Flink 核心概念解析:流数据、并行处理与状态
一、流数据(Stream Data)
1. 有界流(Bounded Stream)
-
定义:有明确起始和结束时间的数据集合,数据量固定,处理逻辑通常是一次性计算所有数据。
-
典型场景:
-
历史交易数据统计(如月度财务报表)
-
批量 ETL 任务(如每日从数据库同步数据到数据仓库)
-
-
技术特性:
-
批处理模式:Flink 可将有界流视为特殊的流,使用
DataSet API或Table API的批处理模式处理。 -
优化策略:由于数据总量已知,可进行全局排序、全量聚合等操作,优化器可选择更高效的执行计划(如 Hash Join)。
-
-
代码示例(批处理 WordCount):
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = env.readTextFile("input.txt");
DataSet<Tuple2<String, Integer>> counts = text.flatMap(new LineSplitter()).groupBy(0).sum(1);
counts.writeAsCsv("output.csv");
2. 无界流(Unbounded Stream)
-
定义:无明确结束时间的数据集合,数据持续产生,需实时处理。
-
典型场景:
-
实时监控(如服务器日志流、IoT 设备数据)
-
金融交易风控(如高频交易实时反欺诈)
-
-
技术挑战:
-
乱序数据:数据到达顺序可能与事件时间不一致,需通过 Watermark 机制处理。
-
资源管理:需通过窗口(Window)和状态清理机制控制资源使用,避免内存溢出。
-
-
代码示例(实时 WordCount):
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.socketTextStream("localhost", 9999);
DataStream<Tuple2<String, Integer>> counts = text.flatMap(new LineSplitter()).keyBy(value -> value.f0).window(TumblingProcessingTimeWindows.of(Time.seconds(5))).sum(1);
counts.print();
二、并行处理(Parallel Processing)
1. 流分区(Stream Partitioning)
-
定义:Flink 将数据流划分为多个分区,每个分区在不同的线程或节点上并行处理,提高吞吐量。
-
分区策略:
-
RoundRobin:数据循环分发给下游算子,保证负载均衡。
-
KeyBy:按指定键的哈希值分区,相同键的数据进入同一分区(如按用户 ID 分区)。
-
Broadcast:每个数据复制到所有下游分区,适用于配置数据同步。
-
Custom:自定义分区函数,满足特定业务需求。
-
-
源码解析(KeyBy 实现):
public <K> KeyedStream<T, K> keyBy(KeySelector<T, K> keySelector) {return new KeyedStream<>(this, new KeyGroupStreamPartitioner<>(keySelector, StreamGraphGenerator.DEFAULT_LOWER_BOUND_MAX_PARALLELISM));
}
2. 算子子任务(Operator Subtasks)
-
定义:每个算子可实例化为多个并行子任务,子任务数即算子并行度,决定了处理能力。
-
并行度设置:
-
全局默认:
env.setParallelism(4) -
算子级别:
dataStream.map(...).setParallelism(8)
-
-
执行原理:
-
每个子任务在单独的线程或容器中运行,通过网络或本地通道交换数据。
-
数据传输时,上游子任务的输出分区与下游子任务的输入分区需匹配。
-
-
并行度与资源关系:
总并行度 = 所有算子的最大并行子任务数
Flink 集群资源需 >= 总并行度 * 单任务资源需求
三、状态(State)
1. 状态类型
-
算子状态(Operator State):
-
与算子实例绑定,不依赖输入数据的键,所有输入分区共享同一状态。
-
典型场景:
-
Source 连接器记录偏移量(如 Kafka Consumer 偏移量)
-
模型预测服务中的全局模型参数
-
-
实现方式:
-
public class MySource implements SourceFunction<String>, CheckpointedFunction {private ListState<Long> offsetState;private long currentOffset = 0L;@Overridepublic void snapshotState(FunctionSnapshotContext context) throws Exception {offsetState.clear();offsetState.add(currentOffset);}
}
-
键控状态(Keyed State):
-
按输入数据的键(Key)隔离,每个键对应独立的状态,必须在
