第J2周:ResNet50V2 算法实战与解析
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
学习目标
✅ 根据TensorFlow代码,编写出相应的Python代码
✅ 了解ResNetV2和ResNet模型的区别
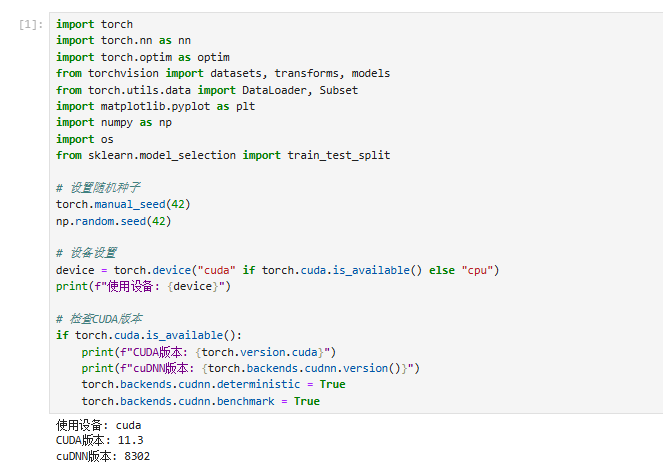
一、环境配置
二、数据预处理

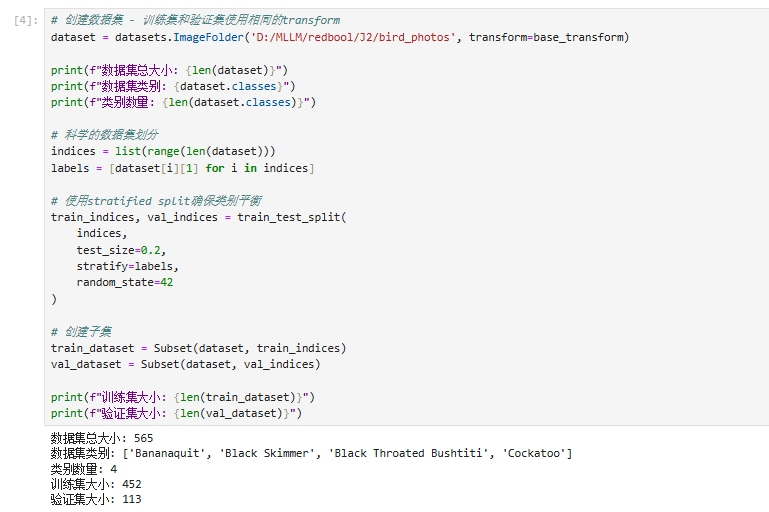
三、创建、划分数据集
四、 创建数据加载器
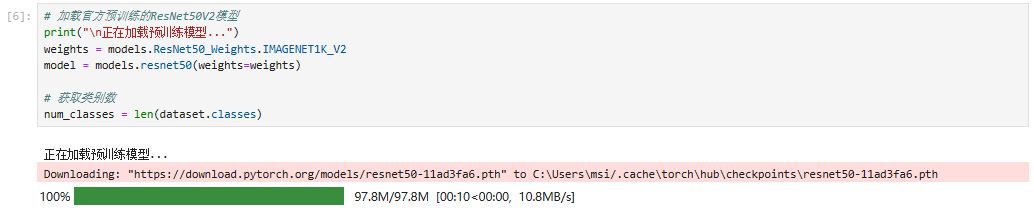
五、加载预训练

六、显示训练数据
# 显示一些训练图像示例
def show_images(loader, title="数据示例"):plt.figure(figsize=(12, 8))plt.suptitle(title, fontsize=16)try:for batch_idx, (images, labels) in enumerate(loader):images = images[:12]labels = labels[:12]breakfor i in range(min(12, len(images))):ax = plt.subplot(3, 4, i + 1)img = images[i].cpu().numpy().transpose((1, 2, 0))# 反标准化mean = np.array([0.485, 0.456, 0.406])std = np.array([0.229, 0.224, 0.225])img = std * img + meanimg = np.clip(img, 0, 1)ax.imshow(img)ax.set_title(f"{dataset.classes[labels[i]]}", fontsize=10)ax.axis("off")plt.tight_layout()plt.show()except Exception as e:print(f"无法显示图像示例: {e}")plt.close()# 显示训练数据示例
print("\n显示训练数据示例...")
show_images(train_loader, "训练数据示例(无数据增强)")

