小白的进阶之路系列之三----人工智能从初步到精通pytorch计算机视觉详解下
我们将继续计算机视觉内容的讲解。
我们已经知道了计算机视觉,用在什么地方,如何用Pytorch来处理数据,设定一些基础的设置以及模型。下面,我们将要解释剩下的部分,包括以下内容:
| 主题 | 内容 |
|---|---|
| Model 1 :加入非线性 | 实验是机器学习的很大一部分,让我们尝试通过添加非线性层来改进我们的基线模型。 |
| Model 2:卷积神经网络(CNN) | 是时候让计算机视觉具体化,并介绍强大的卷积神经网络架构。 |
| 比较我们的模型 | 我们已经建立了三种不同的模型,让我们来比较一下。 |
| 评估我们的最佳模型 | 让我们对随机图像做一些预测,并评估我们的最佳模型。 |
| 制作混淆矩阵 | 混淆矩阵是评估分类模型的好方法,让我们看看如何制作一个。 |
| 保存和载入最佳性能模型 | 由于我们可能希望稍后使用我们的模型,让我们保存它并确保它正确地加载回来。 |
下面开始正文:
6 Model 1:建立一个更好的非线性模型
我们在第二篇文章里学过非线性的力量。
看看我们一直在处理的数据,你认为它需要非线性函数吗?
记住,线性意味着直线,非线性意味着非直线。
让我们来看看。
我们将通过重新创建与之前类似的模型来实现这一点,只不过这次我们将在每个线性层之间放置非线性函数(nn.ReLU())。
# Create a model with non-linear and linear layers
class FashionMNISTModelV1(nn.Module):def __init__(self, input_shape: int, hidden_units: int, output_shape: int):super().__init__()self.layer_stack = nn.Sequential(nn.Flatten(), # flatten inputs into single vectornn.Linear(in_features=input_shape, out_features=hidden_units),nn.ReLU(),nn.Linear(in_features=hidden_units, out_features=output_shape),nn.ReLU())def forward(self, x: torch.Tensor):return self.layer_stack(x)
看起来不错。
现在让我们用之前使用的相同设置实例化它。
我们需要input_shape=784(等于图像数据的特征数量),hidden_units=10(开始时较小,与基线模型相同)和output_shape=len(class_names)(每个类一个输出单元)。
[!TIP]
注意:注意我们如何保持我们的模型的大部分设置相同,除了一个变化:添加非线性层。这是运行一系列机器学习实验的标准做法,改变一件事,看看会发生什么,然后再做一次,一次,一次。
torch.manual_seed(42)
model_1 = FashionMNISTModelV1(input_shape=784, # number of input featureshidden_units=10,output_shape=len(class_names) # number of output classes desired
).to(device) # send model to GPU if it's available
print(next(model_1.parameters()).device) # check model device )
输出为:
cuda:0
6.1设置损耗、优化器和评估指标
像往常一样,我们将设置一个损失函数、一个优化器和一个评估指标(我们可以设置多个评估指标,但现在我们将坚持准确性)。
from helper_functions import accuracy_fn
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(params=model_1.parameters(), lr=0.1)
6.2训练和测试回路的功能化
到目前为止,我们已经一遍又一遍地编写train和test循环。
我们再写一遍,但是这次我们把它们放在函数里,这样它们就可以被反复调用了。
因为我们现在使用的是与设备无关的代码,我们将确保在特征(X)和目标(y)张量上调用.to(device)。
对于训练循环,我们将创建一个名为train_step()的函数,它接受一个模型、一个数据加载器(DataLoader)、一个损失函数和一个优化器。
测试循环将是类似的,但它将被称为test_step(),它将接受一个模型、一个DataLoader、一个损失函数和一个求值函数。
[!TIP]
注意:由于这些都是函数,您可以以任何喜欢的方式自定义它们。我们在这里所做的可以看作是针对我们的特定分类用例的基本训练和测试功能。
def train_step(model: torch.nn.Module,data_loader: torch.utils.data.DataLoader,loss_fn: torch.nn.Module,optimizer: torch.optim.Optimizer,accuracy_fn,device: torch.device = device):train_loss, train_acc = 0, 0model.to(device)for batch, (X, y) in enumerate(data_loader):# Send data to GPUX, y = X.to(device), y.to(device)# 1. Forward passy_pred = model(X)# 2. Calculate lossloss = loss_fn(y_pred, y)train_loss += losstrain_acc += accuracy_fn(y_true=y,y_pred=y_pred.argmax(dim=1)) # Go from logits -> pred labels# 3. Optimizer zero gradoptimizer.zero_grad()# 4. Loss backwardloss.backward()# 5. Optimizer stepoptimizer.step()# Calculate loss and accuracy per epoch and print out what's happeningtrain_loss /= len(data_loader)train_acc /= len(data_loader)print(f"Train loss: {train_loss:.5f} | Train accuracy: {train_acc:.2f}%")def test_step(data_loader: torch.utils.data.DataLoader,model: torch.nn.Module,loss_fn: torch.nn.Module,accuracy_fn,device: torch.device = device):test_loss, test_acc = 0, 0model.to(device)model.eval() # put model in eval mode# Turn on inference context managerwith torch.inference_mode(): for X, y in data_loader:# Send data to GPUX, y = X.to(device), y.to(device)# 1. Forward passtest_pred = model(X)# 2. Calculate loss and accuracytest_loss += loss_fn(test_pred, y)test_acc += accuracy_fn(y_true=y,y_pred=test_pred.argmax(dim=1) # Go from logits -> pred labels)# Adjust metrics and print outtest_loss /= len(data_loader)test_acc /= len(data_loader)print(f"Test loss: {test_loss:.5f} | Test accuracy: {test_acc:.2f}%\n")
哦吼!
现在我们有了一些用于训练和测试模型的函数,让我们运行它们。
我们将在每个epoch的另一个循环中这样做。
这样,对于每个epoch,我们都要经历一个训练步骤和一个测试步骤。
[!TIP]
