李宏毅《深度学习》:Self-attention 自注意力机制
一,问题分析:
什么情况下需要使用self-attention架构,或者说什么问题是CNN等经典网络架构解决不了的问题,我们需要开发新的网络架构?
要解决什么问题《——》对应开发self-attention架构的目的?
1,模型输入input:
前几堂课程的介绍,输入都是固定形状的 vector,而输出可能是一个数值 (Regression),或者一个类别 (Classification)。
无论是预测视频观看人数还是图像处理,输入都可以看作是一个向量,输出是一个数值(scalar,就是回归)或类别(class,就是分类)。
但当我们遇到更复杂的问题时 (自然语言),输入可能会变成一排向量,而且每次输入的长度不一样。
但是我们会遇到输入是一系列向量(vector sets,向量集合,也就是序列,sequence)的情况,并且sequence的长度会变化。
也就是问题:输入是sequence,且长度会变化
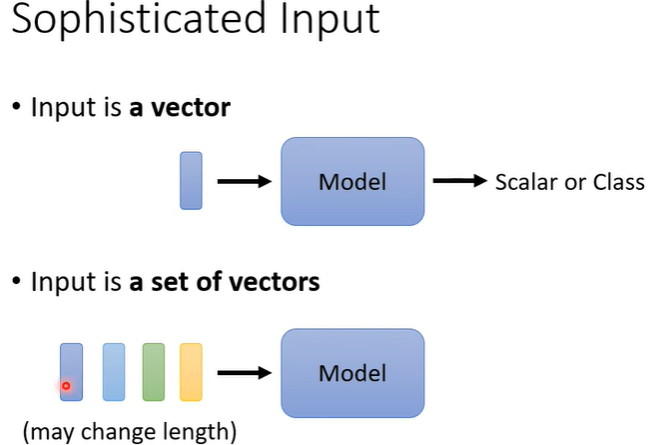
举例:
文字处理:在做自然语言的任务时,我们需要先将文字转换成向量 (word embedding),才能输入到 model 裡面。每个字符串都是一个向量,因此一句话就会变成一排向量。
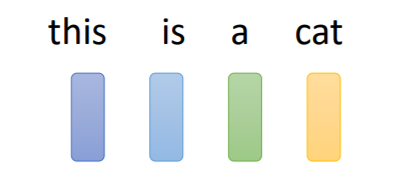
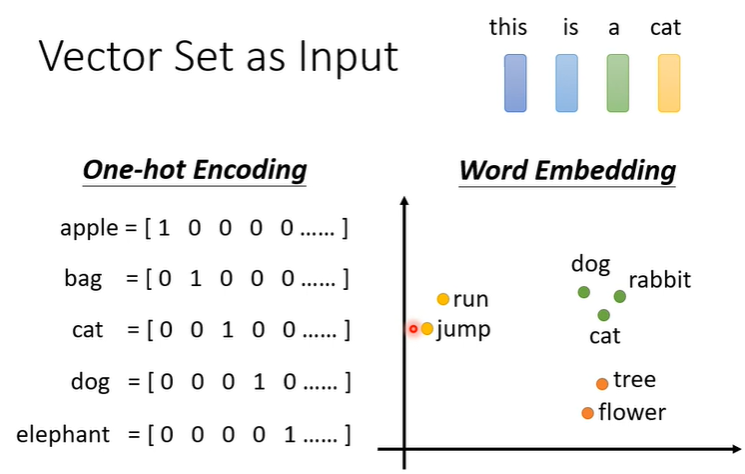
将单词表示为向量的方法:
1️⃣One-hot Encoding(独热编码)。向量的长度就是世界上所有词汇的数目,用不同位的1(其余位置为0)表示一个词汇,如下所示:
- apple = [1, 0, 0, 0, 0, …]
- bag = [0, 1, 0, 0, 0, …]
- cat = [0, 0, 1, 0, 0, …]
- dog = [0, 0, 0, 1, 0, …]
- computer = [0, 0, 0, 0, 1, …]
但是它并不能区分出同类别的词汇,里面没有任何有意义的信息。也就是说cat和dog都是动物,但是在one-hot编码的vector上其实看不出vector之间的相似性;apple植物和cat动物之间的差异也看不出。
2️⃣另一个方法是Word Embedding:给单词一个向量,这个向量有语义的信息,一个句子就是一排长度不一的向量。将Word Embedding画出来,就会发现同类的单词就会聚集,因此它能区分出类别。
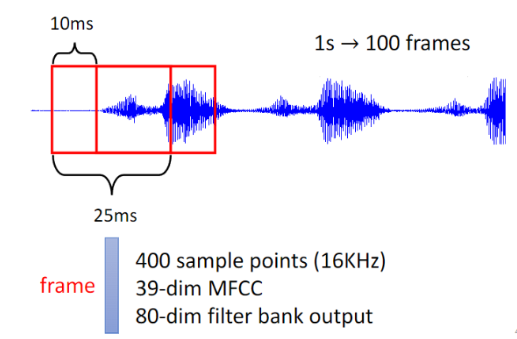
语音:在语音上会先取一个 window(帧),然后用一个向量去表示某段时间的声音(25ms),window 每次往右移动 10ms 直到语音结束。
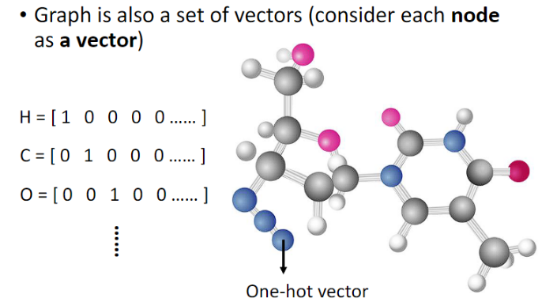
图:一个社交网络或者分子的结构都是图的形式,每个节点都是一个向量,很多节点就是一堆向量。
| 语音信号 | 图论 |
|---|---|
| 取一段语音信号作为窗口,把其中的信息描述为一个向量(帧),滑动这个窗口就得到这段语音的所有向量 | ①社交网络的每个节点就是一个人,节点之间的关系用线连接。每一个人就是一个向量 ②分子上的每个原子就是一个向量(每个元素可用One-hot编码表示),分子就是一堆向量 |
 |   |
2,模型输出output:
当输入是一排向量时,输出有三种类型:
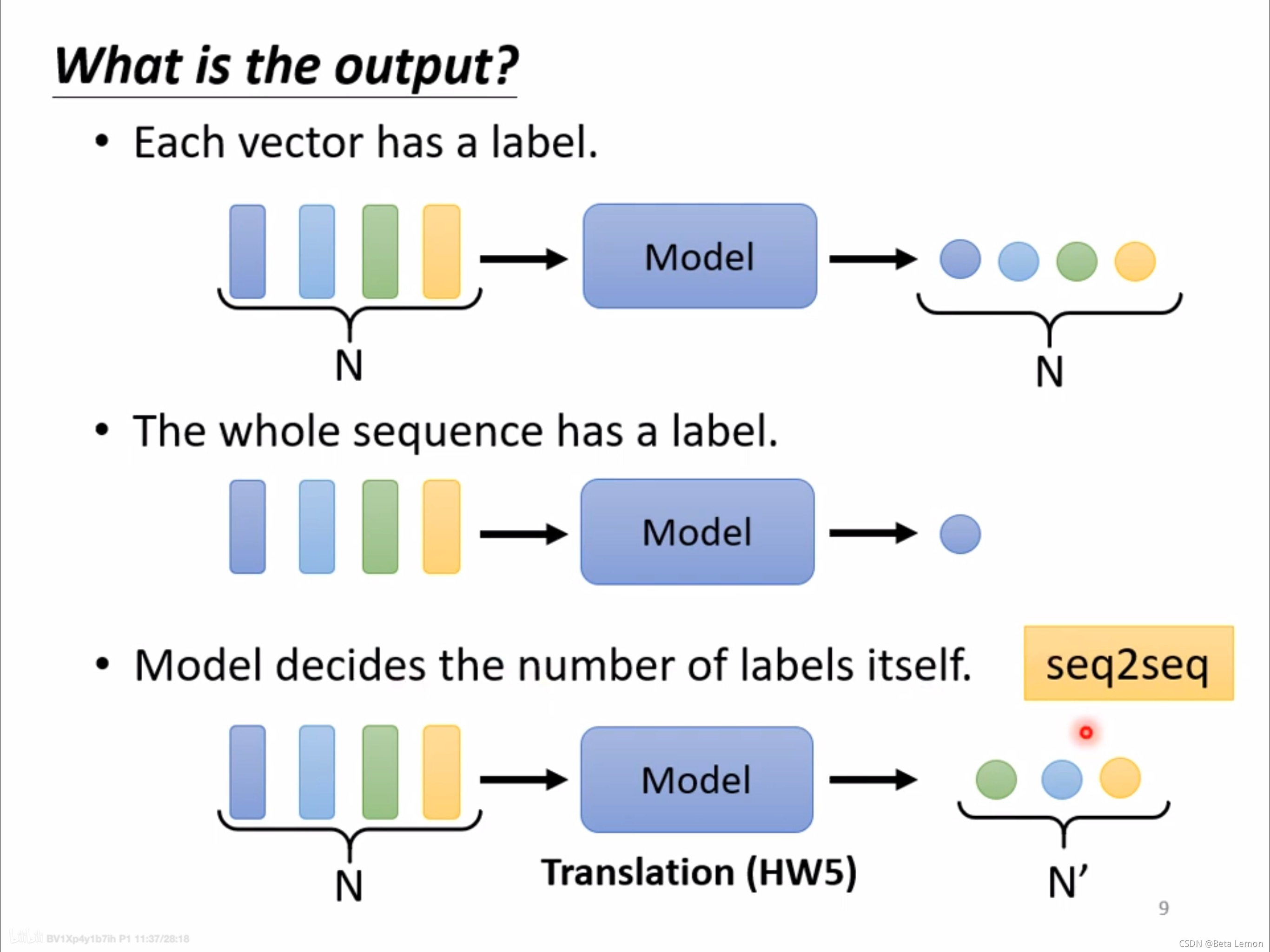
(1)输入和输出的长度一样,每一个向量对应一个 label,如词性标注、音标识别、节点特性(如会不会买某件商品)
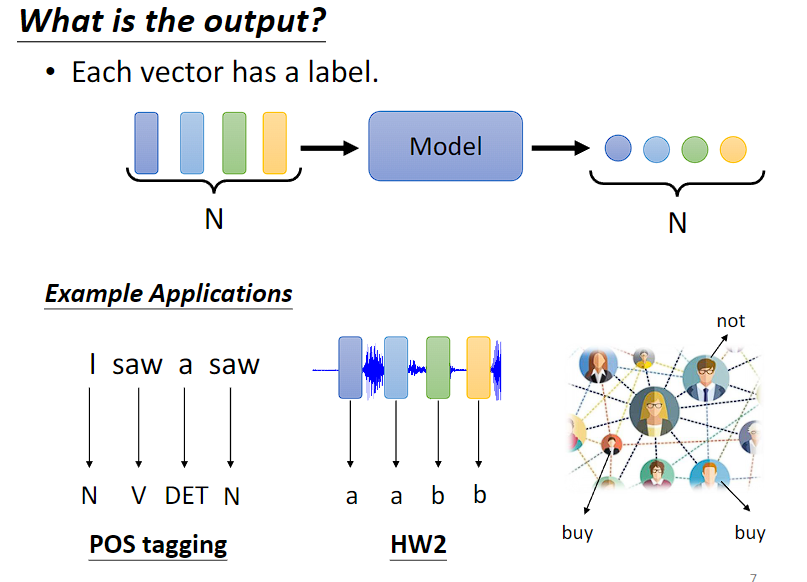
类型一:一对一(Sequence Labeling)
每个输入向量对应一个输出标签。
- 文字处理:词性标注(每个输入的单词都输出对应的词性)。
- 语音处理:一段声音信号里面有一串向量,每个向量对应一个音标。
- 图像处理:在社交网络中,推荐某个用户商品(可能会买或者不买)。
(2)一整个 Sequence 只需输出一个 label,如情感分析、语者辨识、分子亲水性检测
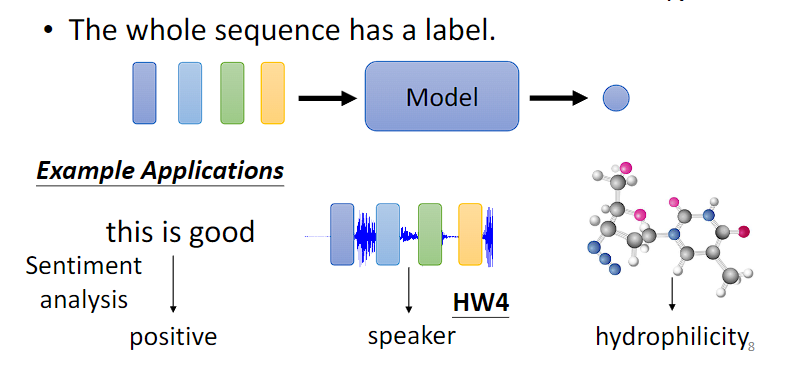
类型二:多对一
多个输入向量对应一个输出标签。
- 语义分析:正面评价、负面评价。
- 语音识别:识别某人的音色。
- 图像:给出分子的结构,判断其亲水性。
(3)输出的 label 数目由机器决定,这种任务又叫 seq2seq,如翻译、语音辨识
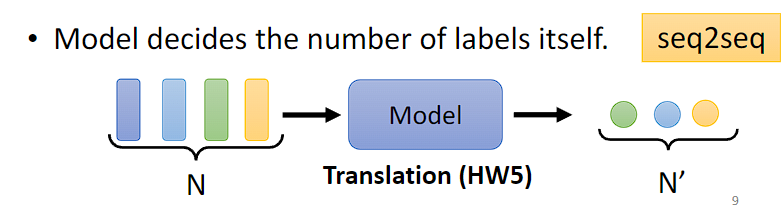
类型三:由模型自定(seq2seq)
不知道应该输出多少个标签,机器自行决定。
- 翻译:语言A到语言B,单词字符数目不同
- 语音识别
3,序列标注 (Sequnce Labeling) 的问题
李宏毅老师课上讲的是第一种输出类型,即每一个输入向量对应一个 label 来深入 Self-attention。
第一种输出类型也叫 Sequence Labeling,那如何实现呢?假如现在要做词性分析,简单的想法是给将每个输入向量都单独丢入一个全连接层(以下简称 FC)中,然后生成一个 label。
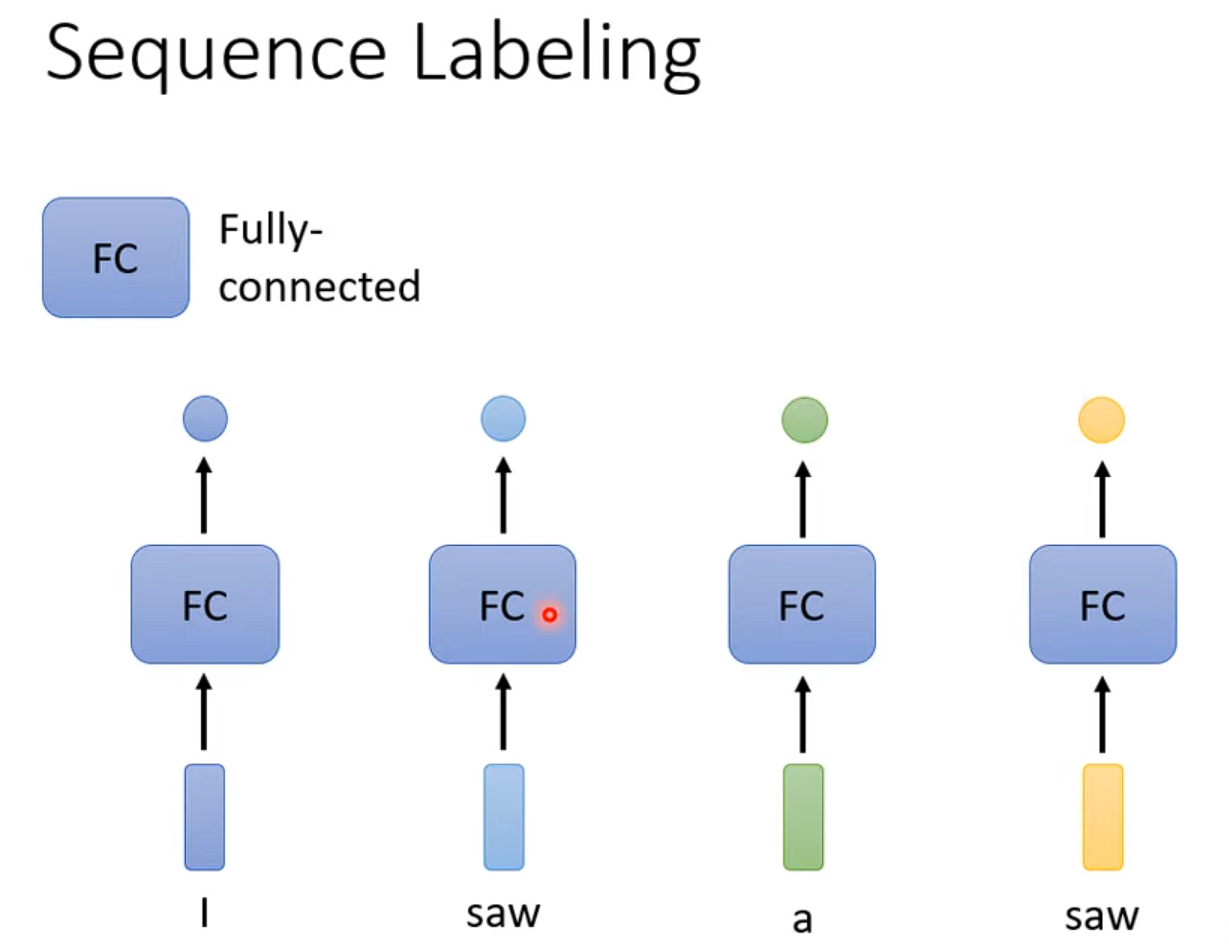
当这会带来一个问题,对于 saw 这个词来说,第一个 saw 是动词,第二个 saw 是名词,但是对于 FC 来说它俩并无区别。
要区分 saw 是动词还是名词,显然要根据上下文信息决定,所以可以考虑把上下文信息一起丢入 FC,如此一来即可对 saw 进行区分。
假设是词性标注的任务,若直接用全连接网络来处理,会发现同样文字在句子的前后,标签是不同的词性。
也就是我对于输入序列中的每一个向量,单独每个向量丢到全连接网络中,也就是不考虑上下文,然后单独得到1个输出,这样的每个单独输入向量得到的单个输出的label。
比如说下面两个saw,因为我是独立丢进去的,所以实际上它并没有考虑到两个saw的上下文关系,那么都是同样的词,没道理丢给Fully-connected network之后会出现不一样的结果,所以就分不出词性。因为词性分析是需要结合上下文来进行的。
I saw a saw,第一个 saw 是动词,第二个 saw 是名词,但对于全连接网络来说,这两个 saw 是完全一样的。
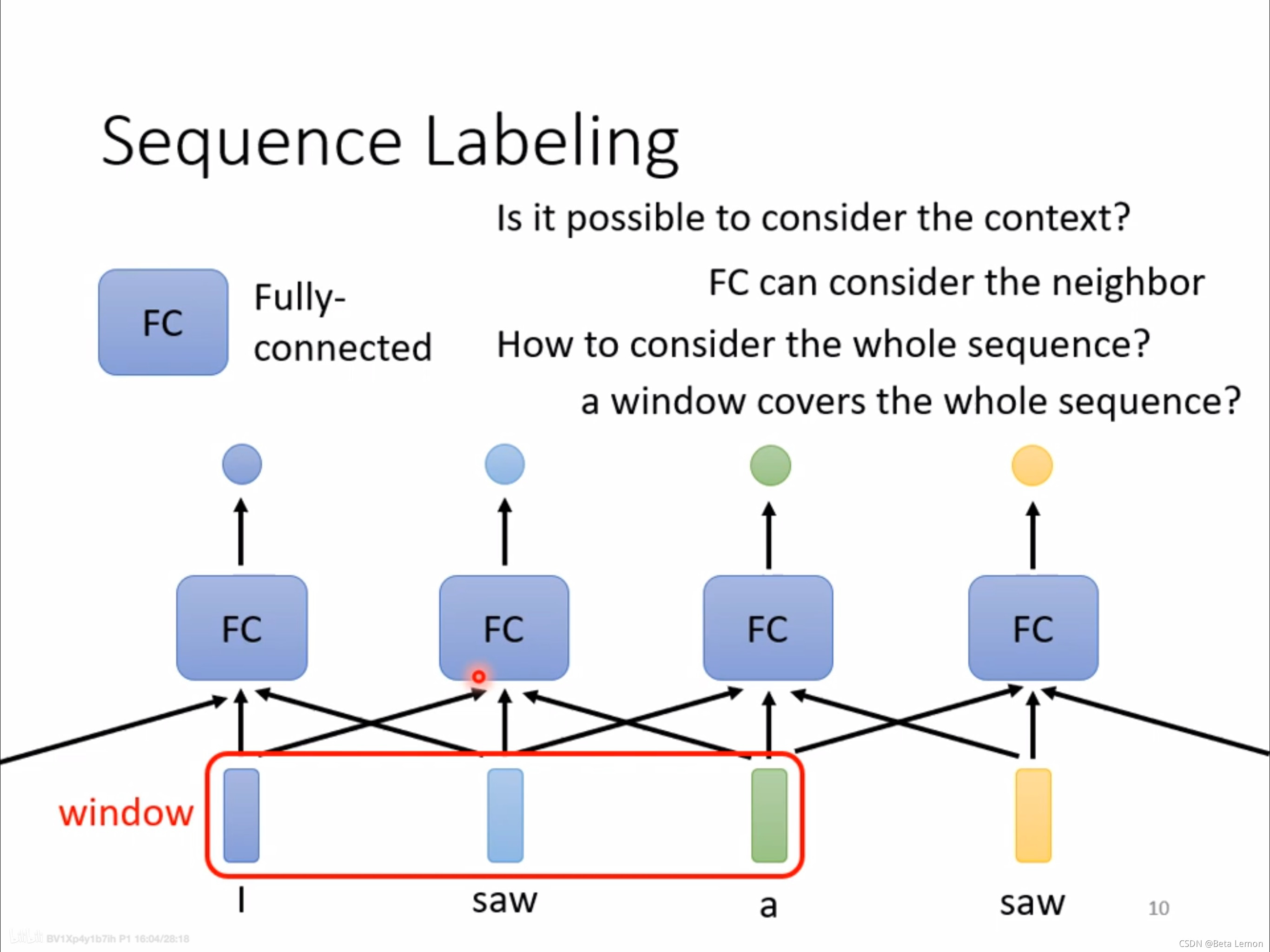
利用全连接网络,输入一个句子,输出对应单词数目的标签。当一个句子里出现两个相同的单词,并且它们的词性不同(例如:I saw a saw. 我看见一把锯子),这个时候就需要考虑上下文:利用滑动窗口,每个向量查看窗口中相邻的其他向量的性质。
但是这种方法不能解决整条语句的分析问题,即语义分析。这就引出了 Self-attention 技术。
也就是说,从全连接网络考虑邻近的数据
我们可以开一个窗口,将邻近的数据都考虑进来,或是更极端,直接开一个窗口覆盖所有数据。
这种方法确实会比原来的 fc 更好,但由于我们的输入有长有短,因此如果要真的开一个 window 来覆盖所有数据,那么除了运算量很大之外,也容易过拟合(这个时候其实是需要我们看training set中所有sequence长度,才能定下来max window)。
这个例子中考虑的上下文并不长,假如有一个待解决问题要考虑整个 Sequence 才能够解决,一个直接的想法是把 window 开大点,直到包括整个 Sequence,但是 Sequence 的大小是不固定的,你需要统计出最长的 sequence,并且 window 开大了,就意味着 FC 需要非常多的参数,不仅运算量很大,还容易导致 overfitting。
Self-attention 就是一个考虑整个 input sequence 资讯的好办法。
二、Self-attention 自注意力机制
简单来说:
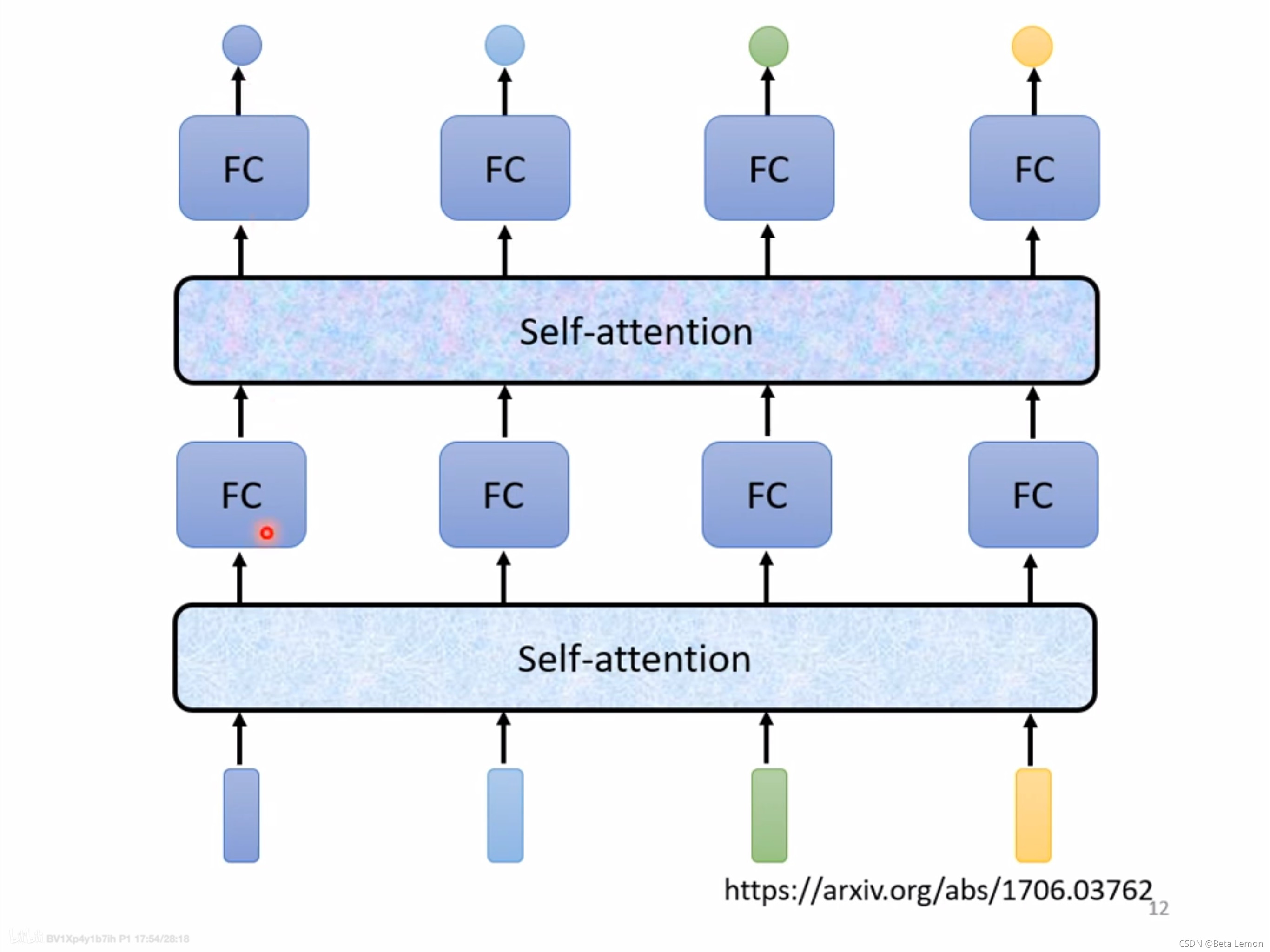
输入整个语句的向量到self-attention中,输出对应个数的向量,再将其结果输入到全连接网络,最后输出标签。以上过程可多次重复——》
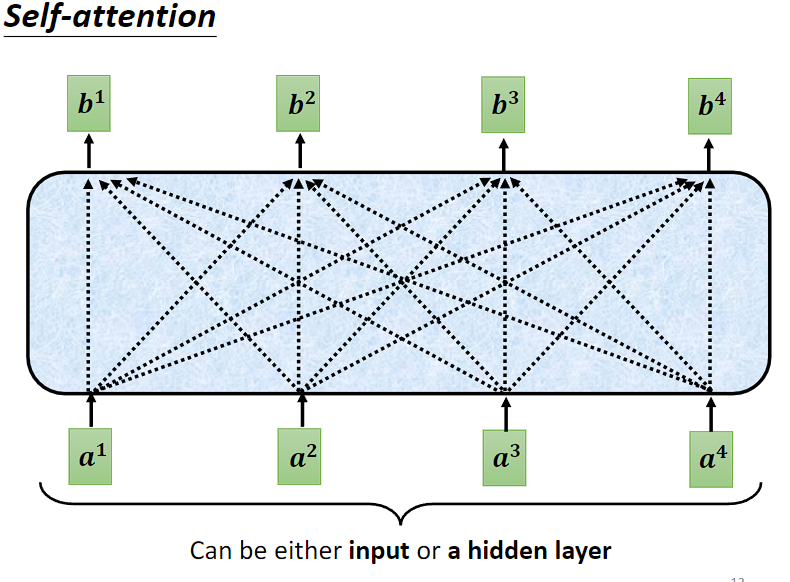
1,Self-attention 的运作方式
Self-attention 会吃一整个 input sequence,然后输出同等长度的 sequence,输出的每个向量都是考虑了整个 input sequence 才得到的。然后再将 Self-attention的输出丢入 FC,如此一来 FC 就考虑整个 input sequence 的资讯再来决定应该输出什么样的结果。
Self-attention 可以叠加很多次:FC 输出后可以再丢入 Self-attention,再考虑一次整个 sequence 的资讯。可以把 Self-attention 和 FC 交替使用,Self-attention 处理整个 sequence 的资讯,FC 专注于处理某个位置的资讯。
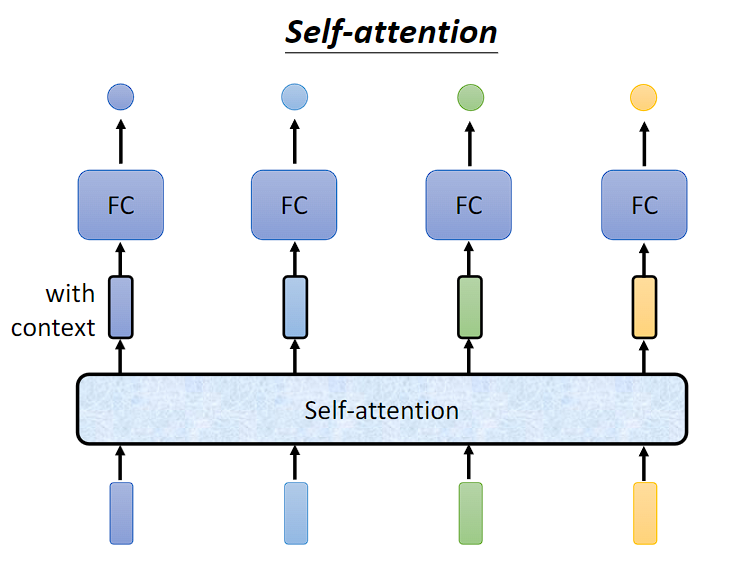
从概念上讲:
- 以序列标注任务为例,输入4个向量,输出4个向量。
输入向量可以是整个模型的输入,也可以是某一隐藏层输出的向量。 - 每一个输出的向量,都是考虑过所有输入向量后才得到的結果。
- 深蓝色的输入,通过 self-attention 后,会得到一个深蓝色的输出,以此类推。
- 接着在把有考虑整个句子的向量,丢到 fully-connected 去输出我们想要的数值、类别。
- 如此一来,fc 就可以考虑到整组句子的信息。
- 自注意力机制与全连接层重叠使用
Google 提出 Transformer 的架构,其中最重要的模块就是自注意力机制,
Google 根据自注意力机制在《Attention is all you need》中提出了 Transformer 架构。
2,Self-attention 的内部实现
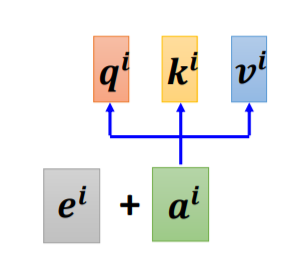
由于 Self-attention 可以叠加,所以它的输入不仅来自训练数据还可能来自隐藏层,所以此处用a而不是用x来表示输入。
 都是考虑了整个 input sequence 才得到的。
都是考虑了整个 input sequence 才得到的。
现在以 为例说明是如何由 input sequence 得到
为例说明是如何由 input sequence 得到  ,序列标注的输出 b1 如何产生?
,序列标注的输出 b1 如何产生?
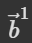 是
是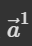 对应的考虑了整个 Sequence 的 Self-attention 输出,因此第一步是找出哪些部分与决定
对应的考虑了整个 Sequence 的 Self-attention 输出,因此第一步是找出哪些部分与决定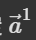 对应的 label 是有关的。
对应的 label 是有关的。
比如说下面的a1和a4,我们需要计算输入序列中任意两个向量之间的相似性、相关程度,也就是α。
α1:表示输入的 a1 与其他输入向量之间的相关性,它会考虑其他向量里面,有没有哪些信息是a1 输出到 b1 会用到。
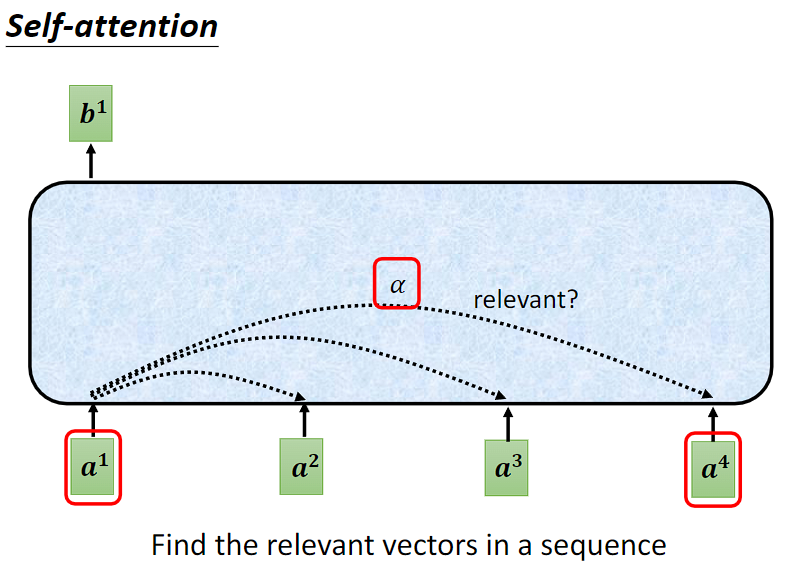
那么如何计算这个relevant的表征呢?相关性怎么计算?