KeyedStream上使用。 -
状态类型:
-
| 状态类型 | 描述 | 示例方法 |
|---|---|---|
| ValueState | 单值状态 | update(value), value() |
| ListState | 列表状态 | add(value), get() |
| MapState | 键值对状态 | put(key, value), get(key) |
| ReducingState | 聚合状态(需提供 ReduceFunction) | add(value) |
| AggregatingState | 自定义聚合状态(需提供 AggregateFunction) | add(value) |
2. 状态后端(State Backends)
-
MemoryStateBackend:
-
特点:状态存储在 TaskManager 的 JVM 堆中,Checkpoint 存储在 JobManager 内存中。
-
适用场景:开发测试、小状态场景(如窗口大小较小)。
-
局限性:状态数据不能超过 TaskManager 堆内存,Checkpoint 可能影响性能。
-
-
FsStateBackend:
-
特点:状态存储在 TaskManager 堆内存中,Checkpoint 存储在外部文件系统(如 HDFS)。
-
适用场景:中等状态规模,需高可用性。
-
优势:支持大状态 Checkpoint,JobManager 故障不丢失状态。
-
-
RocksDBStateBackend:
-
特点:状态存储在本地 RocksDB 数据库(磁盘 + 内存),Checkpoint 存储在外部文件系统。
-
适用场景:超大状态(GB 级以上),如长时间窗口聚合、复杂 CEP 模式。
-
性能优化:
-
增量 Checkpoint:仅上传自上次 Checkpoint 以来的变更数据。
-
堆外内存:减少 GC 压力,提高吞吐量。
-
-
3. 精确一次语义(Exactly-Once)
- 实现原理:Flink 通过 状态快照(Checkpoint) 和 流重放(Stream Replay) 实现精确一次语义:
-
Checkpoint 触发:JobManager 定期向所有 Source 算子发送 Checkpoint Barrier。
-
Barrier 传播:Barrier 随数据流动,算子接收到 Barrier 时暂停处理,保存当前状态。
-
状态持久化:状态后端将状态写入持久化存储(如 HDFS)。
-
故障恢复:从最近成功的 Checkpoint 恢复状态,重新消费未处理的数据。
- 端到端精确一次:需 Source 和 Sink 支持事务或幂等写入:
// Kafka Source 支持精确一次偏移量记录
KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("localhost:9092").setTopics("input_topic").setGroupId("my-group").setStartingOffsets(OffsetsInitializer.earliest()).build();// Kafka Sink 支持两阶段提交
KafkaSink<String> sink = KafkaSink.<String>builder().setBootstrapServers("localhost:9092").setRecordSerializer(KafkaRecordSerializationSchema.builder().setTopic("output_topic").setValueSerializationSchema(new SimpleStringSchema()).build()).setTransactionalIdPrefix("my-tx-") // 启用事务.build();
四、状态管理最佳实践
- 状态清理策略:
// 设置状态 TTL(1 天后过期)
StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.days(1)).setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite).setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired).build();
valueStateDescriptor.enableTimeToLive(ttlConfig);
- 状态迁移:
-
升级 Flink 版本或修改状态结构时,需通过
StateMigrationStrategy确保兼容性。 -
使用
UID固定算子 ID:
dataStream.keyBy(...).map(...).uid("my-operator-uid");
- 监控与调优:
-
通过 Flink Web UI 查看状态大小、Checkpoint 耗时等指标。
-
对 RocksDB 状态后端,调整
rocksdb.block.cache.size参数优化内存使用。
五、总结
Flink 的状态管理是其核心竞争力之一,通过精确一次语义、灵活的状态类型和可扩展的状态后端,支持大规模实时计算场景。理解流数据、并行处理和状态的底层原理,是开发高性能、高可靠性 Flink 应用的关键。
相关文章:

Flink 核心概念解析:流数据、并行处理与状态
一、流数据(Stream Data) 1. 有界流(Bounded Stream) 定义:有明确起始和结束时间的数据集合,数据量固定,处理逻辑通常是一次性计算所有数据。 典型场景: 历史交易数据统计…...

C++23 范围迭代器作为非范围算法的输入 (P2408R5)
文章目录 一、引言二、C23及范围迭代器的背景知识2.1 C23概述2.2 范围迭代器的概念 三、P2408R5提案的内容3.1 提案背景3.2 提案内容 四、范围迭代器作为非范围算法输入的优势4.1 代码简洁性4.2 提高开发效率4.3 更好的兼容性 五、具体的代码示例5.1 使用范围迭代器进行并行计算…...

PHP-FPM 调优配置建议
1、动态模式 pm dynamic; 最大子进程数(根据服务器内存调整) pm.max_children 100 //每个PHP-FPM进程大约占用30-50MB内存(ThinkPHP框架本身有一定内存开销)安全值:8GB内存 / 50MB ≈ 160,保守设置为100 ; 启动时创建的进程数&…...
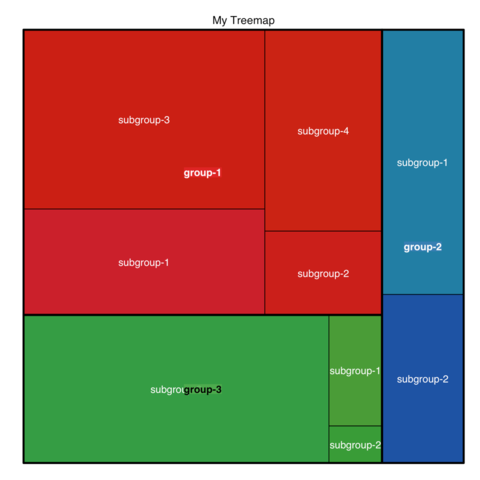
2025.05.20【Treemap】树图数据可视化技巧
Multi-level treemap How to build a treemap with group and subgroups. Customization Customize treemap labels, borders, color palette and more 文章目录 Multi-level treemapCustomization Treemap 数据可视化技巧什么是 TreemapTreemap 的应用场景如何在 R 中绘制 T…...

Elasticsearch 写入性能优化有哪些常见手段?
Elasticsearch 写入性能优化常见手段主要有以下 10 个方向,建议根据具体业务场景组合使用: 批量写入优化 使用_bulk API 批量提交文档建议每批次 5-15MB 数据量并发执行多个批量请求 索引配置调优 PUT /my_index {"settings": {"inde…...

