重拾GMP
目录
- GMP总结
- 线程
- 协程
- 三家对比
- GMP调度模型
- m
- g
- p
- 过一遍流程
- g
- 一个G的生命周期
- m
- p
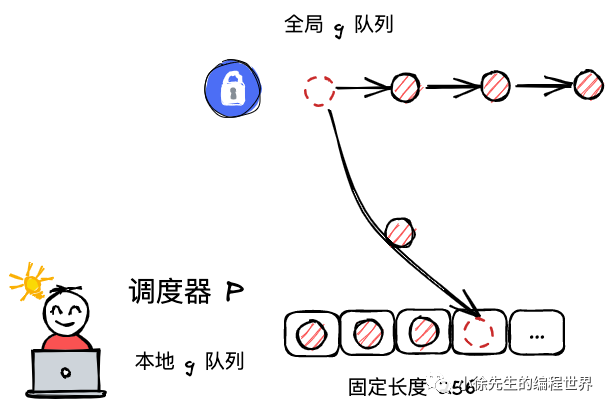
- schedt全局队列
- g0视角看看G的调度流程
- 四大调度类型
- 主动调度
- 被动调度
- 正常调度
- 抢占调度
- 四大调度类型
- 宏观的调度流程
- 上面流程的具体细节
- schedule()
- findRunnable()
- execute()
- gosched_m()
- park_m()与ready()
- goexit0()
- retake()
- reentersyscall 和 exitsyscall
GMP总结
线程
线程是跑在操作系统内核上的一段程序,是内核态的一段程序,是操作系统调度的基本单位。
可以举个例子,比如一个网站的程序整体就是一个线程。这个线程对于用户是不透明的
协程
协程是线程的一个子集,是一种逻辑上的概念,在《计算机操作系统》这门课中只有线程的概念,
然而在具体的工程实践中,工程师们为了方便创建了协程这一概念。
协程是一种用户态的程序,一般与线程形成N:1的关系,也就是说一个线程下面可以绑定多个协程。
举个例子,一个网站中有用户管理的部分和文章管理的部分,这两个部分是等级的协程,共同
被绑定在这个网站的线程之下。(实际上可能更加复杂)。
但是这就造成了一个大问题:因为用户态的协程对于操作系统来说是不可见的,因此当多个协程中由于某个协程
阻塞导致整个线程发生阻塞时,操作系统无法找到对应的协程,其他协程也无法运行。这个问题在并发编程中
十分常见:
比如小米YU7即将上市,在抢购的网站服务器中,会启动多个协程用于接收用户的订购请求,但是当一个用户可能因为
网络问题无法访问服务器,则与这个用户的协程绑在一起的整个线程就会发生阻塞,导致整个线程上的用户集体卡顿。
这就是传统协程,线程N:1模式的问题。
为了解决这个问题GMP调度模型应运而生。
三家对比
GMP模型与协程和线程相比:
- 它和协程一样是一种用户态的协程。
- 它兼顾线程的可并行特性,并且可以应对协程阻塞并且在这个方面比线程更加优秀。
- 额外的,goroutine的栈相对于传统线程是可以动态扩展的,增加了栈空间的利用率。
刚才讲过,传统协程与线程的关系是N:1的,而GMP调度模型是N:M的。
- 而GMP调度模型是N:M的
- 创建,销毁,调度在用户态完成,对内核透明,足够轻便。
- 通过调度器的斡旋,实现线程间动态绑定和灵活调度
- 栈空间大小动态扩展,降低了内存消耗
GMP调度模型
gmp=goroutine+machine+processor
m
m就是线程在golang中的一个抽象概念。
通常就是指线程!!!
- m不能和传统线程一样直接执行g,而是要先和p绑定后才能调度g。
- 注意,m不需要和p绑死,因此可以实现动态解绑和绑定。
g
- g就是goroutine(go协程)
- go有自己的运行栈,状态和要执行的函数
- g需要绑定到p才能执行,从g的视角来看,p就是g的cpu
p
- p是processor,就是go协程调度器,他是gmp调度模型的核心。
- 对于m而言,p就是一个执行代理,p要为m提供g和内存等情况,m只有和p结合才能执行调度。
- p的数量决定了g的数量,可以由GOMAXPROCS来设置。
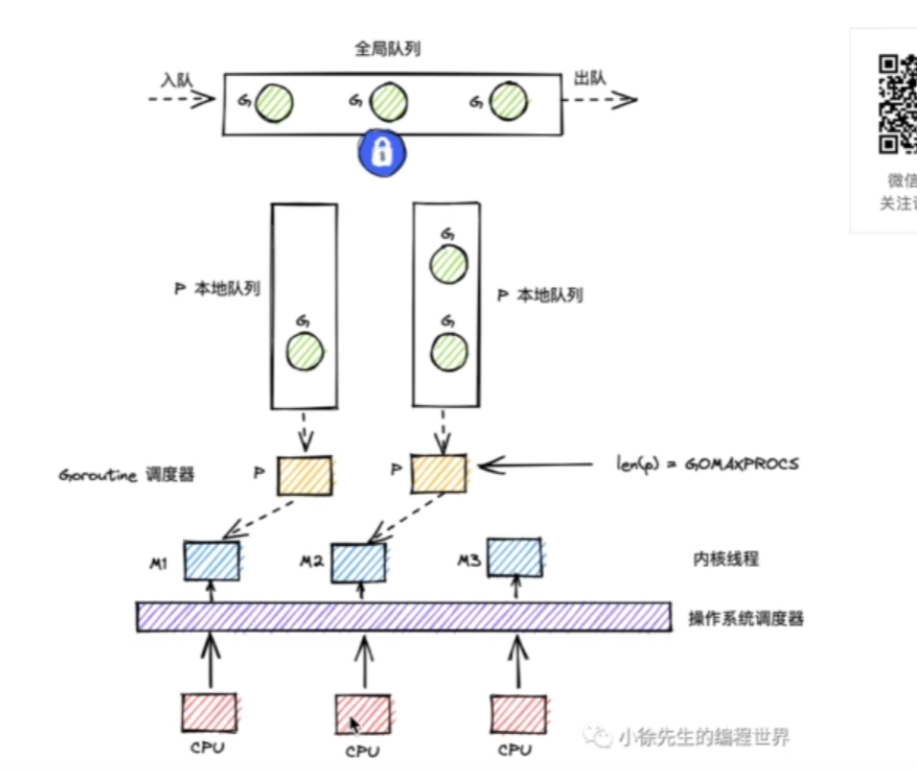
过一遍流程:
现在假如已经创建了很多G,已经形成了一定的规模。
- 首先p的数量通过GOMAXPROCS来设置,设置后会创建一定数量的m,然后将m和p绑定。(m和p的数量并不是一一对应的!!)
- 然后讲G和P绑定放到P的本地队列中。
- 然后M会从绑定的P的本地对立中取出G来执行。
- 当其中某个P的本地队列执行完的时候,会从全局队列中取G
- 当全局队列和本地队列都为空的时候,会从其他P的本地队列中偷取G(work stealing机制)
因为所有的P都有可能从globel queue中取G,所以需要对全局队列加锁。
因为P的本地队列之间会有work stealing机制,所以P队列之间也存在并发安全的问题,只不过出现的频率比较小,所以接近无锁化而不是真正的无锁化。
g