简单来说,Self-attention 有一个模块,能将两个向量作为输入,然后输出注意力分数α,α以用来表示两个向量间的关联程度。这个模块有许多实现,其中两种实现方式分别是 Dot-product (向量之间的点乘,也就是内积,其实就是余弦相似性,可以参考https://zh.wikipedia.org/zh-hans/%E4%BD%99%E5%BC%A6%E7%9B%B8%E4%BC%BC%E6%80%A7)和 Additive。
存在多种不同的方法,最常见的是点积。
假设要计算 a1 和 a4 的相关性,就会将这两个向量分别乘上两个不同的矩阵(wq, wk),得到 q 和 k 之后,再对 q 和 k 做点积,得到一个数值(α)。
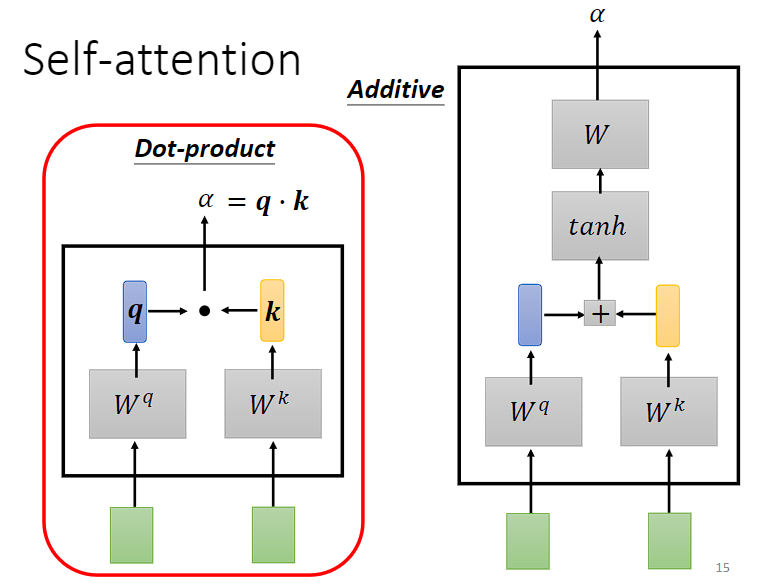
简单来说,Dot-product 是对两个输入向量分别做线性变换(也就是乘上了1个矩阵,可学习的矩阵 W)得到query查询向量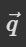 和key键向量
和key键向量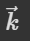 ,这样做的目的是将原始输入映射到一个更高维度的表示空间中,以增加模型的表达能力(这一点其实从线性代数角度很好理解,矩阵乘法的本质实际上就是坐标系变换,对1个矩阵乘上1个矩阵,实际上就是对这个矩阵的base基向量做一个线性变换,维度的话高低看乘上去的矩阵)。
,这样做的目的是将原始输入映射到一个更高维度的表示空间中,以增加模型的表达能力(这一点其实从线性代数角度很好理解,矩阵乘法的本质实际上就是坐标系变换,对1个矩阵乘上1个矩阵,实际上就是对这个矩阵的base基向量做一个线性变换,维度的话高低看乘上去的矩阵)。
Additve 是将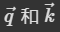 串联起来,然后丢给激活函数tanh,最后再通过线性变换(矩阵乘法)得到α。
串联起来,然后丢给激活函数tanh,最后再通过线性变换(矩阵乘法)得到α。
其中 Dot-product 简单有效,被用于 transformer 中。
我们以点积为例,了解self-attention的内部实现。
计算每个向量和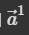 的注意力分数(也就是α),还要经过soft-max归一化处理,将注意力分数转换为概率分布,表示了对应位置的重要程度。这样可以避免某些位置的注意力权重过大或过小,提高了注意力机制的稳定性和有效性。并且将注意力分数进行 Soft-max 归一化后,得到的注意力权重可以看作是对应位置的输入的加权平均,其中权重表示了每个位置对于当前位置的重要程度。这样可以更好地捕捉输入序列中不同位置的相关性,提高了模型的性能。(我们可以这样来思考:某个位置的向量发出询问/查询query,想知道和这个向量最相关的向量在什么位置上,所以通过这个查询向量的query,去查询其他每个向量的key向量,当然包括自身)。
的注意力分数(也就是α),还要经过soft-max归一化处理,将注意力分数转换为概率分布,表示了对应位置的重要程度。这样可以避免某些位置的注意力权重过大或过小,提高了注意力机制的稳定性和有效性。并且将注意力分数进行 Soft-max 归一化后,得到的注意力权重可以看作是对应位置的输入的加权平均,其中权重表示了每个位置对于当前位置的重要程度。这样可以更好地捕捉输入序列中不同位置的相关性,提高了模型的性能。(我们可以这样来思考:某个位置的向量发出询问/查询query,想知道和这个向量最相关的向量在什么位置上,所以通过这个查询向量的query,去查询其他每个向量的key向量,当然包括自身)。
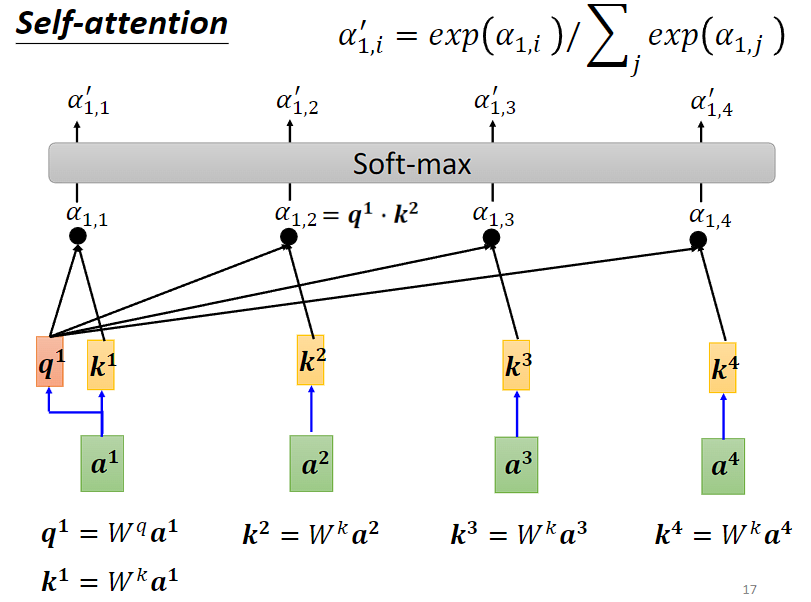
自此已经得到了注意力权重,接下来就是通过加权求和得到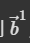 (其实这里就是提取哪个位置向量的信息和a1最接近,b1和a1的提取信息目标对应)。按理来说对于a1,我们已经获得了其对应每一个位置向量之间的相关关系,也就是α,或者soft-max之后的α’,理论上我们可以直接将α或者α’求和相加,这样就能够得到a1向量对应的位置相关信息b1。
(其实这里就是提取哪个位置向量的信息和a1最接近,b1和a1的提取信息目标对应)。按理来说对于a1,我们已经获得了其对应每一个位置向量之间的相关关系,也就是α,或者soft-max之后的α’,理论上我们可以直接将α或者α’求和相加,这样就能够得到a1向量对应的位置相关信息b1。
但是:
但在此之前,为保证向量与注意力权重维度匹配(a1是我们的输入向量,我们计算的attention score α或者α’是标量,如果我们按照前面的说法我们是为了提取出和a1最相关的位置的向量信息,所以按理来说注意力分数只是个权重,只是个系数,我们需要权重最大的系数对应的那个位置的向量,所以形式上我们需要a1的输出b1,应该还是系数*向量的形式,也就是b1应该是和最和a1接近那个ai向量维度形式信息接近;
再者要再进入混用的FC+attention层,我们其实需要保持一定维度的向量输入,也就是对于b1,我们在形式上要和a1再对应,我们可以理解为query+key操作之后,我们需要回复值value的形式,所以要再和value值向量进行计算),需要对原始向量进行线性变换得到数值向量 ,然后再加权求和。
,然后再加权求和。
然后依据这个分数(关联性)抽取重要信息。
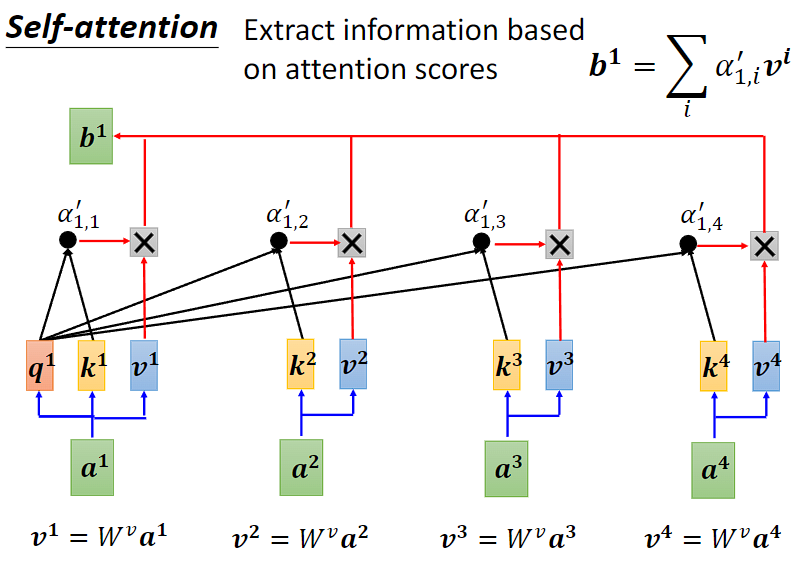
这么来记忆:
要算b1,a1来查询query(所有向量和a1之间的相关性),其他向量提供key,计算注意力score(系数)之后,为了保持在值value的维度形式,score要和value再做运算(注意加权组合,系数是和基对应的,所以key所有其他向量提供,value也是所有其他向量提供)。
总结来说——》Self-Attention 流程:
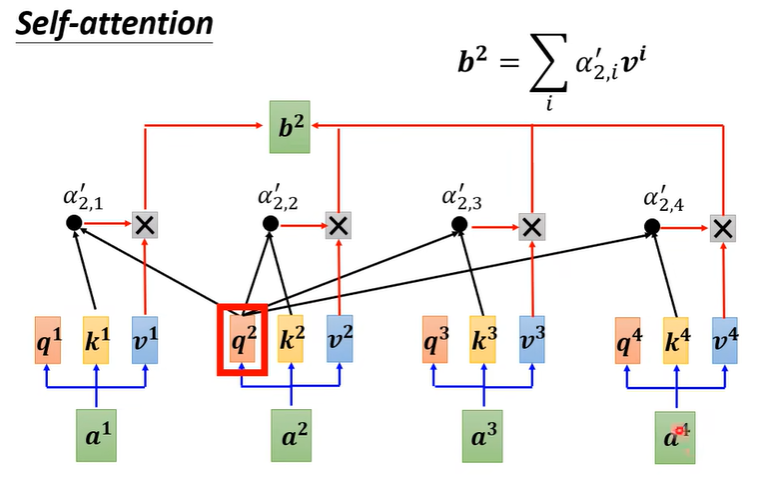
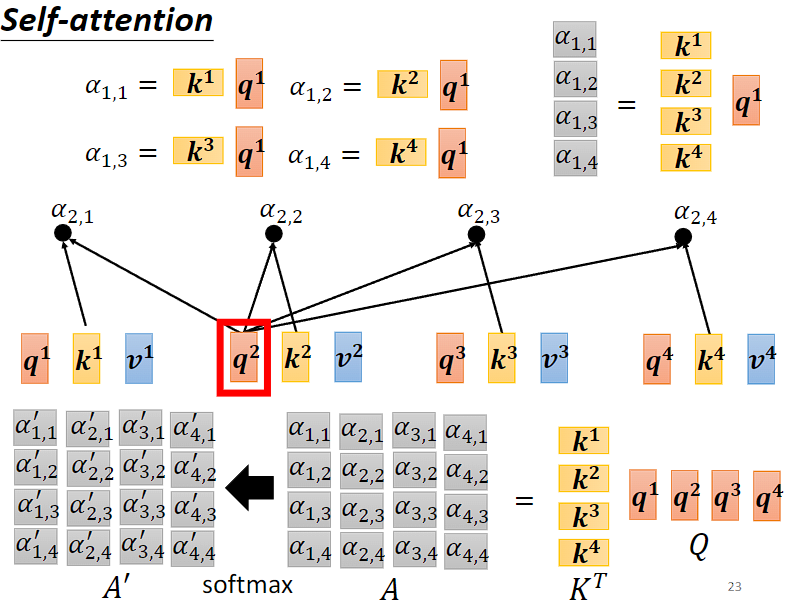
(1)计算 Attention Score
刚刚提到的 q 被称为 query,k 被称为 key。
实际要算出α1 时,需要分别去计算 a1 跟 a2, a3, a4 的相关性。
- 因此我们会将 a1 乘上一个矩阵,得到 q1,a2 乘上一个矩阵,得到 k2,a3, a4 也分别乘上矩阵得出 k3, k4。
- 对 q1, k2 做点积就可以计算出α1,2,这个数字被称为注意力分数。
- 然后分别对 q1, k3、q1, k4 做同样的事情,就可以得到 α1,3、α1,4。
实际操作时也会让 a1 跟自己做关联性(k1),因此也会得到一个 α1,1。
这时我们就有 α1,1、α1,2、α1,3、α1,4。 - 接着会再过一层激活函数,最常见的是 softmax,但也可以用其他函数替代。
(2) 计算 a1 的输出 b1
根据计算出来的 α,我们已经知道哪些输入的向量,跟 a1 最有关系,接着要通过 attention score 来抽取 sequence 中重要的信息。
- 将 a1, a2, a3, a4 乘上一组新的矩阵(Wv),得到 v1, v2, v3, v4。
- 接着将 α1,1 乘上 v1, α1,2 乘上 v2,以此类推,最后加总起来得到 b1。
因此谁的 attention score 比较大,也就是哪个向量跟 a1 的相关性比较大,就更会影响到 b1(这就是我前面说b1形式上维度上和受影响最大、相关性最大的ai向量接近,所以要value向量善后),而这样的结果也符合我们的预期。
到这边就完成了计算输入一排向量 a1, a2, a3, a4,得到输出向量 b1 的过程。
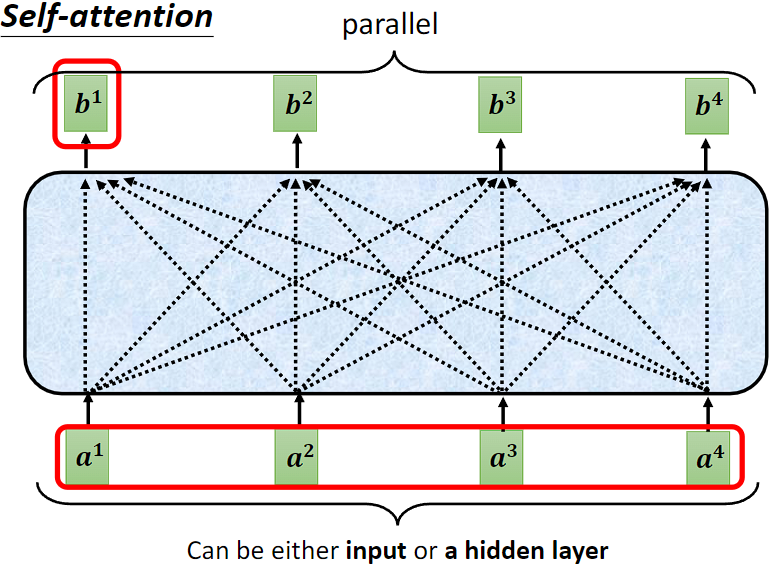
显然通过这种计算方式,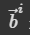 是一次同时被计算出来的。
是一次同时被计算出来的。
计算 b2, b3, b4,与计算 b1 的方式相同,计算过程这里就省略。
另外,在实际运算时,b1、b2、b3、b4 是并行计算的。
3,Self-attention 的内部实现——》矩阵乘法的角度
因为是并行运算,大规模需要使用矩阵运算,所以我们实际上是在矩阵乘法的角度来执行上面的操作:
接下来从矩阵乘法角度来看下平行计算出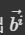 的过程。
的过程。
(1)获取Query、Key、Value向量:
Query
在计算每个向量的 query 时,都需要先乘上一个矩阵(Wq)。
q1 = Wq * a1
q2 = Wq * a2,以此类推。
但我们其实可以将 a1, a2, a3, a4 当作一个矩阵(I),这个矩阵乘以 Wq 得到 q1, q2, q3, q4 这个矩阵(Q)。
因此可以写成 Q = Wq * I。
Wq 就是机器需要学习出来的一组参数。
Key
K = Wk * I
Value
V = Wq * I
每一个输入向量都要经过线性变换产生查询向量、键向量和数值向量,将这些向量分别组合成矩阵 I、Q、K 和 V,运算操作如下图。
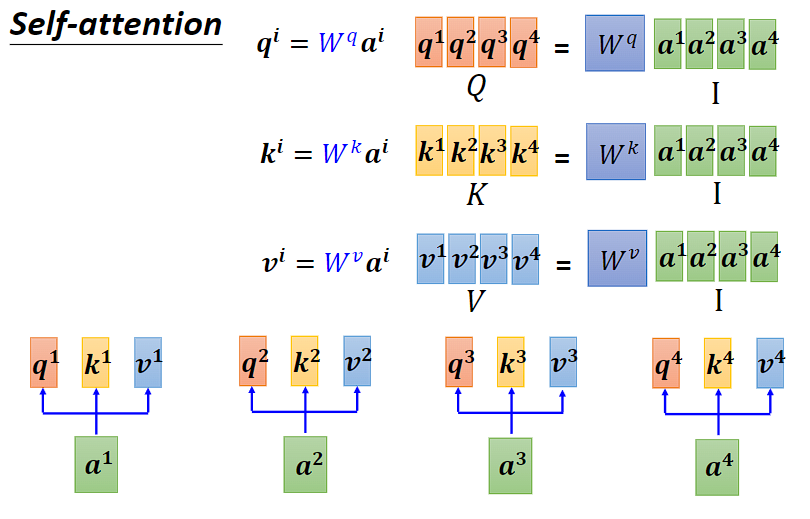
(2)Attention Score:注意力分数(对 Query 和 Key 做点积)
α1,1= kT * q¹(T 是转置),
α1, 2 = kT * q²,以此类推。
我们其实可以将 k1, k2, k3, k4 看作一个矩阵(k, 行是 k1, k2, k3, k4),乘上 q1 这个向量,而得到 α1 这个矩阵(α1,1, α1,2, α1,3, α1,4),代表着注意力分数。
α1 = K * q1
α2 = K * q2
注意力分数就可以当作两个矩阵的相乘。
A = KT * Q,
K 的行是 k1, k2, k3, k4,Q 的列则是 q1, q2, q3, q4。
因为 A 还会通过一个激活函数,所以用 A’ 来代表通过后的输出。
注意力分数矩阵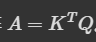 ,然后将 A 经过 Soft-max 得到注意力权重矩阵
,然后将 A 经过 Soft-max 得到注意力权重矩阵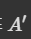
(3)self-attention 的输出:b
我们可以将 v1, v2, v3, v4 做成一个矩阵(V)。
将 V 乘上刚才算出来的 attention score 的结果(A’)。
就可以得到 B 这个矩阵,它的列是 b1, b2, b3, b4。
Self-attention 的输出矩阵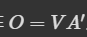
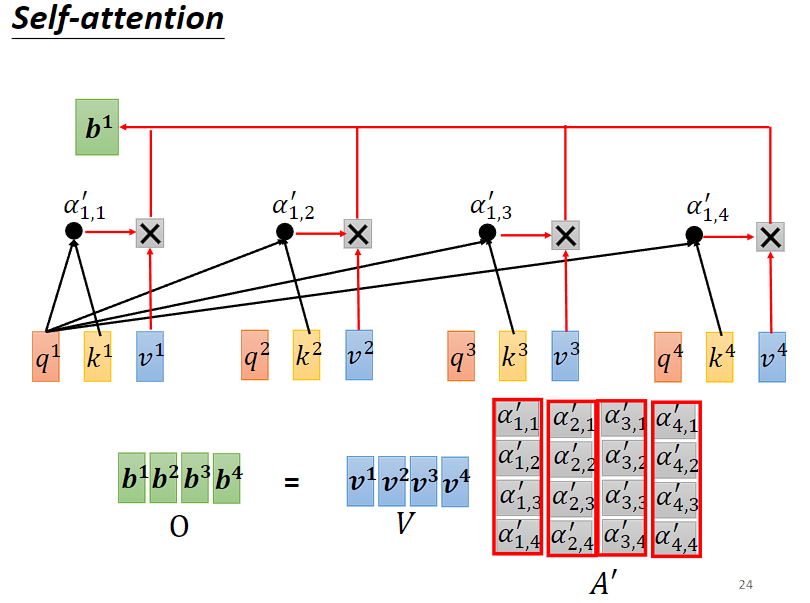
(4)总结Self-attentin 的总体计算流程:
我们有一堆输入的向量(I)。
- 计算 Query, Key, Value
输入向量(I)分别乘以上三种不同的矩阵(Wq, Wk, Wv),得到 Q, K, V(Query, Key, Value)。 - 计算 Attention Score
通过 K 的转置乘上矩阵 Q,得到 A,并且通过激活函数(softmax 或其他),得到 A’(Attention Matrix)。 - 计算输出向量(O)
最终要将矩阵 V,乘上矩阵 A’,就可以得到输出矩阵 O。
虽然好像做了很复杂的操作,但其实只有 Wq, Wk, Wv 是需要通过训练数据找出来的,只有这3个是参数,是未知的,是需要学习的。
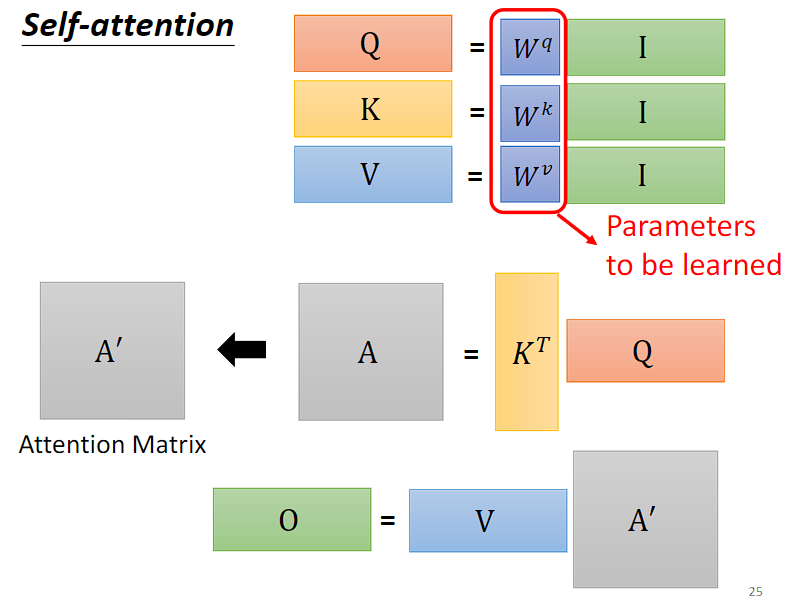

