比较,导致搜索效率降低。最大的缺陷就是空间利用率比较低
二次探测
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法为: H i H_i Hi = ( H 0 H_0 H0 + i 2 i^2 i2 )% m, 或者: H i H_i Hi = ( H 0 H_0 H0 - i 2 i^2 i2 )% m。其中:i = 1,2,3…, H 0 H_0 H0是通过散列函数Hash(x)对元素的关键码 key 进行计算得到的位置,m是表的大小。
4.3开散列
- 概念:
又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
每个哈希桶中放的都是发生哈希冲突的元素。
哈希桶扩容时不适合复用insert涉及节点的开辟和销毁
哈希桶的实现
基本结构
namespace hash_bucket
{template<class K,class V>struct HashNode{pair<K, V> _kv;HashNode<K, V>* next;HashNode(const pair<K, V>& _kv):_kv(kv), newxt(nullptr){ }};template<class K,class V,class HashFunc= DefaultHashFunc<K>>class HashTable{typedef HashNode<K, V> Node;private:vector<Node*> _table;//指针数组size_t _n = 0;};
1.定义在哈希桶命名空间内,方便调用区分
2.节点的定义与哈希表相比不需要表明状态,替换成一个next指针,能直接完成插入,删除操作
3。vector<Node*> _table;定义指针数组,vector可自动扩容,每个槽位存储一个指向链表头节点的指针,每个链表存储多个具有相同哈希值的元素
析构函数
~HashTable()
{for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->next;delete cur;cur = next;}_table[i] = nullptr;}
}
vector<Node*> _table中vector 是一个动态数组,当它超出作用域或被销毁时,其内部管理的内存空间会自动被释放。
Node* 是指向堆上分配的 Node 对象的指针,是内置类型,不会自动调用析构函数,需要手动释放
代码逻辑:
1.创建cur来遍历每个槽位头节点所指向的链表,循环中要提前保存next指针,然后销毁cur中对象并释放内存,更新cur,将 _table[i] 指针置空,确保 _table[i] 不再指向已经被释放的内存
插入
bool Insert(const pair<K, V>& kv)
{if (Find(kv.first)){return false;}HashFunc hf;//检查扩容,载荷因子到1就扩容if (_n == _table.size()){size_t newsize = _table.size() * 2;vector<Node*> newtable;newtable.resize(newsize, nullptr);//遍历旧表,将节点转移挂到新表for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];//在数组中向下遍历处理每一个哈希桶while (cur){size_t hashi = hf(cur->_kv.first) % newsize;Node* next = cur->_next;cur->_next = newtable[hashi];newtable[hashi]=cur;//更新节点cur = next;}_table[i] = nullptr;}//交换新旧表_table.swap(newtable);}//插入新节点size_t hashi = hf(kv.first) % _table.size();Node* newnode = new Node(kv);newnode->_next = _table[hashi];_table[hashi] = newnode;++_n;return true;
}
思路解析:
1.首先判断要插入节点是否存在
2.检查扩容:
桶的个数是一定的,随着元素的不断插入,每个桶中元素的个数不断增多,极端情况下,可能会导致一个桶中链表节点非常多,会影响的哈希表的性能。开散列最好的情况是:每个哈希桶中刚好挂一个节点,再继续插入元素时,每一次都会发生哈希冲突,因此,在元素个数刚好等于桶的个数时,可以给哈希表增容。
具体操作:
a:与闭散列哈希表相比不需要建立一张新表来接收旧表,直接建立一个新动态数组即可,因为哈希桶中不需要维护状态,链表可以直接完成插入删除操作。
b:计算新容量,先计算hashi索引,循环遍历旧表节点到新表,缓解原表哈希冲突,每遍历完一个哈希桶,原表当前槽位记得置空,方便后续与新表交换
3.插入新节点:
计算hashi索引,然后new一个新节点,进行头插操作,将新节点的_next指针指向当前槽位中链表头节点,然后将头节点赋值为新节点,完成。更新当前元素有效个数。
查找
Node* Find(const K& key)
{HashFunc hf;size_t hashi = hf(key) % _table.size();//在该哈希桶中遍历寻找Node* cur = _table[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;
}
先计算hashi索引,在当前哈希桶中遍历链表寻找,找到返回当前节点,否则返回空。
删除
bool Erase(const K& key)
{HashFunc hf;size_t hashi = hf(key) % _table.size();Node* cur = _table[hashi];Node* prev = nullptr;while (cur){if (cur->_kv.first == key){//判断要删除节点为头节点情况if (prev == nullptr){_table[hashi] = cur->_next;}else{prev = cur->_next;}--_n;delete cur;return true;}//更新节点继续遍历prev = cur;cur = cur->_next;}return false;
}
1.提前保存删除节点的上一个节点prev,方便重新链接
2.注意判断删除节点为头节点和链表中间节点的情况
3.更新链接关系后删除释放当前cur
相关文章:

【C++】哈希的概念与实现
1.哈希概念 通过某种函数使元素的存储位置与它的关键码之间能够建立一一映射的关系,可以不经过任何比较,一次直接从表中得到要搜索的元素。 当向该结构中: 插入元素: 根据待插入元素的关键码,以此函数计算出该元素的…...
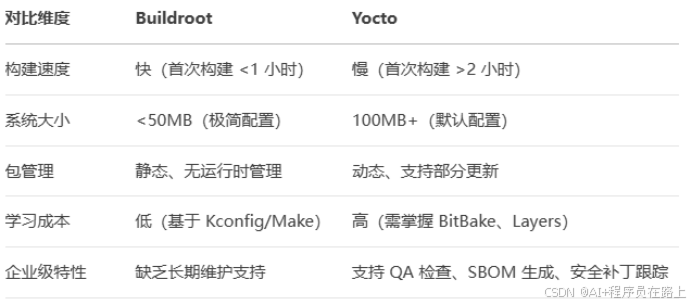
Yocto和Buildroot功能和区别
一.介绍 Yocto 和 Buildroot 都是用于嵌入式 Linux 系统开发的工具集,它们的目的是帮助开发者轻松构建定制的 Linux 系统镜像,以便在嵌入式设备上运行。 二.对比 1.Yocto Yocto 是一个开源的嵌入式 Linux 构建系统,它允许开发者创建自定义…...

物联网数据湖架构
物联网海量数据湖分析架构(推荐实践) ┌──────────────┐ │ IoT设备端 │ └──────┬───────┘│(MQTT/HTTP)▼ ┌──────────────┐ │ EMQX等 │ 可选(也可…...
详解RabbitMQ工作模式之发布订阅模式
目录 发布订阅模式 概念 概念介绍 特点和优势 应用场景 注意事项 代码案例 引入依赖 常量类 编写生产者代码 编写消费者1代码 运行代码 发布订阅模式 概念 RabbitMQ的发布订阅模式(Publish/Subscribe)是一种消息传递模式,它允许消…...

什么是子网委派?
Azure 子网委派的概念 子网委托使您能够为所选的 Azure PaaS 服务指定一个特定的子网,并将其注入到您的虚拟网络中。子网委托为客户提供了完全的控制权,可以管理 Azure 服务与其虚拟网络的集成。 当您将子网委托给 Azure 服务时,您允许该服务为该子网建立一些基本的网络配…...
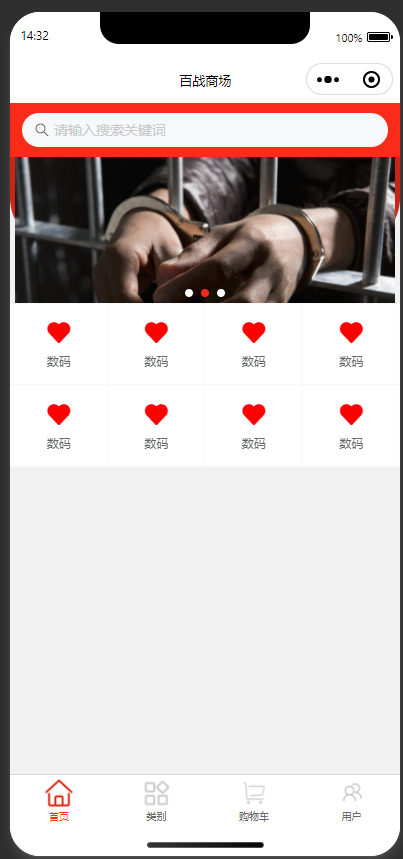
微信学习之导航功能
先看这个功能的效果: 然后开始学习吧。 一、我们这里用的是vant的Grid控件,首先我们导入: { "usingComponents": {"van-search": "vant/weapp/search/index","my-swiper":"../../components…...

