篇章十 消息持久化(二)
目录
1.消息持久化-创建MessageFileManger类
1.1 创建一个类
1.2 创建关于路径的方法
1.3 定义内部类
1.4 实现消息统计文件读写
1.5 实现创建消息目录和文件
1.6 实现删除消息目录和文件
1.7 实现消息序列化
1. 消息序列化的一些概念:
2. 方案选择:
3.验证版本
4.序列化代码
1.8 把消息写入文件
1.写入消息长度
2.线程安全问题
3.加锁代码
1.9 删除文件中的消息
1.随机访问
2.删除代码
1.10 加载文件中的所有消息
1.消息持久化-创建MessageFileManger类
1.1 创建一个类
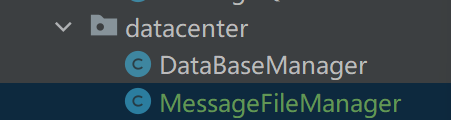
1.2 创建关于路径的方法
获取消息文件所在的目录的方法
// 预定消息文件所在的目录和文件名// 这个方法, 用在获取到 指定队列 对应的 消息文件所在路径private String getQueueDir(String queueName) {return "./data/" + queueName;}// 这个方法用来获取 该队列的 消息数据文件路径// 注意:二进制文件,使用 txt 作为后缀, 不太合适. txt一般表示文本。// .bin .datprivate String getQueueDataPath(String queueName) {return getQueueDir(queueName) + "/queue_data.txt";}// 这个方法用来获取 该队列的 消息统计文件路径private String getQueueStatPath(String queueName) {return getQueueDir(queueName) + "/queue_stat.txt";}
1.3 定义内部类
定义一个内部类, 来表示该队列的统计信息
// 定义一个内部类, 来表示该队列的统计信息
// 优先考虑使用 static, 静态内部类.
static public class Stat {
// 此处直接定义成 public, 就不再搞 get set方法
// 对于这样的简单类,直接使用成员,类似于 C的结构体
public int totalCount; // 总消息数量
public int validCount; // 有效消息数量
}1.此处采用静态内部类:
静态内部类 不会依赖上面外部类的 this ,这样解耦更彻底
如果确实需要访问外部类的属性,这时不使用static。这种想在内部类使用外部类非静态属性的,只有外部类有 this 的情况下才行。
此处很显然不会使用外部类的非静态属性,所以使用static,限制更少,更方便。
3.使用public:
虽然此类只在这里使用,但是为了测试方便,所以使用public,更方便访问。
1.4 实现消息统计文件读写
1.由于 消息统计文件是文本格式,所以可以直接使用Scanner来读取文件
2.需要注意的是写文件时,使用的时FileOutputStream,它的第二个参数可以控制:
(默认)false:直接覆盖原文
true:追加文本
private Stat readStat(String queueName) {// 由于当前的消息统计文件是文本文件, 可以直接使用 Scanner 来读取文件内容Stat stat = new Stat();try (InputStream inputStream = new FileInputStream(getQueueStatPath(queueName))){Scanner scanner = new Scanner(inputStream);stat.totalCount = scanner.nextInt();stat.validCount = scanner.nextInt();return stat;} catch (IOException e) {e.printStackTrace();}return null;}private void writeStat(String queueName, Stat stat) {// 使用 PrintWriter 来写文件// OutputStream 打开文件, 默认情况下会直接把原文件清空.此时相当于新的数据覆盖了旧的.try (OutputStream outputStream = new FileOutputStream(getQueueStatPath(queueName))){PrintWriter printWriter = new PrintWriter(outputStream);printWriter.write(stat.totalCount + "\t" + stat.validCount);printWriter.flush();} catch (IOException e) {throw new RuntimeException(e);}}1.5 实现创建消息目录和文件
此方法 创建对应的文件和目录
包括:
队列对应的消息目录 testQueue1
消息数据文件 queue_data.txt
消息统计文件 queue_stat.txt
并且为消息统计文件设置初始值 0\t0
// 创建队列对应的文件和目录private void createQueueFiles(String queueName) throws IOException {// 创建队列对应的消息目录File baseDir = new File(getQueueDir(queueName));if(!baseDir.exists()) {// 不存在就创建这个目录boolean ok = baseDir.mkdirs();if (!ok) {throw new IOException("创建目录失败! baseDir = " + baseDir.getAbsolutePath());}}// 创建消息数据文件File queueDataFile = new File(getQueueDataPath(queueName));if (!queueDataFile.exists()) {boolean ok = queueDataFile.createNewFile();if (!ok) {throw new IOException("创建文件失败! queueDataFile = " + queueDataFile.getAbsolutePath());}}// 创建消息统计文件File queueStatFile = new File(getQueueStatPath(queueName));if (!queueStatFile.exists()) {boolean ok = queueStatFile.createNewFile();if (!ok) {throw new IOException("创建文件失败! queueStatFile = " + queueStatFile.getAbsolutePath());}}// 给消息统计文件 设定初始值 0\t0Stat stat = new Stat();stat.totalCount = 0;stat.validCount = 0;writeStat(queueName, stat);}1.6 实现删除消息目录和文件
此方法用于删除 1.5 方法创建的消息目录和文件
注意:
1. 先删除文件,在删除目录
2. 一个删除失败就整体失败
3.并且给出一个检查目录文件是否存在的方法:
后续有生产者给 Broker Server 生产消息,这个消息可能需要记录到文件上,要保证对应的目录文件是存在的。
