Python-多进程编程 (multiprocessing 模块)
目录
- 一、创建进程
- 1. Process 的语法结构
- 2. 进程不共享全局变量
- 二、进程间通信
- 1. 队列通信
- 2. 管道通信
- 三、进程池
- 1. 常用函数
- 2. 进程池中的 Queue
- 四、应用:复制文件夹(多进程版)
- 五、守护进程和进程同步
- 六、注意事项
通过使用 multiprocessing 模块,Python 程序可以在多核处理器上实现并行处理,提高程序的执行效率和响应速度。
一、创建进程
要创建一个新的进程,需要实例化 multiprocessing.Process 类,并调用它的 start() 方法。Process 类的构造函数接受参数 target 作为子进程需要执行的函数,args 和 kwargs 作为传递给 target 函数的参数。
1. Process 的语法结构
① 创建 Process 对象:Process(group , target , name , args , kwargs)
- target :表示调用对象,指定子进程要执行的函数。
- args :传递给 target 函数的参数 (tuple) 。
- kwargs :传递给 target 函数的关键字参数 (dict) 。
- name :子进程名称,可以不设定。
- group :指定进程组,大多数情况下用不到,默认值为 None 。
② Process 创建的实例对象的常用方法:
start():启动子进程实例。
注:
- 创建 Process 对象时,实际上是创建了子进程的 “描述对象” ,此时还没有真正启动子进程。
- 子进程真正启动是在调用 p.start() 的时候,操作系统才会分配资源创建子进程,执行对应代码。
- 之后,子进程执行传入的 target 函数或重写的 run() 方法中的代码。
- start() 是非阻塞的,父进程继续执行,而子进程代码则独立运行。
-
is_alive():判断子进程是否还活着。 -
join(timeout=None):用于阻塞当前(父)进程,直到子进程执行结束。如果不调用该函数,主进程会继续执行,不管子进程是否完成。
timeout(可选):指定等待子进程结束的最长时间,单位是秒。如果在超时时间内子进程结束,join() 返回,父进程继续,否则超时后父进程继续(子进程仍继续执行)。
terminate():调用后,操作系统会立即杀死子进程,不管子进程是否完成任务。
terminate() 是个强制退出方法,子进程不会正常执行清理工作(如 finally 代码块、关闭文件等可能不被执行)。一般用于子进程 “无响应” 或超时等情况下,强制结束子进程。
| 时机 | 行为 |
|---|---|
| 创建 Process 对象 | 创建子进程描述对象,尚未启动 |
| 调用 start() | 操作系统创建子进程并运行子进程代码 |
| 子进程执行传入的 target 函数 | 子进程代码开始在子进程空间运行 |
| 调用 join() | 父进程等待子进程运行结束 |
Python 代码示例:
# !/usr/bin/python
# -*- coding:utf-8 -*-from multiprocessing import Processdef run_proc(name, age, **kwargs):"""子进程要执行的代码"""print(f'My name is {name} and my age is {age}')print(kwargs)# print(1 / 0) # 退出码是 1exit(12)if __name__ == '__main__':p = Process(target=run_proc, args=('Alice', 20), kwargs={'city':'beijing', 'country':'China'})p.start()print(f'1.子进程是否存活:{p.is_alive()}')# p.terminate() # 退出码是 -15p.join()# p.join(0)print(f'2.子进程是否存活:{p.is_alive()}')print(f'子进程的退出码是:{p.exitcode}')print('父进程结束')
③ Process 创建的实例对象的常用属性:
- name :当前进程的别名,默认为 Process-N ,N 为从 1 开始递增的整数
- pid :当前进程的 pid(进程号)
- exitcode :子进程的退出码
④ 其他:
-
孤儿进程 :父进程退出(kill 杀死父进程),子进程变为孤儿。
-
僵尸进程 :子进程退出,父进程在忙碌,没有回收它,要避免僵尸。
-
Python 的
os模块封装了常见的系统调用,其中就包括:- 创建子进程:
os.fork() - 获取自身 ID :
os.getpid() - 获取父进程 ID :
os.getppid()
- 创建子进程:
Python 代码示例:
# !/usr/bin/python
# -*- coding:utf-8 -*-from multiprocessing import Process
import os
import timedef run_proc():"""子进程要执行的代码"""print('运行子进程 : pid = %d , ppid = %d' % (os.getpid(), os.getppid()))print('子进程运行结束')if __name__ == '__main__':print('运行父进程 : pid = %d' % os.getpid()) # os.getpid 获取当前进程的进程号p = Process(target=run_proc)p.start()time.sleep(1)print('父进程运行结束')
2. 进程不共享全局变量
进程不共享全局变量或者列表,主要原因是每个进程拥有独立的内存空间。具体来说:
-
独立的地址空间:每个进程在操作系统中都有自己独立的虚拟地址空间,全局变量和列表都存储在该进程的内存空间内。不同进程的内存空间相互隔离,不能直接访问对方的变量。
-
进程隔离保证安全和稳定:这种隔离防止一个进程意外(或恶意)修改另一个进程的数据,从而保证系统的稳定性和安全性。
-
复制而非共享:当创建新进程(如使用
fork),父进程的内存会被复制给子进程,这样变量看似 “相同” ,但其实是不同地址的独立副本,修改一个进程的变量不会影响另一个进程。 -
共享数据需显式机制:如果需要进程间通信(IPC)和共享数据,必须使用特殊机制,如共享内存(
shm)、消息队列、管道(pipe)、信号量、套接字等,而不能直接共享普通的全局变量或数据结构。
总结:进程间的内存隔离使得全局变量、列表等数据结构不被共享,确保各进程运行互不干扰。
Python 代码示例:
# !/usr/bin/python
# -*- coding:utf-8 -*-import os
import time
from multiprocessing import Processnums = [11, 22]
