【图像生成大模型】HunyuanVideo:大规模视频生成模型的系统性框架
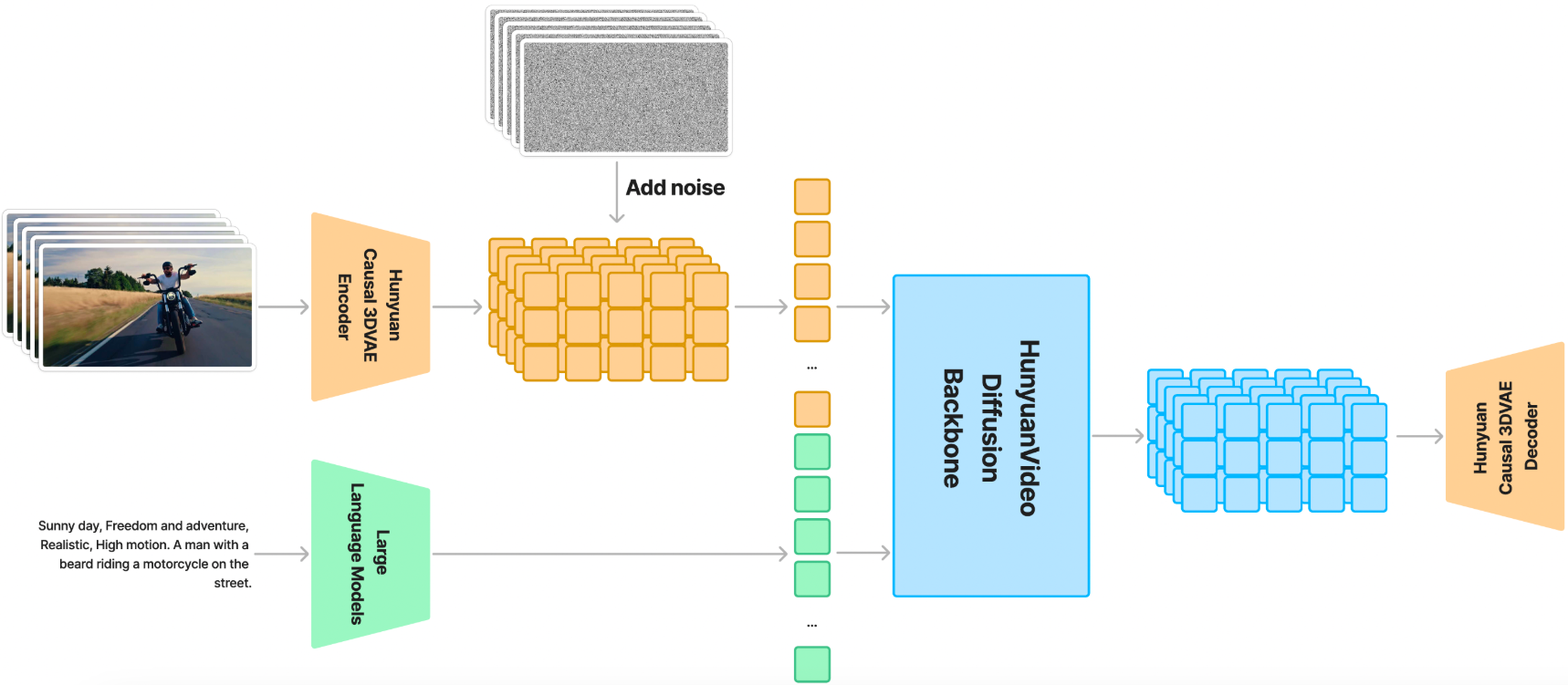
HunyuanVideo:大规模视频生成模型的系统性框架
- 引言
- HunyuanVideo 项目概述
- 核心技术
- 1. 统一的图像和视频生成架构
- 2. 多模态大语言模型(MLLM)文本编码器
- 3. 3D VAE
- 4. 提示重写(Prompt Rewrite)
- 项目运行方式与执行步骤
- 1. 环境准备
- 2. 安装依赖
- 3. 下载预训练模型
- 4. 单 GPU 推理
- 使用命令行
- 运行 Gradio 服务器
- 5. 多 GPU 并行推理
- 6. FP8 推理
- 执行报错与问题解决
- 1. 显存不足
- 2. 环境依赖问题
- 3. 模型下载问题
- 相关论文与研究
- 1. 扩散模型(Diffusion Models)
- 2. Transformer 架构
- 3. 3D 变分自编码器(3D VAE)
- 4. 多模态大语言模型(MLLM)
- 总结
引言
随着人工智能技术的快速发展,视频生成领域正逐渐成为研究和应用的热点。视频生成技术能够根据文本描述生成相应的视频内容,广泛应用于视频创作、广告制作、教育娱乐等多个领域。腾讯的 HunyuanVideo 项目正是这一领域的前沿成果,它提供了一个系统性的框架,用于大规模视频生成模型的开发和应用。
HunyuanVideo 项目概述
HunyuanVideo 是一个开源的大规模视频生成模型框架,旨在推动视频生成技术的发展。该项目的核心目标是通过系统性的设计和优化,实现高效、高质量的视频生成。HunyuanVideo 的主要特点包括:
- 高性能:HunyuanVideo 在视频生成质量上达到了与领先闭源模型相当甚至更优的水平。
- 统一的图像和视频生成架构:通过 Transformer 设计和全注意力机制,实现图像和视频的统一生成。
- 多模态大语言模型(MLLM)文本编码器:使用预训练的 MLLM 作为文本编码器,提升文本特征的表达能力。
- 3D VAE:通过因果卷积 3D VAE 压缩视频和图像,显著减少后续扩散 Transformer 模型的 token 数量。
- 提示重写(Prompt Rewrite):通过提示重写模型,优化用户提供的文本提示,提升模型对用户意图的理解。
核心技术
1. 统一的图像和视频生成架构
HunyuanVideo 引入了 Transformer 设计,采用全注意力机制实现图像和视频的统一生成。具体来说,HunyuanVideo 采用了“双流到单流”(Dual-stream to Single-stream)的混合模型设计。在双流阶段,视频和文本 token 通过多个 Transformer 块独立处理,使每种模态都能学习到自己的调制机制,避免相互干扰。在单流阶段,将视频和文本 token 连接起来,输入后续的 Transformer 块,实现有效的多模态信息融合。这种设计能够捕捉视觉和语义信息之间的复杂交互,提升模型的整体性能。
2. 多模态大语言模型(MLLM)文本编码器
HunyuanVideo 使用预训练的多模态大语言模型(MLLM)作为文本编码器,与传统的 CLIP 和 T5-XXL 文本编码器相比,具有以下优势:
- 更好的图像-文本对齐:MLLM 在视觉指令微调后,能够更好地对齐图像和文本的特征空间,减轻扩散模型中指令遵循的难度。
