python 打卡DAY27
##注入所需库
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import random
import numpy as np
import time
import shap
# from sklearn.svm import SVC #支持向量机分类器
# # from sklearn.neighbors import KNeighborsClassifier #K近邻分类器
# # from sklearn.linear_model import LogisticRegression #逻辑回归分类器
import xgboost as xgb #XGBoost分类器
# import lightgbm as lgb #LightGBM分类器
from sklearn.ensemble import RandomForestClassifier #随机森林分类器
# # from catboost import CatBoostClassifier #CatBoost分类器
# # from sklearn.tree import DecisionTreeClassifier #决策树分类器
# # from sklearn.naive_bayes import GaussianNB #高斯朴素贝叶斯分类器
# from skopt import BayesSearchCV
# from skopt.space import Integer
# from deap import base, creator, tools, algorithms
# from sklearn.model_selection import StratifiedKFold, cross_validate # 引入分层 K 折和交叉验证工具
# from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 用于评估分类器性能的指标
from sklearn.metrics import classification_report, confusion_matrix #用于生成分类报告和混淆矩阵
from sklearn.metrics import make_scorer#定义函数
# import warnings #用于忽略警告信息
# warnings.filterwarnings("ignore") # 忽略所有警告信息
#聚类
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
#3D可视化
from mpl_toolkits.mplot3d import Axes3D
import plotly.express as px
import plotly.graph_objects as go
# 导入 Pipeline 和相关预处理工具
from imblearn.over_sampling import SMOTE
from sklearn.pipeline import Pipeline # 用于创建机器学习工作流
from sklearn.compose import ColumnTransformer # 用于将不同的预处理应用于不同的列
from sklearn.preprocessing import OrdinalEncoder, OneHotEncoder, StandardScaler # 用于数据预处理(有序编码、独热编码、标准化)
from sklearn.impute import SimpleImputer # 用于处理缺失值
##设置中文字体&负号正确显示
plt.rcParams['font.sans-serif']=['STHeiti']
plt.rcParams['axes.unicode_minus']=True
plt.rcParams['figure.dpi']=100
#读取数据
data=pd.read_csv(r'data.csv')
x=data.drop(['Id','Credit Default'],axis=1)
y=data['Credit Default']
#定义pipeline相关定义&处理步骤
object_cols=x.select_dtypes(include=['object']).columns.tolist()
numeric_cols=x.select_dtypes(exclude=['object']).columns.tolist()
ordinal_features=['Years in current job']
ordinal_catagories=[['< 1 year', '1 year', '2 years', '3 years', '4 years', '5 years', '6 years', '7 years', '8 years', '9 years', '10+ years']] # Years in current job 的顺序 (对应1-11)
ordinal_transforms=Pipeline(steps=[
('imputer',SimpleImputer(strategy='most_frequent')),
('encoder',OrdinalEncoder(categories=ordinal_catagories,handle_unknown='use_encoded_value',unknown_value=-1))
])
print("有序特征处理 Pipeline 定义完成。")
nominal_features=['Home Ownership', 'Purpose', 'Term']
nominal_transformer=Pipeline(steps=[
('imputer',SimpleImputer(strategy='most_frequent')),
('onehot',OneHotEncoder(handle_unknown='ignore'))
])
print("标称特征处理 Pipeline 定义完成。")
continuous_cols=x.columns.difference(ordinal_features+nominal_features).tolist()
continuous_transformer=Pipeline(steps=[
('imputer',SimpleImputer(strategy='mean'))
])
print("连续特征处理 Pipeline 定义完成。")
# --- 构建 ColumnTransformer ---
preprocessor=ColumnTransformer(
transformers=[
('ordinal',ordinal_transforms,ordinal_features),
('nominal',nominal_transformer,nominal_features),
('continuous',continuous_transformer,continuous_cols)
],remainder='passthrough',verbose_feature_names_out=False
)
print("\nColumnTransformer (预处理器) 定义完成。")
pipeline=Pipeline(steps=[
('preprocessor',preprocessor)
])
print("\n完整的 Pipeline 定义完成。")
print("\n开始对原始数据进行预处理...")
start_time=time.time()
x_processed=pipeline.fit_transform(x)
end_time=time.time()
print(f"预处理完成,耗时: {end_time - start_time:.4f} 秒")
feature_names=preprocessor.get_feature_names_out()
x_processed_df=pd.DataFrame(x_processed,columns=feature_names)
print(x_processed_df.info())
#划分数据集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x_processed_df,y,test_size=0.2,random_state=42)
#SMOTE(为了训练模型)
from imblearn.over_sampling import SMOTE
smote=SMOTE(random_state=42)
x_train_smote,y_train_smote=smote.fit_resample(x_train,y_train)
#标准化数据(为了聚类)
scaler=StandardScaler()
x_scaled=scaler.fit_transform(x_processed_df)
#kmeans++
k_range=(2,5)
inertia_value=[]
silhouette_scores=[]
ch_scores=[]
db_scores=[]
start_time=time.time()
for k in k_range:
kmeans=KMeans(n_clusters=k,random_state=42)
kmeans_label=kmeans.fit_predict(x_scaled)
inertia_value.append(kmeans.inertia_)
silhouette=silhouette_score(x_scaled,kmeans_label)
silhouette_scores.append(silhouette)
ch=calinski_harabasz_score(x_scaled,kmeans_label)
ch_scores.append(ch)
db=davies_bouldin_score(x_scaled,kmeans_label)
db_scores.append(db)
print(f'聚类分析耗时:{end_time-start_time:.4f}')