- m 是一个指向m的指针
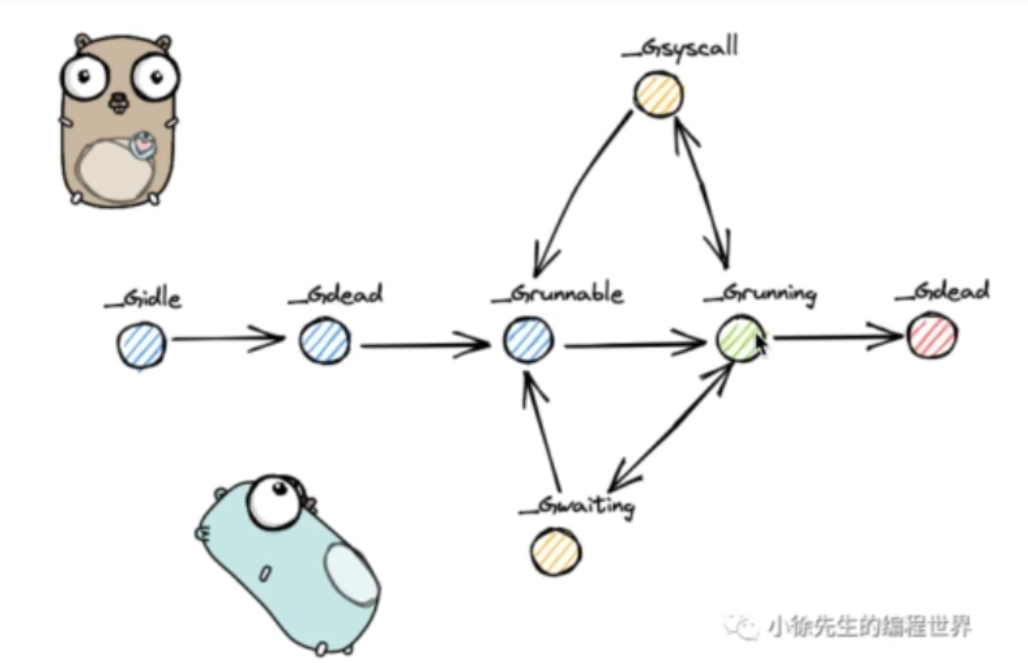
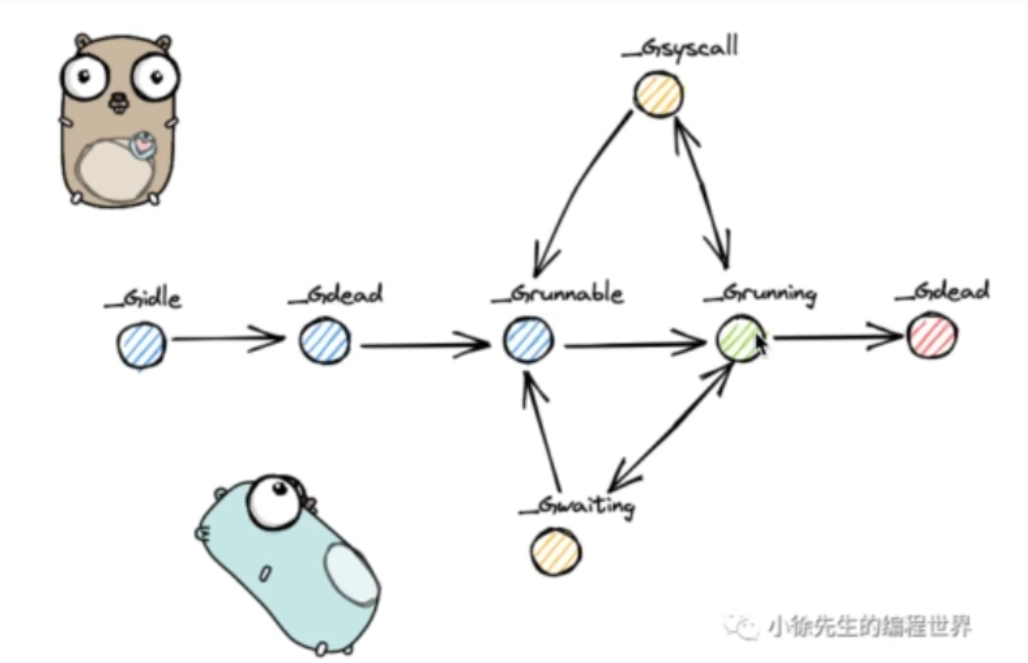
一个G的生命周期
- G被创建,状态标记为_Gidle
- 然后会被搁置为_Gdead
- 这时所有环境被准备好,状态为_Grunnable
- 当G正在被执行时状态变成_Grunning
- G在被执行的时候如果逻辑代码需要进入内核态则状态变成_Gsyscall
- G在被执行时遇到阻塞,状态变成_Gwaiting
- 然后G从_Gwaiting或者_Gsyscall状态返回_Grunnable
- 等待从新被执行变成_Grunning
- G执行完成状态标记为_Gdead,然后被销毁。
m
g0又叫做始祖goroutine,用来帮助m进行g之间的切换调度,与m关系为1:1.
p

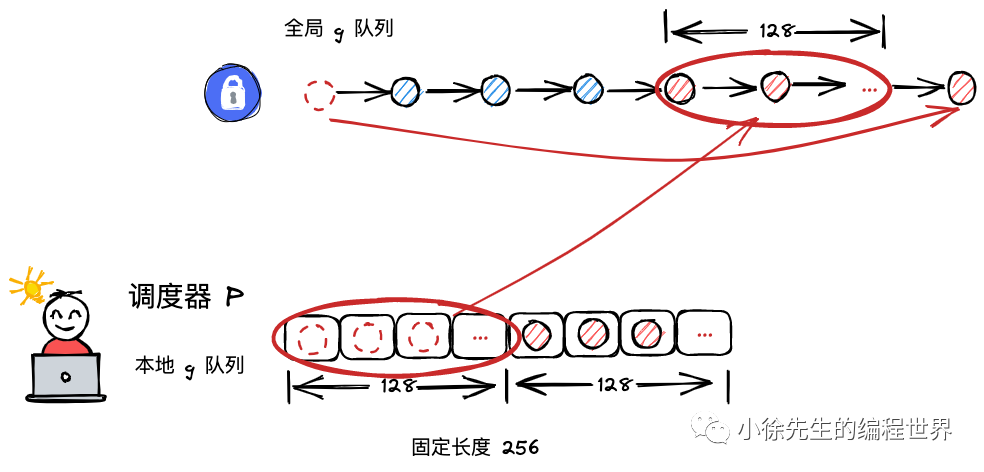
可以看到p的数据结构中存在队列的数据结构。
本地goroutine队列最大长度为256。
- runqhead指向队列头
- runqtail指向队列尾部
- runqnext指向下一个要执行的goroutine
schedt全局队列

