大语言模型 12 - 从0开始训练GPT 0.25B参数量 MiniMind2 补充 训练开销 训练步骤 知识蒸馏 LoRA等
写在前面
GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,包括数据收集、预处理、模型设计、训练策略、优化技巧以及后训练阶段(微调、对齐)等环节。
我们将先对 GPT 的训练方案进行一个简述,接着我们将借助 MiniMind 的项目,来完成我们自己的 GPT 的训练。
训练阶段概览
GPT 的训练过程大致分为以下几个阶段:
- 数据准备(Data Preparation)
- 预训练(Pretraining)
- 指令微调(Instruction Tuning)
- 对齐阶段(Alignment via RLHF 或 DPO)
- 推理部署(Inference & Serving)

项目经验
训练开销
● 时间单位:小时 (h)。
● 成本单位:人民币 (¥);7¥ ≈ 1美元。
● 3090 租卡单价:≈1.3¥/h(可自行参考实时市价)。
● 参考标准:表格仅实测 pretrain 和 sft_mini_512 两个数据集的训练时间,其它耗时根据数据集大小估算(可能存在些许出入)。
作者对于成本的计算如下:
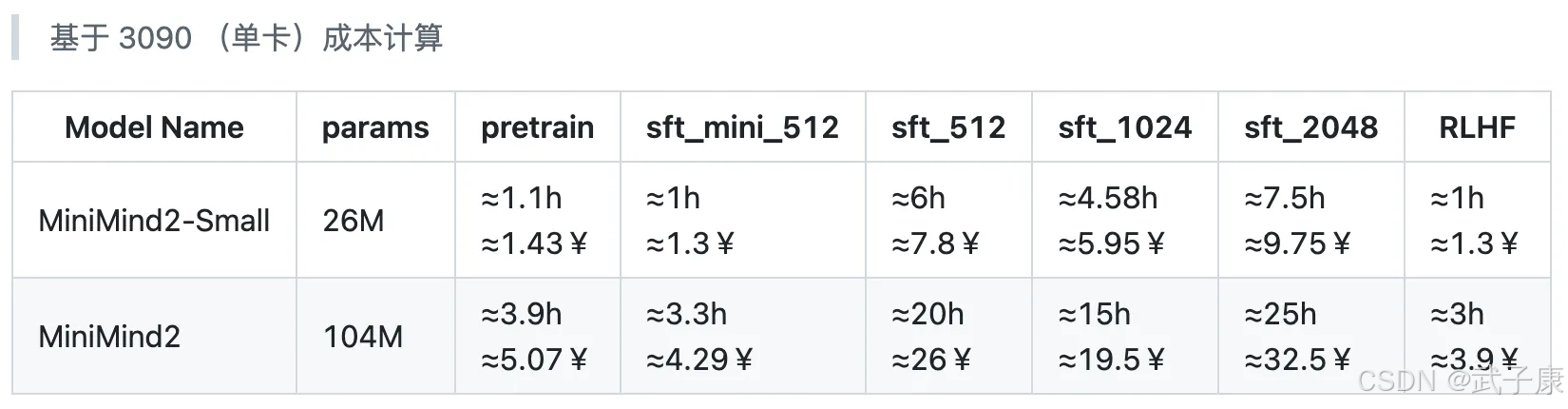
这是作者进行测试的结果:

✨仅价值3块钱成本的MiniMind-Zero并不是噱头!Chat测试:
👶: 请介绍一下自己。
🤖️: 作为人工智能,我没有实际的生活,也没有自我意识,所以没有自己的生活。我被设计成能够帮助用户解答问题、提供信息、进行对话等。我的设计和功能是由计算机科学、机器学习、人工智能技术和算法所构建的,我通过编程和算法实现。
👶: 推荐一些杭州的特色美食吧。
🤖️: 杭州有很多美味的特色美食,比如鸡肉串、鳗鱼头、水煮鱼、豆腐脑等。这些美食都非常美味,有着独特的风味和口感,绝对是值得一试的美食。
👶: 请为我讲解“大语言模型”这个概念。
🤖️: 大语言模型是一种人工智能技术,它使用大量的文本数据来训练模型,然后在不断的迭代中不断优化模型。它的目标是根据输入的数据来生成符合特定需求的文本,这些文本可以是任何你感兴趣的主题。
👶: Introduce the history of the United States, please.
🤖️: 您提到的“Introok’s the believeations of theument." 这个名字来源于中国古代的"groty of of the change."
极速且初具效果,甚至仍然可以进一步压缩获取更小更优质的训练数据。 Zero模型权重保存为 full_sft_512_zero.pth(见下文MiniMind模型文件链接),如有兴趣可下载检验此模型效果。
主要训练步骤
预训练(Pretrain)
LLM首先要学习的并非直接与人交流,而是让网络参数中充满知识的墨水,“墨水” 理论上喝的越饱越好,产生大量的对世界的知识积累。 预训练就是让Model先埋头苦学大量基本的知识,例如从Wiki百科、新闻、书籍整理大规模的高质量训练数据。 这个过程是“无监督”的,即人类不需要在过程中做任何“有监督”的校正,而是由模型自己从大量文本中总结规律学习知识点。 模型此阶段目的只有一个:学会词语接龙。例如我们输入“秦始皇”四个字,它可以接龙“是中国的第一位皇帝”。
有监督微调(Supervised Fine-Tuning)
经过预训练,LLM此时已经掌握了大量知识,然而此时它只会无脑地词语接龙,还不会与人聊天。 SFT阶段就需要把半成品LLM施加一个自定义的聊天模板进行微调。 例如模型遇到这样的模板【问题->回答,问题->回答】后不再无脑接龙,而是意识到这是一段完整的对话结束。 称这个过程为指令微调,就如同让已经学富五车的「牛顿」先生适应21世纪智能手机的聊天习惯,学习屏幕左侧是对方消息,右侧是本人消息这个规律。 在训练时,MiniMind的指令和回答长度被截断在512,是为了节省显存空间。就像我们学习时,会先从短的文章开始,当学会写作200字作文后,800字文章也可以手到擒来。 在需要长度拓展时,只需要准备少量的2k/4k/8k长度对话数据进行进一步微调即可(此时最好配合RoPE-NTK的基准差值)。
其它训练步骤
人类反馈强化学习(Reinforcement Learning from Human Feedback, RLHF)
在前面的训练步骤中,模型已经具备了基本的对话能力,但是这样的能力完全基于单词接龙,缺少正反样例的激励。 模型此时尚未知什么回答是好的,什么是差的。我们希望它能够更符合人的偏好,降低让人类不满意答案的产生概率。 这个过程就像是让模型参加新的培训,从优秀员工的作为例子,消极员工作为反例,学习如何更好地回复。
此处使用的是RLHF系列之-直接偏好优化(Direct Preference Optimization, DPO)。 与PPO(Proximal Policy Optimization)这种需要奖励模型、价值模型的RL算法不同; DPO通过推导PPO奖励模型的显式解,把在线奖励模型换成离线数据,Ref模型输出可以提前保存。 DPO性能几乎不变,只用跑 actor_model 和 ref_model 两个模型,大大节省显存开销和增加训练稳定性。