注意:您可以自定义执行测试步骤的频率。有时人们每隔5个时期或10个时期做一次,在我们的例子中,每个时期做一次。
我们还可以计时,看看代码在GPU上运行需要多长时间。
# Import tqdm for progress bar
from tqdm.auto import tqdmtorch.manual_seed(42)# Measure time
from timeit import default_timer as timer
train_time_start_on_gpu = timer()epochs = 3
for epoch in tqdm(range(epochs)):print(f"Epoch: {epoch}\n---------")train_step(data_loader=train_dataloader, model=model_1, loss_fn=loss_fn,optimizer=optimizer,accuracy_fn=accuracy_fn)test_step(data_loader=test_dataloader,model=model_1,loss_fn=loss_fn,accuracy_fn=accuracy_fn)train_time_end_on_gpu = timer()
total_train_time_model_1 = print_train_time(start=train_time_start_on_gpu,end=train_time_end_on_gpu,device=device)
输出为:
0%| | 0/3 [00:00<?, ?it/s]Epoch: 0
---------
Train loss: 1.09199 | Train accuracy: 61.34%
Test loss: 0.95636 | Test accuracy: 65.00%33%|████████████████████████████ | 1/3 [00:05<00:11, 5.79s/it]Epoch: 1
---------
Train loss: 0.78101 | Train accuracy: 71.93%
Test loss: 0.72227 | Test accuracy: 73.91%67%|████████████████████████████████████████████████████████ | 2/3 [00:12<00:06, 6.26s/it]Epoch: 2
---------
Train loss: 0.67027 | Train accuracy: 75.94%
Test loss: 0.68500 | Test accuracy: 75.02%100%|████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:19<00:00, 6.39s/it]
Train time on cuda: 19.161 seconds
太好了!
我们的模型训练了,但是训练时间更长?
[!TIP]
注意:CUDA vs CPU的训练时间很大程度上取决于你使用的CPU/GPU的质量。请继续阅读,以获得更详细的答案。
问题:“我用了GPU,但我的模型训练得并不快,这是为什么呢?”
答:嗯,一个原因可能是因为你的数据集和模型都很小(就像我们正在使用的数据集和模型),使用GPU的好处被实际传输数据所需的时间所抵消。
在将数据从CPU内存(默认)复制到GPU内存之间存在一个小瓶颈。
因此,对于较小的模型和数据集,CPU实际上可能是进行计算的最佳位置。
但对于更大的数据集和模型,GPU提供的计算速度通常远远超过获取数据的成本。
然而,这在很大程度上取决于您使用的硬件。通过练习,您将习惯训练模型的最佳地点。
让我们使用eval_model()函数对训练好的model_1求值,看看结果如何。
# Note: This will error due to `eval_model()` not using device agnostic code
model_1_results = eval_model(model=model_1, data_loader=test_dataloader,loss_fn=loss_fn, accuracy_fn=accuracy_fn)
print(model_1_results )
输出为:
...
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument mat1 in method wrapper_CUDA_addmm)
噢,不!
看起来我们的eval_model()函数出错了:
RuntimeError:期望所有张量都在同一设备上,但发现至少有两个设备,cuda:0和cpu!(当检查wrapper_addmm方法中参数mat1的参数时)
这是因为我们已经将数据和模型设置为使用与设备无关的代码,而不是我们的求值函数。
我们通过将目标设备参数传递给eval_model()函数来解决这个问题怎么样?
然后我们再试着计算结果。
# Move values to device
torch.manual_seed(42)
def eval_model(model: torch.nn.Module, data_loader: torch.utils.data.DataLoader, loss_fn: torch.nn.Module, accuracy_fn, device: torch.device = device):"""Evaluates a given model on a given dataset.Args:model (torch.nn.Module): A PyTorch model capable of making predictions on data_loader.data_loader (torch.utils.data.DataLoader): The target dataset to predict on.loss_fn (torch.nn.Module): The loss function of model.accuracy_fn: An accuracy function to compare the models predictions to the truth labels.device (str, optional): Target device to compute on. Defaults to device.Returns:(dict): Results of model making predictions on data_loader."""loss, acc = 0, 0model.eval()with torch.inference_mode():for X, y in data_loader:# Send data to the target deviceX, y = X.to(device), y.to(device)y_pred = model(X)loss += loss_fn(y_pred, y)acc += accuracy_fn(y_true=y, y_pred=y_pred.argmax(dim=1))# Scale loss and accloss /= len(data_loader)acc /= len(data_loader)return {"model_name": model.__class__.__name__, # only works when model was created with a class"model_loss": loss.item(),"model_acc": acc}# Calculate model 1 results with device-agnostic code
model_1_results = eval_model(model=model_1, data_loader=test_dataloader,loss_fn=loss_fn, accuracy_fn=accuracy_fn,device=device
)
print(model_1_results)
输出为:
{'model_name': 'FashionMNISTModelV1', 'model_loss': 2.302107095718384, 'model_acc': 10.75279552715655}
# Check baseline results
print(model_0_results)
输出为:
{'model_name': 'FashionMNISTModelV0', 'model_loss': 2.3190648555755615, 'model_acc': 10.85263578相关文章:

小白的进阶之路系列之三----人工智能从初步到精通pytorch计算机视觉详解下
我们将继续计算机视觉内容的讲解。 我们已经知道了计算机视觉,用在什么地方,如何用Pytorch来处理数据,设定一些基础的设置以及模型。下面,我们将要解释剩下的部分,包括以下内容: 主题内容Model 1 :加入非线性实验是机器学习的很大一部分,让我们尝试通过添加非线性层来…...
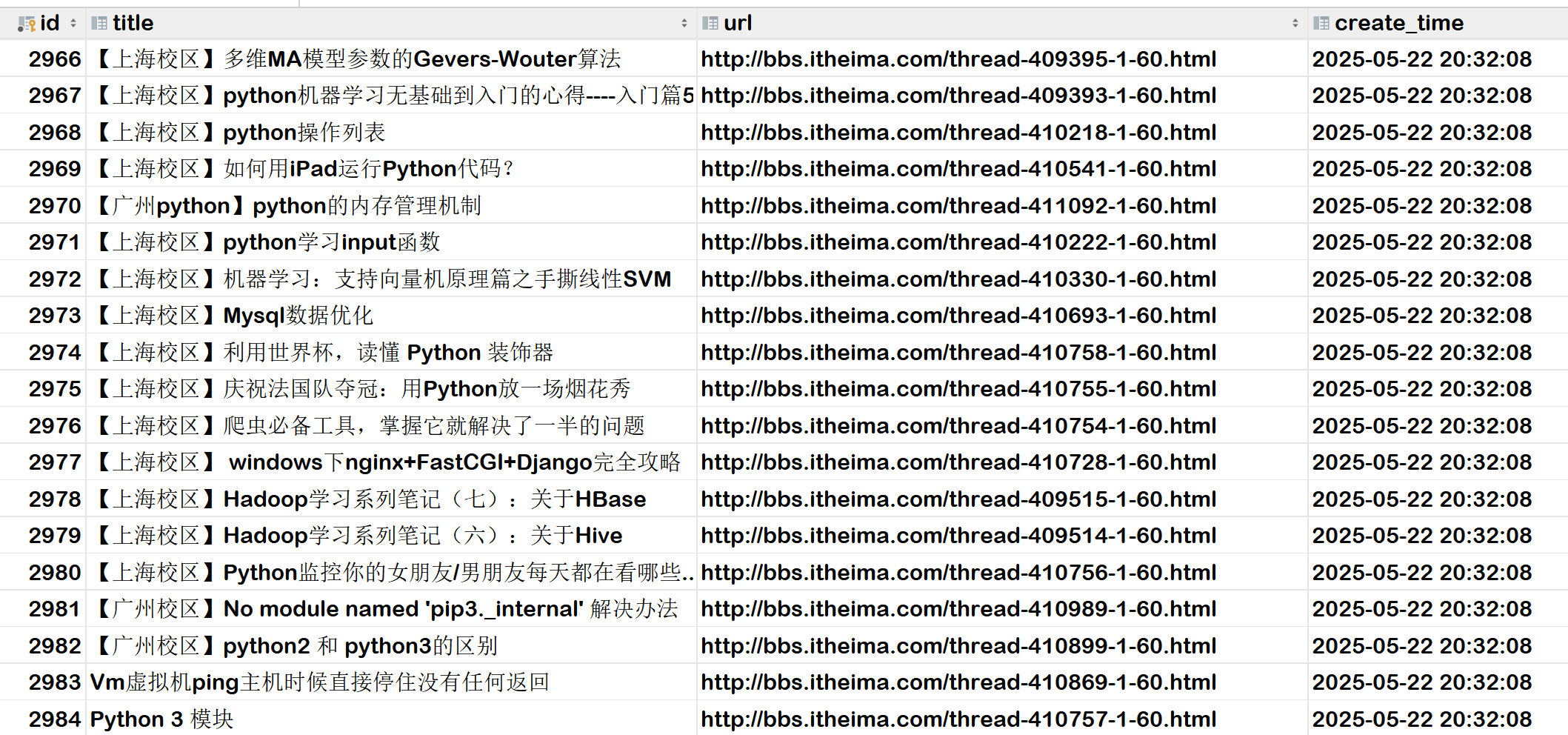
Scrapy爬取heima论坛所有页面内容并保存到MySQL数据库中
前期准备: Scrapy入门_win10安装scrapy-CSDN博客 新建 Scrapy项目 scrapy startproject mySpider # 项目名为mySpider 进入到spiders目录 cd mySpider/mySpider/spiders 创建爬虫 scrapy genspider heima bbs.itheima.com # 爬虫名为heima ,爬…...