七、编写训练函数、测试函数、设置早停机制
# 训练函数
def train_epoch(model, device, train_loader, optimizer, criterion):model.train()running_loss = 0.0running_corrects = 0total = 0for batch_idx, (inputs, labels) in enumerate(train_loader):try:inputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()_, preds = torch.max(outputs, 1)running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)total += labels.size(0)if batch_idx % 10 == 0:print(f'Batch: {batch_idx}/{len(train_loader)}, Loss: {loss.item():.4f}')# 清理GPU内存del inputs, labels, outputs, lossif torch.cuda.is_available():torch.cuda.empty_cache()except Exception as e:print(f"训练批次 {batch_idx} 出现错误: {e}")if torch.cuda.is_available():torch.cuda.empty_cache()continueepoch_loss = running_loss / total if total > 0 else float('inf')epoch_acc = running_corrects.double() / total if total > 0 else 0return epoch_loss, epoch_acc# 验证函数
def validate(model, device, val_loader, criterion):model.eval()running_loss = 0.0running_corrects = 0total = 0with torch.no_grad():for inputs, labels in val_loader:try:inputs, labels = inputs.to(device), labels.to(device)outputs = model(inputs)loss = criterion(outputs, labels)_, preds = torch.max(outputs, 1)running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)total += labels.size(0)# 清理内存del inputs, labels, outputs, lossif torch.cuda.is_available():torch.cuda.empty_cache()except Exception as e:print(f"验证过程中出现错误: {e}")if torch.cuda.is_available():torch.cuda.empty_cache()continueepoch_loss = running_loss / total if total > 0 else float('inf')epoch_acc = running_corrects.double() / total if total > 0 else 0return epoch_loss, epoch_acc
# 早停机制
class EarlyStopping:def __init__(self, patience=7, verbose=False, delta=0.001, path='best_resnet50v2.pth'):self.patience = patienceself.verbose = verboseself.counter = 0self.best_score = Noneself.early_stop = Falseself.val_loss_min = np.Infself.delta = deltaself.path = pathdef __call__(self, val_loss, model):score = -val_lossif self.best_score is None:self.best_score = scoreself.save_checkpoint(val_loss, model)elif score < self.best_score + self.delta:self.counter += 1if self.verbose:print(f'EarlyStopping counter: {self.counter} out of {self.patience}')if self.counter >= self.patience:self.early_stop = Trueelse:self.best_score = scoreself.save_checkpoint(val_loss, model)self.counter = 0def save_checkpoint(self, val_loss, model):if self.verbose:print(f'Validation loss decreased ({self.val_loss_min:.6f} --> {val_loss:.6f}). Saving model ...')torch.save(model.state_dict(), self.path)self.val_loss_min = val_loss
八、开始训练
# 开始训练
print("\n开始训练...")
num_epochs = 25
early_stopping = EarlyStopping(patience=5, verbose=True)train_losses = []
train_accs = []
val_losses = []
val_accs = []
lr_history = []for epoch in range(num_epochs):print(f'\nEpoch {epoch+1}/{num_epochs}')print('-' * 10)try:# 记录当前学习率current_lr = optimizer.param_groups[0]['lr']lr_history.append(current_lr)# 训练阶段train_loss, train_acc = train_epoch(model, device, train_loader, optimizer, criterion)train_losses.append(train_loss)train_accs.append(train_acc.item())# 验证阶段val_loss, val_acc = validate(model, device, val_loader, criterion)val_losses.append(val_loss)val_accs.append(val_acc.item())# 更新学习率scheduler.step()# 打印结果print(f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc*100:.2f}%')print(f'Val Loss: {val_loss:.4f}, Val Acc: {val_acc*100:.2f}%')print(f'Learning Rate: {current_lr:.6f}')# 早停检查early_stopping(val_loss, model)if early_stopping.early_stop:print("Early stopping")breakexcept Exception as e:print(f"Epoch {epoch+1} 出现错误: {e}")print("尝试清理内存并继续...")if torch.cuda.is_available():torch.cuda.empty_cache()continueprint("\n训练完成!")
开始训练...Epoch 1/25
----------
Batch: 0/28, Loss: 1.3802
Batch: 10/28, Loss: 1.0213
Batch: 20/28, Loss: 0.4903
Train Loss: 0.8478, Train Acc: 85.49%
Val Loss: 0.1881, Val Acc: 99.12%
Learning Rate: 0.000100
Validation loss decreased (inf --> 0.188087). Saving model ...Epoch 2/25
----------
Batch: 0/28, Loss: 0.2666
Batch: 10/28, Loss: 0.0800
Batch: 20/28, Loss: 0.0263
Train Loss: 0.0922, Train Acc: 99.55%
Val Loss: 0.0231, Val Acc: 100.00%
Learning Rate: 0.000100
Validation loss decreased (0.188087 --> 0.023144). Saving model ...Epoch 3/25
----------
Batch: 0/28, Loss: 0.0139
Batch: 10/28, Loss: 0.0292
Batch: 20/28, Loss: 0.0233
Train Loss: 0.0256, Train Acc: 100.00%
Val Loss: 0.0150, Val Acc: 100.00%
Learning Rate: 0.000100
Validation loss decreased (0.023144 --> 0.015029). Saving model ...Epoch 4/25
