数据结构实验10.1:内部排序的基本运算
文章目录
- 一,实验目的
- 二,实验内容
- 1. 数据生成与初始化
- 2. 排序算法实现
- (1)直接插入排序
- (2)二分插入排序
- (3)希尔排序
- (4)冒泡排序
- (5)快速排序
- (6)简单选择排序
- (7)堆排序
- (8)二路归并排序
- 3. 统计与输出
- 三,实验要求
- (1)实验步骤与要求
- (2)注意事项
- 四、数据结构设计
- 五,示例代码
- 10-1.cpp源代码
- 六,操作步骤
- 七,运行结果
一,实验目的
- 深入理解排序原理:掌握排序的基本概念、分类及稳定性等特性,明确不同排序算法的适用场景。
- 熟练实现经典算法:通过编码实现直接插入、二分插入、希尔、冒泡、快速、简单选择、堆、二路归并等8种排序算法,加深对算法逻辑的理解。
- 提升算法应用能力:运用排序算法解决实际数据处理问题,通过统计比较次数和移动次数量化分析算法效率,增强算法优化思维。
二,实验内容
1. 数据生成与初始化
- 使用随机数函数
rand()生成范围在[1, MAXNUM-1]的随机整数序列(MAXNUM设为100),确保序列长度可由用户指定(1~99)。 - 示例序列(假设长度为8):
[49, 38, 65, 97, 76, 13, 27, 49]。
2. 排序算法实现
(1)直接插入排序
- 思想:从第二个元素开始,将当前元素插入到已排序子序列的合适位置,通过顺序比较和移动实现。
- 稳定性:稳定。
(2)二分插入排序
- 优化:利用二分查找确定插入位置,减少比较次数,移动次数与直接插入相同。
- 稳定性:稳定。
(3)希尔排序
- 思想:按增量序列分组,对每组进行直接插入排序,逐步缩小增量至1。
- 增量序列:
5, 3, 1(示例)。 - 稳定性:不稳定。
(4)冒泡排序
- 思想:相邻元素比较,逆序时交换,每趟将最大元素“冒泡”到末尾。
- 优化:设置标记
change,若某趟无交换则提前终止。 - 稳定性:稳定。
(5)快速排序
- 思想:选择基准值,通过分区操作将序列分为两部分,递归排序。
- 分区策略:Hoare法(左右指针交替移动)。
- 稳定性:不稳定。
(6)简单选择排序
- 思想:每趟选择未排序部分的最小元素,与当前位置交换。
- 稳定性:不稳定(相同元素相对顺序可能改变)。
(7)堆排序
- 思想:构建大顶堆,每次将堆顶元素与末尾元素交换,调整堆结构。
- 步骤:建堆 → 交换堆顶与末尾 → 调整堆。
- 稳定性:不稳定。
(8)二路归并排序
- 思想:递归分割序列,合并两个有序子序列。
- 辅助空间:需要额外数组存储临时合并结果。
- 稳定性:稳定。
3. 统计与输出
- 比较次数(cp):记录关键字比较操作的总次数。
- 移动次数(mv):记录元素赋值操作的总次数(如交换、插入等)。
- 输出内容:
- 原始序列与排序后序列;
- 各算法的比较次数和移动次数;
- 算法效率对比表格。
三,实验要求
(1)实验步骤与要求
-
代码补全:
- 参照提供的参考程序,补全各算法中缺失的代码(如循环条件、指针移动逻辑等),确保算法逻辑正确。
- 示例补全点:
- 快速排序分区函数中左右指针的移动条件(
j--/i++); - 冒泡排序的交换标记
change初始化与更新。
- 快速排序分区函数中左右指针的移动条件(
-
调试与测试:
- 测试用例:
- 随机序列(如长度10、50、99);
- 特殊序列(正序、逆序、重复元素多的序列)。
- 调试要点:
- 确保随机数生成正确,无越界访问;
- 验证各算法排序结果是否正确,统计计数器(
cp、mv)是否准确。
- 测试用例:
-
数据记录与分析:
- 表格示例:
| 排序算法 | 比较次数(cp) | 移动次数(mv) | 耗时(ms) | 稳定性 |
|---|---|---|---|---|
| 直接插入排序 | 35 | 28 | 12 | 稳定 |
| 快速排序 | 22 | 15 | 5 | 不稳定 |
- 分析方向:
- 比较次数与序列初始有序度的关系(如冒泡排序在正序时比较次数最少);
- 移动次数与算法特性的关联(如归并排序移动次数较多但比较次数稳定);
- 稳定性对特定场景的影响(如稳定排序适用于多关键字排序)。
(2)注意事项
- 空间复杂度:归并排序需要额外空间(
O(n)),其他算法多为原地排序(O(1),除堆排序的辅助空间)。 - 时间复杂度对比:
- 最优/平均情况:快速排序、归并排序(
O(n log n)); - 最坏情况:直接插入、冒泡、简单选择(
O(n²))。
- 最优/平均情况:快速排序、归并排序(
- 代码规范:添加必要注释,确保变量命名清晰(如
cp为comparison count,mv为movement count)。
四、数据结构设计
#define MAXNUM 100
typedef int KeyType; // 定义关键字类型为整型
typedef struct {
KeyType key; // 关键字项int other; // 其他数据项
}ElemType; // 元素类型
typedef struct {ElemType r[MAXNUM+1]; // r[0]闲置或用作哨兵int length; // 待排序元素个数
} SqList; // 顺序表类型五,示例代码
10-1.cpp源代码
#define MAXNUM 100
#define TRUE 1
#define FALSE 0
#include<stdio.h>
#include<stdlib.h>
#include<time.h>typedef int KeyType;
typedef struct { // 定义元素的结构类型KeyType key; int other;
} ElemType;typedef struct { // 定义排序表结构类型ElemType r[MAXNUM+1];int length;
} SqList;//(1)创建随机数排序表
void CreatList(SqList &L) {int i;do {printf(" 输入排序表长度(1-%d)==>", MAXNUM-1);scanf("%d", &L.length);} while(L.length<1 || L.length>MAXNUM-1);srand((unsigned)time(NULL));for(i=1; i<=L.length; i++) // 随机产生排序表L.r[i].key = 1 + rand()%(MAXNUM-1);
}// (2)直接插入排序
void InsertSort(SqList &L, int &cp, int &mv) {int i, j;for(i=2; i<=L.length; i++) {cp++;if (L.r[i].key < L.r[i-1].key) {L.r[0] = L.r[i]; mv++;for(j=i-1; L.r[0].key < L.r[j].key; j--) {L.r[j+1] = L.r[j]; cp++; mv++;}cp++; L.r[j+1] = L.r[0]; mv++;}//if}
}// (3)折半插入排序
void BinSort(SqList &L, int &cp, int &mv) {int i, j, low, high, mid;for(i=2; i<=L.length; i++) {L.r[0] = L.r[i]; mv++;low = 1; high = i-1;while(low <= high) { // 定位插入点mid = (low + high)/2; cp++;if (L.r[0].key < L.r[mid].key) high = mid-1;else low = mid+1;}for(j=i-1; j>=high+1; j--) { L.r[j+1] = L.r[j]; mv++;}L.r[high+1] = L.r[0]; mv++;}
}// (4)希尔排序
void ShellInsert(SqList &L, int dk, int &cp, int &mv) {//对顺序表L作一趟希尔排序int i, j;for(i=dk+1; i<=L.length; i++) {cp++;if(L.r[i].key < L.r[i-dk].key) { //需将L.r[i]插入有序增量子表mv++;L.r[0] = L.r[i]; //L.r[i]暂存入L.r[0]for(j=i-dk; j>0 && L.r[0].key < L.r[j].key; j-=dk) { L.r[j+dk] = L.r[j]; //寻找插入位置时记录后移cp++; mv++;}cp++; mv++; L.r[j+dk] = L.r[0]; //插入}//if}//for
} //ShellInsertSortvoid ShellSort(SqList &L, int &cp, int &mv) {//按增量序列5,3,1进行希尔排序ShellInsert(L, 5, cp, mv); //一趟增量为5的希尔排序ShellInsert(L, 3, cp, mv); //二趟增量为3的希尔排序ShellInsert(L, 1, cp, mv); //三趟增量为1的希尔排序
} //ShellInsertSort//(5)冒泡排序