# #绘制评估指标图
# plt.figure(figsize=(12,6))
# ##肘部法则图
# plt.subplot(2,2,1)
# plt.plot(k_range,inertia_value,marker='o')
# plt.title('肘部法则确定最优聚类数 k(惯性,越小越好)')
# plt.xlabel('聚类数 (k)')
# plt.ylabel('惯性')
# plt.grid(True)
# ##轮廓系数图
# plt.subplot(2,2,2)
# plt.plot(k_range,silhouette_scores,marker='o',color='orange')
# plt.title('轮廓系数确定最优聚类数 k(越大越好)')
# plt.xlabel('聚类数 (k)')
# plt.ylabel('轮廓系数')
# plt.grid(True)
# #CH系数图
# plt.subplot(2,2,3)
# plt.plot(k_range,ch_scores,marker='o',color='yellow')
# plt.title('Calinski-Harabasz 指数确定最优聚类数 k(越大越好)')
# plt.xlabel('聚类数 (k)')
# plt.ylabel('CH 指数')
# plt.grid(True)
# ##DB系数图
# plt.subplot(2,2,4)
# plt.plot(k_range,db_scores,marker='o',color='red')
# plt.title('DB 指数确定最优聚类数 k(越小越好)')
# plt.xlabel('聚类数 (k)')
# plt.ylabel('DB 指数')
# plt.grid(True)
# plt.tight_layout()
# plt.show()
#选择K值进行聚类
selected_k=3
kmeans=KMeans(n_clusters=selected_k,random_state=42)
kmeans_label=kmeans.fit_predict(x_scaled)
x['KMeans_cluster']=kmeans_label
# ##PCA降维
# print(f"\n--- PCA 降维 ---")
# pca=PCA(n_components=3)
# x_pca=pca.fit_transform(x_scaled)
# ##聚类可视化
# plt.figure(figsize=(6,5))
# df_pca_2d=pd.DataFrame({
# 'x':x_pca[:,0],
# 'y':x_pca[:,1],
# 'cluster':kmeans_label})
# sample_size_2d=min(1000,len(df_pca_2d))
# df_sample_2d=df_pca_2d.sample(sample_size_2d,random_state=42)
# sns.scatterplot(
# x='x',y='y',
# hue='cluster',
# data=df_sample_2d,
# palette='viridis'
# )
# plt.title(f'KMean Clustering with k={selected_k} (PCA Visualization)')
# plt.xlabel('PCA Component 1')
# plt.ylabel('PCA Component 2')
# plt.show()
# ##3D可视化
# df_pca=pd.DataFrame(x_pca)
# df_pca['cluster']=x['KMeans_cluster']
# sample_size_3d=min(1000,len(df_pca))
# df_sample_3d=df_pca.sample(sample_size_3d,random_state=42)
# fig=px.scatter_3d(
# df_sample_3d,x=0,y=1,z=2,
# color='cluster',
# color_discrete_sequence=px.colors.qualitative.Bold,
# title='3D可视化'
# )
# fig.update_layout(
# scene=dict(
# xaxis_title='pca_0',
# yaxis_title='pca_1',
# zaxis_title='pca_2'
# ),
# width=1200,
# height=1000
# )
# fig.show()
# print(f"\n---t-SNE 降维 ---")
# n_component_tsne=3
# tsne=TSNE(
# n_components=n_component_tsne,
# perplexity=1000,
# n_iter=250,
# learning_rate='auto',
# random_state=42,
# n_jobs=-1
# )
# print("正在对训练集进行 t-SNE fit_transform...")
# start_time=time.time()
# x_tsne=tsne.fit_transform(x_scaled)
# end_time=time.time()
# print(f"训练集 t-SNE耗时: {end_time - start_time:.2f} 秒")
# # ##3D可视化
# # ##准备数据
# df_tsne=pd.DataFrame(x_tsne)
# df_tsne['cluster']=x['KMeans_cluster']
# fig=px.scatter_3d(
# df_tsne,x=0,y=1,z=2,
# color='cluster',
# color_discrete_sequence=px.colors.qualitative.Bold,
# title='T-SNE特征选择的3D可视化'
# )
# fig.update_layout(
# scene=dict(
# xaxis_title='tsne_0',
# yaxis_title='tsne_1',
# zaxis_title='tsne_2'
# ),
# width=1200,
# height=1000
# )
# fig.show()
##打印KMeans聚类前几行
print(f'KMeans Cluster labels(k={selected_k}added to x):')
print(x[['KMeans_cluster']].value_counts())
# # #SHAP分析
# start_time=time.time()
# rf1_model=RandomForestClassifier(random_state=42,class_weight='balanced')
# rf1_model.fit(x_train_smote,y_train_smote)
# explainer=shap.TreeExplainer(rf1_model)
# shap_value=explainer.shap_values(x_processed_df)
# print(shap_value.shape)
# end_time=time.time()
# print(f'SHAP分析耗时:{end_time-start_time:.4f}')
# # --- 1. SHAP 特征重要性蜂巢图 (Summary Plot - violin) ---
# print("--- 1. SHAP 特征重要性蜂巢图 ---")
# shap.summary_plot(shap_value[:,:,0],x_processed_df,plot_type='violin',show=False)
# plt.title('shap feature importance (bar plot)')
# plt.tight_layout()
# plt.show()
selected_features=['Credit Score','Current Loan Amount','Annual Income','Term_Long Term']
# fig,axes=plt.subplots(2,2,figsize=(10,8))
# axes=axes.flatten()
# for i,feature in enumerate(selected_features):
# unique_count=x_processed_df[feature].nunique()
# if unique_count<10:
# sns.countplot(x=x_processed_df[feature],ax=axes[i])
# axes[i].set_title(f'countplot of {feature}')
# axes[i].set_xlabel(feature)
# axes[i].set_ylabel('count')
# else:
# sns.histplot(x=x_processed_df[feature],ax=axes[i])
# axes[i].set_xlabel(feature)
# axes[i].set_ylabel('frequency')
# plt.tight_layout()
# plt.show()
print(x[['KMeans_cluster']].value_counts())
x_cluster0=x_processed_df[x['KMeans_cluster']==0]
x_cluster1=x_processed_df[x['KMeans_cluster']==1]
x_cluster2=x_processed_df[x['KMeans_cluster']==2]
# ##簇0
# fig,axes=plt.subplots(2,2,figsize=(6,4))
# axes=axes.flatten()
# for i,feature in enumerate(selected_features):
# unique_count=x_cluster0[feature].nunique()
# if unique_count<10:
# sns.countplot(x=x_cluster0[feature],ax=axes[i])
# axes[i].set_title(f'countplot of {feature}')
# axes[i].set_xlabel(feature)
# axes[i].set_ylabel('count')
# else:
# sns.histplot(x=x_cluster0[feature],ax=axes[i])
# axes[i].set_title(f'histplot of {feature}')
# axes[i].set_xlabel(feature)
# axes[i].set_ylabel('frequence')
# plt.tight_layout()
# plt.show()
# #簇1
# fig,axes=plt.subplots(2,2,figsize=(6,4))
# axes=axes.flatten()
# for i,feature in enumerate(selected_features):
# unique_count=x_cluster1[feature].nunique()
# if unique_count<10:
# sns.countplot(x=x_cluster1[feature],ax=axes[i])
# axes[i].set_title(f'countplot of {feature}')
# axes[i].set_xlabel(feature)
# axes[i].set_ylabel('count')