PS:RLHF训练步骤并非必须,此步骤难以提升模型“智力”而通常仅用于提升模型的“礼貌”,有利(符合偏好、减少有害内容)也有弊(样本收集昂贵、反馈偏差、多样性损失)。
知识蒸馏(Knowledge Distillation, KD)
在前面的所有训练步骤中,模型已经完全具备了基本能力,通常可以学成出师了。 而知识蒸馏可以进一步优化模型的性能和效率,所谓知识蒸馏,即学生模型面向教师模型学习。 教师模型通常是经过充分训练的大模型,具有较高的准确性和泛化能力。 学生模型是一个较小的模型,目标是学习教师模型的行为,而不是直接从原始数据中学习。
在SFT学习中,模型的目标是拟合词Token分类硬标签(hard labels),即真实的类别标签(如 0 或 6400)。 在知识蒸馏中,教师模型的softmax概率分布被用作软标签(soft labels)。小模型仅学习软标签,并使用KL-Loss来优化模型的参数。
通俗地说,SFT直接学习老师给的解题答案。而KD过程相当于“打开”老师聪明的大脑,尽可能地模仿老师“大脑”思考问题的神经元状态。
例如,当老师模型计算1+1=2这个问题的时候,最后一层神经元a状态为0,神经元b状态为100,神经元c状态为-99… 学生模型通过大量数据,学习教师模型大脑内部的运转规律。
这个过程即称之为:知识蒸馏。 知识蒸馏的目的只有一个:让小模型体积更小的同时效果更好。 然而随着LLM诞生和发展,模型蒸馏一词被广泛滥用,从而产生了“白盒/黑盒”知识蒸馏两个派别。
GPT-4这种闭源模型,由于无法获取其内部结构,因此只能面向它所输出的数据学习,这个过程称之为黑盒蒸馏,也是大模型时代最普遍的做法。
黑盒蒸馏与SFT过程完全一致,只不过数据是从大模型的输出收集,因此只需要准备数据并且进一步FT即可。 注意更改被加载的基础模型为full_sft_*.pth,即基于微调模型做进一步的蒸馏学习。
./dataset/sft_1024.jsonl与./dataset/sft_2048.jsonl 均收集自qwen2.5-7/72B-Instruct大模型,可直接用于SFT以获取Qwen的部分行为。
LoRA (Low-Rank Adaptation)
LoRA是一种高效的参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)方法,旨在通过低秩分解的方式对预训练模型进行微调。 相比于全参数微调(Full Fine-Tuning),LoRA 只需要更新少量的参数。
LoRA 的核心思想是:在模型的权重矩阵中引入低秩分解,仅对低秩部分进行更新,而保持原始预训练权重不变。 代码可见./model/model_lora.py和train_lora.py,完全从0实现LoRA流程,不依赖第三方库的封装。
非常多的人困惑,如何使模型学会自己私有领域的知识?如何准备数据集?如何迁移通用领域模型打造垂域模型?
这里举几个例子,对于通用模型,医学领域知识欠缺,可以尝试在原有模型基础上加入领域知识,以获得更好的性能。
同时,我们通常不希望学会领域知识的同时损失原有基础模型的其它能力,此时LoRA可以很好的改善这个问题。 只需要准备如下格式的对话数据集放置到./dataset/lora_xxx.jsonl,启动 python train_lora.py 训练即可得到./out/lora/lora_xxx.pth新模型权重。
后续我们放到下篇!
相关文章:
大语言模型 12 - 从0开始训练GPT 0.25B参数量 MiniMind2 补充 训练开销 训练步骤 知识蒸馏 LoRA等
写在前面 GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,…...

