知识图谱(KG)与大语言模型(LLM)
知识图谱(KG)以其结构化的知识表示和推理能力,为大语言模型(LLM)的“幻觉”、知识更新滞后和可解释性不足等问题提供了有力的解决方案。反过来,LLM的强大文本理解和生成能力也为KG的构建、补全、查询和应用带来了革命性的进步。二者的融合旨在结合符号主义AI(以KG为代表)和连接主义AI(以LLM为代表)的优势,推动人工智能向更智能、更可信、更易用的方向发展。
一、背景与动机 (Background and Motivation)
-
大语言模型 (LLM) 的优势与局限:
- 优势:
- 强大的自然语言理解和生成能力。
- 在开放域对话、文本摘要、代码生成等任务中表现出色。
- 通过预训练从海量文本数据中学习了广泛的世界知识(隐式知识)。
- 局限:
- 幻觉 (Hallucination): 可能生成不准确或完全虚构的信息。
- 知识更新滞后: 预训练模型中的知识是静态的,难以实时更新。
- 可解释性差: “黑箱”模型,决策过程难以理解和追溯。
- 逻辑推理能力有限: 尤其在复杂的多跳推理上表现不佳。
- 事实性不足: 容易受到训练数据中偏见和错误信息的影响。
- 计算成本高昂: 训练和微调大型模型需要巨大的计算资源。
- 优势:
-
知识图谱 (KG) 的优势与局限:
- 优势:
- 结构化知识: 以实体-关系-实体的三元组形式存储知识,清晰明了。
- 精确性与一致性: 存储经过验证的事实,保证知识的准确性。
- 可解释性强: 知识路径清晰,推理过程可追溯。
- 支持复杂推理: 基于图结构可以进行符号逻辑推理。
- 局限:
- 构建成本高: 需要大量人工或复杂的自动化流程,且难以覆盖所有领域知识。
- 知识不完备性: 现实世界的知识是动态变化的,KG难以做到完全覆盖。
- 处理自然语言能力弱: 理解和生成自然语言的灵活性和流畅性远不如LLM。
- 可扩展性问题: 巨大规模KG的存储、查询和更新面临挑战。
- 优势:
-
融合动机:
- 优势互补: KG为LLM提供事实依据、可解释性和推理能力;LLM为KG提供自然语言接口、知识获取和表示能力。
- 提升LLM性能:
- 减少幻觉,提高事实准确性。
- 增强对专业领域知识的理解和应用。
- 提高推理能力和可解释性。
- 实现知识的动态更新。
- 赋能KG发展:
- 自动化或半自动化KG构建和补全。
- 提供更自然的KG查询方式(自然语言问答)。
- 丰富KG的语义表示。
- 推动下一代AI: 构建更接近人类认知智能的系统,兼具感知、认知、推理和生成能力。
二、前沿核心技术模块与融合范式 (Cutting-edge Core Technical Modules and Fusion Paradigms)
KG与LLM的融合主要可以分为三大范式:
-
知识图谱增强大语言模型 (KG-enhanced LLMs / Knowledge-Augmented LLMs):
- 目标: 利用KG中显式的结构化知识来提升LLM的性能和可靠性。
- 核心模块:
- 增强输入 (Input Augmentation / Prompting with KG):
- 检索增强生成 (Retrieval Augmented Generation, RAG): 在LLM生成回答前,先从KG中检索与问题相关的知识片段(三元组、子图、路径等),并将其作为上下文信息融入LLM的提示(Prompt)中。这是目前最主流和实用的方式之一。
- 序列化知识注入 (Serialization): 将KG中的三元组或子图序列化为文本,直接拼接到输入文本中。
- 改进模型结构与预训练 (Model Architecture & Pre-training Modification):
- 知识注入层 (Knowledge Injection Layers): 在LLM的某些层(如注意力层、前馈网络层)中显式地融入KG的表示(如实体/关系嵌入)。例如,KnowBERT, ERNIE, JAKET等。
- 联合预训练 (Joint Pre-training): 设计新的预训练任务,让LLM在预训练阶段同时学习文本和KG中的知识。例如,通过掩码语言模型(MLM)和知识图谱链接预测(Link Prediction)等任务进行联合优化。
- 优化输出与后处理 (Output Optimization & Post-processing):
- 事实校验 (Fact Verification): 利用KG对LLM生成的文本进行事实性校验和修正。
- 知识指导的解码 (Knowledge-Guided Decoding): 在LLM生成文本的过程中,利用KG引导生成过程,使其更符合事实逻辑。
- 增强输入 (Input Augmentation / Prompting with KG):
-
大语言模型赋能知识图谱 (LLM-enhanced KGs / LLM-Empowered KGs):
- 目标: 利用LLM强大的自然语言理解和生成能力来辅助KG的构建、补全、查询和应用。
- 核心模块:
- 知识图谱构建 (KG Construction):
- 实体识别与链接 (Named Entity Recognition & Linking, NER & NEL): LLM可以从非结构化文本中高效抽取实体,并将其链接到KG中已有的实体或新的实体。
- 关系抽取 (Relation Extraction, RE): LLM可以判断文本中实体对之间的关系,甚至发现新的关系类型。
- 事件抽取 (Event Extraction): LLM可以抽取复杂的事件结构及其参与者。