明显的看到有一把互斥锁
g0视角看看G的调度流程
上文讲过,g0是众多g中最特殊的一个,它和m是1:1的关系,用于调度权的切换
他与普通G的调度关系如下:
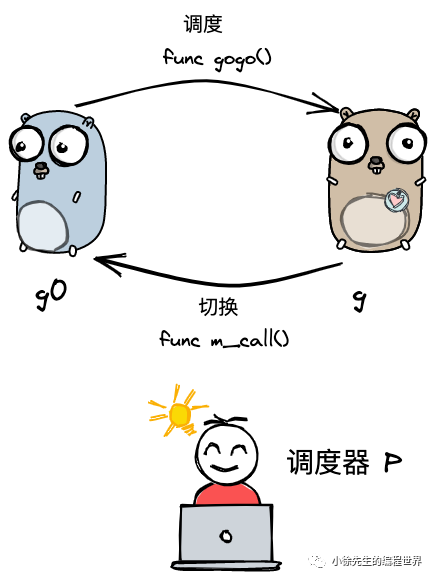
func gogo:g0将调度权交由普通g执行
func mcall:普通g将调度权还给g0
四大调度类型:
-
主动调度
-
被动调度
-
正常调度
-
抢占调度
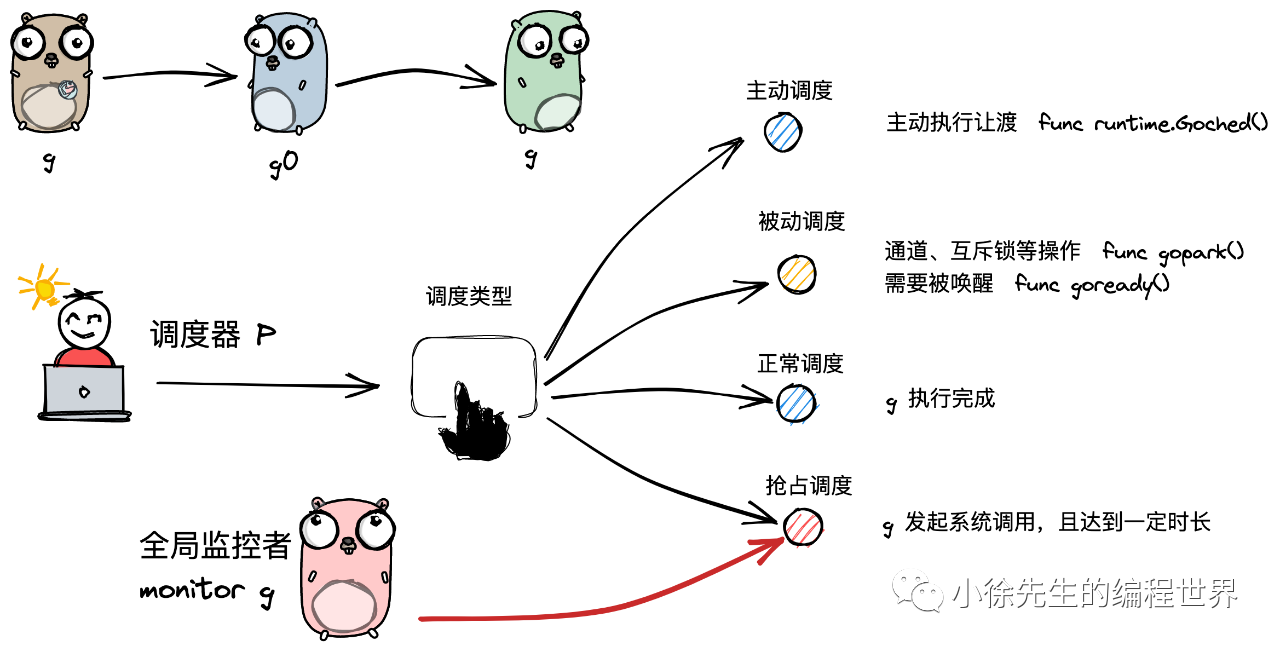
通常,调度指的是由 g0 按照特定策略找到下一个可执行 g 的过程. 而本小节谈及的调度类型是广义上的“调度”,指的是调度器 p 实现从执行一个 g 切换到另一个 g 的过程.
主动调度
主动调度就是由用户主动将调度权交给g0,g0再去寻找可以执行的下一个g0.用户通过调用runtime.Gosched()来实现,让当前g让出执行权
主动进入队列等待下次被调度。
func Gosched() {checkTimeouts()mcall(gosched_m)//交出执行权
}
被动调度
被动调度一般是指,当前g不满足某种执行条件,g可能会陷入阻塞,直到条件达成g才能从阻塞中被唤醒,重新进入执行队列等待被调度。
一般的:满的channel加入队列,或者互斥锁等操作会让底层走进gopark方法。
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceEv byte,traceskip int){//... mcall(park_m)//交出执行权
}
goready 方法通常与 gopark 方法成对出现,能够将 g 从阻塞态中恢复,重新进入等待执行的状态.
func goready(gp *g, traceskip int) {systemstack(func() {ready(gp,traceskip,true)})
}
正常调度
g 中的执行任务已完成,g0 会将当前 g 置为死亡状态,发起新一轮调度.
抢占调度
倘若 g 执行系统调用超过指定的时长(有一个全局监控器),且全局的 p 资源比较紧缺,此时将 p 和 g 解绑,抢占出来用于其他 g 的调度.
等 g 完成系统调用后,会重新进入可执行队列中等待被调度.
值得一提的是,前 3 种调度方式都由 m 下的 g0 完成,唯独抢占调度不同.
因为发起系统调用时需要打破用户态的边界进入内核态,此时 m 也会因系统调用而陷入僵直,无法主动完成抢占调度的行为.
因此,在 Golang 进程会有一个全局监控协程 monitor g 的存在,这个 g 会越过 p 直接与一个 m 进行绑定,不断轮询对所有
p 的执行状况进行监控. 倘若发现满足抢占调度的条件,则会从第三方的角度出手干预,主动发起该动作.
宏观的调度流程
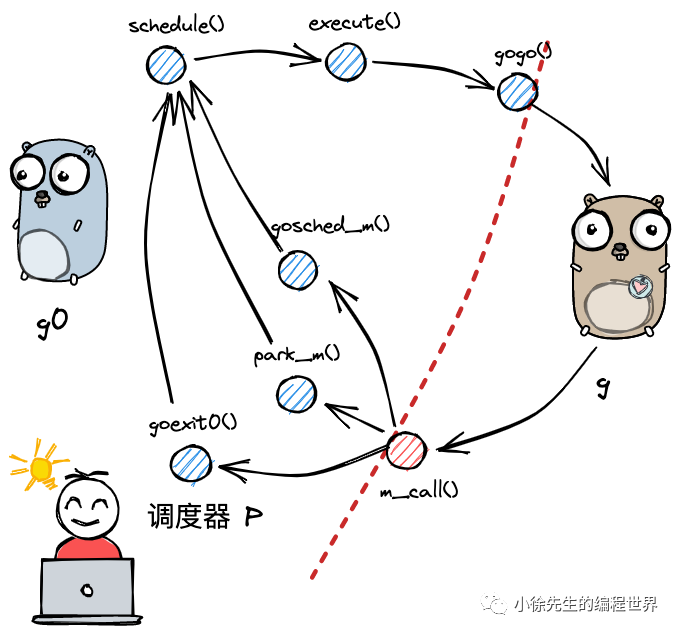
上面图的流程:
- 以g0->g->g0的一轮循环举例
- g0 执行 schedule() 函数,寻找到用于执行的 g;
- g0 执行 execute() 方法,更新当前 g、p 的状态信息,并调用 gogo() 方法,将执行权交给 g;
- g 因主动让渡( gosche_m() )、被动调度( park_m() )、正常结束( goexit0() )等原因,调用 m_call 函数,执行权重新回到 g0 手中;
- g0 执行 schedule() 函数,开启新一轮循环.
上面流程的具体细节
schedule()
当执行这个函数时,执行权尚在g0手中。
func schedule() {// ... gp,inheritTime,tryWakeP:=findRunnable() //todo 寻找下一个可执行g// ...execute(gp, inheritTime)//todo 执行找到的g
}
findRunnable()
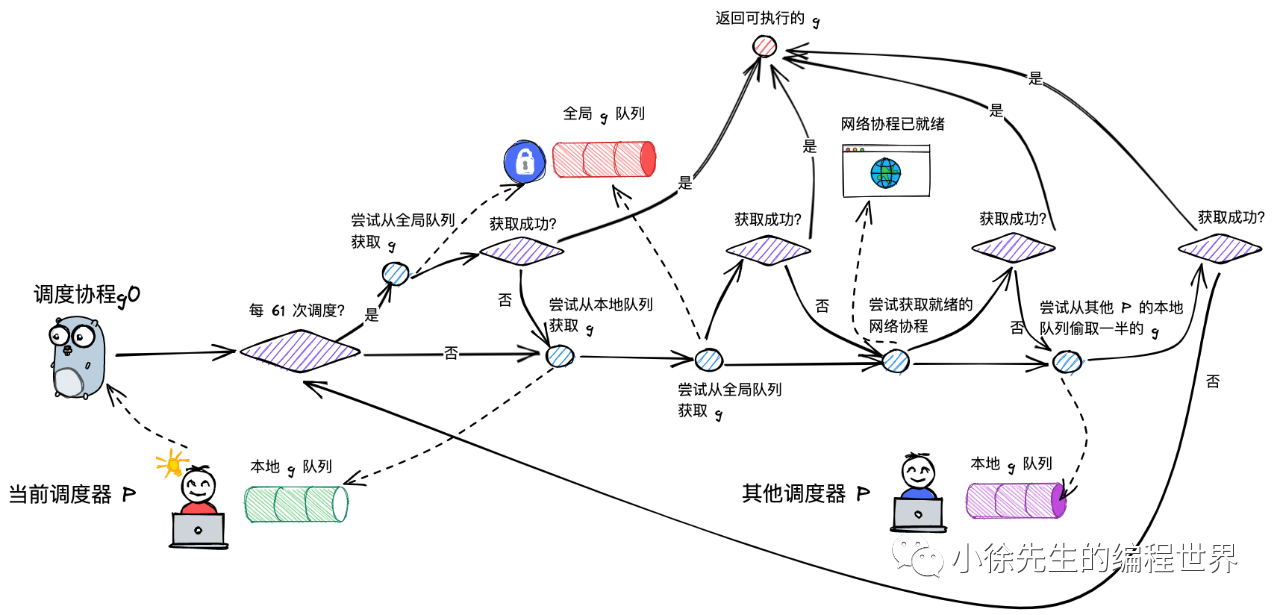
调度流程中,一个非常核心的步骤,就是为 m 寻找到下一个执行的 g,这部分内容位于 runtime/proc.go 的 findRunnable 方法中
func findRunnable() (gp *g, inheritTime, tryWakeP bool) {_g_ := getg()top:_p_ := _g_.m.p.ptr()// ...if _p_.schedtick%61 == 0 && sched.runqsize > 0 {//todo 每执行61次,从全局队列中获取一个glock(&sched.lock)gp = globrunqget(_p_, 1)unlock(&sched.lock)if gp != nil {return gp, false, false}}// ...if gp, inheritTime := runqget(_p_); gp != nil {return gp, inheritTime, false}// ...if sched.runqsize != 0 {lock(&sched.lock)gp := globrunqget(_p_, 0)unlock(&sched.lock)if gp != nil {return gp, false, false}}if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 {if list := netpoll(0); !list.empty() { // non-blockinggp := list.pop()injectglist(&list)casgstatus(gp, _Gwaiting, _Grunnable)return gp, false, false}}// ...procs := uint32(gomaxprocs)if _g_.m.spinning || 2*atomic.Load(&sched.nmspinning) < procs-atomic.Load(&sched.npidle) {if !_g_.m.spinning {_g_.m.spinning = trueatomic.Xadd(&sched.nmspinning, 1)}gp, inheritTime, tnow, w, newWork := stealWork(now)now = tnowif gp != nil {// Successfully stole.return gp, inheritTime, false}if newWork {// There may be new timer or GC work; restart to// discover.goto top}if w != 0 && (pollUntil == 0 || w < pollUntil) {// Earlier timer to wait for.pollUntil = w}}//
除了获取一个 g 用于执行外,还会额外将一个 g 从全局队列转移到 p 的本地队列,让全局队列中的 g 也得到更充分的执行机会.
func globrunqget(_p_ *p, max int32) *g {if sched.runqsize == 0 {return nil}n := sched.runqsize/gomaxprocs + 1if n > sched.runqsize {n = sched.runqsize}if max > 0 && n > max {n = max}if n > int32(len(_p_.runq))/2 {n = int32(len(_p_.runq)) / 2}sched.runqsize -= ngp := sched.runq.pop()n--for ; n > 0; n-- {gp1 := sched.runq.pop()runqput(_p_, gp1, false)}return gp
将一个 g 由全局队列转移到 p 本地队列的执行逻辑位于 runqput 方法中:
func runqput(_p_ *p, gp *g, next bool) {// ...retry:h := atomic.LoadAcq(&_p_.runqhead) //todo 取得 p 本地队列队首的索引,同时对本地队列加锁t := _p_.runqtailif t-h < uint32(len(_p_.runq)) {_p_.runq[t%uint32(len(_p_.runq))].set(gp)atomic.StoreRel(&_p_.runqtail, t+1) //todo 倘若 p 的局部队列未满,则成功转移 g,将 p 的对尾索引 runqtail 值加 1 并解锁队列.return}if runqputslow(_p_, gp, h, t) {return}// the queue is not full, now the put above must succeedgoto retry
III 倘若发现本地队列 runq 已经满了,则会返回来将本地队列中一半的 g 放回全局队列中,帮助当前 p 缓解执行压力,这部分内容位于 runqputslow 方法中.
- 尝试从p本地队列中获取一个可以执行的goroutine,核心逻辑位于 runqget 方法中:
func runqget(_p_ *p) (gp *g, inheritTime bool) {if next != 0 && _p_.runnext.cas(next, 0) {return next.ptr(), true}for {h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with other consumerst := _p_.runqtailif t == h {return nil, false}gp := _p_.runq[h%uint32(len(_p_.runq))].ptr()if atomic.CasRel(&_p_.runqhead, h, h+1) { // cas-release, commits consumereturn gp, false}}
execute()
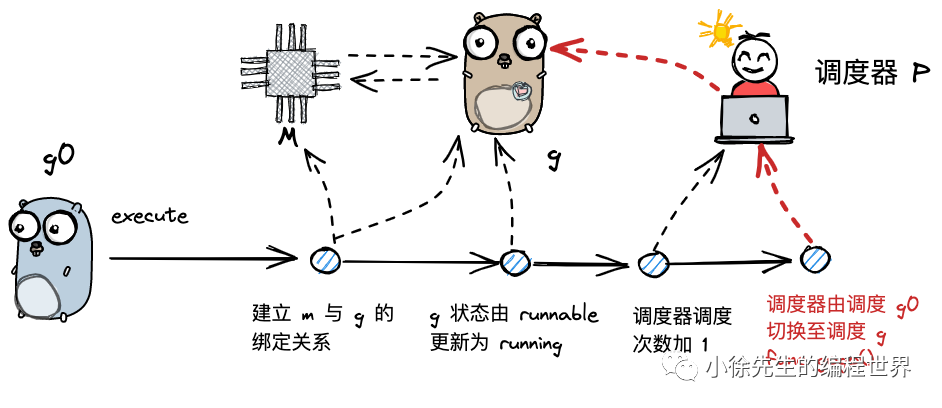
当 g0 为 m 寻找到可执行的 g 之后,接下来就开始执行 g. 这部分内容位于 runtime/proc.go 的 execute 方法中:
func execute(gp *g, inheritTime bool) {_g_ := getg()_g_.m.curg = gpgp.m = _g_.mcasgstatus(gp, _Grunnable, _Grunning)// todo 更新G的状态信息gp.waitsince = 0gp.preempt = falsegp.stackguard0 = gp.stack.lo + _StackGuardif !inheritTime {_g_.m.p.ptr().schedtick++// todo 更新 p 的调度计数器}gogo(&gp.sched)// todo 跳转到 gp 的调度地址,开始执行 g.
gosched_m()
g 执行主动让渡时,会调用 mcall 方法将执行权归还给 g0,并由 g0 调用 gosched_m 方法,位于 runtime/proc.go 文件中:
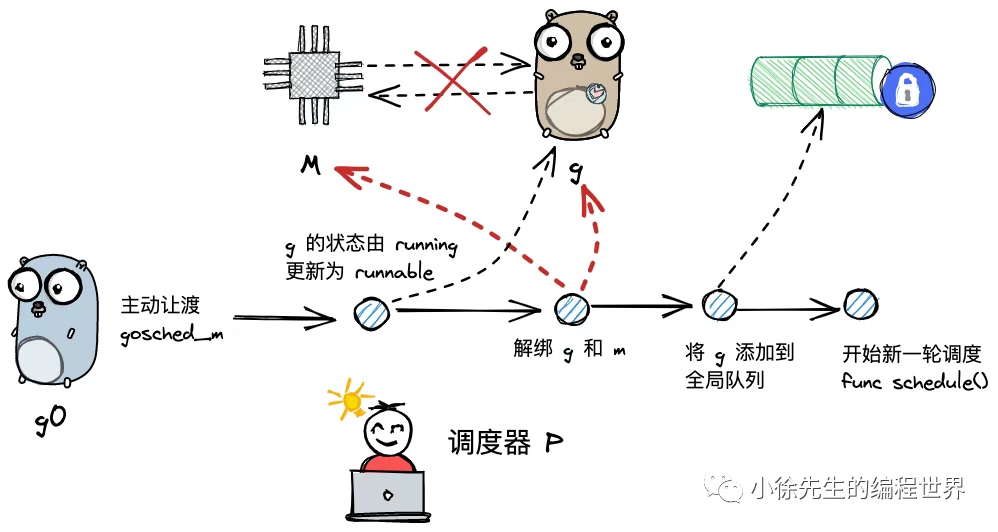
func gosched_m(gp *g) {goschedImpl(gp)
}func goschedImpl(gp *g) {status := readgstatus(gp)if status&^_Gscan != _Grunning {dumpgstatus(gp)throw("bad g status")}casgstatus(gp, _Grunning, _Grunnable)// todo 更新 g 的状态信息为_Grunnabledropg()// todo 将当前g与m解绑lock(&sched.lock)globrunqput(gp)// todo 将 g 放入全局队列中unlock(&sched.lock)schedule()// todo 开始新一轮调度
park_m()与ready()
g 需要被动调度时,会调用 mcall 方法切换至 g0,并调用 park_m 方法将 g 置为阻塞态,执行流程位于 runtime/proc.go 的 gopark 方法当中:
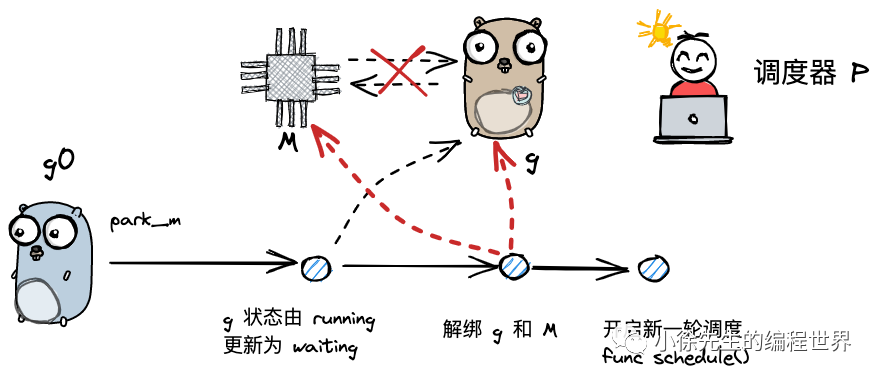
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceEv byte, traceskip int) {// ...mcall(park_m)// todo 将当前 g 与 m 解绑,并调用 park_m 方法
}
func park_m(gp *g) {_g_ := getg()casgstatus(gp, _Grunning, _Gwaiting)// todo 更新 g 的状态信息为_Gwaitingdropg()// todo 将当前g与m解绑// ...schedule()// todo 开始一轮调度
当因被动调度陷入阻塞态的 g 需要被唤醒时,会由其他协程执行 goready 方法将 g 重新置为可执行的状态,方法位于 runtime/proc.go .
被动调度如果需要唤醒,则会其他 g 负责将 g 的状态由 waiting 改为 runnable,然后会将其添加到唤醒者的 p 的本地队列中:
func goready(gp *g, traceskip int) {systemstack(func() {ready(gp, traceskip, true)})
}
func ready(gp *g, traceskip int, next bool) {// ..._g_ := getg()// ...casgstatus(gp, _Gwaiting, _Grunnable)// todo 更新 g 的状态信息为_Grunnablerunqput(_g_.m.p.ptr(), gp, next)// todo 调用 runqput 将当前 g 添加到唤醒者 p 的本地队列中,如果队列满了,会连带 g 一起将一半的元素转移到全局队列.// ...
}
goexit0()
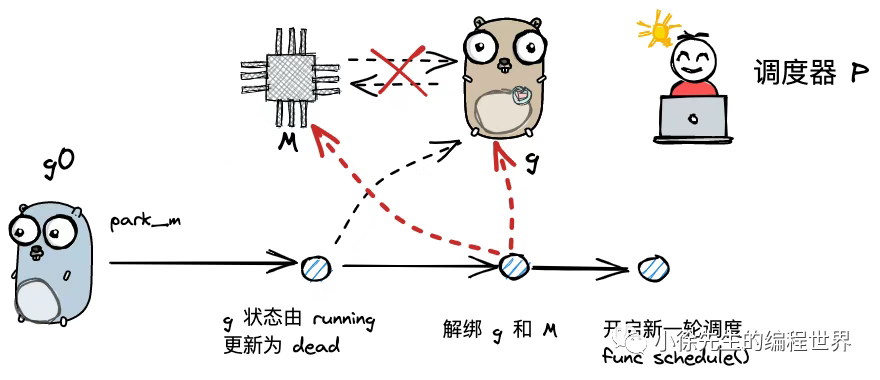
当 g 执行完成时,会先执行 mcall 方法切换至 g0,然后调用 goexit0 方法,内容为 runtime/proc.go:
// Finishes execution of the current goroutine.
func goexit1() {// ...mcall(goexit0)
}
func goexit0(gp *g) {_g_ := getg()_p_ := _g_.m.p.ptr()casgstatus(gp, _Grunning, _Gdead)// todo 更新 g 的状态信息为_Gdead// ...gp.m = nil// ...dropg()// todo 将当前g与m解绑// ...schedule()// todo 开始一轮调度
retake()