void BubbleSort(SqList &L, int &cp, int &mv) {int i, j, change;for(i = 1, change = TRUE; i < L.length && change; i++) {change = FALSE;for(j = 1; j < L.length - i + 1; ++j) { cp++;if (L.r[j].key > L.r[j+1].key) {L.r[0] = L.r[j]; L.r[j] = L.r[j+1]; L.r[j+1] = L.r[0]; change = TRUE; mv += 3;}//if} //for }//for
} // BubbleSort//(6)快速排序
int Partition(SqList &L, int low, int high, int &cp, int &mv) {int i, j;KeyType pivotkey;L.r[0] = L.r[low]; mv++; pivotkey = L.r[0].key; i = low; j = high;while (i < j) {while (i < j && L.r[j].key >= pivotkey) {j--; cp++;}if(i < j) cp++;L.r[i] = L.r[j]; mv++;while (i < j && L.r[i].key <= pivotkey) {i++; cp++;}if(i < j) cp++;L.r[j] = L.r[i]; mv++;}L.r[i] = L.r[0]; mv++;return i;
}//Partitionvoid QSort(SqList &L, int low, int high, int &cp, int &mv) {//对L.r[low]~L.r[high]的元素进行快速排序int pivotloc;if (low < high) { pivotloc = Partition(L, low, high, cp, mv); //一趟划分QSort(L, low, pivotloc-1, cp, mv);QSort(L, pivotloc+1, high, cp, mv);}//if
} //QSort//(7)简单选择排序
void SelectSort(SqList &L, int &cp, int &mv) {//对顺序表作简单选择排序int i, j, k; // j保存剩余元素中最小值元素的下标for(i=1; i<L.length; i++) {for(k=i, j=i; k<=L.length; k++) {cp++;if(L.r[k].key < L.r[j].key) j = k;}if (j != i) {L.r[0] = L.r[i]; L.r[i] = L.r[j]; L.r[j] = L.r[0]; mv += 3;} } //for
} // SelectSort//(8)堆排序
void HeapAdjust(SqList &H, int s, int m, int &cp, int &mv) {// H.r[s .. m]中除H.r[s].key外均满足堆的定义// 调整H.r[s]的关键字,使H.r[s .. m]成为一个大顶堆int j;H.r[0] = H.r[s]; mv++;for(j=2*s; j<=m; j*=2) { //沿key较大的孩子结点向下筛选if(j<m && H.r[j].key < H.r[j+1].key) ++j; //j为key较大的记录的下标 if(j<m) cp++;cp++; if(H.r[0].key >= H.r[j].key) break; H.r[s] = H.r[j]; //较大的孩子结点值换到父结点位置mv++;s = j;}H.r[s] = H.r[0]; mv++; //H.r[0]应插入的位置在s处
} // HeapAdjustvoid HeapSort(SqList &H, int &cp, int &mv) { //对顺序表H进行堆排序int i;for(i=H.length/2; i>0; --i) // 把H建成大顶堆HeapAdjust(H, i, H.length, cp, mv);for(i=H.length; i>1; --i) {H.r[0] = H.r[1]; H.r[1] = H.r[i]; H.r[i] = H.r[0]; mv += 3;//堆顶记录和当前未排子序列中最后一个记录相交换HeapAdjust(H, 1, i-1, cp, mv); //将H.r[1 .. i - 1] 重新调整为大顶堆 }
}// HeapSort //(9)二路归并排序
void Merge(SqList &L, SqList &temp, int i, int m, int n, int &cp, int &mv)
{ // 引入辅助空间tempint b = i, j, k;for(j = m+1, k = 1; i <= m && j <= n; ++k) {if (L.r[i].key < L.r[j].key) temp.r[k] = L.r[i++];else temp.r[k] = L.r[j++];cp++; mv++;}for (; i <= m; ) {temp.r[k++] = L.r[i++]; mv++;}for (; j <= n; ) {temp.r[k++] = L.r[j++]; mv++;}for(i = b, k = 1; i <= n; ) {L.r[i++] = temp.r[k++]; mv++;}
} // Mergevoid MergeSort(SqList &L, SqList &temp, int s, int t, int &cp, int &mv) {//归并排序int m;if (s < t) {m = (s + t)/2;MergeSort(L, temp, s, m, cp, mv);MergeSort(L, temp, m+1, t, cp, mv);Merge(L, temp, s, m, t, cp, mv); //合并L.r[s]~L.r[m]与L.r[m+1]~L.r[t]}//if
} // MergeSort//(10)输出排序表
void OutputList(SqList L) {int i;for(i=1; i<=L.length; i++)printf("%3d", L.r[i].key);printf("\n");
}int main() {SqList LL, L; //LL为待排序表,L为排序表SqList temp; //二路归并算法中所使用的临时顺序表int cp, mv; //cp记录元素关键字比较次数,mv记录元素移动次数printf("(1)创建随机数排序表......\n");CreatList(LL); //待排序序列保存在LL表中printf(" 排序表输出:");OutputList(LL);getchar();printf("(2)直接插入排序......\n");L = LL; cp = mv = 0;InsertSort(L, cp, mv);printf(" 排序结果:");OutputList(L);printf(" 排序效率:比较次数%d,移动次数%d。\n", cp, mv);getchar();printf("(3)折半插入排序......\n");L = LL; cp = mv = 0;BinSort(L, cp, mv);printf(" 排序结果:");OutputList(L);printf(" 排序效率:比较次数%d,移动次数%d。\n", cp, mv);getchar();printf("(4)希尔排序......\n");L = LL; cp = mv = 0;ShellSort(L, cp, mv);printf(" 排序结果:");OutputList(L);printf(" 排序效率:比较次数%d,移动次数%d。\n", cp, mv);getchar();printf("(5)冒泡排序......\n");L = LL; cp = mv = 0;BubbleSort(L, cp, mv);printf(" 排序结果:");OutputList(L);printf(" 排序效率:比较次数%d,移动次数%d。\n", cp, mv);getchar();printf("(6)快速排序......\n");L = LL; cp = mv = 0;QSort(L, 1, L.length, cp, mv);printf(" 排序结果:");OutputList(L);printf(" 排序效率:比较次数%d,移动次数%d。\n", cp, mv);getchar();printf("(7)简单选择排序......\n");L = LL; cp = mv = 0;SelectSort(L, cp, mv);printf(" 排序结果:");OutputList(L);printf(" 排序效率:比较次数%d,移动次数%d。\n", cp, mv);getchar();printf("(8)堆排序......\n");L = LL; cp = mv = 0;HeapSort(L, cp, mv);printf(" 排序结果:");OutputList(L);printf(" 排序效率:比较次数%d,移动次数%d。\n", cp, mv);getchar();printf("(9)二路归并排序......\n");L = LL; cp = mv = 0;MergeSort(L, temp, 1, L.length, cp, mv);printf(" 排序结果:");OutputList(L);printf(" 排序效率:比较次数%d,移动次数%d。\n", cp, mv);return 0;
}
六,操作步骤
1,双击Visual Studio程序快捷图标,启动程序。

