Model 速通系列(一)nanoGPT
这个是新开的一个系列用来手把手复现一些模型工程,之所以开这个系列是因为有人留言说看到一个工程不知道从哪里读起,出于对自身能力的提升与兴趣,故新开了这个系列。由于主要动机是顺一遍代码并提供注释。
该系列第一篇博客是 nanoGPT ,这个仓库是前OpenAI大佬 karpathy Andrej 的工程,基本是GPT的mini版,虽然最近一次更新是在2年前,部分组件和理念已经有些过时了,但作为入门工程而言是再适合不过的。
- 项目链接:https://github.com/karpathy/nanoGPT
- 代码分支:master
- commit:93a43d9a5c22450bbf06e78da2cb6eeef084b717
- 代码仓库:https://github.com/GaohaoZhou-ops/Model-Reproduction/tree/main/nanoGPT
写在最前面
- 在没有特殊说明的情况下不会对训练和微调进行实际操作,但会包含相关代码;
- 项目中的文件实现顺序以大标题的1,2,3 … 为依据,按照该顺序即可构建出完成工程;
- 文章会尽可能保留原始工程的目录结构,但对于一些git、assets等文件夹就不进行赘述;
- 文章的主要目的是过一遍代码,特别是模型工程的构建流程,如果你想直接使用工程建议还是去拉取原始仓库;
- 每篇文章都会在我的github仓库中对应一个文件夹,建议在阅读时配合代码仓库一起看;
- 期间中会根据情况删除、添加、翻译一些注释;
Github 仓库:https://github.com/GaohaoZhou-ops/Model-Reproduction
1. 模型构建 model.py
这个工程相对比较简单,在模型构建方面只用到了pytorch的一些基本组件,通过以下命令可以查看原始工程中 model.py 文件的库依赖关系:
【Note】:这一步需要在原始工程文件夹中执行,你也可以不执行只看我的推演过程。
(model) $ pydeps model.py --max-bacon=1
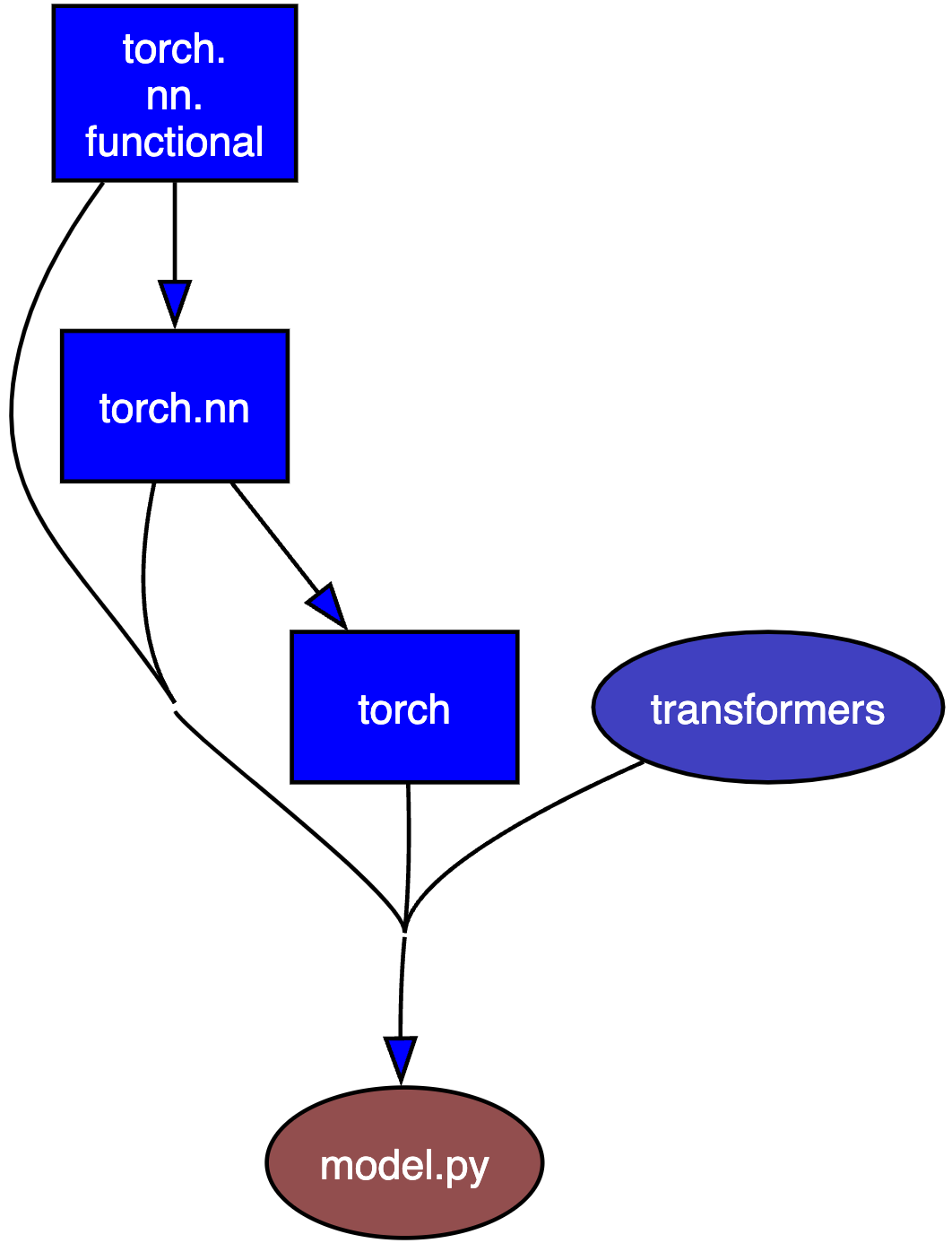
导入必要的包:
import math
import inspect
from dataclasses import dataclassimport torch
import torch.nn as nn
from torch.nn import functional as F
定义归一化层类:
因为torch自带的 layer_norm 对象没有设置 bias 为None 的选项,所以这里需要覆写一下类:
class LayerNorm(nn.Module):def __init__(self, ndim, bias):super().__init__()self.weight = nn.Parameter(torch.ones(ndim))self.bias = nn.Parameter(torch.zeros(ndim)) if bias else Nonedef forward(self, input):return F.layer_norm(input, self.weight.shape, self.weight, self.bias, 1e-5)
定义CausalSelfAttention类:
- 参考文章:https://zhuanlan.zhihu.com/p/663840848
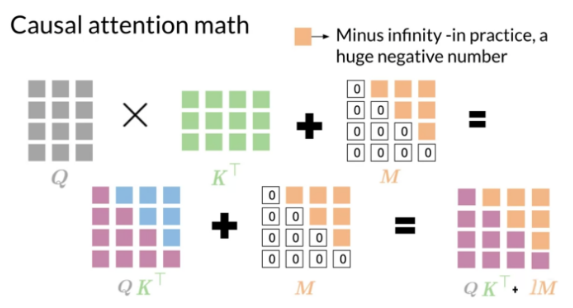
CausalSelfAttention 是一种自注意力机制,主要用于序列到序列的任务中,例如机器翻译、文本摘要等。主要特点如下:
- 仅允许注意力模型 访问当前和之前的输入,不能访问之后的输入,例如在机器翻译任务中,翻译某个词时不能访问该词之后的内容;
- 通过掩盖(masking)未来的输入来实现因果性。具体方法是在计算注意力权重时,对角线以上的权重置零,从而避免模型看到未来的信息;
- 可用于 Transformer 和其变种模型中捕捉序列的时间依赖关系。Transformer 原本是并行计算的,使用
CausalSelfAttention赋予其顺序处理能力; CausalSelfAttention学习到的表示更符合时间顺序,更有利于序列生成任务;- 一般用于编码器端,而解码器端则使用 MaskedSelfAttention,它允许解码器访问编码器输出的所有时刻,以使用整个输入序列的上下文信息;
class CausalSelfAttention(nn.Module):def __init__(self, config) -> None:super().__init__()assert config.n_embd % config.n_head == 0 # 确保嵌入维度(n_embd)能被注意力头数(n_head)整除,每个头将分配到相同大小的子空间self.c_attn = nn.Linear(config.n_embd, 3*config.n_head, bias=config.bias) # 线性变换层,用于生成查询(Q)、键(K)和值(V),将嵌入维度扩展为三倍,以便后续拆分为 Q、K、V。self.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=config.bias) # 将注意力输出重新投影回原始维度self.attn_dropout = nn.Dropout(config.dropout) # 用于注意力矩阵(防止过拟合)self.resid_dropout = nn.Dropout(config.dropout) # 用于残差连接的输出self.n_head = config.n_headself.n_embd = config.n_embdself.dropout = config.dropputself.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention')if not self.flash: # 判断是否支持GPU 加速的Flash Attentionprint("WARNING: using slow attention. Flash Attention requires PyTorch >= 2.0")# 使用下三角矩阵构建因果掩码,确保只关注左侧信息(即历史信息)self.register_buffer("bias", torch.tril(torch.ones(config.block_size, config.block_size)).view(1,1, config.block_size, config.block_size))def forward(self, x):B,T,C = x.size() # batch_size, token_length, embedding_dimq,k,v = self.c_attn(x).split(self.n_embd, dim=2) # 计算 Q、K、Vk = k.view(B, T, self.n_head, C // self.n_head).transpose(1,2) # shape=(B,nh,T,hs)q = q.view(B, T, self.n_head, C // self.n_head).transpose(1,2) # shape=(B,nh,T,hs)v = v.view(B, T, self.n_head, C // self.n_head).transpose(1,2) # shape=(B,nh,T,hs)if self.flash: # 如果支持GPU加速,则使用flash attentiony = torch.nn.functional.scaled_dot_product_attention(q,k,v, attn_mask=None, dropout_p=self.dropout if self.training else 0, is_causal=True)else: # 否则手动计算att = (q @ k.transpose(-2,-1)) * (1.0 / math.sqrt(k.size(-1)))att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf')) att = F.softmax(att, dim=-1)att = self.attn_dropout(att)y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)y = y.transpose(1,2).contiguous().view(B,T,C) # 还原为原始形状,便于后续处理y = self.resid_dropout(self.c_proj(y))return y
定义 MLP 类
该类用于线性映射,总体结构非常简单
class MLP(nn.Module):def __init__(self, config) -> None:super().__init__()self.c_fc = nn.Linear(config.n_embd, 4*config.n_embd, bias=config.bias)self.gelu = nn.GELU()self.c_proj = nn.Linear(4*config.n_embd, config.n_embd, bias=config.bias)self.dropout = nn.Dropout(config.dropout)def forward(self, x):x = self.c_fc(x)x = self.gelu(x)x = self.c_proj(x)x = self.dropout(x)return x
定义单个计算单元 Block
class Block(nn.Module):def __init__(self, config) -> None:super().__init__()self.ln_1 = LayerNorm(config.n_embd, bias=config.bias)self.attn = CausalSelfAttention(config)self.ln_2 = LayerNorm(config.n_embd, bias=config.bias)self.mlp = MLP(config)def forward(self, x):x = x + self.attn(self.ln_1(x))x = x + self.mlp(self.ln_2(x))return x
定义GPT类需要的配置对象
@dataclass
class GPTConfig:block_size: int=1024vocab_size: int=50304n_layer: int=12n_head: int=12n_embd: int=768dropout: float=0.0bias: bool=True
定义完整GPT模型
在模型中使用了 AdamW 优化器,相对与Adam的改动其实十分简单,其将权重衰减项从梯度的计算中拿出来直接加在了最后的权重更新步骤上。其提出的动机在于:原先Adam的实现中如果采用了L2权重衰减,则相应的权重衰减项会被直接加在loss里,从而导致动量的一阶与二阶滑动平均均考虑了该权重衰减项,而这影响了Adam的优化效果,而将权重衰减与梯度的计算进行解耦能够显著提升Adam的效果。
目前,AdamW现在已经成为transformer训练中的默认优化器。
- 参考链接:https://www.zhihu.com/question/536185388/answer/83259341287
class GPT(nn.Module):def __init__(self, config:GPTConfig) -> None:super().__init__()assert config.vocab_size is not None # 检查配置中 词汇表大小(vocab_size)和块大小(block_size)是否有效。assert config.block_size is not Noneself.config = configself.transformer = nn.ModuleDict(dict( # Transformer结构wte=nn.Embedding(config.vocab_size, config.n_embd), # 词嵌入(wte):将词索引映射为向量表示,shape=(vocab_size, n_embd)wpe=nn.Embedding(config.block_size, config.n_embd), # 位置嵌入(wpe):将位置索引映射为向量,shape=(block_size, n_embd)drop=nn.Dropout(config.dropout),h=nn.ModuleList([Block(config) for _ in range(config.n_layer)]), # 多个并列的注意力块,每个块由自定义 Block(config) 生成ln_f = LayerNorm(config.n_embd, bias=config.bias), # 最终输出的层归一化))self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False) # 语言模型头:将最后的特征映射回词汇表空间,用于词预测self.transformer.wte.weight = self.lm_head.weight # 权重绑定:词嵌入层和输出投影层共享权重,减少参数量,提高性能self.apply(self._init_weights) # 权重初始化for pn, p in self.named_parameters(): # 对残差连接权重(c_proj)进行特殊初始化,符合 GPT-2 论文规范if pn.endswith('c_proj.weight'):torch.nn.init.normal_(p, mean=0.0, std=0.02/math.sqrt(2*config.n_layer))print("number of parameters: %.2fM" % (self.get_num_params()/1e6,))# 获得参数总量def get_num_params(self, non_embedding=True):n_params = sum(p.numel() for p in self.parameters())if non_embedding:n_params -= self.transformer.wpe.weight.numel()return n_params# 初始化整体权重def _init_weights(self, module):if isinstance(module, nn.Linear):torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)if module.bias is not None:torch.nn.init.zeros_(module.bias)elif isinstance(module, nn.Embedding):torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)def forward(self, idx, targets=None):device = idx.deviceb,t = idx.size()assert t <= self.config.block_size, f"Cannot forward sequence of length {t}, block size is only {self.config.block_size}" # 确保输入序列长度不超过配置的块大小pos = torch.arange(0, t, dtype=torch.long, device=device) # 位置编码,shape=(t)# 嵌入层前向计算:词嵌入 & 位置嵌入tok_emb = self.transformer.wte(idx) # shape=(b, t, n_embd)pos_emb = self.transformer.wpe(pos) # shape=(t, n_embd)x = self.transformer.drop(tok_emb+pos_emb)# 逐层通过多层注意力块(Block),最后进行层归一化for block in self.transformer.h:x = block(x)x = self.transformer.ln_f(x)if targets is not None: # 训练阶段logits = self.lm_head(x) # 计算预测分布(logits):使用语言模型头得到词概率分布loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1) # 交叉熵损失:比较预测值和目标值,忽略填充索引 -1else: # 推理阶段logits = self.lm_head(x[:, [-1], :]) # 仅计算最后一个时间步的预测,减少推理时的计算量loss = Nonereturn logits, lossdef crop_block_size(self, block_size):assert block_size <= self.config.block_sizeself.config.block_size = block_sizeself.transformer.wpe.weight = nn.Parameter(self.transformer.wpe.weight[:block_size])for block in self.transformer.h:if hasattr(block.attn, 'bias'):block.attn.bias = block.attn.bias[:, :, :block_size, :block_size]@classmethoddef from_pretrained(cls, model_type, override_args=None):assert model_type in {'gpt2', 'gpt2-medium', 'gpt2-large', 'gpt2-xl'}override_args = override_args or {}assert all(k=='dropout' for k in override_args)from transformers import GPT2LMHeadModelprint("loading weights from pretrained gpt: %s" % model_type)# 模型配置参数config_args = {'gpt2': dict(n_layer=12, n_head=12, n_embd=768), # 124M params'gpt2-medium': dict(n_layer=24, n_head=16, n_embd=1024), # 350M params'gpt2-large': dict(n_layer=36, n_head=20, n_embd=1280), # 774M params'gpt2-xl': dict(n_layer=48, n_head=25, n_embd=1600), # 1558M params}[model_type]print("forcing vocab_size=50257, block_size=1024, bias=True")config_args['vocab_size'] = 50257config_args['block_size'] = 1024config_args['bias'] = True# 如果 dropout 在参数列表中则对齐进行覆写if 'dropout' in override_args: print(f"overriding dropout rate to {override_args['dropout']}")config_args['dropout'] = override_args['dropout']config = GPTConfig(**config_args)model = GPT(config)sd = model.state_dict()sd_keys = sd.keys()sd_keys = [k for k in sd_keys if not k.endswith('.attn.bias')]# 加载预训练权重model_hf = GPT2LMHeadModel.from_pretrained(model_type)sd_hf = model_hf.state_dict()# 因为这里是nanoGPT,所以只需要从完整GPT模型中拷贝一部分权重即可sd_keys_hf = sd_hf.keys()sd_keys_hf = [k for k in sd_keys_hf if not k.endswith('.attn.masked_bias')]sd_keys_hf = [k for k in sd_keys_hf if not k.endswith('.attn.bias')]transposed = ['attn.c_attn.weight', 'attn.c_proj.weight', 'mlp.c_fc.weight', 'mlp.c_proj.weight']assert len(sd_keys_hf) == len(sd_keys), f"mismatched keys: {len(sd_keys_hf)} != {len(sd_keys)}"for k in sd_keys_hf:if any(k.endswith(w) for w in transposed):assert sd_hf[k].shape[::-1] == sd[k].shapewith torch.no_grad():sd[k].copy_(sd_hf[k].t())else:assert sd_hf[k].shape == sd[k].shapewith torch.no_grad():sd[k].copy_(sd_hf[k])return model # 配置 AdamW 优化器def configure_optimizers(self, weight_decay, learning_rate, betas, device_type):param_dict = {pn: p for pn,p in self.named_parameters()}param_dict = {pn: p for pn,p in param_dict.items() if p.requires_grad}decay_params = [p for n,p in param_dict.items() if p.dim() >= 2]nodecay_params = [p for n,p in param_dict.items() if p.dim() < 2]optim_groups = [{'params': decay_params, 'weight_decay': weight_decay},{'params': nodecay_params, 'weight_decay': 0.0}]num_decay_params = sum(p.numel() for p in decay_params)num_nodecay_params = sum(p.numel() for p in nodecay_params)print(f"num decayed parameter tensors: {len(decay_params)}, with {num_decay_params:,} parameters")print(f"num non-decayed parameter tensors: {len(nodecay_params)}, with {num_nodecay_params:,} parameters")fused_available = 'fused' in inspect.signature(torch.optim.AdamW).parametersuse_fused = fused_available and device_type == 'cuda'extra_args = dict(fused=True) if use_fused else dict()optimizer = torch.optim.AdamW(optim_groups, lr=learning_rate, betas=betas, **extra_args)print(f"using fused AdamW: {use_fused}")return optimizer# 估算模型的GPU利用率def estimate_mfu(self, fwdbwd_per_iter, dt):N = self.get_num_params()cfg = self.configL,H,Q,T = cfg.n_layer, cfg.n_head, cfg.n_embd//cfg.n_head, cfg.block_sizeflops_per_token = 6*N + 12*L*H*Q*Tflops_per_fwdbwd = flops_per_token * Tflops_per_iter = flops_per_fwdbwd * fwdbwd_per_iterflops_achieved = flops_per_iter * (1.0/dt)flops_promised = 312e12mfu = flops_achieved / flops_promisedreturn mfu@torch.no_grad()def generate(self, idx, max_new_tokens, temperature=0.1, top_k=None):for _ in range(max_new_tokens):idx_cond = idx if idx.size(1) <= self.config.block_size else idx [:, -self.config.block_size:]logits, _ = self(idx_cond)logits = logits[:, -1, :] / temperatureif top_k is not None:v, _ = torch.topk(logits, min(top_k, logits.size(-1)))logits[logits < v[:, [-1]]] = -float('Inf')probs = F.softmax(logits, dim=-1)idx_next = torch.multinomial(probs, num_samples=1)idx = torch.cat((idx, idx_next), dim=1)return idx
2. 训练用的快捷配置导入 configuration.py
因为在模型训练时需要导入很多公共配置信息,这里额外给了一个文件用来从 config 文件夹中加载模型配置,这部分就是python简单的文件与sys读取。
具体用法如下:
(model) $ python train.py config/override_file.py --batch_size=32
config 文件夹结构如下:
(model) $ tree -L 2
├── config
│ ├── eval_gpt2.py
│ ├── eval_gpt2_large.py
│ ├── eval_gpt2_medium.py
│ ├── eval_gpt2_xl.py
│ ├── finetune_shakespeare.py
│ ├── train_gpt2.py
│ └── train_shakespeare_char.py
代码如下:
import sys
from ast import literal_evalfor arg in sys.argv[1:]:if '=' not in arg:assert not arg.startswith('--')config_file = argprint(f"Overriding config with {config_file}:")with open(config_file) as f:print(f.read())exec(open(config_file).read())else:assert arg.startswith('--')key, val = arg.split('=')key = key[2:]if key in globals():try:attempt = literal_eval(val)except (SyntaxError, ValueError):attempt = valassert type(attempt) == type(globals()[key])print(f"Overriding: {key} = {attempt}")globals()[key] = attemptelse:raise ValueError(f"Unknown config key: {key}")
3. 训练模型 train.py
定义好模型后通常是进行训练,这里的训练是基于huggingface上的预训练权重进行的。
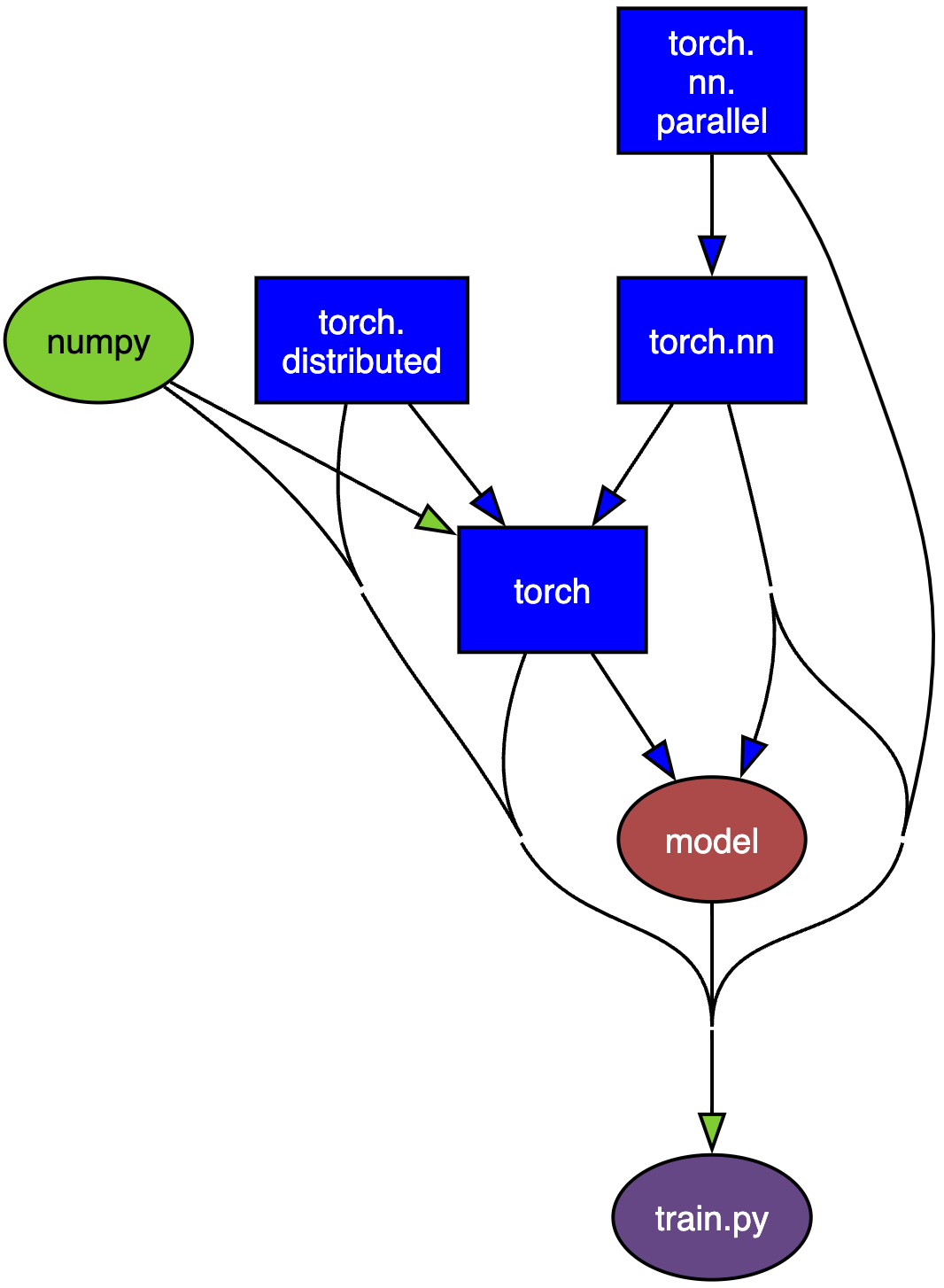
导入必要的包
import os, time, math, pickle
from contextlib import nullcontextimport numpy as np
import torch
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_groupfrom model import GPTConfig, GPT
配置模型超参数
# I/O 相关
out_dir = 'out'
eval_interval = 2000
log_interval = 1
eval_iters = 200
eval_only = False
always_save_checkpoint = True
init_from = 'scratch' # 'scratch' or 'resume' or 'gpt2*'# wandb logging 日志
wandb_log = False
wandb_project = 'owt'
wandb_run_name = 'gpt2'# data
dataset = 'openwebtext'
gradient_accumulation_steps = 5 * 8
batch_size = 12
block_size = 1024# model
n_layer = 12
n_head = 12
n_embd = 768
dropout = 0.0
bias = False# adamw optimizer
learning_rate = 6e-4
max_iters = 600000
weight_decay = 1e-1
beta1 = 0.9
beta2 = 0.95
grad_clip = 1.0# learning rate 衰减
decay_lr = True
warmup_iters = 2000
lr_decay_iters = 600000
min_lr = 6e-5# DDP settings
backend = 'nccl' # 'nccl', 'gloo', etc.# system
device = 'cuda' # 'cpu', 'cuda', 'cuda:0', 'cuda:1', 'mps'
dtype = 'bfloat16' if torch.cuda.is_available() and torch.cuda.is_bf16_supported() else 'float16' # 'float32', 'bfloat16', 'float16'
compile = True # 使用 PyTorch 2.0 编译得到更快的模型config_keys = [k for k,v in globals().items() if not k.startswith('_') and isinstance(v, (int, float, bool, str))]
exec(open('configurator.py').read())
config = {k: globals()[k] for k in config_keys}
配置多GPU并行计算
ddp = int(os.environ.get('RANK', -1)) != -1
if ddp:init_process_group(backend=backend)ddp_rank = int(os.environ['RANK'])ddp_local_rank = int(os.environ['LOCAL_RANK'])ddp_world_size = int(os.environ['WORLD_SIZE'])device = f'cuda:{ddp_local_rank}'torch.cuda.set_device(device)master_process = ddp_rank == 0seed_offset = ddp_rankassert gradient_accumulation_steps % ddp_world_size == 0gradient_accumulation_steps //= ddp_world_size
else:master_process = Trueseed_offset = 0ddp_world_size = 1
tokens_per_iter = gradient_accumulation_steps * ddp_world_size * batch_size * block_size
print(f"tokens per iteration will be: {tokens_per_iter:,}")
初始化torch的一些训练用配置
if master_process:os.makedirs(out_dir, exist_ok=True)
torch.manual_seed(1337 + seed_offset)
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
device_type = 'cuda' if 'cuda' in device else 'cpu'
ptdtype = {'float32': torch.float32, 'bfloat16': torch.bfloat16, 'float16': torch.float16}[dtype]
ctx = nullcontext() if device_type == 'cpu' else torch.amp.autocast(device_type=device_type, dtype=ptdtype)data_dir = os.path.join('data', dataset)
def get_batch(split):if split == 'train':data = np.memmap(os.path.join(data_dir, 'train.bin'), dtype=np.uint16, mode='r')else:data = np.memmap(os.path.join(data_dir, 'val.bin'), dtype=np.uint16, mode='r')ix = torch.randint(len(data) - block_size, (batch_size,))x = torch.stack([torch.from_numpy((data[i:i+block_size]).astype(np.int64)) for i in ix])y = torch.stack([torch.from_numpy((data[i+1:i+1+block_size]).astype(np.int64)) for i in ix])if device_type == 'cuda':x, y = x.pin_memory().to(device, non_blocking=True), y.pin_memory().to(device, non_blocking=True)else:x, y = x.to(device), y.to(device)return x, yiter_num = 0
best_val_loss = 1e9meta_path = os.path.join(data_dir, 'meta.pkl')
meta_vocab_size = None
if os.path.exists(meta_path):with open(meta_path, 'rb') as f:meta = pickle.load(f)meta_vocab_size = meta['vocab_size']print(f"found vocab_size = {meta_vocab_size} (inside {meta_path})")
初始化模型
model_args = dict(n_layer=n_layer, n_head=n_head, n_embd=n_embd, block_size=block_size,bias=bias, vocab_size=None, dropout=dropout)# 根据配置信息初始化模型
if init_from == 'scratch':print("Initializing a new model from scratch")if meta_vocab_size is None:print("defaulting to vocab_size of GPT-2 to 50304 (50257 rounded up for efficiency)")model_args['vocab_size'] = meta_vocab_size if meta_vocab_size is not None else 50304gptconf = GPTConfig(**model_args)model = GPT(gptconf)
elif init_from == 'resume':print(f"Resuming training from {out_dir}")ckpt_path = os.path.join(out_dir, 'ckpt.pt')checkpoint = torch.load(ckpt_path, map_location=device)checkpoint_model_args = checkpoint['model_args']for k in ['n_layer', 'n_head', 'n_embd', 'block_size', 'bias', 'vocab_size']:model_args[k] = checkpoint_model_args[k]gptconf = GPTConfig(**model_args)model = GPT(gptconf)state_dict = checkpoint['model']unwanted_prefix = '_orig_mod.'for k,v in list(state_dict.items()):if k.startswith(unwanted_prefix):state_dict[k[len(unwanted_prefix):]] = state_dict.pop(k)model.load_state_dict(state_dict)iter_num = checkpoint['iter_num']best_val_loss = checkpoint['best_val_loss']
elif init_from.startswith('gpt2'):print(f"Initializing from OpenAI GPT-2 weights: {init_from}")override_args = dict(dropout=dropout)model = GPT.from_pretrained(init_from, override_args)for k in ['n_layer', 'n_head', 'n_embd', 'block_size', 'bias', 'vocab_size']:model_args[k] = getattr(model.config, k)if block_size < model.config.block_size:model.crop_block_size(block_size)model_args['block_size'] = block_size
model.to(device)# 初始化 GradScaler
scaler = torch.cuda.amp.GradScaler(enabled=(dtype == 'float16'))
配置优化器
optimizer = model.configure_optimizers(weight_decay, learning_rate, (beta1, beta2), device_type)
if init_from == 'resume':optimizer.load_state_dict(checkpoint['optimizer'])