CICD编译时遇到npm error code EINTEGRITY的问题
场景 CICD编译时抛出npm error code EINTEGRITY的错误 npm error code EINTEGRITY npm error sha512-PlhdFcillOINfeV7Ni6oF1TAEayyZBoZ8bcshTHqOYJYlrqzRK5hagpagky5o4HfCzzd1TRkXPMFq6cKk9rGmA integrity checksum failed when using sha512: wanted sha512-PlhdFcillOINfeV…...
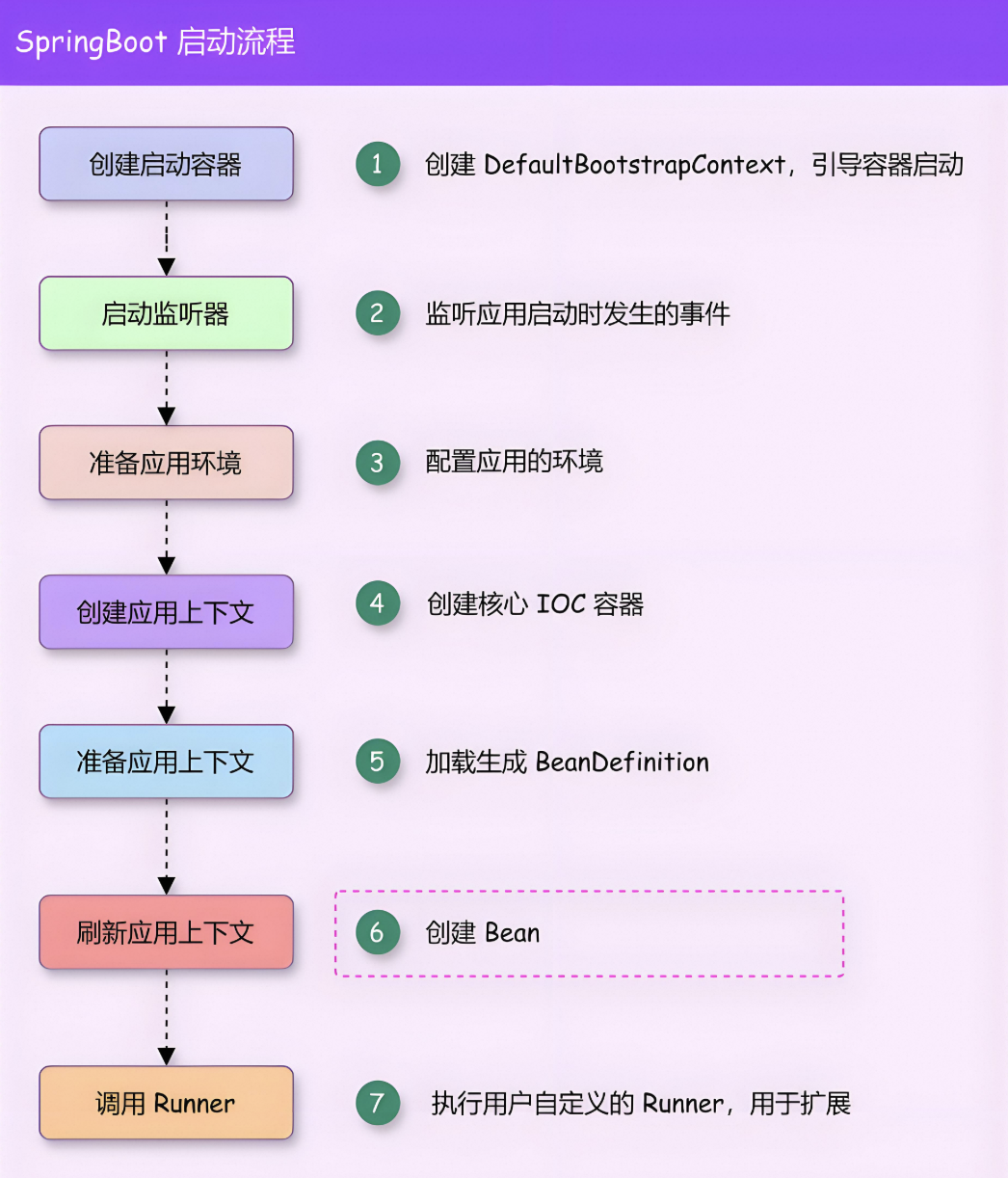
深入了解Springboot框架的启动流程
目录 1、介绍 2、执行流程 1、运行run方法 2、初始化SpringApplication对象 1、确定容器类型 3、加载所有的初始化器 4、加载Spring上下文监听器 5、设置程序运行的主类 3、进入run方法 1、开启计时器 2、Headless模式配置 3、获取并启用监听器 4、准备环境 1、设…...

DataWhale llm universe
搭建向量知识库 向量以及向量知识库 向量词与向量 词向量:是一种以单词为单位的将每个单词转化为实数向量的技术,这些实数可以被计算机更好的理解,如果是相近的理念或者相关的对象在向量空间中距离很近 词向量实际上将单词转化为固定的静态…...

LLaMA-Factory微调LLM-Research/Llama-3.2-3B-Instruct模型
1、GPU环境 nvidia-smi 2、pyhton环境安装 git clone https://github.com/hiyouga/LLaMA-Factory.git conda create -n llama_factory python3.10 conda activate llama_factory cd LLaMA-Factory pip install -e .[torch,metrics] 3、微调模型下载(LLM-Research/…...

DB-MongoDB-00002--Workload Generator for MongoDB
## DB-MongoDB-00002–Workload Generator for MongoDB 1、介绍 Workload Generator for MongoDB was designed to help MongoDB users effortlessly generate data and simulate workloads for both sharded and non-sharded clusters. The generated workloads include s…...

