嵌入式学习笔记DAY23(树,哈希表)
一、树
1.树的概念
之前我们一直在谈的是一对一的线性结构,现实中,还存在很多一对多的情况需要处理,一对多的线性结构——树。

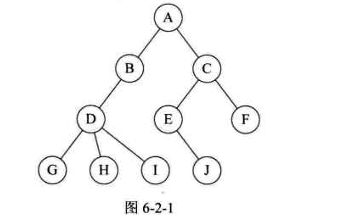
树的结点包括一个数据元素及若干指向其子树的分支,结点拥有的子树数称为结点的度。度为0的结点称为叶结点或者终端结点;度不为0的结点称为非终端结点或者分支节点。除根节点外,分支节点也称为内部节点树的度是树内各节点的度的最大值。

结点的关系:结点的子树的根称为该结点的孩子,相应地,该结点称为孩子的双亲。
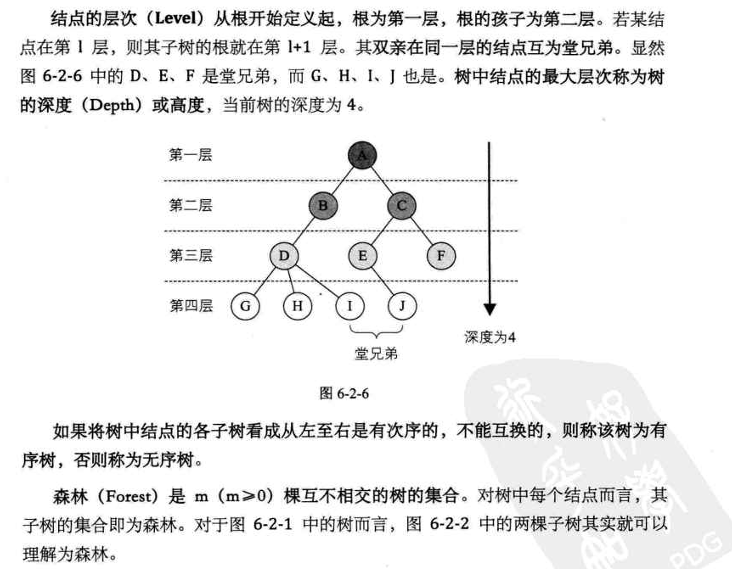
结点的层次:
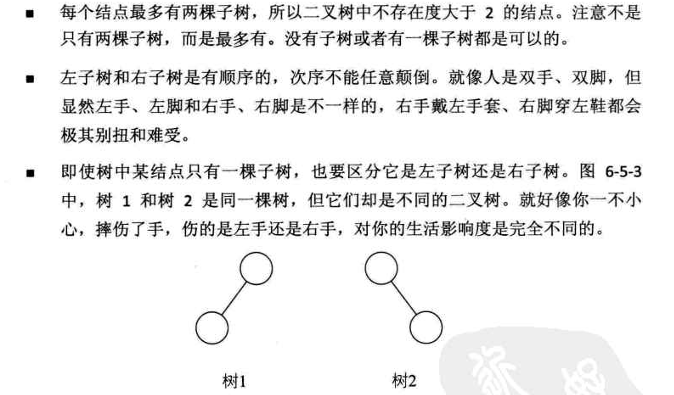
2. 二叉树

