编译原理 期末速成
一、基本概念
1. 翻译程序 vs 编译程序
翻译程序的三种方式
- 编译:将高级语言编写的源程序翻译成等价的机器语言或汇编语言。(生成文件,等价)
- 解释:将高级语言编写的源程序翻译一句执行一句,不生成目标文件,直接执行源代码文件。(一句一句,不生成为文件)
- 汇编:用汇编语言编写的源程序翻译成与之等价的机器语言。
编译程序的五个阶段
-
词法分析:对源程序的字符串进行扫描和分解,识别出每个单词符号。
-
语法分析:根据语言的语法规则,把单词符号分解成各类语法单位。
-
语义分析与中间代码生成:对各种语法范畴进行静态语义检查,若正确则进行中间代码翻译。
-
代码优化:遵循程序的等价变换规则。
-
目标代码生成:将中间代码变换成特定机器上的低级语言代码。
问题:源代码中括号不匹配的错误一般在编译的哪个阶段(采用五阶段划分模型)被检查出来,简述这一阶段的名称和主要任务
- 名称:语法分析
- 主要任务:读取词法符号,进行语法分析,判断源程序是否符合程序语法,并生成抽象语法树或语法符号
2. 上下文无关文法
标准格式( V T , V N , S , ξ V_T, V_N, S, \xi VT,VN,S,ξ)
- V T V_T VT:非空有限集,每个元素都是终结符
- V N V_N VN:非空有限集,每个元素都是非终结符
- S S S:非终极符号,即 开始符号
- ξ \xi ξ:产生式集合(有限),每个产生式的形式是 p → α p \rightarrow \alpha p→α,其中 P ∈ V N P \in V_N P∈VN, α ∈ ( V T ∪ V N ) ∗ \alpha \in (V_T \cup V_N)^* α∈(VT∪VN)∗
如果 G 是一个文法,S 为开始符号,如果 S ⇒ α S \Rightarrow \alpha S⇒α,则称 α \alpha α 为一个 句型。仅含 终结符的句型是一个句子。文法 G 所产生的句子的全体是一个语言,记为 L(G)
3. 语法分析树
编译原理笔记9:语法分析树、语法树、二义性的消除
语法分析树是语言推导过程的图形化表示方法。这种表示方法反映了语言的实质以及语言的推导过程。
定义:对于 CFG G 的句型,分析树被定义为具有下述性质的一棵树:
-
根由开始符号所标记;
-
每个叶子由一个终结符、非终结符或 ε 标记;
-
每个内部节点都是非终结符;
-
若 A 是某节点的内部标记,且 X 1 、 X 2 … X n X_1、X_2…X_n X1、X2…Xn 是该节点从左到右的所有孩子的标记。则: A → X 1 X 2 … X n A→X_1X_2…X_n A→X1X2…Xn 是一个产生式。若 A→ε,则标记为 A 的节点可以仅有一个标记为 ε 的孩子。
以 E => -E => -(E) => -(E+E) => -(id+E) => -(id+id) 为例