# else:
# sns.histplot(x=x_cluster1[feature],ax=axes[i])
# axes[i].set_title(f'histplot of {feature}')
# axes[i].set_xlabel(feature)
# axes[i].set_ylabel('frequence')
# plt.tight_layout()
# plt.show()
# #簇2
# fig,axes=plt.subplots(2,2,figsize=(6,4))
# axes=axes.flatten()
# for i,feature in enumerate(selected_features):
# unique_count=x_cluster0[feature].nunique()
# if unique_count<10:
# sns.countplot(x=x_cluster2[feature],ax=axes[i])
# axes[i].set_title(f'countplot of {feature}')
# axes[i].set_xlabel(feature)
# axes[i].set_ylabel('count')
# else:
# sns.histplot(x=x_cluster2[feature],ax=axes[i])
# axes[i].set_title(f'histplot of {feature}')
# axes[i].set_xlabel(feature)
# axes[i].set_ylabel('count')
# plt.tight_layout()
# plt.show()
print("--- 递归特征消除 (RFE) ---")
from sklearn.feature_selection import RFE
start_time=time.time()
base_model=xgb.XGBClassifier(random_state=42,class_weight='balanced')
rfe=RFE(base_model,n_features_to_select=3)
rfe.fit(x_train_smote,y_train_smote)
x_train_rfe=rfe.transform(x_train_smote)
x_test_rfe=rfe.transform(x_test)
selected_features_rfe=x_train.columns[rfe.support_]
print(f"RFE筛选后保留的特征数量: {len(selected_features_rfe)}")
print(f"保留的特征: {selected_features_rfe}")
end_time=time.time()
print(f'RFE分析耗时:{end_time-start_time:.4f}')
##3D可视化
x_selected=x_processed_df[selected_features_rfe]
df_viz=pd.DataFrame(x_selected)
df_viz['cluster']=x['KMeans_cluster']
fig=px.scatter_3d(
df_viz,
x=selected_features_rfe[0],
y=selected_features_rfe[1],
z=selected_features_rfe[2],
color='cluster',
color_discrete_sequence=px.colors.qualitative.Bold,
title='RFE特征选择的3D可视化'
)
fig.update_layout(
scene=dict(
xaxis_title=selected_features_rfe[0],
yaxis_title=selected_features_rfe[1],
zaxis_title=selected_features_rfe[2]
),
width=1200,
height=1000
)
fig.show()
##训练XGBOOST模型
xgb_model_rfe=xgb.XGBClassifier(random_state=42,class_weight='balanced')
xgb_model_rfe.fit(x_train_rfe,y_train_smote)
xgb_pred_rfe=xgb_model_rfe.predict(x_test_rfe)
print("\nRFE筛选后XGBOOST在测试集上的分类报告:")
print(classification_report(y_test, xgb_pred_rfe))
print("RFE筛选后XGBOOST在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, xgb_pred_rfe))
# def outer():
# def inner():
# print('aaaa')
# return inner
# f=outer()
# print(f())
# def chocolate(func):
# print("🍫 [1] 巧克力包装机准备好了!") # 装饰器定义时立即执行这句
# def wrapper():
# print("🍫 [2] 开始包装蛋糕(外壳)")
# func() # 原始蛋糕制作
# print("🎁 [3] 包装完成,可以出售了")
# return wrapper # 返回 wrapper 替代原函数
# @chocolate # 在定义阶段就会触发 chocolate(make_cake)
# def make_cake():
# print("🎂 [ 中间 ] 蛋糕正在烘焙...")
# print("\n🟢 [4] 现在开始执行 make_cake():\n")
# print(make_cake())
# import time
# def display_time(func):
# def wrapper():
# start_time=time.time()
# func()
# end_time=time.time()
# print(f"执行时间: {end_time - start_time} 秒")
# return wrapper
# def is_prime(num):
# if num<2:
# return False
# elif num==2:
# return True
# else:
# for i in range(2,num):
# if num%i==0:
# return False
# return True
# @display_time
# def prime_nums():
# for i in range(2,99999):
# if is_prime(i):
# # print(i)
# continue
# print(prime_nums())
# def logger(func):
# def wrapper(*args,**kwargs):
# print(f'开始执行函数{func.__name__},参数:{args},{kwargs}')
# result=func(*args,**kwargs)
# print(f'函数{func.__name__}执行完毕,返回值:{result}')
# return result
# return wrapper
# @logger
# def multiply(a,b):
# return a*b
# print(multiply(2,3))
# def class_logger(cls):
# original_init=cls.__init__
# def new_init(self,*args,**kwargs):
# print(f'[LOG]实例化对象:{cls.__name__}')
# original_init(self,*args,**kwargs)
# cls.__init__=new_init
# def log_message(self,message):
# print(f'[LOG]{message}')
# cls.log=log_message
# return cls
# @class_logger
# class SimplePrinter:
# def __init__(self,name):
# self.name=name
# def print_text(self,text):
# print(f'{self.name}:{text}')
# printer=SimplePrinter('Alice')
# printer.print_text('hello wrold')
# printer.log('这是装饰器添加的日志方法')
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
iris=load_iris()
df=pd.DataFrame(iris.data,columns=iris.feature_names)
df['target']=iris.target
features=iris.feature_names
target='target'
x_train,x_test,y_train,y_test=train_test_split(df[features],df[target],test_size=0.2,random_state=42)
model=RandomForestClassifier(n_estimators=100,random_state=42)
model.fit(x_train,y_train)
import pdpbox
from pdpbox.info_plots import TargetPlot
print(pdpbox.__version__)
feature='petal length (cm)'
feature_name=feature
target_plot=TargetPlot(
df=df,
feature=feature,
feature_name=feature_name,
target='target',
grid_type='percentile',
num_grid_points=10
)
# print(target_plot.plot())
# print(type(target_plot.plot()))
# print(target_plot.plot()[0])
fig,axes,summary_df=target_plot.plot(
which_classes=None,
show_percentile=True,
engine='plotly',
template='plotly_white'
)
fig.update_layout(
width=800,
height=500,
title=dict(text=f'Target Plot:{feature_name}',x=0.5)
)
fig.show()
相关文章:

python 打卡DAY27
##注入所需库 import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import random import numpy as np import time import shap # from sklearn.svm import SVC #支持向量机分类器 # # from sklearn.neighbors import KNeighborsClassifier …...

位运算及其算法
计算机中的所有数在内存中都是以二进制形式进行存储的 ,位运算就是直接对整数二进制位进行操作,有些时候在程序中使用位运算进行操作,会得到极高的便利性。 有符号整数与无符号整数 我们以int整型为例,每个int占4个字节32个bit位…...

flutter getx路由管理、状态管理、路由守卫中间件、永久储存get_storage
一个简单的路由跳转、状态管理 目录 lib/ ├── main.dart ├── routes/index.dart // 路由表 ├── middlewares/auth_middleware.dart // 登录守卫 ├── pages/ │ ├── home_page.dart │ ├── login_page.dart │ └── profile_page.dart └─…...

贪心算法之跳跃游戏问题
问题背景 本文背景是leetcode的一道经典题目:跳跃游戏,描述如下: 给定一个非负整数数组 nums,初始位于数组的第一个位置(下标0)。数组中的每个元素表示在该位置可以跳跃的最大长度。判断是否能够到达最后…...

Dockers Compose常用指令介绍
Dockers Compose常用指令 1、常用指令介绍 1.1、version 指令 顶级一级指令,指定 compose 指定文件格式版本 version: "3.8" services: 不同版本支持的功能不同。常用版本有 ‘2’, ‘3’, ‘3.8’ 等。 1.2、services 指令 顶级一级指令࿰…...

YOLOv11 性能评估与横向对比
在第二章中,我们深入剖析了 YOLOv11 的核心技术,从骨干网络、颈部网络到头部,再到损失函数、数据增强和训练策略的创新,揭示了其高性能背后的奥秘。然而,理论的强大最终需要通过严谨的实验数据来验证。本章将详细阐述 …...