- 属性抽取 (Attribute Extraction): LLM可以从文本中为实体抽取属性信息。
- 三元组抽取 (Triplet Extraction): LLM可以直接从文本中抽取 (头实体, 关系, 尾实体) 的三元组。
- 知识图谱补全 (KG Completion / Link Prediction): LLM可以基于已有的KG结构和文本描述,预测KG中缺失的链接(关系)或实体。
- 知识图谱问答/查询 (KG Question Answering / KG Querying):
- 自然语言到查询语言 (NL2Query): LLM可以将用户的自然语言问题转换为KG的标准查询语言(如SPARQL, Cypher)。
- 端到端问答 (End-to-End QA): LLM直接基于问题和KG上下文生成答案,可能内部隐式地进行了推理。
- 知识图谱表示学习 (KG Representation Learning): LLM可以帮助学习更丰富的实体和关系嵌入,捕捉其深层语义。
- 知识图谱的文本描述生成 (KG-to-Text Generation): LLM可以将KG中的子图或路径转换为流畅的自然语言描述,增强KG的可理解性。
- 知识图谱构建 (KG Construction):
-
协同进化与深度融合 (Synergistic Co-evolution and Deep Fusion):
- 目标: 实现KG和LLM之间更深层次、更动态的交互和共同进化。这代表了更长远的研究方向。
- 核心模块:
- 统一表示空间 (Unified Representation Space): 学习一个统一的向量空间,能够同时表示文本语义和KG结构。
- 迭代式增强 (Iterative Enhancement): LLM帮助完善KG,完善后的KG反过来又提升LLM的能力,形成一个正反馈循环。
- 神经符号混合推理 (Neuro-Symbolic Reasoning): 结合LLM的模式匹配能力和KG的符号推理能力,进行更复杂的推理任务。例如,LLM生成推理路径的候选,KG进行验证和筛选。
- 可解释性双向增强 (Bidirectional Interpretability Enhancement): KG为LLM的决策提供依据,LLM帮助解释KG中的复杂关系和模式。
三、技术细节和要点 (Technical Details and Key Points)
-
表示学习 (Representation Learning):
- KG嵌入 (KG Embeddings): 如TransE, DistMult, ComplEx, RotatE等,将实体和关系映射到低维向量空间。
- 文本嵌入 (Text Embeddings): 如Word2Vec, GloVe, BERT embeddings等。
- 对齐与融合 (Alignment & Fusion): 关键在于如何有效地对齐和融合来自KG和文本的表示。这可以通过联合训练、多模态融合技术等实现。
-
检索增强生成 (RAG):
- 检索器 (Retriever): 通常使用密集向量检索(Dense Passage Retrieval, DPR)或稀疏检索(如BM25)从KG或文本化KG中找到相关知识。需要将KG三元组或子图转换为可检索的文本单元。
- 生成器 (Generator): 通常是预训练的LLM,将检索到的知识和原始问题一起作为输入来生成答案。
- 关键点: 检索的质量、检索内容与问题的相关性、如何将检索到的结构化知识有效地融入LLM的上下文。
-
提示工程 (Prompt Engineering):
- 在KG增强LLM的范式中,如何设计有效的Prompt至关重要。这包括如何序列化KG知识、如何向LLM提问以引导其利用这些知识。
- 对于LLM赋能KG,Prompt可以用来引导LLM进行实体抽取、关系抽取等任务,例如通过In-Context Learning (ICL) 或 Chain-of-Thought (CoT) prompting。
-
微调策略 (Fine-tuning Strategies):
- 适配器微调 (Adapter Tuning): 冻结大部分LLM参数,只微调少量插入的适配器模块,以较低成本将KG知识融入LLM。
- 指令微调 (Instruction Tuning): 使用包含KG知识的指令数据集对LLM进行微调,使其学会遵循指令并利用KG信息。
- 领域自适应微调: 针对特定领域的KG和文本数据进行微调。
-
知识的表示与粒度:
- 是将三元组、路径、子图还是整个KG的摘要信息注入LLM?不同粒度的知识对LLM的影响不同。
- 如何处理KG中的数值、日期等属性信息。
-
评估指标 (Evaluation Metrics):
- 对于KG增强LLM: 除了标准的语言模型评估指标(如Perplexity, BLEU, ROUGE),还需要关注事实准确性(如F1-score for factuality)、知识覆盖率、推理能力等。
- 对于LLM赋能KG: 传统的KG构建评估指标(如Precision, Recall, F1-score for NER/RE)、链接预测指标(如MRR, Hits@k)。
四、相关的知识拓展和补充 (Related Knowledge Expansion and Supplements)
-
应用场景:
- 智能问答系统: 更准确、可解释的答案,尤其在专业领域(医疗、金融、法律)。
- 搜索引擎: 结合结构化知识和非结构化文本,提供更精准的搜索结果。
