【Java微服务组件】异步通信P2—Kafka与消息
欢迎来到啾啾的博客🐱。
记录学习点滴。分享工作思考和实用技巧,偶尔也分享一些杂谈💬。
欢迎评论交流,感谢您的阅读😄。
目录
- 引言
- Kafka与消息
- 生产者发送消息到Kafka
- 批处理发送设计
- 消息的幂等信息
- 确保消息送达
- acks配置
- send()方法返回
- retries配置
- 消息在Kafka的存储
- Kafka Cluster\Broker\Topic\Partition
- Cluster
- Broker
- Topic/Partition
- 数据冗余与分布式协调带来可靠
- 零拷贝和操作系统内存利用是高吞吐的核心
- 消息怎么过期(移除)
- 消息滞后风险
- 消息者消费消息
- 消费者群组
- 偏移量
- 消息积压怎么处理
- Kafka为什么快
引言
在上一篇【Java微服务组件】异步通信P1—消息队列基本概念
中已经简单介绍了MQ。
目前主流的消息队列应该就是Kafka与RocketMQ了。在RocketMQ官网中有讲解其与Kafka的区别,如下:
| 消息产品 | 客户端 SDK | 协议与规范 | 顺序消息 | 定时消息 | 批量消息 | 广播消息 | 消息过滤 | 服务端触发重投递 | 消息存储 | 消息回溯 | 消息优先级 | 高可用与故障转移 | 消息轨迹 | 配置方式 | 管理与运维工具 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Kafka | Java, Scala 等 | 拉模型 (Pull Model), 支持 TCP 协议 | 保证分区内消息有序 | 不支持 | 支持, 通过异步生产者实现 | 不支持 | 支持, 可使用 Kafka Streams 进行消息过滤 | 不支持 | 高性能文件存储 | 支持, 通过偏移量 (offset) 定位 | 不支持 | 支持, 依赖 ZooKeeper 服务 | 不支持 | Kafka 使用键值对格式进行配置。这些值可以通过文件或编程方式提供。 | 支持, 使用终端命令暴露核心指标 |
| RocketMQ | Java, C++, Go | 拉模型 (Pull Model), 支持 TCP, JMS, OpenMessaging 协议 | 保证严格顺序消息, 且能优雅地水平扩展 | 支持 | 支持, 通过同步模式避免消息丢失 | 支持 | 支持, 基于 SQL92 的属性过滤表达式 | 支持 | 高性能、低延迟文件存储 | 支持, 通过时间戳和偏移量 (offset) 两种方式定位 | 不支持 | 支持, 主从模型, 无需额外组件 | 支持 | 开箱即用, 用户只需关注少量配置 | 支持, 丰富的 Web 界面和终端命令暴露核心指标 |
但今天我们还是先深入了解Kafka的设计与功能。因为Kafka快。
资料引用自《Kafka权威指南》、https://developer.confluent.io/courses/architecture/broker/
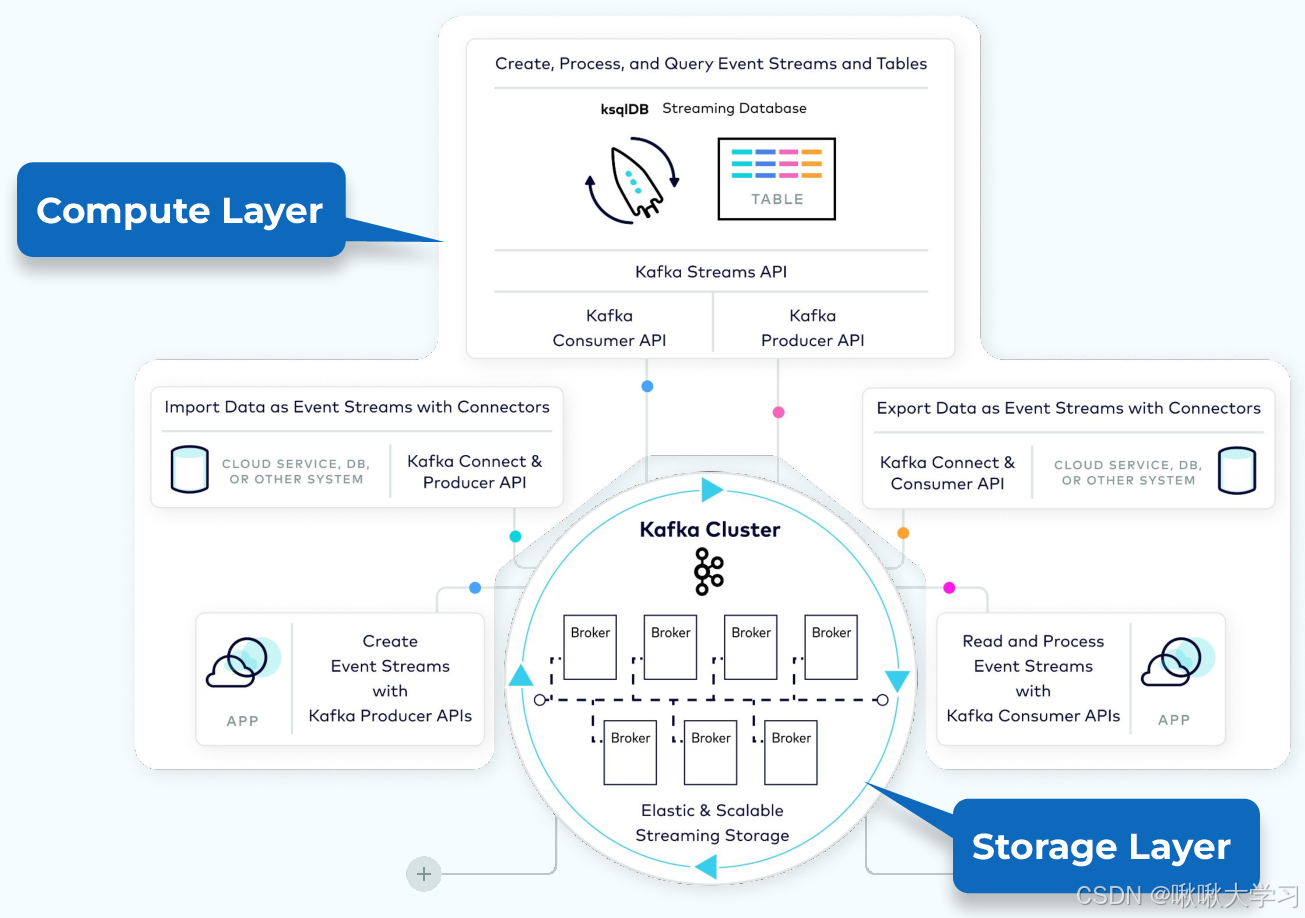
Kafka与消息
生产者发送消息到Kafka
怎么可靠、高效地发送消息到Kafka呢?