n = 10def work1():"""子进程要执行的代码"""global nn = 100print("in process1 pid=%d , nums=%s" % (os.getpid(), nums)) # nums=[11, 22]for i in range(3):nums.append(i)time.sleep(1)print("in process1 pid=%d , nums=%s" % (os.getpid(), nums)) # nums=[11, 22, 0, 1, 2]print("in process1 pid=%d , n=%d" % (os.getpid(), n)) # n=100def work2():"""子进程要执行的代码"""print("in process2 pid=%d , nums=%s" % (os.getpid(), nums)) # nums=[11, 22]print("in process2 pid=%d , n=%d" % (os.getpid(), n)) # n=10if __name__ == '__main__':p1 = Process(target=work1)p1.start()p1.join()print('-' * 50)p2 = Process(target=work2)p2.start()
二、进程间通信
进程间的通信通常通过 Queue 或 Pipe 实现。Queue 是一个进程安全的队列,可以用于多个进程之间的数据传递。Pipe 则提供了两个连接对象,通过管道连接,允许两个进程间的双向通信。
1. 队列通信
初始化 Queue() 对象时(例如:q=Queue()),若括号中没有指定最大可接收的消息数量,或数量为负值,那么就代表可接受的消息数量没有上限(直到内存的尽头)。
-
Queue.qsize():返回当前队列包含的消息数量。 -
Queue.empty():如果队列为空,返回 True ,反之返回 False 。 -
Queue.full():如果队列满了,返回 True ,反之返回 False 。 -
Queue.get([block[, timeout]]):获取队列中的一条消息,然后将其从列队中移除,block 默认值为 True 。- 如果 block 使用默认值,且没有设置 timeout(单位秒),消息列队如果为空,此时程序将被阻塞(停在读取状态),直到从消息列队读到消息为止,如果设置了 timeout ,则会等待 timeout 秒,若还没读取到任何消息,则抛出 “Queue.Empty” 异常。
- 如果 block 值为 False,消息列队如果为空,则会立刻抛出 “Queue.Empty” 异常。
-
Queue.get_nowait():相当于Queue.get(block=False)。 -
Queue.put(item,[block[, timeout]]):将 item 消息写入队列,block 默认值为 True 。- 如果 block 使用默认值,且没有设置 timeout(单位秒),消息列队如果已经没有空间可写入,此时程序将被阻塞(停在写入状态),直到从消息列队腾出空间为止,如果设置了 timeout ,则会等待 timeout 秒,若还没空间,则抛出 “Queue.Full” 异常。
- 如果 block 值为 False,消息列队如果没有空间可写入,则会立刻抛出 “Queue.Full” 异常。
-
Queue.put_nowait(item):相当于Queue.put(item, False)。
Python 代码示例:
# !/usr/bin/python
# -*- coding:utf-8 -*-from multiprocessing import Process, Queue
import timedef write(q):for i in range(10):print('Put %d to queue...' % i)q.put(i)time.sleep(0.1)def read(q):while True:if not q.empty():print('Get %d from queue.' % q.get())time.sleep(0.2)else:breakif __name__ == '__main__':q = Queue()p_w = Process(target=write, args=(q,))p_r = Process(target=read, args=(q,))p_w.start()p_r.start()p_w.join()p_r.join()
2. 管道通信
通常情况下,管道有 2 个口,而 Pipe 也常用来实现 2 个进程之间的通信,这 2 个进程分别位于管道的两端,一端用来发送数据,另一端用来接收数据。
使用 Pipe 实现进程通信,首先需要调用 multiprocessing.Pipe() 函数来创建一个管道。该函
数的语法格式为:conn1, conn2 = multiprocessing.Pipe([duplex=True]) 。
其中,conn1 和 conn2 分别用来接收 Pipe 函数返回的 2 个端口;duplex 参数默认为 True ,表示该管道是双向的,即位于 2 个端口的进程既可以发送数据,也可以接受数据,而如果将 duplex 值设为 False ,则表示管道是单向的,conn1 只能用来接收数据,而 conn2 只能用来发送数据。另外值得一提的是,conn1 和 conn2 都属于 PipeConnection 对象。
三、进程池
当需要创建的子进程数量不多时,可以直接利用 multiprocessing 中的 Process 动态成生多个进程,但当有大量的任务(上百甚至上千个)需要并行处理时,手动的去创建进程的工作量巨大,此时就可以用到 multiprocessing 模块提供的 Pool 方法。
进程池允许将任务分配给池中的工作进程执行,这样可以有效管理进程的创建和销毁,避免系统资源的浪费。初始化 Pool 时,可以指定一个最大进程数,当有新的请求提交到 Pool 中时:
-
如果池中的进程数没有达到指定的最大值,那么就会创建一个新的进程用来执行该请求;
-
如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,该进程会被用来执行新的任务。
1. 常用函数
multiprocessing.Pool 常用函数解析:
-
apply_async(func[, args[, kwds]]):使用非阻塞方式调用 func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args 为传递给 func 的参数列表,kwds 为传递给 func 的关键字参数列表。 -
close():关闭 Pool ,使其不再接受新的任务。 -
terminate():不管任务是否完成,立即终止。 -
join():主进程阻塞,等待子进程的退出, 必须在 close 或 terminate 之后使用。
Python 代码示例:
# !/usr/bin/python
# -*- coding:utf-8 -*-from multiprocessing.pool import Pool
import os, time, randomdef worker(msg):t_start = time.time()print(f'{os.getpid()} 开始执行任务 {msg}')# random.random()随机生成 0~1 之间的浮点数time.sleep(random.random() * 2)t_stop = time.time()print("任务 %d 执行完毕,%d 释放,耗时%0.2f" % (msg, os.getpid(), t_stop - t_start))if __name__ == '__main__':po = Pool(3) # 定义一个进程池,最大进程数 3(注意这句必须放在 main 下面)for i in range(0, 10):# Pool().apply_async(要调用的目标,(传递给目标的参数元祖,))# 每次循环将会用空闲出来的子进程去调用目标po.apply_async(worker, (i,)) # 这里的 worker 不能是对象方法print("------start------")po.close() # 关闭进程池,关闭后 po 不再接收新的请求po.join() # 等待 po 中所有子进程执行完成,必须放在 close 语句之后print("-------end-------")
2. 进程池中的 Queue
如果要使用 Pool 创建进程,就需要使用 multiprocessing.Manager().Queue() ,而不是 multiprocessing.Queue() ,否则会得到一条如下的错误信息:
RuntimeError: Queue objects should only be shared between processes through inheritance.
Python 代码示例:
# !/usr/bin/python
# -*- coding:utf-8 -*-from multiprocessing import Manager, Pool
import time, osdef reader(q):print("reader 启动 (%s) , 父进程为 (%s)" % (os.getpid(), os.getppid()))for i in range(q.qsize()):print("reader 从 Queue 获取到消息:%s" % q.get())def writer(q):print("writer 启动 (%s) , 父进程为 (%s)" % (os.getpid(), os.getppid()))for i in "hello":q.put(i)time.sleep(1)if __name__ == "__main__":print("(%s) start" % os.getpid())q = Manager().Queue() # 使用 Manager 中的 Queuepo = Pool()po.apply_async(writer, (q,))time.sleep(1) # 先让上面的任务向 Queue 存入数据,然后再让下面的任务开始从中取数据po.apply_async(reader, (q,))po.close()po.join()print("(%s) End" % os.getpid())
四、应用:复制文件夹(多进程版)
# !/usr/bin/python
# -*- coding:utf-8 -*-import multiprocessing
import os
import time
import randomdef copy_file(queue, file_name, source_folder_name, dest_folder_name):"""copy 文件到指定的路径"""f_read = open(source_folder_name + "/" + file_name, "rb")f_write = open(dest_folder_name + "/" + file_name, "wb")while True:time.sleep(random.random())content = f_read.read(1024)if content:f_write.write(content)else:breakf_read.close()f_write.close()# 发送已经拷贝完毕的文件名字queue.put(file_name)def main():# 获取要复制的文件夹source_folder_name = input("请输入要复制文件夹名字:")# 整理目标文件夹dest_folder_name = source_folder_name + "[副本]"# 创建目标文件夹try:os.mkdir(dest_folder_name)except FileExistsError:print('该文件夹已存在') # 如果文件夹已经存在,那么创建会失败# 获取这个文件夹中所有的普通文件名file_names = os.listdir(source_folder_name)# 创建 Queuequeue = multiprocessing.Manager().Queue()# 创建进程池pool = multiprocessing.Pool(3)for file_name in file_names:# 向进程池中添加任务pool.apply_async(copy_file, args=(queue, file_name, source_folder_name, dest_folder_name))# 主进程显示进度pool.close()all_file_num = len(file_names)while True:file_name = queue.get()if file_name in file_names:file_names.remove(file_name)copy_rate = (all_file_num - len(file_names)) * 100 / all_file_numprint("\r%.2f...(%s)" % (copy_rate, file_name) + " "*50, end="")if copy_rate >= 100:breakprint()if __name__ == "__main__":main()
五、守护进程和进程同步
multiprocessing 模块还提供了守护进程(daemon process)的概念,守护进程会在主进程代码执行结束后自动终止。此外,模块中还包含了锁(Lock)和信号量(Semaphore)等同步原语,用于在进程间同步操作。
六、注意事项
-
使用 multiprocessing 时,应避免在多个进程间共享状态。
-
确保传递给 Process 类的所有参数都是可序列化的。
-
在主模块中使用
if __name__ == "__main__":来保护程序的入口点。 -
尽量不要使用 Process.terminate() 来终止进程,因为这可能会导致共享资源变得不可用。
相关文章:
)
Python-多进程编程 (multiprocessing 模块)
目录 一、创建进程1. Process 的语法结构2. 进程不共享全局变量 二、进程间通信1. 队列通信2. 管道通信 三、进程池1. 常用函数2. 进程池中的 Queue 四、应用:复制文件夹(多进程版)五、守护进程和进程同步六、注意事项 通过使用 multiprocess…...