- 推荐系统: 基于用户画像知识图谱和物品知识图谱进行更个性化和可解释的推荐。
- 对话系统/聊天机器人: 生成更连贯、有信息量且不易跑题的对话。
- 代码生成与理解: 结合API知识库或代码知识图谱,生成更可靠的代码。
- 药物研发、金融风控、智能制造等专业领域。
-
面临的挑战:
- 异构性问题: KG和LLM的知识表示形式不同,如何有效融合异构信息。
- 可扩展性: 如何处理大规模KG和LLM的融合,平衡效率和效果。
- 动态知识更新: 如何使融合模型能够高效地处理新增或变化的知识。
- 推理的深度与复杂性: 如何实现更深层次、更复杂的联合推理。
- 可解释性的真正实现: 如何不仅知道“是什么”,还知道“为什么”。
- 评估体系的完善: 如何全面、公正地评估KG-LLM融合系统的性能。
- 数据稀疏性: 很多领域的KG仍然不够完善。
-
相关领域:
- 神经符号计算 (Neuro-Symbolic Computing): 旨在结合神经网络的学习能力和符号系统的推理能力,KG-LLM融合是其重要实践方向。
- 多模态学习 (Multi-modal Learning): 将知识图谱视为一种模态,与文本、图像等其他模态融合。
- 可信AI (Trustworthy AI): KG的引入有助于提升AI系统的透明度、鲁棒性和公平性。
五、 Research Gaps with High Innovation Potential
-
统一的神经符号表示与推理框架:
- 空白点: 目前多数融合方法仍偏向某一侧(KG增强LLM或LLM增强KG),缺乏真正深度统一的表示学习和推理框架,使得两者能力无法充分协同。
- 潜力: 设计能够同时对符号知识和子符号模式进行建模、学习和推理的统一架构,实现端到端的神经符号推理。
- 论文方向: “Towards a Unified Neuro-Symbolic Representation for KG-LLM Reasoning”, “Learning to Reason: Integrating Deductive Logic with Language Models via Knowledge Graphs”。
-
动态知识图谱与LLM的持续协同进化:
- 空白点: 现有模型大多基于静态KG,或知识更新流程复杂低效。如何让LLM感知KG的动态变化,并反过来高效、准确地帮助KG进行实时更新和演化,是一个巨大挑战。
- 潜力: 研究KG流数据处理、增量学习、持续学习技术在KG-LLM融合模型中的应用,实现模型知识的“终身学习”。
- 论文方向: “Lifelong Learning for KG-LLM: Continual Adaptation to Evolving Knowledge”, “Synergistic Evolution of Knowledge Graphs and Language Models in Dynamic Environments”。
-
多模态知识图谱与LLM的融合:
- 空白点: 当前KG主要还是以文本和符号为主,但现实世界知识是多模态的(图像、视频、音频等)。如何构建多模态KG,并将其与LLM有效融合,以支持更丰富的跨模态理解和生成任务。
- 潜力: 探索多模态知识的统一表示、跨模态对齐、以及基于多模态KG的LLM增强方法。
- 论文方向: “MM-KG-LLM: Fusing Multi-modal Knowledge Graphs with Large Language Models for Enhanced Comprehension and Generation”, “Grounding Language Models in a Multi-modal World: The Role of Visual Knowledge Graphs”。
-
可解释性、可控性与因果推断的深度融合:
- 空白点: 虽然KG能提升LLM的可解释性,但目前主要停留在“溯源”层面。如何让LLM不仅能“知其然”(提供事实),还能“知其所以然”(解释原因、进行因果推断),并能精确控制生成内容的风格、观点和知识范围。
- 潜力: 结合KG的结构化因果信息与LLM的上下文理解能力,探索更深层次的因果推断和可控文本生成。
- 论文方向: “Causal Reasoning in KG-LLM: Towards Explainable and Controllable Text Generation”, “From Correlation to Causation: Empowering LLMs with Causal Knowledge Graphs”。
-
面向低资源和小众领域的KG-LLM融合:
- 空白点: 当前研究主要集中在通用领域或资源丰富的领域。对于低资源语言、小众领域或只有小型KG的场景,如何有效进行KG-LLM融合是一个实际且重要的问题。
- 潜力: 研究小样本学习、迁移学习、元学习等技术,在低资源条件下实现有效的知识注入和利用。利用LLM的泛化能力辅助构建和增强小型KG。
- 论文方向: “Few-Shot KG-Augmented LLMs for Specialized Domains”, “Cross-Lingual Knowledge Transfer for LLM-Empowered KG Construction in Low-Resource Languages”。
-
KG-LLM融合的自动化与自适应调优:
- 空白点: 当前融合策略往往需要大量人工设计和调优(如Prompt工程、检索策略选择、模型结构调整)。如何自动化地根据任务特性和数据特点选择最优的融合策略,并进行自适应优化。