批处理发送设计
如果每一条消息都单独穿行于网络中,那么就会导致大量的网络开销,把消息分成批次传输可以减少网络开销。
所以,Kafka Producer 的核心设计之一就是客户端批处理。生产者会将多条消息收集到一个批次 (Batch) 中,然后一次性将整个批次发送给对应的Broker。
为此,Kafka Producer 内部有一个缓冲区 (Accumulator / RecordAccumulator)。消息在缓冲区按照目标的Topic-Partition进行组织,满足以下任一条件后随批次发送给Broker:
- batch.size: 某个批次的消息累积大小达到了配置的 batch.size(默认16KB)。
- linger.ms: 距离该批次第一条消息进入缓冲区的时间超过了配置的 linger.ms(默认0ms,但实际中为了启用批处理,通常会设置一个大于0的值,比如5ms, 10ms)。即使批次未满 batch.size,到达 linger.ms 后也会发送,以避免消息在缓冲区停留过久导致延迟。
- producer.flush()被调用: 应用程序显式要求将所有缓冲区的消息立即发送。
- producer.close()被调用: 在关闭生产者之前,会确保所有缓冲区的消息都被发送出去。
![![[异步通信P2—Kafka.png]]](https://i-blog.csdnimg.cn/direct/7bde829548de4d31afdabe356e09834c.png)
批处理设计通过牺牲一点点单条消息的即时性,节省网络开销(TCP/IP开销、传输数据量)、磁盘开销,从整体提升消息吞吐量、网络效率、资源利用率。
对于大多数高吞吐量的消息系统场景来说,这样做是非常值得的。
消息的幂等信息
Q:怎么保证Kafka存储(收到)的消息是唯一的?
从 Kafka 3.0.0 版本开始,Kafka 生产者内置了幂等性支持。幂等可以防止因Broker未及时响应ack导致消息在Broker重复存储。
配置默认为true。
spring.kafka.producer.enable-idempotence=true
它通过为每个生产者分配一个唯一的生产者ID (PID) 和为发送到每个分区的每条消息分配一个序列号来实现。Broker 会跟踪这些 (PID, Partition, SequenceNumber) 组合,并丢弃重复的写入尝试。
需要注意的时,幂等启动时,除非用户显示配置了其他值,retries 会被设置为 Integer.MAX_VALUE,acks 会被设置为 all,max.in.flight.requests.per.connection 会被限制为 <= 5 (默认为5)。
确保消息送达
生产者发送消息的producer.send() 方法本身是异步的,它将消息放入生产者的发送缓冲区,并由一个后台线程负责批量发送(哪怕linger.ms配置为0)。
生产者有以下方式来确保消息送达。
acks配置
这个参数决定了生产者在认为一个请求完成之前需要等待多少个 Broker 副本的确认。它有三个主要的值:
- acks=0
完全没有送达保证。 - acks=1
Leader确认后则认为送达。 - acks=all
Leader Broker 在自己写入并且所有ISR都向它报告已写入后,才向生产者发送确认响应。
一般配置acks=all,虽然会略微增加延迟,但数据不丢失通常是更重要的考量。
acks一般还与min.insync.replicas一起使用,min.insync.replicas默认值通常是1,这意味着只要有一个副本(包括leader副本)已经接收并同步了消息,就可以认为该消息是成功写入的。
所以配置acks=all时,一般推荐min.insync.replicas=2,即有两个副本同步了消息。
send()方法返回
producer.send(record) 方法会返回一个 java.util.concurrent.Future<RecordMetadata> 对象。常用的KafkaTemplate.send()则返回一个ListenableFuture<SendResult<K, V>>,两者都可以用于等待返回结果(阻塞或非阻塞)。
// 阻塞等待try {SendResult<String, String> result = kafkaTemplate.send("myTopic", "key", "value").get();RecordMetadata metadata = result.getRecordMetadata();log.info("Sent message to topic " + metadata.topic() +" partition " + metadata.partition() +" offset " + metadata.offset());
} catch (InterruptedException | ExecutionException e) {// 处理发送失败,e.getCause() 通常是 KafkaExceptionlog.error("Failed to send message: " + e.getMessage());
}// 非阻塞
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send("myTopic", "key", "value");