二叉树的特点:
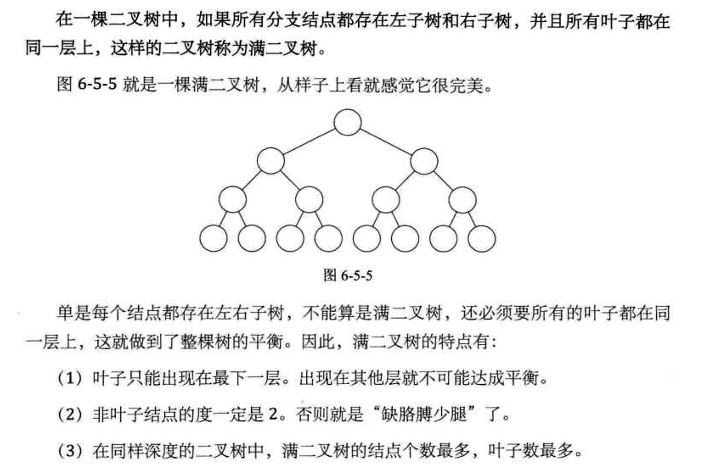
3. 特殊二叉树
- 斜树
- 满二叉树
- 完全二叉树

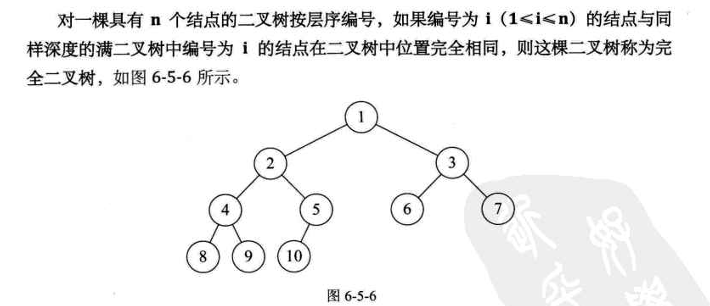
4. 树的存储结构
二叉树每个结点最多有两个孩子,所以为它设计一个数据域和两个指针域,我们称这样的链表叫做二叉链表:
![]()
其中data是数据域,Ichild和rchild都是指针域,分别存放指向左孩子和右孩子的指针。
5.树的基本操作
- 树的结构定义
typedef char DATATYPE; // 定义树节点存储的数据类型为字符
typedef struct _tree_node_
{DATATYPE data; // 节点存储的数据struct _tree_node_ *left, *right; // 左右子树指针
} TreeNode; // 二叉树节点结构// 创建二叉树(双星指针用于修改外部指针的值)
char data[]="abd#f###c#eg###"; // 带空节点标记的先序遍历序列
int ind = 0; // 全局索引,用于遍历数据数组
- 创建树
void CreateTree(TreeNode** root)
{char c = data[ind++]; // 读取当前字符并移动索引if('#' == c) // '#'表示空节点{*root = NULL; // 当前节点置空return;}else{*root = malloc(sizeof(TreeNode)); // 创建新节点if(NULL == *root){fprintf(stderr, "CreateTree malloc error");return;}(*root)->data = c; // 设置节点数据CreateTree(&(*root)->left); // 递归创建左子树CreateTree(&(*root)->right); // 递归创建右子树}
}- 树的三种遍历方式
// 前序遍历(根-左-右)
void PreOrderTraverse(TreeNode* root)
{if(NULL == root) // 空节点直接返回{return;}printf("%c", root->data); // 访问根节点PreOrderTraverse(root->left); // 递归遍历左子树PreOrderTraverse(root->right); // 递归遍历右子树
}
// 中序遍历(左-根-右)
void InOrderTraverse(TreeNode* root)
{if (root == NULL) return;InOrderTraverse(root->left);printf("%c", root->data);InOrderTraverse(root->right);
}// 后序遍历(左-右-根)
void PostOrderTraverse(TreeNode* root)
{if (root == NULL) return;PostOrderTraverse(root->left);PostOrderTraverse(root->right);printf("%c", root->data);
}
- 树的销毁
void DestroyTree(TreeNode* root)
{if (root == NULL) {return;}DestroyTree(root->left);DestroyTree(root->right);free(root);
}二、哈希表

