征程 6 J6E/M linear 双int16量化支持替代方案
1.背景简介
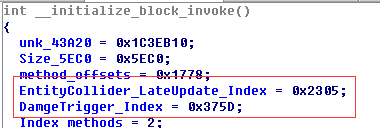
当发现使用 plugin 精度 debug 工具定位到是某个 linear 敏感时,示例如下:
op_name sensitive_type op_type L1 quant_dtype flops
------------------------------------- --------------- ----------------------------- ---------------- ------------------------- ------- ------------- --------------
model.layernorm.rsqrt activation <class 'horizon_plugin_pytorch.nn.qat.segment_lut.SegmentLUT'> 6.52537 qint16 0(0%)
model.linear2 weight <class 'horizon_plugin_pytorch.nn.qat.linear.Linear'> 5.02445 qint8 3072000(0.00%)
model.layernorm.var_mean.pre_mean activation <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> 3.1683 qint16 0(0%)
可以发现,model.linear2 weight 排在了前面,且是 int8 量化。
接下来看下 baseline_statistic.txt 与 analysis_statistic.txt,其中有 model.linear2 的 input、weight、output 的数值分布范围,示例如下:
| Op Name | Mod Name | Attr | Min | Max | Mean | Var | Shape |
|---------------------------------------------------------------------------------------------------------------------------------------------------------------
| torch.nn.modules.linear.Linear | model.linear2 | input | 0.0000000 | 15.4210167 | 4.0793311 | 0.2532279 | torch.Size([2, 100, 256]) |
| torch.nn.modules.linear.Linear | model.linear2 | weight | -41.6590347 | 31.2311363 | -0.0053362 | 0.4427260 | torch.Size([60, 256]) |
| torch.nn.modules.linear.Linear | model.linear2 | bias | -0.4426649 | 0.3714900 | 0.0053294 | 0.0112585 | torch.Size([60]) |
| torch.nn.modules.linear.Linear | model.linear2 | output | -32.0065079 | 5.7881856 | 0.4558742 | 3.8736136 | torch.Size([2, 100, 60]) |
解决方案:使用 int16 来量化这个敏感 linear 的 weight。
如果必须要求 linear input weight output 都是 int16 量化,怎么办呢?
2.知识基础
在 征程 6E/M 上,地平线 BPU 对 linear 支持的情况如下:
本文发布时是这样的

可以看到:input 和 weight 不能同时为 int16。
3.Linear input weight both int16
对于 linear input 和 weight 均需要 int16 量化的情况,可使用 broadcast mul sum 来替代验证,无需重训 float。
异同简介:broadcast_mul_sum_replace_linear 在 float 层面可以等价替换 linear,但在量化方式上存在区别:Linear weight 是 per channel 量化,weight 作为 mul 输入时,是 per tensor 量化。一般情况下:weight int8 perchannel 变成 per tensor int16,精度是正向优化。
替换方案:在 float 训练完成后替换,然后进行 calib+qat。
class SmallModel(nn.Module):def __init__(self, linear2_weight, linear2_bias):super(SmallModel, self).__init__()# 第一个 Linear: 输入 [2, 100, 256] -> 输出 [2, 100, 256]self.linear1 = nn.Linear(256, 256)self.layernorm = nn.LayerNorm(256) # 对最后一维进行归一化self.relu = nn.ReLU()# 第二个 Linear: 输入 [2, 100, 256] -> 输出 [2, 100, 60]# self.linear2 = nn.Linear(256, 60)self.linear2_weight = linear2_weightself.linear2_bias = linear2_bias# 第三个 Linear: 输入 [2, 100, 60] -> 输出 [2, 100, 60]self.linear3 = nn.Linear(60, 60)self.quant = QuantStub()self.dequant = DeQuantStub()self.quant_linear2_weight = QuantStub()self.quant_linear2_bias = QuantStub()def forward(self, x):x = self.quant(x)linear2_weight = self.quant_linear2_weight(self.linear2_weight)linear2_bias = self.quant_linear2_bias(self.linear2_bias)# 第一个 Linearx = self.linear1(x) # [2, 100, 256]x = self.layernorm(x) # [2, 100, 256]x = self.relu(x) # [2, 100, 256]# 第二个 Linear# x = self.linear2(x) # [2, 100, 60]# ===================================# 使用 broadcast mul + sum 替换linear# ===================================# 广播乘法:输入 [2, 100, 256] 与权重 [60, 256] 进行广播broadcast_mul = x.reshape(2, 100, 1, 256) * linear2_weight.reshape(1, 1, 60, 256) # [2, 100, 60, 256]# 按最后一个维度求和:sum 操作模拟线性层的加权求和sum_output = broadcast_mul.sum(dim=-1) # [2, 100, 60]# 加上偏置x = sum_output + linear2_bias # [2, 100, 60]# 第三个 Linearx = self.linear3(x)x = self.dequant(x)return x
broadcast mul sum 替换方案,均支持 int16。
注意事项:如果 mul 的输出 绝大多数 数值都在 0 附近 -> MSE 校准受异常值影响较大 -> 输出 scale 非常大 -> 0 附近的大量小数值被舍入成 0 -> sum 和发生巨大偏差。
影响范围:mul 后面跟着 sigmoid 或 add+sigmoid 时影响很大。
解决方案:mul 输出设置 fixed scale 为 7/32767,因为 sigmoid 并不需要太大的输入,而 mul 的输出分布需要小 scale。
4.全流程示例
从表中可以看到,在 linear 需要 int16 量化的场景,input/output int16 对应的 latency 最短,其次是 weight output int16 input int8,最差的是三者都需要 int16,针对这三种情况,下面分别提供完整的例子供参考。
信息描述