分析树与语言和文法的关系
- 每一直接推导(每个产生式),对应一仅有父子关系的子树,即产生式左部非终结符“长出”右部的孩子;
- 分析树的叶子,从左到右构成 CFG G 的一个句型(T、N两掺的串)。若叶子仅由终结符标记(+ 、- 、* 之类的运算符号也算是终结符),则构成一个句子
短语:子树末端节点字符串相对于子树根,即 叶子
简单短语(直接短语):相当于简单子树
句柄:最左简单子树的末端节点组成字符串
- 注意:句柄这个概念有且仅会出现在 最右推导中
二义性:一个文法中存在某个句子,有两个不同的最左(最右)推导,则称这个文法是二义的
4. 语言分类🧠
| 类型 | 名称 | 限制条件 |
|---|---|---|
| 0型 | 短语结构文法 | 没有约束(只要左边至少有一个非终结符) |
| 1型 | 上下文有关文法 | 所有产生式形如 α → β,其中 |
| 2型 | 上下文无关文法 | 所有产生式形如 A → β,其中 A 是单个非终结符 |
| 3型 | 正规文法 | 所有产生式为 A → a 或 A → aB(右线性),或 A → Ba(左线性) |
0型文法(短语文法,上下文无关文法),每个产生式的左边 α ∈ ( V N ∪ V T ) ∗ α∈({V}^N∪{V}^T)^* α∈(VN∪VT)∗且至少含有一个非终结符号
- 定义:若文法 G [ Z ] = ( V N , V T , P , Z ) G[Z]=({V}^N,{V}^T ,P,Z) G[Z]=(VN,VT,P,Z)中的每个产生式规则的形式为: α → β α→β α→β,其中 α ∈ ( V N ∪ V T ) ∗ α∈({V}^N∪{V}^T)^* α∈(VN∪VT)∗且至少含有一个非终结符号,而 β ∈ ( V N ∪ V T ) ∗ β∈({V}^N∪{V}^T)^* β∈(VN∪VT)∗,则G[Z]为0型文法
- 特点:0型文法的能力相当于图灵机,识别能力最强
1型文法(上下文敏感文法)
-
定义:若文法 G [ Z ] = ( V N , V T , P , Z ) G[Z]=({V}^N,{V}^T,P,Z) G[Z]=(VN,VT,P,Z)中的每个产生式规则的形式为: α A β → α v β αAβ→αvβ αAβ→αvβ,其中 α , β ∈ ( V N ∪ V T ) α,β∈({V}^N∪{V}^T) α,β∈(VN∪VT), A ∈ V N A∈{V}^N A∈VN , v ∈ ( V N ∪ V T ) + v∈({V}^N∪{V}^T)^+ v∈(VN∪VT)+,则G[Z]为1型文法
-
例如
S → aAB AB → BA BA → a其中 AB → BA 这类规则长度不变,但左部是多个符号,所以是 上下文有关文法 (1型)
2型文法(上下文无关文法)
-
定义:若文法 G [ Z ] = ( V N , V T , P , Z ) G[Z]=({V}^N,{V}^T,P,Z) G[Z]=(VN,VT,P,Z)中的每个产生式规则的形式为: A → v A→v A→v,其中 A ∈ V N A∈{V}^N A∈VN, v ∈ ( V N ∪ V T ) ∗ v∈( {V}^N ∪ {V}^T )^* v∈(VN∪VT)∗,则G[Z]为2型文法
-
特点:语法结构上下文无关,一般用于识别程序设计语言的语法结构
-
例如
S → aSb | ε这是一个 上下文无关文法 (2型),因为它每个产生式的左部都是一个单独的非终结符
3型语言(正规文法)
-
种类:右线性文法、左线性文法
正则文法 左(右)线性文法 -
右线性文法:若文法 G [ Z ] = ( V N , V T , P , Z ) G[Z]=({V}^N, {V}^T,P,Z) G[Z]=(VN,VT,P,Z) 中的每个产生式规则的形式为: A → α B A→αB A→αB 或 A → α A→α A→α,其中 A , B ∈ V N , α ∈ ( V N ∪ V T ) A,B∈ {V}^N,α∈({V}^N∪{V}^T) A,B∈VN,α∈(VN∪VT),则 G[Z] 为右线性文法。(非终结部分永远在右部)
-
左线性文法:若文法 G [ Z ] = ( V N , V T , P , Z ) G[Z]=({V}^N, {V}^T,P,Z) G[Z]=(VN,VT,P,Z) 中的每个产生式规则的形式为: A → B α A→Bα A→Bα或 A → α A→α A→α,其中 A , B ∈ V N , α ∈ ( V N ∪ V T ) A,B∈ {V}^N,α∈({V}^N∪{V}^T) A,B∈VN,α∈(VN∪VT),则G[Z]为左线性文法。(非终结部分永远在左部)
-
特点:作为定义程序设计语言规则的文法
-
正规语言:3型文法定义的语言
-
例如
A → a A → aB B → b这类产生式符合右线性正规文法,属于 3型文法
📌 总结步骤:
- 检查是否每个产生式左边是一个非终结符 → 是:2型或以下
- 再检查右边是否只能是“一个终结符”或“一个终结符+一个非终结符”,并且方向一致(左线性或右线性)→ 是:3型
- 如果某些产生式左边是多个符号,则可能是1型
- 否则是0型
当我们判断一个文法属于哪一型时,我们要找它能归入的最严格类型 (也就是编号最大的那个类型)
🧠 乔姆斯基文法的层级关系(包含关系)
| 类型 | 名称 | 包含关系 |
|---|---|---|
| 0型 | 短语结构文法 | 最广泛,包含所有其他类型 |
| 1型 | 上下文有关文法 | 包含 2型和 3型 |