checkpoint = None
Pytorch 2.0 编译模型(可选)
if compile:print("compiling the model... (takes a ~minute)")unoptimized_model = modelmodel = torch.compile(model)# 配置分布式训练
if ddp:model = DDP(model, device_ids=[ddp_local_rank])
定义评估损失函数
@torch.no_grad()
def estimate_loss():out = {}model.eval()for split in ['train', 'val']:losses = torch.zeros(eval_iters)for k in range(eval_iters):X,Y = get_batch(split)with ctx:logits, loss = model(X,Y)losses[k] = loss.item()out[split] = losses.mean()model.train()return out
定义学习率衰减计划
def get_lr(it):if it < warmup_iters:return learning_rate * (it + 1) / (warmup_iters + 1)if it > warmup_iters:return min_lrdecay_ratio = (it - warmup_iters) / (lr_decay_iters - warmup_iters)assert 0 <= decay_ratio <= 1coeff = 0.5 * (1.0 + math.cos(math.pi * decay_ratio))return min_lr + coeff * (learning_rate - min_lr)
初始化日志
if wandb_log and master_process:import wandbwandb.init(project=wandb_project, name=wandb_run_name, config=config)
启动训练
X, Y = get_batch('train')
t0 = time.time()
local_iter_num = 0
raw_model = model.module if ddp else model
running_mfu = -1.0while True:lr = get_lr(iter_num) if decay_lr else learning_ratefor param_group in optimizer.param_groups:param_group['lr'] = lr# 根据当前迭代的次数进行日志与evalif iter_num % eval_interval == 0 and master_process:losses = estimate_loss()print(f"step {iter_num}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}")if wandb_log:wandb.log({"iter": iter_num,"train/loss": losses['train'],"val/loss": losses['val'],"lr": lr,"mfu": running_mfu*100, # convert to percentage})if losses['val'] < best_val_loss or always_save_checkpoint:best_val_loss = losses['val']if iter_num > 0:checkpoint = {'model': raw_model.state_dict(),'optimizer': optimizer.state_dict(),'model_args': model_args,'iter_num': iter_num,'best_val_loss': best_val_loss,'config': config,}print(f"saving checkpoint to {out_dir}")torch.save(checkpoint, os.path.join(out_dir, 'ckpt.pt'))if iter_num == 0 and eval_only:break# 前向传播与训练for micro_step in range(gradient_accumulation_steps):if ddp:model.require_backward_grad_sync = (micro_step == gradient_accumulation_steps - 1)with ctx:logits, loss = model(X, Y)loss = loss / gradient_accumulation_stepsX, Y = get_batch('train')# 反向传播更新梯度scaler.scale(loss).backward()# 优化器根据梯度对参数进行更新if grad_clip != 0.0:scaler.unscale_(optimizer)torch.nn.utils.clip_grad_norm_(model.parameters(), grad_clip)scaler.step(optimizer)scaler.update()optimizer.zero_grad(set_to_none=True)# 训练期间的日志与计时t1 = time.time()dt = t1 - t0t0 = t1if iter_num % log_interval == 0 and master_process:lossf = loss.item() * gradient_accumulation_stepsif local_iter_num >= 5: mfu = raw_model.estimate_mfu(batch_size * gradient_accumulation_steps, dt)running_mfu = mfu if running_mfu == -1.0 else 0.9*running_mfu + 0.1*mfuprint(f"iter {iter_num}: loss {lossf:.4f}, time {dt*1000:.2f}ms, mfu {running_mfu*100:.2f}%")iter_num += 1local_iter_num += 1if iter_num > max_iters:break# 终止分布式配置
if ddp:destroy_process_group()
4. 使用示例 sample.py
在定义好模型结构、训练流程后就可以调用使用示例了,这里的使用示例就是一个纯推理。
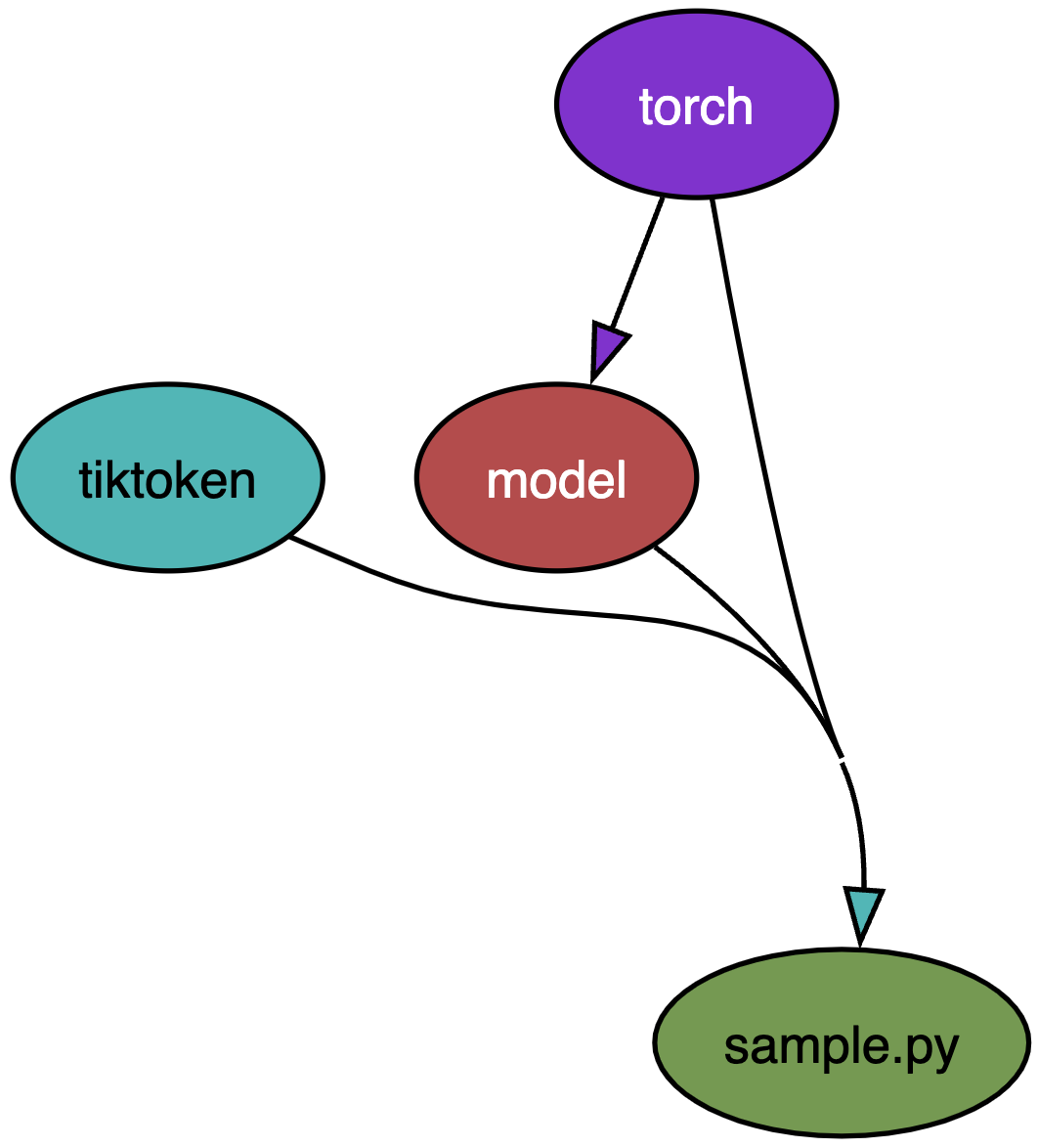
导入必要的包
import os, pickle, torch, tiktoken
from contextlib import nullcontext
from model import GPTConfig, GPT
配置超参数
init_from = 'resume' # 'resume' or 'gpt2-xl'
out_dir = 'out'
start = "\n"
num_samples = 10
max_new_tokens = 500
temperature = 0.8
top_k = 200
seed = 1337
device = 'cuda' # 'cpu', 'cuda', 'cuda:0', 'cuda:1'
dtype = 'bfloat16' if torch.cuda.is_available() and torch.cuda.is_bf16_supported() else 'float16' # 'float32' or 'bfloat16' or 'float16'
compile = False # PyTorch 2.0 加速编译
exec(open('configurator.py').read())
配置torch
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
device_type = 'cuda' if 'cuda' in device else 'cpu'
ptdtype = {'float32': torch.float32, 'bfloat16': torch.bfloat16, 'float16': torch.float16}[dtype]
ctx = nullcontext() if device_type == 'cpu' else torch.amp.autocast(device_type=device_type, dtype=ptdtype)
初始化模型
if init_from == 'resume':ckpt_path = os.path.join(out_dir, 'ckpt.pt')checkpoint = torch.load(ckpt_path, map_location=device)gptconf = GPTConfig(**checkpoint['model_args'])model = GPT(gptconf)state_dict = checkpoint['model']unwanted_prefix = '_orig_mod.'for k,v in list(state_dict.items()):if k.startswith(unwanted_prefix):state_dict[k[len(unwanted_prefix):]] = state_dict.pop(k)model.load_state_dict(state_dict)
elif init_from.startswith('gpt2'):model = GPT.from_pretrained(init_from, dict(dropout=0.0))model.eval()
model.to(device)
if compile:model = torch.compile(model)
初始化环境
load_meta = False
if init_from == 'resume' and 'config' in checkpoint and 'dataset' in checkpoint['config']:meta_path = os.path.join('data', checkpoint['config']['dataset'], 'meta.pkl')load_meta = os.path.exists(meta_path)
if load_meta:print(f"Loading meta from {meta_path}...")with open(meta_path, 'rb') as f:meta = pickle.load(f)stoi, itos = meta['stoi'], meta['itos']encode = lambda s: [stoi[c] for c in s]decode = lambda l: ''.join([itos[i] for i in l])
else:print("No meta.pkl found, assuming GPT-2 encodings...")enc = tiktoken.get_encoding("gpt2")encode = lambda s: enc.encode(s, allowed_special={"<|endoftext|>"})decode = lambda l: enc.decode(l)
对提示词进行编码
if start.startswith('FILE:'):with open(start[5:], 'r', encoding='utf-8') as f:start = f.read()
start_ids = encode(start)
x = (torch.tensor(start_ids, dtype=torch.long, device=device)[None, ...])
进行测试
with torch.no_grad():with ctx:for k in range(num_samples):y = model.generate(x, max_new_tokens, temperature=temperature, top_k=top_k)print(decode(y[0].tolist()))print('---------------')
5. benchmark评估 bench.py
在训练和测试完模型后通常需要对其进行一次bench评估,如果要发论文的话这步是必不可少的环节。
导入必要的包
import os
from contextlib import nullcontext
import numpy as np
import time
import torch
from model import GPTConfig, GPT
配置超参数
batch_size = 12
block_size = 1024
bias = False
real_data = True
seed = 1337
device = 'cuda' # 'cpu', 'cuda', 'cuda:0', 'cuda:1'
dtype = 'bfloat16' if torch.cuda.is_available() and torch.cuda.is_bf16_supported() else 'float16' # 'float32' or 'bfloat16' or 'float16'
compile = True # PyTorch 2.0 加速编译
profile = False # 是否使用 pytorch profiler 或只进行简单评估
exec(open('configurator.py').read())
配置torch
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
device_type = 'cuda' if 'cuda' in device else 'cpu'
ptdtype = {'float32': torch.float32, 'bfloat16': torch.bfloat16, 'float16': torch.float16}[dtype]
ctx = nullcontext() if device_type == 'cpu' else torch.amp.autocast(device_type=device_type, dtype=ptdtype)
加载数据并初始化 - openwebtext
if real_data:dataset = 'openwebtext'data_dir = os.path.join('data', dataset)train_data = np.memmap(os.path.join(data_dir, 'train.bin'), dtype=np.uint16, mode='r')def get_batch(split):data = train_dataix = torch.randint(len(data) - block_size, (batch_size,))x = torch.stack([torch.from_numpy((data[i:i+block_size]).astype(np.int64)) for i in ix])y = torch.stack([torch.from_numpy((data[i+1:i+1+block_size]).astype(np.int64)) for i in ix])x, y = x.pin_memory().to(device, non_blocking=True), y.pin_memory().to(device, non_blocking=True)return x, y
else: # 直接给一堆噪声x = torch.randint(50304, (batch_size, block_size), device=device)y = torch.randint(50304, (batch_size, block_size), device=device)get_batch = lambda split: (x, y)
模型初始化
gptconf = GPTConfig(block_size = block_size,n_layer = 12, n_head = 12, n_embd = 768, dropout = 0, bias = bias,
)
model = GPT(gptconf)
model.to(device)optimizer = model.configure_optimizers(weight_decay=1e-2, learning_rate=1e-4, betas=(0.9, 0.95), device_type=device_type)if compile:print("Compiling model...")model = torch.compile(model) # pytorch 2.0
benchmark评估
if profile:wait, warmup, active = 5, 5, 5num_steps = wait + warmup + activewith torch.profiler.profile(activities=[torch.profiler.ProfilerActivity.CPU, torch.profiler.ProfilerActivity.CUDA],schedule=torch.profiler.schedule(wait=wait, warmup=warmup, active=active, repeat=1),on_trace_ready=torch.profiler.tensorboard_trace_handler('./bench_log'),record_shapes=False,profile_memory=False,with_stack=False,with_flops=True,with_modules=False,) as prof:X, Y = get_batch('train')for k in range(num_steps):with ctx:logits, loss = model(X, Y)X, Y = get_batch('train')optimizer.zero_grad(set_to_none=True)loss.backward()optimizer.step()lossf = loss.item()print(f"{k}/{num_steps} loss: {lossf:.4f}")prof.step()
else: # simple benchmarkingtorch.cuda.synchronize()for stage, num_steps in enumerate([10, 20]):t0 = time.time()X, Y = get_batch('train')for k in range(num_steps):with ctx:logits, loss = model(X, Y)X, Y = get_batch('train')optimizer.zero_grad(set_to_none=True)loss.backward()optimizer.step()lossf = loss.item()print(f"{k}/{num_steps} loss: {lossf:.4f}")torch.cuda.synchronize()t1 = time.time()dt = t1-t0mfu = model.estimate_mfu(batch_size * 1 * num_steps, dt)if stage == 1:print(f"time per iteration: {dt/num_steps*1000:.4f}ms, MFU: {mfu*100:.2f}%")
相关文章:
Model 速通系列(一)nanoGPT
这个是新开的一个系列用来手把手复现一些模型工程,之所以开这个系列是因为有人留言说看到一个工程不知道从哪里读起,出于对自身能力的提升与兴趣,故新开了这个系列。由于主要动机是顺一遍代码并提供注释。 该系列第一篇博客是 nanoGPT &…...