城市内涝监测预警系统守护城市安全
一、系统背景 城市内涝是指由于强降水或连续性降水超过城市排水能力,导致城市内产生积水灾害的现象。随着气候变化和城市化进程的加快,城市内涝现象愈发频繁和严重。传统的城市排水系统已难以满足当前的城市排水需求,特别是在暴雨等极端天气条…...
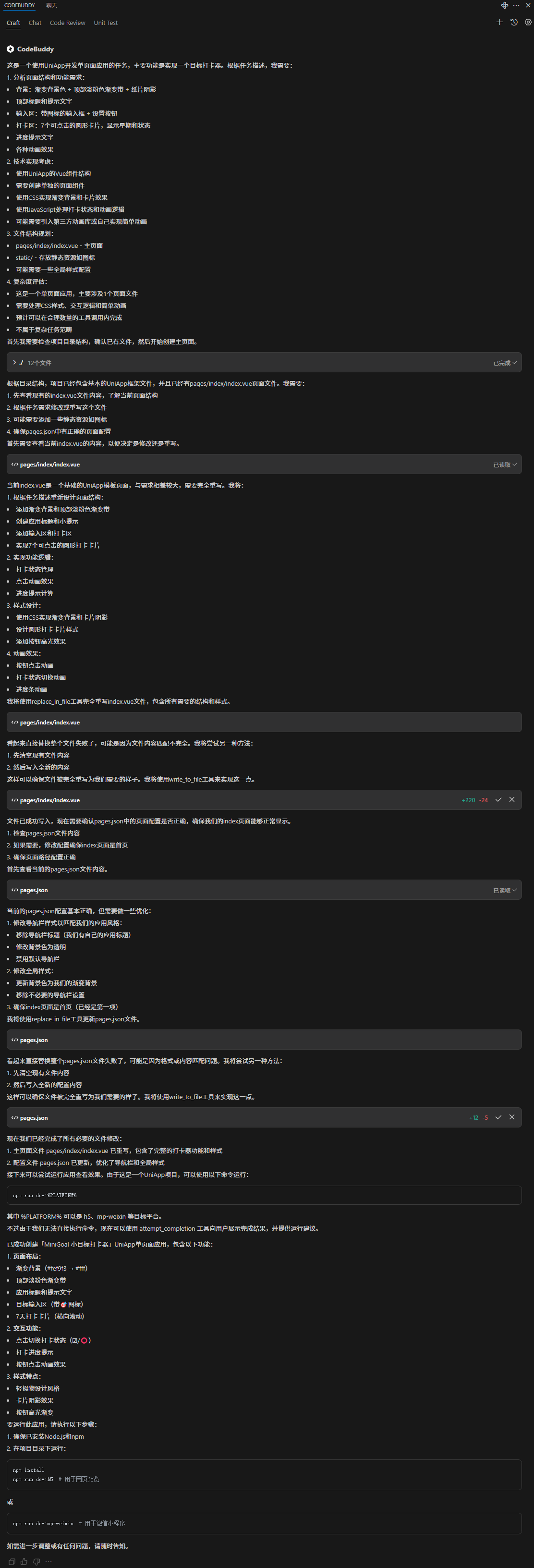
用 CodeBuddy 搭建「MiniGoal 小目标打卡器」:一次流畅的 UniApp 开发体验
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 在日常生活中,我们总是希望能够坚持一些小习惯,比如每天锻炼十分钟、读一页书、早睡十分…...