注意:非完全等价,仅作为参考
4.1 示例代码
import torch
from horizon_plugin_pytorch import set_march, March
set_march(March.NASH_M)
from horizon_plugin_pytorch.quantization import prepare, set_fake_quantize, FakeQuantState
from horizon_plugin_pytorch.quantization import QuantStub
from horizon_plugin_pytorch.quantization.hbdk4 import export
from horizon_plugin_pytorch.quantization.qconfig_template import calibration_8bit_weight_16bit_act_qconfig_setter, ModuleNameQconfigSetter
from horizon_plugin_pytorch.quantization.qconfig import get_qconfig, MSEObserver, MinMaxObserver
from horizon_plugin_pytorch.dtype import qint8, qint16
from torch.quantization import DeQuantStub
import torch.nn as nn
from horizon_plugin_pytorch.quantization import hbdk4 as hb4
from hbdk4.compiler import convert, save, hbm_perf, visualize, compileimport torch
import torch.nn as nn# 定义网络结构
class SmallModel(nn.Module):def __init__(self, linear2_weight, linear2_bias):super(SmallModel, self).__init__()# 第一个 Linear: 输入 [2, 100, 256] -> 输出 [2, 100, 256]self.linear1 = nn.Linear(256, 256)self.layernorm = nn.LayerNorm(256) # 对最后一维进行归一化self.relu = nn.ReLU()# 第二个 Linear: 输入 [2, 100, 256] -> 输出 [2, 100, 60]# self.linear2 = nn.Linear(256, 60)self.linear2_weight = linear2_weightself.linear2_bias = linear2_bias# 第三个 Linear: 输入 [2, 100, 60] -> 输出 [2, 100, 60]self.linear3 = nn.Linear(60, 60)self.quant = QuantStub()self.dequant = DeQuantStub()self.quant_linear2_weight = QuantStub()self.quant_linear2_bias = QuantStub()def forward(self, x):x = self.quant(x)linear2_weight = self.quant_linear2_weight(self.linear2_weight)linear2_bias = self.quant_linear2_bias(self.linear2_bias)# 第一个 Linearx = self.linear1(x) # [2, 100, 256]x = self.layernorm(x) # [2, 100, 256]x = self.relu(x) # [2, 100, 256]# 第二个 Linear# x = self.linear2(x) # [2, 100, 60]# ===================================# 使用 broadcast mul + sum 替换linear# ===================================# 广播乘法:输入 [2, 100, 256] 与权重 [60, 256] 进行广播broadcast_mul = x.reshape(2, 100, 1, 256) * linear2_weight.reshape(1, 1, 60, 256) # [2, 100, 60, 256]# 按最后一个维度求和:sum 操作模拟线性层的加权求和sum_output = broadcast_mul.sum(dim=-1) # [2, 100, 60]# 加上偏置x = sum_output + linear2_bias # [2, 100, 60]# 第三个 Linearx = self.linear3(x)x = self.dequant(x)return xfloat_ckpt_path = "model_path/float-checkpoint.ckpt"
float_state_dict = torch.load(float_ckpt_path)
# 遍历 OrderedDict,查找包含 "linear2" 的键
for key, value in float_state_dict.items():# if "linear2" in key:# print(f"Key: {key}, Value: {value.shape}")if key == "linear2.weight":linear2_weight = valueif key == "linear2.bias":linear2_bias = value# example_input = torch.randn(2, 100, 256)
file_path = "random_data.pt"
example_input = torch.load(file_path)
model = SmallModel(linear2_weight, linear2_bias)
missing_keys, unexpected_keys = model.load_state_dict(float_state_dict, strict=False)
print("missing_keys & unexpected_keys:", missing_keys, '\n', unexpected_keys)# 前向传播