| 2型 | 上下文无关文法 | 包含 3型 |
| 3型 | 正规文法 | 最严格,是最小的集合 |
例题: 已知文法 G(S) 的产生式集为: S->bA,A-> aA|a,请判断这个文法属于乔姆斯基几型文法
第一步:检查是否符合 2型文法(上下文无关文法,CFG)
2型文法的定义:
- 所有产生式的左边必须是一个单独的非终结符 。
观察该文法:
S → bA:左边是 S(一个非终结符)A → aA | a:左边是 A(一个非终结符)
✔️ 全部产生式的左边都是单个非终结符 ,所以这是一个上下文无关文法(CFG) ,即2型文法
第二步:是否属于更严格的 3型文法(正规文法,Regular Grammar)
3型文法要求:
- 所有产生式必须是以下形式之一:
- 右线性:A → a 或 A → aB(一个非终结符变成一个终结符后跟一个非终结符)
- 左线性:A → Ba 或 A → a
看看当前文法:
S → bA✔️ 符合右线性A → aA✔️ 符合右线性A → a✔️ 是终结符,也符合右线性
✔️ 所有产生式都满足右线性正规文法的要求
➡️ 所以这个文法不仅是 2型文法,而且还是 3型文法(正规文法),因此最终结论:该文法属于乔姆斯基的第 3 型文法(正规文法)
5. LL(1) 分析方法
First集(最左边可能出现的终结符):设G[Z]=(VN,VT,P,Z),α∈(VN∪VT),符号串α的首符号集合的定义为:
- F i r s t ( α ) = a ∣ α ⇒ a … 且 a ∈ V T 若 α ⇒ ∗ ε First(α)={a|α ⇒ a…且a∈V_T}若α ⇒* ε First(α)=a∣α⇒a…且a∈VT若α⇒∗ε,则规定 ε ∈ F i r s t ( α ) ε∈First(α) ε∈First(α)
Follow集:设G[Z]=(VN,VT,P,Z),A∈VN,非终结符号A的后继符号集合的定义为:
- F o l l o w ( A ) = a ∣ Z ⇒ ∗ … A a … 且 a ∈ V T ,若 Z ⇒ ∗ … A Follow(A)={a|Z ⇒* …A_a…且a∈V_T},若Z ⇒* …A Follow(A)=a∣Z⇒∗…Aa…且a∈VT,若Z⇒∗…A,则规定#∈First(A)。#为结束符
回溯的判断:对一个上下文无关文法 G [ Z ] = ( V N , V T , P , Z ) G[Z]=(V_N,V_T,P,Z) G[Z]=(VN,VT,P,Z),对某个产生式规则 A → α 1 ∣ α 2 ∣ … α n A→α_1|α_2|…α_n A→α1∣α2∣…αn,若存在 a ∈ V T a∈V_T a∈VT,使得 a ∈ F i r s t ( α i ) ∩ F i r s t ( α j ) ( 1 ≤ i , j ≤ n 且 i ≠ j ) a∈First(α_i)∩First(α_j)(1≤i,j≤n且i≠j) a∈First(αi)∩First(αj)(1≤i,j≤n且i=j)或 a ∈ F i r s t ( α i ) ∩ F o l l o w ( A ) ( 1 ≤ i ≤ n , A ⇒ ∗ ε ) a∈First(αi)∩Follow(A)(1≤i≤n,A ⇒* ε) a∈First(αi)∩Follow(A)(1≤i≤n,A⇒∗ε) 或 $αi ⇒* ε $且 α j ⇒ ∗ ε ( 1 ≤ i , j ≤ n 且 i ≠ j ) α_j ⇒* ε(1≤i,j≤n且i≠j) αj⇒∗ε(1≤i,j≤n且i=j),则对应于文法G的自顶向下分析需要回溯。
LL(1)文法定义(也是 LL(1) 文法的判断条件)
- 文法不含左递(如果有左递归,必须消除后再继续判断是否为 LL(1))
- 每个非终结符的各个候选式的 FIRST 集互不相交:对某个非终结符A,若其对应的产生式规则为 A → α 1 ∣ α 2 ∣ … α n A→α_1|α_2|…α_n A→α1∣α2∣…αn,则 F i r s t ( α i ) ∩ F i r s t ( α j ) = Ø ( 1 ≤ i , j ≤ n 且 i ≠ j ) First(α_i)∩First(α_j)=Ø(1≤i,j≤n且i≠j) First(αi)∩First(αj)=Ø(1≤i,j≤n且i=j)
- 如果有某个候选式能推出 ε(空串):即 A → α 和 A → β,其中 β ⇒* ε(即 ε ∈ FIRST(β)) 则 F i r s t ( α ) ∩ F o l l o w ( A ) = Ø 则First(α)∩Follow(A)=Ø 则First(α)∩Follow(A)=Ø
6. 左递归
含有A→Aa形式产生式的文法称为是直接左递归的 (immediate left recursive)
- 直接左递归:如果一个文法中有一个非终结符A使得对某个串a存在一个推导 A ⇒ + A a A\Rightarrow ^+Aa A⇒+Aa,那么这个文法就是直接左递归的
- 间接左递归:经过两步或两步以上推导产生的左递归称为是间接左递归的
左递归缺点:容易产生死循环
消除直接左递归规则
- 若某个文法中非终结符A的产生式规则是 直接左递归规则:A→Aα|β,其中 α , β ∈ ( V N ∪ V T ) ∗ α,β∈(V_N∪V_T)* α,β∈(VN∪VT)∗。其中 β β β 不以A打头,
- 则将A的产生式规则改写为: A → β A ’, A ’ → α A ’ ∣ ε A→βA’,A’→αA’|ε A→βA’,A’→αA’∣ε。 A ’ A’ A’ 是新增加的非中介符号