4,变形:多头注意力机制 (Multi-head Self-attention)
Multi-head Self-attention 是 Self-attention 的进阶版本。前面所讲的 Self-attention 计算两个向量之间的注意力分数只用了一个 ,相当于只从一个角度观察两个向量的关联,Multi-head Self-attention 则是同时从不同的角度进行观察,用不同的
,相当于只从一个角度观察两个向量的关联,Multi-head Self-attention 则是同时从不同的角度进行观察,用不同的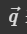 来负责不同的观察角度。
来负责不同的观察角度。
为什么要用多头?
关于这件事可能有很多种形式,可以把它想象成,为了找到数据中不同种类的相关性,所以才设置多个多头的自注意力(也就是说对于某种类型信息的相关性,我们有1组query,对应1组key,然后对1组value做加权求和,也也就是说这一组Q/K/V对应1个head,用于提取这一种这一类信息的相关性;但是真实数据是有很多信息的,也就意味着我们有很多类型的相关性需要提取,所以需要不同的head来处理,相当于专门的事情由专人来做,专业类型的信息由专门的head来提取)。
而需要用多少个 head,是一个超参数。
在语音识别、翻译等任务中,可能会需要用到比较多个 head。
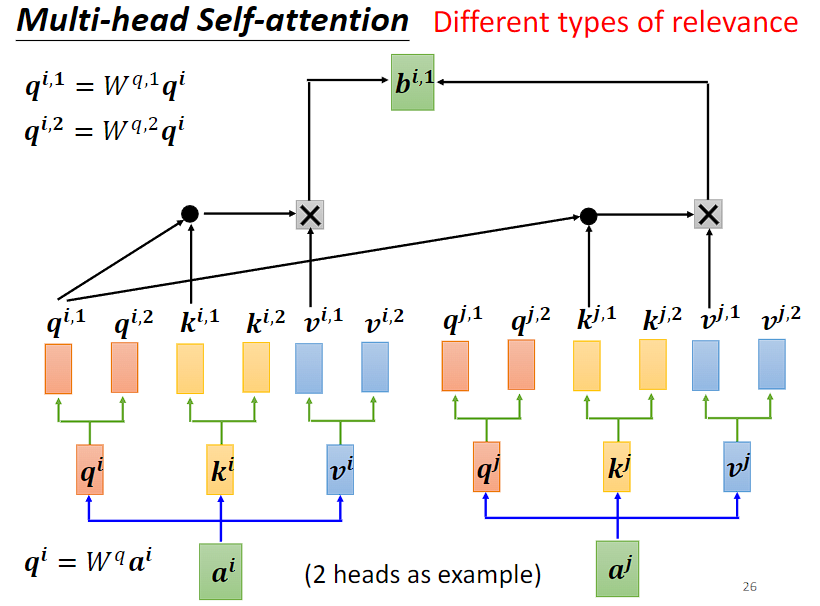
假设 multi-head 设定为 2,代表想要找到的相关性的种类有两个,
因此 query, key, value 这些要学的参数也会有两种。
以 2 头为例,每个头的计算方式与 Self-attention 一致。
第一个头的输出:
q1只和k1做内积,用于计算注意力score,最后只和v1做加权求和,我们不考虑q2、k2、v2
第二个头的输出:
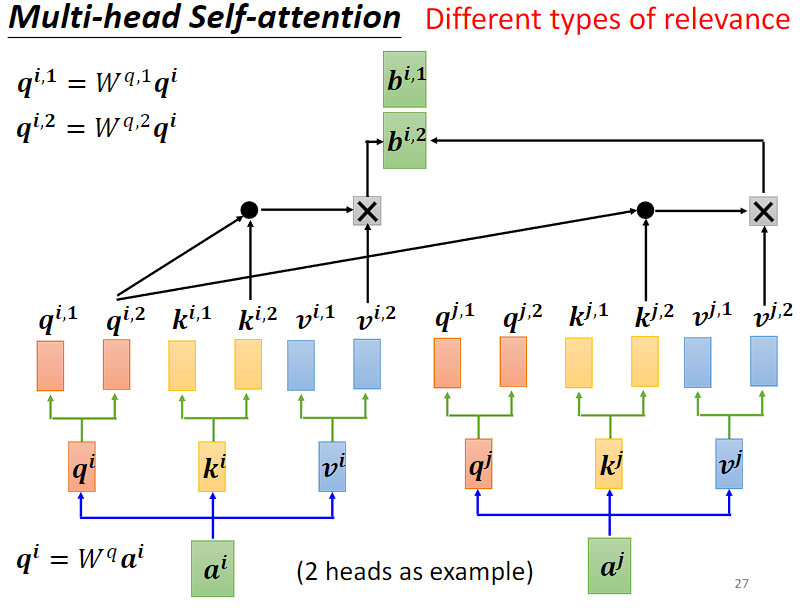
将每个头的输出拼接起来,得到多头自注意力的最终输出。通常会再进行一次线性变换,将多头输出映射到期望的输出维度上。
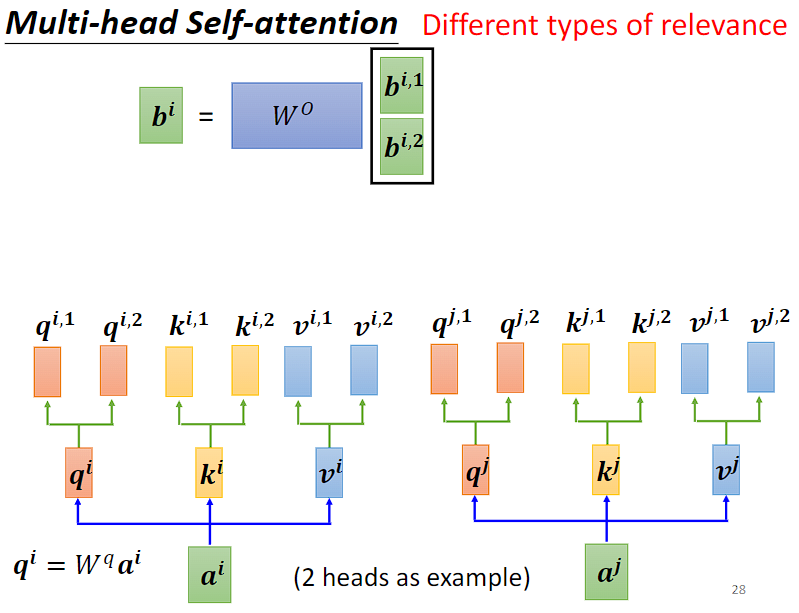

