分布式ID生成器:原理、对比与WorkerID实战
一、为什么需要分布式ID?
在微服务架构下,单机自增ID无法满足跨服务唯一性需求,且存在:
• 单点瓶颈:数据库自增ID依赖单表写入
• 全局唯一性:跨服务生成可能重复
• 扩展性差:分库分表后ID规则冲突
• 信息安全:连续ID易被猜测引发安全风险
二、主流方案对比分析
| 方案 | 核心原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| UUID | 128位随机数 | 本地生成无依赖 | 存储占用大、索引效率低 | 非核心业务ID |
| 数据库自增 | SELECT LAST_INSERT_ID() | 实现简单 | 单点瓶颈、横向扩展难 | 小规模分表 |
| Snowflake | 时间戳+WorkerID+序列号 | 高性能、趋势递增 | 时钟回拨问题 | 高并发分布式系统 |
| Redis INCR | 原子操作生成自增值 | 简单可靠 | 依赖Redis可用性 | 中等规模在线业务 |
| Leaf-Segment | 数据库号段模式 | 天然支持分库分表 | 需维护号段状态 | 高可用性要求场景 |
三、基于WorkerID的Snowflake方案详解
3.1 架构设计
+---------------------+
| ID生成服务集群 |
| +---------------+ |
| | Worker节点1 | |
| | (workerId=1) | |
| +---------------+ |
| +---------------+ |
| | Worker节点2 | |
| | (workerId=2) | |
| +---------------+ |
| ZooKeeper/Etcd |
| (协调WorkerID分配) |
+---------------------+
3.2 核心原理
ID结构(64位Long型):
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+---------------+---------------+-----------------+-------------+
| 符号位 | 时间戳 | WorkerID | 序列号 |
+---------------+---------------+-----------------+-------------+
• 符号位:固定0保证正数
• 时间戳:41位支持约69年(2^41ms ≈ 69年)
• WorkerID:10位支持1024个节点
• 序列号:12位支持每毫秒4096个ID
3.3 核心问题解决方案
3.3.1 WorkerID分配
// 使用ZooKeeper持久化分配
public class WorkerIdAllocator {private CuratorFramework client;public int allocateWorkerId() {InterProcessMutex lock = new InterProcessMutex(client, "/worker_id_lock");try {lock.acquire();// 从持久化存储获取最小可用IDreturn fetchNextAvailableId();} finally {lock.release();}}
}
3.3.2 时钟回拨处理
public synchronized long nextId() {long currentTimestamp = timeGen();if (currentTimestamp < lastTimestamp) {// 时钟回拨处理:等待或抛出异常long offset = lastTimestamp - currentTimestamp;if (offset <= 5) {Thread.sleep(offset << 1);currentTimestamp = timeGen();} else {throw new ClockBackwardException("时钟回拨超过允许范围");}}// 正常生成逻辑...
}
四、实战开发指南
4.1 Java实现核心代码
public class SnowflakeIdGenerator {private final long workerId;private long lastTimestamp = -1L;private long sequence = 0L;public SnowflakeIdGenerator(long workerId) {this.workerId = workerId;}public synchronized String nextId() {long timestamp = System.currentTimeMillis();if (timestamp < lastTimestamp) {throw new RuntimeException("时钟回拨");}if (timestamp == lastTimestamp) {sequence = (sequence + 1) & 0xFFF;if (sequence == 0) {timestamp = waitNextMillis(timestamp);}} else {sequence = 0L;}lastTimestamp = timestamp;return String.format("%d-%04d-%04d",timestamp,workerId,sequence);}private long waitNextMillis(long currentTimestamp) {while (currentTimestamp <= lastTimestamp) {currentTimestamp = System.currentTimeMillis();}return currentTimestamp;}
}
4.2 WorkerID分配策略
- 静态配置:手动分配(适合固定节点)
- 动态协调:ZooKeeper/Etcd选举(适合动态扩缩容)
- 虚拟节点:Redis原子计数(适合云环境)
4.3 配置参数优化
| 参数 | 推荐值 | 说明 |
|---|---|---|
| workerIdBits | 10 | 支持1024个节点 |
| timestampBits | 41 | 支持69年时间范围 |
| sequenceBits | 12 | 每节点每毫秒4096个ID |
| epoch | 自定义起始时间 | 延长可用时间范围 |
五、性能测试报告
5.1 测试环境
• 服务器:4核8G CentOS 7.9
• 并发数:10,000线程
• 测试工具:JMeter 5.6 + WebSocketSampler
• ID生成器:Snowflake实现(单机部署)
5.2 测试结果
| 指标 | 数值 |
|---|---|
| 吞吐量(TPS) | 1,220,000 |
| 平均延迟 | 0.8ms |
| CPU利用率 | 38% |
| 内存消耗 | 256MB/小时 |
| 时钟回拨触发次数 | 0(NTP同步下) |
5.3 性能优化建议
- 批量生成:预生成1000个ID缓存
- 时钟同步:配置NTP服务(同步精度<1ms)
- 多节点部署:横向扩展WorkerID数量
- 异步日志:分离ID生成与业务日志
六、生产环境部署实践
6.1 高可用架构
+---------------------+
| ID生成集群 |
| +---------------+ |
| | Node1 | |
| | (workerId=1) | |
| +---------------+ |
| +---------------+ |
| | Node2 | |
| | (workerId=2) | |
| +---------------+ |
| ZooKeeper集群 |
| (服务发现+选举) |
+---------------------+
6.2 监控指标
• 时钟偏移量:监控系统与NTP服务器差值
• WorkerID冲突:通过Redis分布式锁检测
• 序列号溢出:记录异常日志并报警
七、扩展方案对比
7.1 Snowflake vs Leaf-Segment
| 特性 | Snowflake | Leaf-Segment |
|---|---|---|
| 依赖组件 | ZooKeeper/NTP | 数据库 |
| ID有序性 | 时间趋势递增 | 号段内有序 |
| 扩容复杂度 | 需协调WorkerID | 自动分配号段 |
| 存储压力 | 无 | 需维护号段表 |
7.2 阿里Leaf方案特点
- 双Buffer号段:预加载下一个号段
- 失效转移:心跳检测自动切换节点
- 多DB支持:兼容MySQL/Oracle
八、总结与选型建议
• 中小规模系统:Snowflake + ZooKeeper(简单高效)
• 金融级系统:Leaf双Buffer方案(强一致性)
• 云原生环境:Snowflake + 云厂商时间服务(如AWS Time Sync)
相关文章:

分布式ID生成器:原理、对比与WorkerID实战
一、为什么需要分布式ID? 在微服务架构下,单机自增ID无法满足跨服务唯一性需求,且存在: • 单点瓶颈:数据库自增ID依赖单表写入 • 全局唯一性:跨服务生成可能重复 • 扩展性差:分库分表后ID规…...