消除间接左递归:
例 S → A a ∣ b , A → A c ∣ S d ∣ ε S→Aa |b,A→Ac| Sd | \varepsilon S→Aa∣b,A→Ac∣Sd∣ε
将S的定义代入A-产生式,得: A → A c ∣ A a d ∣ b d ∣ ε A→Ac|Aad|bd |\varepsilon A→Ac∣Aad∣bd∣ε
消除A-产生式的直接左递归,得:
A → > b d A ’ ∣ A A ’ → > c A ’ ∣ a d A ’ ∣ ε A→>bdA’|A \\ A’→> cA’| a d A’|\varepsilon A→>bdA’∣AA’→>cA’∣adA’∣ε
二、习题练习
1. 文法化简
- 若一个非终结符不能推导出终结字符串,则该非终结符是无用的,删除所有包括该非终结符的产生式规则
- 若一个符号不能出现在文法的任何句型中,则该符号是无用的,删除所有包括该符号的产生式规则
题目: S → a A B S , S → b c A c d , A → b A B , A → c S A , A → c C C , B → b A B , B → c S B S\rightarrow aABS,S\rightarrow bcAcd,A\rightarrow bAB,A\rightarrow cSA,A\rightarrow cCC,B\rightarrow bAB,B\rightarrow cSB S→aABS,S→bcAcd,A→bAB,A→cSA,A→cCC,B→bAB,B→cSB
解:
(1)从 S 开始,将含有非终结符不能推导出终结字符串消除,比如 C,因此删除 S → a A B S , A → b A B , A → c C C , B → b A B , B → c S B S\rightarrow aABS,A\rightarrow bAB,A\rightarrow cCC,B\rightarrow bAB,B\rightarrow cSB S→aABS,A→bAB,A→cCC,B→bAB,B→cSB
(2)最后结果为: S → b c A c d , A → b A B , A → c S A , A → c C C S\rightarrow bcAcd,A\rightarrow bAB,A\rightarrow cSA,A\rightarrow cCC S→bcAcd,A→bAB,A→cSA,A→cCC
2. NFA、DFA 确定化、最小化
正归式转 NFA 规则如下:
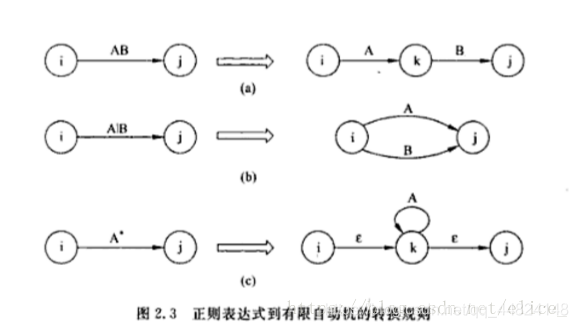
比如当前正则表达式为 ( a b ) ∗ ( a ∗ ∣ b ∗ ) ( b a ) ∗ (ab)^*(a^*|b^*)(ba)^* (ab)∗(a∗∣b∗)(ba)∗,求其等价的 DFA
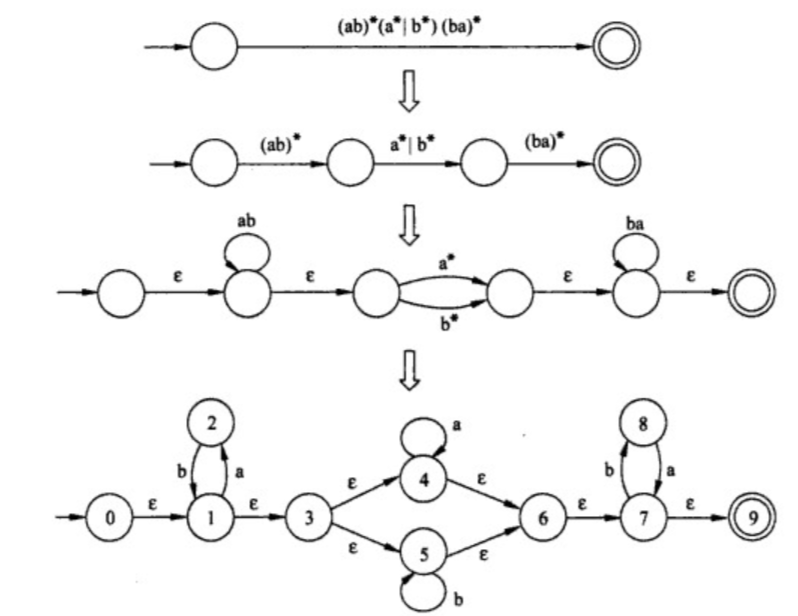
NFA 确定化
要求确定化之前,需要判断是否有从该点出发的某个路径可以到达两个不同终点
题目如下:0 是终结 符号,求其 确定化,和 最小化的结果
graph LR;0 --> |a|0(((0)))0 ---> |a, b| 1((1));1 --> |a| 0;
- 注意:如果路径上有 ε,那么相当于无需任何条件可直接到达
由于 0 的 a 路径有两条,因此其并不是确定化,确定化状态转换矩阵如下:
| I | I a I_a Ia | I b I_b Ib |
|---|---|---|
| {0} | {0, 1} | {1} |
| {0, 1} | {0, 1} | {1} |
| {1} | {0} | Φ \Phi Φ |
| Φ \Phi Φ | Φ \Phi Φ | Φ \Phi Φ |
- 注意:一般计算的时候也可以不考虑 Φ \Phi Φ
先入 0 这个点到队列中,然后再把其通过 a, b 路径得到的值 依次入队列,然后按照 先进先出 的顺序取出,然后对 状态重新编号,如下:
| I | I a I_a Ia | I b I_b Ib |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 1 | 2 |
| 2 | 0 | 3 |
| 3 | 3 | 3 |
因此其 DFA 状态图为
graph LR;0(((0))) ---> |a|1((1))0 ---> |b|2((2))1--->|a|11--->|b|22--->|b|3((3))2--->|a|03--->|a, b|3
其最小化求解如下:
包含最初的终结节点 0 的都属于 终态组,其他的就属于非终态组,比如:上面 DFA 确定化中 终态组{0, 1},非终态组 {2,3}
由于 {0, 1} => {1}(a 路径下),{0,1} => {2}(b 路径下)