关键逻辑说明(除留取余法):
哈希函数与冲突处理:
- 使用简单的取模运算作为哈希函数,可能导致较多冲突(如 12 和 24 对 12 取模均为 0)。
- 采用线性探测法处理冲突:当槽位被占时,依次尝试下一个槽位(
ind = (ind + 1) % tlen)。插入流程:
- 插入数据时,若遇到冲突(槽位非 - 1),持续探测直到找到空槽位(值为 - 1)。
- 示例中输出冲突信息,可观察线性探测过程(如 67%12=7,若槽位 7 被占,尝试 8、9...)。
查找流程:
- 从初始哈希值开始探测,若未找到则按顺序查找下一个槽位。
- 通过记录初始索引
old_ind,避免在满表时陷入无限循环。内存管理:
- 示例中未释放哈希表内存,实际使用中需在程序结束前调用
free释放hs->head和hs,避免内存泄漏。示例输出与分析
假设插入数据
array时的冲突过程如下(以 12 和 67 为例):
- 12%12=0:槽位 0 为空,直接插入。
- 67%12=7:槽位 7 为空,直接插入。
- 56%12=8:槽位 8 为空,直接插入。
- 16%12=4:槽位 4 为空,直接插入。
- 25%12=1:槽位 1 为空,直接插入。
- 37%12=1:槽位 1 已被 25 占用,探测 2→空,插入槽位 2。
- ...(其他数据类似,可能产生多次冲突)
查找 37 时,计算哈希值 1→探测 2,找到数据,返回槽位 2。
#include <stdio.h> // 标准输入输出
#include <stdlib.h> // 内存分配函数(malloc/free)
#include <string.h> // 字符串处理(此处未用到,但保留可能的扩展需求)// 定义数据类型别名(当前为整数,可修改为其他类型)
typedef int DATATYPE;// 哈希表结构体定义
typedef struct {DATATYPE* head; /**< 指向哈希表数组的指针,存储数据 */int tlen; /**< 哈希表的长度(数组大小) */
} HSTable;/*** @brief 创建哈希表并初始化* @param len 哈希表的长度(数组大小)* @return HSTable* 指向新创建的哈希表的指针,失败时返回NULL* @note 哈希表数组元素初始化为-1(假设-1表示空槽位)*/
HSTable* CreateHsTable(int len) {// 1. 分配哈希表结构体内存HSTable* hs = malloc(sizeof(HSTable));if (NULL == hs) {// 内存分配失败,输出错误信息到标准错误流fprintf(stderr, "CreateHsTable: 分配结构体内存失败\n");return NULL;}// 2. 分配哈希表数据数组内存hs->head = malloc(sizeof(DATATYPE) * len);if (NULL == hs->head) {// 数据数组分配失败,释放已分配的结构体内存fprintf(stderr, "CreateHsTable: 分配数据数组内存失败\n");free(hs); // 避免内存泄漏return NULL;}// 3. 初始化哈希表数组:所有槽位标记为-1(空)hs->tlen = len;int i = 0;for (i = 0; i < len; i++) {hs->head[i] = -1;}return hs;
}
/*** @brief 哈希函数:计算数据的哈希值(取模运算)* @param hs 哈希表指针(用于获取表长度)* @param data 待计算的数据源指针* @return int 哈希值(即数组索引)* @note 直接使用数据值对表长取模,简单但可能导致较多冲突*/
int HSFun(HSTable* hs, DATATYPE* data) {return *data % hs->tlen; // 例如:数据12对12取模得到0
}/*** @brief 向哈希表中插入数据(开放寻址法处理冲突,线性探测)* @param hs 哈希表指针* @param data 待插入的数据指针* @return int 0表示成功,其他值可扩展为错误码* @note 当槽位被占用时,逐个探测下一个槽位(线性探测)*/
int HSInsert(HSTable* hs, DATATYPE* data) {// 1. 计算初始哈希值int ind = HSFun(hs, data);// 2. 线性探测寻找空槽位while (hs->head[ind] != -1) {// 输出冲突信息(调试用)printf("冲突:位置 %d 已被占用,数据 %d 尝试下一个位置\n", ind, *data);// 移动到下一个槽位(取模实现循环探测)ind = (ind + 1) % hs->tlen;}// 3. 插入数据到空槽位hs->head[ind] = *data;return 0;
}/*** @brief 在哈希表中查找数据* @param hs 哈希表指针* @param data 待查找的数据指针* @return int 找到时返回数据所在槽位索引,-1表示未找到* @note 使用线性探测法遍历可能的槽位,避免陷入死循环*/
int HsSearch(HSTable* hs, DATATYPE* data) {// 1. 计算初始哈希值int ind = HSFun(hs, data);// 记录初始索引,用于判断是否绕表一周(避免死循环)int old_ind = ind;// 2. 线性探测查找数据while (hs->head[ind] != *data) {// 移动到下一个槽位ind = (ind + 1) % hs->tlen;// 若回到初始索引,说明未找到if (old_ind == ind) {return -1;}}return ind; // 返回找到的槽位索引
}int main(int argc, char** argv) {// 1. 创建长度为12的哈希表HSTable* hs = CreateHsTable(12);if (hs == NULL) {return 1; // 创建失败,退出程序}// 2. 测试数据数组int array[] = {12, 67, 56, 16, 25, 37, 22, 29, 15, 47, 48, 34};int i = 0;int array_len = sizeof(array) / sizeof(array[0]); // 计算数组长度(12)// 3. 插入数据到哈希表for (i = 0; i < array_len; i++) {HSInsert(hs, &array[i]);}// 4. 查找数据37int want_num = 37;int ret = HsSearch(hs, &want_num);// 5. 输出查找结果if (-1 == ret) {printf("未找到数据 %d\n", want_num);} else {printf("找到数据 %d,位于槽位 %d\n", hs->head[ret], ret);}// 6. 释放哈希表内存(示例中未实现,实际需添加)// free(hs->head);// free(hs);return 0;
}三、内核链表
1、Linux内核链表是一种数据结构,它在Linux内核编程中广泛使用,用于管理各种类
型的数据元素。链表由一系列节点组成,每个节点包含指向下一个节点和前一个节点的
指针。这种设计使得链表在插入和删除操作时非常高效,因为不需要移动其他元素。
2、链表的定义和初始化
(1)在Linux内核中,链表通过包含list_head结构体的方式在各种数据结构中实现。
(2)list_head结构体定义在<linux/list.h>头文件中,包含next和prev两个指针,分别指
向链表的下一个和前一个元素。要使用内核链表,首先需要包含这个头文件。
(3)初始化链表时,可以使用INIT_LIST_HEAD宏,它将链表的next和prev指针都指向
链表本身,形成一个循环链表。
内核链表是双向循环链表:
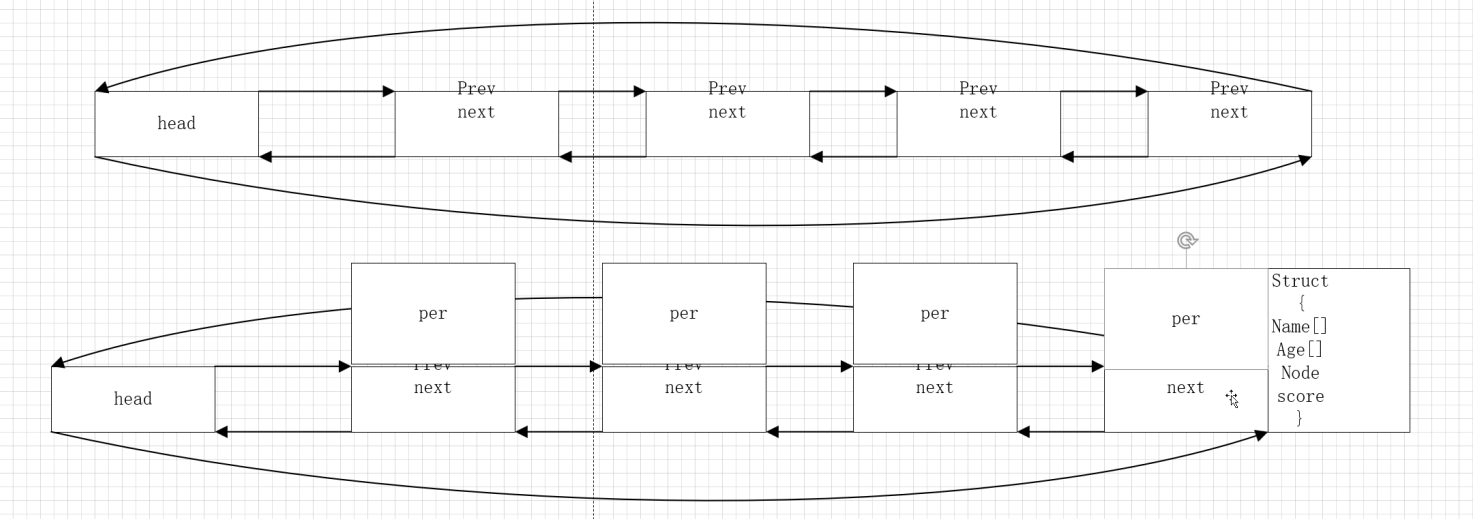
注:内部增删改查已经写好,将需要的内容组合到结构体中即可使用
(可通过www.kernel.org去下载内核)
3、内核链表的思想:普通链表与数据耦合性高,自己定义结构体,将数据放入;
(1)offset宏:传入结构体,成员,通过宏进入,计算node的偏移量是多少;
(2)contrainof宏:返回该类型指针的地址。
4、内核链表提供了一系列宏和函数来进行操作,如添加、删除和遍历节点:
(1)添加节点:使用list_add或list_add_tail函数可以在链表的头部或尾部添加新节点。
(2)删除节点:使用list_del函数可以从链表中删除节点。
(3)遍历链表:使用list_for_each或list_for_each_entry宏可以遍历链表中的每个元素。
5、注意事项在:使用内核链表时,需要注意几个重要的点:
(1)内存管理:当添加新节点到链表时,需要确保为节点分配了内存。同样,从链表
中删除节点时,需要释放节点占用的内存。
(2)同步:在多线程环境中操作链表时,可能需要使用锁来避免竞态条件。
(3)性能:虽然链表在插入和删除操作时非常高效,但在查找元素时可能需要遍历整
个链表,这可能会影响性能。
相关文章:
嵌入式学习笔记DAY23(树,哈希表)
一、树 1.树的概念 之前我们一直在谈的是一对一的线性结构,现实中,还存在很多一对多的情况需要处理,一对多的线性结构——树。 树的结点包括一个数据元素及若干指向其子树的分支,结点拥有的子树数称为结点的度。度为0的结点称为叶…...