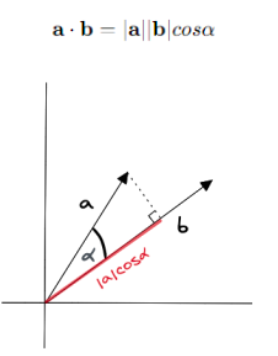
java 代码查重(三)常见的距离算法和相似度(相关系数)计算方法
目录 一、几种距离度量方法 【 海明距离 /汉明距离】 【 欧几里得距离(Euclidean Distance) 】 【 曼哈顿距离 】 【 切比雪夫距离 】 【 马氏距离 】 二、相似度算法 【 余弦相似度 】 【 皮尔森相关系数 】 【 Jaccard相似系数 /杰卡德距离】…...
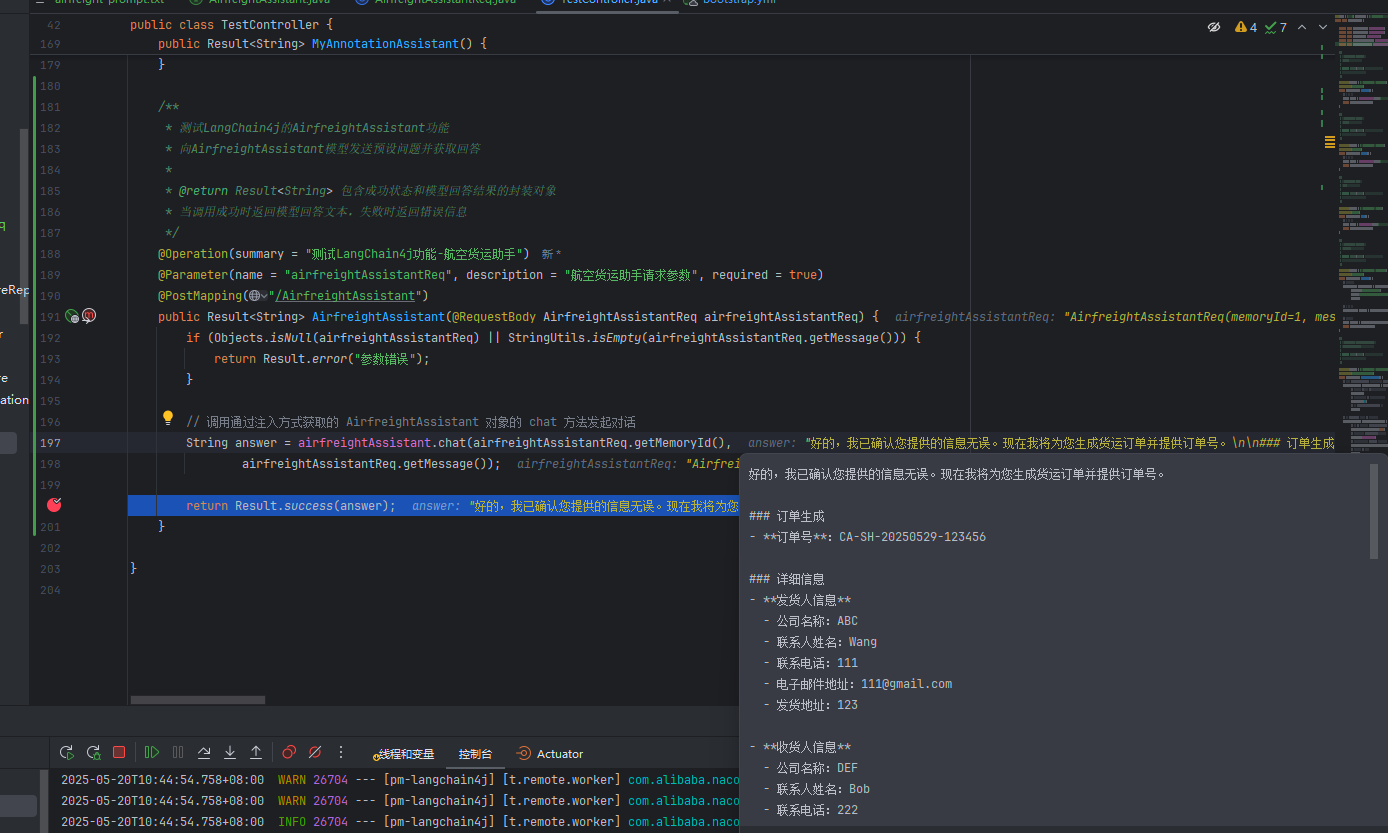
LangChain4j入门AI(六)整合提示词(Prompt)
前言 提示词(Prompt)是用户输入给AI模型的一段文字或指令,用于引导模型生成特定类型的内容。通过提示词,用户可以告诉AI“做什么”、 “如何做”以及“输出格式”,从而在满足需求的同时最大程度减少无关信息的生成。有…...
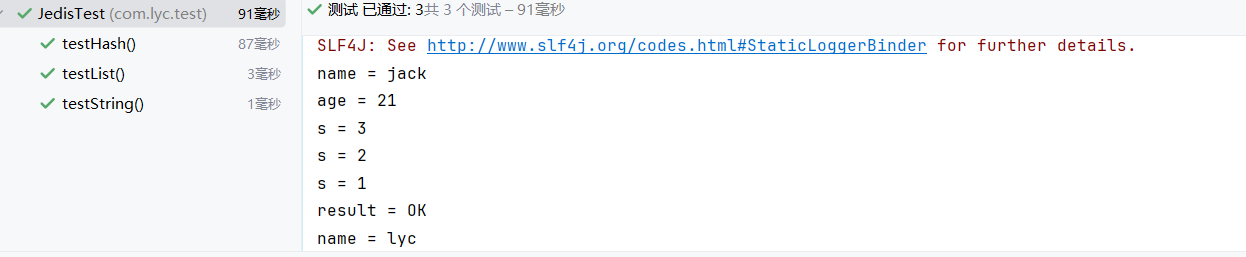
redis--redisJava客户端:Jedis详解
在Redis官网中提供了各种语言的客户端,地址: https://redis.io/docs/latest/develop/clients/ Jedis 以Redis命令做方法名称,学习成本低,简单实用,但是对于Jedis实例是线程不安全的(即创建一个Jedis实例&a…...