- 更强的图像细节描述和复杂推理能力:MLLM 在图像细节描述和复杂推理方面表现出色,优于 CLIP。
- 零样本学习能力:MLLM 可以作为零样本学习器,通过在用户提示前添加系统指令,帮助文本特征更关注关键信息。
此外,MLLM 基于因果注意力,而 T5-XXL 使用双向注意力,这使得 MLLM 为扩散模型提供了更好的文本引导。因此,HunyuanVideo 引入了一个额外的双向 token 优化器来增强文本特征。
3. 3D VAE
HunyuanVideo 使用因果卷积 3D VAE 压缩像素空间的视频和图像,将其转换为紧凑的潜在空间。具体来说,视频长度、空间和通道的压缩比分别设置为 4、8 和 16。这种压缩可以显著减少后续扩散 Transformer 模型的 token 数量,使模型能够在原始分辨率和帧率下训练视频。
4. 提示重写(Prompt Rewrite)
为了应对用户提供的文本提示在语言风格和长度上的多样性,HunyuanVideo 使用 Hunyuan-Large 模型微调的提示重写模型,将原始用户提示适应为模型偏好的提示。HunyuanVideo 提供了两种重写模式:普通模式(Normal mode)和大师模式(Master mode)。普通模式旨在增强视频生成模型对用户意图的理解,而大师模式则增强了对构图、灯光和镜头运动的描述,倾向于生成视觉质量更高的视频。然而,这种强调有时可能会导致一些语义细节的丢失。
项目运行方式与执行步骤
1. 环境准备
在开始运行 HunyuanVideo 之前,需要确保你的开发环境已经准备好。以下是推荐的环境配置:
- 操作系统:推荐使用 Linux,Windows 用户可能需要额外配置 WSL 或虚拟机。
- Python 版本:建议使用 Python 3.10 或更高版本。
- CUDA 和 GPU:确保你的系统安装了 CUDA,并且 GPU 驱动程序是最新的。推荐使用具有 80GB 内存的 GPU 以获得更好的生成质量。
2. 安装依赖
首先,需要克隆项目仓库并安装依赖项:
git clone https://github.com/Tencent/HunyuanVideo.git
cd HunyuanVideo
创建并激活 Conda 环境:
conda create -n HunyuanVideo python==3.10.9
conda activate HunyuanVideo
安装 PyTorch 和其他依赖项:
# For CUDA 11.8
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=11.8 -c pytorch -c nvidia# For CUDA 12.4
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.4 -c pytorch -c nvidia
安装 pip 依赖项:
python -m pip install -r requirements.txt
安装 Flash Attention v2 以加速推理:
python -m pip install ninja
python -m pip install git+https://github.com/Dao-AILab/flash-attention.git@v2.6.3
安装 xDiT 用于多 GPU 并行推理:
python -m pip install xfuser==0.4.0
3. 下载预训练模型