----------
Batch: 0/28, Loss: 0.0086
Batch: 10/28, Loss: 0.0055
Batch: 20/28, Loss: 0.0183
Train Loss: 0.0079, Train Acc: 100.00%
Val Loss: 0.0113, Val Acc: 100.00%
Learning Rate: 0.000100
Validation loss decreased (0.015029 --> 0.011310). Saving model ...Epoch 5/25
----------
Batch: 0/28, Loss: 0.0280
Batch: 10/28, Loss: 0.0064
Batch: 20/28, Loss: 0.0134
Train Loss: 0.0059, Train Acc: 100.00%
Val Loss: 0.0104, Val Acc: 100.00%
Learning Rate: 0.000100
EarlyStopping counter: 1 out of 5Epoch 6/25
----------
Batch: 0/28, Loss: 0.0039
Batch: 10/28, Loss: 0.0042
Batch: 20/28, Loss: 0.0041
Train Loss: 0.0209, Train Acc: 99.78%
Val Loss: 0.0122, Val Acc: 100.00%
Learning Rate: 0.000100
EarlyStopping counter: 2 out of 5Epoch 7/25
----------
Batch: 0/28, Loss: 0.0015
Batch: 10/28, Loss: 0.0026
Batch: 20/28, Loss: 0.0007
Train Loss: 0.0171, Train Acc: 99.78%
Val Loss: 0.0115, Val Acc: 100.00%
Learning Rate: 0.000100
EarlyStopping counter: 3 out of 5Epoch 8/25
----------
Batch: 0/28, Loss: 0.0041
Batch: 10/28, Loss: 0.0077
Batch: 20/28, Loss: 0.0032
Train Loss: 0.0071, Train Acc: 100.00%
Val Loss: 0.0112, Val Acc: 100.00%
Learning Rate: 0.000050
EarlyStopping counter: 4 out of 5Epoch 9/25
----------
Batch: 0/28, Loss: 0.0051
Batch: 10/28, Loss: 0.0014
Batch: 20/28, Loss: 0.0037
Train Loss: 0.0026, Train Acc: 100.00%
Val Loss: 0.0091, Val Acc: 100.00%
Learning Rate: 0.000050
Validation loss decreased (0.011310 --> 0.009129). Saving model ...Epoch 10/25
----------
Batch: 0/28, Loss: 0.0164
Batch: 10/28, Loss: 0.0057
Batch: 20/28, Loss: 0.0015
Train Loss: 0.0058, Train Acc: 100.00%
Val Loss: 0.0080, Val Acc: 100.00%
Learning Rate: 0.000050
Validation loss decreased (0.009129 --> 0.008041). Saving model ...Epoch 11/25
----------
Batch: 0/28, Loss: 0.0019
Batch: 10/28, Loss: 0.0017
Batch: 20/28, Loss: 0.0009
Train Loss: 0.0197, Train Acc: 99.78%
Val Loss: 0.0116, Val Acc: 100.00%
Learning Rate: 0.000050
EarlyStopping counter: 1 out of 5Epoch 12/25
----------
Batch: 0/28, Loss: 0.0011
Batch: 10/28, Loss: 0.0018
Batch: 20/28, Loss: 0.0016
Train Loss: 0.0030, Train Acc: 100.00%
Val Loss: 0.0123, Val Acc: 100.00%
Learning Rate: 0.000050
EarlyStopping counter: 2 out of 5Epoch 13/25
----------
Batch: 0/28, Loss: 0.0019
Batch: 10/28, Loss: 0.0079
Batch: 20/28, Loss: 0.0068
Train Loss: 0.0040, Train Acc: 100.00%
Val Loss: 0.0085, Val Acc: 100.00%
Learning Rate: 0.000050
EarlyStopping counter: 3 out of 5Epoch 14/25
----------
Batch: 0/28, Loss: 0.0009
Batch: 10/28, Loss: 0.0091
Batch: 20/28, Loss: 0.0007
Train Loss: 0.0052, Train Acc: 99.78%
Val Loss: 0.0106, Val Acc: 100.00%
Learning Rate: 0.000050
EarlyStopping counter: 4 out of 5Epoch 15/25
----------
Batch: 0/28, Loss: 0.0020
Batch: 10/28, Loss: 0.0004
Batch: 20/28, Loss: 0.0061
Train Loss: 0.0026, Train Acc: 100.00%
Val Loss: 0.0094, Val Acc: 100.00%
Learning Rate: 0.000025
EarlyStopping counter: 5 out of 5
Early stopping训练完成!
九、评估
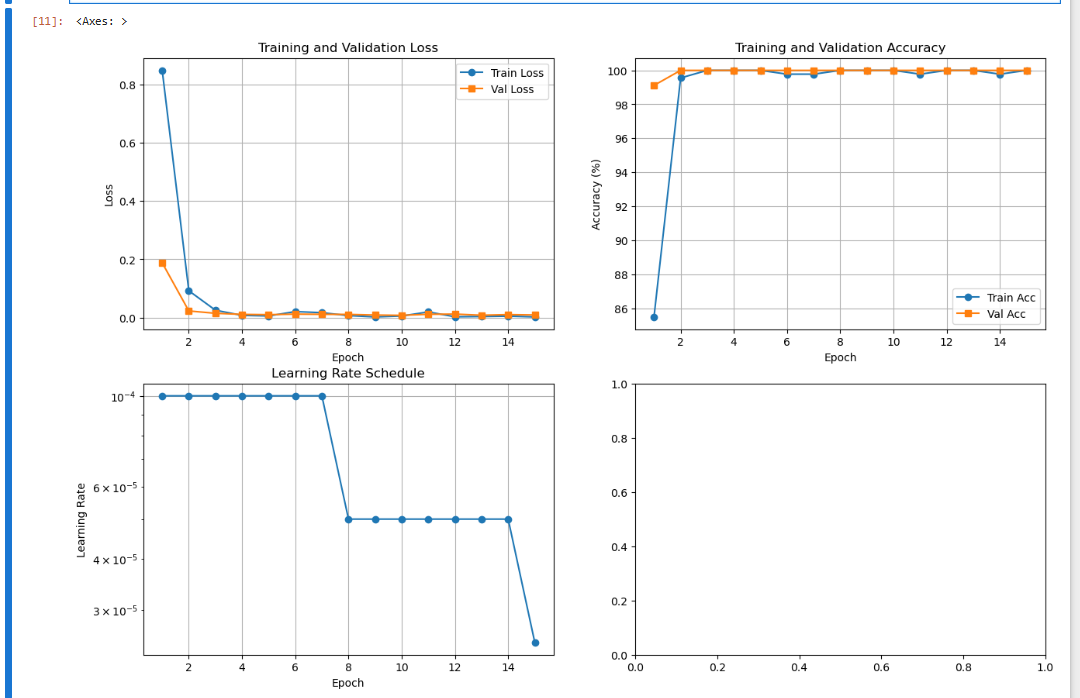
# 绘制训练曲线
plt.figure(figsize=(15, 10))plt.subplot(2, 2, 1)
plt.plot(range(1, len(train_losses)+1), train_losses, label='Train Loss', marker='o')
plt.plot(range(1, len(val_losses)+1), val_losses, label='Val Loss', marker='s')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.grid(True)plt.subplot(2, 2, 2)
plt.plot(range(1, len(train_accs)+1), [acc*100 for acc in train_accs], label='Train Acc', marker='o')
plt.plot(range(1, len(val_accs)+1), [acc*100 for acc in val_accs], label='Val Acc', marker='s')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.grid(True)plt.subplot(2, 2, 3)
plt.plot(range(1, len(lr_history)+1), lr_history, marker='o')
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.title('Learning Rate Schedule')
plt.yscale('log')
plt.grid(True)plt.subplot(2, 2, 4)
十、总结
ResNet v2的主要改进点。可能包括:1. 使用预激活结构,把BatchNorm和ReLU放在卷积之前。这样在残差块中,激活函数先于卷积层应用,这样梯度流动更顺畅,更有效地解决梯度消失的问题。2. 可能还调整了残差路径的设计,比如在跳跃连接中避免不必要的操作,保持恒等映射。3. 可能还涉及到了更深的网络结构或者更高效的训练方法。
然后,我需要总结ResNet v2的架构变化。比如,原来的残差块是conv-BN-ReLU的序列,而v2可能调整为BN-ReLU-conv的顺序,也就是预激活。这样的调整如何影响网络的表现?比如训练更稳定,准确率更高。此外,可能还探讨了不同的残差块设计,比如是否在跳跃连接中加入额外的卷积或BN层,而v2可能简化了这部分,保持跳跃连接尽可能简单,以保留恒等映射的特性。
另外,ResNet v2可能还进行了实验验证,比如在CIFAR-10、ImageNet等数据集上的表现,证明其有效性。比如,更深的网络(如1000层)是否能够稳定训练,准确率是否有提升。
需要注意的是,用户可能需要对比ResNet v1和v2的区别,所以总结时应该明确列出这些区别。比如预激活结构、恒等映射的改进、更优的梯度流动等。
相关文章:
第J2周:ResNet50V2 算法实战与解析
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 学习目标 ✅ 根据TensorFlow代码,编写出相应的Python代码 ✅ 了解ResNetV2和ResNet模型的区别 一、环境配置 二、数据预处理 三、创建、划分数据…...