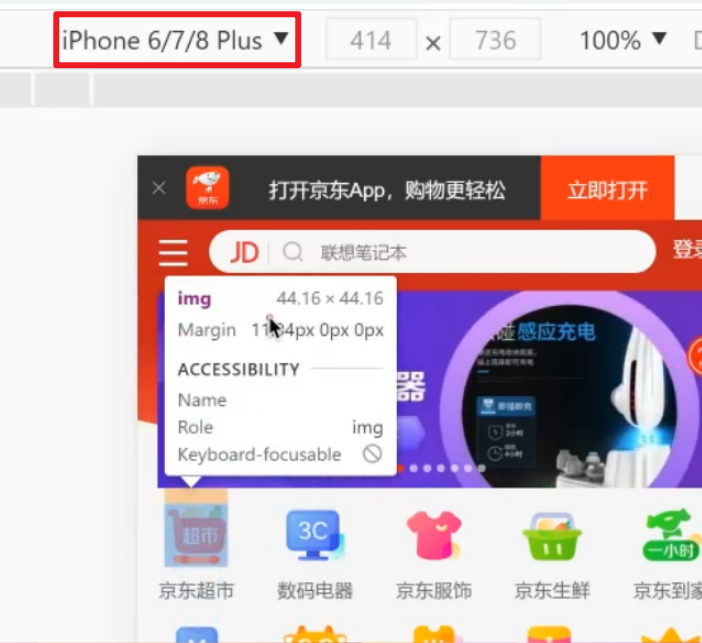
[CSS3]百分比布局
移动端特点 PC和手机 PC端网页和移动端网页的有什么不同? PC屏幕大,网页固定版心手机屏幕小,网页宽度多数为100% 谷歌模拟器 使用谷歌模拟器可以在电脑里面调试移动端的网页 屏幕尺寸 了解屏幕尺寸概念 屏幕尺寸: 指的是屏幕对角线的长度ÿ…...
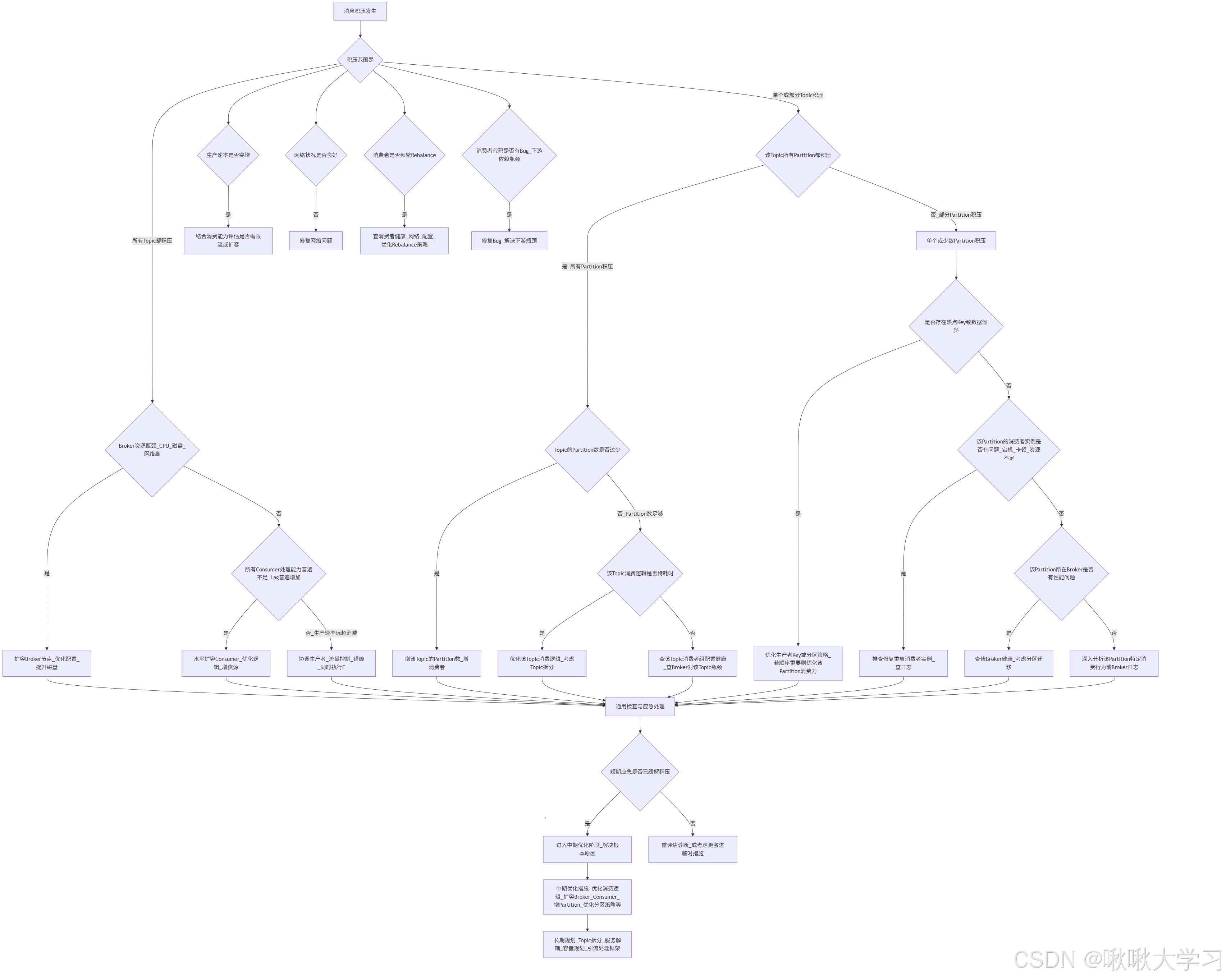
【Java微服务组件】异步通信P2—Kafka与消息
欢迎来到啾啾的博客🐱。 记录学习点滴。分享工作思考和实用技巧,偶尔也分享一些杂谈💬。 欢迎评论交流,感谢您的阅读😄。 目录 引言Kafka与消息生产者发送消息到Kafka批处理发送设计消息的幂等信息确保消息送达acks配置…...