与 4.7-4.9 小节的区别在于,抢占调度的执行者不是 g0,而是一个全局的 monitor g,代码位于 runtime/proc.go 的 retake 方法中:
func retake(now int64) uint32 {n := 0lock(&allpLock)// todo 因为是全局队列,所以需要加锁//加锁后,遍历全局的 p 队列,寻找需要被抢占的目标:for i := 0; i < len(allp); i++ {_p_ := allp[i]if _p_ == nil {// This can happen if procresize has grown// allp but not yet created new Ps.continue}pd := &_p_.sysmontick// 倘若某个 p 同时满足下述条件,则会进行抢占调度:if s == _Psyscall { // ...if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now {//执行系统调用超过 10 ms//p 本地队列有等待执行的 g//或者当前没有空闲的 p 和 mcontinue}unlock(&allpLock)if atomic.Cas(&_p_.status, s, _Pidle) {n++_p_.syscalltick++handoffp(_p_)}incidlelocked(1)lock(&allpLock)}}unlock(&allpLock)return uint32(n)
}- 加锁后,遍历全局的p队列,寻找需要被抢占的目标:
lock(&allpLock)for i := 0; i < len(allp); i++ {_p_ := allp[i]// ...}unlock(&allpLock)
- 倘若某个 p 同时满足下述条件,则会进行抢占调度:
- I 执行系统调用超过 10 ms;
- II p 本地队列有等待执行的 g;
- III 或者当前没有空闲的 p 和 m.
- 抢占调度的步骤是,先将当前 p 的状态更新为 idle,然后步入 handoffp 方法中,判断是否需要为 p 寻找接管的 m(因为其原本绑定的 m 正在执行系统调用):
if atomic.Cas(&_p_.status, s, _Pidle) {n++_p_.syscalltick++handoffp(_p_)}
- 当以下四个条件满足其一时,则需要为 p 获取新的 m:
- I 当前 p 本地队列还有待执行的 g;
- II 全局繁忙(没有空闲的 p 和 m,全局 g 队列为空)
- III 需要处理网络 socket 读写请求
func handoffp(_p_ *p) {if !runqempty(_p_) || sched.runqsize != 0 {startm(_p_, false)return}if atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) == 0 && atomic.Cas(&sched.nmspinning, 0, 1) {startm(_p_, true)return}lock(&sched.lock)// ...if sched.runqsize != 0 {unlock(&sched.lock)startm(_p_, false)return}// If this is the last running P and nobody is polling network,// need to wakeup another M to poll network.if sched.npidle == uint32(gomaxprocs-1) && atomic.Load64(&sched.lastpoll) != 0 {unlock(&sched.lock)startm(_p_, false)return}// ...
- 获取 m 时,会先尝试获取已有的空闲的 m,若不存在,则会创建一个新的 m
func startm(_p_ *p, spinning bool) {mp := acquirem()lock(&sched.lock)// ...nmp := mget()if nmp == nil {id := mReserveID()unlock(&sched.lock)var fn func()// ...newm(fn, _p_, id)// ...return}unlock(&sched.lock)// ...
}
reentersyscall 和 exitsyscall