Web技术与Nginx网站环境部署
目录 一.web基础 1.域名和DNS (1).域名的概念 (2).hosts文件 (3).DNS (4).域名注册 2.网页与HTML (1).网页简介 (2).HTML &a…...
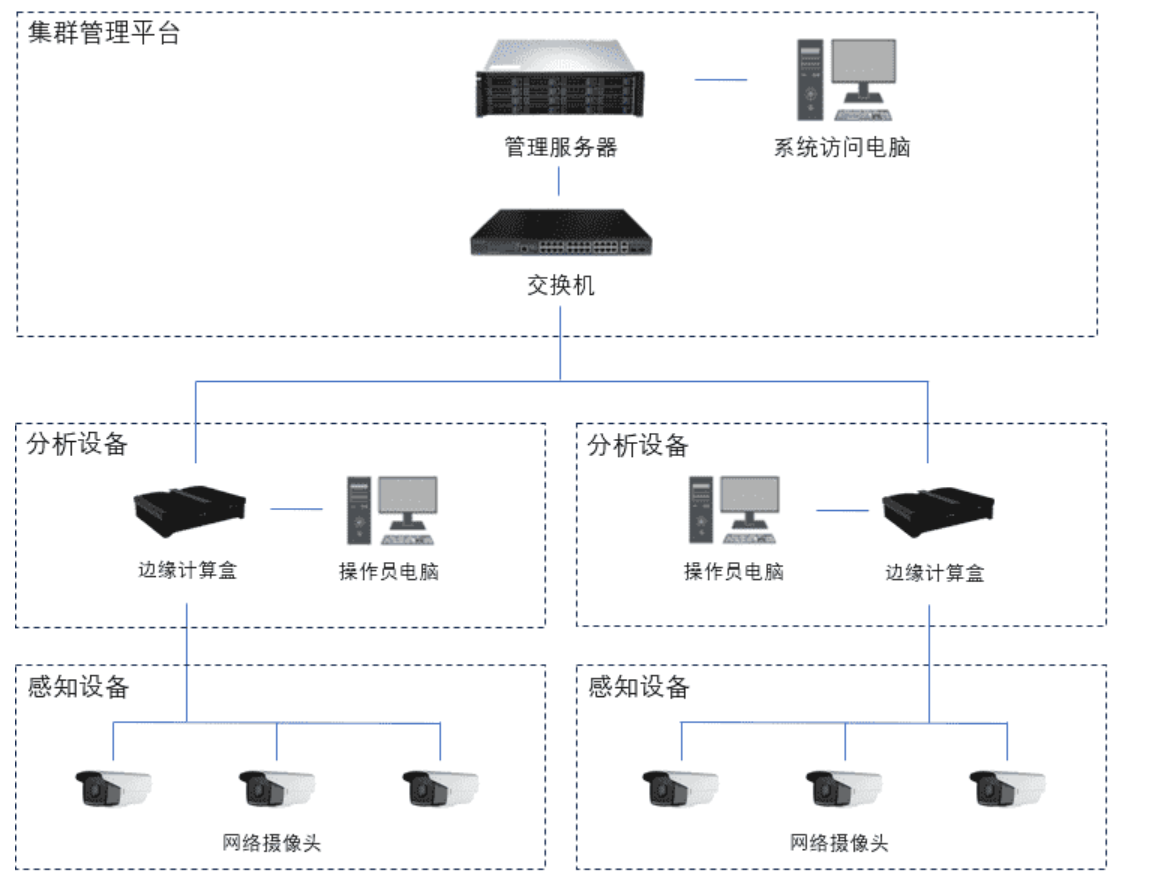
AI移动监测:仓储环境安全的“全天候守护者”
AI移动监测在仓储方面的应用:技术赋能与场景突破 一、背景:仓储环境的“隐形威胁”与AI破局 仓储行业长期面临设备损坏、货物损失、卫生隐患等风险。传统监控依赖人工巡检或固定摄像头,难以实时捕捉动态风险。例如: 动物入侵&a…...