kafka在线增加分区副本数
1、问题来源 线上有一个物联网项目依赖kafka集群中指定主题消费,前些天kafka集群中的某一台机器出现了故障,导致kafka这个主题的数据一直无法消费,经查发现为了保证消息的顺序性此主题仅设置了一个分区,但是副本也仅有一个&#…...
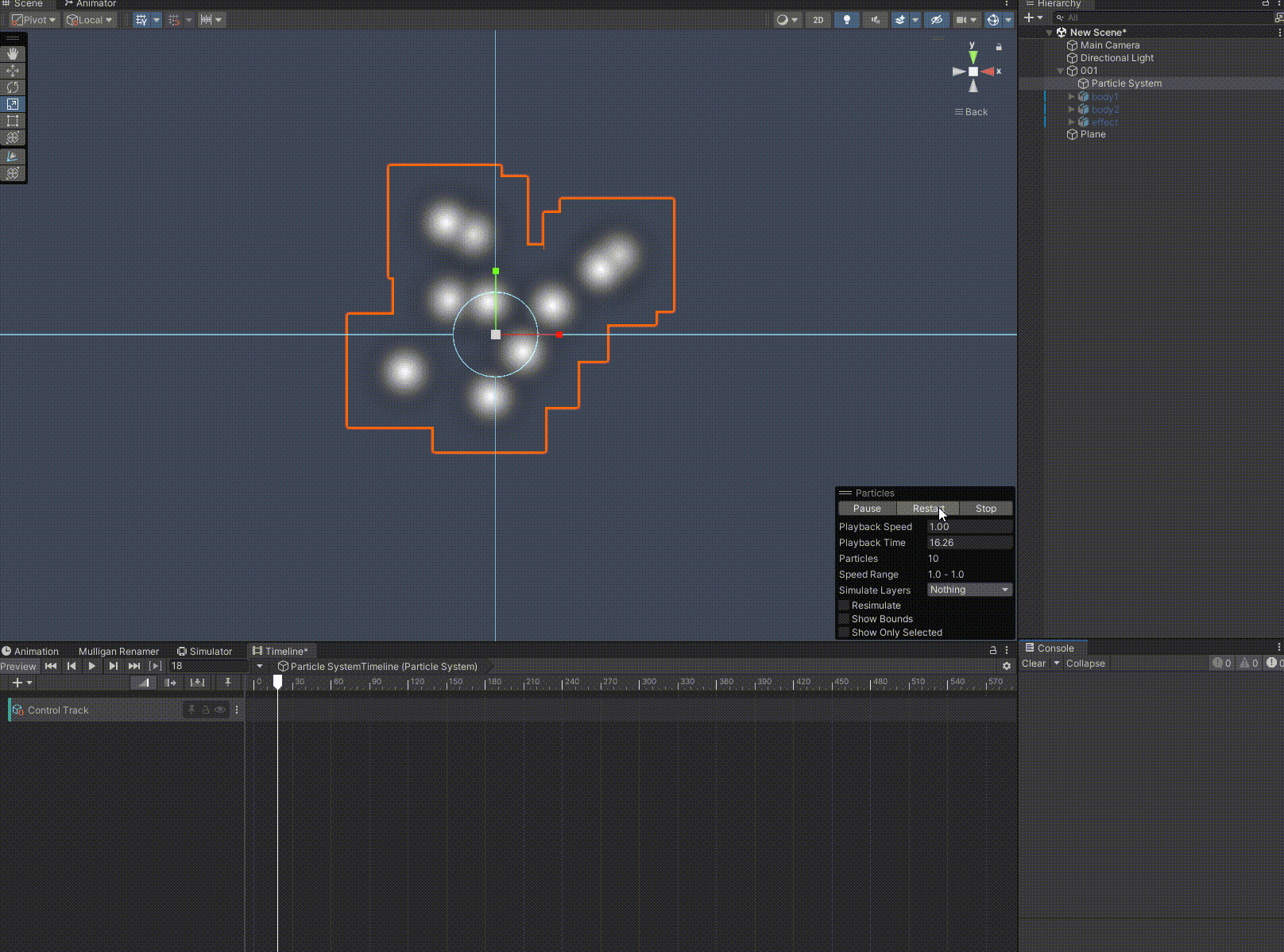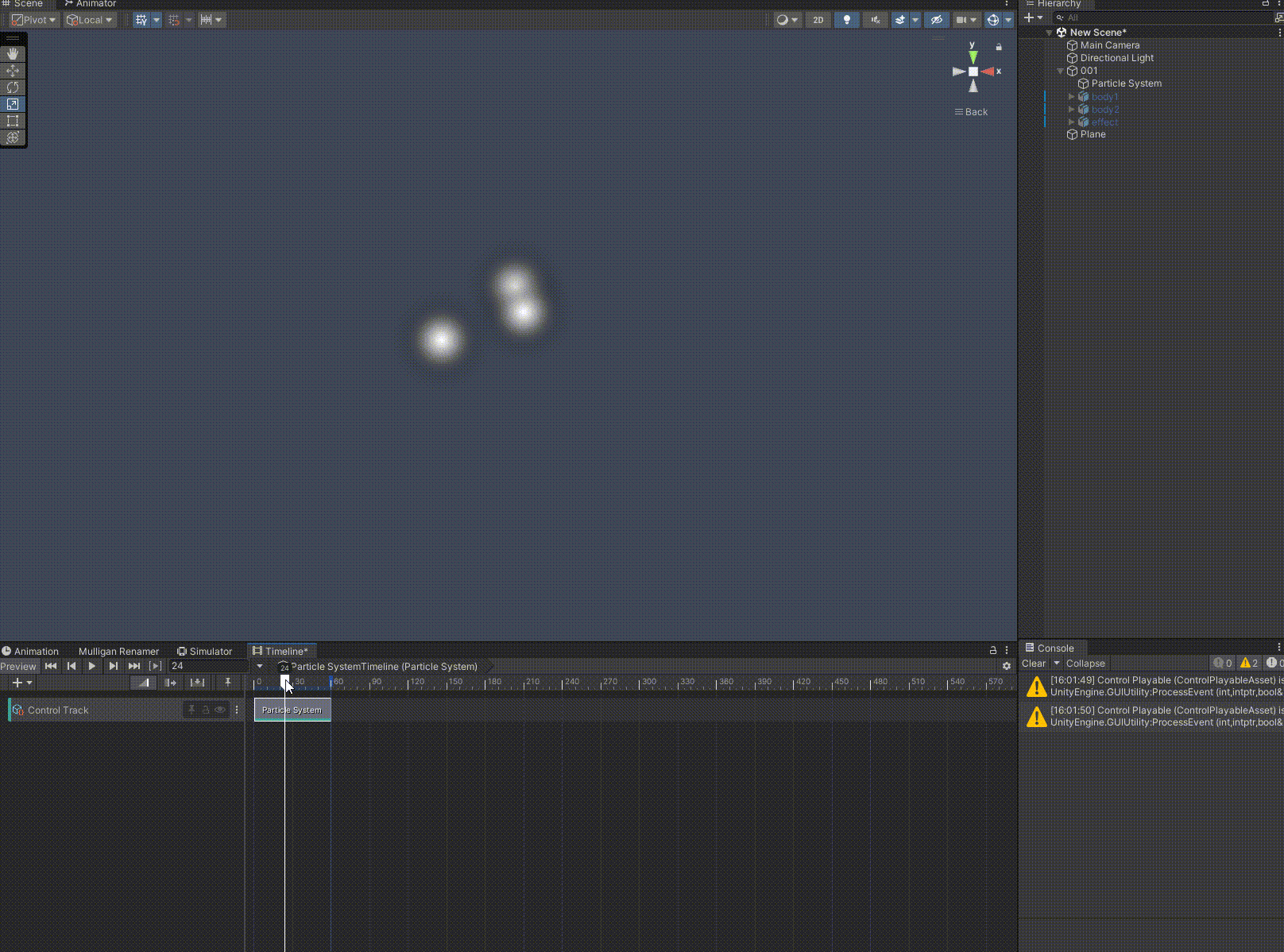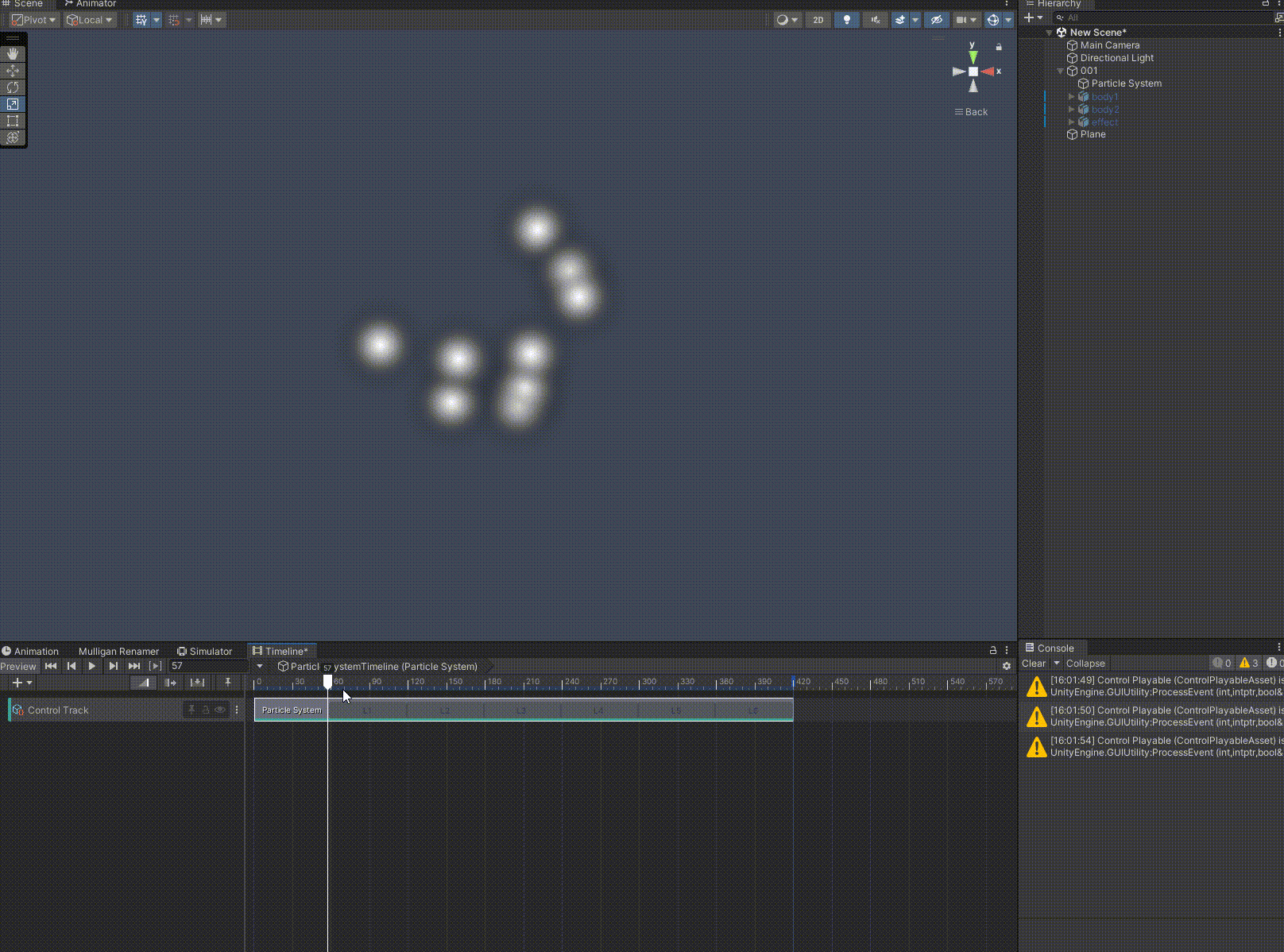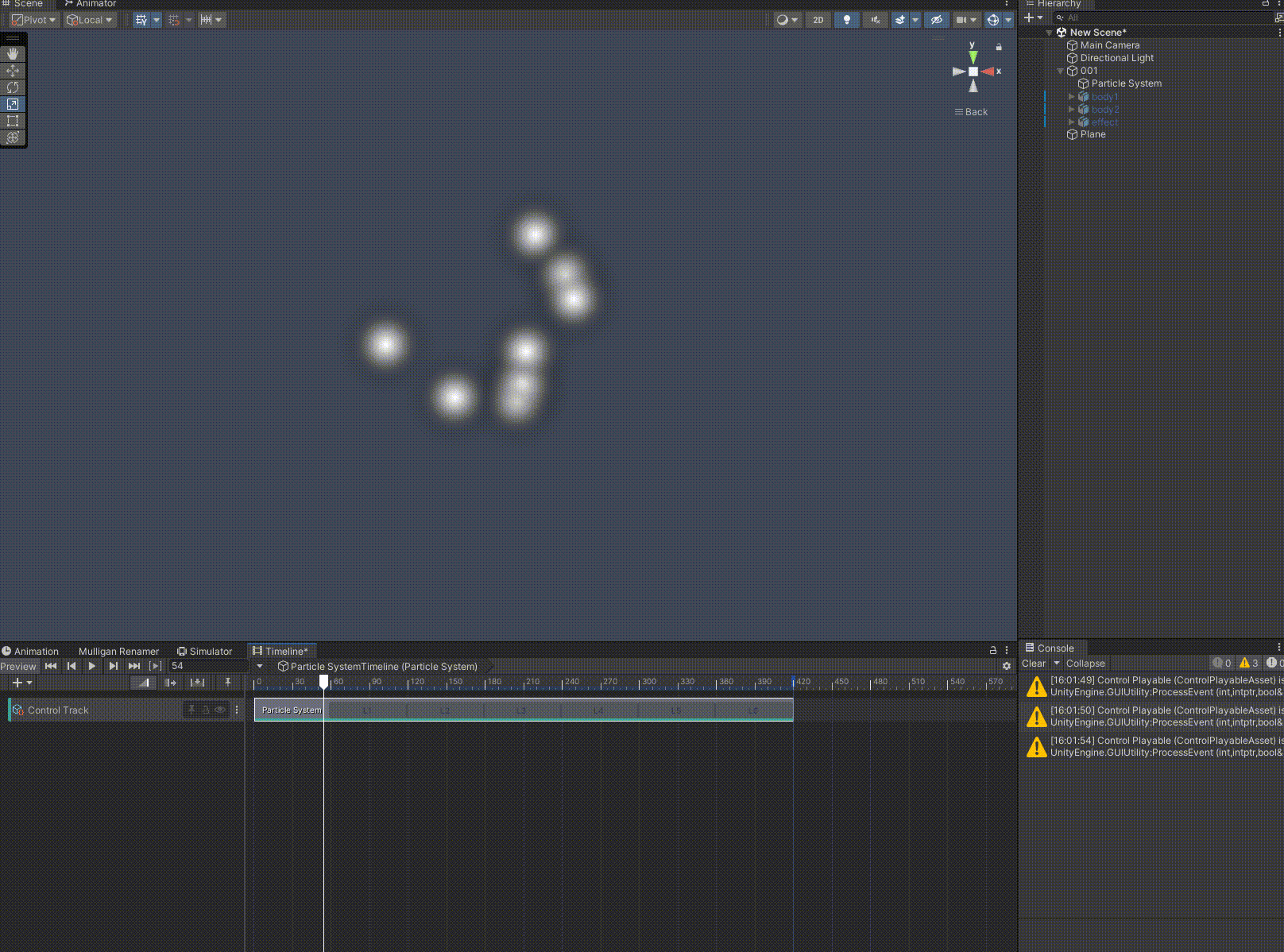
Unity 如何使用Timeline预览、播放特效
在使用unity制作和拟合动画时,我们常用到Timeline,前后拖动滑轨,预览动画正放倒放非常方便。如果我们想对特效也进行这个操作,可以使用下文的步骤。 至此,恭喜你又解锁了一个新的技巧。如果我的分享对你有帮助…...
)
GIM发布新版本了 (附rust CLI制作brew bottle流程)