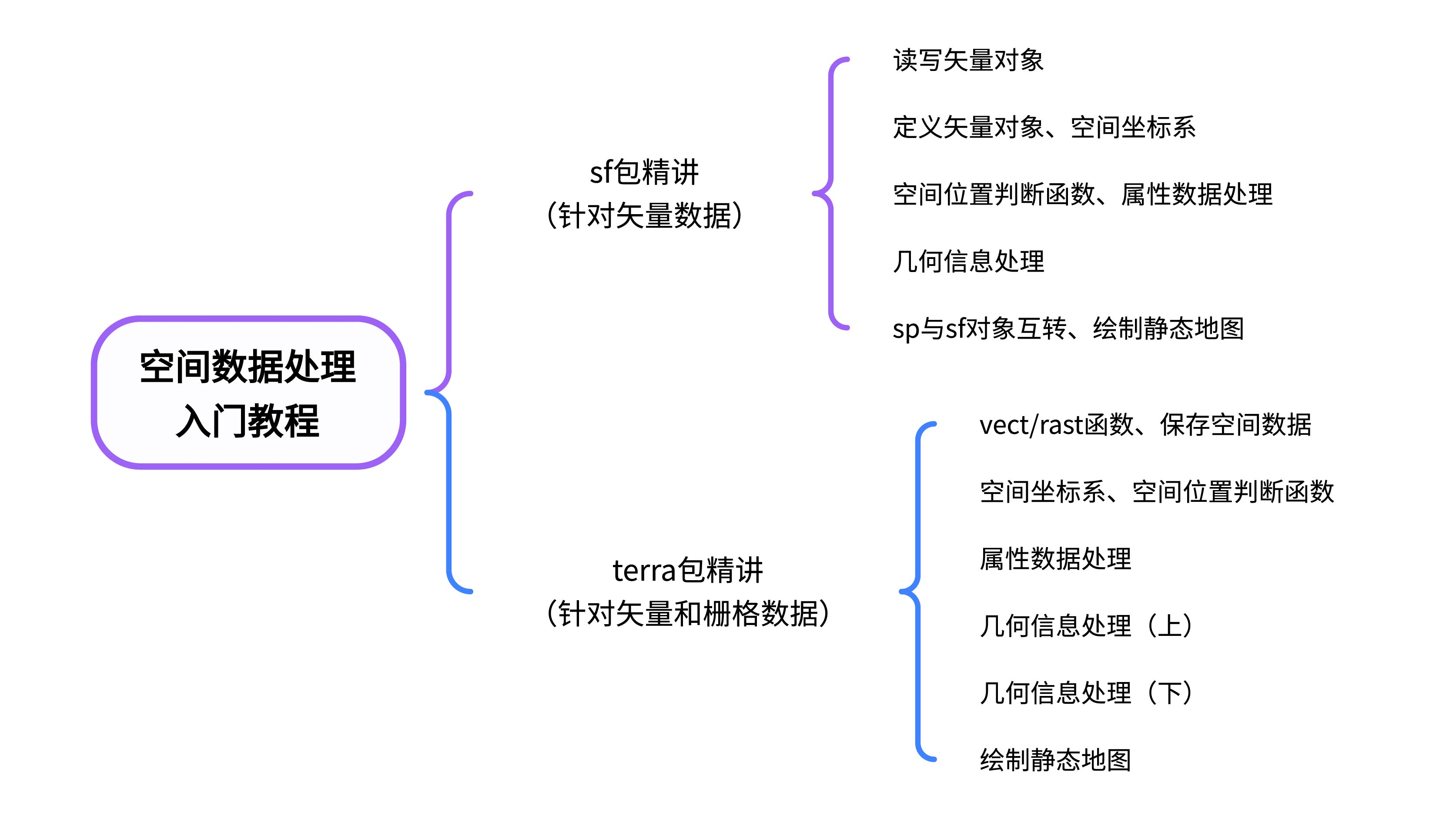
R语言空间数据处理入门教程
我的课程《R语言空间数据处理入门教程》已重新恢复课程售卖,有需要的读者可以学习。 👇点击下方链接(文末“阅读原文”可直达),立即开启你的空间数据之旅: https://www.bilibili.com/cheese/play/ss13775…...
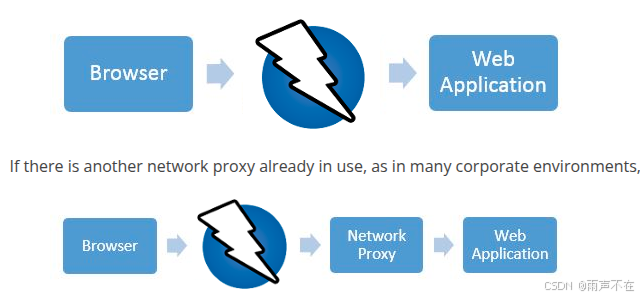
使用zap,对web应用/API接口 做安全检测
https://www.zaproxy.org/getting-started/ 检测方法 docker pull ghcr.io/zaproxy/zaproxy:stable# 执行baseline测试 docker run -t ghcr.io/zaproxy/zaproxy:stable zap-baseline.py \ -t https://baseline.yeshen.org# 执行api测试 docker run -t ghcr.io/zaproxy/zaproxy…...

UE5.6新版本—— 动画光照系统重点更新
UE5.6预览版已经可以下载,发布会在下个月的6.5号发布。 5.6界面UI设计 5.6 对引擎进行了大规模的重新设计,先看整体内容,主题UI设计 被调整了位置,左边大多数的选择,框选工具,吸附工具,挪到了左…...

TypeScript 泛型讲解
如果说 TypeScript 是一门对类型进行编程的语言,那么泛型就是这门语言里的(函数)参数。本章,我将会从多角度讲解 TypeScript 中无处不在的泛型,以及它在类型别名、对象类型、函数与 Class 中的使用方式。 一、泛型的核…...