【数据库】数据库故障排查指南
数据库故障排查指南 数据库连接问题 检查数据库服务是否正常运行,确认网络连接是否畅通,验证数据库配置文件的正确性,确保防火墙或安全组规则允许数据库端口的访问。 性能问题 分析慢查询日志,优化SQL语句,检查索引…...
)
mariadb 升级 (通过yum)
* 注意下 服务名, 有的服务器上是mysql,有的叫mariadb,mysqld的 #停止 systemctl stop mysql #修改源 vi /etc/yum.repos.d/MariaDB.repo baseurl http://yum.mariadb.org/11.4/centos7-amd64 #卸载 yum remove mysql #安装 yum install MariaDB-server galera-4 MariaDB-…...

2025年5月华为H12-821新增题库带解析
IS-IS核心知识 四台路由器运行IS-IS且已经建立邻接关系,区域号和路由器的等级如图中标记,下列说法中正确的有? R2和R3都会产生ATT置位的Level-1的LSPR1没有R4产生的LSP,因此R1只通过缺省路由和R4通信R2和R3都会产生ATT置位的Leve1-2的LSPR2和…...
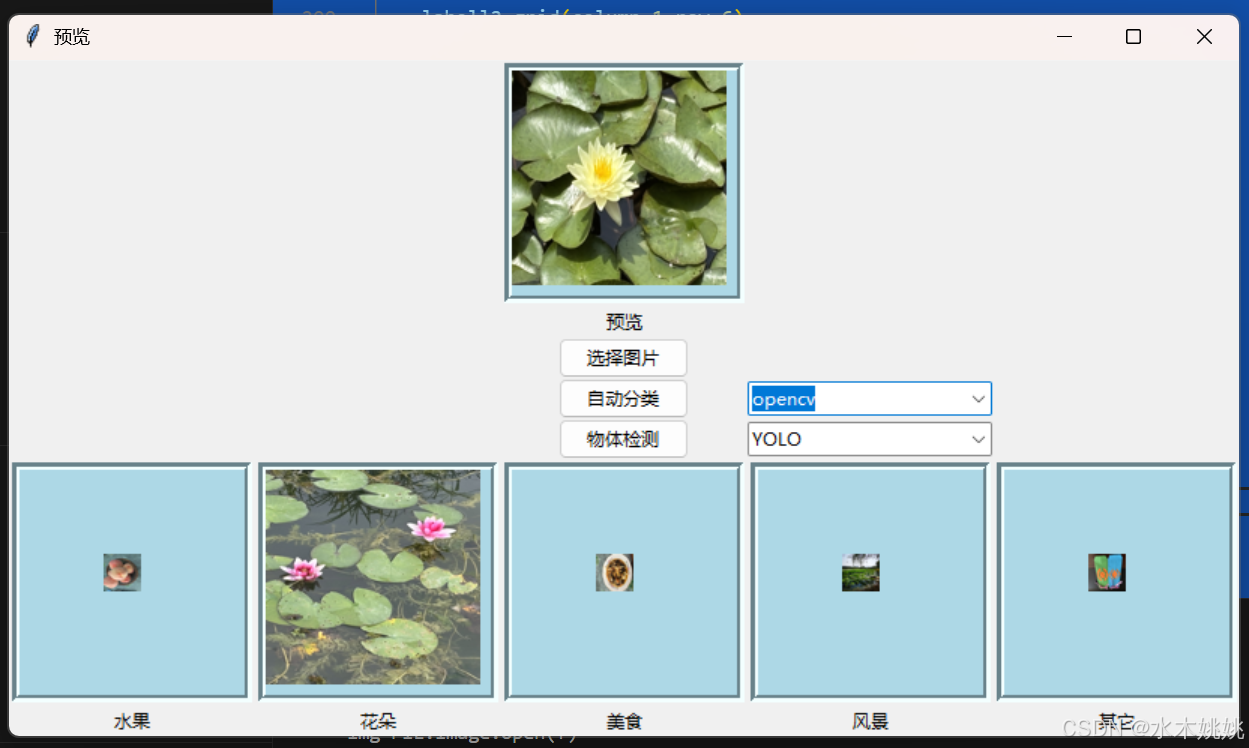
用 python 编写的一个图片自动分类小程序(三)
图片自动分类识别小程序记录 2025/5/18 0:38修改程序界面,增加一些功能 用 python 编写的一个图片自动识别分类小程序。 操作系统平台:Microsoft Windows 11 编程语言和 IDE:python 3.10 Visual studio code 一:图片自动分…...