微信小程序中,一个页面的数据改变了,怎么通知另一个页面也改变?
在微信小程序中,当一个页面的数据改变后通知另一个页面更新,可以通过以下步骤实现: 方法一:使用全局事件总线(推荐) 步骤说明: 在 app.js 中创建事件系统 在全局 App 实例中实现事件监听和触发…...
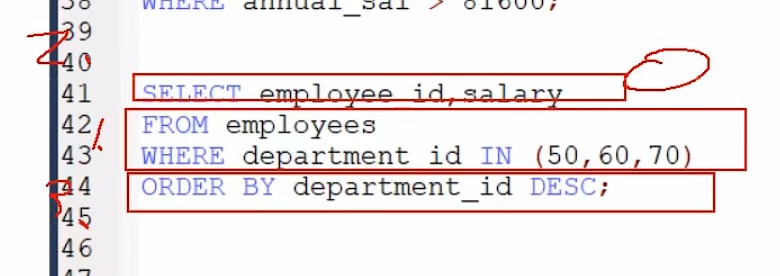
MySQL--day4--排序与分页
(以下内容全部来自上述课程) 1. 排序数据 1.1 排序基本使用 #1.排序 #如果没有使用排序操作,默认情况下查询返回的数据是按照添加数据的顺序显示的 SELECT * FROM employees;# 练习:按照salary从高到低的顺序显示员工信息 # 使用 ORDER …...