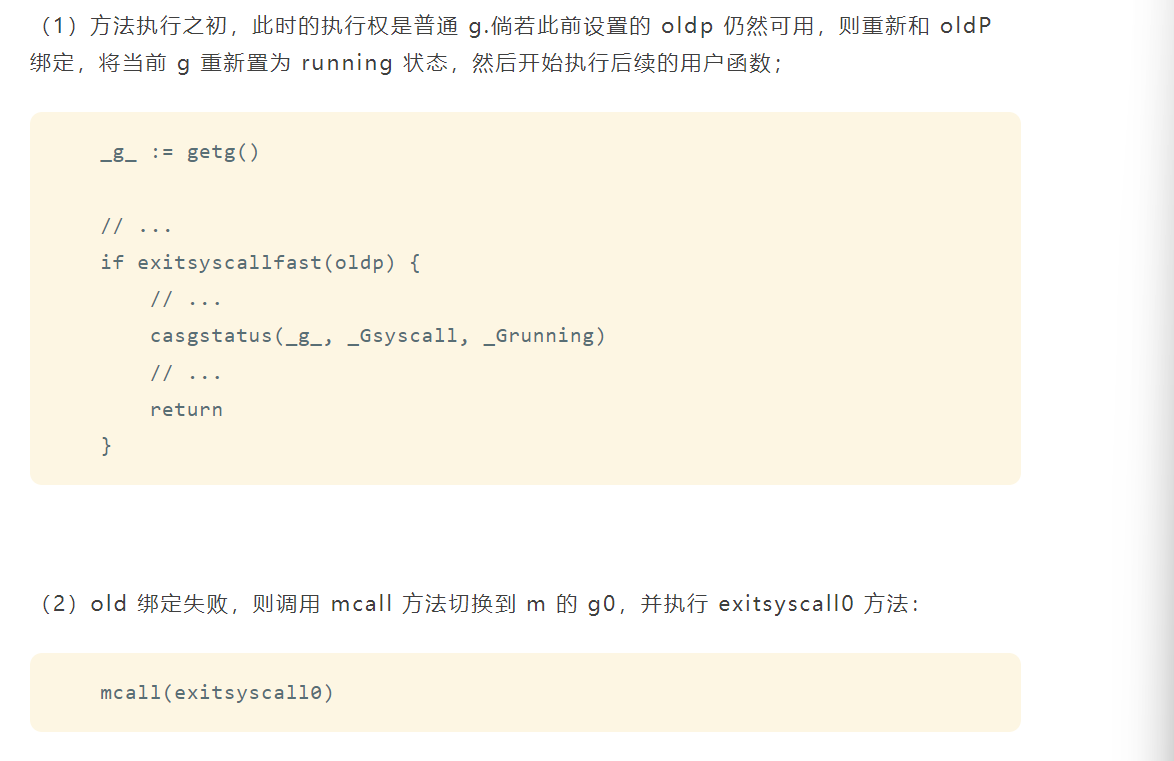
func exitsyscall0(gp *g) {casgstatus(gp, _Gsyscall, _Grunnable)dropg()lock(&sched.lock)var _p_ *pif schedEnabled(gp) {_p_, _ = pidleget(0)}var locked boolif _p_ == nil {globrunqput(gp)} unlock(&sched.lock)if _p_ != nil {acquirep(_p_)execute(gp, false) // Never returns.}// ...stopm()schedule() // Never returns.
}

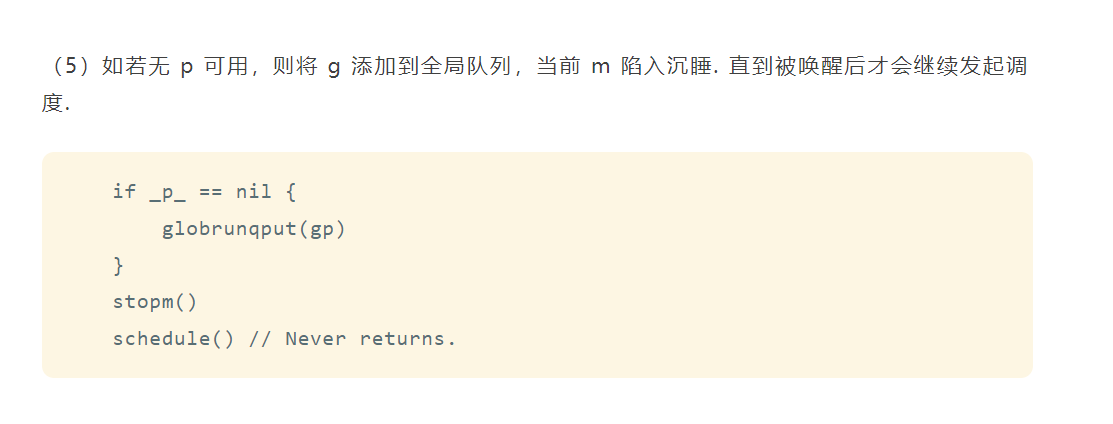
func exitsyscall0(gp *g) {casgstatus(gp, _Gsyscall, _Grunnable)dropg()lock(&sched.lock)var _p_ *pif schedEnabled(gp) {_p_, _ = pidleget(0)}var locked boolif _p_ == nil {globrunqput(gp)} unlock(&sched.lock)if _p_ != nil {acquirep(_p_)execute(gp, false) // Never returns.}// ...stopm()schedule() // Never returns.
}
相关文章:
重拾GMP
目录 GMP总结 线程协程三家对比GMP调度模型 mgp过一遍流程 g 一个G的生命周期 mpschedt全局队列g0视角看看G的调度流程 四大调度类型 主动调度被动调度正常调度抢占调度 宏观的调度流程上面流程的具体细节 schedule()findRunnable()execute()gosched_m()park_m()与ready()goe…...

实验分享|基于千眼狼sCMOS科学相机的流式细胞仪细胞核成像实验
实验背景 流式细胞仪与微流控技术,为细胞及细胞核成像提供新的路径。传统流式细胞仪在细胞核成像检测方面存在检测通量低,荧光信号微弱等局限,故某光学重点实验室开发一种基于高灵敏度sCMOS科学相机并集成在自组荧光显微镜的微流控细胞核成像…...