Live Search API :给大模型装了一个“实时搜索引擎”的插件
6月5号前免费使用。 Live Search 是一项xAI API功能,允许 LLM 在生成响应时查询和考虑实时数据。通过此功能,您可以直接从 API 获得包含实时数据的聊天响应,而无需自己协调网络搜索和大型语言模型(LLM)工具调用。 可以…...
)
每天分钟级别时间维度在数据仓库的作用与实现——以Doris和Hive为例(开箱即用)
在现代数据仓库建设中,时间维度表是不可或缺的基础维表之一。尤其是在金融、电力、物联网、互联网等行业,分钟级别的时间维度表对于高频数据的统计、分析、报表、数据挖掘等场景具有极其重要的作用。本文将以 Doris 为例,详细讲解每天分钟级别时间维度表在数据仓库中的作用、…...
虚拟机Centos7:Cannot find a valid baseurl for repo: base/7/x86_64问题解决
问题 解决:更新yum仓库源 # 备份现有yum配置文件 sudo cp -r /etc/yum.repos.d /etc/yum.repos.d.backup# 编辑CentOS-Base.repo文件 vi /etc/yum.repos.d/CentOS-Base.repo[base] nameCentOS-$releasever - Base baseurlhttp://mirrors.aliyun.com/centos/$relea…...