HunyuanVideo 提供了多种预训练模型,可以通过以下链接下载:
- HunyuanVideo 模型权重
- HunyuanVideo FP8 模型权重
4. 单 GPU 推理
使用命令行
以下是一个简单的命令,用于在单 GPU 上运行视频生成任务:
cd HunyuanVideopython3 sample_video.py \--video-size 720 1280 \--video-length 129 \--infer-steps 50 \--prompt "A cat walks on the grass, realistic style." \--flow-reverse \--use-cpu-offload \--save-path ./results
运行 Gradio 服务器
你也可以运行一个 Gradio 服务器,通过 Web 界面进行视频生成:
python3 gradio_server.py --flow-reverse
5. 多 GPU 并行推理
HunyuanVideo 支持使用 xDiT 在多 GPU 上进行并行推理。以下是一个使用 8 个 GPU 的命令示例:
cd HunyuanVideotorchrun --nproc_per_node=8 sample_video.py \--video-size 1280 720 \--video-length 129 \--infer-steps 50 \--prompt "A cat walks on the grass, realistic style." \--flow-reverse \--seed 42 \--ulysses-degree 8 \--ring-degree 1 \--save-path ./results
6. FP8 推理
HunyuanVideo 还提供了 FP8 量化权重,可以显著减少 GPU 内存占用。以下是一个使用 FP8 权重的命令示例:
cd HunyuanVideoDIT_CKPT_PATH={PATH_TO_FP8_WEIGHTS}/{WEIGHT_NAME}_fp8.ptpython3 sample_video.py \--dit-weight ${DIT_CKPT_PATH} \--video-size 1280 720 \--video-length 129 \--infer-steps 50 \--prompt "A cat walks on the grass, realistic style." \--seed 42 \--embedded-cfg-scale 6.0 \--flow-shift 7.0 \--flow-reverse \--use-cpu-offload \--use-fp8 \--save-path ./results
执行报错与问题解决
在运行 HunyuanVideo 项目时,可能会遇到一些常见的问题。以下是一些常见问题及其解决方法:
1. 显存不足
如果在运行时遇到显存不足的错误,可以尝试以下方法:
- 使用 CPU 卸载:通过
--use-cpu-offload参数将部分模型参数卸载到 CPU,减少 GPU 内存使用。 - 降低分辨率:降低生成视频的分辨率,例如从 720p 降低到 540p。
- 减少推理步数:通过调整
--infer-steps参数来减少推理步数。 - 使用 FP8 权重:使用 FP8 量化权重可以显著减少 GPU 内存占用。
2. 环境依赖问题
如果在安装依赖时遇到问题,可以尝试以下方法:
- 更新 pip 和 setuptools:确保 pip 和 setuptools 是最新版本。
- 手动安装依赖:对于某些依赖项,可以尝试手动安装,例如
torch和transformers。
3. 模型下载问题
如果在下载模型时遇到问题,可以尝试以下方法:
- 检查网络连接:确保你的网络连接正常,能够访问 Hugging Face。
- 手动下载模型:如果自动下载失败,可以手动下载模型文件并放置到指定目录。
相关论文与研究
HunyuanVideo 的开发基于多项前沿研究,其中一些关键的论文和技术包括:
1. 扩散模型(Diffusion Models)
扩散模型是一种基于噪声扩散和去噪过程的生成模型。其核心思想是通过逐步添加噪声将数据分布转换为先验分布,然后通过去噪过程恢复原始数据分布。HunyuanVideo 使用了扩散模型的框架,结合了 Flow Matching 技术,显著提高了生成视频的质量。
2. Transformer 架构
HunyuanVideo 的模型架构基于 Transformer,这种架构在自然语言处理和计算机视觉领域都取得了巨大成功。Transformer 的自注意力机制能够有效地捕捉长距离依赖关系,使其在视频生成任务中表现出色。
3. 3D 变分自编码器(3D VAE)
HunyuanVideo 使用因果卷积 3D VAE 压缩视频和图像,显著减少了后续扩散 Transformer 模型的 token 数量。这种压缩不仅加速了训练和推理过程,还与扩散过程对压缩表示的偏好相一致。
4. 多模态大语言模型(MLLM)
HunyuanVideo 使用预训练的多模态大语言模型(MLLM)作为文本编码器,显著提升了文本特征的表达能力。MLLM 在图像-文本对齐、图像细节描述和复杂推理方面表现出色,优于传统的 CLIP 和 T5-XXL 文本编码器。
总结
HunyuanVideo 项目以其卓越的性能、高效的实现方式和开源性,为视频生成领域提供了一个强大的工具。通过本文的详细介绍,读者可以全面了解 HunyuanVideo 的技术架构,并掌握如何在实际项目中应用这一模型。无论是研究人员还是开发者,都可以从 HunyuanVideo 中受益,推动视频生成技术的发展和应用。
未来,随着技术的不断进步,HunyuanVideo 有望在更多领域发挥更大的作用,为人类创造更加丰富多彩的视觉内容。
相关文章:
【图像生成大模型】HunyuanVideo:大规模视频生成模型的系统性框架
HunyuanVideo:大规模视频生成模型的系统性框架 引言HunyuanVideo 项目概述核心技术1. 统一的图像和视频生成架构2. 多模态大语言模型(MLLM)文本编码器3. 3D VAE4. 提示重写(Prompt Rewrite) 项目运行方式与执行步骤1. …...
)
GitHub 趋势日报 (2025年05月19日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1public-apis/public-apis免费API的集体清单⭐ 1821⭐ 344364Python2virattt/a…...
如何使用Java生成pdf报告
文章目录 一、环境准备与Maven依赖说明二、核心代码解析1. 基础文档创建2. 中文字体处理3. 复杂表格创建4. 图片插入 三、完整代码示例四、最终效果 这篇主要说一下如何使用Java生成pdf,包括标题,文字,图片,表格的插入和调整等相关…...