output = model(example_input)
print("float输出数据:", output)
torch.save(output, "model_path/6_model_float_output.pt")
print("输入形状:", example_input.shape)
print("输出形状:", output.shape)# A global march indicating the target hardware version must be setted before prepare qat.
set_march(March.NASH_M)calib_model = prepare(model.eval(), example_input,qconfig_setter=(calibration_8bit_weight_16bit_act_qconfig_setter,),)calib_model.eval()
set_fake_quantize(calib_model, FakeQuantState.CALIBRATION)
calib_model(example_input)calib_model.eval()
set_fake_quantize(calib_model, FakeQuantState.VALIDATION)
calib_out = calib_model(example_input)
print("calib输出数据:", calib_out)
qat_bc = export(calib_model, example_input)
hb_quantized_model = convert(qat_bc, March.NASH_M)
4.2 比较替代方案的输出一致性
- linear2 weight input output int16
float输出数据: tensor([[[-0.3016, 0.1338, -0.5251, ..., -0.0551, -0.2093, -0.0308],[-0.1969, -0.0131, -0.3287, ..., 0.3234, -0.0869, -0.0637],[-0.3056, 0.1478, -0.2673, ..., 0.2355, -0.3487, 0.0134],...,[-0.3990, -0.0389, -0.1686, ..., -0.0046, -0.4131, 0.0482],[-0.1059, 0.2431, -0.1886, ..., 0.0787, -0.3454, 0.0231],[-0.2134, -0.1071, -0.0575, ..., 0.3434, -0.1661, 0.2248]]],grad_fn=<ViewBackward0>)calib输出数据: tensor([[[-0.3038, 0.1370, -0.5269, ..., -0.0571, -0.2111, -0.0296],[-0.1975, -0.0111, -0.3280, ..., 0.3215, -0.0884, -0.0637],[-0.3052, 0.1488, -0.2677, ..., 0.2348, -0.3479, 0.0132],...,[-0.3988, -0.0393, -0.1662, ..., -0.0055, -0.4117, 0.0484],[-0.1058, 0.2442, -0.1890, ..., 0.0780, -0.3447, 0.0240],[-0.2142, -0.1061, -0.0587, ..., 0.3422, -0.1657, 0.2255]]],grad_fn=<ViewBackward0>)
- broadcast mul sum int16
float输出数据: tensor([[[-0.3016, 0.1338, -0.5251, ..., -0.0551, -0.2093, -0.0308],[-0.1969, -0.0131, -0.3287, ..., 0.3234, -0.0869, -0.0637],[-0.3056, 0.1478, -0.2673, ..., 0.2355, -0.3487, 0.0134],...,[-0.3990, -0.0389, -0.1686, ..., -0.0046, -0.4131, 0.0482],[-0.1059, 0.2431, -0.1886, ..., 0.0787, -0.3454, 0.0231],[-0.2134, -0.1071, -0.0575, ..., 0.3434, -0.1661, 0.2248]]],grad_fn=<ViewBackward0>)
calib输出数据: tensor([[[-0.3038, 0.1370, -0.5269, ..., -0.0571, -0.2111, -0.0296],[-0.1975, -0.0111, -0.3280, ..., 0.3215, -0.0884, -0.0637],[-0.3051, 0.1487, -0.2678, ..., 0.2349, -0.3478, 0.0132],...,[-0.3988, -0.0392, -0.1662, ..., -0.0055, -0.4117, 0.0484],[-0.1058, 0.2442, -0.1890, ..., 0.0780, -0.3447, 0.0240],[-0.2142, -0.1061, -0.0586, ..., 0.3423, -0.1657, 0.2255]]],grad_fn=<ViewBackward0>)...,[-0.3988, -0.0392, -0.1662, ..., -0.0055, -0.4117, 0.0484],[-0.1058, 0.2442, -0.1890, ..., 0.0780, -0.3447, 0.0240],[-0.2142, -0.1061, -0.0586, ..., 0.3423, -0.1657, 0.2255]]],grad_fn=<ViewBackward0>)
相关文章:
征程 6 J6E/M linear 双int16量化支持替代方案
1.背景简介 当发现使用 plugin 精度 debug 工具定位到是某个 linear 敏感时,示例如下: op_name sensitive_type op_type L1 quant_dty…...
深度学习模块缝合拼接方法套路+即插即用模块分享
前言 在深度学习中,模型的设计往往不是从头开始,而是通过组合不同的模块来构建。这种“模块缝合”技术,就像搭积木一样,把不同的功能模块拼在一起,形成一个强大的模型。今天,我们就来聊聊四种常见的模块缝…...