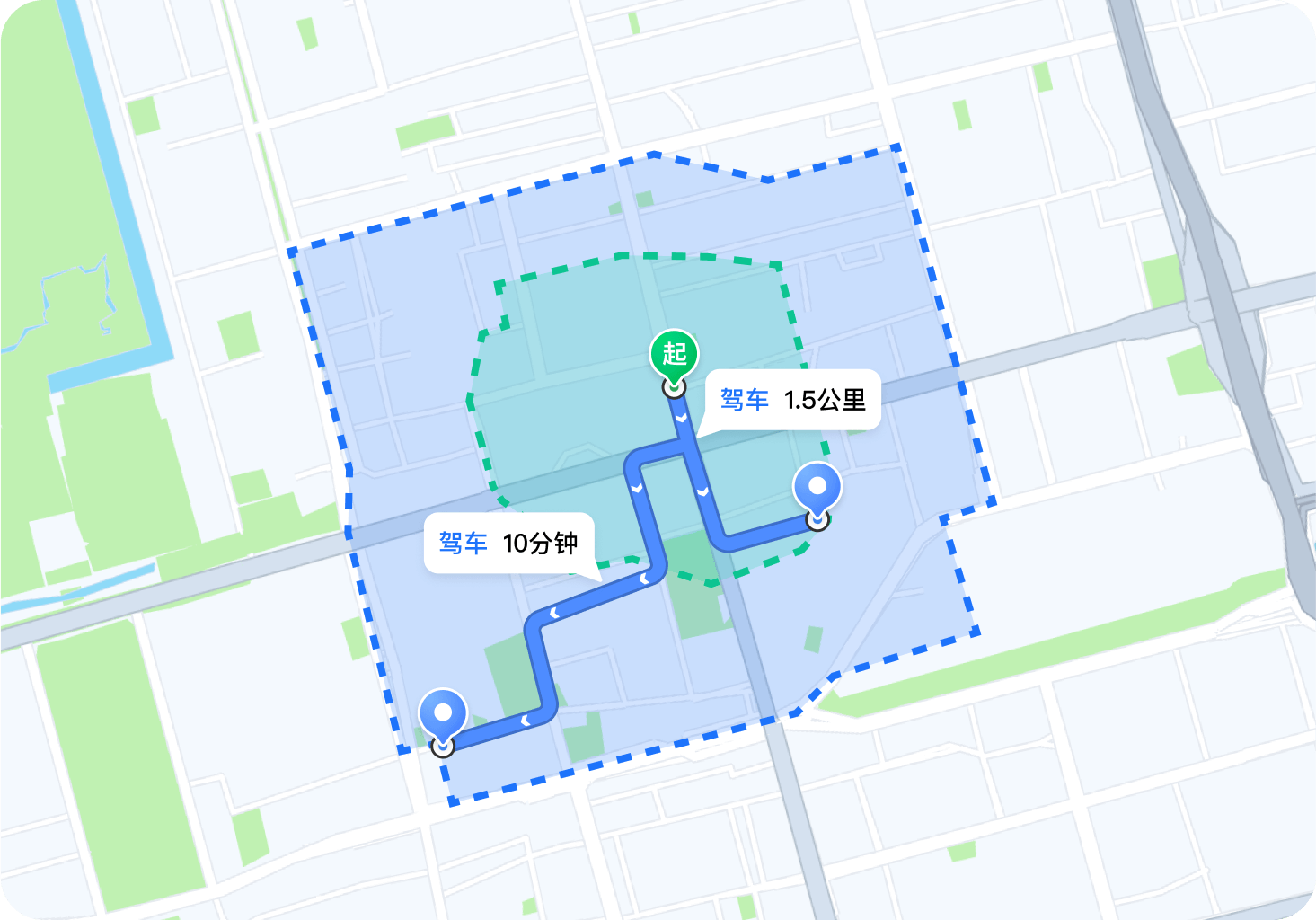
腾讯位置服务重构出行行业的技术底层逻辑
位置智能:重构出行行业的技术底层逻辑 在智慧城市建设与交通出行需求爆发的双重驱动下,位置服务正从工具层跃升为出行行业的核心基础设施。腾讯位置服务以“连接物理世界与数字空间”为核心理念,通过构建高精度定位、实时数据融合、智能决策…...

面试相关的知识点
1 vllm 1.1常用概念 1 vllm:是一种大模型推理的框架,使用了张量并行原理,把大型矩阵分割成低秩矩阵,分散到不同的GPU上运行。 2 模型推理与训练:模型训练是指利用pytorch进行对大模型进行预训练。 模型推理是指用训…...