GIM 发布新版本了!现在1.3.0版本可用了 可以通过brew upgrade git-intelligence-message升级。 初次安装需要先执行 brew tap davelet/gim GIM 是一个根据git仓库内文件变更自动生成git提交消息的命令行工具,参考前文《GIM: 根据代码变更自动生成git提交…...
)
GitHub 趋势日报 (2025年05月21日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1microsoft/WSLLinux的Windows子系统⭐ 1731⭐ 25184C2virattt/ai-hedge-fundA…...
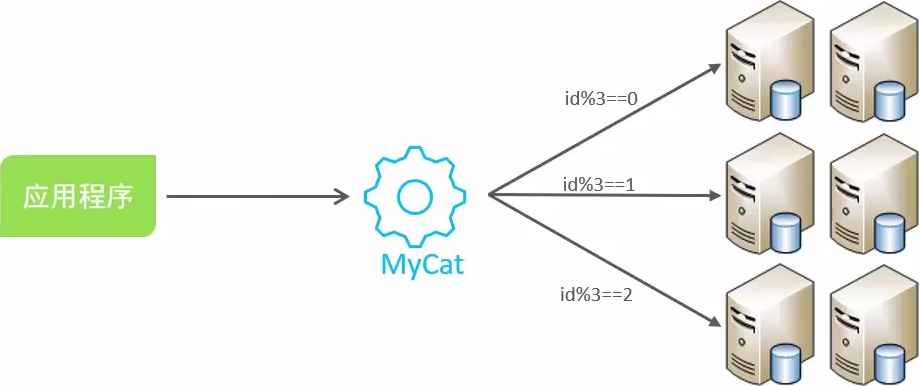
MySQL篇-其他面试题
MySQL事务 问题:事务是什么?ACID问题 事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。 1、事务…...