- 潜力: 探索AutoML、强化学习等技术,用于自动化设计KG-LLM融合流程,优化超参数,甚至动态调整融合模块。
- 论文方向: “Automating the Fusion: An AutoML Framework for Optimal KG-LLM Integration”, “Adaptive Knowledge Retrieval and Fusion for LLMs using Reinforcement Learning”。
-
伦理、偏见与鲁棒性研究:
- 空白点: KG本身可能带有偏见,LLM也可能放大这些偏见。如何检测、量化和缓解KG-LLM融合系统中的偏见,并增强其对抗攻击的鲁棒性。
- 潜力: 开发公平性感知的KG构建方法、偏见缓解的融合算法、以及针对融合模型的鲁棒性评估基准和增强技术。
- 论文方向: “Fairness and Bias in KG-Enhanced Large Language Models”, “Robustness of Neuro-Symbolic Systems: An Investigation into KG-LLM Adversarial Attacks and Defenses”。
参考论文与综述:
- 综述类:
- Pan, S., Luo, L., Wang, Y., Chen, C., Wang, J., & Wu, X. (2024). Unifying Large Language Models and Knowledge Graphs: A Roadmap. IEEE Transactions on Knowledge and Data Engineering. (或其他同类权威期刊/会议的最新综述)
- Dai, Y., Wang, S., Xiong, C., & Li, J. (Year). A Survey on Knowledge Graph-Enhanced Large Language Models. arXiv preprint. (搜索arXiv上近期的相关综述)
- KG增强LLM (RAG方向):
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., … & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33, 9459-9474. (奠基性RAG论文)
- LLM赋能KG:
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., … & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824-24837. (虽然不是直接针对KG,但CoT对复杂任务分解和LLM用于KG构建有启发)
- 相关会议如ACL, EMNLP, NAACL, AAAI, IJCAI, WWW, ISWC, ESWC, KDD等会持续有相关论文发表。
Conclusion
知识图谱与大语言模型的融合是当前人工智能领域具有潜力的发展方向。它不仅为解决各自的固有缺陷提供了新思路,更为构建下一代更智能、更可信、更通用的AI系统铺平了道路。尽管目前仍面临诸多挑战,但随着技术的不断进步和创新,KG-LLM的融合将在科研和产业界催生出更多突破性的成果。
相关文章:
与大语言模型(LLM))
知识图谱(KG)与大语言模型(LLM)
知识图谱(KG)以其结构化的知识表示和推理能力,为大语言模型(LLM)的“幻觉”、知识更新滞后和可解释性不足等问题提供了有力的解决方案。反过来,LLM的强大文本理解和生成能力也为KG的构建、补全、查询和应用…...
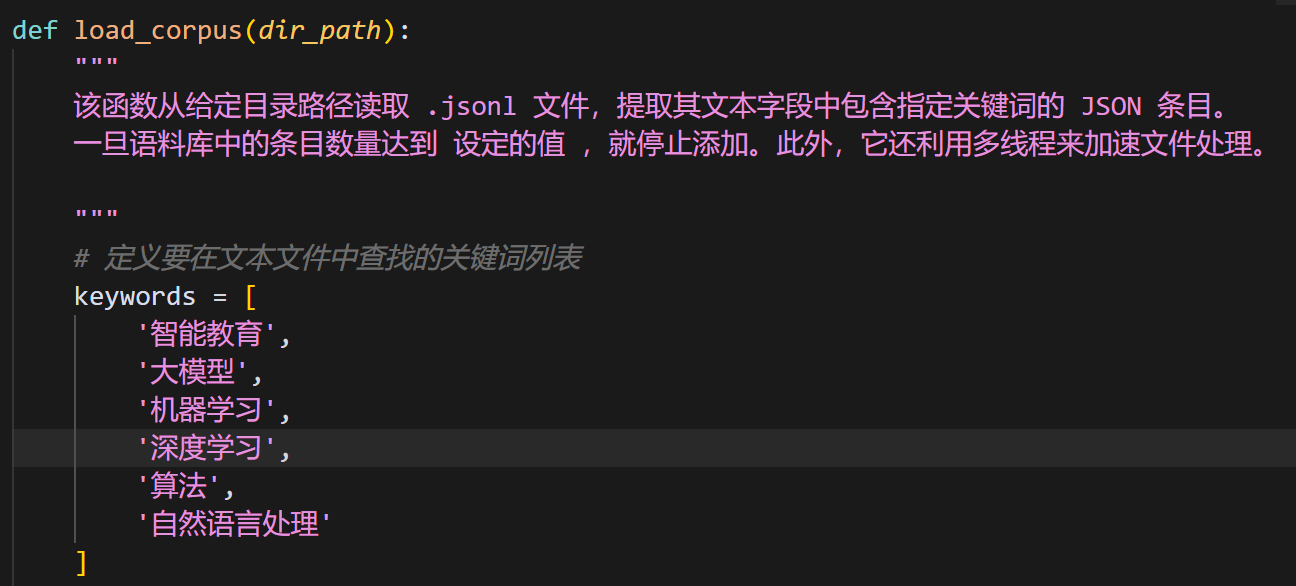
构建共有语料库 - Wiki 语料库
中文Wiki语料库主要指的是从中文Wikipedia(中文维基百科)提取的文本数据。维基百科是一个自由的、开放编辑的百科全书项目,覆盖了从科技、历史到文化、艺术等广泛的主题。 对于基于RAG的应用来说,把Wiki语料作为一个公有的语料库…...
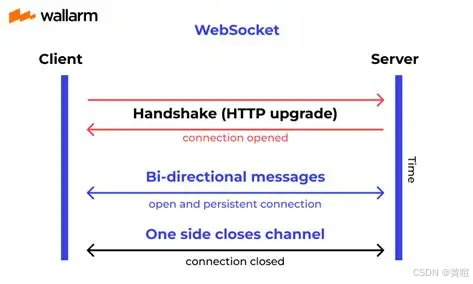
苍穹外卖项目中的 WebSocket 实战:实现来单与催单提醒功能
🚀 苍穹外卖项目中的 WebSocket 实战:实现来单与催单提醒功能 在现代 Web 应用中,实时通信成为提升用户体验的关键技术之一。WebSocket 作为一种在单个 TCP 连接上进行全双工通信的协议,被广泛应用于需要实时数据交换的场景&#…...
:移情阶段的深度博弈——如何避开客户访谈的认知陷阱)
精益数据分析(59/126):移情阶段的深度博弈——如何避开客户访谈的认知陷阱
精益数据分析(59/126):移情阶段的深度博弈——如何避开客户访谈的认知陷阱 在创业的移情阶段,客户访谈是挖掘真实需求的核心手段,但人类认知偏差往往导致数据失真。今天,我们结合《精益数据分析》的方法论…...
Win10 安装单机版ES(elasticsearch),整合IK分词器和安装Kibana
一. 先查看本机windows是否安装了ES(elasticsearch),检查方法如下: 检查进程 按 Ctrl Shift Esc 组合键打开 “任务管理器”。在 “进程” 选项卡中,查看是否有 elasticsearch 相关进程。如果有,说明系统安装了 ES。 检查端口…...