HarmonyOS NEXT~鸿蒙系统下的Cordova框架应用开发指南
HarmonyOS NEXT~鸿蒙系统下的Cordova框架应用开发指南 1. 简介 Apache Cordova是一个流行的开源移动应用开发框架,它允许开发者使用HTML5、CSS3和JavaScript构建跨平台移动应用。随着华为鸿蒙操作系统(HarmonyOS)的崛起,将Cordova应用适配到…...
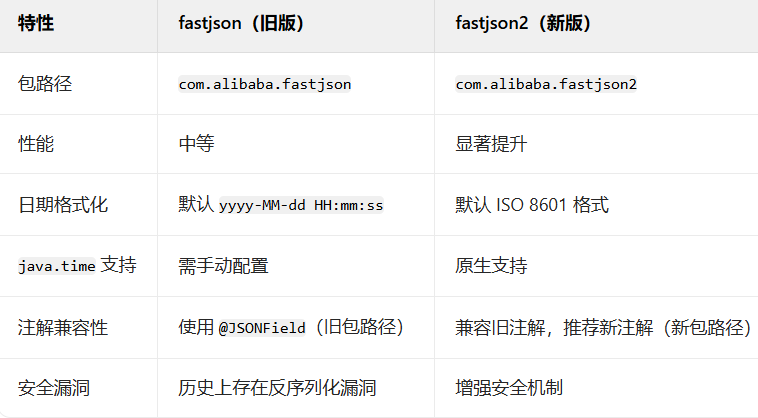
com.alibaba.fastjson2 和com.alibaba.fastjson 区别
1,背景 最近发生了一件很奇怪的事:我们的服务向第三方发送请求参数时,第三方接收到的字段是首字母大写的 AppDtoList,但我们需要的是小写的 appDtoList。这套代码是从其他项目A原封不动复制过来的,我们仔细核对了项目…...