- 保证得到的状态集是属于当前集合的子集,就不用再分
因此终态组无需再分
然后再来看非终态组
由于 {2, 3} => {0,3}(a 路径下),{2,3} => {3}(b 路径下),前者不是当前集合子集,所以需要划分为 {2} {3},故最小化的结果为 {0, 1},{2},{3}
然后再重新编号 ,最小化图为
graph LR;0 ---> |a|0(((0)))0--->|b|1((1))1--->|a|01--->|b|2((2))2--->|a, b|2
3. 根据右线性文法求左线性文法
给定右线性文法 G: S → 0 S ∣ 1 S ∣ 1 A ∣ 0 B , A → 1 C ∣ 1 , B → 0 C ∣ 0 , C → 0 C ∣ 1 C ∣ 0 ∣ 1 S\rightarrow 0S|1S|1A|0B,A\rightarrow 1C|1,B\rightarrow 0C|0,C\rightarrow 0C|1C|0|1 S→0S∣1S∣1A∣0B,A→1C∣1,B→0C∣0,C→0C∣1C∣0∣1
画图得其 NFA 如下:
graph LR;0((S)) ---> |0,1|0(((0)))0 ---> |1|1((A)) 0 ---> |0|2((B))1 ---> |1|3((C)) 1 ---> |1|4((F))2 ---> |0|32 ---> |0|43 ---> |0,1|33 ---> |0, 1|4
- 这里,S是起始状态,但是不是单纯的起点,它接收0或者1能够到达S状态。F是终止状态,是单纯的终点。
根据图,可以写出对应的左线性文法:
-
F->A1|B0|C0|C1
-
C->A1|B0|C0|C1
-
B->S0(B是初始状态S接收0得到的,但是初始状态S并不是单纯的起点,它是状态S接收0/1得到的,所以需要写出来,如果写成B->0,是不对的,表达的不是一个意思,初始状态和终止状态写出来还是不写出来是严格确定的,如果写错,代表的是不同的自动机)
-
A->S1
-
S->S0|S1
4. 计算文法G的 FIRST 和 FOLLOW 集
文法 G 如下:
E → E + T ∣ T T → T ∗ F ∣ F F → ( E ) ∣ i E \rightarrow E + T | T\\ T \rightarrow T * F | F\\ F \rightarrow (E) | i E→E+T∣TT→T∗F∣FF→(E)∣i
消除直接左递归结果如下:
E → T E ′ E ’ → + T E ’ ∣ ε T → F T ′ T ′ → ∗ F T ′ ∣ ε F → ( E ) ∣ i E \rightarrow TE'\\ E’ \rightarrow +TE’ |ε\\ T \rightarrow FT'\\ T' \rightarrow *FT'|ε\\ F \rightarrow (E) | i E→TE′E’→+TE’∣εT→FT′T′→∗FT′∣εF→(E)∣i
如何求First集与Follow集(超详细) – 具体步骤在这
思路:
求 FIRST 集合:
- 单个终结符 a
- 如果 X = a(a 是终结符),那么:FIRST(a)={a}
- 空串 ε
- 如果 X = ε,那么:FIRST(ε)={ε}
- 单个非终结符 A
- 对于每个非终结符 A,我们要看它所有的产生式右边的内容。
- 对于每一个 A → α 的产生式:
- 把 FIRST(α) 中的元素加入到 FIRST(A) 中
FOLLOW 集合的构造规则
-
初始化:
- 如果 S 是文法的开始符号,则
# ∈ FOLLOW(S),其中#表示输入结束符。
- 如果 S 是文法的开始符号,则
-
基本规则:
-
对于每一个产生式: A → α B β A→αBβ A→αBβ
其中:
- A、B 是非终结符
- α、β 是任意符号串(可以为空)
则将 FIRST(β) 中除去 ε 的所有符号 加入到 FOLLOW(B) 中。
-
-
**ε 规则:**如果有产生式: A → α B A→αB A→αB或 A → α B β A→αBβ A→αBβ且 ε∈FIRST(β) 则将 FOLLOW(A) 中的所有符号加入到 FOLLOW(B) 中
-
**重复直到稳定:**因为 FOLLOW 集之间可能存在依赖关系,所以要反复应用上述规则,直到所有 FOLLOW 集不再变化为止
| 非终结符 | FIRST | FOLLOW |
|---|---|---|
| E E E | (,i | ),# |
| E ′ E' E′ | +,ε | ),# |
| T T T | (,i | ),+,# |
| T ′ T' T′ | *,ε | ),+,# |
| F F F | (,i | *,),+,# |