Ansible模块——主机名设置和用户/用户组管理
设置主机名 ansible.builtin.hostname: name:要设置的主机名 use:更新主机名的方式(默认会自动选择,不指定的话,物理机一般不会有问题,容器可能会有问题,一般是让它默认选择) syst…...

【Redis】List 列表
文章目录 初识列表常用命令lpushlpushxlrangerpushrpushxlpop & rpoplindexlinsertllen阻塞操作 —— blpop & brpop 内部编码应用场景 初识列表 列表类型,用于存储多个字符串。在操作和实现上,类似 C 的双端队列,支持随机访问(O(N)…...
JUC入门(四)
ReadWriteLock 代码示例: package com.yw.rw;import java.util.HashMap; import java.util.Map; import java.util.concurrent.locks.ReentrantReadWriteLock;public class ReadWriteDemo {public static void main(String[] args) {MyCache myCache new MyCache…...
【HarmonyOS 5】鸿蒙mPaaS详解
【HarmonyOS 5】鸿蒙mPaaS详解 一、mPaaS是什么? mPaaS 是 Mobile Platform as a Service 的缩写,即移动开发平台。 蚂蚁移动开发平台mPaaS ,融合了支付宝科技能力,可以为移动应用开发、测试、运营及运维提供云到端的一站式解决…...