C++学习:六个月从基础到就业——C++11/14:其他语言特性
C学习:六个月从基础到就业——C11/14:其他语言特性 本文是我C学习之旅系列的第四十四篇技术文章,也是第三阶段"现代C特性"的第六篇,主要介绍C11/14中引入的其他重要语言特性。查看完整系列目录了解更多内容。 引言 在前…...
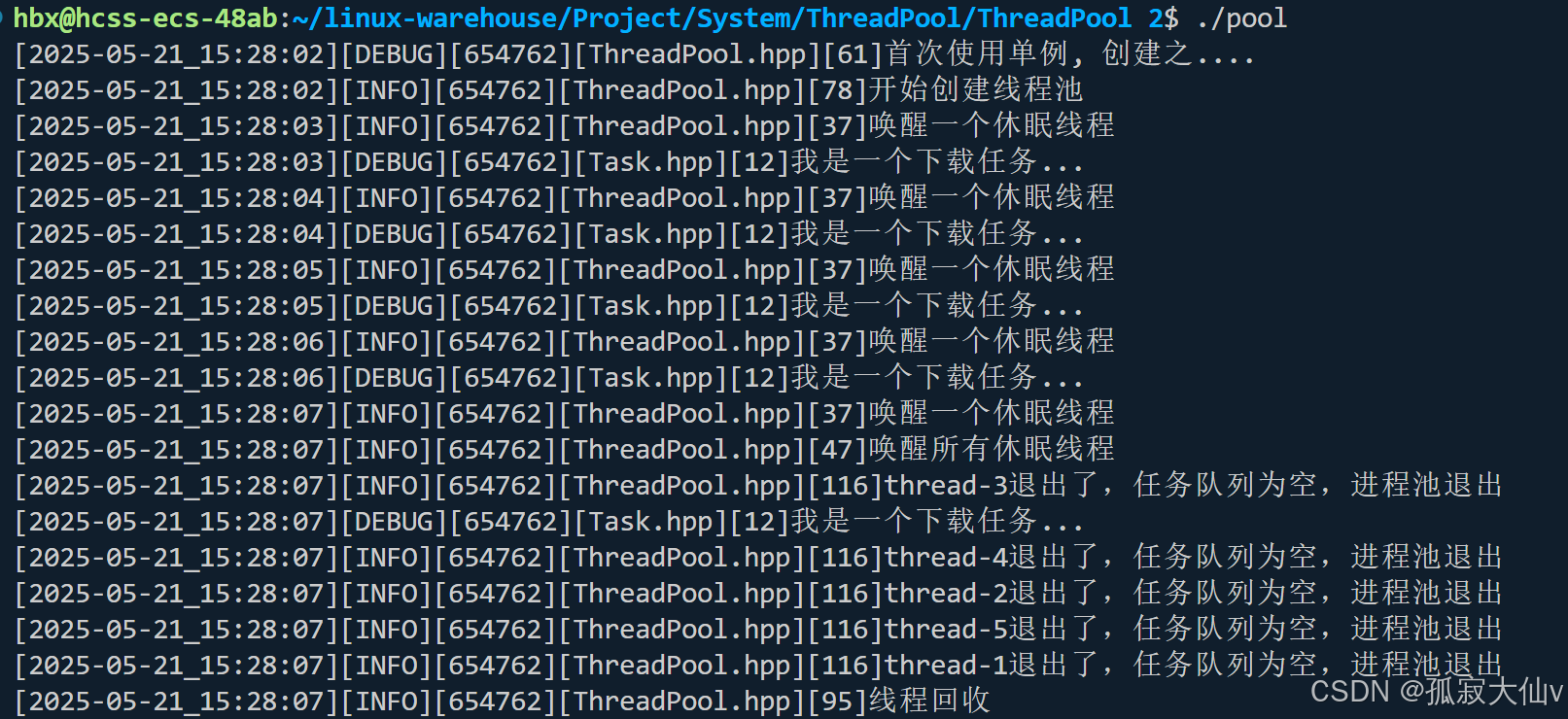
【Linux笔记】——线程池项目与线程安全单例模式
🔥个人主页🔥:孤寂大仙V 🌈收录专栏🌈:Linux 🌹往期回顾🌹: 【Linux笔记】——简单实习一个日志项目 🔖流水不争,争的是滔滔不息 一、线程池设计二…...

数据驱动的社会舆情监测与分析——用算法洞察世界脉动
数据驱动的社会舆情监测与分析——用算法洞察世界脉动 在信息爆炸的时代,社会舆情的变化可以在极短时间内产生深远影响。从企业品牌到公共政策,社交媒体和新闻平台上的讨论能够直接影响决策者的策略制定。因此,数据驱动的舆情监测与分析 逐渐成为政府、企业以及社会机构的重…...

OD 算法题 B卷 【最佳植树距离】
文章目录 最佳植树距离 最佳植树距离 在直线的公路上种树,给定坑位数量和位置,及需要种多少棵树苗;树苗之间的最小距离是多少时,可以保证种的最均匀(树苗之间的最小距离最大); 输入描述&#…...
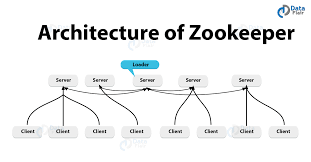
ZooKeeper 原理解析及优劣比较
大家好,这里是架构资源栈!点击上方关注,添加“星标”,一起学习大厂前沿架构! 引言 在分布式系统中,服务注册、配置管理、分布式锁、选举等场景都需要一个高可用、一致性强的协调服务。Apache ZooKeeper 凭…...

实战5:个性化数字艺术生成与销售
盈利思路 数字艺术销售: 平台销售:将生成的数字艺术作品上传到像OpenSea、Foundation等NFT平台进行售卖。每一件独特的艺术品可以通过NFT技术保证其唯一性,吸引收藏家和投资者。 定价策略:根据作品的复杂度、创意性以及市场需求来…...
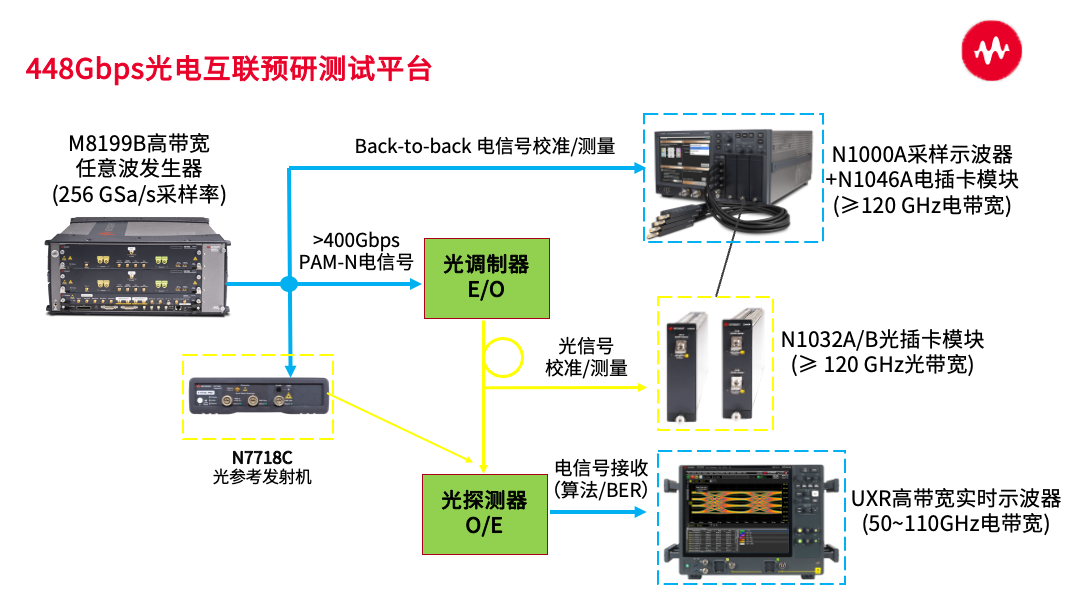
是德科技 | 单通道448G未来之路:PAM4? PAM6? PAM8?
内容来源:是德科技 随着数据中心规模的不断扩大以及AI大模型等技术的兴起,市场对高速、大容量数据传输的需求日益增长。例如,AI训练集群中GPU等设备之间的互联需要更高的传输速率来提升效率。在技术升级方面,SerDes技术的不断进步…...
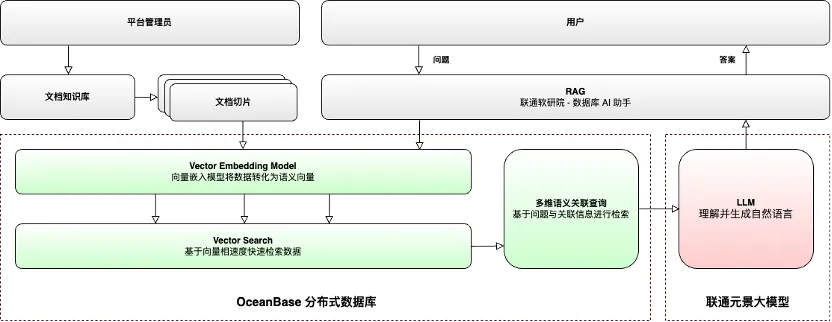
OceanBase 开发者大会,拥抱 Data*AI 战略,构建 AI 数据底座
5 月 17 号以“当 SQL 遇见 AI”为主题的 OceanBase 开发者大会在广州举行,因为行程的原因未能现场参会,仍然通过视频直播观看了全部的演讲。总体来说,这届大会既有对未来数据库演进方向的展望,也有 OceanBase 新产品的发布&#…...
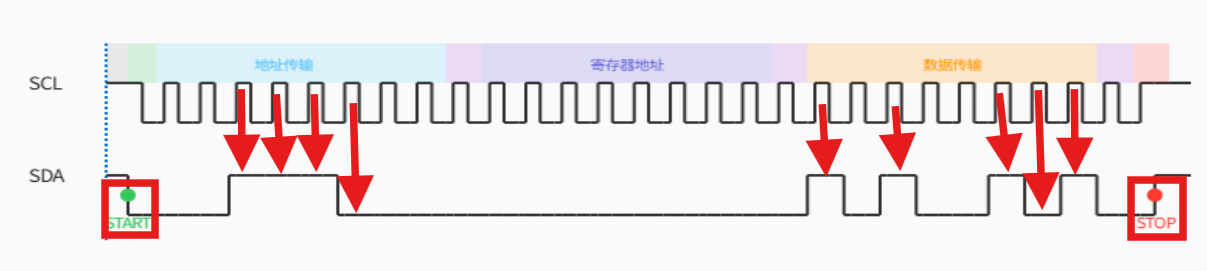
STM32IIC协议基础及Cube配置
STM32IIC协议基础及Cube配置 一,IC协议简介1,核心特点2,应用场景 二,IC协议基础概念1,总线结构2,主从架构3,设备寻址4,起始和停止条件5,数据传输6,应答机制 三…...