GraphQL在.NET 8中的全面实践指南
一、GraphQL与.NET 8概述 GraphQL是一种由Facebook开发的API查询语言,它提供了一种更高效、更灵活的替代REST的方案。与REST不同,GraphQL允许客户端精确指定需要的数据结构和字段,避免了"过度获取"或"不足获取"的问题。…...

在mobaxterm下面执行shell脚本报错
关键步骤:在 MobaXterm 的 SSH 会话中强制指定 Bash 解释器 若你曾通过 高级 SSH 设置中的「执行命令」 填写 /bin/bash 解决脚本问题,以下是具体操作和原理说明: 1. 设置位置 打开 MobaXterm,选择需要配置的 SSH 会话࿰…...

系统集成项目管理工程师学习笔记之启动过程组
第十章 启动过程组 制定项目章程 定义 制定项目章程是编写一份正式批准项目并授权项目经理在项目活动中使用组织资源的文件的过程。 正式批准的项目文件 作用 1、明确项目与组织战略目标之间的直接联系 2、确立项目的正式地位 3、展示组织对项目的承诺 本过程仅开展一…...
)
OceanBase数据库全面指南(数据操作篇DML)
文章目录 一、OceanBase插入数据全指南1.1 INSERT语句基础用法1.2 高级INSERT用法1.2.1 插入查询结果1.2.2 多表插入1.2.3 条件插入1.3 INSERT性能优化技巧1.3.1 批量插入优化1.3.2 使用APPEND提示1.3.3 并行插入二、OceanBase批量插入优化2.1 多行插入语法详解2.2 批量绑定技术…...