多线BGP服务器优化实践与自动化运维方案
背景:企业级网络架构中的线路选择难题 在分布式业务部署场景下,如何通过三网融合BGP服务器实现低延迟、高可用访问?本文以某电商平台流量调度优化为案例,解析动态BGP服务器的实战价值。 技术方案设计 核心架构:采用…...

无法加载文件 E:\Program Files\nodejs\npm.ps1,因为在此系统上禁止运行脚本
遇到“无法加载文件 E:\Program Files\nodejs\npm.ps1,因为在此系统上禁止运行脚本”这类错误,通常是因为你的 PowerShell 执行策略设置为不允许运行脚本。在 Windows 系统中,默认情况下,出于安全考虑,PowerShell 可能会阻止运行未…...
【C++模板与泛型编程】实例化
目录 一、模板实例化的基本概念 1.1 什么是模板实例化? 1.2 实例化的触发条件 1.3 实例化的类型 二、隐式实例化 2.1 隐式实例化的工作原理 2.2 类模板的隐式实例化 2.3 隐式实例化的局限性 三、显式实例化 3.1 显式实例化声明(extern templat…...

TB开拓者策略交易信号闪烁根因及解决方法
TB开拓者策略信号闪烁分析 TB开拓者策略交易信号闪烁根因 TB开拓者策略交易信号闪烁根因分析 信号闪烁是交易策略开发中常见的问题,特别是在TB(TradeBlazer)开拓者等平台上。以下是信号闪烁的主要根因分析: 主要根因 未来函数问题 使用了包含未来信息…...
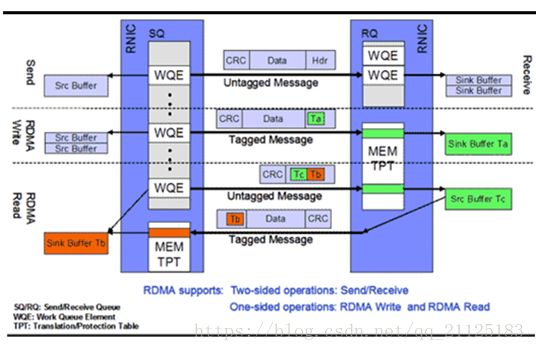
什么是RDMA?
什么是RDMA? RDMA(RemoteDirect Memory Access)技术全称远程直接内存访问,就是为了解决网络传输中服务器端数据处理的延迟而产生的。它将数据直接从一台计算机的内存传输到另一台计算机,无需双方操作系统的介入。这允许高吞吐、低延迟的网络…...

C++面试3——const关键字的核心概念、典型场景和易错陷阱
const关键字的核心概念、典型场景和易错陷阱 一、const本质:类型系统的守护者 1. 与#define的本质差异 维度#defineconst编译阶段预处理替换编译器类型检查作用域无作用域(全局污染)遵循块作用域调试可见性符号消失保留符号信息类型安全无类…...

ASIC和FPGA,到底应该选择哪个?
ASIC和FPGA各有优缺点。 ASIC针对特定需求,具有高性能、低功耗和低成本(在大规模量产时);但设计周期长、成本高、风险大。FPGA则适合快速原型验证和中小批量应用,开发周期短,灵活性高,适合初创企…...

【C++】嵌套类访问外部类成员
文章目录 C嵌套类访问外部类成员详解:权限、机制与最佳实践一、默认访问权限:并非友元二、访问外部类私有成员的方法1. 声明友元关系2. 通过公有接口访问 三、静态成员 vs. 非静态成员四、实际应用案例:Boost.Asio线程池场景需求实现关键代码…...

mac下载、使用mysql
1.如果对版本没有特别要求,那么直接使用brew install mysql安装即可。 2.使用 brew services start mysql 启动mysql。 3.使用 mysql -u root 登录mysql,这个时候还是不需要密码的 4.退出数据库:exit 5.给root设置一个密码,使用 m…...