3.8.1 利用RDD实现词频统计
在本次实战中,我们通过Spark的RDD实现了词频统计功能。首先,准备了包含单词的文件并上传至HDFS。接着,采用交互式方式逐步完成词频统计,包括创建RDD、单词拆分、映射为二元组、按键归约以及排序等操作。此外,还通过创建…...
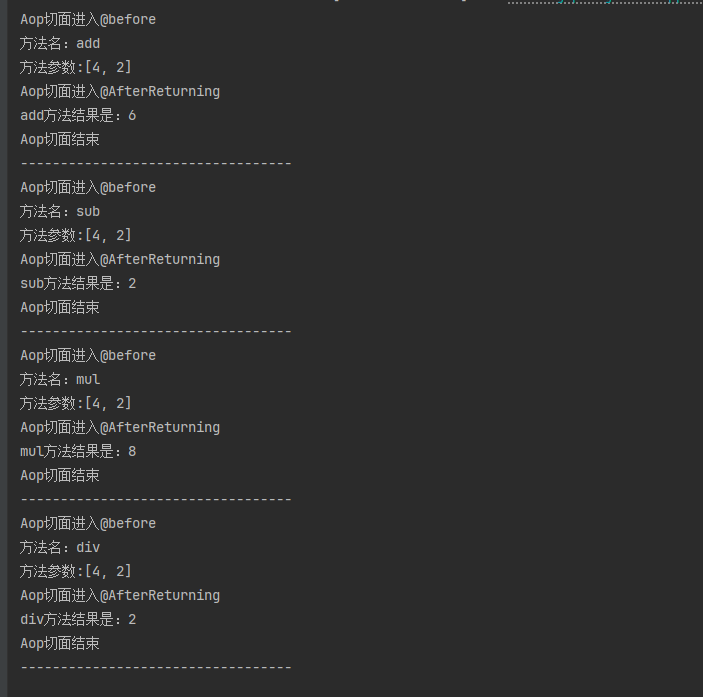
Spring Ioc和Aop,Aop的原理和实现案例,JoinPoint,@Aspect,@Before,@AfterReturning
DAY25.2 Java核心基础 Spring两大核心:Ioc和Aop IOC Ioc容器:装载bean的容器,自动创建bean 三种方式: 1、基于xml配置:通过在xml里面配置bean,然后通过反射机制创建bean,存入进Ioc容器中 …...
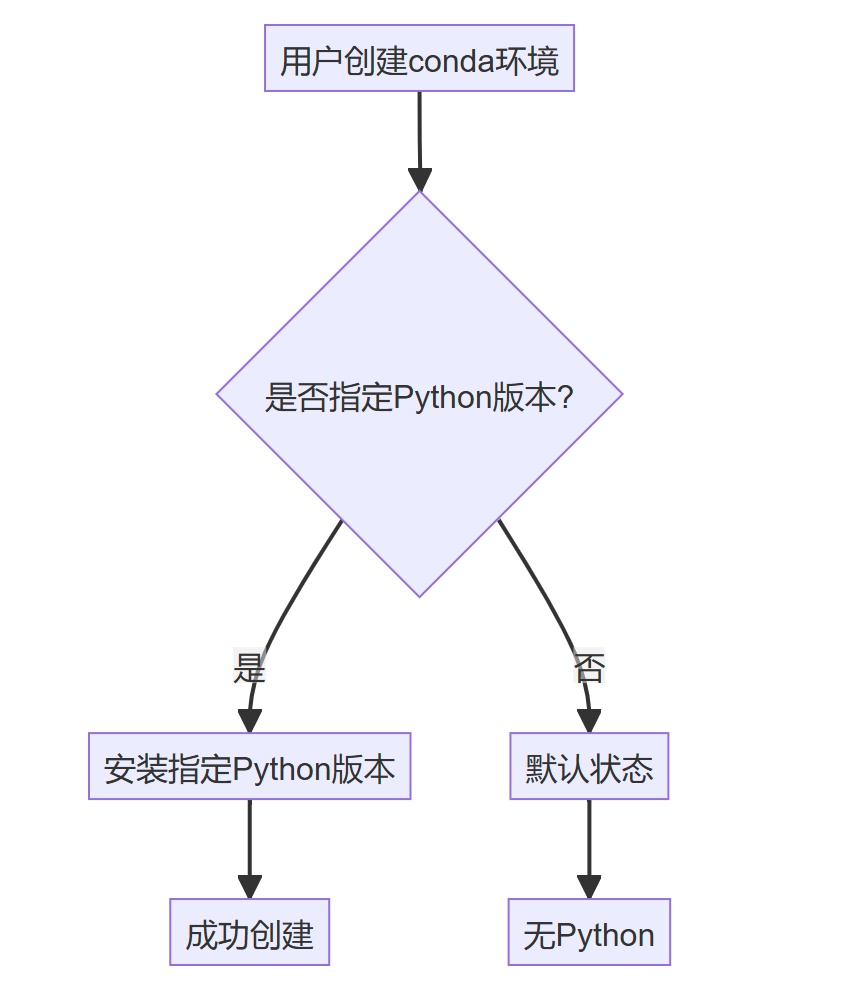
[解决conda创建新的虚拟环境没用python的问题]
问题复现 使用conda create -n env的时候,在对应的虚拟环境的文件里面找不到对应的python文件 为什么 首先,我们来看一下创建环境时的触发链路: 这表明当前环境中找不到Python可执行文件。 解决方法 所以很明显,我们需要指定…...