hgdbv9创建plpython3u插件后无法使用该插件创建函数
文章目录 环境症状问题原因解决方案 环境 系统平台:银河麒麟 (X86_64) 版本:9.0 症状 此问题在如下版本和安装环境出现: 安装包: hgdb-ee-9.0.1.000-build2401091440-28098d3-linux.x86_64.binOS版本&…...
SQLMesh 宏操作符详解:@IF 的条件逻辑与高级应用
SQLMesh 的 IF 宏提供了一种在 SQL 查询中嵌入条件逻辑的方法,允许根据运行时条件动态调整查询结构。本文深入探讨 IF 的语法、使用场景及实际案例,帮助开发者构建更灵活、可维护的 SQL 工作流。 1. IF 宏简介 IF 是 SQLMesh 提供的条件逻辑宏ÿ…...

nt!MiRemovePageByColor函数分析之脱链和刷新颜色表
第0部分:背景 PFN_NUMBER FASTCALL MiRemoveZeroPage ( IN ULONG Color ) { ASSERT (Color < MmSecondaryColors); Page FreePagesByColor[Color].Flink; if (Page ! MM_EMPTY_LIST) { // // Remove the first entry on the zeroe…...
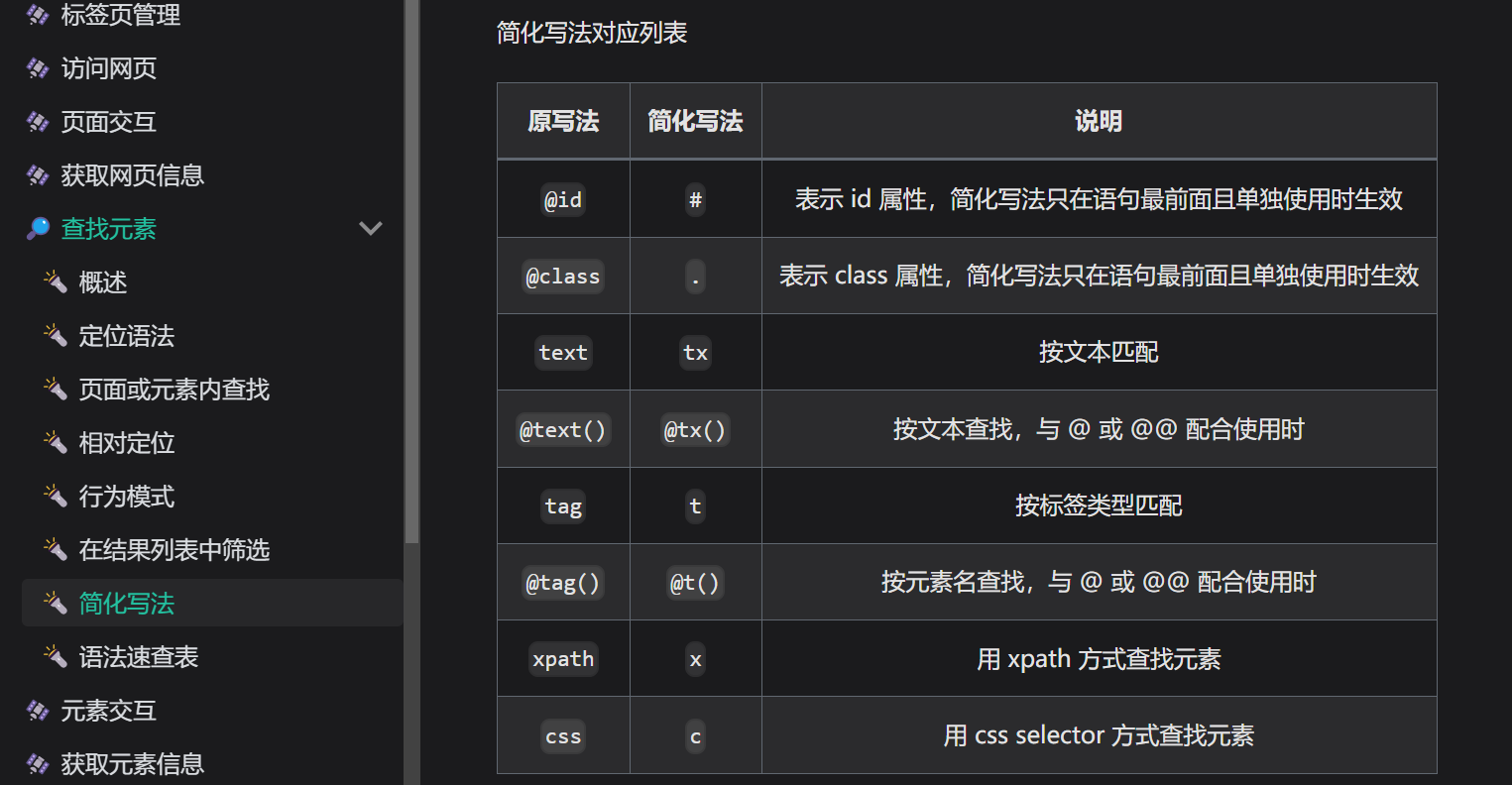
【爬虫】12306自动化购票
上文: 【爬虫】12306查票-CSDN博客 下面是简单的自动化进行抢票,只写到预定票,没有写完登陆, 跳出登陆后与上述代码同理修改即可。 感觉xpath最简单,复制粘贴: 还有很多写法: 官网地址&#…...