自动化测试脚本点击运行后,打开Chrome很久??
亲爱的小伙伴们大家好。 小编最近刚换了电脑,这几天做自动化测试发现打开Chrome浏览器需要等待好长时间,起初还以为代码有问题,或者Chromedriver与Chrome不匹配造成的,但排查后发现并不是!! 在driver.py中…...

iOS热更新技术要点与风险分析
iOS的热更新技术允许开发者在无需重新提交App Store审核的情况下,动态修复Bug或更新功能,但需注意苹果的审核政策限制。以下是iOS热更新的主要技术方案及要点: 一、主流热更新技术方案 JavaScript动态化框架 React Native & Weex 通过Jav…...
:统一过程模型(RUP))
系统架构设计(十二):统一过程模型(RUP)
简介 RUP 是由 IBM Rational 公司提出的一种 面向对象的软件工程过程模型,以 UML 为建模语言,是一种 以用例为驱动、以架构为中心、迭代式、增量开发的过程模型。 三大特征 特征说明以用例为驱动(Use Case Driven)需求分析和测…...

系分论文《论软件系统安全分析和应用》
系统分析师论文范文系列 【摘要】 2023年3月,我司承接了某知名电商企业“智能化供应链管理系统”的开发任务,我作为系统分析师负责全面的安全分析与设计工作。该系统以提升电商供应链效率为核心,整合仓储、物流、支付等模块,并需应…...