用户行为日志分析的常用架构
## 1. 经典Lambda架构 Lambda架构是一种流行的大数据处理架构,特别适合用户行为日志分析场景。 ### 1.1 架构组成 Lambda架构包含三层: - **批处理层(Batch Layer)**: 存储全量数据并进行离线批处理 - **实时处理层(Speed Layer)**: 处理最新数据&…...
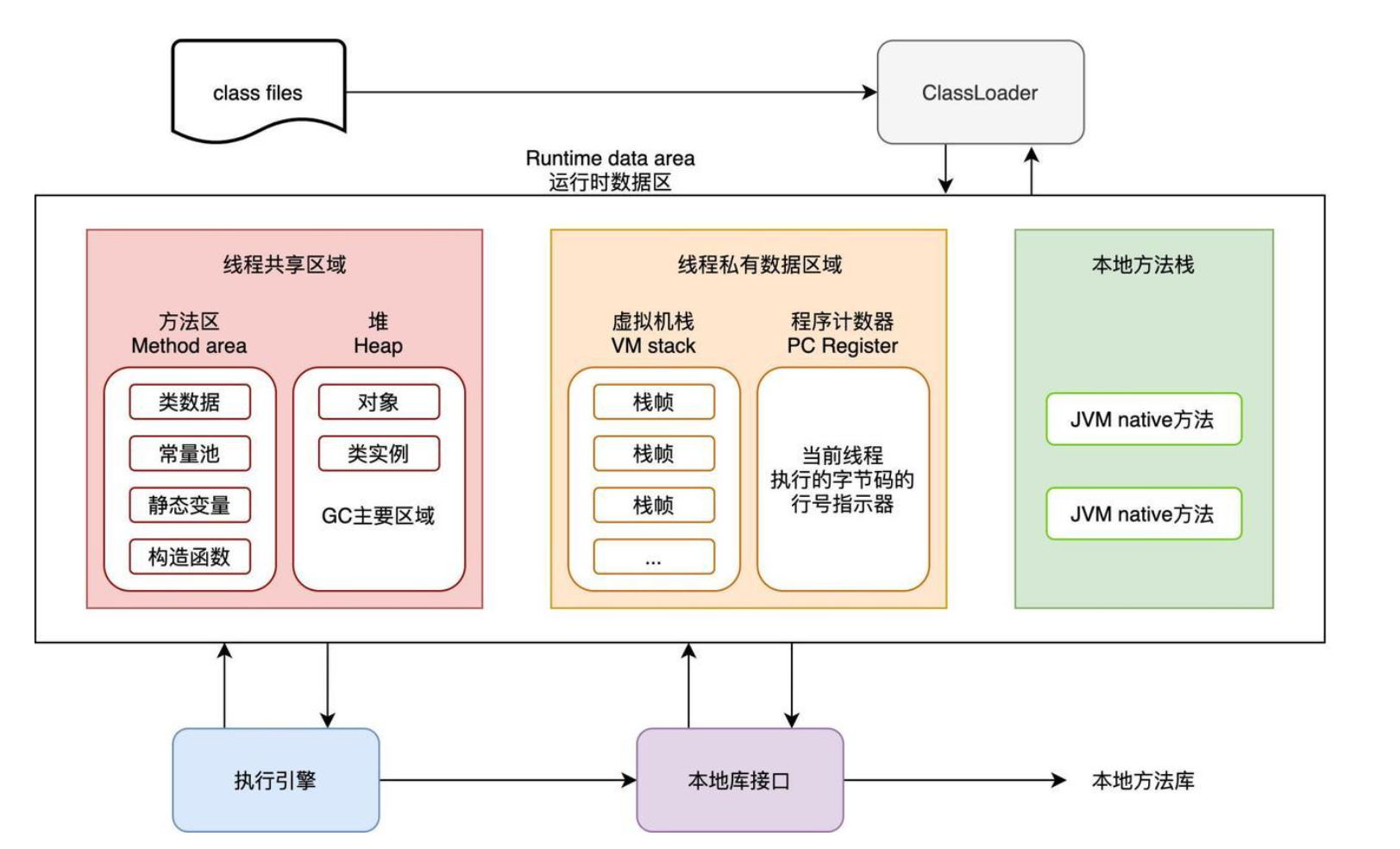
初识 java
目录 前言 一、jdk,JRE和JVM之间的关系 二、JVM的内存划分 前言 初步了解 jdk,JRE,JVM 之间的关系,JVM 的内存划分。 一、jdk,JRE和JVM之间的关系 jdk 是 java 开发工具集,包含JRE; JRE 是…...
简介)
3D 数据交换格式(.3DXML)简介
3DXML 是一种基于 XML 的 3D 数据交换格式,由达索系统(Dassault Systmes)开发,主要用于其 CATIA、SOLIDWORKS 和 3DEXPERIENCE 等产品中。 基本概述 全称:3D XML开发者:达索系统主要用途:3D…...
frida 配置
1.环境 1.1 下载 frida-server firda-server github下载地址 这边推荐使用最新版的上一个版本 根据虚拟机自行选择版本 我使用这个版本 frida-server-16.7.17-android-x86_64 1.2 启动 frida-server-16.7.17-android-x86_64 将文件解压至虚拟机目录 使用adb命令执行 chmo…...