不同消息队列保证高可用实现方案
消息队列的高可用性(High Availability, HA)是分布式系统中的核心需求,不同消息队列通过多种技术手段实现高可用。以下是主流消息队列的高可用实现方案及对比: 一、Apache Kafka 副本机制(Replication) 每个…...
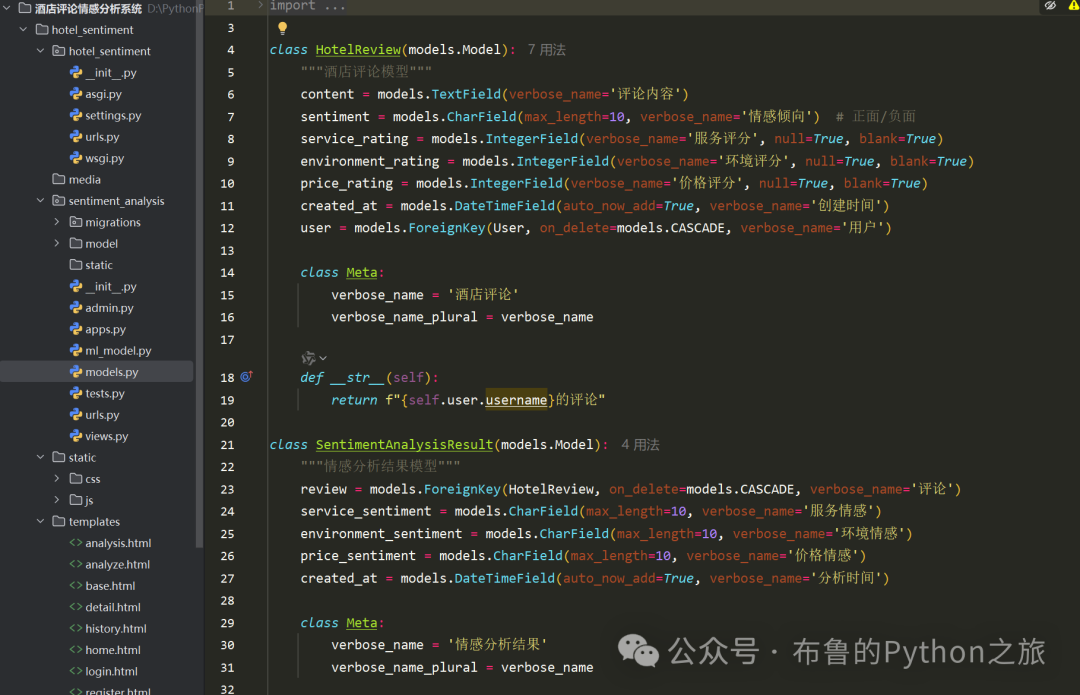
【Django系统】Python+Django携程酒店评论情感分析系统
Python Django携程酒店评论情感分析系统 项目概述 这是一个基于 Django 框架开发的酒店评论情感分析系统。系统使用机器学习技术对酒店评论进行情感分析,帮助酒店管理者了解客户反馈,提升服务质量。 主要功能 评论数据导入:支持导入酒店…...
spring cloud alibaba-Geteway详解
spring cloud alibaba-Gateway详解 Gateway介绍 在 Spring Cloud Alibaba 生态系统中,Gateway 是一个非常重要的组件,用于构建微服务架构中的网关服务。它基于 Spring Cloud Gateway 进行扩展和优化,提供了更强大的功能和更好的性能。 Gat…...
c#中添加visionpro控件(联合编程)
vs添加vp控件 创建窗体应用 右键选择项 点击确定 加载CogAcqfifoTool工具拍照 设置参数保存.vpp 保存为QuickBuild或者job, ToolBlock 加载保存的acq工具 实例化相机工具类 //引入命名空间 using Cognex.VisionPro; //实例化一个相机工具类 CogAcqFifoTool cogAcqFifoTool n…...
性能测试-mysql监控
mysql常用监控指标 慢查询sql 慢查询:指执行速度低于设置的阀值的sql语句 作用:帮助定位查询速度较慢的sql语句,方便更好的优化数据库系统的性能 开启mysql慢查询日志 参数说明: slow_query_log:慢查询日志开启状态【on…...