2,之前创建过项目的话,直接打开即可,这里选择【创建新项目】。
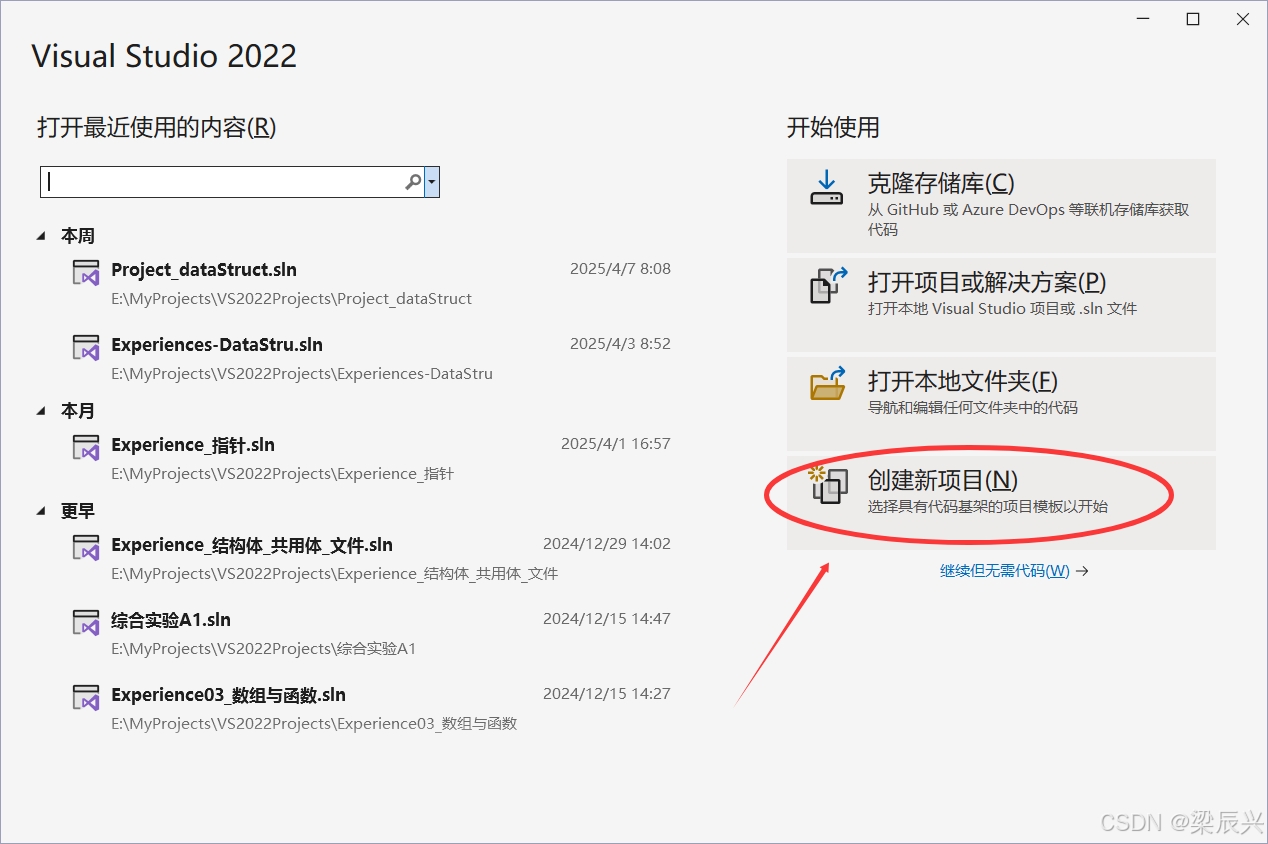
3,单击选择【空项目】——单击【下一步】按钮。
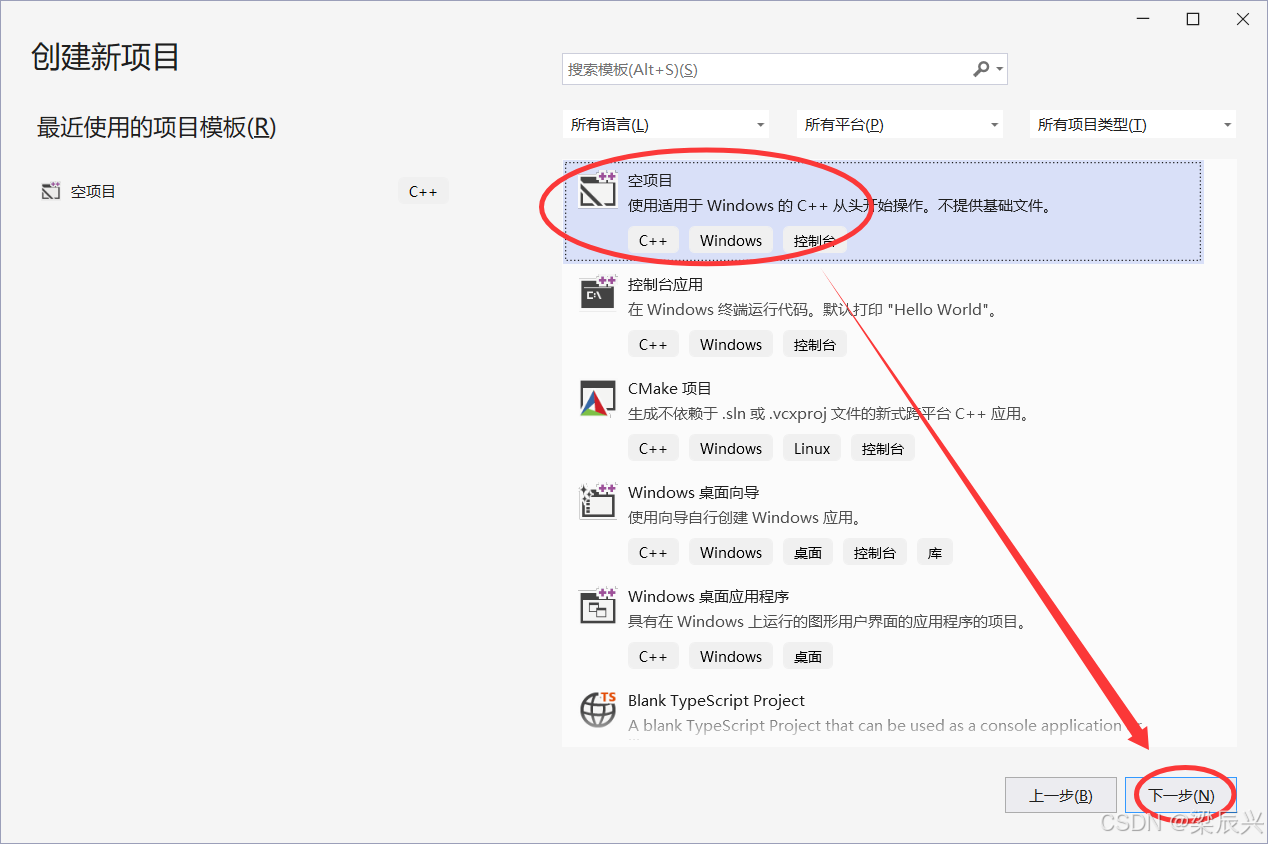
4,编辑好项目的名称和存放路径,然后单击【创建】按钮。
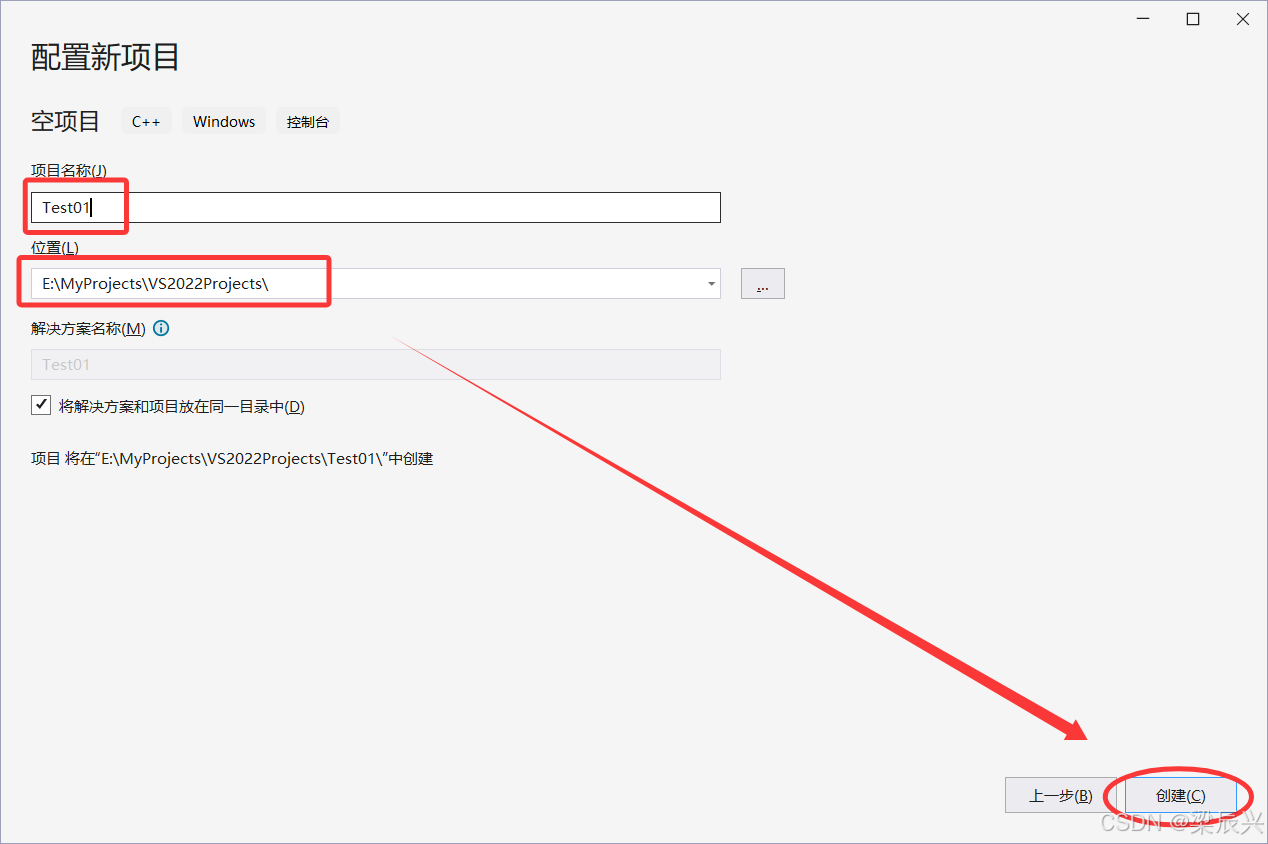
