大模型微调与高效训练
随着预训练大模型(如BERT、GPT、ViT、LLaMA、CLIP等)的崛起,人工智能进入了一个新的范式:预训练-微调(Pre-train, Fine-tune)。这些大模型在海量数据上学习到了通用的、强大的表示能力和世界知识。然而,要将这些通用模型应用于特定的下游任务或领域,通常还需要进行微调(Fine-tuning)。
微调的核心在于调整预训练模型的参数,使其更好地适应目标任务的数据分布和特定需求。但大模型通常拥有数十亿甚至数万亿的参数,直接进行全参数微调会带来巨大的计算资源和存储挑战。本章将深入探讨大模型微调的策略,以及如何采用高效训练技术来应对这些挑战。
4.1 大模型微调:从通用到专精
4.1.1 为什么需要微调?
尽管预训练大模型具有强大的泛化能力,但它们在预训练阶段看到的数据通常是通用的、领域无关的。当我们需要它们完成特定领域的任务时,例如医疗文本分类、法律问答、特定风格的图像生成等,通用知识可能不足以满足需求。微调的目的是:
- 适应任务特异性: 调整模型,使其更好地理解和处理特定任务的输入输出格式及语义。
- 适应数据分布: 将模型知识迁移到目标任务的特定数据分布上,提高模型在目标数据上的性能。
- 提升性能: 通常,经过微调的模型在特定下游任务上的表现会显著优于直接使用预训练模型。
- 提高效率: 相较于从头开始训练一个新模型,微调一个预训练大模型通常更快、更有效。
4.1.2 全参数微调 (Full Fine-tuning)
核心思想: 全参数微调是最直接的微调方法,它解冻(unfreeze)预训练模型的所有参数,并使用目标任务的标注数据对其进行端到端(end-to-end)的训练。
原理详解: 在全参数微调中,我们加载一个预训练模型的权重,然后像训练一个普通神经网络一样,使用新的数据集和损失函数来训练它。由于模型的所有层都参与梯度计算和参数更新,理论上模型可以最大程度地适应新任务。
优点:
- 性能潜力大: 如果资源允许且数据集足够大,全参数微调通常能达到最佳性能。
- 概念简单: 实现起来相对直接。
缺点:
- 计算资源需求巨大: 对于拥有数十亿参数的大模型,全参数微调需要大量的GPU显存和计算时间。
- 存储成本高昂: 每个下游任务都需要存储一套完整的模型参数,不便于多任务部署。
- 灾难性遗忘(Catastrophic Forgetting): 在小规模数据集上进行微调时,模型可能会“遗忘”在预训练阶段学到的通用知识,导致在其他任务上的性能下降。
Python示例:简单文本分类的全参数微调
我们将使用一个预训练的BERT模型进行情感分类任务的全参数微调。
Python
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset, Dataset
import numpy as np
from sklearn.metrics import accuracy_score, precision_recall_fscore_support# 1. 加载预训练模型和分词器
model_name = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2) # 2个类别:正面/负面情感# 2. 准备数据集 (使用Hugging Face datasets库加载一个情感分析数据集)
# 这里使用 'imdb' 数据集作为示例
# 如果是第一次运行,会自动下载
print("Loading IMDb dataset...")
dataset = load_dataset("imdb")# 预处理数据
def preprocess_function(examples):return tokenizer(examples["text"], truncation=True, padding="max_length", max_length=128)tokenized_imdb = dataset.map(preprocess_function, batched=True)# 重命名标签列为 'labels' 以符合Trainer的要求
tokenized_imdb = tokenized_imdb.rename_columns({"label": "labels"})
# 移除原始文本列
tokenized_imdb = tokenized_imdb.remove_columns(["text"])
# 设置格式为PyTorch tensors
tokenized_imdb.set_format("torch")# 划分训练集和测试集
small_train_dataset = tokenized_imdb["train"].shuffle(seed=42).select(range(2000)) # 使用小部分数据进行演示
small_eval_dataset = tokenized_imdb["test"].shuffle(seed=42).select(range(500))# 3. 定义评估指标
def compute_metrics(p):predictions, labels = ppredictions = np.argmax(predictions, axis=1)precision, recall, f1, _ = precision_recall_fscore_support(labels, predictions, average='binary')acc = accuracy_score(labels, predictions)return {'accuracy': acc,'f1': f1,'precision': precision,'recall': recall}# 4. 配置训练参数
training_args = TrainingArguments(output_dir="./results_full_finetune",num_train_epochs=3, # 训练轮次per_device_train_batch_size=16, # 训练批次大小per_device_eval_batch_size=16, # 评估批次大小warmup_steps=500, # 学习率预热步数weight_decay=0.01, # 权重衰减logging_dir='./logs_full_finetune', # 日志目录logging_steps=100,evaluation_strategy="epoch", # 每个epoch结束后评估save_strategy="epoch", # 每个epoch结束后保存模型load_best_model_at_end=True, # 训练结束后加载最佳模型metric_for_best_model="f1", # 衡量最佳模型的指标report_to="none" # 不上传到任何在线平台
)# 5. 初始化Trainer并开始训练
trainer = Trainer(model=model,args=training_args,train_dataset=small_train_dataset,eval_dataset=small_eval_dataset,compute_metrics=compute_metrics,
)print("\n--- BERT 全参数微调示例 ---")
# 检查是否有GPU可用
if torch.cuda.is_available():print(f"Using GPU: {torch.cuda.get_device_name(0)}")
else:print("No GPU available, training on CPU (will be slow).")trainer.train()print("\nFull fine-tuning completed. Evaluation results:")
eval_results = trainer.evaluate()
print(eval_results)代码说明:
- 我们使用了Hugging Face
transformers库的TrainerAPI,它极大地简化了训练过程。 AutoTokenizer和AutoModelForSequenceClassification自动加载BERT模型和对应的分词器。load_dataset("imdb")用于获取情感分类的示例数据。preprocess_function将文本转换为模型可以理解的token ID序列。TrainingArguments用于配置各种训练参数,如学习率、批次大小、保存策略等。compute_metrics定义了用于评估模型性能的指标。trainer.train()启动训练过程。
4.1.3 参数高效微调 (Parameter-Efficient Fine-tuning, PEFT)
核心思想: PEFT旨在解决全参数微调的缺点,它通过只微调预训练模型中少量新增或现有参数,同时冻结大部分预训练参数,从而大大降低计算和存储成本,并有效避免灾难性遗忘。
PEFT方法可以分为几大类:
- 新增适配器模块: 在预训练模型的中间层或输出层插入小型的可训练模块(Adapter)。
- 软提示: 优化输入中少量连续的、可学习的“软提示”或“前缀”,而不是修改模型参数。
- 低秩适应: 通过低秩分解来近似全参数更新,减少可训练参数。
我们将重点介绍其中最流行且高效的几种方法。
4.1.3.1 LoRA (Low-Rank Adaptation)