// 删除队列的目录和文件// 队列也是可以被删除的, 当队列删除目录之后, 对应的消息文件自然而然也要删除public void destroyQueueFiles(String queueName) throws IOException {// 先删除文件 再删除目录File queueStatFile = new File(getQueueStatPath(queueName));boolean ok1 = queueStatFile.delete();File queueDataFile = new File(getQueueDataPath(queueName));boolean ok2 = queueDataFile.delete();File baseDir = new File(getQueueDir(queueName));boolean ok3 = baseDir.delete();if (!ok1 || !ok2 || !ok3) {// 有任意一个删除失败 算整体删除失败throw new IOException("删除队列目录和文件失败!baseDir = " + baseDir.getAbsolutePath());}}// 检查队列的目录和文件是否存在// 比如后续有生产者给 Broker Server 生产消息了 这个消息可能需要记录到文件上(取决于消息是否需要持久化)public boolean checkFilesExist(String queueName) {File queueDataFile = new File(getQueueDataPath(queueName));if (!queueDataFile.exists()) {return false;}File queueStatFile = new File(getQueueStatPath(queueName));if (!queueStatFile.exists()) {return false;}return true;}1.7 实现消息序列化
此处抽出写一篇文章,主要介绍 Java中的序列化和反序列化是什么?
1. 消息序列化的一些概念:
消息序列化:
是什么: 简单来说就是 -> 把一个对象(结构化数据)转成一个字符串/字节数组(可以和 降维打击联想在一起)
为什么:序列化之后,方便存储和传输。
存储:一般就是存储在文件中(就像此处消息存到文件里),因为文件只能存字符串/二进制数据,不能直接存对象
传输:通过网络传输。
2. 方案选择:
方案一:
使用 JSON 来完成序列化,反序列化:jackson,ObjectMapper(就像把arguments字段存到数据库中一样,把(集合)结构化数据转成字符串)
不可行:因为 Message,里面存储的 body 部分,是二进制数据,不太方便使用 JSON 进行序列化。JSON序列化得到的结果是文本数据,无法存储二进制。
有关JSON序列化的一些小记:
1.为什么JSON无法存储二进制
JSON 格式中有很多特殊符号, : " {} 这些符号会影响 JSON 格式的解析。如果存文本,你的键值对中不会包含上述特殊符号。如果存二进制,某个二进制的字节正好就和上述特殊符号ASCII对应,此时可能会引起JSON解析格式错误。
2.如果就想使用 JSON序列化,而且以二进制存储怎么办?
可以针对二进制数据进行base64编码,base64作用就是用 4 个字节,表示三个字节的信息,会保证4个字节 都是使用 文本字符。
(像HTML 中如果嵌入一个图片,图片是二进制数据,就可以把图片的二进制 base64 编码然后就可以 直接以文本的形式 嵌入 HTML中)
但是这种方法效率底,有额外的转码开销,同时,还会使空间变大。
关于base64的使用,我会写一篇博文
针对二进制序列化有很多种解决方案
方案二 Java标准库就提供了序列化的方案 ObjectInputStream 和 ObjectOutputStream
方案三 Hessian也是一个解决方案
方案四 protobuffer
方案五 thrift
此处使用第二个方案,好处:不必引入额外的依赖。
3.验证版本
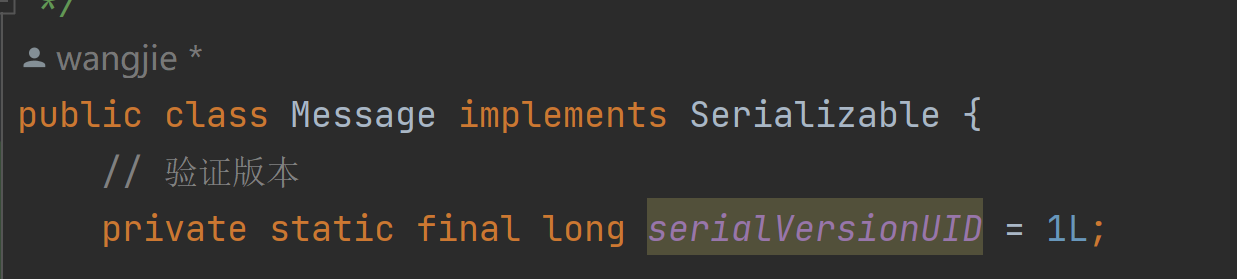
此处 private static final long serialVersionUID = 1L;
是用来验证版本的。实际中开发代码是不断修改更新的。
1. 将Message信息序列化存储到文件中
2.更新了Message类结构
3.针对以前的旧数据进行反序列化,大概率失败
4.所以,通过此验证版本,一旦发现版本不一致,直接报错,不允许反序列化,提醒程序员数据有问题。
4.序列化代码
package com.xj.mq.common;import java.io.*;/*** Created with IntelliJ IDEA* Description 序列化工具类* 并不仅仅是 Message 其他的Java对象 也是可以通过这样的逻辑 进行序列化和反序列化* 如果要让这个对象能序列化和反序列化 需要让它的类实现 Serializable 接口* User: 王杰* Date: 2025-05-20* Time: 9:56*/
public class BinaryTool {// 把 一个对象 序列化 成一个字节数组public static byte[] toBytes(Object object) throws IOException {// 这个流对象相当于一个变长的字节数组// 就可以把 object 序列化的数据给逐渐的写入到 byteArrayOutputStream 中 再统一转成 byte[]try (ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream()){try (ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream)){// 此处的 writeObject 就会把该对象进行序列化 生成的二进制字节数据 就会写入到// ObjectOutputStream 中// 由于 ObjectOutputStream 又关联到了 ByteArrayOutputStream 最终结果就写入到 ByteArrayOutputStream 里了objectOutputStream.writeObject(object);}// 这个操作就是把 byteArrayOutputStream 中持有的二进制数据取出来 转成 byte[]return byteArrayOutputStream.toByteArray();}}// 把 一个字节数组 反序列化 成一个对象public static Object fromBytes(byte[] data) throws IOException, ClassNotFoundException {Object object = null;try (ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream()){try (ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream)){// 此处的 readObject 就是从 data 这个 byte[] 中读取数据并且反序列化object = objectInputStream.readObject();}return object;}}
}
1.8 把消息写入文件
实现把消息写入文件
1.写入消息长度
我们需要往这个文件中,先写入消息的长度(四个字节),是需要把 长度这个 int 的四个字节,一次写入到文件中:
如果选择 outputStream.write(messageBinary.length)会出现一些问题
虽然这个 write的参数类型是 int类型,但是实际上只能写一个字节
在流对象中,经常会涉及到,使用 int 表示 byte 的情况,具体该怎么做呢?
可以把 int 的四个字节分别取出来,一个字节一个字节的写:

很显然不用我们亲自写这些,Java标准库已经提供了现成的类,帮我们封装好了上述操作(让我们感受Java的魅力吧!)
DataInputStream/DataOutputStream
// 写入消息到数据文件 注意 是追加写入到数据文件末尾
try (OutputStream outputStream = new FileOutputStream(queueDataFile, true)) {try (DataOutputStream dataOutputStream = new DataOutputStream(outputStream)) {// 接下来要先写出来 当前消息的长度 占据 4个字节的dataOutputStream.writeInt(messageBinary.length);// 写入消息本体dataOutputStream.write(messageBinary);}
}2.线程安全问题
问题如下图所示:

怎么办?加锁!
确定锁对象
写到 synchronized() 里的对象,当前就以 queue 队列对象 进行加锁即可。
如果两个线程,是往同一个队列中写消息,此时就阻塞等待
如果两个线程,往不同的队列里写消息,此时不需要阻塞等待
3.加锁代码
// 把一个新的消息 放到队列对应的文件中// queue 表示要把消息写入的队列, massage 表示要写的消息public void sendMessage(MessageQueue queue, Message message) throws MqException, IOException {// 检查一下 当前要写入的队列 对应的文件 是否存在if (!checkFilesExist(queue.getName())) {throw new MqException("[MessageFileManager] 队列对应的文件不存在!queueName = " + queue.getName());}// 把Message对象 进行序列化 转成二进制的字节数组byte[] messageBinary = BinaryTool.toBytes(message);synchronized (queue) {// 先获取到当前的队列数据文件的长度 用这个来计算 该Message 对象的 offsetBeg 和 offsetEnd// 把新的 Message 数据 写入到队列数据文件的末尾 此时Message对象的 offsetBeg 就是文件长度 + 4// offsetEnd 就是当前文件长度 + 4 + message自身长度File queueDataFile = new File(getQueueDataPath(queue.getName()));// 通过 queueDataFile.length() 就能获取到文件的长度 单位字节message.setOffsetBeg(queueDataFile.length() + 4);message.setOffsetEnd(queueDataFile.length() + 4 + messageBinary.length);// 写入消息到数据文件 注意 是追加写入到数据文件末尾try (OutputStream outputStream = new FileOutputStream(queueDataFile, true)){try (DataOutputStream dataOutputStream = new DataOutputStream(outputStream)){// 接下来要先写出来 当前消息的长度 占据 4个字节的dataOutputStream.writeInt(messageBinary.length);// 写入消息本体dataOutputStream.write(messageBinary);}}// 更新 消息统计文件Stat stat = readStat(queue.getName());stat.totalCount += 1;stat.validCount += 1;writeStat(queue.getName(), stat);}}
1.9 删除文件中的消息
1.随机访问
之前用的 FileInputStream 和 FileOutputStream 都是从文件头读写的。而此处我们需要的是,在文件中的指定位置进行读写 ,随机访问。此处用到的类是 RandomAccessFile
三个方法:
read:读取时会移动光标
write:写入时会移动光标
seek:调整当前的文件光标(当前要读写的位置)
2.删除代码
// 删除消息的方法// 这里的删除时 逻辑删除 也就是把硬盘上存储这个数据里边的哪个 isValid 属性 设置成 0// 先把文件中的这一段数据 读出来 还原回 Message 对象// 把 isValid 改成 0// 把上述数据重新写回到文件// 此处这个参数中的 message 对象 必须得包含有效的 offsetBeg 和 offsetEndpublic void deleteMessage(MessageQueue queue, Message message) throws IOException, ClassNotFoundException {synchronized (queue) {try (RandomAccessFile randomAccessFile = new RandomAccessFile(getQueueDataPath(queue.getName()), "rw")){// 先从文件中读取对应的 Message 数据byte[] bufferSrc = new byte[(int)(message.getOffsetEnd() - message.getOffsetBeg())];randomAccessFile.seek(message.getOffsetBeg());randomAccessFile.read(bufferSrc);// 