5,创建C++程序文件,右击【源文件】——选择【添加】——【新建项】。
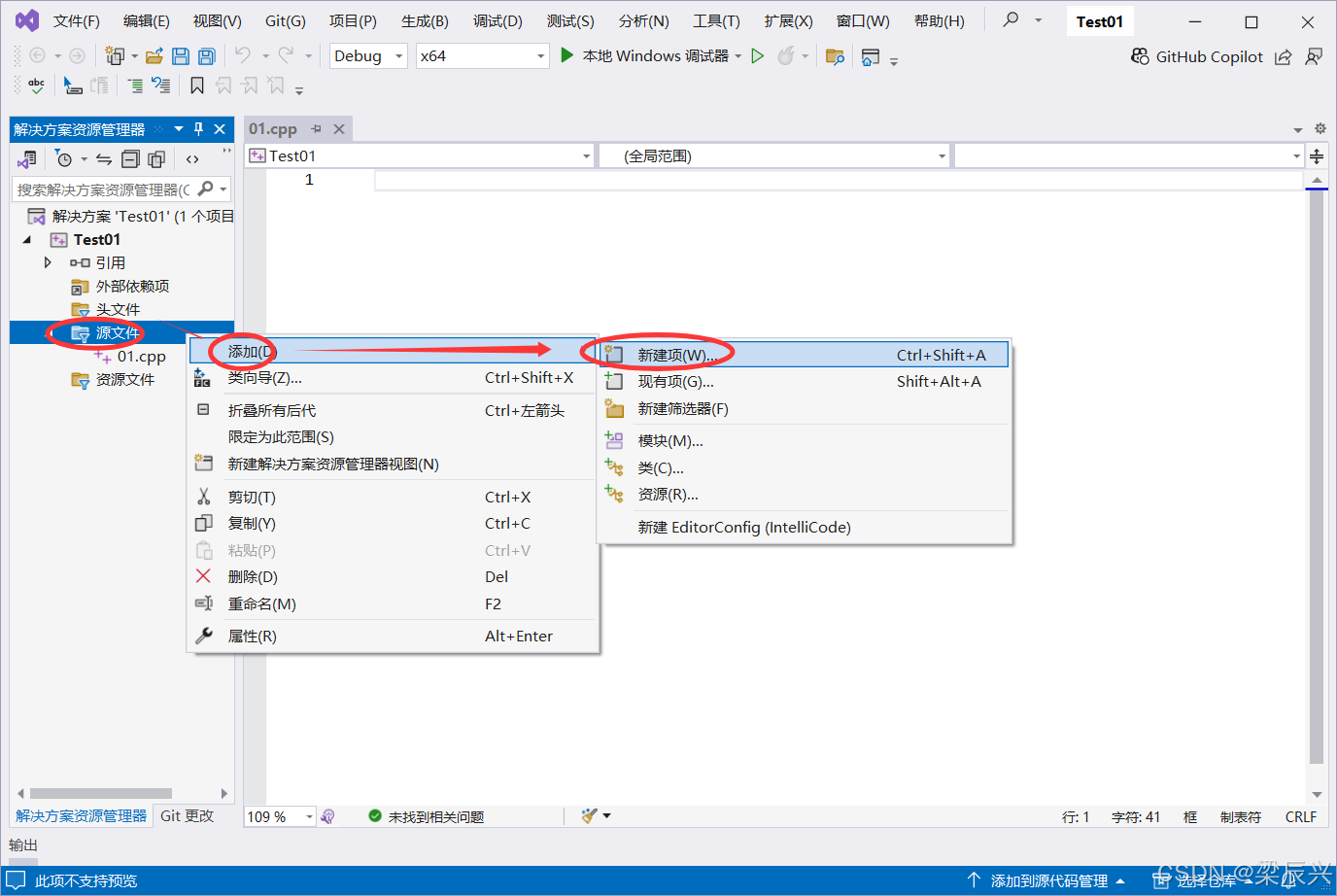
6,输入项目名称10-1.cpp,单击【添加】按钮。
7,编写代码,单击运行按钮,运行程序。
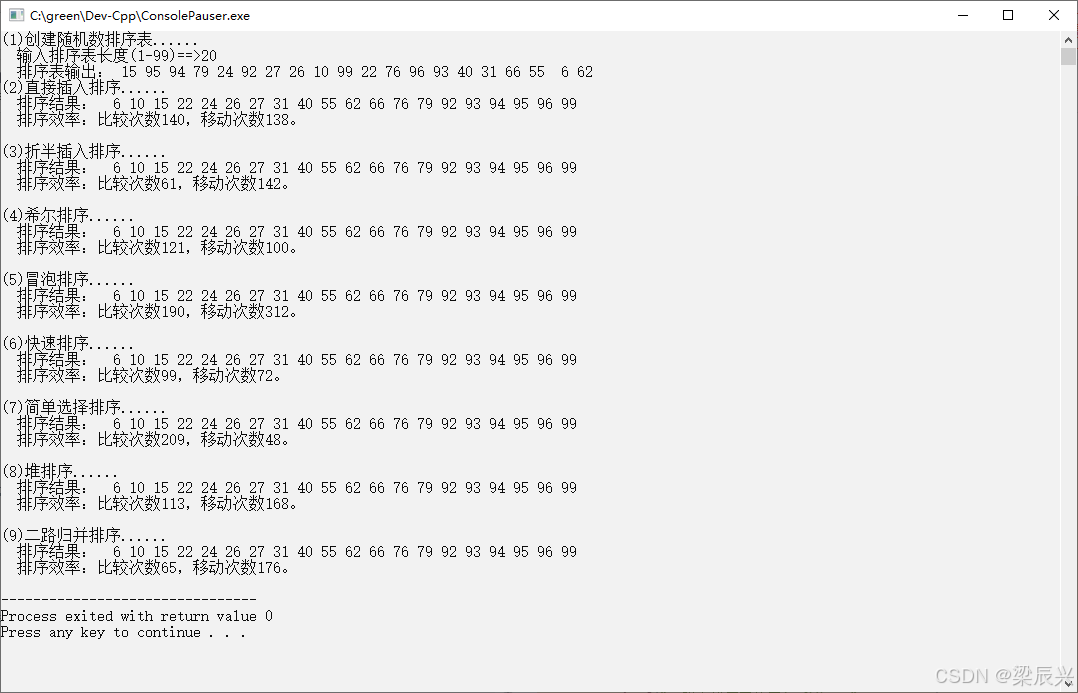
七,运行结果
1,实验要求的测试结果。