【优秀三方库研读】在 quill 开源库 LogMarcos.h 中知识点汇总及讲解
以下是LogMarcos.h中的主要知识点汇总及详细讲解: 大纲目录 编译时日志级别过滤预处理宏与条件编译可变参数处理技巧格式化字符串生成日志宏的分发机制线程本地存储(TLS)零成本抽象设计动态日志级别支持结构化日志标签日志频率限制机制1. 编译时日志级别过滤 核心宏:QUILL…...
openjdk17 c++源码垃圾回收之安全点阻塞状态线程在安全点同步中无需调用block函数的详细流程解析)
jvm安全点(五)openjdk17 c++源码垃圾回收之安全点阻塞状态线程在安全点同步中无需调用block函数的详细流程解析
关于阻塞状态线程在安全点同步中无需调用block函数的详细流程解析: 1. 安全点同步入口:SafepointSynchronize::begin() VM线程调用此函数启动安全点,核心步骤如下: 获取线程锁(Threads_lock):防…...

C++ 中的 **常变量** 与 **宏变量** 比较
🔍 C 中的 常变量 与 宏变量 比较 C 中定义不可修改值的方式主要有两种:常变量(const/constexpr) 和 宏变量(#define)。它们在机制、类型安全性、作用域和调试支持方面存在显著差异。 ✅ 1. 常变量&#x…...
【C++】控制台小游戏
移动:W向上,S上下,A向左,D向右 程序代码: #include <iostream> #include <conio.h> #include <windows.h> using namespace std;bool gameOver; const int width 20; const int height 17; int …...

配合本专栏前端文章对应的后端文章——从模拟到展示:一步步搭建传感器数据交互系统
对应文章:进一步完善前端框架搭建及vue-konva依赖的使用(Vscode)-CSDN博客 目录 一、后端开发 1.模拟传感器数据 2.前端页面呈现数据后端互通 2.1更新模拟传感器数据程序(多次请求) 2.2🧩 功能目标 …...

React中常用的钩子函数:
一. 基础钩子 (1)useState 用于在函数组件中添加局部状态。useState可以传递一个参数,做为状态的初始值,返回一个数组,数组的第一个元素是返回的状态变量,第二个是修改状态变量的函数。 const [state, setState] useState(ini…...

springboot IOC
springboot IOC IoC Inversion of Control Inversion 反转 依赖注入 DI (dependency injection ) dependency 依赖 injection 注入 Qualifier 预选赛 一文带你快速理解JavaWeb中分层解耦的思想及其实现,理解 IOC和 DI https://zhuanlan.…...