CNN vs ViT:图像世界的范式演进
一、图像建模,是不是也可以“大一统” 在前文中我们提到,多模态大模型打破“只能处理文字”的限制。 在 NLP 世界里,Transformer 已经证明自己是理解语言的王者。那么在图像世界,我们是否也能有一种“通用架构”,让模…...
cocos creator使用jenkins打包微信小游戏,自动上传资源到cdn,windows版运行jenkins
cocos 版本2.4.11 在windows上jenkins的具体配置和部署,可参考上一篇文章cocos creator使用jenkins打包流程,打包webmobile_jenkins打包,发布,部署cocoscreator-CSDN博客 特别注意,windows上运行jenkins需要关闭windows自己的jenkins服务&a…...
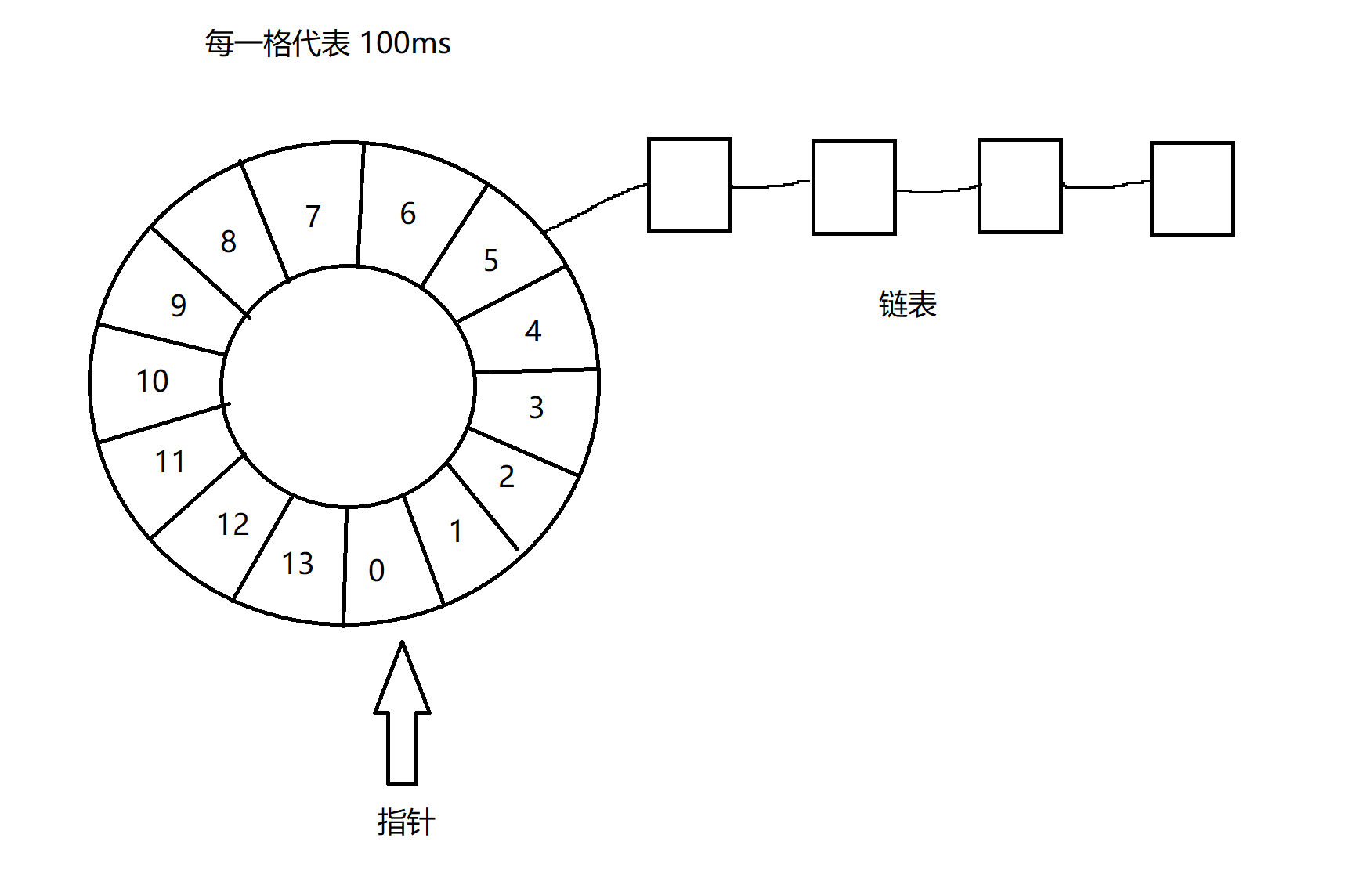
定时器的两种实现方式
1、基于优先级队列/堆 队列是先进先出,优先级队列是优先级越高就存放在队列之前,我们可以将过期时间越早设置为优先级越高,那么临近过期时间的任务就会在队列前面,距离过期时间越晚的任务就在队列后面。 可以分配一个线程&#…...

Python、Pytorch、TensorFlow、Anconda、PySide、Jupyter
一、Python Python是一种高级、通用、解释型的开源编程语言,由Guido van Rossum于1990年代初设计。它具有以下显著特点: 1.语言特性 (1) 语法简洁易读,接近自然语言(如print(“Hello World!”)) (2) 采用强制缩进而非大括号定义代码块 (3) 支持面向对象、函数式和过…...

[Java实战]Spring Boot整合MinIO:分布式文件存储与管理实战(三十)
[Java实战]Spring Boot整合MinIO:分布式文件存储与管理实战(三十) 一、MinIO简介与核心原理 MinIO 是一款高性能、开源的分布式对象存储系统,兼容 Amazon S3 API,适用于存储图片、视频、日志等非结构化数据。其核心特…...
安装macOS Catalina所需时间)
MacBook Air A2179(Intel版)安装macOS Catalina所需时间
MacBook Air A2179(Intel版)安装macOS Catalina所需时间如下: 一、标准安装时间范围 常规安装(通过App Store) • 下载时间:约30-60分钟(取决于网络速度,安装包约8GB) •…...

AI在人力资源领域的应用:把握时代浪潮
借鉴历史经验,引领技术变革 历史总是呈现出惊人的相似性。十年前,众多企业未能及时洞察移动技术与社交技术的潜在价值,迟迟没有将这些创新引入职场环境。随着时间推移,这些组织才意识到BYOD(自带设备办公)…...
】常用函数汇总)
【VxWorks 实时操作系统(RTOS)】常用函数汇总
VxWorks 实时操作系统(RTOS)中的核心函数 1. taskSpawn 函数 功能:用于动态创建并激活一个新任务(线程)。参数解析(以 VxWorks 为例):int taskSpawn(char *name, // 任务名…...

vr制作公司提供什么服务?
随着科技的迅猛进步,虚拟现实(Virtual Reality,简称VR)技术已经悄然渗透到我们的日常生活与工作中,成为推动数字化转型的重要力量。VR制作公司,作为前沿领域的探索者和实践者,以专业的技术和创新…...

下一代电子电气架构(EEA)的关键技术
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...

matlab慕课学习3.5
于20250520 3.5 用while 语句实现循环结构 3.5.1while语句 多用于循环次数不确定的情况,循环次数确定的时候用for更为方便。 3.5.2break语句和continue语句 break用来跳出循环体,结束整个循环。 continue用来结束本次循环,接着执行下一次…...
如何通过“思考时间”(即推理时的计算资源)提升推理能力)
大语言模型(LLM)如何通过“思考时间”(即推理时的计算资源)提升推理能力
大语言模型(LLM)如何通过“思考时间”(即推理时的计算资源)提升推理能力 核心围绕人类思维机制、模型架构改进、训练方法优化等展开 一、人类思维的启发:快思考与慢思考 类比心理学: 人类思维分两种模式: 快思考(系统1):直觉驱动,快速但易出错(如估算简单问题)。…...

Ollama 如何在显存资源有限的情况下合理分配给不同的服务?
在 Windows PowerShell 中启动两个 Ollama 实例的推荐步骤是: 打开第一个 PowerShell 窗口,并执行: $env:OLLAMA_HOST"0.0.0.0:11434" ollama serve打开第二个 PowerShell 窗口,并执行: $env:OLLAMA_HOST&qu…...