- 显著减少可训练参数: 大幅降低显存消耗和训练时间。
- 避免灾难性遗忘: 预训练权重冻结,保护了通用知识。
- 部署高效: 可以在推理时合并权重,不增加额外延迟。
- 多任务部署: 针对不同任务,只需存储和加载很小的 (BA) 矩阵。
Python示例:使用peft库进行LoRA微调
我们将使用Hugging Face的peft库对预训练的GPT-2模型进行LoRA微调,用于文本生成任务。
首先,确保安装peft库:
Bash
<
相关文章:
大模型微调与高效训练
随着预训练大模型(如BERT、GPT、ViT、LLaMA、CLIP等)的崛起,人工智能进入了一个新的范式:预训练-微调(Pre-train, Fine-tune)。这些大模型在海量数据上学习到了通用的、强大的表示能力和世界知识。然而,要将这些通用模型应用于特定的下游任务或领域,通常还需要进行微调…...

LLM驱动的未来软件工程范式与架构策略
历史回顾与范式奠基 软件工程自其诞生以来,经历了数次里程碑式的范式变革。最初的汇编语言时代,程序员与机器指令直接对话,效率低下,代码难以复用。随后,高级语言(如Fortran、C)的出现,通过抽象层极大地提升了开发效率,并催生了面向过程的编程范式。进入20世纪末,面…...
OpenCv高阶(十六)——Fisherface人脸识别
文章目录 前言一、Fisherface人脸识别原理1. 核心思想:LDA与Fisher准则2. 实现步骤(1) 数据预处理(2) 计算类内散布矩阵 SW对每个类别(每个人)计算均值向量 μi:(3) 计算类间散布矩阵 SB(4) 求解投影矩阵 W(5) 降维与分类 3. Fish…...