改写视频生产流程!快手SketchVideo开源:通过线稿精准控制动态分镜的AI视频生成方案
Sketch Video 的核心特点 Sketch Video 通过手绘生成动画的形式,将复杂的信息以简洁、有趣的方式展现出来。其核心特点包括: 超强吸引力 Sketch Video 的手绘风格赋予了视频一种质朴而真实的质感,与常见的精致特效视频形成鲜明对比。这种独…...

Graphics——基于.NET 的 CAD 图形预览技术研究与实现——CAD c#二次开发
一、Graphics 类的本质与作用 Graphics 是 .NET 框架中 System.Drawing 命名空间下的核心类,用于在二维画布(如 Bitmap 图像)上绘制图形、文本或图像。它相当于 “绘图工具”,提供了一系列方法(如 DrawLine、FillElli…...

ElasticSearch 8.x 快速上手并了解核心概念
目录 核心概念概念总结 常见操作索引的常见操作常见的数据类型指定索引库字段类型mapping查看索引库的字段类型最高频使用的数据类型 核心概念 在新版Elasticsearch中,文档document就是一行记录(json),而这些记录存在于索引库(index)中, 索引名称必须是…...

AI神经网络降噪 vs 传统单/双麦克风降噪的核心优势对比
1. 降噪原理的本质差异 对比维度传统单/双麦克风降噪AI神经网络降噪技术基础基于固定规则的信号处理(如谱减法、维纳滤波)基于深度学习的动态建模(DNN/CNN/Transformer)噪声样本依赖预设有限噪声类型训练数据覆盖数十万种真实环境…...
04-Web后端基础(基础知识)
而像HTML、CSS、JS 以及图片、音频、视频等这些资源,我们都称为静态资源。 所谓静态资源,就是指在服务器上存储的不会改变的数据,通常不会根据用户的请求而变化。 那与静态资源对应的还有一类资源,就是动态资源。那所谓动态资源&…...
Spring Cloud生态与技术选型指南:如何构建高可用的微服务系统?
引言:为什么选择Spring Cloud? 作为全球开发者首选的微服务框架,Spring Cloud凭借其开箱即用的组件、与Spring Boot的无缝集成,以及活跃的社区生态,成为企业级微服务架构的基石。但在实际项目中,如何从众多…...
手写简单的tomcat
首先,Tomcat是一个软件,所有的项目都能在Tomcat上加载运行,Tomcat最核心的就是Servlet集合,本身就是HashMap。Tomcat需要支持Servlet,所以有servlet底层的资源:HttpServlet抽象类、HttpRequest和HttpRespon…...