leetcode239 滑动窗口最大值deque方式
这段文字描述的是使用单调队列(Monotonic Queue) 解决滑动窗口最大值问题的优化算法。我来简单解释一下: 核心思路 问题分析:在滑动窗口中,若存在两个下标 i < j 且 nums[i] ≤ nums[j],则 nums[i] 永远…...
仓颉开发语言入门教程:搭建开发环境
仓颉开发语言作为华为为鸿蒙系统自研的开发语言,虽然才发布不久,但是它承担着极其重要的历史使命。作为鸿蒙开发者,掌握仓颉开发语言将成为不可或缺的技能,今天我们从零开始,为大家分享仓颉语言的开发教程,…...

Axure中继器高保真交互原型的核心元件
Axure作为一款强大的原型设计工具,中继器无疑是打造高保真交互原型的核心利器。今天,就让我们深入探讨一下Axure中继器的核心地位、操作难点,以及如何借助优秀案例来提升我们的中继器使用技能。 一、核心地位 中继器在Axure中的地位举足轻重…...

【SpringBoot】✈️整合飞书群机器人发送消息
💥💥✈️✈️欢迎阅读本文章❤️❤️💥💥 🏆本篇文章阅读大约耗时3分钟。 ⛳️motto:不积跬步、无以千里 📋📋📋本文目录如下:🎁🎁&am…...
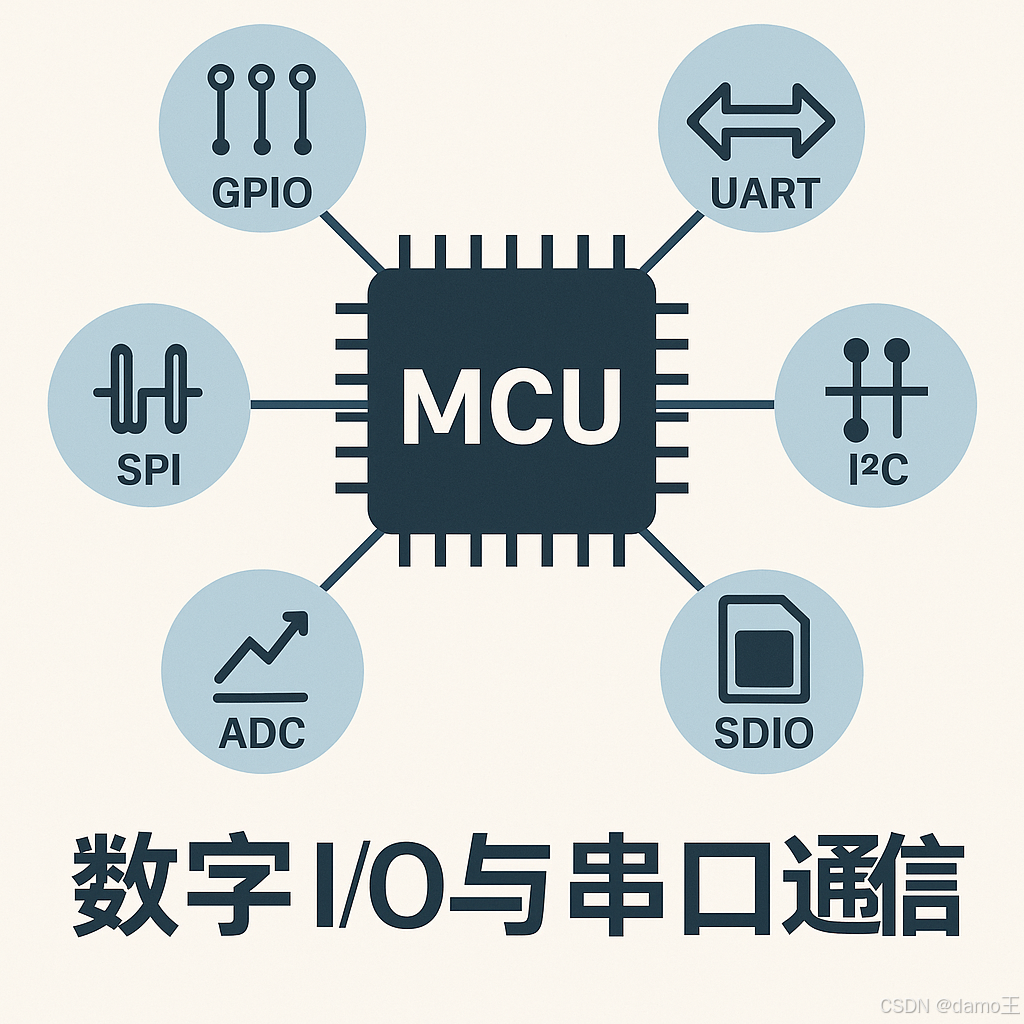
第 1 章:数字 I/O 与串口通信(GPIO UART)
本章目标: 掌握 GPIO 的硬件原理、寄存器配置与典型驱动框架 深入理解 UART/USART 的帧格式、波特率配置、中断与 DMA 驱动 通过实战案例,将 GPIO 与 UART 结合,实现 AT 命令式外设控制 章节结构 GPIO 概述与硬件原理 GPIO 驱动实现:寄存器、中断与去抖 UART/USART 原理与帧…...