把当前读出来的二进制数据 转换回 Message 对象Message diskMessage = (Message) BinaryTool.fromBytes(bufferSrc);// 把 isValid 设置为无效message.setIsValid((byte) 0x0);// 此处不需要 给参数 message的 isValid 设为0 因为这个参数代表的是内存中管理的 Message 对象// 而这个对象 马上也要被从内存中销毁// 重新写入文件byte[] bufferDest = BinaryTool.toBytes(diskMessage);// 虽然上面已经 seek过了 但是上面 seek完了 进行了读操作 这导致 文件光标往后移动// 移动到下一个消息的位置 因此想让接下来的写入 能够刚好写回到之前的位置 就需要重新调整光标位置randomAccessFile.seek(message.getOffsetBeg());randomAccessFile.write(bufferDest);// 通过上述代码 只是改变了一个重要的有效标记位 (一个字节)}// 不要忘了 更新统计文件 把一个消息设为无效 此时有效消息个数要 -1Stat stat = readStat(queue.getName());if (stat.validCount > 0) {stat.validCount -= 1;}writeStat(queue.getName(), stat);}}1.10 加载文件中的所有消息
读取文件中所有的消息内容:
此处注意这个方法是在程序启动时调用 此时服务器还不能处理请求 不涉及多线程操作文件
// 使用这个方法 从文件中 读取出所有的消息内容 加载到内存中 (具体来说就是放在一个链表里)// 使用这个方法 准备在程序启动的时候 进行调用// 这里使用了一个 LinkedList 主要目的是为了后续进行头删操作// 这个方法参数 只是一个queueName 而不是 MessageQueue对象 因为这个方法不需要加锁 只使用 queueName 就够了// 由于该方法是在程序启动时调用 此时服务器还不能处理请求 不涉及多线程操作文件public LinkedList<Message> loadAllMessageFromQueue(String queueName) throws IOException, MqException, ClassNotFoundException {LinkedList<Message> messages = new LinkedList<>();try (InputStream inputStream = new FileInputStream(getQueueDataPath(queueName))){try (DataInputStream dataInputStream = new DataInputStream(inputStream)){// 这个变量记录当前文件光标long currentOffset = 0;// 一个文件 包含了很多信息 此处势必 循环读取while (true) {// 读取当前消息的长度// readInt 方法读到文件末尾 会抛出 EOFException 异常 这一点和以前的流对象不同int messageSize = dataInputStream.readInt();// 按照这个长度 读取消息内容byte[] buffer = new byte[messageSize];int actualSize = dataInputStream.read(buffer);if (messageSize != actualSize) {// 如果不匹配 说明文件有问题 格式错乱了throw new MqException("[MessageFileManager] 文件格式错误!" + queueName);}// 当读到这个二进制数据 反序列化回 Message 对象Message message = (Message)BinaryTool.fromBytes(buffer);// 判断一下看看这个消息对象 是不是无效对象if (message.getIsValid() != 0x1) {// 无效数据 直接跳过// 虽然消息是无效数据 但是 offset 不要忘记更新currentOffset += (4 + messageSize);continue;}// 有效数据 则需要把这个 Message对象加入到链表中 加入之前还需要填写 offsetBeg 和 offsetEnd// 进行计算 offset的时候 需要知道当前文件光标的位置 由于当前使用的是 dataInputStream 并不方便直接获取文件光标// 因此就需要手动计算下文件光标message.setOffsetBeg(currentOffset + 4);message.setOffsetEnd(currentOffset + 4 + messageSize);currentOffset += (4 + messageSize);messages.add(message);}}catch (EOFException e) {// 这个 catch 并非真是处理 “异常” 而是处理 “正常” 的业务逻辑 文件读到末尾 会被 readInt 抛出该异常// 这个 catch 语句中也不需要做什么System.out.println("[MessageFileManager] 恢复 Message 数据完成");}}return messages;}相关文章:
篇章十 消息持久化(二)
目录 1.消息持久化-创建MessageFileManger类 1.1 创建一个类 1.2 创建关于路径的方法 1.3 定义内部类 1.4 实现消息统计文件读写 1.5 实现创建消息目录和文件 1.6 实现删除消息目录和文件 1.7 实现消息序列化 1. 消息序列化的一些概念: 2. 方案选择…...