Unity3D 异步加载材质显示问题排查
前言 在Unity3D中异步加载材质后未正确显示的问题,通常涉及资源加载流程、材质引用或Shader配置。以下是逐步排查和解决问题的方案: 对惹,这里有一个游戏开发交流小组,希望大家可以点击进来一起交流一下开发经验呀! …...

【Django Serializer】一篇文章详解 Django 序列化器
第一章 Django 序列化器概述 1.1 序列化器的定义 1.1.1 序列化与反序列化的概念 1. 序列化 想象你有一个装满各种物品(数据对象)的大箱子(数据库),但是你要把这些物品通过一个狭窄的管道(网络ÿ…...
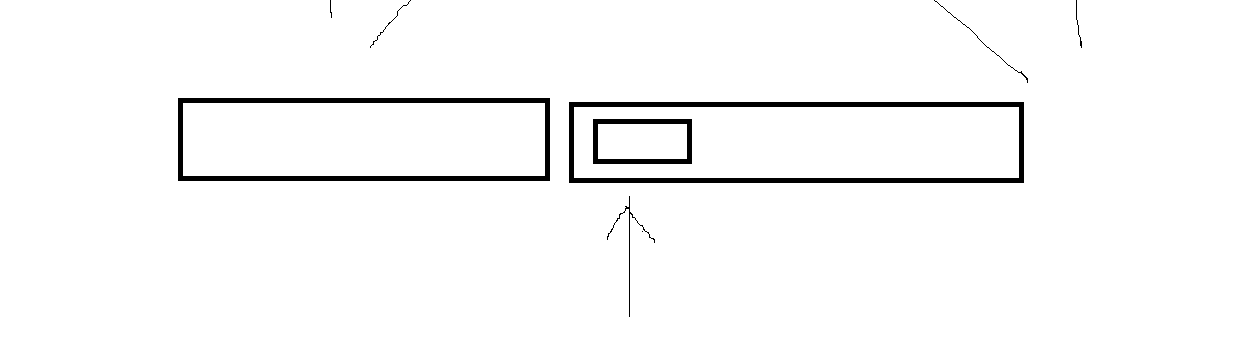
二分算法的补充说明
在上一节中我们简单介绍了二分算法,通过区分小于等于,大于或者小于,大于等于我们可以求出它们的边界值。 具体方法是先看一下要求哪里的边界值,分成两部分让如果求小于等于的右边界,我们根据条件让rightmid-1,leftmid…...

C++:array容器
array容器是序列容器,它的特点是:静态,固定数目。可以看作更安全的数组。 它还有一些成员函数,如begin():返回指向容器中第一个元素的随机访问迭代器。 #include<iostream>//数组容器 #…...

java每日精进 5.19【Excel 导入导出】
基于 EasyExcel 实现 Excel 的读写操作,可用于实现最常见的 Excel 导入导出等功能。 Excel 导入导出功能涉及前后端协作,后端处理数据查询、文件生成和解析,前端提供用户交互和文件下载/上传界面。以下是全流程解析,分为导出流程…...

java基础(api)
包: 导包,不同包的程序名相同。 但是要用两个的话可以这样子写: String String概述 String的常用方法 String使用时的注意事项 String的应用案例...

CentOS7/Ubuntu SSH配置允许ROOT密码登录
CentOS7 打开SSHD配置文件 vim /etc/ssh/sshd_config 找到注释行,如果没有就添加。 #PermitRootLogin yes 把注释取消掉。 执行下述命令,重启SSHD服务即可。 systemctl restart sshd.service Ubuntu 先安装SSH服务器,CentOS7默认就安…...

C++ HTTP框架推荐
1. Crow 特点:高性能异步框架,支持Linux、macOS和Windows 优势: 轻量级:整个框架只有一个头文件,易于集成到项目中 简单易用:API设计简洁直观,学习曲线平缓 高性能:基于Boost.Asi…...

算法打卡第二天
5.爬楼梯(动态规划) 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 示例 1: 输入:n 2 输出:2 解释:有两种方法可以爬到楼顶。 1. 1 阶 1 阶 2…...