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {@Overridepublic void onSuccess(SendResult<String, String> result) {RecordMetadata metadata = result.getRecordMetadata();log.info("Successfully sent message to topic " + metadata.topic() +" partition " + metadata.partition() +" offset " + metadata.offset());}@Overridepublic void onFailure(Throwable ex) {// 处理发送失败log.error("Failed to send message: " + ex.getMessage());}
});
retries配置
Kafka 生产者客户端内置了重试机制,用于处理可恢复的错误(如网络抖动、Leader 切换等)。
spring.kafka.producer.retries一般设置3或者5。
另外还有控制重试等待时间的spring.kafka.producer.properties.retry.backoff.ms。
控制producer.send() 和 producer.flush() 调用完成的总时间的spring.kafka.producer.properties.delivery.timeout.ms。这个时间包括消息在缓冲区等待的时间+网络传输时间+Broker确认时间+所有重试时间。如果超过这个时间,send()返回的Future会报超时。
默认的两分钟通常是够的。
spring.kafka.producer.retries=3
spring.kafka.producer.properties.retry.backoff.ms=1000 # 例如设置为1秒
spring.kafka.producer.properties.delivery.timeout.ms=120000
# 如果开启幂等性 (通常推荐)
spring.kafka.producer.enable-idempotence=true
# 当 enable-idempotence=true 时,retries 默认为 Integer.MAX_VALUE, acks 默认为 all
# max.in.flight.requests.per.connection 默认为 5
消息在Kafka的存储
消息在Kafka是怎么存储的,怎么保证数据安全可靠?
Kafka Cluster\Broker\Topic\Partition
Cluster
一个 Kafka Cluster 由一个或多个 Broker 组成。这些 Broker 协同工作,提供消息的存储、读取和高可用性。
可以通过增加Broker来扩展集群的处理能力和存储容量。集群之间的数据共享(通信)早起是ZooKeeper,现在是KRaft控制器。
![![[异步通信P2—Kafka-6.png]]](https://i-blog.csdnimg.cn/direct/cbfbb8ed191147da8ff1682fed131dd7.png)
Broker
集群中的一个服务器实例就是一个Broker,每个Broker有唯一的数字ID。 Broker 负责接收来自生产者的消息,并将它们存储在磁盘上(以分区的形式)。
![![[异步通信P2—Kafka-5.png]]](https://i-blog.csdnimg.cn/direct/c3bd230fe37844639a2e3c99d39df685.png)
生产者请求到Broker后进入请求队列,然后由I/O线程验证并存储批次最后持久化到磁盘。
Kafka利用了操作系统本身的Page Cache,即,Kafka的读写操作基本上是基于系统内存的,读写性能得到了极大的提升。
同时,Broker使用了零拷贝技术,消费取消息时不走用户空间缓存区,数据从磁盘读取到内存空间page cache后,直接复制到socket缓冲区。避免了内核空间到用户空间的来回拷贝,也极大提升了性能。
集群中会有一个 Broker被选举为 Controller。Controller 负责管理集群的元数据,例如创建/删除 Topic、分区分配、Leader 选举等。
Broker的Leader-Follower只负责管理Kafka Cluster的集群元数据、监控Broker状态、执行管理操作、发起Leader选举。并不进行消息读写管理。
Topic/Partition
Kafka的消息通过Topic进行分类,生产者将消息发布到特定的 Topic,消费者订阅特定的 Topic 来消费消息。
Topic是一个逻辑概念,会通过分散到集群的多个Broker上。
Topic被分为若干个Partition,一个Partition就是一个提交日志。
- Partition日志
Partition日志并不是一个无限大的文件,而是一系列的日志短文件(LOg Segment Files)组成的。
一般用文件中第一条消息的offset命名,如00000000000000000000.log,00000000000000170123.log 等。
每个日志文件都有两个索引文件:偏移量索引与时间戳索引。- 偏移量索引 (.index): 存储相对偏移量(相对于该段的基准偏移量)到消息在 .log 文件中物理位置(字节偏移)的稀疏映射。这使得 Kafka 可以通过 Offset 快速定位到消息在日志段中的大致位置,然后顺序扫描一小段来找到确切的消息。
- 时间戳索引 (.timeindex): 存储时间戳到消息相对偏移量的稀疏映射。这使得 Kafka 可以通过时间戳快速定位到某个时间点附近的消息。
消息会以追加的方式被写入Partition,然后按照先入先出的顺序读取。一个Partition只能有一个Leader位于某个Broker上,且所有读写都在Leader上进行,其他Follower用于保障数据安全。
具体关系如下:
![![[异步通信P2—Kafka-7.png]]](https://i-blog.csdnimg.cn/direct/3fda96dc4edc42a59502e03992c4b8d6.png)