Qt音视频开发过程中一个疑难杂症的解决方法/ffmpeg中采集本地音频设备无法触发超时回调
一、前言 最近在做实时音视频通话的项目中,遇到一个神奇的问题,那就是用ffmpeg采集本地音频设备,当音频设备拔掉后,采集过程会卡死在av_read_frame函数中,尽管设置了超时时间,也设置了超时回调interrupt_c…...

基于注意力机制与iRMB模块的YOLOv11改进模型—高效轻量目标检测新范式
随着深度学习技术的发展,目标检测在自动驾驶、智能监控、工业质检等场景中得到了广泛应用。针对当前主流目标检测模型在边缘设备部署中所面临的计算资源受限和推理效率瓶颈问题,YOLO系列作为单阶段目标检测框架的代表,凭借其高精度与高速度的平衡优势,在工业界具有极高的应…...
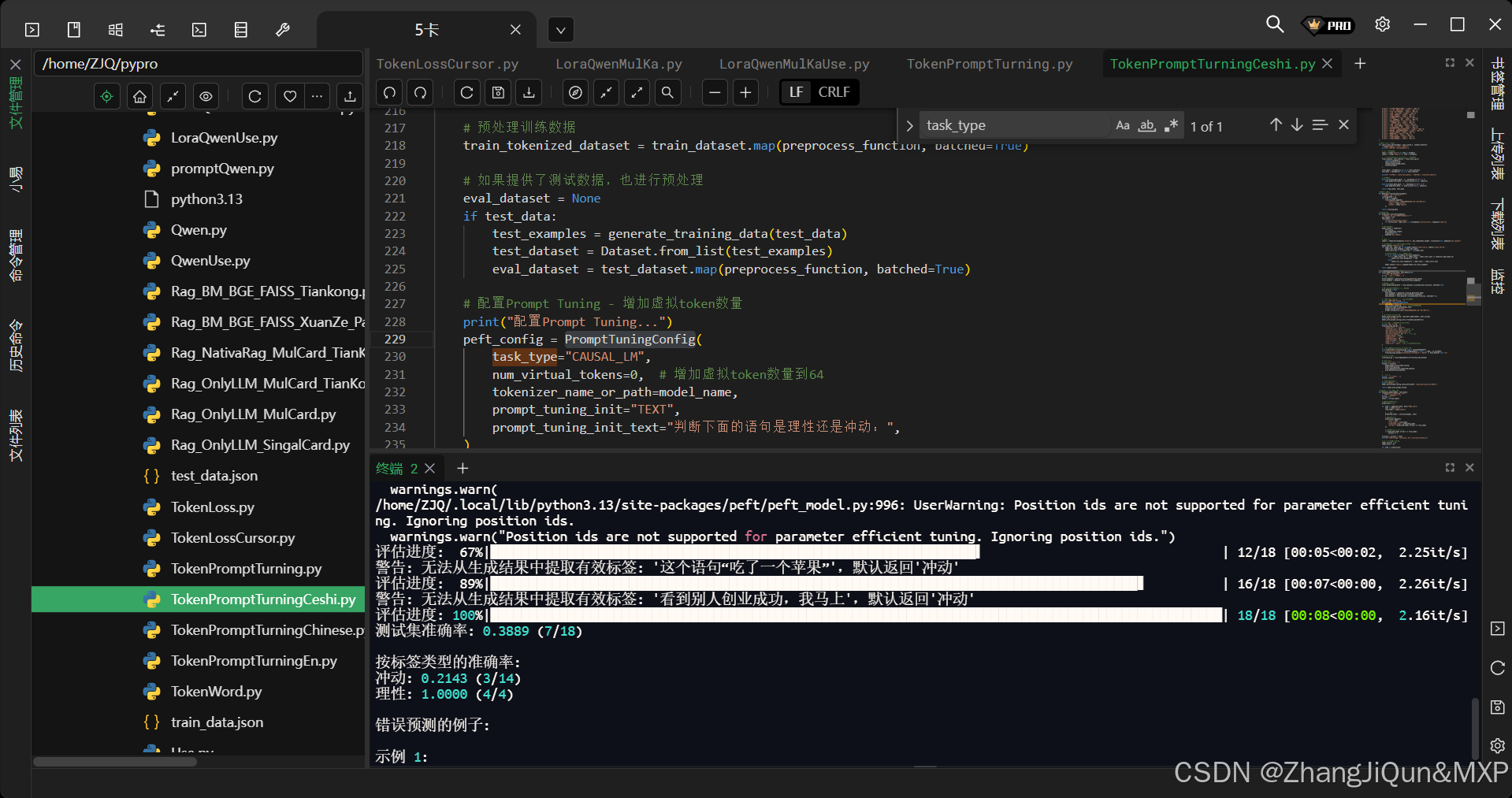
PEFT库PromptTuningConfig 配置
PEFT库 PromptTuningConfig 配置 "Prompt Tuning"的参数高效微调 PromptTuningConfig 核心参数解析 1. task_type="CAUSAL_LM" 作用:指定任务类型为因果语言模型(Causal LM)。说明:因果语言模型从左到右生成文本(如GPT系列),这与任务需求匹配(模…...

操作系统----软考中级软件工程师(自用学习笔记)
目录 1、计算机系统层次结构 2、程序顺序执行的特征 3、程序并发执行的特征 4、三态模型 5、同步与互斥 6、信号量机制 7、PV操作 8、死锁 9、进程资源图 10、死锁避免 11、线程 12、程序局部性原理 13、分页存储管理 14、单缓冲器 15、双缓冲区 16、磁盘调度算…...

SQL 多表关联与分组聚合:解密答题正确率分析
一、问题拆解:从业务需求到SQL逻辑 1.1 需求分析 题目要求:计算浙江大学用户在不同难度题目下的答题正确率,并按正确率升序排序。 关键分析点: 数据来源: user_profile:存储用户信息(大学&a…...
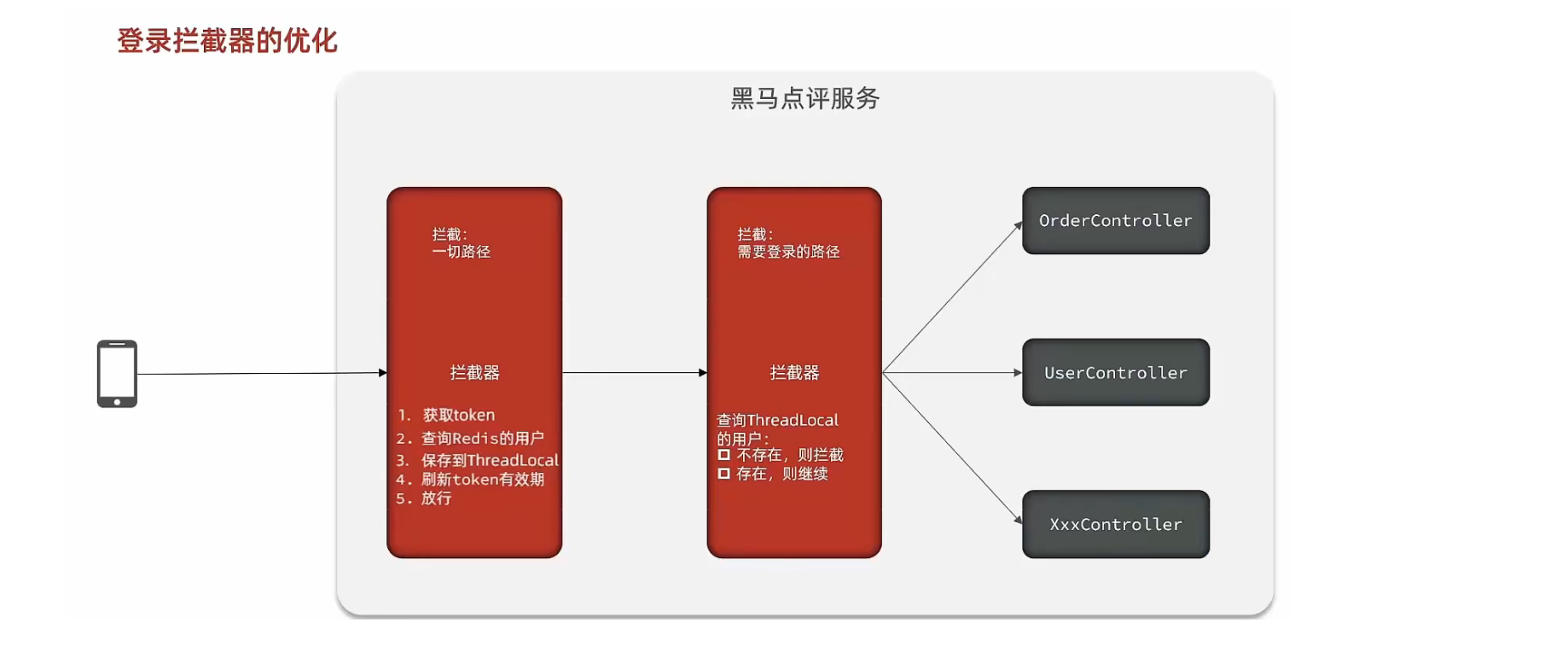
基于 Redis 实现短信验证码登录功能的完整方案
🧱 一、技术栈与依赖配置 使用 Spring Boot Redis 实现短信验证码登录,以下是推荐的 Maven 依赖: <dependencies><!-- Spring Boot Web --><dependency><groupId>org.springframework.boot</groupId><ar…...