java Lombok 对象模版和日志注解
目录 1、依赖: 2、在Idea中确认是否安装Lombok 插件 3、 Lombok常用注解 3.1 Getter 和 Setter 3.2 ToString 3.3 AllArgsConstructor 和 NoArgsConstructor 3.4 Data 3.5 FieldDefaults 4、 Slf4j 日志注解 4.2 日志级别 4.3 设置日志级别 1、依赖:…...
Python学习笔记--使用Django操作mysql
注意:本笔记基于python 3.12,不同版本命令会有些许差别!!! Django 模型 Django 对各种数据库提供了很好的支持,包括:PostgreSQL、MySQL、SQLite、Oracle。 Django 为这些数据库提供了统一的调…...

win11下,启动springboot时,提示端口被占用的处理方式
注:此操作可能存在风险!! 在启动springboot时,提示端口被占用。于是执行 #查看所有的占用的端口 netstat -ano | findStr 8080 结果发现并没有什么进程占据8080端口。再次执行: # 查看系统保留端口 netsh int ipv4…...

计算机视觉设计开发工程师学习路线
以下是一条系统化的计算机视觉(CV)学习路线,从基础到进阶,涵盖理论、工具和实践,适合逐步深入,有需要者记得点赞收藏哦: 相关学习:python深度学习,python代码定制 python…...

AI大模型从0到1记录学习numpy pandas day25
第 3 章 Pandas 3.1 什么是Pandas Pandas 是一个开源的数据分析和数据处理库,它是基于 Python 编程语言的。 Pandas 提供了易于使用的数据结构和数据分析工具,特别适用于处理结构化数据,如表格型数据(类似于Excel表格)…...
)
Opencv C++写中文(来自Gemini)
基于与Google Gemini交互获取的Opencv在图片上写汉字的实现 sudo apt-get install libfreetype6-dev sudo apt-get install fonts-wqy-zenhei CMakeLists.txt cmake_minimum_required(VERSION 3.10) # Or a more recent versionproject(OpenCVChineseText)set(CMAKE_CXX_STAN…...

下载和导出文件名称乱码问题
只对文件名称进行乱码处理,和文件中的内容无关。 import lombok.SneakyThrows; import org.springframework.web.context.request.RequestAttributes; import org.springframework.web.context.request.RequestContextHolder; import org.springframework.web.cont…...