HarmonyOS鸿蒙应用规格开发指南
在鸿蒙生态系统中,应用规格是确保应用符合系统要求的基础。本文将深入探讨鸿蒙应用的规格开发实践,帮助开发者打造符合规范的应用。 应用包结构规范 1. 基本配置要求 包结构规范 符合规范的应用包结构正确的HAP配置文件完整的应用信息 示例配置&…...

【Harmony】【鸿蒙】List列表View如何刷新内部的自定义View的某一个控件
创建自定义View Component export struct TestView{State leftIcon?:Resource $r(app.media.leftIcon)State leftText?:Resource | string $r(app.string.leftText)State rightText?:Resource | string $r(app.string.rightText)State rightIcon?:Resource $r(app.med…...

iisARR负均衡
IIS ARR负载均衡详细配置指南 🎯 什么是ARR(Application Request Routing) ARR是IIS的一个扩展模块,它可以: 负载均衡:将请求分发到多个服务器反向代理:隐藏后端服务器架构健康检查…...

uniapp打包报错:重新在manifest.json中生成自己的APPID
在UniApp开发过程中,打包时可能会遇到报错提示需要在manifest.json中重新生成自己的APPID。以下是解决该问题的具体方法: 检查并生成APPID 打开项目根目录下的manifest.json文件,找到appid字段。如果该字段为空或为默认值,需要重…...

人脸识别备案开启安全防护模式!紧跟《办法》!
国家互联网信息办公室与公安部于 2025 年 3 月 13 日联合公布了《人脸识别技术应用安全管理办法》(以下简称《办法》),并自 2025 年 6 月 1 日起正式施行。其中,人脸识别备案成为了规范技术应用、守护信息安全的关键一环。 一、…...

【爬虫】DrissionPage-7
官方文档: https://www.drissionpage.cn/browser_control/get_page_info/ 1. 页面信息 📌 html 描述:返回当前页面的 HTML 文本。注意:不包含 <iframe> 元素的内容。返回类型:str 示例: html_co…...

新浪《经济新闻》丨珈和科技联合蒲江政府打造“数字茶园+智能工厂+文旅综合体“创新模式
5月14日,新浪网《经济新闻》频道专题报道珈和科技在第十四届四川国际茶业博览会上的精彩亮相,并深度聚焦我司以数字技术赋能川茶产业高质量发展创新技术路径,及在成都市“茶业建圈强链”主题推介会上,珈和科技与蒲江县人民政府就智…...

git 撤销最近的几次push
要实现将远程仓库回退到最近5次push之前的状态,同时保留本地改动,可以按照以下步骤操作: 一、本地分支回退(保留改动) # 1. 查看提交历史确认要回退的提交点 git log --oneline# 2. 回退到5次提交前的状态࿰…...

水滴前端面经及参考答案
盒模型是什么,标准盒模型和 IE 盒模型有什么区别? 盒模型是 CSS 中一个基础概念,它描述了元素在页面中所占的空间大小。每个元素都可以看作是一个矩形盒子,从内到外由内容区(content)、内边距(padding)、边框(border)和外边距(margin)组成。 标准盒模型的宽度和高…...
 Hook的使用详解及注意事项)
React 第四十五节 Router 中 useHref() Hook的使用详解及注意事项
前言 React Router 中的 useHref 是一个用于生成完整 URL 路径的钩子, 它可以将相对路径解析为绝对路径,并确保在不同路由层级中正确工作。 它常用于自定义导航组件或需要手动构建链接的场景。 一、useHref核心用途 解析相对路径:自动将相…...

50、js 中var { ipcRenderer } = require(‘electron‘);是什么意思?
在 JavaScript 中,var { ipcRenderer } require(‘electron’); 这行代码的含义是: 1. require(‘electron’) 这是 Node.js 的模块引入语法,用于加载 Electron 的核心模块。electron 是 Electron 框架的主模块,提供了构建桌面…...