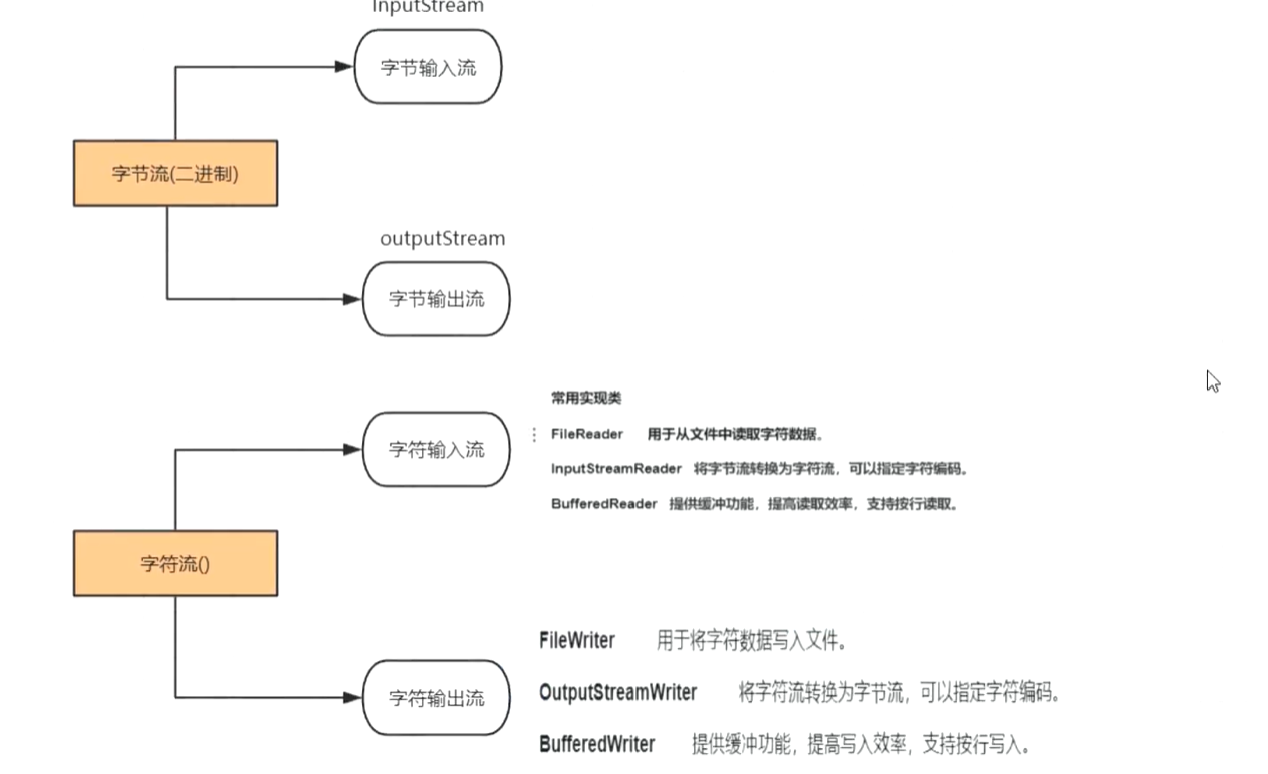
如何用JAVA手写一个Tomcat
一、初步理解Tomcat Tomcat是什么? Tomcat 是一个开源的 轻量级 Java Web 应用服务器,核心功能是 运行 Servlet/JSP。 Tomcat的核心功能? Servlet 容器:负责加载、实例化、调用和销毁 Servlet。 HTTP 服务器:监听端口…...
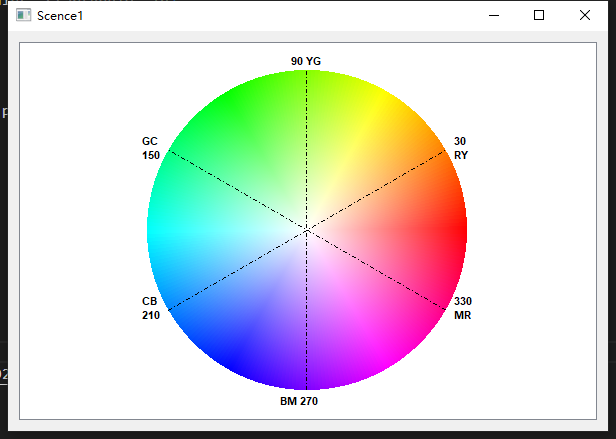
使用 Qt QGraphicsView/QGraphicsScene 绘制色轮
使用 Qt QGraphicsView/QGraphicsScene 绘制色轮 本文介绍如何在 Qt 中利用 QGraphicsView 和 QGraphicsScene 实现基础圆形绘制,以及进阶的色轮(Color Wheel)效果。 色轮是色彩选择器的常见控件,广泛应用于图形设计、绘画和 UI …...
:Python复刻「崩坏星穹铁道」嗷呜嗷呜事务所---源码级解析该小游戏背后的算法与设计模式【纯原创】)
游戏开发实战(三):Python复刻「崩坏星穹铁道」嗷呜嗷呜事务所---源码级解析该小游戏背后的算法与设计模式【纯原创】
文章目录 奇美拉类摸鱼仔,负能量,真老实,小坏蛋,压力怪治愈师小团体画饼王平凡王坏脾气抗压包请假狂请假王内卷王受气包跑路侠看乐子背锅侠抢功劳急先锋说怪话帮倒忙小夸夸工作狂职业经理严酷恶魔职场清流 开始工作吧小奇美拉没想…...
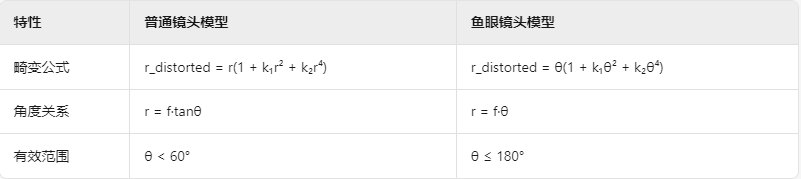
使用glsl 来做视频矫正
描述、优点 使用glsl来代替opencv的undistort 和 鱼眼矫正,并且最后使用opencv的LUT给glsl 来使用,来达到加速的目的,并且做到和opencv 一模一样的效果,达到实时视频的加速矫正。 优点: 没有cuda,也可以做到实时视频矫正,包含各类板子和amd的cpu,intel核显 矫正的基本作…...
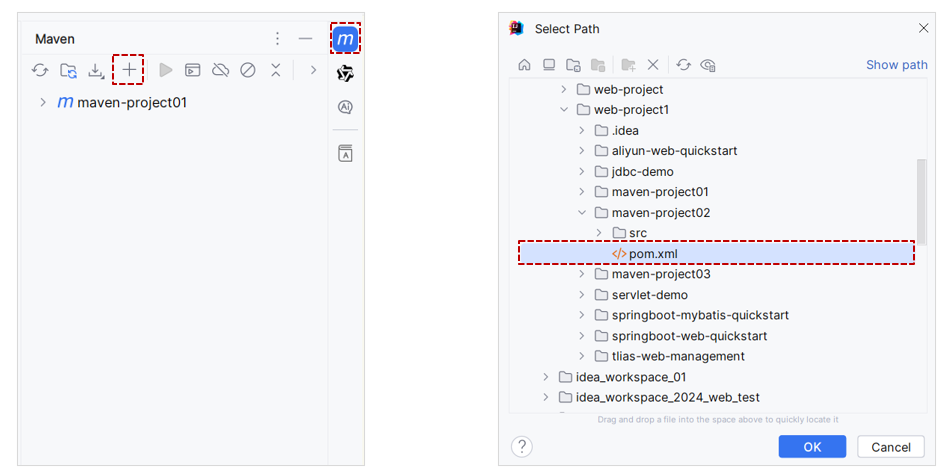
03-Web后端基础(Maven基础)
1. 初始Maven 1.1 介绍 Maven 是一款用于管理和构建Java项目的工具,是Apache旗下的一个开源项目 。 Apache 软件基金会,成立于1999年7月,是目前世界上最大的最受欢迎的开源软件基金会,也是一个专门为支持开源项目而生的非盈利性…...