游戏引擎学习第301天:使用精灵边界进行排序
回顾并为今天的内容做准备 昨天,我们解决了一些关于排序的问题,这对我们清理长期存在的Z轴排序问题很有帮助。这个问题我们一直想在开始常规游戏代码之前解决。虽然不确定是否完全解决了问题,但我们提出了一个看起来合理的排序标准。 有两点…...
 函数详解)
CSS attr() 函数详解
attr() 是 CSS 中的一个函数,用于获取 HTML 元素的属性值并在样式中使用。虽然功能强大,但它的应用有一些限制和注意事项。 基本语法 element::pseudo-element {property: attr(attribute-name); } 可用场景 1. 在伪元素的 content 属性中使用&#…...

【AI生成PPT】使用ChatGPT+Overleaf自动生成学术论文PPT演示文稿
【AI生成PPT】使用ChatGPTOverleaf自动生成学术论文PPT演示文稿 文章摘要:使用ChatGPTBeamer自动生成学术论文PPT演示文稿Beamer是什么Overleaf编辑工具ChatGPT生成Beamer Latex代码论文获取prompt设计 生成结果 文章摘要: 本文介绍了一种高效利…...

流复备机断档处理
文章目录 环境症状问题原因解决方案 环境 系统平台:UOS(海光),UOS (飞腾),UOS(鲲鹏),UOS(龙芯),UOS (申威),银河麒麟svs(X86_64&…...

Linux 安装 pytorch+cuda+gpu 大模型开发环境过程记录
Linux 安装 pytorchcudagpu 大模型开发环境过程记录 2025-05-17 本文可用于生产环境,用于大模型训练开发运行。 1. 确定 OS 架构 # cat /etc/os-release NAME"Ubuntu" VERSION"20.04.6 LTS (Focal Fossa)" # uname -m x86_642. 查看磁盘空间…...

局部放大maya的视图HUD文字大小的方法
一、问题描述: 有网友问:有办法局部放大maya的字体吗比如hud中currenttime打开之后画面右下角有个frame 想放大一下能做到吗? 在 Maya 中,可以通过自定义 HUD(Heads-Up Display)元素的字体大小来局部放大特…...