Mac安装redis
1、 去往网址 http://编download.编redis.io/releases/ 找到任意 结尾为* .tar.gz的文件下载下来 2、使用终端进入下载下来的redis文件 3、直接执行redis-server 如果出现redis标志性的图代表成功 如果显示command not found :redis-server 则在终端再进入src文件夹下&…...
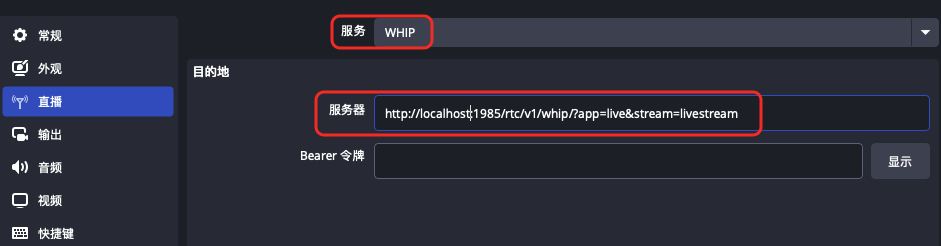
srs-7.0 支持obs推webrtc流
demo演示 官方教程: https://ossrs.net/lts/zh-cn/blog/Experience-Ultra-Low-Latency-Live-Streaming-with-OBS-WHIP 实现原理就是通过WHIP协议来传输 SDP信息 1、运行 ./objs/srs -c conf/rtc.conf 2、obs推流 3、web端播放webrtc流 打开web:ht...
Babylon.js学习之路《七、用户交互:鼠标点击、拖拽与射线检测》
文章目录 1. 引言:用户交互的核心作用1.1 材质与纹理的核心作用 2. 基础交互:鼠标与触摸事件2.1 绑定鼠标点击事件2.2 触摸事件适配 3. 射线检测(Ray Casting)3.1 射线检测的原理3.2 高级射线检测技巧 4. 拖拽物体的实现4.1 拖拽基…...
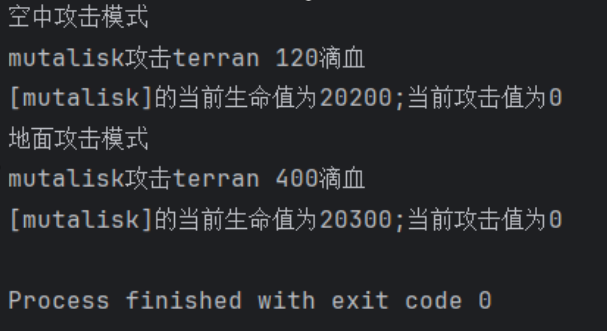
星际争霸小程序:用Java实现策略模式的星际大战
在游戏开发的世界里,策略模式是一种非常实用的设计模式,它允许我们在运行时动态地选择算法或行为。今天,我将带你走进一场星际争霸的奇幻之旅,用Java实现一个简单的星际争霸小程序,通过策略模式来模拟不同种族单位的战…...