深入解析AI中的Prompt工程:从理论到实践
目录 引言:Prompt在AI中的核心地位 第一部分:Prompt基础理论 1.1 什么是Prompt 1.2 ICIO框架:Prompt设计的结构化方法 1.3 为什么需要Prompt 1.4 Prompt的终极价值 第二部分:Prompt工程实践 2.1 Prompt工程概述 2.2 Prompt工程的具体内容 2.3 Prompt Engineer的工…...
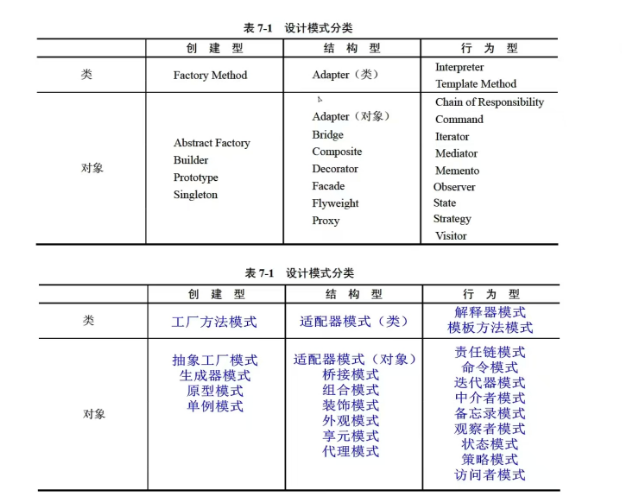
软考中级软件设计师——设计模式篇
一、设计模式核心分类 设计模式分为 3 大类,共 23 种模式(考试常考约 10-15 种): 分类核心模式考试重点创建型模式工厂方法、抽象工厂、单例、生成器、原型单例模式的实现(懒汉、饿汉)、工厂模式的应用场…...

matlab二维随机海面模拟
二维随机海面模拟是一种重要的技术,广泛应用于海洋工程、船舶设计、雷达系统和光学通信等领域。利用蒙特卡罗方法结合二维海浪功率谱模型,可以生成符合实际海面特性的随机表面。 步骤 1: 定义海浪功率谱模型 海浪功率谱模型描述了海浪能量在不同频率和…...
Axure系统原型设计列表版方案
列表页面是众多系统的核心组成部分,承担着数据呈现与基础交互的重要任务。一个优秀的列表版设计,能够极大提升用户获取信息的效率,优化操作体验。下面,我们将结合一系列精心设计的列表版方案图片,深入探讨如何打造出实…...
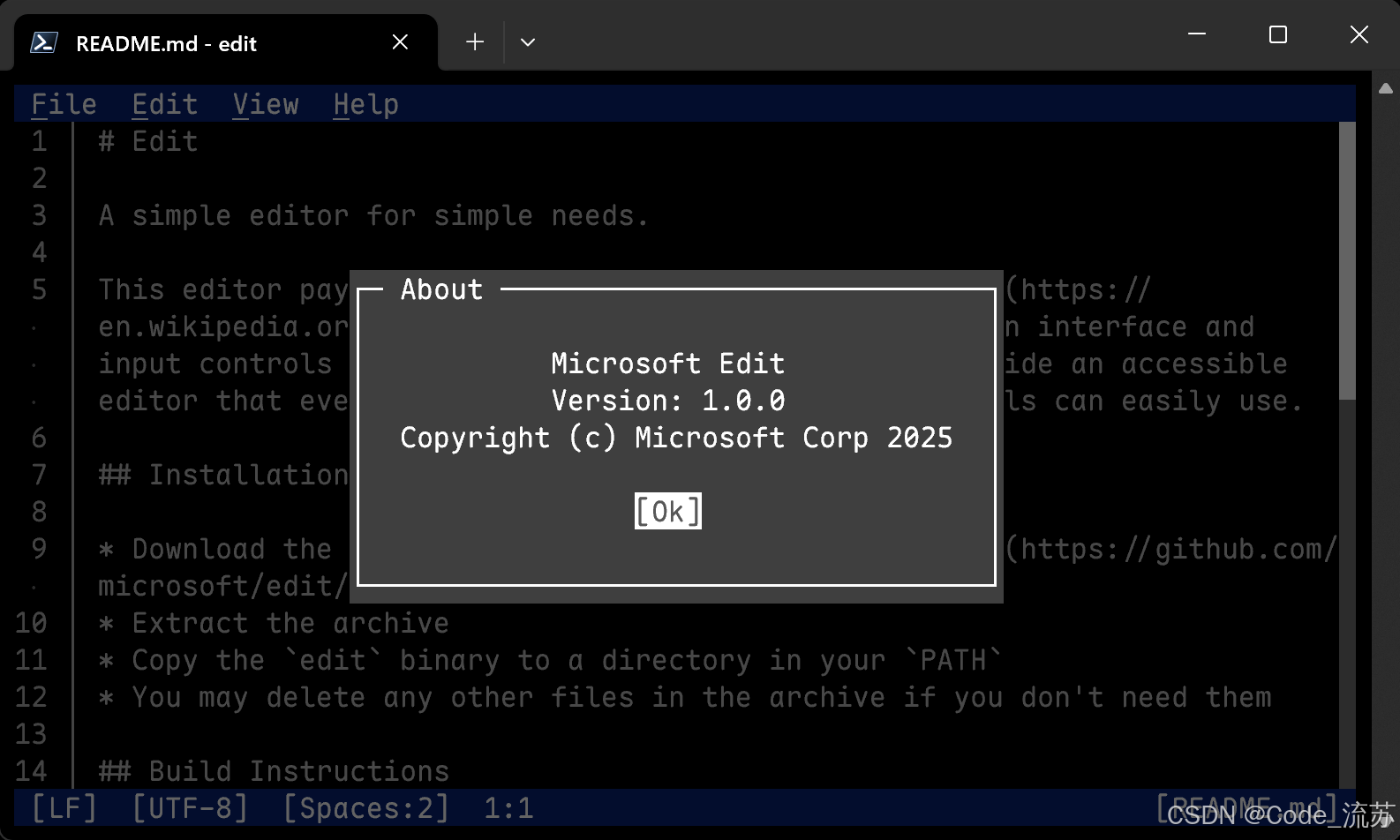
微软全新开源命令行文本编辑器:Edit — 致敬经典,拥抱现代
名人说:博观而约取,厚积而薄发。——苏轼《稼说送张琥》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、引言:命令行的新利器二、Edit:致敬经典,拥抱现代1. 命令行的“新升级”2. 为什么要有 Edit?三、核心功能与特性一览1. 完全开源、MIT 许可证…...
年会招标抽奖活动软件———仙盟创梦IDE
年会是企业一年的总结与欢庆时刻,而抽奖环节更是点燃全场气氛的关键。如何让抽奖环节既大气又充满仪式感?选对抽奖软件至关重要!本文精心挑选了 3 款兼具实用性与氛围感的年会抽奖软件,从界面设计到功能特色,全方位为你…...