【图像生成大模型】Wan2.1:下一代开源大规模视频生成模型
Wan2.1:下一代开源大规模视频生成模型 引言Wan2.1 项目概述核心技术1. 3D 变分自编码器(Wan-VAE)2. 视频扩散 Transformer(Video Diffusion DiT)3. 数据处理与清洗 项目运行方式与执行步骤1. 环境准备2. 安装依赖3. 模…...

java配置webSocket、前端使用uniapp连接
一、这个管理系统是基于若依框架,配置webSocKet的maven依赖 <!--websocket--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId></dependency> 二、配…...
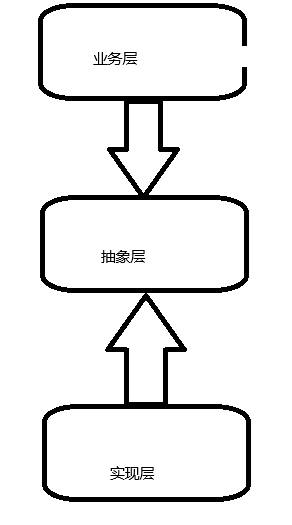
interface接口和defer场景分析
接口 接口这里主要两点: 设计业务结构时采用依赖倒转:业务层向下依赖抽象层,实现层向上依赖抽象层。 相比于之前: 之后: 注意struct中嵌套interface和不嵌套interface的区别: type Myinterface interfac…...

02、基础入门-Spring生态圈
02、基础入门-Spring生态圈 # Spring生态圈概述 **Spring生态圈**是基于Spring框架的一系列开源项目和工具的集合,涵盖了各种领域,包括Web开发、数据访问、集成、测试、安全等。 ## 主要组成部分 1. **Spring Framework**:是整个生态圈的核心…...

前后端交互中的绝对路径和相对路径
前端 <form action"hello" method"post"> 1. 不加斜杠 (相对路径,如 action"hello") 解析规则:基于当前页面的 URL 路径部分 进行拼接。 假设当前页面 URL 是 http://域名:端口/应用上下文…...
:一文详解three.js中的着色器Shader)
从零开始学习three.js(18):一文详解three.js中的着色器Shader
在WebGL和Three.js的3D图形渲染中,着色器(Shader) 是实现复杂视觉效果的核心工具。通过编写自定义的着色器代码,开发者可以直接操作GPU,实现从基础颜色渲染到动态光照、粒子效果等高级图形技术。本文将深入解析Three.j…...
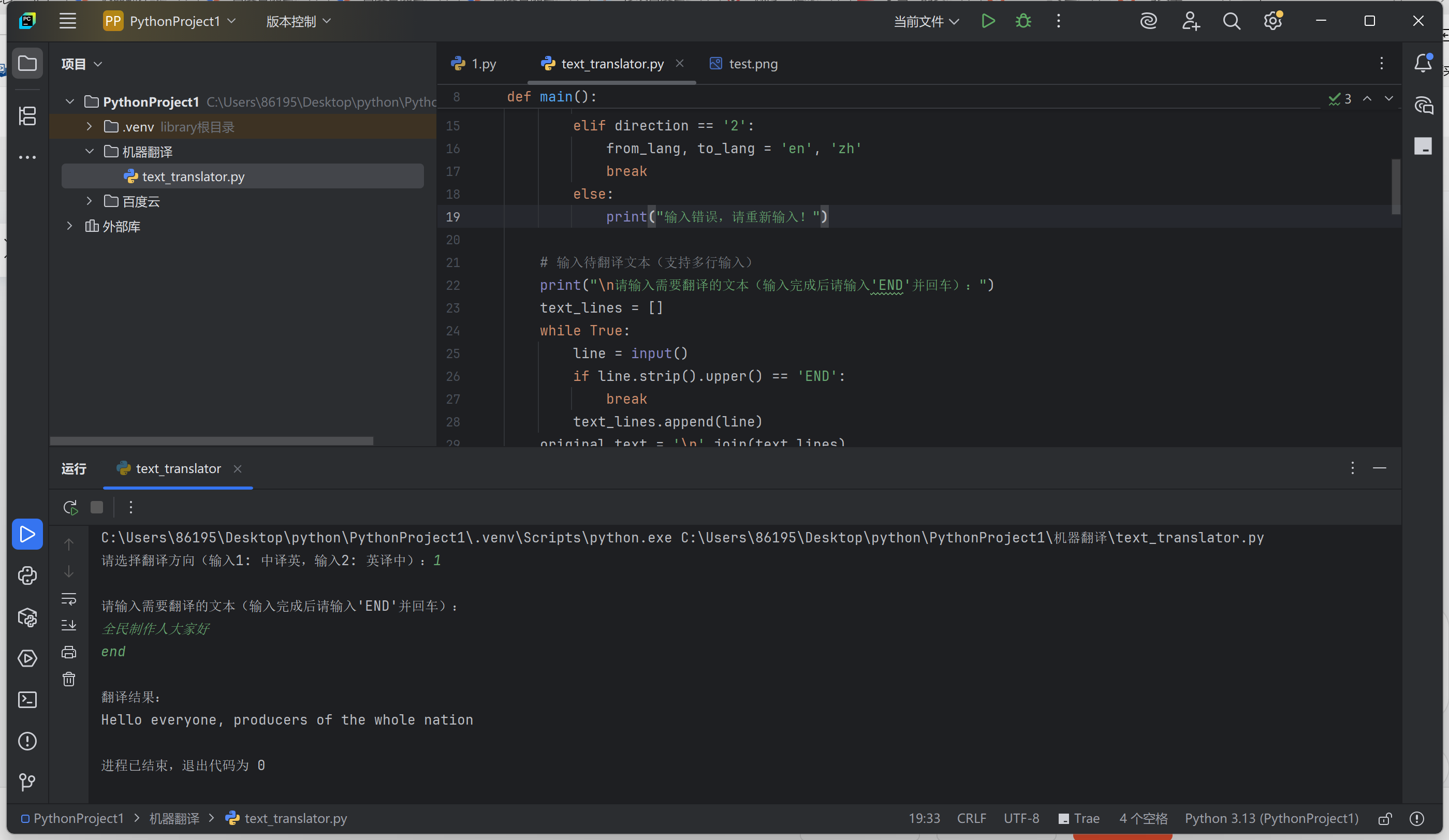
调用百度云API机器翻译
新建Python文件,叫 text_translator.py 输入 import requests import jsonAPI_KEY "glYiYVF2dSc7EQ8n78VDRCpa" # 替换为自己的API Key SECRET_KEY "kUlhze8OQZ7xbVRp" # 替换为自己的Secret Keydef main():# 选择翻译方向while True:di…...