16-看门狗和RTC
一、独立看门狗 1、独立看门狗概述 在由单片机构成的微型计算机系统中,由于单片机的工作常常会受到来自外界电磁场的干扰,造成程序的跑飞(不按照正常程序进行运行,如程序重启,但是如果我们填加看门狗的技术࿰…...
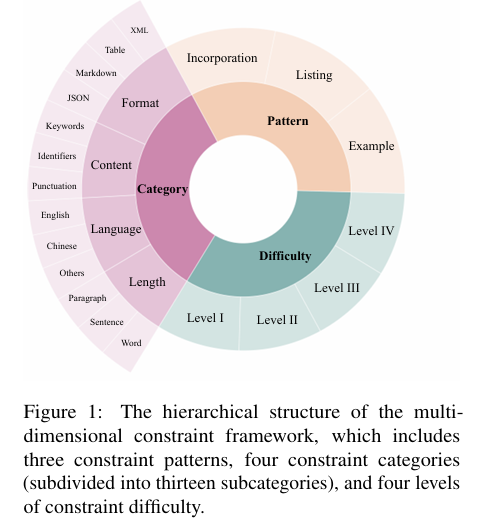
【AI论文】用于评估和改进大型语言模型中指令跟踪的多维约束框架
摘要:接下来的指令评估了大型语言模型(LLMs)生成符合用户定义约束的输出的能力。 然而,现有的基准测试通常依赖于模板化的约束提示,缺乏现实使用的多样性,并限制了细粒度的性能评估。 为了填补这一空白&…...

AUTOSAR图解==>AUTOSAR_SRS_TimeService
AUTOSAR TimeService模块详解 AUTOSAR经典平台时间服务分析与图解 目录 1. 概述2. TimeService架构分析 2.1 模块位置与组件关系2.2 模块功能职责3. TimeService组件结构 3.1 预定义定时器类型3.2 时间函数功能3.3 与GPT驱动关系4. TimeService定时器实例 4.1 实例数据结构4.2 …...

设计模式的原理及深入解析
创建型模式 创建型模式主要关注对象的创建过程,旨在通过不同的方式创建对象,以满足不同的需求。 工厂方法模式 定义:定义一个创建对象的接口,让子类决定实例化哪一个类。 解释:工厂方法模式通过定义一个创建对象的…...
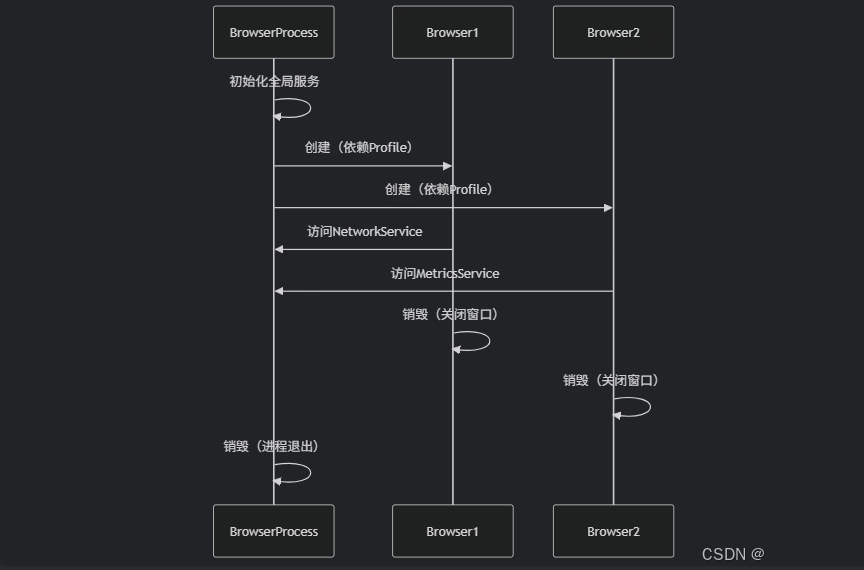
Chromium 浏览器核心生命周期剖析:从 BrowserProcess 全局管理到 Browser 窗口实例
在 Chromium 浏览器架构中,BrowserProcess 和 Browser 是两个核心类,分别管理 浏览器进程的全局状态 和 单个浏览器窗口的实例。它们的生命周期设计直接影响浏览器的稳定性和资源管理。以下是它们的详细生命周期分析: 1. BrowserProcess 的生…...
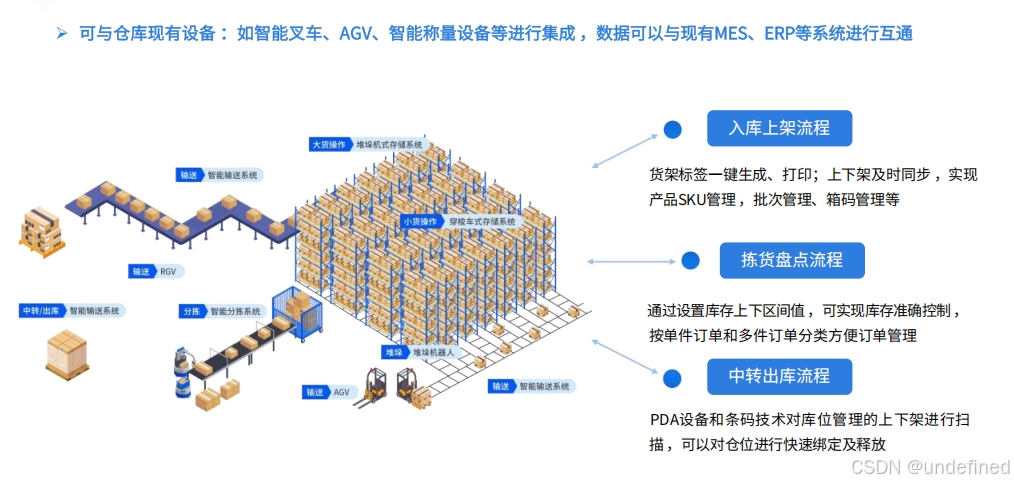
易境通海外仓系统:一件代发全场景数字化解决方案
随着全球经济一体化和消费升级,一件代发业务的跨境电商市场规模持续增长。然而,一件代发的跨境运营也面临挑战,传统海外仓管理模式更因效率低下、协同困难成为业务扩张的瓶颈。 一、一件代发跨境运营痛点 1、多平台协同:卖家往往…...