一个 Topic 的不同分区(及其副本)会分布到集群中的不同 Broker 上。Kafka可以保证消息在当前Partition的顺序。
Kafka Producer可以指定消息发送到哪个Topic,也可以指定到哪个Partition。没有指定Partition时,Kafka Producer会使用分区器 Partitioner来决定消息应该到哪个partition,策略以前是轮询,2.4版本后是“粘性分区”(简单来说就是先选一个分区一直发,然后换一个一直发)。
决定消息发往哪个Partition后,生产者会讲消息发给Partition中的Leader。然后Follower从Partition拉去信息同步进自己的文件中。
消费者也是连接Leader进行消费。
通常会把一个Topic的数据看成一个流。
数据冗余与分布式协调带来可靠
Kafka通过acks和min.insync.replicas配置防止消息发送失败,然后通过将数据冗余(数据副本)存放到多个 Follower Partition以及分布式共识选举机制来保障数据的可靠。
零拷贝和操作系统内存利用是高吞吐的核心
Kafka的读写操作基本上是基于系统内存的,读写性能得到了极大的提升。同时使用零拷贝技术,提升了消费的速率。
消息怎么过期(移除)
Kafka的数据过期(移除)和消费者是否消费完消息没有直接关系。消息移除主要由Topic级别配置的数据保留策略(Retention Policy)决定。
主要的数据保留策略如下:
- 基于时间
配置参数: retention.ms (毫秒) 或 retention.hours (小时) 或 retention.days (天,较老版本,retention.ms 更精确且优先)。
时间从消息写入开始算。 - 基于大小
配置参数: retention.bytes (字节)。每个Partition日志文件的最大总大小。
当一个 Partition 的日志文件总大小超过这个配置值时,Kafka 会从日志的最旧端开始删除消息段 (Log Segments),直到该 Partition 的大小回落到配置的限制以下。 - 日志压缩
配置参数: cleanup.policy=compact (默认是 delete)。
对于启用了日志压缩的 Topic,Kafka 会保留每个消息 Key 的最新版本的值。旧版本的消息(具有相同 Key 的旧值)会被删除。这主要用于构建状态存储、变更数据捕获 (CDC) 等场景,而不是传统的队列消息传递。
消息滞后风险
因此,kafka存在消息滞后风险,如果长时间没有消费消息,消息可能丢失。
因此,监控消费情况、设计兜底很重要。
消息者消费消息
Q:消费者该怎么消费?
A:Kafka限定消费者实例必须属于一个消费者组(有group.id)。
通常同一个消费者组内的所有实例应该订阅相同的Topic,让每个消费者组专注于自己需要处理的Topic集合。
consumer.subscribe(Collection<String> topics)
不同的消费者组消费消息表现得像发布-订阅模式。每个消费者组会独立跟踪自己的消费进度。
而在同一个消费者组内部,一个 Topic 的一个 Partition 在同一时间只会被该组内的一个消费者实例消费。
为同组消费者实例分配不同Partition的机制是Rebalance。机制有负载均衡的效果,将工作分散到多个实例上,提高整体的吞吐量。
所以设计上推荐消费者指定到具体的Topic即可,然后利用Rebalance机制提高吞吐。
即,消费者逻辑上属于一个消费组然后消费指定的Topic,且同一个消费者组内不同消费者消费不同Partition。
Q:消费者怎么确定消费倒哪了?
A:每个消费者组都会追踪自己订阅的Topic的自己的消费记录——偏移量。
每个消息都有一个整数偏移量。
消费者组在消费完消息后,会发送一个Offset Commit请求到Broker。由Broker记录消费者组消费到的最新偏移量(以前是zk)。
Kafka消费者采用的是拉模型(Pull Model)。消费者根据自己的处理能力和节奏,向 Kafka Broker 发送 Fetch 请求来获取消息。
在拉取消息前,消费者需要向负责所属消费者的Broker(Group Coordinator)询问自己被分配了哪些Topic(尽管订阅指定了Topic,还是需要重新获取)和Partition,然后Broker返回之前消费到的最新偏移量。
消费者群组
![![[异步通信P2—Kafka-8.png]]](https://i-blog.csdnimg.cn/direct/6746a64a999e474caa1e27dd620cef0a.png)
Kafka限定消费者实例必须属于一个消费者组(有group.id)。一个消费者组内的所有实例应该订阅相同的Topic,让每个消费者组专注于自己需要处理的Topic集合。
偏移量
偏移量:偏移量是一种元数据,不断递增的整数值。由Broker(Leader)在消息被成功写入Partition时,分配并添加到消息的元数据中,仅在当前Partition唯一。
消息的元数据有:offset、timestamp、key、partition 、Headers、topic
消费者会按照消息写入Partition的顺序读取消息,并通过检查消息的偏移量来区分已经读取过的消息。
消费者会定期或在消费完成后向 Kafka(或外部存储)提交(commit)它所消费的偏移量。
当消费者重启或因故障切换时,可以从上次提交的偏移量之后开始继续消费。
消息积压怎么处理
首先,检查消费速率,看是否消费者代码异常。
代码是否有bug,性能需要优化?
然后,检查生产者消息,是否消息过大?是否需要优化传输效率?
再然后,检查积压情况,看是怎么积压的?