大模型训练计算显存占用
在大模型训练过程中,GPU显存中需要存储多种类型的数据,这些数据的合理管理直接影响训练效率和模型规模。需要放入GPU的关键数据类型如下: 注意: 在计算大模型训练占用的显存时,一般只计算 模型参数、梯度、优化器 的显…...

uni-app学习笔记六-vue3响应式基础
一.使用ref定义响应式变量 在组合式 API 中,推荐使用 ref() 函数来声明响应式状态,ref() 接收参数,并将其包裹在一个带有 .value 属性的 ref 对象中返回 示例代码: <template> <view>{{ num1 }}</view><vi…...

亚远景-ASPICE与ISO 21434在汽车电子系统开发中的应用案例
在汽车电子系统开发中,ASPICE(Automotive Software Process Improvement and Capacity Determination)与ISO 21434(Road vehicles — Cybersecurity engineering)是两个关键标准,分别从软件开发流程和网络安…...

『已解决』Python virtualenv_ error_ unrecognized arguments_--wheel-bundle
📣读完这篇文章里你能收获到 🐍 了解 virtualenv 参数错误的原因及解决方案📦 学习如何正确配置 Python 虚拟环境文章目录 前言一、问题描述1.1 错误现象1.2 影响范围二、问题分析2.1 根本原因三、解决方案3.1 兼容处理3.2 完整解决方案四、总结前言 本文详细介绍了在 D…...

详细介绍一下Python连接MySQL数据库的完整步骤
以下是 Python 连接 MySQL 数据库的完整步骤,包含环境准备、连接建立、数据操作、错误处理和性能优化等内容: 一、环境准备 安装 MySQL 服务器 Windows/macOS:下载安装包 MySQL Installer Linux: bash Ubuntu/Debian sudo apt-…...

【Unity 2023 新版InputSystem系统】新版InputSystem 如何进行人物移动(包括配置、代码详细实现过程)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、InputSystem配置二、GameInput 游戏输入脚本1.实现思路2.完整代码三、Player 游戏人物移动脚本1.实现思路2.完整代码四、场景脚本设置1.组件设置五、问题解决1.人物一直下落2.人物跳跃时,…...
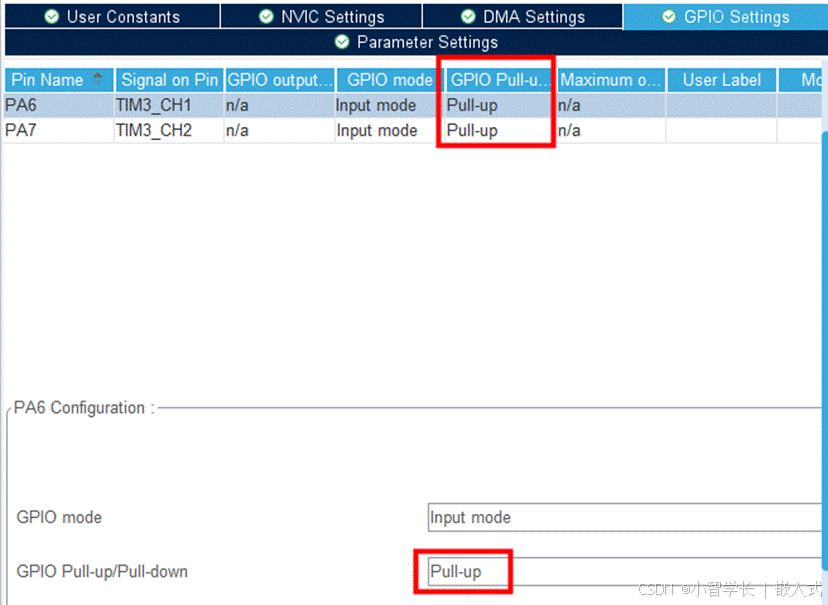
单片机-STM32部分:13-1、编码器
飞书文档https://x509p6c8to.feishu.cn/wiki/BpEywhaX9iqbiLkdqdAcmDnwnab EC旋转编码器 在产品开发过程中,需要位置闭环的的产品,类似电机类产品来说,编码器至关重要,它不仅可以使我们对带年纪进行精确的速度闭环,位…...