通过多个头并行计算注意力,模型能够从不同的角度对输入序列进行关注,捕捉更丰富的信息,提高模型的性能和表现力。
总的来说,此处所谓的多头,其实每一个head头都是指一次QKV运算。
5,Position Encoding位置编码
问题出在自注意力层并不会考虑输入向量的位置信息。
回顾 self attention 的计算过程,我们发现 self-attention 没有考虑位置信息,只计算互相关性。比如某个字词,不管它在句首、句中、句尾, self-attention 的计算结果都是一样的。但是,有时 Sequence 中的位置信息还是挺重要的。
我们仔细回想一下自注意力机制的操作过程:对于每一个向量ai,qkv这3个向量都是本身数据的投影,只是矩阵操作,实际上并不包含向量本身的位置信息,就算向量ai放在任意一个位置针对其本身计算出来的qkv向量是没有区别的(我们假设是前面句子"i saw a saw"中的a词,我们把a词放在第3个位置或者是第1个位置,我们求这个词这个token的qkv向量都是一样的);
然后我们知道q向量和所有其他向量的k向量之间是计算attention score,但是我们知道实际上这个score是所有两两之间都计算的,ai的query和a1…i…n任意从n中取出1个向量的key做点积,得到的attention score是全局的,全都算的,也是没有位置信息的,因为无论ai放在哪个位置,ai和其他所有向量token的相关性都是一样的,这是计算角度的问题;然后attention score对所有a向量做的加权求和,也同样是没有位置信息;
总之,前面qkv处理得到的bi的输出和ai输入在哪一个位置实际上是完全没有关系的,无论ai在哪一个位置,计算出来的b1都是一样的。
对于层来说,当 a1 出现在第一个位置和最后一个位置是一致的,因为它们都只是去计算 a1 和其他输入的相关性。
若要添加位置信息,可以在 ai 输入到 self-attention 层之前,先添加 ei 这个向量,ei 就代表位置的信息。
而如何生成 ei 向量有很多种方法,可以是统计出来的,也可以是机器学习出来的,但这些方法都称为位置编码。
总之,前面的矩阵一顿操作是不够的,到目前为止还缺少一个也许很重要的资讯,即位置的资讯。对于 Self-attention 而言,对每一个输入的操作是一模一样的,输入向量是出现在 sequence 的哪个位置,它是完全不知道的。例如,在做词性标注时动词比较不容易出现句首,那么位置资讯可能就很有用。
如何为输入向量塞入位置资讯呢?Position Encoding 为每个输入向量设置一个唯一的位置向量 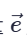 ,将位置向量加上输入向量即可让 Self-attention 了解到位置资讯。
,将位置向量加上输入向量即可让 Self-attention 了解到位置资讯。