积压情况关键指标——Consumer Lag (消费滞后量):
表示某个 Partition 最新消息的 Offset 与消费者已提交 Offset 之间的差值。
如果是所有Topic都积压,则需要考虑扩容提Broker和Consumer。垂直扩容、水平扩容。
如果是单个Topic积压,则要从生产者做Topic、Partition的消费拆分。
单个Partition积压,则拆具体生产者消息。全部Partition积压,则拆Topic。
具体情况具体分析:
![![[Kafka消息积压处理2.png]]](https://i-blog.csdnimg.cn/direct/f5854abdc8f5486f9bf998e1d9da317b.png)
Kafka为什么快
-
发的快
设计有批量发送+与服务端轻量高效的通信协议,整体吞吐快。 -
存的快
利用了系统内存page cache+磁盘顺序读写,Kafka存的快。 -
消息取的快
文件分区分段且有索引+零拷贝,给消费者取消息取的快。
相关文章:
【Java微服务组件】异步通信P2—Kafka与消息
欢迎来到啾啾的博客🐱。 记录学习点滴。分享工作思考和实用技巧,偶尔也分享一些杂谈💬。 欢迎评论交流,感谢您的阅读😄。 目录 引言Kafka与消息生产者发送消息到Kafka批处理发送设计消息的幂等信息确保消息送达acks配置…...
R语言空间数据处理入门教程
我的课程《R语言空间数据处理入门教程》已重新恢复课程售卖,有需要的读者可以学习。 👇点击下方链接(文末“阅读原文”可直达),立即开启你的空间数据之旅: https://www.bilibili.com/cheese/play/ss13775…...
使用zap,对web应用/API接口 做安全检测
https://www.zaproxy.org/getting-started/ 检测方法 docker pull ghcr.io/zaproxy/zaproxy:stable# 执行baseline测试 docker run -t ghcr.io/zaproxy/zaproxy:stable zap-baseline.py \ -t https://baseline.yeshen.org# 执行api测试 docker run -t ghcr.io/zaproxy/zaproxy…...

UE5.6新版本—— 动画光照系统重点更新
UE5.6预览版已经可以下载,发布会在下个月的6.5号发布。 5.6界面UI设计 5.6 对引擎进行了大规模的重新设计,先看整体内容,主题UI设计 被调整了位置,左边大多数的选择,框选工具,吸附工具,挪到了左…...

TypeScript 泛型讲解
如果说 TypeScript 是一门对类型进行编程的语言,那么泛型就是这门语言里的(函数)参数。本章,我将会从多角度讲解 TypeScript 中无处不在的泛型,以及它在类型别名、对象类型、函数与 Class 中的使用方式。 一、泛型的核…...
腾讯位置服务重构出行行业的技术底层逻辑
位置智能:重构出行行业的技术底层逻辑 在智慧城市建设与交通出行需求爆发的双重驱动下,位置服务正从工具层跃升为出行行业的核心基础设施。腾讯位置服务以“连接物理世界与数字空间”为核心理念,通过构建高精度定位、实时数据融合、智能决策…...

面试相关的知识点
1 vllm 1.1常用概念 1 vllm:是一种大模型推理的框架,使用了张量并行原理,把大型矩阵分割成低秩矩阵,分散到不同的GPU上运行。 2 模型推理与训练:模型训练是指利用pytorch进行对大模型进行预训练。 模型推理是指用训…...
如何用JAVA手写一个Tomcat
一、初步理解Tomcat Tomcat是什么? Tomcat 是一个开源的 轻量级 Java Web 应用服务器,核心功能是 运行 Servlet/JSP。 Tomcat的核心功能? Servlet 容器:负责加载、实例化、调用和销毁 Servlet。 HTTP 服务器:监听端口…...
使用 Qt QGraphicsView/QGraphicsScene 绘制色轮
使用 Qt QGraphicsView/QGraphicsScene 绘制色轮 本文介绍如何在 Qt 中利用 QGraphicsView 和 QGraphicsScene 实现基础圆形绘制,以及进阶的色轮(Color Wheel)效果。 色轮是色彩选择器的常见控件,广泛应用于图形设计、绘画和 UI …...
:Python复刻「崩坏星穹铁道」嗷呜嗷呜事务所---源码级解析该小游戏背后的算法与设计模式【纯原创】)
游戏开发实战(三):Python复刻「崩坏星穹铁道」嗷呜嗷呜事务所---源码级解析该小游戏背后的算法与设计模式【纯原创】
文章目录 奇美拉类摸鱼仔,负能量,真老实,小坏蛋,压力怪治愈师小团体画饼王平凡王坏脾气抗压包请假狂请假王内卷王受气包跑路侠看乐子背锅侠抢功劳急先锋说怪话帮倒忙小夸夸工作狂职业经理严酷恶魔职场清流 开始工作吧小奇美拉没想…...
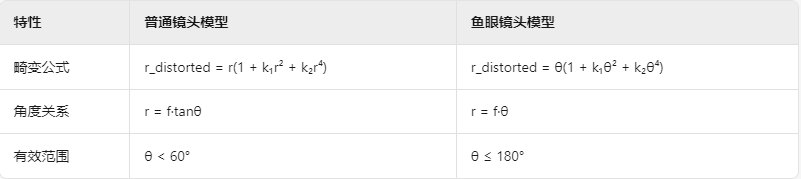
使用glsl 来做视频矫正
描述、优点 使用glsl来代替opencv的undistort 和 鱼眼矫正,并且最后使用opencv的LUT给glsl 来使用,来达到加速的目的,并且做到和opencv 一模一样的效果,达到实时视频的加速矫正。 优点: 没有cuda,也可以做到实时视频矫正,包含各类板子和amd的cpu,intel核显 矫正的基本作…...