相关文章:
编译原理 期末速成
一、基本概念 1. 翻译程序 vs 编译程序 翻译程序的三种方式 编译:将高级语言编写的源程序翻译成等价的机器语言或汇编语言。(生成文件,等价)解释:将高级语言编写的源程序翻译一句执行一句,不生成目标文件…...

echarts之漏斗图
vue3echarts实现漏斗图 echarts中文官网:https://echarts.apache.org/examples/zh/index.html 效果图如下: 整体代码如下: <template><div id"funnelChart" style"width:100%;height:400px;"></div&g…...
零基础设计模式——第二部分:创建型模式 - 原型模式
第二部分:创建型模式 - 5. 原型模式 (Prototype Pattern) 我们已经探讨了单例、工厂方法、抽象工厂和生成器模式。现在,我们来看创建型模式的最后一个主要成员——原型模式。这种模式关注的是通过复制现有对象来创建新对象,而不是通过传统的…...

Honeywell TK-PRS021 C200
Honeywell C200/C200E 是一款高性能的集成控制与安全系统(ICSS),采用紧凑型 A 系列机箱 设计,适用于工业自动化、过程控制和批处理管理。C200 控制器最初随 PlantScape R200 发布,而 C200E 则与 Experion PKS R400 兼容…...
java 进阶 1.0.3
Thread API说明 自己滚去看文档 CPU线程调度 每一个线程的优先使用权都是系统随机分配的,人人平等 谁先分配到就谁先用 也可以耍赖,就是赋予某一个线程拥有之高使用权:优先级 这样的操作就叫做线程调度 最基本的是系统轮流获得 java的做法是抢…...

从 Docker 到 runC
从 Docker 到 runC:容器底层原理详解 目录 1. Docker 与 runC 的关系 2. Docker 的核心组件 3. runC 的核心功能 4. 实战示例:从 Docker 到 runC 4.1 示例场景:运行一个简单容器 4.2 Docker 底层调用 runC 的流程 4.3 查看 runC 的调用 4.4 直接调用 runC 创建容器 …...

PET,Prompt Tuning,P Tuning,Lora,Qlora 大模型微调的简介
概览 到2025年,虽然PET(Pattern-Exploiting Training)和Prompt Tuning在学术界仍有探讨,但在工业和生产环境中它们已基本被LoRA/QLoRA等参数高效微调(PEFT)方法取代 。LoRA因其实现简单、推理零开销&#…...
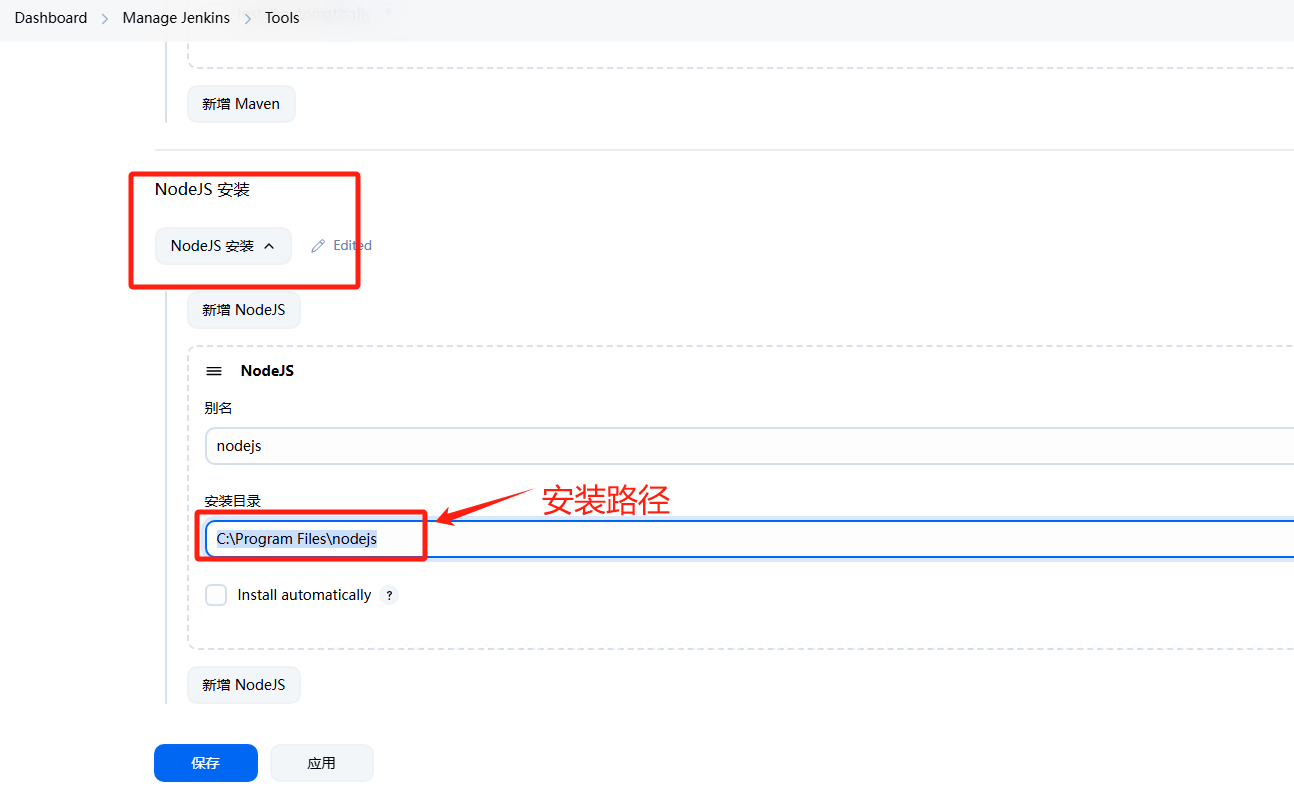
02-jenkins学习之旅-基础配置
0 配置主路径 jenkins安装目录下找到jenkins.xml文件,C:\ProgramData\Jenkins\.jenkins目录下会存放jenkins相关的配置信息。 1 jdk配置 jenkins是java开发开源的项目,进而服务器需要jdk环境 1.1 服务器安装jdk 1.2 jenkins jdk配置 2 git配置 在je…...