VSCode推出开源Github Copilot:AI编程新纪元
文章目录 开源决策的背后GitHub Copilot的演进历程Copilot Chat核心功能解析1. 聊天界面集成2. 代码理解与生成3. 多文件编辑能力4. 智能代理模式 开源后的影响与展望对开发者的影响对AI编程工具市场的影响未来发展方向 如何开始使用GitHub Copilot结语相关学习资源 在AI编程助…...
Mujoco 学习系列(四)官方模型仓库 mujoco_menagerie
mujoco 官方在 Github 上发布了一个他们自己整理的高质量的模型仓库,这个仓库是一个持续维护的项目,里面包含了目前市面上常见的人形机器人、机械臂、底盘等模型,对于初学者而言是一个非常好的学习资料,无论是想在仿真环境中尝试还…...

代码走读 Go 语言 Map 的实现
序言 在日常的开发当中,我们一定离不开一个数据结构字典。不仅可以存储关联数据对,还可以在 O(1) 的时间复杂度进行查找。很久之前在 一篇文章带你实现 哈希表 介绍了相关的原理以及简单的实现。所以这篇文章中我们就不多赘述哈希表的原理,而…...

PostgreSQL14 +patroni+etcd+haproxy+keepalived 集群部署指南
使用postgresql etcd patroni haproxy keepalived可以实现PG的高可用集群,其中,以postgresql做数据库,Patroni监控本地的PostgreSQL状态,并将本地PostgreSQL信息/状态写入etcd来存储集群状态,所以,patr…...
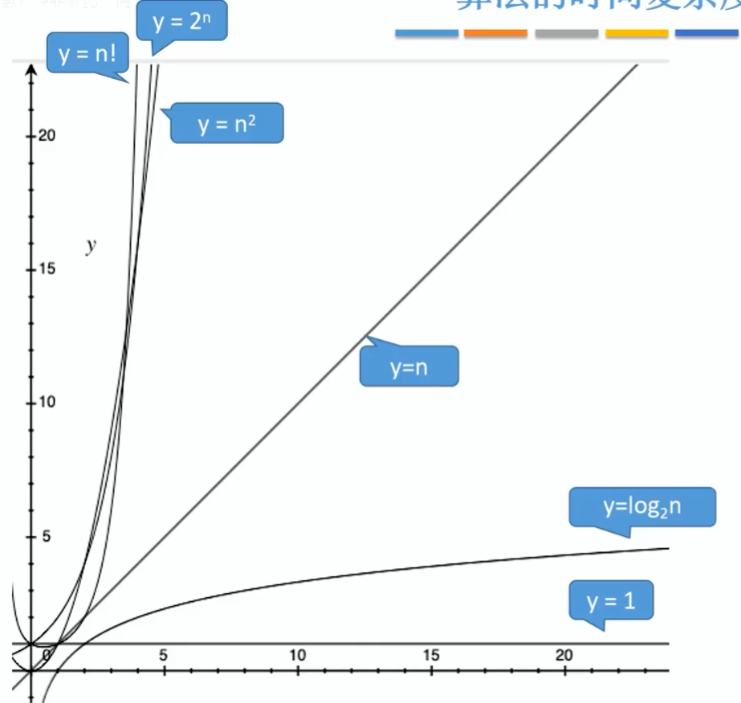
数据结构知识点汇总
1、在数据结构中,随机访问是指能够直接访问任一元素,而不需要从特定的起始位置开始,也不需要按顺序访问其他元素。这种访问方式通常不涉及遍历。例如,数组(array)支持随机访问,你可以直接通过索…...

雅思英语考试基本介绍
考试分类 雅思(国际英语语言测试系统,International English Language Testing System 即IELTS)主要分为两大类: 学术类(A类) 这是我可能会选择的一种(✓),专为申请大学…...

基于YOLO11深度学习的变压器漏油检测系统【Python源码+Pyqt5界面+数据集+安装使用教程+训练代码】【附下载链接】
文章目录 引言软件主界面源码目录文件说明一、环境安装(1)安装python(2)安装软件所需的依赖库 二、软件核心功能介绍及效果演示(1)软件核心功能(2)软件效果演示 三、模型的训练、评估与推理(1)数据集准备与训练(2)训练结果评估(3)使用训练好的模型识别 四、完整相关文件及源码下…...