STM32实战指南:DHT11温湿度传感器驱动开发与避坑指南
知识点1【DHT11的概述】 1、概述 DHT是一款温湿度一体化的数字传感器(无需AD转换)。 2、驱动方式 通过单片机等微处理器简单的电路连接就能实时采集本地湿度和温度。DHT11与单片机之间采用单总线进行通信,仅需要一个IO口。 相对于单片机…...
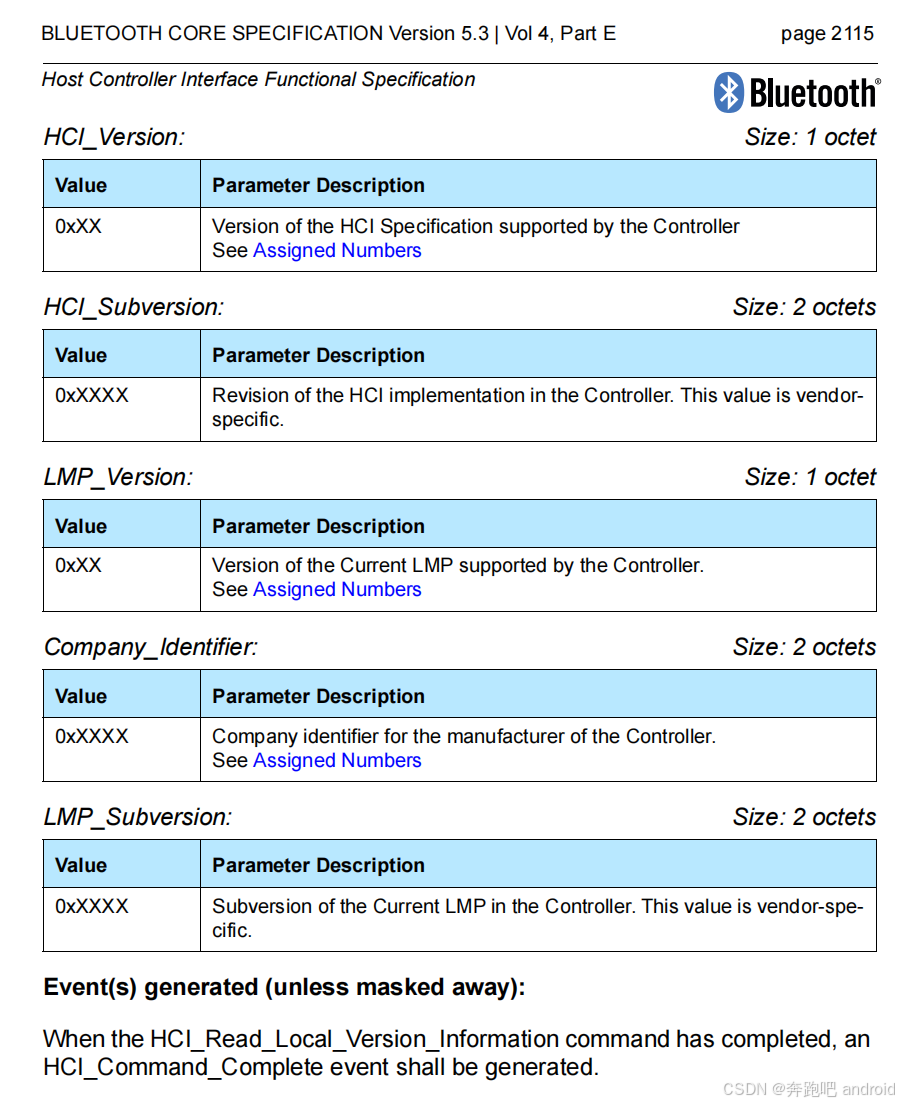
【android bluetooth 协议分析 01】【HCI 层介绍 8】【ReadLocalVersionInformation命令介绍】
1. HCI_Read_Local_Version_Information 命令介绍 1. 功能(Description) HCI_Read_Local_Version_Information 命令用于读取本地 Bluetooth Controller 的版本信息,包括 HCI 和 LMP 层的版本,以及厂商 ID 和子版本号。 这类信息用…...
esp32课设记录(四)摩斯密码的实现 并用mqtt上传
摩斯密码(Morse Code)是一种通过点(.)和划(-)组合来表示字符的编码系统。下面我将在esp32上实现摩斯密码的输入,并能够发送到mqtt的broker。 先捋一下逻辑,首先esp32的按键已经编写了短按与长按功能,这将是输出摩斯密码点和划的基础。然后当2…...
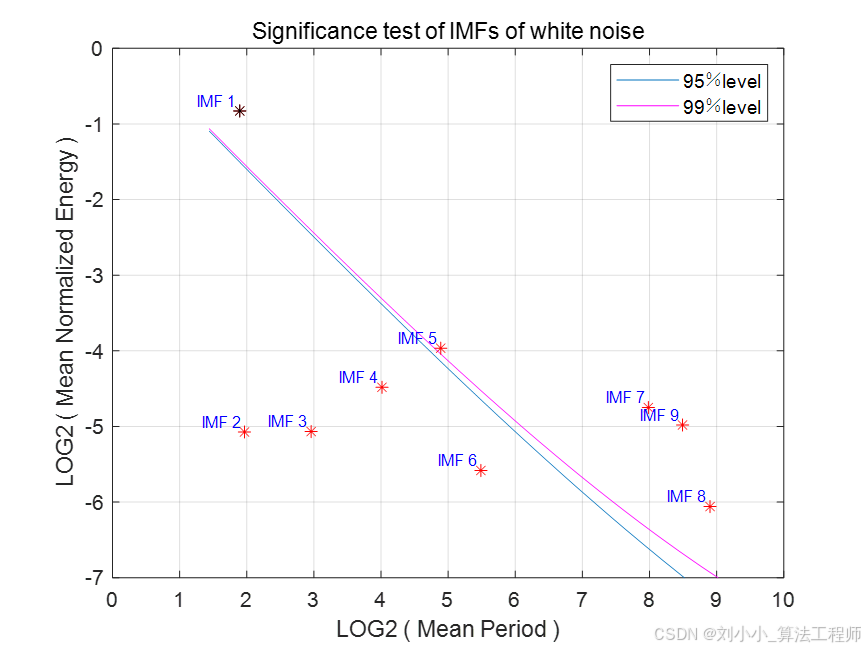
「HHT(希尔伯特黄变换)——ECG信号处理-第十三课」2025年5月19日
一、引言 心电信号(ECG)是反映心脏电活动的重要生理信号,其特征提取对于心脏疾病的诊断和监测具有关键意义。Hilbert - Huang Transform(HHT)作为一种强大的信号处理工具,在心电信号特征提取领域得到了广泛…...
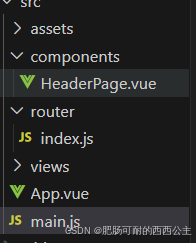
前端(vue)学习笔记(CLASS 6):路由进阶
1、路由的封装抽离 将之前写在main.js文件中的路由配置与规则抽离出来,放置在router/index.js文件中,再将其导入回main.js文件中,即可实现路由的封装抽离 例如 //index.js import { createMemoryHistory, createRouter } from vue-routerim…...