智防火灾,慧控能耗:物联网赋能金融行业电气安全革新
摘要 随着金融行业对电气安全需求的不断提升,传统用电管理模式已难以满足现代金融机构对火灾防控、能耗管理和智能运维的要求。本文基于物联网、云计算及大数据分析技术,提出一套针对金融行业的安全用电解决方案。该方案通过智能化硬件部署与平台化管理…...
)
Any类(C++17类型擦除,也称上帝类)
Any类(C17类型擦除,也称上帝类) 在C中,std::any 是C17标准引入的一个灵活的类型安全容器,用于存储任意类型的单个值。 1. std::any 的核心特性 类型安全:存储的值必须通过明确的类型转换(any_…...

jquery.table2excel方法导出
jquery提供了一个table2excel方法可以用来导出页面到xls等 $("#grid_595607").table2excel({exclude: ".noExport", // 排除类名为 noExport 的元素filename: "导出数据.xls",exclude_img: true, // 不导出图片exclude_links: true, // 不导…...

Spring Boot 多租户架构实现:基于上下文自动传递的独立资源隔离方案
一、核心设计思想 通过线程上下文自动传递租户ID,结合动态数据源路由和中间件连接工厂,实现MySQL、Redis、RocketMQ的完全自动化资源隔离。关键设计如下: #mermaid-svg-ZjXCGSWoCuNFMIch {font-family:"trebuchet ms",verdana,aria…...
在 JavaScript 中正确使用 Elasticsearch,第二部分
作者:来自 Elastic Jeffrey Rengifo 回顾生产环境中的最佳实践,并讲解如何在无服务器环境中运行 Elasticsearch Node.js 客户端。 想获得 Elastic 认证?查看下一期 Elasticsearch Engineer 培训的时间! Elasticsearch 拥有大量新…...
更新nvidia-container-toolkit 1.17.7-1后,运行--gpus all 卡死问题
用Arch每日一滚,结果今天用 sudo docker run -it --runtimenvidia --gpus all居然卡死了,排雷排了几小时,才从开源库发现问题 nvidia-container-toolkit 1.17.7-1 是有问题的,而且在ubuntu和arch上都存在问题。 只好Downgrade 1.…...