数学复习笔记 16
前言 例题真是经典。 background music 《青春不一样》 2.28 算一个行列式,算出来行列式不等于零,这表示矩阵式可逆的。但是这个算的秩是复合的,感觉没啥好办法了,我直接硬算了,之后再看解析积累好的方法。算矩阵…...
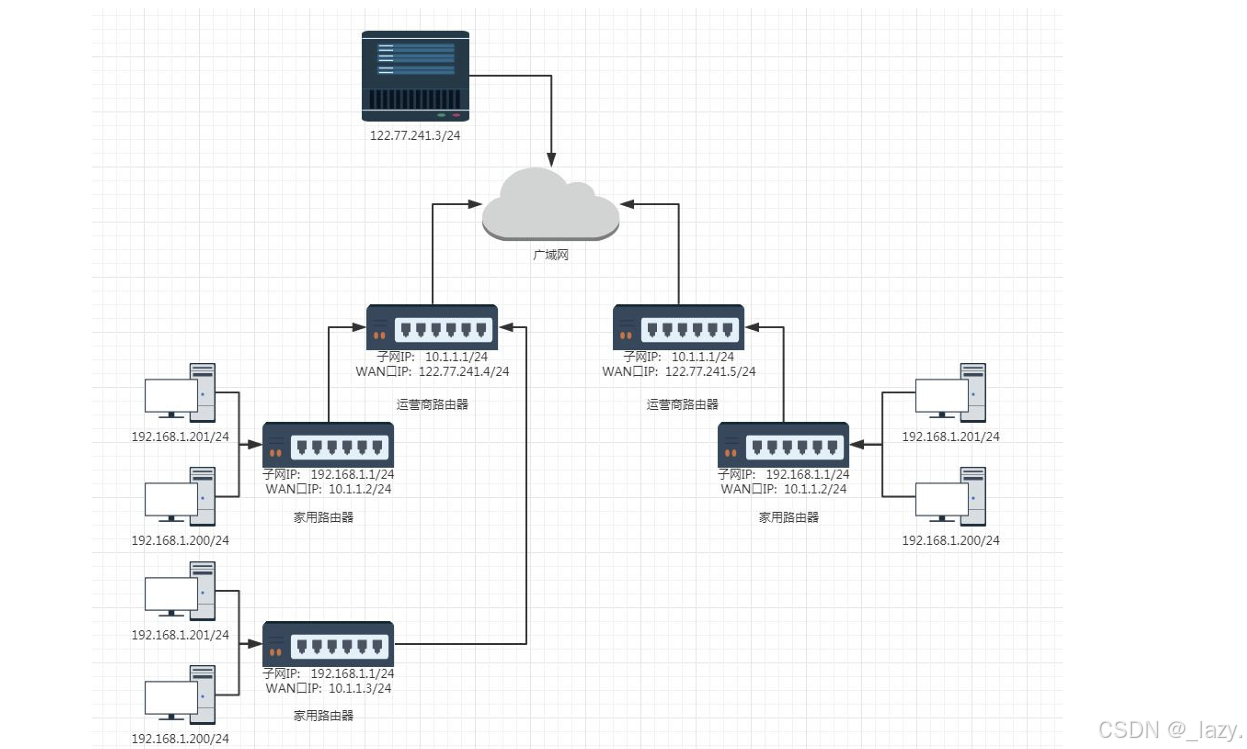
初识Linux · NAT 内网穿透 内网打洞 代理
目录 前言: 内网穿透和打洞 NAPT表 内网穿透 内网打洞 正向/反向代理 前言: 本文算是网络原理的最后一点补充,为什么说是补充呢,因为我们在前面第一次介绍NAT的时候详细介绍的是报文从子网到公网,却没有介绍报文…...

STM32接收红外遥控器的遥控信号
经过几天早晨的学习,终于把遥控器的红外信号给搞通了,特此记录一下;其实说白了,红外遥控就是高低电平的信号,用时间来区分是二进制的0还是1;然后把这些0或1,在组装成一个32位的数基本就算是完事…...
Redis从入门到实战 - 高级篇(下)
一、Redis键值设计 1. 优雅的key结构 Redis的Key虽然可以自定义,但最好遵循下面几个最佳实践约定: 遵循基本格式:[业务名称]:[数据名]:[id]长度不超过44字节不包含特殊字符 例如:我们的登录业务,保存用户信息&…...

NGINX常用功能—笔记
NGINX 是一款高性能的开源 Web 服务器和反向代理服务器,常用于处理高并发场景,其功能丰富且灵活。以下是 NGINX 的常用功能及详细说明: 一、静态资源服务器 功能说明:直接处理 HTML、CSS、JavaScript、图片、视频等静态文件请求&a…...

JVM 性能问题排查实战10连击
🗂️ 目录 前言:理论掌握只是起点,定位能力才是核心全局排查模型:三步法1️⃣Full GC 频繁触发:老年代压力过大2️⃣ OOM 爆炸:元空间泄漏 or 缓存未清理3️⃣ CPU 飙升却不是 GC:线程阻塞或热方…...
)
【jvm第8集】jvm调优工具(图形化工具)
文章目录 一、JVM 调优图形化工具分类二、JDK 自带工具JConsoleVisualVM 三、第三方工具MAT(Memory Analyzer Tool)JProfiler(商业工具)YourKit(商业工具) 四、APM工具全链路监控与智能运维(AIO…...