线上 Linux 环境 MySQL 磁盘 IO 高负载深度排查与性能优化实战
目录 一、线上告警 二、问题诊断 1. 系统层面排查 2. 数据库层面分析 三、参数调优 1. sync_binlog 参数优化 2. innodb_flush_log_at_trx_commit 参数调整 四、其他优化建议 1. 日志文件位置调整 2. 生产环境核心参数配置模板 3. 突发 IO 高负载应急响应方案 五、…...

【洛谷 P9025】 [CCC2021 S3] Lunch Concert 题解
题目: 洛谷 P9025 分析: 为了解决这个问题,我们需要找到一个整数位置 c 来举办音乐会,使得所有人移动到能听到音乐会的位置的时间总和最小。每个人移动后的位置应该在其听力范围内,并且尽可能靠近自己的初始位置以减少…...

Python 包管理工具核心指令uvx解析
uvx 是 Python 包管理工具 uv 的重要组成部分,主要用于在隔离环境中快速运行 Python 命令行工具或脚本,无需永久安装工具包。以下是其核心功能和使用场景的详细解析: 一、uvx 的定位与核心功能 工具执行器的角色 uvx 是 uv tool run 的别名&a…...

苍穹外卖05 Redis常用命令在Java中操作Redis_Spring Data Redis使用方式店铺营业状态设置
2-8 Redis常用命令 02 02-Redis入门 ctrlc :快捷结束进程 配置密码: 以后再启动客户端的时候就需要进行密码的配置了。使用-a 在图形化界面中创建链接: 启动成功了。 03 03-Redis常用数据类型 04 04-Redis常用命令_字符串操作命令 05 05-Redis常用命令…...

AI工程师系列——面向copilot编程
前言 笔者已经使用copilot协助开发有一段时间了,但一直没有总结一个协助代码开发的案例,特别是怎么问copilot,按照什么顺序问,哪些方面可以高效的生成需要的代码,这一次,笔者以IP解析需求为例,沉淀一个实践案例,供大家参考 当然,其实也不局限于copilot本身,类似…...
【竖排繁体识别】如何将竖排繁体图片文字识别转横排繁体,转横排简体导出文本文档,基于WPF和腾讯OCR的实现方案
一、应用场景 在古籍数字化、繁体文档处理、两岸三地文化交流等场景中,经常需要将竖排繁体文字转换为横排文字。例如: 古籍研究人员需要将竖排繁体文献转换为现代横排简体格式以便编辑和研究出版行业需要将繁体竖排排版转换为简体横排格式两岸三地交流中需要将繁体竖排文档转…...

梳理Spring Boot中三种异常处理
在 Spring Boot 中处理异常确实有多个方式,比如使用 ControllerAdvice、 BasicErrorController、HandlerExceptionResolver等。不同方式适合不同的场景,下面是对这些方式的分析以及如何选择的建议: 🧩 1. ControllerAdvice Exce…...

NFS服务器实验
实验要求 架设一台NFS服务器,并按照以下要求配置 1、开放/nfs/shared目录,供所有用户查询资料 2、开放/nfs/upload目录,为192.168.xxx.0/24网段主机可以上传目录,并将所有用户及所属的组映射为nfs-upload,其UID和GID均为210 3…...

ffmpeg 转换视频格式
使用FFmpeg将视频转换为MP4格式的常用命令: ffmpeg -i input.mov -c:v libx264 -crf 23 -c:a aac output.mp4 -i input.avi:指定输入文件 -c:v libx264:使用H.264视频编码器 -crf 23:控制视频质量(范围18-28&#…...

Java进阶之新特性
Java新特性 参考 官网:https://docs.oracle.com/en/ JDK5新特性 1.自动装箱与拆箱 自动装箱的过程:每当需要一种类型的对象时,这种基本类型就自动地封装到与它相同类型的包装类中。 自动拆箱的过程:每当需要一个值时…...

Python基础学习-Day32
面对一个全新的官方库,是否可以借助官方文档的写法了解其如何使用。 我们以pdpbox这个机器学习解释性库来介绍如何使用官方文档。 大多数 Python 库都会有官方文档,里面包含了函数的详细说明、用法示例以及版本兼容性信息。 通常查询方式包含以下2种&…...