【Nginx学习笔记】:Fastapi服务部署单机Nginx配置说明
服务部署单机Nginx配置说明 服务.conf配置文件: upstream asr_backend {server 127.0.0.1:8010; }server {listen 80;server_name your_domain.com;location / {proxy_pass http://localhost:8000;proxy_set_header Host $host;proxy_set_header X-Real-IP $remot…...

相机标定与图像处理涉及的核心坐标系
坐标系相互关系 #mermaid-svg-QxaMjIcgWVap0awV {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-QxaMjIcgWVap0awV .error-icon{fill:#552222;}#mermaid-svg-QxaMjIcgWVap0awV .error-text{fill:#552222;stroke:#552…...
是处理 HTTP 请求的核心组件)
在 ASP.NET 中,HTTP 处理程序(HttpHandler)是处理 HTTP 请求的核心组件
ASP.NET 中 HttpHandler 的用法详解 在 ASP.NET 中,HTTP 处理程序(HttpHandler)是处理 HTTP 请求的核心组件。根据你的配置文件,我将详细解释 <handlers> 节点的各种用法和配置选项。 1. HttpHandler 概述 HttpHandler 是…...
通义灵码 2.5 版深度评测:智能编程的边界在哪里?
通义灵码 2.5 版深度评测:智能编程的边界在哪里? 评测目标 全面测试智能体模式:是否真正具备自主决策能力?MCP 工具集成体验:能否提升开发效率?AI 记忆自感知能力:是否能真正理解开发者习惯&a…...

电商项目-商品微服务-规格参数管理,分类与品牌管理需求分析
本文章介绍:规格参数管理与分类与品牌管理的需求分析和表结构的设计。 一、规格参数管理 规格参数模板是用于管理规格参数的单元。规格是例如颜色、手机运行内存等信息,参数是例如系统:安卓(Android)后置摄像头像素&…...
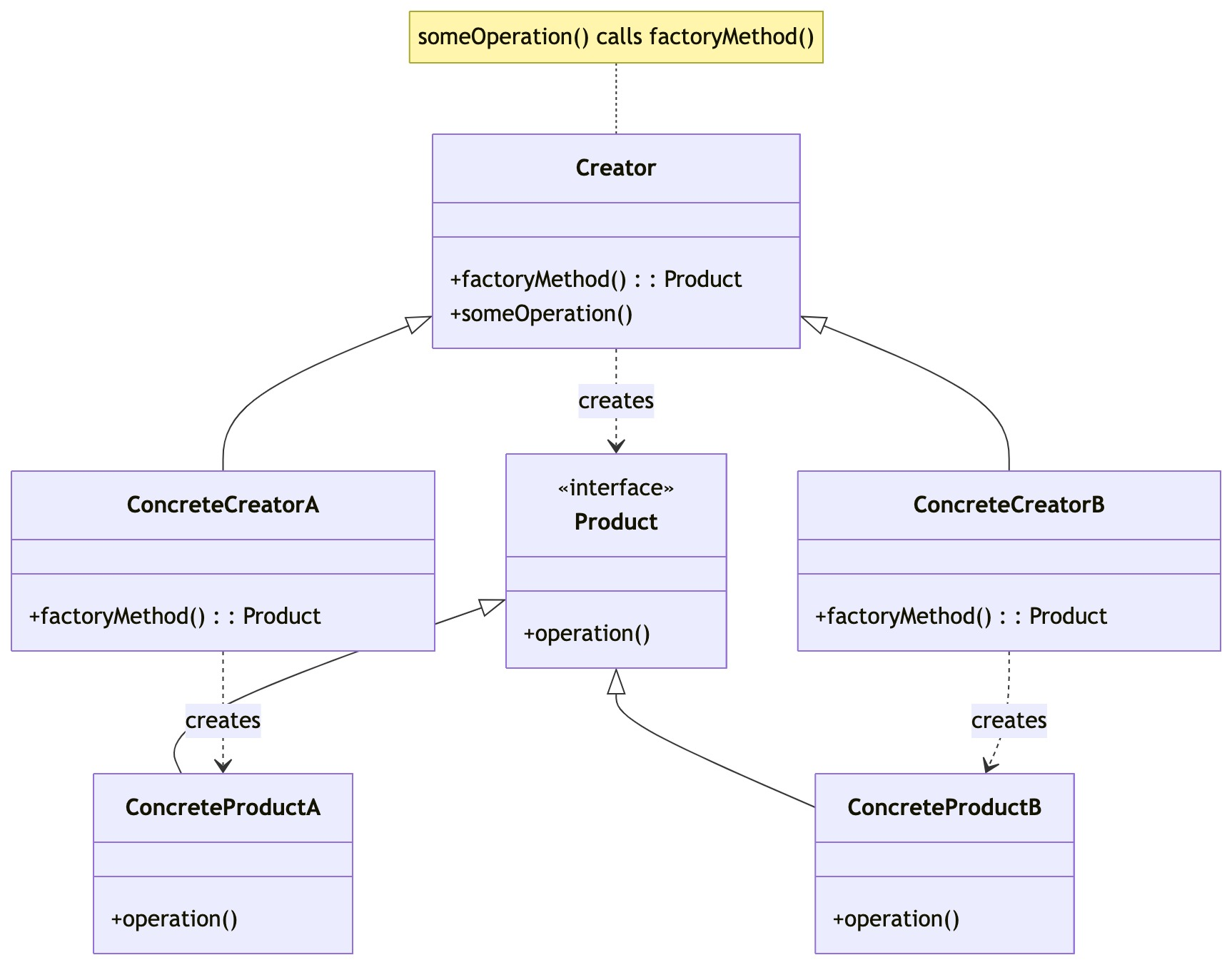
零基础设计模式——创建型模式 - 工厂方法模式
第二部分:创建型模式 - 工厂方法模式 (Factory Method Pattern) 上一节我们学习了单例模式,它关注如何保证一个类只有一个实例。现在,我们来看另一个重要的创建型模式——工厂方法模式。它关注的是如何创建对象,但将创建的决定权…...