【IDEA】删除/替换文件中所有包含某个字符串的行
目录 前言 正则表达式 示例 使用方法 前言 在日常开发中,频繁地删除无用代码或清理空行是不可避免的操作。许多开发者希望找到一种高效的方式,避免手动选中代码再删除的繁琐过程。 使用正则表达式是处理字符串的一个非常有效的方法。 正则表达式 …...
基于深度学习的不良驾驶行为为识别检测
一.研究目的 随着全球汽车保有量持续增长,交通安全问题日益严峻,由不良驾驶行为(如疲劳驾驶、接打电话、急加速/急刹车等)引发的交通事故频发,不仅威胁生命财产安全,还加剧交通拥堵与环境污染。传统识别方…...

FD+Mysql的Insert时的字段赋值乱码问题
方法一 FDQuery4.SQL.Text : INSERT INTO 信息表 (中心, 分组) values(:中心,:分组); FDQuery4.Params[0].DataType : ftWideString; //必须加这个数据类型的定义,否则会有乱码 FDQuery4.Params[1].DataType : ftWideString; //ftstring就不行,必须是…...
第十周作业
一、CSRF 1、DVWA-High等级 2、使用Burp生成CSRF利用POC并实现攻击 二、SSRF:file_get_content实验,要求获取ssrf.php的源码 三、RCE 1、 ThinkPHP 2、 Weblogic 3、Shiro...

Python操作PDF书签详解 - 添加、修改、提取和删除
目录 简介 使用工具 Python 向 PDF 添加书签 添加书签 添加嵌套书签 Python 修改 PDF 书签 Python 展开或折叠 PDF 书签 Python 提取 PDF 书签 Python 删除 PDF 书签 简介 PDF 书签是 PDF 文件中的导航工具,通常包含一个标题和一个跳转位置(如…...

One-shot和Zero-shot的区别以及使用场景
Zero-shot是模型在没有任务相关训练数据的情况下进行预测,依赖预训练知识。 One-shot则是提供一个示例,帮助模型理解任务。两者的核心区别在于是否提供示例,以及模型如何利用这些信息。 在机器学习和自然语言处理中,Zero-Shot 和…...