iOS 蓝牙开发中的 BT 与 BLE
在 iOS 开发者的语境里,大家把 BT 和 BLE 当成两种不同的蓝牙技术在谈——它们来自同一个 Bluetooth 规范,但面向的场景、协议栈乃至 Apple 提供的 API 都截然不同。 缩写全称 / 技术名称规范层叫法iOS 支持现状典型用途BTBluetooth Classic(…...

Git的工作区,暂存区,本地仓库
Git 核心概念解析 1. 工作区(Working Directory) - 日常操作代码的目录,包含项目所有文件和子目录 - 开发者直接编辑和修改文件的位置 - 实际可见的项目文件结构 2. 暂存区(Staging Area) - 临时保存修改记录的缓冲区…...
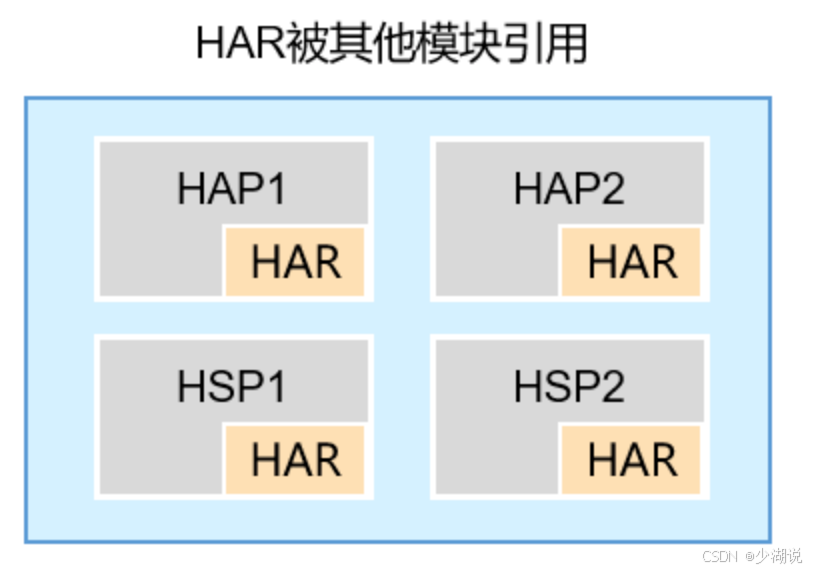
鸿蒙Flutter实战:21-混合开发详解-1-概述
引言 在前面的系列文章中,我们从搭建开发环境开始,讲到如何使用、集成第三方插件,如何将现有项目进行鸿蒙化改造,以及上架审核等内容;还以高德地图的 HarmonyOS SDK 的使用为例, 讲解了如何将高德地图集成…...
解决方案:SUPER权限缺失与二进制日志启用冲突的3种处理方式)
MySQL错误1419(HY000)解决方案:SUPER权限缺失与二进制日志启用冲突的3种处理方式
一、错误背景与原因分析 错误描述 在执行存储过程、函数或触发器时,MySQL可能抛出以下错误: ERROR 1419 (HY000): You do not have the SUPER privilege and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable)…...