LLM驱动下的软件工程再造:驾驭调试、测试与工程化管理的智能新范式
摘要: 大语言模型(LLM)驱动的软件开发正以前所未有的力量重塑整个行业,从以人为中心的编码模式迅速转向意图驱动和AI编排的智能生成。这场变革带来了生产力的指数级飞跃,但也对传统软件工程中调试、测试和代码工程化管理的核心支柱发起了深刻挑战。本文将剖析这些根本性转…...

大语言模型与人工智能:技术演进、生态重构与未来挑战
目录 技术演进:从专用AI到通用智能的跃迁核心能力:LLM如何重构AI技术栈应用场景:垂直领域的技术革命生态关系:LLM与AI技术矩阵的协同演进挑战局限:智能天花板与伦理困境未来趋势:从语言理解到世界模型1. 技术演进:从专用AI到通用智能的跃迁 1.1 三次技术浪潮的跨越 #me…...

SpringSecurity授权、认证
引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-thymeleaf</artifactId> </dependency> <dependency><groupId>org.springframework.boot</groupId><artifactI…...
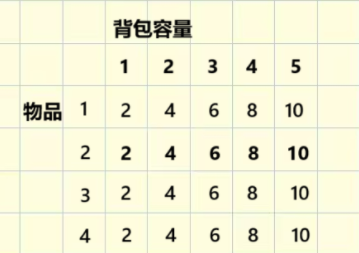
蓝桥杯19682 完全背包
问题描述 有 N 件物品和一个体积为 M 的背包。第 i 个物品的体积为 vi,价值为 wi。每件物品可以使用无限次。 请问可以通过什么样的方式选择物品,使得物品总体积不超过 M 的情况下总价值最大,输出这个最大价值即可。 输入格式 第一行…...

DeepSeek源码解构:从MoE架构到MLA的工程化实现
文章目录 **一、代码结构全景:从模型定义到分布式训练****二、MoE架构:动态路由与稀疏激活的工程化实践****1. 专家路由机制(带负载均衡)****数学原理:负载均衡损失推导** **三、MLA注意力机制:低秩压缩与解…...

leetcode 3355. 零数组变换 I 中等
给定一个长度为 n 的整数数组 nums 和一个二维数组 queries,其中 queries[i] [li, ri]。 对于每个查询 queries[i]: 在 nums 的下标范围 [li, ri] 内选择一个下标 子集。将选中的每个下标对应的元素值减 1。 零数组 是指所有元素都等于 0 的数组。 …...
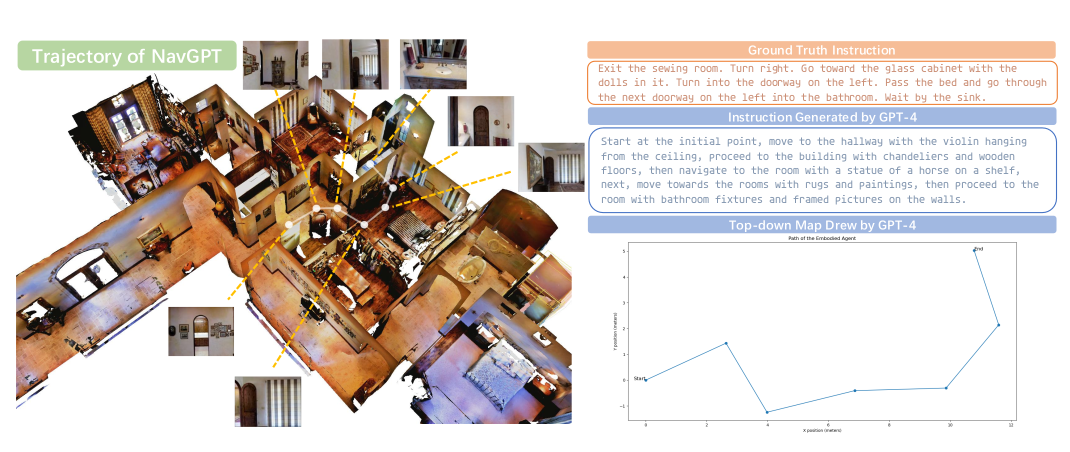
【VLNs篇】02:NavGPT-在视觉与语言导航中使用大型语言模型进行显式推理
方面 (Aspect)内容总结 (Content Summary)论文标题NavGPT: 在视觉与语言导航中使用大型语言模型进行显式推理 (NavGPT: Explicit Reasoning in Vision-and-Language Navigation with Large Language Models)核心问题探究大型语言模型 (LLM) 在复杂具身场景(特别是视…...
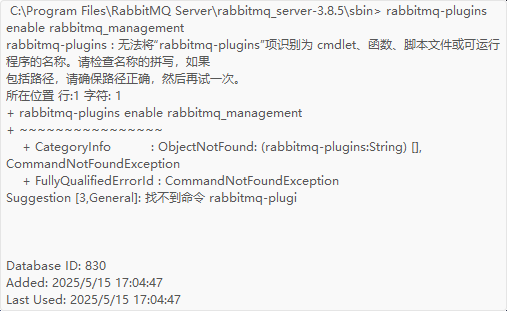
(T_T),不小心删掉RabbitMQ配置文件数据库及如何恢复
一、不小心删除 今天是2025年5月15日,非常沉重的一天,就在今早8点左右的时候我打算继续做我的毕业设计,由于开机的过程十分缓慢(之前没有),加上刚开机电脑有卡死的迹象,再加上昨天晚上关电脑前…...

创建react工程并集成tailwindcss
1. 创建工程 npm create vite admin --template react 2.集成tailwndcss 打开官网跟着操作一下就行。 Installing Tailwind CSS with Vite - Tailwind CSS...