LeetCode 438. 找到字符串中所有字母异位词 | 滑动窗口与字符计数数组解法
文章目录 问题描述核心思路:滑动窗口 字符计数数组1. 字符计数数组2. 滑动窗口 算法步骤完整代码实现复杂度分析关键点总结类似问题 问题描述 给定两个字符串 s 和 p,要求找到 s 中所有是 p 的**字母异位词(Anagram)**的子串的起…...

@RequestParam 和 @RequestBody、HttpServletrequest 与HttpServletResponse
在Java Web开发中,RequestParam、RequestBody、HttpServletRequest 和 HttpServletResponse 是常用的组件,它们用于处理HTTP请求和响应。下面分别介绍它们的使用场景和使用方法: 1. RequestParam RequestParam 是Spring MVC框架中的注解&am…...
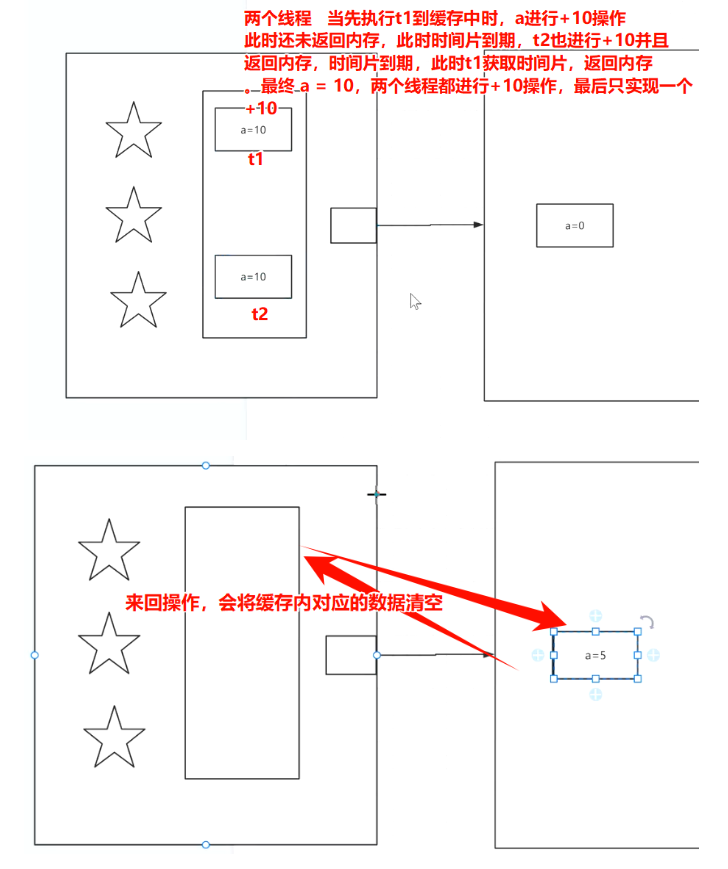
计算机底层的多级缓存以及缓存带来的数据覆盖问题
没有多级缓存的情况 有多级缓存的情况 缓存带来的操作覆盖问题 锁总线带来的消耗太大了。...
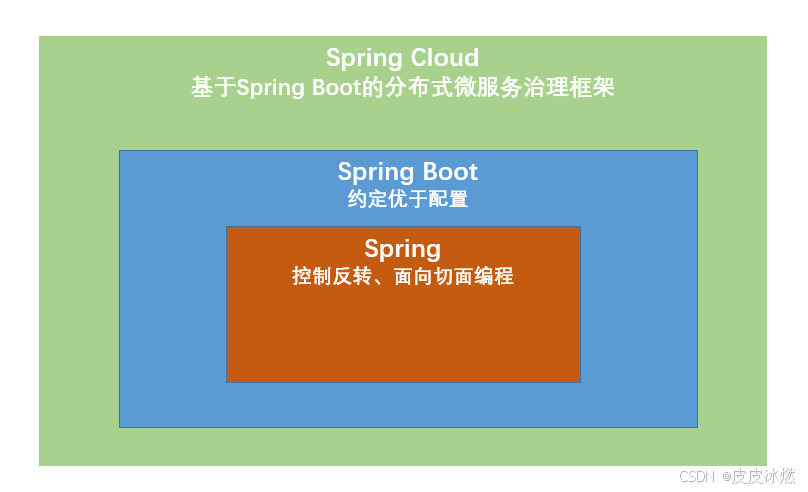
SpringBoot-1-入门概念介绍和第一个Spring Boot项目
文章目录 1 开发JAVA EE应用1.1 EJB1.2 Spring框架1.2.1 IoC(Inversion of Control)控制反转1.2.2 DI(Dependency Injection)依赖注入1.2.3 AOP面向切面编程1.3 Spring Boot1.4 Spring Cloud框架1.5 开发工具2 创建Spring Boot项目2.1 在线项目生成向导2.2 使用IDEA导入项目2.3…...