微软 Build 2025:开启 AI 智能体时代的产业革命
在 2025 年 5 月 19 日的微软 Build 开发者大会上,萨提亚・纳德拉以 "我们已进入 AI 智能体时代" 的宣言,正式拉开了人工智能发展的新纪元。这场汇聚了奥特曼、黄仁勋、马斯克三位科技领袖的盛会,不仅发布了 50 余项创新产品&#…...
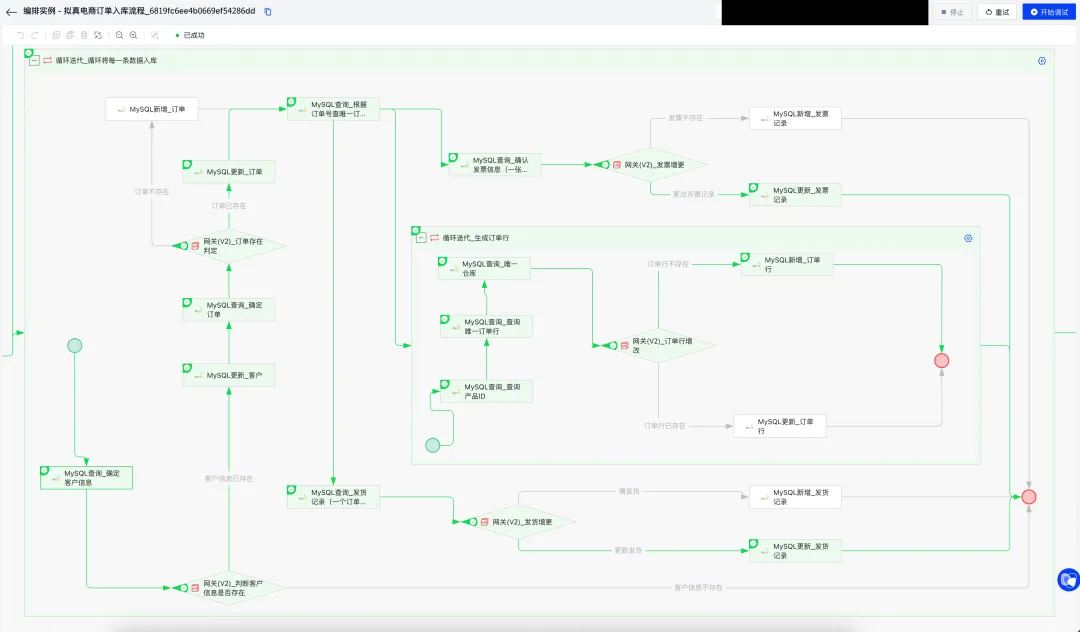
集星獭 | 重塑集成体验:新版编排重构仿真电商订单数据入库
概要介绍 新版服务编排以可视化模式驱动电商订单入库流程升级,实现订单、客户、库存、发票、发货等环节的自动化处理。流程中通过循环节点、判断逻辑与数据查询的编排,完成了低代码构建业务逻辑,极大提升订单处理效率与业务响应速度。 背景…...

多模态大语言模型arxiv论文略读(八十八)
MammothModa: Multi-Modal Large Language Model ➡️ 论文标题:MammothModa: Multi-Modal Large Language Model ➡️ 论文作者:Qi She, Junwen Pan, Xin Wan, Rui Zhang, Dawei Lu, Kai Huang ➡️ 研究机构: ByteDance, Beijing, China ➡️ 问题背景…...

创建Workforce
创建你的Workforce 3.3.1 简单实践 1. 创建 Workforce 实例 想要使用 Workforce,首先需要创建一个 Workforce 实例。下面是最简单的示例: from camel.agents import ChatAgent from camel.models import ModelFactory from camel.types import Model…...

Cribl 中 Parser 扮演着重要的角色 + 例子
先看文档: Parser | Cribl Docs Parser The Parser Function can be used to extract fields out of events or reserialize (rewrite) events with a subset of fields. Reserialization will preserve the format of the events. For example, if an event contains comma…...

WebSocket 从入门到进阶实战
好记忆不如烂笔头,能记下点东西,就记下点,有时间拿出来看看,也会发觉不一样的感受. 聊天系统是WebSocket的最佳实践,以下是使用WebSocket技术实现的一个聊天系统的关键代码,可以通过这些关键代码ÿ…...

CSS:vertical-align用法以及布局小案例(较难)
文章目录 一、vertical-align说明二、布局案例 一、vertical-align说明 上面的文字介绍,估计大家也看不懂 二、布局案例...