互联网大厂Java求职面试:云原生架构与AI应用集成解决方案
互联网大厂Java求职面试:云原生架构与AI应用集成解决方案 场景一:短视频与直播平台的高并发架构设计 面试官提问 面试官(技术总监): 郑薪苦,你有处理过千万级用户同时在线的直播系统吗?如何设…...

Python爬虫实战:研究Crawley 框架相关技术
1. Crawley 框架相关定义 1.1 网络爬虫定义 网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。它通过 HTTP 协议与 Web 服务器进行交互,获取网页内容并进行解析处理,是数据采集和信息检索的重要工具。 1.2 Crawley 框架定义 Crawley 是一个基于 Pytho…...

C#实现List导出CSV:深入解析完整方案
C#实现List导出CSV:深入解析完整方案 在数据交互场景中,CSV文件凭借其跨平台兼容性和简洁性,成为数据交换的重要载体。本文将基于C#反射机制实现的通用CSV导出方案,结合实际开发中的痛点,从基础实现、深度优化到生产级…...
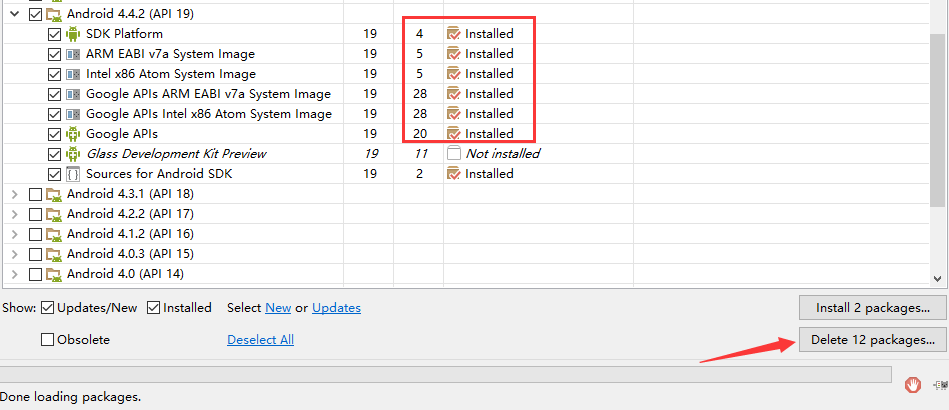
Appium+python自动化(三)- SDK Manager
简介 一开始打算用真机做的,所以在前边搭建环境时候就没有下载SDK,但是考虑到绝大多数人都没有真机,所以顺应民意整理一下模拟器。SDK顾名思义,Android SDK Manager就是一个Android软件开发工具包管理器,就像一个桥梁&…...

3D Gaussian Splatting for Real-Time Radiance Field Rendering——文章方法精解
SfM → Point-NeRF → 3D Gaussian Splatting 🟦SfM Structure-from-Motion(运动恢复结构,简称 SfM)是一种计算机视觉技术,可以: 利用多张从不同角度拍摄的图像,恢复出场景的三维结构和相机的…...

主成分分析基本概念及python代码使用
目录 1. 前言 2. 主成分分析的基本概念 3. PCA的适应场景 4. PCA算法的理论基础 4.1 标准化数据 4.2 计算协方差矩阵 4.3 求解特征值和特征向量 4.4 选择主成分 4.5 投影到新坐标系 5. 完整的PCA示例 5.1 使用手写数字数据集 5.2 可视化降维后的数据 6. PCA的优缺…...

MCP如何助力智能交通系统?从数据融合到精准决策
MCP如何助力智能交通系统?从数据融合到精准决策 近年来,智能交通系统(ITS)正在全球范围内快速发展,它结合人工智能(AI)、物联网(IoT)和数据分析,致力于提高交通效率、减少拥堵、增强安全性。而MCP(Multi-Constraint Pathfinding,多约束路径寻优)技术作为一种复杂…...

什么是抽象类?是所有函数都是纯虚函数吗?
什么是抽象类? 抽象类(Abstract Class)是一种特殊的类,它不能被直接实例化,但可以作为基类被其他类继承。抽象类的主要用途是定义一组接口规范,这些规范由派生类实现。 在C中,抽象类是通过包含…...