[架构之美]从PDMan一键生成数据库设计文档:Word导出全流程详解(二十)
[架构之美]从PDMan一键生成数据库设计文档:Word导出全流程详解(二十) 一、痛点 你是否经历过这些场景? 数据库字段频繁变更,维护文档耗时费力用Excel维护表结构,版本混乱难以追溯手动编写Word文档&#…...

大量程粗糙度轮廓仪适用于哪些材质和表面?
大量程粗糙度轮廓仪是一种能够在广泛的测量范围内对工件表面进行粗糙度分析的精密仪器。它通常采用接触式或非接触式传感器,通过对工件表面的扫描,捕捉表面微观的起伏和波动,从而获取粗糙度数据。该仪器不仅能测量微小的表面细节,…...

linux 查看java的安装路径
一、验证Java安装状态 java -version正常安装会显示版本信息: openjdk version "1.8.0_65" OpenJDK Runtime Environment (build 1.8.0_65-b17) OpenJDK 64-Bit Server VM (build 25.65-b01, mixed mode)二、检查环境变量配置 若已配置JAVA_HOME&#…...
 函数)
C 语言程序终止的艺术:理解 return main 与 exit() 函数
各类资料学习合集下载地址: https://pan.quark.cn/s/472bbdfcd014 每个 C 语言程序都有其起点——main 函数。同样,每个程序也都有其终点,即程序执行完毕并退出。在 C 语言中,主要有两种方式可以优雅或立即地终止整个程序的执行,并将一个状态码传递给…...

数据实时同步:inotify + rsync 实现数据实时同步
1 数据实时同步 在生产环境中,某些场景下,要将数据或文件进行实时同步,保证数据更新后其它节点能立即获得最新的数据。 数据同步的两种方式 PULL:拉,使用定时任务的方式配合同步命令或脚本等,从指定服务…...

LeetCode 404.左叶子之和的迭代求解:栈结构与父节点定位的深度解析
一、题目解析:左叶子的定义与问题本质 题目描述 LeetCode 404. 左叶子之和要求计算二叉树中所有左叶子节点的值之和。左叶子的定义是:如果一个节点是其父节点的左子节点,并且它本身没有左右子节点,则称为左叶子。 关键要点 左…...
Unity-编辑器扩展
之前我们关于Unity的讨论都是针对于Unity底层的内容或者是代码层面的东西,这一次我们来专门研究Unity可视化的编辑器,在已有的基础上做一些扩展。 基本功能 首先我们来认识三个文件夹: Editor,Gizmos,Editor Defaul…...

【自用-python】生成准心居中exe程序,防止云电脑操作时候鼠标偏移
封装exe:: altf12是终端---我理解的就是最初始python的运行台 看where python(Windows的)看是在那个路径 再确保之前pip安装了pyinstaller 然后pyinstaller --onefile --noconsole --name 输出exe的文件名称 你的py文件名称.py…...
Lucide:一款精美的开源矢量图标库,前端图标新选择
名人说:博观而约取,厚积而薄发。——苏轼《稼说送张琥》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、前言:为何选择 Lucide?二、Lucide 是什么?1.…...

在Rocky Linux 8.10上安装Nginx
如果没有配置操作系统安装源,并且不连接网络,先配置安装源。 sudo dnf install nginx sudo systemctl enable nginx sudo systemctl start nginx systemctl status nginx curl http://ip [rootrocky810 work]# sudo dnf install nginx Last metadata …...

Mac如何允许安装任何来源软件?
打开系统偏好设置-安全性与隐私,点击右下角的解锁按钮,选择允许从任何来源。 如果没有这一选项,请到打开终端,输入命令行:sudo spctl --master-disable, 输入命令后回车,输入电脑的开机密码后回车。 返回“…...

YOLO学习笔记 | YOLO11对象检测,实例分割,姿态评估的TensorRT部署c++
以下是YOLOv11在TensorRT上部署的步骤指南,涵盖对象检测、实例分割和姿态评估: 1. 模型导出与转换 1.1 导出ONNX模型 import torch from models.experimental import attempt_loadmodel = attempt_load(yolov11s.pt, fuse=True) model.eval...

2025最新版Visual Studio Code for Mac安装使用指南
2025最新版Visual Studio Code for Mac安装使用指南 Installation and Application Guide to The Latest Version of Visual Studio Code in 2025 By JacksonML 1. 什么是Visual Studio Code? Visual Studio Code,通常被称为 VS Code,是由…...

机器学习第二十三讲:CNN → 用放大镜局部观察图片特征层层传递
机器学习第二十三讲:CNN → 用放大镜局部观察图片特征层层传递 资料取自《零基础学机器学习》。 查看总目录:学习大纲 关于DeepSeek本地部署指南可以看下我之前写的文章:DeepSeek R1本地与线上满血版部署:超详细手把手指南 CNN详…...

【嵙大o】C++作业合集
参考: C swap(交换)函数 指针/引用/C自带-CSDN博客 Problem IDTitleCPP指针CPP引用1107 Problem A编写函数:Swap (I) (Append Code)1158 Problem B整型数据的输出格式1163 Problem C时间:24小时制转12小时制1205…...