IP风险度自检,多维度守护网络安全
如今IP地址不再只是网络连接的标识符,更成为评估安全风险的核心维度。IP风险度通过多维度数据建模,量化IP地址在网络环境中的安全威胁等级,已成为企业反欺诈、内容合规、入侵检测的关键工具。据Gartner报告显示,2025年全球78%的企…...

NV066NV074美光固态颗粒NV084NV085
NV066NV074美光固态颗粒NV084NV085 在存储技术的快速发展浪潮中,美光科技(Micron Technology)始终扮演着引领者的角色。其NV系列闪存颗粒凭借创新设计和卓越性能,成为技术爱好者、硬件开发者乃至企业级用户关注的焦点。本文将围绕…...

C++ 日志系统实战第六步:性能测试
全是通俗易懂的讲解,如果你本节之前的知识都掌握清楚,那就速速来看我的项目笔记吧~ 本文项目结束! 性能测试 下面对日志系统做一个性能测试,测试一下平均每秒能打印多少条日志消息到文件。 主要的测试方法是:每秒能…...

低代码平台搭建
学习低代码平台搭建需要掌握几个核心模块,尤其是动态表单引擎和DSL(领域特定语言)设计,以下是系统化的知识总结: 一、低代码平台的核心模块 低代码平台的核心是让用户通过可视化交互快速生成应用,核心模块包括: 可视化设计器(拖拽布局、组件配置)DSL(领域特定语言)…...

AI编程对传统软件开发的冲击和思考
2025年,如果你所在的软件公司还活着,恭喜,你的老板很坚挺,很有福报。 不过,25年年底的时候,就不好说了! Claude说年底的时候,Claude就可以实现不间断一直编程模式。 一个比996还狠…...

Java桌面应用开发详解:自制截图工具从设计到打包的全流程【附源码与演示】
🔥 本文详细介绍一个Java/JavaFX学习项目——轻量级智能截图工具的开发实践。通过这个项目,你将学习如何使用Java构建桌面应用,掌握JavaFX界面开发、系统托盘集成、全局快捷键注册等实用技能。本文主要关注基础功能实现,适合Java初…...

手写一个简单的线程池
手写一个简单的线程池 项目仓库:https://gitee.com/bossDuy/hand-tearing-thread-pool 基于一个b站up的课程:https://www.bilibili.com/video/BV1cJf2YXEw3/?spm_id_from333.788.videopod.sections&vd_source4cda4baec795c32b16ddd661bb9ce865 理…...
)
AI开发实习生面试总结(持续更新中...)
1.广州视宴(ai开发实习生) 首先是自我介绍~ 1.第二个项目中的热力图是用怎么样的方式去做的? 2.在第二个项目中,如何用热力图去实现它的实时变化 答:我这里直接说我项目里面其实静态的热力图,不是动态的…...

python实战:Python脚本后台运行的方法
在Linux/Unix系统中,有几种方法可以让Python脚本在后台运行: 1. 使用 & 符号 最简单的后台运行方式是在命令末尾添加 &: python your_script.py &这样会将脚本放入后台运行,但关闭终端时脚本可能会被终止。 2. 使用 nohup 命令 nohup 可以让脚本在退出终端…...
siparmyknife:SIP协议渗透测试的瑞士军刀!全参数详细教程!Kali Linux教程!
简介 SIP Army Knife 是一个模糊测试器,用于搜索跨站点脚本、SQL 注入、日志注入、格式字符串、缓冲区溢出等。 安装 源码安装 通过以下命令来进行克隆项目源码,建议请先提前挂好代理进行克隆。 git clone https://github.com/foreni-packages/sipa…...

【Hexo】2.常用的几个命令
new 在根目录下执行 hexo new "文章标题" 命令,会在 source/_posts 目录下生成一个 .md 文件。 hexo new "文章标题"clean 在根目录下执行 hexo clean 命令,会清除 public 目录下的所有文件。 hexo cleangenerate 在根目录下执…...