高等数学-积分
一、不定积分 定理:如果函数f(x)在区间I上连续,那么f(x)在区间I上一定有原函数,即一定存在区间I上的可导函数F(x),使得F(x)f(x) ,x∈I 简单地说:连续函数必有原函数。 极限lim*0->x {[∫*0^x sin(t^2)…...
IOS平台Unity3D AOT全局模块结构分析
分析背景 由于IOS平台中不允许执行动态代码,Unity 4.6之前的版本在IOS平台中采用了AOT的处理方式,提前将C#代码静态编译为机器识别的二进制机器码。Unity引擎4.6之前的版本中IOS框架采用了Mono的AOT机制实现静态编译和处理,本文针对全局AOT模…...

Vue 3.0中自定义指令
自定义指令是增强 Vue 组件的重要手段。常见的内置指令有: v-if、v-show、v-model、v-bind、v-on等。 本文将详细讲解如何创建和使用自定义指令,关注以下几个关键点: 1. 指令的钩子函数:类似于生命周期钩子函数。 2. 指令钩子函…...

在 语义分割 和 图像分类 任务中,image、label 和 output 的形状会有所不同。
1. 图像分类 (Image Classification) 图像分类 任务是将整个图像分类为一个类别。通常,output 是对整个图像的类别的预测,而 label 是该图像的真实类别。 1.1 image 的形状 image 是输入图像数据,通常是一个四维张量: 形状&…...

C++面试4-sizeof解析
C++sizeof关键字的深度解析 一、本质认知:编译器的尺度 1. 编译期操作符的基因 int arr[5]; cout << sizeof(arr); // 输出20(假设int为4字节)非运行时特性:在编译阶段完成计算,不会生成任何机器指令表达式不求值:sizeof(++i)不会改变i的值类型感知:对类型名使…...

CyberSecAsia专访CertiK首席安全官:区块链行业亟需“安全优先”开发范式
近日,权威网络安全媒体CyberSecAsia发布了对CertiK首席安全官Wang Tielei博士的专访,双方围绕企业在进军区块链领域时所面临的关键安全风险与防御策略展开深入探讨。 Wang博士在采访中指出,跨链桥攻击、智能合约漏洞以及私钥管理不当&#x…...

uniapp如何设置uni.request可变请求ip地址
文章目录 简介方法一:直接在请求URL中嵌入变量方法二:使用全局变量方法三:使用环境变量方法四:服务端配置方法五:使用配置文件(如config.js):总结 简介 在uni-app中,uni.request 用…...

文件操作和IO-3 文件内容的读写
文件内容的读写——数据流 流是操作系统提供的概念,Java对操作系统的流进行了封装。 数据流就像水流,生生不息,绵延不断。 水流的特点:比如要100mL的水,可以一次接10mL,分10次接完,也可以一次接…...

架构的设计
搭建架构的最低前提 1.设计清晰: 需求文档: 有哪些界面 每个界面提够了哪些功能 这些功能是怎样操作的 会有哪些反馈 2.技术: 写架构的同学:这次项目设计的技术 都要有料及(用到的技术有哪些特点 有哪些缺点&…...
SpringAI 大模型应用开发篇-SpringAI 项目的新手入门知识
🔥博客主页: 【小扳_-CSDN博客】 ❤感谢大家点赞👍收藏⭐评论✍ 1.0 SpringAI 概述 目前大模型应用开发最常见的框架就是 LangChain,然而 LangChain 是基于 Python 语言,虽然有 LangChain4j,但是对于大量使…...
编程速递-RAD Studio 12.3 Athens五月补丁:May Patch Available
编程速递-RAD Studio 12.3 Athens四月补丁:关注软件性能的开发者,安装此补丁十分必要 今天 (2025 年 5 月 19 日)Embarcadero 发布了 RAD Studio、Delphi 和 CBuilder 12.3 Athens(雅典)的第二个补丁。 RA…...
)
Vue3实现轮播表(表格滚动)
在这之前,写过一篇Vue2实现该效果的博文:vue-seamless-scroll(一个简单的基于vue.js的无缝滚动) 有兴趣也可以去看下,这篇是用vue3实现,其实很简单,目的是方便后面用到直接复制既可以了。 安装: <...
Python爬虫高阶:动态页面破解与验证码OCR识别全流程实战)
Python爬虫(33)Python爬虫高阶:动态页面破解与验证码OCR识别全流程实战
目录 一、技术背景与行业痛点二、核心技术与实现路径2.1 动态页面处理方案对比2.2 Selenium深度集成实践2.3 OCR验证码破解方案1. 预处理阶段:2. 识别阶段:3. 后处理阶段 三、典型应用场景解析3.1 电商价格监控系统1. 技术架构2. 实现效果 3.2 社交媒体舆…...