探索数据结构的时间与空间复杂度:编程世界的效率密码
在计算机科学的世界里,数据结构是构建高效算法的基石。而理解数据结构的时间复杂度和空间复杂度,则是评估算法效率的关键。无论是优化现有代码,还是设计新的系统,复杂度分析都是程序员必须掌握的核心技能。本文将深入探讨这两个重…...

std::ranges::views::stride 和 std::ranges::stride_view
std::ranges::views::stride 是 C23 中引入的一个范围适配器,用于创建一个视图,该视图只包含原始范围中每隔 N 个元素的元素(即步长为 N 的元素)。 基本概念 std::ranges::stride_view 是一个范围适配器,接受一个输…...

了解Android studio 初学者零基础推荐(2)
在kotlin中编写条件语句 if条件语句 fun main() {val trafficLight "gray"if (trafficLight "red") {println("Stop!")} else if (trafficLight "green") {println("go!")} else if (trafficLight "yellow")…...

矩阵短剧系统:如何用1个后台管理100+小程序?技术解析与实战应用
引言:短剧行业的效率革命 2025年,短剧市场规模已突破千亿,但传统多平台运营模式面临重复开发成本高、用户数据分散、内容同步效率低等痛点。行业亟需一种既能降本增效又能聚合流量的解决方案——“矩阵短剧系统”。通过“1个后台管理100小程…...

C# 初学者的 3 种重构模式
(Martin Fowlers Example) 1. 积极使用 Guard Clause(保护语句) "如果条件不满足,立即返回。将核心逻辑放在最少缩进的地方。" 概念定义 Guard Clause(保护语句) 是一种在函数开头检查特定条件是否满足&a…...
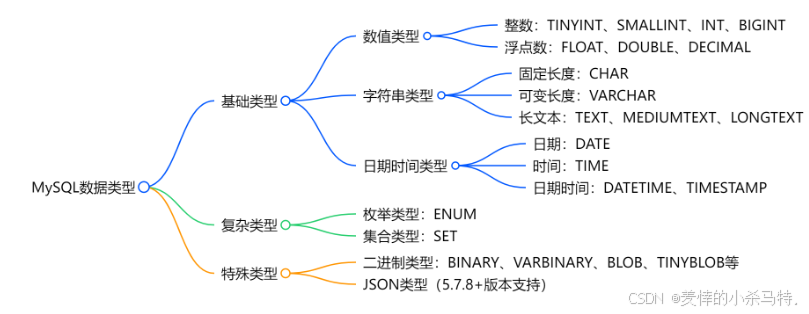
MySQL 数据类型深度全栈实战,天花板玩法层出不穷!
在 MySQL 数据库的世界里,数据类型是构建高效、可靠数据库的基石。选择合适的数据类型,不仅能节省存储空间,还能提升数据查询和处理的性能 目录 编辑 一、MySQL 数据类型总览 二、数值类型 三、字符串类型 四、日期时间类型 五、其他…...
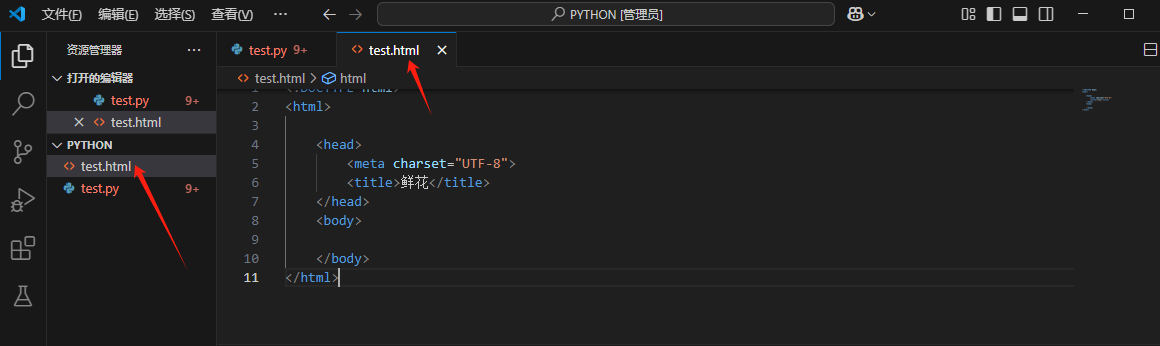
前端vscode学习
1.安装python 打开Python官网:Welcome to Python.org 一定要点PATH,要不然要自己设 点击install now,就自动安装了 键盘winR 输入cmd 点击确定 输入python,回车 显示这样就是安装成功了 2.安装vscode 2.1下载软件 2.2安装中文 2.2.1当安…...