OceanBase 系统表查询与元数据查询完全指南
文章目录 一、OceanBase 元数据基础概念1.1 元数据的定义与重要性1.2 OceanBase 元数据分类体系二、系统表查询核心技术2.1 核心系统表详解2.1.1 集群管理表2.1.2 租户资源表2.2 高级查询技巧2.2.1 跨系统表关联查询2.2.2 历史元数据查询三、元数据查询实战应用3.1 日常运维场景…...

【Java高阶面经:微服务篇】4.大促生存法则:微服务降级实战与高可用架构设计
一、降级决策的核心逻辑:资源博弈下的生存选择 1.1 大促场景的资源极限挑战 在电商大促等极端流量场景下,系统面临的资源瓶颈呈现指数级增长: 流量特征: 峰值QPS可达日常的50倍以上(如某电商大促下单QPS从1万突增至50万)流量毛刺持续时间短(通常2-4小时),但对系统稳…...
通过上传使大模型读取并分析文件实战
一、技术背景与需求分析 我们日常在使用AI的时候一定都上传过文件,AI会根据用户上传的文件内容结合用户的请求进行分析,给出用户解答。但是这是怎么实现的呢?在我们开发自己的大模型应用时肯定是不可避免的要思考这个问题,今天我会…...
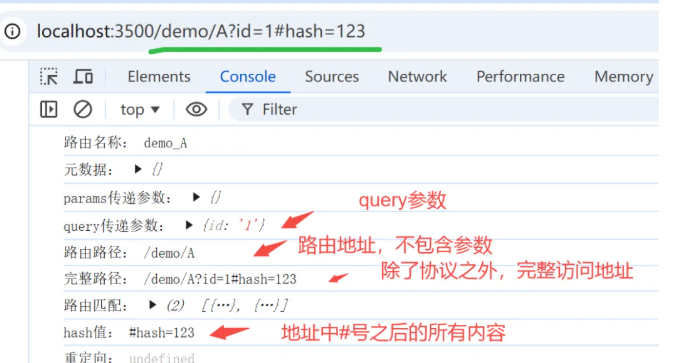
VueRouter路由组件的用法介绍
1.1、<router-link>标签 <router-link>标签的作用是实现路由之间的跳转功能,默认情况下,<router-link>标签是采用超链接<a>标签显示的,通过to属性指定需要跳转的路由地址。当然,如果你不想使用默认的<…...
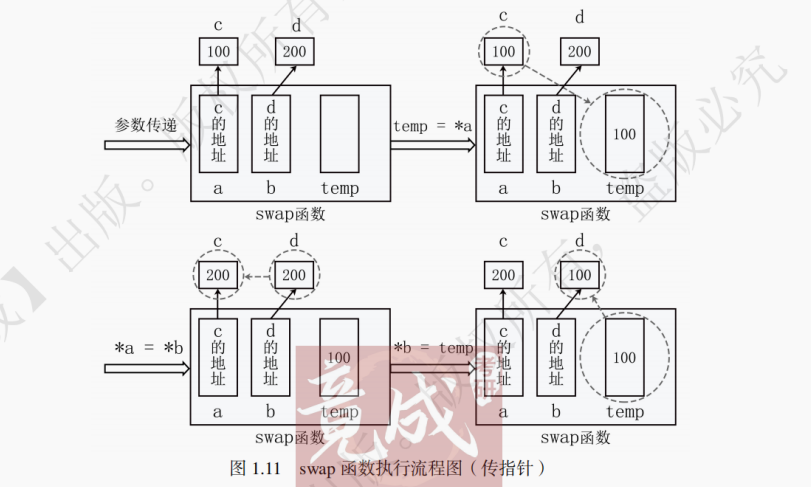
数据结构第1章 (竟成)
第 1 章 编程基础 1.1 前言 因为数据结构的代码大多采用 C 语言进行描述。而且,408 考试每年都有一道分值为 13 - 15 的编程题,要求使用 C/C 语言编写代码。所以,本书专门用一章来介绍 408 考试所需的 C/C 基础知识。有基础的考生可以快速浏览…...
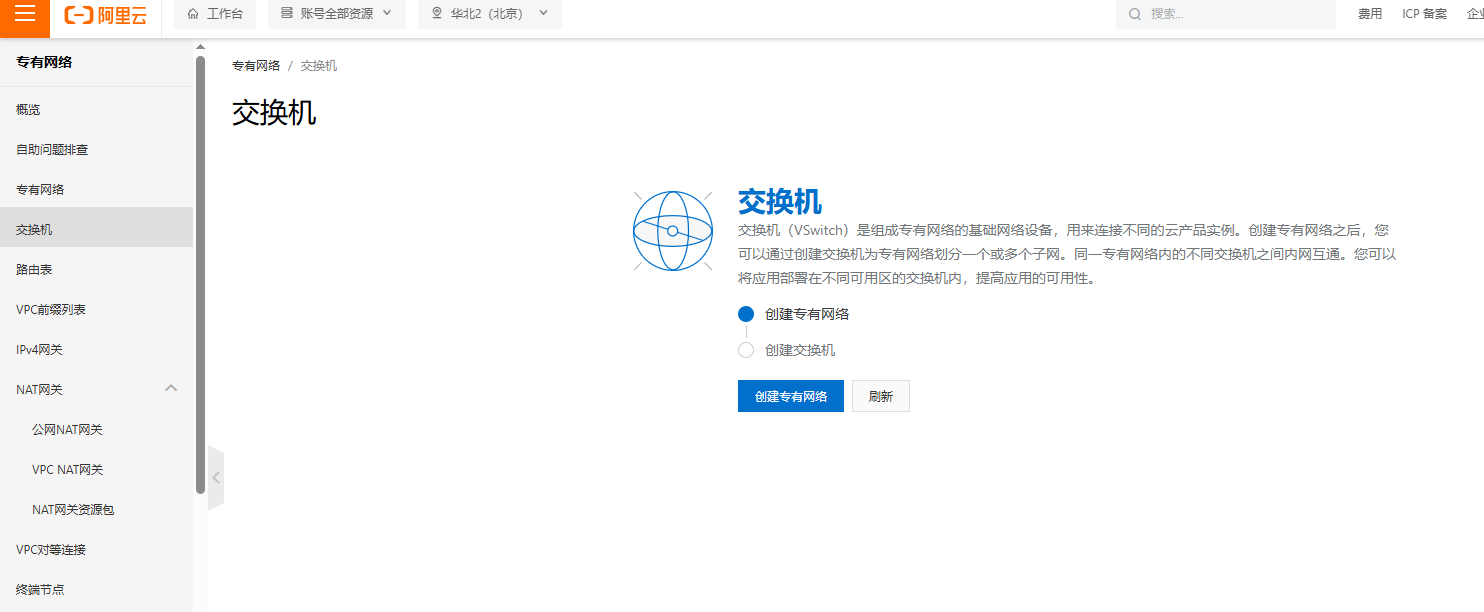
Terraform创建阿里云基础组件资源
这里首先要找到阿里云的官方使用说明: 中文版:Terraform(Terraform)-阿里云帮助中心 英文版:Terraform Registry 各自创建一个阿里云的RAM子账号,并给与OPAPI的调用权限,(就是有aksk,生成好之后保存下.) 创建路径: 登陆阿里云主账号-->控制台-->右上角企业-->人员…...