Matlab学习合集
1.变量 2.常见的数学函数 3. 向量 向量的创建: 直接创建:针对于数量少的情况 冒号法 函数创建:...
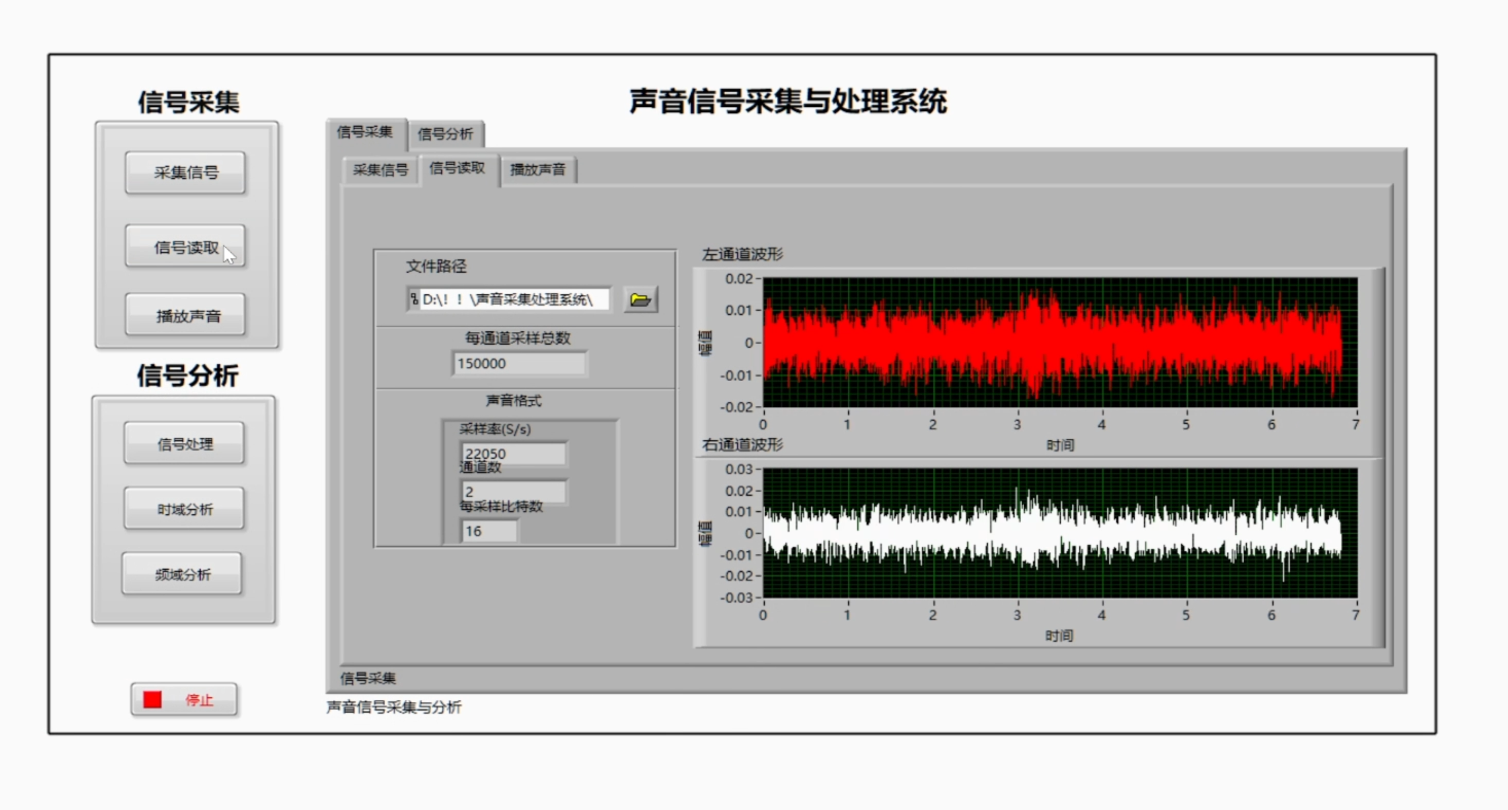
基于labview的声音采集与存储分析系统
基于LabVIEW的声音信号采集与存储分析系统开发实战:从原理到代码实现 (内含源码)基于labview的声音采集与处理系统 点击跳转工坊 点击跳转视频 引言 在音频技术与工业监测领域,声音信号的实时采集与分析是一项基础且关键的任务。…...
【项目记录】部门增删改及日志技术
1 删除部门 1.1 需求 删除部门数据。在点击 "删除" 按钮,会根据ID删除部门数据。 了解了需求之后,我们再看看接口文档中,关于删除部门的接口的描述,然后根据接口文档进行服务端接口的开发。 1.2 接口描述 1.2.1 基…...