03-Web后端基础(Maven基础)
1. 初始Maven 1.1 介绍 Maven 是一款用于管理和构建Java项目的工具,是Apache旗下的一个开源项目 。 Apache 软件基金会,成立于1999年7月,是目前世界上最大的最受欢迎的开源软件基金会,也是一个专门为支持开源项目而生的非盈利性…...

LLM驱动下的软件工程再造:驾驭调试、测试与工程化管理的智能新范式
摘要: 大语言模型(LLM)驱动的软件开发正以前所未有的力量重塑整个行业,从以人为中心的编码模式迅速转向意图驱动和AI编排的智能生成。这场变革带来了生产力的指数级飞跃,但也对传统软件工程中调试、测试和代码工程化管理的核心支柱发起了深刻挑战。本文将剖析这些根本性转…...

大语言模型与人工智能:技术演进、生态重构与未来挑战
目录 技术演进:从专用AI到通用智能的跃迁核心能力:LLM如何重构AI技术栈应用场景:垂直领域的技术革命生态关系:LLM与AI技术矩阵的协同演进挑战局限:智能天花板与伦理困境未来趋势:从语言理解到世界模型1. 技术演进:从专用AI到通用智能的跃迁 1.1 三次技术浪潮的跨越 #me…...

SpringSecurity授权、认证
引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-thymeleaf</artifactId> </dependency> <dependency><groupId>org.springframework.boot</groupId><artifactI…...
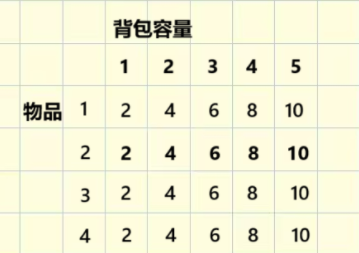
蓝桥杯19682 完全背包
问题描述 有 N 件物品和一个体积为 M 的背包。第 i 个物品的体积为 vi,价值为 wi。每件物品可以使用无限次。 请问可以通过什么样的方式选择物品,使得物品总体积不超过 M 的情况下总价值最大,输出这个最大价值即可。 输入格式 第一行…...

DeepSeek源码解构:从MoE架构到MLA的工程化实现
文章目录 **一、代码结构全景:从模型定义到分布式训练****二、MoE架构:动态路由与稀疏激活的工程化实践****1. 专家路由机制(带负载均衡)****数学原理:负载均衡损失推导** **三、MLA注意力机制:低秩压缩与解…...

leetcode 3355. 零数组变换 I 中等
给定一个长度为 n 的整数数组 nums 和一个二维数组 queries,其中 queries[i] [li, ri]。 对于每个查询 queries[i]: 在 nums 的下标范围 [li, ri] 内选择一个下标 子集。将选中的每个下标对应的元素值减 1。 零数组 是指所有元素都等于 0 的数组。 …...
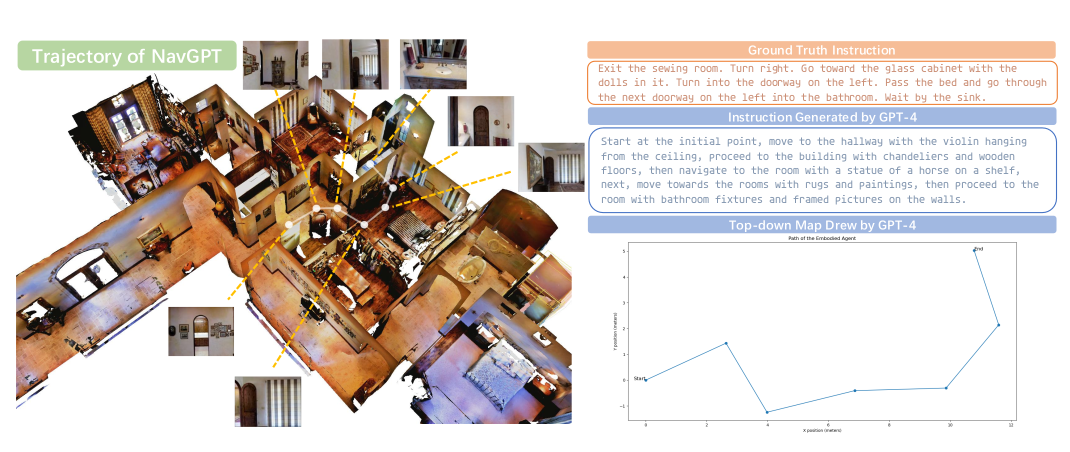
【VLNs篇】02:NavGPT-在视觉与语言导航中使用大型语言模型进行显式推理
方面 (Aspect)内容总结 (Content Summary)论文标题NavGPT: 在视觉与语言导航中使用大型语言模型进行显式推理 (NavGPT: Explicit Reasoning in Vision-and-Language Navigation with Large Language Models)核心问题探究大型语言模型 (LLM) 在复杂具身场景(特别是视…...