企业级调度器LVS
访问效果 涉及内容:浏览拆分、 DNS 解析、反向代理、负载均衡、数据库等 1 集群 1.1 集群类型简介 对于⼀个业务项⽬集群来说,根据业务中的特性和特点,它主要有三种分类: 高扩展 (LB) :单个主机负载不足的时候…...
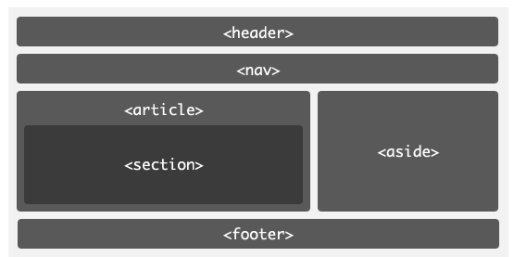
【Web前端】HTML网页编程基础
HTML5简介与基础骨架 HTML5是用来描述网页的一种语言,被称为超文本标记语言。用HTML5编写的文件,后缀以.html结尾 HTML是一种标记语言,标记语言是一套标记标签。标签是由尖括号包围的关键字,例如<html> 标签有两种表现形…...
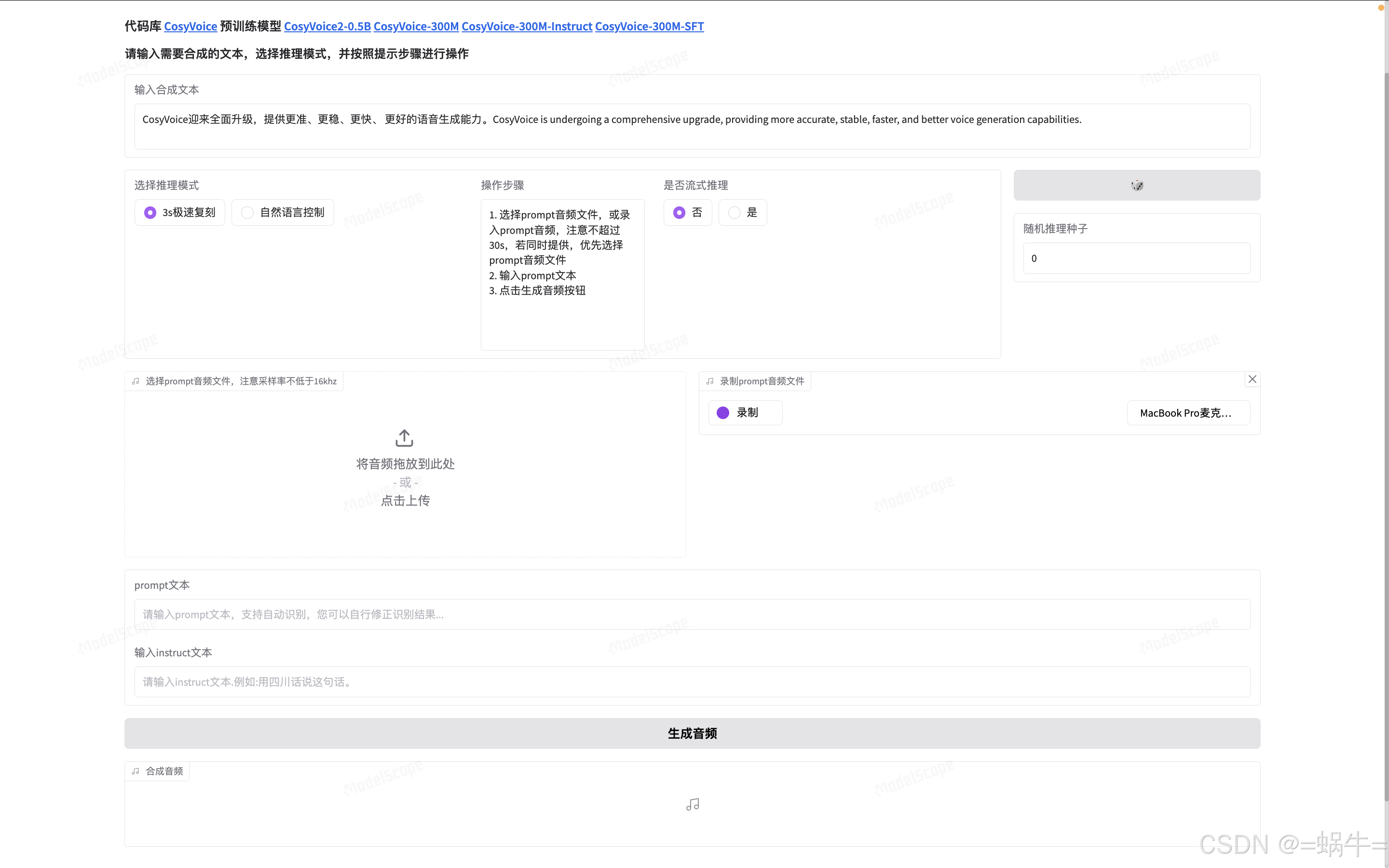
阿里开源 CosyVoice2:打造 TTS 文本转语音实战应用
1、引言 1.1、CosyVoice2 简介 阿里通义实验室推出音频基座大模型 FunAudioLLM,包含 SenseVoice 和 CosyVoice 两大模型。 CosyVoice:模拟音色与提升情感表现力 多语言 支持的语言: 中文、英文、日文、韩文、中文方言(粤语、四川话、上海话、天津话、武汉话等)跨语言及…...