计算机视觉与深度学习 | Python实现ARIMA-WOA-CNN-LSTM时间序列预测(完整源码和数据
以下是一个结合ARIMA、鲸鱼优化算法(WOA)、CNN和LSTM进行时间序列预测的Python实现框架。由于完整代码和数据量较大,此处提供核心代码结构和示例数据集,您可根据需求扩展。 1. 数据准备(示例数据) 使用airline-passengers.csv(航空乘客数据集): import pandas as pd…...

【Unity实战笔记】第二十四 · 使用 SMB+Animator 实现基础战斗系统
转载请注明出处:🔗https://blog.csdn.net/weixin_44013533/article/details/146409453 作者:CSDN|Ringleader| 1 结构 1.1 状态机 1.2 SMB 2 代码实现 2.1 核心控制 Player_Base_SMB 继承 StateMachineBehaviour ,控制变量初始…...

C/C++的OpenCV 进行图像梯度提取
使用 C/OpenCV 进行图像梯度提取 图像梯度表示图像中像素强度的变化率和方向。它是图像分析中的一个基本概念,广泛应用于边缘检测、特征提取和物体识别等任务。OpenCV 提供了多种计算图像梯度的函数。本文将介绍几种常用的梯度算子及其在 C/OpenCV 中的实现。 预备…...

Redis 缓存使用的BigKey问题
一、什么是 BigKey? BigKey 指在 Redis 中存储的 单个 Key 对应的 Value 过大,通常表现为: String 类型:Value 长度 > 10KB。Hash/List/Set/ZSet:元素数量 > 5,000 或总大小 > 10MB。 二、BigKey 的危害 问…...

【Java高阶面经:消息队列篇】22、消息队列核心应用:高并发场景下的解耦、异步与削峰
一、消息队列:分布式系统的核心枢纽 在分布式架构日益普及的今天,消息队列(Message Queue, MQ)已成为解决系统复杂性的核心组件。它通过异步通信、系统解耦和流量控制等能力,有效应对高并发场景下的数据流动挑战。 1.1 核心特性:异步、解耦与弹性 1.1.1 异步通信:释放…...
软媒魔方——一款集合多种系统辅助组件的软件
停更4年,但依旧吊炸天! 亲们,是不是觉得电脑用久了就像老牛拉车,慢得让人着急?别急,我今天要给大家安利一个超好用的电脑优化神器——软媒魔方! 软件介绍 首先,这货真心是免费的&a…...

Unity场景的加载与卸载
Unity场景的加载与卸载 使用方法:把SceneLoader 脚本代码挂在场景中 使用示例: SceneLoader.Instance.LoadAdditiveScene(8);//通过场景索引加载SceneLoader.Instance.UnloadScene("ShiWaiScene");//通过场景名字卸载脚本代码如下࿱…...
多路径可靠传输协议(比如 MPTCP)为什么低效
可靠就不能多路径,多路径求可靠必然要多费劲。这不难理解,多路径必异步,这无疑增加了可靠性判断的难度。 前文 多路径传输(比如 MPTCP)对性能的意义 阐述了作为单连接的多子流 MPTCP 对传输性能的意义是无意义,本文接着阐述作为隧…...

塔能高温冰蓄冷技术:工厂能耗精准节能的创新之路
在工厂的能耗构成中,制冷系统是重要的耗能环节。传统的水蓄冷和冰蓄冷技术在实际应用中存在一些局限性,难以满足工厂对节能和成本控制的更高要求。塔能科技的高温冰蓄冷技术,凭借其独特的优势,为工厂能耗精准节能提供了创新的解决…...

内存优化笔记1
欢迎关注更多精彩 关注我,学习常用算法与数据结构,一题多解,降维打击。 问题提出 在很多工业软件中,需要对对象进行微分细化,这样会产生很多(几百万到几千万)对象。随着业务的发展,…...
人脸识别,使用 deepface + api + flask, 改写 + 调试
1. 起因, 目的, 感受: github deepface 这个项目写的很好, 继续研究使用这个项目,改写 api。增加一个前端 flask app 2. 先看效果 3. 过程: 大力改写原始项目中 api 这部分的代码, 原始项目的文件结构太繁杂了: 我把…...
代码管理平台Gitlab如何通过快解析实现远程访问?
一、Gitlab功能介绍 Gitlab是被广泛使用的基于git的开源代码管理平台,用于管理、存储开发人员代码,同时可以协同开发 二、外网试用Gitlab遇到的问题 运维人员将Gitlab服务器部署在总部机房,而分公司开发人员和出差运维人员就无法访问Gitlab…...
基于SpringBoot+Vue的足球青训俱乐部管理后台系统的设计与开发
项目背景与概述 随着足球青训行业的快速发展,如何高效、规范地管理学员、教练以及课程等日常工作,成为了青训俱乐部运营的重要课题。为了提升俱乐部的管理效率与用户体验,基于 Spring Boot 和 Vue.js 开发了一个 足球青训俱乐部管理后台系统…...

Redis 是否适合像 MySQL 一样当数据库使用?
Redis 可以在特定场景下作为数据库使用,但与 MySQL 等关系型数据库还是有很大的差异。Redis 确实有持久化功能,开启 AOF 并把 appendfsync 设置为 always 后,它会把每一次数据操作都立刻记录到文件里,相当于每发生一件事就马上记下…...