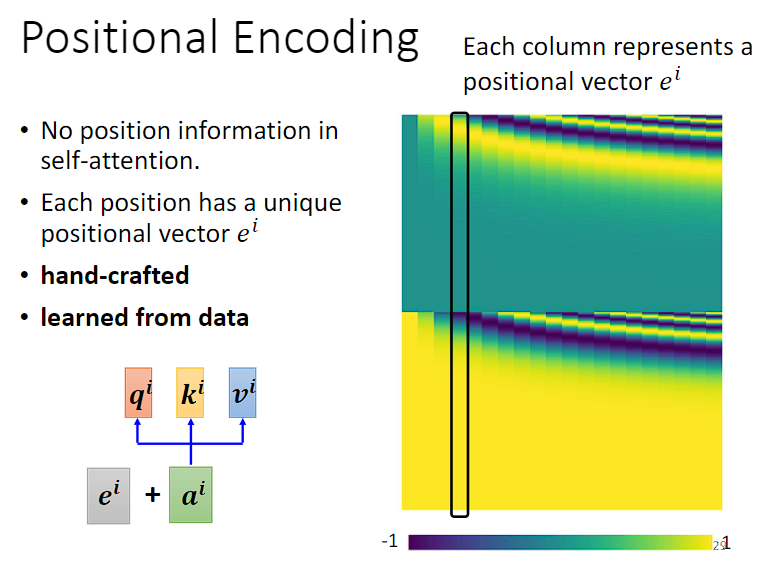
有各种方法产生位置向量,可以人工设置、Sinusoidal、通过学习得到。
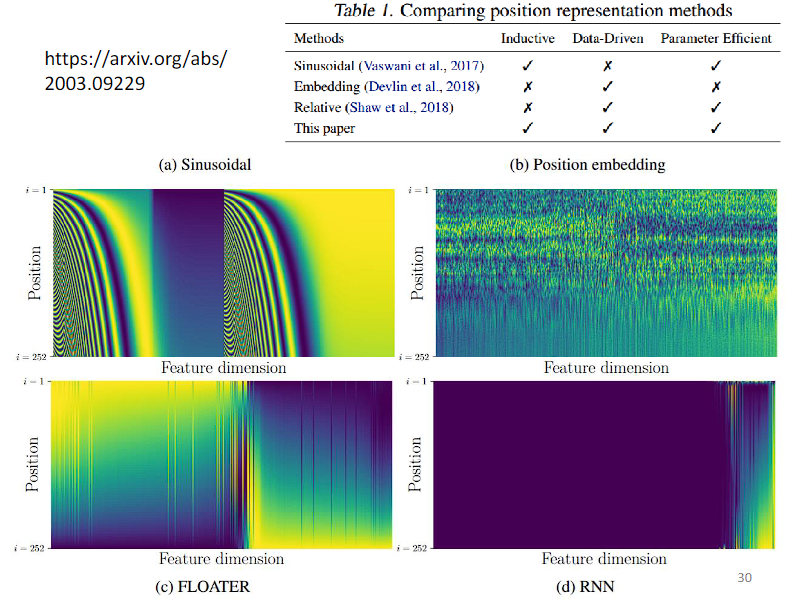
通常使用 Sinusoidal 来计算,位置编码矩阵中的每一行对应一个位置,每一列对应一个位置编码维度。
三,其他引用:
1,语音识别:
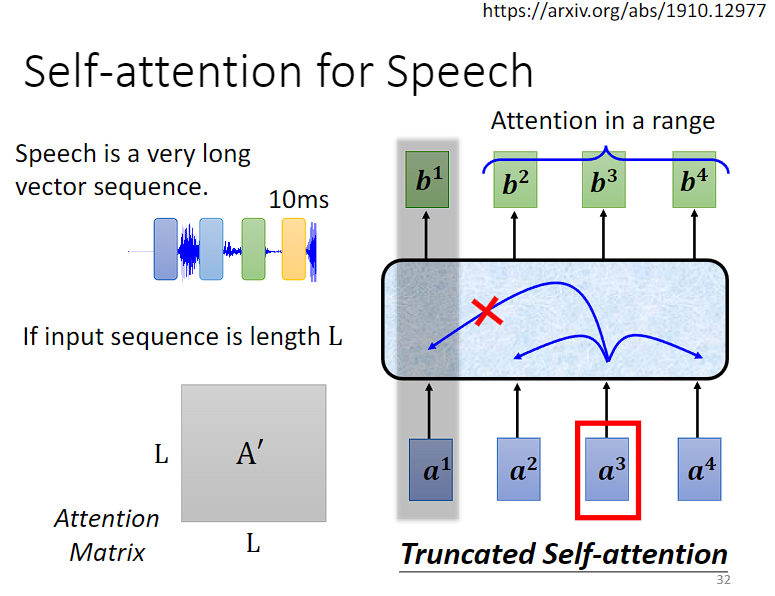
Self-attention 应用于语音,不过要经过一些小小改动,通常语音的每一个向量只代表了 10ms 的长度(前面提到的window),一段语音的 sequence 太长了,可能会导致计算和内存开销过大的问题。
——》因为attention计算的核心其实都在计算attention score矩阵上,而这个矩阵本质上是任意两个向量的query和key做点积,所以时间复杂度其实是O(N^2)。
截断自注意力(Truncated Self-attention)是一种用于处理长序列的自注意力机制的技术。截断自注意力通过限制每个位置只与其周围的一部分位置进行交互来解决这个问题,而不是与整个序列进行交互。具体来说,对于每个位置,只选择与其距离不超过一定阈值的邻近位置进行注意力计算,忽略超出阈值的远距离位置。——》全局感受野是自注意力机制,局部感受野是普通卷积,截断上下文序列其实就是对感受野范围做了一个简单的限制,所以说就是在attention算子和卷积算子之间的一种平衡取舍。
通过截断自注意力,可以减少计算和内存开销,并且更适合处理长序列。然而,截断自注意力也可能会损失一些长距离依赖性信息,因此需要根据具体任务和序列性质来进行权衡和选择。
——》思考:Truncated Self-attention 感觉有点像 CNN 的 receptive field
2,图像识别:
从本质上讲每一张图片都是一个向量,或者严谨点说都是矩阵/数组,宽和高的像素pixel x 颜色通道数(channel),灰度图片就是channel数=1,彩色图片RGB则channel为3;
所以一张正常的图片,一般是宽pixel x 高pixel x 色彩通道channel数的矩阵,我们可以通过串联的方式contact成1个向量,总之1张图片可以表示成1个向量。
将图片的每一个像素看成是一个三维的向量,下面这张图片就有 5∗10 个向量。从这个角度看待图片,当然也可以用 Self-attention 处理图片(其实就和分块矩阵一样,你怎么分都可以)。
在做CNN的时候,一张图片可看做一个很长的向量。它也可看做 一组向量:一张5 ∗ 10 的RGB图像可以看做5 ∗ 10的三个(通道)矩阵,把三个通道的相同位置看做一个三维向量。
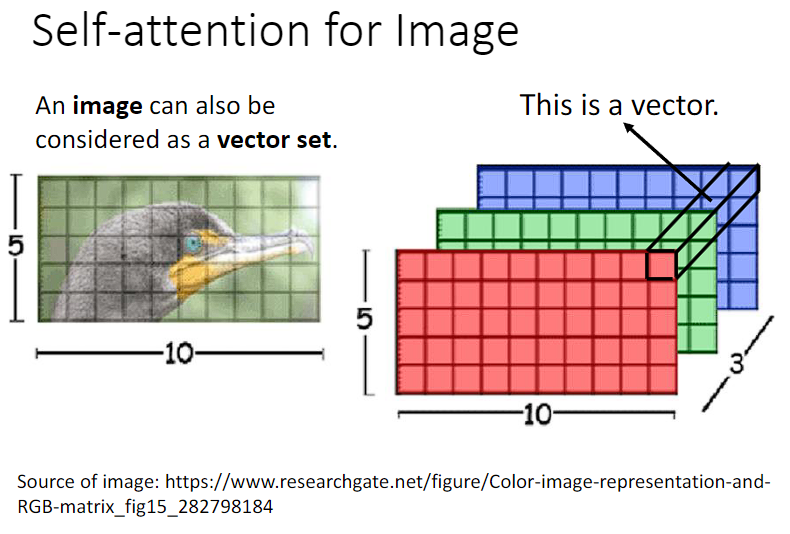
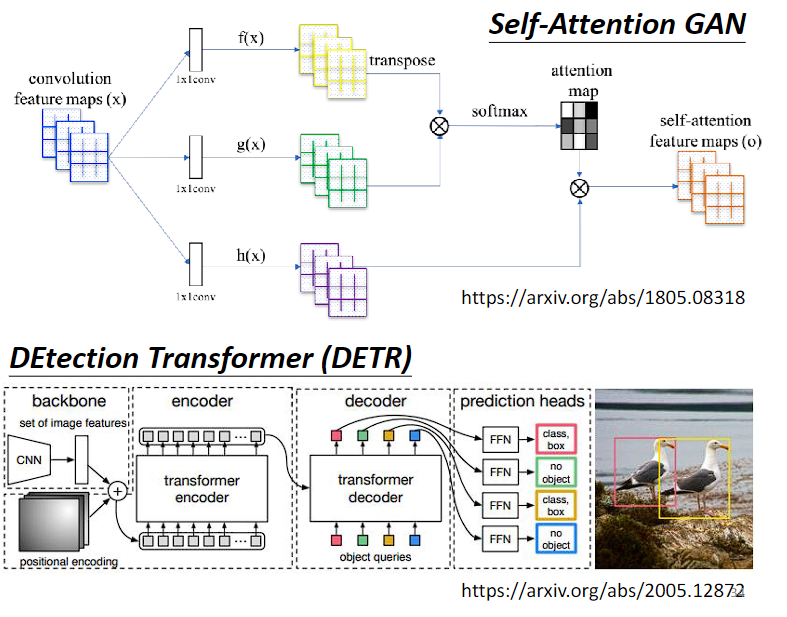
具体应用:GAN、DETR
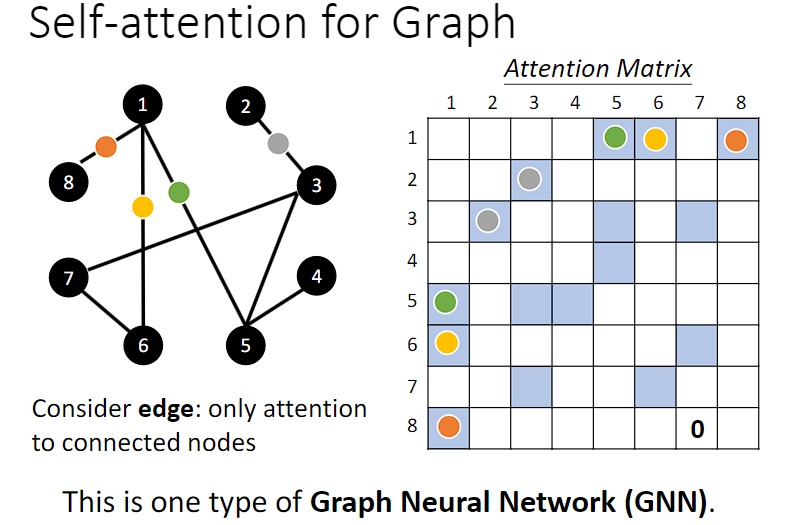
3,应用于图论graph:
Self-attention 可以用于 Graph 上。之前做 Self-attention 时关联性都是要找出来的,Graph 中的边保存着关联信息,就不再需要通过机器寻找 node 之间的关联性(也就是说我们原本需要考query和key向量寻找两两之间attention score,最后做加权求和才能确定的谁关联性大小,在Graph这里实际上直接看有没有edge边,就能够确定哪两个向量是有关联的了)。
把 Self-attention 用在 Graph 上是 GNN 的某一种类型。
4,自注意力机制和CNN的差异:
我们来看下 Self-attention 与 CNN 的对比。在图片识别中,CNN 只考虑感受域(感受野,receptive field)里的资讯,而 Self-attention 考虑整张图片的资讯。Self-attention 就好像是一个复杂版的 CNN,用 attention 找出相关的像素,就好像是感受域是自动被学习出来的,network 自己决定感受域是什么样子。
——》至于感受野的问题,前面也说了,本质上就是你的模型能够提取的上下文信息的能力范围的问题,1个是全局感受野,一个是局部感受野;
其实,Self-attention 可以看成是更加灵活的 CNN。为什么这么说呢?
把一个像素点当作一个 vector,CNN 只看 receptive field 范围的相关性,可以理解成中心的这个 vector 只看其相邻的 vectors,如下图所示。从 Self-attention 的角度来看,这就是在 receptive field 而不是整个 sequence 的 Self-attention。因此, CNN 模型是简化版的 Self-attention。
另一方面,CNN 的 receptive field 的大小由人为设定 ,比如: kernel size 为 3x3。而 Self-attention 求解 attention score 的过程,其实可以看作在学习并确定 receptive field 的范围大小。与 CNN 相比,self-attention 选择 receptive field时跳出了相邻像素点的限制,可以在整幅图像上挑选。因此,Self-attention 是复杂版的 CNN 模型。