Linux 正则表达式 扩展正则表达式 gawk
什么是正则表达式 正则表达式是我们所定义的模式模板(pattern template),Linux工具用它来过滤文本。Linux工具(比如sed编辑器或gawk程序)能够在处理数据时,使用正则表达式对数据进行模式匹配。如果数据匹配…...
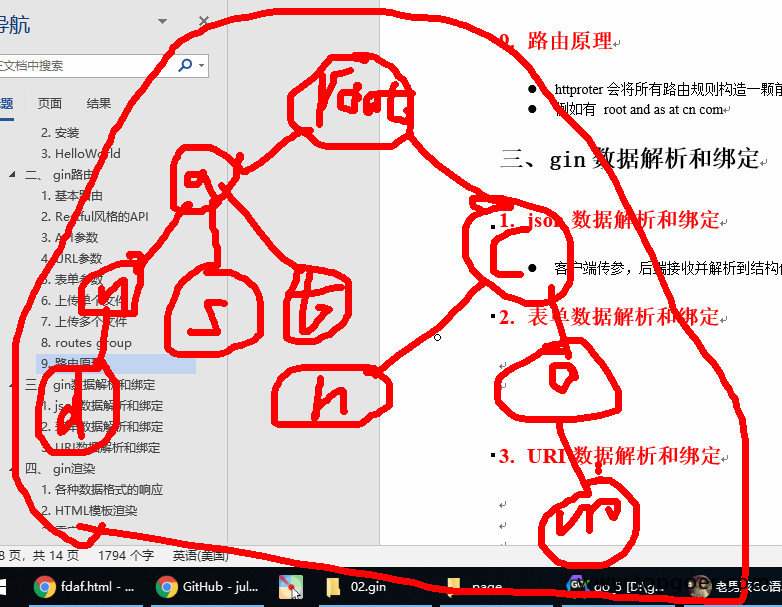
Java转Go日记(五十四):gin路由
1. 基本路由 gin 框架中采用的路由库是基于httprouter做的 地址为:https://github.com/julienschmidt/httprouter package mainimport ("net/http""github.com/gin-gonic/gin" )func main() {r : gin.Default()r.GET("/", func(c …...
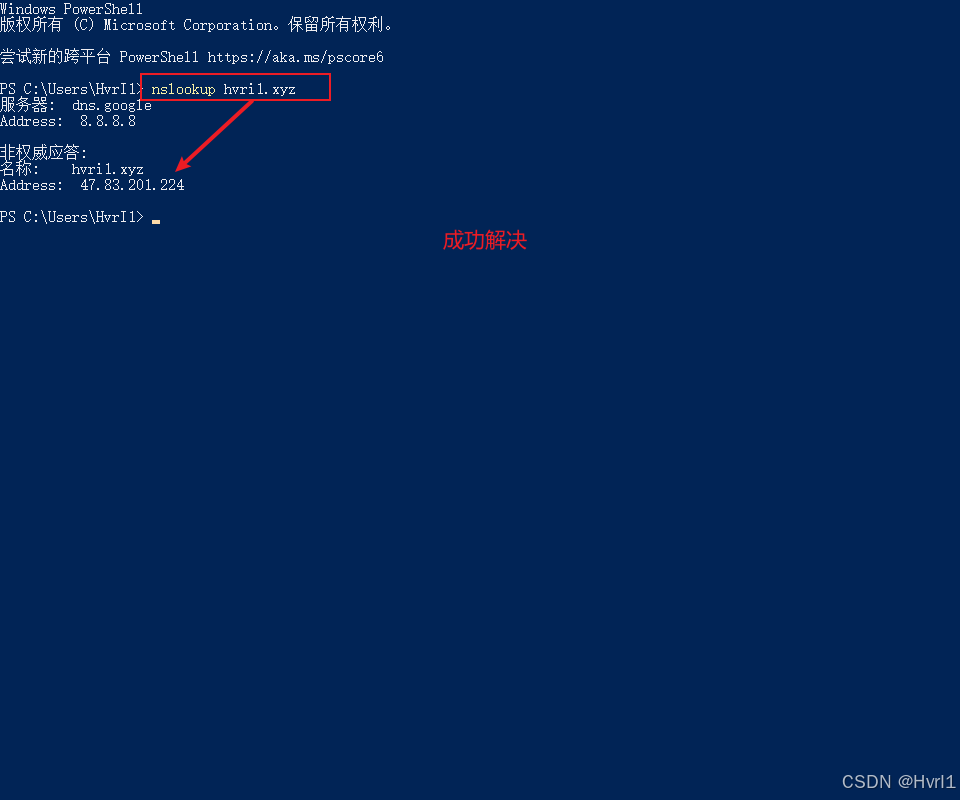
【解决】自己的域名任何端口都访问不到,公网地址正常访问,服务器报错500。
一、问题描述 后端项目部署在服务器上,通过域名访问接口服务器报错500,通过浏览器访问域名的任何端口都是无法访问此网站。 但是通过公网地址访问是可以正常访问到的,感觉是域名出现了问题 二、解决过程 先说结论:问题原因是…...

探秘鸿蒙 HarmonyOS NEXT:Navigation 组件的全面解析
鸿蒙 ArkTS 语言中 Navigation 组件的全面解析 一、引言 本文章基于HarmonyOS NEXT操作系统,API12以上的版本。 在鸿蒙应用开发中,ArkTS 作为一种简洁、高效的开发语言,为开发者提供了丰富的组件库。其中,Navigation 组件在构建…...
)
订单导入(常见问题和sql)
1.印章取行,有几行取几行 union select PARAM07 name, case when regexp_count(PO_PARAM_20, chr(10)) > 0 then substr(PO_PARAM_20, 0, instr(PO_PARAM_20, chr(10)) - 1) else PO_PARAM_20 end value,PO_ID …...
PyTorch中diag_embed和transpose函数使用详解
torch.diag_embed 是 PyTorch 中用于将一个向量(或批量向量)**嵌入为对角矩阵(或批量对角矩阵)**的函数。它常用于图神经网络(GNN)或线性代数中生成对角矩阵。 函数原型 torch.diag_embed(input, offset0,…...