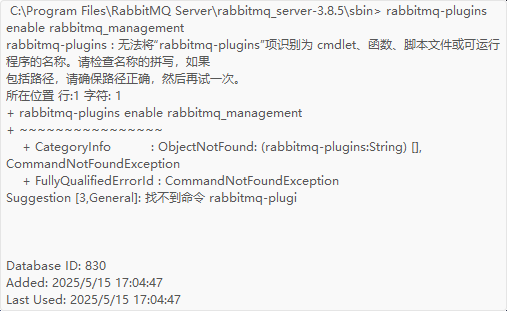
(T_T),不小心删掉RabbitMQ配置文件数据库及如何恢复
一、不小心删除 今天是2025年5月15日,非常沉重的一天,就在今早8点左右的时候我打算继续做我的毕业设计,由于开机的过程十分缓慢(之前没有),加上刚开机电脑有卡死的迹象,再加上昨天晚上关电脑前…...

创建react工程并集成tailwindcss
1. 创建工程 npm create vite admin --template react 2.集成tailwndcss 打开官网跟着操作一下就行。 Installing Tailwind CSS with Vite - Tailwind CSS...
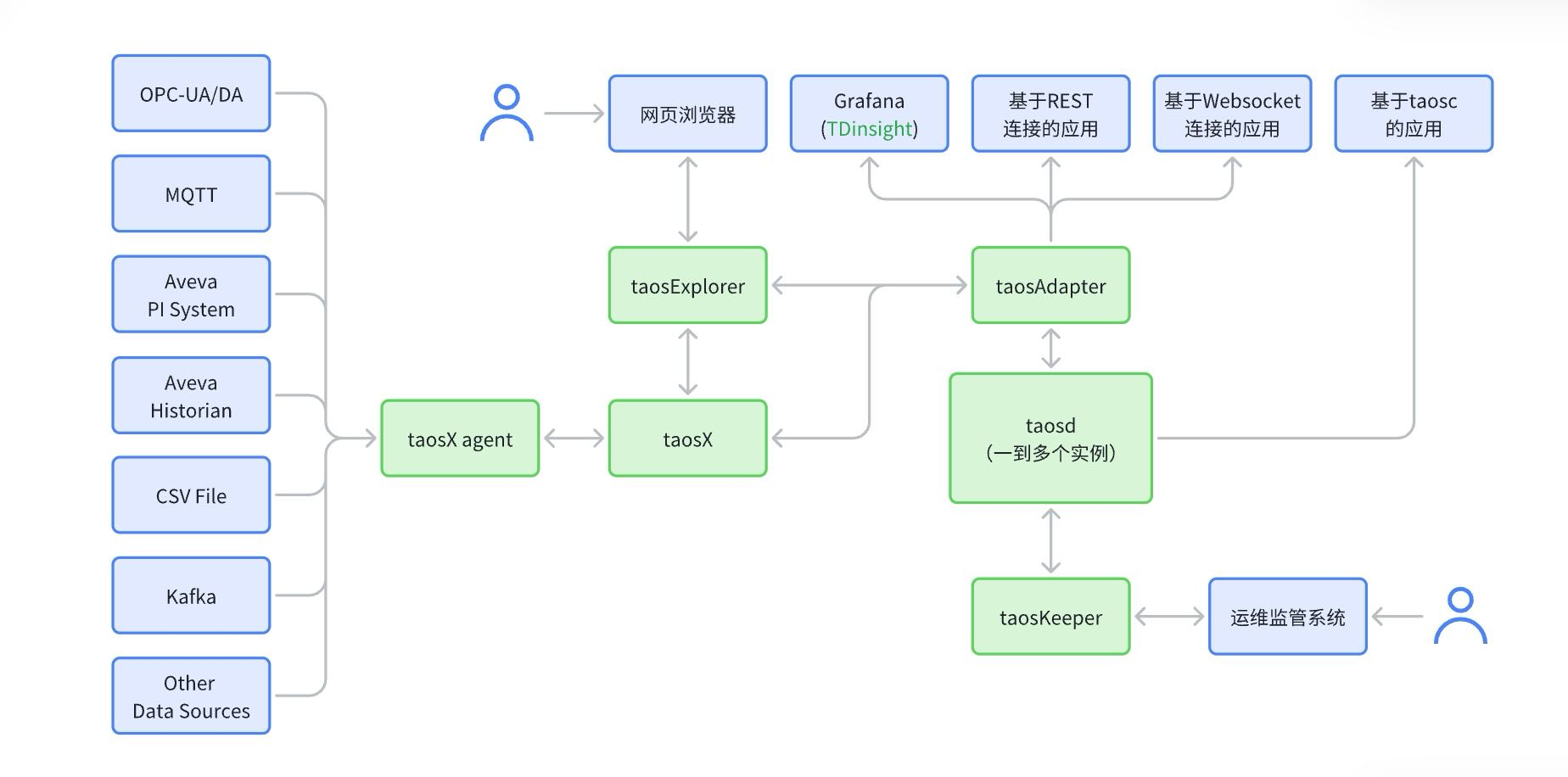
TDengine 安全部署配置建议
背景 TDengine 的分布式、多组件特性导致 TDengine 的安全配置是生产系统中比较关注的问题。本文档旨在对 TDengine 各组件及在不同部署方式下的安全问题进行说明,并提供部署和配置建议,为用户的数据安全提供支持。 安全配置涉及组件 TDengine 包含多…...
)
Axure全链路交互设计:快速提升实现能力(基础交互+高级交互)
想让你的设计稿像真实App一样丝滑?本专栏带你玩转Axure交互,从选中高亮到动态面板骚操作,再到中继器表单花式交互,全程动图教学,一看就会! 本专栏系统讲解多个核心交互效果,是你的Axure交互急救…...