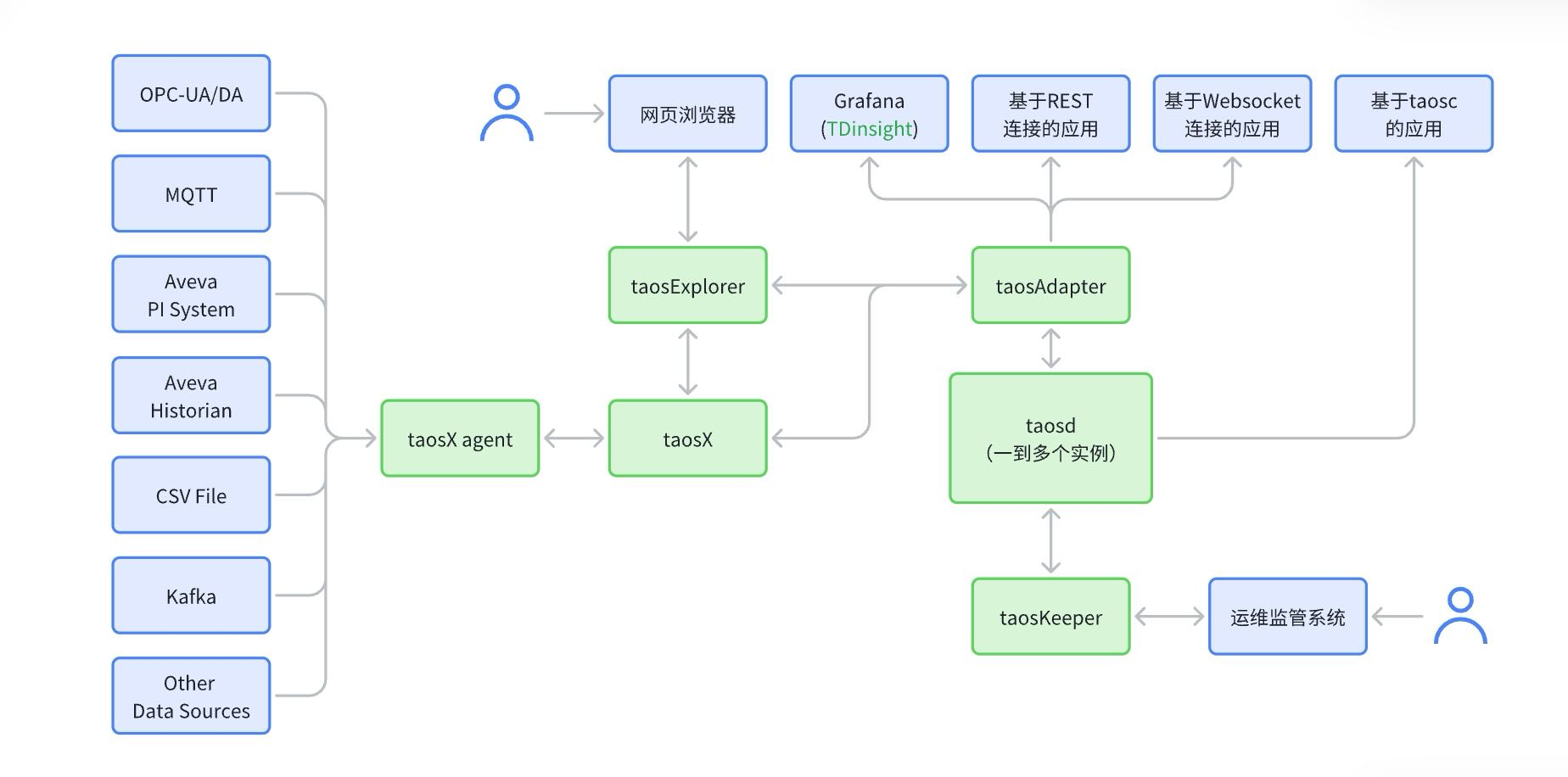
TDengine 安全部署配置建议
背景 TDengine 的分布式、多组件特性导致 TDengine 的安全配置是生产系统中比较关注的问题。本文档旨在对 TDengine 各组件及在不同部署方式下的安全问题进行说明,并提供部署和配置建议,为用户的数据安全提供支持。 安全配置涉及组件 TDengine 包含多…...
)
Axure全链路交互设计:快速提升实现能力(基础交互+高级交互)
想让你的设计稿像真实App一样丝滑?本专栏带你玩转Axure交互,从选中高亮到动态面板骚操作,再到中继器表单花式交互,全程动图教学,一看就会! 本专栏系统讲解多个核心交互效果,是你的Axure交互急救…...

为什么wifi有信号却连接不上?
WiFi有信号,无法连接WiFi网络的可能原因及解决方法: 1.长时间使用路由器,路由器可能会出现假死现象。重启无线路由器即可。 2.认证类型不合适。尝试更改路由器的认证类型,选择安全的 “WPA2-PSK” 类型模式要好,下面…...
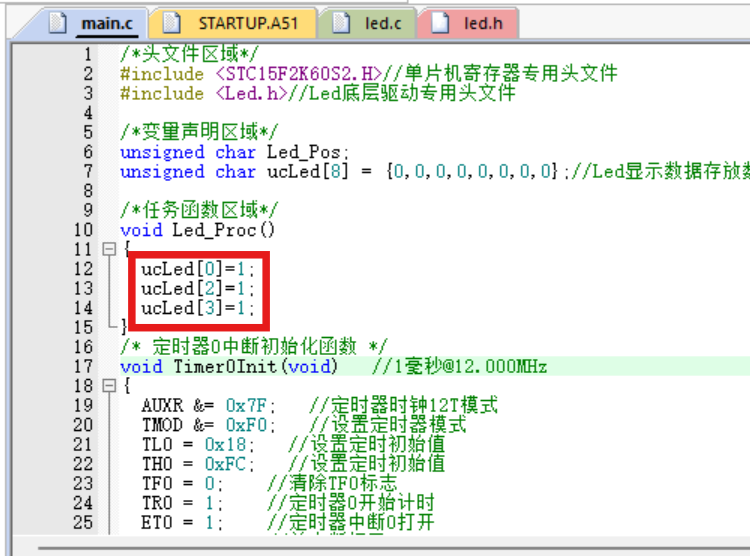
蓝桥杯框架-LED蜂鸣器继电器
蓝桥杯框架-LED蜂鸣器继电器 一,新建工程文件二,配置keil三,完善框架 一,新建工程文件 在桌面上新建一个文件夹:用于存放所有工程文件 在文件夹中再建立一个文件夹DEMO_01:这是我们的第一个工程文件 在第…...