服务器多用户共享Conda环境操作指南——Ubuntu24.02
1. 使用阿里云镜像下载 Anaconda 最新版本 wget https://mirrors.aliyun.com/anaconda/archive/Anaconda3-2024.02-1-Linux-x86_64.sh bug解决方案 若出现:使用wget在清华镜像站下载Anaconda报错ERROR 403: Forbidden. 解决方案:wget --user-agent“M…...
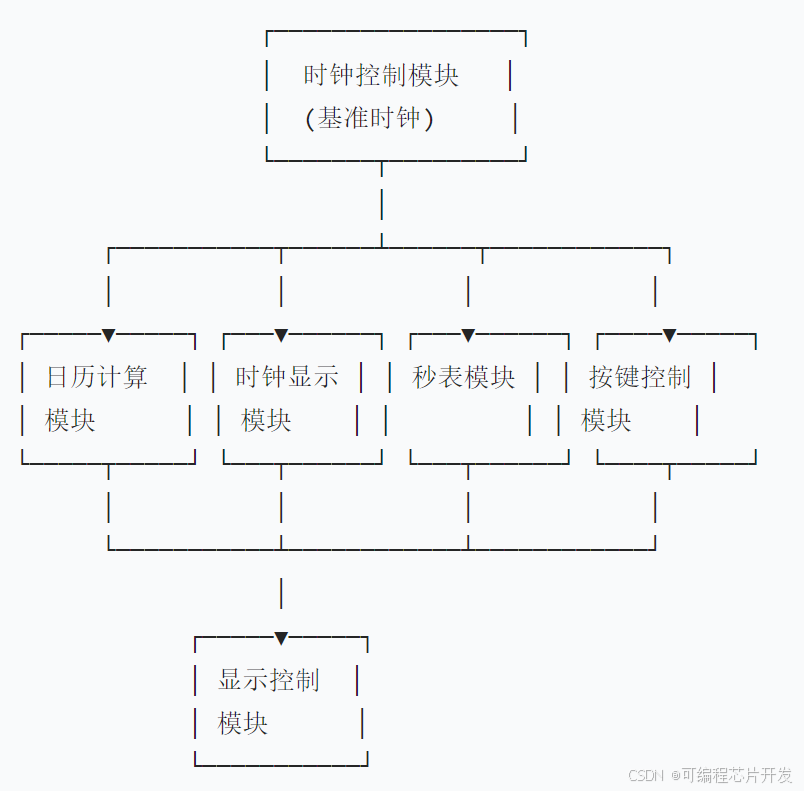
基于FPGA的电子万年历系统开发,包含各模块testbench
目录 1.课题概述 2.系统仿真结果 3.核心程序与模型 4.系统原理简介 5.完整工程文件 1.课题概述 基于FPGA的电子万年历系统开发,包含各模块testbench。主要包含以下核心模块: 时钟控制模块:提供系统基准时钟和计时功能。 日历计算模块:…...