机器学习第十二讲:特征选择 → 选最重要的考试科目做录取判断
机器学习第十二讲:特征选择 → 选最重要的考试科目做录取判断 资料取自《零基础学机器学习》。 查看总目录:学习大纲 关于DeepSeek本地部署指南可以看下我之前写的文章:DeepSeek R1本地与线上满血版部署:超详细手把手指南 一、学…...

关于我在使用stream().toList()遇到的问题
关于我在使用stream().toList()遇到的问题 问题描述 在测试以上程序的时候抛出了空指针异常 于是我以为是我数据库中存在null字段,但查看后发现并不存在为null的数据 问题排查 起初我以为问题出现在sort排序方法这,事实也确实是,当我把s…...
javascript与Node.js)
javascript 编程基础(2)javascript与Node.js
文章目录 一、Node.js 与 JavaScript1、基本概念1.1、JavaScript:动态脚本语言1.2、Node.js:JavaScript 运行时环境 2、核心区别3、执行环境差异3.1、浏览器中的JavaScript3.2、Node.js中的JavaScript 4、共同点5、为什么需要Node.js? 一、No…...

Spring Boot 集成 druid,实现 SQL 监控
文章目录 背景Druid 简介监控统计 StateFilter其它 Filter详细步骤第 1 步:添加依赖第 2 步:添加数据源配置【通用部分】第 3 步:添加监控配置【关键部分】第 3 步:访问 druid 页面参考背景 😂 在 Code Review 过程中发现,经常有开发会忘记给表加索引。这就导致,生产运…...

多卡跑ollama run deepseek-r1
# 设置环境变量并启动模型 export CUDA_VISIBLE_DEVICES0,1,2,3 export OLLAMA_SCHED_SPREAD1 # 启用多卡负载均衡 ollama run deepseek-r1:32b 若 deepseek-r1:32b 的显存需求未超过单卡容量(如单卡 24GB),Ollama 不会自动启用多卡 在run…...

HTML向四周扩散背景
<!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, initial-scale1.0" /><title>扩散背景效果</title><style>body {…...
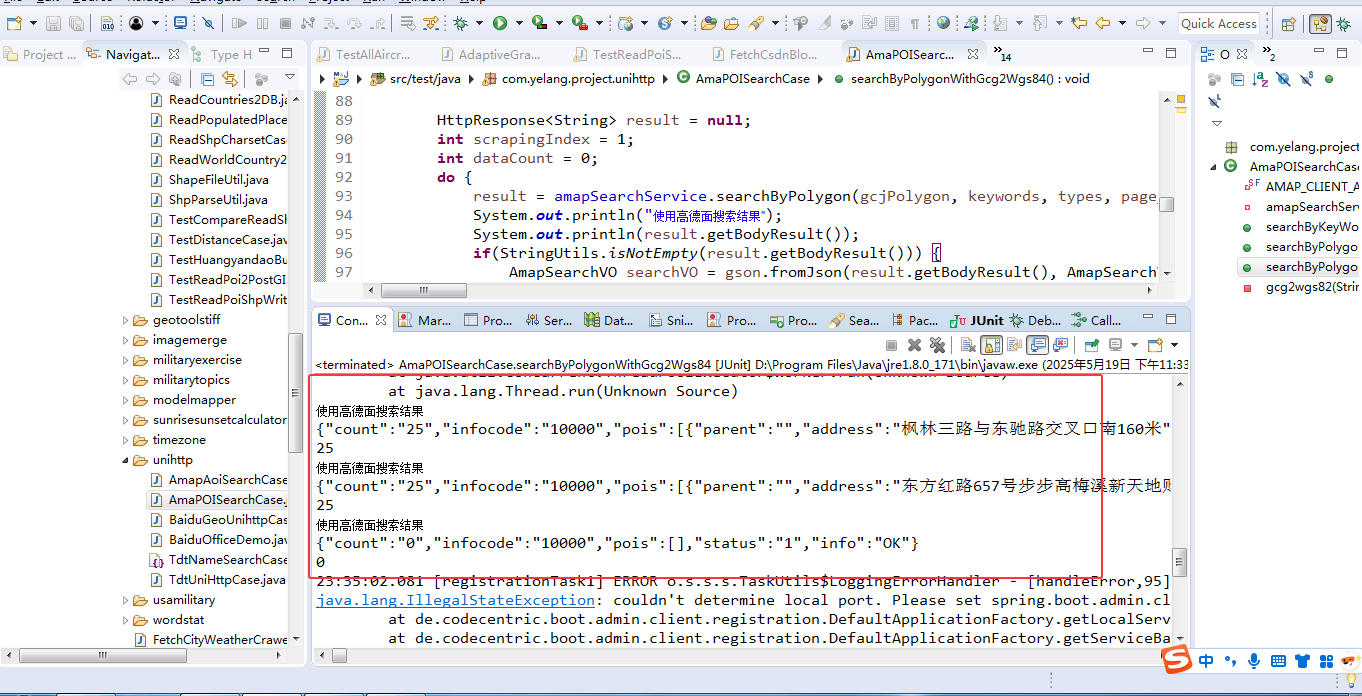
基于Java在高德地图面查询检索中使用WGS84坐标的一种方法-以某商场的POI数据检索为例
前言 随着移动互联网的飞速发展,基于位置的服务(LBS)需求日益增长,越来越多的应用需要从地图中检索特定区域内的地理信息,例如商业场所、公共服务设施等。商场作为城市商业活动的重要载体,其周边的地理信息…...