Flink 非确定有限自动机NFA
Flink 是一个用于状态化计算的分布式流处理框架,而非确定有限自动机(NFA, Non-deterministic Finite Automaton)是一种在计算机科学中广泛使用的抽象计算模型,常用于正则表达式匹配、模式识别等领域。 Apache Flink 提供了对 NFA…...

YoloV9改进策略:卷积篇|风车卷积|即插即用
论文信息 论文标题:《Pinwheel-shaped Convolution and Scale-based Dynamic Loss for Infrared Small Target Detection》 论文链接:https://arxiv.org/pdf/2412.16986 GitHub链接:https://github.com/JN-Yang/PConv-SDloss-Data 论文翻译 摘要 https://arxiv.org/pd…...

【Python训练营打卡】day30 @浙大疏锦行
DAY 30 模块和库的导入 知识点回顾: 1. 导入官方库的三种手段 2. 导入自定义库/模块的方式 3. 导入库/模块的核心逻辑:找到根目录(python解释器的目录和终端的目录不一致) 作业:自己新建几个不同路径文件尝试下如何…...

超越想象:利用MetaGPT打造高效的AI协作环境
前言 在人工智能迅速发展的今天,如何让多个大语言模型(LLM)高效协同工作成为关键挑战。MetaGPT 作为一种创新的多智能体框架,成功模拟了一个真实软件公司的运作流程,实现了从需求分析到代码实现的全流程自动化&#x…...

仿腾讯会议——添加音频
1、实现开启或关闭音频 2、 定义信号 3、实现开始暂停音频 4、实现信号槽连接 5、回收资源 6、初始化音频视频 7、 完成为每个人创建播放音频的对象 8、发送音频 使用的是对象ba,这样跨线程不会立刻回收,如果使用引用,跨线程会被直接回收掉&a…...

虚幻引擎5-Unreal Engine笔记之`GameMode`、`关卡(Level)` 和 `关卡蓝图(Level Blueprint)`的关系
虚幻引擎5-Unreal Engine笔记之GameMode、关卡(Level) 和 关卡蓝图(Level Blueprint)的关系 code review! 参考笔记: 1.虚幻引擎5-Unreal Engine笔记之GameMode、关卡(Level) 和 关卡蓝图&…...