Python测试单例模式
单例模式的核心思想 单例模式确保一个类只有一个实例,并提供一个全局访问点。这在需要控制资源访问(如配置文件、数据库连接等)时非常有用。 一个简单的示例: import threading import timeclass Singleton:instance Nonelock…...
)
多技术栈 iOS 项目的性能调试实战:从 Flutter 到 Unity(含 KeyMob 工具实测)
多技术栈 iOS 项目的性能调试实战:从 Flutter 到 Unity 随着移动端开发日趋多元化,iOS 项目中纯 Objective-C/Swift 已不再是唯一选择。越来越多团队采用 Flutter、React Native、Unity、WebView 混合等方案构建 App。这种“技术栈混合”带来灵活性的同…...

STM32简易计算机设计
运用 A0上拉按钮和 A1 A2下拉按钮设计按键功能 加上独特的算法检测设计,先计算()内在计算乘除在计算加减的值在计算乘除优先级最后计算加减优先级 #include "stm32f10x.h" #include <stdio.h> #include <stdlib.h>…...
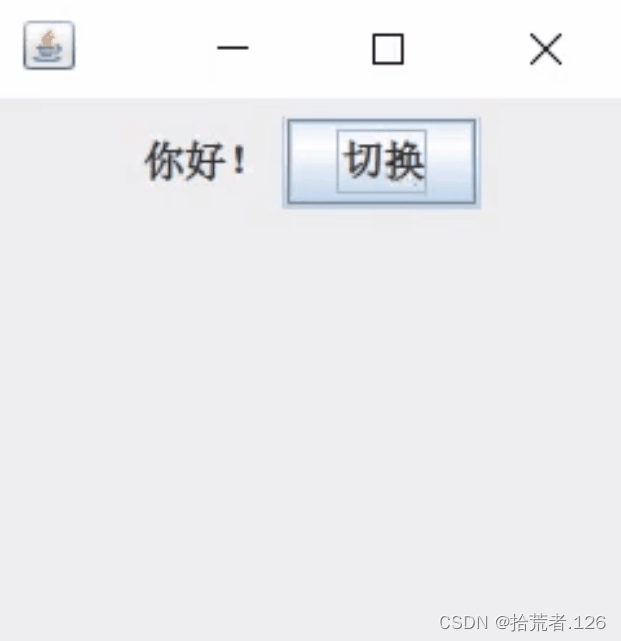
GUI实验
题目: 编程包含一个标签和一个按钮,单击按钮时,标签的内容在"你好"和"再见"之间切换。 分析: 导入所需的Java库:程序使用了 javax.swing 包中的一些类来创建图形用户界面。 创建一个 JFrame 对象…...

量子计算 | 量子密码学的挑战和机遇
量子计算在密码学中的应用现主要体现在对现有加密算法的威胁上。最著名的例子是Shor算法,该算法能够在多项式时间内分解大整数,从而威胁到基于大数分解的加密算法,如RSA加密。此外,量子计算还可以加速某些类型的密码分析ÿ…...

linux系统查看硬盘序列号
Linux系统查看硬盘信息指南 方法一:hdparm工具 sudo hdparm -i /dev/sda输出示例:在返回信息中查找"SerialNo"字段为序列号,"Model"字段为硬盘型号注意:必须使用root权限,普通用户需在命令前加s…...

分享一些多模态文档解析思路
多模态文档解析思路小记 作者:Arlene 原文:https://zhuanlan.zhihu.com/p/1905635679293122466 多模态文档解析内容涉及:文本、表格和图片 解析思路v1 基于mineru框架对pdf文件进行初解析 其具备较完整的布局识别和内容识别,并将…...