2,编写代码测试测试的结果。
相关文章:
数据结构实验10.1:内部排序的基本运算
文章目录 一,实验目的二,实验内容1. 数据生成与初始化2. 排序算法实现(1)直接插入排序(2)二分插入排序(3)希尔排序(4)冒泡排序(5)快速…...

C#:多线程
一.线程常用概念 线程(Thread):操作系统执行程序的最小单位 进程(Process):程序在内存中的运行实例 并发(Concurrency):多个任务交替执行(单核CPU࿰…...

基于Zynq SDK的LWIP UDP组播开发实战指南
一、为什么选择LWIP组播? 在工业控制、智能安防、物联网等领域,一对多的高效数据传输需求日益增长。Zynq-7000系列SoC凭借其ARM+FPGA的独特架构,结合LWIP轻量级网络协议栈,成为嵌入式网络开发的理想选择。本文将带您实现: LWIP组播配置全流程动态组播组切换技术零拷贝数据…...

c#将json字符串转换为对象数组
在C#中,将JSON字符串转换为对象数组是一个常见的需求,特别是在处理来自Web API的响应或需要反序列化本地文件内容时。这可以通过使用Newtonsoft.Json(也称为Json.NET)库或.NET Core内置的System.Text.Json来完成。以下是如何使用这…...

机器学习在智能水泥基复合材料中的应用与实践
“机器学习在智能水泥基复合材料中的应用与实践” 课程 内容 机器学习基础模型与复合材料研究融合 机器学习在复合材料中的应用概述机器学习用于复合材料研究的流程复合材料数据收集与数据预处理 实例:数据的收集和预处理 复合材料机器学习特征工程与选择 实例&a…...
wps编辑技巧
1、编辑模式 2、图片提取方法:右键保存图片 可以直接右键保存下来看看是否是原始图,如果歪着的图,可能保存下来是正的,直接保存试下 3、加批注...
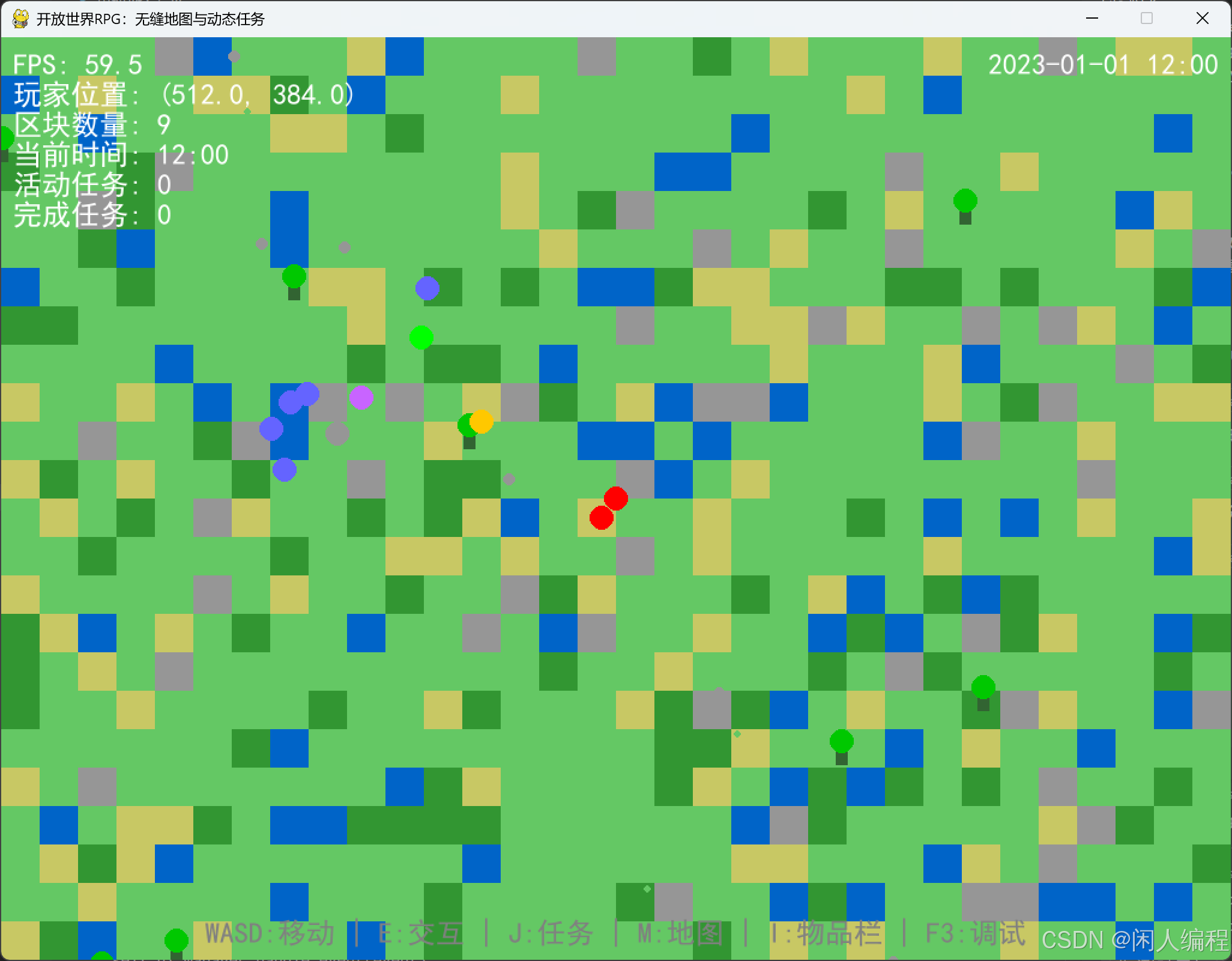
开放世界RPG:无缝地图与动态任务的拓扑学架构
目录 开放世界RPG:无缝地图与动态任务的拓扑学架构引言第一章 地图分块系统1.1 动态加载算法1.2 内存管理模型第二章 任务拓扑网络2.1 任务依赖图2.2 动态可达性分析第三章 NPC行为系统3.1 行为森林架构3.2 日程规划算法第四章 动态事件系统4.1 事件传播模型4.2 玩家影响指标第…...

【图像处理入门】1. 数字图像的本质:从像素到色彩模型
作为图像处理的开篇,本文将带你拆解数字图像的底层逻辑:从模拟图像到数字信号的神奇转换,到像素世界的微观构成,再到彩色图像的编码奥秘。通过 Python 代码实战,你将亲手触摸图像的 “基因”—— 像素值,并…...
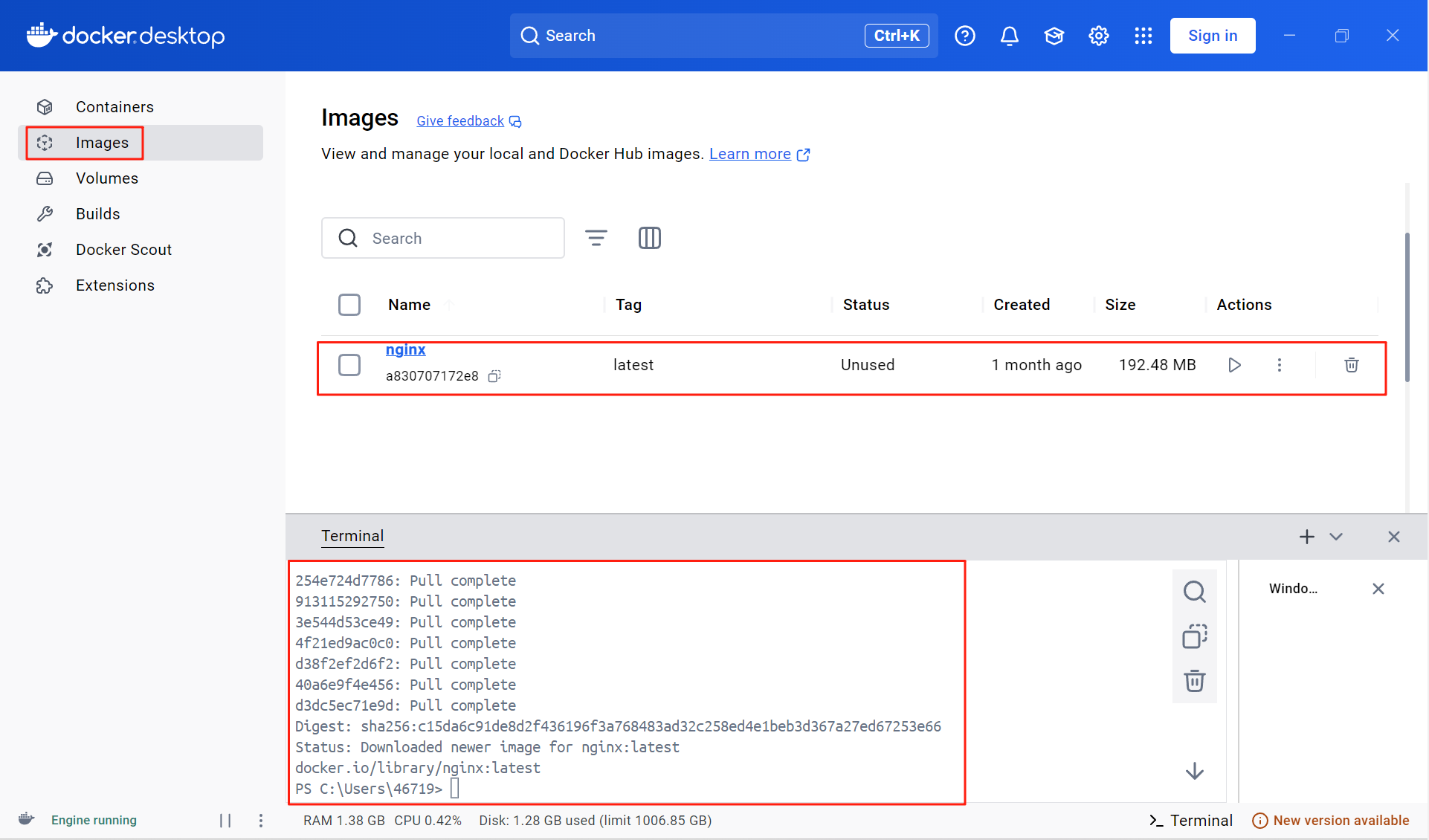
(已解决:基于WSL2技术)Windows11家庭中文版(win11家庭版)如何配置和使用Docker Desktop
目录 问题现象: 问题分析: 拓展: 解决方法: 1、使用WSL2技术(亲测有效) 注意: 2、开启Hyper-V功能(未经亲测,待研究) 问题现象: 今天想在本…...