请问交换机和路由器的区别?vlan 和 VPN 是什么?
交换机和路由器的区别 特性交换机(Switch)路由器(Router)工作层级数据链路层(L2,基于MAC地址)网络层(L3,基于IP地址)主要功能在局域网(LAN&#…...
BERT 作为Transformer的Encoder 为什么采用可学习的位置编码
摘要 BERT 在位置编码上与原始 Transformer 论文中的 sin/cos 公式不同,选择了可学习(learned)的位置嵌入方案。本文将从 Transformer 原始位置编码选项入手,分析 BERT 选择 learned positional embeddings 的四大核心原因&#x…...
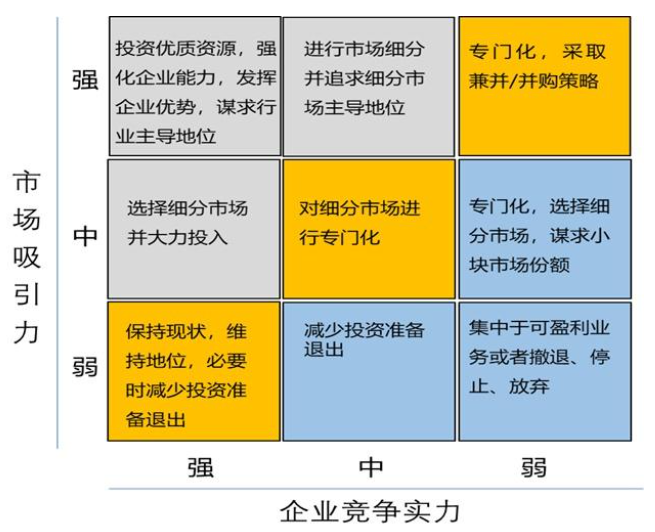
Python数据可视化高级实战之一——绘制GE矩阵图
目录 一、课程概述 二、GE矩阵? 三、GE 矩阵图的适用范围 五、GE 矩阵的评估方法 (一)市场吸引力的评估要素 二、企业竞争实力的评估要素 三、评估方法与实践应用 1. 定量与定性结合法 2. 数据来源 六、GE矩阵的图形化实现 七、总结:GE 矩阵与 BCG 矩阵的对比分析 (一)GE…...