LeetCode 404.左叶子之和的递归求解:终止条件与递归逻辑的深度剖析
一、题目解析:左叶子的定义与递归求解思路 题目描述 LeetCode 404. 左叶子之和要求计算二叉树中所有左叶子节点的值之和。左叶子的严格定义是:如果一个节点是其父节点的左子节点,并且它本身没有左右子节点,则称为左叶子。 关键…...
蓝桥杯5130 健身
问题描述 小蓝要去健身,他可以在接下来的 1∼n 天中选择一些日子去健身。 他有 m 个健身计划,对于第 i 个健身计划,需要连续的 天,如果成功完成,可以获得健身增益 si ,如果中断,得不到任何…...

电商虚拟户:重构资金管理逻辑,解锁高效归集与智能分账新范式
一、电商虚拟户的底层架构与核心价值 在数字经济浪潮下,电商交易的复杂性与日俱增,传统账户体系已难以满足平台企业对资金管理的精细化需求。电商虚拟户作为基于银行或持牌支付机构账户体系的创新解决方案,通过构建“主账户子账户”的虚拟账户…...

腾讯2025年校招笔试真题手撕(二)
一、题目 最近以比特币为代表的数字货币市场非常动荡,聪明的小明打算用马尔科夫链来建模股市。如图所示,该模型有三种状态:“行情稳定”,“行情大跌”以及“行情大涨”。每一个状态都以一定的概率转化到下一个状态。比如…...

DeepSeek快速搭建个人网页
一、环境准备 注册DeepSeek账号(https://www.deepseek.com/)安装VSCode插件:DeepSeek Coder准备基础开发环境:# 推荐使用Node.js环境 npm install -g live-server二、三步搭建基础框架 步骤1:生成基础模板 在DeepSeek对话框输入: 生成一个响应式个人网页的HTML模板,包…...
安装完dockers后就无法联网了,执行sudo nmcli con up Company-WiFi,一直在加载中
Docker服务状态检查 执行 systemctl status docker 确认服务是否正常 若未运行,使用 sudo systemctl start docker && sudo systemctl enable docker 网络配置冲突 Docker会创建docker0虚拟网桥,可能与宿主机网络冲突 检查路由表 ip route sho…...

【深度学习新浪潮】2025年谷歌I/O开发者大会keynote观察
1. 2025年谷歌I/O开发者大会keynote重点信息 本次Google I/O大会的核心策略是降低AI使用门槛与加速开发者创新,通过端侧模型(Gemini Nano)、云端工具(Vertex AI)和基础设施(TPU)的全链路优化,进一步巩固其在生成式AI领域的领先地位。同时,高价订阅服务和企业级安全功…...