Ubuntu20.04部署KVM
文章目录 一. 环境准备关闭防火墙(UFW)禁用 SELinux更换镜像源检查 CPU 虚拟化支持 二. 安装KVM安装 KVM 及相关组件启动 libvirtd 服务验证安装创建虚拟机 一. 环境准备 4C8G,50G硬盘——VMware Workstation需要给虚拟机开启虚拟化引擎 roo…...
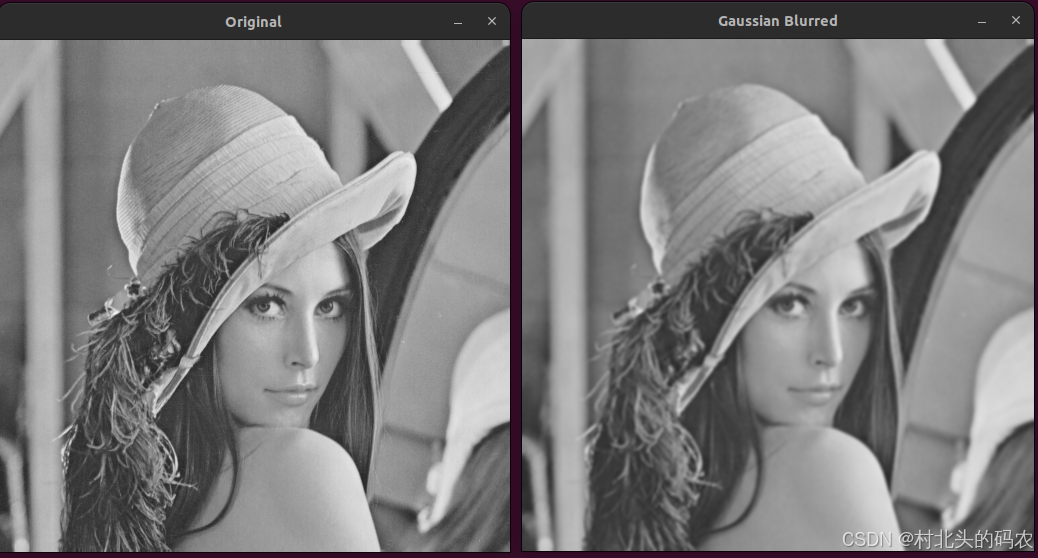
OpenCV CUDA 模块图像过滤------创建一个高斯滤波器函数createGaussianFilter()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::createGaussianFilter 是 OpenCV CUDA 模块中的一个工厂函数,用于创建一个高斯滤波器。这个滤波器可以用来平滑图像&#…...
)
计算机视觉与深度学习 | matlab实现ARIMA-WOA-CNN-LSTM时间序列预测(完整源码和数据)
以下是一个基于MATLAB的ARIMA-WOA-CNN-LSTM时间序列预测框架。由于完整代码较长,此处提供核心模块和实现思路,完整源码和数据可通过文末方式获取。 1. 数据准备(示例数据) 使用MATLAB内置的航空乘客数据集: % 加载数据 data = readtable(airline-passengers.csv); data …...
可视化图解算法43:数组中的逆序对
1. 题目 牛客网 面试笔试TOP101 描述 在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数P。并将P对1000000007取模的结果输出。 即输出P mod 1000000007 数据范围&…...

【Python】使用Python实现调用API获取图片存储到本地
使用Python实现调用API获取图片存储到本地 目录 使用Python实现调用API获取图片存储到本地1、项目概述2、核心功能3、环境准备4、代码实现5、结果查看 1、项目概述 开发一个自动化工具,用于从JSON数据源中提取图像ID,通过调用指定API获取未经压缩的原始…...
腾讯2025年校招笔试真题手撕(一)
一、题目 有n 把钥匙,m 个锁,每把锁只能由一把特定的钥匙打开,其他钥匙都无法打开。一把钥匙可能可以打开多把锁,钥匙也可以重复使用。 对于任意一把锁来说,打开它的钥匙是哪一把是等概率的。但你无法事先知道是哪一把…...
Vue3 与 Vue2 区别
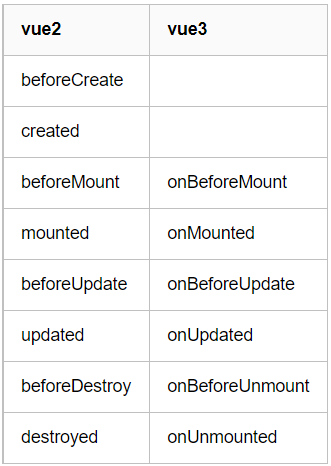
一、Vue3 与 Vue2 区别 对于生命周期来说,整体上变化不大,只是大部分生命周期钩子名称上 “on”,功能上是类似的。不过有一点需要注意,组合式API的Vue3 中使用生命周期钩子时需要先引入,而 Vue2 在选项API中可以直接…...

java集合详细讲解
Java 8 集合框架详解 Java集合框架是Java中最重要、最常用的API之一,Java 8对其进行了多项增强。下面我将全面讲解Java 8中的集合框架。 一、集合框架概述 Java集合框架主要分为两大类: Collection - 单列集合 List:有序可重复Set…...
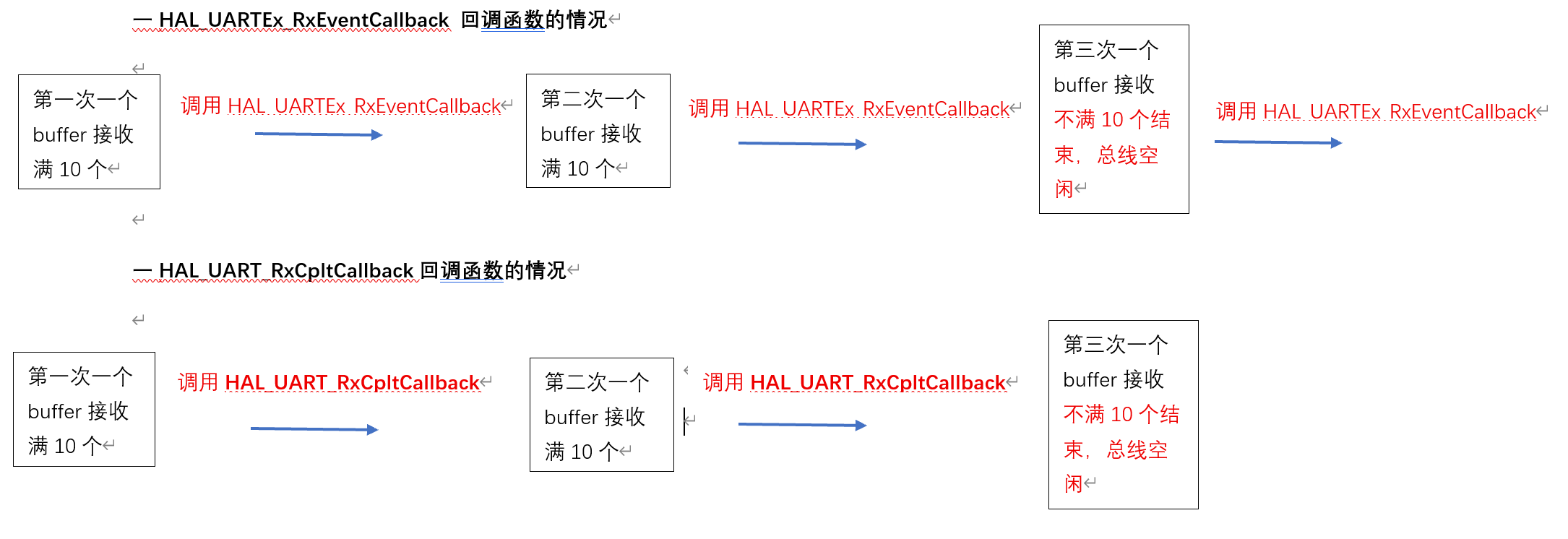
嵌入式学习笔记 - STM32 U(S)ART 模块HAL 库函数总结
一 串口发送方式: ①轮训方式发送,也就是主动发送,这个容易理解,使用如下函数: HAL_UART_Transmit(UART_HandleTypeDef *huart, const uint8_t *pData, uint16_t Size, uint32_t Timeout); ②中断方式发送ÿ…...