算法分析与设计实验:找零钱问题的贪心算法与动态规划解决方案
在计算机科学中,贪心算法和动态规划是两种常用的算法设计策略。本文将通过一个经典的找零钱问题,详细讲解这两种算法的实现和应用。我们将会提供完整的C代码,并对代码进行详细解释,帮助读者更好地理解和掌握这两种算法。 问题描述…...
制作 MacOS系统 の Heic动态壁纸
了解动态桌面壁纸 当macOS 10.14发布后,会发现系统带有动态桌面壁纸,设置后,我们的桌面背景将随着一天从早上、到下午、再到晚上的推移而发生微妙的变化。 虽然有些软件也有类似的动态变化效果,但是在新系统中默认的HEIC格式的动…...
大数据 笔记
kafka kafka作为消息队列为什么发送和消费消息这么快? 消息分区:不受单台服务器的限制,可以不受限的处理更多的数据顺序读写:磁盘顺序读写,提升读写效率页缓存:把磁盘中的数据缓存到内存中,把…...

js中encodeURIComponent函数使用场景
encodeURIComponent 是 JavaScript 中的一个内置函数,它的作用是: 将字符串编码为可以安全放入 URL 的形式。 ✅ 为什么需要它? URL 中有一些字符是有特殊意义的,比如: ? 用来开始查询参数 & 分隔多个参数 连接…...

iOS工厂模式
iOS工厂模式 文章目录 iOS工厂模式简单工厂模式(Simple Factory)工厂方法模式(Factory Method)抽象工厂模式(Abstract Factory)三种模式对比 简单工厂模式(Simple Factory) 定义&am…...
【数据库】-1 mysql 的安装
文章目录 1、mysql数据库1.1 mysql数据库的简要介绍 2、mysql数据库的安装2.1 centos安装2.2 ubuntu安装 1、mysql数据库 1.1 mysql数据库的简要介绍 MySQL是一种开源的关系型数据库管理系统(RDBMS),由瑞典MySQL AB公司开发,目前…...

【缓存】JAVA本地缓存推荐Caffeine和Guava
🌟 引言 在软件开发过程中,缓存是提升系统性能的常用手段。对于基础场景,直接使用 Java集合框架(如Map/Set/List)即可满足需求。然而,当面对更复杂的缓存场景时: 需要支持多种过期策略&#x…...

Prometheus的服务命令和配置文件
一、Prometheus的服务端命令和启动方式 1.服务端命令(具体详情可以--help查看) --config.file“prometheus.yml”指定配置文件,默认是当前目录下的prometheus.yml--web.listen-address"0.0.0.0:9090"web页面的地址与端口…...
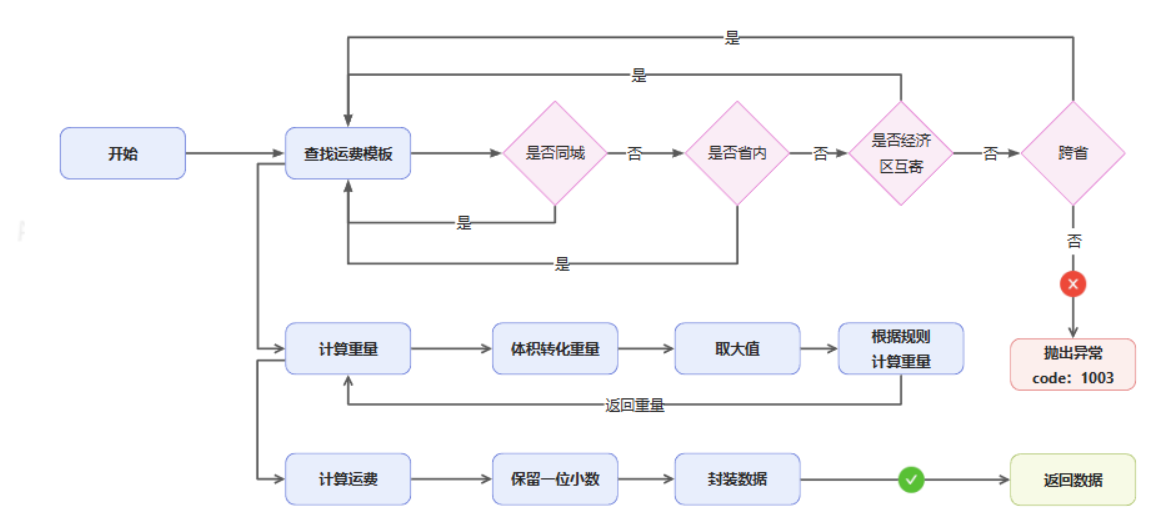
物流项目第五期(运费计算实现、责任链设计模式运用)
前四期: 物流项目第一期(登录业务)-CSDN博客 物流项目第二期(用户端登录与双token三验证)-CSDN博客 物流项目第三期(统一网关、工厂模式运用)-CSDN博客 物流项目第四期(运费模板列…...

前端JavaScript-嵌套事件
点击 如果在多层嵌套中,对每层都设置事件监视器,试试看 <!DOCTYPE html> <html lang"cn"> <body><div id"container"><button>点我!</button></div><pre id"output…...