TDengine 更多安全策略
简介 上一节我们介绍了 TDengine 安全部署配置建议,除了传统的这些配置外,TDengine 还有其他的安全策略,例如 IP 白名单、审计日志、数据加密等,这些都是 TDengine Enterprise 特有功能,其中白名单功能在 3.2.0.0 版本…...

电子制造企业智能制造升级:MES系统应用深度解析
在全球电子信息产业深度变革的2025年,我国电子信息制造业正经历着增长与转型的双重考验。据权威数据显示,2025年一季度行业增加值同比增长11.5%,但智能手机等消费电子产量同比下降1.1%,市场竞争白热化趋势显著。叠加关税政策调整、…...
Java使用Collections集合工具类
1、Collections 集合工具类 Java 中的 Collections 是一个非常有用的工具类,它提供了许多静态方法来操作或返回集合。这个类位于 java.util 包中,主要包含对集合进行操作的方法,比如排序、搜索、线程安全化等。 Java集合工具类的使用&#x…...

磁盘空间不足,迁移Docker 数据目录
停止 Docker 服务。 sudo systemctl stop docker 将现有的 Docker 数据移动到新位置(例如 /home/docker-data)。 sudo mv /var/lib/docker /home/docker-data 在原位置创建一个指向新位置的符号链接。 sudo ln -s /home/docker-data /var/lib/dock…...
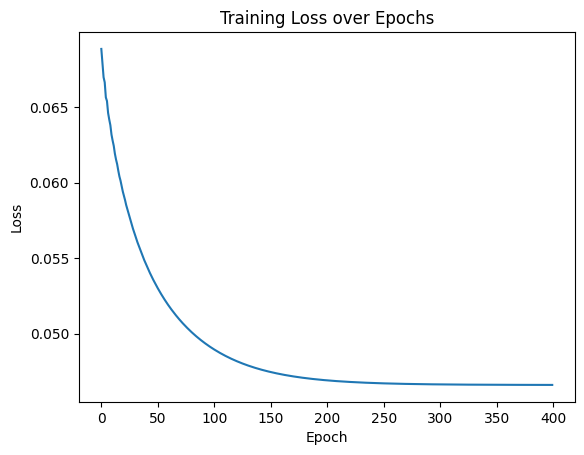
python打卡day33
知识点回顾: PyTorch和cuda的安装查看显卡信息的命令行命令(cmd中使用)cuda的检查简单神经网络的流程 数据预处理(归一化、转换成张量)模型的定义 继承nn.Module类定义每一个层定义前向传播流程 定义损失函数和优化器定…...