java面试每日一背 day2
1.什么是缓存击穿?怎么解决? 缓存击穿是指在高并发场景下,某个热点key突然过期失效,此时大量请求同时访问这个已经过期的key,导致所有请求都直接打到数据库上,造成数据库瞬时压力过大甚至崩溃的情况。 解…...
Ajax01-基础
一、AJAX 1.AJAX概念 使浏览器的XMLHttpRequest对象与服务器通信 浏览器网页中,使用 AJAX技术(XHR对象)发起获取省份列表数据的请求,服务器代码响应准备好的省份列表数据给前端,前端拿到数据数组以后,展…...
服务器增加ipv6配置方法)
(37)服务器增加ipv6配置方法
(1)172.25.38.93服务器,IPv6地址如下: IPv6地址:2405:6F00:E033:B800:0000:0000:0003:0A5D IPv6掩码:/120 IPv6网关地址:2405:6F00:E033:B800:0000:0000:0003:0AFF 配置: # 静态 IPv6 地址和前缀(根据实际情况填写) IPV6ADDR=2405:6F00:E033:B800:0000:0000:0003:0…...
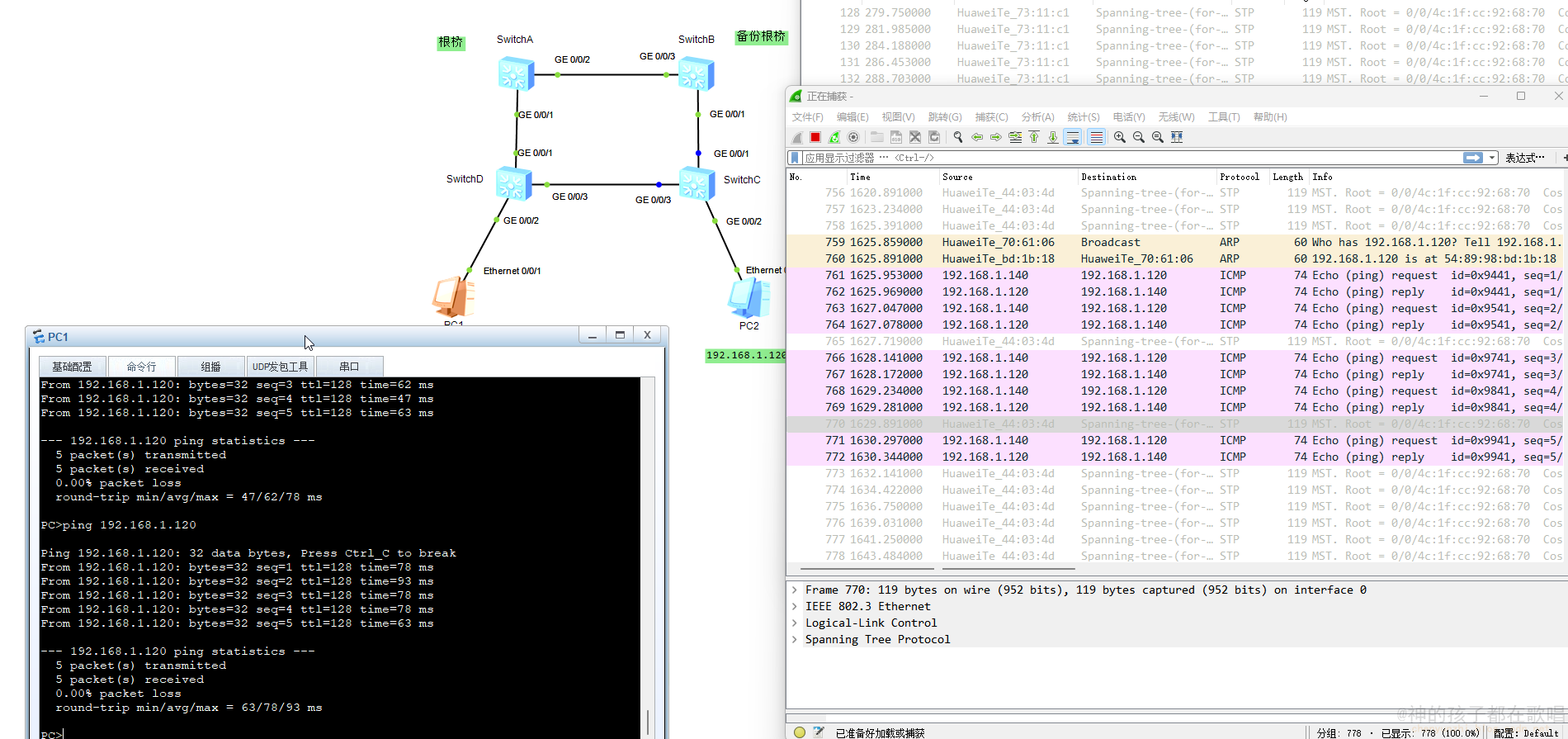
生成树协议(STP)配置详解:避免网络环路的最佳实践
生成树协议(STP)配置详解:避免网络环路的最佳实践 生成树协议(STP)配置详解:避免网络环路的最佳实践一、STP基本原理二、STP 配置示例(华为交换机)1. 启用生成树协议2. 配置根桥3. 查…...