【VLNs篇】04:SayNav-为新环境中的动态规划到导航进行大型语言模型的基础构建
栏目内容论文标题SayNav: 为新环境中的动态规划到导航进行大型语言模型的基础构建 (SayNav: Grounding Large Language Models for Dynamic Planning to Navigation in New Environments)研究问题自主代理在未知环境中执行复杂导航任务(如MultiON)时&…...

MySQL中添加一个具有创建数据库权限的用户
要在MySQL中添加一个具有创建数据库权限的用户,可按以下步骤操作: 1. 登录MySQL 使用拥有足够权限(一般是root用户 )的账号登录到MySQL数据库。在命令行输入: mysql -u root -p然后输入对应的密码,即可进…...
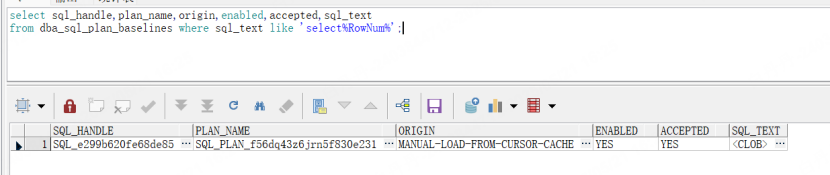
oracle使用SPM控制执行计划
一 SPM介绍 Oracle在11G中推出了SPM(SQL Plan management),SPM是一种主动的稳定执行计划的手段,能够保证只有被验证过的执行计划才会被启用,当由于种种原因(比如统计信息的变更)而导致目标SQL产生了新的执…...
)
[Java实战]Spring Boot整合Seata:分布式事务一致性解决方案(三十一)
[Java实战]Spring Boot整合Seata:分布式事务一致性解决方案(三十一) 引言 在微服务架构中,业务逻辑被拆分为多个独立的服务,每个服务可能拥有独立的数据库。当需要跨服务操作多个数据库时,如何保证数据的…...
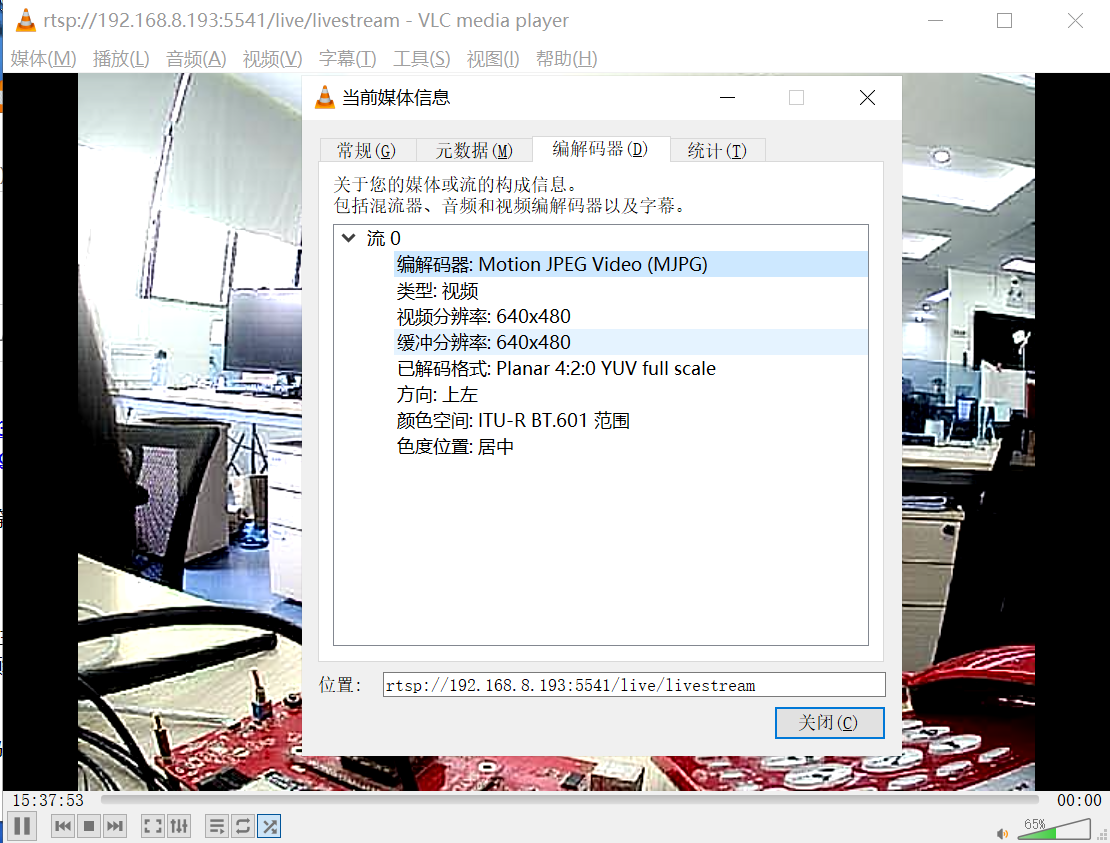
Openwrt下使用ffmpeg配合自建RTSP服务器实现推流
目前在Openwrt下时mjpg_streamer实现UVC摄像头转网络摄像头的方案很多,这种方案视频服在路由模组中,在局域网中使用很方便。但是对于需要远程监控管理的情况,mjpg_streamer不适应,因为不在局域网中的播放器无法访问到路由模组中的…...

MySQL 索引的增删改查
MySQL 索引的增删改查 1 建表时创建索引 [UNIQUE|FULLTEXT|SPATIAL] INDEX|KEY [别名] (字段名 [(长度)] [ASC|DESC] )主键直接写: PRIMARY KEY (Id)例如: CREATE TABLE people (id int NOT NULL PRIMARY KEY AUTO_INCREMENT,last_name varchar(10)…...
)
MySQL Host 被封锁解决方案(全版本适用 + Java 后端优化)
引言 MySQL 中 “Host is blocked because of many connection errors” 是生产环境常见问题,若处理不当会导致服务中断。本文结合 MySQL 官方文档(5.5/8.0)、Java 后端最佳实践及企业级经验,提供从 “快速解封” 到 “根源优化”…...