在《On the Relationship between Self-Attention and Convolutional Layers》这篇论文上用数学的方式说明了 CNN 就是 Self-attention 的特例,只要设置合适的参数,Self-attention 可以做到和 CNN 一模一样的事。
——》所以,用标准CNN的,其实都可以用attention模块直接代替(节省学习成本,直接学大一统的那个)。
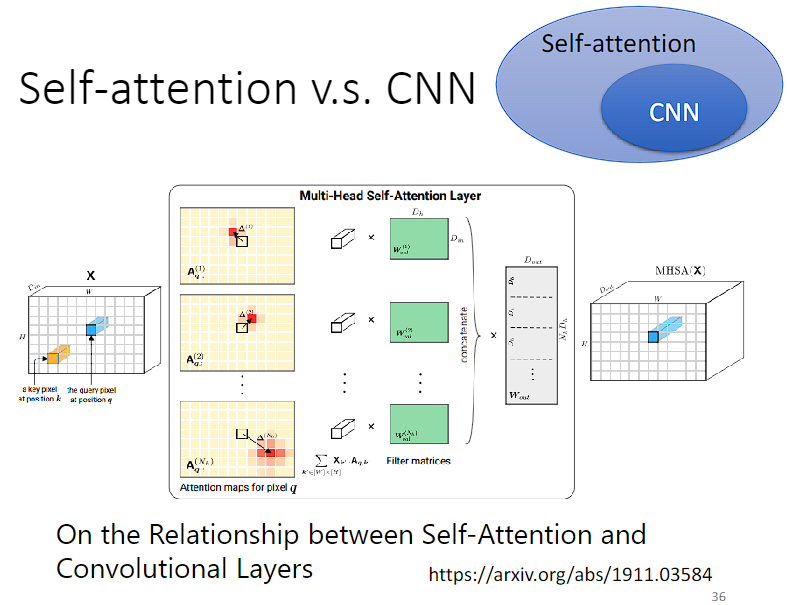
所以,Self-attention 是更 flexible 的 CNN,CNN 是有限制的 Self-attention。
学过统计学习的都知道偏差-方差分解,就是评估模型的时候的bias-variance tradeoff问题,如果一个模型越复杂,也就是越大一统、越能够适用于各种情况各种任务,就越有可能在训练过程中过拟合。
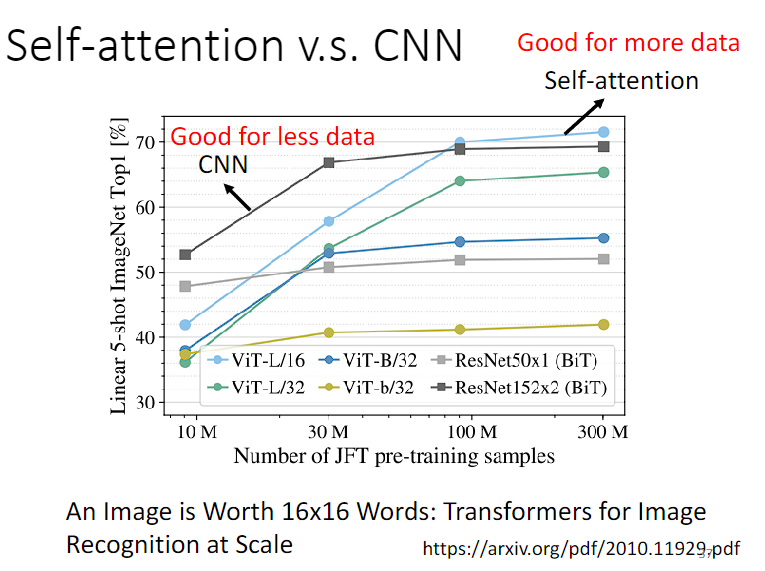
越 flexible 的模型需要越多的训练数据,否则有可能 overfitting。下面实验用不同量级的训练数据训练 Self-attention 和 CNN:
CNN 弹性较小,在比较少的训练数据上表现较 Self-attention 好;训练数据较多时,Self-attention 弹性大,能更拟合数据,而 CNN 没有办法从更大量的训练数据获取好处,效果自然不如 Self-attention。
5,自注意力机制和RNN(循环神经网络)的差异:
RNN 是循环神经网络(Recurrent Neural Network)的缩写,是一种经典的神经网络结构,和 Self-attention 一样用于处理序列数据。
RNN 在每个时间步接收输入数据和上一个时间步的隐藏状态,计算当前时间步的隐藏状态和输出,并将隐藏状态保存用于下一个时间步的计算。这样就能够在序列数据中建模时间上的依赖关系,并进行各种任务的预测和分析。
Self-attention 和 RNN 的区别:
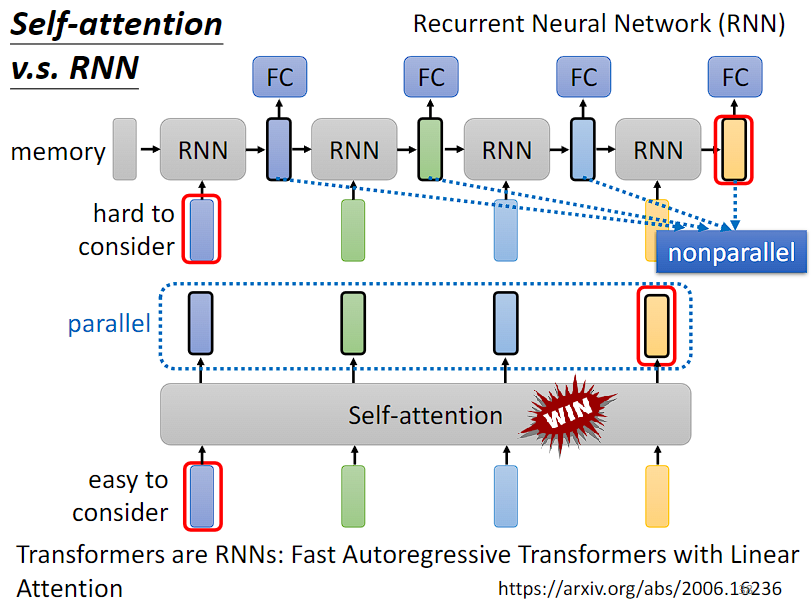
- 并行性:由于 RNN 是逐步处理序列数据的(也就是只有计算完上一个时间步的数据,才能处理下一个输入下一个时间步,****RNN 前面的输出又作为后面的输入,因此要依次计算,无法并行处理。而且如果单向看的话,其实每个时间步的输入只有左边的输出被记忆下来了,这个其实不是全局依赖关系,当然RNN可以做到双向),因此在训练和推理过程中,很难实现并行计算,导致计算效率较低。自注意力机制中,元素之间的相关性可以并行计算(直接提取每个向量和所有其他向量之间的注意力分数),因此可以更有效地利用硬件资源,提高计算效率。——》注意如果只是线性处理的RNN,确实每一个时间步只考虑了左边所有序列的信息,相当于只考虑了之前所有输入的因素;但是RNN可以做到双向,此时每一个输出也可看做考虑了所有的输入信息。自注意力机制能够并行处理输入,每一个输出都考虑了所有输入的影响。
- 长期依赖关系:传统的 RNN 在处理长序列数据时容易出现梯度消失或梯度爆炸的问题,难以捕捉长期依赖关系(也就是说左右两边距离非常远的输入之间的关系,需要隔着很长的时间步才能传过来,但是注意力可以直接通过Q和K之间的投影,直接做内积,就可以分析任意两个任意距离的向量之间的关系)。自注意力机制可以直接捕捉序列中不同位置之间的关系,不受距离限制,因此可以更好地处理长期依赖关系。——》简单来说,如果RNN 最后一个 vector 要联系第一个 vector,比较难,需要把第一个 vector 的输出一直保存在 memory 中。而这对 self-attention 来说,很简单。整个 Sequence 上任意位置的 vector 都可以联系,“天涯若比邻”,距离不是问题
因此很多的应用逐渐把RNN的架构改为Self-attention架构。
四,代码实现:
参考:
https://zhuanlan.zhihu.com/p/410776234
https://blog.csdn.net/kkm09/article/details/120855658
参考引用:
本文所有图片,均参考引用李宏毅老师《深度学习》2021版slide,视频在油管、B站也有搬运;
https://www.bilibili.com/video/BV1JA411c7VT/?p=11&vd_source=00f11bdb0cf4cafcaf7d8413135e5bb7
https://www.bilibili.com/video/BV1JA411c7VT?vd_source=00f11bdb0cf4cafcaf7d8413135e5bb7&p=12&spm_id_from=333.788.videopod.episodes
另外参考:
https://www.cnblogs.com/hzyuan/p/18048084
https://fredrick84823.medium.com/%E6%9D%8E%E5%AE%8F%E6%AF%85%E8%80%81%E5%B8%AB2021%E7%B3%BB%E5%88%97-%E8%87%AA%E6%B3%A8%E6%84%8F%E5%8A%9B%E6%A9%9F%E5%88%B6-self-attention-b4cf8f9ff7d9
https://blog.csdn.net/kkm09/article/details/120855658
相关文章:
李宏毅《深度学习》:Self-attention 自注意力机制
一,问题分析: 什么情况下需要使用self-attention架构,或者说什么问题是CNN等经典网络架构解决不了的问题,我们需要开发新的网络架构? 要解决什么问题《——》对应开发self-attention架构的目的? 1&#…...