为什么wifi有信号却连接不上?
WiFi有信号,无法连接WiFi网络的可能原因及解决方法: 1.长时间使用路由器,路由器可能会出现假死现象。重启无线路由器即可。 2.认证类型不合适。尝试更改路由器的认证类型,选择安全的 “WPA2-PSK” 类型模式要好,下面…...
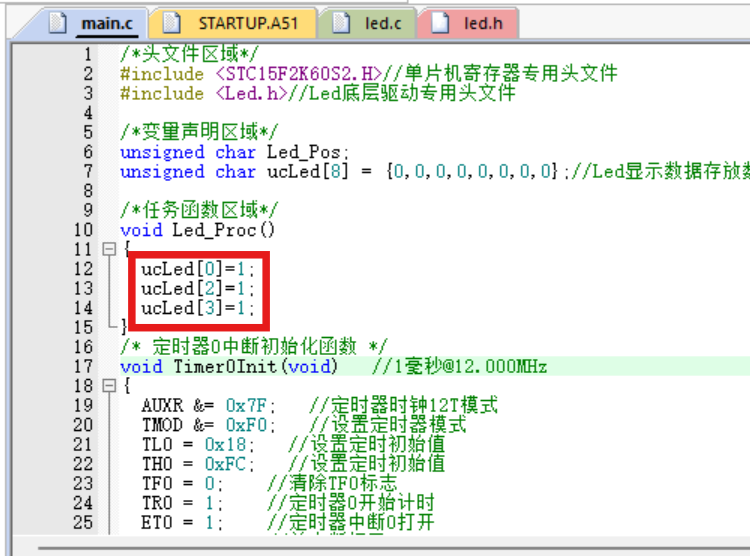
蓝桥杯框架-LED蜂鸣器继电器
蓝桥杯框架-LED蜂鸣器继电器 一,新建工程文件二,配置keil三,完善框架 一,新建工程文件 在桌面上新建一个文件夹:用于存放所有工程文件 在文件夹中再建立一个文件夹DEMO_01:这是我们的第一个工程文件 在第…...
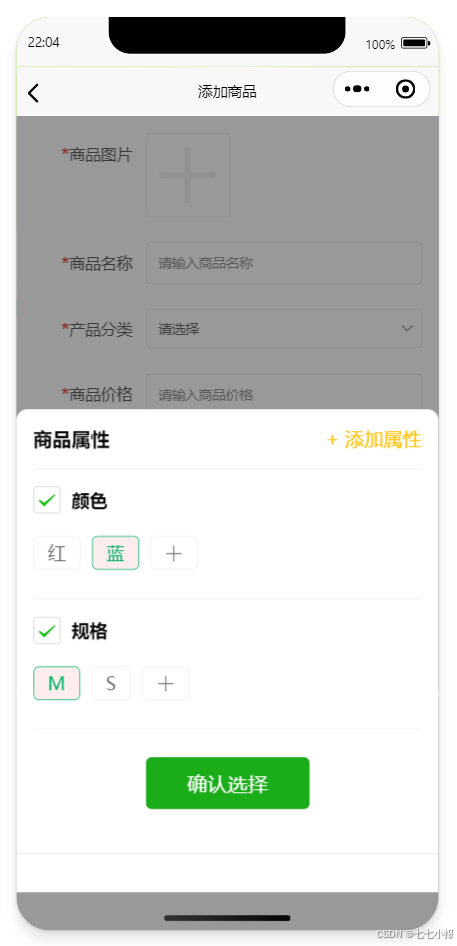
uniapp-商城-64-后台 商品列表(商品修改---页面跳转,深浅copy应用,递归调用等)
完成了商品的添加和展示,下面的文字将继续进行商品页面的处理,主要为商品信息的修改的页面以及后天逻辑的处理。 本文主要介绍了商品信息修改页面的实现过程。首先,页面布局包括编辑和删除功能,未来还可添加上架和下架按钮。通过c…...
Dify的大语言模型(LLM) AI 应用开发平台-本地部署
前言 今天闲着,捣鼓一下 Dify 这个开源平台,在 mac 系统上,本地部署并运行 Dify 平台,下面记录个人在本地部署Dify 的过程。 Dify是什么? Dify是一个开源的大语言模型(LLM)应用开发平台&#…...

使用教程:8x16模拟开关阵列可级联XY脚双向导通自动化接线
以下通过点亮LED进行基本使用流程演示,实际可以连接复杂外设(SPI、CAN、ADC等) 单模块使用 RX、TX、5V和GND接到串口模块;X5接5V;Y2接LED;LED-接GND 串口模块插上电脑后,LED没有亮;因为此时模…...

移动端前端调试调研纪实:从痛点出发,到 WebDebugX 的方案落地
这个月我接到一个内部调研任务:为公司的新一代 Hybrid 框架选型合适的前端调试解决方案。初衷其实很简单——以前的调试方式效率太低,影响开发和测试协同,产品问题总是复现难、修复慢。 于是我花了两周时间,试用了包括 Eruda、Re…...

8 种快速易用的Python Matplotlib数据可视化方法
你是否曾经面对一堆复杂的数据,却不知道如何让它们变得直观易懂?别慌,Python 的 Matplotlib 库是你数据可视化的最佳伙伴!它简单易用、功能强大,能将枯燥的数字变成引人入胜的图表。无论是学生、数据分析师还是程序员&…...