【C/C++】红黑树插入/删除修复逻辑解析
文章目录 红黑树插入修复逻辑解析✅ 函数原型✅ 外层循环条件✅ 拿到祖父节点✅ Case 1:父节点是祖父的左孩子① 叔叔节点是红色 → 情况1:**颜色翻转(Recolor)**② 叔叔节点是黑色或为空 → 情况2或3:**旋转 颜色修复…...

RabbitMQ可靠传输——持久性、发送方确认
一、持久性 前面学习消息确认机制时,是为了保证Broker到消费者直接的可靠传输的,但是如果是Broker出现问题(如停止服务),如何保证消息可靠性?对此,RabbitMQ提供了持久化功能: 持久…...

AWS stop/start 使实例存储lost + 注意点
先看一下官方的说明: EC2有一个特性,当执行stop/start操作(注意,这个并不是重启/reboot,而是先停止/stop,再启动/start)时,该EC2会迁移到其它的底层硬件上。 对于实例存储来说,由于实例存储是由其所在的底层硬件来提供的,此时相当于分配到了一块全新的空的磁盘。 但是从…...

数字计数--数位dp
1.不考虑前导零 2.每一位计数,就是有点“数页码”的意思 P2602 [ZJOI2010] 数字计数 - 洛谷 相关题目:记得加上前导零 数页码--数位dp-CSDN博客 https://blog.csdn.net/2301_80422662/article/details/148160086?spm1011.2124.3001.6209 #include…...

掌握递归:编程中的优雅艺术
当然可以!你愿意迈出学习递归的重要一步,真的很棒!🌟 递归,虽然一开始看着有点绕,但掌握之后,你会发现它是编程中非常优雅且强大的工具。 我用简单又清晰的方式教你。请跟着我一步步来…...

无人机开启未来配送新篇章
低空物流(无人机物流)是利用无人机等低空飞行器进行货物运输的物流方式,依托低空空域(通常在120-300米)实现快速、高效、灵活的配送服务。它是低空经济的重要组成部分,广泛应用于快递配送、医疗物资运输、农…...