wifi 如果检查失败,UI 就会出现延迟或缺失打勾的现象。
问题:connectedSsid 的初始化依赖 onCreate 中的状态检查,如果检查失败,UI 就会出现延迟或缺失打勾的现象。 WIFI界面上上的一个标识代表成功连接。重启后出现偶尔不打勾的情况。 原始代码: // if (connectedSsid !…...
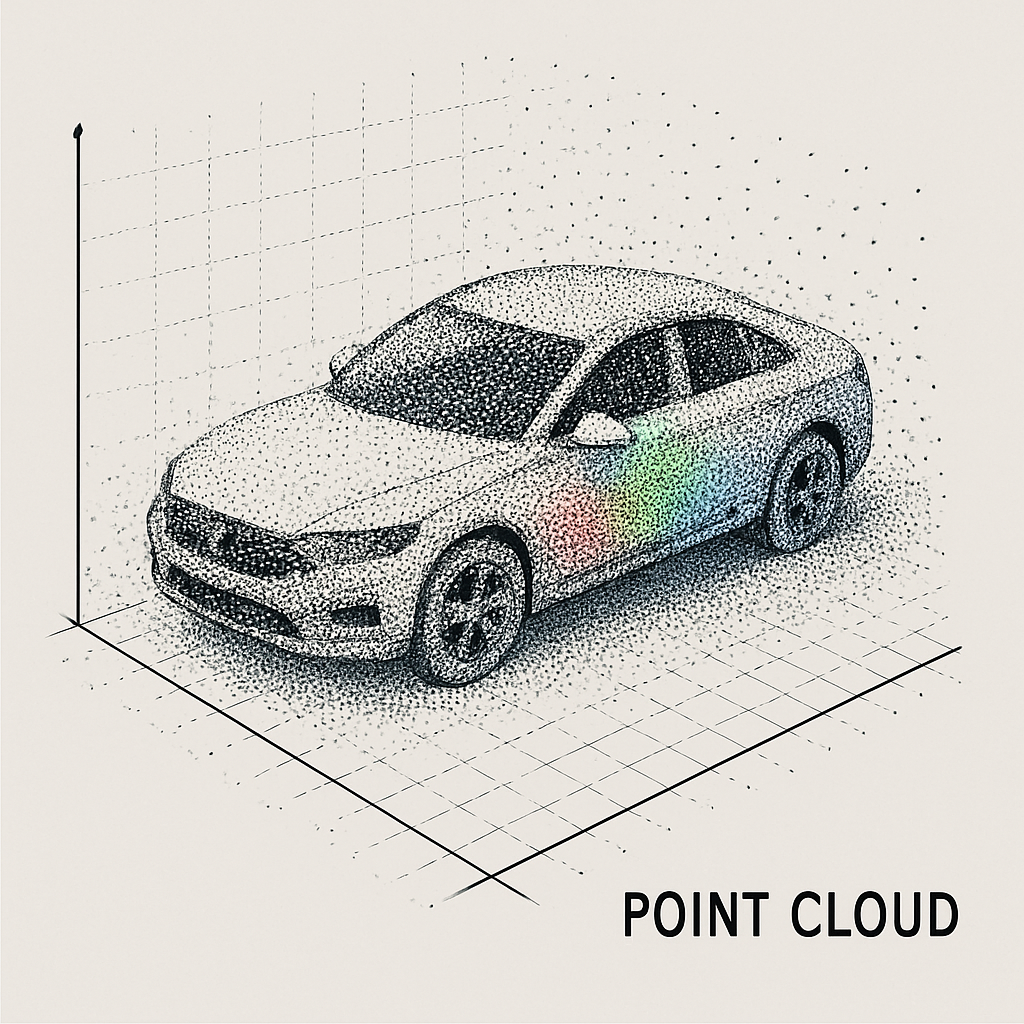
点云(point cloud):自动驾驶的“三维扫描图“
点云(Point Cloud):就是用很多“点”来表示一个物体或场景的三维形状和结构。(用点描绘的3D画,好比素描,但不是用线条勾勒,而是“点点点点”拼出物体形状) 观察这幅图像,…...

Redis 中如何保证缓存与数据库的数据一致性?
在 Redis 中保证缓存与数据库的数据一致性是一个关键问题,尤其是在高并发环境下。由于缓存和数据库是两个独立的数据存储系统,它们之间的数据同步存在延迟和不确定性,因此需要采取一系列策略来保证数据的一致性。以下是几种常用的方法和策略&…...
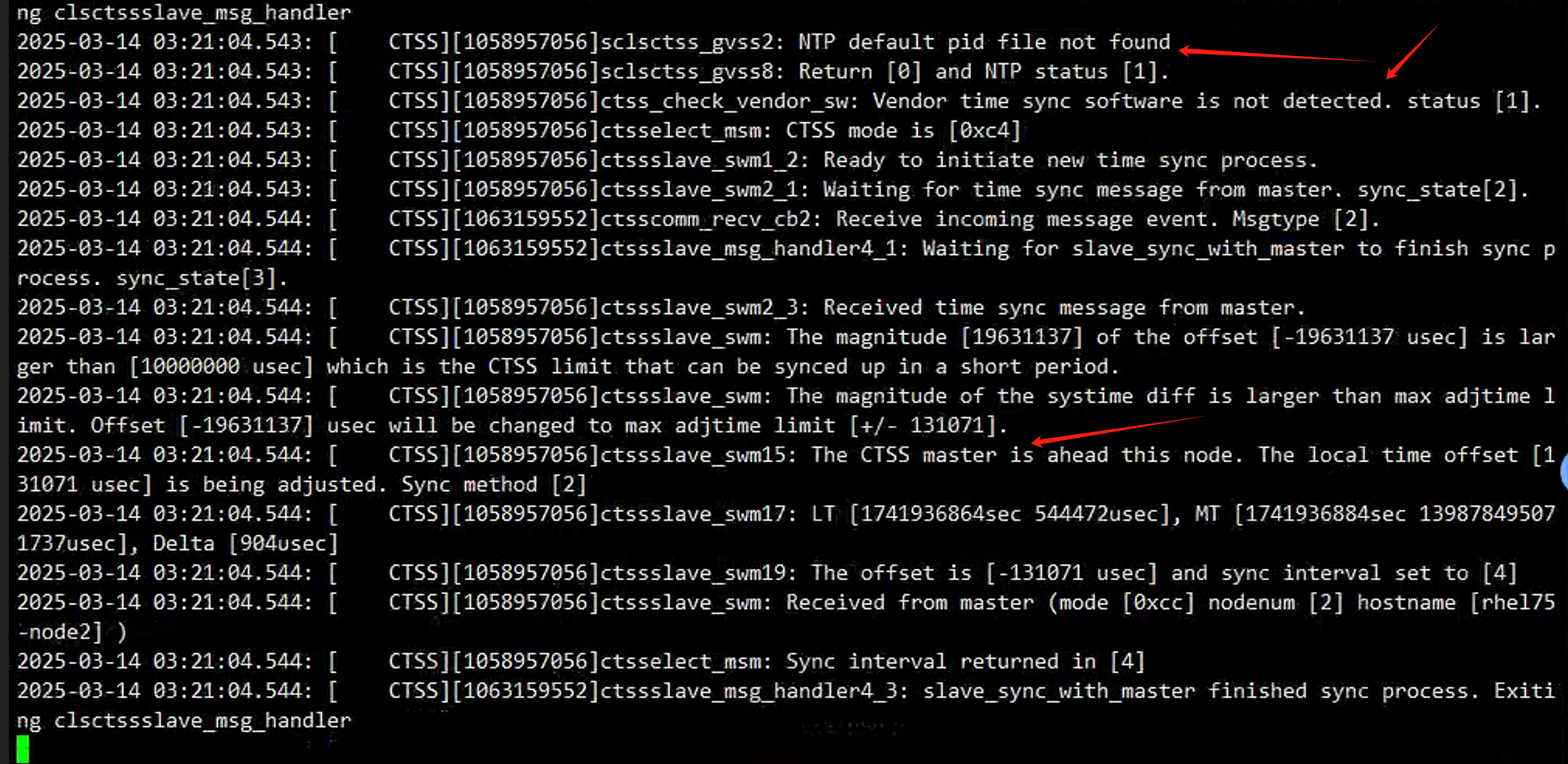
Oracle RAC节点时间差异同步测试
前言: Oracle Real Application Clusters (RAC) 集群依赖于各节点间的心跳检测与缓存融合等机制,这些机制对节点间的时钟同步性有极高的要求。如果集群内不同节点之间存在显著的时间偏差,可能会导致整个集群运行异常。在较早版本的RAC中&…...

python 打卡DAY27
##注入所需库 import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import random import numpy as np import time import shap # from sklearn.svm import SVC #支持向量机分类器 # # from sklearn.neighbors import KNeighborsClassifier …...