C++初阶-list的使用1
目录 1.std::list简介 2.成员函数 2.1构造函数的使用 2.2list::operator的使用 3.迭代器 4.容量 4.1list::empty函数的使用 4.2list::size函数的使用 4.3list::max_size函数的使用 5.元素访问 6.修饰符 6.1list::assign函数的使用 6.2push_back和pop_back和push_fr…...

Linux中的tty与login之间的关系
agetty 进程和 login 进程之间的关系: 一、简要概括 agetty 是登录前的终端初始化程序。 login 是处理用户登录认证的程序。 关系:agetty 启动后等待用户输入用户名,然后调用 login 进程进行用户认证。 二、详细过程 1. agetty 的作用 a…...
Python web 开发 Flask HTTP 服务
Flask 是一个轻量级的 Web 应用框架,它基于 Python 编写,特别适合构建简单的 Web 应用和 RESTful API。Flask 的设计理念是提供尽可能少的约定和配置,从而让开发者能够灵活地构建自己的 Web 应用。 https://andi.cn/page/622189.html...

分享|16个含源码和数据集的计算机视觉实战项目
本文将分享16个含源码和数据集的计算机视觉实战项目。具体包括: 1. 人数统计工具 2. 颜色检测 3. 视频中的对象跟踪 4. 行人检测 5. 手势识别 6. 人类情感识别 7. 车道线检测 8. 名片扫描仪 9. 车牌识别 10. 手写数字识别 11.鸢尾花分类 12. 家庭照片人脸检测 13. 乐…...
二十三、面向对象底层逻辑-BeanDefinitionParser接口设计哲学
一、引言:Spring XML配置的可扩展性基石 在Spring框架的演进历程中,XML配置曾长期作为定义Bean的核心方式。虽然现代Spring应用更倾向于使用注解和Java Config,但在集成第三方组件、兼容遗留系统或实现复杂配置逻辑的场景下,XML配…...
[Vue]路由基础使用和路径传参
实际项目中不可能就一个页面,会有很多个页面。在Vue里面,页面与页面之间的跳转和传参会使用我们的路由: vue-router 基础使用 要使用我们需要先给我们的项目添加依赖:vue-router。使用命令下载: npm install vue-router 使用路由会涉及到下面几个对象:…...
使用VGG-16模型来对海贼王中的角色进行图像分类
动漫角色识别是计算机视觉的典型应用场景,可用于周边商品分类、动画制作辅助等。 这个案例是一个经典的深度学习应用,用于图像分类任务,它使用了一个自定义的VGG-16模型来对《海贼王》中的七个角色进行分类,演示如何将经典CNN模型…...

OSI 网络七层模型中的物理层、数据链路层、网络层
一、OSI 七层模型 物理层、数据链路层、网络层、传输层、会话层、表示层、应用层 1. 物理层(Physical Layer) 功能:传输原始的比特流(0和1),通过物理介质(如电缆、光纤、无线电波)…...

WooCommerce缓存教程 – 如何防止缓存破坏你的WooCommerce网站?
我们在以前的文章中探讨过如何加快你的WordPress网站的速度,并研究过各种形式的缓存。 然而,像那些使用WooCommerce的动态电子商务网站,在让缓存正常工作方面往往会面临重大挑战。 在本指南中,我们将告诉你如何为WooCommerce设置…...
)
AtCoder Beginner Contest 406(ABCD)
前言 我仿佛在梦游…… 一、A - Not Acceptable #include <bits/stdc.h> using namespace std;typedef long long ll; typedef pair<int,int> pii;void solve() {int dueH,dueM,upH,upM;cin>>dueH>>dueM>>upH>>upM;if(upH>dueH){cou…...
第J2周:ResNet50V2 算法实战与解析
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 学习目标 ✅ 根据TensorFlow代码,编写出相应的Python代码 ✅ 了解ResNetV2和ResNet模型的区别 一、环境配置 二、数据预处理 三、创建、划分数据…...