StreamSaver实现大文件下载解决方案
StreamSaver实现大文件下载解决方案 web端 安装 StreamSaver.js npm install streamsaver # 或 yarn add streamsaver在 Vue 组件中导入 import streamSaver from "streamsaver"; // 确保导入名称正确完整代码修正 <!--* projectName: * desc: * author: dua…...

【Vue 3全栈实战】从响应式原理到企业级架构设计
目录 🌟 前言🏗️ 技术背景与价值🩹 当前技术痛点🛠️ 解决方案概述👥 目标读者说明 🧠 一、技术原理剖析📊 核心概念图解💡 核心作用讲解🔧 关键技术模块说明⚖️ 技术选…...

Java线程池调优与实践经验
在Java面试中,线程池调优是一个常见且重要的考察点,尤其是当涉及Spring生态时,ThreadPoolTaskExecutor的使用经验通常会被深入追问。以下是针对该问题的结构化回答,结合原理、实践和调优经验: 1. 线程池调优的核心参数…...

【科研项目】大三保研人科研经历提升
大三保研人,五月科研项目经历提升 现在已经是五月下旬,各大高校的夏令营通知陆续发布,九月的预推免也近在眼前。我知道很多大三的同学正在焦虑——绩点已经定型,竞赛经历又不够丰富,简历上能写的东西太少,面…...

期刊采编系统安装升级错误
我们以ojs系统为例: PHP Fatal error: Uncaught Error: Call to a member function getId() on null in /esci/data/html/classes/install/Upgrade.inc.php:1019 Stacktrace: #0 /esci/data/html/lib/pkp/classes/install/Installer.inc.php(415): Upgrade->con…...
CSS【详解】弹性布局 flex
适用场景 一维(行或列)布局 基本概念 包裹所有被布局元素的父元素为容器 所有被布局的元素为项目 项目的排列方向(垂直/水平)为主轴 与主轴垂直的方向交交叉轴 容器上启用 flex 布局 将容器的 display 样式设置为 flex 或 i…...

自回归图像编辑 EditAR: Unified Conditional Generation with Autoregressive Models
Paperhttps://arxiv.org/pdf/2501.04699 Code (coming soon) 目录 方法 实验 EditAR是一个统一的自回归框架,用于各种条件图像生成任务——图像编辑、深度到图像、边缘到图像、分割到图像。 next-token预测的功效尚未被证明用于图像编辑。 EditAR主要构建在Ll…...
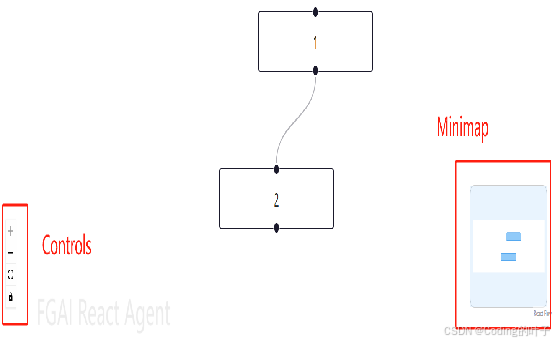
React Flow 中 Minimap 与 Controls 组件使用指南:交互式小地图与视口控制定制(含代码示例)
本文为《React Agent:从零开始构建 AI 智能体》专栏系列文章。 专栏地址:https://blog.csdn.net/suiyingy/category_12933485.html。项目地址:https://gitee.com/fgai/react-agent(含完整代码示例与实战源)。完整介绍…...

基于YOLOv8 的分类道路目标系统-PyTorch实现
本文源码: https://download.csdn.net/download/shangjg03/90873939 1. 引言 在智能交通和自动驾驶领域,道路目标分类是一项关键技术。通过对摄像头捕获的图像或视频中的目标进行分类识别,可以帮助车辆或系统理解周围环境,做出更安全的决策。本教程将介绍如何使用 PyTorch …...
STM32之串口通信WIFI上云
一、W模块的原理与应用 基本概念 如果打算让硬件设备可以通过云服务器进行通信(数据上报/指令下发),像主流的云服务器有阿里云、腾讯云、华为云,以及其他物联网云平台:巴法云.......,硬件设备需要通过TCP…...
PCB智能报价系统——————仙盟创梦IDE
软件署名 代码贡献: 紫金电子科技有限公司 文案正路:cybersnow 正文 对企业的竞争力有着深远影响。传统的 PCB 报价方式往往依赖人工核算,不仅耗时较长,还容易出现误差。随着科技的发展,PCB 自动报价系统应运而生&a…...

EXO分布式部署deepseek r1
EXO 是一个支持分布式 AI 计算的框架,可以用于在多个设备(包括 Mac Studio)上运行大语言模型(LLM)。以下是联调 Mac Studio 512GB 的步骤: 安装 EXO • 从 EXO GitHub 仓库 下载源码或使用 git clone 获取…...
))详细讲解版)
每日算法 -【Swift 算法】寻找两个有序数组的中位数(O(log(m+n)))详细讲解版
🧠 用 Swift 寻找两个有序数组的中位数(O(log(mn)))详细讲解版 寻找两个有序数组的中位数,是 LeetCode 上非常经典的一道题,难度为 困难(Hard),但它的本质是一个 二分查找 的变形应…...

Linux问题排查-找到偷偷写文件的进程
在 Linux 系统中,若要通过已修改的文件找到修改该文件的进程 PID,可以结合以下方法分析,具体取决于文件是否仍被进程打开或已被删除但句柄仍存在: 一、文件仍被进程打开(未删除) 如果文件当前正在被某个进…...

SOPHGO算能科技BM1688内存使用与编解码开发指南
1. BM1688内存分配接口详解 1.1 设备内存分配接口区别 BM1688提供了三个主要的设备内存分配接口,它们的主要区别如下: // 基本设备内存分配接口 void* bm_malloc_device_byte(bm_handle_t handle, unsigned int size);// 指定heap区域的设备内存分配 void*</...

kotlin flow的两种SharingStarted策略的区别
一 两种 SharingStarted 策略的区别: SharingStarted.Eagerly: 立即开始收集上游流,即使没有下游订阅者持续保持活跃状态,直到 ViewModel 被清除优点:响应更快,数据始终保持最新缺点:消耗更多资源&#x…...