使用 Terraform 创建 Azure Databricks
使用 Terraform 创建 Azure Databricks Terraform 是一种基础设施即代码(IaC)工具,允许用户通过声明式配置文件来管理和部署云资源。Azure Databricks 是一个基于 Apache Spark 的分析平台,专为数据工程和数据科学设计。通过 Terraform,可以自动化 Azure Databricks 的创…...
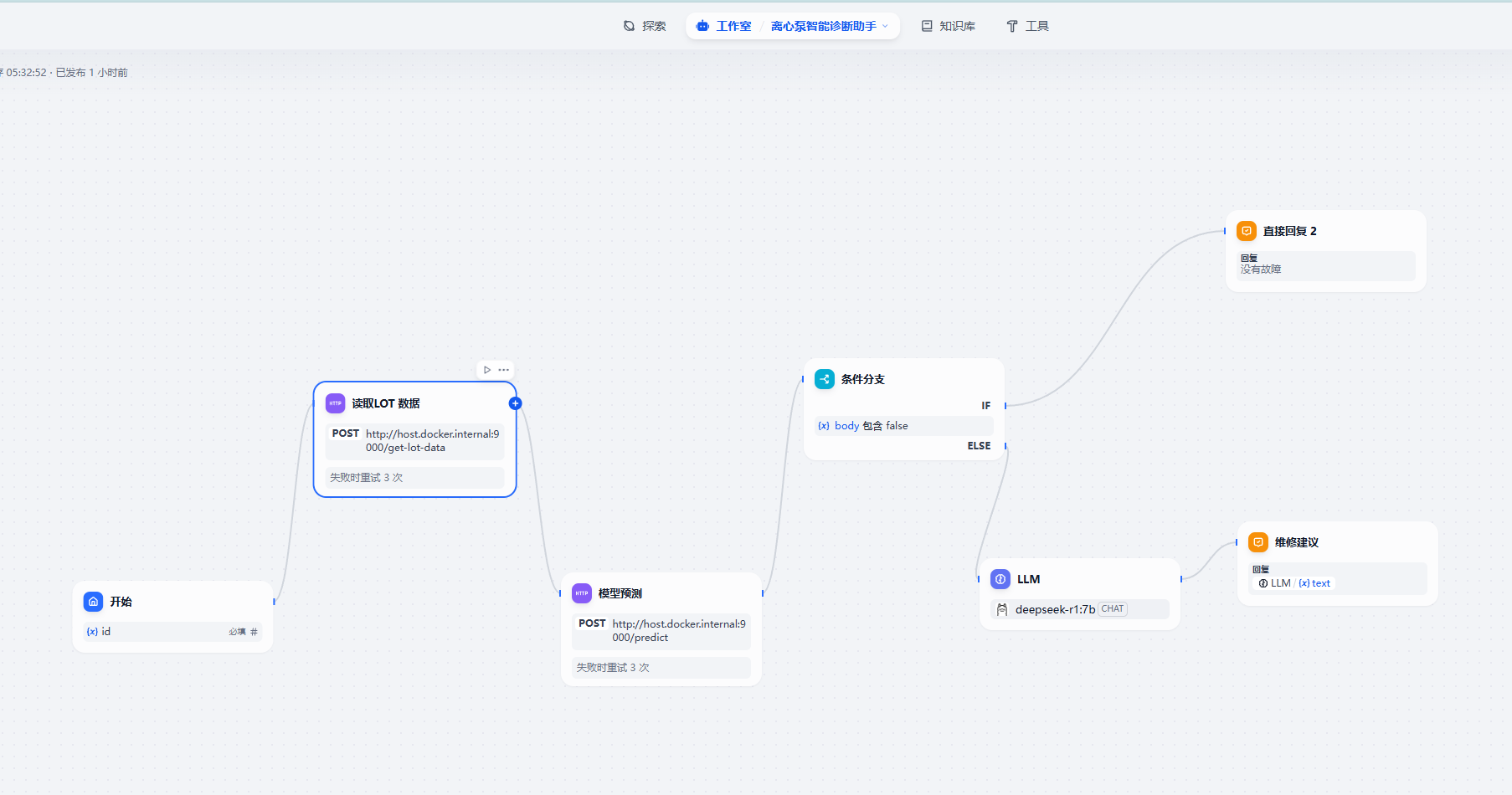
本地部署dify+ragflow+deepseek ,结合小模型实现故障预测,并结合本地知识库和大模型给出维修建议
1.准备工作 使用ollama 拉取deepseek-r1:7b 官网下载ollama ollama run deepseek-r1:7b ollama list Ragflow专注于构建基于检索增强生成(RAG)的工作流,强调模块化和轻量化,适合处理复杂文档格式和需要高精度检索的场景。Dify…...

SECERN AI提出3D生成方法SVAD!单张图像合成超逼真3D Avatar!
SECERN AI提出的3D生成方法SVAD通过视频扩散生成合成训练数据,利用身份保留和图像恢复模块对其进行增强,并利用这些经过优化的数据来训练3DGS虚拟形象。SVAD在新的姿态和视角下保持身份一致性和精细细节方面优于现有最先进(SOTA)的…...