Live Search API :给大模型装了一个“实时搜索引擎”的插件
6月5号前免费使用。 Live Search 是一项xAI API功能,允许 LLM 在生成响应时查询和考虑实时数据。通过此功能,您可以直接从 API 获得包含实时数据的聊天响应,而无需自己协调网络搜索和大型语言模型(LLM)工具调用。 可以…...
)
每天分钟级别时间维度在数据仓库的作用与实现——以Doris和Hive为例(开箱即用)
在现代数据仓库建设中,时间维度表是不可或缺的基础维表之一。尤其是在金融、电力、物联网、互联网等行业,分钟级别的时间维度表对于高频数据的统计、分析、报表、数据挖掘等场景具有极其重要的作用。本文将以 Doris 为例,详细讲解每天分钟级别时间维度表在数据仓库中的作用、…...
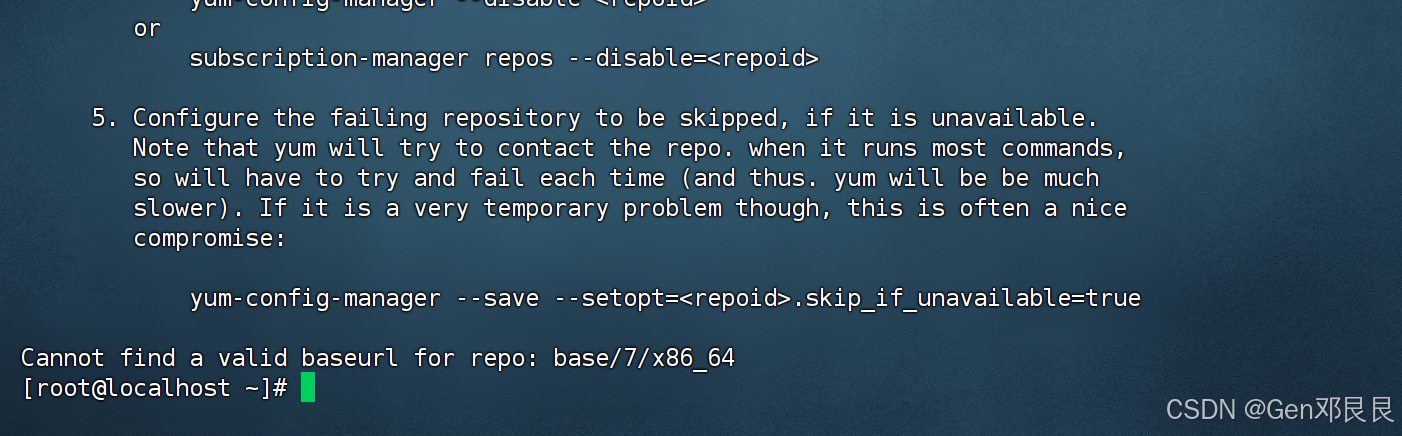
虚拟机Centos7:Cannot find a valid baseurl for repo: base/7/x86_64问题解决
问题 解决:更新yum仓库源 # 备份现有yum配置文件 sudo cp -r /etc/yum.repos.d /etc/yum.repos.d.backup# 编辑CentOS-Base.repo文件 vi /etc/yum.repos.d/CentOS-Base.repo[base] nameCentOS-$releasever - Base baseurlhttp://mirrors.aliyun.com/centos/$relea…...

IP风险度自检,多维度守护网络安全
如今IP地址不再只是网络连接的标识符,更成为评估安全风险的核心维度。IP风险度通过多维度数据建模,量化IP地址在网络环境中的安全威胁等级,已成为企业反欺诈、内容合规、入侵检测的关键工具。据Gartner报告显示,2025年全球78%的企…...

NV066NV074美光固态颗粒NV084NV085
NV066NV074美光固态颗粒NV084NV085 在存储技术的快速发展浪潮中,美光科技(Micron Technology)始终扮演着引领者的角色。其NV系列闪存颗粒凭借创新设计和卓越性能,成为技术爱好者、硬件开发者乃至企业级用户关注的焦点。本文将围绕…...

C++ 日志系统实战第六步:性能测试
全是通俗易懂的讲解,如果你本节之前的知识都掌握清楚,那就速速来看我的项目笔记吧~ 本文项目结束! 性能测试 下面对日志系统做一个性能测试,测试一下平均每秒能打印多少条日志消息到文件。 主要的测试方法是:每秒能…...

低代码平台搭建
学习低代码平台搭建需要掌握几个核心模块,尤其是动态表单引擎和DSL(领域特定语言)设计,以下是系统化的知识总结: 一、低代码平台的核心模块 低代码平台的核心是让用户通过可视化交互快速生成应用,核心模块包括: 可视化设计器(拖拽布局、组件配置)DSL(领域特定语言)…...

AI编程对传统软件开发的冲击和思考
2025年,如果你所在的软件公司还活着,恭喜,你的老板很坚挺,很有福报。 不过,25年年底的时候,就不好说了! Claude说年底的时候,Claude就可以实现不间断一直编程模式。 一个比996还狠…...

Java桌面应用开发详解:自制截图工具从设计到打包的全流程【附源码与演示】
🔥 本文详细介绍一个Java/JavaFX学习项目——轻量级智能截图工具的开发实践。通过这个项目,你将学习如何使用Java构建桌面应用,掌握JavaFX界面开发、系统托盘集成、全局快捷键注册等实用技能。本文主要关注基础功能实现,适合Java初…...

手写一个简单的线程池
手写一个简单的线程池 项目仓库:https://gitee.com/bossDuy/hand-tearing-thread-pool 基于一个b站up的课程:https://www.bilibili.com/video/BV1cJf2YXEw3/?spm_id_from333.788.videopod.sections&vd_source4cda4baec795c32b16ddd661bb9ce865 理…...
)
AI开发实习生面试总结(持续更新中...)
1.广州视宴(ai开发实习生) 首先是自我介绍~ 1.第二个项目中的热力图是用怎么样的方式去做的? 2.在第二个项目中,如何用热力图去实现它的实时变化 答:我这里直接说我项目里面其实静态的热力图,不是动态的…...

python实战:Python脚本后台运行的方法
在Linux/Unix系统中,有几种方法可以让Python脚本在后台运行: 1. 使用 & 符号 最简单的后台运行方式是在命令末尾添加 &: python your_script.py &这样会将脚本放入后台运行,但关闭终端时脚本可能会被终止。 2. 使用 nohup 命令 nohup 可以让脚本在退出终端…...
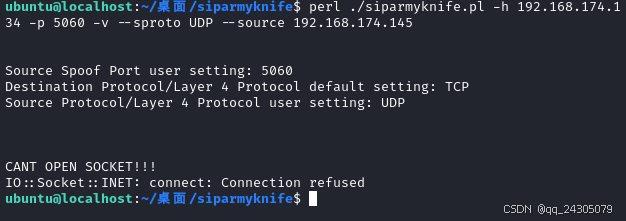
siparmyknife:SIP协议渗透测试的瑞士军刀!全参数详细教程!Kali Linux教程!
简介 SIP Army Knife 是一个模糊测试器,用于搜索跨站点脚本、SQL 注入、日志注入、格式字符串、缓冲区溢出等。 安装 源码安装 通过以下命令来进行克隆项目源码,建议请先提前挂好代理进行克隆。 git clone https://github.com/foreni-packages/sipa…...

【Hexo】2.常用的几个命令
new 在根目录下执行 hexo new "文章标题" 命令,会在 source/_posts 目录下生成一个 .md 文件。 hexo new "文章标题"clean 在根目录下执行 hexo clean 命令,会清除 public 目录下的所有文件。 hexo cleangenerate 在根目录下执…...

OceanBase 系统表查询与元数据查询完全指南
文章目录 一、OceanBase 元数据基础概念1.1 元数据的定义与重要性1.2 OceanBase 元数据分类体系二、系统表查询核心技术2.1 核心系统表详解2.1.1 集群管理表2.1.2 租户资源表2.2 高级查询技巧2.2.1 跨系统表关联查询2.2.2 历史元数据查询三、元数据查询实战应用3.1 日常运维场景…...

【Java高阶面经:微服务篇】4.大促生存法则:微服务降级实战与高可用架构设计
一、降级决策的核心逻辑:资源博弈下的生存选择 1.1 大促场景的资源极限挑战 在电商大促等极端流量场景下,系统面临的资源瓶颈呈现指数级增长: 流量特征: 峰值QPS可达日常的50倍以上(如某电商大促下单QPS从1万突增至50万)流量毛刺持续时间短(通常2-4小时),但对系统稳…...
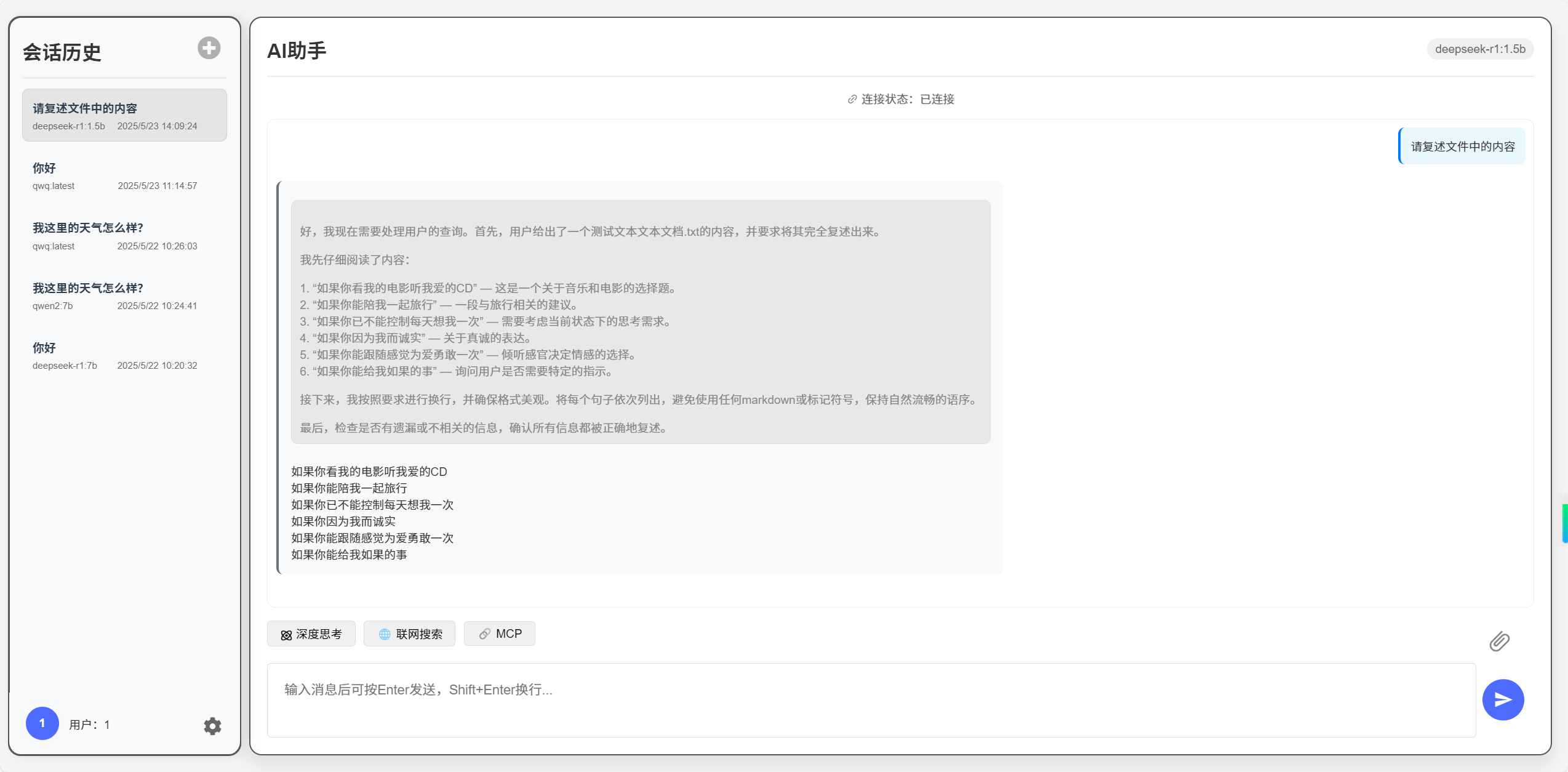
通过上传使大模型读取并分析文件实战
一、技术背景与需求分析 我们日常在使用AI的时候一定都上传过文件,AI会根据用户上传的文件内容结合用户的请求进行分析,给出用户解答。但是这是怎么实现的呢?在我们开发自己的大模型应用时肯定是不可避免的要思考这个问题,今天我会…...
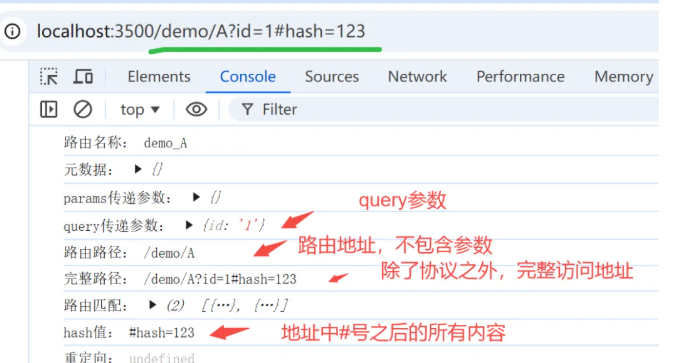
VueRouter路由组件的用法介绍
1.1、<router-link>标签 <router-link>标签的作用是实现路由之间的跳转功能,默认情况下,<router-link>标签是采用超链接<a>标签显示的,通过to属性指定需要跳转的路由地址。当然,如果你不想使用默认的<…...