Leetcode刷题 | Day63_图论08_拓扑排序
一、学习任务 拓扑排序代码随想录 二、具体题目 1.拓扑排序117. 软件构建 【题目描述】 某个大型软件项目的构建系统拥有 N 个文件,文件编号从 0 到 N - 1,在这些文件中,某些文件依赖于其他文件的内容,这意味着如果文件 A 依…...
MySQL 可观测性最佳实践
MySQL 简介 MySQL 是一个广泛使用的开源关系型数据库管理系统(RDBMS),以其高性能、可靠性和易用性而闻名,适用于各种规模的应用,从小型网站到大型企业级系统。 监控 MySQL 指标是维护数据库健康、优化性能和确保数据…...
 : Tuning Efforts)
系统性能分析基本概念(3) : Tuning Efforts
系统性能调优(Tuning Efforts)是指通过优化硬件、软件或系统配置来提升性能,减少延迟、提高吞吐量或优化资源利用率。以下是系统性能调优的主要努力方向,涵盖硬件、操作系统、应用程序和网络等多个层面,结合实际应用场…...
函数速查表)
OceanBase数据库全面指南(函数篇)函数速查表
文章目录 一、数学函数1.1 基本数学函数1.2 三角函数二、字符串函数2.1 基本字符串函数2.2 高级字符串处理函数三、日期时间函数3.1 基本日期时间函数3.2 日期时间计算函数四、聚合函数4.1 常用聚合函数4.2 分组聚合4.3 高级聚合函数五、条件判断函数5.1 基本条件函数5.2 CASE表…...

SpringBoot 对象转换 MapStruct
文章目录 工作原理核心优势为什么不使用 BeanUtils使用步骤添加依赖定义实体类和VO类定义映射接口测试数据 参考 工作原理 基于 Java 的 JSR 269 规范,该规范允许在编译期处理注解,也就是 Java 注解处理器。MapStruct 通过定义的注解处理器,…...

计算机网络——Session、Cookie 和 Token
在 Web 开发中,Session、Cookie 和 Token 是实现用户会话管理和身份验证的核心技术。它们既有联系,也有明显区别。以下从定义、原理、联系、区别和应用场景等方面详细解析。 一、基本定义与原理 1. Cookie 定义: 是浏览器存储在客户端的小…...
01-jenkins学习之旅-window-下载-安装-安装后设置向导
1 jenkins简介 百度百科介绍:Jenkins是一个开源软件项目,是基于Java开发的一种持续集成工具,用于监控持续重复的工作,旨在提供一个开放易用的软件平台,使软件项目可以进行持续集成。 [1] Jenkins官网地址 翻译&…...

Spark,SparkSQL操作Mysql, 创建数据库和表
以下是使用 Spark SQL 在 MySQL 中创建数据库和表的步骤(基于 Scala API): 1. 准备工作 - 添加 MySQL 驱动依赖 同前所述,需在 Spark 环境中引入 MySQL Connector JAR 包(如 mysql-connector-java-8.0.33.jar &#…...

AttributeError: module ‘cv2.dnn‘ has no attribute ‘DictValue‘错误解决方法
源代码如下: # 读取图像 import cv2 im cv2.imread("./test.png", 1) # 1表示3通道彩色,0表示单通道灰度 cv2.imshow("test", im) # 在test窗口中显示图像 print(type(im)) # 打印数据类型 print(im.shape) # 打印图像尺寸 cv2.wai…...

HarmonyOS 鸿蒙应用开发基础:@Watch装饰器详解及与@Monitor装饰器对比分析
在鸿蒙系统的开发中,状态管理和组件之间的通信是至关重要的部分。为此,鸿蒙提供了多种装饰器来帮助开发者监听和处理数据变化。今天我们将深入探讨Watch装饰器,并与新的状态管理组件V2中的Monitor装饰器进行对比。 Watch装饰器详解 基本概念…...