自动驾驶传感器数据处理:Python 如何让无人车更智能?
自动驾驶传感器数据处理:Python 如何让无人车更智能? 1. 引言:为什么自动驾驶离不开数据处理? 自动驾驶一直被誉为人工智能最具挑战性的应用之一,而其背后的核心技术正是 多传感器融合与数据处理。 一辆智能驾驶汽车,通常搭载: 激光雷达(LiDAR) —— 3D 环境感知,…...

从电商角度设计大模型的 Prompt
从电商角度设计大模型的 Prompt,有一个关键核心思路:围绕具体业务场景明确任务目标输出格式,帮助模型为运营、客服、营销、数据分析等工作提效。以下是电商场景下 Prompt 设计的完整指南,包含通用思路、模块范例、实战案例等内容。…...

利用 SQL Server 作业实现异步任务处理:一种简化系统架构的实践方案
在中小型企业系统架构中,很多业务场景需要引入异步任务处理机制,例如: 订单完成后异步生成报表; 用户操作后触发异步推送; 后台批量导入数据后异步校验; 跨系统的数据同步与转换。 传统做法是引入消息…...

平安健康2025年一季度深耕医养,科技赋能见成效
近日,平安健康医疗科技有限公司(股票简称“平安好医生”,1833.HK)公布截至2025年3月31日止三个月的业绩报告,展现出强劲的发展势头与潜力。 2025年一季度,中国经济回升向好,平安健康把握机遇&a…...

Index-AniSora技术升级开源:动漫视频生成强化学习
B站升级动画视频生成模型Index-AniSora技术并开源,支持番剧、国创、漫改动画、VTuber、动画PV、鬼畜动画等多种二次元风格视频镜头一键生成! 整个工作技术原理基于B站提出的 AniSora: Exploring the Frontiers of Animation Video Generation in the So…...

LLVM编译C++测试
安装命令 sudo apt install clang sudo apt-get install llvm 源码 hello.cpp #include <iostream> using namespace std; int main(){cout << "hello world" << endl;return 0; }编译 clang -emit-llvm -S hello.cpp -o hello.ll 执行后&#…...

ubuntu24.04+RTX5090D 显卡驱动安装
初步准备 Ubuntu默认内核太旧,用mainline工具安装新版: sudo add-apt-repository ppa:cappelikan/ppa sudo apt update && sudo apt full-upgrade sudo apt install -y mainline mainline list # 查看可用内核列表 mainline install 6.13 # 安装…...

MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
原文链接:tecdat.cn/?p42189 在工业数字化转型的浪潮中,设备剩余寿命(RUL)预测作为预测性维护的核心环节,正成为数据科学家破解设备运维效率难题的关键。本文改编自团队为某航空制造企业提供的智能运维咨询项目成果&a…...
鸿蒙应用开发:Navigation组件使用流程
一、编写navigation相关代码 1.在index.ets文件中写根视图容器 2.再写两个子页面文件 二、创建rote_map.json文件 三、在module.json5文件中配置路由导航 子页配置信息 4.跳转到其他页面 但是不支持返回到本页面的 用以下方式 以下是不能返回的情况 onClick(()>{this.pag…...

javaweb的拦截功能,自动跳转登录页面
我们开发系统时候,肯定希望用户登录后才能进入主页面去访问其他服务,但要是没有拦截功能的话,他就可以直接通过url访问或者post注入攻击了。 因此我们可以通过在后端添加拦截过滤功能把没登录的用户给拦截下来,让他去先登录&#…...

【Linux】系统在输入密码后进入系统闪退锁屏界面
问题描述 麒麟V10系统,输入密码并验证通过后进入桌面,1秒左右闪退回锁屏问题 问题排查 小白鸽之前遇到过类似问题,但是并未进入系统桌面内直接闪退到锁屏。 之前问题链接: https://blog.csdn.net/qq_51228157/article/details/140…...

当物联网“芯”闯入纳米世界:ESP32-S3驱动的原子力显微镜能走多远?
上次咱们把OV2640摄像头“盘”得明明白白,是不是感觉ESP32-S3这小东西潜力无限?今天,咱们玩个更刺激的,一个听起来就让人肾上腺素飙升的挑战——尝试用ESP32-S3这颗“智慧芯”,去捅一捅科学界的“马蜂窝”,…...

微信小程序webview与VUE-H5实时通讯,踩坑无数!亲测可实现
背景:微信小程序、vue3搭建开发的H5页面 在微信小程序开发中,会遇到嵌套H5页面,H5页面需要向微信小程序发消息触发微信小程序某个函数方法,微信开发文档上写的非常不清楚,导致踩了很多坑,该文章总结可直接使…...

Web请求与相应
目录 HTTP协议 一、协议基础特性 二、协议核心组成 三、完整通信流程(TCP/IP层) 1. 基础方法 2. 扩展方法 3. 安全性与幂等性 4. 应用场景示例 三、关键版本演进 四、典型工作流程 HTTP状态码 一、状态码分类体系 二、详细状态码表格&#…...

LeetCode222_完全二叉树的结点个数
LeetCode222_完全二叉树的结点个数 标签:#位运算 #树 #二分查找 #二叉树Ⅰ. 题目Ⅱ. 示例 0. 个人方法 标签:#位运算 #树 #二分查找 #二叉树 Ⅰ. 题目 给你一棵 完全二叉树 的根节点 root ,求出该树的节点个数。 完全二叉树 的定义如下&…...
STM32之温湿度传感器(DHT11)
KEIL软件实现printf格式化输出 一般在标准C库是提供了格式化输出和格式化输入等函数,用户想要使用该接口,则需要包含头文件 #include ,由于printf函数以及scanf函数是向标准输出以及标准输入中进行输出与输入,标准输出一般指的是…...

在微创手术中使用Kinova轻型机械臂进行多视图图像采集和3D重建
在微创手术中,Kinova轻型机械臂通过其灵活的运动控制和高精度的操作能力,支持多视图图像采集和3D重建。这种技术通过机械臂搭载的光学系统实现精准的多角度扫描,为医疗团队提供清晰且详细的解剖结构模型。其核心在于结合先进的传感器配置与重…...

2025版 JavaScript性能优化实战指南从入门到精通
JavaScript作为现代Web应用的核心技术,其性能直接影响用户体验。本文将深入探讨JavaScript性能优化的各个方面,提供可落地的实战策略。 一、代码层面的优化 1. 减少DOM操作 DOM操作是JavaScript中最昂贵的操作之一: // 不好的做法&#x…...

FluxCD入门操作文档
文章目录 FluxCD使用文档一、入门1.1 什么是FluxCD1.2 什么是GitOps1.3 什么是持续交付1.4 什么是**Source(源)**1.5 **什么是Reconciliation(协调)**1.6 什么是**Kustomization****与 kustomize 工具的区别**1.7 什么是**Bootstrap(引导)**1.8 安装Flux CLI1.9 配置flux…...