面向 C 语言项目的系统化重构实战指南
摘要: 在实际开发中,C 语言项目往往随着功能演进逐渐变得混乱:目录不清、宏滥用、冗余代码、耦合高、测试少……面对这样的“技术债积累”,盲目大刀阔斧只会带来更多混乱。本文结合 C 语言的特点,从项目评估、目录规划、宏与内联、接口封装、冗余剔除、测试与 CI、迭代重构…...

网络层——蚂蚁和信鸽的关系VS路由原理和相关配置
前言(🐜✉️🕊️) 今天内容的主角是蚂蚁(动态路由)和信鸽(静态路由),为什么这么说呢,来看一则小故事吧。 森林里,森林邮局要送一份重要信件&am…...
Python Pandas库简介及常见用法
Python Pandas库简介及常见用法 一、 Pandas简介1. 简介2. 主要特点(一)强大的数据结构(二)灵活的数据操作(三)时间序列分析支持(四)与其他库的兼容性 3.应用场景(一&…...

第十六届蓝桥杯复盘
文章目录 1.数位倍数2.IPv63.变换数组4.最大数字5.小说6.01串7.甘蔗8.原料采购 省赛过去一段时间了,现在复盘下,省赛报完名后一直没准备所以没打算参赛,直到比赛前两天才决定参加,赛前两天匆匆忙忙下载安装了比赛要用的编译器ecli…...
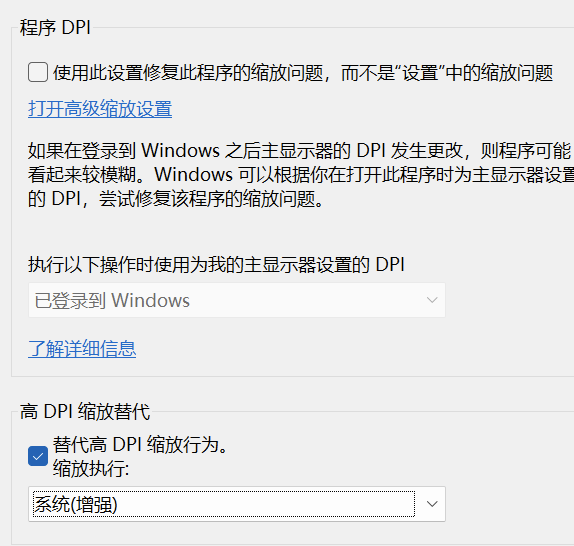
【已解决】HBuilder X编辑器在外接显示器或者4K显示器怎么界面变的好小问题
触发方式:主要涉及DPI缩放问题,可能在电脑息屏有概率触发 修复方式: 1.先关掉软件直接更改屏幕缩放,然后打开软件,再关掉软件恢复原来的缩放,再打开软件就好了 2.(不推荐)右键HBuilder在属性里…...

直线型绝对值位移传感器:精准测量的科技利刃
在科技飞速发展的今天,精确测量成为了众多领域不可或缺的关键环节。无论是工业自动化生产线上的精细操作,还是航空航天领域中对零部件位移的严苛把控,亦或是科研实验中对微小位移变化的精准捕捉,都离不开一款高性能的测量设备——…...